 J.8.3
J.8.3
An adder that computes carries using Equation J.8.3 is called a carry-lookahead adder, or CLA. A CLA requires one logic level to form p and g, two levels to form the carries, and two for the sum, for a grand total of five logic levels. This is a vast improvement over the 2n levels required for the ripple-carry adder.
Unfortunately, as is evident from Equation J.8.3 or from Figure J.14, a carrylookahead adder on n bits requires a fan-in of n + 1 at the OR gate as well as at the rightmost AND gate. Also, the pn − 1 signal must drive n AND gates. In addition, the rather irregular structure and many long wires of Figure J.14 make it impractical to build a full carry-lookahead adder when n is large.

However, we can use the carry-lookahead idea to build an adder that has about log2n logic levels (substantially fewer than the 2n required by a ripplecarry adder) and yet has a simple, regular structure. The idea is to build up the p’s and g’s in steps. We have already seen that

This says there is a carry-out of the 0th position (c1) either if there is a carry generated in the 0th position or if there is a carry into the 0th position and the carry propagates. Similarly,

G01 means there is a carry generated out of the block consisting of the first two bits. P01 means that a carry propagates through this block. P and G have the following logic equations:

More generally, for any j with i < j, j + 1 < k, we have the recursive relations:
 J.8.4
J.8.4 J.8.5
J.8.5 J.8.6
J.8.6Equation J.8.5 says that a carry is generated out of the block consisting of bits i through k inclusive if it is generated in the high-order part of the block (j + 1, k) or if it is generated in the low-order part of the block (i,j) and then propagated through the high part. These equations will also hold for i ≤ j < k if we set Gii = gi and Pii = pi.
With these preliminaries out of the way, we can now show the design of a practical CLA. The adder consists of two parts. The first part computes various values of P and G from pi and gi, using Equations J.8.5 and J.8.6; the second part uses these P and G values to compute all the carries via Equation J.8.4. The first part of the design is shown in Figure J.15. At the top of the diagram, input numbers a7… a0 and b7… b0 are converted to p’s and g’s using cells of type 1. Then various P’s and G’s are generated by combining cells of type 2 in a binary tree structure. The second part of the design is shown in Figure J.16. By feeding c0 in at the bottom of this tree, all the carry bits come out at the top. Each cell must know a pair of (P,G) values in order to do the conversion, and the value it needs is written inside the cells. Now compare Figures J.15 and J.16. There is a one-to-one correspondence between cells, and the value of (P,G) needed by the carry-generating cells is exactly the value known by the corresponding (P,G)-generating cells. The combined cell is shown in Figure J.17. The numbers to be added flow into the top and downward through the tree, combining with c0 at the bottom and flowing back up the tree to form the carries. Note that one thing is missing from Figure J.17: a small piece of extra logic to compute c8 for the carry-out of the adder.

As signals flow from the top to the bottom, various values of P and G are computed.

Signals flow from the bottom to the top, combining with P and G to form the carries.

This is the combination of Figures J.15 and J.16. The numbers to be added enter at the top, flow to the bottom to combine with c0, and then flow back up to compute the sum bits.
The bits in a CLA must pass through about log2 n logic levels, compared with 2n for a ripple-carry adder. This is a substantial speed improvement, especially for a large n. Whereas the ripple-carry adder had n cells, however, the CLA has 2n cells, although in our layout they will take n log n space. The point is that a small investment in size pays off in a dramatic improvement in speed.
A number of technology-dependent modifications can improve CLAs. For example, if each node of the tree has three inputs instead of two, then the height of the tree will decrease from log2 n to log3 n. Of course, the cells will be more complex and thus might operate more slowly, negating the advantage of the decreased height. For technologies where rippling works well, a hybrid design might be better. This is illustrated in Figure J.19. Carries ripple between adders at the top level, while the “B” boxes are the same as those in Figure J.17. This design will be faster if the time to ripple between four adders is faster than the time it takes to traverse a level of “B” boxes. (To make the pattern more clear, Figure J.19 shows a 16-bit adder, so the 8-bit adder of Figure J.17 corresponds to the right half of Figure J.19.)
Carry-Skip Adders
A carry-skip adder sits midway between a ripple-carry adder and a carry-lookahead adder, both in terms of speed and cost. (A carry-skip adder is not called a CSA, as that name is reserved for carry-save adders.) The motivation for this adder comes from examining the equations for P and G. For example,

Computing P is much simpler than computing G, and a carry-skip adder only computes the P’s. Such an adder is illustrated in Figure J.18. Carries begin rippling simultaneously through each block. If any block generates a carry, then the carry-out of a block will be true, even though the carry-in to the block may not be correct yet. If at the start of each add operation the carry-in to each block is 0, then no spurious carry-outs will be generated. Thus, the carry-out of each block can be thought of as if it were the G signal. Once the carry-out from the least-significant block is generated, it not only feeds into the next block but is also fed through the AND gate with the P signal from that next block. If the carry-out and P signals are both true, then the carry skips the second block and is ready to feed into the third block, and so on. The carry-skip adder is only practical if the carry-in signals can be easily cleared at the start of each operation—for example, by precharging in CMOS.

This is a 20-bit carry-skip adder (n = 20) with each block 4 bits wide (k = 4).

In the top row, carries ripple within each group of four boxes.
To analyze the speed of a carry-skip adder, let’s assume that it takes 1 time unit for a signal to pass through two logic levels. Then it will take k time units for a carry to ripple across a block of size k, and it will take 1 time unit for a carry to skip a block. The longest signal path in the carry-skip adder starts with a carry being generated at the 0th position. If the adder is n bits wide, then it takes k time units to ripple through the first block, n/k − 2 time units to skip blocks, and k more to ripple through the last block. To be specific: if we have a 20-bit adder broken into groups of 4 bits, it will take 4 + (20/4 − 2) + 4 = 11 time units to perform an add. Some experimentation reveals that there are more efficient ways to divide 20 bits into blocks. For example, consider five blocks with the least-significant 2 bits in the first block, the next 5 bits in the second block, followed by blocks of size 6, 5, and 2. Then the add time is reduced to 9 time units. This illustrates an important general principle. For a carry-skip adder, making the interior blocks larger will speed up the adder. In fact, the same idea of varying the block sizes can sometimes speed up other adder designs as well. Because of the large amount of rippling, a carry-skip adder is most appropriate for technologies where rippling is fast.
Carry-Select Adder
A carry-select adder works on the following principle: Two additions are performed in parallel, one assuming the carry-in is 0 and the other assuming the carry-in is 1. When the carry-in is finally known, the correct sum (which has been precomputed) is simply selected. An example of such a design is shown in Figure J.20. An 8-bit adder is divided into two halves, and the carry-out from the lower half is used to select the sum bits from the upper half. If each block is computing its sum using rippling (a linear time algorithm), then the design in Figure J.20 is twice as fast at 50% more cost. However, note that the c4 signal must drive many muxes, which may be very slow in some technologies. Instead of dividing the adder into halves, it could be divided into quarters for a still further speedup. This is illustrated in Figure J.21. If it takes k time units for a block to add k-bit numbers, and if it takes 1 time unit to compute the mux input from the two carry-out signals, then for optimal operation each block should be 1 bit wider than the next, as shown in Figure J.21. Therefore, as in the carry-skip adder, the best design involves variable-size blocks.

At the same time that the sum of the low-order 4 bits is being computed, the high-order bits are being computed twice in parallel: once assuming that c4 = 0 and once assuming c4 = 1.

As soon as the carry-out of the rightmost block is known, it is used to select the other sum bits.
As a summary of this section, the asymptotic time and space requirements for the different adders are given in Figure J.22. (The times for carry-skip and carry-select come from a careful choice of block size. See Exercise J.26 for the carry-skip adder.) These different adders shouldn’t be thought of as disjoint choices, but rather as building blocks to be used in constructing an adder. The utility of these different building blocks is highly dependent on the technology used. For example, the carry-select adder works well when a signal can drive many muxes, and the carry-skip adder is attractive in technologies where signals can be cleared at the start of each operation. Knowing the asymptotic behavior of adders is useful in understanding them, but relying too much on that behavior is a pitfall. The reason is that asymptotic behavior is only important as n grows very large. But n for an adder is the bits of precision, and double precision today is the same as it was 20 years ago—about 53 bits. Although it is true that as computers get faster, computations get longer—and thus have more rounding error, which in turn requires more precision—this effect grows very slowly with time.

J.9 Speeding Up Integer Multiplication and Division
The multiplication and division algorithms presented in Section J.2 are fairly slow, producing 1 bit per cycle (although that cycle might be a fraction of the CPU instruction cycle time). In this section, we discuss various techniques for higher-performance multiplication and division, including the division algorithm used in the Pentium chip.
Shifting over Zeros
Although the technique of shifting over zeros is not currently used much, it is instructive to consider. It is distinguished by the fact that its execution time is operand dependent. Its lack of use is primarily attributable to its failure to offer enough speedup over bit-at-a-time algorithms. In addition, pipelining, synchronization with the CPU, and good compiler optimization are difficult with algorithms that run in variable time. In multiplication, the idea behind shifting over zeros is to add logic that detects when the low-order bit of the A register is 0 (see Figure J.2(a) on page J-4) and, if so, skips the addition step and proceeds directly to the shift step—hence the term shifting over zeros.
What about shifting for division? In nonrestoring division, an ALU operation (either an addition or subtraction) is performed at every step. There appears to be no opportunity for skipping an operation. But think about division this way: To compute a/b, subtract multiples of b from a, and then report how many subtractions were done. At each stage of the subtraction process the remainder must fit into the P register of Figure J.2(b) (page J-4). In the case when the remainder is a small positive number, you normally subtract b; but suppose instead you only shifted the remainder and subtracted b the next time. As long as the remainder was sufficiently small (its high-order bit 0), after shifting it still would fit into the P register, and no information would be lost. However, this method does require changing the way we keep track of the number of times b has been subtracted from a. This idea usually goes under the name of SRT division, for Sweeney, Robertson, and Tocher, who independently proposed algorithms of this nature. The main extra complication of SRT division is that the quotient bits cannot be determined immediately from the sign of P at each step, as they can be in ordinary nonrestoring division.
More precisely, to divide a by b where a and b are n-bit numbers, load a and b into the A and B registers, respectively, of Figure J.2 (page J-4).
SRT Division
- 1. If B has k leading zeros when expressed using n bits, shift all the registers left k bits.
- 2. For i = 0, n − 1,
- a) If the top three bits of P are equal, set qi = 0 and shift (P,A) one bit left.
- b) If the top three bits of P are not all equal and P is negative, set qi = − 1 (also written as
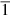 ), shift (P,A) one bit left, and add B.
), shift (P,A) one bit left, and add B. - c) Otherwise set qi = 1, shift (P,A) one bit left, and subtract B.
End loop - 3. If the final remainder is negative, correct the remainder by adding B, and correct the quotient by subtracting 1 from q0. Finally, the remainder must be shifted k bits right, where k is the initial shift.
A numerical example is given in Figure J.23. Although we are discussing integer division, it helps in explaining the algorithm to imagine the binary point just left of the most-significant bit. This changes Figure J.23 from 010002/00112 to 0.10002/.00112. Since the binary point is changed in both the numerator and denominator, the quotient is not affected. The (P,A) register pair holds the remainder and is a two’s complement number. For example, if P contains 111102 and A = 0, then the remainder is 1.11102 = − 1/8. If r is the value of the remainder, then − 1 ≤ r < 1.

The quotient bits are shown in bold, using the notation 1 for − 1.
Given these preliminaries, we can now analyze the SRT division algorithm. The first step of the algorithm shifts b so that b ≥ 1/2. The rule for which ALU operation to perform is this: If − 1/4 ≤ r < 1/4 (true whenever the top three bits of P are equal), then compute 2r by shifting (P,A) left one bit; if r < 0 (and hence r < − 1/4, since otherwise it would have been eliminated by the first condition), then compute 2r + b by shifting and then adding; if r ≥ 1/4 and subtract b from 2r. Using b ≥ 1/2, it is easy to check that these rules keep − 1/2 ≤ r < 1/2. For nonrestoring division, we only have |r| ≤ b, and we need P to be n + 1 bits wide. But, for SRT division, the bound on r is tighter, namely, − 1/2 ≤ r < 1/2. Thus, we can save a bit by eliminating the high-order bit of P (and b and the adder). In particular, the test for equality of the top three bits of P becomes a test on just two bits.
The algorithm might change slightly in an implementation of SRT division. After each ALU operation, the P register can be shifted as many places as necessary to make either r ≥ 1/4 or r < − 1/4. By shifting k places, k quotient bits are set equal to zero all at once. For this reason SRT division is sometimes described as one that keeps the remainder normalized to |r| ≥ 1/4.
Notice that the value of the quotient bit computed in a given step is based on which operation is performed in that step (which in turn depends on the result of the operation from the previous step). This is in contrast to nonrestoring division, where the quotient bit computed in the ith step depends on the result of the operation in the same step. This difference is reflected in the fact that when the final remainder is negative, the last quotient bit must be adjusted in SRT division, but not in nonrestoring division. However, the key fact about the quotient bits in SRT division is that they can include . Although Figure J.23 shows the quotient bits being stored in the low-order bits of A, an actual implementation can’t do this because you can’t fit the three values − 1, 0, 1 into one bit. Furthermore, the quotient must be converted to ordinary two’s complement in a full adder. A common way to do this is to accumulate the positive quotient bits in one register and the negative quotient bits in another, and then subtract the two registers after all the bits are known. Because there is more than one way to write a number in terms of the digits − 1, 0, 1, SRT division is said to use a redundant quotient representation.
The differences between SRT division and ordinary nonrestoring division can be summarized as follows:
- 1. ALU decision rule—In nonrestoring division, it is determined by the sign of P; in SRT, it is determined by the two most-significant bits of P.
- 2. Final quotient—In nonrestoring division, it is immediate from the successive signs of P; in SRT, there are three quotient digits (1, 0, ), and the final quotient must be computed in a full n-bit adder.
- 3. Speed—SRT division will be faster on operands that produce zero quotient bits.
The simple version of the SRT division algorithm given above does not offer enough of a speedup to be practical in most cases. However, later on in this section we will study variants of SRT division that are quite practical.
Speeding Up Multiplication with a Single Adder
As mentioned before, shifting-over-zero techniques are not used much in current hardware. We now discuss some methods that are in widespread use. Methods that increase the speed of multiplication can be divided into two classes: those that use a single adder and those that use multiple adders. Let’s first discuss techniques that use a single adder.
In the discussion of addition we noted that, because of carry propagation, it is not practical to perform addition with two levels of logic. Using the cells of Figure J.17, adding two 64-bit numbers will require a trip through seven cells to compute the P’s and G’s and seven more to compute the carry bits, which will require at least 28 logic levels. In the simple multiplier of Figure J.2 on page J-4, each multiplication step passes through this adder. The amount of computation in each step can be dramatically reduced by using carry-save adders (CSAs). A carry-save adder is simply a collection of n independent full adders. A multiplier using such an adder is illustrated in Figure J.24. Each circle marked “+” is a single-bit full adder, and each box represents one bit of a register. Each addition operation results in a pair of bits, stored in the sum and carry parts of P. Since each add is independent, only two logic levels are involved in the add—a vast improvement over 28.

Each circle represents a (3,2) adder working independently. At each step, the only bit of P that needs to be shifted is the low-order sum bit.
To operate the multiplier in Figure J.24, load the sum and carry bits of P with zero and perform the first ALU operation. (If Booth recoding is used, it might be a subtraction rather than an addition.) Then shift the low-order sum bit of P into A, as well as shifting A itself. The n − 1 high-order bits of P don’t need to be shifted because on the next cycle the sum bits are fed into the next lower-order adder. Each addition step is substantially increased in speed, since each add cell is working independently of the others, and no carry is propagated.
There are two drawbacks to carry-save adders. First, they require more hardware because there must be a copy of register P to hold the carry outputs of the adder. Second, after the last step, the high-order word of the result must be fed into an ordinary adder to combine the sum and carry parts. One way to accomplish this is by feeding the output of P into the adder used to perform the addition operation. Multiplying with a carry-save adder is sometimes called redundant multiplication because P is represented using two registers. Since there are many ways to represent P as the sum of two registers, this representation is redundant. The term carry-propagate adder (CPA) is used to denote an adder that is not a CSA. A propagate adder may propagate its carries using ripples, carry-lookahead, or some other method.
Another way to speed up multiplication without using extra adders is to examine k low-order bits of A at each step, rather than just one bit. This is often called higher-radix multiplication. As an example, suppose that k = 2. If the pair of bits is 00, add 0 to P; if it is 01, add B. If it is 10, simply shift b one bit left before adding it to P. Unfortunately, if the pair is 11, it appears we would have to compute b + 2b. But this can be avoided by using a higher-radix version of Booth recoding. Imagine A as a base 4 number: When the digit 3 appears, change it to and add 1 to the next higher digit to compensate. An extra benefit of using this scheme is that just like ordinary Booth recoding, it works for negative as well as positive integers (Section J.2).
The precise rules for radix-4 Booth recoding are given in Figure J.25. At the ith multiply step, the two low-order bits of the A register contain a2i and a2i + 1. These two bits, together with the bit just shifted out (a2i − 1), are used to select the multiple of b that must be added to the P register. A numerical example is given in Figure J.26. Another name for this multiplication technique is overlapping triplets, since it looks at 3 bits to determine what multiple of b to use, whereas ordinary Booth recoding looks at 2 bits.

For example, if the two low-order bits of the A register are both 1, and the last bit to be shifted out of the A register is 0, then the correct multiple is − b, obtained from the second-to-last row of the table.

The column labeled L contains the last bit shifted out the right end of A.
Besides having more complex control logic, overlapping triplets also requires that the P register be 1 bit wider to accommodate the possibility of 2b or − 2b being added to it. It is possible to use a radix-8 (or even higher) version of Booth recoding. In that case, however, it would be necessary to use the multiple 3B as a potential summand. Radix-8 multipliers normally compute 3B once and for all at the beginning of a multiplication operation.
Faster Multiplication with Many Adders
If the space for many adders is available, then multiplication speed can be improved. Figure J.27 shows a simple array multiplier for multiplying two 5-bit numbers, using three CSAs and one propagate adder. Part (a) is a block diagram of the kind we will use throughout this section. Parts (b) and (c) show the adder in more detail. All the inputs to the adder are shown in (b); the actual adders with their interconnections are shown in (c). Each row of adders in (c) corresponds to a box in (a). The picture is “twisted” so that bits of the same significance are in the same column. In an actual implementation, the array would most likely be laid out as a square instead.

The 5-bit number in A is multiplied by b4b3b2b1b0. Part (a) shows the block diagram, (b) shows the inputs to the array, and (c) expands the array to show all the adders.
The array multiplier in Figure J.27 performs the same number of additions as the design in Figure J.24, so its latency is not dramatically different from that of a single carry-save adder. However, with the hardware in Figure J.27, multiplication can be pipelined, increasing the total throughput. On the other hand, although this level of pipelining is sometimes used in array processors, it is not used in any of the single-chip, floating-point accelerators discussed in Section J.10. Pipelining is discussed in general in Appendix C and by Kogge [1981] in the context of multipliers.
Sometimes the space budgeted on a chip for arithmetic may not hold an array large enough to multiply two double-precision numbers. In this case, a popular design is to use a two-pass arrangement such as the one shown in Figure J.28. The first pass through the array “retires” 5 bits of B. Then the result of this first pass is fed back into the top to be combined with the next three summands. The result of this second pass is then fed into a CPA. This design, however, loses the ability to be pipelined.

Multiplies two 8-bit numbers with about half the hardware that would be used in a one-pass design like that of Figure J.27. At the end of the second pass, the bits flow into the CPA. The inputs used in the first pass are marked in bold.
If arrays require as many addition steps as the much cheaper arrangements in Figures J.2 and J.24, why are they so popular? First of all, using an array has a smaller latency than using a single adder—because the array is a combinational circuit, the signals flow through it directly without being clocked. Although the two-pass adder of Figure J.28 would normally still use a clock, the cycle time for passing through k arrays can be less than k times the clock that would be needed for designs like the ones in Figures J.2 or J.24. Second, the array is amenable to various schemes for further speedup. One of them is shown in Figure J.29. The idea of this design is that two adds proceed in parallel or, to put it another way, each stream passes through only half the adders. Thus, it runs at almost twice the speed of the multiplier in Figure J.27. This even/odd multiplier is popular in VLSI because of its regular structure. Arrays can also be speeded up using asynchronous logic. One of the reasons why the multiplier of Figure J.2 (page J-4) needs a clock is to keep the output of the adder from feeding back into the input of the adder before the output has fully stabilized. Thus, if the array in Figure J.28 is long enough so that no signal can propagate from the top through the bottom in the time it takes for the first adder to stabilize, it may be possible to avoid clocks altogether. Williams et al. [1987] discussed a design using this idea, although it is for dividers instead of multipliers.

The first two adders work in parallel. Their results are fed into the third and fourth adders, which also work in parallel, and so on.
The techniques of the previous paragraph still have a multiply time of 0(n), but the time can be reduced to log n using a tree. The simplest tree would combine pairs of summands  , cutting the number of summands from n to n/2. Then these n/2 numbers would be added in pairs again, reducing to n/4, and so on, and resulting in a single sum after log n steps. However, this simple binary tree idea doesn’t map into full (3,2) adders, which reduce three inputs to two rather than reducing two inputs to one. A tree that does use full adders, known as a Wallace tree, is shown in Figure J.30. When computer arithmetic units were built out of MSI parts, a Wallace tree was the design of choice for high-speed multipliers. There is, however, a problem with implementing it in VLSI. If you try to fill in all the adders and paths for the Wallace tree of Figure J.30, you will discover that it does not have the nice, regular structure of Figure J.27. This is why VLSI designers have often chosen to use other log n designs such as the binary tree multiplier, which is discussed next.
, cutting the number of summands from n to n/2. Then these n/2 numbers would be added in pairs again, reducing to n/4, and so on, and resulting in a single sum after log n steps. However, this simple binary tree idea doesn’t map into full (3,2) adders, which reduce three inputs to two rather than reducing two inputs to one. A tree that does use full adders, known as a Wallace tree, is shown in Figure J.30. When computer arithmetic units were built out of MSI parts, a Wallace tree was the design of choice for high-speed multipliers. There is, however, a problem with implementing it in VLSI. If you try to fill in all the adders and paths for the Wallace tree of Figure J.30, you will discover that it does not have the nice, regular structure of Figure J.27. This is why VLSI designers have often chosen to use other log n designs such as the binary tree multiplier, which is discussed next.

An example of a multiply tree that computes a product in 0(log n) steps.
The problem with adding summands in a binary tree is coming up with a (2,1) adder that combines two digits and produces a single-sum digit. Because of carries, this isn’t possible using binary notation, but it can be done with some other representation. We will use the signed-digit representation 1, , and 0, which we used previously to understand Booth’s algorithm. This representation has two costs. First, it takes 2 bits to represent each signed digit. Second, the algorithm for adding two signed-digit numbers ai and bi is complex and requires examining aiai − 1ai − 2 and bibi − 1bi − 2. Although this means you must look 2 bits back, in binary addition you might have to look an arbitrary number of bits back because of carries.
We can describe the algorithm for adding two signed-digit numbers as follows. First, compute sum and carry bits si and ci + 1 using Figure J.31. Then compute the final sum as si + ci. The tables are set up so that this final sum does not generate a carry.

The leftmost sum shows that when computing 1 + 1, the sum bit is 0 and the carry bit is 1.
Example
What is the sum of the signed-digit numbers  and 0012?
and 0012?
Answer
The two low-order bits sum to  , the next pair sums to
, the next pair sums to  , and the high-order pair sums to 1 + 0 = 01, so the sum is
, and the high-order pair sums to 1 + 0 = 01, so the sum is  .
.
This, then, defines a (2,1) adder. With this in hand, we can use a straightforward binary tree to perform multiplication. In the first step it adds b0A + b1A in parallel with b2A + b3A, …, bn − 2A + bn − 1A. The next step adds the results of these sums in pairs, and so on. Although the final sum must be run through a carry-propagate adder to convert it from signed-digit form to two’s complement, this final add step is necessary in any multiplier using CSAs.
To summarize, both Wallace trees and signed-digit trees are log n multipliers. The Wallace tree uses fewer gates but is harder to lay out. The signed-digit tree has a more regular structure, but requires 2 bits to represent each digit and has more complicated add logic. As with adders, it is possible to combine different multiply techniques. For example, Booth recoding and arrays can be combined. In Figure J.27 instead of having each input be biA, we could have it be bibi − 1A. To avoid having to compute the multiple 3b, we can use Booth recoding.
Faster Division with One Adder
The two techniques we discussed for speeding up multiplication with a single adder were carry-save adders and higher-radix multiplication. However, there is a difficulty when trying to utilize these approaches to speed up nonrestoring division. If the adder in Figure J.2(b) on page J-4 is replaced with a carry-save adder, then P will be replaced with two registers, one for the sum bits and one for the carry bits (compare with the multiplier in Figure J.24). At the end of each cycle, the sign of P is uncertain (since P is the unevaluated sum of the two registers), yet it is the sign of P that is used to compute the quotient digit and decide the next ALU operation. When a higher radix is used, the problem is deciding what value to subtract from P. In the paper-and-pencil method, you have to guess the quotient digit. In binary division, there are only two possibilities. We were able to finesse the problem by initially guessing one and then adjusting the guess based on the sign of P. This doesn’t work in higher radices because there are more than two possible quotient digits, rendering quotient selection potentially quite complicated: You would have to compute all the multiples of b and compare them to P.
Both the carry-save technique and higher-radix division can be made to work if we use a redundant quotient representation. Recall from our discussion of SRT division (page J-45) that by allowing the quotient digits to be − 1, 0, or 1, there is often a choice of which one to pick. The idea in the previous algorithm was to choose 0 whenever possible, because that meant an ALU operation could be skipped. In carry-save division, the idea is that, because the remainder (which is the value of the (P,A) register pair) is not known exactly (being stored in carry-save form), the exact quotient digit is also not known. But, thanks to the redundant representation, the remainder doesn’t have to be known precisely in order to pick a quotient digit. This is illustrated in Figure J.32, where the x-axis represents ri, the remainder after i steps. The line labeled qi = 1 shows the value that ri + 1 would be if we chose qi = 1, and similarly for the lines qi = 0 and qi = − 1. We can choose any value for qi, as long as ri + 1 = 2ri − qib satisfies |ri + 1| ≤ b. The allowable ranges are shown in the right half of Figure J.32. This shows that you don’t need to know the precise value of ri in order to choose a quotient digit qi. You only need to know that r lies in an interval small enough to fit entirely within one of the overlapping bars shown in the right half of Figure J.32.

The x-axis represents the ith remainder, which is the quantity in the (P,A) register pair. The y-axis shows the value of the remainder after one additional divide step. Each bar on the right-hand graph gives the range of ri values for which it is permissible to select the associated value of qi.
This is the basis for using carry-save adders. Look at the high-order bits of the carry-save adder and sum them in a propagate adder. Then use this approximation of r (together with the divisor, b) to compute qi, usually by means of a lookup table. The same technique works for higher-radix division (whether or not a carry-save adder is used). The high-order bits P can be used to index a table that gives one of the allowable quotient digits.
The design challenge when building a high-speed SRT divider is figuring out how many bits of P and B need to be examined. For example, suppose that we take a radix of 4, use quotient digits of 2, 1, 0, ,  , but have a propagate adder. How many bits of P and B need to be examined? Deciding this involves two steps. For ordinary radix-2 nonrestoring division, because at each stage |r| ≤ b, the P buffer won’t overflow. But, for radix 4, ri + 1 = 4ri − qib is computed at each stage, and if ri is near b, then 4ri will be near 4b, and even the largest quotient digit will not bring r back to the range |ri + 1| ≤ b. In other words, the remainder might grow without bound. However, restricting |ri| ≤ 2b/3 makes it easy to check that ri will stay bounded.
, but have a propagate adder. How many bits of P and B need to be examined? Deciding this involves two steps. For ordinary radix-2 nonrestoring division, because at each stage |r| ≤ b, the P buffer won’t overflow. But, for radix 4, ri + 1 = 4ri − qib is computed at each stage, and if ri is near b, then 4ri will be near 4b, and even the largest quotient digit will not bring r back to the range |ri + 1| ≤ b. In other words, the remainder might grow without bound. However, restricting |ri| ≤ 2b/3 makes it easy to check that ri will stay bounded.
After figuring out the bound that ri must satisfy, we can draw the diagram in Figure J.33, which is analogous to Figure J.32. For example, the diagram shows that if ri is between (1/12)b and (5/12)b, we can pick q = 1, and so on. Or, to put it another way, if r/b is between 1/12 and 5/12, we can pick q = 1. Suppose the divider examines 5 bits of P (including the sign bit) and 4 bits of b (ignoring the sign, since it is always nonnegative). The interesting case is when the high bits of P are  , while the high bits of b are
, while the high bits of b are  . Imagine the binary point at the left end of each register. Since we truncated, r (the value of P concatenated with A) could have a value from 0.00112 to 0.01002, and b could have a value from .10012 to .10102. Thus, r/b could be as small as 0.00112/.10102 or as large as 0.01002/.10012, but 0.00112/.10102 = 3/10 < 1/3 would require a quotient bit of 1, while 0.01002/.10012 = 4/9 > 5/12 would require a quotient bit of 2. In other words, 5 bits of P and 4 bits of b aren’t enough to pick a quotient bit. It turns out that 6 bits of P and 4 bits of b are enough. This can be verified by writing a simple program that checks all the cases. The output of such a program is shown in Figure J.34.
. Imagine the binary point at the left end of each register. Since we truncated, r (the value of P concatenated with A) could have a value from 0.00112 to 0.01002, and b could have a value from .10012 to .10102. Thus, r/b could be as small as 0.00112/.10102 or as large as 0.01002/.10012, but 0.00112/.10102 = 3/10 < 1/3 would require a quotient bit of 1, while 0.01002/.10012 = 4/9 > 5/12 would require a quotient bit of 2. In other words, 5 bits of P and 4 bits of b aren’t enough to pick a quotient bit. It turns out that 6 bits of P and 4 bits of b are enough. This can be verified by writing a simple program that checks all the cases. The output of such a program is shown in Figure J.34.


The top row says that if the high-order 4 bits of b are 10002 = 8, and if the top 6 bits of P are between 1101002 = − 12 and 1110012 = − 7, then − 2 is a valid quotient digit.
Example
Using 8-bit registers, compute 149/5 using radix-4 SRT division.
Answer
Follow the SRT algorithm on page J-45, but replace the quotient selection rule in step 2 with one that uses Figure J.34. See Figure J.35.

The Pentium uses a radix-4 SRT division algorithm like the one just presented, except that it uses a carry-save adder. Exercises J.34(c) and J.35 explore this in detail. Although these are simple cases, all SRT analyses proceed in the same way. First compute the range of ri, then plot ri against ri + 1 to find the quotient ranges, and finally write a program to compute how many bits are necessary. (It is sometimes also possible to compute the required number of bits analytically.) Various details need to be considered in building a practical SRT divider. For example, the quotient lookup table has a fairly regular structure, which means it is usually cheaper to encode it as a PLA rather than in ROM. For more details about SRT division, see Burgess and Williams [1995].
J.10 Putting It All Together
In this section, we will compare the Weitek 3364, the MIPS R3010, and the Texas Instruments 8847 (see Figures J.36 and J.37). In many ways, these are ideal chips to compare. They each implement the IEEE standard for addition, subtraction, multiplication, and division on a single chip. All were introduced in 1988 and run with a cycle time of about 40 nanoseconds. However, as we will see, they use quite different algorithms. The Weitek chip is well described in Birman et al. [1990], the MIPS chip is described in less detail in Rowen, Johnson, and Ries [1988], and details of the TI chip can be found in Darley et al. [1989].

The cycle times are for production parts available in June 1989. The cycle counts are for double-precision operations.



In the left-hand columns are the photomicrographs; the right-hand columns show the corresponding floor plans.
These three chips have a number of things in common. They perform addition and multiplication in parallel, and they implement neither extended precision nor a remainder step operation. (Recall from Section J.6 that it is easy to implement the IEEE remainder function in software if a remainder step instruction is available.) The designers of these chips probably decided not to provide extended precision because the most influential users are those who run portable codes, which can’t rely on extended precision. However, as we have seen, extended precision can make for faster and simpler math libraries.
In the summary of the three chips given in Figure J.36, note that a higher transistor count generally leads to smaller cycle counts. Comparing the cycles/op numbers needs to be done carefully, because the figures for the MIPS chip are those for a complete system (R3000/3010 pair), while the Weitek and TI numbers are for stand-alone chips and are usually larger when used in a complete system.
The MIPS chip has the fewest transistors of the three. This is reflected in the fact that it is the only chip of the three that does not have any pipelining or hardware square root. Further, the multiplication and addition operations are not completely independent because they share the carry-propagate adder that performs the final rounding (as well as the rounding logic).
Addition on the R3010 uses a mixture of ripple, CLA, and carry-select. A carry-select adder is used in the fashion of Figure J.20 (page J-43). Within each half, carries are propagated using a hybrid ripple-CLA scheme of the type indicated in Figure J.19 (page J-42). However, this is further tuned by varying the size of each block, rather than having each fixed at 4 bits (as they are in Figure J.19). The multiplier is midway between the designs of Figures J.2 (page J-4) and J.27 (page J-50). It has an array just large enough so that output can be fed back into the input without having to be clocked. Also, it uses radix-4 Booth recoding and the even/odd technique of Figure J.29 (page J-52). The R3010 can do a divide and multiply in parallel (like the Weitek chip but unlike the TI chip). The divider is a radix-4 SRT method with quotient digits − 2, − 1, 0, 1, and 2, and is similar to that described in Taylor [1985]. Double-precision division is about four times slower than multiplication. The R3010 shows that for chips using an 0(n) multiplier, an SRT divider can operate fast enough to keep a reasonable ratio between multiply and divide.
The Weitek 3364 has independent add, multiply, and divide units. It also uses radix-4 SRT division. However, the add and multiply operations on the Weitek chip are pipelined. The three addition stages are (1) exponent compare, (2) add followed by shift (or vice versa), and (3) final rounding. Stages (1) and (3) take only a half-cycle, allowing the whole operation to be done in two cycles, even though there are three pipeline stages. The multiplier uses an array of the style of Figure J.28 but uses radix-8 Booth recoding, which means it must compute 3 times the multiplier. The three multiplier pipeline stages are (1) compute 3b, (2) pass through array, and (3) final carry-propagation add and round. Single precision passes through the array once, double precision twice. Like addition, the latency is two cycles.
The Weitek chip uses an interesting addition algorithm. It is a variant on the carry-skip adder pictured in Figure J.18 (page J-42). However, Pij, which is the logical AND of many terms, is computed by rippling, performing one AND per ripple. Thus, while the carries propagate left within a block, the value of Pij is propagating right within the next block, and the block sizes are chosen so that both waves complete at the same time. Unlike the MIPS chip, the 3364 has hardware square root, which shares the divide hardware. The ratio of double-precision multiply to divide is 2:17. The large disparity between multiply and divide is due to the fact that multiplication uses radix-8 Booth recoding, while division uses a radix-4 method. In the MIPS R3010, multiplication and division use the same radix.
The notable feature of the TI 8847 is that it does division by iteration (using the Goldschmidt algorithm discussed in Section J.6). This improves the speed of division (the ratio of multiply to divide is 3:11), but means that multiplication and division cannot be done in parallel as on the other two chips. Addition has a two-stage pipeline. Exponent compare, fraction shift, and fraction addition are done in the first stage, normalization and rounding in the second stage. Multiplication uses a binary tree of signed-digit adders and has a three-stage pipeline. The first stage passes through the array, retiring half the bits; the second stage passes through the array a second time; and the third stage converts from signed-digit form to two’s complement. Since there is only one array, a new multiply operation can only be initiated in every other cycle. However, by slowing down the clock, two passes through the array can be made in a single cycle. In this case, a new multiplication can be initiated in each cycle. The 8847 adder uses a carry-select algorithm rather than carry-lookahead. As mentioned in Section J.6, the TI carries 60 bits of precision in order to do correctly rounded division.
These three chips illustrate the different trade-offs made by designers with similar constraints. One of the most interesting things about these chips is the diversity of their algorithms. Each uses a different add algorithm, as well as a different multiply algorithm. In fact, Booth recoding is the only technique that is universally used by all the chips.
J.11 Fallacies and Pitfalls
- Fallacy Underflows rarely occur in actual floating-point application code
Although most codes rarely underflow, there are actual codes that underflow frequently. SDRWAVE [Kahaner 1988], which solves a one-dimensional wave equation, is one such example. This program underflows quite frequently, even when functioning properly. Measurements on one machine show that adding hardware support for gradual underflow would cause SDRWAVE to run about 50% faster.
- Fallacy Conversions between integer and floating point are rare
In fact, in spice they are as frequent as divides. The assumption that conversions are rare leads to a mistake in the SPARC version 8 instruction set, which does not provide an instruction to move from integer registers to floating-point registers.
- Pitfall Don’t increase the speed of a floating-point unit without increasing its memory bandwidth
A typical use of a floating-point unit is to add two vectors to produce a third vector. If these vectors consist of double-precision numbers, then each floating-point add will use three operands of 64 bits each, or 24 bytes of memory. The memory bandwidth requirements are even greater if the floating-point unit can perform addition and multiplication in parallel (as most do).
- Pitfall − x is not the same as 0 − x
This is a fine point in the IEEE standard that has tripped up some designers. Because floating-point numbers use the sign magnitude system, there are two zeros, + 0 and − 0. The standard says that 0 − 0 = + 0, whereas − (0) = − 0. Thus, − x is not the same as 0 − x when x = 0.
J.12 Historical Perspective and References
The earliest computers used fixed point rather than floating point. In “Preliminary Discussion of the Logical Design of an Electronic Computing Instrument,” Burks, Goldstine, and von Neumann [1946] put it like this:
There appear to be two major purposes in a “floating” decimal point system both of which arise from the fact that the number of digits in a word is a constant fixed by design considerations for each particular machine. The first of these purposes is to retain in a sum or product as many significant digits as possible and the second of these is to free the human operator from the burden of estimating and inserting into a problem “scale factors”—multiplicative constants which serve to keep numbers within the limits of the machine.
There is, of course, no denying the fact that human time is consumed in arranging for the introduction of suitable scale factors. We only argue that the time so consumed is a very small percentage of the total time we will spend in preparing an interesting problem for our machine. The first advantage of the floating point is, we feel, somewhat illusory. In order to have such a floating point, one must waste memory capacity that could otherwise be used for carrying more digits per word. It would therefore seem to us not at all clear whether the modest advantages of a floating binary point offset the loss of memory capacity and the increased complexity of the arithmetic and control circuits.
This enables us to see things from the perspective of early computer designers, who believed that saving computer time and memory were more important than saving programmer time.
The original papers introducing the Wallace tree, Booth recoding, SRT division, overlapped triplets, and so on are reprinted in Swartzlander [1990]. A good explanation of an early machine (the IBM 360/91) that used a pipelined Wallace tree, Booth recoding, and iterative division is in Anderson et al. [1967]. A discussion of the average time for single-bit SRT division is in Freiman [1961]; this is one of the few interesting historical papers that does not appear in Swartzlander.
The standard book of Mead and Conway [1980] discouraged the use of CLAs as not being cost effective in VLSI. The important paper by Brent and Kung [1982] helped combat that view. An example of a detailed layout for CLAs can be found in Ngai and Irwin [1985] or in Weste and Eshraghian [1993], and a more theoretical treatment is given by Leighton [1992]. Takagi, Yasuura, and Yajima [1985] provide a detailed description of a signed-digit tree multiplier.
Before the ascendancy of IEEE arithmetic, many different floating-point formats were in use. Three important ones were used by the IBM 370, the DEC VAX, and the Cray. Here is a brief summary of these older formats. The VAX format is closest to the IEEE standard. Its single-precision format (F format) is like IEEE single precision in that it has a hidden bit, 8 bits of exponent, and 23 bits of fraction. However, it does not have a sticky bit, which causes it to round halfway cases up instead of to even. The VAX has a slightly different exponent range from IEEE single: Emin is − 128 rather than − 126 as in IEEE, and Emax is 126 instead of 127. The main differences between VAX and IEEE are the lack of special values and gradual underflow. The VAX has a reserved operand, but it works like a signaling NaN: It traps whenever it is referenced. Originally, the VAX’s double precision (D format) also had 8 bits of exponent. However, as this is too small for many applications, a G format was added; like the IEEE standard, this format has 11 bits of exponent. The VAX also has an H format, which is 128 bits long.
The IBM 370 floating-point format uses base 16 rather than base 2. This means it cannot use a hidden bit. In single precision, it has 7 bits of exponent and 24 bits (6 hex digits) of fraction. Thus, the largest representable number is 1627 = 24 × 27 = 229, compared with 228 for IEEE. However, a number that is normalized in the hexadecimal sense only needs to have a nonzero leading digit. When interpreted in binary, the three most-significant bits could be zero. Thus, there are potentially fewer than 24 bits of significance. The reason for using the higher base was to minimize the amount of shifting required when adding floating-point numbers. However, this is less significant in current machines, where the floating-point add time is usually fixed independently of the operands. Another difference between 370 arithmetic and IEEE arithmetic is that the 370 has neither a round digit nor a sticky digit, which effectively means that it truncates rather than rounds. Thus, in many computations, the result will systematically be too small. Unlike the VAX and IEEE arithmetic, every bit pattern is a valid number. Thus, library routines must establish conventions for what to return in case of errors. In the IBM FORTRAN library, for example,  returns 2!
returns 2!
Arithmetic on Cray computers is interesting because it is driven by a motivation for the highest possible floating-point performance. It has a 15-bit exponent field and a 48-bit fraction field. Addition on Cray computers does not have a guard digit, and multiplication is even less accurate than addition. Thinking of multiplication as a sum of p numbers, each 2p bits long, Cray computers drop the low-order bits of each summand. Thus, analyzing the exact error characteristics of the multiply operation is not easy. Reciprocals are computed using iteration, and division of a by b is done by multiplying a times 1/b. The errors in multiplication and reciprocation combine to make the last three bits of a divide operation unreliable. At least Cray computers serve to keep numerical analysts on their toes!
The IEEE standardization process began in 1977, inspired mainly by W. Kahan and based partly on Kahan’s work with the IBM 7094 at the University of Toronto [Kahan 1968]. The standardization process was a lengthy affair, with gradual underflow causing the most controversy. (According to Cleve Moler, visitors to the United States were advised that the sights not to be missed were Las Vegas, the Grand Canyon, and the IEEE standards committee meeting.) The standard was finally approved in 1985. The Intel 8087 was the first major commercial IEEE implementation and appeared in 1981, before the standard was finalized. It contains features that were eliminated in the final standard, such as projective bits. According to Kahan, the length of double-extended precision was based on what could be implemented in the 8087. Although the IEEE standard was not based on any existing floating-point system, most of its features were present in some other system. For example, the CDC 6600 reserved special bit patterns for INDEFINITE and INFINITY, while the idea of denormal numbers appears in Goldberg [1967] as well as in Kahan [1968]. Kahan was awarded the 1989 Turing prize in recognition of his work on floating point.
Although floating point rarely attracts the interest of the general press, newspapers were filled with stories about floating-point division in November 1994. A bug in the division algorithm used on all of Intel’s Pentium chips had just come to light. It was discovered by Thomas Nicely, a math professor at Lynchburg College in Virginia. Nicely found the bug when doing calculations involving reciprocals of prime numbers. News of Nicely’s discovery first appeared in the press on the front page of the November 7 issue of Electronic Engineering Times. Intel’s immediate response was to stonewall, asserting that the bug would only affect theoretical mathematicians. Intel told the press, “This doesn’t even qualify as an errata … even if you’re an engineer, you’re not going to see this.”
Under more pressure, Intel issued a white paper, dated November 30, explaining why they didn’t think the bug was significant. One of their arguments was based on the fact that if you pick two floating-point numbers at random and divide one into the other, the chance that the resulting quotient will be in error is about 1 in 9 billion. However, Intel neglected to explain why they thought that the typical customer accessed floating-point numbers randomly.
Pressure continued to mount on Intel. One sore point was that Intel had known about the bug before Nicely discovered it, but had decided not to make it public. Finally, on December 20, Intel announced that they would unconditionally replace any Pentium chip that used the faulty algorithm and that they would take an unspecified charge against earnings, which turned out to be $300 million.
The Pentium uses a simple version of SRT division as discussed in Section J.9. The bug was introduced when they converted the quotient lookup table to a PLA. Evidently there were a few elements of the table containing the quotient digit 2 that Intel thought would never be accessed, and they optimized the PLA design using this assumption. The resulting PLA returned 0 rather than 2 in these situations. However, those entries were really accessed, and this caused the division bug. Even though the effect of the faulty PLA was to cause 5 out of 2048 table entries to be wrong, the Pentium only computes an incorrect quotient 1 out of 9 billion times on random inputs. This is explored in Exercise J.34.
Exercises
- J.1 [12] < J.2 > Using n bits, what is the largest and smallest integer that can be represented in the two’s complement system?
- J.2 [20/25] < J.2 > In the subsection “Signed Numbers” (page J-7), it was stated that two’s complement overflows when the carry into the high-order bit position is different from the carry-out from that position.
- J.3 [12] < J.2 > Using 4-bit binary numbers, multiply − 8 × − 8 using Booth recoding.
- J.4 [15] < J.2 > Equations J.2.1 and J.2.2 are for adding two n-bit numbers. Derive similar equations for subtraction, where there will be a borrow instead of a carry.
- J.5 [25] < J.2 > On a machine that doesn’t detect integer overflow in hardware, show how you would detect overflow on a signed addition operation in software.
- J.6 [15/15/20] < J.3 > Represent the following numbers as single-precision and double-precision IEEE floating-point numbers:
- J.7 [12/12/12/12/12] < J.3 > Below is a list of floating-point numbers. In single precision, write down each number in binary, in decimal, and give its representation in IEEE arithmetic.
- J.8 [15] < J.3 > Is the ordering of nonnegative floating-point numbers the same as integers when denormalized numbers are also considered?
- J.9 [20] < J.3 > Write a program that prints out the bit patterns used to represent floating-point numbers on your favorite computer. What bit pattern is used for NaN?
- J.10 [15] < J.4 > Using p = 4, show how the binary floating-point multiply algorithm computes the product of 1.875 × 1.875.
- J.11 [12/10] < J.4 > Concerning the addition of exponents in floating-point multiply:
- J.12 [15/12] < J.4 > In the discussion of overflow detection for floating-point multiplication, it was stated that (for single precision) you can detect an overflowed exponent by performing exponent addition in a 9-bit adder.
- J.13 [15/10] < J.4 > Floating-point multiplication:
- J.14 [15] < J.4 > Give an example of a product with a denormal operand but a normalized output. How large was the final shifting step? What is the maximum possible shift that can occur when the inputs are double-precision numbers?
- J.15 [15] < J.5 > Use the floating-point addition algorithm on page J-23 to compute 1.0102 − .10012 (in 4-bit precision).
- J.16 [10/15/20/20/20] < J.5 > In certain situations, you can be sure that a + b is exactly representable as a floating-point number, that is, no rounding is necessary.
- a. [10] < J.5 > If a, b have the same exponent and different signs, explain why a + b is exact. This was used in the subsection “Speeding Up Addition” on page J-25.
- b. [15] < J.5 > Give an example where the exponents differ by 1, a and b have different signs, and a + b is not exact.
- c. [20] < J.5 > If a ≥ b ≥ 0, and the top two bits of a cancel when computing a − b, explain why the result is exact (this fact is mentioned on page J-22).
- d. [20] < J.5 > If a ≥ b ≥ 0, and the exponents differ by 1, show that a − b is exact unless the high order bit of a − b is in the same position as that of a (mentioned in “Speeding Up Addition,” page J-25).
- e. [20] < J.5 > If the result of a − b or a + b is denormal, show that the result is exact (mentioned in the subsection “Underflow,” on page J-36).
- J.17 [15/20] < J.5 > Fast floating-point addition (using parallel adders) for p = 5.
- J.18 [12] < J.4, J.5 > How would you use two parallel adders to avoid the final round-up addition in floating-point multiplication?
- J.19 [30/10] < J.5 > This problem presents a way to reduce the number of addition steps in floating-point addition from three to two using only a single adder.
- a. [30] < J.5 > Let A and B be integers of opposite signs, with a and b their magnitudes. Show that the following rules for manipulating the unsigned numbers a and b gives A + B.
- 1. Complement one of the operands.
- 2. Use end-around carry to add the complemented operand and the other (uncomplemented) one.
- 3. If there was a carry-out, the sign of the result is the sign associated with the uncomplemented operand.
- 4. Otherwise, if there was no carry-out, complement the result, and give it the sign of the complemented operand.
- b. [10] < J.5 > Use the above to show how steps 2 and 4 in the floating-point addition algorithm on page J-23 can be performed using only a single addition.
- a. [30] < J.5 > Let A and B be integers of opposite signs, with a and b their magnitudes. Show that the following rules for manipulating the unsigned numbers a and b gives A + B.
- J.20 [20/15/20/15/20/15] < J.6 > Iterative square root.
- a. [20] < J.6 > Use Newton’s method to derive an iterative algorithm for square root. The formula will involve a division.
- b. [15] < J.6 > What is the fastest way you can think of to divide a floating-point number by 2?
- c. [20] < J.6 > If division is slow, then the iterative square root routine will also be slow. Use Newton’s method on f(x) = 1/x2 − a to derive a method that doesn’t use any divisions.
- d. [15] < J.6 > Assume that the ratio division by 2 : floating-point add : floating-point multiply is 1:2:4. What ratios of multiplication time to divide time makes each iteration step in the method of part (c) faster than each iteration in the method of part (a)?
- e. [20] < J.6 > When using the method of part (a), how many bits need to be in the initial guess in order to get double-precision accuracy after three iterations? (You may ignore rounding error.)
- f. [15] < J.6 > Suppose that when spice runs on the TI 8847, it spends 16.7% of its time in the square root routine (this percentage has been measured on other machines). Using the values in Figure J.36 and assuming three iterations, how much slower would spice run if square root were implemented in software using the method of part(a)?
- J.21 [10/20/15/15/15] < J.6 > Correctly rounded iterative division. Let a and b be floating-point numbers with p-bit significands (p = 53 in double precision). Let q be the exact quotient q = a/b, 1 ≤ q < 2. Suppose that
 is the result of an iteration process, that has a few extra bits of precision, and that
is the result of an iteration process, that has a few extra bits of precision, and that  . For the following, it is important that
. For the following, it is important that  , even when q can be exactly represented as a floating-point number.
, even when q can be exactly represented as a floating-point number.- a. [10] < J.6 > If x is a floating-point number, and 1 ≤ x < 2, what is the next representable number after x?
- b. [20] < J.6 > Show how to compute q′ from , where q′ has p + 1 bits of precision and |q − q′| < 2− p.
- c. [15] < J.6 > Assuming round to nearest, show that the correctly rounded quotient is either q′, q′ − 2− p, or q′ + 2− p.
- d. [15] < J.6 > Give rules for computing the correctly rounded quotient from q′ based on the low-order bit of q′ and the sign of a − bq′.
- e. [15] < J.6 > Solve part (c) for the other three rounding modes.
- J.22 [15] < J.6 > Verify the formula on page J-30. (Hint: If
 , then
, then  .)
.) - J.23 [15] < J.7 > Our example that showed that double rounding can give a different answer from rounding once used the round-to-even rule. If halfway cases are always rounded up, is double rounding still dangerous?
- J.24 [10/10/20/20] < J.7 > Some of the cases of the italicized statement in the “Precisions” subsection (page J-33) aren’t hard to demonstrate.
- a. [10] < J.7 > What form must a binary number have if rounding to q bits followed by rounding to p bits gives a different answer than rounding directly to p bits?
- b. [10] < J.7 > Show that for multiplication of p-bit numbers, rounding to q bits followed by rounding to p bits is the same as rounding immediately to p bits if q ≥ 2p.
- c. [20] < J.7 > If a and b are p-bit numbers with the same sign, show that rounding a + b to q bits followed by rounding to p bits is the same as rounding immediately to p bits if q ≥ 2p + 1.
- d. [20] < J.7 > Do part (c) when a and b have opposite signs.
- J.25 [Discussion] < J.7 > In the MIPS approach to exception handling, you need a test for determining whether two floating-point operands could cause an exception. This should be fast and also not have too many false positives. Can you come up with a practical test? The performance cost of your design will depend on the distribution of floating-point numbers. This is discussed in Knuth [1981] and the Hamming paper in Swartzlander [1990].
- J.26 [12/12/10] < J.8 > Carry-skip adders.
- J.27 [10/15/20] < J.8 > Complete the details of the block diagrams for the following adders.
- a. [10] < J.8 > In Figure J.15, show how to implement the “1” and “2” boxes in terms of AND and OR gates.
- b. [15] < J.8 > In Figure J.19, what signals need to flow from the adder cells in the top row into the “C” cells? Write the logic equations for the “C” box.
- c. [20] < J.8 > Show how to extend the block diagram in J.17 so it will produce the carry-out bit c8.
- J.28 [15] < J.9 > For ordinary Booth recoding, the multiple of b used in the ith step is simply ai − 1 − ai. Can you find a similar formula for radix-4 Booth recoding (overlapped triplets)?
- J.29 [20] < J.9 > Expand Figure J.29 in the fashion of J.27, showing the individual adders.
- J.30 [25] < J.9 > Write out the analog of Figure J.25 for radix-8 Booth recoding.
- J.31 [18] < J.9 > Suppose that an − 1 … a1a0 and bn − 1 … b1b0 are being added in a signed-digit adder as illustrated in the example on page J-53. Write a formula for the ith bit of the sum, si, in terms of ai, ai − 1, ai − 2, bi, bi − 1, and bi − 2.
- J.32 [15] < J.9 > The text discussed radix-4 SRT division with quotient digits of − 2, − 1, 0, 1, 2. Suppose that 3 and − 3 are also allowed as quotient digits. What relation replaces |ri| ≤ 2b/3?
- J.33 [25/20/30] < J.9 > Concerning the SRT division table, Figure J.34:
- a. [25] < J.9 > Write a program to generate the results of Figure J.34.
- b. [20] < J.9 > Note that Figure J.34 has a certain symmetry with respect to positive and negative values of P. Can you find a way to exploit the symmetry and only store the values for positive P?
- c. [30] < J.9 > Suppose a carry-save adder is used instead of a propagate adder. The input to the quotient lookup table will be k bits of divisor and l bits of remainder, where the remainder bits are computed by summing the top l bits of the sum and carry registers. What are k and l? Write a program to generate the analog of Figure J.34.
- J.34 [12/12/12] < J.9, J.12 > The first several million Pentium chips produced had a flaw that caused division to sometimes return the wrong result. The Pentium uses a radix-4 SRT algorithm similar to the one illustrated in the example on page J-56 (but with the remainder stored in carry-save format; see Exercise J.33(c)). According to Intel, the bug was due to five incorrect entries in the quotient lookup table.
- a. [12] < J.9, J.12 > The bad entries should have had a quotient of plus or minus 2, but instead had a quotient of 0. Because of redundancy, it’s conceivable that the algorithm could “recover” from a bad quotient digit on later iterations. Show that this is not possible for the Pentium flaw.
- b. [12] < J.9, J.12 > Since the operation is a floating-point divide rather than an integer divide, the SRT division algorithm on page J-45 must be modified in two ways. First, step 1 is no longer needed, since the divisor is already normalized. Second, the very first remainder may not satisfy the proper bound (|r| ≤ 2b/3 for Pentium; see page J-55). Show that skipping the very first left shift in step 2(a) of the SRT algorithm will solve this problem.
- c. [12] < J.9, J.12 > If the faulty table entries were indexed by a remainder that could occur at the very first divide step (when the remainder is the divisor), random testing would quickly reveal the bug. This didn’t happen. What does that tell you about the remainder values that index the faulty entries?
- J.35 [12] < J.6, J.9 > The discussion of the remainder-step instruction assumed that division was done using a bit-at-a-time algorithm. What would have to change if division were implemented using a higher-radix method?
- J.36 [25] < J.9 > In the array of Figure J.28, the fact that an array can be pipelined is not exploited. Can you come up with a design that feeds the output of the bottom CSA into the bottom CSAs instead of the top one, and that will run faster than the arrangement of Figure J.28?
