CHAPTER 6
ORGANIZING FOR BIG DATA GOVERNANCE
This chapter includes contributions from Bob Leo (IBM).
As we discussed in chapter 1, big data exposes the natural tensions across different functions. The big data governance program needs to adopt the following best practices to improve organizational alignment:
6.1 Map key processes and establish a responsibility assignment matrix to identify the stakeholders in big data governance.
6.2 Determine the appropriate mix of new and existing roles.
6.3 Appoint big data stewards as appropriate.
6.4 Add big data responsibilities to traditional information governance roles as appropriate.
6.5 Establish a merged information governance organization with responsibilities that include big data.
Each best practice is discussed in detail in the following pages.
6.1 Map Key Processes and Establish a RACI Matrix to Identify Stakeholders in Big Data Governance
A responsibility assignment (RACI) matrix can demonstrate how different organizations might be engaged in big data governance. “RACI” stands for the following:
- Responsible—This is the person who has delegated responsibility to manage an attribute. There may be multiple responsible parties for one attribute.
- Accountable—This is the person who has ultimate accountability for the data attribute. The accountable person may delegate the responsibility to manage an attribute to a responsible party. There should be only one accountable party.
- Consulted—This is the person or persons who are consulted via bi-directional communications.
- Informed—This is the person or persons who are kept informed via uni-directional communications.
Case Study 6.1 demonstrates the use of process mapping and a RACI matrix at a large health plan. To set the context for this case study, a brief primer on claim codes will be helpful.
A Primer on Claim Codes Used by Health Plans
Health plans use claim codes to reimburse providers and hospitals, to benchmark costs and quality of service, and to offer care management services that reduce medical costs.
Health plans require their providers (doctors) to include the appropriate ICD-9, ICD-10, and CPT codes when submitting claims:
- ICD-9-CM codes—The International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM) is based on the World Health Organization’s ICD-9. ICD-9 was originally published in 1979 and was designed to promote international comparability in the collection, processing, classification, and presentation of mortality statistics. ICD-9-CM is the official system of assigning codes to diagnoses associated with hospital utilization in the United States.
- ICD-10-CM codes—The tenth revision of the ICD was published by the World Health Organization in 1999 and significantly increased the number of codes. For example, ICD-9 has just one code for angioplasty, a procedure used to widen blocked blood vessels. Under ICD-10, medical practitioners can choose among 1,170 coded descriptions that pinpoint such factors as the location and the device involved for each patient.1 The objective of ICD-10 is to provide fine-grained analyses of the causes of diseases. The United States Department of Health and Human Services requires the implementation of ICD-10 by October 1, 2013.
- CPT codes—Current Procedural Terminology (CPT) codes are copyrighted by the American Medical Association and describe a uniform set of medical, surgical, and diagnostic services for physicians, patients, accreditation organizations, and healthcare payers for administrative, financial, and analytical purposes. CPT coding is similar to ICD-9-CM and ICD-10-CM coding, except that it identifies the services rendered rather than the diagnosis on the claim. The critical relationship between these codes is that the diagnosis (ICD-9-CM) should support the medical necessity of the procedure (CPT). Since both ICD-9 and CPT are numeric codes, health insurers have designed software that compares the codes for a logical relationship. For example, a claim for CPT 31256 (nasal/sinus endoscopy) would not be supported by ICD-9 826.0 (closed fracture of phalanges of the foot). Such a claim would be quickly identified and rejected.2
Case Study 6.1: Big claims transaction data governance at a large health plan
A large health plan processed 500 millions claims per year. Each claims record contained approximately 600 attributes, in addition to unstructured text. The health plan decided to focus on claims data governance because it spent about 85 cents of every premium dollar on claims, as was the norm in the industry. The business intelligence department conducted analytics on claims data. This activity drove several downstream activities, including care management. For example, if an elderly member (patient) made a number of doctor visits for “ankle pain,” a nurse from healthcare services would call the person to consider treatment for arthritis. This proactive approach would improve the quality of life for the member while also reducing medical costs for the plan (insurer).
The business intelligence department noticed that a number of entries in the diagnosis code field were not ICD-9 codes. Upon profiling the data, the business intelligence team determined that the field included both ICD-9 (diagnosis) codes and CPT codes. The business intelligence team then met with the network management team that was responsible for managing provider (doctor) relationships. After many meetings, it became clear that the network management team had allowed doctors to use either ICD-9 codes or CPT codes, despite stringent guidelines that the field was only for ICD-9 codes. As a result, the claims reports showed inconsistent data, which resulted in the health plan devoting scarce nurse resources to dealing with low-risk patients.
The business intelligence team also conducted text analytics on the freeform text fields in the claims documents. The team compared the results with the reference data for CPT codes and found several anomalies. For example, the free-form text seemed to indicate that the procedure was “flu shot” but the CPT code was “99214,” which may be used for a physical. The conclusion was that providers might have been inadvertently entering incorrect procedure codes into the claims documents. Additionally, the business intelligence team analyzed text such as “chronic congestion” and “blood sugar monitoring” to determine that members might be candidates for disease management programs for asthma and diabetes, respectively.
Figure 6.1 describes a simple process to administer big claims transaction data at the health plan.
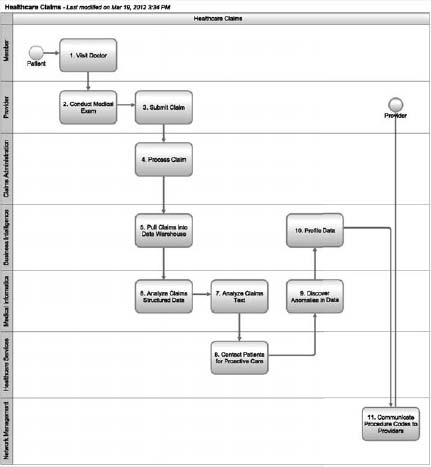
Figure 6.1: A simple claims administration process at a health plan.
There are a number of actors in the claims administration process:
- Health plan—This is the entity that pays for the medical costs of an insured party (also referred to as a healthcare payer or a health insurer).
- Member—This is a person who is covered under a health insurance policy, either as an enrollee or as a dependent.
- Provider—This refers to a doctor, therapist, practice, or hospital that provides medical services.
- Claims administration—This department within the health plan processes claims that are submitted by providers.
- Business intelligence—This department within the health plan is responsible for the data warehouse and analytics environment.
- Medical informatics—This department within the health plan deals with the use of information technology to solve clinical problems.
- Healthcare services—This department within the health plan deals with the clinical aspects of healthcare.
- Network management—This department within the health plan is responsible for managing the network of providers.
The health plan had to establish a number of policies to govern its big claims transaction data. A mapping of the key activities from Figure 6.1 to the big data governance policies is described in Table 6.1.
| Table 6.1: Big Data Governance Policies for Big Claims Transaction Data at a Large Health Plan |
| Seq. |
Activity |
Big Data Governance Policy |
| 4. |
Process claim |
The United States Health Insurance Portability and Accountability Act (HIPAA) safeguards the security and privacy of protected health information (PHI). The information security team established database monitoring to ensure that only authorized personnel could access claims records. For example, the insurer did not want the claims data for its senior executives and for high-profile celebrities to be randomly accessed by database administrators out of idle curiosity. |
| 7. |
Analyze claims text |
As discussed earlier, the health plan used text analytics to uncover inconsistencies, such as when the procedure was “flu shot” but the CPT code was “99214,” which may be used for a physical. The health plan used reference data for ICD-9 and CPT codes to support these analytics. (We discuss reference data in chapter 11, on master data integration.) |
| 9. |
Discover anomalies in the data |
The medical informatics team noticed that a number of entries in the procedure code field were not ICD-9 codes. |
| 10. |
Profile data |
Upon profiling the data, the business intelligence team determined that the diagnosis field incorrectly included both ICD-9 codes and CPT codes, despite stringent guidelines that the field was only for ICD-9 codes. As a result, the claims reports showed inconsistent data. |
| 11. |
Communicate procedure codes to providers |
The big data governance program established a policy that the network management team would ask providers to only use ICD-9 codes in the relevant fields in claims documents. |
As summarized in Table 6.2, the business intelligence team developed a RACI matrix to understand overall roles and responsibilities. The business intelligence team was accountable for the quality of data that drove claims analytics. However, the network management team was ultimately responsible to ensure that providers used the codes in a consistent manner. In addition, the medical informatics, healthcare services, and claims administration departments were consulted because they used the claims information on a day-to-day basis.

6.2 Determine the Appropriate Mix of New and Existing Roles for Information Governance
Once an information governance program has reached a certain state of maturity, it will already have a number of existing roles, such as a chief data officer, an information governance officer, and data stewards. The organization needs to determine if the existing roles should also assume responsibility for big data. Alternatively, the organization may appoint new roles that are specifically focused on big data. There is no right or wrong answer. Every organization needs to balance the revenues, costs, and risks while making these trade-offs. Section 6.3 discusses the roles and responsibilities of big data stewards. Section 6.4 discusses the additional responsibilities that might need to be assumed by existing information governance roles. While we do our best to provide insight, many of these roles are still emerging, and their specific responsibilities will continue to evolve.
6.3 Appoint Big Data Stewards as Appropriate
A data steward ideally reports into the business and, by virtue of his or her deep subject matter expertise, is responsible for improving the trustworthiness and privacy of data as an enterprise asset. Organizations may choose to appoint big data stewards or to extend the roles and responsibilities of existing stewards. This section describes the roles for stewards who are responsible for specific types of big data.
Web and Social Media Stewards
These stewards are responsible for clickstream data and social media. Here are the roles and responsibilities of these data stewards:
- Work with senior management, the privacy department, legal counsel, and other stakeholders to achieve consensus on the acceptable use of web and social media data in the context of local regulations and customs, such as the following:
- Using web cookies, especially third-party cookies, for behavioral profiling
- Leveraging Facebook data for claims adjudication within insurance
- Responding to public unsolicited requests for off-label information by life sciences companies in the light of United States Food and Drug Administration regulations
- Using social media for banking credit decisions given regulations such as the United States Fair Credit Reporting Act that potentially limit data collection and sharing
- Provide input relating to business definitions (e.g., different web analytics tools having inconsistent definitions for the term “unique visitor”)
- Support the MDM initiative, as follows:
- Working with the MDM team to identify attributes to link a user’s social media ID with his or her MDM record
- Defining confidence intervals such as a higher threshold (above which records are auto-linked) and a lower threshold (below which records are auto-rejected)
- For records between the higher and lower thresholds, manually matching social media and MDM records within the data stewardship console
- Participate in data quality initiatives (e.g., working with marketing to determine if Twitter users are demographically representative of the company’s customer base)
The deployment patterns for web and social media data stewards are still very immature. However, here are a few emerging developments:
- Web analytics team—The web analytics team might appoint data stewards for clickstream data.
- Mid-sized European bank—A bank was taking its first steps into social media by introducing its own Facebook page. The CEO appointed the corporate relations department as the overall owner of the social media strategy, including for sentiment analysis.
M2M Data Stewards
These stewards are responsible for data from utility smart meters, equipment sensors, RFID, and the like. Here are the roles and responsibilities of these stewards:
- Ensure that machines are calibrated correctly
- Create business rules to remove erroneous readings, such as with RFID readers in areas with high traffic or lots of moisture
- Define, capture, and maintain business metadata (e.g., consistent naming conventions for geospatial data to avoid situations where the oil and gas company double pays for the same dataset)
- Provide input into policies regarding the acceptable use of sensitive data (e.g., retailers needing to deactivate products with RFID tags to avoid tracking individuals, or telecommunications operators needing to decide how to use geospatial data that can track an individual’s movements)
- Ensure that smart meters, SCADA, sensors, and similar equipment are properly secured against cyber attacks
- Create archiving and defensible disposition policies (e.g., utility smart meter readings needing to be archived after 24 months and deleted after three years)
Here are some examples of M2M data stewards:
- North American telecommunications operator—An operator created billions of events on a sub-second basis to record dropped calls, network congestion, and the like. The performance monitoring team within network operations appointed stewards for this data.
- North American utility—A utility deployed hundreds of thousands of smart meters to record electricity consumption at hourly intervals for residential and business customers. The customer service department was the overall steward for smart meter data. The customer service department had to ensure that the meter readings were available for presentment via the web to the customers. In addition, it established policies to monitor the privacy of customers’ smart meter readings.
- Upstream oil and gas company—Case Study 6.2 describes the stewardship of production volumetrics at an upstream oil and gas company.
Case Study 6.2: Stewardship of production volumetrics at an upstream oil and gas company
Oil and gas companies consume vast amounts of high velocity data in structured, semi-structured, and unstructured formats to measure production. In many cases, this data comes from sensors on rigs and other platforms. The production data is reported to partners and governments, usually on a daily, monthly, or yearly basis. These figures are also reported quarterly to the stock market and can have a material impact on the stock price of publicly traded companies. In addition, incorrect production data can affect joint venture accounting. For example, all the leases in the North Sea are owned by joint ventures between two or more companies. As a result, incorrect production data can result in inaccuracies in profit sharing, as part of the joint venture. Finally, companies pay taxes based on the metering of their production of oil and gas, which heightens the importance of this data.
A large upstream oil and gas company decided to implement an information governance program around production volumetric data. The information governance program started with a focus on the metadata around the production reports. The program defined 50 key information artifacts such as “well” that had a major impact on the consistency of definitions across reports. The information governance program then defined a number of child terms, including “well origin,” “well completion,” “wellbore,” and “wellbore completion.” The information governance program leveraged the Professional Petroleum Data Management (PPDM) Association model for well data and definitions.
The company had a highly complex and matrixed organization, consisting of geographically-based production business units including the Gulf of Mexico, West Africa, Canada, the North Sea, and Asia. Each business unit had its own definitions for production volumetrics. Ultimately, the organization determined that the shared services organization was the overall sponsor for production volumetrics. Because the shared services organization included reservoir management, facilities engineering, and drill completion, it included some degree of accountability for production volumetrics.
Given the complex nature of the enterprise, the stewards for production volumetrics actually reported into IT. However, the definitions for critical business terms had to be approved by a cross-functional team consisting of IT and business executives.
Big Transaction Data Stewards
These stewards are responsible for big transaction data such as insurance claims, telecommunications CDRs, and consumer packaged goods DSRs (demand signal repositories). Here are the roles and responsibilities of big transaction data stewards:
- Establish business rules for data quality (e.g., requiring the claims-paid date to be later than or equal to the claims-receipt date)
- Define, capture, and maintain business metadata (e.g., “policy term” for insurance claims)
- Identify sensitive data (e.g., calling from and calling to phone numbers within telecommunications CDR records for senior executives and celebrities)
- Ensure that all sensitive data has been discovered and tagged within the metadata repository
- Create archival and defensible disposition policies (e.g., requiring telecommunications call detail records to be archived after three months and deleted after two years)
Here are some examples of big transaction data stewards:
- North American Health Plan—Building on Case Study 6.1, the health plan decided to appoint stewards for big claims transaction data. Multiple functions could have potentially appointed claims stewards with different priorities:
- Network management, but their focus was on managing the network of providers
- Business intelligence, but the department reported into IT
- Medical informatics, but their focus was on analytics
- Healthcare services, but their focus was on the clinical aspects of health insurance
Finally, the organization decided to have the claims stewards report into claims administration. The claims stewards also had dotted-line responsibility into the information governance council that had senior representation from business intelligence, network management, medical informatics, healthcare services, and claims administration.
- Multinational consumer packaged goods manufacturer—Manufacturers implement demand signal repositories (DSRs), which are business intelligence environments to understand what items are selling and to manage replenishment at retail stores. The DSR leverages multiple data sources, including vendor managed inventory, ERP, direct marketing, point-of-sale transaction logs from retailers, externally purchased information, and social media. A multinational consumer packaged goods manufacturer appointed DSR data stewards to improve the trustworthiness of this data.
- Asian telecommunications operator—An operator created billions of CDRs each day that added up to several petabytes of storage over time. The billing department appointed stewards for CDR data.
Biometric Data Stewards
The use of biometric data outside of the law enforcement and intelligence communities is very limited. Hence, we can only speculate whether organizations will ever deploy biometric data stewards. A possible candidate might be human resources for biometric data that is collected when employees log into applications.
Human-Generated Data Stewards
Organizations are only beginning to use their treasure troves of human-generated data for analytics. Once again, the deployment patterns for human-generated stewards are largely unknown today. A possible candidate might be customer service that analyzes voice data for quality assurance and operating efficiencies.
Data Scientists
Many organizations are hiring data scientists to get their arms around big data. Data science is a discipline that combines math, programming, and scientific insight.3 In Building Data Science Teams, D. J. Patil, former head of products and chief scientist at LinkedIn, says that the best data scientists have the following characteristics4:
- Technical expertise—Typically, deep expertise in some scientific discipline
- Curiosity—A desire to go beneath the surface, discover, and distill a problem down into a very clear set of hypotheses that can be tested
- Storytelling—The ability to use data to tell a story and to be able to communicate it effectively
- Cleverness—The ability to look at a problem in different, creative ways
Because data scientists grapple with poor data quality and inconsistent definitions on a daily basis, they may also act as big data stewards.
6.4 Add Big Data Responsibilities to Traditional Information Governance Roles as Appropriate
This section describes the additional responsibilities that may be assumed by existing information governance roles.
Chief Data Officer
Many organizations, especially those in the financial services industry, are appointing chief data officers who are responsible for the trustworthiness of information at the enterprise level. Chief data officers are accountable for enterprise information governance programs, and it is highly likely that they will bring big data within their purview as well.
Information Governance Officer
Many organizations have appointed owners for information governance who may also perform other functions, including enterprise data architecture, business intelligence, risk management, and information security. However, information governance positions are increasingly being staffed on a full-time basis, as organizations recognize the value of information as an enterprise asset. The information governance officer may need to assume the following additional responsibilities to govern big data:
- Determine the big data types that need to be governed
- Assist with the development of a business case to support big data governance
- Evangelize big data with business stakeholders
- Support activities that integrate big data into MDM
- Align with multiple organizations, including legal, marketing, privacy, and senior management, to establish policy regarding the acceptable use of big data
- Work with the chief information security officer to protect SCADA, smart meters, and similar assets from cyber attacks
- Oversee the information governance working group that meets on a regular basis, and ensure that its activities are consistent with those of the information governance council
- Oversee the big data stewards who report into the business
- Ensure that big data stewards have the appropriatebuy-infrom the line of business management
- Ensure that big data stewards operate consistently and that the business continues to see value in the stewardship program
Information Governance Council
The information governance council consists of the executive sponsors for the program. The council sets the overall direction for the information governance program, provides alignment within the organization across business and IT, and acts as a tiebreaker in case of disagreements. Depending on the underlying business problem, the chief information officer, the vice president of information management, the chief information security officer, the chief risk officer, or some other executive will chair the information governance council. The council may also include functional representation from finance, legal, and HR, as well as representatives from various lines of business that have a stake in information as an enterprise asset. These executives are the overall champions for the information governance program and ensure buy-in across the organization. The information governance council may meet monthly or quarterly.
Sample big data topics on the agenda of the information governance council may include the following:
- Review the business case for big data governance
- Oversee the relationship between big data and master data (e.g., use of the calling patterns from telecommunications CDRs to improve householding within MDM)
- Sponsor a big data quality initiative
Information Governance Working Group
The information governance working group is the next level down from the council in the organization. The working group runs the information governance program on a day-to-day basis. It is also responsible for oversight of the data stewardship community. The information governance officer may chair the information governance working group. The information governance working group includes middle management and may meet weekly or monthly. The information governance working group discusses topics that are similar to the information governance council, but at a greater level of granularity.
Customer Data Steward
The customer data steward may need to assume the following additional responsibilities to govern big data:
- Provide input into the attributes to match semi-structured and unstructured data, such as social media profiles, with MDM records
- Leverage the data stewardship console to link, de-duplicate, and merge unstructured data with customer MDM records (e.g., determine if the Susie Smith from Facebook is the same as Susan Smith in the customer MDM)
- Work with legal counsel, the privacy department, and business stakeholders to assess the privacy implications of big data
Materials Data Steward
The materials data steward may need to assume additional responsibilities to govern big data. Case Study 11.3 in chapter 11 describes the use of web content to improve the quality of product data at an information services provider.
Asset Data Steward
The asset data steward’s responsibilities may also extend to big data. For example, an asset steward needs to standardize equipment naming conventions across plants and operating units to facilitate the optimal usage of sensor data. When machine sensor data predicts the failure of a pump at a plant, the operations team might need to replace similar pumps at other plants. However, this can only happen if the pumps have similar naming conventions.
Chief Data Steward
Data stewards should ideally report into the business. Because data stewards report into multiple business units or functions, the organization should ideally appoint a chief data steward to ensure consistency across the various stewardship roles and to ensure a sense of community. The chief data steward should oversee stewards across the entire information governance program, including big data.
Big Data Custodian
The data custodian is responsible for the repositories and technical infrastructure to manage big data. IT is often the custodian for big data and other traditional data types.
6.5 Establish a Merged Information Governance Organization with Responsibilities That Include Big Data
Using a combination of new and existing roles, the information governance organization needs to extend its charter and membership to address both big and traditional data types. Figure 6.2 describes the information governance organization at a health plan. At the very bottom, the stewardship community includes a steward for big claims transaction data. At the middle level, the information governance working group also includes a representative from claims administration. At the very highest level, the chief operating officer represents claims administration that reports into him or her.
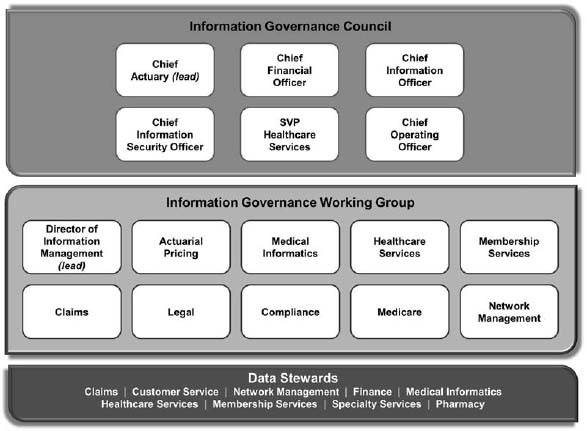
Figure 6.2: The information governance organization at a health plan.
As shown in Case Study 6.3, executive sponsorship for big data governance in government may be across multiple agencies and elected officials. (This case study has been disguised.)
Case Study 6.3: Executive sponsorship for student longitudinal data within a state
State governments in the U.S. are building longitudinal data warehouses with information from preschool, early learning programs, K-12 education, post-secondary education, and work force institutions to address pressing public policy questions. The source data for these so-called “P20W” data warehouses comes from a variety of agencies led by different elected officials or independent boards. In one state, a small research group located in the governor’s budget office is responsible for building the P20W longitudinal data warehouse. The research group has a number of statutory partners across the government, including the following:
- The Early Childhood Education Department
- The State Education Executive, who is an independent elected official
- The Educator Standards Board
- The State Board of Education
- The State Board of Higher Education
- The Council of Presidents from public four-year higher education institutions
- The State Board for Community and Technical Colleges
- The Workforce Training and Education Board
The success of the P20W initiative depends on careful information governance based on proper data sharing agreements and adherence to differing laws and rules around the release of data from different organizations. Executive sponsorship and buy-in across the multiple organizations is critical for successfully building and operating a longitudinal P20W data warehouse. Critical to building the level of executive sponsorship needed for success is an understanding that data from the source systems is an asset of the state, not just of the contributing organization.
Most of the content in the P20W data warehouse is not big data in the context of this book. The data has limited volume, is largely structured, and is only updated on a monthly basis. However, we anticipate that the information governance program will have to grapple with a number of questions relating to big data. For example, the P20W data warehouse does not always have the full post-graduation employment history of the students (“constituents”). The key question is whether the P20W team can use social media like LinkedIn and Facebook to update the employment status for these constituents. These rapidly evolving privacy issues will pose a continuing challenge to the P20W team.
Summary
The information governance organization needs to extend its charter to assume responsibility for big data. The information governance organization also needs to either extend the responsibilities of existing roles, add new roles, or both.
