FIVE
Expectations, Information, Search, and Neighborhood Change
In chapter 2 I defined neighborhood as the bundle of spatially based attributes associated with a proximate cluster of occupied residences, sometimes in conjunction with other land uses. Here it is important to draw out implications from the fact that these spatially based attributes vary considerably in their durability. Some, like certain topographical features, are permanent from the perspective of human time, save major cataclysms. Sewer and water infrastructure and buildings typically last generations. Others, such as tax and public service packages and demographic and socioeconomic status profiles of an area, can change noticeably over the course of a few years. The area’s social interrelationships can also change quite rapidly. This means that although some of the key features defining a desirable neighborhood from the perspective of current and prospective households and residential property investors can be counted on to remain constant (and therefore predictable) for extended periods, many others cannot. This implies that decision makers’ expectations about future changes in these less durable features will play a major role in determining choices about mobility, financial investments, and psychological investments in neighborhoods over the long term.
Unfortunately, these expectations about less durable features of the neighborhood are inherently fraught with a great deal of uncertainty, for at least five reasons. First, what happens to a neighborhood is a function of potential changes in numerous malleable attributes, each of which has an indeterminate future to varying degrees. The thoughtful decision maker must form expectations about a wide array of distinct aspects of neighborhood, and then form some summary expectation about how the predicted individual attribute changes will yield net changes in the aggregate.
Second, many households and residential property owners of different types and motivations are present in the typical neighborhood. Their aggregate behavior is crucial for shaping many future neighborhood attributes, yet it is exceedingly difficult to anticipate that behavior accurately, especially given the degree to which it may be influenced by social interactions such as strategic gaming, which I will explore later.
Third, uncertain metropolitan area–wide shocks related to the regional economy, technological innovation, population, immigration, government policy, and vagaries of nature will influence the flow of resources across all neighborhoods in a metropolitan area. Thus, raw data useful in forming expectations about the future of a particular neighborhood should extend over a much wider set of substantive domains, and not be confined to indicators about this neighborhood alone. I summarized this point above in the Proposition of Externally Generated Change.
Fourth, the Proposition of Externally Generated Change provides a corollary reason for uncertainty on the part of an existing resident or owner: the evaluation of their neighborhood by prospective in-movers, investors, and developers will typically be based on a comparison of attributes in competing neighborhoods, not only on the intrinsic, absolute characteristics of the particular neighborhood’s attribute set.1 Perhaps the most obvious example is the status dimension. The absolute income levels of households in a particular neighborhood may rise. Yet, if they are rising at least as much in all other neighborhoods in the metropolitan area, there likely will be no change in outsiders’ evaluations of that neighborhood’s status attribute, because its relative ranking has not improved. One can make analogous arguments regarding other attributes such as proximity, school quality, and public safety. The upshot is that the relative attractiveness of a particular neighborhood can change when new neighborhoods arise through large-scale construction or rehabilitation projects, and when existing competing neighborhoods are transformed by substantial investments or disinvestments by their owners. This increases uncertainty for households and investors there because different relative market evaluations will alter flows of resources across space, while absolute changes will occur in the neighborhood under consideration. Thus, as a basis for forming expectations about the future of a particular neighborhood, the relevant information pertains to a much wider geographic scale than this neighborhood alone.
Fifth, decision-makers cannot blithely rely on market valuations established in the housing market to capitalize present and future trends in neighborhood attributes accurately. The spatially based attributes comprising neighborhood vary in the degree to which the market can evaluate them accurately. In order for potential consumers to make informed bid offers for a commodity, they must have some modicum of information about the quantity and quality of that commodity and what likely benefit they would receive from its consumption. Real estate markets may meet this criterion for a large number of spatially based attributes like structural size and features, accessibility, tax/public service packages, demographic and socioeconomic status composition of residents, and pollution.2 However, current owneroccupiers likely have “inside” information about local trends in some of these conditions, which they can exploit to their market advantage.3 Moreover, the market cannot accurately price most social-interactive dimensions of neighborhood because they are hard for prospective bidders to assess ex ante. The idiosyncratic and personalized nature of neighborhood social interactions means that prospective in-movers will only be able to ascertain how they will “fit in” after an extended period of residence. One implication is that long-term resident-investors may have considerably different market evaluations (“reservation prices,” in the terminology of chapter 3) for their neighborhood than prospective residents or investors, because the former have capitalized (positively or negatively) their assessments of the social interactive dimension. Thus, the former may be highly resistant to external market forces when they assess a positive social environment, and may be more easily outbid and eventually supplanted by new owners and residents when they assess a negative one. Another implication is that neighborhoods are particularly prone to forms of insider dealing, with privileged information communicated to preferred buyers and in-movers by current residents, owners, and their market intermediaries.
The crucial importance of accurate expectations, coupled with their great uncertainty, translates into substantial long-term risk because, once made, decisions about mobility and financial investments in neighborhoods are not easily or cheaply reversible. Choosing to occupy or own a dwelling involves substantial out-of-pocket and perhaps psychological transactions costs, which most households and investors are loathe to incur frequently. Many large-scale investments in structures and infrastructures have long projected life spans and are spatially fixed. The high-uncertainty/high-risk nature of neighborhood choice and property investments holds important implications for some of the characteristics associated with neighborhood change, such as threshold effects discussed in chapter 6.
Because of its obvious importance to understanding neighborhood change, this chapter explores how households, property owners, and residential developers go about acquiring information, forming expectations, assessing risks and ultimately making choices under terms of uncertainty. Next, I present a conceptual model of this process.4 I then synthesize empirical research findings about how people form expectations and make decisions to draw implications for neighborhood change processes.
A Model of Neighborhood Information Acquisition
Overview
I base my model on a holistic view of human behavior: that it results from both external forces (such as social status and cultural norms) and internal forces (such as drives and needs). Both types of forces mold the degree and manner in which people process sensory data about themselves and the world, form beliefs, and arrive at some behavioral decision. People act based on the meaning they assign to an object or an event, and these meanings are both unique because of individual perceptions and common because of social interaction.5 Thus, while all people can be seen in a general sense as “data acquirers and processors,” the method of gathering, interpreting, evaluating, and responding to data is not the same for all, nor is it even constant for the same individual in all circumstances. In some instances, people undertake considerable deliberation in an effort to find the near-optimal decision; they try to become well-informed about a situation and dispassionately weigh the evidence. In other circumstances, people quickly make decisions based what externally might be viewed as insufficient information that is evaluated informally and with passion. In the words of Daniel Kahneman, people at some times “think slow” and at other times “think fast.”6 Though both types are likely involved to some degree with forming expectations about neighborhoods, the significant risks associated with residential mobility and investment behaviors are so large that most people would employ a great deal of “slow thinking” in the process. Regardless, people’s beliefs and behaviors are not capricious; they demonstrate underlying consistencies that are verifiable empirically, in principle. The model presented below provides a framework for understanding these regularities amid the human variety.
I summarize the foregoing introductory discussion diagrammatically with figure 5.1. It suggests that the nature of information that key decision makers (households or investors) have regarding both the local and the metropolitan-wide housing market will shape their beliefs and expectations about a variety of neighborhoods. These beliefs and expectations will, in turn, influence their decisions about whether to move and, if so, where; whether to maintain or change the quality of the current dwelling while retaining ownership; whether to sell the current dwelling; whether to abandon the current dwelling; whether to choose a dwelling in a different neighborhood; and whether to invest in a newly constructed dwelling or a conversion of a former nonresidential structure. The aggregation of these behaviors will determine the patterns of household and financial resource flows across metropolitan space, creating a cascading series of neighborhood changes and concomitant alterations in individuals’ quality of life and opportunities, housing investors’ rates of return, and the financial health of local retailers and political jurisdictions, as we saw in chapters 3 and 4.
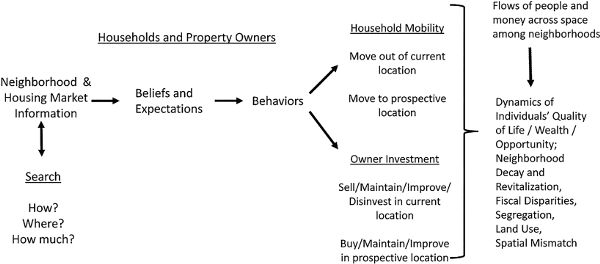
Figure 5.1. Housing search, information acquisition, mobility, investment, and neighborhood change: overarching framework
Housing market search holds a prominent place in this schematic portrayal. I define housing market search as
active, intentional acquisition of data regarding multiple characteristics of a metropolitan housing market (that is, currently or prospectively occupied neighborhoods, currently or prospectively owned or occupied residential properties, or other potential external shocks that may affect part or all of the metropolitan housing market).
We can parse previous formulations of the housing market search process into “neoclassical” and “behaviorist” views. In simplest terms, the former view posits fully informed optimizing by the searcher based on predetermined and fixed housing preferences, whereas the latter sees searchers practicing partially informed, rule-of-thumb, heuristic behaviors with preferences being malleable depending on what is discovered during the search process.7 My formulation attempts to synthesize aspects of both views, though it proceeds primarily from the latter perspective. I expand the realm of information acquisition beyond intentional, active housing search, emphasizing the crucial role of passively acquired information in not only forming beliefs and expectations but also triggering and spatially shaping the search process itself. In this sense, I consider the housing market search endogenous in the larger processes of information acquisition; hence the double-headed arrow in figure 5.1.
Conceptual Model
I present the conceptual model proposed for an individual’s information acquisition, processing, and behavioral response in figure 5.2.8 It starts with the distinction between actively and passively acquired data that the individual may have at her disposal as the basis for a decision. One produces by definition actively acquired data through the search process; passively acquired data are all others acquired unintentionally during the course of life. One can gain both actively and passively acquired data through a variety of means, as amplified below.
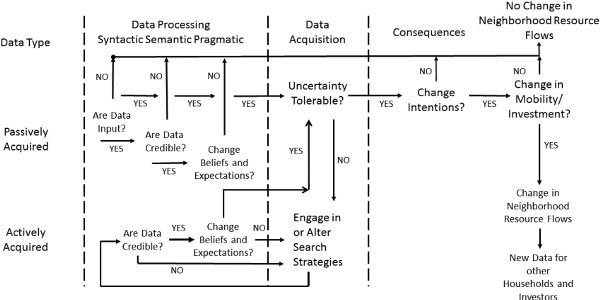
Figure 5.2. Conceptual model of an individual’s acquisition and processing of information and behavioral response
As a matter of course, a sentient being is exposed to a tremendous amount of raw material consisting of sensory inputs. Before such data can possibly change beliefs and expectations, one must subject them to three stages of cognitive processing: syntactic, semantic and pragmatic.9 See the upper portion of figure 5.2. One first assesses in the syntactic component whether the data are worth paying attention to; do they potentially convey information or are they just “noise?” The “datum” of an object is not the object itself; people’s perception and interpretation of the object is the datum. The person’s “definition of the situation” is thus both subjective and relational because it is socially formed—a key point to which I will return. The syntactic stage not only serves as an interpretive filter for data, but also serves as a regulatory filter adjusting the amount and type of data that one can perceive. People try to strike a balance between being open to receiving new data that potentially provide variety, learning, and innovation and closing off those that might threaten the memory, tradition, and cohesion needed for maintaining individual identity.10 The relationship between being open or closed to additional data varies contextually with personal circumstances, the nature of the perceived content, and the form of its transmission.
A person will judge data to be potentially useful if they pass the syntactic stage, then assess their credibility in the semantic stage. Credibility is a function of the discrepancy between the individual’s assessed probability that something is true and the new data’s assessment of such, mediated by a set of facilitating factors involving characteristics of the data, their source, and the individual.11 If discrepancy were zero, the individual would view new data as valid since they merely reconfirm prior beliefs. At the other extreme of maximum discrepancy, the individual may view data as invalid because they provide such an “outlandish view of reality” compared to the individual’s previous view. At any degree of discrepancy, the perceived veracity of data will be influenced by the logic of the order in which they are conveyed, the emotions to which they appeal (e.g., affirmation vs. fear), whether their content is implicit or explicit, and whether they apply to beliefs that are more salient from the individual’s perspective. Similarly, perceived veracity will depend on the medium through which it is communicated, as I will expand upon below. Finally, characteristics of the individual receiving the data may affect its acceptance, such as intelligence, credulity, and self-esteem.
If data are assessed as valid, one then proceeds to inquire pragmatically about whether they alter the individual’s prior beliefs and expectations—that is, whether the data convey useful information. A change could occur either by expanding the relevant belief set (adding possibilities or new attributes that were unknown previously) or by altering the strengths of the individual’s beliefs within the set. Two outcomes are possible. One is that acceptance of valid information reinforces strongly held convictions or strengthens what previously were only weak beliefs. In this case, the pragmatic result is a reduction in uncertainty associated with a belief set. In such circumstances, people are unlikely to seek further corroborating data; instead, they turn to discerning the implications of their reinforced beliefs on their intentions and behaviors.
The other possible pragmatic outcome is that the new, valid information weakens prior beliefs and/or raises new possibilities in a way that increases uncertainty. In this instance, the decision maker must question whether the resultant uncertainty is tolerable. If not, the person undertakes active search; see the lower portion of figure 5.2.12 The individual then subjects data actively acquired to semantic and pragmatic processing, analogous to passively acquired data. Should such new data prove either not credible or not effective in changing or solidifying beliefs, the decision maker will need to consider continuing the active search and perhaps altering the search strategy. Only when the active search finally produces a tolerable reduction in uncertainty because it sufficiently supports a set of beliefs and expectations will the individual discontinue it.
At this point, the decision maker may feel supported in the current course of action, so there is no intention to change course. On the other hand, a new set of beliefs and expectations may alter an intention, but not an associated behavior, if the decision maker is constrained in undertaking the desired choice because of financial, physical, psychological, legal, or other limitations. The individual will alter a residential mobility or investment decision only if the intended change can be actualized. Such a decision alters on the margin the conditions in both the origin and the destination neighborhoods of the individual in question; and, if replicated by others, it will alter the aggregate resource flows governing the overall conditions of these places. Once executed, of course, these altered decisions and flows provide new data for other decision makers to process, potentially leading to knock-on effects. See the right-hand side of figure 5.2.
Multiple Dimensions of Information
With this framing, it is now appropriate to consider more deeply the multiple potential sources through which people gain data, because this leads to the notion of a multidimensional portrait of information acquisition; see figure 5.3. This representation suggests that we can usefully categorize data along four independent dimensions: who acquires it and how it is acquired, through what media, and in what spaces. Two dimensions have already been introduced: households residing in the neighborhood and owners of dwellings in the neighborhood constitute the two key sets of actors who passively and actively acquire information.
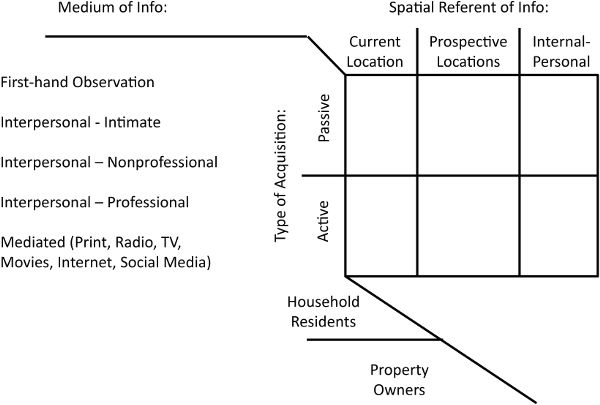
The third dimension represents the not mutually exclusive media through which data potentially are conveyed. An individual can make firsthand observations of the world. Alternatively, an individual may gain relevant data from interpersonal contacts with intimate acquaintances (kin or friends), nonprofessionals (known associates and anonymous interpersonal contacts), and real estate professionals (not only brokers, developers, and landlords, but all those with expertise in the particular subject). These contacts can take the form of face-to-face conversations or those transmitted via telephone or electronic media. Finally, an individual typically gets data from a range of impersonal print or electronic media, such as newspapers, television, radio, and the internet. Each of these data sources may differ considerably in their perceived veracity depending on the individual data-gatherer in question. People typically assess information as valid when “it was right before their eyes”; so, too, is that provided by trusted experts. The power of other sources’ data will depend on their perceived credibility.
The fourth dimension represents the spatial referent of the information gained. The new data could apply to the individual or her household and inform her about an internal change that would have potential impacts on residential mobility or investing calculus, such as a change in housing preferences or ability to pay for housing. Alternatively, the data could be relevant for particular places: the current dwelling and neighborhood and other dwellings and neighborhoods that could be alternative destinations for moving or investing are of primary interest here. These latter two, spatially related categories of data are of particular relevance for neighborhoods.
Although these four dimensions are conceptually distinct and independent, it is likely that in practice people observe only certain combinations. For example, most internal-personal information is gained passively, via firsthand observation (e.g., when your boss informs you of a substantial raise in salary), though in some cases it might involve active search involving contact with a professional (e.g., a medical doctor). Similarly, active search that involves securing the services of a real estate professional likely will provide information about current and prospective neighborhoods.
To posit that information relevant for understanding neighborhood change has features that vary across four dimensions is not to imply that an individual seeks information using only one combination of those dimensions. On the contrary, the formulation summarized in figure 5.2 emphasizes that it is passively acquired information that ultimately spurs actively acquired information. Moreover, various media likely deliver both passively and actively acquired information in a typical information acquisition episode.
Spatial Biases in Information Acquisition and Neighborhood Effects
Having introduced figure 5.3, I can now tease out its provocative implications regarding spatial biases that characterize information acquisition. First, the spaces to which the individual is exposed during the common course of daily life will form the geographic locus of passively acquired data through firsthand observation. Thus, individuals typically will become better informed about neighborhoods that comprise their routine activity spaces: their current place of residence, of course, but also neighborhoods in which are located their venues of employment, socialization, worship, entertainment, and recreation. Because passively acquired information must yield an intolerable degree of uncertainty before people actively acquire additional information, that subsequent search will also focus on the same spaces as a means of reducing this uncertainty. A long-standing empirical literature has indeed confirmed that most active household residential searches within the same metropolitan housing market are relatively close to their prior residence and are otherwise anchored to their routine activity spaces.13
Second, both passively and actively acquired information through intimate and nonprofessional interpersonal contacts will be spatially selective insofar as those people will replicate in part the routine activity spaces of those whom they contact. That is, kin, close friends, work colleagues, and members of organizations to which the individual belongs will provide the richest information about their respective places of residences.14 The degree to which these two processes yield information about a limited sample of neighborhoods is variable, of course, depending on the spatial extent of the routine activity spaces of the individual under consideration and her primary set of interpersonal contacts. At one extreme, the “cosmopolitan” individual who regularly travels around the metropolitan area and surrounds himself with equally well-travelled associates is unlikely to have his range of neighborhood options constrained by limited, spatially selective data. At the other extreme, “parochial” people who spend the vast amount of their lives within the confines of their own neighborhood and socialize only with their neighbors will possess little information about residential opportunities elsewhere. Stefanie DeLuca and colleagues have found this limited sociospatial world to be especially important in spatially constraining the housing market searches of low-income minority households.15
Geography enters into the information acquisition process in yet another deeper way. The individual’s social interrelationships within the current neighborhood can affect the syntactic and pragmatic processing of both actively and passively acquired data. Neighbors may socialize residents to accept collective norms about what sources of data are trustworthy and the degree to which any particular datum has veracity based on whether it confirms or denies deeply held beliefs of the group. For example, neighbors may be quick to challenge an individual’s firsthand observation of a change in a salient feature of the neighborhood (by discounting its generality or providing contrary observations) when the new data contradict a long and firmly held belief about that aspect of the neighborhood. Alternatively, neighbors may suggest that an individual actively search using information sources that they have employed in the past, thereby biasing the data that the individual will glean from searching in ways that will confirm the group’s perceptions. In other instances, individuals may find comfortable certainty in conforming to the “herd mentality” of the neighborhood instead of undertaking an independent assessment of the credibility and potential import of new data confronting them.
The foregoing demonstrates the first way in which “neighborhoods make us”: through molding the information we have about the world. The neighborhood supplies a crucial though variable component comprising the routine activity spaces in which we passively acquire information. Social interactive processes within the neighborhood can further shape what sources we trust when acquiring information passively and actively, and what sorts of standards we apply when assessing whether new information is sufficient to warrant altering our beliefs and expectations. Thus, neighborhoods are both a cause and an effect of human action; they shape the beliefs and expectations driving decisions that guide the flow of people and financial resources across space that, in turn, shapes neighborhoods.
Implications of Behavioral Economics for Information and Neighborhood Change Processes
At this point it is appropriate to ask: After passing the syntactic, semantic, and pragmatic stages of the model, what types of information are most likely to generate altered behaviors by residents and investors? Evidence gathered from behavioral economics provides two strong suggestions: (1) information about one’s current neighborhood should be more powerful than equivalent information about other prospective neighborhoods; and (2) information indicating that one’s current neighborhood is declining should be more powerful than equivalent information that it is improving.
Alex Marsh and Kenneth Gibb have contributed a valuable synthesis of empirical findings from the field of behavioral economics that can aid our understanding of housing search and neighborhood dynamics.16 Of salience here are:
- • status quo bias: People prefer what they know, even if the prospect offers greater gain.
- • loss aversion: People place more absolute value on a loss of well-being or money than on an equivalent gain.
- • experienced versus prospective utility: People discount the well-being associated with not-yet-experienced alternatives because it is more subject to variation.17
- • anchoring: People underrate the differences between two alternatives when an absolute value is associated with one of them, as opposed to neither of them being benchmarked.
- • downward trend aversion: People prefer a progressively more desirable sequence of outcomes than a progressively less desirable sequence, even when both have equivalent aggregate values.
Status quo bias, experience versus prospective utility, and anchoring work jointly to make information about one’s current neighborhood a more powerful predictor of altered mobility or investment behavior than equivalently valid information about an alternative neighborhood. Hypothetical residence or property investment in a different neighborhood will inherently appear more risky, since the current and future conditions appertaining there will appear less certain than they are for the current neighborhood. Thus, only if a new alternative promises to be a hugely superior option will its risk-adjusted premium be sufficient to induce a household to move there or an investor to buy a property there. Yet people will partly discount this premium due to anchoring based on relevant status quo values, further disempowering information about an alternative neighborhood from triggering a move or an altered investment.
Aversion to loss and downward trends together imply that information indicating current neighborhood decline will be more powerful behaviorally than equivalent information that it is improving. If current households and investors now perceive, because of new information, that residents of a somewhat higher socioeconomic status are moving in and property values are rising, they may be delighted. They will not, however, alter their earlier decisions to continue residing or reinvesting in the neighborhood. Conversely, equivalent new information about eroding status and values is more likely to trigger intentions to move elsewhere, and to divest and buy elsewhere, before losses in satisfaction and rates of return mount.
The Proposition of Asymmetric Informational Power
If we combine these two lessons from behavioral economics on what sorts of information are likely to be most powerful in altering intentions and behaviors we can deduce the second major proposition of this book:
The Proposition of Asymmetric Informational Power: Information about the absolute decline of the current neighborhood will prove more powerful in altering residents’ and owners’ mobility and investment behaviors than information about its relative decline or its absolute improvement.
To put this proposition differently, information about contextual changes (i.e., information external to the individual’s personal circumstances) is more powerful to the degree that it works to “push” people to move out and/or disinvest in their neighborhood. By contrast, new information about prospectively superior options in other neighborhoods that render the current neighborhood only relatively less desirable is, all else being equal, less likely to “pull” people out. Of course, new information that the current neighborhood is improving absolutely will have no impact on either mobility or investment behaviors. This proposition suggests that households will be more likely to leave in response to information about the absolutely deteriorating external conditions in their neighborhood than to do so in response to information that physical conditions in another equally expensive neighborhood nearby have improved to the point where they are now superior. Property owners will be more likely to disinvest by downgrading the quality of their dwellings if they expect, based on new information, that their absolute rates of return are soon to fall, than they are likely to do in response to new information of even better rates of return elsewhere. Note how this proposition adds nuance to the Housing Submarket Model employed in chapters 3 and 4, which did not refer to asymmetries in adjustment processes. This proposition suggests that submarket forces that work to “push” households and property owners out of one submarket into another will likely be more frequent and quantitatively significant than those that work to “pull” them from one to another.
Unfortunately, there is only a smattering of evidence supporting this proposition. A long-standing literature on residential satisfaction and intraurban mobility provides suggestive support. This research leaves no doubt that households become dissatisfied, develop moving intentions, and often move from neighborhoods that they perceive as deteriorated, unsafe, and inhabited by those of inferior socioeconomic status.18 However, these studies typically do not measure changes in conditions in the current neighborhood (only levels), nor do they compare indicators across competing neighborhoods. With two exceptions, they also do not consider the role of expectations in shaping residential satisfaction and triggering decisions (a topic to which we turn below). Clarence Wurdock found that white households were more likely to plan moving out when they expected the neighborhood to become 50 percent or more black-occupied within five years.19 Garry Hesser and I found that greater pessimism about property value appreciation in the future was associated with plans to leave the neighborhood sooner.20
Key Indicators for Forming Expectations about Neighborhood Change
I argued above that there were many powerful reasons why people’s expectations about the neighborhood inevitably shape household and investor decisions governing the flow of resources across neighborhoods. In succeeding sections of this chapter, I provided a model of how people gather data in an effort to inform these expectations, and the implications that follow from these efforts about what general sorts of information pertaining to what geographies are likely to be most salient. Now we examine whether any particular data domains seem to be especially powerful in predicting the future of neighborhoods.
Evidence from Statistical Models of Predictive Neighborhood Indicators
The vast majority of the previous empirical work related to building predictive statistical models of neighborhood change have employed census data to model decennial changes in particular census tract characteristics of interest. These regression-modeling efforts specified how neighborhood indicators measured at the beginning of a decade correlated with subsequent decadal changes in neighborhood outcome indicators.21 By far the most sophisticated and convincing example of this genre is the work of John Hipp, who found that higher violent or property crime rates in a neighborhood led to more concentrated poverty, more residential turnover, a weaker retail sector, and a higher share of black population ten years later.22
As valuable as these pioneering efforts have been in building our understanding of long-tern neighborhood changes, data points separated by ten years impose many limitations when thinking about dynamics over a finer grain of time. One cannot precisely ascertain the degree to which decadal changes have been constant throughout the period. This is especially crucial when the phenomenon in question exhibits threshold points or other nonlinear adjustments, as I will explore in the next chapter. Moreover, these works make the untenable assumption that the neighborhood indicator measured at the beginning of the decade was indeed an exogenous predictor, as opposed to an endogenous one or a spurious correlate of previous trends in the neighborhood manifested before the period under analysis.23
By contrast, recent efforts have attempted to exploit newly available annual, quarterly, or even monthly observations of neighborhood indicators in building more dynamic models. Peter Tatian and I developed the first predictive statistical hazard model of gentrification: consistent, substantial home price appreciation in disadvantaged neighborhoods in the District of Columbia.24 We found that the key predictors of the onset of neighborhood housing appreciation were (1) the income levels, denial rates, and Hispanic shares of those taking out mortgages to buy homes and condominiums in the neighborhood two years earlier; (2) adjacency to neighborhoods that were rapidly appreciating during the prior two years; and (3) the rate of home and condominium sales in the neighborhood one year before.
Jackelyn Hwang and Robert Sampson also modeled gentrification, using a rich dataset for Chicago neighborhoods during 2007 to 2009.25 They found that, past a threshold point, the concentrations of black and Hispanic residents in a neighborhood deterred the inflow of higher-income, predominantly white households. Perceptions of disorder had a similar deterrence effect, though objective measures of disorder did not. Complementary findings emerged from modeling of the Los Angeles housing market undertaken by John Hipp, George Tita, and Robert Greenbaum.26 They found that increased neighborhood property and violent crime rates predicted increased housing turnover (and, in the case of violent crime, lower home values) in the subsequent year, but not vice versa.
Three sophisticated longitudinal econometric analyses have demonstrated that crime may not be the ultimate predictive neighborhood indicator, however; home foreclosures lead to more crime nearby, after some lag. Ingrid Ellen, Johanna Lacoe, and Claudia Sharygin (2012) found that a marginal increase in foreclosures in New York City resulted in 3 percent more total crimes, almost 6 percent more violent crimes, and 3 percent more public nuisance crimes on the block face in the subsequent quarter.27 Charles Katz, Danielle Wallace, and E. C. Hedberg revealed that for every additional foreclosure in Glendale, Arizona, there was a cumulative impact over the next three or four months of twelve more property crimes and three more violent crimes per thousand population.28 Sonya Williams, Nandita Verma, and I discovered in our analysis of Chicago that home foreclosures temporally preceded a variety of other neighborhood indicators (property and violent crime, total and mean home purchase mortgage loan amounts, small business loans) but that the reverse did not occur. By contrast, all other indicators exhibited complicated temporal patterns of interrelationships, implying that they often were mutually causal.29
In sum, statistical modeling efforts that carefully establish temporal sequences (and thus, implicitly, direction of causation) point consistently to two candidates for neighborhood indicators that hold strong predictive power for subsequent flows of resources into neighborhoods: foreclosed homes and crime. Unfortunately, only by inference can we deduce from these studies that decision makers controlling these flows were using information that they acquired about foreclosures and crime to shape their perceptions, expectations and, ultimately, behaviors.
Survey Evidence about Formation of Perceptions and Expectations in Neighborhoods
Other research has probed more directly through personal surveys what domains of data households and investors focus upon when forming perceptions and expectations about their neighborhoods. In the only study to investigate neighborhood expectations explicitly, Garry Hesser and I interviewed homeowners in Minneapolis and in Wooster, a small Ohio town; we measured their separate expectations about future changes in both their neighborhoods’ property values and quality of life, and then statistically related their relationships with other perceptions and objective neighborhood indicators. We found that current levels of objective indicators of the physical, demographic, and socioeconomic characteristics of neighborhoods generally were weak predictors of both types of expectations compared to homeowners’ own subjective impressions about recent trends in the neighborhoods. These two types of expectations proved quite independent; moreover, they exhibited distinct sets of predictors. For example, though some white homeowners viewed a higher proportion of black neighbors as a basis for a more pessimistic outlook on property-value appreciation, this did not affect their expectations regarding general neighborhood quality of life.30 These findings suggest that new information about neighborhoods may trigger adjustments in owners’ investment behavior without changing households’ satisfaction or intentions to move, and vice versa. Importantly, the social-interactive dimension of neighborhood context proved crucial in shaping homeowners’ expectations. Both the individual and collective degrees of neighborhood identification and social integration were strong contributors to optimism about property-value changes. This perhaps indicates that homeowners closely identifying with a cohesive neighborhood believe that, collectively, the area will be successful in warding off elements that could erode values or will be less susceptible to strategic gaming—a topic I will discuss in chapter 10 in the context of policy proposals. Finally, elderly homeowners were much more pessimistic in their expectations about property-value appreciation than any other age group, all else being equal. This result is consistent with the hypothesis that those who are least likely to obtain large amounts of reliable, contemporary housing market information, and who thus are less certain about the future, exhibit a bias toward greater pessimism.
Several other survey-based studies investigated the basis of perceptions about current conditions in neighborhoods. Though distinct from expectations, it is likely that perceptions and expectations will be highly correlated.31 Richard Taub, Garth Taylor, and Jan Dunham interviewed homeowners in the Chicago area and elicited their perceptions and expectations about the neighborhood and their likelihood of reinvesting in their properties.32 They discerned that perceptions of increasing crime or increasing percentages of black residents led homeowners to worry about the market competitiveness of their neighborhood, which in turn reduced their likelihood of investing in their properties but strengthened their intention to move out. They found clear evidence of racial encoding by not only white but also black and Hispanic homeowners: perceived higher percentages of black residents were positively associated with greater perceived crime problems.
Lincoln Quillian and Devah Pager uncovered complementary relationships between perceived crime and racial composition in their analyses of surveys from Chicago, Baltimore, and Seattle.33 They observed that respondents assessed their neighborhoods’ safety on the basis of what the foregoing model would predict: information gleaned from personal experience (that is, victimization) and official police statistics about crime. What was more significant is that the respondents also viewed their neighborhoods as less safe when they had higher percentages of young black males as neighbors, even after controlling for official crime rate, the socioeconomic composition, the percentage of Latino residents, the neighborhood’s physical appearance, and measures of disorder in the neighborhood, along with respondents’ personal characteristics. Remarkably, this racialized perception of safety held for whites and blacks alike.
Probing further into the perceptions of safety, we see that perceptions of disorder, such as graffiti and groups of loitering youths, are key predictors of perceptions of crime. Wesley Skogan’s Chicago study identified strong relationships between residents’ perceptions of neighborhood disorder, their beliefs that the neighborhood was unsafe, and their ensuing behaviors of disinvesting and moving out, all leading to a cumulative spiral of neighborhood decay.34 Robert Sampson and Stephen Raudenbush pushed deeper into the information used to shape these beliefs by employing other Chicago survey data.35 They discovered that, as expected, residents’ perceptions of disorder positively correlated with objective observers’ visual ratings of several indicators of disorder. What was startling was that the percentages of black and poor residents of the neighborhood proved to be even more powerful predictors, for both black and white residents.
Finally, an innovative survey study employing videos of neighborhood vignettes with different class and racial dimensions revealed the depth of how whites in Detroit and Chicago negatively stereotype neighborhoods with black residents, though it did not focus on crime and disorder in particular. Maria Krysan, Mick Couper, Reynolds Farley, and Tyrone Forman found that whites perceived neighborhoods as much more “desirable” when only white neighbors appeared in the videos, in comparison to scenarios where racially mixed groups or only black neighbors appeared.36
The Proposition of Racially Encoded Signals
The aforementioned findings provide a consensual portrait about how many urban residents gain information about their neighborhoods’ disorder, safety, and competitive prospects: they use the share of black residents as a proxy indicator.37 Crucially, more than simple racial prejudice appears to produce this phenomenon, since blacks are often as likely as whites to be influenced by black population composition in shaping their perceptions of neighborhoods. These findings strongly suggest that prior beliefs involving stigmatization of concentrations of black poverty supplement both white and black residents’ observational data regarding their current neighborhoods’ “objective” indicators of disorder and crime. Put differently, social constructs related to race inform perceptions of key features of neighborhoods that clearly influence mobility and financial investments.
Several other studies support the notion that racial composition serves as a convenient proxy for a variety of other aspects of neighborhoods that may be harder to evaluate. David Harris shows that the percentage of black population in a neighborhood is associated with lower property values primarily because it serves as a proxy for a lower-income, poorly educated population.38 In another study, he draws similar conclusions about why residents are less satisfied in neighborhoods with higher percentages of black residents.39 Ingrid Gould Ellen analyzes this issue comprehensively.40 She finds that white homeowners are less satisfied with, more likely to leave, and less likely to move into neighborhoods with recently growing black populations, even when the neighborhood’s physical conditions, socioeconomic composition, and overall percentage of black and other minority residents is controlled.41 She deduces that white homeowners employ substantial recent black population growth as a predictor of future neighborhood decline.
All this evidence leads to the third proposition of the book:
The Proposition of Racially Encoded Signals: Key types of information shaping perceptions and expectations about the neighborhood will influence the behaviors of residents and property owners; a significant amount of such information lies encoded within the share and the growth of the black population in the neighborhood.
Conclusion
Understanding why neighborhoods change fundamentally requires an understanding of how households and property owners form their perceptions and expectations about neighborhoods. This implies that we must probe the nature of how people acquire and process data and form beliefs. Social psychology and behavioral economics yield notable insights here.
First, since passively acquired information provides the foundation of active search for housing market and neighborhood information, decision makers’ amount of information and the certainty of their beliefs will take on distinctive spatial configurations. These geographic configurations will roughly correspond to an individual’s routine activity spaces.
Second, the neighborhood itself supplies a crucial (though variable) component comprising the routine activity spaces in which we passively acquire information. Social interactive processes within the neighborhood can further shape what sources we trust when acquiring information passively and actively, and what sorts of standards we apply when assessing whether new information is sufficient to warrant altering our beliefs and expectations. Thus, the neighborhood helps to “make us” in terms of what we believe, which in turn influences the residential mobility and investment decisions we make that collectively “make the neighborhood.”
Third, evidence suggests that (1) information about one’s current neighborhood should be more powerful than equivalent information about other, prospective neighborhoods; and (2) information indicating that one’s current neighborhood is declining should be more powerful in altering behaviors than equivalent information that it is improving. I summarize this as the Proposition of Asymmetric Informational Power.
Fourth, statistical studies show that increases in home foreclosures and crime powerfully predict future declines in various indicators of neighborhood health. Resident surveys similarly show the power of perceived crime and disorder in shaping beliefs about and satisfaction with the neighborhood. However, not only “objective” data like official statistics, but also the perceived racial context of the neighborhood shape these perceptions. A significant amount of information for both white and black residents lies encoded within the share of the black population in the neighborhood and the change in this share, a point I summarize as the Proposition of Racially Encoded Signals.