In questo capitolo
 I termini di base della statistica
I termini di base della statistica
Individuazione delle tendenze fondamentali in un campione di dati
Analisi delle deviazioni in un campione di dati
Calcolo delle analogie fra due campioni di dati
Analisi per percentili
Conteggio selettivo degli elementi in un campione di dati
Provate a sfogliare un quotidiano o ad accendere la televisione o la radio. Siamo letteralmente bombardati di dati e cifre che sono il risultato di operazioni statistiche: “Le probabilità di precipitazioni sono del 60%”; “L’indice MIB ha guadagnato il 2,8%”; “Gli Sharks sono favoriti contro gli Skorpions 4 a 3”; e così via.
I dati statistici vengono usati per raccontarci il mondo che ci circonda.
Ma, soprattutto, i dati statistici vengono abusati per mentirci sul mondo: vengono continuamente manipolati per confondere o nascondere le informazioni. Immaginatevi di aver provato un pasticcino straordinario. Potete tranquillamente affermare senza mentire che piace al 100% delle persone che conoscete e che l’hanno provato!
Talvolta le statistiche producono conclusioni completamente fuorvianti, a dire poco! Bill Gates visita un centro profughi per dare il proprio sostegno.
Il reddito medio della quarantina di persone presenti in quel momento al centro profughi si dà il caso che sia di un miliardo di dollari. Perché? Perché nella media si deve contare anche il patrimonio di Bill Gates, il quale, però, altera la media al punto da toglierle ogni significato. E poi un classico. Notizia al telegiornale: “Il prezzo dei carburanti calerà del 6%”. “Evviva! Andiamo al mare!” Ma su cosa si basa questo calo del 6%? Il confronto è rispetto al prezzo dei carburanti della settimana scorsa, del mese scorso o dell’anno scorso? Magari il prezzo dei carburanti cala del 6% rispetto al mese scorso. Peccato che sia comunque superiore del 20% rispetto all’anno scorso. È ancora, davvero, una buona notizia?
I calcoli statistici si dividono tradizionalmente in due tipi. Le statistiche descrittive, l’argomento di questo capitolo, aiutano a trarre informazioni utili dai dati. Le statistiche inferenziali, trattate nel Capitolo 10, vengono utilizzate per trarre conclusioni a partire da confronti sui dati.

Molte funzioni statistiche sono state aggiornate in Excel 2010. Generalmente, di ogni funzione esistono varianti per campione o per popolazione; varianti inclusive o esclusive (comprendenti o meno i valori estremi); varianti su più intervalli o su un unico intervallo e così via. In questo capitolo le funzioni vengono trattate in questo nuovo formato.
Avete una statura media? Percepite un reddito medio? I vostri figli meritano voti superiori alla media? Vi è più di un modo per determinare il valore medio di un gruppo di valori. In particolare vi sono tre funzioni statistiche che trovano il valore “centrale” di una popolazione di valori: si tratta della media, della mediana e della moda.

Il termine popolazione fa riferimento a tutte le misurazioni possibili o a tutti i dati, mentre il termine campione fa riferimento alle misurazioni o ai dati che sono effettivamente in nostro possesso. Per esempio, se state conducendo un sondaggio riguardante gli elettori di una determinata regione, la popolazione è costituita da tutti gli elettori registrati, mentre il campione è dato dai soli elettori considerati dal sondaggio.
Tecnicamente, il termine media fa riferimento al valore medio, ma, nel linguaggio comune, il termine media può essere utilizzato anche per considerare la mediana o la moda. Questo dà ai pubblicitari la possibilità di inventare slogan eccezionali e a chiunque la possibilità di affermare (quasi) qualsiasi cosa.

È importante memorizzare la differenza fra i seguenti termini.
 Media: si sommano tutti i valori di un elenco, dividendo poi la somma per il numero di valori. Per esempio, la somma dei numeri 1, 2 e 3 è uguale a 2, in quanto (1 + 2 + 3) / 3 è uguale a 2.
Media: si sommano tutti i valori di un elenco, dividendo poi la somma per il numero di valori. Per esempio, la somma dei numeri 1, 2 e 3 è uguale a 2, in quanto (1 + 2 + 3) / 3 è uguale a 2.
Mediana: è il valore centrale in elenco ordinato di valori. Se il numero di elementi considerati è dispari, allora la mediana è, effettivamente, il valore centrale. Se, invece, il numero di elementi è pari, non esiste un valore centrale. In questo caso, la mediana è pari alla media dei due valori centrali. Per esempio, la mediana di 1, 2, 3, 4 e 5 è 3, il valore centrale. La mediana di 1, 2, 3, 4, 5 e 6 è 3,5, equivalente alla media dei due valori centrali, 3 e 4.
Moda: è il valore maggiormente presente in un elenco di valori. Al limite, quindi, la moda potrebbe anche non esistere! Nell’elenco di valori 1, 2, 3, 4, non esiste una moda, poiché ciascun numero è presente lo stesso numero di volte. Al contrario, nell’elenco di valori 1, 2, 2, 3, 4, la moda è 2, poiché tale numero compare per due volte, mentre tutti gli altri compaiono una sola volta.
La media, la mediana e la moda vengono talvolta chiamate indicatori di tendenza centrale, poiché riassumono un campione di dati con un unico valore statistico.
Torniamo a Excel! I seguenti passi consentono di calcolare tre risultati in un foglio di lavoro, utilizzando le funzioni MEDIA, MEDIANA e MODA.
1.Inserite nel foglio un elenco di valori numerici.
Potete inserire tutti i valori numerici che desiderate.
2.Posizionate il cursore nella cella in cui volete calcolare la media.
3.Inserite =MEDIA( per iniziare la funzione.
4.Trascinate il puntatore del mouse sull’elenco o specificate l’indirizzo dell’intervallo.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio per concludere la funzione MEDIA.
6.Posizionate il cursore nella cella in cui volete calcolare la mediana.
7.Inserite =MEDIANA( per iniziare la funzione.
8.Trascinate il puntatore del mouse sull’elenco o specificate l’indirizzo dell’intervallo.
9.Inserite una parentesi chiusa, ), e premete il tasto Invio per concludere la funzione MEDIANA.
10.Posizionate il cursore nella cella in cui volete calcolare la moda.
11.Inserite =MODA( per iniziare la funzione.
12.Trascinate il puntatore del mouse sull’elenco o specificate l’indirizzo dell’intervallo.
13.Inserite una parentesi chiusa, ), e premete il tasto Invio per concludere la funzione MODA.
A seconda dei numeri inseriti, i tre risultati possono essere uguali (ma è altamente improbabile!), abbastanza simili o sensibilmente differenti.
La funzione MODA potrebbe anche restituire #N/D, se i dati non contengono valori ripetuti.
Immaginate la seguente situazione: tre persone usano un nuovo dentifricio per sei mesi e poi vanno dal dentista. Due di loro non hanno alcuna carie.
“Ehi, il nuovo dentifricio non è male!” Ma la terza persona ha tre carie. “Oh oh!”
| Persona |
Carie |
| A |
0 |
| B |
0 |
| C |
3 |
Il numero medio di carie di questo gruppo è 1. Sempre che utilizziate la funzione MEDIA per calcolare la media. Le cose non vanno poi tanto bene con questo dentifricio se, in media, ogni persona che l’ha utilizzata sviluppa una carie! Al contrario, sia la mediana, sia la moda sono uguali a 0. La mediana è uguale a 0 poiché questo è il valore centrale nell’elenco ordinato. Anche la moda è uguale a 0, poiché questo è il valore che ricorre più frequentemente. Come potete vedere, valori statistici differenti dimostrano che il nuovo dentifricio produce, mediamente, 0 carie. Più o meno…
Un altro esempio: la Figura 9.1 mostra i risultati di un ipotetico test di valutazione di una classe di studenti. A lato potete vedere la media, la mediana e la moda relative alla distribuzione dei voti.
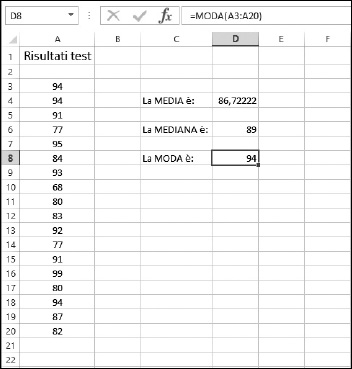
Figura 9.1 Calcolo delle tendenze centrali in un elenco di voti.
Come accade quasi sempre, la media, la mediana e la moda risultano essere valori differenti. In senso stretto, possiamo dire che il voto medio è 86,72.
Ma se l’insegnante o la scuola vogliono mettere l’accento sull’eccellenza dei propri studenti, potranno affermare senza tema di smentita che il voto più frequente è 94. Questa è la moda e, in effetti, ben tre studenti hanno ricevuto tale valutazione. Ma si tratta della rappresentazione migliore dei risultati ottenuti? Probabilmente no.
Utilizzando le funzioni che restituiscono questi indicatori delle tendenze centrali (MEDIA, MEDIANA e MODA) potete ottenere risultati interessanti e, talvolta, fuorvianti. Ecco un altro esempio di come queste tre funzioni possano fornire risultati ampiamente discordanti per gli stessi dati.
Ecco i dati di spesa di sei clienti presso un’azienda:
| Cliente |
Spesa totale l’anno scorso |
| A |
300 euro |
| B |
90 euro |
| C |
2.600 euro |
| D |
850 euro |
| E |
28.400 euro |
| F |
300 euro |
La MEDIA è 5.423,33 euro, la MEDIANA è 575 euro e la MODA è 300 euro: tre valori che non si somigliano neppure! Quale dei tre rappresenta meglio la somma che un cliente medio ha speso presso la società l’anno scorso?
Il problema di questo insieme di dati è che uno dei valori, 28.400 euro, è molto maggiore rispetto agli altri, al punto che, da solo, altera completamente il calcolo della media. La media, infatti, porta erroneamente a ritenere che ogni cliente abbia speso 5.423,33 euro. Ma osservando i valori reali, ci si accorge che vi è un solo cliente che ha speso una somma di denaro rilevante. Nessuno degli altri ha effettuato spese neppure vicine alla media. Pertanto, che senso ha calcolare e usare questa “media”?
La Figura 9.2 rappresenta questa situazione, in cui un valore è talmente differente dagli altri (si parla di valore atipico) da togliere ogni significato alla media. La Figura 9.2 mostra anche quanto cambia la media se si trascura questo grosso cliente, mentre trascurando qualsiasi altro cliente, la media cambia di pochissimo.
Nello Scenario 2, il cliente E non viene considerato. In questo modo, la media può rappresentare, ragionevolmente, la spesa media dei clienti nel corso dell’anno.
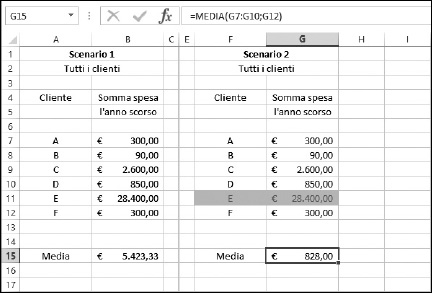
Figura 9.2 Cosa fare con i valori atipici?
Ma potete davvero pensare di escludere dai conteggi un cliente così importante? Piuttosto potete considerare un paio di soluzioni creative per calcolare la media. In alcuni casi potete utilizzare la mediana; in altri potete impiegare una media pesata, una media che tiene in considerazione la rilevanza di ciascun valore. La Figura 9.3 mostra i risultati di questi approcci.
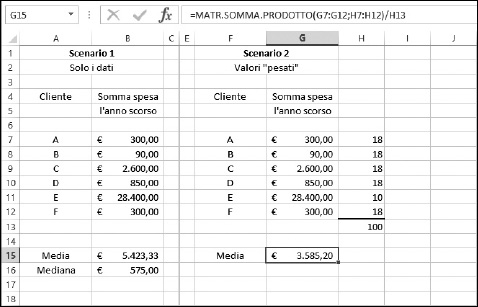
Figura 9.3 Calcolo creativo della media.
Lo Scenario 1 mostra la media e la mediana per l’insieme delle somme spese dai clienti. In questo caso la mediana è una rappresentazione migliore della tendenza centrale del gruppo.
Quando si producono report con risultati basati su calcoli atipici, è utile aggiungere una nota che spieghi come è stato calcolato il risultato. Se il report dice che la spesa “media” è stata di 575 euro, la nota dovrebbe spiegare che il calcolo tiene in considerazione la mediana e non la media.
Lo Scenario 2, sempre nella Figura 9.3, è un po’ più complesso. Prevede la creazione di una media pesata, dove i pesi stabiliscono la significatività dei singoli valori, i quali saranno così più o meno influenti nel calcolo della media. Questo è esattamente ciò di cui avete bisogno. È importante che il cliente E abbia un peso minore nel calcolo della media.
Le medie pesate sono il risultato dell’applicazione di un peso a ciascun valore utilizzato nel calcolo della media. Nell’esempio, a tutti i clienti viene attribuito un fattore pari a 18, tranne che al cliente E, al quale viene attribuito il fattore 10. Ciò significa che tutti i clienti, tranne il cliente E, avranno lo stesso peso, mentre il cliente E avrà un peso inferiore, in quanto le sue spese sono troppo atipiche rispetto a quelle degli altri. La somma dei pesi deve essere uguale a 100. Senza applicare alcun fattore di peso “esterno”, ogni cliente avrebbe un peso pari a 16,667 (100 diviso per 6, il numero di clienti). Attribuendo un peso pari a 10 al cliente E e pari a 18 tutti gli altri clienti, la somma rimane 100: (18 × 5) + 10. I valori 18 e 10 sono stati scelti soggettivamente. Quando impiegate dei fattori di peso per calcolare una media pesata, dovete informare di questo fatto nella presentazione dei risultati.
La media nello Scenario 2 è pari a 3.585,20 euro. Questo valore è ancora molto superiore alla media e perfino alla media dei cinque clienti rimanenti, escludendo il cliente E (Figura 9.2). Tuttavia si tratta di un risultato più reale rispetto a quanto indicato nello Scenario 1 e questo significa che riflette meglio il contenuto dei dati.
A proposito, la media dello Scenario 2 non è stata calcolata con la funzione MEDIA, che non è in grado di gestire medie pesate. Al suo posto è stata utilizzata la funzione MATR.SOMMA.PRODOTTO. La formula impiegata nella cella G15 è quella che segue:
=MATR.SOMMA.PRODOTTO(G7:G12;H7:H12)/H13
L’importo che ciascun cliente ha pagato l’anno scorso viene moltiplicato per il peso del singolo cliente; tutti i prodotti vengono poi sommati con MATR.SOMMA.PRODOTTO. Infine, il risultato viene diviso per la somma dei pesi.
Il mondo è bello perché è vario! E la media di un gruppo non ne riflette certo la variabilità. Supponete di dover svolgere un’indagine sui redditi relativi a varie occupazioni e che l’occupazione A preveda un reddito medio annuo di 75.000 euro e l’occupazione B risulti avere esattamente la stessa media. Questo significa che i due gruppi sono uguali? Non necessariamente.
Supponiamo che nel gruppo A i redditi vadano da 65.000 a 85.000 euro, mentre nel gruppo B gli stipendi vadano da 35.000 a 115.000. Questa differenza (la distanza dei valori rispetto alla media) è chiamata varianza. Excel offre delle funzioni per calcolare la varianza, un fattore fondamentale di molte presentazioni statistiche.
Misurazione della varianza
La varianza misura la dispersione di un insieme di dati rispetto alla media e viene calcolata sommando le deviazioni al quadrato rispetto alla media.
Le operazioni matematiche
In particolare, la varianza viene calcolata nel modo seguente.
1.Calcolate la media di un insieme di valori.
2.Calcolate poi la differenza di ciascuno dei valori e la media.
3.Elevate al quadrato ogni differenza.
4.Sommate i quadrati.
5.Dividete la somma dei quadrati per il numero di elementi del campione, meno 1.
Un campione è un insieme selezionato di valori, tratto dalla popolazione.
Pertanto è più facile lavorare su un campione rispetto all’intera popolazione. Per esempio, i risultati statistici calcolati su 1.000 transazioni di vendita probabilmente restituiranno valori molto, molto simili ai risultati statistici calcolati sull’intera popolazione di 10.000 transazioni.
Notate che l’ultimo passo della procedura precedente cambia a seconda del fatto che venga impiegata la funzione VAR.C o VAR.P. La funzione VAR.C (C come “campione”) usa come denominatore il numero degli elementi meno 1, mentre VAR.P (P come “popolazione”) usa il numero degli elementi.
La Figura 9.4 mostra i passi da seguire per calcolare la varianza senza ricorrere alle funzioni di Excel. La colonna B contiene un insieme di valori. La colonna C mostra la deviazione di ciascun valore rispetto alla media dei valori. La “media”, che è uguale a 7,8, non viene mai presentata. Al contrario, la media viene calcolata nella formula che calcola le differenze. Per esempio, la cella C8 contiene la seguente formula:
La colonna D calcola il quadrato dei valori contenuti nella colonna C. Si tratta di un calcolo molto semplice. Ecco il contenuto della cella D8: =C8^2.
Infine, la somma delle deviazioni al quadrato viene divisa per il numero di elementi, meno 1. La formula nella cella D12 è dunque =SOMMA(D4:D8)/(CONTA.NUMERI(B4:B8)-1).
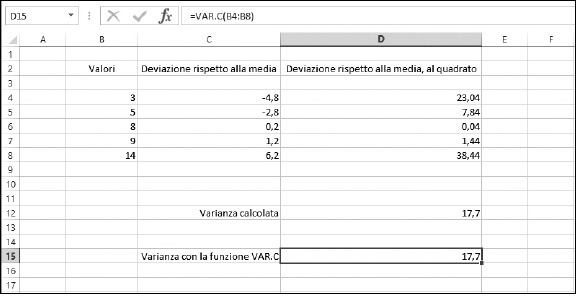
Figura 9.4 Calcolo della varianza rispetto alla media.
Le funzioni da utilizzare: VAR.C e VAR.P
Ora che siete in grado di calcolare la varianza come descritto nei libri di testo, dimenticatevela pure! Vi ho mostrato i calcoli matematici solo per farvi comprendere meglio ciò che accade “dietro le quinte” dei calcoli, ma Excel, per questi compiti, utilizza due funzioni che svolgono tutto il “lavoro sporco”: VAR.C e VAR.P.
Nella Figura 9.4, la cella D15 mostra la varianza calcolata direttamente con la funzione VAR.C: =VAR.C(B4:B8).
Provate da soli: ecco come fare.
1.Inserite un elenco di valori numerici.
Va bene un elenco qualsiasi di valori.
2.Posizionate il cursore nella cella in cui volete far comparire la varianza del campione.
3.Inserite =VAR.C( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio.
La varianza viene calcolata sull’intera popolazione dei dati o su un campione della popolazione.
La funzione VAR.C calcola la varianza su un campione dei dati della popolazione.
La funzione VAR.P calcola la varianza sull’intera popolazione.
I due calcoli sono leggermente differenti per il fatto che il denominatore della varianza di una popolazione (VAR.P) è il numero di elementi. Il denominatore della varianza di un campione (VAR.C) è il numero di elementi meno 1. La Figura 9.5 mostra come le funzioni VAR.C e VAR.P vengono applicate a un campione e all’intera popolazione. Le celle A4:A43 contengono il numero di ore di televisione cui sono state esposte quaranta persone.
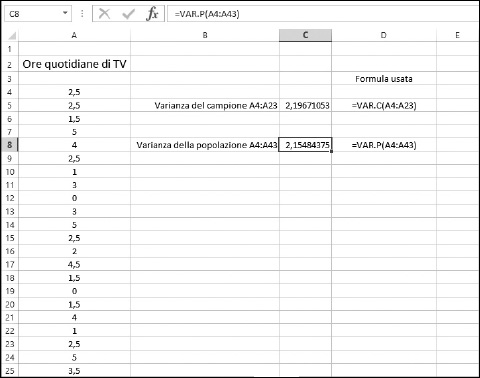
Figura 9.5 Calcolo della varianza del campione e della popolazione.
La funzione VAR.C calcola la varianza di un campione di 20 valori. La funzione VAR.P calcola la varianza dell’intera popolazione di 40 valori. Entrambe le funzioni vengono però usate allo stesso modo.
1.Inserite un elenco di valori numerici.
Va bene un elenco qualsiasi di valori.
2.Posizionate il cursore nella cella in cui volete far comparire la varianza della popolazione.
3.Inserite =VAR.P( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio.
Analisi delle deviazioni
Spesso la media non rappresenta adeguatamente un campione di dati.
O quanto meno non è sufficiente per rappresentarlo: occorre conoscere anche la deviazione dei dati. In pratica occorre sapere, in media, quanto i singoli valori differiscono rispetto alla media del campione. Per esempio, potreste voler conoscere il voto medio di un test, ma anche di quanto i vari voti, mediamente, si discostano rispetto a tale media. La deviazione media è un altro modo per specificare la varianza. Ecco un esempio.
| Punteggio |
Deviazione rispetto alla media di 84,83 |
| 78 |
6,83 |
| 92 |
7,17 |
| 97 |
12,17 |
| 80 |
4,83 |
| 72 |
12,83 |
| 90 |
5,17 |
La media di questo campione di valori è 84,83; potete verificarlo con la funzione MEDIA. Ogni singolo valore ha una specifica deviazione rispetto alla media. Per esempio, 92 ha una deviazione di 7,17 rispetto alla media. Una semplice equazione dimostra che, infatti, 92 - 84,83 = 7,17.
Se utilizzate la funzione MEDIA per ottenere la media delle deviazioni, avrete la deviazione media. Per semplificare le cose, Excel offre la funzione MEDIA. DEV, che calcola prima la media dei valori, poi le deviazioni dei singoli valori rispetto alla media e infine la media di tali deviazioni, il tutto in unico passo. Ecco come utilizzare la funzione MEDIA.DEV.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire la deviazione media.
3.Inserite =MEDIA.DEV( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio.
La funzione MEDIA.DEV calcola la media delle deviazioni in termini assoluti. In altre parole, le deviazioni negative (i casi in cui i dati sono inferiori rispetto alla media) vengono convertite in termini positivi per eseguire il calcolo. Per esempio, se la media è 50, il valore 10 avrà una deviazione di -40 rispetto alla media, infatti 10 - 50 = -40. Tuttavia, MEDIA.DEV usa il valore assoluto della deviazione, ovvero 40 al posto di -40.
La varianza, di cui abbiamo parlato in precedenza, funge da base per un noto valore statistico chiamato deviazione standard. Tecnicamente, la deviazione standard è la radice quadrata della varianza. Ricordate che la varianza viene calcolata elevando al quadrato le deviazioni rispetto alla media?
La varianza e la deviazione standard sono entrambi indicatori validi della deviazione. Tuttavia, la varianza può essere un valore difficile da usare come riferimento. Nella Figura 9.6, la varianza è pari a 14,16, mentre il gruppo di valori si estende su solo 11 unità (il minimo è 3 e il massimo è 14). Come può questa distanza di 11 unità fra i valori produrre una varianza di 14,16 unità? Questa “poca confrontabilità” della varianza può essere corretta utilizzando la deviazione standard. Annullando, con una radice quadrata, l’elevamento al quadrato, si ottiene un valore che torna a essere confrontabile con l’intervallo di dati. Questo è il motivo per cui nei calcoli statistici la deviazione standard è più utilizzata della varianza. Excel permette di calcolare la deviazione standard utilizzando la funzione DEV. ST.P. Ecco come utilizzarla.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire la deviazione standard.
3.Inserite =DEV.ST.P( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio.
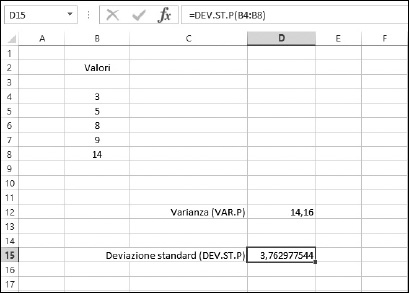
Figura 9.6 Calcolo della deviazione standard.
La Figura 9.6 prende i dati rappresentati nella Figura 9.4 e calcola la varianza e la deviazione standard della popolazione. La deviazione standard è pari a 3,762977544, un numero direttamente confrontabile con l’intervallo dei dati campionati.
Alla ricerca della distribuzione normale
La deviazione standard è uno degli indicatori più utilizzati in statistica. Spesso viene utilizzata per analizzare la deviazione in una distribuzione normale. Una distribuzione è la frequenza di occorrenze dei valori in una popolazione o in un campione. Una distribuzione normale spesso si presenta in grossi insiemi di dati che hanno un attributo naturale o casuale. Per esempio, prendendo la misura della statura di 1000 bambini di dieci anni, si ottiene una distribuzione normale. La maggior parte delle misurazioni si concentrerà attorno a una certa statura, con una certa deviazione rispetto alla media. Solo poche misurazioni risulteranno a valori estremi (notevolmente maggiori o notevolmente inferiori rispetto alla media)
Per chi suona la (curva a) campana?
Una distribuzione normale viene frequentemente rappresentata come un grafico a forma di campana, da cui il nome di curva a campana. La Figura 9.7 rappresenta una distribuzione normale.
Una distribuzione normale è dotata di alcune caratteristiche.
La curva è simmetrica attorno alla media: metà delle misurazioni sono maggiori e metà sono inferiori rispetto alla media.
La media, la mediana e la moda coincidono.
Il punto più elevato della curva coincide con la media.
La larghezza e l’altezza sono determinate dalla deviazione standard. Maggiore è la deviazione standard, più ampia e piatta sarà la curva. Potete avere due distribuzioni normali aventi la stessa media, ma con deviazioni standard differenti.
Il 68,2% dell’area sottostante la curva (a sinistra come a destra) rientra nella deviazione standard della media; il 95,44% dell’area sottostante la curva rientra nel doppio della deviazione standard; il 99,72% dell’area sottostante la curva rientra nel triplo della deviazione standard.
Le estremità sinistra e destra della curva sono chiamate code. Nelle code si trovano i valori estremi. Per esempio, nella distribuzione della statura, le stature molto basse si trovano nella coda a sinistra e le stature molto alte si trovano nella coda a destra.
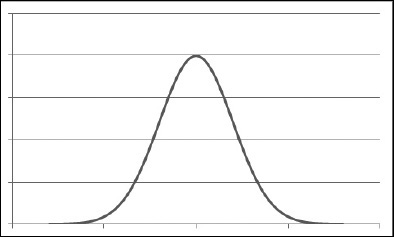
Figura 9.7 Rappresentazione grafica di una distribuzione normale.
Insiemi di dati differenti producono quasi sempre medie e deviazioni standard differenti e, pertanto, una curva a campana differente. La Figura 9.8 mostra due distribuzioni normali sovrapposte. Entrambe sono distribuzioni normali perfettamente valide; tuttavia ognuna di esse ha la propria media e la propria deviazione standard; in particolare la campana più stretta ha una deviazione standard inferiore.
L’analisi statistica usa frequentemente le distribuzioni normali per determinare le probabilità. Per esempio, qual è la probabilità che l’altezza di un bambino di dieci anni sia di 130 cm? A un certo punto della curva, si troverà un punto che rappresenta tale statura. Ulteriori calcoli (che non rientrano negli scopi di questa discussione) ne restituiranno la probabilità. Che dire poi della probabilità che un bambino di dieci anni abbia una statura di 130 cm o maggiore? Occorre considerare l’area sottostante la curva. Questi sono i tipi di domande e di risposte che operano sulle distribuzioni normali.
Molte delle analisi statistiche relative alle distribuzioni normali riguardano i valori delle code, le aree che occupano le estremità sinistra e destra della curva di distribuzione normale.
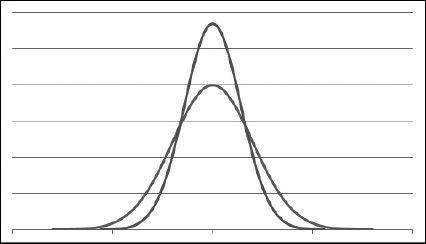
Figura 9.8 Due distribuzioni normali con altezze e larghezze differenti.
Tutte le distribuzioni normali hanno una media e una deviazione standard. Nella distribuzione normale standard la media è uguale a 0 e la deviazione standard è uguale a 1.
Esistono tabelle per determinare le probabilità in base alle aree racchiuse dalla curva normale standard. Queste tabelle sono utili per lavorare con dati adattati alla distribuzione normale standard. Si trovano nella sezione di appendice di tutti i libri di statistica. Potete anche trovarle in Internet, ricercando “tavole distribuzione normale standard”.
Uso di NORMALIZZA
Per utilizzare questa tabella delle probabilità della curva normale standard, i dati in questione devono essere normalizzati. In Excel potete utilizzare per questo scopo la funzione NORMALIZZA. Tale funzione richiede tre argomenti: il valore (tratto dai dati), la media e la deviazione standard. Il valore restituito è quello in cui la media è 0 e la deviazione standard è 1.
Un valore di una distribuzione normale non standard è chiamato x. Un valore di una distribuzione normale standard è chiamato z.
La Figura 9.9 mostra il modo in cui la funzione NORMALIZZA modifica i valori grezzi per trasformarli in valori normalizzati. La deviazione standard dei dati grezzi è pari a 8,58677172, mentre la deviazione standard dei valori normalizzati è uguale a 1, e la media è uguale a 0.

Figura 9.9 Normalizzazione di una distribuzione di dati
La colonna B della Figura 9.9 contiene 1.200 valori. La media è 15,60657312, come si può vedere nella cella C2. La deviazione standard è 8,58677172, come si può vedere nella cella C3. Per ogni valore contenuto nella colonna B, viene calcolato il valore normalizzato (colonna E). L’elenco dei valori della colonna E è stato prodotto dalla funzione NORMALIZZA.
La funzione NORMALIZZA accetta tre argomenti:
il valore;
la media della distribuzione;
la deviazione standard della distribuzione.
Per esempio, questa è la formula contenuta nella cella E7: =NORMALIZZA(B7;C$2;C$3).
Notate che alcune proprietà chiave della distribuzione sono cambiate dopo che i valori sono stati normalizzati:
la deviazione standard è uguale a 1;
la media è uguale a 0;
i valori normalizzati rientrano nell’intervallo 1,674819793, -1,813954598.
Questo terzo punto è determinato utilizzando, rispettivamente, le funzioni MIN e MAX nelle celle I7 e I8. dato che i valori rientrano in un intervallo normalizzato (centrato sullo 0) è possibile analizzarli con la tabella della distribuzione normale standard, descritta in precedenza.
Ecco come utilizzare la funzione NORMALIZZA.
1.Inserite in una colonna un elenco di valori numerici.
Questo elenco può essere un insieme di dati rilevabili casualmente, per esempio stature, pesi o percentuali di piovosità mensile.
2.Calcolate la media e la deviazione standard.
Per informazioni consultate il paragrafo “Dritti al centro, con MEDIA, MEDIANA e MODA”.
La funzione NORMALIZZA fa riferimento a questi valori. La media viene calcolata con la funzione MEDIA e la deviazione standard con la funzione DEV.ST.P. Si usa DEV.ST.P al posto di DEV.ST.C poiché viene considerata l’intera popolazione dei dati.
3.Collocate il cursore nella cella adiacente al primo valore inserito nel passo 1.
4.Inserite =NORMALIZZA( per avviare la funzione.
5.Fate clic sulla cella contenente il primo valore dei dati.
6.Inserite un punto e virgola (;).
7.Fate clic sulla cella contenente la media della popolazione.
8.Inserite un punto e virgola (;).
9.Fate clic sulla cella contenente la deviazione standard della popolazione.
10.Inserite una parentesi chiusa, ), per concludere la funzione.
La formula con la funzione NORMALIZZA è ora completa. Tuttavia dovete correggerla per far sì che i riferimenti alle celle contenenti la media e la deviazione standard siano assoluti, in modo che non cambino applicando la formula alle altre celle.
11.Fate doppio clic sulla cella contenente la formula, per attivare la modalità di editing.
12.Anteponete il segno di dollaro ($) alla riga e alla colonna del riferimento alla cella che contiene la media.
13.Anteponete il segno di dollaro ($) alla riga e alla colonna del riferimento alla cella che contiene la deviazione standard.
14.Premete il tasto Invio, Tab o Esc per concludere l’intervento.
15.Utilizzate la maniglia di replicazione per trascinare la formula verso il basso sulle celle adiacenti ai dati.
È importante che i riferimenti alle celle della media e della deviazione standard siano assoluti, in modo che non cambino quando la formula viene trascinata sulle celle adiacenti. In questo caso, occorre rendere assoluti solo i riferimenti alla riga. Pertanto la formula avrà il seguente aspetto: =NORMALIZZA(B7;C$2;C$3). Notate la presenza dei segni $.
Ma tu non sei normale!
In una distribuzione possiamo calcolare la deviazione, ma chi l’ha detto che debba essere esattamente la stessa a entrambi i lati della media? Non tutte le distribuzioni sono normali. Alcune sono asimmetriche, ovvero si ha una maggiore quantità di valori sopra oppure sotto la media:
quando più valori sono situati sopra la media, si dice che la distribuzione ha un’asimmetria negativa;
quando più valori sono situati sotto la media, si dice che la distribuzione ha un’asimmetria positiva.
La seguente tabella presenta alcuni esempi.
| Valori |
Media |
Commento |
| 1, 2, 3, 4, 5 |
3 |
Curva simmetrica: sopra e sotto la media si situa lo stesso numero di valori. |
| 1, 2, 3, 6, 8 |
4 |
La distribuzione ha un’asimmetria positiva: la maggior parte dei valori si situa sotto la media. |
| 1, 2, 8, 9, 10 |
6 |
La distribuzione ha un’asimmetria negativa: la maggior parte dei valori si situa sopra la media. |
La Figura 9.10 mostra un grafico di una distribuzione, in cui 1000 valori sono collocati in una distribuzione che va da 0 a 100. I valori sono riepilogati in una tabella delle frequenze (di cui parleremo più avanti in questo capitolo). Il grafico si basa proprio sulla tabella delle frequenze.
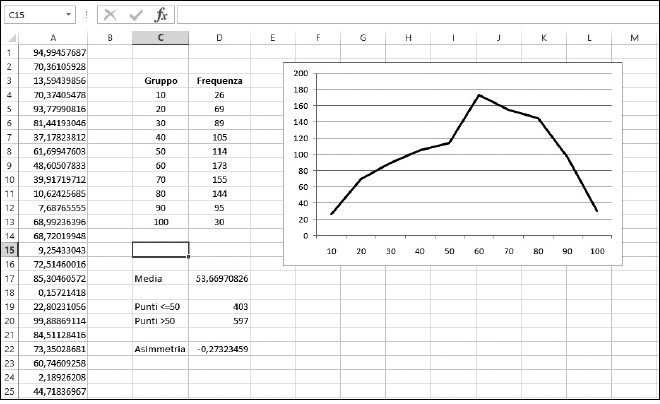
Figura 9.10 Operare su dati asimmetrici.
La media della distribuzione è 53,669…, rappresentata nella cella D17. Le celle D19 e D20 mostrano il numero di valori situati sopra e sotto la media, con una netta prevalenza di valori sopra la media. La distribuzione, pertanto, ha un’asimmetria negativa.
Il fattore di asimmetria calcolato è -0,27323459. La formula nella cella D22 è =ASIMMETRIA(A1:A1000). Il grafico chiarisce l’entità dell’asimmetria.
In particolare è sbilanciato verso destra.
Trovare l’entità dell’asimmetria in una distribuzione può aiutare a identificare eventuali perturbazioni dei dati. Se, per esempio, i dati dovrebbero manifestare una distribuzione normale (simmetrica), come nel caso della statura dei bambini di dieci anni, e sono invece asimmetrici, occorre chiedersi se essi non contengano perturbazioni. Magari, per errore, è stato misurato anche un gruppo di ragazzi di quattordici anni. Naturalmente, l’asimmetria non è, di per se stessa, un’indicazione del fatto che vi siano errori di rilevamento. Alcune distribuzioni sono asimmetriche per natura.
La funzione ASIMMETRIA
Ecco come utilizzare la funzione ASIMMETRIA per determinare l’asimmetria di una distribuzione.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire l’asimmetria.
3.Inserite =ASIMMETRIA( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio.
La funzione CURTOSI
Un altro modo in cui una distribuzione può differire rispetto alla distribuzione normale è la curtosi. Questo valore misura la ripidità della distribuzione rispetto alla distribuzione normale. Misura anche la lunghezza delle code della curva. La funzione CURTOSI restituisce un valore positivo se la distribuzione è relativamente ripida, con code più corte rispetto alla distribuzione normale. Una curtosi negativa significa che la distribuzione è relativamente piatta, con lunghe code.
La Figura 9.11 mostra le curve di due distribuzioni. Quella a sinistra ha una curtosi negativa pari a -0,82096, il che indica una distribuzione piuttosto piatta. La curva a destra è superiore a 1 e, infatti, si può notare un picco pronunciato e code piuttosto corte.
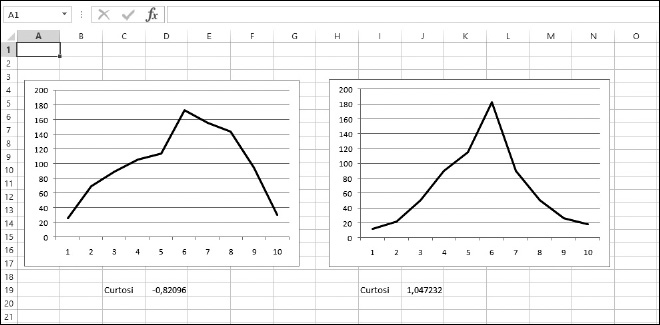
Figura 9.11 Misurazione della curtosi di due distribuzioni.
Ecco come utilizzare la funzione CURTOSI.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire la curtosi.
3.Inserite =CURTOSI( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio.
Dati a confronto
Talvolta occorre confrontare fra loro due insiemi di dati, per scoprire le relazioni che li legano. Per esempio, in quale modo le precipitazioni nevose influenzano il numero di clienti che entrano in negozio? Il denaro speso in pubblicità incrementa il numero di nuovi clienti? Potete rispondere a queste domande determinando se i due insiemi di dati sono correlati.
Excel fornisce due funzioni per questo compito: COVARIANZA.C (o COVARIANZA.P) e CORRELAZIONE. Queste funzioni restituiscono, rispettivamente, i coefficienti di covarianza e correlazione derivanti dal confronto fra i due insiemi di dati.
Le funzioni COVARIANZA.C e COVARIANZA.P
Entrambe le funzioni COVARIANZA accettano come argomenti due matrici e restituiscono un singolo valore, che può essere positivo o negativo. Un valore positivo significa che le due matrici di dati tendono a muoversi nella stessa direzione: quando aumenta (o diminuisce) l’insieme di dati A, aumenta (o diminuisce) anche l’insieme di dati B. Un valore negativo significa che i due insiemi di dati tendono a muoversi in direzioni opposte: quando A aumenta, B diminuisce (e viceversa). Il valore assoluto della covarianza stabilisce l’entità di questa relazione.
Quando COVARIANZA.C o COVARIANZA.P restituiscono 0, non esiste alcuna relazione fra i due insiemi di dati.
Le vendite di fette biscottate vanno intuitivamente di pari passo con le vendite di marmellata, dato che i due alimenti sono correlati. In altre parole, è probabile che la quantità di marmellata venduta segua la quantità di fette biscottate vendute. Più confezioni di fette biscottate, più vasetti di marmellata:
| Giorno |
Confezioni di fette biscottate |
Vasetti di marmellata |
| Lunedì |
62 |
12 |
| Martedì |
77 |
15 |
| Mercoledì |
95 |
26 |
Aumentando le vendite di fette biscottate, aumenteranno anche le vendite di marmellata. Pertanto le vendite di marmellata avranno probabilmente una correlazione positiva con le vendite di fette biscottate. Si tratta di articoli complementari. Al contrario, le fette biscottate e i croissant sono in concorrenza tra loro. Quando si vendono più fette biscottate, è probabile che le vendite di croissant si riducano, poiché se la gente fa colazione con fette biscottate e marmellata, probabilmente non mangia anche un croissant. Anche senza dover ricorrere a una funzione di Excel, potete quindi concludere che le vendite di fette biscottate e di marmellata vadano nella stessa direzione e che le vendite di fette biscottate e croissant vadano in direzioni opposte. Ma di quale entità?
La Figura 9.12 mostra un esempio che raffronta le precipitazioni nevose e il numero di clienti che entrano in un negozio. Vengono forniti due calcoli di covarianza: uno riguarda le precipitazioni nevose fra 0 e 10 centimetri e uno le precipitazioni fra 0 e 20 centimetri.
Nella Figura 9.12, la prima COVARIANZA misura la relazione fra precipitazioni nervose e numero di clienti, ma solo per precipitazioni fino a 10 centimetri di neve. La formula nella cella F10 è =COVARIANZA.P(B5:B10;D5:D10).
Il risultato è -36,5.

Figura 9.12 Uso della funzione COVARIANZA per individuare le relazioni fra due insiemi di dati.
Questo significa che, aumentando le precipitazioni, il numero di clienti si riduce. I due insiemi di dati procedono in direzioni opposte: quando uno sale, l’altro scende. Questo fatto è confermato dai risultati commerciali negativi.
La formula contenuta nella cella F15 è =COVARIANZA.P(B5:B15;D5:D15). Questo valore considera tutti i valori degli insiemi di dati, compresi quelli fino a 20 centimetri di neve. La covarianza è pari a -119,455. Questo dato conferma che, aumentando ulteriormente le precipitazione nevose, il numero di clienti si riduce ancora di più.
Tuttavia, notate che la covarianza del primo calcolo, fino a 10 centimetri di neve, non presenta una situazione grave quanto quella del secondo calcolo (fino a 20 centimetri di neve). Quando ci sono 10 centimetri di neve per terra, solo alcuni clienti rinunciano a fare la spesa. Ma quando ci sono fino a 20 centimetri di neve, in negozio non si presenta praticamente nessun cliente. La prima covarianza è molto inferiore alla seconda: -36,5 rispetto a -119,455. Il primo valore dice che qualche centimetro di neve non ha un effetto poi così grave sul numero dei clienti. L’ultimo numero, invece, dice che quando ci sono 20 centimetri di neve, i clienti preferiscono quasi tutti starsene a casa.
Notate che nella cella F10 viene utilizzata la funzione COVARIANZA.P anche se i dati sono solo quelli delle righe da 5 a 10 poiché questi punti vengono considerati come una popolazione e non come un campione della popolazione.
Ecco come utilizzare la funzione COVARIANZA.P.
1.Inserite due elenchi di valori numerici.
Gli elenchi devono avere le stesse dimensioni.
2.Posizionate il cursore nella cella in cui volete far comparire la covarianza.
3.Inserite =COVARIANZA.P( per iniziare la funzione.
4.Trascinate il puntatore sul primo elenco di valori o specificate l’intervallo di celle.
5.Inserite un punto e virgola (;).
6.Trascinate il puntatore sul secondo elenco di valori o specificate l’intervallo di celle.
7.Inserite una parentesi chiusa, ), e premete il tasto Invio.
La funzione CORRELAZIONE
La funzione CORRELAZIONE funziona un po’ come COVARIANZA, ma il risultato è sempre compreso fra -1 e 1. In pratica il risultato è normalizzato. In tal modo il risultato di una correlazione può essere confrontato con un altro. Un risultato negativo significa che esiste una correlazione inversa. Quando un insieme di dati cresce, l’altro cala. L’effettivo valore negativo dice qual è il grado di correlazione inversa. Il valore -1 significa che i due insiemi di dati si muovono esattamente in direzioni opposte. Il valore -0,5, per esempio, significa che i due insiemi di dati si muovono, più o meno, in direzioni opposte.
La funzione CORRELAZIONE restituisce un valore compreso fra -1 e 1. Un valore positivo significa che i due insiemi di dati si muovono nella stessa direzione e un valore negativo significa che i due insiemi di dati si muovono in direzioni opposte. Il valore 0 significa che non esiste alcuna correlazione fra i due insiemi di dati.
La Figura 9.13 mostra tre esempi di correlazione. Le correlazioni mostrano il comportamento dei clienti (in termini di incrementi percentuali delle vendite) rispetto a tre tipi di investimenti pubblicitari. Le tre campagne manifestano tutte una correlazione positiva. Aumentando l’investimento pubblicitario, aumenta anche la spesa dei clienti (o almeno non si ha un’inversione di direzione).
Tutti e tre i valori di correlazione rientrano nell’intervallo compreso fra 0 e 1 e, pertanto, sono facili da confrontare fra loro e il risultato è chiaro: le campagne direct-mail non sono efficaci come le pubblicità su carta stampata e radio. Le pubblicità su riviste e alla radio mostrano un valore elevato: i valori restituiti sono prossimi a 1. Al contrario, le campagne di direct-mail manifestano una correlazione pari a 0,4472…. Esiste ancora una correlazione positiva, ovvero le campagne di direct-mail generano comunque un incremento nelle vendite. Ma la correlazione non è al livello delle pubblicità su riviste o radiofonica. Il denaro speso in campagne di direct-mail potrebbe essere speso meglio in altro modo.
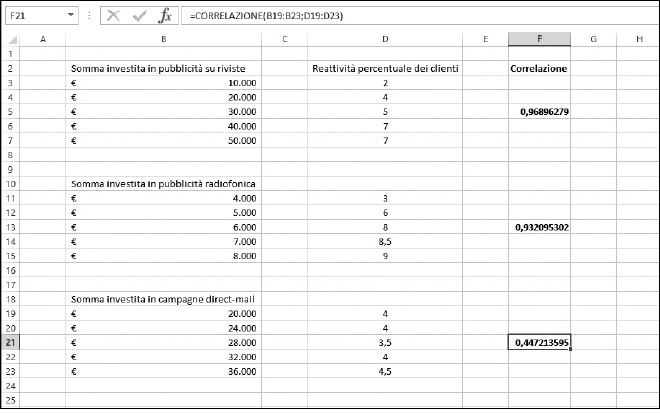
Figura 9.13 Confronto dei risultati di tre campagne pubblicitarie.
Ecco come utilizzare la funzione CORRELAZIONE.
1.Inserite due elenchi di valori numerici.
Gli elenchi devono avere le stesse dimensioni.
2.Posizionate il cursore nella cella in cui volete far comparire la correlazione.
3.Inserite =CORRELAZIONE( per iniziare la funzione.
4.Trascinate il puntatore sul primo elenco di valori o specificate l’intervallo di celle.
5.Inserite un punto e virgola (;).
6.Trascinate il puntatore sul secondo elenco di valori o specificate l’intervallo di celle.
7.Inserite una parentesi chiusa, ), e premete il tasto Invio.
I percentili sono una tecnica per l’analisi dei dati: determinano il modo in cui i valori si rapportano, in termini percentuali, all’intero insieme di dati. Immaginate la situazione: una casa farmaceutica sta provando l’efficacia di un nuovo principio, che dovrebbe ridurre il colesterolo. I dati sono costituiti da 500 esami del sangue delle persone che formano il campione. Nella Figura 9.14, questi 500 risultati sono situati nella colonna A. Siamo interessati a scoprire in quale modo i dati possono essere suddivisi al 25%, al 50% e al 75%. In pratica, quali valori (negli esami del colesterolo presente nel sangue) sono maggiori del 25% dei dati (e pertanto più piccoli del 75% dei dati)? Quale valore si trova nella posizione 50%? Queste misure sono chiamate quartili, poiché dividono il campione in quattro quarti.
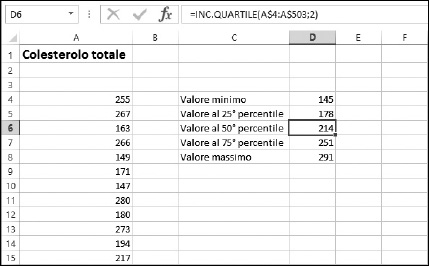
Figura 9.14 Calcolo dei valori ai quartili.
Le funzioni INC.QUARTILE e ESC.QUARTILE
Le funzioni QUARTILE consentono di svolgere questo tipo di analisi. La funzione accetta due argomenti: uno è l’intervallo dei dati campionati e l’altro indica quale quartile restituire. Il secondo argomento può essere 0, 1, 2, 3 o 4 se si utilizza INC.QUARTILE oppure 1, 2 o 3 se si utilizza ESC. QUARTILE. Quest’ultima funzione viene utilizzata quando occorre escludere i valori minimo e massimo: per questo tale versione della funzione non accetta i valori 0 o 4 per il secondo argomento:
| Formula |
Risultato |
=INC.QUARTILE(A$4:A$503;0) |
Valore minimo fra i dati. |
=INC.QUARTILE(A$4:A$503;1) |
Valore situato al 25° percentile. |
=INC.QUARTILE(A$4:A$503;2) |
Valore situato al 50° percentile. |
=INC.QUARTILE(A$4:A$503;3) |
Valore situato al 75° percentile. |
=INC.QUARTILE(A$4:A$503;4) |
Valore massimo fra i dati. |
Le funzioni INC.QUARTILE ed ESC.QUARTILE operano su dati ordinati, ma non richiedono di eseguirne l’ordinamento: se ne occupa direttamente la funzione. Nella Figura 9.14 vengono calcolati i quartili dei valori. I valori minimo e massimo vengono restituiti utilizzando, rispettivamente, i valori 0 e 4 come secondo argomento.
Ecco come utilizzare la funzione INC.QUARTILE.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire il quartile desiderato.
3.Inserite =INC.QUARTILE( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite un punto e virgola (;).
6.Inserite un valore compreso fra 0 e 4, a seconda del quartile desiderato.
7.Inserite una parentesi chiusa, ), e premete il tasto Invio.
Le funzioni INC.PERCENTILE ed ESC.PERCENTILE
Le funzioni INC.PERCENTILE ed ESC.PERCENTILE sono simili alle funzioni INC. QUARTILE ed ESC.QUARTILE, tranne per il fatto che permettono di specificare quale percentile utilizzare. Non siete pertanto legati a percentili fissi, come 25, 50 o 75. Le due funzioni PERCENTILE richiedono due argomenti:
l’intervallo del campione;
un valore compreso fra 0 e 1.
Il secondo argomento dice alla funzione quale percentile utilizzare. Per esempio, 0,1 (10%) corrisponde al decimo percentile, 0,2 (20%) al ventesimo e così via.
Utilizzate la funzione INC.QUARTILE per analizzare i dati a percentili fissi di 25, 50 o 75 percentili. Utilizzate la funzione INC.PERCENTILE per analizzare i dati ai percentili desiderati. ESC.PERCENTILE viene utilizzata quando il secondo argomento esclude gli estremi: 0 e 1. In altre parole, il secondo argomento può essere qualsiasi valore compreso tra 0 e 1, esclusi però questi due estremi.
La Figura 9.15 mostra un esempio di risultati di un test in una classe di studenti. Chi si è situato dal 90° percentile in su? Gli studenti con una valutazione elevata meritano un riconoscimento speciale. Tenete in considerazione che il fatto di entrare nel 90° percentile non significa ottenere un voto di 90 o più. I valori dal 90° percentile in su sono quelli che rientrano nel 10% superiore fra i valori del campione.
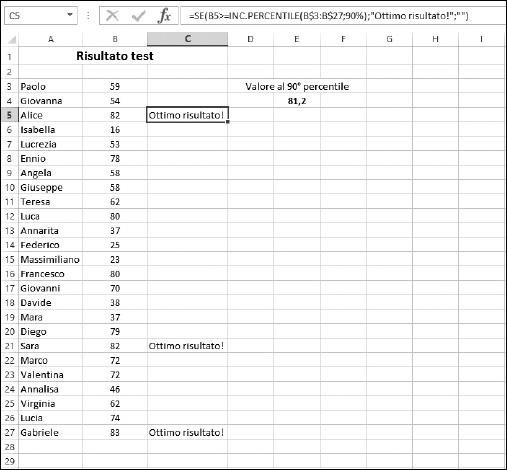
Figura 9.15 Uso della funzione PERCENTILE per trovare le valutazioni più elevate.
In effetti, il voto collocato al 90° percentile, è 81,2. La cella E4 contiene la formula =INC.PERCENTILE(B3:B27;90%), che utilizza 90% (equivalente a 0,9) come secondo argomento.
Le celle C3:C27 contengono una formula che controlla se la cella corrispondente, nella colonna B, è al 90° percentile o superiore. Per esempio, la cella C5 contiene la seguente formula: =SE(B5>=INC. PERCENTILE(B$3:B$27;90%);"Ottimo risultato!";"").
Se il valore nella cella B4 è uguale o superiore rispetto al valore al 90° percentile, allora la cella C4 visualizzerà il testo di congratulazioni. Il valore nella cella B4 è 54, che non rientra nella categoria dei migliori. Al contrario, il valore contenuto nella cella B5 è maggiore di 81,2 e dunque la cella C5 visualizza questo messaggio.
Ecco come utilizzare la funzione ESC.PERCENTILE.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire il percentile desiderato.
3.Inserite =INC.PERCENTILE( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite un punto e virgola (;).
6.Inserite un valore compreso fra 0 e 1, o una percentuale compresa fra 0% e 100%, a seconda del percentile desiderato.
7.Inserite una parentesi chiusa, ), e premete il tasto Invio.
La funzione RANGO
La funzione RANGO.UG (o RANGO.MEDIA) dice il rango di un determinato numero, in altre parole dove si situa il valore, all’interno di una distribuzione. In un campione di dieci valori, per esempio, un numero può essere il più piccolo (rango = 1), il più grande (rango = 10) o un valore intermedio. La funzione accetta tre argomenti.
Il numero di cui occorre conoscere il rango: se questo numero non è presente nei dati, viene restituito un errore.
L’intervallo da considerare: un riferimento all’intervallo di celle.
0 o 1, determina il modo in cui ordinare la distribuzione: il valore 0 (il valore predefinito utilizzato anche quando l’argomento viene omesso) chiede alla funzione di ordinare i valori in senso discendente. Il valore 1 chiede alla funzione di ordinarli in senso ascendente. L’ordinamento cambia il modo in cui vengono interpretati i risultati. Siamo interessati al rango partendo dal valore maggiore o minore dei dati?
La differenza fra RANGO.UG e RANGO.MEDIA è nel fatto che se più valori hanno lo stesso rango, RANGO.UG utilizza il valore maggiore, mentre RANGO.MEDIA utilizza la media dei valori trovati.
La Figura 9.16 visualizza un elenco di dipendenti e i premi di produzione ricevuti. Supponete di essere il dipendente che ha ricevuto 4.800 euro. Volete sapere qual è il vostro rango nell’intervallo dei premi. La cella F4 contiene una formula che impiega la funzione RANGO.UG: =RANGO. UG(C9;C3:C20). La funzione restituisce la risposta 4: siete al quarto posto. Notate che la funzione è stata specificata senza il terzo argomento: chiediamo alla funzione di ordinare la distribuzione in senso discendente, per determinare dove si colloca il valore in questione. Questo consente di determinare quanto il valore cui siamo interessati è vicino alla cima dell’elenco.

Figura 9.16 Determinare il rango di un valore.
Ecco come utilizzare la funzione RANGO.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire il rango.
3.Inserite =RANGO.UG( per iniziare la funzione.
4.Fate clic sulla cella contenente il valore di cui volete calcolare il rango.
Potete anche specificare direttamente il valore.
5.Inserite un punto e virgola (;).
6.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
7.Se volete che il valore venga confrontato su un elenco ordinato in senso ascendente, inserite un punto e virgola (;) e poi il valore 1.
Se l’ordine desiderato è discendente, non è necessario specificare il valore 0.
8.Inserite una parentesi chiusa, ), e premete il tasto Invio.
Le funzioni PERCENT.RANGO
Anche le funzioni INC.PERCENT.RANGO ed ESC.PERCENT.RANGO restituiscono il rango di un valore, ma la sua posizione viene specificata in termini percentuali. In altre parole, le funzioni PERCENT.RANGO possono dire che un determinato valore è collocato al 20% nella distribuzione ordinata. Le funzioni PERCENT.RANGO richiedono tre argomenti:
l’intervallo del campione;
il numero da valutare rispetto al campione;
un indicatore del numero di punti decimali da utilizzare nella risposta (l’argomento è opzionale; se tralasciato, vengono impiegate 3 cifre decimali).
La funzione ESC.PERCENT.RANGO viene utilizzata quando deve essere restituito un rango compreso fra 0 e 100% (fra 0 e 1, ma escludendo gli estremi, 0 e 1). Nella Figura 9.16, il rango percentuale del valore 4.800 euro viene calcolato all’82,3% (0,823). Pertanto, il rango di 4.800 euro è alla posizione percentuale 82,3 nel campione. La formula contenuta nella cella F8 è =INC.PERCENT.RANGO(C3:C20;C9).
Nella funzione RANGO.UG, come primo argomento va specificato il valore valutato e come secondo argomento l’intervallo di valori. Nella funzione INC.PERCENT.RANGO, l’ordine di questi argomenti è invertito.
Ecco come utilizzare la funzione INC.PERCENT.RANGO.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire la percentuale del rango.
3.Inserite =INC.PERCENT.RANGO( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite un punto e virgola (;).
6.Fate clic sulla cella contenente il valore di cui volete calcolare il rango.
Potete anche specificare direttamente il valore.
7.Se volete che il valore contenga più (o meno) di tre cifre decimali, inserite un punto e virgola (;) e poi il numero di decimali.
8.Inserite una parentesi chiusa, ), e premete il tasto Invio.
La funzione FREQUENZA
La funzione FREQUENZA esegue la suddivisione dei valori di un campione in gruppi. Un gruppo rappresenta un intervallo di valori, per esempio fra 0 e 1 o fra 20 e 29. Tipicamente, i gruppi utilizzati nelle analisi statistiche hanno le stesse dimensioni e coprono l’intera gamma di valori. Per esempio, se i dati sono tutti compresi fra 1 e 100, potreste creare dieci gruppi, ognuno dei quali avrà un’ampiezza di 10 unità. Il primo gruppo conterrà i valori da 1 a 10, il secondo da 11 a 20 e così via.
La Figura 9.17 illustra questa suddivisione. Vi sono 300 valori nell’intervallo B3:B302. I valori sono casuali, compresi fra 1 e 100. Le celle da D3 a D12 sono configurate come gruppi che coprono ciascun intervallo di dieci valori. Notate che, per ciascun gruppo, viene utilizzato il valore massimo dell’intervallo. Per esempio, il gruppo 30 conterrà i valori compresi fra 21 e 30.
Un gruppo contiene il numero di valori che rientrano nell’intervallo numerico. Il numero di gruppo è il massimo dell’intervallo.
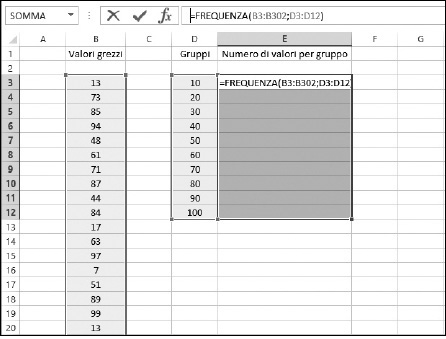
Figura 9.17 Configurazione dei gruppi utilizzando la funzione FREQUENZA.
La funzione FREQUENZA è una funzione a matrici e pertanto richiede alcuni speciali passi per poter essere utilizzata correttamente.
1.Inserite un elenco di valori.
Può trattarsi di un lungo elenco, che può rappresentare dati rilevati, come l’età delle persone che utilizzano la biblioteca o il numero di chilometri percorsi per svolgere un lavoro. Naturalmente, potete utilizzare ogni tipo di dato osservabile.
2.Determinate i valori massimo e minimo presenti nei dati.
Per farlo potete utilizzare le funzioni MAX e MIN.
3.Determinate la composizione dei gruppi.
Si tratta di una scelta soggettiva. Per esempio, se i dati contengono valori compresi fra 1 e 100, potete utilizzare dieci gruppi, ognuno dei quali contiene dieci valori. Oppure potete utilizzare venti gruppi, ognuno dei quali contiene cinque valori, ma potete anche utilizzare cinque gruppi, ognuno dei quali contiene venti valori.
4.Create un elenco di gruppi specificando il valore più elevato di ciascun gruppo, come illustrato nelle celle D3:D12 (Figura 9.17).
5.Fate clic sulla prima cella in cui intendete visualizzare il risultato di FREQUENZA.
6.Eseguite un trascinamento verso il basso per selezionare le altre celle.
Ora dovreste aver selezionato un intervallo di celle. Le dimensioni di questo intervallo dovrebbero corrispondere con il numero di gruppi. La Figura 9.18 mostra l’aspetto del foglio di lavoro in questa fase.
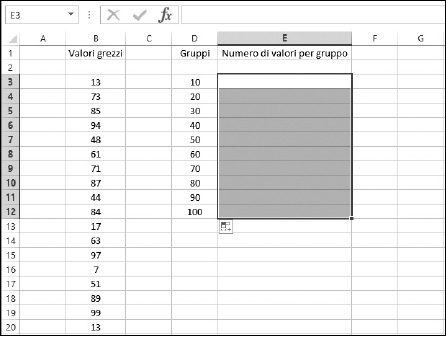
Figura 9.18 Preparazione per l’inserimento della funzione FREQUENZA.
7.Inserite =FREQUENZA( per iniziare la funzione.
8.Trascinate il cursore sui dati del campione o specificate l’indirizzo dell’intervallo.
9.Inserite un punto e virgola (;).
10.Trascinate il cursore sull’elenco dei gruppi oppure specificate l’indirizzo di tale intervallo.
La Figura 9.19 mostra l’aspetto del foglio di lavoro in questa fase.
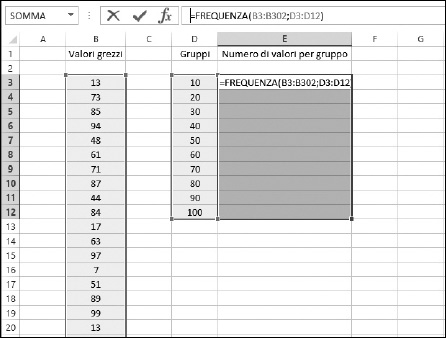
Figura 9.19 Completamento della funzione FREQUENZA.
11.Inserite una parentesi chiusa, ).
NON premete ancora Invio
12.Premete Ctrl + Maiusc + Invio contemporaneamente per concludere l’inserimento della funzione. Ecco fatto! Avete inserito la funzione a matrici. Tutte le celle dell’intervallo in cui è stata inserita la funzione FREQUENZA conterranno ora la stessa formula. I valori restituiti in tali celle rappresentano il conteggio dei valori dei dati che rientrano nei rispettivi gruppi. Questa è chiamata una distribuzione di frequenze.
Ora possiamo prendere la distribuzione e tracciare un grafico.
1.Selezionate l’intervallo di dati del “Numero di valori per gruppo”.
In questo caso si tratta dell’intervallo di celle E3:E12.
2.Fate clic sulla scheda INSERISCI della barra multifunzione.
3.Nella sezione Grafici, fate clic sulla voce Inserisci istogramma, per visualizzare una selezione di grafici a istogramma (Figura 9.20).
4.Selezionate lo stile di grafico desiderato.
La Figura 9.21 mostra il grafico delle distribuzioni di frequenze completato.
Una distribuzione di frequenze è chiamata anche istogramma.
Figura 9.20 Preparazione al tracciamento della distribuzione di frequenze.
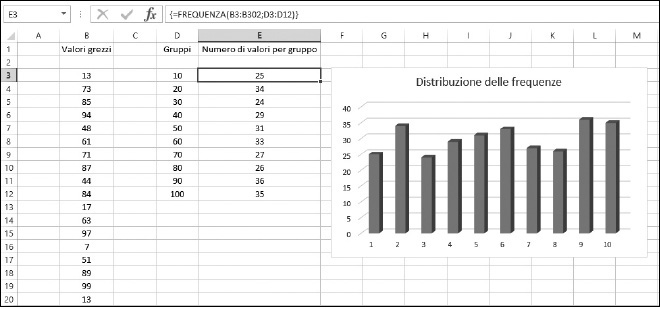
Figura 9.21 Visualizzazione di una distribuzione di frequenze come un grafico a colonne.
Le funzioni MIN e MAX
Excel offre due funzioni, MIN e MAX, che restituiscono rispettivamente il valore minimo e massimo in un insieme di dati. Il loro utilizzo è molto semplice. Le funzioni accettano fino a 255 argomenti, che possono essere celle, intervalli di celle o valori.
La Figura 9.22 mostra un elenco di vendite di lotti immobiliari. Quali sono il valore minimo e il valore massimo? La cella F4 visualizza il prezzo più basso dell’elenco, utilizzando la formula =MIN(C4:C1000). La cella F6 visualizza invece il prezzo più elevato, con la formula =MAX(C4:C1000).
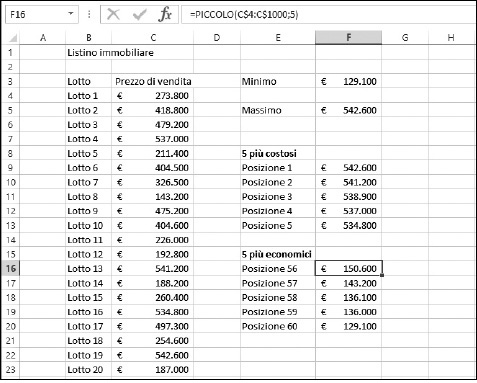
Figura 9.22 Ricerca dei valori minimo e massimo.
Ecco come utilizzare le funzioni MIN o MAX:
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire il minimo o il massimo.
3.Inserite =MIN( o =MAX( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio.
Le funzioni MIN e MAX restituiscono il valore più piccolo e più elevato fra i dati. Come fare per conoscere il secondo valore più elevato? E il terzo?
Le funzioni GRANDE e PICCOLO
Le funzioni GRANDE e PICCOLO consentono di scoprire un valore posizionato in una determinata posizione nei dati. La funzione GRANDE può essere utilizzata per trovare il valore posizionato a una specifica distanza rispetto al massimo e PICCOLO per trovare il valore posizionato a una specifica distanza rispetto al minimo.
La Figura 9.22 visualizza i cinque lotti immobiliari più costosi e anche i cinque più economici. Le funzioni GRANDE e PICCOLO accettano due argomenti: l’intervallo di dati e la posizione relativa rispetto al massimo o al minimo.
I cinque prezzi più elevati possono essere trovati utilizzando la funzione GRANDE. La casa più costosa, nella cella F9, si trova con la formula =GRANDE(C$4:C$1000;1). Poiché la funzione utilizzata in questo caso è GRANDE e il secondo argomento è 1, la funzione restituisce il valore alla prima posizione. Naturalmente questo è lo stesso valore restituito dalla funzione MAX.
Per trovare la seconda casa più costosa, basta specificare 2 quale secondo argomento di GRANDE. La cella F10 contiene la seguente formula: =GRANDE(C$4:C$1000;2). Il terzo, il quarto e il quinto valore fra i lotti immobiliari più costosi vengono calcolati allo stesso modo, utilizzando, rispettivamente, 3, 4 e 5 come secondo argomento.
I cinque lotti più economici si ottengono esattamente allo stesso modo, utilizzando la funzione PICCOLO. Per esempio, la cella F20 contiene la formula =PICCOLO(C$4:C$1000;1). Il valore restituito, 129.100 euro, corrisponde al valore restituito dalla funzione MIN. La cella che si trova appena sopra, F19, contiene la seguente formula: =PICCOLO(C$4:C$1000;2).
Attenzione: forse avete notato che le funzioni ricercano valori fino alla riga 1000, anche se l’elenco è costituito da 60 elementi. Una cosa interessante da notare in questo esempio è che tutte le funzioni utilizzano la riga 1000 come ultima riga in cui eseguire la ricerca, ma non obbligano a inserire altrettanti valori. La scelta è intenzionale. Attualmente l’elenco conta solo 60 vendite. Ma cosa accadrebbe se in futuro venissero aggiunte altre vendite all’elenco? Offrendo alle funzioni un intervallo ben superiore rispetto a quello richiesto, abbiamo la possibilità di accogliere un elenco di vendite ben superiore. È interessante vedere, però, come le etichette sono state create rispetto ai risultati effettivamente disponibili.
Le etichette nelle celle E9:E13 (Posizione 1, Posizione 2 e così via) possono essere specificate come sono. Chiaramente, dovendo partire dall’inizio, si partirà da 1, procedendo con 2 e così via.
Al contrario, le etichette nelle celle E16:E20 (Posizione 56, Posizione 57 e così via) sono state create utilizzando delle formule. È stata utilizzata la funzione CONTA.NUMERI per contare il numero totale di elementi. Anche se la funzione ricerca fino alla riga 1000, trova solo 60 elementi e questo è il conteggio restituito. L’etichetta Posizione 60 si basa dunque su questo conteggio. Le altre etichette (Posizione 59, Posizione 58 e così via) vengono create riducendo il conteggio, rispettivamente, di 1, 2, 3 e 4 unità:
La formula nella cella E20 è ="Posizione "&CONTA.NUMERI(C$4:C$1000)
La formula nella cella E19 è ="Posizione "&CONTA.NUMERI(C$4:C$1000)-1
La formula nella cella E18 è ="Posizione "&CONTA.NUMERI(C$4:C$1000)-2
La formula nella cella E17 è ="Posizione "&CONTA.NUMERI(C$4:C$1000)-3
La formula nella cella E16 è ="Posizione "&CONTA.NUMERI(C$4:C$1000)-4
Ecco come utilizzare la funzione GRANDE o PICCOLO.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire il risultato.
3.Inserite =GRANDE( (o =PICCOLO() per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite un punto e virgola (;).
6.Inserite un numero per indicare la posizione cui siete interessati.
7.Inserite una parentesi chiusa, ), e premete il tasto Invio.
Si usa GRANDE per trovare la posizione di un valore rispetto al valore più elevato. Si usa PICCOLO per trovare la posizione di un valore rispetto al valore più piccolo.
Le funzioni CONTA.NUMERI e CONTA.SE restituiscono, naturalmente, un conteggio. Cos’altro potrebbero fare, con un nome così?
La funzione CONTA.NUMERI
Il suo utilizzo è semplice. Conta quanti elementi numerici vi sono in un intervallo di valori. In pratica non considera le celle contenenti testi o vuote.
La funzione CONTA.VALORI funziona allo stesso modo di CONTA.NUMERI, ma considera tutte le celle non vuote, comprese quelle contenenti testi.
Ecco come utilizzare la funzione CONTA.NUMERI.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire il valore.
3.Inserite =CONTA.NUMERI( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco di valori o specificate l’intervallo di celle.
5.Inserite una parentesi chiusa, ), e premete il tasto Invio.
La Figura 9.23 mostra un elenco di cinquanta film di grande successo e degli incassi relativi a ciascuna pellicola. La cella F4 mostra il conteggio dei film, restituito con la funzione CONTA.NUMERI. La formula contenuta nella cella F4 è =CONTA.NUMERI(B4:B53).
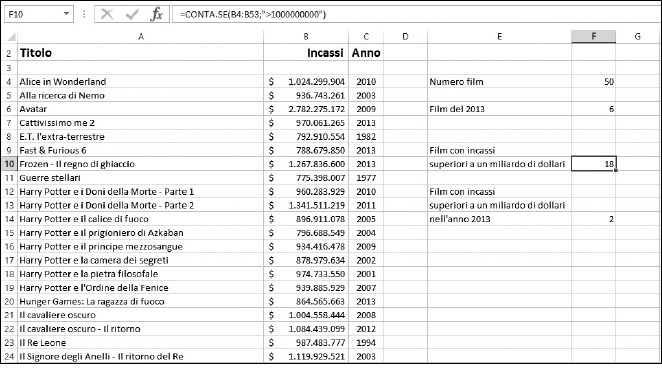
Figura 9.23 Conteggio con e senza criteri.
Notate che l’intervallo inserito nella funzione esegue la ricerca nei dati che indicano i profitti. La scelta è intenzionale. Si tratta di valori numerici. Se avessimo usato la funzione CONTA.NUMERI sui titoli dei film, nella colonna A, il conteggio avrebbe dato 0, poiché questa colonna contiene solo dati testuali.
La funziona CONTA.SE
La funzione CONTA.SE è comoda quando dovete contare quanti elementi di un elenco rispondono a una determinata condizione. Nella Figura 9.23, la cella F6 mostra il conteggio dei film prodotti nell’anno 2002. La formula contenuta nella cella F6 è =CONTA.SE(C4:C53;2002).
La funzione CONTA.SE accetta due argomenti:
l’intervallo di celle da considerare;
il criterio.
La Tabella 9.1 presenta alcuni esempi di criteri impiegabili con la funzione CONTA.SE.
| Tabella 9.1 |
Uso di criteri per la funzione CONTA.SE |
| Esempio |
Commento |
=CONTA.SE(C4:C53;"=2002") |
Restituisce il numero di film prodotti nel 2002. |
=CONTA.SE(C4:C53;2002) |
Restituisce il numero di film prodotti nel 2002. Notate che questo criterio può non essere racchiuso fra doppi apici. Questo è dovuto al fatto che il criterio è una semplice uguaglianza. =CONTA.SE(C4:C53;"<2002") Restituisce il numero di film prodotti prima del 2002. |
=CONTA.SE(C4:C53;">=2002") |
Restituisce il numero di film prodotti dal 2002 in poi. |
=CONTA.SE(C4:C53;"<>2002") |
Restituisce il numero di film non prodotti nell’anno 2002. |
Il criterio può anche basarsi sul testo. Per esempio, CONTA.SE può contare tutte le occorrenze di una città in un elenco di viaggi d’affari. Potete anche utilizzare dei caratteri jolly con la funzione CONTA.SE. In particolare, l’asterisco (*) rappresenta un qualsiasi numero di caratteri e il punto interrogativo (?) rappresenta un unico carattere.
Per esempio, utilizzando un asterisco dopo "Pirati dei Caraibi" otterrete il numero di film il cui titolo è Pirati dei Caraibi nella colonna A (Figura 9.23). La formula avrà dunque il seguente aspetto: =CONTA. SE(A5:A53;"Pirati dei Caraibi*"). Notate la presenza dell’asterisco dopo Caraibi. In questo modo la funzione considererà i titoli Pirati dei Caraibi - Ai confini del mondo, Pirati dei Caraibi - La maledizione del forziere fantasma e Pirati dei Caraibi - Oltre i confini del mare.
Il criterio può essere specificato in una cella invece che direttamente nella funzione CONTA.SE. A questo punto basterà utilizzare semplicemente l’indirizzo della cella nella funzione. Per esempio, se specificate "Pirati dei Caraibi*" nella cella C1, allora la funzione =CONTA.SE(A5:A53;C1) darà lo stesso risultato dell’esempio precedente. La cella F10 della Figura 9.23 restituisce il numero di film che hanno incassato complessivamente più di un miliardo di dollari. La formula è =CONTA.SE(B4:B53;">1000000000").
In quale modo potete determinare il numero di elementi che rispondono a due condizioni? La formula nella cella F14 restituisce il numero di film prodotti nel 2013 che hanno incassato più di un miliardo di dollari. Tuttavia, CONTA.SE non può essere impiegata per condizioni multiple. Al suo posto si utilizza la funzione MATR.SOMMA.PRODOTTO. La formula nella cella F15 è quella che segue:
=MATR.SOMMA.PRODOTTO((B4:B53>1000000000)*(C4:C53=2013))
Che ci crediate o no, la formula funziona. Anche se questa formula sembra moltiplicare il numero di film che hanno incassato più di un miliardo di dollari per il numero di film prodotti nel 2013, in realtà restituisce il numero di film che rispondono a entrambe le condizioni. A proposito, piccolo quiz: qual è l’unico film degli anni Settanta che resiste ancora fra i cinquanta incassi più elevati di tutti i tempi? La risposta è [rullo di tamburi] Guerre stellari!
Per utilizzare la funzione CONTA.SE, procedete nel modo seguente.
1.Inserite un elenco di valori numerici.
2.Posizionate il cursore nella cella in cui volete far comparire il risultato.
3.Inserite =CONTA.SE( per iniziare la funzione.
4.Trascinate il puntatore sull’elenco oppure specificate l’indirizzo dell’intervallo.
5.Inserite un punto e virgola (;).
6.Inserite una condizione racchiusa fra doppi apici.
Potete utilizzare i seguenti simboli:
•= (uguale)
•> (maggiore)
•< (minore)
•* (ogni sequenza di caratteri, anche vuota)
•? (ogni carattere)
•<> (diverso)
7.Inserite una parentesi chiusa, ), e premete il tasto Invio per concludere la formula.
Il risultato è il numero delle celle che esaudiscono la condizione.
Esiste anche la funzione CONTA.PIÙ.SE, che consente di utilizzare più intervalli e criteri per restituire un conteggio. CONTA.PIÙ.SE è abbastanza simile a SOMMA.PIÙ.SE, già presentata nel Capitolo 8.