In questo capitolo
 Le tendenze lineari ed esponenziali
Le tendenze lineari ed esponenziali
Previsione dei dati futuri a partire dai dati esistenti
Le distribuzioni normali e di Poisson
Le tendenze lineari ed esponenziali
Previsione dei dati futuri a partire dai dati esistenti
Le distribuzioni normali e di Poisson
Nell’analisi statistica, uno dei passi più importanti consiste nel determinare il modello seguito dai dati. Non stiamo parlando di auto o sfilate di moda, ma di modelli matematici: trovare una formula che descriva i dati. La scelta del modello è utile per tutti i dati formati da coppie X-Y, come i seguenti casi.
 Confronti fra misure di peso e statura.
Confronti fra misure di peso e statura.
Dati sul reddito rispetto al titolo di studio.
Numero di pesci che nuotano vicino alla riva del fiume rispetto all’ora del giorno.
Numero di permessi di malattia rispetto al giorno della settimana.
Supponete di voler tracciare i dati su un grafico, un grafico a dispersione nella terminologia di Excel. Quale aspetto assumerà la curva? Se i dati sono lineari, cadranno, più o meno, lungo una linea retta. Se la linea si piega, i dati non sono lineari; probabilmente, sono esponenziali. Questi due modelli, lineare ed esponenziale, sono quelli più comunemente utilizzati in statistica ed Excel offre due funzioni per utilizzarli.
In un modello lineare, la formula matematica che modella i dati è quella che segue:
Y = b + X * m

La formula dice che per un qualsiasi valore X, è possibile calcolare il valore Y moltiplicando X per una costante m e poi sommando un altro valore costante, b. Il valore m è chiamato pendenza della linea e b è l’intercettazione di Y (il valore di Y e in cui X = 0). Questa formula genera una curva perfettamente lineare e i dati rilevati difficilmente cadranno su una linea di questo tipo. Questo perché la linea, chiamata curva di regressione lineare, è solo la migliore approssimazione dei dati. Le costanti m e b sono differenti per ciascun insieme di dati.
In un modello esponenziale, i dati sono modellati da una formula come la seguente:
Y = b + X^m
Anche in questo caso i valori b e m sono costanti. Molti processi naturali, compresa la proliferazione dei batteri e i cambiamenti di temperatura, sono modellati da curve esponenziali. La Figura 11.1 mostra un esempio di curva esponenziale. Questa curva è il risultato della formula precedente, dove b = 2 e m = 2,4.
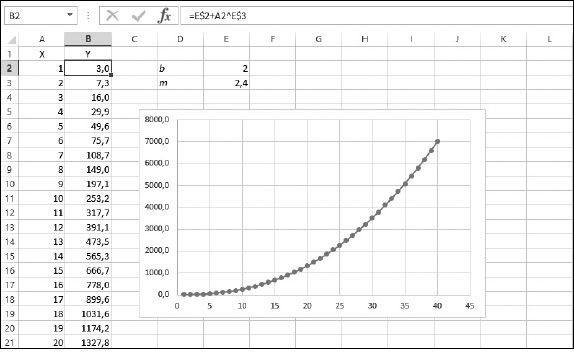
Figura 11.1 Una curva esponenziale.

Anche in questo caso, b e m sono costanti e sono differenti per ciascun insieme di dati.
Come abbiamo appena detto, molti insiemi di dati possono essere modellati tramite una semplice linea: si tratta di dati che hanno una natura lineare.
La linea che modella i dati, chiamata curva di regressione lineare, è caratterizzata da una specifica pendenza e da un punto di intercettazione dell’asse Y. Per calcolare questi due valori per una curva di regressione lineare e per l’insieme di coppie di dati, Excel mette a disposizione le funzioni PENDENZA e INTERCETTA.
Le funzioni PENDENZA e INTERCETTA accettano entrambe gli stessi due argomenti:
un intervallo o una matrice contenente i valori Y dell’insieme di dati;
un intervallo o una matrice contenente i valori X dell’insieme di dati;
I due intervalli devono contenere lo stesso numero di valori, altrimenti Excel produrrà un errore. Ecco come utilizzare queste funzioni:
1.In una cella vuota del foglio di lavoro, inserite =PENDENZA( o =INTERCETTA( per dare inizio alla funzione.
2.Trascinate il mouse sull’intervallo contenente i valori Y dei dati oppure specificate manualmente tale intervallo.
3.Inserite un punto e virgola (;).
4.Trascinate il mouse sull’intervallo contenente i valori X dei dati oppure specificate manualmente tale intervallo.
5.Inserite una parentesi chiusa,), e premete il tasto Invio.

Quando conoscete la pendenza e l’intercettazione Y di una curva di regressione lineare, potete calcolare i valori previsti di Y per qualsiasi X utilizzando la formula Y = b + m * X, dove b è l’intercettazione Y e m è la pendenza. Per svolgere i calcoli, Excel fornisce le funzioni PREVISIONE e TENDENZA.
Ora sappiamo che cosa sono la pendenza e l’intercettazione Y di una curva di regressione lineare, ma a cosa servono queste informazioni? Per esempio, potete tracciare la curva di regressione lineare utilizzando i dati in vostro possesso. I numeri sono “aridi”; come si sa, un grafico vale più di mille parole (o di numeri). Consente di scoprire quanto i dati seguono il modello e di individuare tendenze.
Per vedere come funziona la cosa, osservate la Figura 11.2, in cui il grafico mostra un tracciamento disperso dei dati. Sembra evidente che i dati hanno un andamento grossomodo lineare e che con essi sia possibile utilizzare le funzioni PENDENZA e INTERCETTA. Il primo passo consiste nell’inserire queste funzioni nel foglio di lavoro nel modo seguente. Potete utilizzare un qualsiasi foglio di lavoro contenente dati lineari X-Y.
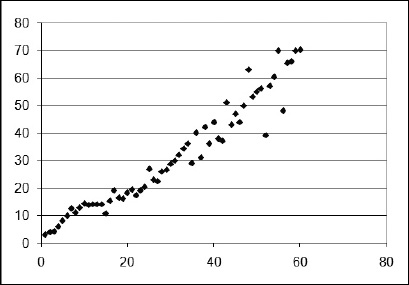
Figura 11.2 Il grafico a dispersione indica che i dati X e Y operano in modo lineare.
1.Inserite l’etichetta Pendenza in una cella vuota.
2.Nella cella alla sua destra, specificate =PENDENZA( per aprire la funzione.
3.Trascinate il mouse sull’intervallo contenente i valori Y oppure specificate manualmente l’intervallo di celle.
4.Inserite un punto e virgola (;).
5.Trascinate il mouse sull’intervallo contenente i valori X oppure specificate manualmente l’intervallo di celle.
6.Inserite una parentesi chiusa, ).
7.Premete Invio per completare la formula.
8.Nella cella sotto l’etichetta Pendenza, specificate l’etichetta Intercetta
9.Nella cella alla sua destra, specificate =INTERCETTA( per aprire la funzione.
10.Trascinate il mouse sull’intervallo contenente i valori Y oppure specificate manualmente l’intervallo di celle.
11.Inserite un punto e virgola (;).
12.Trascinate il mouse sull’intervallo contenente i valori X oppure specificate manualmente l’intervallo di celle.
13.Inserite una parentesi chiusa, ) e premete il tasto Invio per completare la formula.
A questo punto, il foglio di lavoro mostra i valori di pendenza e intercettazione Y della curva di regressione lineare per i dati. Il prossimo passo consiste nel visualizzare questa curva sul grafico.
1.Se necessario, aggiungete una nuova colonna vuota al foglio di lavoro, a destra della colonna dei valori Y.
Per farlo fate clic in una cella della colonna immediatamente a destra della colonna dei valori Y e poi selezionate il comando HOME 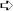 Celle Inserisci Inserisci colonne foglio.
Celle Inserisci Inserisci colonne foglio.
2.Collocate il cursore in questa colonna, nella stessa riga del primo valore X.
3.Inserite un segno di uguaglianza (=) per avviare una formula.
4.Fate clic sulla cella in cui è situata la funzione PENDENZA per inserire nella formula il suo indirizzo.
5.Premete F4 per convertire l’indirizzo in un riferimento assoluto.
L’indirizzo verrà affiancato dal segno di dollaro ($).
6.Inserite il segno di moltiplicazione (*).
7.Fate clic sulla cella contenente il valore X di tale riga.
8.Inserite il segno di somma (+).
9.Fate clic sulla cella contenente la funzione INTERCETTA per inserire nella formula il suo indirizzo.
10.Premete F4 per convertire l’indirizzo in un riferimento assoluto.
L’indirizzo verrà affiancato dal segno di dollaro ($).
11.Premete Invio per completare la formula.
12.Assicuratevi che il cursore sia ancora nella cella in cui avete appena inserito la formula.
13.Premete Ctrl + C per copiare la formula negli Appunti.
14.Mantenete premuto il tasto Maiusc e premete il tasto ↓ finché l’intera colonna non sarà evidenziata, fino alla riga contenente l’ultimo valore X.
15.Premete Invio per replicare la formula su tutte le celle selezionate.
A questo punto, la colonna di dati che avete appena creato conterrà i valori Y da impiegare per tracciare la curva di regressione lineare. L’ultimo passo consiste nel creare un grafico che visualizzi sia i dati effettivamente rilevati, sia la curva di regressione lineare calcolata.
1.Evidenziate le tre colonne di dati: i valori X, i valori Y effettivi e la stima dei valori Y calcolati.
2.Fate clic sulla scheda INSERISCI nella Barra multifunzione (Figura 11.3).
3.Fate clic sul pulsante Inserisci grafico a dispersione (X, Y) o grafico a bolle.

Figura 11.3 Creazione di un grafico a dispersione.
4.Selezionate il tipo di grafico Dispersione con linee smussate e indicatori (oppure Dispersione con linee rette e indicatori).
5.Fate clic sul pulsante Fine.
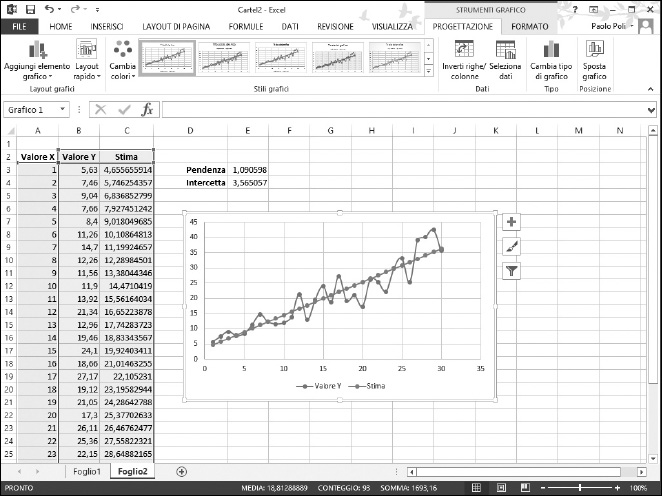
Il grafico comparirà nel foglio di lavoro (Figura 11.4). Potete vedere due insiemi di punti. Quelli dispersi sono i dati effettivi, mentre la linea retta rappresenta la curva di regressione lineare calcolata.
Figura 11.4 Un insieme di dati visualizzati insieme alla loro curva di regressione lineare calcolata.
La funzione PREVISIONE fa esattamente quello che potete immaginare: prevede dati sconosciuti a partire dai dati esistenti, misurati. La funzione si basa su un unico importante assunto: che i dati siano lineari. Che cosa significa?
I dati utilizzati da PREVISIONE sono a coppie: vi è un valore X e un corrispondente valore Y. Per esempio, supponete di voler conoscere la relazione esistente fra la statura e il peso delle persone. Ogni coppia di valori sarà data dalla statura della persona (il valore X), e dal suo peso (il valore Y). Molti tipi di dati hanno questo aspetto, per esempio le vendite in funzione del mese dell’anno o i redditi in funzione del titolo di studio.
Potete utilizzare la funzione CORRELAZIONE per determinare il livello di relazione lineare fra due insiemi di dati. La funzione CORRELAZIONE è stata trattata nel Capitolo 9.
Per utilizzare la funzione PREVISIONE, dovete avere un insieme di coppie di dati X-Y. Fornite un nuovo valore di X, la funzione restituirà il relativo valore di Y. La funzione accetta tre argomenti:
il valore X per il quale si vuole eseguire la previsione;
un intervallo contenente i valori noti di Y;
un intervallo contenente i valori noti di X.
Notate che gli intervalli X e Y devono contenere lo stesso numero di valori o la funzione restituirà un errore. I valori X e Y di questi intervalli si intendono accoppiati.

Non utilizzate la funzione PREVISIONE su dati non lineari, in quanto produrrebbe risultati imprecisi.
Ora potete osservare un esempio d’uso della funzione PREVISIONE. Immaginate di essere il direttore commerciale di una grande azienda. Le vendite dei vostri rappresentanti sono legate al numero di anni di esperienza. Avete assunto un nuovo rappresentante che ha 16 anni di esperienza. Quante vendite potete ragionevolmente attendervi da lui?
La Figura 11.5 mostra i dati esistenti, relativamente al rappresentante: gli anni di esperienza e le vendite annue dell’anno scorso. Questo foglio di lavoro contiene anche un grafico a dispersione dei dati, per dimostrare che si tratta di valori lineari. È chiaro che i punti formano una linea retta. Ecco come creare la previsione.
1.In una cella vuota del foglio di lavoro, inserite =PREVISIONE(per dare inizio alla funzione.
Nella Figura 11.5 si tratta della cella C24.
2.Inserite 16, il valore X per il quale richiedete la previsione.
3.Inserite un punto e virgola (;).
4.Trascinate il mouse sull’intervallo contenente i valori Y dei dati oppure specificate manualmente tale intervallo.
Nella Figura 11.5 si tratta dell’intervallo di celle C3:C17.
5.Inserite un punto e virgola (;).
6.Trascinate il mouse sull’intervallo contenente i valori X dei dati oppure specificate manualmente tale intervallo.
Nella Figura 11.5 si tratta dell’intervallo di celle B3:B17.
7.Inserite una parentesi chiusa, ), e premete il tasto Invio.
Figura 11.5 Previsioni sul futuro.
Dopo aver formattato la cella come una valuta, il risultato rappresentato nella Figura 11.5 prevede che il venditore produrrà approssimativamente 27.093 euro di vendite già dal primo anno. Naturalmente questa è solo una previsione e non una garanzia!
Abbiamo appena visto come la funzione PREVISIONE possa predire un valore Y per un determinato valore X sulla base di un insieme esistente di dati lineari X-Y. Come fare quando occorre eseguire previsioni per più di un valore X? Si utilizza la funzione TENDENZA. Ciò che PREVISIONE fa per un unico valore X, TENDENZA fa per un’intera serie di valori X.
Come PREVISIONE, anche la funzione TENDENZA può operare solo su dati lineari. Se provate ad applicarla a dati di natura non lineare, restituirà risultati errati.
La funzione TENDENZA e richiede quattro argomenti.
Un intervallo contenente i valori noti di Y.
Un intervallo contenente i valori noti di X.
Un intervallo contenente i valori X che intendete prevedere.
Un valore logico che dice alla funzione se forzare la costante b a 0. Se il quarto argomento è VERO o viene omesso, la curva di regressione lineare (utilizzata per prevedere i valori Y) viene calcolata normalmente. Se questo argomento è FALSO, la curva di regressione lineare viene forzata a passare dall’origine (dove X e Y sono uguali a 0).
Notate che gli intervalli di valori X e Y noti devono contenere lo stesso numero di valori.
La funzione TENDENZA restituisce una matrice di valori: una previsione di Y per ogni valore X. In altre parole, si tratta di una funzione a matrici, che deve essere trattata come tale (Capitolo 3). In particolare, questo significa che occorre selezionare l’intervallo in cui devono essere collocati i risultati della formula a matrici, digitare la formula e poi premere Ctrl + Maiusc + Invio invece di premere semplicemente Invio per completare la formula.
Quando si usa la funzione TENDENZA? Ecco un esempio: avete iniziato un’attività part-time e il vostro reddito è cresciuto stabilmente nel corso degli ultimi 12 mesi. La crescita sembra essere lineare e volete prevedere quanto guadagnerete fra 6 mesi. La funzione TENDENZA è ideale per questa situazione. Ecco come utilizzarla.
1.In un nuovo foglio di lavoro, inserite i numeri da 1 a 12, per rappresentare gli ultimi dodici mesi, tutti in una colonna.
2.Nelle celle adiacenti, collocate i dati effettivi per ciascuno dei mesi.
3.Assegnate a questa colonna l’etichetta Dati effettivi.
4.In un’altra sezione del foglio di lavoro, inserite in una colonna i numeri da 13 a 18, per rappresentare i successivi sei mesi.
5.Nella colonna adiacente ai numeri dei mesi da prevedere, selezionate sei celle adiacenti (attualmente vuote) con un’operazione di trascinamento.
6.Digitate =TENDENZA(per avviare la funzione.
7.Trascinate il mouse sull’intervallo di valori noti Y o inserite l’intervallo.
I valori Y noti sono i dati di reddito inseriti nel Passo 2.
8.Inserite un punto e virgola (;).
9.Trascinate il mouse sull’intervallo di valori X noti o inserite manualmente l’intervallo.
I valori X noti sono i numeri da 1 a 12 inseriti nel passo 1.
10.Inserite un punto e virgola (;).
11.Trascinate il mouse sull’elenco dei numeri di mesi dei quali volete avere la previsione (i numeri da 13 a 18).
Questi sono i nuovi valori X.
12.Inserite una parentesi chiusa, ).
13.Completate la formula premendo la combinazione di tasti Ctrl + Maiusc + Invio.
Dopo aver completato questi passi, avrete i dati relativi alle previsioni, calcolati dalla funzione TENDENZA (Figura 11.6). Non c’è alcuna garanzia che questo sarà effettivamente il vostro reddito, che (perché no?) potrebbe essere anche più elevato! Cercate di fare del vostro meglio.
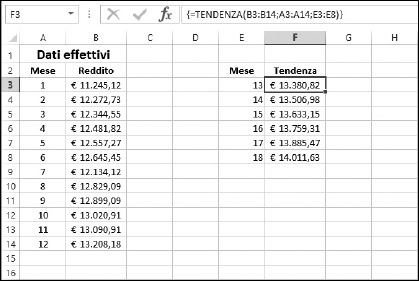
Figura 11.6 Uso della funzione TENDENZA per calcolare previsioni per una serie di valori.
La funzione CRESCITA è simile a TENDENZA, in quanto utilizza i dati esistenti per prevedere i valori di Y per un determinato insieme di valori X. La differenza consiste nel fatto che è adatta a un modello esponenziale. La funzione richiede quattro argomenti.
Un intervallo o matrice contenente i valori noti di Y.
Un intervallo o matrice contenente i valori noti di X.
Un intervallo o matrice contenente i valori X per i quali intendete prevedere i valori Y.
Un valore logico che dice alla funzione se forzare la costante b a 1. Se il quarto argomento è VERO o viene omesso, la curva utilizzata per prevedere i valori Y viene calcolata normalmente. Se questo argomento è FALSO, la curva di regressione lineare viene forzata a 1 (si utilizza in casi speciali).
Il numero di X e Y noti deve essere lo stesso o la funzione CRESCITA produrrà un errore. Come potete immaginare, CRESCITA è una funzione a matrici e pertanto deve essere inserita in modo appropriato.
Per utilizzare la funzione CRESCITA, utilizzate la seguente procedura. Si presuppone che abbiate già un foglio di lavoro che contiene dei valori X e Y noti, i quali seguono un modello esponenziale.
1.Inserite in una colonna del foglio di lavoro i valori X per i quali volete prevedere i valori Y.
2.Selezionate in una colonna un intervallo di celle contenente lo stesso numero di righe dei valori X inseriti nel passo 1.
Spesso per questo intervallo si usa la colonna a lato dei valori X.
3.Inserite =CRESCITA(per iniziare la funzione.
4.Trascinate il mouse sull’intervallo contenente i valori noti di Y o inserite manualmente tale intervallo.
5.Inserite un punto e virgola (;).
6.Trascinate il mouse sull’intervallo contenente i valori noti di X o inserite manualmente tale intervallo.
7.Inserite un punto e virgola (;).
8.Trascinate il mouse sull’intervallo contenente i valori di X per i quali volete prevedere i valori di Y o inserite l’indirizzo dell’intervallo.
9.Inserite una parentesi chiusa, ).
10.Premete la combinazione Ctrl + Maiusc + Invio per completare la formula.
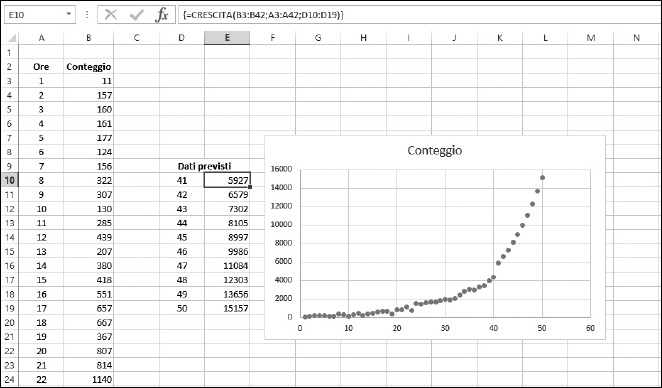
La Figura 11.7 mostra un esempio d’uso della funzione CRESCITA per prevedere dei dati di natura esponenziale. Le colonne A e B contengono i dati noti e l’intervallo D10:D19 contiene i valori X per i quali richiediamo una previsione. La formula a matrici CRESCITA è stata inserita nelle celle E10:E19. Il grafico mostra i dati effettivi, fino a X = 40 e i dati previsti, per valori X superiori a 40. Potete vedere come i dati in proiezione continuino la curva esponenziale tracciata dai dati effettivi.
Figura 11.7 Uso della funzione CRESCITA con dati esponenziali.
Abbiamo già introdotto la distribuzione normale nel Capitolo 9. Per riepilogare, una distribuzione normale è caratterizzata dalla sua media (il valore medio della distribuzione) e dalla sua deviazione standard (la dispersione dei valori a entrambi i lati della media). La distribuzione normale è “continua”, ovvero i valori X possono essere frazionari e non si limitano agli interi. Questo tipo di distribuzione ha moltissimi utilizzi, in quanto si adatta a moltissime attività umane ed eventi naturali.
L’aggettivo “normale”, in questo contesto, non ha un significato di “corretto” e, infatti, una distribuzione “non normale” non ha alcun difetto; viene utilizzata nell’accezione “tipico” o “più comune”.
Excel fornisce la funzione DISTRIB.NORM.N per calcolare le probabilità a partire da una distribuzione normale. La funzione utilizza quattro argomenti:
Un valore per il quale occorre calcolare la probabilità.
La media della distribuzione normale.
La deviazione standard della distribuzione normale.
Un valore logico. Se il quarto argomento è VERO, cerchiamo la probabilità cumulativa. Se è FALSO, cerchiamo la probabilità non cumulativa.
Una probabilità cumulativa è la probabilità di ottenere un valore compreso fra 0 e il valore specificato. Una probabilità non cumulativa è la proprietà di ottenere esattamente il valore specificato.
Le distribuzioni normali entrano in gioco per un’ampia gamma di indicatori. Per esempio la pressione sanguigna, i livelli di anidride carbonica nell’atmosfera, l’altezza delle onde, le dimensioni delle foglie e la temperatura dei forni. Se conoscete la media e la deviazione standard di una distribuzione, potete utilizzare la funzione DISTRIB.NORM.N per calcolare tutte le probabilità.
Ecco un esempio. La vostra azienda produce ferramenta e un cliente vuole acquistare una grande quantità di bulloni da 50 mm. A causa dei processi di produzione, la lunghezza dei bulloni varia leggermente. Il cliente accetterà l’ordine solo se possiamo garantire che almeno il 95% dei bulloni sarà compreso fra 49,9 e 50,1 mm. Non possiamo misurarli uno per uno, ma i dati in nostro possesso dicono che le dimensioni dei bulloni prodotti manifesta una distribuzione normale con media pari a 50 e deviazione standard pari a 0,05. Potete quindi utilizzare Excel e la funzione DISTRIB.NORM.N per rispondere a questa domanda.
1.Utilizzate la funzione DISTRIB.NORM.N per determinare la probabilità cumulativa che un bullone sia lungo al massimo 50,1 mm.
2.Utilizzate la funzione DISTRIB.NORM.N per determinare la probabilità cumulativa che un bullone sia lungo al massimo 49,9 mm.
3.Sottraete il secondo valore dal primo per ottenere la probabilità che la lunghezza del bullone sia compresa fra 49,9 e 50,1 mm.
Ecco l’operazione da svolgere.
1.In un nuovo foglio di lavoro, inserite i valori per la media, la deviazione standard, il limite superiore e il limite inferiore in celle distinte.
Come opzione, potete anche specificare delle etichette per aiutare a identificare le celle.
2.In un’altra cella, inserite =DISTRIB.NORM.N( per iniziare la funzione.
3.Fate clic sulla cella contenente il valore del limite inferiore (49,9) o inserite l’indirizzo della cella.
4.Inserite un punto e virgola (;).
5.Fate clic sulla cella contenente la media o inserite l’indirizzo della cella.
6.Inserite un punto e virgola (;).
7.Fate clic sulla cella contenente la deviazione standard o inserite l’indirizzo della cella.
8.Inserite un punto e virgola (;).
9.Inserite VERO).
10.Premete Invio per completare la funzione.
Ora questa cella visualizza la probabilità che la lunghezza del bullone sia minore del limite inferiore.
11.In un’altra cella, specificate =DISTRIB.NORM.N( per iniziare la funzione.
12.Fate clic sulla cella contenente il valore del limite superiore (50,1) o inserite l’indirizzo della cella.
13.Ripetete i passi da 4 a 10.
Ora questa cella visualizza la probabilità che la lunghezza del bullone sia minore del limite superiore.
14.In un’altra cella, inserite una formula che sottragga le probabilità del limite inferiore dalle probabilità del limite superiore.
Ora questa cella visualizza la probabilità che la lunghezza del bullone sia nei limiti specificati.
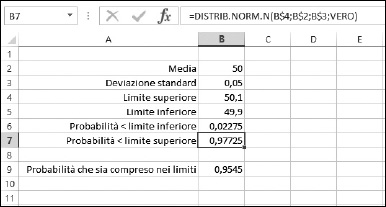
La Figura 11.8 mostra un foglio di lavoro creato per risolvere questo problema. Potete vedere dalla cella B8 che la risposta è 0,9545. In altre parole, il 95,45% dei bulloni rientrerà nei limiti sottoscritti e quindi potete accettare l’ordine del cliente. In questo foglio di lavoro notate che le formule nelle celle B6:B8 vengono presentate in celle adiacenti, in modo da poterle confrontare.
DISTRIB.POISSON è un altro tipo di distribuzione utilizzato in molti campi statistici. Il suo utilizzo più comune consiste nel modellare eventi che si svolgono a intervalli prefissati. Supponete di dover modellare il numero di dipendenti in malattia per giorno della settimana o il numero di articoli difettosi prodotti in fabbrica ogni settimana. Per queste situazioni è appropriata una distribuzione di Poisson.
Figura 11.8 Uso della funzione DISTRIB. NORM.N per calcolare le probabilità.
La distribuzione di Poisson è utile per analizzare eventi rari. Che cosa significa, esattamente, rari? Non è poi così raro che le persone si mettano in malattia al lavoro. Ma il fatto che esattamente un determinato numero di dipendenti si metta in malattia è raro, almeno in termini statistici. Le situazioni in cui è applicabile la distribuzione di Poisson comprende il numero di incidenti d’auto, il numero di clienti in arrivo, i difetti di produzione e così via. Un modo per esprimerlo è che gli eventi sono singolarmente rari, ma vi sono molte opportunità che essi si verifichino.
Quella di Poisson è una distribuzione discreta. Questo significa che i valori di X della distribuzione possono assumere solo numeri interi: X = 1, 2, 3, 4, 5 e così via. È pertanto differente rispetto alla distribuzione normale, che è continua e in cui X può assumere qualsiasi valore (anche 0,034, 1,2365 e così via). La natura discreta della distribuzione di Poisson è adatta a vari tipi di utilizzi. Per esempio, parlando di dipendenti che chiamano in azienda perché sono malati, potete ricevere 1, 5 o 8 telefonate ogni giorno, certamente non 1,45, 7,2 o 9,15!
La Figura 11.9 mostra una distribuzione di Poisson con una media pari a 20. I valori sull’asse X sono le occorrenze (del fenomeno che si sta studiando) e i valori sull’asse Y sono le probabilità. Potete utilizzare questa distribuzione per determinare la probabilità che si verifichi un determinato numero di situazioni. Per esempio, questo grafico dice che la probabilità che si verifichino esattamente 15 situazioni monitorate è approssimativamente pari a 0,05 (5%).
Quella di Poisson è una distribuzione discreta e viene utilizzata solo quando i dati hanno una natura discreta (sono interi, come nei casi di conteggi).
Una distribuzione di Poisson non è sempre simmetrica come quella rappresentata nella Figura 11.9. Valori negativi di X non hanno senso in una distribuzione di Poisson. Dopo tutto, è impossibile avere meno di 0 dipendenti malati! Se la media è un valore piccolo, la distribuzione può essere asimmetrica, come quella rappresentata nella Figura 11.10, che mostra una distribuzione di Poisson con media uguale a 4.
Figura 11.9 Una distribuzione di Poisson con media uguale a 20.
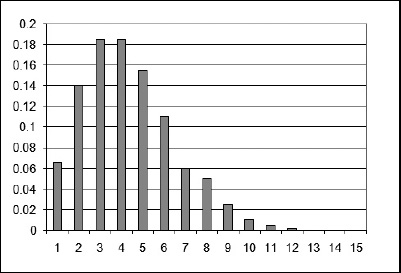
Figura 11.10 Una distribuzione di Poisson con media uguale a 4.
La funzione DISTRIB.POISSON consente di calcolare la probabilità che si verifichi un determinato numero di eventi. Tutto ciò che occorre sapere è la media della distribuzione. Questa funzione può calcolare la probabilità in due modi.
Cumulativa: la probabilità che si verifichino da 0 a X eventi.
Non cumulativa: la probabilità che si verifichino esattamente X eventi.
I due grafici di Poisson presentati in precedenza rappresentavano probabilità non cumulative. La Figura 11.11 mostra la distribuzione di Poisson cumulativa corrispondente alla Figura 11.9. Potete vedere da questo grafico che la probabilità cumulativa di 15 eventi (la probabilità che si verifichino da 0 a 15 eventi) è pari a circa 0,15 (15%).
Come fare per calcolare la probabilità che si verifichino più di X eventi? Semplice! Basta calcolare la probabilità cumulativa di X e poi sottrarre i risultati da 1.
La funzione DISTRIB.POISSON accetta tre argomenti.
Il numero di eventi per i quali intendete calcolare la probabilità. Deve essere un valore intero maggiore di 0.
La media della distribuzione di Poisson da usare. Anche questo deve essere un valore intero maggiore di 0.
Un valore logico. VERO per calcolare la probabilità cumulativa e FALSO per calcolare la probabilità non cumulativa.

Figura 11.11 Una distribuzione cumulativa di Poisson con media uguale a 20.
Per esempio, supponete di essere il direttore di una fabbrica che produce pastiglie per freni. Il responsabile di zona ha annunciato un incentivo: riceverete un premio per ogni giorno in cui il numero di pastiglie per freni difettose è minore di 20. Quanti giorni al mese raggiungerete questo obiettivo, sapendo che il numero medio di pastiglie per freni difettose è di 25 al giorno? Ecco i passi da seguire.
1.In un nuovo foglio di lavoro, inserite in una cella il numero medio di difetti per giorno (25).
Se lo desiderate, potete specificare un’etichetta a lato della cella.
2.Nella cella sottostante, digitate =DISTRIB.POISSON( per iniziare la funzione.
3.Inserite il valore 20.
4.Inserite un punto e virgola (;).
5.Fate clic sulla cella in cui avete inserito i difetti medi quotidiani o specificatene l’indirizzo.
6.Inserite un punto e virgola (;).
7.Inserite VERO).
8.Premete Invio per completare la formula.
9.Se lo desiderate, collocate un’etichetta in una cella adiacente per identificare questo valore come la probabilità di avere non più di 20 difetti.
10.Nella cella sottostante, specificate una formula che moltiplica il numero di giorni lavorativi mensili (22) per il risultato appena calcolato con la funzione DISTRIB.POISSON.
Nel foglio di lavoro, la formula è =22*B3, specificata nella cella B4.
11.Se lo desiderate, specificate un’etichetta in una cella adiacente, per identificare questo valore come il numero di giorni mensili in cui potete aspettarvi di avere al massimo 20 difetti.
Il foglio di lavoro, terminato, ha l’aspetto rappresentato nella Figura 11.12. In questo esempio, le celle B3:B4 sono formattate con due cifre decimali. Potete vedere che con una media di 25 difetti al giorno, potete aspettarvi di avere un premio quattro giorni al mese.
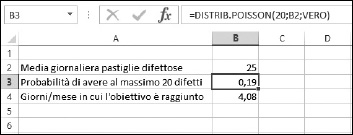
Figura 11.12 Uso della funzione DISTRIB. POISSON per calcolare una probabilità cumulativa.