Mark-compact garbage collection
Fragmentation1 can be a problem for non-moving collectors. Although there may be space available in the heap, either there may be no contiguous chunk of free space sufficiently large to handle an allocation request, or the time taken to allocate may become excessive as the memory manager has to search for suitable free space. Allocators may alleviate this problem by storing small objects of the same size together in blocks [Boehm and Weiser, 1988] especially, as we noted earlier, for applications that do not allocate many very large objects and whose ratios of different objects sizes do not change much. However, many long running applications, managed by non-moving collectors, will fragment the heap and performance will suffer.
In this and the next chapter we discuss two strategies for compacting live objects in the heap in order to eliminate external fragmentation. The major benefit of a compacted heap is that it allows very fast, sequential allocation, simply by testing against a heap limit and ‘bumping’ a free pointer by the size of the allocation request (we discuss allocation mechanisms further in Chapter 7). The strategy we consider in this chapter is in-place compaction2 of objects into one end of the same region. In the next chapter we discuss a second strategy, copying collection — the evacuation of live objects from one region to another (for example, between semispaces).
Mark-compact algorithms operate in a number of phases. The first phase is always a marking phase, which we discussed in the previous chapter. Then, further compacting phases compact the live data by relocating objects and updating the pointer values of all live references to objects that have moved. The number of passes over the heap, the order in which these are executed and the way in which objects are relocated varies from algorithm to algorithm. The compaction order has locality implications. Any moving collector may rearrange objects in the heap in one of three ways.
Arbitrary: objects are relocated without regard for their original order or whether they point to one another.
Linearising: objects are relocated so that they are adjacent to related objects, such as ones to which they refer, which refer to them, which are siblings in a data structure, and so on, as far as this is possible.
Sliding: objects are slid to one end of the heap, squeezing out garbage, thereby maintaining their original allocation order in the heap.
Most compacting collectors of which we are aware use arbitrary or sliding orders. Arbitrary order compactors are simple to implement and fast to execute, particularly if all nodes are of a fixed size, but lead to poor spatial locality for the mutator because related objects may be dispersed to different cache lines or virtual memory pages. All modern mark-compact collectors implement sliding compaction, which does not interfere with mutator locality by changing the relative order of object placement. Copying collectors can even improve mutator locality by varying the order in which objects are laid out by placing them close to their parents or siblings. Conversely, recent experiments with a collector that compacts in an arbitrary order confirm that its rearrangement of objects’ layout can lead to drastic reductions in application throughput [Abuaiadh et al, 2004].
Compaction algorithms may impose further constraints. Arbitrary order algorithms handle objects of only a single size or compact objects of different sizes separately. Compaction may require two or three passes through the heap. It may be necessary to provide an extra slot in object headers to hold relocation information: such an overhead is likely to be significant for a general purpose memory manager. Compaction algorithms may impose restrictions on pointers. For example, in which direction may references point? Are interior pointers allowed? We discuss the issues they present in Chapter 11.
We examine several styles of compaction algorithm. First, we introduce Edwards’s Two-Finger collector [Saunders, 1974]. Although this algorithm is simple to implement and fast to execute, it disturbs the layout of objects in the heap. The second compacting collector is a widely used sliding collector, the Lisp 2 algorithm. However, unlike the Two-Finger algorithm, it requires an additional slot in each object’s header to store its forwarding address, the location to which it will be moved. Our third example, Jonkers’s threaded compaction [1979], slides objects without any space overhead. However, it makes two passes over the heap, both of which tend to be expensive. The final class of compacting algorithms that we consider are fast, modern sliding collectors that similarly require no per-object storage overhead. Instead, they compute forwarding addresses on the fly. All compaction algorithms are invoked as follows:
atomic collect():
markFromRoots()
compact()
Edwards’s Two-Finger algorithm [Saunders, 1974] is a two-pass, arbitrary order algorithm, best suited to compacted regions containing objects of a fixed size. The idea is simple: given the volume of live data in the region to be compacted, we know where the high-water mark of the region will be after compaction. Live objects above this threshold are moved into gaps below the threshold. Algorithm 3.1 starts with two pointers or ‘fingers’, free which points to the start of the region and scan which starts at the end of the region. The first pass repeatedly advances the free pointer until it finds a gap (an unmarked object) in the heap, and retreats the scan pointer until it finds a live object. If the free and scan fingers pass each other, the phase is complete. Otherwise, the object at scan is moved into the gap at free, overwriting a field of the old copy (at scan) with a forwarding address, and the process continues. This is illustrated in Figure 3.1, where object A has been moved to its new location A′ and some slot of A (say, the first slot) has been overwritten with the address A′. Note that the quality of compaction depends on the size of the gap at free closely matching the size of the live object at scan. Unless this algorithm is used on fixed-size objects, the degree of defragmentation might be very poor indeed. At the end of this phase, free points at the high-water mark. The second pass updates the old values of pointers that referred to locations beyond the high-water mark with the forwarding addresses found in those locations, that is, with the objects’ new locations.
Figure 3.1: Edwards’s Two-Finger algorithm. Live objects at the top of the heap are moved into free gaps at the bottom of the heap. Here, the object at A has been moved to A′. The algorithm terminates when the free and scan pointers meet.
Algorithm 3.1: The Two-Finger compaction algorithm
1 compact():
2 relocate(HeapStart, HeapEnd)
3 updateReferences(HeapStart, free)
4
5 relocate(start, end):
6 free ← start
7 scan ← end
8
9 while free < scan
10 while isMarked(free)
11 unsetMarked(free)
12 free ← free + size(free) | /* find next hole */ |
13
14 while not isMarked(scan) && scan > free
15 scan ← scan — size(scan) | /* find previous live object */ |
16
17 if scan > free
18 unsetMarked(scan)
19 move(scan, free)
20 *scan ← free | /* leave forwarding address (destructively) */ |
21 free ← free + size(free)
22 scan ← scan — size(scan)
23
24 updateReferences(start, end):
25 for each fld in Roots | /* update roots that pointed to moved objects */ |
26 ref ← *fld
27 if ref ≥ end
28 *fld ← *ref | /* use the forwarding address left in first pass */ |
29
30 scan ← start
31 while scan < end | /* update fields in live region */ |
32 for each fld in Pointers (scan)
33 ref ← *fld
34 if ref ≥ end
35 *fld ← *ref | /* use the forwarding address left in first pass */ |
36 scan ← scan + size(scan) | /* next object */ |
The benefits of this algorithm are that it is simple and fast, doing minimal work at each iteration. It has no memory overhead, since forwarding addresses are written into slots above the high-water mark only after the live object at that location has been relocated: no information is destroyed. The algorithm supports interior pointers. Its memory access patterns are predictable, and hence provide opportunities for prefetching (by either hardware or software) which should lead to good cache behaviour in the collector. The scan pointer movement in relocate requires that the heap (or at least the live objects) can be parsed ‘backwards’ — not a problem as objects are fixed size here; alternatively, this could be done by storing mark bits in a separate bitmap, or recording the start of each object in a bitmap when it is allocated. Unfortunately, the order of objects in the heap that results from this style of compaction is arbitrary, and this tends to harm the mutator’s locality. Nevertheless, it is easy to imagine how mutator locality might be improved somewhat. Since related objects tend to live and die together in clumps, rather than moving individual objects, we could move groups of consecutive live objects into large gaps. In the remainder of this chapter, we look at sliding collectors which maintain the layout order of the mutator.
The Lisp 2 collector (Algorithm 3.2) is widely used, either in its original form or adapted for parallel collection [Flood et al, 2001]. It can be used with objects of varying sizes and, although it makes three passes over the heap, each iteration does little work (compared, for example, with threaded compactors). Although all mark-compact collectors have relatively poor throughput, a complexity study by Cohen and Nicolau [1983] found the Lisp 2 compactor to be the fastest of the compaction algorithms they studied. However, they did not take cache or paging behaviour into account, which is an important factor as we have seen before. The chief drawback of the Lisp 2 algorithm is that it requires an additional full-slot field in every object header to store the address to which the object is to be moved; this field can also be used for the mark bit.
The first pass over the heap (after marking) computes the location to which each live object will be moved, and stores this address in the object’s forwardingAddress field (Algorithm 3.2). The computeLocations routine takes three arguments: the addresses of the start and the end of the region of the heap to be compacted, and the start of the region into which the compacted objects are to be moved. Typically the destination region will be the same as the region being compacted, but parallel compactor threads may use their own distinct source and destination regions. The computeLocations procedure moves two ‘fingers’ through the heap: scan iterates through each object (live or dead) in the source region, and free points to the next free location in the destination region. If the object discovered by scan is live, it will (eventually) be moved to the location pointed to by free so free is written into its forwardingAddress field, and is then incremented by the size of the object (plus any alignment padding). If the object is dead, it is ignored.
The second pass (updateReferences in Algorithm 3.2) updates the roots of mutator threads and references in marked objects so that they refer to the new locations of their targets, using the forwarding address stored in each about-to-be-relocated object’s header by the first pass. Finally, in the third pass, relocate moves each live (marked) object in a region to its new destination.
Notice that the direction of the passes (upward, from lower to higher addresses in our code) is opposite to the direction in which the objects will move (downward, from higher to lower addresses). This guarantees that when the third pass copies an object, it is to a location that has already been vacated. Some parallel compactors that divide the heap into blocks slide the contents of alternating blocks in opposite directions. This results in larger ‘clumps’, and hence larger free gaps, than sliding each block’s contents in the same direction [Flood et al, 2001]. An example is shown in Figure 14.8.
Algorithm 3.2: The Lisp 2 compaction algorithm
1 compact():
2 computeLocations(HeapStart, HeapEnd, HeapStart)
3 updateReferences(HeapStart, HeapEnd)
4 relocate(HeapStart, HeapEnd)
5
6 computeLocations(start, end, toRegion):
7 scan ← start
8 free ← toRegion
9 while scan < end
10 if isMarked(scan)
11 forwardingAddress(scan) ← free
12 free ← free + size(scan)
13 scan ← scan + size(scan)
14
15 updateReferences (start, end):
16 for each fld in Roots | /* update roots */ |
17 ref ← *fld
18 if ref = null
19 *fld ← forwardingAddress(ref)
20
21 scan ← start | /* update fields */ |
22 while scan < end
23 if isMarked(scan)
24 for each fld in Pointers (scan)
25 if *fld ≠ null
26 *fld ← forwardingAddress(*fld)
27 scan ← scan + size(scan)
28
29 relocate(start, end):
30 scan ← start
31 while scan < end
32 if isMarked(scan)
33 dest ← forwardingAddress(scan)
34 move(scan, dest)
35 unsetMarked(dest)
36 scan ← scan + size(scan)
Figure 3.2: Threading pointers
This algorithm can be improved in several ways. Data can be prefetched in similar ways as for the sweep phase of mark-sweep collectors. Adjacent garbage can be merged after line 10 of computeLocations in order to improve the speed of subsequent passes.
The most immediate drawbacks of the Lisp 2 algorithm are (i) that it requires three complete passes over the heap, and (ii) that space is added to each object for a forwarding address. The one is the consequence of the other. Sliding compacting garbage collection is a destructive operation which overwrites old copies of live data with new copies of other live data. It is essential to preserve forwarding address information until all objects have been moved and all references updated. The Lisp 2 algorithm is non-destructive at the cost of requiring an extra slot in the object header to store the forwarding address. The Two-Finger algorithm is non-destructive because the forwarding addresses are written beyond the live data high-water mark into objects that have already been moved, but it reorders objects arbitrarily which is undesirable.
Fisher [1974] solved the pointer update problem with a different technique, threading, that requires no extra storage yet supports sliding compaction. Threading needs there to be sufficient room in object headers to store an address (if necessary overwriting other data), which is not an onerous requirement, and that pointers can be distinguished from other values, which may be harder. The best known threading is probably that due to Morris [1978, 1979, 1982] but Jonkers [1979] imposes fewer restrictions (for example, on the direction of pointers). The goal of threading is to allow all references to a node N to be found from N. It does so by temporarily reversing the direction of pointers. Figure 3.2 shows how fields previously referring to N can be found by following the threaded pointers from N. Notice that, after threading as in Figure 3.2b, the contents info of N’s header has been written into a pointer field of A. When the collector chases the pointers to unthread and update them, it must be able to recognise that this field does not hold a threaded pointer.
Algorithm 3.3: Jonkers’s threaded compactor
1 compact():
2 updateForwardReferences()
3 updateBackwardReferences()
4
5 thread(ref): | /* thread a reference */ |
6 if *ref ≠ null
7 *ref, **ref ← **ref, ref
8
9 update(ref, addr): | /* unthread all references, replacing with |
10 tmp ← *ref
11 while isReference(tmp)
12 *tmp, tmp ← addr, *tmp
13 *ref ← tmp
14
15 updateForwardReferences():
16 for each fld in Roots
17 thread(*fld)
18
19 free ← HeapStart
20 scan ← HeapStart
21 while scan ≤ HeapEnd
22 if isMarked(scan)
23 update(scan, free) | /* forward refs to |
24 for each fld in Pointers (scan)
25 thread(fld)
26 free ← free + size(scan)
27 scan ← scan + size(scan)
29 updateBackwardReferences():
30 free ← HeapStart
31 scan ← HeapStart
32 while scan ≤ HeapEnd
33 if isMarked(scan)
34 update(scan, free) | /* backward refs to |
35 move(scan, free) | /* slide |
36 free ← free + size(scan)
37 scan ← scan + size(scan)
Jonkers requires two passes over the heap, the first to thread references that point forward in the heap, and the second to thread backward pointers (see Algorithm 3.3). The first pass starts by threading the roots. It then sweeps through the heap, start to finish, computing a new address free for each live object encountered, determined by summing the volume of live data encountered so far. It is easiest to understand this algorithm by considering a single marked (live) node N. When the first pass reaches A, it will thread the reference to N. By the time that the pass reaches N, all the forward pointers to N will have been threaded (see Figure 3.2b). This pass can then update all the forward references to N by following this chain and writing the value of free, the address of the location to which N will be moved, into each previously referring slot. When it reaches the end of the chain, the collector will restore N’s info header word. The next step on this pass is to increment free and thread N’s children. By the end of this pass, all forward references will have been updated to point to their new locations and all backward pointers will have been threaded. The second pass similarly updates references to N, this time by following the chain of backward pointers. This pass also moves N.
The chief advantage of this algorithm is that it does not require any additional space, although object headers must be large enough to hold a pointer (which must be distinguishable from a normal value). However, threading algorithms suffer a number of disadvantages. They modify each pointer field of live objects twice, once to thread and once to unthread and update references. Threading requires chasing pointers so is just as cache unfriendly as marking but has to chase pointers three times (marking, threading and unthreading) in Jonkers’s algorithm. Martin [1982] claimed that combining the mark phase with the first compaction pass improved collection time by a third but this is a testament to the cost of pointer chasing and modifying pointer fields. Because Jonkers modifies pointers in a destructive way, it is inherently sequential and so cannot be used for concurrent compaction. For instance, in Figure 3.2b, once the references to N have been threaded, there is no way to discover that the first pointer field of B held a reference to N (unless that pointer is stored at the end of the chain as an extra slot in A’s header, defeating the goal of avoiding additional storage overhead). Finally, Jonkers does not support interior pointers, which may be an important concern for some environments. However, the threaded compactor from Morris [1982] can accommodate interior pointers at the cost of an additional tag bit per field, and the restriction that the second compaction pass must be in the opposite direction to the first (adding to the problem of heap parsability).
If we are to reduce the number of passes a sliding collector makes over the heap to two (one to mark and one to slide objects), and avoid the expense of threading, then we must store forwarding addresses in a side table that is preserved throughout compaction. Abuaiadh et al [2004], and Kermany and Petrank [2006] both designed high performance mark-compact algorithms for multiprocessors that do precisely this. The former is a parallel, stop-the-world algorithm (it employs multiple compaction threads); the latter can also be configured to be concurrent (allowing mutator threads to run alongside collector threads), and incremental (periodically suspending a mutator thread briefly to perform a small quantum of compaction work). We discuss the parallel, concurrent and incremental aspects of these algorithms in later chapters. Here, we focus on the core compaction algorithms in a stop-the-world setting.
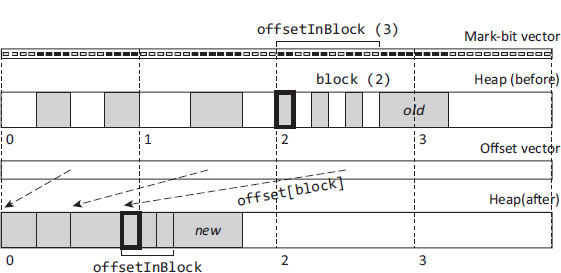
Both algorithms use a number of side tables or vectors. Common to many collectors, marking uses a bitmap with one bit for each granule (say, a word). Marking sets the bits corresponding to all (or, more efficiently, the first and the last) granules of each live object. For example, bits 44–51 are set for the object marked old in Figure 3.3. By scrutinising the mark bitmap in the compaction phase, the collector can calculate the size of any live object.
Figure 3.3: The heap (before and after compaction) and metadata used by Compressor [Kermany and Petrank, 2006]. Bits in the mark bit vector indicate the start and end of each live object. Words in the offset vector hold the address to which the first live object that starts in their corresponding block will be moved. Forwarding addresses are not stored but are calculated when needed from the offset and mark bit vectors.
Second, a table is used to store forwarding addresses. It would be prohibitively expensive to do this for every object (especially if we assume that objects are word-aligned) so both these algorithms divide the heap into small, equal-sized blocks (256 or 512 bytes, respectively). The offset table stores the forwarding address of the first live object in each block. The new locations of the other live objects in a block can be computed on the fly from the offset and mark bit vectors. Similarly, given a reference to any object, we can compute its block number and thus derive its forwarding address from the entry in the offset table and the mark bits for that block. This allows the algorithms to replace multiple passes over the full heap to relocate objects and to update pointers with a single pass over the mark bit vector to construct the offset vector and a single pass over the heap (after marking) to move objects and update references by consulting these summary vectors. Reducing the number of heap passes has consequent advantages for locality. Let us consider the details as they appear in Algorithm 3.4.
After marking is complete, the computeLocations routine passes over the mark bit vector to produce the offset vector. Essentially, it performs the same calculation as in Lisp 2 (Algorithm 3.2) but does not need to touch any object in the heap. For example, consider the first marked object in block 2, shown with a bold border in Figure 3.3. Bits 4–7, and 12–15 are set in the first block, and bits 6–11 in the second (in this example, each block comprises 16 slots). This represents 14 granules (words) that are marked in the bitmap before this object. Thus the first live object in block 2 will be relocated to the fourteenth slot in the heap. This address is recorded in the offset vector for the block (see the dashed arrow marked offset[block] in the figure).
Once the offset vector has been calculated, the roots and live fields are updated to reflect the new locations. The Lisp 2 algorithm had to separate the updating of references and moving of objects because relocation information was held in the heap and object movement destroyed this information as relocated objects are slid over old objects. In contrast, Compressor-type algorithms relocate objects and update references in a single pass, updateReferencesRelocate in Algorithm 3.4. This is possible because new addresses can be calculated reasonably quickly from the mark bitmap and the offset vector on the fly: Compressor does not have to store forwarding addresses in the heap. Given the address of any object in the heap, newAddress obtains its block number (through shift and mask operations), and uses this as an index into the offset vector. The offset vector gives the forwarding address of the first object in that block. Compressor must then consult the bitmap for that block to discover how much live data precedes this object in its block, and therefore how much to add to the offset. This can be done in constant time by a table lookup. For example, the old object in the figure has an offset of 6 marked slots in its block so it is moved to slot 20: offset[block]=14 plus offsetInBlock(old)=6.
Algorithm 3.4: Compressor
1 compact():
2 computeLocations(HeapStart, HeapEnd, HeapStart)
3 updateReferencesRelocate(HeapStart, HeapEnd)
4
5 computeLocations (start, end, toRegion):
6 loc ← toRegion
7 block ← getBlockNum(start)
8 for b ← 0 to numBits(start, end)—1
9 if b % BITS_IN_BLOCK = 0 | /* crossed block boundary? */ |
10 offset[block] ← loc | /* first object will be moved to |
11 block ← block + 1
12 if bitmap[b] = MARKED
13 loc ← loc + BYTES_PER_BIT | /* advance by size of live objects */ |
14
15 newAddress (old):
16 block ← getBlockNum(old)
17 return offset[block] + offsetInBlock(old)
18
19 updateReferencesRelocate(start, end):
20 for each fld in Roots
21 ref ← *fld
22 if ref ≠ null
23 *fld ← newAddress(ref)
24 scan ← start
25 while scan < end
26 scan ← nextMarkedObject(scan) | /* use the bitmap */ |
27 for each fld in Pointers (scan) | /* update references */ |
28 ref ← *fld
29 if ref ≠ null
30 *fld ← newAddress(ref)
31 dest ← newAddress(scan)
32 move(scan, dest)
Mark-sweep garbage collection uses less memory than other techniques such as copying collection (which we discuss in the next chapter). Furthermore, since it does not move objects, a mark-sweep collector need only identify (a superset of) the roots of the collection; it does not need to modify them. Both of these considerations may be important in environments where memory is tight or where the run-time system cannot provide type-accurate identification of references (see Section 11.2).
As a non-moving collector, mark-sweep is vulnerable to fragmentation. Using a parsimonious allocation strategy like segregated-fits (see Section 7.4) reduces the likelihood of fragmentation becoming a problem, provided that the application does not allocate very many large objects and that the ratio of object sizes does not change much. However, fragmentation is certainly likely to be a problem if a general-purpose, non-moving allocator is used to allocate a wide variety of objects in a long-running application. For this reason, most production Java virtual machines use moving collectors that can compact the heap.
Throughput costs of compaction
Sequential allocation in a compacted heap is fast. If the heap is large compared to the amount of memory available, mark-compact is an appropriate moving collection strategy. It has half the memory requirements of copying collectors. Algorithms like Compressor are also easier to use with multiple collector threads than many copying algorithms (as we shall see in Chapter 14). There is, of course, a price to be paid. Mark-compact collection is likely to be slower than either mark-sweep or copying collection. Furthermore, many compaction algorithms incur additional overheads or place restrictions on the mutator.
Mark-compact algorithms offer worse throughput than mark-sweep or copying collection largely because they tend to make more passes over objects in the heap; Compressor is an exception. Each pass tends to be expensive, not least because many require access to type information and object pointer fields, and these are the costs that tend to dominate after ‘pointer chasing’, as we saw in Chapter 2. A common solution is to run with mark-sweep collection for as long as possible, switching to mark-compact collection only when fragmentation metrics suggest that this be profitable [Printezis, 2001; Soman et al, 2004].
It is not uncommon for long-lived or even immortal data to accumulate near the beginning of the heap in moving collectors. Copying collectors handle such objects poorly, repeatedly copying them from one semispace to another. On the other hand, generational collectors (which we examine in Chapter 9) deal with these well, by moving them to a different space which is collected only infrequently. However, a generational solution might not be acceptable if heap space is tight. It is also obviously not a solution if the space being collected is the oldest generation of a generational collector! Mark-compact, however, can simply elect not to compact objects in this ‘sediment’. Hanson [1977] was the first to observe that these objects tended to accumulate at the bottom of the ‘transient object area’ in his SITBOL system. His solution was to track the height of this ‘sediment’ dynamically, and simply avoid collecting it unless absolutely necessary, at the expense of a small amount of fragmentation. Sun Microsystems’ HotSpot Java virtual machine uses mark-compact as the default collector for its old generation. It too avoids compacting objects in the user-configurable ‘dense prefix’ of the heap [Sun Microsystems, 2006]. If bitmap marking is used, the extent of a live prefix of desired density can be determined simply by examining the bitmap.
Mark-compact collectors may preserve the allocation order of objects in the heap or they may rearrange them arbitrarily. Although arbitrary order collectors may be faster than other mark-compact collectors and impose no space overheads, the mutator’s locality is likely to suffer from an arbitrary scrambling of object order. Sliding compaction has a further benefit for some systems: the space occupied by all objects allocated after a certain point can be reclaimed in constant time, just by retreating the free space pointer.
Limitations of mark-compact algorithms
A wide variety of mark-compact collection algorithms has been proposed. A fuller account of many older compaction strategies can be found in Chapter 5 of Jones [1996]. Many of these have properties that may be undesirable or unacceptable. The issues to consider include what space overheads may be incurred to store forwarding pointers (although this cost will be lower than that of a copying collector). Some compaction algorithms place restrictions on the mutator. Simple compactors like the Two-Finger algorithm can only manage fixed-size objects. It is certainly possible to segregate objects by size class, but in this case, to what extent is compaction necessary? Threaded compaction requires that it be possible to distinguish pointers from non-pointer values temporarily stored in pointer fields. Threading is also incompatible with concurrent collection because it (temporarily) destroys information in pointer fields. Morris’s [1978,1979,1982] threaded algorithm also restricts the direction in which references may point. Finally, most compaction algorithms preclude the use of interior pointers: the Two-Finger algorithm is an exception.
1We discuss fragmentation in more detail in Section 7.3.
2Often called compactifying in older papers.