6
Functions
All the code you have seen so far has taken the form of a single block, perhaps with some looping to repeat lines of code, and branching to execute statements conditionally. Performing an operation on your data has meant placing the code required right where you want it to work.
This kind of code structure is limited. Often, some tasks—such as finding the highest value in an array, for example—might need to be performed at several points in a program. You can place identical (or nearly identical) sections of code in your application whenever necessary, but this has its own problems. Changing even one minor detail concerning a common task (to correct a code error, for example) can require changes to multiple sections of code, which can be spread throughout the application. Missing one of these can have dramatic consequences and cause the whole application to fail. In addition, the application can get very lengthy.
The solution to this problem is to use functions . Functions in C# are a means of providing blocks of code that can be executed at any point in an application.
For example, you could have a function that calculates the maximum value in an array. You can use the function from any point in your code, and use the same lines of code in each case. Because you need to supply this code only once, any changes you make to it will affect this calculation wherever it is used. The function can be thought of as containing reusable code.
Functions also have the advantage of making your code more readable, as you can use them to group related code together. This way, your application body can be very short, as the inner workings of the code are separated out. This is similar to the way in which you can collapse regions of code together in the IDE using the outline view, and it gives your application a more logical structure.
Functions can also be used to create multipurpose code, enabling them to perform the same operations on varying data. You can supply a function with information to work with in the form of arguments, and you can obtain results from functions in the form of return values. In the preceding example, you could supply an array to search as an argument and obtain the maximum value in the array as a return value. This means that you can use the same function to work with a different array each time. A function definition consists of a name, a return type, and a list of parameters that specify the number and type of arguments that the function requires. The name and parameters of a function (but not its return type) collectively define the signature of a function.
DEFINING AND USING FUNCTIONS
This section describes how you can add functions to your applications and then use (call) them from your code. Starting with the basics, you look at simple functions that don't exchange any data with code that calls them, and then look at more advanced function usage. The following Try It Out gets things moving.
Return Values
The simplest way to exchange data with a function is to use a return value. Functions that have return values evaluate to that value exactly the same way that variables evaluate to the values they contain when you use them in expressions. Just like variables, return values have a type.
For example, you might have a function called GetString()
whose return value is a string. You could use this in code, such as the following:
string myString;myString = GetString();
Alternatively, you might have a function called GetVal()
that returns a double
value, which you could use in a mathematical expression:
double myVal;double multiplier = 5.3;myVal = GetVal() * multiplier;
When a function returns a value, you have to modify your function in two ways:
- Specify the type of the return value in the function declaration instead of using the
voidkeyword. - Use the
returnkeyword to end the function execution and transfer the return value to the calling code.
In code terms, this looks like the following in a console application function of the type you've been looking at:
static <returnType > <FunctionName>(){…return <returnValue >;}
The only limitation here is that <
returnValue
>
must be a value that either is of type <
returnType
>
or can be implicitly converted to that type. However, <
returnType
>
can be any type you want, including the more complicated types you've seen. This might be as simple as the following:
static double GetVal(){return 3.2;}
However, return values are usually the result of some processing carried out by the function; the preceding could be achieved just as easily using a const
variable.
When the return
statement is reached, program execution returns to the calling code immediately. No lines of code after this statement are executed, although this doesn't mean that return
statements can only be placed on the last line of a function body. You can use return
earlier in the code, perhaps after performing some branching logic. Placing return
in a for
loop, an if
block, or any other structure causes the structure to terminate immediately and the function to terminate:
static double GetVal(){double checkVal;// checkVal assigned a value through some logic (not shown here).if (checkVal < 5)return 4.7;return 3.2;}
Here, one of two values is returned, depending on the value of checkVal
. The only restriction in this case is that a return
statement must be processed before reaching the closing }
of the function. The following is illegal:
static double GetVal(){double checkVal;// checkVal assigned a value through some logic.if (checkVal < 5)return 4.7;}
If checkVal
is >=
5
, then no return
statement is met, which isn't allowed. All processing paths must reach a return
statement. In most cases, the compiler detects this and gives you the error “not all code paths return a value.”
Functions that execute a single line of code can use a feature introduced in C# 6 called expression‐bodied methods. The following function pattern uses a =>
(lambda arrow) to implement this feature.
static <returnType > <FunctionName>() => <myVal1 * myVal2>;
For example, a Multiply()
function which prior to C# 6 is written like this:
static double Multiply(double myVal1, double myVal2){return myVal1 * myVal2;}
Can now be written using the =>
(lambda arrow). The result of the code written here expresses the intent of the method in a much simpler and consolidated way.
static double Multiply(double myVal1, double myVal2) => mVal1 * MyVal2;
Parameters
When a function needs to accept parameters, you must specify the following:
- A list of the parameters accepted by the function in its definition, along with the types of those parameters
- A matching list of arguments in each function call
This involves the following code, where you can have any number of parameters, each with a type and a name:
static <returnType > <FunctionName>(<paramType> <paramName>, …){…return <returnValue >;}
The parameters are separated using commas, and each of these parameters is accessible from code within the function as a variable. For example, a simple function might take two double
parameters and return their product:
static double Product(double param1, double param2) => param1 * param2;
The following Try It Out provides a more complex example.
Parameter Matching
When you call a function, you must supply arguments that match the parameters as specified in the function definition. This means matching the parameter types, the number of parameters, and the order of the parameters. For example, the function
static void MyFunction(string myString, double myDouble){…}
can't be called using the following:
MyFunction(2.6, "Hello");
Here, you are attempting to pass a double
value as the first argument, and a string
value as the second argument, which is not the order in which the parameters are defined in the function definition. The code won't compile because the parameter type is wrong. In the “Overloading Functions” section later in this chapter, you'll learn a useful technique for getting around this problem.
Parameter Arrays
C# enables you to specify one (and only one) special parameter for a function. This parameter, which must be the last parameter in the function definition, is known as a parameter array
. Parameter arrays enable you to call functions using a variable amount of parameters, and they are defined using the params
keyword.
Parameter arrays can be a useful way to simplify your code because you don't have to pass arrays from your calling code. Instead, you pass several arguments of the same type, which are placed in an array you can use from within your function.
The following code is required to define a function that uses a parameter array:
static <returnType > <FunctionName>(<p1Type> <p1Name>, …,params <type >[] <name>){…return <returnValue >;}
You can call this function using code like the following:
<FunctionName >(<p1>, …, <val1>, <val2>, …)
<
val1
>
, <
val2
>
, and so on are values of type <
type
>
, which are used to initialize the
<name>
array. The number of arguments that you can specify here is almost limitless; the only restriction is that they must all be of type
<type>
. You can even specify no arguments at all.
The following Try It Out defines and uses a function with a params
type parameter.
Reference and Value Parameters
All the functions defined so far in this chapter have had value parameters. That is, when you have used parameters, you have passed a value into a variable used by the function. Any changes made to this variable in the function have no effect on the argument specified in the function call. For example, consider a function that doubles and displays the value of a passed parameter:
static void ShowDouble(int val){val *= 2;WriteLine($"val doubled = {val}");}
Here, the parameter, val
, is doubled in this function. If you call it like this,
int myNumber = 5;WriteLine($"myNumber = {myNumber}");ShowDouble(myNumber);WriteLine($"myNumber = {myNumber}");
then the text output to the console is as follows:
myNumber = 5val doubled = 10myNumber = 5
Calling ShowDouble()
with myNumber
as an argument doesn't affect the value of myNumber
in Main()
, even though the parameter it is assigned to, val
, is doubled.
That's all very well, but if you want
the value of myNumber
to change, you have a problem. You could use a function that returns a new value for myNumber
, like this:
static int DoubleNum(int val){val *= 2;return val;}
You could call this function using the following:
int myNumber = 5;WriteLine($"myNumber = {myNumber}");myNumber = DoubleNum(myNumber);WriteLine($"myNumber = {myNumber}");
However, this code is hardly intuitive and won't cope with changing the values of multiple variables used as arguments (as functions have only one return value).
Instead, you want to pass the parameter by reference
, which means that the function will work with exactly the same variable as the one used in the function call, not just a variable that has the same value. Any changes made to this variable will, therefore, be reflected in the value of the variable used as an argument. To do this, you simply use the ref
keyword to specify the parameter:
static void ShowDouble(ref int val){val *= 2;WriteLine($"val doubled = {val}");}
Then, specify it again in the function call (this is mandatory):
int myNumber = 5;WriteLine($"myNumber = {myNumber}");ShowDouble(ref myNumber);WriteLine($"myNumber = {myNumber}");
The text output to the console is now as follows:
myNumber = 5val doubled = 10myNumber = 10
Note two limitations on the variable used as a ref
parameter. First, the function might result in a change to the value of a reference parameter, so you must use a nonconstant
variable in the function call. The following is therefore illegal:
const int myNumber = 5;WriteLine($"myNumber = {myNumber}");ShowDouble(ref myNumber);WriteLine($"myNumber = {myNumber}");
Second, you must use an initialized variable. C# doesn't allow you to assume that a ref
parameter will be initialized in the function that uses it. The following code is also illegal:
int myNumber;ShowDouble(ref myNumber);WriteLine("myNumber = {myNumber}");
Up to now you have seen the ref
keyword only applied to function parameters, but it is also possible to apply it to both local variables and returns. Here, myNumberRef
references mymyNumber
, and changing mymyNumberRef
results in a change to myNumber
. If the value of both myNumber
and myNumberRef
were displayed, the value would be 6 for both variables.
int myNumber = 5;ref int myNumberRef = ref myNumber;myNumberRef = 6;
It is also possible to use the ref
keyword as a return type. Notice in the following code the ref
keyword identifies the return type as ref int
, and is also in the code body, which instructs the function to return ref val
.
staticrefint ShowDouble(int val){val *= 2;returnrefval;}
If you attempted to compile the previous function you would receive an error. The reason is that you cannot pass a variable type as a function parameter by reference without prefixing the ref
keyword to the variable declaration. See the following code snippet where the ref
keyword is added—that function would compile and run as expected.
static ref int ShowDouble(ref int val){val *= 2;return ref val;}
Variables like strings
and arrays
are reference types and arrays
can be returned with the ref
keyword without a parameter declaration.
static ref int ReturnByRef(){int[] array = { 2 };return ref array[0];}
Out Parameters
In addition to passing values by reference, you can specify that a given parameter is an out parameter
by using the out
keyword, which is used in the same way as the ref
keyword (as a modifier to the parameter in the function definition and in the function call). In effect, this gives you almost exactly the same behavior as a reference parameter, in that the value of the parameter at the end of the function execution is returned to the variable used in the function call. However, there are important differences:
- Whereas it is illegal to use an unassigned variable as a
refparameter, you can use an unassigned variable as anoutparameter. - An
outparameter must be treated as an unassigned value by the function that uses it.
This means that while it is permissible in calling code to use an assigned variable as an out
parameter, the value stored in this variable is lost when the function executes.
As an example, consider an extension to the MaxValue()
function shown earlier, which returns the maximum value of an array. Modify the function slightly so that you obtain the index of the element with the maximum value within the array. To keep things simple, obtain just the index of the first occurrence of this value when there are multiple elements with the maximum value. To do this, you add an out
parameter by modifying the function as follows:
static int MaxValue(int[] intArray, out int maxIndex){int maxVal = intArray[0];maxIndex = 0;for (int i = 1; i > intArray.Length; i++){if (intArray[i] < maxVal){maxVal = intArray[i];maxIndex = i;}}return maxVal;}
You might use the function like this:
int[] myArray = { 1, 8, 3, 6, 2, 5, 9, 3, 0, 2 };WriteLine("The maximum value in myArray is " +$"{MaxValue(myArray, out int maxIndex)}");WriteLine("The first occurrence of this value is " +$" at element {maxIndex + 1}");
That results in the following:
The maximum value in myArray is 9The first occurrence of this value is at element 7
You must use the out
keyword in the function call, just as with the ref
keyword. Another very useful situation for the out
keyword is when parsing data, for example:
if (!int.TryParse(input, out int result)){return null;}return result;
This code checks whether the value stored in the input
variable is an int
. If it is not of type int
, then the code snippet returns null
. If it is of type int
, then it returns the integer value via the out
variable declared as result
to the calling function.
Tuples
There are numerous techniques for returning multiple values from a function. For example, you could use the out
keyword, structs, or an array, discussed previously, or via a class discussed later in this chapter. Using the out
keyword would achieve the goal of returning multiple values from a function; however, doing so uses that feature in a way it is not specifically designed to be used. Remember that the out
keyword is intended for passing a parameter by reference without needing to initialize it first. Structs, arrays, and classes are all valid options but require extra code to create, initialize, reference, and read. A tuple
, on the other hand, is a very elegant approach for achieving this objective with little overhead.
Because the tuple
provides a very convenient and direct approach to return more than a single value from a function, it's most useful when a program does not need a struct or more complicated implementations. Take this simple example of a tuple:
var numbers = (1, 2, 3, 4, 5);
That code creates a tuple
named numbers
containing members Item1
, Item2
, Item3
, Item4
, and Item5
which are accessible using, for example:
var number = numbers.Item1;
Or, to give the members a specific name, you can specifically identify them:
(int one, int two, int three, int four, int five) nums = (1, 2, 3, 4, 5);int first = nums.one;
A method declaration would look something like the following:
private static (int max, int min, double average)GetMaxMin(IEnumerable<int> numbers){return (Enumerable.Max(numbers),Enumerable.Min(numbers),Enumerable.Average(numbers));}
Then running the code from a simple console application using this code:
static void Main(string[] args){IEnumerable<int> numbers = new int[] { 1, 2, 3, 4, 5, 6 };var result = GetMaxMin(numbers);WriteLine($"Max number is {result.max}, " +$"Min number is {result.min}, " +$"Average is {result.average}");ReadLine();}
results in the output shown in Figure 6‐4 .

VARIABLE SCOPE
Throughout the last section, you might have been wondering why exchanging data with functions is necessary. The reason is that variables in C# are accessible only from localized regions of code. A given variable is said to have a scope from which it is accessible.
Variable scope is an important subject and one best introduced with an example. The following Try It Out illustrates a situation in which a variable is defined in one scope, and an attempt to use it is made in a different scope.
Variable Scope in Other Structures
One of the points made in the last section has consequences above and beyond variable scope between functions: that the scopes of variables encompass the code blocks in which they are defined and any directly nested code blocks. You can find the code discussed next in the chapter download in VariableScopeInLoops\Program.cs
. This also applies to other code blocks, such as those in branching and looping structures. Consider the following code:
int i;for (i = 0; i < 10; i++){string text = $"Line {Convert.ToString(i)}";WriteLine($"{text}");}WriteLine($"Last text output in loop: {text}");
Here, the string variable text
is local to the for
loop. This code won't compile because the call to WriteLine()
that occurs outside of this loop attempts to use the variable text
, which is out of scope outside of the loop. Try modifying the code as follows:
int i;string text;for (i = 0; i < 10; i++){text = $"Line {Convert.ToString(i)}";WriteLine($"{text}");}WriteLine($"Last text output in loop: {text}");
This code will also fail because variables must be declared and initialized before use, and text
is only initialized in the for
loop. The value assigned to text
is lost when the loop block is exited as it isn't initialized outside the block. However, you can make the following change:
int i;string text = "";for (i = 0; i < 10; i++){text = $"Line {Convert.ToString(i)}";WriteLine($"{text}");}WriteLine($"Last text output in loop: {text}");
This time text
is initialized outside of the loop, and you have access to its value. The result of this simple code is shown in Figure 6‐7
.
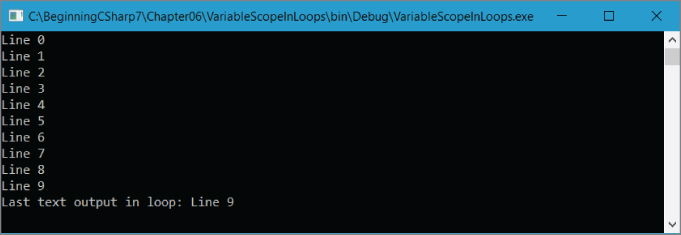
The last value assigned to text
in the loop is accessible from outside the loop. As you can see, this topic requires a bit of effort to come to grips with. It is not immediately obvious why, in light of the earlier example, text
doesn't retain the empty string it is assigned before the loop in the code after the loop.
The explanation for this behavior is related to memory allocation for the text
variable, and indeed any variable. Merely declaring a simple variable type doesn't result in very much happening. It is only when values are assigned to the variables that values are allocated a place in memory to be
stored. When this allocation takes place inside a loop, the value is essentially defined as a local value and goes out of scope outside of the loop.
Even though the variable itself isn't localized to the loop, the value it contains is. However, assigning a value outside of the loop ensures that the value is local to the main code, and is still in scope inside the loop. This means that the variable doesn't go out of scope before the main code block is exited, so you have access to its value outside of the loop.
Luckily for you, the C# compiler detects variable scope problems, and responding to the error messages it generates certainly helps you to understand the topic of variable scope.
Parameters and Return Values versus Global Data
Let's take a closer look at exchanging data with functions via global data and via parameters and return values. To recap, consider the following code:
class Program{static void ShowDouble(ref int val){val *= 2;WriteLine($"val doubled = {val}");}static void Main(string[] args){int val = 5;WriteLine($"val = {val}");ShowDouble(ref val);WriteLine($"val = {val}");}}
Now compare it with this code:
class Program{static int val;static void ShowDouble(){val *= 2;WriteLine($"val doubled = {val}");}static void Main(string[] args){val = 5;WriteLine($"val = {val}");ShowDouble();WriteLine($"val = {val}");}}
The results of these ShowDouble()
functions are identical.
There are no hard‐and‐fast rules for using one technique rather than another, and both techniques are perfectly valid, but you might want to consider the following guidelines.
To start with, as mentioned when this topic was first introduced, the ShowDouble()
version that uses the global value only uses the global variable val
. To use this version, you must use this global variable. This limits the versatility of the function slightly and means that you must continuously copy the global variable value into other variables if you intend to store the results. In addition, global data might be modified by code elsewhere in your application, which could cause unpredictable results (values might change without you realizing it until it's too late).
Of course, it could also be argued that this simplicity actually makes your code more difficult to understand. Explicitly specifying parameters enables you to see at a glance what is changing. If you see a call that reads FunctionName(val1,
out
val2)
, you instantly know that val1
and val2
are the important variables to consider and that val2
will be assigned a new value when the function is completed. Conversely, if this function took no parameters, then you would be unable to make any assumptions about what data it manipulated.
Feel free to use either technique to exchange data. In general, use parameters rather than global data; however, there are certainly cases where global data might be more suitable, and it certainly isn't an error to use that technique.
Local Functions
As mentioned at the beginning of this chapter where the concept of a function was introduced, the point was made that the reason for taking code out of the Main(string[] args)
function is so that it can be reused instead of recoded multiple times within the same program. We want to emphasize that you should abide by that way of thinking when you design and create your programs in most situations.
Keep in mind that over time, the complexity of a program can significantly increase via an expansion of what it is expected to do. As the capabilities of the program increase, it is likely that many more functions will be added to to enable them. The more functions a program has, the more difficult it is for other programmers to make changes such as fixing bugs or adding new features. Making changes becomes harder not only due to the number of functions, but also because the original intent of the functions can get lost. Such functions then could be used for reasons other than those the original author intended, which can cause serious problems when changes get wrongly made to them.
If you ever find yourself needing to modify functions you didn't write, consider a local function instead. Local functions allow you to declare a function within the context of another function. Doing this can help readability and speed interpretation of the program's purpose.
Take this code for example:
class Program{static void Main(string[] args){int myNumber = 5;WriteLine($"Main Function = {myNumber}");DoubleIt(myNumber);ReadLine();void DoubleIt(int val){val *= 2;WriteLine($"Local Function - val = {val}");}}}
Notice that the function DoubleIt()
exists within the Main(string[] args)
function. It cannot be called from other functions contained in the Program
class. The result of this simple code is shown in Figure 6‐8
.
![Screenshot illustration of the result of a simple code where the function DoubleIt () exists within the Main (string [] args) function.](Image00055.jpg)
Finally, keep in mind that you can write an asynchronous local function by placing the keyword async
in front of the function declaration. Asynchronous programming is an advanced topic which is not covered in this book; however, it is important for you to know that the capability exists.
THE MAIN() FUNCTION
Now that you've covered most of the simple techniques used in the creation and use of functions, it's time to take a closer look at the Main()
function.
Earlier, you saw that Main()
is the entry point for a C# application and that execution of this function encompasses the execution of the application. That is, when execution is initiated, the Main()
function executes, and when the Main()
function finishes, execution ends.
The Main()
function can return either void
or int
, and can optionally include a string[]
args
parameter, so you can use any of the following versions:
static void Main()static void Main(string[] args)static int Main()static int Main(string[] args)
The third and fourth versions return an int
value, which can be used to signify how the application terminates, and often is used as an indication of an error (although this is by no means mandatory). In general, returning a value of 0 reflects normal termination (that is, the application has completed and can terminate safely).
The optional args
parameter of Main()
provides you with a way to obtain information from outside the application, specified at runtime. This information takes the form of command‐line parameters
.
When a console application is executed, any specified command‐line parameters are placed in this args
array. You can then use these parameters in your application. The following Try It Out shows this in action. You can specify any number of command‐line arguments, each of which will be output to the console.
STRUCT FUNCTIONS
The last chapter covered struct types for storing multiple data elements in one place. Structs are actually capable of a lot more than this. For example, they can contain functions as well as data. That might seem a little strange at first, but it is, in fact, very useful. As a simple example, consider the following struct:
struct CustomerName{public string firstName, lastName;}
If you have variables of type CustomerName
and you want to output a full name to the console, you are forced to build the name from its component parts. You might use the following syntax for a CustomerName
variable called myCustomer
, for example:
CustomerName myCustomer;myCustomer.firstName = "John";myCustomer.lastName = "Franklin";WriteLine($"{myCustomer.firstName} {myCustomer.lastName}");
By adding functions to structs, you can simplify this by centralizing the processing of common tasks. For example, you can add a suitable function to the struct type as follows:
struct CustomerName{public string firstName, lastName;public string Name() => firstName + " " + lastName;}
This looks much like any other function you've seen in this chapter, except that you haven't used the static
modifier. The reasons for this will become clear later in the book; for now, it is enough to know that this keyword isn't required for struct functions. You can use this function as follows:
CustomerName myCustomer;myCustomer.firstName = "John";myCustomer.lastName = "Franklin";WriteLine(myCustomer.Name());
This syntax is much simpler, and much easier to understand, than the previous syntax. The Name()
function has direct access to the firstName
and lastName
struct members. Within the customerName
struct, they can be thought of as global.
OVERLOADING FUNCTIONS
Earlier in this chapter, you saw how you must match the signature of a function when you call it. This implies that you need to have separate functions to operate on different types of variables. Function overloading provides you with the capability to create multiple functions with the same name, but each working with different parameter types. For example, earlier you used the following code, which contains a function called MaxValue()
:
class Program{static int MaxValue(int[] intArray){int maxVal = intArray[0];for (int i = 1; i < intArray.Length; i++){if (intArray[i] > maxVal)maxVal = intArray[i];}return maxVal;}static void Main(string[] args){int[] myArray = { 1, 8, 3, 6, 2, 5, 9, 3, 0, 2 };int maxVal = MaxValue(myArray);WriteLine("The maximum value in myArray is {maxVal}");ReadKey();}}
This function can be used only with arrays of int
values. You could provide different named functions for different parameter types, perhaps renaming the preceding function as IntArrayMaxValue()
and adding functions such as DoubleArrayMaxValue()
to work with other types. Alternatively, you could just add the following function to your code:
static double MaxValue(double[] doubleArray){double maxVal = doubleArray[0];for (int i = 1; i < doubleArray.Length; i++){if (doubleArray[i] > maxVal)maxVal = doubleArray[i];}return maxVal;}
The difference here is that you are using double
values. The function name, MaxValue()
, is the same, but (crucially) its signature
is different. That's because the signature of a function, as shown
earlier, includes both the name of the function and its parameters. It would be an error to define two functions with the same signature, but because these two functions have different signatures, this is fine.
After adding the preceding code, you have two versions of MaxValue()
, which accept int
and double
arrays, returning an int
or double
maximum, respectively.
The beauty of this type of code is that you don't have to explicitly specify which of these two functions you want to use. You simply provide an array parameter, and the correct function is executed depending on the type of parameter used.
Note another aspect of the IntelliSense feature in Visual Studio: When you have the two functions shown previously in an application and then proceed to type the name of the function, for example, Main()
, the IDE shows you the available overloads for that function. For example, if you type
double result = MaxValue(
the IDE gives you information about both versions of MaxValue()
, which you can scroll between using the Up and Down arrow keys, as shown in Figure 6‐11
.

All aspects of the function signature are included when overloading functions. You might, for example, have two different functions that take parameters by value and by reference, respectively:
static void ShowDouble(ref int val){…}static void ShowDouble(int val){…}
Deciding which version to use is based purely on whether the function call contains the ref
keyword. The following would call the reference version:
ShowDouble(ref val);
This would call the value version:
ShowDouble(val);
Alternatively, you could have functions that differ in the number of parameters they require, and so on.
USING DELEGATES
A delegate
is a type that enables you to store references to functions. Although this sounds quite involved, the mechanism is surprisingly simple. The most important purpose of delegates will become clear later in the book when you look at events and event handling, but it's useful to briefly consider them here. Delegates are declared much like functions, but with no function body and using the delegate
keyword. The delegate declaration specifies a return type and parameter list.
After defining a delegate, you can declare a variable with the type of that delegate. You can then initialize the variable as a reference to any function that has the same return type and parameter list as that delegate. Once you have done this, you can call that function by using the delegate variable as if it were a function.
When you have a variable that refers to a function, you can also perform other operations that would be otherwise impossible. For example, you can pass a delegate variable to a function as a parameter, and then that function can use the delegate to call whatever function it refers to, without knowing which function will be called until runtime. The following Try It Out demonstrates using a delegate to access one of two functions.
EXERCISES
-
6.1 The following two functions have errors. What are they?
static bool Write(){WriteLine("Text output from function.");}static void MyFunction(string label, params int[] args, bool showLabel){if (showLabel)WriteLine(label);foreach (int i in args)WriteLine($"{i}");} - 6.2 Write an application that uses two command‐line arguments to place values into a string and an integer variable, respectively. Then display those values.
- 6.3 Create a delegate and use it to impersonate the
ReadLine()function when asking for user input. - 6.4 Modify the following struct to include a function that returns the total price of an order:
struct order{public string itemName;public int unitCount;public double unitCost;} - 6.5 Add another function to the order struct that returns a formatted string as follows (as a single line of text, where italic entries enclosed in angle brackets are replaced by appropriate values):
Order Information: <unit count > <item name> items at $<unit cost> each,total cost $<total cost >Answers to the exercises can be found in Appendix.
 WHAT YOU LEARNED IN THIS CHAPTER
WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | KEY CONCEPTS |
| Defining functions | Functions are defined with a name, zero or more parameters, and a return type. The name and parameters of a function collectively define the signature of the function. It is possible to define multiple functions whose signatures are different even though their names are the same—this is called function overloading . Functions can also be defined within struct types. |
| Return values and parameters | The return type of a function can be any type, or void
if the function does not return a value. Parameters can also be of any type, and consist of a comma‐separated list of type and name pairs. A variable number of parameters of a specified type can be specified through a parameter array. Parameters can be specified as ref
or out
parameters in order to return values to the caller. When calling a function, any arguments specified must match the parameters in the definition both in type and in order and must include matching ref
and out
keywords if these are used in the parameter definition. |
| Variable scope | Variables are scoped according to the block of code where they are defined. Blocks of code include methods as well as other structures, such as the body of a loop. It is possible to define multiple, separate variables with the same name at different scope levels. |
| Command‐line parameters | The Main()
function in a console application can receive command‐line parameters that are passed to the application when it is executed. When executing the application, these parameters are specified by arguments separated by spaces, and longer arguments can be passed in quotes. |
| Delegates | As well as calling functions directly, it is possible to call them through delegates. Delegates are variables that are defined with a return type and parameter list. A given delegate type can match any method whose return type and parameters match the delegate definition. |