8
Data-Snooping Biases in Tests of Financial Asset Pricing Models
Introduction
THE RELIANCE OF ECONOMIC SCIENCE upon nonexperimental inference is, at once, one of the most challenging and most nettlesome aspects of the discipline. Because of the virtual impossibility of controlled experimentation in economics, the importance of statistical data analysis is now well-established. However, there is a growing concern that the procedures under which formal statistical inference have been developed may not correspond to those followed in practice.1 For example, the classical statistical approach to selecting a method of estimation generally involves minimizing an expected loss function, irrespective of the actual data. Yet in practice the properties of the realized data almost always influence the choice of estimator.
Of course, ignoring obvious features of the data can lead to nonsensical inferences even when the estimation procedures are optimal in some metric. But the way we incorporate those features into our estimation and testing procedures can affect subsequent inferences considerably. Indeed, by the very nature of empirical innovation in economics, the axioms of classical statistical analysis are violated routinely: future research is often motivated by the successes and failures of past investigations. Consequently, few empirical studies are free of the kind of data-instigated pretest biases discussed in Leamer (1978). Moreover, we can expect the degree of such biases to increase with the number of published studies performed on any single data set—the more scrutiny a collection of data is subjected to, the more likely will interesting (spurious) patterns emerge. Since stock market prices are perhaps the most studied economic quantities to date, tests of financial asset pricing models seem especially susceptible.
In this paper, we attempt to quantify the inferential biases associated with one particular method of testing financial asset pricing models such as the capital asset pricing model (CAPM) and the arbitrage pricing theory (APT). Because there are often many more securities than there are time series observations of stock returns, asset pricing tests are generally performed on the returns of portfolios of securities. Besides reducing the cross-sectional dimension of the joint distribution of returns, grouping into portfolios has also been advanced as a method of reducing the impact of measurement error. However, the selection of securities to be included in a given portfolio is almost never at random, but is often based on some of the stocks' empirical characteristics. The formation of size-sorted portfolios, portfolios based on the market value of the companies' equity, is but one example. Conducting classical statistical tests on portfolios formed this way creates potentially significant biases in the test statistics. These are examples of “data-snooping statistics,” a term used by Aldous (1989, p. 252) to describe the situation “where you have a family of test statistics T(a) whose null distribution is known for fixed a, but where you use the test statistic T = T(a) for some a chosen using the data.” In our application the quantity a may be viewed as a vector of zeros and ones that indicates which securities are to be included in or omitted from a given portfolio. If the choice of a is based on the data, then the sampling distribution of the resulting test statistic is generally not the same as the null distribution with a fixed a; hence, the actual size of the test may differ substantially from its nominal value under the null. Under plausible assumptions our calculations show that this kind of data snooping can lead to rejections of the null hypothesis with probability 1 even when the null hypothesis is true!
Although the term “data snooping” may have an unsavory connotation, our usage neither implies nor infers any sort of intentional misrepresentation or dishonesty. That prior empirical research may influence the way current investigations are conducted is often unavoidable, and this very fact results in what we have called data snooping. Moreover, it is not at all apparent that this phenomenon necessarily imparts a “bias” in the sense that it affects inferences in an undesirable way. After all, the primary reason for publishing scientific discoveries is to add to a store of common knowledge on which future research may build.
But when scientific discovery is statistical in nature, we must weigh the significance of newly discovered relations in view of past inferences. This is recognized implicitly in many formal statistical circumstances, as in the theory of sequential hypothesis testing. But it is considerably more difficult to correct for the effects of specification searches in practice since such searches often consist of sequences of empirical studies undertaken by many individuals over many years.2 For example, as a consequence of the many investigations relating the behavior of stock returns to size, Chen, Roll, and Ross (1986, p. 394) write: “It has been facetiously noted that size may be the best theory we now have of expected returns. Unfortunately, this is less of a theory than an empirical observation.” Then, as Merton (1987, p. 107) asks in a related context: “Is it reasonable to use the standard t-statistic as a valid measure of significance when the test is conducted on the same data used by many earlier studies whose results influenced the choice of theory to be tested?” We rephrase this question in the following way: Are standard tests of significance valid when the construction of the test statistics is influenced by empirical relations derived from the very same data to be used in the test? Our results show that using prior information only marginally correlated with statistics of interest can distort inferences dramatically.
In Section 8.1 we quantify the data-snooping biases associated with testing financial asset pricing models with portfolios formed by sorting on some empirically motivated characteristic. Using the theory of induced order statistics, we derive in closed form the asymptotic distribution of a commonly used test statistic before and after sorting. This not only yields a measure of the effect of data snooping, but also provides the appropriate sampling theory when snooping is unavoidable. In Section 8.2 we report the results of Monte Carlo experiments designed to gauge the accuracy of the asymptotic approximations used in Section 8.1. In Section 8.3 two empirical examples are provided that illustrate the potential importance of data-snooping biases in existing tests of asset pricing models, and in Section 8.4, we show how these biases can arise naturally from our tendency to focus on the unusual. We conclude in Section 8.5.
8.1 Quantifying Data-Snooping Biases With Induced Order Statistics
Many tests of the CAPM and APT have been conducted on returns of groups of securities rather than on individual security returns, where the grouping is often according to some empirical characteristic of the securities. Perhaps the most common attribute by which securities are grouped is market value of equity or “size.” The prevalence of size-sorted portfolios in recent tests of asset pricing models has not been precipitated by any economic theory linking size to asset prices. It is a consequence of a series of empirical studies demonstrating the statistical relation between size and the stochastic behavior of stock returns.3 Therefore, we must allow for our fore-knowledge of size-related phenomena in evaluating the actual significance of tests performed on size-sorted portfolios. More generally, grouping securities by some characteristic that is empirically motivated may affect the size of the usual significance tests,4 particularly when the empirical motivation is derived from the very data set on which the test is based. We quantify these effects in the following sections by appealing to asymptotic results for induced order statistics, and show that even mild forms of data snooping can change inferences substantially. In Section 8.1.1, a brief summary of the asymptotic properties of induced order statistics, is provided. In Section 8.1.2, results for tests based on individual securities are presented, and in Section 8.1.3, corresponding results for portfolios are reported. We provide a more positive interpretation of data-snooping biases as power against deviations from the null hypothesis in Section 8.1.4.
8.1.1 Asymptotic Properties of Induced Order Statistics
Since the particular form of data snooping we are investigating is most common in empirical tests of financial asset pricing models, our exposition will lie in that context. Suppose for each of N securities we have some consistent estimator  of a parameter
of a parameter  which is to be used in the construction of an aggregate test statistic. For example, in the Sharpe-Lintner CAPM, would be the estimated intercept from the following regression:
which is to be used in the construction of an aggregate test statistic. For example, in the Sharpe-Lintner CAPM, would be the estimated intercept from the following regression:

where Rit, Rmt, and Rft are the period-t returns on security i, the market portfolio, and a risk-free asset, respectively. A test of the null hypothesis that = 0 would then be a proper test of the Sharpe-Lintner version of the CAPM; thus, may serve as a test statistic itself. However, more powerful tests may be obtained by combining the 's for many securities. But how should we combine them?
Suppose for each security i we observe some characteristic Xi, such as its out-of-sample market value of equity or average annual earnings, and we learn that Xi is correlated empirically with . By this we mean that the relation between Xi and is an empirical fact uncovered by “searching” through the data, and not motivated by any a priori theoretical considerations. This search need not be a systematic sifting of the data, but may be interpreted as any one of Leamer's (1978) six specification searches, which even the most meticulous of classical statisticians has conducted at some point. The key feature is that our interest in characteristic Xi is derived from a look at the data, the same data to be used in performing our test. Common intuition suggests that using information contained in the Xi's can yield a more powerful test of economic restrictions on the 's. But if this characteristic is not a part of the original null hypothesis, and only catches our attention after a look at the data (or after a look at another's look at the data), using it to form our test statistics may lead us to reject those economic restrictions even when they obtain. More formally, if we write  as
as

then it is evident that under the null hypothesis where = 0, any correlation between Xi and must be due to correlation between the characteristic and estimation or measurement error  . Although measurement error is usually assumed to be independent of all other relevant economic variables, the very process by which the characteristic comes to our attention may induce spurious correlation between Xi and . We formalize this intuition in Section 8.4 and proceed now to show that such spurious correlation has important implications for testing the null hypothesis.
. Although measurement error is usually assumed to be independent of all other relevant economic variables, the very process by which the characteristic comes to our attention may induce spurious correlation between Xi and . We formalize this intuition in Section 8.4 and proceed now to show that such spurious correlation has important implications for testing the null hypothesis.
This is most evident in the extreme case where the null hypothesis = 0 is tested by performing a standard t-test on the largest of the 's. Clearly such a test is biased toward rejection unless we account for the fact that the largest has been drawn from the set { }. Otherwise, extreme realizations of estimation error will be confused with a violation of the null hypothesis. If, instead of choosing by its value relative to other 's our choice is based on some characteristic Xi correlated with the estimation errors of , a similar bias might arise, albeit to a lesser degree.
}. Otherwise, extreme realizations of estimation error will be confused with a violation of the null hypothesis. If, instead of choosing by its value relative to other 's our choice is based on some characteristic Xi correlated with the estimation errors of , a similar bias might arise, albeit to a lesser degree.
To formalize the preceding intuition, suppose that only a subset of n securities is used to form the test statistic and these n are chosen by sorting the Xi's. That is, let us reorder the bivariate vectors [Xi ]' according to their first components, yielding the sequence

where  and the notation Xi:N follows that of the statistics literature in denoting the ith order statistic from the sample of N observations {Xi}.5 The notation
and the notation Xi:N follows that of the statistics literature in denoting the ith order statistic from the sample of N observations {Xi}.5 The notation  denotes the ith induced order statistic corresponding to Xi:N, or the ith concomitant of the order statistic Xi:N.6 That is, if the bivariate vectors [Xi ]' are ordered according to the Xi entries, is defined to be the second component of the ith ordered vector. The 's are not themselves ordered but correspond to the ordering of the Xi:N's.7 For example, if Xi is firm size and is the intercept from a market-model regression of firm i's excess return on the excess market return, then
denotes the ith induced order statistic corresponding to Xi:N, or the ith concomitant of the order statistic Xi:N.6 That is, if the bivariate vectors [Xi ]' are ordered according to the Xi entries, is defined to be the second component of the ith ordered vector. The 's are not themselves ordered but correspond to the ordering of the Xi:N's.7 For example, if Xi is firm size and is the intercept from a market-model regression of firm i's excess return on the excess market return, then  is the
is the  of the jth smallest of the N firms. We call this procedure induced ordering of the 's.
of the jth smallest of the N firms. We call this procedure induced ordering of the 's.
It is apparent that if we construct a test statistic by choosing n securities according to the ordering (8.1.3), the sampling theory cannot be the same as that of n securities selected independently of the data. From the following remarkably simple result by Yang (1977), an asymptotic sampling theory for test statistics based on induced order statistics may be derived analytically:8
Theorem 8.1.1. Let the vectors  be independently and identically distributed and let l < i1 < i2 < N be sequences of integers such that, as
be independently and identically distributed and let l < i1 < i2 < N be sequences of integers such that, as  . Then
. Then

where Fx(·) is the marginal cumulative distribution function of Xi.
Proof See Yang (1977).
This result gives the large-sample joint distribution of a finite subset of induced order statistics whose identities are determined solely by their relative rankings  (as ranked according to the order statistics Xi:N). From (8.1.4) it is evident that the 's are mutually independent in large samples. If Xi were the market value of equity of the ith company, Theorem 8.1.1 shows that the of the security with size at, for example, the 27th percentile is asymptotically independent of the
(as ranked according to the order statistics Xi:N). From (8.1.4) it is evident that the 's are mutually independent in large samples. If Xi were the market value of equity of the ith company, Theorem 8.1.1 shows that the of the security with size at, for example, the 27th percentile is asymptotically independent of the  of the security with size at the 45th percentile.9 If the characteristics {Xi} and {} are statistically independent, the joint distribution of the latter clearly cannot be influenced by ordering according to the former. It is tempting to conclude that as long as the correlation between Xi and is economically small, induced ordering cannot greatly affect inferences. Using Yang's result we show the fallacy of this argument in Sections 8.1.2 and 8.1.3.
of the security with size at the 45th percentile.9 If the characteristics {Xi} and {} are statistically independent, the joint distribution of the latter clearly cannot be influenced by ordering according to the former. It is tempting to conclude that as long as the correlation between Xi and is economically small, induced ordering cannot greatly affect inferences. Using Yang's result we show the fallacy of this argument in Sections 8.1.2 and 8.1.3.
8.1.2 Biases of Tests Based on Individual Securities
We evaluate the bias of induced ordering under the following assumption:
(Al) The vectors  are independently and identically distributed bivariate normal random vectors with mean
are independently and identically distributed bivariate normal random vectors with mean  , variance
, variance  , and correlation ρ
, and correlation ρ 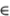 (–1, 1).
(–1, 1).
The null hypothesis H is then

Examples of asset pricing models that yield restrictions of this form are the Sharpe-Lintner CAPM and the exact factor pricing version of Ross's APT.10 Under this null hypothesis, the 's deviate from zero solely through estimation error.
Since the sampling theory provided by Theorem 8.1.1 is asymptotic, we construct our test statistics using a finite subset of n securities where it is assumed that n « N. If these securities are selected without the prior use of data, then we have the following well-known result:

where  is any consistent estimator of .11 Therefore, a 5 percent test of H may be performed by checking whether θ is greater or less than
is any consistent estimator of .11 Therefore, a 5 percent test of H may be performed by checking whether θ is greater or less than  where
where  is defined by
is defined by

and  is the cumulative distribution function of a
is the cumulative distribution function of a  variate.
variate.
Now suppose we construct θ from the induced order statistics  , k= 1,…n, instead of the 's. Specifically, define the following test statistic:
, k= 1,…n, instead of the 's. Specifically, define the following test statistic:

Using Theorem 8.1.1, the following proposition is easily established:
Proposition 8.1.1. Under the null hypothesis H and assumption (Al), as N increases without bound the induced order statistics (k = 1, …n) converge in distribution to independent Gaussian random variables with mean µk and variance  , where
, where

which implies

with noncentrality parameter

where Φ(·) is the standard normal cumulative distribution function.
Proof This follows directly from the definition of a noncentral chi-squared variate. The second equality in (8.1.8) follows from the fact that  =
= 

Proposition 8.1.1 shows that the null hypothesis H is violated by induced ordering since the means of the ordered 's are no longer zero. Indeed, the mean of may be positive or negative depending on ρ and the (limiting) relative rank  . For example, if ρ = 0.10 and σα = 1, the mean of the induced order statistic in the 95th percentile is 0.164.
. For example, if ρ = 0.10 and σα = 1, the mean of the induced order statistic in the 95th percentile is 0.164.
The simplicity of  's asymptotic distribution follows from the fact that the 's become independent as N increases without bound. It follows from the fact that induced order statistics are conditionally independent when conditioned on the order statistics that determine the induced ordering. This seemingly counterintuitive result is easy to see when [Xi ] is bivariate normal, since, in this case
's asymptotic distribution follows from the fact that the 's become independent as N increases without bound. It follows from the fact that induced order statistics are conditionally independent when conditioned on the order statistics that determine the induced ordering. This seemingly counterintuitive result is easy to see when [Xi ] is bivariate normal, since, in this case

where Xi and Zi are independent. Therefore, the induced order statistics may be represented as

where the  are independent of the (order) statistics
are independent of the (order) statistics  . But since is an order statistic, and since the sequence ik/N converges to , converges to the th quantile,F–l(). Using (8.1.13) then shows that is Gaussian, with mean and variance given by (8.1.8) and (8.1.9), and independent of the other induced order statistics.12
. But since is an order statistic, and since the sequence ik/N converges to , converges to the th quantile,F–l(). Using (8.1.13) then shows that is Gaussian, with mean and variance given by (8.1.8) and (8.1.9), and independent of the other induced order statistics.12
To evaluate the size of a 5 percent test based on the statistic , we need only evaluate the cumulative distribution function of the noncentral  at the point
at the point  /( 1 – ρ2), where is given in (8.1.6). Observe that the noncentrality parameter λ is an increasing function of ρ2. If ρ2 = 0 then the distribution of reduces to a central
/( 1 – ρ2), where is given in (8.1.6). Observe that the noncentrality parameter λ is an increasing function of ρ2. If ρ2 = 0 then the distribution of reduces to a central  which is identical to the distribution of θ in (8.1.5)—sorting on a characteristic that is statistically independent of the 's cannot affect the null distribution of θ. As and Xi become more highly correlated, the noncentral X2 distribution shifts to the right. However, this does not imply that the actual size of a 5 percent test necessarily increases since the relevant critical value for , /(1 – ρ2), also grows with ρ2.13
which is identical to the distribution of θ in (8.1.5)—sorting on a characteristic that is statistically independent of the 's cannot affect the null distribution of θ. As and Xi become more highly correlated, the noncentral X2 distribution shifts to the right. However, this does not imply that the actual size of a 5 percent test necessarily increases since the relevant critical value for , /(1 – ρ2), also grows with ρ2.13
Numerical values for the size of a 5 percent test based on may be obtained by first specifying choices for the relative ranks of the n securities. We choose three sets of {}, yielding three distinct test statistics 1, 2, and 3:

where n ≡ 2n0 and n0 is an arbitrary positive integer. The first method (8.1.14) simply sets the 's so that they divide the unit interval into n equally spaced increments. The second procedure (8.1.15) first divides the unit interval into m + 1 equally spaced increments, sets the first half of the 's to divide the first such increment into equally spaced intervals each of width l/(m + l)(n0 + l), and then sets the remaining half so as to divide the last increment into equally spaced intervals also of width 1 /(m + 1 )(n0 +1) each. The third procedure is similar to the second, except that the 's are chosen to divide the second smallest and second largest m + 1 increments into equally spaced intervals of width l/(m + 1)(n0 + 1).
These three ways of choosing n securities allow us to see how an attempt to create (or remove) dispersion—as measured by the characteristic Xi— affects the null distribution of the statistics. The first choice for the relative ranks is the most dispersed, being evenly distributed on (0, 1). The second yields the opposite extreme: the 's selected are those with characteristics in the lowest and highest 100/(m + l)-percentiles. As the parameter m is increased, more extreme outliers are used to compute 2. This is also true for 3 but to a lesser extent since the statistic is based on 's in the second lowest and second highest 100/(m + l)-percentiles.
Table 8.1 shows the size of the 5 percent test using 1, 2 and 3 for various values of n, ρ2, and m. For concreteness, observe that ρ2 is simply the R2 of the cross-sectional regression of on Xi, so that ρ = ±.10 implies that only 1 percent of the variation in is explained by Xi. For this value of R2, the entries in the second panel of Table 8.1 show that the size of a 5 percent test using 1 is 4.9 percent for samples of 10 to 100 securities. However, using securities with extreme characteristics does affect the size, as the entries in the “2-test” and “3-test” columns indicate. Nevertheless the largest deviation is only 8.1 percent. As expected, the size is larger for the test based on 2 than 3 for that of 3 since the former statistic is based on more extreme induced order statistics than the latter.
Table 8.1. Theoretical sizes of nominal 5 percent -tests of H: αl = 0 (i = 1,…,n) using the test statistics j, where j  , j = 1, 2, 3, for various sample sizes n. The statistic 1 is based on induced order statistics with relative ranks evenly spaced in (0, 1); 2 is constructed from induced order statistics ranked in the lowest and highest 100/(m + 1)-percent fractiles; and 3 is constructed from those ranked in the second lowest and second highest 100/(m + 1)-percent fractiles. The R2 is the square of the correlation between and the sorting characteristic.
, j = 1, 2, 3, for various sample sizes n. The statistic 1 is based on induced order statistics with relative ranks evenly spaced in (0, 1); 2 is constructed from induced order statistics ranked in the lowest and highest 100/(m + 1)-percent fractiles; and 3 is constructed from those ranked in the second lowest and second highest 100/(m + 1)-percent fractiles. The R2 is the square of the correlation between and the sorting characteristic.

When the R2 increases to 10 percent the bias becomes more important. Although tests based on a set of securities with evenly spaced characteristics still have sizes approximately equal to their nominal 5 percent value, the size deviates more substantially when securities with extreme characteristics are used. For example, the size of the 2 test that uses the 100 securities in the lowest and highest characteristic decile is 42.3 percent! In comparison, the 5 percent test based on the second lowest and second highest deciles exhibits only a 5.8 percent rejection rate. These patterns become even more pronounced for R2's higher than 10 percent.
The intuition for these results may be found in (8.1.8)—the more extreme induced order statistics have means farther away from zero; hence, a statistic based on evenly distributed 's will not provide evidence against the null hypothesis α = 0. If the relative ranks are extreme, as is the case for 2 and 3, the resulting 's may appear to be statistically incompatible with the null.
8.1.3 Biases of Tests Based on Portfolios of Securities
The entries in Table 8.1 show that as long as the n securities chosen have characteristics evenly distributed in relative rankings, test statistics based on individual securities yield little inferential bias. However, in practice the ordering by characteristics such as market value of equity is used to group securities into portfolios, and the portfolio returns are used to construct test statistics. For example, let n  , where n0 and q are arbitrary positive integers, and consider forming q portfolios with n0 securities in each portfolio, where the portfolios are formed randomly. Under the null hypothesis H we have the following:
, where n0 and q are arbitrary positive integers, and consider forming q portfolios with n0 securities in each portfolio, where the portfolios are formed randomly. Under the null hypothesis H we have the following:

where Φk is the estimated alpha of portfolio k and θp is the aggregate test statistic for the q portfolios. To perform a 5 percent test of H using θp, we simply compare it with the critical value  defined by
defined by

Suppose, however, we compute this test statistic using the induced order statistics {} instead of randomly chosen {}. From Theorem 8.1.1 we have:
Proposition 8.1.2. Under the null hypothesis H and assumption (Al), as N increases without bound, the statistics  (k = 1, 2,…, q) and
(k = 1, 2,…, q) and  converge in distribution to the following:
converge in distribution to the following:

with noncentrality parameter

Proof Again, this follows directly from the definition of a noncentral chi-squared variate and the asymptotic independence of the induced order statistics.
The noncentrality parameter (8.1.22) is similar to that of the statistic based on individual securities—it is increasing in ρ2 and equals zero when ρ = 0. However, it differs in one respect: because of portfolio aggregation, each term of the outer sum (the sum with respect to k) is the average of Φ–1( ) over all securities in the kth portfolio. To see the importance of this, consider the case where the relative ranks are chosen to be evenly spaced in (0,1), that is,
) over all securities in the kth portfolio. To see the importance of this, consider the case where the relative ranks are chosen to be evenly spaced in (0,1), that is,

Recall from Table 8.1 that for individual securities the size of 5 percent tests based on evenly spaced 's was not significantly biased. Table 8.2 reports the size of 5 percent tests based on the portfolio statistic , also using evenly spaced relative rankings. The contrast is striking—even for as low an R2 as 1 percent, which implies a correlation of only ±10 percent between and Xi, a 5 percent test based on 50 portfolios with 50 securities in each rejects 67 percent of the time! We can also see how portfolio grouping affects the size of the test for a fixed number of securities by comparing the (q = i, n0 = j) entry with the (q = j, n0 = i) entry. For example, in a sample of 250 securities a test based on 5 portfolios of 50 securities has size 16.5 percent, whereas a test based on 50 portfolios of 5 securities has only a 7.5 percent rejection rate. Grouping securities into portfolios increases the size considerably. The entries in Table 8.2 are also monotonically increasing across rows and across columns, implying that the test size increases with the number of securities, regardless of whether the number of portfolios or the number of securities per portfolio is held fixed.
To understand why forming portfolios yields much higher rejection rates than using individual securities, recall from (8.1.8) and (8.1.9) that the mean of is a function of its relative rank ik/N (in the limit), whereas its variance  (1 – ρ2) is fixed. Forming a portfolio of the induced order statistics within a characteristic-fractile amounts to averaging a collection of n0 approximately independent random variables with similar means and identical variances. The result is a statistic with a comparable mean but with a variance n0 times smaller than each of the 's. This variance reduction amplifies the importance of the deviation of the mean from zero, and is ultimately reflected in the entries of Table 8.2. A more dramatic illustration is provided in Table 8.3, which reports the appropriate 5 percent critical values for the tests in Table 8.2—when R2 = 0.05, the 5 percent critical value for the X2 test with 50 securities in each of 50 portfolios is 211.67. If induced ordering is unavoidable, these critical values may serve as a method for bounding the effects of data snooping on inferences.
(1 – ρ2) is fixed. Forming a portfolio of the induced order statistics within a characteristic-fractile amounts to averaging a collection of n0 approximately independent random variables with similar means and identical variances. The result is a statistic with a comparable mean but with a variance n0 times smaller than each of the 's. This variance reduction amplifies the importance of the deviation of the mean from zero, and is ultimately reflected in the entries of Table 8.2. A more dramatic illustration is provided in Table 8.3, which reports the appropriate 5 percent critical values for the tests in Table 8.2—when R2 = 0.05, the 5 percent critical value for the X2 test with 50 securities in each of 50 portfolios is 211.67. If induced ordering is unavoidable, these critical values may serve as a method for bounding the effects of data snooping on inferences.
Table 8.2. Theoretical sizes of nominal 5 percent  -tests of H : αi = 0 (i = 1,…, n) using the test statistic , where
-tests of H : αi = 0 (i = 1,…, n) using the test statistic , where  , and
, and  is constructed from portfolio k, with portfolios formed by sorting on some characteristic correlated with estimates . This induced ordering alters the null distribution of
is constructed from portfolio k, with portfolios formed by sorting on some characteristic correlated with estimates . This induced ordering alters the null distribution of  from to (1 — R2)/(λ) where the noncentrality parameter λ is a function of the number q of portfolios, the number n0 of securities in each portfolio, and the squared correlation coefficient R2 between and the sorting characteristic.
from to (1 — R2)/(λ) where the noncentrality parameter λ is a function of the number q of portfolios, the number n0 of securities in each portfolio, and the squared correlation coefficient R2 between and the sorting characteristic.

Table 8.3. Critical values C.05 for 5 percent X2 -tests of H : = O (i = 1,…, n) using the test statistic , where  , and
, and  is constructed from portfolio k, with portfolios formed by sorting on some characteristic correlated with estimates . This induced ordering alters the null distribution of from to (1 — R2)/(λ) where the noncentrality parameter λ is a function of the number q of portfolios, the number n0 of securities in each portfolio, and the squared correlation coefficient R2 between and the sorting characteristic. C.05 is defined implicitly by the relation Pr( > C.05) = 1 –
is constructed from portfolio k, with portfolios formed by sorting on some characteristic correlated with estimates . This induced ordering alters the null distribution of from to (1 — R2)/(λ) where the noncentrality parameter λ is a function of the number q of portfolios, the number n0 of securities in each portfolio, and the squared correlation coefficient R2 between and the sorting characteristic. C.05 is defined implicitly by the relation Pr( > C.05) = 1 –  (C.05/(l – R2)) = 0.05. For comparison, we also report the 5 percent critical value of the central distribution in the second column.
(C.05/(l – R2)) = 0.05. For comparison, we also report the 5 percent critical value of the central distribution in the second column.

When the R2 increases to 10 percent, implying a cross-sectional correlation of about ±32 percent between and Xi, the size approaches unity for tests based on 20 or more portfolios with 20 or more securities in each portfolio. These results are especially surprising in view of the sizes reported in Table 8.1, since the portfolio test statistic is based on evenly spaced induced order statistics . Using 100 securities, Table 8.1 shows a size of 4.3 percent with evenly spaced 's; Table 8.2 shows that placing those 100 securities into 5 portfolios with 20 securities in each increases the size to 56.8 percent. Computing with extreme would presumably yield even higher rejection rates. The biases reported in Tables 8.2 and 8.3 are even more surprising in view of the limited use we have made of the data. The only data-related information impounded in the induced order statistics is the rankings of the characteristics {Xi}. Nowhere have we exploited the values of the Xi's, which contain considerably more precise information about the 's.
8.1.4 Interpreting Data-Snooping Bias as Power
We have so far examined the effects of data snooping under the null hypothesis that αi = 0, for all i. Therefore, the degree to which induced ordering increases the probability of rejecting this null is implicitly assumed to be a bias, an increase in type I error. However, the results of the previous sections may be reinterpreted as describing the power of tests based on induced ordering against certain alternative hypotheses.
Recall from (8.1.2) that is the sum of αi and estimation error . Since all αi's are zero under H, the induced ordering of the estimates creates a spurious incompatibility with the null arising solely from the sorting of the estimation errors . But if the 's are nonzero and vary across i, then sorting by some characteristic Xi related to αi and forming portfolios does yield a more powerful test. Forming portfolios reduces the estimation error through diversification (or the law of large numbers), and grouping by Xi maintains the dispersion of the αi's across portfolios. Therefore what were called biases in Sections 8.1.1-8.1.3 may also be viewed as measures of the power of induced ordering against alternatives in which the αi's differ from zero and vary cross-sectionally with Xi. The values in Table 8.2 show that grouping on a marginally correlated characteristic can increase the power substantially.14
To formalize the above intuition within our framework, suppose that the αi were IID random variables independent of and have mean µα and variance  . Then the 's are still independently and identically distributed, but the null hypothesis that αi = 0 is now violated. Suppose the estimation error were identically zero, so that all variation in was due to variations in αi. Then the values in Table 8.2 would represent the power of our test against this alternative, where the squared correlation is now given by
. Then the 's are still independently and identically distributed, but the null hypothesis that αi = 0 is now violated. Suppose the estimation error were identically zero, so that all variation in was due to variations in αi. Then the values in Table 8.2 would represent the power of our test against this alternative, where the squared correlation is now given by

If, as under our null hypothesis, all αi's were identically zero, then the values in Table 8.2 must be interpreted as the size of our test, where the squared correlation reduces to

More generally, the squared correlation ρ2 is related to  and
and  in the following way:
in the following way:

Holding the correlations ρs and ρp fixed, the importance of the spurious portion of ρ2, given by ρs, increases with  the fraction of variability in due to estimation error. Conversely, if the variability of is largely due to fluctuations in αi, then ρ2 will reflect mostly .
the fraction of variability in due to estimation error. Conversely, if the variability of is largely due to fluctuations in αi, then ρ2 will reflect mostly .
Of course, the essence of the problem lies in our inability to identify except in very special cases. We observe an empirical relation between Xi and , but we do not know whether the characteristic varies with αi or with estimation error . It is a type of identification problem that is unlikely to be settled by data analysis alone, but must be resolved by providing theoretical motivation for a relation, or no relation, between Xi and αi. That is, economic considerations must play a dominant role in determining . We shall return to this issue in the empirical examples of Section 8.3.
8.2 Monte Carlo Results
Although the values in Table 8.1–8.3 quantify the magnitude of the biases associated with induced ordering, their practical relevance may be limited in at least three respects. First, the test statistics we have considered are similar in spirit to those used in empirical tests of asset pricing models, but implicitly use the assumption of cross-sectional independence. The more common practice is to estimate the covariance matrix of the N asset returns using a finite number T of time series observations, from which an. F-distributed quadratic form may be constructed. Both sampling error from the covariance matrix estimator and cross-sectional dependence will affect the null distribution of in finite samples.
Second, the sampling theory of Section 8.1 is based on asymptotic approximations, and few results on rates of convergence for Theorem 8.1.1 are available.15 How accurate are such approximations for empirically realistic sample sizes?
Finally, the form of the asymptotics does not correspond exactly to procedures followed in practice. Recall that the limiting result involves a finite number n of securities with relative ranks that converge to fixed constants  as the number of securities N increases without bound. This implies that as N increases, the number of securities in between any two of our chosen n must also grow without bound. However, in practice characteristic-sorted portfolios are constructed from all securities within a fractile, not just from those with particular relative ranks. Although intuition suggests that this may be less problematic when n is large (so that within any given fractile there will be many securities), it is surprisingly difficult to verify.16
as the number of securities N increases without bound. This implies that as N increases, the number of securities in between any two of our chosen n must also grow without bound. However, in practice characteristic-sorted portfolios are constructed from all securities within a fractile, not just from those with particular relative ranks. Although intuition suggests that this may be less problematic when n is large (so that within any given fractile there will be many securities), it is surprisingly difficult to verify.16
In this section we report results from Monte Carlo experiments that show the asymptotic approximations of Section 8.1 to be quite accurate in practice despite these three reservations. In Section 8.2.1, we evaluate the quality of the asymptotic approximations for the test used in calculating Tables 8.2 and 8.3. In Section 8.2.2, we consider the effects of induced ordering on F-tests with fixed N and T when the covariance matrix is estimated and the data-generating process is cross-sectionally independent. In Section 8.2.3, we consider the effects of relaxing the independence assumption.
8.2.1 Simulation Results for p
The Xq2(λ) limiting distribution of p obtains because any finite collection of induced order statistics, each with a fixed distinct limiting relative rank  in (0, 1), becomes mutually independent as the total number N of securities increases without bound. This asymptotic approximation implies that between any two of the n chosen securities there will be an increasing number of securities omitted from all portfolios as N increases. In practice, all securities within a particular characteristic fractile are included in the sorted portfolios; hence, the theoretical sizes of Table 8.2 may not be an adequate approximation to this more empirically relevant situation. To explore this possibility we simulate bivariate normal vectors (i, Xi) with squared correlation R2, form portfolios using the induced ordering by the Xi's, compute p using all the
in (0, 1), becomes mutually independent as the total number N of securities increases without bound. This asymptotic approximation implies that between any two of the n chosen securities there will be an increasing number of securities omitted from all portfolios as N increases. In practice, all securities within a particular characteristic fractile are included in the sorted portfolios; hence, the theoretical sizes of Table 8.2 may not be an adequate approximation to this more empirically relevant situation. To explore this possibility we simulate bivariate normal vectors (i, Xi) with squared correlation R2, form portfolios using the induced ordering by the Xi's, compute p using all the  (in contrast to the asymptotic experiment where only those induced order statistics of given relative ranks are used), and then repeat this procedure 5,000 times to obtain the finite sample distribution.
(in contrast to the asymptotic experiment where only those induced order statistics of given relative ranks are used), and then repeat this procedure 5,000 times to obtain the finite sample distribution.
Table 8.4 reports the results of these simulations for the same values of R2, no, and q as in Table 8.2. Except when both n0 and q are small, the empirical sizes of Table 8.4 match their asymptotic counterparts in Table 8.2 closely. Consider, for example, the R2 = 0.05 panel; with 5 portfolios each with 5 securities, the difference between the theoretical and empirical size is 1.1 percentage points, whereas this difference is only 0.2 percentage points for 25 portfolios each with 25 securities. When n0 and q are both small, the theoretical and empirical sizes differ more for larger R2, by as much as 7.4 percent when R2 = 0.20. However, for the more relevant values of R2, the empirical and theoretical sizes of the p test are virtually identical.
8.2.2 Effects of Induced Ordering on F-Tests
Although the results of Section 8.2.1 support the accuracy of our asymptotic approximation to the sampling distribution of p, the closely related F-statistic is used more frequently in practice. In this section we consider the finite-sample distribution of the F-statistic after induced ordering. We perform Monte Carlo experiments under the now standard multivariate data-generating process common to virtually all static financial asset pricing models. Let rit denote the return of asset i between dates t – 1 and t, where i = 1, 2,…,N, and t = 1,2,…,T, We assume that for all assets i and dates t the following obtains:

where αi and βij are fixed parameters, rtj is the return on some portfolio j (systematic risk), and it is mean-zero (idiosyncratic) noise. Depending on the particular application, rit, may be taken to be nominal, real, or excess asset returns. The process (8.2.1) may be viewed as a factor model where the factors correspond to particular portfolios of traded assets, often called the “mimicking portfolios” of an exact factor pricing model. In matrix notation, we have

Here, rt is the N × 1 vector of asset returns at time t, B is the N × k matrix of factor loadings, rtp is the k × l vector of time-i spanning portfolio returns, and α and t are N × 1 vectors of asset return intercepts and disturbances, respectively.
Table 8.4. Empirical sizes of nominal 5 percent Xq2-tests of H: = 0 (i = 1,…, n) using the test statistic p, where  is constructed from portfolio k, with portfolios formed by sorting on some characteristic correlated with estimates . This induced ordering alters the null distribution of
is constructed from portfolio k, with portfolios formed by sorting on some characteristic correlated with estimates . This induced ordering alters the null distribution of  from Xq2 to (1 – R2) – Xq2(λ) where the noncentrality parameter λ is a function of the number q of portfolios, the number no of securities in each portfolio, and the squared correlation coefficient R2 between and the sorting characteristic. Each simulation is based on 5000 replications; asymptotic standard errors for the size estimates may be obtained from the usual binomial approximation, and is 3.08 × 10–3 for the 5 percent test.
from Xq2 to (1 – R2) – Xq2(λ) where the noncentrality parameter λ is a function of the number q of portfolios, the number no of securities in each portfolio, and the squared correlation coefficient R2 between and the sorting characteristic. Each simulation is based on 5000 replications; asymptotic standard errors for the size estimates may be obtained from the usual binomial approximation, and is 3.08 × 10–3 for the 5 percent test.

This data-generating process is the starting point of the two most popular static models of asset pricing, the CAPM and the APT. Further restrictions are usually imposed by the specific model under consideration, often reducing to the following null hypothesis:

where the function g is model dependent.17 Many tests simply set g(α, B) = α and define rt as excess returns, such as those of the Sharpe-Lintner CAPM and the exact factor-pricing APT. With the added assumption that rt and  are jointly normally distributed, the finite-sample distribution of the following test statistic is well known:
are jointly normally distributed, the finite-sample distribution of the following test statistic is well known:

where  are the maximum likelihood estimators of the covariance matrices of the disturbances
are the maximum likelihood estimators of the covariance matrices of the disturbances  t and the spanning portfolio returns , respectively, and
t and the spanning portfolio returns , respectively, and  is the vector of sample means of . If the number of available securities N is greater than the number of time series observations T less k + 1, the estimator
is the vector of sample means of . If the number of available securities N is greater than the number of time series observations T less k + 1, the estimator  is singular and the test statistic (8.2.5) cannot be computed without additional structure. This problem is most often circumvented in practice by forming portfolios. That is, let rt be a q × 1 vector of returns of q portfolios of securities where « N. Since the returngenerating process is linear for each security i, a linear relation also obtains for portfolio returns. However, as the analysis of Section 8.1 foreshadows, if the portfolios are constructed by sorting on some characteristic correlated with then the null distribution of
is singular and the test statistic (8.2.5) cannot be computed without additional structure. This problem is most often circumvented in practice by forming portfolios. That is, let rt be a q × 1 vector of returns of q portfolios of securities where « N. Since the returngenerating process is linear for each security i, a linear relation also obtains for portfolio returns. However, as the analysis of Section 8.1 foreshadows, if the portfolios are constructed by sorting on some characteristic correlated with then the null distribution of  is altered.
is altered.
To evaluate the null distribution of under characteristic-sorting data snooping, we design our simulation experiments in the following way. The number of time series observations T is set to 60 for all simulations. With little loss in generality, we set the number of spanning portfolios k to zero so that  To separate the effects of estimating the covariance matrix from the effects of cross-sectional dependence, we first assume that the covariance matrix ∑ of t is equal to the identity matrix I—this assumption is relaxed in Section 8.2.3. We simulate T observations of the N×1 Gaussian vector rt (where N takes the values 200, 500, and 1000), and compute . We then form q portfolios (where q takes the values 10 and 20) by constructing a characteristic Xi, that has correlation ρ with (where ρ2 takes the values 0.005, 0.01, 0.05, 0.10, and 0.20), and then sorting the 's by this characteristic. To do this, we define
To separate the effects of estimating the covariance matrix from the effects of cross-sectional dependence, we first assume that the covariance matrix ∑ of t is equal to the identity matrix I—this assumption is relaxed in Section 8.2.3. We simulate T observations of the N×1 Gaussian vector rt (where N takes the values 200, 500, and 1000), and compute . We then form q portfolios (where q takes the values 10 and 20) by constructing a characteristic Xi, that has correlation ρ with (where ρ2 takes the values 0.005, 0.01, 0.05, 0.10, and 0.20), and then sorting the 's by this characteristic. To do this, we define

Having constructed the Xi's, we order {} to obtain { }, construct portfolio intercept estimates that we call
}, construct portfolio intercept estimates that we call  k = 1,…, n,
k = 1,…, n,

from which we form the F-statistic,

where  denotes the q×1 vector of 's, and is the maximum likelihood estimator of the q × q covariance matrix of the q portfolio returns. This procedure is repeated 5000 times, and the mean and standard deviation of the resulting distribution for the statistic are reported in Table 8.5, as well as the size of 1, 5, and 10 percent. F-tests.
denotes the q×1 vector of 's, and is the maximum likelihood estimator of the q × q covariance matrix of the q portfolio returns. This procedure is repeated 5000 times, and the mean and standard deviation of the resulting distribution for the statistic are reported in Table 8.5, as well as the size of 1, 5, and 10 percent. F-tests.
Even for as small an R2 as 1 percent, the empirical size of the 5 percent F-test differs significantly from its nominal value for all values of q and no. For the sample of 1000 securities grouped into ten portfolios, the empirical rejection rate of 36.7 percent deviates substantially from 5 percent. When the 1000 securities are grouped into 20 portfolios, the size is somewhat lower–26.8 percent–matching the pattern in Table 8.2. Also similar is the monotonicity of the size with respect to the number of securities. For 200 securities the empirical size is only 7.1 percent with 10 portfolios, but it is more than quintupled with 1000 securities. When the squared correlation between and Xi increases to 10 percent, the size of the F-test is essentially unity for sample sizes of 500 or more. Thus even for finite sample sizes of practical relevance, the importance of data snooping via induced ordering cannot be overemphasized.
Table 8.5. Empirical size of Fq,T–q tests based on q portfolios sorted by a random characteristic whose squared correlation with i is R2. n0 is the number of securities in each portfolio and n ≡ n0q is the total number of securities. The number of time series observations T is set to 60. The mean and standard deviation of the test statistic over the 5000 replications are reported. The population mean and standard deviation F10,50 are 1.042 and 0.523, respectively; those of the F20,40 are 1.053 and 0.423, respectively. Asymptotic standard errors for the size estimates may be obtained from the usual binomial approximation; they are 4.24 × 10–3, 3.08 × 10–3, and 1.41 × 10–3 for the 10, 5, and 1 percent tests, respectively.

8.2.3 F-Tests With Cross-Sectional Dependence
The substantial bias that induced ordering imparts on the size of portfoliobased F-tests comes from the fact that the induced order statistics {} generally have nonzero means;18 hence, the averages of these statistics within sorted portfolios also have nonzero means but reduced variances about those means. Alternatively, the bias from portfolio formation is a result of the fact that the i's of the extreme portfolios do not approach zero as more securities are combined, whereas the residual variances of the portfolios (and consequently the variances of the portfolio 's) do tend to zero. Of course, our assumption that the disturbances  t of (8.2.2) are cross-sectionally independent implies that the portfolio residual variance approaches zero rather quickly (at rate 1/no). But in many applications (such as the CAPM), cross-sectional independence is counterfactual. Firm size and industry membership are but two factors that might induce cross-sectional correlation in return residuals. In particular, when the residuals are positively cross-sectionally correlated, the bias is likely to be smaller since there is less variance reduction in forming portfolios than in the cross-sectionally independent case.
t of (8.2.2) are cross-sectionally independent implies that the portfolio residual variance approaches zero rather quickly (at rate 1/no). But in many applications (such as the CAPM), cross-sectional independence is counterfactual. Firm size and industry membership are but two factors that might induce cross-sectional correlation in return residuals. In particular, when the residuals are positively cross-sectionally correlated, the bias is likely to be smaller since there is less variance reduction in forming portfolios than in the cross-sectionally independent case.
To see how restrictive the independence assumption is, we simulate a data-generating process in which disturbances are cross-sectionally correlated. The design is identical to that of Section 8.2.2 except that the residual covariance matrix ∑ is no longer diagonal. Instead, we set

where δ is an N × 1 vector of parameters and I is the identity matrix. Such a covariance matrix would arise, for example, from a single common factor model for the N × 1 vector of disturbances t:

where Λt is some IID zero-mean unit-variance common factor independent of vt, and vt is N-dimensional vector white noise with covariance matrix I.
Table 8.6. Empirical size of Fq,T-q tests based on q portfolios sorted by a random characteristic whose squared correlation with i approximately 0.05. no is the number of securities in each portfolio and n ≡ noq is the total number of securities. The i's of the portfolios are cross-sectionally correlated, where the source of correlation is an IID zero-mean common factor in the returns. The number of time series observations T is set to 60. The mean and standard deviation of the test statistic over the 5000 replications are reported. The population mean and standard deviation of F20,40 are 1.042 and 0523, respectively; those of the F20,40 are 1.053 and 0423, respectively. Asymptotic standard errors for the size estimates may be obtained from the usual binomial approximation; they are 4.24 × 10–3, 3.08 × 10–3, and 1.41 × 10–3 for the 10, 5, and 1 percent tests, respectively.

For our simulations, the parameters δ are chosen to be equally spaced in the interval [–1, 1]. With this design the crosscorrelation of the disturbances will range from –0.5 to 05. The Xi's are constructed as in (8.2.6) with

where ρ2 is fixed at 0.05.
Under this design, the results of the simulation experiments may be compared to the third panel of Table 8.5, and are reported in Table 8.6.19 Despite the presence of cross-sectional dependence, the impact of induced ordering on the size of the F-test is still significant. For example, with 20 portfolios each containing 25 securities the empirical size of the 5 percent test is 32.3 percent; with 10 portfolios of 50 securities each the empirical size increases to 82.0 percent. As in the cross-sectionally independent case, the bias increases with the number of securities given a fixed number of portfolios, and the bias decreases as the number of portfolios is increased given a fixed number of securities. Not surprisingly, for fixed no and q, cross-sectional dependence of the 's lessens the bias. However, the entries in Table 8.6 demonstrate that the effects of data-snooping may still be substantial even in the presence of cross-sectional dependence.
8.3 Two Empirical Examples
To illustrate the potential relevance of data-snooping biases associated with induced ordering, we provide two examples drawn from the empirical literature. The first example is taken from the early tests of the Sharpe-Lintner CAPM, where portfolios were formed by sorting on out-of-sample betas. We show that such tests can be biased towards falsely rejecting the CAPM if insample betas are used instead, underscoring the importance of the elaborate sorting procedures used by Black, Jensen, and Scholes (1972) and Fama and MacBeth (1973). Our second example concerns tests of the APT that reject the zero-intercept null hypothesis when applied to portfolio returns sorted by market value of equity. We show that data-snooping biases can account for much the same results, and that only additional economic restrictions will determine the ultimate source of the rejections.
8.3.1 Sorting By Beta
Although tests of the Sharpe-Lintner CAPM may be conducted on individual securities, the potential benefits of using multiple securities are well known. One common approach for allocating securities to portfolios has been to rank them by their betas and then group the sorted securities. Beta-sorted portfolios will exhibit more risk dispersion than portfolios of randomly chosen securities, and may therefore yield more information about the CAPM's risk-return relation. Ideally, portfolios would be formed according to their true betas. However, since the population betas are unobservable, in practice portfolios have grouped securities by their estimated betas. For example, both Black, Jensen, and Scholes (1972) and Fama and MacBeth (1973) use portfolios formed by sorting on estimated betas, where the betas are estimated with a prior sample of stock returns. Their motivation for this more complicated procedure was to to avoid grouping common estimation or measurement error since, within the sample, securities with high estimated betas will tend to have positive realizations of estimation error, and vice versa for securities with low estimated betas.
Suppose, instead, that securities are grouped by betas estimated in-sample. Can grouping common estimation error change inferences substantially? To answer this question within our framework, suppose the Sharpe-Lintner CAPM obtains so that

where rit denotes the excess return of security rmt is the excess market return, and t is the N × 1 vector of disturbances. To assess the impact of sorting on in-sample betas, we require the squared correlation of and  . However, since our framework requires that both and be independently and identically distributed, and since is the sum of βi and estimation error ζi, we assume to be random to allow for cross-sectional variation in the betas. Therefore, let
. However, since our framework requires that both and be independently and identically distributed, and since is the sum of βi and estimation error ζi, we assume to be random to allow for cross-sectional variation in the betas. Therefore, let

where each βi is independent of all jt in (8.3.1). The squared correlation between and may then be explicitly calculated as

where  are the sample mean and standard deviation of the excess market return, respectively,
are the sample mean and standard deviation of the excess market return, respectively, is the ex post Sharpe measure, and T is the number of time series observations used to estimate the αi's and βi's.
is the ex post Sharpe measure, and T is the number of time series observations used to estimate the αi's and βi's.
The term  in (8.3.2) captures the essence of the errors-in-variables problem for in-sample beta sorting. This is simply the ratio of the cross-sectional variance in betas,
in (8.3.2) captures the essence of the errors-in-variables problem for in-sample beta sorting. This is simply the ratio of the cross-sectional variance in betas,  to the variance of the beta estimation error,
to the variance of the beta estimation error,  . When the cross-sectional dispersion of the betas is much larger than the variance of the estimation errors, this ratio is large, implying a small value for ρ2 and little data-snooping bias. In fact, since the estimation error of the betas declines with the number of observations T, as the time period lengthens, in-sample beta sorting becomes less problematic. However, when the variance of the estimation error is large relative to the cross-sectional variance of the betas, then ρ2 is large and grouping common estimation errors becomes a more serious problem.
. When the cross-sectional dispersion of the betas is much larger than the variance of the estimation errors, this ratio is large, implying a small value for ρ2 and little data-snooping bias. In fact, since the estimation error of the betas declines with the number of observations T, as the time period lengthens, in-sample beta sorting becomes less problematic. However, when the variance of the estimation error is large relative to the cross-sectional variance of the betas, then ρ2 is large and grouping common estimation errors becomes a more serious problem.
To show just how serious this might be in practice, we report in Table 8.7 the estimated ρ2 between i and for five-year subperiods from January 1954 to December 1988, where each estimate is based on the first 200 securities listed in the CRSP monthly returns files with complete return histories within the particular five-year subsample, and the CRSP equal-weighted index. Also reported is the probability of rejecting the null hypothesis a αi = 0 when it is true using a 5 percent test, assuming a sample of 2500 securities, where the number of portfolios q is 10, 20, or 50 and the number of securities per portfolio n0 is defined accordingly.20
Table 8.7. Theoretical sizes of nominal 5 percent  -tests under the null hypothesis of the Sharpe-Lintner CAPM using q in-sample beta-sorted portfolios with no securities per portfolio, where
-tests under the null hypothesis of the Sharpe-Lintner CAPM using q in-sample beta-sorted portfolios with no securities per portfolio, where  is the estimated squared correlation between and under the null hypothesis that αi = 0 and that the βi's are IID normal random variables with mean and variance (
is the estimated squared correlation between and under the null hypothesis that αi = 0 and that the βi's are IID normal random variables with mean and variance ( and , respectively. Within each subsample, the estimate is based on the first 200 stocks in the CRSP monthly returns files with complete return histories over the five-year subperiod, and the CSRP equal-weighted index. For illustrative purposes, the theoretical size is computed under the assumption that the total number of securities n ≡ n0q is fixed at 2500.
and , respectively. Within each subsample, the estimate is based on the first 200 stocks in the CRSP monthly returns files with complete return histories over the five-year subperiod, and the CSRP equal-weighted index. For illustrative purposes, the theoretical size is computed under the assumption that the total number of securities n ≡ n0q is fixed at 2500.

The entries in Table 8.7 show that the null hypothesis is quite likely to be rejected even when it is true. For many of the subperiods, the probability of rejecting the null is unity, and when only 10 beta-sorted portfolios are used, the smallest size of anominal5 percent test is still 18.3 percent. We conclude, somewhat belatedly, that the elaborate out-of-sample sorting procedures used by Black, Jensen, and Scholes (1972) and Fama and MacBeth (1973) were indispensable to the original tests of the Sharpe-Lintner CAPM.
8.3.2 Sorting By Size
As a second example of the practical relevance of data-snooping biases, we consider Lehmann and Modest's (1988) multivariate test of a 15-factor APT model, in which they reject the zero-intercept null hypothesis using five portfolios formed by grouping securities ordered by market value of equity.21 We focus on this particular study because of the large number of factors employed—our framework requires the disturbances et of (8.2.2) to be cross-sectionally independent, and since 15 factors are included in Lehmann and Modest's cross-sectional regressions, a diagonal covariance matrix for t is not implausible.
It is well-known that the estimated intercept from the single-period CAPM regression (excess individual security returns regressed on an intercept and the market risk premium) is negatively cross-sectionally correlated with log size.22 Since this will in general be correlated with the estimated intercept from a 15-factor APT regression, it is likely that the estimated APT-intercept and log size will also be empirically correlated.23 Unfortunately, we do not have a direct measure of the correlation of the APT intercept and log size which is necessary to derive the appropriate null distribution after induced ordering.24 As an alternative, we estimate the cross-sectional R2 of the estimated CAPM alpha with the logarithm of size, and we use this R2 as well as ½R2 and ¼R2 to estimate the bias attributable to induced ordering.
Following Lehmann and Modest (1988), we consider four five-year time periods from January 1963 to December 1982. Xi is defined to be the logarithm of beginning-of-period market values of equity. The 's are the intercepts from regressions of excess returns on the market risk premium as measured by the difference between an equal-weighted NYSE index and monthly Treasury bill returns, where the NYSE index is obtained from the Center for Research in Security Prices (CRSP) database. The R2's of these regressions are reported in the second column of Table 8.8. One cross-sectional regression of on log size Xi is run for each five-year time period using monthly NYSE-AMEX data from CRSP. We run regressions only for those stocks having complete return histories within the relevant five-year period.
Table 8.8 contains the test statistics for a 15-factor APT framework using five size-sorted portfolios. The first four rows contain results for each of the four subperiods and the last row contains aggregate test statistics. To apply the results of Sections 8.1 and 8.2 we transform Lehmann and Modest's (1988) F-statistics into (asymptotic) X2 variates.25 The total number of available securities ranges from a minimum of 1001 for the first five-year subperiod to a maximum of 1359 for the second subperiod. For each test statistic in Table 8.8 we report four different p-values: the first is with respect to the null distribution that ignores data snooping, and the next three are with respect to null distributions that account for induced ordering to various degrees.
The entries in Table 8.8 show that the potential biases from sorting by characteristics that have been empirically selected can be immense. The p-values range from 0008 to 0070 in the four subperiods according to the standard theoretical null distribution, yielding an aggregate p-value of 0.00014, considerable evidence against the null. When we adjust for the fact that the sorting characteristic is selected empirically (using the R2 from the cross-sectional regression of on Xi), the p-values for these same four sub-periods range from 0.272 to 1.000, yielding an aggregate p-value of 1.000! Therefore, whether or not induced ordering is allowed for can change inferences dramatically.
Table 8.8. Comparison of p-values for Lehmann and Modest's (1988) tests of the APT with and without correcting for the effects of induced ordering. In the absence of data snooping, the appropriate test statistics and their p-values (using the central X2 distribution) are given in Lehmann and Modest (1988, Table 1) and reported below in columns 4 and 5 (we transform their F-statistics into X2 variates for purposes of comparison). Corresponding p-values that account for induced ordering are calculated in columns labelled “X 2 (λi) p-value” (i = 1, 2, 3) (using the noncentral X2 distribution), where λ1, λ2 and λ3 are noncentrality parameters computed with  respectively. In all cases, five portfolios are formed from the total number of securities; this yields five degrees of freedom for the X2 statistics in the first four rows, and 20 degrees of freedom for the aggregate X2 statistics.
respectively. In all cases, five portfolios are formed from the total number of securities; this yields five degrees of freedom for the X2 statistics in the first four rows, and 20 degrees of freedom for the aggregate X2 statistics.

The appropriate R2 in the preceding analysis is the squared correlation between log size and the intercept from a 15-factor APT regression, and not the one used in Table 8.8. To see how this may affect our conclusions, recall from (8.1.2) that the cross-sectional correlation between log and size can arise from two sources: the estimation error in , and the cross-sectional dispersion in the “true” CAPM αi (which is zero under the null hypothesis). Correlation between Xi and will be partially reflected in correlation between the estimated APT intercept and log size. The second source of correlation will not be relevant under the APT null hypothesis since under that scenario we assume that the 15-factor APT obtains and therefore the intercept vanishes for all securities. As a conservative estimate for the appropriate R2 to be used in Table 8.8, we set the squared correlation equal to  , yielding the p-values reported in the last two columns of Table 8.8. Even when the squared correlation is only
, yielding the p-values reported in the last two columns of Table 8.8. Even when the squared correlation is only  the inferences change markedly after induced ordering, with p-values ranging from 0078 to 0720 in the four subperiods and 0298 in the aggregate. This simple example illustrates the severity with which even a mild form of data snooping can bias our inferences in practice.
the inferences change markedly after induced ordering, with p-values ranging from 0078 to 0720 in the four subperiods and 0298 in the aggregate. This simple example illustrates the severity with which even a mild form of data snooping can bias our inferences in practice.
Nevertheless, it should not be inferred from Table 8.8 that all size-related phenomena are spurious. After all, the correlation between Xi and may be the result of cross-sectional variations in the population 's, and not estimation error. Even so, tests using size-sorted portfolios are still biased if based on the same data from which the size effect was previously observed. A procedure that is free from such biases is to decide today that size is an interesting characteristic, collect ten years of new data, and then perform tests on size-sorted portfolios from this fresh sample. Provided that the old and new samples are statistically independent, this will yield a perfectly valid test of the null hypothesis H, since the only possible source of correlation between the Xi's and the 's in the new sample is from the 's (presumably the result of some underlying economic relation between the two), and not from the estimation errors. In such cases, induced ordering cannot affect the distribution of the test statistics under the null hypothesis, and will yield a considerably more powerful test against many alternatives.
8.4 How the Data Get Snooped
Whether the probabilities of rejection in Table 8.2 are to be interpreted as size or power depends, of course, on the particular null and alternative hypotheses at hand, the key distinction being the source of correlation between and the characteristic Xi. Since our starting point in Section 8.1 was the assertion that this correlation is “spurious,” we view the values of Table 8.2 as probabilities of falsely rejecting the null hypothesis. We suggested in Section 8.1 that the source of this spurious correlation is correlation between the characteristic and the estimation errors in , since such errors are the only source of variation in under the null. But how does this correlation arise? One possibility is the very mechanism by which characteristics are selected. Without any economic theories for motivation, a plausible behavioral model of how we determine characteristics to be particularly “interesting” is that we tend to focus on those that have unusually large squared sample correlations or R2's with the 's. In the spirit of Ross (1987), economists study “interesting” events, as well as events that are interesting from a theoretical perspective. If so, then even in a collection of K characteristics all of which are independent of the 's, correlation between the 's and the most “interesting” characteristic is artificially induced.
More formally, suppose for each of N securities we have a collection of K distinct and mutually independent characteristics Yik, k = 1, 2,…, K,
where Yik is the kth characteristic of the zth security. Let the null hypothesis obtain so that = 0, for all i, and assume that all characteristics are independent of {}. This last assumption implies that the distribution of a test statistic based on grouped 's is unaffected by sorting on any of the characteristics. For simplicity let each of the characteristics and the 's be normally distributed with zero mean and unit variance, and consider the sample correlation coefficients:

where  are the sample means of characteristic k and the 's, respectively. Suppose we choose as our sorting characteristic the one that has the largest squared correlation with the 's, and call this characteristic Xi. That is, Xi
are the sample means of characteristic k and the 's, respectively. Suppose we choose as our sorting characteristic the one that has the largest squared correlation with the 's, and call this characteristic Xi. That is, Xi  , where the index k* is defined by
, where the index k* is defined by

This Xi is a new characteristic in the statistical sense, in that its distribution is no longer the same as that of the Yik's.26 It is apparent that Xi and are not mutually independent since the 's were used in selecting this characteristic. By construction, extreme realizations of the random variables {Xi} tend to occur when extreme realizations of {} occur.
To estimate the magnitude of correlation spuriously induced between Xi and , first observe that although the correlation between Yik and is zero for all k,  = 1/(N – 1) under our normality assumption. Therefore, 1/(N — 1) should be our benchmark in assessing the degree of spurious correlation between Xi and . Since the
= 1/(N – 1) under our normality assumption. Therefore, 1/(N — 1) should be our benchmark in assessing the degree of spurious correlation between Xi and . Since the  's are well-known to be independently and identically distributed Beta(½, ½(N – 2)) variates, the distribution and density functions of
's are well-known to be independently and identically distributed Beta(½, ½(N – 2)) variates, the distribution and density functions of  , denoted by F*(v) and f*(v), respectively, may be readily derived as27
, denoted by F*(v) and f*(v), respectively, may be readily derived as27

where  and
and  are the cumulative distribution function and probability density function of the Beta distribution with parameters ½ and ½(N – 2). A measure of that portion of squared correlation between Xi with due to sorting on is then given by
are the cumulative distribution function and probability density function of the Beta distribution with parameters ½ and ½(N – 2). A measure of that portion of squared correlation between Xi with due to sorting on is then given by

For 25 securities and 50 characteristics, γ is 20.5 percent!28 With 100 securities, γ is still 5.4 percent and only declines to 1.1 percent for 500 securities. With only 25 characteristics, the values of γ for 25, 100, and 500 securities fall to 16.4, 4.2, and 08 percent, respectively. However, these smaller values of y can still yield misleading inferences for tests based on few portfolios, each containing many securities. This is seen in Table 8.9, in which the theoretical sizes of 5 percent tests with R2's equal to the appropriate y for each cell are displayed. For example, the first entry in the first row of Table 8.9, 0163, is the size of the 5 percent portfolio-based test with five portfolios and five securities in each, where the R2 used to perform the calculation is the y corresponding to 25 securities and 25 characteristics, or 16.4 percent. As the number of securities per portfolio grows, γ declines but the bias worsens—with 50 securities in each of five portfolios, γ is only 1.7 percent but the actual size of a 5 percent test is 26.4 percent. Although there is in fact no statistical relation between any of the characteristics and the 's, a procedure that focuses on the most striking characteristic can create spurious statistical dependence.
As the number of securities N increases, this particular source of dependence becomes less important since all the sample correlation coefficients  converge almost surely to zero, as does γ. However, recall from Table 8.2 that as the sample size grows the bias increases if the number of portfolios is held fixed; hence, as Table 8.9 illustrates, a larger N and thus a smaller y need not imply a smaller bias. Moreover, since γ is increasing in the number of characteristics K, we cannot find refuge in the law of large numbers without weighing the number of securities against the number of characteristics and portfolios in some fashion. Table 8.9 provides one informal measure of this trade-off.
converge almost surely to zero, as does γ. However, recall from Table 8.2 that as the sample size grows the bias increases if the number of portfolios is held fixed; hence, as Table 8.9 illustrates, a larger N and thus a smaller y need not imply a smaller bias. Moreover, since γ is increasing in the number of characteristics K, we cannot find refuge in the law of large numbers without weighing the number of securities against the number of characteristics and portfolios in some fashion. Table 8.9 provides one informal measure of this trade-off.
Table 8.9. Theoretical sizes of nominal 5 percent -tests of H : αi = 0(i = 1,…, n) using the test statistic  , where
, where  is constructed from portfolio k, with portfolios formed by sorting on some characteristic correlated with estimates This induced ordering alters the null distribution of p from
is constructed from portfolio k, with portfolios formed by sorting on some characteristic correlated with estimates This induced ordering alters the null distribution of p from  to (1 — R2).
to (1 — R2).  where the noncentrality parameter λ is a function of the number q of portfolios, the number nο of securities in each portfolio, and the squared correlation coefficient R2 between i and the sorting characteristic. The values of R2 used for the size calculations vary with the total number of securities nοq and with K, the total number of independent characteristics from which the most “interesting” is selected.
where the noncentrality parameter λ is a function of the number q of portfolios, the number nο of securities in each portfolio, and the squared correlation coefficient R2 between i and the sorting characteristic. The values of R2 used for the size calculations vary with the total number of securities nοq and with K, the total number of independent characteristics from which the most “interesting” is selected.

Perhaps even the most unscrupulous investigator might hesitate at the kind of data snooping we have just considered. However, the very review process that published research undergoes can have much the same effect, since competition for limited journal space tilts the balance in favor of the most striking and dissonant of empirical results. Indeed, the “Anomalies” section of the Journal of Economic Perspectives is the most obvious example of our deliberate search for the unusual in economics. As a consequence, interest may be created in otherwise theoretically irrelevant characteristics. In the absence of an economic paradigm, such data-snooping biases are not easily distinguishable from violations of the null hypothesis. This inability to separate pretest bias from alternative hypotheses is the most compelling criticism of “measurement without theory.”
8.5 Conclusion
Although the size effect may signal important differences between the economic structure of small and large corporations, how these differences are manifested in the stochastic properties of their equity returns cannot be reliably determined through data analysis alone. Much more convincing would be the empirical significance of size, or any other quantity, that is based on a model of economic equilibrium in which the characteristic is related to the behavior of asset returns endogenously. Our findings show that tests using securities grouped according to theoretically motivated correlations between Xi and i can be powerful indeed—interestingly, tests of the APT with portfolios sorted by such characteristics (own-variance and dividend yield) no longer reject the null hypothesis (see Lehmann and Modest, 1988). Sorting on size yields rejections whereas sorting on theoretically relevant characteristics such as own-variance and dividend yield does not. This suggests that data-instigated grouping procedures should be employed cautiously.
It is widely acknowledged that incorrect conclusions may be drawn from procedures violating the assumptions of classical statistical inference, but the nature of these violations is often as subtle as it is profound. In observing that economists (as well as those in the natural sciences) tend to seek out anomalies, Merton (1987, p. 104) writes: “All this fits well with what the cognitive psychologists tell us is our natural individual predilection to focus, often disproportionately so, on the unusual…. This focus, both individually and institutionally, together with little control over the number of tests performed, creates a fertile environment for both unintended selection bias and for attaching greater significance to otherwise unbiased estimates than is justified.” The recognition of this possibility is a first step in guarding against it. The results of our paper provide a more concrete remedy for such biases in the particular case of portfolio formation via induced ordering on data-instigated characteristics. However, nonexperimental inference may never be completely free from data-snooping biases since the attention given to empirical anomalies, incongruities, and unusual correlations is also the modus operandi for genuine discovery and progress in the social sciences. Formal statistical analyses such as ours may serve as primitive guides to a better understanding of economic phenomena, but the ability to distinguish between the spurious and the substantive is likely to remain a cherished art.
1Perhaps the most complete analysis of such issues in economic applications is by Leamer (1978). Recent papers by Lakonishok and Smidt (1988), Merton (1987), and Ross (1987) address data snooping in financial economics. Of course, data snooping has been a concern among probabilists and statisticians for quite some time, and is at least as old as the controversy between Bayesian and classical statisticians. Interested readers should consult Berger and Wolpert (1984, Chapter 4.2) and Leamer (1978, Chapter 9) for further discussion.
2Statisticians have considered a closely related problem, known as the “file drawer problem,” in which the overall significance of several published studies must be assessed while accounting for the possibility of unreported insignificant studies languishing in various investigators' file drawers. An excellent review of the file drawer problem and its remedies, which has come to be known as “meta-analysis,” is provided by Iyengar and Greenhouse (1988)
3See Banz (1978,1981), Brown, Kleidon, and Marsh (1983), and Chan, Chen, and Hsieh (1985), for example. Although Banz's (1978) original investigation may have been motivated by theoretical considerations, virtually all subsequent empirical studies exploiting the size effect do so because of Banz's empirical findings, and not his theory.
4Unfortunately the use of “size” to mean both market value of equity and type I error is unavoidable. Readers beware.
5It is implicitly assumed throughout that both and Xi have continuous joint and marginal cumulative distribution functions; hence, strict inequalities suffice.
6The term concomitant of an order statistic was introduced by David (1973), who was perhaps the first to systematically investigate its properties and applications. The term induced order statistic was coined by Bhattacharya (1974) at about the same time. Although the former term seems to be more common usage, we use the latter in the interest of brevity. See Bhattacharya (1984) for an excellent review.
7If the vectors are independently and identically distributed and Xi is perfectly correlated with , then are also order statistics. But as long as the correlation coefficient ρ is strictly between –1 and 1, then, for example,  will generally not be the largest .
will generally not be the largest .
8See also David and Galambos (1974) and Watterson (1959). In fact, Yang (1977) provides the exact finite-sample distribution of any finite collection of induced order statistics, but even assuming bivariate normality does not yield a tractable form for this distribution.
9This is a limiting result and implies that the identities of the stocks with 27th and 45th percentile sizes will generally change as N increases.
10See Chamberlain (1983), Huberman and Kandel (1987), Lehmann and Modest (1988), and Wang (1988) for further discussion of exact factor pricing models. Examples of tests that fit into the framework of H are those in Campbell (1987), Connor and Korajczyk (1988), Gibbons, Ross, and Shanken (1989), Huberman and Kandel (1987), Lehmann and Modest (1988), and MacKinlay (1987).
11“In most contexts the consistency of  is with respect to the number of time series observations T. In that case something must be said of the relative rates at which T and N increase without bound so as to guarantee convergence of . However, under H the parameter
is with respect to the number of time series observations T. In that case something must be said of the relative rates at which T and N increase without bound so as to guarantee convergence of . However, under H the parameter  may be estimated cross-sectionally; hence, the relation
may be estimated cross-sectionally; hence, the relation  in (8.1.5) need only represent N-asymptotics.
in (8.1.5) need only represent N-asymptotics.
12In fact, this shows how our parametric specification may be relaxed. If we replace normality by the assumption that and Xi satisfy the linear regression equation

where Zi is independent of Xi, then our results remain unchanged. Moreover, this specification may allow us to relax the rather strong IID assumption since David (1981, Chapters 2.8 and 5.6) does present some results for order statistics in the nonidentically distributed and the dependent cases separately. However, combining and applying them to the above linear regression relation is a formidable task which we leave to the more industrious.
13In fact, if ρ2 = 1, the limiting distribution of is degenerate since the test statistic converges in probability to the following limit:

This limit may be greater or less than depending on the values of hence, ; the size of the test in this case may be either zero or unity.
14However, implicit in Table 8.2 is the assumption that the 's are cross-sectionally independent, which may be too restrictive a requirement for interesting alternative hypotheses. For example, if the null hypothesis αi = 0 corresponds to the Sharpe-Lintner CAPM, then one natural alternative might be a two-factor AFT In that case, the 's of assets with similar factor loadings would tend to be positively cross-sectionally correlated as a result of the omitted factor. This positive correlation reduces the benefits of grouping. Grouping by induced ordering does tend to cluster 's with similar (nonzero) means together, but correlation works against the variance reduction that gives portfolio-based tests their power. The importance of cross-sectional dependence is evident in MacKinlay's (1987) power calculations. We provide further discussion in Section 8.2.3.
15However, see Bhattacharya (1984) and Sen (1981).
16When n is large relative to a finite N, the asymptotic approximation breaks down. In particular, the dependence between adjacent induced order statistics becomes important for nontrivial n/N. A few elegant asymptotic approximations for sums of induced order statistics are available using functional central limit theory and may allow us to generalize our results to the more empirically relevant case. See, for example, Bhattacharya (1974), Nagaraja (1982a, 1982b, 1984), Sandström (1987), Sen (1976,1981), and Yang (1981a, 1981b). However, our Monte Carlo results suggest that this generalization may be unnecessary.
17Example of tests that fit into this framework are those in Campbell (1987), Connor and Korajczyk (1988), Gibbons (1982), Gibbons and Ferson (1985), Gibbons, Ross, and Shanken (1989), Huberman and Kandel(1987), Lehmann and Modest (1988), MacKinlay (1987), Stambaugh (1982), and Shanken (1985)
18Only those  for which
for which  will have zero expectation under the null hype thesis H.
will have zero expectation under the null hype thesis H.
19The correspondence between the two tables is not exact because the dependency intre duced in (8.2.9) induces cross-sectional heteroscedasticity in the 's; hence, ρ2 = 0.05 yields an R2 of 0.05 only approximately.
20our analysis is limited by the counterfactual assumption that the market model disturbances are cross-sectionally uncorrelated. But the simulation results presented in Section 8.2.3 indicate that biases are still substantial even in the presence of cross-sectional dependence. A more involved application would require a deeper analysis of cross-sectional dependence in the it's.
21See Lehmann and Modest (1988, Table 1, last row). Connor and Korajczyk (1988) report similar findings.
22 See for example, Banz (1981) and Brown, Kleidon, and Marsh (1983).
23 We recognize that correlation is not transitive, so if X is correlated with Y and Y with Z, X need not be correlated with Z. However, since the intercepts from the two regressions will be functions of some common random variables, situations in which they are independent are the exception rather than the rule.
24 Nor did Lehmann and Modest prior to their extensive investigations. If they are subject to any data-snooping biases it is only from their awareness of size-related empirical results for the single-period CAPM, and of corresponding results for the APT as in Chan, Chen, and Hsieh (1985)
25 Since Lehmann and Modest (1988) use weekly data, the null distribution of their test statistics is F5,240. In practice the inferences are virtually identical using the  distribution after multiplying the test statistic by 5.
distribution after multiplying the test statistic by 5.
26 In fact, if we denote by Yk the N × 1 vector containing values of characteristic k for each of the N securities, then the vector most highly correlated with (which we have called X) may be viewed as the concomitant YK:K of the Kth order statistic  . As in the scalar case, induced ordering does change the distribution of the vector concomitants.
. As in the scalar case, induced ordering does change the distribution of the vector concomitants.
27 That the squared correlation coefficients are IID Beta random variables follows from our assumptions of normality and the mutual independence of the characteristics and the 's [see Stuart and Ord (1987, Chapter 16.28) for example]. The distribution and density functions of the maximum follow directly from this.
28 Note that γ is only an approximation to the squared population correlation:

However, Monte Carlo simulations with 10,000 replications show that this approximation is excellent even for small sample sizes. For example, fixing K at 50, the correlation from the simulations is 22.82 percent for N = 25, whereas (8.4.5) yields γ = 20.47 percent; for N = 100 the simulations yield a correlation of 6.25 percent, compared to a γ of 5.39 percent.