Experimentation
Happy are they, remarked the Roman poet Virgil, “who have been able to perceive the causes of things.” How might psychologists sleuth out the causes in correlational studies, such as the correlation between breast feeding and intelligence?
Experimental Manipulation
Some researchers (not all) have found that breast-fed infants develop higher childhood intelligence scores than do bottle-fed infants—an average 3 IQ point difference in a review of 17 studies (Horta et al., 2015; von Stumm & Plomin, 2015; Walfisch et al., 2014). Moreover, the longer infants breast feed, the higher their later IQ scores (Jedrychowski et al., 2012; Victora et al., 2015).
What do such findings mean? Do the nutrients of mother’s milk contribute to brain development? Or do smarter mothers have smarter children? (Breast-fed children tend to be healthier and higher achieving than other children. But their bottle-fed siblings, born and raised in the same families, tend to be similarly healthy and high achieving [Colen & Ramey, 2014].) Even big data from a million or a billion mothers and their offspring couldn’t tell us. To find answers to such questions—to isolate cause and effect—researchers must experiment. Experiments enable researchers to isolate the effects of one or more factors by (1) manipulating the factors of interest and (2) holding constant (“controlling”) other factors. To do so, they often create an experimental group, in which people receive the treatment, and a contrasting control group that does not receive the treatment.
Earlier, we mentioned the place of random sampling in a well-done survey. Consider now the equally important place of random assignment in a well-done experiment. To minimize any preexisting differences between the two groups, researchers randomly assign people to the two conditions. Random assignment—whether with a random numbers table or flip of the coin—effectively equalizes the two groups. If one-third of the volunteers for an experiment can wiggle their ears, then about one-third of the people in each group will be ear wigglers. So, too, with age, attitudes, and other characteristics, which will be similar in the experimental and control groups. Thus, if the groups differ at the experiment’s end, we can surmise that the treatment had an effect. (Note the difference between random sampling—which creates a representative survey sample—and random assignment, which equalizes experimental groups.)
To experiment with breast feeding, one research team randomly assigned some 17,000 Belarus newborns and their mothers either to a control group given normal pediatric care or to an experimental group that promoted breast feeding, thus increasing expectant mothers’ breast intentions (Kramer et al., 2008). At three months of age, 43 percent of the infants in the experimental group were being exclusively breast-fed, as were 6 percent in the control group. At age 6, when nearly 14,000 of the children were restudied, those who had been in the breast-feeding promotion group had intelligence test scores averaging six points higher than their control condition counterparts.
With parental permission, one British research team directly experimented with breast milk. They randomly assigned 424 hospitalized premature infants either to formula feedings or to breast-milk feedings (Lucas et al., 1992). Their finding: On intelligence tests taken at age 8, those nourished with breast milk scored significantly higher than those who were formula-fed. Breast was best.

No single experiment is conclusive, of course. But randomly assigning participants to one feeding group or the other effectively eliminated all factors except nutrition. If a behavior (such as test performance) changes when we change an experimental variable (such as infant nutrition), then we infer the variable is having an effect.
The point to remember: Unlike correlational studies, which uncover naturally occurring relationships, an experiment manipulates a variable to determine its effect.
Procedures and the Placebo Effect
Consider, then, how we might assess therapeutic interventions. Our tendency to seek new remedies when we are ill or emotionally down can produce misleading testimonies. If three days into a cold we start taking zinc tablets and find our cold symptoms lessening, we may credit the pills rather than the cold naturally subsiding. In the 1700s, bloodletting seemed effective. People sometimes improved after the treatment; when they didn’t, the practitioner inferred the disease was too advanced to be reversed. So, whether or not a remedy is truly effective, enthusiastic users will probably endorse it. To determine its effect, we must control for other variables.

“If I don’t think it’s going to work, will it still work?”
And that is precisely how new medications and new methods of psychological therapy are evaluated (Modules 72 and 73). Investigators randomly assign participants in these studies to research groups. One group receives a treatment (such as a medication). The other group receives a pseudotreatment—an inert placebo (perhaps a pill with no drug in it). The participants are often blind (uninformed) about what treatment, if any, they are receiving. If the study is using a double-blind procedure, neither the participants nor those who administer the drug and collect the data will know which group is receiving the treatment. Thus neither participants’ or researchers’ expectations can bias the results.
In double-blind studies, researchers can check a treatment’s actual effects apart from the participants’ and the staff’s belief in its healing powers. Just thinking you are getting a treatment can boost your spirits, relax your body, and relieve your symptoms. This placebo effect is well documented in reducing pain, depression, and anxiety (Kirsch, 2010). Athletes have run faster when given a supposed performance-enhancing drug (McClung & Collins, 2007). Decaf-coffee drinkers have reported increased vigor and alertness—when they thought their brew had caffeine in it (Dawkins et al., 2011). People have felt better after receiving a phony mood-enhancing drug (Michael et al., 2012). And the more expensive the placebo, the more “real” it seems to us—a fake pill that costs $2.50 worked better than one costing 10 cents (Waber et al., 2008). To know how effective a therapy really is, researchers must control for a possible placebo effect.
Independent and Dependent Variables
 Flip It Video: Variables in Experiments
Flip It Video: Variables in Experiments
Here is a practical experiment: In a not yet published study, Victor Benassi and his colleagues gave college psychology students frequent in-class quizzes. Some items served merely as review—students were given questions with answers. Other self-testing items required students to actively produce the answers. When tested weeks later on a final exam, students did far better on material on which they had been tested (75 percent correct) rather than merely reviewed (51 percent correct). By a wide margin, testing beat restudy.
This simple experiment manipulated just one variable: the study procedure (reading answers versus self-testing). We call this experimental factor the independent variable because we can vary it independently of other factors, such as the students’ memories, intelligence, and age. These other factors that can potentially influence a study’s results are called confounding variables. Random assignment controls for possible confounding variables.
Experiments examine the effect of one or more independent variables on some measurable behavior, called the dependent variable because it can vary depending on what takes place during the experiment. Both variables are given precise operational definitions, which specify the procedures that manipulate the independent variable (the review versus self-testing study method in this experiment) or measure the dependent variable (final exam performance). These definitions answer the “What do you mean?” question with a level of precision that enables others to replicate the study. (See Figure 6.3 for the previously mentioned British breast-milk experiment’s design.)
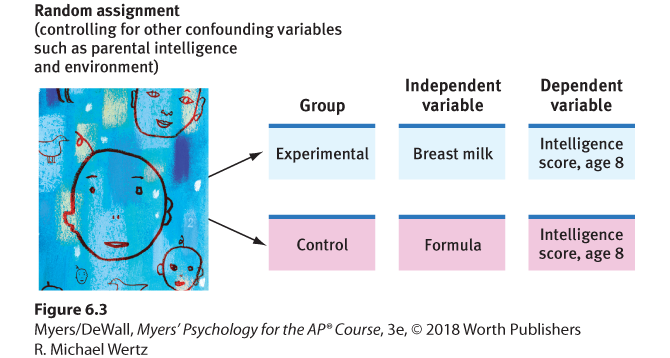
Figure 6.3 Experimentation
To discern causation, psychologists control for confounding variables by randomly assigning some participants to an experimental group, others to a control group. Measuring the dependent variable (later intelligence test score) will determine the effect of the independent variable (type of milk).
Let’s pause to check your understanding using a simple psychology experiment: To test the effect of perceived ethnicity on the availability of rental housing, researchers sent identically worded e-mail inquiries to 1115 Los Angeles–area landlords (Carpusor & Loges, 2006). The researchers varied the ethnic connotation of the sender’s name and tracked the percentage of landlords’ positive replies (invitations to view the apartment in person). “Patrick McDougall,” “Said Al-Rahman,” and “Tyrell Jackson” received, respectively, 89 percent, 66 percent, and 56 percent invitations. (In this experiment, what was the independent variable? The dependent variable?)6
“ [We must guard] against not just racial slurs, but . . . against the subtle impulse to call Johnny back for a job interview, but not Jamal.”
U.S. President Barack Obama, Eulogy for Clementa Pinckney, June 26, 2015
A key goal of experimental design is validity, which means the experiment will test what it is supposed to test. In the rental housing experiment, we might ask, “Did the e-mail inquiries test the effect of perceived ethnicity? Did the landlords’ response actually vary with the ethnicity of the name?”
Experiments can also help us evaluate social programs. Do early childhood education programs boost impoverished children’s chances for success? What are the effects of different antismoking campaigns? Do school sex-education programs reduce teen pregnancies? To answer such questions, we can experiment: If an intervention is welcomed but resources are scarce, we could use a lottery to randomly assign some people (or regions) to experience the new program and others to a control condition. If later the two groups differ, the intervention’s effect will be supported (Passell, 1993).
Let’s recap. A variable is anything that can vary (infant nutrition, intelligence, TV exposure—anything within the bounds of what is feasible and ethical to measure). Experiments aim to manipulate an independent variable, measure a dependent variable, and control confounding variables. An experiment has at least two different conditions: an experimental condition and a comparison or control condition. Random assignment works to minimize preexisting differences between the groups before any treatment effects occur. In this way, an experiment tests the effect of at least one independent variable (what we manipulate) on at least one dependent variable (the outcome we measure).