Incident Preparation
Any business use if IT resources will inevitably include responding to computer security incidents; in short, it’s not a matter of “if” an incident will occur, but “when.” Many sources (including books, web sites, and formal training courses) provide information on what type of information should be collected in an incident and resources (such as tools) that can be used to collect it.
However, in my role as an incident response consultant, I am continually surprised at how often in practice this type of preparation is not done. This chapter will reiterate the importance of preparation and the steps that can be taken both prior to and immediately following an incident to ensure the best response and analysis, whether those tasks are performed by internal IT staff, third-party consultants, or both.
Keywords
Immediate; incident; response
Information in This Chapter

Introduction
Much of what we read regarding incident response is that computer security incidents are a fact of life when we employ IT resources. It’s long been said that it’s not a matter of if your organization will experience a computer security incident, but when that incident will occur. If the media has made anything clear at all during the past several years, it’s that no organization is immune to computer security incidents, whether that’s a web page defaced, intellectual property copied, sensitive corporate emails exposed, or sensitive financial data compromised. Even computer security consulting firms have fallen victim to intrusions and breaches.
Most books on incident response discuss and demonstrate a variety of tools and techniques that are helpful (or even critical) in preparing for and responding to an incident, so these procedures should be both common knowledge and common practice. In reality, this is often not the case. When an incident does occur, responders—whether internal IT or incident response staff or third-party consultants that are called to respond—only have access to the data that is actually available. If a company has not prepared appropriately, they may not have access to critical data, may not know where sensitive information is stored, and may not know how to collect key time-sensitive data following the detection of an incident. This is true when internal staff is responsible for incident response, but is even more critical in cases where a company hires a third-party consulting firm to provide incident response services.
In such cases it can often take several days for the contracting process to run its course and for the responding consultants to actually get on a plane and travel to the customer’s site. Once they arrive, they usually have to go about determining the layout of the infrastructure they’re responding to, the nature of the incident, where critical assets are located, etc. All of this goes on while the upper level management of the organization is anxiously awaiting answers.
Given all of this, it behooves an organization to prepare for an incident and to be prepared to perform some modicum of response when those inevitable incidents are identified. In this chapter, we will discuss how organizations can better prepare themselves to respond to incidents, from the perspective of a consultant who has responded to incidents. The purpose of this is to ensure that response personnel—whether internal staff or third-party responders—have data that allows them to resolve the incident in a satisfactory manner. This chapter will not address overall infrastructure design, development of a complete computer security incident response plan (CSIRP), or “best practices” for network and system configuration, as all of these can require considerable thought, effort, and resources to implement in any environment; any book that tries to address all possible factors and configurations will not succeed. Rather, we will discuss some of the things that are easy for the local staff to do, that will have a considerable impact on improving incident response and resolution.
Being prepared to respond
As an incident responder, the vast majority of incidents I have seen have progressed in pretty much the same manner; our team would get a call from an organization that had been notified by an outside third party that an incident had occurred within their infrastructure, and during the initial call, we would ask the point of contact (PoC) a series of questions to determine the nature of the incident as best we could. Many times, those questions were met with the telephonic equivalent of blank stares, and in the extreme cases, due to the nature of the incident, with frantic requests to “just get someone here as fast as you can!” We would send responders on-site, based on what we knew about the incident, and by the time the responders made it on-site, little if anything had been done to prepare for their arrival. After introductions, the questions that had been originally asked on the telephone were asked again, and we (the responders—most often, just one person) had to work with local IT staff in order to develop an understanding of the network infrastructure and traffic flows, as well as the nature of the incident itself. Many times, much of the information (network maps, etc.) wasn’t available, or the people who knew the answers to the questions weren’t available, and considerable time could be spent trying to simply develop a clear and accurate picture of what had been reported or identified, and what had happened. This was never a quick process, and sometimes we would simply have to start arbitrarily collecting and analyzing data, which also takes time and in some cases, would prove to be fruitless in the long run, as the systems from which the data was collected were later found to not have been involved in the incident.
While the scenario I’ve described involved the use of outside consulting help, the situation is not all that different from what might occur with internal responders whenever an organization is not prepared to respond. Sounds pretty bad, doesn’t it? So you’re probably wondering, what’s my point? Well, my point is that the clock doesn’t start ticking once an organization becomes aware of an incident; in fact, it’s already been ticking by that point, we just don’t know for how long as the incident may have occurred well before it was identified or reported. And when it comes to incident response and digital forensic analysis, a great deal of what can (or can’t) be determined about the incident is predicated on time; that is, how much time has passed between when the incident occurred and when pertinent data is collected and analyzed.
Several years ago at a SANS Forensic Summit, Aaron Walters (the creator of the Volatility Framework) used the term “temporal proximity” to describe this gap between the incident and response, and really brought to light just how critical time is with respect to incident response. Why is time so important? Consider what occurs on a live Windows system, even when it sits idle; there’s actually quite a lot that goes on “under the hood” that most of us never see. Processes complete, and the space (bytes) used by those processes in memory is freed for use by other processes. Deleted files are overwritten by native, “organic” processes that are simply part of the operating system (i.e., the creation and deletion of System Restore Points on Windows XP and Volume Shadow Copies on Vista and Windows 7). On Windows XP systems, a System Restore Point is created by default every 24 hours, and often one may be deleted, as well. In addition, every three days a limited defragmentation of selected files on the hard drive occurs. On Windows 7 systems, not only are Volume Shadow Copies created and deleted, but every 10 days a backup is made of the main Registry hives. Windows systems are typically configured to automatically download and install updates; many common desktop applications (Adobe Reader, Apple’s Quicktime application, etc.) provide the same functionality. In short, whether you see it or not, a lot of activity occurs on Windows systems even when a user isn’t interacting with it. As such, as time passes, information that would give clear indications as to the extent of what occurred begins to fade and be obscured, and is finally simply no longer available. Given this, it is absolutely critical that those most capable of performing immediate incident response actually do so. As it can be some time before the scope of the incident and the need for assistance is really realized, it is critical that the local IT staff be able to react immediately to collect and preserve data.
Members of the military are well acquainted with incident response. Soldiers and Marines are trained in basic first aid procedures so that they can assist themselves or a buddy until more suitable medical response is at hand. They can respond immediately and apply bandages or a tourniquet to keep their buddy alive. Sailors are trained in damage control procedures so that they can respond to any issues impacting their ship, contain it, and keep the ship afloat until they can reach a safe port. Data available from annual reports illustrates that organizations would do well to take a similar approach, detecting and then immediately and decisively responding to incidents.
Questions
Once an incident has been detected, everyone has questions. Senior management most often wants to know how the intruder or malware got into the network, what data was taken, where it went, and the risk to which the organization may be exposed, and they want to know it immediately. The nature of the compromised data—and any legal, regulatory, or reporting requirements associated with it—is often of great concern to legal counsel and compliance staff, as well. Something to keep in mind is that there is often a significant gap between business needs during an incident, and the deeply technical information, the 1s and 0s, that responders tend to immerse themselves in. Therefore, it is critical for incident response staff to understand the types of questions that will be asked by key stakeholders in the company, so that the data collection and analysis process can answer those questions—especially when failure to do so may result in significant legal or financial penalties being incurred by the organization.
If an outside consulting firm is called to provide emergency incident response, they will also have a number of questions, and how fast they respond and who they send will be predicated on the responses to those questions. These questions are often technical, or the answers that are being looked for are more technical than the PoC is prepared to provide. Examples of these questions can include such things as how many systems and locations are impacted, what operating systems (i.e., Windows, Linux, AS/400) and applications are involved, etc. As such, an organization can greatly facilitate both the response time and efficiency by having detailed information about the incident (or the personnel most able to provide that information) available for those preliminary discussions.
Third-party consulting firms are often contacted to perform emergency incident response for a variety of reasons. Perhaps the biggest reason is that while the internal IT staff is technically skilled at maintaining systems, applications, and the overall infrastructure, they do not possess the investigative experience and expertise in order to address the incident. While they may be able to troubleshoot an MS Exchange server issue or set up an Active Directory, they aren’t often called upon to dump physical memory from a live Windows system and determine if there is any malware on that system. Another reason is that any investigation performed by the local IT staff may be viewed as being skewed in favor of the company, in a sort of “fox guarding the hen house” manner, and as such, the final answers to the questions being asked may be suspect. It is important to keep in mind that when a third-party consulting firm is called, they will ask you a number of questions, usually based on their experience responding to a wide range of incidents (malware, intrusions, data breaches, etc.) in a wide range of environments. And these will often be questions the local IT staff hadn’t thought of, let alone experienced before, as they come from an entirely different perspective.
For example, the IT manager may “know” that a system (or systems) is infected with malware or has been compromised by a remote intruder, but the consultant on the other end of the phone is likely going to ask questions in order to better understand how the IT manager came to this understanding. The best thing to do is to ensure that those employees who have the necessary information to accurately respond to these questions are available, and to respond without making assumptions regarding where you think the questions may be leading. Consultants may have a much different breadth of experience than an IT manager, and responding with assumptions as to where the consultant may be taking their questions can take the response itself offtrack and lead to delays. If the organization was notified of the incident by an external entity, it is best to have the employee who took the call, as well as any other staff who may have engaged with the caller (legal counsel, etc.) available to answer questions. For more technical questions regarding the affected systems and the network infrastructure, having the appropriate employees available to respond to questions can be very valuable.
The consulting firm will use your responses to scope the incident. They will also use the responses to determine which skill sets are necessary to respond to the incident, who to send, and how many consultants they will need to send in order to resolve the incident in a timely manner. If accurate information is not available, too many responders may be sent, incurring addition cost for travel and lodging up front, or too few responders may be sent, which would incur not only additional costs (for travel, lodging, labor, etc.) but would also lead to delays in the overall response.
The importance of preparation
Did you see the first “Mission: Impossible” movie? After Ethan’s (Tom Cruise’s character) team is decimated, he makes his way back to a safe house. As he approaches the top of the stairs in the hotel, he takes off his jacket, takes the light bulb out of the fixture in the hallway, crushes the bulb in his jacket and spreads the shards in the now-darkened hallway as he backs toward the door, covering the only means of approach to his room. Does what he did make sense? He knew that he couldn’t prevent someone from approaching his location, but he also knew that he could set up some sort of measures to detect when someone was approaching, because as they entered the darkened hallway, they wouldn’t see the glass shards on the floor, and they’d make a very distinctive noise when they stepped on them, alerting him to their presence. And that’s exactly what happened shortly thereafter in the movie.
Let’s take a look at some examples of how being prepared can affect the outcome of an incident. In my experience as an emergency incident responder, the way the response process (internal to an organization) works has usually been that someone becomes aware of an incident, perhaps does some checking of the information they receive, and then calls a company that provides emergency computer security incident response services for assistance. Many times, they feel that the information they’ve received could be very credible, and (rightly so) they want someone on-site to assist as soon as possible. From that point, depending upon the relationship with the consulting company, it can be anywhere from 6 to 72 hours (or more) before someone arrives on-site.
For example, I’ve worked with customers in California (I’m based on the east coast) and told them, if you call me at 3 pm Pacific Standard Time, that’s 6 pm Eastern Standard Time—the earliest flight out is 6 am the next day, and it’s a 6-hour flight, depending upon the location in California. At that point, I wouldn’t be on the ground at the remote airport until 18 hours after you called, assuming that there were no issues with getting the contract through the approval process, flight delays, and a direct flight was available. Once I arrive at the destination airport, I have to collect up my “go kit” (Pelican case full of gear weighing 65 lbs or more), get to the rental car agency and drive to your location (I’ve been on engagements where the site was a 2-hour drive from the airport). Once I arrive on-site, we have to get together and try to determine the scope of the incident, hoping that you have the appropriate staff available to address the questions I will have. I have responded to assist organizations that used part-time system administration staff, and the next scheduled visit from the system administrator was two days after I arrived on-site. As you can see, even under ideal conditions, it can be 24 hours or more before any actual incident response activities begin.
Now, most times when would I arrive on-site, considerable work would need to be done in order to determine the nature and range of the incident and figure out which systems were affected, or “in scope.” (Note that this is an essential step, whether performed by outside consultants or your own internal staff.) When the incident involved the potential exposure of “sensitive data” (regardless of the definition you choose), there may have been a strong indication that someone had accessed the infrastructure and gained access to some sensitive data; what this means is that someone with no prior knowledge of the network infrastructure may have accessed it remotely and found this sensitive data (i.e., database or files containing credit card data or transaction information, personally identifiable information, medical records). As such, when trying to scope the incident, one of the first things I (and most responders) ask is, where does the data in question reside? Very often, this is not known, or not completely understood.
As a result, considerable time can be spent trying to determine the answers to the questions responders ask prior to as well as once they arrive on-site. It is important that these questions be answered accurately and in a timely manner, as responders usually arrive on-site after a contract is signed, and that contract often includes an hourly rate for that responder, or responders. The sooner incident response activities can commence, with accurate information, the less expensive those incident response activities are going to be in the long run. Where internal staff is performing response, these time delays may not translate (directly) into dollars spent on outside help; but any delay will still postpone the identification and collection of relevant data, perhaps to the point where the data is degraded or lost completely.
This is not to say that all organizations I’ve responded to are not prepared for a computer security incident, at least to some extent. During one particular engagement, I arrived on-site to find that rather than having an active malware infection, the IT staff had already responded to and removed the malware, and the IT manager was interested in having me validate their process. In fact (and I was very impressed by this), the staff not only had a documented malware response process, but they also had a checklist (with check boxes and everything) for that process, and I was handed a copy of the completed checklist for the incident. Apparently, once the first malware infections were found on several desktops within their infrastructure, the IT staff mobilized and checked other systems, found several infected systems in various departments (finance, billing, HR, etc.), and removed those infections from the systems. Unfortunately, there were no samples of the malware left to be analyzed, and all we had left was the completed checklist which included a name used by an antivirus (AV) vendor to identify the malware.
Now, something else that I did find out about this incident was that during a staff meeting following the response to the incident, the IT manager had announced proudly that his team had reacted swiftly and decisively to remove this threat to the infrastructure—at which point, corporate counsel began asking some tough questions. It seems that several of the systems were in departments where very sensitive information was stored and processed; for instance, the billing department handled bank routing information, and the HR and payroll departments handled a great deal of sensitive personal information about the company employees. As such, an infection of malware that was capable of either stealing this information or providing an attacker with access to that information posed significant risk to the organization with respect to various regulatory bodies. In addition, there were legislative compliance issues that needed to be addressed. It seems that the IT department had put a great deal of effort into developing their malware response process, but had done so in isolation from other critical players within the organization. As such, there was a chance that the organization may have been exposed to even more risk, as many regulatory and legislative compliance policies state that if you can’t identify exactly which records (personally identifiable information, PCI information, etc.) were accessed, you must notify that regulatory body that all of the records could have been exposed. As the malware had simply been eradicated and no investigation of any kind had been conducted (root cause or otherwise), there was no information available regarding what data could have been accessed, let alone what (if any) data was actually accessed or exfiltrated from the infrastructure.
Now and again, I have had the opportunity to work with an organization that has taken great pains and put a lot of effort toward being prepared for those inevitable incidents to occur. I had another response engagement where as soon as I had arrived on-site and completed my in-brief, I was ushered to a room (yes, they provided me with a place to work without my having to ask!) where there were a dozen drives stacked up on a desk, along with a thumb drive and manila folder. It turns out that while the IT director was calling my team for assistance, his staff was already responding to the incident. They had collected and reviewed network logs and identified 12 affected systems, and replaced the drives in those systems—I was looking at the original drives sitting on the desk. The thumb drive contained the network logs, and the folder contained a print out of the network map (there was a soft copy on the thumb drive). With all of this, I began imaging the provided hard drives and reviewing the logs.
The incident that they’d experienced involved someone gaining unauthorized access to their infrastructure via Microsoft’s Remote Desktop Protocol (RDP). They allowed employees to work from remote locations, requiring them to access the infrastructure via a virtual private network (VPN) and then connect to specific systems on the internal infrastructure via RDP. As such, they had VPN and domain authentication logs, as well as logs that clearly demonstrated the account used by the intruder. They had used these logs to identify the 12 systems that the intruder had connected to via the VPN, which corresponded to the 12 hard drives I was imaging. Their response was quick and decisive, and their scoping and analysis of the initial incident was thorough. They had also mapped exactly where, within their infrastructure, certain data existed. In this case, their primary concern was a single file, a spreadsheet that contained some sensitive data that was not encrypted.
The intruder had apparently connected to the VPN and used a single account to access the 12 internal machines using RDP. Once I began analyzing the drive images, it was a relatively straightforward process to map his activities across the various systems. As a result of this analysis, I was able to identify an additional 13 systems that had been accessed internally, via lateral inside the network. As these accesses were internal, indicators were not found within the VPN logs but were visible due to the fact that a profile for the user account the intruder was using was created on each system they accessed (on Windows systems, a user account—either local or a domain account—can be created, but a profile will not be created until the first time the user logs in via that account). I was also able to identify many of the actions that the intruder performed while accessing the various systems and when those actions occurred. These activities included running searches and accessing various files. However, none of the accessed files were spreadsheets, and specifically not the spreadsheet with which the IT director was most concerned. Ultimately, we were able to build a very strong case to present to the regulatory body that indicated that the sensitive data had not been accessed or exposed.
Logs
Throughout this book and in particular in Chapter 4, we will discuss logs that are available on Windows systems, both as part of the operating system and through applications installed on those systems. The two primary concerns during an incident with respect to logs are, where are they located and what’s in them—both of which can have a significant impact on the outcome of your incident response activities. Logs often play a significant role in incident response because as mentioned previously, response happens after an incident occurs, and sometimes this can be a significant amount of time. The state of live systems can change pretty quickly, but logs can provide a considerable historical record of previous activity on the system —if they are available.
One of the challenges of responding to incidents, whether as a consultant or an internal employee, is not having the necessary information to accurately and effectively respond to the questions your customer (or management) has regarding the incident, and therefore not being able to provide an accurate picture of what happened. Most organizations don’t maintain full packet captures of what happens on their networks, and even if they did, this would still only be part of the picture, as you would still need to know what happened or actions were taken on the host. Windows systems have the ability to maintain records of what occurred on the host via the Event Logs (on Vista and Windows 7 systems, this is referred to as “Windows Event Logging”; Event Logs are discussed in more detail in Chapter 4); however, a number of times I have referred to the Event Logs only to find that either the specific events (i.e., logins) were not being audited, or Event Logging was not even enabled. This limits not just what data is being recorded but also how complete a picture an analyst can develop, and how effectively they can respond and answer the critical questions that are being asked by senior management. As such, one of the most effective steps in incident preparedness is to understand the logging mechanisms of your systems. A critical step that you can take quickly (and for free) to improve what information will be available when an incident is identified is to ensure that logging is enabled, that appropriate activities are being logged, and that the logs are large enough (or rotated often enough) to ensure sufficient data is available after an incident—which may be identified 6 or 12 months or more after the fact.
For example, Windows Event Logs have several characteristics that can be modified in order to enable more effective logging. One characteristic is the file size; increasing the size of the Event Logs will mean that more events will be recorded and available for analysis.
Another characteristic is what is actually being recorded. Recording successful and failed login attempts can be very useful, particularly in domain environments, and on servers or other systems which multiple users may access. In one analysis engagement, we found a considerable amount of extremely valuable data in the Event Log because “Process Tracking” had been enabled, along with auditing of successful (and failed) login attempts, as illustrated in Figure 2.1.
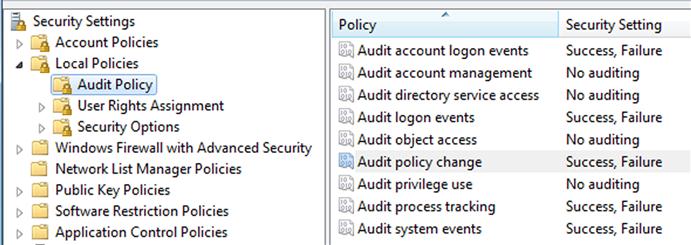
The actual settings you employ within your infrastructure depend heavily on what makes sense in your environment. Enabling auditing for success and failure process tracking events is very useful, as some processes run and complete very quickly, and are no longer visible mere seconds after they were launched. Enabling this auditing capability, as well as increasing the size of the logs (or, better yet, forward the logs from source systems to a collector system, per the instructions for Windows 7 and higher systems found online at http://technet.microsoft.com/en-us/library/cc748890.aspx), will provide a persistent record of applications that have been executed on the system. Something to keep in mind when enabling this auditing functionality on servers as well as workstations is that, for the most part, there aren’t a great number of processes that are launched on a Windows system. For example, once a server is booted and running, how many users log into the console and begin browsing the web or checking their email? Administrators may log in and perform system maintenance or troubleshooting, but for the most part, once the server is up and running, there won’t be a considerable amount of interaction via the console. Also, on workstations and laptops, users tend to run the same set of applications—email client, web browser, etc—on pretty much a daily basis. As such, enabling this functionality can provide information that is invaluable during incident response.
There are other things you can do to increase both the amount and quality of information available from Windows systems during incident response. Some commercial products may offer additional features such as increased logging capabilities, log consolidation, or log searching. For example, Kyrus Technology, Inc. (http://www.kyrus-tech.com) has developed a sensor application called “Carbon Black” that is installed on Windows systems and monitors application execution on that system, sending its logs to a server for consolidation. That server can be maintained within the corporate infrastructure, or (for much smaller infrastructures) you can send the logs offsite to a server managed by the vendor. As of this writing, Carbon Black version 3 is available online at http://www.carbonblack.com/.
Carbon Black is a lightweight (less than 100 kilobytes in size) sensor that you can install on Windows systems that you want to monitor. The sensor monitors the execution of applications, including child processes, file modifications, and loaded modules (as of this writing; future versions of Carbon Black will also record Registry key modifications and network connections). Carbon Black also records the MD5 hash of the executable file, as well as the start and end time for the process, and will provide a copy of the binary executable file, as well. All of these elements can also be searched within the logged information available via the server. A portion of the information available via the Carbon Black server is illustrated in Figure 2.2.

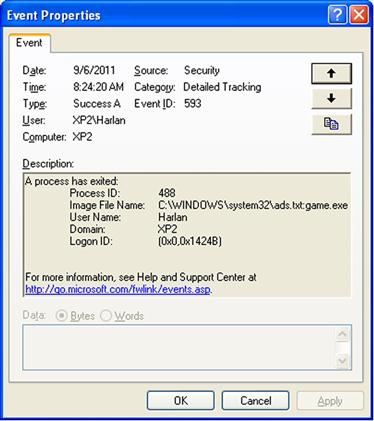
Again, this information can be extremely useful during incident response. As an example of this, and to get a little more familiar with what the data collected by Carbon Black looks like, I logged into a monitored Windows XP system (on my own internal “lab network”) and created a “suspicious” application by copying the Solitaire game file (sol.exe) into an NTFS alternate data stream (ADS) attached to a file named “ads.txt.” I then launched the game by typing “start.\ads.txt:game.exe” at the command prompt. Having already enabled Process Tracking within the audit policy for the system, I opened the Event Log on the system and found the event record that illustrated the application being launched. This record (event ID 593 indicates that the process has exited) is illustrated in Figure 2.3.
I then logged into the system to which the Carbon Black logs are sent, and accessed the user interface via the Chrome web browser (any web browser could have been used). I was able to quickly locate the log entry for the “suspicious” process, and even search for it based on the fact that I knew it was a child process of the “cmd.exe” process. The Carbon Black log entry is illustrated in Figure 2.4.

For the process illustrated in Figure 2.4, the exit time (although not displayed) correlated exactly with what is illustrated in the Event Log record in Figure 2.3. Now, this example was a bit contrived, in that it was a test and I knew what I was looking for via the Carbon Black interface. However, an analyst can use regular expressions as well as other search criteria (times, “new” processes, names of modified files, etc.) to locate potentially suspicious processes. Other search criteria can be used, such as the loaded modules (locate processes that have loaded a specific module, or DLL), MD5 hashes (of processes or loaded modules), and even file modifications. Figure 2.5 illustrates the results of a search for file modifications that include “ads.txt,” via the Carbon Black interface.

As you can see, Carbon Black can be a powerful tool for use during incident response, and can be used to very quickly determine the extent and scope of an incident across monitored systems. Using various search criteria, a suspicious process can be found, and its source can quickly be identified (i.e., following the parent processes for a suspicious process leads to java.exe and then to firefox.exe might indicate a browser drive-by compromise). From there, additional searches can reveal any other systems that may have experienced something similar. While Event Logs may “roll over” and new entries push out older ones, the information logged by Carbon Black can be available for a much longer period of time, going back much farther into the past. Once monitoring of network connections has been added to the sensor, an analyst can search across all of the logs to see any other monitored systems that may have attempted to establish connections to a particular IP address, or created a specific Registry key (the significance of this will be a bit more clear once you read Chapter 6). That said, it’s important to note that while Carbon Black is a great tool, its functionality and flexibility are based upon the fact that logging is configured, appropriate logging is occurring, and log data is being collected and preserved. These same principles apply whether you choose to use an add-on commercial product or native Windows functionality and tools.
Carbon Black (and other logging tools or products) may also have uses beyond incident response. One example of how Carbon Black has been used was in an organization that determined which components of the Microsoft Office Professional suite were being used by its employees, and that information was then used to reduce the overall corporate license for the software suite, saving the organization a significant amount of money on an annual basis.
Data collection
In addition to your preincident preparation, your response team needs to be prepared to begin collecting critical and / or volatile data once an incident is detected. The main purpose of immediate response is the timely collection of data. It is of paramount importance that IT staff who work with your systems on a regular basis also be trained so that they can begin collecting data from those systems soon after an incident is identified. Processes—particularly malicious processes—often do not run continually on systems. These processes may execute only long enough to perform their designated task, such as downloading additional malware, collecting the contents of Protected Storage from the system, or sending collected data off of the system to a waiting server. Malicious processes that may run on a continual basis include such things as packet sniffers and keystroke loggers.
However, it is unlikely that you will see continuous, ongoing malicious activity on your system. An intruder that has compromised your infrastructure does not go to one system, open a browser, and spend hours surfing the Failblog.org website. In fact, in a good number of instances, executables may be downloaded to a system, run, the data those processes collect sent off of the system to a waiting server on the Internet, and then the executables and their repository files are deleted. Of course, following this, the first forensic artifacts to decay are the network connections, and then as the system continues to function, MFT entries for the deleted files get reused, as do sectors on the disk that were once part of the files of interest. Therefore, collecting data as soon as the incident is identified can go a long way toward aiding the follow-on incident response and analysis efforts. In fact, with the proper procedures in place, having specific personnel implement a documented procedure for collecting data can obviate the need to do so later—such as days later (or longer), once the third-party responders arrive on-site.
During immediate response, the first data that you will want to collect is the contents of physical memory. When collecting memory from live Windows systems, perhaps the easiest (and free) approach is the DumpIt utility from MoonSol (found online at http://www.moonsols.com/ressources/). DumpIt is a simple to employ application written by Matthieu Suiche; simply place a copy of the application on a thumb drive or external USB drive enclosure, and launch the application from the command prompt. You will be asked a confirmation question, and once you respond with “y,” a raw dump of memory will be created on the media (therefore, the media needs to be writeable), as illustrated in Figure 2.6.
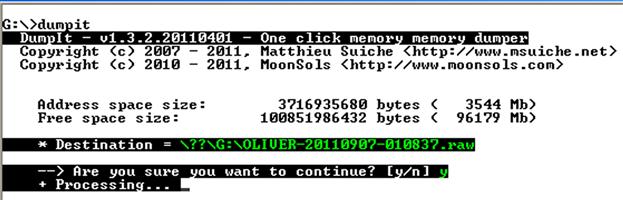
When the process completes, the word “Success” appears in green following “Processing…”. The resulting file (in this example “Oliver-20110907-010837.raw”) is named using the system name (“Oliver”) and the UTC time at which the process was initiated; in this case, the date and time in the filename correlate to 9:08 pm on September 6, 2011, Eastern Standard Time. What this means is that physical memory can be collected from multiple systems, or even multiple times from the same system, very easily and without having to use additional media. In fact, it’s so easy that all you have to do is have a copy of DumpIt on a couple of USB external drives (or appropriately sized thumb drives), and you’re ready to go. The sooner memory is collected after an incident has been identified, the better. Over time, not only do processes complete, but systems can be rebooted, or even taken out of service, and once the memory is gone, it’s gone.
Collecting the contents of physical memory is just the start, however. Other freely available options for collecting the contents of physical memory include (but are not limited to) FTK Imager (found online at http://accessdata.com/support/product-downloads#), the Volatility winpmem tool (found online at https://volatility.googlecode.com/svn/branches/scudette/docs/pmem.html), or the BelkaSoft RAM-Capturer tool (found online at http://forensic.belkasoft.com/en/ram-capturer).
You can also use FTK Imager to collect copies of specific files from the system (MFT, Registry hives, Windows Event Logs, etc.), or initiate logical or full physical image acquisition from those systems, in fairly quick order.
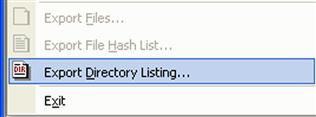
For example, a great deal of analysis work can be performed rather quickly using a partial acquisition (rather than acquiring a full image) of data from a live system. Adding FTK Imager Lite to a USB external hard drive (often referred to as a “wallet” drive due to the size) will provide suitable storage space for acquired images and files in a small form factor, and when needed the drive can be connected to a system and FTK Imager launched. The IT staff member performing the acquisition can then choose to add either the physical drive of the system, or the logical volume for the C:\ drive (depending upon the response plan that’s already been established and documented within the organization). From there, a directory listing that includes the last modified, last accessed, and creation dates (from the $STANDARD_INFORMATION attribute in the MFT; see Chapters 4 and 7 for more detail) for all files within the selected volume (as well as their paths) can easily be exported to the storage media using the “Export Directory Listing…” functionality, as illustrated in Figure 2.7.
Once the directory listing has been exported, specific files can then be exported through FTK Imager, allowing for rapid analysis and assessment of the state of the system. These files may include such files as Registry hives, Event Logs, Prefetch files, Jump Lists (Windows 7), application (Scheduled Task, AV, etc.) log files, etc.
Training
In order for employees to perform their jobs effectively, they must be trained. Payroll and accounting staffs within organizations have training to attend, and then return to their organization and begin working in their field. The same is true with a lot of other departments within your business, as well as with professionals in other areas (emergency medical technicians, police officers, firefighters, doctors, nurses, etc.). Many organizations offer a variety of types of training to their employees, often ranging from the use of office suite applications, to professional development, and even basic first aid.
The same must also be true for those individuals responsible when an incident is identified by the organization. It does no good to have a CSIRP, but to not have designated staff trained in their activities when the plan needs to be implemented. Several regulatory bodies state that in order to be compliant (all “compliance vs. security” arguments aside), organizations subject to the regulations must not only have a CSIRP with all response personnel identified within the plan, but they must also receive annual training with respect to the CSIRP and the actions they are to take.
Running an exercise during which the CSIRP is tested or taken for a “shake-down cruise” (please excuse the naval vernacular, as I’m a former Marine officer) should include actually collecting the data that you’ve decided will be collected. Are you going to collect memory from Windows systems, and if so, how? Will it work? Challenges I’ve encountered include older systems with USB version 1.0 interfaces, which usually result in processes that should take a short time ultimately taking an inordinate amount of time to complete. How will you address such situations, and have you identified all of the pertinent systems that may have this issue (regardless of the issue)? How will you address virtual systems? How will you collect data from production systems that cannot be “taken down” (due to service level agreements, transaction processing, etc.)? All of these questions (and likely more) need to be addressed before an incident occurs; otherwise, critical, sensitive data will continue to be lost (either exfiltrated or degraded) while managers and staff members try to decide how to react.
Business models
So far in this chapter, I’ve loosely addressed business models from the perspective of the organization facing the incident, and hopefully been able to convince you, the reader, to some degree of the need for immediate response.
Much of the way that I’ve seen incident response “done” is akin to someone getting hurt, and then calling and waiting for a surgeon to arrive. What I mean is that an organization becomes or is made aware that they may have been subject to a breach or intrusion, and they call an incident response team for assistance, and do nothing until that team arrives on-site. This is what I refer to as the “classic emergency response service (ERS)” model. And as we’ve covered in this chapter thus far, it’s not a particularly good or useful model, especially for the customer.
Why do I say that? Well, one of the things you see with the military is that soldiers and Marines are trained in basic first aid procedures, so that if they or a buddy become injured, they can provide immediate aid and assist their buddy until a medic or corpsman (someone with more specialized training) arrives. Navy sailors are trained in damage control, so that if anything should happen while the ship is at sea, they can respond immediately to an incident, contain and mitigate the risk, allowing the ship to remain afloat and make it to port of repairs. I can go on and on with more examples, but my overall point is that for years, and even to some degree now, incident response models have been based on organizations calling incident responders for help and waiting for them to arrive, while doing little to address the issue. Or worse, someone within the organization takes steps (running AV scans, wiping systems, etc.) that while attempting to address the incident, have simply made matters worse by eradicating crucial information that could be used to determine the extent of the incident. This is what I refer to as the “classic ERS” model of incident response.
Let’s take a look at the other side of the coin. We’ve already discussed some of the costs associated with this model from the perspective of the organization that experienced the incident. From a consulting perspective, staffing a bench for the classic ERS model is difficult. How many analysts do you have available? Remember, the classic ERS model of incident response is sporadic—you have to wait for someone to call you for assistance, all while your sales and marketing function are “putting the word out” that this is what you do. If you have too many analysts on your bench, you’re paying their salaries while you have no incoming work; if you have too few analysts, the ones you do have will be run at a high “burn rate” (meaning that they will be on the road a great deal) and you will likely be turning down work due to not having anyone available to send on-site. Do this too many times, and word gets around. This model can be very expensive for the consulting firm, and as such, that expense needs to be made up when work does become available.
So, why do we continue with this model? Why not move on to something new, something better? We understand the need for immediate response by this point in the chapter, and we also have an understanding that there’s nothing “immediate” about the classic ERS model of incident response. Many organizations are subject to some sort of compliance regulations that state that they must have an incident response capability; for example, the PCI Data Security Standards (DSS) Chapter 12.9 states that the organization will maintain an incident response plan and be prepared to respond immediately to an incident. The best way to do that is to develop a relationship with “trusted advisor,” or a consulting firm that can help guide you down the path to creating that capability, and will then be available to provide assistance, when needed. Incident response then becomes “immediate,” as the initial responders are those who work with and maintain the infrastructure on a daily basis. This not only assists in the detection of incidents, but you get the added benefit of having your responders right there, with no travel required—and last minute plane tickets are expensive. Local IT staff trained in incident response can immediately begin collecting and analyzing data, and even begin containing and remediating the incident.
Summary
When an incident is identified within an organization, it is critical that local IT staff be trained and knowledgeable in collecting pertinent data from Windows systems. Considerable time (hours, days, etc.) may pass before third-party consultants arrive on-site to begin performing incident response activities, and even then, the fact that they are not familiar with the organization’s infrastructure can extend the overall response time. Being prepared for those inevitable computer security incidents to occur, simply by having documentation, as well as network and system data, available will make a significant difference in the ultimate outcome of the incident. This will be true regardless of whether an incident or data breach needs to ultimately be addressed a compliance oversight body, or by law enforcement interested in intelligence or evidence to pursue prosecution. Properly trained local IT staff can immediately collect data that would otherwise expire or be unavailable hours or days later. Local responders should be able to collect the contents of physical memory, as well as partial, logical or complete physical images from systems, and have that data ready and documented for the analysis effort that inevitably follows data collection.