5.1 A Simple Example of Solving Tensor Network Contraction by Eigenvalue Decomposition
As discussed in the previous sections, the TN algorithms are understood mostly based on the linear algebra, such as eigenvalue and singular value decompositions. Since the elementary building block of a TN is a tensor, it is very natural to think about using the MLA to understand and develop TN algorithms. MLA is also known as tensor decompositions or tensor algebra [1]. It is a highly inter-disciplinary subject. One of its tasks is to generalize the techniques in the linear algebra to higher-order tensors. For instance, one key question is how to define the rank of a tensor and how to determine its optimal lower-rank approximation. This is exactly what we need in the TN algorithms.
![$$\displaystyle \begin{aligned} \begin{array}{rcl} \text{Tr} \mathscr{M} = \text{Tr}(M^{[1]} M^{[2]} \cdots M^{[N]}) = \text{Tr} \prod_{n=1}^{N} M^{[n]}, {} \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ1.png)
Allow us to firstly use a clumsy way to do the calculation: contract the shared bonds one by one from left to right. For each contraction, the computational cost is O(χ 3), thus the total cost is O(Nχ 3).



 for a > 0. It means all the contributions except for the dominant eigenvalue vanish when the TN is infinitely long. What we should do is just to compute the dominant eigenvalue. The efficiency can be further improved by numerous more mature techniques (such as Lanczos algorithm).
for a > 0. It means all the contributions except for the dominant eigenvalue vanish when the TN is infinitely long. What we should do is just to compute the dominant eigenvalue. The efficiency can be further improved by numerous more mature techniques (such as Lanczos algorithm).5.1.1 Canonicalization of Matrix Product State
Before considering a 2D TN, let us take some more advantages of the eigenvalue decomposition on the 1D TN’s, which is closely related to the canonicalization of MPS proposed by Orús and Vidal for non-unitary evolution of MPS [2]. The utilization of canonicalization is mainly in two aspects: locating optimal truncations of the MPS, and fixing the gauge degrees of freedom of the MPS for better stability and efficiency.
5.1.2 Canonical Form and Globally Optimal Truncations of MPS
As discussed in the above chapter, when using iTEBD to contract a TN , one needs to find the optimal truncations of the virtual bonds of the MPS . In other words, the problem is how to optimally reduce the dimension of an MPS.
 that has one big physical and one virtual index. Another matrix denoted as
that has one big physical and one virtual index. Another matrix denoted as  can be obtained by doing the same thing on the right hand side. The conjugate of R is taken there to obey some conventions.
can be obtained by doing the same thing on the right hand side. The conjugate of R is taken there to obey some conventions.
An impractical scheme to get the global optimal truncation of the virtual bond (red). First, the MPS is cut into two parts. All the indexes on each side of the cut are grouped into one big index. Then by contracting the virtual bond and doing the SVD , the virtual bond dimension is optimally reduced to χ by only taking the χ-largest singular values and the corresponding vectors

In practice, we do not implement the SVD above. It is actually the decomposition of the whole wave-function, which is exponentially expensive. Canonicalization provides an efficient way to realize the SVD through only local operations.


The MPS with two-site translational invariance




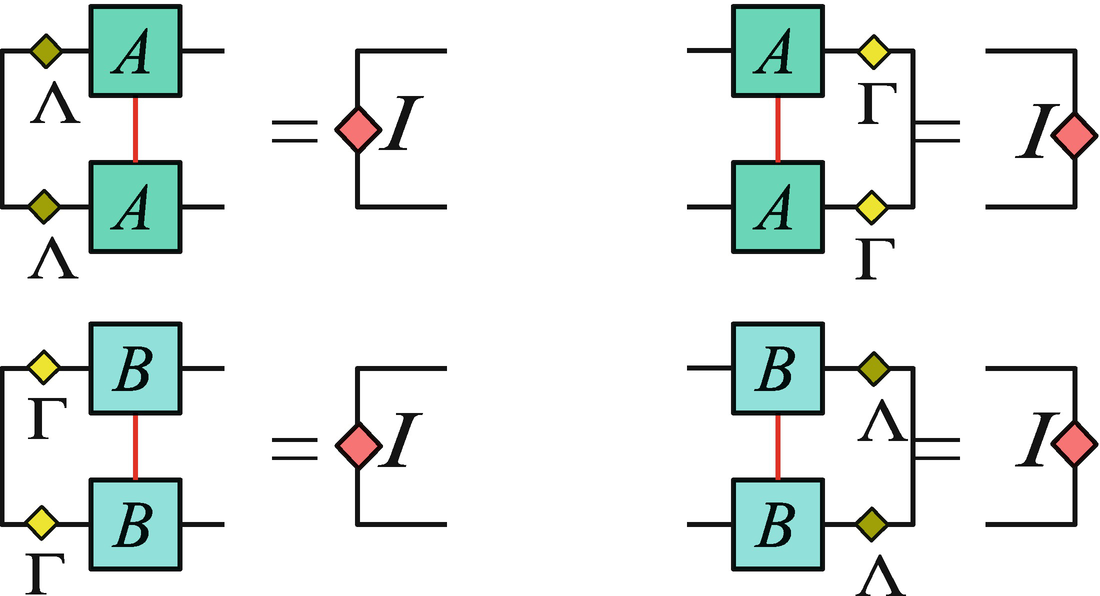
Four canonical conditions of an MPS
In the canonical form, Λ or Γ directly give the singular values by cutting the MPS on the corresponding bond. To see this, let us calculate Eq. (5.5) from a canonical MPS. From the canonical conditions, matrices L and R are unitary, satisfying L †L = I and R †R = I (the physical indexes are contracted). Meanwhile, Λ (or Γ) is positive-defined, thus L, Λ (or Γ) and R of a canonical MPS directly define the SVD, and Λ or Γ is indeed the singular value spectrum. Then the optimal truncations of the virtual bonds are reached by simply keeping χ-largest values of Λ and the corresponding basis of the neighboring tensors. This is true when cutting any one of the bonds of the MPS. From the uniqueness of SVD , Eqs. (5.7) and (5.8) leads to a unique MPS representation, thus such a form is called “canonical”. In other words, the canonicalization fixes the gauge degrees of freedom of the MPS.






Simply from the canonical conditions, it does not require the “identity” to be dominant eigenvector. However, if the identity is not the dominant one, the canonical conditions will become unstable under an arbitrarily small noise. Below, we will show that the canonicalization algorithm assures that the identity is the leading eigenvector, since it transforms the leading eigenvector to an identity. In addition, if the dominant eigenvector of M L and M R (also N L and N R) is degenerate, the canonical form will not be unique. See Ref. [2] for more details.
5.1.3 Canonicalization Algorithm and Some Related Topics
Considering the iTEBD algorithm [3] (see Sect. 3.4), while the MPO represents a unitary operator, the canonical form of the MPS will be reserved by the evolution (contraction). For the imaginary-time evolution, the MPO is near-unitary. For the Trotter step τ → 0, the MPO approaches to be an identity. It turns out that in this case, the MPS will be canonicalized by the evolution in the standard iTEBD algorithm. When the MPO is non-unitary (e.g., when contracting the TN of a 2D statistic model) [2], the MPS will not be canonical, and the canonicalization might be needed to better truncate the bond dimensions of the MPS.
An algorithm to canonicalize an arbitrary MPS was proposed by Orús and Vidal [2]. The idea is to compute the first eigenvectors of the transfer matrices, and introduce proper gauge transformations on the virtual bonds that map the leading eigenvector to identity.


 .
. on this bond. Apply SVD
on
on this bond. Apply SVD
on  as
as  , where we have the updated spectrum
, where we have the updated spectrum  on this bond. Meanwhile, we obtain the gauge transformations to update A and B as
on this bond. Meanwhile, we obtain the gauge transformations to update A and B as  and
and  , where the transformations are implemented as
, where the transformations are implemented as 


The illustration of the canonical transformations








From the canonical conditions, A
L, A
R, B
L, and B
R are non-square orthogonal matrices (e.g.,  ), called isometries. A
M is called the central tensor of the central-orthogonal MPS. This MPS
form is the state ansatz behind the DMRG
algorithm [4, 5], and is very useful in TN-based methods (see, for example, the works of McCulloch [6, 7]). For instance, when applying DMRG to solve 1D quantum model, the tensors A
L and B
L define a left-to-right RG
flow that optimally compresses the Hilbert space of the left part of the chain. A
R and B
R define a right-to-left RG flow similarly. The central tensor between these two RG flows is in fact the ground state of the effective Hamiltonian given by the RG flows of DMRG. Note that the canonical MPS is also called the central canonical form, where the directions of the RG flows can be switched arbitrarily by gauge transformations, thus there is no need to define the directions of the flows or a specific center.
), called isometries. A
M is called the central tensor of the central-orthogonal MPS. This MPS
form is the state ansatz behind the DMRG
algorithm [4, 5], and is very useful in TN-based methods (see, for example, the works of McCulloch [6, 7]). For instance, when applying DMRG to solve 1D quantum model, the tensors A
L and B
L define a left-to-right RG
flow that optimally compresses the Hilbert space of the left part of the chain. A
R and B
R define a right-to-left RG flow similarly. The central tensor between these two RG flows is in fact the ground state of the effective Hamiltonian given by the RG flows of DMRG. Note that the canonical MPS is also called the central canonical form, where the directions of the RG flows can be switched arbitrarily by gauge transformations, thus there is no need to define the directions of the flows or a specific center.
It is worth mentioning the TTD [8] proposed in the field of MLA . As argued in Chap. 2, one advantage of MPS is it lowers the number of parameters from an exponential size dependence to a polynomial one. Let us consider a similar problem: for a N-th order tensor that has d N parameters, how to find its optimal MPS representation, where there are only [2dχ + (N − 2)dχ 2] parameters? TTD was proposed for this aim: by decomposing a tensor into a tensor-train form that is similar to a finite open MPS, the number of parameters becomes linearly relying to the order of the original tensor. The TTD algorithm shares many similar ideas with MPS and the related algorithms (especially DMRG which was proposed about two decades earlier). The aim of TTD is also similar to the truncation tasks in the TN algorithms, which is to compress the number of parameters.
5.2 Super-Orthogonalization and Tucker Decomposition

The first two figures show the iPEPS on tree and square lattices, with two-site translational invariance. The last one shows the super-orthogonal conditions
5.2.1 Super-Orthogonalization
Let us start from the iPEPS on the (infinite) Bethe lattice with the coordination number z = 4. It is formed by two tensors P and Q on the sites as well as four spectra Λ (k) (k = 1, 2, 3, 4) on the bonds, as illustrated in Fig. 5.5. Here, we still take the two-site translational invariance for simplicity.


In the canonicalization of MPS , the vectors on the virtual bonds give the bipartite entanglement defined by Eq. (5.5). Meanwhile, the bond dimensions can be optimally reduced by discarding certain smallest elements of the spectrum. In the super-orthogonalization, this is not always true for iPEPSs. For example, given a translational invariant iPEPS defined on a tree (or called Bethe lattice, see Fig. 5.5a) [12–19], the super-orthogonal spectrum indeed gives the bipartite entanglement spectrum by cutting the system at the corresponding place. However, when considering loopy lattices, such as the iPEPS defined on a square lattice (Fig. 5.5b), this will no longer be true. Instead, the super-orthogonal spectrum provides an approximation of the entanglement of the iPEPS by optimally ignoring the loops. One can still truncate the bond dimensions according to the super-orthogonal spectrum, giving in fact the simple update (see Sect. 4.3). We will discuss the loopless approximation in detail in Sect. 5.3 using the rank-1 decomposition.
5.2.2 Super-Orthogonalization Algorithm
 of the k-rectangular matrix of the tensor P (Eq. (5.30)) as
of the k-rectangular matrix of the tensor P (Eq. (5.30)) as 
 when the PEPS is super-orthogonal. Similarly, we define the reduced matrix
when the PEPS is super-orthogonal. Similarly, we define the reduced matrix  of the tensor Q.
of the tensor Q. and
and  are not identities but Hermitian matrices. Decompose them as
are not identities but Hermitian matrices. Decompose them as  and
and  . Then, insert the identities X
(k)[X
(k)]−1 and Y
(k)[Y
(k)]−1 on the virtual bonds to perform gauge transformations along four directions as shown in Fig. 5.6. Then, we can use SVD
to renew the four spectra by
. Then, insert the identities X
(k)[X
(k)]−1 and Y
(k)[Y
(k)]−1 on the virtual bonds to perform gauge transformations along four directions as shown in Fig. 5.6. Then, we can use SVD
to renew the four spectra by  . Meanwhile, we transform the tensors as
. Meanwhile, we transform the tensors as ![$$\displaystyle \begin{aligned} \begin{array}{rcl} P_{s,\cdots a_k \cdots} \leftarrow \sum_{a_k^{\prime}a_k^{\prime\prime}} P_{s,\cdots a_k^{\prime} \cdots} [X^{(k)}]^{-1}_{a_k^{\prime}a_k^{\prime\prime}} U^{(k)}_{a_k^{\prime\prime} a_k}, \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ32.png)
![$$\displaystyle \begin{aligned} \begin{array}{rcl} Q_{s,\cdots a_k \cdots} \leftarrow \sum_{a_k^{\prime}a_k^{\prime\prime}} Q_{s,\cdots a_k^{\prime} \cdots} [Y^{(k)}]^{-1}_{a_k^{\prime}a_k^{\prime\prime}} V^{(k)\ast}_{a_k^{\prime\prime} a_k}. \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ33.png)
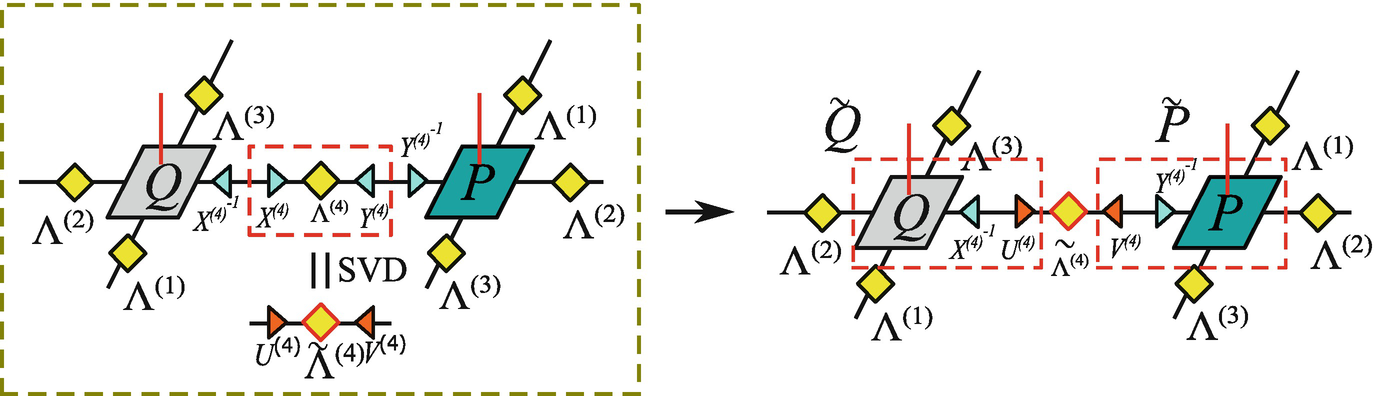
The illustrations of gauge transformations in the super-orthogonalization algorithm
Compared with the canonicalization algorithm of MPS , one can see that the gauge transformations in the super-orthogonalization algorithm are quite similar. The difference is that one cannot transform a PEPS into the super-orthogonal form by a single step, since the transformation on one bond might cause some deviation from obeying the super-orthogonal conditions on other bonds. Thus, the above procedure should be iterated until all the tensors and spectra converge.
5.2.3 Super-Orthogonalization and Dimension Reduction by Tucker Decomposition
Such an iterative scheme is closely related to the Tucker decomposition in MLA [10]. Tucker decomposition is considered as a generalization of (matrix) SVD to higher-order tensors, thus it is also called higher-order or multi-linear SVD. The aim is to find the optimal reductions of the bond dimensions for a single tensor.


Unitarity. U (k) are unitary matrices satisfying U (k)U (k)† = I.
- All-orthogonality. For any k, the k-reduced matrix M (k) of the tensor S is diagonal, satisfying
 (5.36)
(5.36) Ordering. For any k, the elements of Γ (k) in the k-reduced matrix are positive-defined and in the descending order, satisfying Γ 0 > Γ 1 > ⋯.

The illustrations of Tucker decomposition (Eq. (5.35))


 as
as 

For the algorithms of Tucker decomposition, one simple way is to do the eigenvalue decomposition of each k-reduced matrix, or the SVD of each k-rectangular. Then for a K-th ordered tensor, K SVDs will give us the Tucker decomposition and a lower-rank approximation. This algorithm is often called higher-order SVD (HOSVD) , which has been successfully applied to implement truncations in the TRG algorithm [20]. The accuracy of HOSVD can be improved. Since the truncation on one index will definitely affect the truncations on other indexes, there will be some “interactions” among different indexes (modes) of the tensor. The truncations in HOSVD are calculated independently, thus such “interactions” are ignored. One improved way is the high-order orthogonal iteration (HOOI) , where the interactions among different modes are considered by iteratively doing SVDs until reaching the convergence. See more details in Ref. [10].
- Super-orthogonality. For any k, the reduced matrix of the k-rectangular matrix
 (Eq. (5.31)) is diagonal, satisfying
(Eq. (5.31)) is diagonal, satisfying  (5.41)
(5.41) Ordering. For any k, the elements of Γ (k) are positive-defined and in the descending order, satisfying Γ 0 > Γ 1 > ⋯.
In the Tucker decomposition, the “all-orthogonality” and “ordering” lead to an SVD associated to a single tensor, which explains how the optimal truncations work from the decompositions in linear algebra. In the NTD, the SVD picture is generalized from a single tensor to a non-local PEPS. Thus, the truncations are optimized in a non-local way.
 (and
(and  on the other side). Then the state given by the iPEPS can be written as
on the other side). Then the state given by the iPEPS can be written as 

 from its boundary. If the PEPS
is super-orthogonal, the spectra must be on the boundary of the TN
because the super-orthogonal conditions are satisfied everywhere.1 Then the contractions of the tensors on the boundary satisfy Eq. (5.29), which gives identities. Then we have on the new boundary again the spectra to iterate the contractions. All tensors can be contracted by iteratively using the super-orthogonal conditions, which in the end gives identities as Eq. (5.43). Thus, Ψ
L and Ψ
R are indeed isometries and Eq. (5.42) indeed gives the SVD
of the whole wave-function. The truncations of the bond dimensions are globally optimized by taking the whole tree PEPS as the environment.
from its boundary. If the PEPS
is super-orthogonal, the spectra must be on the boundary of the TN
because the super-orthogonal conditions are satisfied everywhere.1 Then the contractions of the tensors on the boundary satisfy Eq. (5.29), which gives identities. Then we have on the new boundary again the spectra to iterate the contractions. All tensors can be contracted by iteratively using the super-orthogonal conditions, which in the end gives identities as Eq. (5.43). Thus, Ψ
L and Ψ
R are indeed isometries and Eq. (5.42) indeed gives the SVD
of the whole wave-function. The truncations of the bond dimensions are globally optimized by taking the whole tree PEPS as the environment.For an iPEPS , it can be similarly proven that Ψ L and Ψ R are isometries. One way is to put any non-zero spectra on the boundary and iterate the contraction by Eq. (5.31). While the spectra on the boundary can be arbitrary, the results of the contractions by Eq. (5.31) converge to identities quickly [9]. Then the rest of the contractions are exactly given by the super-orthogonal conditions (Eq. (5.29)). In other words, the identity is a stable fixed point of the above iterations. Once the fixed point is reached, it can be considered that the contraction is from infinitely far away, meaning from the “boundary” of the iPEPS. In this way, one proves Ψ L and Ψ R are isometries, i.e., Ψ L†Ψ L = I and Ψ R†Ψ R = I.
5.3 Zero-Loop Approximation on Regular Lattices and Rank-1 Decomposition
5.3.1 Super-Orthogonalization Works Well for Truncating the PEPS on Regular Lattice: Some Intuitive Discussions
From the discussions above, we can see that the “canonical” form of a TN state is strongly desired, because it is expected to give the entanglement and the optimal truncations of the bond dimensions. Recall that to contract a TN that cannot be contracted exactly, truncations are inevitable, and locating the optimal truncations is one of the main tasks in the computations. The super-orthogonal form provides a robust way to optimally truncate the bond dimensions of the PEPS defined on a tree, analog to the canonicalization of MPS .
Interestingly, the super-orthogonal form does not require the tree structure. For an iPEPS defined on a regular lattice, for example, the square lattice, one can still super-orthogonalize it using the same algorithm. What is different is that the SVD picture of the wave-function (generally, see Eq. (5.5)) will not rigorously hold, as well as the robustness of the optimal truncations. In other words, the super-orthogonal spectrum does not exactly give the entanglement. A question rises: can we still truncate iPEPS defined on a square lattice according to the super-orthogonal spectrum?
Surprisingly, numeric simulations show that the accuracy by truncating according to the super-orthogonal spectrum is still good in many cases. Let us take the ground-state simulation of a 2D system by imaginary-time evolution as an example. As discussed in Sect. 4.2, the simulation becomes the contraction of a 3D TN . One usual way to compute this contraction is to contract layer by layer to an iPEPS (see, e.g., [22, 23]). The contraction will enlarge the virtual bond dimensions, and truncations are needed. When the ground state is gapped (see, e.g., [9, 23]), the truncations produce accurate results, which means the super-orthogonal spectrum approximates the true entanglement quite well.
It has been realized that using the simple update algorithm [23], the iPEPS will converge to the super-orthogonal form for a vanishing Trotter step τ → 0. The success of the simple update suggests that the optimal truncation method on trees still works well for regular lattices. Intuitively, this can be understood in the following way. Comparing a regular lattice with a tree, if it has the same coordination number, the two lattices look exactly the same if we only inspect locally on one site and its nearest neighbors. The difference appears when one goes round the closed loops on the regular lattice, since there is no loop in the tree. Thus, the error applying the optimal truncation schemes (such as super-orthogonalization) of a tree to a regular lattice should be characterized by some non-local features associated to the loops. This explains in a descriptive way why the simple update works well for gapped states, where the physics is dominated by short-range correlations. For the systems that possess small gaps or are gapless, simple update is not sufficiently accurate [24], particularly for the non-local physical properties such as the correlation functions.
5.3.2 Rank-1 Decomposition and Algorithm




The illustrations of rank-1 decomposition (Eq. (5.44))


The illustrations of self-consistent conditions for the rank-1 decomposition (Eq. (5.47))
Apart from some very special cases, such an optimization problem is concave, thus rank-1 decomposition is unique.2 Furthermore, if one arbitrarily chooses a set of norm-1 vectors, they will converge to the fixed point exponentially fast with the iterations. To the best of our knowledge, the exponential convergence has not been proved rigorously, but observed in most cases.
5.3.3 Rank-1 Decomposition, Super-Orthogonalization, and Zero-Loop Approximation
Let us still consider an translational invariant square TN that is formed by infinite copies of the 4th-order tensor T (Fig. 2.28). The rank-1 decomposition of T provides an approximative scheme to compute the contraction of the TN, which is called the theory of network contractor dynamics (NCD) [11].

Using the self-consistent conditions of the rank-1 decomposition, a tree TN with no loops can grow to cover the infinite square lattice. The four vectors gathering in a same site give the rank-1 approximation of the original tensor
By repeating the substitution, the TN can be grown to cover the whole square lattice, where each site is allowed to put maximally one T. Inevitably, some sites will not have T, but four vectors instead. These vectors (also called contractors) give the rank-1 decomposition of T as Eq. (5.44). This is to say that some tensors in the square TN are replaced by its rank-1 approximation, so that all loops are destructed and the TN becomes a loopless tree covering the square lattice. In this way, the square TN is approximated by such a tree TN on square lattice, so that its contraction is simply computed by Eq. (5.45).
The growing process as well as the optimal tree TN is only to understand the zero-loop approximation with rank-1 decomposition. There is no need to practically implement such a process. Thus, it does not matter how the TN is grown or where the rank-1 tensors are put to destroy the loops. All information we need is given by the rank-1 decomposition. In other words, the zero-loop approximation of the TN is encoded in the rank-1 decomposition.




 . Thus, the super-orthogonal spectrum provides an optimal approximation for the truncations of the bond dimensions in the zero-loop level. This provides a direct connection between the simple update scheme and rank-1 decomposition.
. Thus, the super-orthogonal spectrum provides an optimal approximation for the truncations of the bond dimensions in the zero-loop level. This provides a direct connection between the simple update scheme and rank-1 decomposition.5.3.4 Error of Zero-Loop Approximation and Tree-Expansion Theory Based on Rank-Decomposition
The error of NCD (and simple update) is an important issue. From the first glance, the error seems to be the error of rank-1 decomposition ε = |T −∏kv (k)|. This would be true if we replaced all tensors in the square TN by the rank-1 version. In this case, the PEPS is approximated by a product state with zero entanglement. In the NCD scheme, however, we only replace a part of the tensors to destruct the loops. The corresponding approximative PEPS is an entanglement state with a tree structure. Therefore, the error of rank-1 decomposition cannot properly characterize the error of simple update.

 .
.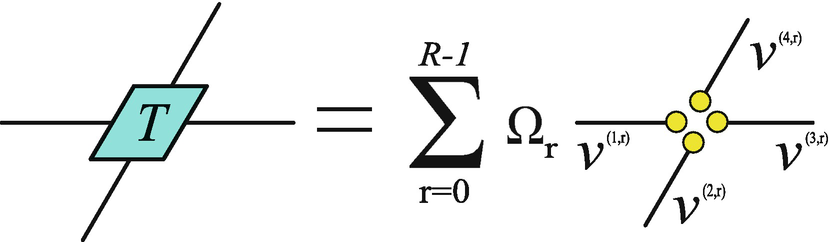
The illustrations of rank-1 decomposition (Eq. (5.52))
In the optimal tree TN
, let us replace the rank-1 tensors back by the full rank tensor in Eq. (5.52). We suppose the rank decomposition is exact, thus we will recover the original TN by doing so. The TN contraction becomes the summation of  terms with
terms with  the number of rank-1 tensors in the zero-loop TN. Each term is the contraction of a tree TN, which is the same as the optimal tree TN except that certain vectors are changed to v
(k, r) instead of the rank-1 term v
(k, 0). Note that in all terms, we use the same tree structure; the leading term in the summation is the zero-loop TN in the NCD
scheme. It means with rank decomposition, we expand the contraction of the square TN by the summation of the contractions of many tree TN’s.
the number of rank-1 tensors in the zero-loop TN. Each term is the contraction of a tree TN, which is the same as the optimal tree TN except that certain vectors are changed to v
(k, r) instead of the rank-1 term v
(k, 0). Note that in all terms, we use the same tree structure; the leading term in the summation is the zero-loop TN in the NCD
scheme. It means with rank decomposition, we expand the contraction of the square TN by the summation of the contractions of many tree TN’s.
 as the number of the impurity tensors appearing in one of the tree TN in the summation, the expansion can be written as
as the number of the impurity tensors appearing in one of the tree TN in the summation, the expansion can be written as 
 to denote the set of all possible configurations of
to denote the set of all possible configurations of  number of the impurity tensors, where there are
number of the impurity tensors, where there are  of T
1s located in different positions in the tree. Then
of T
1s located in different positions in the tree. Then  denotes the contraction of such a tree TN with a specific configuration of T
1’s. In general, the contribution is determined by the order of |Ω
1∕Ω
0| since |Ω
1∕Ω
0| < 1 (Fig. 5.12).
denotes the contraction of such a tree TN with a specific configuration of T
1’s. In general, the contribution is determined by the order of |Ω
1∕Ω
0| since |Ω
1∕Ω
0| < 1 (Fig. 5.12).
The illustrations of the expansion with rank decomposition. The yellow and red circles stand for  (zeroth order terms in the rank decomposition) and
(zeroth order terms in the rank decomposition) and  (first order terms), respectively. Here, we consider the tensor rank R = 2 for simplicity
(first order terms), respectively. Here, we consider the tensor rank R = 2 for simplicity
To proceed, we choose one tensor in the tree as the original point, and always contract the tree TN
by ending at this tensor. Then the distance  of a vector is defined as the number of tensors in the path that connects this vector to the original point. Note that one impurity tensor is the tensor product of several vectors, and each vector may have different distance to the original point. For simplicity, we take the shortest one to define the distance of an impurity tensor.
of a vector is defined as the number of tensors in the path that connects this vector to the original point. Note that one impurity tensor is the tensor product of several vectors, and each vector may have different distance to the original point. For simplicity, we take the shortest one to define the distance of an impurity tensor.
Now, let us utilize the exponential convergence of the rank-1 decomposition. After contracting any vectors with the tensor in the tree, the resulting vector approaches to the fixed point (the vectors in the rank-1 decomposition) in an exponential speed. Define  as the average number of the contractions that will project any vectors to the fixed point with a tolerable difference. Consider any impurity tensors with the distance
as the average number of the contractions that will project any vectors to the fixed point with a tolerable difference. Consider any impurity tensors with the distance  , their contributions to the contraction are approximately the same, since after
, their contributions to the contraction are approximately the same, since after  contractions, the vectors have already been projected to the fixed point.
contractions, the vectors have already been projected to the fixed point.
From the above argument, we can see that the error is related not only to the error of the rank-1 decomposition, but also to the speed of the convergence to the rank-1 component. The smaller  is, the smaller the error (the total contribution from the non-dominant terms) will be. Calculations show that the convergence speed is related to the correlation length (or gap) of the physical system, but their rigorous relations have not been established yet. Meanwhile, the expansion theory of the TN
contraction given above requires the rank decomposition, which, however, is not uniquely defined of an arbitrarily given tensor.
is, the smaller the error (the total contribution from the non-dominant terms) will be. Calculations show that the convergence speed is related to the correlation length (or gap) of the physical system, but their rigorous relations have not been established yet. Meanwhile, the expansion theory of the TN
contraction given above requires the rank decomposition, which, however, is not uniquely defined of an arbitrarily given tensor.
5.4 iDMRG, iTEBD, and CTMRG Revisited by Tensor Ring Decomposition
We have shown that the rank-1 decomposition solves the contraction of infinite-size tree TN and provides a mathematic explanation of the approximation made in the simple update. Then, it is natural to think: can we generalize this scheme beyond being only rank-1, in order to have better update schemes? In the following, we will show that besides the rank decomposition, the tensor ring decomposition (TRD) [28] was suggested as another rank-N generalization for solving TN contraction problems.
TRD is defined by a set of self-consistent eigenvalue equations (SEEs) with certain constraints. The original proposal of TRD requires all eigenvalue equations to be Hermitian [28]. Later, a generalize version was proposed [29] that provides an unified description of the iDMRG [4, 5, 7], iTEBD [3], and CTMRG [30] algorithms. We will concentrate on this version in the following.
5.4.1 Revisiting iDMRG, iTEBD, and CTMRG: A Unified Description with Tensor Ring Decomposition


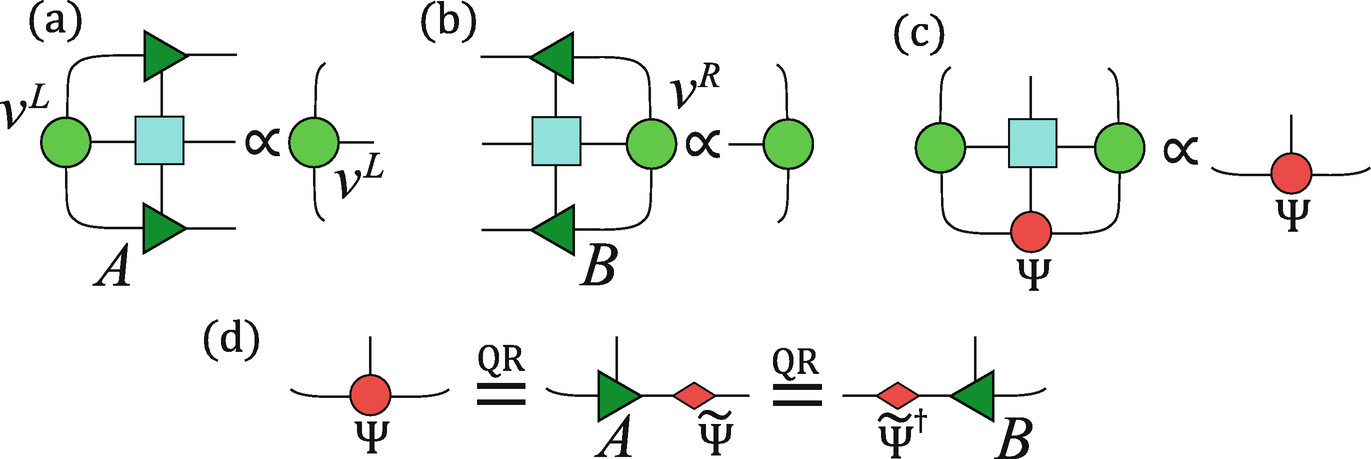


One can see that each of the eigenvalue problems is parametrized by the solutions of others, thus we solve them in a recursive way. First, we initialize arbitrarily the central tensors Ψ and get A and B by Eq. (5.56). Note that a good initial guess can make the simulations faster and more stable. Then we update v
L and v
R by multiplying with M
L and M
R as Eqs. (5.54) and (5.55). Then we have the new Ψ by solving the dominant eigenvector of  in Eq. (5.57) that is defined by the new v
L and v
R. We iterate such a process until all variational tensors converge.
in Eq. (5.57) that is defined by the new v
L and v
R. We iterate such a process until all variational tensors converge.

 ” to represent the contraction relation up to a difference of a constant factor.
” to represent the contraction relation up to a difference of a constant factor.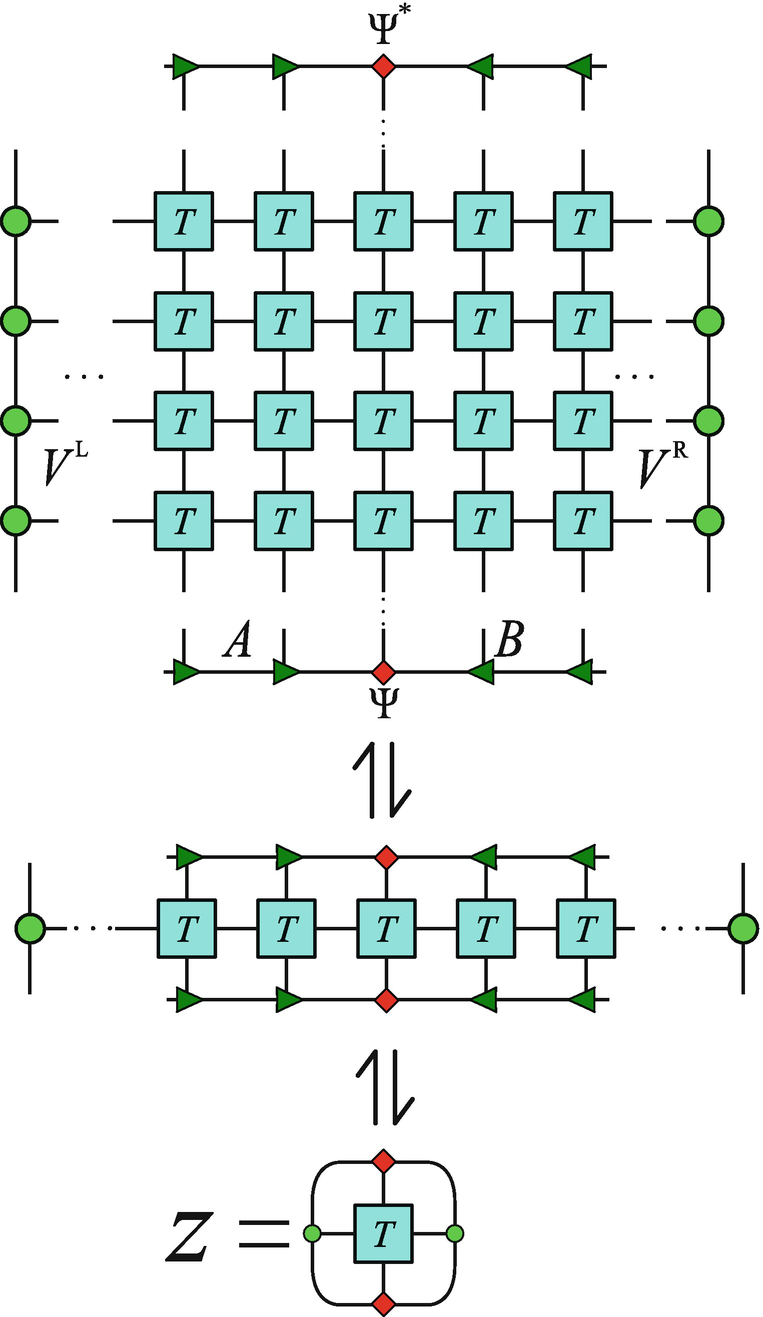
The eigenvalue equations as illustrated “encode” the infinite TN



After the substitutions from Eqs. (5.58)–(5.60), Z is still maximized by the given Φ, since v
L and v
R are the dominant eigenvectors. Note that such a maximization is reached under the assumption that the dominant eigenvector Φ can be well represented in an MPS
with finite bond dimensions. Meanwhile, one can easily see that the MPS is normalized  , thanks to the orthogonality of A and B. Then we come to a conclusion that Φ is the optimal MPS that gives the dominant eigenvector of ρ, satisfying
, thanks to the orthogonality of A and B. Then we come to a conclusion that Φ is the optimal MPS that gives the dominant eigenvector of ρ, satisfying  .3 Then, we can rewrite the TN
contraction as
.3 Then, we can rewrite the TN
contraction as  , where the infinite TN appears as ρ
K (Fig. 5.14).
, where the infinite TN appears as ρ
K (Fig. 5.14).
Z (Eq. (5.58)) is maximized under the constraint that v L and v R are normalized,
Φ †ρΦ is maximized under the constraint that Φ is normalized,
 as
as 
 (Eq. (5.58)) is maximized. Like the NTD
and rank-1 decomposition, TRD belongs to the decompositions that encode infinite TN’s, i.e., an infinite TN can be reconstructed from the self-consistent equations (note the rank decomposition does not encode any TN’s). Comparing with Eq. (5.47), TRD is reduced to the rank-1 decomposition by taking the dimensions of {b} as one.
(Eq. (5.58)) is maximized. Like the NTD
and rank-1 decomposition, TRD belongs to the decompositions that encode infinite TN’s, i.e., an infinite TN can be reconstructed from the self-consistent equations (note the rank decomposition does not encode any TN’s). Comparing with Eq. (5.47), TRD is reduced to the rank-1 decomposition by taking the dimensions of {b} as one.
The illustrations of the TRD in Eq. (5.62)

![$$v^{[L(R)]} \leftrightharpoons M^{[L(R)]} v^{[L(R)]}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq48.png) ; the QR decomposition in Eq. (5.56) guaranties that the “truncations in iTEBD” are implemented by isometries. In other words, one can consider another MPS
defined in the vertical direction, which is formed by v
[L(R)] and updated by the iTEBD algorithm. It means that while implementing iDMRG in the parallel direction of the TN, one is in fact simultaneously implementing iTEBD to update another MPS along the vertical direction.
; the QR decomposition in Eq. (5.56) guaranties that the “truncations in iTEBD” are implemented by isometries. In other words, one can consider another MPS
defined in the vertical direction, which is formed by v
[L(R)] and updated by the iTEBD algorithm. It means that while implementing iDMRG in the parallel direction of the TN, one is in fact simultaneously implementing iTEBD to update another MPS along the vertical direction.Particularly, when one uses iDMRG to solve the ground state of a 1D system, the MPS formed by v [L(R)] in the imaginary-time direction satisfies the continuous structure [29, 38] that was originally proposed for continuous field theories [39]. Such an iTEBD calculation can also be considered as the transverse contraction of the TN [38, 40, 41].
CTMRG
[30, 42] is also closely related to the scheme given above, which leads to the CTMRG without the corners. The tensors Ψ, v
L and v
R correspond to the row and column tensors, and the equations for updating these tensors are the same to the equations of updating the row and column tensors in CTMRG (see Eqs. (3.27) and (3.31)). Such a relation becomes more explicit in the rank-1 case, when corners become simply scalars. The difference is that in the original CTMRG by Orús et al. [30], the tensors are updated with a power method, i.e.,  and v
[L(R)] ← M
[L(R)]v
[L(R)]. Recently, eigen-solvers instead of power method were suggested in CTMRG ([42] and a related review [43]), where the eigenvalue equations of the row and column tensors are the same to those given in TRD
. The efficiency was shown to be largely improved with this modification.
and v
[L(R)] ← M
[L(R)]v
[L(R)]. Recently, eigen-solvers instead of power method were suggested in CTMRG ([42] and a related review [43]), where the eigenvalue equations of the row and column tensors are the same to those given in TRD
. The efficiency was shown to be largely improved with this modification.
5.4.2 Extracting the Information of Tensor Networks From Eigenvalue Equations: Two Examples
In the following, we present how to extract the properties of the TN by taking the free energy and correlation length as two example related to the eigenvalue equations. Note that these quantities correspond to the properties of the physical model and have been employed in many places (see, e.g., a review [44]). In the following, we treated these two quantities as the properties of the TN itself. When the TN is used to represent different physical models, these quantities will be interpreted accordingly to different physical properties.

 the value of the contraction in theory and N denoting the number of tensors. Such a definition is closely related to some physical quantities, such as the free energy of classical models and the average fidelity of TN states [45]. Meanwhile, f can enable us to compare the values of the contractions of two TN’s without actually computing
the value of the contraction in theory and N denoting the number of tensors. Such a definition is closely related to some physical quantities, such as the free energy of classical models and the average fidelity of TN states [45]. Meanwhile, f can enable us to compare the values of the contractions of two TN’s without actually computing  .
.The free energy is given by the dominant eigenvalues of M
L and M
R. Let us reverse the above reconstructing process to show this. Firstly, we use the MPS in Eq. (5.59) to contract the TN
in one direction, and have  with η the dominant eigenvalue of ρ. The problem becomes getting η. By going from Φ
†ρΦ to Eq. (5.58), we can see that the eigenvalue problem of Φ is transformed to that of
with η the dominant eigenvalue of ρ. The problem becomes getting η. By going from Φ
†ρΦ to Eq. (5.58), we can see that the eigenvalue problem of Φ is transformed to that of  in Eq. (5.57) multiplied by a constant
in Eq. (5.57) multiplied by a constant  with κ
0 the dominant eigenvalue of M
L and M
R and
with κ
0 the dominant eigenvalue of M
L and M
R and  the number of tensors in ρ. Thus, we have
the number of tensors in ρ. Thus, we have  with η
0 the dominant eigenvalue of
with η
0 the dominant eigenvalue of  . Finally, we have the TN contraction
. Finally, we have the TN contraction ![$$\mathscr {Z} = [\eta _0 \kappa _0^{\tilde {K}}]^K = \eta _0^K \kappa _0^{N}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq58.png) with
with  . By substituting into Eq. (5.64), we have
. By substituting into Eq. (5.64), we have  .
.
![$$\displaystyle \begin{aligned} \begin{array}{rcl} F\left(\tilde{T}^{[{\mathbf{r}}_1]}, \tilde{T}^{[{\mathbf{r}}_2]}\right) &\displaystyle =&\displaystyle \mathscr{Z}\left(\tilde{T}^{[{\mathbf{r}}_1]}, \tilde{T}^{[{\mathbf{r}}_2]}\right)/\mathscr{Z} - \mathscr{Z}\left(\tilde{T}^{[{\mathbf{r}}_1]}, T^{[{\mathbf{r}}_2]}\right) \\ &\displaystyle &\displaystyle \mathscr{Z}\left(T^{[{\mathbf{r}}_1]}, \tilde{T}^{[{\mathbf{r}}_2]}\right) / \mathscr{Z}^2,\quad {} \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ65.png)
![$$\mathscr {Z}(\tilde {T}^{[{\mathbf {r}}_1]}, \tilde {T}^{[{\mathbf {r}}_2]})$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq61.png) denotes the contraction of the TN
after substituting the original tensors in the positions r
1 and r
2 by two different tensors
denotes the contraction of the TN
after substituting the original tensors in the positions r
1 and r
2 by two different tensors ![$$\tilde {T}^{[{\mathbf {r}}_1]}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq62.png) and
and ![$$\tilde {T}^{[{\mathbf {r}}_2]}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq63.png) . T
[r] denotes the original tensor at the position r.
. T
[r] denotes the original tensor at the position r.![$$\tilde {T}^{[{\mathbf {r}}_1]}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq64.png) and
and ![$$\tilde {T}^{[{\mathbf {r}}_2]}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq65.png) are in a same column, F satisfies
are in a same column, F satisfies 

 . If
. If ![$$\tilde {T}^{[{\mathbf {r}}_1]}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq67.png) and
and ![$$\tilde {T}^{[{\mathbf {r}}_2]}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq68.png) are in a same row, one has
are in a same row, one has 
![$$\mathscr {Z}(\tilde {T}^{[{\mathbf {r}}_1]}, \tilde {T}^{[{\mathbf {r}}_2]})/\mathscr {Z}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq69.png) as
as ![$$\displaystyle \begin{aligned} \begin{array}{rcl} \mathscr{Z}\left(\tilde{T}^{[{\mathbf{r}}_1]}, \tilde{T}^{[{\mathbf{r}}_2]}\right)/\mathscr{Z} = [\varPhi^{\dagger} \rho\left(\tilde{T}^{[{\mathbf{r}}_1]}, \tilde{T}^{[{\mathbf{r}}_2]}\right) \varPhi]/\left(\varPhi^{\dagger} \rho \varPhi\right). \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ69.png)
 with
with  . With the eigenvalue decomposition of
. With the eigenvalue decomposition of  with D the matrix dimension and v
j the j-th eigenvectors, one can further simply the equation as
with D the matrix dimension and v
j the j-th eigenvectors, one can further simply the equation as ![$$\displaystyle \begin{aligned} \begin{array}{rcl} \mathscr{Z}\left(\tilde{T}^{[{\mathbf{r}}_1]}, \tilde{T}^{[{\mathbf{r}}_2]}\right)/\mathscr{Z} = \sum_{j=0}^{D-1} \left(\eta_j/\eta_0\right)^{|{\mathbf{r}}_1 - {\mathbf{r}}_2|} v_0^{\dagger} \mathscr{M}\left(\tilde{T}^{[{\mathbf{r}}_1]}\right) v_{j} v_{j}^{\dagger} \mathscr{M}\left(\tilde{T}^{[{\mathbf{r}}_1]}\right) v_0, \\ \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ70.png)
![$$\mathscr {M}(\tilde {T}^{[\mathbf {r}]})$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq73.png) the transfer matrix after substituting the original tensor at r with
the transfer matrix after substituting the original tensor at r with ![$$\tilde {T}^{[\mathbf {r}]}$$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_IEq74.png) . Similarly, one has
. Similarly, one has ![$$\displaystyle \begin{aligned} \begin{array}{rcl} \mathscr{Z}\left(\tilde{T}^{[{\mathbf{r}}_1]}, T\right)/\mathscr{Z} = v_0^{\dagger} \mathscr{M}\left(\tilde{T}^{[{\mathbf{r}}_1]}\right) v_0, \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ71.png)
![$$\displaystyle \begin{aligned} \begin{array}{rcl} \mathscr{Z}\left(T,\tilde{T}^{[{\mathbf{r}}_2]}\right)/\mathscr{Z} = v_0^{\dagger} \mathscr{M}\left(\tilde{T}^{[{\mathbf{r}}_2]}\right) v_0. \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ72.png)
![$$\displaystyle \begin{aligned} \begin{array}{rcl} F\left(\tilde{T}^{[{\mathbf{r}}_1]}, \tilde{T}^{[{\mathbf{r}}_2]}\right) = \sum_{j=1}^{D-1} \left(\eta_j/\eta_0\right)^{|{\mathbf{r}}_1 - {\mathbf{r}}_2|} v_0^{\dagger} \mathscr{M}\left(\tilde{T}^{[{\mathbf{r}}_1]}\right) v_{j} v_{j}^{\dagger} \mathscr{M}\left(\tilde{T}^{[{\mathbf{r}}_1]}\right) v_0.\quad \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ73.png)
![$$\displaystyle \begin{aligned} \begin{array}{rcl} F\left(\tilde{T}^{[{\mathbf{r}}_1]}, \tilde{T}^{[{\mathbf{r}}_2]}\right) \simeq \left(\eta_1/\eta_0\right)^{|{\mathbf{r}}_1 - {\mathbf{r}}_2|} v_0^{\dagger} \mathscr{M}\left(\tilde{T}^{[{\mathbf{r}}_1]}\right) v_{1} v_{1}^{\dagger} \mathscr{M}\left(\tilde{T}^{[{\mathbf{r}}_1]}\right) v_0. \end{array} \end{aligned} $$](../images/489509_1_En_5_Chapter/489509_1_En_5_Chapter_TeX_Equ74.png)
 . The second case can be proven similarly.
. The second case can be proven similarly.These two quantities are defined independently on specific physical models that the TN might represent, thus they can be considered as the mathematical properties of the TN. By introducing physical models, these quantities are closely related to the physical properties. For example, when the TN represents the partition function of a classical lattice model, Eq. (5.64) multiplied by the temperature is exactly the free energy. And the correlation lengths of the TN are also the physical correlation lengths of the model in two spatial directions. When the TN gives the imaginary-time evolution of an infinite 1D quantum chain, the correlation lengths of the TN are the spatial and dynamical correlation length of the ground state.
It is a huge topic to investigate the properties of the TN’s or TN states. Paradigm examples include injectivity and symmetries [46–61], statistics and fusion rules [62–65]. These issues are beyond the scope of this lecture notes. One may refer to the related works if interested.

Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.