Sometimes the tools we select change the way we approach a problem. As the proverb goes, if all you have is a hammer, everything looks like a nail. And sometimes our tools, over time, actually interfere with the process of solving a problem.
For most of the past three decades, SQL has been synonymous with database work. A couple of generations of programmers have grown up with relational databases as the de facto standard. Consider that while “NoSQL” has become quite a popular theme, most vendors in the Big Data space have been rushing (circa 2013Q1) to graft SQL features onto their frameworks.
Looking back four decades to the origins of the relational model—in the 1970 paper by Edgar Codd, “A Relational Model of Data for Large Shared Data Banks”—the point was about relational models and not so much about databases and tables and structured queries. Codd himself detested SQL. The relational model was formally specified as a declarative “data sublanguage” (i.e., to be used within some other host language) based on first-order predicate logic. SQL is not that. In comparison, it forces programmers to focus largely on control flow issues and the structure of tables—to a much greater extent than the relational model intended. SQL’s semantics are also disjoint from the programming languages in which it gets used: Java, C++, Ruby, PHP, etc. For that matter, the term “relational” no longer even appears in the SQL-92 specifications.
Codd’s intent, effectively, was to avoid introducing unnecessary complexities that would hamper software systems. He articulated a process for structuring data as relations of tuples, as opposed to using structured data that is managed in tables. He also intended queries to be expressed within what we would now call a DSL. Those are subtle points that have enormous implications, which we’ll explore in Chapter 7.
Cascalog is a DSL in Clojure that implements first-order predicate logic for large-scale queries based on Cascading. This work originated at a company called BackType, which was subsequently acquired by Twitter.
Clojure is a dialect of Lisp intended for functional programming and parallel processing. The name “Cascalog” is a portmanteau of CASCading and datALOG. Through the Leiningen build system, you can also run Cascalog in an interpretive prompt called a REPL. This represents a powerful combination, because a developer could test snippets with sample data in a Read-Evaluate-Print Loop (REPL), then compile to a JAR file for production use on a Hadoop cluster.
The best resources for getting started with Cascalog are the project wiki and API documentation on GitHub.
In addition to Git and Java, which were set up in Chapter 1, you will need to have a tool called Leiningen installed for the examples in this chapter. Make sure that you have Java 1.6, and then read the steps given on the wiki page.
Our example shows using ~/bin as a target directory for the installation of lein,
but you could use any available location on your system:
$exportLEIN_HOME=~/bin$mkdir -p$LEIN_HOME$cd$LEIN_HOME$wget https://raw.github.com/technomancy/leiningen/preview/bin/lein$chmod 755 lein$exportPATH=$LEIN_HOME:$PATH$exportJAVA_OPTS=-Xmx768m
That downloads the lein script, makes it executable, and adds it to your PATH environment variable.
The script will update itself later.
This provides a build system for Clojure, along with an interactive prompt for evaluating ad hoc queries.
Test your installation of lein with the following:
$lein Leiningen is a toolforworking with Clojure projects.
There will probably be much more usage text printed out.
Now connect somewhere you have space for downloads, and then use Git to clone the latest update from the master branch of the Cascalog project on GitHub:
$ git clone git://github.com/nathanmarz/cascalog.gitConnect into that newly cloned directory and run the following steps with lein to get Cascalog set up:
$cdcascalog$lein repl
That should initiate quite a large number of downloads from the Clojars and Conjars Maven repos. Afterward, you should see an interactive prompt called a REPL:
user=>Nathan Marz, the author of Cascalog, wrote an excellent tutorial to introduce the language. Let’s run through some of those code snippets.
First, load an in-memory data set called playground, which is great to use for simple experimentation:
user=>(use'cascalog.playground)(bootstrap)nilniluser=>
Great, that is now loaded into memory. Next, let’s run a query:
user=>(?<-(stdout)[?person](age?person25))davidemily
Note that many console log lines from Cascading and Apache Hadoop have been redacted—look for the output tuples after a RESULTS line in the console log.
The query results david and emily are the persons in the playground data set under age 25.
Next let’s try a range query:
user=>(?<-(stdout)[?person](age?person?age)(<?age30))alicedavidemilygarykumar
Translated, we have the following:
-
The
?<-operator that defines and runs a query -
The query that writes to a sink tap (
stdout) -
A list of all matching persons (
[?person]) -
A generator from the age tap identifier [
(age ?person ?age)] -
A predicate that constrains the result set by
?ageless than 30
Note that the generator (age ?person ?age) causes the age of each person to be bound to the ?age variable.
In Cascalog you specify only what you require, not how it must be achieved.
Also, the ordering of predicates is irrelevant.
Even though no join operation was specified, this code required an implied join of the person and age data:
(defperson[;; [person]["alice"]["bob"]["chris"]["david"]["emily"]["george"]["gary"]["harold"]["kumar"]["luanne"]])(defage[;; [person age]["alice"28]["bob"33]["chris"40]["david"25]["emily"25]["george"31]["gary"28]["kumar"27]["luanne"36]])
Nathan Marz has an excellent tutorial about different kinds of joins and filters in Cascalog.
Next let’s modify the query to show the age for each person.
We simply add the ?age variable to the output tuple scheme:
user=>(?<-(stdout)[?person?age](age?person?age)(<?age30))alice28david25emily25gary28kumar27
A gist on GitHub shows building and running this app. If your results look similar, you should be good to go.
Otherwise, if you have any troubles, contact the Cascalog developer community—which in general is a subset of the Cascading developer community.
You can also reach the cascalog-user email forum or tweet to #Cascalog on Twitter.
Very helpful developers are available to assist.
The tutorial examples show Cascalog code snippets run in the interactive REPL.
Next let’s use lein to build a “fat jar” that can also run on an Apache Hadoop cluster.
Paul Lam of uSwitch has translated each of the “Impatient” series of Cascading apps into Cascalog, some of which are more expressive than the originals.
Connect somewhere you have space for downloads, and then use Git to clone the Cascalog version of “Impatient” on GitHub:
$ git clone git://github.com/Quantisan/Impatient.gitConnect into the part8 subdirectory. Then we’ll review an app in Cascalog for a distributed file copy, similar to Example 1: Simplest Possible App in Cascading:
cd Impatient/part1Source is located in the src/impatient/core.clj file:
(nsimpatient.core(:use[cascalog.api][cascalog.more-taps:only(hfs-delimited)])(:gen-class))(defn-main[inout&args](?<-(hfs-delimitedout)[?doc?line]((hfs-delimitedin:skip-header?true)?doc?line)))
The first four lines, which begin with a macro ns, define a namespace.
Java and Scala use packages and imports for similar reasons, but in general Clojure namespaces are more advanced.
For example, they provide better features for avoiding naming collisions.
Namespaces are also first-class constructs in Clojure, so they can be composed dynamically.
In this example, the namespace imports the Cascalog API, plus additional definitions for Cascading taps—such as TextDelimited for TSV format.
The next four lines, which begin with a macro defn, define a function, which is analogous to the Main method in .
It has arguments for the in source tap identifier and the out sink tap identifier,
plus an args argument list for arity overloading.
A query writes output in TSV format for each tuple of ?doc and ?line fields from the input tuple stream.
Note the property :skip-header? set to true, which causes the source tap to skip headers in the input TSV data.
Next we compile and build to create a “fat jar.” This packages up all the project files and dependencies into a single JAR file. Dependencies are defined in the project.clj build script:
(defprojectimpatient"0.1.0-SNAPSHOT":description"Cascalog for the Impatient - Part 1":url"https://github.com/Quantisan/Impatient/tree/cascalog/part1":license{:name"Eclipse Public License":url"http://www.eclipse.org/legal/epl-v10.html"}:uberjar-name"impatient.jar":aot[impatient.core]:mainimpatient.core:dependencies[[org.clojure/clojure"1.4.0"][cascalog"1.10.0"][cascalog-more-taps"0.3.0"]]:profiles{:provided{:dependencies\[[org.apache.hadoop/hadoop-core"0.20.2-dev"]]}})
Note that this build script is written in Clojure. For detailed descriptions of all the configuration options available in a project.clj script, see the annotated sample.
Given the range and complexities of JVM-based build systems—Maven, Ivy, Gradle, Ant, SBT, etc.—navigating through a build script is perhaps the single biggest hurdle encountered when programmers start to learn about these frameworks. Clojure and Leiningen make this essential concern quite simple. No surprises. The build is written in the language.
To build with lein:
$lein clean$lein uberjar Created /Users/ceteri/opt/Impatient/part1/target/impatient.jar
The resulting JAR should now be located at target/impatient.jar with everything needed for Hadoop standalone mode. To run it:
$rm -rf output$hadoop jar ./target/impatient.jar data/rain.txt output/rain
Take a look at the output in the output/rain/part-00000 partition file. It should be the same as for . Again, a gist on GitHub shows a log of this.
Next, let’s review the Cascalog code for an app similar to the Cascading version in Example 4: Replicated Joins. Starting from the “Impatient” source code directory that you cloned in Git, connect into the part4 subdirectory. Look at the code in src/impatient/core.clj:
(nsimpatient.core(:use[cascalog.api][cascalog.more-taps:only(hfs-delimited)])(:require[clojure.string:ass][cascalog.ops:asc])(:gen-class))(defmapcatopsplit[line]"reads in a line of string and splits it by regex"(s/splitline#"[\[\]\\\(\),.)\s]+"))(defn-main[inoutstop&args](let[rain(hfs-delimitedin:skip-header?true)stop(hfs-delimitedstop:skip-header?true)](?<-(hfs-delimitedout)[?word?count](rain_?line)(split?line:>?word-dirty)((c/comps/trims/lower-case)?word-dirty:>?word)(stop?word:>false)(c/count?count))))
Again, this begins with a namespace, which serves as the target of a compilation.
This namespace also imports the Clojure string library (denoted by an s/ prefix) plus the Cascalog aggregator operations (denoted by a c/ prefix).
Next there is a defmapcatop macro that defines a split operation to split text lines into a token output stream—effectively a generator.
This is based on a regex function in the Clojure string library.
Next there is the main definition, similar to , which now includes a stop source tap identifier to read the stop words list:
- Define and run a query.
-
Write output tuples to the
outsink tap, in TSV format. -
Output tuple scheme has
?wordand?countfields. -
Generator from the
rainsource tap identifier, in TSV format. -
Input tuple scheme uses only the
?linefield; the_ignores the first field. -
Each line is split into tokens, represented by the
?word-dirtyvariable. -
A composition
c/compperforms a string trim and converts the token represented by?wordto lowercase. -
The
stopdata filters out matched tokens, implying a left join. -
An aggregator
c/countcounts each token, represented by?count.
It’s interesting that the Cascalog code for the Replicated Joins example is actually longer than its Scalding equivalent. Even so, in Scalding much more of the “how”—the imperative programming aspects—must be articulated. For example, the join, aggregation, and filters in the Scalding version are more explicit. Also, to be fair, writing those Scalding examples took some effort to find approaches that conformed to Scala requirements for the pipes.
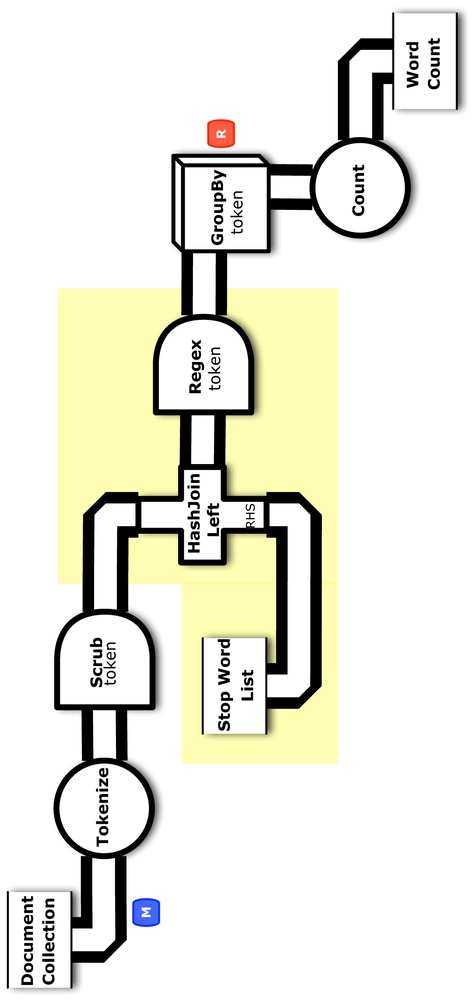
Figure 5-1 shows the conceptual flow diagram for .
Note that here in the Cascalog version, there is no “pipeline” per se.
The workflow is exactly the definition of the main function.
Whereas the Scalding code provides an almost pure expression of the Cascading flow,
the Cascalog version expresses the desired end goal of the workflow with less imperative “controls” defined.
For example, the GroupBy is not needed.
Again, in Cascalog you specify what is required, not how it must be achieved.
To build:
$lein clean$lein uberjar Created /Users/ceteri/opt/Impatient/part4/target/impatient.jar
To run:
$rm -rf output$hadoop jar ./target/impatient.jar data/rain.txt output/wc data/en.stop
To verify:
$ cat output/wc/part-00000The results should be the same as in the Cascading version ().
The TF-IDF with Testing example in Cascalog by Paul Lam is brilliant. It uses approximately 70 lines of Cascalog code, versus approximately 180 lines of Cascading (Java). Plus, the Cascalog version is much simpler to follow.
Starting from the “Impatient” source code directory that you cloned in Git, connect into the part6 subdirectory. Look at the code in src/impatient/core.clj, starting with the namespace and definitions we used earlier in :
(nsimpatient.core(:use[cascalog.api][cascalog.checkpoint][cascalog.more-taps:only(hfs-delimited)])(:require[clojure.string:ass][cascalog[ops:asc][vars:asv]])(:gen-class))(defmapcatopsplit[line]"reads in a line of string and splits it by regex"(s/splitline#"[\[\]\\\(\),.)\s]+"))(defnscrub-text[s]"trim open whitespaces and lower case"((comps/trims/lower-case)s))
Great, those are essentially the same as in the earlier example. The next two definitions create the stream assertion used to drop badly formed input tuples:
(defnassert-tuple[predmsgx]"helper function to add assertion to tuple stream"(when(nil?(assert(predx)msg))true))(defassert-doc-id^{:doc"assert doc-id is correct format"}(partialassert-tuple#(re-seq#"doc\d+"%)"unexpected doc-id"))
The remainder of the app is divided into three subqueries: ETL, Word Count, and TF-IDF. First comes the ETL subquery, which loads input, tokenizes lines of text, filters stop words, applies the stream assertion, and binds a failure trap:
(defnetl-docs-gen[rainstop](<-[?doc-id?word](rain?doc-id?line)(split?line:>?word-dirty)(scrub-text?word-dirty:>?word)(stop?word:>false)(assert-doc-id?doc-id)(:trap(hfs-textline"output/trap":sinkmode:update))))
Next we have the Word Count functionality from before, now as a simplified subquery because it follows immediately after the point where the text lines get tokenized:
(defnword-count[src]"simple word count across all documents"(<-[?word?count](src_?word)(c/count?count)))
Next we have functions for the three branches, “D,” “DF,” and “TF.” Note that in Cascalog a branch is defined as a function—to some extent, this reinforces the concept of closures in functional programming, at least much better than could be performed in Java.
A similar construct was also leveraged in the failure trap used in the stream assertion, for the etl-docs-gen subquery.
In Cascading, branch names get propagated through a pipe assembly, then used in a flow definition to bind failure traps.
The specification of a failure trap gets dispersed through different portions of a Cascading app.
In contrast, Cascalog has branches and traps specified concisely within a function definition, as first-class language constructs.
(defnD[src](let[src(select-fieldssrc["?doc-id"])](<-[?n-docs](src?doc-id)(c/distinct-count?doc-id:>?n-docs))))(defnDF[src](<-[?df-word?df-count](src?doc-id?df-word)(c/distinct-count?doc-id?df-word:>?df-count)))(defnTF[src](<-[?doc-id?tf-word?tf-count](src?doc-id?tf-word)(c/count?tf-count)))
Note the use of another Cascalog aggregator, the c/distinct-count function.
This is equivalent to the Unique filter in Cascading.
Next we construct two definitions to calculate TF-IDF.
The first is the actual formula, which shows how to use math functions.
It also uses a Clojure threading operator ->> for caching the query results in memory.
The second definition is the function for the “TF-IDF” branch, which implies the joins needed for the “D,” “DF,” and “TF” branches.
(defntf-idf-formula[tf-countdf-countn-docs](->>(+1.0df-count)(divn-docs)(Math/log)(*tf-count)))(defnTF-IDF[src](let[n-doc(first(flatten(??-(Dsrc))))](<-[?doc-id?tf-idf?tf-word]((TFsrc)?doc-id?tf-word?tf-count)((DFsrc)?tf-word?df-count)(tf-idf-formula?tf-count?df-countn-doc:>?tf-idf))))
Last, we have the main function, which handles the command-line arguments for the tap identifiers.
Notice that it uses a workflow macro, which is an important construct in Cascalog.
The workflow macro, authored by Sam Ritchie at Twitter, is described in detail at his GitHub site.
calculates TF-IDF metrics by abstracting the problem into subqueries. Each step within the workflow is named, and as a collection these steps represent the required subqueries for the app:
-
etl-step - The ETF subquery
-
tf-step - The TF-IDF subquery
-
wrd-step - The Word Count subquery
The main function is a collection of these three subqueries:
(defn-main[inoutstoptfidf&args](workflow["tmp/checkpoint"]etl-step([:tmp-dirsetl-stage](let[rain(hfs-delimitedin:skip-header?true)stop(hfs-delimitedstop:skip-header?true)](?-(hfs-delimitedetl-stage)(etl-docs-genrainstop))))tf-step([:depsetl-step](let[src(name-vars(hfs-delimitedetl-stage:skip-header?true)["?doc-id""?word"])](?-(hfs-delimitedtfidf)(TF-IDFsrc))))wrd-step([:depsetl-step](?-(hfs-delimitedout)(word-count(hfs-delimitedetl-stage))))))
The workflow is a first-class construct in Cascalog, unlike in Cascading or Scalding, where workflows get inferred from the pipe assemblies. The steps each list their dependencies, and the steps may run in parallel if they are independent. To be clear, recognize that this term “step” is quite different from an Apache Hadoop job step.
Instead the Cascalog step is used for checkpoints, which are built directly into workflows.
Notice the definition ["tmp/checkpoint"] just before the first step.
That specifies a location for checkpointed data.
If any steps cause the app to fail, then when you resubmit the app, the workflow macro will skip all the steps preceding the point of failure.
To build:
$lein clean$lein uberjar Created /Users/ceteri/opt/Impatient/part6/target/impatient.jar
To run:
$rm -rf output$hadoop jar target/impatient.jar data/rain.txt output/wc\data/en.stop output/tfidf
To verify the output:
$cat output/trap/part-m-00001-00001 zoink$head output/tfidf/part-00000 doc02 0.22314355131420976 area doc01 0.44628710262841953 area doc03 0.22314355131420976 area doc05 0.9162907318741551 australia doc05 0.9162907318741551 broken doc04 0.9162907318741551 california's doc04 0.9162907318741551 cause doc02 0.9162907318741551 cloudcover doc04 0.9162907318741551 death doc04 0.9162907318741551 deserts
also includes unit tests, with source code in the test/impatient/core_test.clj file:
(nsimpatient.core-test(:useimpatient.coreclojure.testcascalog.api[midjesweetcascalog]))(deftestscrub-text-test(fact(scrub-text"FoO BAR ")=>"foo bar"))(deftestetl-docs-gen-test(let[rain[["doc1""a b c"]]stop[["b"]]](fact(etl-docs-genrainstop)=>(produces[["doc1""a"]["doc1""c"]]))))
Note the reference to midje in the namespace.
These tests are based on a test framework called Midje-Cascalog, described by Ritchie on his GitHub project
and in substantially more detail in his article about best practices for Cascalog testing.
Midje enables you to test Cascalog queries as functions, whether they are isolated or within part of a workflow.
Each test definition shown in the preceding code uses fact to make a statement about a query and its expected results.
These tests duplicate the unit tests that were used in Example 6: TF-IDF with Testing.
Midje also has features for stubs and mocks. Ritchie explains how Midje in Cascalog represents a game-changer for testing MapReduce apps:
Without proper tests, Hadoop developers can’t help but be scared of making changes to production code. When creativity might bring down a workflow, it’s easiest to get it working once and leave it alone.[1]
This approach is not just better than the state of the art of MapReduce testing, as defined by Cloudera; it completely obliterates the old way of thinking, and makes it possible to build very complex workflows with a minimum of uncertainty.[2]
— Sam Ritchie
Incorporating TDD, assertions, traps, and checkpoints into the Cascalog workflow macro was sheer brilliance, for Enterprise data workflows done right. Moreover, fact-based tests separate a Cascalog app’s logic from concerns about how its data is stored—reducing the complexity of required testing.
$leintestRetrieving org/clojure/clojure/maven-metadata.xml(2k)from http://repo1.maven.org/maven2/ Retrieving org/clojure/clojure/maven-metadata.xml(1k)from https://clojars.org/repo/ Retrieving org/clojure/clojure/maven-metadata.xml(2k)from http://repo1.maven.org/maven2/ Retrieving org/clojure/clojure/maven-metadata.xml from http://oss.sonatype.org/content/repositories/snapshots/ Retrieving org/clojure/clojure/maven-metadata.xml from http://oss.sonatype.org/content/repositories/releases/ leintestimpatient.core-test Ran 2 tests containing 2 assertions. 0 failures, 0 errors.
Again, a gist on GitHub shows a log of this run.
A common critique from programmers who aren’t familiar with Clojure is that they would need to learn Lisp. Actually, the real learning curve for Cascalog is more often the need to learn Prolog. Datalog is formally a subset of Prolog—in terms of its syntax.
Unlike Prolog, however, Datalog represents a truly declarative logic programming language: it expresses the logic for a unit of work without needing to specify its control flow. This is great for query languages, and Datalog did influence “recursive queries” in Oracle, “Magic Sets” in DB2, etc. Declarative logic programming is also the basis for specifying “what” is needed instead of “how” it must be achieved. Within the context of a functional programming paradigm—and especially within the context of Cascading workflows and parallel processing—many decisions about “how” can be deferred to the flow planner to leverage the underlying topology.
Cascalog leverages Datalog and Cascading within Clojure to provide several key benefits:
- Code is very compact, generally smaller than with other Hadoop abstraction layers.
- An interactive REPL makes development and testing convenient and efficient.
- Generating queries dynamically is easy and idiomatic—unlike in SQL.
- Interspersing queries within the rest of the application logic is trivial—unlike in Java + SQL.
- Custom operations get defined just like any other function—unlike the UDFs used in Hive, Pig, etc.
An interesting aspect of having the REPL is that Cascalog provides many of the benefits of Apache Hive—convenient for ad hoc queries, roll-ups, etc. However, the queries are more expressive than SQL and, in general, an order of magnitude less code is required for comparable Cascalog apps. Meanwhile, Cascalog apps provide deterministic workflows within a functional programming paradigm. Apache Hive does not.
There are a number of published articles and case studies about large-scale commercial deployments of Cascalog. Nathan Marz authored the language while working at BackType, which was subsequently acquired by Twitter. The publisher analytics team at Twitter uses Cascalog apps at very large scale for ETL, ad hoc queries, predictive modeling, etc.
Other interesting deployments include:
- The Climate Corporation
- Insuring farmers against crop losses due to global warming
- Nokia
- Location services, mobile maps, etc.
- uSwitch
- Price comparison and switching
- Factual
- Geolocation data sets
- Harvard School of Public Health
- Next-generation gene sequencing
- Yieldbot
- Real-time customer intent for advertising
- Linkfluence
- Preparing social graph data sets prior to analysis in Gephi or Neo4j
- Lumosity
- Data analytics for R&D in cognitive enhancement
While preparing code samples for this book, the build systems used for Cascading, Scalding, and Cascalog showed some contrasts.
Scalding scripts used sbt, Gradle, and Maven.
Simple tasks were simple to perform, but more complicated work required troubleshooting, digging through manuals, workarounds, etc.
In contrast, developing the Cascalog examples with lein was amazingly straightforward.
On the one hand, preferences for programming languages vary widely between individuals and organizations, and many people find that the Lisp syntax in Clojure is difficult to understand.
On the other hand, you’ll need to search far and wide to find many complaints about Leiningen.