This chapter covers a feature of C# whose name usually takes programmers by surprise: unsafe code. Unsafe code often involves the use of pointers. Together, unsafe code and pointers enable C# to be used to create applications that one might normally associate with C++: high-performance, systems code. Moreover, the inclusion of unsafe code and pointers gives C# capabilities that are lacking in Java.
Also covered in this chapter are nullable types, partial class and partial method definitions, fixed-size buffers, and the new dynamic type. The chapter concludes by discussing the few keywords that have not been covered by the preceding chapters.
C# allows you to write what is called “unsafe” code. Although this statement might seem shocking, it really isn’t. Unsafe code is not code that is poorly written; it is code that does not execute under the full management of the common language runtime (CLR). As explained in Chapter 1, C# is normally used to create managed code. It is possible, however, to write code that does not execute under the full control of the CLR. This unmanaged code is not subject to the same controls and constraints as managed code, so it is called “unsafe” because it is not possible to verify that it won’t perform some type of harmful action. Thus, the term unsafe does not mean that the code is inherently flawed. It simply means that it is possible for the code to perform actions that are not subject to the supervision of the managed context.
Given that unsafe code might cause problems, you might ask why anyone would want to create such code. The answer is that managed code prevents the use of pointers. If you are familiar with C or C++, then you know that pointers are variables that hold the addresses of other objects. Thus, pointers are a bit like references in C#. The main difference is that a pointer can point anywhere in memory; a reference always refers to an object of its type. Because a pointer can point anywhere in memory, it is possible to misuse a pointer. It is also easy to introduce a coding error when using pointers. This is why C# does not support pointers when creating managed code. Pointers are, however, both useful and necessary for some types of programming (such as system-level utilities), and C# does allow you to create and use pointers. However, all pointer operations must be marked as unsafe since they execute outside the managed context.
The declaration and use of pointers in C# parallels that of C/C++—if you know how to use pointers in C/C++, then you can use them in C#. But remember, the essence of C# is the creation of managed code. Its ability to support unmanaged code allows it to be applied to a special class of problems. It is not for normal C# programming. In fact, to compile unmanaged code, you must use the /unsafe compiler option.
Since pointers are at the core of unsafe code, we will begin there.
A pointer is a variable that holds the address of some other object, such as another variable. For example, if x contains the address of y, then x is said to “point to” y. When a pointer points to a variable, the value of that variable can be obtained or changed through the pointer. Operations through pointers are often referred to as indirection.
Pointer variables must be declared as such. The general form of a pointer variable declaration is
type* var-name;
Here, type is the pointer’s referent type, which must be a nonreference type. Thus, you cannot declare a pointer to a class object. A pointer’s referent type is also sometimes called its base type. Notice the placement of the *. It follows the type name. var-name is the name of the pointer variable.
Here is an example. To declare ip to be a pointer to an int, use this declaration:
int* ip;
For a float pointer, use
float* fp;
In general, in a declaration statement, following a type name with an * creates a pointer type.
The type of data that a pointer will point to is determined by its referent type. Thus, in the preceding examples, ip can be used to point to an int, and fp can be used to point to a float. Understand, however, that there is nothing that actually prevents a pointer from pointing elsewhere. This is why pointers are potentially unsafe.
If you come from a C/C++ background, then you need to be aware of an important difference between the way C# and C/C++ declare pointers. When you declare a pointer type in C/C++, the * is not distributive over a list of variables in a declaration. Thus, in C/C++, this statement
int* p, q;
declares an int pointer called p and an int called q. It is equivalent to the following two declarations:
int* p;
int q;
However, in C#, the * is distributive and the declaration
int* p, q;
creates two pointer variables. Thus, in C# it is the same as these two declarations:
int* p;
int* q;
This is an important difference to keep in mind when porting C/C++ code to C#.
Two operators are used with pointers: * and &. The & is a unary operator that returns the memory address of its operand. (Recall that a unary operator requires only one operand.) For example,
int* ip;
int num = 10;
ip = #
puts into ip the memory address of the variable num. This address is the location of the variable in the computer’s internal memory. It has nothing to do with the value of num. Thus, ip does not contain the value 10 (num’s initial value). It contains the address at which num is stored. The operation of & can be remembered as returning “the address of” the variable it precedes. Therefore, the preceding assignment statement could be verbalized as “ip receives the address of num.”
The second operator is*, and it is the complement of &. It is a unary operator that evaluates to the value of the variable located at the address specified by its operand. That is, it refers to the value of the variable pointed to by a pointer. Continuing with the same example, if ip contains the memory address of the variable num, then
int val = *ip;
will place into val the value 10, which is the value of num, which is pointed to by ip. The operation of * can be remembered as “at address.” In this case, then, the statement could be read as “val receives the value at address ip.”
The* can also be used on the left side of an assignment statement. In this usage, it sets the value pointed to by the pointer. For example,
*ip = 100;
This statement assigns 100 to the variable pointed to by ip, which is num in this case. Thus, this statement can be read as “at address ip, put the value 100.”
Any code that uses pointers must be marked as unsafe by using the unsafe keyword. You can mark types (such as classes and structures), members (such as methods and operators), or individual blocks of code as unsafe. For example, here is a program that uses pointers inside Main( ), which is marked unsafe:
// Demonstrate pointers and unsafe.
using System;
class UnsafeCode {
// Mark Main as unsafe.
unsafe static void Main() {
int count = 99;
int* p; // create an int pointer
p = &count; // put address of count into p
Console.WriteLine("Initial value of count is " + *p);
*p = 10; // assign 10 to count via p
Console.WriteLine("New value of count is " + *p);
}
}
The output of this program is shown here:
Initial value of count is 99
New value of count is 10
The fixed modifier is often used when working with pointers. It prevents a managed variable from being moved by the garbage collector. This is needed when a pointer refers to a field in a class object, for example. Because the pointer has no knowledge of the actions of the garbage collector, if the object is moved, the pointer will point to the wrong object. Here is the general form of fixed:
fixed (type* p = &fixedObj) {
// use fixed object
}
Here, p is a pointer that is being assigned the address of an object. The object will remain at its current memory location until the block of code has executed. You can also use a single statement for the target of a fixed statement. The fixed keyword can be used only in an unsafe context. You can declare more than one fixed pointer at a time using a comma-separated list.
Here is an example of fixed:
// Demonstrate fixed.
using System;
class Test {
public int num;
public Test(int i) { num = i; }
}
class FixedCode {
// Mark Main as unsafe.
unsafe static void Main() {
Test o = new Test(19);
fixed (int* p = &o.num) { // use fixed to put address of o.num into p
Console.WriteLine("Initial value of o.num is " + *p);
*p = 10; // assign 10 to o.num via p
Console.WriteLine("New value of o.num is " + *p);
}
}
}
The output from this program is shown here:
Initial value of o.num is 19
New value of o.num is 10
Here, fixed prevents o from being moved. Because p points to o.num, if o were moved, then p would point to an invalid location.
A pointer can point to an object of a structure type as long as the structure does not contain reference types. When you access a member of a structure through a pointer, you must use the arrow operator, which is –>, rather than the dot (.) operator. For example, given this structure,
struct MyStruct {
public int a;
public int b;
public int Sum() { return a + b; }
}
you would access its members through a pointer, like this:
MyStruct o = new MyStruct();
MyStruct* p; // declare a pointer
p = &o;
p->a = 10; // use the -> operator
p->b = 20; // use the -> operator
Console.WriteLine("Sum is " + p->Sum());
There are only four arithmetic operators that can be used on pointers: ++, – –, +, and –. To understand what occurs in pointer arithmetic, we will begin with an example. Let p1 be an int pointer with a current value of 2,000 (that is, it contains the address 2,000). After this expression,
p1++;
the contents of p1 will be 2,004, not 2,001! The reason is that each time p1 is incremented, it will point to the next int. Since int in C# is 4 bytes long, incrementing p1 increases its value by 4. The reverse is true of decrements. Each decrement decreases p1’s value by 4. For example,
p1--;
will cause p1 to have the value 1,996, assuming it previously was 2,000.
Generalizing from the preceding example, each time that a pointer is incremented, it will point to the memory location of the next element of its referent type. Each time it is decremented, it will point to the location of the previous element of its referent type.
Pointer arithmetic is not limited to only increment and decrement operations. You can also add or subtract integers to or from pointers. The expression
p1 = p1 + 9;
makes p1 point to the ninth element of p1’s referent type, beyond the one it is currently pointing to.
Although you cannot add pointers, you can subtract one pointer from another (provided they are both of the same referent type). The remainder will be the number of elements of the referent type that separate the two pointers.
Other than addition and subtraction of a pointer and an integer, or the subtraction of two pointers, no other arithmetic operations can be performed on pointers. For example, you cannot add or subtract float or double values to or from pointers. Also, you cannot use pointer arithmetic with void* pointers.
To see the effects of pointer arithmetic, execute the next short program. It prints the actual physical addresses to which an integer pointer (ip) and a floating-point pointer (fp) are pointing. Observe how each changes, relative to its referent type, each time the loop is repeated.
// Demonstrate the effects of pointer arithmetic.
using System;
class PtrArithDemo {
unsafe static void Main() {
int x;
int i;
double d;
int* ip = &i;
double* fp = &d;
Console.WriteLine("int double\n");
for(x=0; x < 10; x++) {
Console.WriteLine((uint) (ip) + " " + (uint) (fp));
ip++;
fp++;
}
}
}
Sample output is shown here. Your output may differ, but the intervals will be the same.
int double
1243464 1243468
1243468 1243476
1243472 1243484
1243476 1243492
1243480 1243500
1243484 1243508
1243488 1243516
1243492 1243524
1243496 1243532
1243500 1243540
As the output shows, pointer arithmetic is performed relative to the referent type of the pointer. Since an int is 4 bytes and a double is 8 bytes, the addresses change in increments of these values.
Pointers can be compared using the relational operators, such as = =, <, and >. However, for the outcome of a pointer comparison to be meaningful, usually the two pointers must have some relationship to each other. For example, if p1 and p2 are pointers that point to two separate and unrelated variables, then any comparison between p1 and p2 is generally meaningless. However, if p1 and p2 point to variables that are related to each other, such as elements of the same array, then p1 and p2 can be meaningfully compared.
In C#, pointers and arrays are related. For example, within a fixed statement, the name of an array without any index generates a pointer to the start of the array when used as an initializer. Consider the following program:
/* An array name without an index yields a pointer to the
start of the array. */
using System;
class PtrArray {
unsafe static void Main() {
int[] nums = new int[10];
fixed(int* p = &nums[0], p2 = nums) {
if(p == p2)
Console.WriteLine("p and p2 point to same address.");
}
}
}
The output is shown here:
p and p2 point to same address.
As the output shows, the expression
&nums[0]
is the same as
nums
Since the second form is shorter, most programmers use it when a pointer to the start of an array is needed.
When a pointer refers to an array, the pointer can be indexed as if it were an array. This syntax provides an alternative to pointer arithmetic that can be more convenient in some situations. Here is an example:
// Index a pointer as if it were an array.
using System;
class PtrIndexDemo {
unsafe static void Main() {
int[] nums = new int[10];
// Index a pointer.
Console.WriteLine("Index pointer like array.");
fixed (int* p = nums) {
for(int i=0; i < 10; i++)
p[i] = i; // index pointer like array
for(int i=0; i < 10; i++)
Console.WriteLine("p[{0}]: {1} ", i, p[i]);
}
// Use pointer arithmetic.
Console.WriteLine("\nUse pointer arithmetic.");
fixed (int* p = nums) {
for(int i=0; i < 10; i++)
*(p+i) = i; // use pointer arithmetic
for(int i=0; i < 10; i++)
Console.WriteLine("*(p+{0}): {1} ", i, *(p+i));
}
}
}
The output is shown here:
Index pointer like array.
p[0]: 0
p[1]: 1
p[2]: 2
p[3]: 3
p[4]: 4
p[5]: 5
p[6]: 6
p[7]: 7
p[8]: 8
p[9]: 9
Use pointer arithmetic.
*(p+0): 0
*(p+1): 1
*(p+2): 2
*(p+3): 3
*(p+4): 4
*(p+5): 5
*(p+6): 6
*(p+7): 7
*(p+8): 8
*(p+9): 9
As the program illustrates, a pointer expression with this general form
*(ptr + i)
can be rewritten using array-indexing syntax like this:
ptr[i]
There are two important things to understand about indexing a pointer: First, no boundary checking is applied. Thus, it is possible to access an element beyond the end of the array to which the pointer refers. Second, a pointer does not have a Length property. So, using the pointer, there is no way of knowing how long the array is.
Although strings are implemented as objects in C#, it is possible to access the characters in a string through a pointer. To do so, you will assign a pointer to the start of the string to a char* pointer using a fixed statement like this:
fixed(char* p = str) { // ...
After the fixed statement executes, p will point to the start of the array of characters that make up the string. This array is null-terminated, which means that it ends with a zero. You can use this fact to test for the end of the array. Null-terminated character arrays are the way that strings are implemented in C/C++. Thus, obtaining a char* pointer to a string allows you to operate on strings in much the same way as does C/C++.
Here is a program that demonstrates accessing a string through a char* pointer:
// Use fixed to get a pointer to the start of a string.
using System;
class FixedString {
unsafe static void Main() {
string str = "this is a test";
// Point p to start of str.
fixed(char* p = str) {
// Display the contents of str via p.
for(int i=0; p[i] != 0; i++)
Console.Write(p[i]);
}
Console.WriteLine();
}
}
The output is shown here:
this is a test
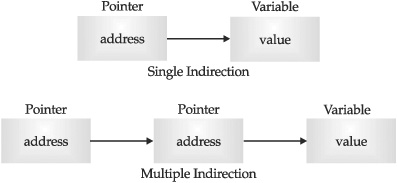
You can have a pointer point to another pointer that points to the target value. This situation is called multiple indirection, or pointers to pointers. Pointers to pointers can be confusing. Figure 20-1 helps clarify the concept of multiple indirection. As you can see, the value of a normal pointer is the address of the variable that contains the value desired. In the case of a pointer to a pointer, the first pointer contains the address of the second pointer, which points to the variable that contains the value desired.
Multiple indirection can be carried on to whatever extent desired, but more than a pointer to a pointer is rarely needed. In fact, excessive indirection is difficult to follow and prone to conceptual errors.
A variable that is a pointer to a pointer must be declared as such. You do this by placing an additional asterisk after the type name. For example, the following declaration tells the compiler that q is a pointer to a pointer of type int:
int** q;
You should understand that q is not a pointer to an integer, but rather a pointer to an int pointer.
FIGURE 20-1 Single and multiple indirection
To access the target value indirectly pointed to by a pointer to a pointer, you must apply the asterisk operator twice, as in this example:
using System;
class MultipleIndirect {
unsafe static void Main() {
int x; // holds an int value
int* p; // holds an int pointer
int** q; // holds a pointer to an int pointer
x = 10;
p = &x; // put address of x into p
q = &p; // put address of p into q
Console.WriteLine(**q); // display the value of x
}
}
The output is the value of x, which is 10. In the program, p is declared as a pointer to an int and q as a pointer to an int pointer.
One last point: Do not confuse multiple indirection with high-level data structures, such as linked lists. These are two fundamentally different concepts.
Pointers can be arrayed like any other data type. The declaration for an int pointer array of size 3 is
int * [] ptrs = new int * [3];
To assign the address of an int variable called myvar to the third element of the pointer array, write
ptrs[2] = &myvar;
To find the value of myvar, write
*ptrs[2]
When working in an unsafe context, you might occasionally find it useful to know the size, in bytes, of one of C#’s value types. To obtain this information, use the sizeof operator. It has this general form:
sizeof(type)
Here, type is the type whose size is being obtained. In general, sizeof is intended primarily for special-case situations, especially when working with a blend of managed and unmanaged code.
You can allocate memory from the stack by using stackalloc. It can be used only when initializing local variables and has this general form:
type* p = stackalloc type[size]
Here, p is a pointer that receives the address of the memory that is large enough to hold size number of objects of type. Also, type must be a nonreference type. If there is not room on the stack to allocate the memory, a System.StackOverflowException is thrown. Finally, stackalloc can be used only in an unsafe context.
Normally, memory for objects is allocated from the heap, which is a region of free memory. Allocating memory from the stack is the exception. Variables allocated on the stack are not garbage-collected. Rather, they exist only while the method in which they are declared is executing. When the method is left, the memory is freed. One advantage to using stackalloc is that you don’t need to worry about the memory being moved about by the garbage collector.
Here is an example that uses stackalloc:
// Demonstrate stackalloc.
using System;
class UseStackAlloc {
unsafe static void Main() {
int* ptrs = stackalloc int[3];
ptrs[0] = 1;
ptrs[1] = 2;
ptrs[2] = 3;
for(int i=0; i < 3; i++)
Console.WriteLine(ptrs[i]);
}
}
The output is shown here:
1
2
3
There is a second use of the fixed keyword that enables you to create fixed-sized, single-dimensional arrays. In the C# documentation, these are referred to as fixed-size buffers. A fixed-size buffer is always a member of a struct. The purpose of a fixed-size buffer is to allow the creation of a struct in which the array elements that make up the buffer are contained within the struct. Normally, when you include an array member in a struct, only a reference to the array is actually held within the struct. By using a fixed-size buffer, you cause the entire array to be contained within the struct. This results in a structure that can be used in situations in which the size of a struct is important, such as in mixed-language programming, interfacing to data not created by a C# program, or whenever a nonmanaged struct containing an array is required. Fixed-size buffers can be used only within an unsafe context.
To create a fixed-size buffer, use this form of fixed:
fixed type buf-name[size];
Here, type is the data type of the array; buf-name is the name of the fixed-size buffer; and size is the number of elements in the buffer. Fixed-size buffers can be specified only within a struct.
To understand why a fixed-size buffer might be useful, consider a situation in which you want to pass bank account information to an account management program that is written in C++. Furthermore, assume that each account record uses the following organization:

In C++, each structure, itself, contains the Name array. This differs from C#, which would normally just store a reference to the array. Thus, representing this data in a C# struct requires the use of a fixed-size buffer, as shown here:
// Use a fixed-size buffer.
unsafe struct FixedBankRecord {
public fixed byte Name[80]; // create a fixed-size buffer
public double Balance;
public long ID;
}
By using a fixed-size buffer for Name, each instance of FixedBankRecord will contain all 80 bytes of the Name array, which is the way that a C++ struct would be organized. Thus, the overall size of FixedBankRecord is 96, which is the sum of its members. Here is a program that demonstrates this fact:
// Demonstrate a fixed-size buffer.
using System;
// Create a fixed-size buffer.
unsafe struct FixedBankRecord {
public fixed byte Name[80]; // create a fixed-size buffer
public double Balance;
public long ID;
}
class FixedSizeBuffer {
// Mark Main as unsafe.
unsafe static void Main() {
Console.WriteLine("Size of FixedBankRecord is " +
sizeof(FixedBankRecord));
}
}
The output is shown here:
Size of FixedBankRecord is 96
Although the size of FixedBankRecord is the exact sum of its members, this may not be the case for all structs that have fixed-size buffers. C# is free to pad the overall length of structure so that it aligns on an even boundary (such as a word boundary) for efficiency reasons. Therefore, the overall length of a struct might be a few bytes greater than the sum of its fields, even when fixed-size buffers are used. In most cases, an equivalent C++ struct would also use the same padding. However, be aware that a difference in this regard may be possible.
One last point: In the program, notice how the fixed-size buffer for Name is created:
public fixed byte Name[80]; // create a fixed-size buffer
Pay special attention to how the dimension of the array is specified. The brackets containing the array size follow the array name. This is C++-style syntax, and it differs from normal C# array declarations. This statement allocates 80 bytes of storage within each FixedBankRecord object.
Beginning with version 2.0, C# has included a feature that provides an elegant solution to what is both a common and irritating problem. The feature is the nullable type. The problem is how to recognize and handle fields that do not contain values (in other words, unassigned fields). To understand the problem, consider a simple customer database that keeps a record of the customer’s name, address, customer ID, invoice number, and current balance. In such a situation, it is possible to create a customer entry in which one or more of those fields would be unassigned. For example, a customer may simply request a catalog. In this case, no invoice number would be needed and the field would be unused.
In the past, handling the possibility of unused fields required the use of either placeholder values or an extra field that simply indicated whether a field was in use. Of course, placeholder values could work only if there was a value that would otherwise be invalid, which won’t be the case in all situations. Adding an extra field to indicate if a field is in use works in all cases, but having to manually create and manage such a field is an annoyance. The nullable type solves both problems.
A nullable type is a special version of a value type that is represented by a structure. In addition to the values defined by the underlying type, a nullable type can also store the value null. Thus, a nullable type has the same range and characteristics as its underlying type. It simply adds the ability to represent a value that indicates that a variable of that type is unassigned. Nullable types are objects of System.Nullable<T>, where T must be a nonnullable value type.
REMEMBER Only value types have nullable equivalents.
A nullable type can be specified two different ways. First, you can explicitly declare objects of type Nullable<T>, which is defined in the System namespace. For example, this creates int and bool nullable types:
System.Nullable<int> count;
System.Nullable<bool> done;
The second way to declare a nullable type is much shorter and is more commonly used. Simply follow the type name with a ?. For example, the following shows the more common way to declare a nullable int and bool type:
int? count;
bool? done;
When using nullable types, you will often see a nullable object created like this:
int? count = null;
This explicitly initializes count to null. This satisfies the constraint that a variable must be given a value before it is used. In this case, the value simply means undefined.
You can assign a value to a nullable variable in the normal way because a conversion from the underlying type to the nullable type is predefined. For example, this assigns the value 100 to count.
count = 100;
There are two ways to determine if a variable of a nullable type is null or contains a value. First, you can test its value against null. For example, using count declared by the preceding statement, the following determines if it has a value:
if(count != null) // has a value
If count is not null, then it contains a value.
The second way to determine if a nullable type contains a value is to use the HasValue read-only property defined by Nullable<T>. It is shown here:
bool HasValue
HasValue will return true if the instance on which it is called contains a value. It will return false otherwise. Using the HasValue property, here is the second way to determine if the nullable object count has a value:
if(count.HasValue) // has a value
Assuming that a nullable object contains a value, you can obtain its value by using the Value read-only property defined by Nullable<T>, which is shown here:
T Value
It returns the value of the nullable instance on which it is called. If you try to obtain a value from a variable that is null, a System.InvalidOperationException will be thrown. It is also possible to obtain the value of a nullable instance by casting it into its underlying type.
The following program puts together the pieces and demonstrates the basic mechanism that handles a nullable type:
// Demonstrate a nullable type.
using System;
class NullableDemo {
static void Main() {
int? count = null;
if(count.HasValue)
Console.WriteLine("count has this value: " + count.Value);
else
Console.WriteLine("count has no value");
count = 100;
if(count.HasValue)
Console.WriteLine("count has this value: " + count.Value);
else
Console.WriteLine("count has no value");
}
}
The output is shown here:
count has no value
count has this value: 100
A nullable object can be used in expressions that are valid for its underlying type. Furthermore, it is possible to mix nullable objects and non-nullable objects within the same expression. This works because of the predefined conversion that exists from the underlying type to the nullable type. When non-nullable and nullable types are mixed in an operation, the outcome is a nullable value.
The following program illustrates the use of nullable types in expressions:
// Use nullable objects in expressions.
using System;
class NullableDemo {
static void Main() {
int? count = null;
int? result = null;
int incr = 10; // notice that incr is a non-nullable type
// result contains null, because count is null.
result = count + incr;
if(result.HasValue)
Console.WriteLine("result has this value: " + result.Value);
else
Console.WriteLine("result has no value");
// Now, count is given a value and result will contain a value.
count = 100;
result = count + incr;
if(result.HasValue)
Console.WriteLine("result has this value: " + result.Value);
else
Console.WriteLine("result has no value");
}
}
The output is shown here:
result has no value
result has this value: 110
If you attempt to use a cast to convert a nullable object to its underlying type, a System.InvalidOperationException will be thrown if the nullable object contains a null value. This can occur, for example, when you use a cast to assign the value of a nullable object to a variable of its underlying type. You can avoid the possibility of this exception being thrown by using the ?? operator, which is called the null coalescing operator. It lets you specify a default value that will be used when the nullable object contains null. It also eliminates the need for the cast.
The ?? operator has this general form:
nullable-object ?? default-value
If nullable-object contains a value, then the value of the ?? is that value. Otherwise, the value of the ?? operation is default-value.
For example, in the following code balance is null. This causes currentBalance to be assigned the value 0.0 and no exception will be thrown.
double? balance = null;
double currentBalance;
currentBalance = balance ?? 0.0;
In the next sequence, balance is given the value 123.75:
double? balance = 123.75;
double currentBalance;
currentBalance = balance ?? 0.0;
Now, currentBalance will contain the value of balance, which is 123.75.
One other point: The right-hand expression of the ?? is evaluated only if the left-hand expression does not contain a value. The following program demonstrates this fact:
// Using ??
using System;
class NullableDemo2 {
// Return a zero balance.
static double GetZeroBal() {
Console.WriteLine("In GetZeroBal().");
return 0.0;
}
static void Main() {
double? balance = 123.75;
double currentBalance;
// Here, GetZeroBal( ) is not called because balance
// contains a value.
currentBalance = balance ?? GetZeroBal();
Console.WriteLine(currentBalance);
}
}
In this program, the method GetZeroBal( ) is not called because balance contains a value. As explained, when the left-hand expression of ?? contains a value, the right-hand expression is not evaluated.
Nullable objects can be used in relational expressions in just the same way as their corresponding non-nullable types. However, there is one additional rule that applies. When two nullable objects are compared using the <, >, <=, or >= operators, the result is false if either of the objects is null. For example, consider this sequence:
byte? lower = 16;
byte? upper = null;
// Here, lower is defined, but upper
if(lower < upper) // false
Here, the result of the test for less than is false. However, somewhat counterintuitively, so is the inverse comparison:
if(lower > upper) // .. also false!
Thus, when one (or both) of the nullable objects used in a comparison is null, the result of that comparison is always false; null does not participate in an ordering relationship.
You can test whether a nullable object contains null, however, by using the == or != operator. For example, this is a valid test that will result in a true outcome:
if(upper == null) // ...
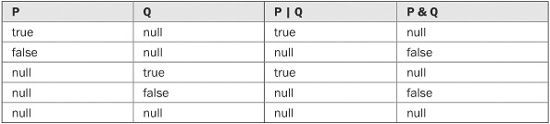
When a logical expression involves two bool? objects, the outcome of that expression will be one of three values: true, false, or null (undefined). Here are the entries that are added to the truth table for the & and | operators that apply to bool?.
One other point: When the ! operator is applied to a bool? value that is null, the outcome is null.
Beginning with C# 2.0, a class, structure, or interface definition can be broken into two or more pieces, with each piece residing in a separate file. This is accomplished through the use of the partial contextual keyword. When your program is compiled, the pieces are united.
When used to create a partial type, the partial modifier has this general form:
partial type typename { // ...
Here, typename is the name of the class, structure, or interface that is being split into pieces. Each part of a partial type must be modified by partial.
Here is an example that divides a simple XY coordinate class into three separate files.
The first file is shown here:
partial class XY {
public XY(int a, int b) {
X = a;
Y = b;
}
}
The second file is shown next:
partial class XY {
public int X { get; set; }
}
The third file is
partial class XY {
public int Y { get; set; }
}
The following file demonstrates the use of XY:
// Demonstrate partial class definitions.
using System;
class Test {
static void Main() {
XY xy = new XY(1, 2);
Console.WriteLine(xy.X + "," + xy.Y);
}
}
To use XY, all files must be included in the compile. For example, assuming the XY files are called xy1.cs, xy2.cs, and xy3.cs, and that the Test class is contained in a file called test.cs, then to compile Test, use the following command line:
csc test.cs xy1.cs xy2.cs xy3.cs
One last point: It is legal to have partial generic classes. However, the type parameters of each partial declaration must match the other parts.
As the preceding section described, you can use partial to create a partial type. Beginning with C# 3.0, there is a second use of partial that lets you create a partial method within a partial type. A partial method has its declaration in one part and its implementation in another part. Thus, in a partial class or structure, partial can be used to allow the declaration of a method to be separate from its implementation.
The key aspect of a partial method is that the implementation is not required! When the partial method is not implemented by another part of the class or structure, then all calls to the partial method are silently ignored. This makes it possible for a class to specify, but not require, optional functionality. If that functionality is not implemented, then it is simply ignored.
Here is an expanded version of the preceding program that creates a partial method called Show( ). It is called by another method called ShowXY( ). (For convenience, all pieces of the partial class XY are shown in one file, but they could have been organized into separate files, as illustrated in the preceding section.)
// Demonstrate a partial method.
using System;
partial class XY {
public XY(int a, int b) {
X = a;
Y = b;
}
// Declare a partial method.
partial void Show();
}
partial class XY {
public int X { get; set; }
// Implement a partial method.
partial void Show() {
Console.WriteLine("{0}, {1}", X, Y);
}
}
partial class XY {
public int Y { get; set; }
// Call a partial method.
public void ShowXY() {
Show();
}
}
class Test {
static void Main() {
XY xy = new XY(1, 2);
xy.ShowXY();
}
}
Notice that Show( ) is declared in one part of XY and implemented by another part. The implementation displays the values of X and Y. This means that when Show( ) is called by ShowXY( ), the call has effect, and it will, indeed, display X and Y. However, if you comment-out the implementation of Show( ), then the call to Show( ) within ShowXY( ) does nothing.
Partial methods have several restrictions, including these: They must return void. They cannot have access modifiers. They cannot be virtual. They cannot use out parameters.
As first mentioned in Chapter 3, C# is a strongly typed language. In general, this means that all operations are checked at compile time, and actions not supported by a type will not be compiled. Although strong typing is a great benefit to the programmer, helping ensure resilient, reliable programs, it can be problematic in situations in which the type of an object is not known until runtime. This situation might be encountered when using reflection, accessing a COM object, or when needing interoperability with a dynamic language, such as IronPython, for example. Prior to C# 4.0, these situations could be difficult to handle. To address this problem, C# 4.0 added a new data type called dynamic.
With an important exception, the dynamic type is similar to object because it can be used to refer to any type of object. The difference between object and dynamic is that all type checking related to a dynamic type is deferred until runtime. (With object, type checking still occurs at compile time.) The benefit of waiting until runtime is that, at compile time, a dynamic object is assumed to support any operation, including the use of operators, calls to methods, access to fields, and so on. This enables code to be compiled without error. Of course, if at runtime the object’s actual type does not support the operation, then a runtime exception will occur.
The following program shows dynamic in action:
// Demonstrate the use of dynamic.
using System;
using System.Globalization;
class DynDemo {
static void Main() {
// Declare two dynamic variables.
dynamic str;
dynamic val;
// Implicit conversion to dynamic types is supported.
// Therefore the following assignments are legal.
str = "This is a string";
val = 10;
Console.WriteLine("str contains " + str);
Console.WriteLine("val contains " + val + '\n');
str = str.ToUpper(CultureInfo.CurrentCulture);
Console.WriteLine("str now contains " + str);
val = val + 2;
Console.WriteLine("val now contains " + val + '\n');
string str2 = str.ToLower(CultureInfo.CurrentCulture);
Console.WriteLine("str2 contains " + str2);
// Implicit conversions from dynamic types are supported.
int x = val * 2;
Console.WriteLine("x contains " + x);
}
}
The output from the program is shown here:
str contains This is a string
val contains 10
str now contains THIS IS A STRING
val now contains 12
str2 contains this is a string
x contains 24
In the program, notice how the two variables, str and val, are declared using the dynamic type. This means that type checking on actions involving these two variables will not occur at compile time. As a result, any operation can be applied to them. In this case, str calls the String methods, ToUpper( ) and ToLower( ), and val uses the addition and multiplication operators. Although these actions are compatible with the types of objects assigned to the variables in this example, the compiler has no way of knowing this. It simply accepts them without question. This, of course, simplifies the coding of dynamic routines, but allows the possibility that such actions will produce a runtime error.
In this example, the program behaves correctly at runtime because the objects assigned to these references support the actions used in the program. Specifically, because val is assigned an integer value, integer operations such as addition are supported. Because str is assigned a string, string operations are supported. Understand, however, that it is your responsibility to ensure that all operations applied to a dynamic type are actually supported by the type of object being referred to. If they aren’t, a program crash will occur.
One other thing to notice in the preceding example: any type of object reference can be assigned to a dynamic variable. This is because an implicit conversion is provided from any type to dynamic. Also, a dynamic type is automatically converted to any other type. Of course, if at runtime such a conversion is invalid, then a runtime error will result. For example, if you add this line to the end of the preceding example,
bool b = val;
a runtime error will result because there is no implicit conversion defined from int (which is the runtime type of val in this case) to bool. Therefore, even though this line will compile without error, it will result in a runtime error.
Before leaving this example, try a short experiment. Change the type of str and val to object, and then try recompiling. As you will see, compile-time errors result. This is because object does not support the actions that are performed on the variables, and this is caught during compilation. This is the primary difference between object and dynamic. Even though both can be used to refer to any other type of object, only those actions supported by object can be used on a variable of type object. By using dynamic, you can specify whatever action you like as long as that action is supported by the actual object being referred to at runtime.
To see how dynamic can simplify certain tasks, we will work through a simple example that uses it with reflection. As explained in Chapter 17, one way to invoke a method on an object of a class that was obtained at runtime via reflection is to call the Invoke( ) method. Although this works, it would be more convenient to invoke that method by name in cases in which the method name is known. For example, you might have a situation in which you know that a certain assembly contains a specific class, which supports methods whose names and actions are known. However, because this assembly is subject to change, you always want to make sure that you are using the latest version. One way to accomplish this is to use reflection to examine the assembly, construct an object of the class, and then invoke the methods defined by the class. By using dynamic, you can now invoke those methods by name (since the names are known) rather than through the Invoke( ) method.
To begin, put the following code in a file called MyClass.cs. This is the code that will be dynamically loaded via reflection.
public class DivBy {
public bool IsDivBy(int a, int b) {
if((a % b) == 0) return true;
return false;
}
public bool IsEven(int a) {
if((a % 2) == 0) return true;
return false;
}
}
Next, compile this file into a DLL called MyClass.dll. If you are using the command-line compiler, then you can use this line:
csc /t:library MyClass.cs
Now, create the following program that uses MyClass.dll, as shown here:
// Use dynamic with reflection.
using System;
using System.Reflection;
class DynRefDemo {
static void Main() {
Assembly asm = Assembly.LoadFrom("MyClass.dll");
Type[] all = asm.GetTypes();
// Find the DivBy class.
int i;
for(i = 0; i < all.Length; i++)
if(all[i].Name == "DivBy") break;
if(i == all.Length) {
Console.WriteLine("DivBy not found in assembly.");
return;
}
Type t = all[i];
// Now, find the default constructor.
ConstructorInfo[] ci = t.GetConstructors();
int j;
for(j = 0; j < ci.Length; j++)
if(ci[j].GetParameters().Length == 0) break;
if(j == ci.Length) {
Console.WriteLine("Default constructor not found.");
return;
}
// Create a DivBy object dynamically.
dynamic obj = ci[j].Invoke(null);
// Now, invoke methods on obj by name. This is legal because
// obj is of type dynamic, and the calls to the methods are
// type-checked at runtime, not compile time.
if(obj.IsDivBy(15, 3))
Console.WriteLine("15 is evenly divisible by 3.");
else
Console.WriteLine("15 is NOT evenly divisible by 3.");
if(obj.IsEven(9))
Console.WriteLine("9 is even.");
else
Console.WriteLine("9 is NOT even.");
}
}
As you can see, the program dynamically loads MyClass.dll and then uses reflection to construct a DivBy object. The object constructed is assigned to obj, which is of type dynamic. Because it is dynamic, the methods IsDivBy( ) and IsEven( ) can be called on obj by name, rather than through the Invoke( ) method. This works, of course, because in this example, obj does, in fact, refer to a DivBy object. If it did not, the program would fail.
Although the preceding example is, obviously, contrived and simplified, it does illustrate in principle the benefit the dynamic type brings to situations in which types are obtained at runtime. In cases in which a type has known characteristics, including methods, operators, fields, and properties, you can use the characteristics by name, through a dynamic type, as in the preceding example. Doing so can make your code cleaner, shorter, and easier to understand.
There is another thing to keep in mind when using dynamic. When a program is compiled, dynamic is actually replaced with object and runtime information is included to describe the usage. Because dynamic is compiled into type object, for the purposes of overloading, dynamic and object are seen as the same. Therefore, the following two overloaded methods will generate a compile-time error:
static void f(object v) { // ... }
static void f(dynamic v) { // ... } // Error!
One last point: dynamic is supported by the Dynamic Language Runtime (DLR), which was added by .NET 4.0.
C# 4.0 adds features that streamline the ability to interact with unmanaged code that is defined by the Component Object Model (COM), especially that used by Office Automation. Some of these features, such as the dynamic type, and named and optional properties, are applicable beyond COM interoperability. COM in general, and Office Automation in particular, is a very large and, at times, complex topic. It is far beyond the scope of this book to discuss it. Therefore, the topic of COM interoperability is also outside the scope of this book.
The preceding notwithstanding, two features related to COM interoperability warrant a brief mention. The first is the use of indexed properties. The second is the ability to pass value arguments to COM methods that require a reference.
As you know, a C# property is normally associated with only one value, with a single get and set accessor. However, this is not the case with all COM properties. To address this situation, beginning with C# 4.0, when working with a COM object, you can use an indexed property to access a COM property that has more than one parameter. This is done by indexing the property name, much as though it were an indexer. For example, assuming an object called myXLApp that is an object of type Microsoft.Office.Interop.Execl.Application, in the past, to set cells C1 through C3 with the string “OK” in an Excel spreadsheet, you could use a statement like this:
myXLapp.get_Range("C1", "C3").set_Value(Type.Missing, "OK");
Here, the range is obtained by calling get_Range( ), specifying the beginning and ending of the range. The values are set by calling set_Value( ), specifying the type (which is optional) and the value. These methods use the Range and Value properties. The reason methods are used is that both of these properties have two parameters. Thus, in the past, you could not refer to them as properties, but needed to use the methods shown. Also, the Type.Missing argument is simply a placeholder that was passed to indicate that the default type be used. However, beginning with C# 4.0, the preceding statement can be written more conveniently as
myXLapp.Range["C1", "C3"].Value = "OK";
In this case, the range values are passed using the indexer syntax, and the Type.Missing placeholder is not needed because this parameter now defaults.
Normally, when a method defines a ref parameter, you must pass a reference to that parameter. However, when working with COM, you can pass a value to a ref parameter without having to first wrap it in an object. This is because the compiler will automatically create a temporary argument for you that is already wrapped in an object, and ref is not needed in the argument list.
It is possible to make one assembly the friend of another. A friend has access to the internal members of the assembly of which it is a friend. This feature makes it possible to share members between selected assemblies without making those members public. To declare a friend assembly, you must use the InternalsVisibleTo attribute.
To conclude Part I, the few remaining keywords defined by C# that have not been described elsewhere are briefly discussed.
The lock keyword is used when creating multithreaded programs. It is examined in detail in Chapter 23, where multithreaded programming is discussed. A brief description is given here for the sake of completeness.
In C#, a program can contain more than one thread of execution. When this is the case, the program is said to be multithreaded, and pieces of the program are executed concurrently. Thus, pieces of the program execute independently and simultaneously. This raises the prospect of a special type of problem: What if two threads try to use a resource that can be used by only one thread at a time? To solve this problem, you can create a critical code section that will be executed by one and only one thread at a time. This is accomplished by lock. Its general form is shown here:
lock(obj) {
// critical section
}
Here, obj is the object on which the lock is synchronized. If one thread has already entered the critical section, then a second thread will wait until the first thread exits the critical section. When the first thread leaves the critical section, the lock is released and the second thread can be granted the lock, at which point the second thread can execute the critical section.
NOTE lock is discussed in detail in Chapter 23.
You can create a read-only field in a class by declaring it as readonly. A readonly field can be given a value only by using an initializer when it is declared or by assigning it a value within a constructor. Once the value has been set, it can’t be changed outside the constructor. Thus, a readonly field is a good way to create a fixed value that has its value set by a constructor. For example, you might use a readonly field to represent an array dimension that is used frequently throughout a program. Both static and non-static readonly fields are allowed.
NOTE Although similar, readonly fields are not the same as const fields, which are described in the following section.
Here is an example that creates a readonly field:
// Demonstrate readonly.
using System;
class MyClass {
public static readonly int SIZE = 10;
}
class DemoReadOnly {
static void Main() {
int[] source = new int[MyClass.SIZE];
int[] target = new int[MyClass.SIZE];
// Give source some values.
for(int i=0; i < MyClass.SIZE; i++)
source[i] = i;
foreach(int i in source)
Console.Write(i + " ");
Console.WriteLine();
// Reverse copy source into target.
for(int i = MyClass.SIZE-1, j = 0; i > 0; i--, j++)
target[j] = source[i];
foreach(int i in target)
Console.Write(i + " ");
Console.WriteLine();
// MyClass.SIZE = 100; // Error!!! Can't change
}
}
Here, MyClass.SIZE is initialized to 10. After that, it can be used, but not changed. To prove this, try removing the comment symbol from before the last line and then compiling the program. As you will see, an error will result.
The const modifier is used to declare fields or local variables that cannot be changed. These variables must be given initial values when they are declared. Thus, a const variable is essentially a constant. For example,
const int i = 10;
creates a const variable called i that has the value 10. Although a const field is similar to a readonly field, the two are not the same. A const field cannot be set within a constructor, but a readonly field can.
The volatile modifier tells the compiler that a field’s value may be changed by two or more concurrently executing threads. In this situation, one thread may not know when the field has been changed by another thread. This is important because the C# compiler will automatically perform certain optimizations that work only when a field is accessed by a single thread of execution. To prevent these optimizations from being applied to a shared field, declare it volatile. This tells the compiler that it must obtain the value of this field each time it is accessed.
In addition to the using directive discussed earlier in this book, using has a second form that is called the using statement. It has these general forms:
using (obj){
// use obj
}
using (type obj = initializer){
// use obj
}
Here, obj is an expression that must evaluate to an object that implements the System.IDisposable interface. It specifies a variable that will be used inside the using block. In the first form, the object is declared outside the using statement. In the second form, the object is declared within the using statement. When the block concludes, the Dispose( ) method (defined by the System.IDisposable interface) will be called on obj. Dispose( ) is called even if the using block ends because of an exception. Thus, a using statement provides a means by which objects are automatically disposed when they are no longer needed. Remember, the using statement applies only to objects that implement the System.IDisposable interface.
Here is an example of each form of the using statement:
// Demonstrate using statement.
using System;
using System.IO;
class UsingDemo {
static void Main() {
try {
StreamReader sr = new StreamReader("test.txt");
// Use object inside using statement.
using(sr) {
// ...
}
} catch(IOException exc) {
// ...
}
try {
// Create a StreamReader inside the using statement.
using(StreamReader sr2 = new StreamReader("test.txt")) {
// ...
}
} catch(IOException exc) {
// ...
}
}
}
The class StreamReader implements the IDisposable interface (through its base class TextReader). Thus, it can be used in a using statement. When the using statement ends, Dispose( ) is automatically called on the stream variable, thus closing the stream.
As the preceding example illustrates, using is particularly useful when working with files because the file is automatically closed at the end of the using block, even if the block ends because of an exception. As a result, closing a file via using often simplifies file-handling code. Of course, using is not limited to just files. There are many other resources in the .NET Framework that implement IDisposable. All can be managed via using.
The extern keyword has two uses. Each is examined here.
The first use of extern indicates that a method is provided by unmanaged code that is not part of the program. In other words, that method is supplied by external code.
To declare a method as external, simply precede its declaration with the extern modifier. The declaration must not include any body. Thus, the general form of an extern declaration is as shown here:
extern ret-type meth-name(arg-list);
Notice that no braces are used.
In this use, extern is often used with the DllImport attribute, which specifies the DLL that contains the method. DllImport is in the System.Runtime.InteropServices namespace. It supports several options, but for most uses, it is sufficient to simply specify the name of the DLL that contains the extern method. In general, extern methods should be coded in C. (If you use C++, then the name of the method within the DLL might be altered with the addition of type decorations.)
To best understand how to use extern methods, it is helpful to work through an example. The example consists of two files. The first is the C file shown here, which defines a method called AbsMax( ). Call this file ExtMeth.c.
#include <stdlib.h>
int __declspec(dllexport) AbsMax(int a, int b) {
return abs(a) < abs(b) ? abs(b) : abs(a);
}
The AbsMax( ) method compares the absolute values of its two parameters and returns the maximum. Notice the use of __declspec(dllexport). This is a Microsoft-specific extension to the C language that tells the compiler to export the AbsMax( ) method within the DLL that contains it. You must use this command line to compile ExtMeth.c.
CL /LD /MD ExtMeth.c
This creates a DLL file called ExtMeth.dll.
Next is a program that uses AbsMax( ):
using System;
using System.Runtime.InteropServices;
class ExternMeth {
// Here an extern method is declared.
[DllImport("ExtMeth.dll")]
public extern static int AbsMax(int a, int b);
static void Main() {
// Use the extern method.
int max = AbsMax(-10, -20);
Console.WriteLine(max);
}
}
Notice the use of the DllImport attribute. It tells the compiler what DLL contains the extern method AbsMax( ). In this case, the file is ExtMeth.dll, which is the file DLL created when the C file was compiled. When the program is run, the value 20 is displayed, as expected.
A second form of extern provides an alias for an external assembly. It is used in cases in which a program includes two separate assemblies that both contain the same type name. For example, if an assembly called test1 contains a class called MyClass and test2 also contains a class called MyClass, then a conflict will arise if both classes need to be used within the same program.
To solve this problem, you must create an alias for each assembly. This is a two-step process. First, you must specify the aliases using the /r compiler option. For example:
/r:Asm1=test1.dll
/r:Asm2=test2.dll
Second, you must specify extern statements that refer to these aliases. Here is the form of extern that creates an assembly alias:
extern alias assembly-name;
Continuing the example, these lines must appear in your program:
extern alias Asm1;
extern alias Asm2;
Now, either version of MyClass can be accessed by qualifying it with its alias.
Here is a complete example that demonstrates an extern alias. It contains three files. The first is shown here. It should be put in a file called test1.cs.
using System;
namespace MyNS {
public class MyClass {
public MyClass() {
Console.WriteLine("Constructing from MyClass1.dll.");
}
}
}
The second file is called test2.cs. It is shown here:
using System;
namespace MyNS {
public class MyClass {
public MyClass() {
Console.WriteLine("Constructing from MyClass2.dll.");
}
}
}
Notice that both test1.cs and test2.cs define a namespace called MyNS, and that within that namespace, both files define a class called MyClass. Thus, without an extern alias, no program could have access to both versions of MyClass.
The third file, test3.cs, which is shown next, uses MyClass from both test1.cs and test2.cs. It is able to do this because of the extern alias statements.
// extern alias statements must be at the top of the file.
extern alias Asm1;
extern alias Asm2;
using System;
class Demo {
static void Main() {
Asm1::MyNS.MyClass t = new Asm1::MyNS.MyClass();
Asm2::MyNS.MyClass t2 = new Asm2::MyNS.MyClass();
}
}
Start by compiling test1.cs and test2.cs into DLLs. This can be done easily from the command line by using these commands:
csc /t:library test1.cs
csc /t:library test2.cs
Next, compile test3.cs by using this command line:
csc /r:Asm1=test1.dll /r:Asm2=test2.dll test3.cs
Notice the use of the /r option, which tells the compiler to reference the metadata found in the associated file. In this case, the alias Asm1 is linked with test1.dll and the alias Asm2 is linked with test2.dll.
Within test3.cs, the aliases are specified by these two extern statements at the top of the file:
extern alias Asm1;
extern alias Asm2;
Within Main( ), the aliases are used to disambiguate the references to MyClass. Notice how the alias is used to refer to MyClass:
Asm1::MyNS.MyClass
The alias is specified first, followed by the namespace resolution operator, followed by the name of the namespace that contains the ambiguous class, followed by the dot operator and the class name. This same general form works with other extern aliases.
The output from the program is shown here:
Constructing from MyClass1.dll.
Constructing from MyClass2.dll.