Configuring tasks to run at a scheduled time or on a recurring basis is a conceptually simple idea. Ken Thompson wrote the original cron at Bell Labs sometime in the mid-1970s, and we use it mostly the same way today. It’s only recently that cloud technology has taken upon itself the improvement of this most venerable of basic task schedulers. Google’s foray into the area came startlingly late, only reaching general availability in March 2019. (Microsoft Azure had scheduling as early as 2015; Amazon Web Services has had it in Lambda nearly since inception, and the Batch service has been available since 2016.)
The use cases for scheduling are varied and endless. Interfacing with older systems may require you to poll periodically to sweep any new data available into BigQuery. Routine maintenance and compliance backups can occur nightly. You may just want to pre-stage reports into views every once in a while.
In Chapter 1, I mentioned that BigQuery has the concept of scheduled queries. It’s true; it does. Unfortunately, the BigQuery native feature has some limitations which might be deal breakers for you. It’s also limited to BigQuery, so if you wanted to chain scheduled queries with some other functionality or run them as part of a larger scheduled job, it wouldn’t suffice.
Cloud Scheduler fills an important gap because it is a serverless complement to all of the other infrastructure we’ve been building and using. As you succeed in lowering or eliminating your self-managed virtual machines, you will come to regard the ones you have left as a burden. Once the majority of your applications are running without the need for manual tuning, you look for ways to eliminate the remainder as soon as possible.
I’ll take the opportunity here to razz some of my support engineers at Google. A few years ago, when I first came across a use case that required scheduling in GCP, I went to the docs to see what my options were. Seeing as I could think of three or four ways to do it in Amazon Web Services without even looking at docs, I was puzzled when I couldn’t find an obvious solution. I contacted my partners at Google and told them what I was looking for. They told me to make a Google App Engine instance and run cron on it—this was the recommended pattern at the time. I am pretty sure I replied with “You want me to muck up my fancy pure serverless infrastructure where the only server runs cron?!” or words to that effect. Now Google Cloud Platform has Cloud Scheduler, everything is serverless again, and all is forgiven. (I very nearly ran schedulers on Amazon Web Services with triggers across to Google Cloud to solve this problem.)
In this chapter, we’ll go over both the native BigQuery scheduling feature and Cloud Scheduler. We’ll also touch on Cloud Tasks’ scheduling capabilities. Using one or more of these tools will help you automate activity on your BigQuery instance that you must do on a regular interval or at a specific time.
BigQuery Scheduled Queries
First, let’s cover the scheduling capabilities built into BigQuery directly. If your needs are limited to operating within BigQuery and its connected services, there may be no reason to incur the overhead of a totally separate service.
BigQuery scheduled queries operate using the BigQuery Data Transfer service. In order to use them, you will first have to enable that service. The first time you go to the Scheduled Queries sidebar, it will first have you do this and then direct you to the main UI screen. If you have no scheduled queries, the main screen will direct you back to the regular console to enter and schedule a query.
Scheduling Queries
To schedule a query, type it into the console window as you would any other interactive query. Run it once to ensure that it returns the data you want. Also, ensure that this data will be changing over time to justify running it on a scheduled basis. You may want to apply a date filter in the WHERE clause to give you only new rows in the last given interval, or you may just want to select all rows that have not been processed by the query yet. A column named ProcessedTime that holds the timestamp of when the query ingested this row could do the trick; then you only need to select all rows where ProcessedTime is NULL. You don’t need to format the query as an INSERT—doing a simple SELECT will still insert the results of that query into the table when you schedule it.
Once you’re satisfied with the query, click “Schedule Query” and “Create New Scheduled Query.” A sidebar appears on the right to allow you to configure the parameters.
Name
Name the query. If you are going to be making a lot of jobs, you can develop a rational naming scheme to keep them straight. For scheduled jobs, I try to use a format like source-destination-action. I don’t put the schedule in the name of the job, because this should be flexible and you may want to change it over time. So, for example, I might name a job “bigquery-email-reporting-sales” to indicate that I’m going to take some sales information from BigQuery and report it over email. Trust me a year from now when someone asks you to stop sending that nightly report, you’ll appreciate that you can distinguish between all of the different jobs you made.
I’ve mentioned it in other contexts, but it’s really important to name things properly. While in an ideal scenario you’d have supplementary documentation for everything you do, in practice things will slip through the cracks. Even if you’re the only person who configures your project, things you did more than a few months in the past may as well have been done by someone else. If many people are working on your project, it is more valuable to standardize and agree on naming conventions for each application than to try to keep up with the rapidly changing names themselves. I have had to excavate many half-finished cloud configurations where it takes me a day to set up the new structure and six weeks to figure out which one of the “sched-job-old-nightly” processes is actually delivering the emails.
Schedule Options
You’ll see common options in the dropdown, where you can just configure hourly, daily, weekly, or monthly. You can also select custom or on-demand.
Custom

This isn’t going to work
When you actually go to schedule the query, it will be rejected. This makes it fairly difficult to determine what formats are actually valid using this sidebar, and it caused me quite a lot of confusion. If you save a custom schedule string and then edit the query, it will appear in the dropdown format, which at least will let you confirm that you did what you expected.
Anyway, the minimum interval is 15 minutes (longer than the 1-minute resolution of Cloud Scheduler), and the maximum interval is 1 year, which you can get with a custom string like “1 of January 00:00”.
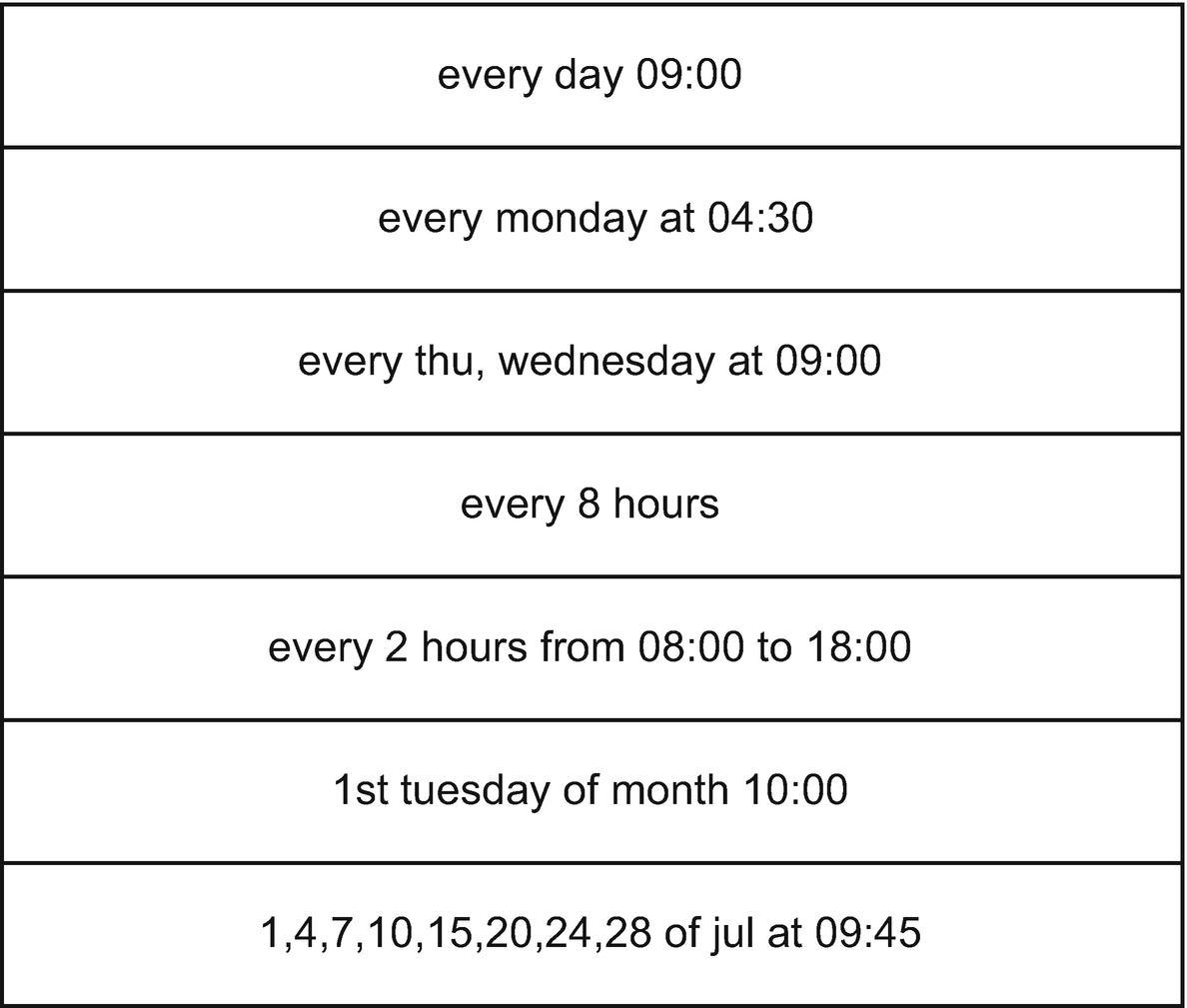
An actual list of schedule strings that work with BigQuery scheduled queries
On-Demand
You can set a query for scheduling and never actually schedule it. If you do this, the only options available for running the query will be via API or by manually running it from the details page. You might use this if you want to save some queries for scheduling but haven’t decided on a schedule yet.
You could also do this to have a safe place to store the queries outside the code and then use an external scheduling solution to invoke the API. That way all of the BigQuery-specific code stays there.
Start Time/End Time
You can also specify when you want this schedule to be active by specifying a start and end time for the recurrence. You could, for example, run your query on every Tuesday at 9 AM, but not start this schedule until a future date and end the schedule some time after that.
Another odd thing that could trip you up is timezones. The schedule options default to your local timezone unless you use a custom time string, in which case they default to UTC. However, for the start and end times, you must specify a timezone, which defaults to your local timezone, but can be changed. Furthermore, you can accidentally set the start time and the end time in different timezones, raising the possibility that your scheduled query actually uses three timezones in its specification—UTC, start timezone, and end timezone.
Even beyond that, once you start using custom schedule strings and timezones, the timezone specifications will lose options, sometimes showing GMT offsets and other times not even allowing the selection of GMT.
Lastly, the scheduler will actually let you specify a recurrence end time which is before the recurrence start time. This should cause the job to never run. Worse yet, it silently removes the end time and creates a sequence that starts on your chosen start date and never ends.
The reason for all of these validation issues is undoubtedly that this sidebar is just an adapter into the transfer service API, which means it has separate logic to construct the API call. Often, when Google does this, there is some way to see what your selections are doing to the generated API call, but I couldn’t find such an option here.
Given all of these inconsistent behaviors and poor timezone handling, I strongly recommend that you review the generated schedule after you save your query and ensure that it does what you expect it to do. (At this writing, this feature is still in beta, so hopefully this will all be resolved by the time it reaches GA.)
Destination for Query Results
This specifies where you want the results of the query to go. At the specified times, the query will be run and the results placed into this table. The table will be created on the first scheduled run. After that, you can choose append or overwrite; append will add the new rows to the bottom of the table, and overwrite will wipe the table and replace it with new data.
Advanced Options
There are two notification options to help you track status of jobs.
Send Email Notifications
If this box is checked, all failed jobs will send an email to the address associated with the query owner. The owner is whatever account you’re logged in as to create the scheduled query—probably your personal email address. This doesn’t give you a lot of options for notifying a distribution group, but for lower-priority work, it’s a good thing to have.
Cloud Pub/Sub Topic
You can also publish job results to a Pub/Sub. Note that while the email only sends failures, the Pub/Sub will receive results for any job run. Since Cloud Scheduler has a similar mechanism, you might write a single function that collates status on all of your scheduled jobs and takes action if something goes wrong. One significant advantage both the BigQuery scheduler and Cloud Scheduler have is that they can tell you when jobs fail. (Traditional cron would just never fire, and so if your job was never invoked, you’d never know it had failed until angry users began calling you.)
Reviewing Queries
After you save your query, you can go to the Scheduled Queries sidebar again, and it will show you a list of your scheduled items. You can also delete or disable them from this window.
Clicking an individual job will let you see its run history and the current configuration. As I mentioned earlier, verify the configuration of your job, specifically the schedule string, start date, and end date, to ensure it matches your expectations. Thankfully, all times are in UTC here, so you should be able to do a straight comparison.
While less robust than the Cloud Scheduler, which we’ll cover next, the BigQuery scheduler works well for operations isolated to BigQuery. These include all kinds of routine maintenance and data preparation. There’s no reason you can’t use more than one solution to fit your needs either, so you may find yourself deploying both scheduled queries and Cloud Scheduler after you’ve learned both.
Cloud Scheduler
To go to the scheduler console, open the hamburger menu and scroll down to tools. “Scheduler” is listed in the tools menu. When you go to the console for the first time, your only option will be to create a new job, or you will see scheduled jobs if you have already made them. Click “CREATE A JOB” to open the scheduling options.
Name
Choose a name for your job, as usual, that is descriptive and doesn’t duplicate other jobs in your project. If you need help, follow the instructions in the preceding “BigQuery Scheduled Queries” section.
There is a nice filter option on the console that supports name, as well as target and the last time the job was run, so worst-case scenario, you can probably still find that needle in the haystack.
Frequency
You can skip this section if you’re familiar with cron. Google Cloud Scheduler uses default cron syntax to describe job frequency. If you are new to cron or need a refresher, read on.
Cron (and, by extension, Cloud Scheduler) uses a shorthand that has been well established for decades. It is relatively flexible and easy to specify and works with pretty much any Unix or Linux scheduler tool. Unfortunately, I have yet to find an appointment scheduling system that lets me schedule my recurring meetings in cron syntax, but one can dream.
Point of note: You will hear both “cron” and “crontab” used to indicate this syntax. Cron is the daemon, or background-running process, that actually executes the scheduled tasks at the desired time. Crontab is the program that allows you to view and edit the syntax of the crontab file, which is the input that cron uses to run its jobs.
Formatting
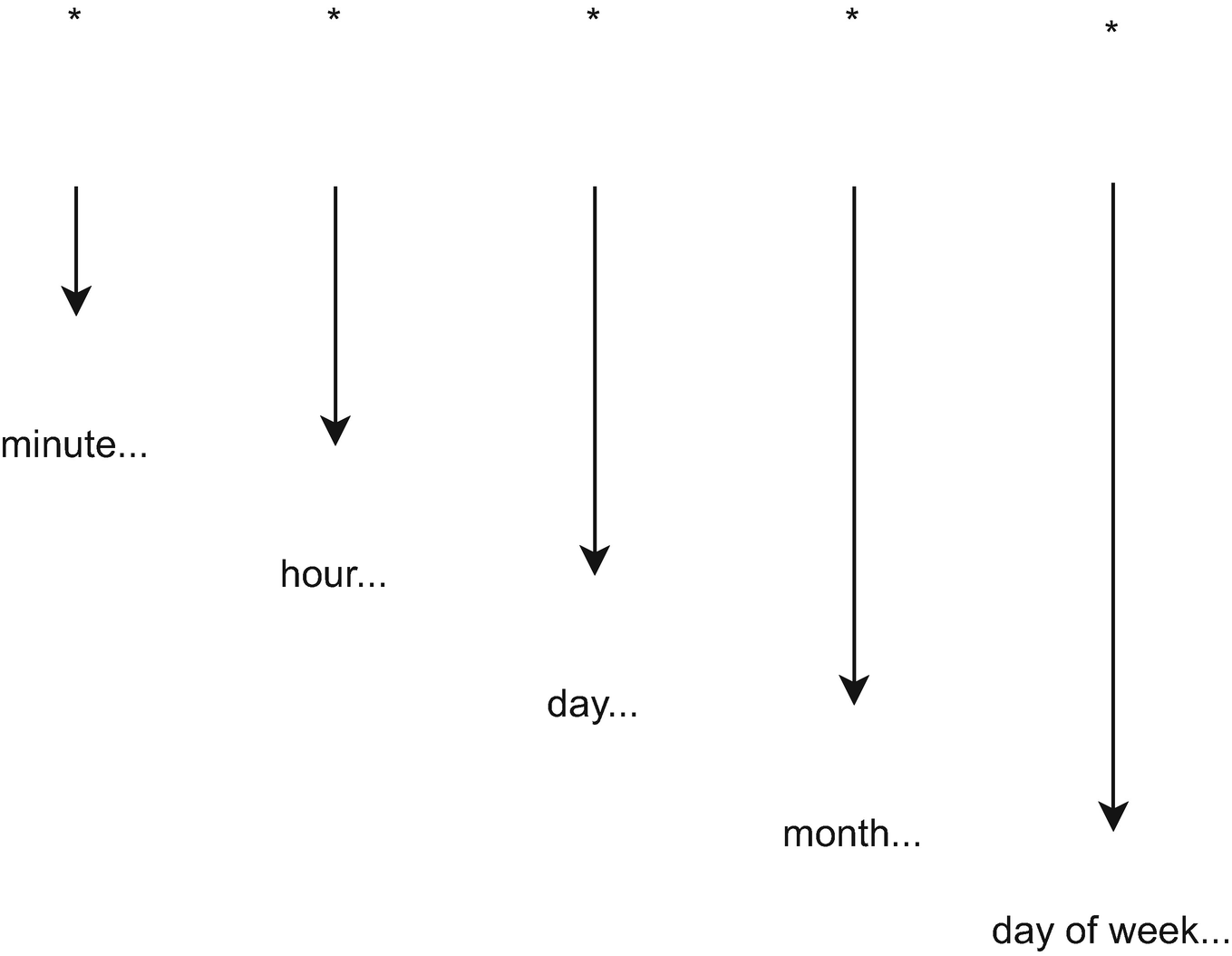
* * * * * (min, hour, day of month, month, day of week)
The values thankfully predate JavaScript and are zero- or one-based as appropriate for the unit. So minutes are 0–59, hours 0–23, day of month 1–31, month of year 1–12, and day of week 0–7, where 0 is Sunday and 6 is Saturday. (7 is Sunday again, interchangeable with 0 in an attempt to support both Sunday and Monday as the start of the week.1)
Cron implementations vary in how they handle illegal specifications. Cloud Scheduler is pretty good at catching invalid dates (like February 30th), but best practice is not to specify schedules that might be interpreted ambiguously, that is, every month on the 29th. Most systems will only run February 29th’s job on every leap year.

Garden-variety cron expressions: once a minute, every Thursday, every other Saturday at 3 AM, once an hour from midnight to noon, that kind of thing
If you want to use the cron format and have some odd use cases (undoubtedly specified by that one stakeholder you couldn’t talk out of it…), you can start your job by doing some additional checking to see if the case is fully met. For example, if you want to run on the first of the month unless it’s a full moon, you can set a cron expression to run on the first of the month and then check at the top of the code in the job if it’s currently a full moon.
I really don’t recommend this if you can avoid it, because you’ll be coupling the schedule of the job to the job itself, which both makes the job less portable and imposes some additional restrictions that are difficult to document. Chances are in the future that some user will reschedule the job and then wonder why it’s not firing. If you do have to do this, make liberal use of both code commenting and logging so that it doesn’t create a tricky situation for someone else trying to reuse the job.
BigQuery Scheduling Format
It’s inconsistently documented, but you can use the “English-like schedule” format from BigQuery scheduling here too. This could give you a little more flexibility when a single cron expression doesn’t capture your schedule. I would still recommend using the cron format if you can, since it will be more widely recognized and understood.
I also found some references in the Google documentation calling it “App Engine cron format,” which makes sense, since Cloud Scheduler was originally a cron service for App Engine only.
Tools
Considering the venerable age of the cron format, there are countless tools for helping you specify, test, and convert cron parameters for usability. One tool I have found especially useful is crontab.guru (http://crontab.guru), which you can use to generate expressions or to parse them into something you can read. It’s also great if you’re just trying to get a feel for the capabilities—you can click “random,” and it will generate and parse a random cron expression. It does use non-standard syntax like @yearly and @daily, which Cloud Scheduler does not support. (Another quick tip: If you don’t like this particular tool, I guarantee there are others for your desired stack or operating system.)
Timezone
Specify the timezone in which you want the job to run. This is actually a nice touch for jobs that need to run in local time to a particular user, but in general as with most time-based applications, you want to use Coordinated Universal Time (UTC).
The primary reason for this is that local time may observe Daylight Savings Time (DST). As we’ll get to in the following, this may cause undesirable results unless you are specifically looking to follow local time.
Target
Cloud Scheduler allows three targets, from which you can trigger anything else you need to. Note that BigQuery itself is not a target, so you will be scheduling jobs in concert with other techniques to hit BigQuery directly. For example, you could use this in tandem with the App Engine stream we set up in Chapter 6 in order to stream data into BigQuery at a given time. That process works for any other code you would want to put into that function as well.
HTTP
HTTP is the most generic of the options. You can hit either an HTTP or an HTTPS endpoint with any method and a request body if required.
One major problem with the UI console is you cannot specify custom headers. Often, if you are hitting an arbitrary URL on a scheduled basis, you will need to identify yourself in some way using the HTTP headers, and that’s not possible in the UI. It is, however, possible in the command line call, and we’ll cover it there.
Scheduler supports all the HTTP methods, including PATCH and OPTIONS. I enjoy the idea that you’d want to make an OPTIONS call to an HTTP endpoint on a recurring basis with no ability to do anything with the output. I can think of only one minimally valuable case for doing this, which is if you wanted to ensure that a given endpoint was currently supporting some form of Cross-Origin Sharing Request (CORS). Either way, you aren’t going to need OPTIONS for BigQuery!
If you specify POST, PUT, or PATCH, you will have the option to supply a request body. This may be useful if you are triggering calls to your APIs on a scheduled basis and need to distinguish between multiple behaviors.
Auth Header
If you have endpoints running on the public Internet (or, really, even if they aren’t), it is a best practice to secure all of your endpoints. The last thing you need is unauthorized users learning about your scheduled endpoints and conducting denial-of-service attacks on them by hitting them repeatedly. Worse yet, the responses to those jobs may have sensitive information about your application’s architecture that may render it vulnerable to other attacks.
Google Scheduler supports two basic methods of authorizing to HTTPS endpoints, OAuth and OIDC (OpenId Connect). Both require additional configuration and have some limitations.
The first is that you can only use the HTTPS scheme. This is a limitation of all authorization schemes, Google or otherwise; the HTTP headers must be transmitted securely so that they cannot be intercepted and used by malicious entities.
The second is that you will need to have a service account with the correct permissions to authorize at the destination. If you are using an OAuth token, that also means that you can only use endpoints on the googleapis.com domain. That service account must also have the proper permissions. At minimum, this is the Cloud Scheduler Service Agent role. The default Cloud Scheduler principal already has this permission. Additionally, the account must have permissions to run whatever the destination service is.
Pub/Sub
This method lets you publish messages to any Pub/Sub endpoint in your project. To use it, you need only specify two things.
Target is the name of the topic in your project. The payload is the string you want to send to that topic. The payload should be specified in whatever format the subscriber to that queue is looking for. Note that some payload is required, even if you don’t need parameters for whatever reason.
This method is best when you need to trigger an external workflow on a schedule. Since services like Dataflow support Pub/Sub as a trigger, you can initiate a Dataflow pipeline on a defined schedule by using this method. Set Cloud Scheduler to trigger a Pub/Sub on your schedule, and have Dataflow subscribe to that Pub/Sub as the job trigger. That pipeline could then handle multiple actions on your data, including insertion to both BigQuery and other destinations, custom logging, and so forth.
One thing to be aware of is that using a Pub/Sub pattern disconnects your scheduled job from the thing that will execute on it. It is fully asynchronous, which means that Cloud Scheduler will consider the job to be successful when it has pushed your message to the queue. If nothing is on the other side to receive it, the job will continue running successfully, but nothing will happen. A job configured to run on a minute-by-minute basis with no target will stack over a thousand messages in the queue, all of which will sit unread.
If you are using Pub/Sub, design defensively around this pattern so that the job behaves in a failure condition.
App Engine HTTP
The presence of this item hints at Cloud Scheduler’s origins. Before Cloud Scheduler existed, App Engine had a built-in cron service—the very same service as was recommended to me in this chapter’s introductory story. That scheduler worked with some substantial limitations. (For example, it only supported the GET method. Maybe that’s why they overcompensated and now you can schedule OPTIONS?) Now, with Cloud Scheduler, you can recreate all of your legacy App Engine crons as scheduler jobs.
This form is also very simple to use: specify the URL and the service. The URL must start with a slash, as it represents an App Engine URL available to your project. The service represents the API on that App Engine application that you want to call.
You specify the usual HTTP method here (minus PATCH and OPTIONS) that you want the endpoint to receive. And as with the HTTP target, if you specify POST or PUT, you will also need to supply a body.
App Engine gives you two additional features here, both of which remedy limitations with the earlier App Engine Scheduler. You can target specific instances or versions of your App Engine applications, whereas before, the App Engine Scheduler was locked to a specific instance and the version that instance was using. Probably also not super useful features for integration with BigQuery, but I note them for the sake of completeness.
As for authorization, with App Engine, Google will automatically be able to authorize the call inside the same project using its built-in security model. This is one area in which GCP has been steadily improving, allowing security parameters to be handled directly by the Identity and Access Management (IAM) system.
Target Use Cases
- HTTP/HTTPS: Use this option for synchronous calls to endpoints either inside or outside of GCP, excepting App Engine:
With OAuth for services inside of GCP
With OIDC for services outside of GCP
Pub/Sub: Use this option for asynchronous calls to workflows within GCP, where you know that the message will be received in a timely fashion or with which you can tolerate stacking or delay.
App Engine HTTP: Use for any endpoint inside App Engine.
Once you’ve specified all of your options, you can save the job. If this was the first job you’ve scheduled, you will now see the regular console, showing all of your jobs.
Status
A couple of nice columns appear here which help you to see the progress and results of your jobs. You can see the last time the job ran (or if it has never run), the result of the job (failure or success), and the logs. You can also trigger a one-time run for testing or to compensate for a missing job.
Two notes on this: First, remember when I said earlier that you shouldn’t couple scheduling logic into the job itself? If your job checks to see if it’s currently a full moon, running an off-schedule job won’t do anything if the conditions internal to the job aren’t met. Keep in mind that you’ll be giving up this flexibility as well as some intelligence about why this particular job didn’t run—although you can compensate for that with the next note.
Scheduled jobs produce events which are recorded in Cloud Logging, which we’ll be covering in greater detail in Chapter 12. You’ll be able to store the logs from the Cloud Scheduler in BigQuery and produce detailed reports of how often jobs succeed and fail, how often they run, and so forth.
You can also, with some loss of precision, use the logging to determine whether a job was run by the scheduler or manually from the console. The first event the scheduler logs is an “AttemptStarted” in this event. This log contains both the received timestamp and the scheduled time for the job. When you run a job manually, the scheduled time remains the next scheduled time the job was to run, whereas the timestamp will be the current time. Assuming you didn’t click the “Run Now” button precisely when the job was supposed to run, you can probably tell what triggered it and use that to inform a different behavior in your job. If you reach this level of complexity for scheduling, you should probably solve the problem with documentation, that is, write a detailed description for the job that includes all of the non-standard things it is doing.
However, I encourage you to take a look at the logs for Cloud Scheduler anyway, since they are relatively simple compared to other services and will help you understand the process of creating event sinks and acting on logging when we get there in Chapter 12.
Command-Line Scheduling
Another way to schedule jobs is to use the Google Cloud command-line tool (gcloud). Since schedulers evolved on the command line, it seems completely natural to continue the trend. Also, Google tends to release new features to the command-line tool that are not available, or not yet available, in the UI. Since Cloud Scheduler is a relatively new service, some of the useful features are not exposed in the UI.
The default behavior is to show you all of your scheduled jobs. The full documentation on the command at https://cloud.google.com/sdk/gcloud/reference/scheduler/jobs is comprehensive and will show you how you could convert the job specification from what we just reviewed on the Cloud UI to the command-line version. However, here are some flags that will configure the behaviors not exposed to the UI.
--attempt-deadline
The --attempt-deadline flag will allow you to set a timeout for initial response from the endpoint. If your request doesn’t respond within this deadline, the job fails.
--headers
The --headers flag will let you specify HTTP headers to send with the job. This works with the HTTP and App Engine targets. (Pub/Sub has no HTTP interface.) If your destination endpoint requires certain headers to operate, this is the only way to specify them.
Yes, you could also use this to allow the scheduler to hit endpoints with Basic Authorization enabled. Please avoid this if at all possible; your credentials will be stored with the job for anyone with the scheduler read permission to see, and this is not in any way secure.
--message-body-from-file
You can create a job’s POST/PUT/PATCH body from a file, rather than in the UI console. This is useful for interoperating with a tool that you may already be using to construct POST bodies, like Insomnia or Postman.
Retries and Backoffs
The other major feature set supported by the CLI but unavailable to the UI is control of the retries and backoff system. Cloud Scheduler will automatically retry the job on a schedule you specify, if you want it to. This lets you get some of the advantages of the asynchronous Pub/Sub method without having to write any code to deal with failures or stacking.
--max-backoff: The longest amount of time between retries along the exponential backoff path
--max-doublings: The number of times to double the wait between retries, that is, how many iterations of exponential backoff
--max-retry-attempts: How many times to retry
--max-retry-duration: How long to retry, in total, from the first attempt
--min-backoff: How long to wait before the first retry
For a deeper explanation of how exponential backoff works, see Chapter 6, where I explained it in the context of request quotas for BigQuery streaming.
Good Scheduling Practices
When creating jobs and managing their environment, there are a number of practices that are worth following to ensure that jobs run the way they are supposed to, have no intended side effects, and are easy to understand and maintain.
Rescheduling
The behavior for how jobs behave if you disable/enable them varies by system. In Cloud Scheduler’s case, if a job was scheduled to run while disabled, that job will run immediately as soon as you reenable it, rather than waiting for the next scheduled time.
This is an important note if you disabled the job because it became unsafe to run or had a potentially negative effect. If the job clears all of your commission values on the fifth of the month and you disable it on the fourth to prevent that, turning it on the sixth will do it anyway, rather than waiting for the next fifth of the month. This has potentially catastrophic consequences.
Idempotency
Idempotency refers to a condition where a function has the same results no matter how many times it is invoked. It’s important in functional programming as a related principle to immutability. The easiest way to comply with idempotency is to have the first call take the action and subsequent calls recognize that the action has already been taken and do nothing.
Cloud Scheduler operates on an “at least once” delivery model. This means that your job is guaranteed to run. However, in some cases it may run more than once. This seems like a silly thing to note, since by definition a recurring job is going to hit an endpoint more than once. However, if your job is doing something that relies on the external environment, make sure you protect it from this situation.
In the full moon example, say that you schedule your job to run daily, but the job does nothing unless it is also a full moon. The job’s responsibility is to toggle the werewolf state for all werewolves in a given GCP region. Correspondingly, it may assume that since only one job in the month will qualify for the full moon state, it can just toggle the state regardless. This means that if Cloud Scheduler sent the message twice and it were a full moon, the job would first turn everyone into werewolves, but then turn them back again! In cases like these, protection for idempotency is critical. (The solution in this case would be, in addition to checking if it is a full moon, to check if the werewolves have already been activated and do nothing if so.)
Timezones
In any event, if you are not using UTC, be sure to choose the correct timezone, even though multiple timezone specifications will have the same UTC offset at any given time. For example, even though in the summertime Pacific Daylight Time and Mountain Standard Time (i.e., Arizona) are both UTC-7, this will not hold true once DST ends in October and the west coast returns to one hour earlier.
This also ties into idempotency in that local time may repeat or skip hours. Daylight Savings Time is implemented in the United States such that when clocks move forward in the springtime, they go from 1:59:59 AM local time directly to 3:00:00 AM. If you have a job scheduled to run every night at 2 AM, this job will not run in US local time that night. In UTC, it will be a fixed time, which means it will run one hour later in local time, but will not be skipped.
If your business operates in a single timezone and you are doing business-related activity that is meant to occur at a given local time, the behavior to run one absolute hour later during part of the year could be correct. I agree that if you are scheduling the start and end of a sale, it’s unusual to have the sale start at midnight in the winter and 1 AM in the summer. In those cases, you’ll have to decide which time is more relevant. But for all these reasons, and many more, prefer UTC everywhere unless you have a compelling reason to do something else.
Testing
When you first create a job, test it both by clicking “Run Now” and by scheduling an invocation to occur several minutes in the future. You might do this when you first buy an alarm clock, to make sure that it works one minute from now, reasoning that it will then also wake you up in the morning. While in most cases running the job manually should replicate all of the test conditions, I also prefer the peace of mind that Cloud Scheduler is running as intended.
Also, be sure to check the logs for the first couple invocations of your job, to make sure it is stable. As I mentioned before, you can run the scheduler logs into a BigQuery sink if you need more detailed information available there.
Resolution
The maximum resolution of Cloud Scheduler (and most standard cron implementations) is one minute. The mechanics of running a serverless and globally distributed timing system make it difficult to guarantee timing to a shorter interval. Additionally, while the task will run inside the minute you specify, it’s not guaranteed to start precisely at the zeroth second of that minute, though it usually gets pretty close. Anyway, you shouldn’t use Cloud Scheduler for tasks that you need to schedule more precisely.
Overlap
Cloud Scheduler will not allow two simultaneous executions of the same job. If your job is still running when the next invocation fires, the second invocation will be delayed.
There are a few ways to handle this. If your job takes too long, set the schedule farther apart; by definition you’ll be running continuously anyway. If your job only takes too long under heavy volume, you could use the Pub/Sub architecture to stack executions asynchronously. When traffic is heavy, the stacked calls will cause the process to run continuously. After traffic falls again, the job will “catch up” and begin running on the regular process again.
Cost/Maintenance
At this time, the free tier for Scheduler allows for three jobs. Additional jobs cost 0.10 USD per month. This is unlikely to break the bank, but if you aren’t using a job, pause or remove it anyway.
Additionally, if the job remains running and is still consuming destination resources, you’ll continue to get billed for those too. A rogue Dataflow pipeline operating on a frequent schedule can become quite expensive. (BigQuery can save the day again, though! You can export Cloud Billing reports to BigQuery too, where you can do analysis on where your costs are leaking.)
If you’re only using Cloud Scheduler for light-duty work, you can almost certainly remain on the free tier. The Pub/Sub free tier allows 10 GB of free data a month. Say you run a job every minute using your free-tier schedule allowance. You could send 3-kilobyte payloads per message and still not pay a penny.
Other Scheduling Methods
Besides Cloud Scheduler, there are several other options for scheduling BigQuery activity. Here are a few additional possibilities.
Cloud Tasks
Cloud Tasks is a service on GCP designed to allow for asynchronous workflows. Essentially, it is a distributed execution queue. The primary use with respect to BigQuery is that you could use Cloud Tasks as an intermediate layer between a user and a long-running database update.
For example, let’s say that you surface data from BigQuery to users on a custom report portal. When the user clicks the button to request a report, BigQuery initiates a process that could take minutes or hours to complete. The user’s synchronous call from the application could create a task in a Cloud Tasks queue and then immediately return to the user to let them know that their report will be ready later. The application flow can continue uninterrupted while the report is queued and executed.
In the context of scheduling, Cloud Tasks also supports running a task at a future time. However, it is not for recurring tasks; a single task is queued and executed once, even if the execution is not until a later point.
Cloud Tasks has no UI for creating and managing tasks, and since it’s not a recurring scheduler, we won’t go into greater depth here. This topic is more of note to applications engineers, who can build it into workflows which have downstream calls to BigQuery.
Nonetheless, it is a powerful tool for separating the user interface of a custom application from long-running processes like complicated BigQuery analysis workflows. If, after your warehouse is up and running, you hear users complaining that “reports take forever” or “when I try to download a report, I have to wait for minutes,” suggest that your engineering team look into Cloud Tasks as a way to let the user know that the process will take some time and they can come back later to retrieve the results.
Cloud Composer
Cloud Composer is the Google Cloud implementation of Apache Airflow, a general-purpose workflow scheduler. On the surface, it looks somewhat similar to Apache Beam (see Chapter 7); but despite its utilization of a DAG (directed-acyclic graph) to execute nodes in a sequence, it is not a data processing solution. You can certainly use Airflow to trigger Beam pipelines—well, let me rephrase. You can certainly use Composer to trigger Dataflow—but the concept of “streaming” really doesn’t make sense in the Airflow paradigm anyway.
GCP will handle the server provisioning for you when you create an environment. You specify the characteristics of the underlying Google Kubernetes Engine (GKE) cluster, and it spins it up for you as an Airflow environment. This takes a while, but then you can begin to build your DAG. Airflow is Python-native, but it can speak other languages as well. Using “operators,” you can connect to other systems and invoke tasks as part of your workflow. There is, of course, a BigQuery operator,2 among many others.
Ah, but back to the main point: Airflow DAGs can be scheduled using cron syntax. Specifying a start date, an end date, and a cron schedule will automatically create an instance of the workflow at the specified times.
If you’re comfortable in Python and want to build more complex workflows, Composer is a good choice. By centralizing the workflows in an open source tool, you also gain some portability, as well as better self-documentation of what your workflows are doing and how they are performing.
BigQuery Transfer Service
The BigQuery Transfer Service is an option if you need a single operation, namely, transferring data inside of BigQuery or from other services such as Amazon S3. To use this service, click “Transfers” on the left side of the BigQuery UI. For a simple dataset operation, choose “Dataset Copy” as the source. You can transfer datasets within the same region or to other regions.
Note that this appears to be a different UI than the Google Cloud Platform “Transfer” service, which can load data into Google Cloud Storage on a recurring basis. Of course, you could combine that with Cloud Scheduler to get regular data imports from Amazon S3 or Azure Storage.
Summary
Google Cloud has several methods you can use to schedule BigQuery processes at a later or recurring schedule. BigQuery has a scheduler built in, which is based on the BigQuery Data Transfer service. The BigQuery scheduler is useful for controlling processes that run entirely inside BigQuery and which can be represented in a BigQuery SQL command. For more complex processes, Google Cloud Scheduler can trigger any arbitrary HTTP, App Engine, or Pub/Sub endpoint, which you can then use to initiate BigQuery tasks. The command-line application for Cloud Scheduler exposes a few additional features that the UI does not. Google Cloud has several other scheduling systems that you may be able to use if you have a specific use case.
In the next chapter, we’ll look at Cloud Functions, GCP’s solution for functions as a service and which will allow you to make your data processing pipelines even more powerful while still remaining completely serverless.