If you’ve been building on the cloud, you have likely encountered the functions-as-a-service (FaaS) paradigm already. Amazon has offered the Lambda service since 2014, and Google’s equivalent, Cloud Functions, has been generally available since 2016. Other public cloud providers have this capability as well, and increasingly we are seeing it even in specialized platforms. For example, Twilio, the popular communications management platform, has its own flavor called “Twilio Functions.” Twilio Functions is actually AWS Lambda under the hood, but augmented with tool-specific logic and shortcuts.
This term is frequently used along with “serverless technology.” Serverless doesn’t specify a compute boundary specifically to be a function, but the premise is related in that you don’t manage (or know about) the underlying servers. Serverless is also somewhat of a marketing misnomer, since there are still servers involved. This technology is distinct from paradigms like peer-to-peer, which do not actually have a “server” designation.
Google Cloud Functions is a great tool to have in your arsenal. Let’s dig into how they work, how they work with BigQuery, and when you can use them to your advantage.
Benefits
Before we get into the construction of functions that augment the power of BigQuery, let’s talk a little bit about what function as a service offers that differs from other solutions. This solution may or may not be appropriate for your use case. There are a few key benefits that make cloud functions worth considering for your workload.
Management
You’re already enjoying one of the major benefits of serverless, which is that BigQuery itself is a serverless technology. It’s not a function as a service, since it has underlying persistent data storage and divides its queries into compute units on its own.
BigQuery and Google Cloud Functions have this benefit in common. Just as you don’t have to provision and configure a data warehouse to use BigQuery, you don’t need to configure a server, set up a runtime, and scale an application in order to use functions.
Scalability
Functions scale automatically based on usage. To the previous item, since you aren’t managing the server, the cloud provider is free to distribute the queries however it needs to in order to service your requests. This is generally accomplished by setting some hard limits on what you can do inside a cloud function, which we’ll go over in “Drawbacks.”
Cost
As we have discussed in earlier chapters for BigQuery, Cloud Functions are also extremely low cost due to the small resource demand they exert per call. Just as with database servers, the cost of running your own application is stepwise and doesn’t decrease with demand. If you’re paying a dollar per hour per server, you’re going to incur 168 dollars in cost a week no matter what you are doing. As soon as you have too much traffic for one server to support, you go to two servers and pay 336 dollars a week, even if you only need that second server to make a few extra calls.
With serverless, you’re paying only for what you use, per function call. If no one uses your application for a week, you maintain availability without paying anything. This technique, where applicable, can generate huge cost savings over more traditional provisioning.
Reliability
One of the largest problems with maintaining your own servers is making sure they are available at all times to service requests. One misbehaving API call might interfere and crash the entire service layer. Tying up resources on the server for one user might impact the experience for all other users. Wearing my platform architect hat, I can guarantee that no client wants to be told their service is degraded because of another client.
Running functions as a service allows you to be confident that your calls will be available to users when they are needed, without any need for effort on your part.
Drawbacks
Latency
If you’ve heard anything from functions-as-a-service detractors, it’s about the dreaded “cold start.” Cold start refers to the latency from when you initiate a function call until a server is ready to handle that call. In the early days of serverless, this was often considered to be a deal breaker for running a back end. Cloud providers have worked to minimize the frequency and duration of cold starts, but deploying a function in a user-facing capacity may cause frustration when a user has to wait several seconds for the application to start responding.
While it’s not something to ignore, there are ways to mitigate this drawback. In my opinion, the best way is not to use serverless in these use cases, but if you’re set on it, you can use a runtime that spins up more quickly or have a scheduled call that pings your functions periodically to “keep them warm.”
Resource Limits
Generally, cloud providers impose limits on how much memory, compute power, or time an individual cloud function can use. This means that serverless is inherently inappropriate for long-running processes.
However, using a more event-driven model, you can parallelize work so that time traditionally spent waiting for the next step in a workflow is spent idling. For example, you can set the trigger for a function to be on an item entering a queue. The function does its work and then submits a message to another queue for the next step in the process.
Portability
You may be familiar with Docker or the concept of containers. Containers aim to bring portability to computing by allowing you to create a package that has all of the dependencies and code necessary to run your application. FaaS is one step more granular and, as such, doesn’t come with any of the same guarantees. Different cloud providers will have different deployment mechanisms, different supported runtimes, and different ways to interface with file systems and databases.
If it’s important to you to have your code easily deployable across clouds and your own data centers, this may be of concern to you. In the scope of this book, you’re already using BigQuery in the Google Cloud Platform so using the companion services is not as much of a hurdle.
It’s also worth noting that there are several solutions intended to address this drawback. NodeJS has a package called “serverless,” which abstracts serverless compute across multiple clouds and allows you to write code that can run in multiple places. While not especially applicable to BigQuery, this may be a consideration for you if you are already running the majority of your workload in another cloud and still need to pipe data around. There are also ways to use the Node serverless package to package and deploy functions you’ve written in other cross-cloud–compatible runtimes such as Python, but that one I’ll leave as an exercise to the reader.
This area is evolving rapidly. Cloud Run—based on knative—reached general availability in late 2019. This allows you to run containers in a serverless environment without dealing with container management. The collection of technologies that comprise Google Anthos are beginning to enable cross-cloud and on-premise deployment in a managed and transparent fashion.1
Organization
In my opinion, this drawback of serverless systems is under-considered. To manage code and databases, we have reliable source control systems and documentation structures rooted in the best practice of several decades ago. When using managed cloud systems, it is a lot harder to understand what you’ve built and how it is working and, to the uninitiated or newly introduced, can appear like magic. Public cloud providers have hundreds of services and, as we’ve repeatedly seen, countless valid implementations across services and clouds. Once you have an arbitrarily large number of cloud functions, it can become difficult to organize and track them.
There are plenty of companies whose technologies solely serve to automate the creation and reconstruction of cloud infrastructure. If this sort of tool is not applicable at your scale, at least be sure to document what you have done for the benefit of others who need to understand and work on it. Unfortunately, on several occasions I’ve only been able to figure out what portions of a cloud infrastructure are actually active and relevant by looking at the monthly bill.
I’m aware this shades fairly far out of data warehouse management and into DevOps, but I think it’s an important skill to develop as you venture outside of the BigQuery walls to build functions and pipelines that interact with other services. Even in the managed services world, these things are often not intuitive.
Cloud Functions and BigQuery
Some interactive workloads are not appropriate for serverless functions, specifically those that will take a long time to return to a user who is waiting for results. Most of the processes we discuss in this book are batch jobs run without a waiting user, that is, scheduled jobs, ETL, or analytics post-processing. These cases are perfect candidates for Cloud Functions, which is why it’s worth the effort to become familiar with them and how they can give you capabilities beyond what is available strictly in BigQuery.
Generally you will be accessing BigQuery from a cloud function, not the other way around. BigQuery can’t execute cloud functions directly, although there are some convoluted ways around this, which we will cover in Chapter 12 with Cloud Logging (formerly known as Stackdriver.)
Creating a Cloud Function
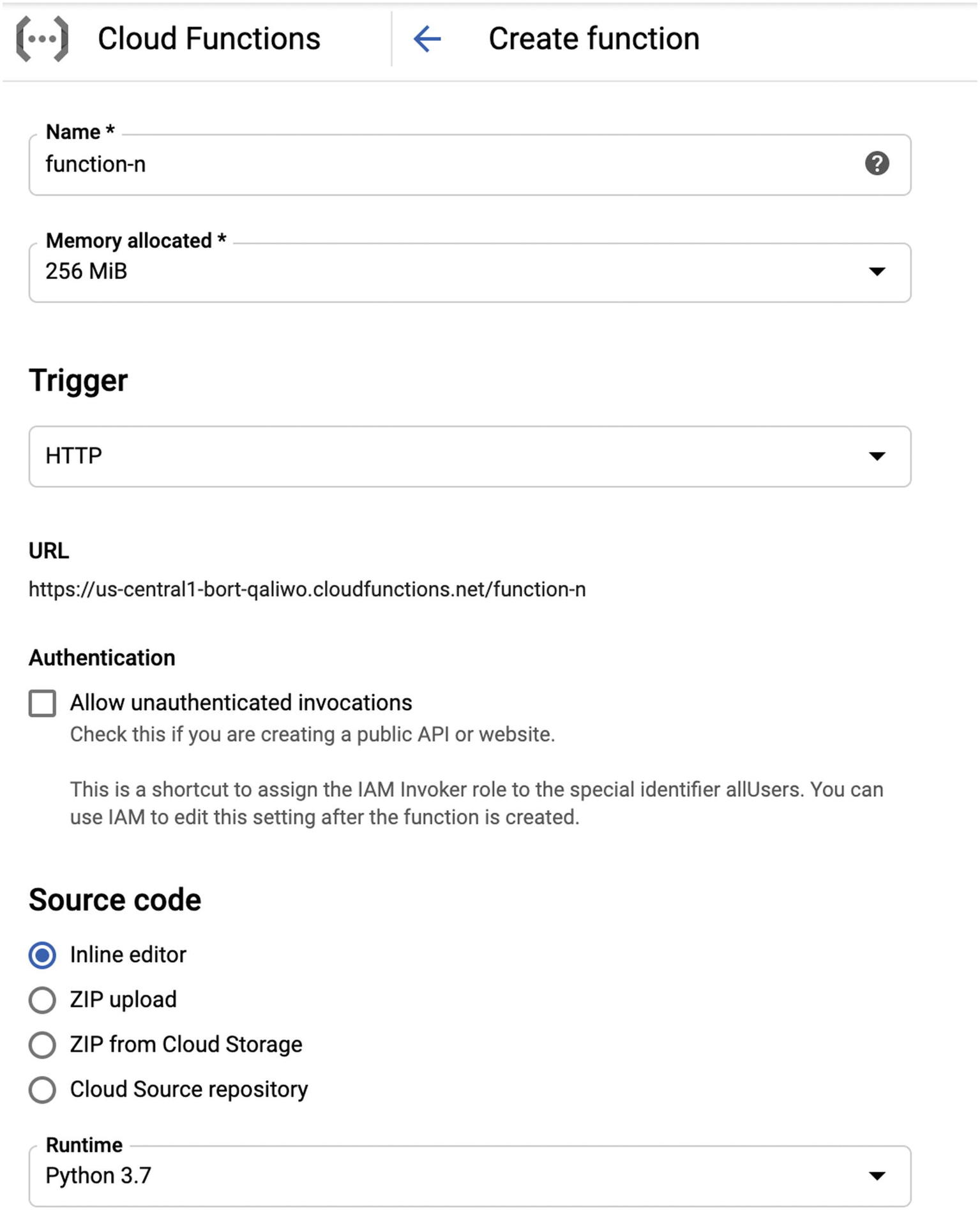
Cloud Function creation screen
Go to the hamburger menu on the cloud console and find “Cloud Functions” under the Compute heading. You may have to enable it for your project, after which you can click “Create Function.” This will open a configuration window for you to specify the parameters.
Name
Your cloud function’s name will determine the URL on which you access it. Choose a name carefully, proceeding from general to specific, that is, application-feature-function-activity. (For example, ramen-bq-ingest-performance-load might take a performance file and load it into the BigQuery instance for the “ramen” application.) There is only one namespace for functions inside each GCP project, so you want to make sure you can distinguish among a lot of things that load data. Using load-1, load-2, load-3, and so on is a good way to cause problems quickly: don’t be that person.
Memory Allocated
You can allocate up to 2 gibibytes of RAM for your function. This directly affects the cost of your function, so choose a reasonable number for the workload your function is performing.
Less commonly known is that this also controls the approximate CPU clock your function will run at. If you need faster invocation, raise the amount of RAM. If you’re serious about this, you would probably also want to time your functions to ensure you actually need the increased processing time. To be clear though, cloud functions cost something along the order of magnitude of a penny an hour, so you might not want to spend too much time tuning this.
Trigger
How your function will be called. This is covered in detail in the next section, but note that as you change the options in the dropdown, the accompanying code sample also changes. This is because the function will expect a different message format depending on where it originated.
Authentication
This is a checkbox indicating whether you want to allow unauthenticated invocations. Essentially, checking this box makes your cloud function public. Only check this box if you want to do that! For ETL, data transformation, and so on, your functions will likely not be public. Using Google Cloud Identity and Access Management (IAM), you can ensure that your internal functions have access to BigQuery and your other services without making anything public.
Source Code
Here, you get to choose where the source for your function comes from.
Inline Editor
If you’re writing an incredibly simple function, you can get away with using the inline editor. You wouldn’t really want to do this at any substantial scale because your source control of that function won’t be very good—Google Cloud will keep track of versions as you update the source, but every time you save a change, it will be automatically deploying the function, which is not great if it’s in production and you break it.
More importantly, you can only upload one code file and one definition file (i.e., requirements.txt) in this mode, which will be pretty severely constraining if you need lots of external packages or any substantive amount of logic.
ZIP Upload
In this mode, you can upload a ZIP file containing all of your code and dependency files. This would at least let you use a code editor, from which you could then zip the file and upload it here. In some ways, this is even more unwieldy than inline, because you have no access to the code, but it’s also not part of any formalized build process.
ZIP from Cloud Storage
This method is the same as the previous, except that the file comes from Cloud Storage instead of your local machine.
Cloud Source Repository
Unknown to nearly everyone, Google has its own GitHub competitor called Cloud Source, and you can use git-like syntax to manage code and builds inside of it. You can load cloud functions directly from Cloud Source branches, enabling a pretty seamless build process from end to end.
While out of scope for this book, Cloud Source also supports mirroring repos to GitHub, and Cloud Build supports automatic triggers to deploy cloud functions, so you can tie auto-deploy, environments, and your full continuous integration solution to cloud functions as well.
Runtime
Google Cloud Functions supports three major flavors of runtime: Golang, NodeJS, and Python. A note if you do use Python: With Python 2.x’s official discontinuation on January 1, 2020, GCP is gradually deprecating support for it. At this writing, Cloud Functions only support Python at version 3.7.
Google Cloud SDKs function equally well in any of these runtimes, so choose the language you are most familiar with or that your organization uses elsewhere. Another major difference between GCP Cloud Functions and other offerings like AWS Lambda and Azure Functions is that runtime support is more limited. GCP does support languages like C#, Java, and Ruby on Google App Engine and Cloud Run, but not here.
There are a few undocumented and unsupported ways to make Cloud Functions use other libraries using dynamic compilation, but I would not recommend them due to lack of official support, increased cold start times, and the relatively easy alternatives.
Function to Execute
The function needs to know its entry point, that is, which method it’s going to start in when the function is invoked. This specification varies by language, but this method will also need a signature that can accept the appropriate payload you asked for earlier, like an HTTP request or Pub/Sub payload.
Region
You can choose the region in which to load your function. Choose the location closest to the majority of your users. Note that some locations are more expensive than others, so consult tier pricing if this is important to you.
Timeout
This specifies how many seconds you want the function to run before aborting unsuccessfully. The default is 60 and the global maximum is 540 (9 minutes). Set this value to the maximum amount of time you expect your function to ever take: if the function churns away uselessly for nine minutes, you’ll be charged for time you didn’t really need to take.
Maximum Function Instances
This specifies how many instances you want to coexist. The default is 0, which means you’ll get as many as you need. You might want to limit this if you are concerned about public denial-of-service attacks or if a huge number of concurrent requests would indicate a bug in the system and you don’t want to pay for that. (I once had a developer rack up a several-hundred-dollar bill in the span of a few minutes because an infinite loop set off thousands of concurrent function requests.)
Service Account
Any activity in GCP needs a principal identity to execute against. Nonuser interactions use service accounts as principals to do this. Following the principle of least privilege, best practice would mean using a service account for this function which has the minimum permissions required to do its job. For instance, if the function is reading a file from Google Cloud Storage and writing it to BigQuery, it needs only Cloud Functions permissions, Cloud Storage reader, and BigQuery writer.2 This prevents someone from being able to upload code that takes other, unwanted actions.
Ingress Settings
This is an additional setting you can use to make sure your cloud function can be accessed only by appropriate parties. By default, it allows all traffic. You can further restrict its accessibility to a single cloud project or a single Virtual Private Cloud (VPC) perimeter.
Egress Settings
This is another security setting you can use to prevent your cloud function from accessing things it shouldn’t. By default, cloud functions will have access to the Internet. Using this feature, you can set them to access only resources within a single Virtual Private Cloud.
The same least privilege principle applies here: if your cloud function doesn’t need access to the Internet to do its job, don’t give it Internet access.
Environment Variables
The purpose of environment variables in any context is to supply settings to code without modifying that code. You can use them similarly here—any variables outside of execution that your function can use to execute can be provided to the environment. This also lets you maintain the same code across multiple environments merely by altering the associated settings.
Your data pipelines may not have multiple environments, but you still might want to store variable values in here like the names of BigQuery datasets or Cloud Storage buckets.
Deploying the Cloud Function

Function deployment
After a short amount of time, you should see a green checkbox showing that the function has been deployed successfully. Clicking the function will show you top-level information about the performance of the function. There shouldn’t be any data here since no one has used the function yet.
You’ll also see all the settings you just selected. If you click Edit, you’ll be brought back into the previous window where you can modify those settings however you like. There’s also a built-in tester you can use to try out your function with the permissions properly set.
Lastly, if you click Trigger, you’ll see how the function is invoked, which we’re just about to cover in the next section. If it’s an HTTP request, you can actually click the link directly and see the function’s URL.
Assuming that you configured it not to be accessible to the Internet, you’ll get a 403 error. That’s good—your function is secure.
Invoking Cloud Functions
There are quite a few ways to execute your cloud function now that you’ve built it. Setting up your execution pipeline will require some operational architecture know-how to serve your particular use case(s). Let’s cover each invocation method with an eye to how it might be useful in your data processing workflows.
HTTP Trigger
This is the lowest common denominator for invoking a function and generally presumes there are other systems out there managing their own infrastructure. You would use this for receiving webhook calls or event data from external systems or even if you just wanted to accept a payload directly from an application for processing into BigQuery.
(If you want to process files, you can use Cloud Storage triggers directly and skip the API call.)
Cloud Pub/Sub Triggers
Cloud Pub/Sub is Google Cloud Platform’s native service for queue management. This is your best bet for gluing services together and making asynchronous workflows for processing. A simple example would be that you want to insert a row into BigQuery to log a certain event. Rather than pausing the event for the BigQuery insert to occur, you can have the event drop a message into a Pub/Sub queue. A cloud function would then pick it up, read the payload, and insert the results into BigQuery. In this case, you have effectively disconnected the BigQuery performance load from the event load itself.
Queue-driven programming is a very common paradigm, so it is good to be familiar with it as you will see it frequently. With BigQuery in the mix, it gives you two benefits: One, as we discussed earlier, is disconnecting the two steps in the process. The other is that you can isolate them logically as well—you can connect whatever you want to the other side of the queue, making more and more complicated responses to the event’s log, without ever changing the code of the event itself.
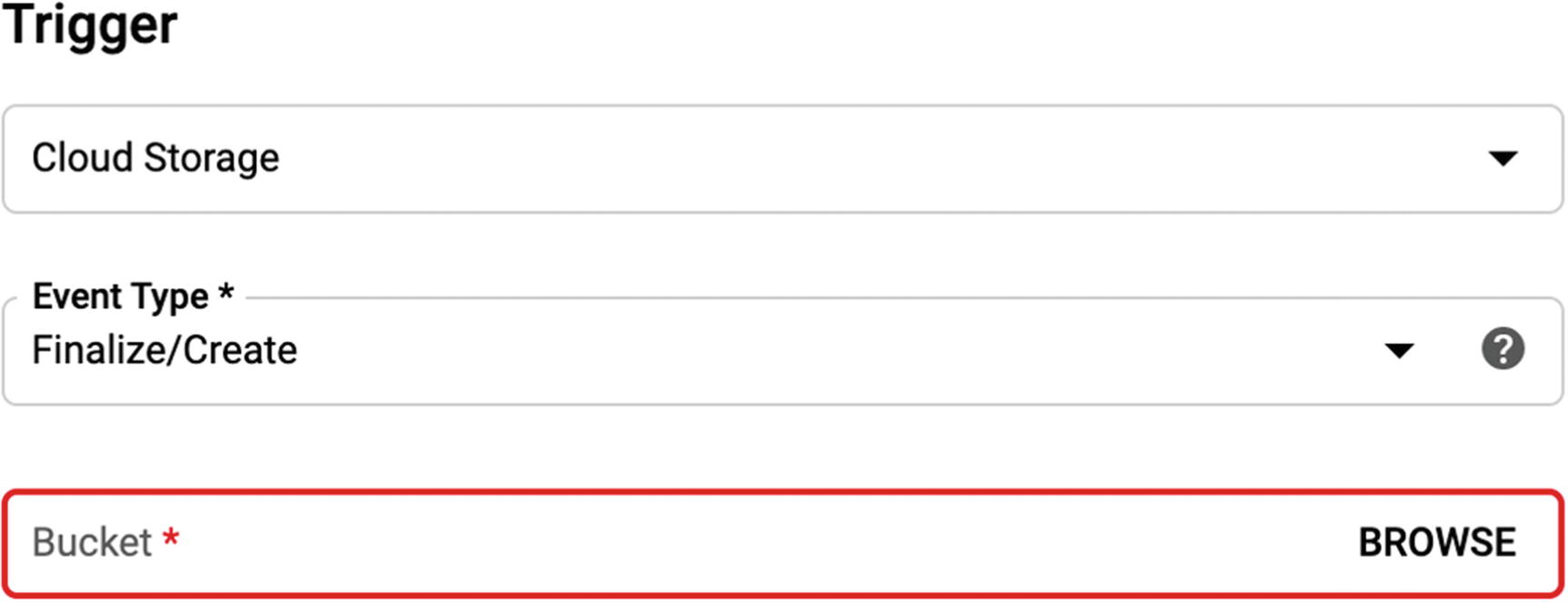
Cloud Storage Triggers
This may be the most interesting of the bunch for its relevance to BigQuery, and in fact we have talked about this in earlier chapters as useful for all kinds of ETL.
In the bad old days, developers used to spend months writing “importer” applications, which often didn’t even do the ETL, later handled by the database layer. Importers only had one job—to monitor for the presence of files in a folder, parse them in some format, and stage them for the database to do something with. I can’t even enumerate all the problems you encounter when building such an importer from scratch: memory overflow, importers failing to notice a file being created, validating records… It’s a wonder these things worked at all.
Using a Cloud Storage pipeline, you can build a serverless importer in an irresponsibly short amount of time. Cloud Storage triggers use Pub/Sub under the hood, but automatically fire events when objects are created or deleted. I’ll detail a working example in the following section.
Cloud Firestore
As we discussed in Chapter 7, Cloud Firestore is Google’s NoSQL managed database technology. It’s great for dumping in data directly for end users, but it’s not designed for (and frankly is terrible at) querying or analyzing the data. The best way to use this with BigQuery is to write a function that listens to changes in your Firestore instance and loads some portion of the data into BigQuery. For straightforward applications with less complex ETL, this can save you the trouble of spinning up a heavy-duty Dataflow pipeline or messing with custom mappers.
That being said, you really do want to watch out for schemas if you go this route. Firestore uses JSON documents, and you will need some way of translating them into a columnar format for BigQuery. If your documents have a lot of nesting and repeating fields and you want to represent those in BigQuery, you may need a more robust approach.
You can also opt just to dump the JSON into BigQuery directly and deal with it later, but that may cause you to have lower performance and higher costs from dealing with the unstructured data directly.
Direct Triggers
I include this for the sake of completeness; direct triggers are only for debugging and not to be used in production workloads. They let you trigger cloud functions directly from the command line for testing. You can use this to simulate the other methods too, that is, by supplying a mock payload for a Pub/Sub message as if it had been triggered directly from the queue.
There’s no direct application to BigQuery for this one, other than that you will want some method of being able to test your cloud functions.
Firebase Triggers
There are some other Firebase triggers that you can use to trigger Cloud Functions. These could be useful to you if you run your mobile back end entirely on Firebase and want to collect data about that application’s performance in BigQuery. In practice, you would use these the same way as the other triggers, having a function collect this information and trigger an insert into BigQuery.
Cloud Scheduler
We covered Cloud Scheduler in the previous chapter, but in this particular area, it can deliver massive benefits to asynchronous workflows. Before Cloud Scheduler debuted, you could set up an amazingly complicated matrix of functions and triggers and quietly humming infrastructure, but there was no managed way to make it execute on a schedule. Organizations found themselves spinning up the only servers in their otherwise serverless landscape solely to run cron jobs and make sure the trains ran on time.
I’m happy to report that that world has also faded into the past, since Cloud Scheduler jobs can invoke Cloud Functions directly. Any transformation, ETL job, or server maintenance that you currently do overnight can now be run as a Cloud Scheduler task. Cloud Scheduler is compatible with cron format, so you can move your maintenance triggers into GCP directly.
Real-World Application
Now that you know what cloud functions are, how they are created, and how your application might handle them in the real world, let’s take a look at a simple example for how this might all plug together.
Clint’s Ramen International is a local chain of ramen restaurants with severely antiquated technology. The restaurants aren’t networked together, and the cash registers aren’t connected to the Internet. As the beleaguered data architect for the organization, you struggle with Microsoft Excel and Access on a daily basis, trying to get basic insights about sales and revenue to present to your marketing team. When the CMO drops by your desk on Monday morning, they ask you how many iced green teas were sold over the weekend. If you start dumping files into your Access database, you might know the answer by Thursday. How can BigQuery help without requiring re-architecture of your system?
This example reflects what a small business goes through on a regular basis. Many organizations pay exorbitant consulting fees to address these problems in suboptimal ways. Other organizations try to force massive change through to their end users, solving the technical problem but risking the business itself. Often the best solution here is something that keeps everything rolling without massive disruption, proves the case, and sets you up for bigger successes as you go.
In this case, you know that each franchise exports its books from its point-of-sale (POS) system every evening and emails them to corporate. Accounting does, well, whatever they do with these things and drops them in a shared folder. You manually then take the files from that folder and load them into the “data warehouse.” Let’s see what we can do about this.
Proposed Design

A workflow to load data through cloud functions into BigQuery
Getting the Files
This design uses everything we’ve covered in the chapter up to this point to create a simple data pipeline to BigQuery. The point-of-sale system exports a CSV already—we’re just going to redirect it to Google Cloud Storage. You could do this in any number of ways, depending on how much access you have to the end users. If you had no access at all, you could actually set up a Pub/Sub function that receives email directly from a box. This would be fairly effort-intensive, so I am going to assume you could have the end users run a small application after exporting that CSV to load it into Google Cloud Storage.
Oddly, there is no direct transfer method between Google Drive and Google Cloud Storage, which would seem like the easiest way. You could apply the same cloud function techniques to transfer data between these services, but it doesn’t work automatically.
You might also consider setting up an (S)FTP server to receive the files. Also oddly, Google Cloud Storage doesn’t support this natively either. (AWS S3 has a managed SFTP transfer service.) One GCP-native way to do this would be to use a utility such as gcsfuse to mount a Google Cloud Storage bucket as a file system and accept (S)FTP uploads into that folder. However, that approach would require you to set up a server and push us somewhat back into the bad old days of importer creation.
There are even more exotic solutions, like using the Amazon S3 SFTP service to receive files, which can trigger a Pub/Sub across to GCP to retrieve the files across clouds. I wouldn’t bother with anything this complicated unless you were already using AWS for everything except BigQuery. You could connect AWS and GCP queues together using—you guessed it—a Google Cloud Function. You could also use the BigQuery Data Transfer service to pull the Amazon S3 bucket over to Google Cloud Storage directly on a schedule.
You could even attempt to write an extension for the point-of-sale system itself, but unless Clint’s Ramen has a surprisingly robust on-site IT function, that would probably also be prohibitively difficult.
My point is that there are many, many valid ways to accomplish each step of the pipeline. Hopefully, armed with a survey of all of them, you can evaluate which delivers the best ROI for your particular use case.
Detecting the Files
Accordingly, after the file arrives at Google Cloud Storage, a trigger will be fired indicating that an object was created.
The finalize event covers any time a new object is created or an existing object is overwritten. There are other Cloud Storage triggers for deletion, archive, and metadata update.3
You could even take this opportunity to email the same file to accounting once you’re finished with it.
Note that I’ve taken advantage of the relatively small scale of this operation to do things in a simpler fashion. These files will all be pretty small and easily accessed in memory by the cloud function. If you’re running millions of transactions daily, you will need something more robust like a Dataflow pipeline. Of course, if you need that, you likely already have a much broader structure to integrate with, and none of this would be necessary in the first place.
Processing the Files
Lastly, you want to ensure that the data arrives in a structure that matches how you intend to use it. This is where you get to apply your knowledge of building data warehouses to do this. You might want to load the data into time-partitioned tables per day, or you might have a store-based system. Your accounting department may also have been relying on the sender’s email address to indicate which store’s data they were looking at, and you need to parse in a column for the store ID itself.
This function, when set to trigger on a file upload, retrieves the fully qualified URI of the file. Then it creates a schema for a date-partitioned table and loads the file to BigQuery. All of the “print” statements log to Cloud Logging (formerly known as Stackdriver).
(You can also change the trigger in the UI Cloud Function creation screen to Cloud Storage and choose these parameters there rather than deploying from command line.)
Getting the Answer
The Final Product
With this pipeline constructed, stores now upload their point-of-sale files on a nightly basis; and those files are automatically detected, transformed, and loaded into BigQuery. These insights are then fed through your reporting system (coming up in Chapter 16) and automatically surfaced to a live dashboard.
When the CMO comes in the following Monday, they swing by your desk again. “Just came by to get you started on the iced tea report again,” they say. “Four hundred and seven,” you reply. They’re astonished. You pull up the report view and show them the data, already processed and validated, thanks to your new pipeline. You also tell them that you emailed a link to this report to them first thing this morning. They didn’t read your email. There’s nothing either of us can do about that.
Caveats
Duplicates: Users may send the same file more than once. This is fairly easily detected by either disallowing overwrites or by checking BigQuery for the given store/date and making sure you have no rows. This gets more complicated if you want to prevent duplication at the row level. Cloud Storage triggers are based on Pub/Sub and are only guaranteed to fire at least once. This means the same trigger may hit multiple times, even if the user only uploaded the file once.
Validation: We assume that because the files are coming from a known external source, they will be valid. This workflow has no protection against people unintentionally or intentionally putting invalid files into the system.
Scale/streaming: As mentioned earlier, this solution will scale relatively well as long as file sizes remain small. Since it uses Cloud Functions, it can accept as many simultaneous files and imports as you care to throw at it. However, if files get too large to be efficiently processed inside a single cloud function’s memory and CPU allocation, they will be rejected by this system.
Schema: This technique is great when you have a single known file type and you know what data you need out of it. This will not work especially well if there are many input file formats, data across multiple files, or evolving schemas. This is where you need to apply your warehouse design know-how to design more robust schemas and move beyond a single function.
Organization: I touched upon this earlier in the chapter as a drawback to serverless systems in general. You need to ensure that you document and understand all the pieces of infrastructure you build so you don’t “lose” them. Tools like Google Deployment Manager can help with this, but your peers should have some idea of how to work with the system you’ve built.
Summary
Functions as a service is a powerful paradigm to write and run code without creating a server or installing an operating system. Much as BigQuery does for data warehouses, Google Cloud Functions allows you to interact with APIs and other GCP services to work with data in BigQuery. Writing a function can be done in a number of ways using the shell tool or directly in the cloud console. Functions can be triggered in a variety of ways, both synchronous and asynchronous, and can be used to insert or select data directly from the project’s BigQuery database. There are countless ways to do this, but we saw in a simple retail example how straightforward it is to build an analysis system to moderate scale with minimal effort.