In diesem Buch werden wir das auf Python basierende Framework Scikit-Learn (http://scikit-learn.org) verwenden. Oft wird auch nur der abgekürzte Name Sklearn genutzt.
Anhand eines kompletten und durchgängigen Beispiels kannst du dich hier schon einmal mit dem Vorgehen beim Machine Learning vertraut machen.
Damit du wirklich lauffähigen Code hast, aber keine Installationsarie durchlaufen musst, haben wir für dich ein sogenanntes Notebook erstellt. Das Notebook erfordert nur einen Browser für seine Darstellung. Der tatsächliche Code wird auf einem Server, auf dem auch sämtliche Software installiert ist, ausgeführt.
Für jedes Kapitel haben wir ein Notebook vorbereitet. Diese sind unter der URL https://github.com/DJCordhose/buch-machine-learning-notebooks (https://bit.ly/ml-kug) öffentlich erreichbar.
Dort kannst du dir das Notebook in der Vorschau inklusive aller Anmerkungen und Ergebnisse ansehen. Du kannst es aber auch auf deinen eigenen Computer herunterladen oder es direkt ohne Installation über die dort vorbereiteten Links auf Google Colab laufen lassen. Dieses Kapitel ist unter dem Namen kap2.ipynb erreichbar.
Gerade im Bereich Machine Learning führen wir oft interaktiv eine Reihe von Codeschnipseln aus, um z.B. einen Datensatz besser zu verstehen oder schnell eine andere Lernstrategie auszuprobieren. Sogenannte Notebooks erlauben uns genau das zusammen mit der Möglichkeit, so ein Notebook auch leicht teilen zu können und damit andere an unseren Ergebnissen partizipieren zu lassen.
In einem Notebook kannst du Texte und Grafiken mit Codeschnipseln mischen. Das Besondere dabei ist, dass diese Codeschnipsel wirklich ausführbar sind. Dabei wird der Code nicht notwendigerweise auf dem Rechner ausgeführt, auf dem das Ergebnis im Browser angezeigt wird. In unserem Beispiel hier wird der Code auf einem Rechner von Google ausgeführt, auf dem auch sämtliche Software installiert ist. Die Ausgabe erfolgt aber in dem Browser auf deinem Rechner, auf dem außer dem Browser nichts weiter installiert sein muss.
Im einfachsten Fall kannst du dir so ein Notebook einfach nur ansehen, ohne es überhaupt auszuführen. Das geht, weil so ein Notebook auch jedes Ergebnis, inklusive Bildern, eines Codeschnipsels speichert.
Mehr Informationen zu Notebooks findest du unter
http://jupyter.org/.
Als Beispiel nehmen wir den Irisdatensatz, der dir im Buch immer wieder begegnen wird (siehe auch den Kasten auf der nächsten Seite). Es geht darum, anhand von vier Eigenschaften der Irisblüten (Features) drei unterschiedliche Irisarten voneinander zu unterscheiden. Features sind die zu einem Datensatz gehörigen Eingaben, Labels sind die zugehörigen Ausgaben. Diese Ausgaben sind in unserem Fall die Zahlen 0 bis 2 für die unterschiedlichen Irisarten. Man unterscheidet die Arten »Iris setosa« (0), »Iris virginica« (1) und »Iris versicolor« (2). Unser Beispiel ist dabei ein Klassifikationsproblem. Anhand der Features wollen wir das zugehörige Label erschließen. Da wir dazu das System mit Datensätzen trainieren, haben wir es mit Supervised Learning zu tun.
Dieser Irisdatensatz wird sehr gut verstanden und für viele Beispiele verwendet. Daher gibt es diverse Ressourcen dafür, und er ist sogar direkt in Scikit-Learn als Beispieldatensatz verfügbar, ohne dass du ihn dir von irgendwo besorgen müsstest. Wie erwähnt, ist Scikit-Learn eine zentrale Python-Bibliothek für Machine Learning, die wir über das ganze Buch hinweg einsetzen werden.
Ursprung des Irisdatensatzes
Der Irisdatensatz wurde von dem Botaniker Edgar Anderson (https://en.wikipedia.org/wiki/Edgar_Anderson) zusammengestellt. Bekanntheit erlangte er über die Verwendung durch den Statistiker Ronald Fisher (https://en.wikipedia.org/wiki/Ronald_Fisher). Dieser nutzte den Datensatz in einem Artikel eines Magazin zur Eugenik als Beispiel für statistische Methoden der Klassifikation. Wir distanzieren uns von Fishers Ansichten (https://en.wikipedia.org/wiki/Ronald_Fisher#Views_on_race) über Existenz und unterschiedliche mentale Fähigkeiten von menschlichen Rassen und generell von der Thematik der Eugenik.
Im ersten Schritt unseres Notebooks nutzen wir nun den Beispieldatensatz direkt aus Scikit-Learn und haben dann die kompletten Daten in der Variablen iris. Es ist bei Scikit-Learn üblich, die Features mit einem großen X und die Labels mit einem kleinen y zu bezeichnen. Der Unterschied in der Groß-/Kleinschreibung soll andeuten, dass y nur ein einfacher Vektor mit der Art der Iris ist, also 0, 1 oder 2. X hat hingegen zwei Dimensionen, da es für jeden Datensatz vier Features gibt:
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
Für jede der drei Arten gibt es jeweils 50 Beispiele. In jedem Beispiel ist zusammen mit der Irisart die Länge und Breite sowohl des Kelchblatts (Sepalum) als auch des Kronblatts (Petalum) erfasst. Das Kronblatt sind die bunten Blätter, die wir typischerweise als Blüte wahrnehmen. Das Kelchblatt ist meist grün wie der Stängel der Pflanze und schützt die Blüte im Knospenzustand. Bei einer blühenden Iris geht das Kelchblatt im Gegensatz zum Kronblatt ziemlich unter. Mehr dazu gibt es auf Wikipedia unter https://de.wikipedia.org/wiki/Portal:Statistik/Datensaetze#Iris.
Für uns ergibt das vier Features:
Diese können wir aus der 150-x-4-Matrix der Features extrahieren und haben dann jeweils einen Vektor mit 150 Einträgen:
X_sepal_length = X[:, 0]
X_sepal_width = X[:, 1]
X_petal_length = X[:, 2]
X_petal_width = X[:, 3]
Die eventuell etwas überraschende Syntax, um einen Vektor aus der Matrix zu bekommen [:, 0], bietet uns NumPy (https://docs.scipy.org/doc/numpy/user/basics.indexing.html), das von Scikit-Learn für Datenstrukturen genutzt wird. Die Syntax besagt, dass wir von der ersten Dimension alle Einträge wünschen und von der zweiten Dimension nur das nullte, erste, zweite und dritte Feature. NumPy ist eine zweite, grundlegendere Python-Bibliothek, die performante Datenstrukturen zur Verfügung stellt. Sie wird uns am Rande immer wieder begegnen und dann auch detaillierter vorgestellt werden. Wie bei vielen Programmiersprachen üblich, fängt auch bei Python die Zählung bei null und nicht bei eins an.
Hier möchten wir nun dem Computer beibringen, die unterschiedlichen Arten der Irisblüten anhand ihrer Features zu unterscheiden. Das ist erstaunlich einfach, da wir mit Scikit-Learn eine Software nutzen, die genau für so etwas gedacht ist. Wir brauchen zuerst einen sogenannten Estimator, also eine Strategie, wie der Computer lernen soll.
Hier nutzen wir wieder das Supervised Learning, das heißt, wir trainieren unseren Estimator mit einer Reihe von Datensätzen, von denen wir die Klassifikation in eine der drei Arten kennen. Danach hoffen wir, dass unser Estimator auch Irisblüten, die wir bisher noch nicht gesehen haben, richtig klassifiziert, also anhand der Größe der Blütenblätter sagen kann, was für eine Art Iris wir vor uns haben. Dies nennt man Generalisierung.
Das mit der Hoffnung ist so eine Sache, und daher nutzen wir nicht alle unsere Datensätze zum Training, sondern halten einige zurück, um danach zu testen, wie gut das Training eigentlich funktioniert hat. Auch dabei unterstützt uns Scikit-Learn mit seinem model_ selection-Paket. Damit können wir unsere Daten vom Zufall gesteuert in Trainings- und Testdaten aufteilen. Ein typisches Verhältnis sind 60 % für das Training und 40 % für den Test:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size=0.4)
Nun haben wir 90 Datensätze in X_train bzw. y_train und 60 in X_ test bzw. y_test:
X_train.shape, y_train.shape, X_test.shape, y_test.shape
> ((90, 4), (90,), (60, 4), (60,))
Hier führen wir auch eine Konvention ein. Vom Code erzeugte Ausgaben schreiben wir direkt hinter den Code und fangen die Zeile mit einem Größerzeichen (>) an. Im Beispiel oben ist ((90, 4), (90,), (60, 4), (60,)) also nicht Teil des Codes, sondern die Ausgabe, die durch X_train.shape, y_train.shape, X_test.shape, y_test.shape im Notebook erzeugt wurde.
Eine wirkliche einfache Strategie heißt Nearest Neighbors Classification (http://scikit-learn.org/stable/modules/neighbors.html#classification). In der simpelsten Version wird untersucht, welchem bekannten Datensatz eine Eingabe am nächsten ist. Dann wird davon ausgegangen, dass diese neue Eingabe von derselben Art ist. Fertig. Das mag naiv klingen, aber erstaunlicherweise ist dieser Ansatz wirklich mächtig. Es ist gar nicht so weit hergeholt, diesen Ansatz mit erkenntnistheoretischen Klassikern zu vergleichen (http://37steps.com/4370/nn-rule-invention/). Vielleicht verarbeiten sogar Fliegen Gerüche mit einem ähnlichen Ansatz (https://twitter.com/dribnet/status/931830521843236864).
Wir sehen uns erst einmal den Code an und welche Ergebnisse diese Lernstrategie für unsere Daten liefert. Als Erstes erzeugen wir einen entsprechenden Estimator. Parameter 1 gibt an, dass wir nur nach dem jeweils nächsten bekannten Datenpunkt entscheiden. Das wird später noch wichtig:
from sklearn import neighbors
clf = neighbors.KNeighborsClassifier(1)
Nun haben wir in clf unseren Estimator und können diesen trainieren. Dankenswerterweise funktioniert das in Scikit-Learn immer auf dieselbe Weise, nämlich indem wir unsere Trainingsfeatures zusammen mit der zugehörigen Irisart in die fit-Methode einfüttern:
clf.fit(X_train, y_train)
Danach können wir Vorhersagen treffen. Nehmen wir an, wir haben die folgenden Angaben über die Maße der Blüte einer Iris: Länge des Kelchblatts = 6,3 cm, Breite des Kelchblatts = 2,7 cm, Länge des Kronblatts = 5,5 cm und Breite des Kronblatts = 1,5 cm. Wir füttern diese Daten nun in die predict-Methode und bekommen die Irisart 2 geliefert (wie erwähnt, werden wir Ausgaben von nun an in einer neuen Zeile darstellen, die mit einem Größerzeichen anfängt):
clf.predict([[6.3, 2.7, 5.5, 1.5]])
> 2
Das ist insofern bemerkenswert, da wir diese Werte nicht für das Training verwendet haben und dennoch eine Antwort bekommen. Woher wissen wir, wie vertrauenswürdig diese Antwort ist? War das Training insgesamt erfolgreich? Auch dafür gibt es eine Methode, die überprüft, wie gut ein Satz von Features auf einen Satz von Labels passt. Das Ergebnis befindet sich zwischen 0 und 1. 0 steht für »überhaupt nicht« und 1 für »passt perfekt«:
Hurra! 1.0 ist das bestmögliche Ergebnis, das war einfach! Aber wir wollen auch bisher nicht gesehene Daten generalisieren und machen daher den Check mit den bereits vorbereiteten Testdaten. Diese hat der Estimator ja bisher noch nicht gesehen, und daher geben sie Aufschluss über das Maß der Generalisierung:
clf.score(X_test, y_test)
> 0.94999999999999996
Dieser Wert besagt, dass wir 95 % aller Testdatensätze richtig vorhersagen können. Nicht perfekt, aber auch nicht so schlecht und in der Praxis meist völlig ausreichend. Das liegt natürlich daran, dass wir einen besonders sauberen und aussagekräftigen Datensatz vorliegen haben. Bei echten Problemen sind die Ergebnisse auch mit viel Aufwand bei der Auswahl der Features, der Trainingsprozedur und der Lernstrategie oft deutlich schlechter.
Unsere Lernstrategie hat den Vorteil, wirklich einfach zu sein, sodass du schnell verstehen kannst, wie sie funktioniert. Am einfachsten geht das mit einer Grafik, in der wir auftragen, wie welcher Datensatz zu welcher Vorhersage führt. Wir sehen dabei gleich ein grundsätzliches Problem von Visualisierungen: Wir haben vier Features und ein Label, wir Menschen können aber nur wenige Dimensionen gleichzeitig erfassen, auf einem 2-D-Medium wie einem Blatt Papier oder einem Bildschirm eigentlich nur 2. Mit etwas Trickserei und Einschränkungen können es auch ein paar mehr werden, aber nicht viel mehr.
Wir entscheiden uns, nur zwei Features, Sepal width und Sepal length, darzustellen und die vorhergesagten Labels als Farbe in die Darstellung hineinzucodieren. Es ist wichtig, zu verstehen, dass wir es uns hier künstlich schwerer machen als nötig, denn mit allen vier Features haben wir es ja zu sehr guten Ergebnissen gebracht. Es geht uns eher darum, den Nearest-Neighbors-Algorithmus besser darzustellen und die Phänomene des Over- und Underfittings zu illustrieren.
Unsere Grafik mit den beiden Features siehst du in Abbildung 2-1.
Abbildung 2-1: Verteilung der Trainingsdaten für Sepal-Features
Unsere beiden Features spannen ein zweidimensionales Koordinatensystem auf. Die Punkte darin sind die einzelnen Trainingsbeispiele. Sie sind an den Stellen des Koordinatensystems angebracht, die zu ihren Features passen. Jede Farbe drückt eine Irisart aus. Diese ist quasi unsere dritte Dimension.
In derselben Grafik zeigen wir in Abbildung 2-2 nun zusätzlich an, welche Vorhersage bei welcher Koordinate gemacht wird. Dabei nutzen wir die gleichen Farben wie für die Trainingsdaten, allerdings etwas heller als Hintergrund.
Noch einmal zur Wiederholung – die Vorhersage funktioniert sehr einfach: Bei jedem Punkt wird geschaut, welche Farbe der nächstliegende Trainingspunkt hat. Es ergeben sich dabei Grenzen zwischen den einzelnen Farben der Vorhersagen, diese nennt man auch Decision Boundaries.
Abbildung 2-2: Decision Boundaries für Sepal-Features
Gerade im Zentrum der Grafik sind die Grenzen zwischen den Decision Boundaries zerklüftet und unruhig, wenig glatt und genau auf unsere Trainingsdaten angepasst. Während es für unsere Trainingsdaten gut aussieht, passen diese Grenzen nicht wirklich gut für die Testdaten, das heißt, wenn wir nur die beiden Sepal-Features nutzen, haben wir es hier mit Overfitting zu tun. Overfitting bedeutet, dass ein Modell deutlich besser auf Trainingsdaten als auf Testdaten funktioniert, also nicht gut auf unbekannte Daten generalisiert. Dieselben Decision Boundaries kannst du in Abbildung 2-3 für die Testdaten sehen.
Schau genau hin: Die Darstellung der Decision Boundaries dominiert, und so kann diese Grafik auf den ersten Blick genau so aussehen wie die vorherige. Entscheidend sind aber die Datenpunkte, die nun nicht mehr für das Training, sondern für den Test eingezeichnet sind.
Die beiden Punkte links von der Mitte passen zum Beispiel überhaupt nicht mehr zur Vorhersage, rechts von der Mitte sieht es ebenso schlecht aus. Oben passt es hingegen ganz gut. Wir werden später in Kapitel 5, Feature-Auswahl, sehen, warum manche Arten ganz gut passen und warum wir bei einer anderen Auswahl der Features plötzlich derartig schlechte Ergebnisse bekommen.
Abbildung 2-3: Unpassende Decision Boundaries für Testdaten
Nun aber hier die Ergebnisse für diese Feature-Auswahl:
clf_sepal.score(X_train_sepal_only, y_train)
> 0.9555555555555556
clf_sepal.score(X_test_sepal_only, y_test)
> 0.80000000000000004
Das passt zu unserem Eindruck aus den Grafiken: Für die Trainingsdaten sieht es nicht schlecht aus (95 % passend), aber die Testdaten liefern mit nur 80% Genauigkeit kein gutes Bild ab.
Das Bild des Overfittings verfestigt sich hier. Unser Modell ist also zu speziell und zu komplex. Es passt sich zu genau den Trainingsdaten an und ist dann nicht mehr allgemein genug für die Testdaten.
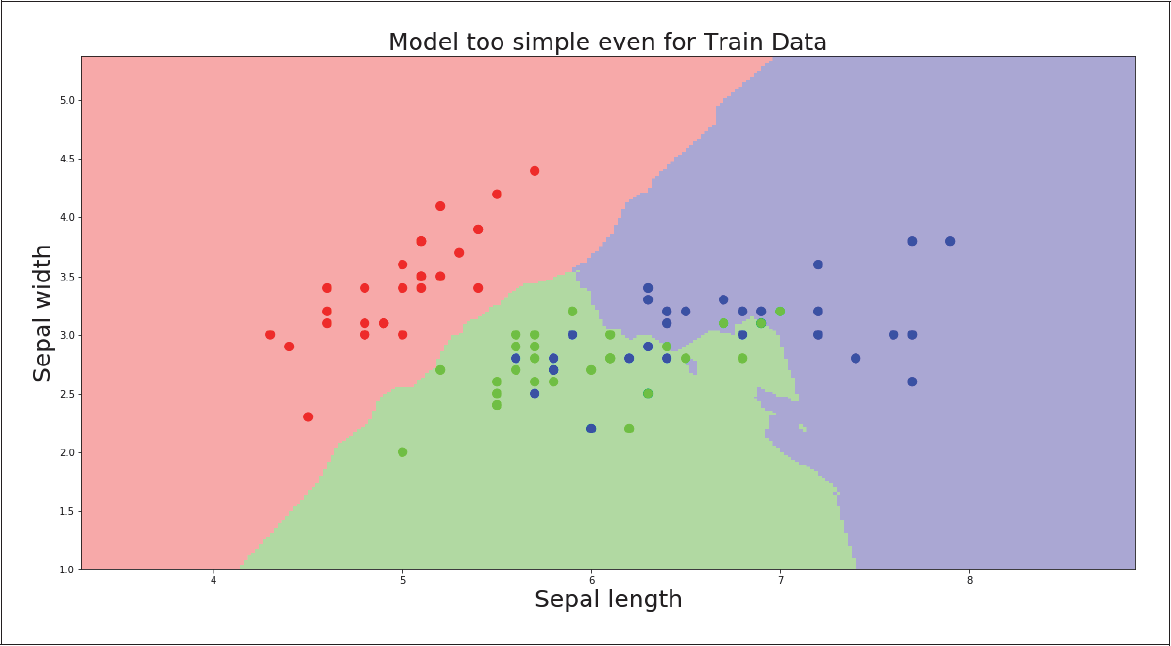
Gut, dann also ein einfacheres Modell? Erstaunlicherweise bekommen wir das hin, indem wir nicht nur die Nähe zu einem einzigen Nachbarn bei der Vorhersage in Erwägung ziehen, sondern die Nähe mehrerer. Wir probieren einmal zehn Nachbarn aus:
clf_sepal_10 = neighbors.KNeighborsClassifier(10)
Abbildung 2-4 zeigt die passende Grafik für die Trainingsdaten, an der man schön die viel sanfteren Übergänge der Decision Boundaries sehen kann.
Abbildung 2-4: Glatte Decision Boundaries, aber dieses Mal sogar schwach für die Trainingsdaten
Leider kann man genauso schön sehen, dass nicht einmal die Trainingsdaten gut vorhergesagt werden können. Wir haben es jetzt also mit Underfitting zu tun. Von Underfitting spricht man, wenn ein Modell zu einfach ist und nicht einmal die Trainingsdaten annähernd reproduzieren kann.
Das bestätigen uns auch die Scores, die für Trainings- und Testdaten ähnlich schwach sind:
clf_sepal_10.score(X_train_sepal_only, y_train)
> 0.80000000000000004
clf_sepal_10.score(X_test_sepal_only, y_test)
> 0.76666666666666672
Der Sweet Spot liegt irgendwo zwischen dem zu komplexen und dem zu einfachen Modell. Wir verraten dir jetzt schon einmal: Egal wie wir unser Modell hier anpassen, wir bekommen nie gute Ergebnisse. Das liegt daran, dass dieser Satz an Features einfach nicht ausreicht, um die einzelnen Arten voneinander zu trennen. Nichts zu machen. In der Praxis ist so etwas ernüchternd. Wenn du nicht die richtigen, zu schlechte oder zu wenige Daten hast, kannst du noch so schlau sein, du wirst nie zu guten Ergebnissen kommen. Mehr dazu findest du in Kapitel 3, Datenimport und -vorbereitung, und Kapitel 5, Feature-Auswahl.
Umso erstaunlicher ist es, dass wir mit den Petal-Features sehr viel weiterkommen und fast Werte erzielen wie für alle vier Features zusammen. Wir bleiben bei zehn Nachbarn und bekommen diese Decision Boundaries, die wir in Abbildung 2-5 zuerst zusammen mit den Trainingsdaten anzeigen.
Abbildung 2-5: Petal-Features-Decision-Boundaries mit Trainingsdaten
Du kannst glatte Übergänge sehen und ebenso nur geringe Fehler bei den beiden Klassen in der Mitte und rechts. Das spiegelt sich auch in den Scores wider:
clf_petal_10.score(X_train_petal_only, y_train)
> 0.96666666666666667
Nicht perfekt, aber sehr gut, und vor allem sehr ähnliche Scores bei den Testdaten:
clf_petal_10.score(X_test_petal_only, y_test)
> 0.94999999999999996
In Abbildung 2-6 kannst du nun noch einmal dieselben Decision Boundaries sehen, dieses Mal aber mit den Testdaten. An der Decision Boundary rechts kann es keine glatte Grenze geben, die sowohl für die Trainingsdaten als auch für die Testdaten gute Ergebnisse liefert.
Abbildung 2-6: Petal-Features: Decision Boundaries mit Testdaten
Das Erstaunliche und Bemerkenswerte hier: Wir haben zwar wieder nur zwei Features verwendet, aber dieses Mal viel bessere Ergebnisse bekommen. Wir lernen daraus, dass es nicht nur auf die Menge der Features ankommt, sondern auch darauf, welche Features man auswählt. Hier hatten wir nur mehr oder weniger Glück mit der Auswahl, wie man das aber systematisch macht und warum das hier so gut geklappt hat, lernst du in Kapitel 5, Feature-Auswahl, und Kapitel 6, Modellvalidierung.
Die hier erklärte Nearest Neighbors Classification ist relativ einfach, aber erstaunlich häufig ausreichend. In Kapitel 4, Supervised Learning, zeigen wir dir weitere Lernstrategien, die grundsätzlich anders funktionieren.
Wir hoffen zudem, auf die theoretisch anspruchsvolleren Kapitel 5 und Kapitel 6 neugierig gemacht zu haben. Wie wir trainieren und wie wir Features auswählen, ist offensichtlich essenziell für unseren Erfolg.