Chapter 6
From Molecules to Cells
After taking part in the unraveling of the DNA double helix, Francis Crick moved to the logical next step: investigating the expression of genetic information—how the sequence of nucleotides so neatly lined up in the double helix structure is eventually translated into amino acid sequences. With his wildly creative thinking, he contributed some insights that turned out to be true (such as the adaptor hypothesis, which essentially predicted the role of transfer RNAs) and others that were perhaps just that little bit too imaginative, such as the “comma-less” genetic code, which restricted the use of three-letter codons to those that would be safe against one-letter shifts of the reading frame (we describe the genetic code later in this chapter). He was much intrigued by both the complexity of the protein biosynthesis machinery and the universality of its language.
In 1972, Crick resorted to yet another wild idea to explain the puzzling phenomenon that all the millions of species on our planet use essentially the same, incredibly complex protein synthesis machinery, with the same genetic code. In a paper he coauthored with Leslie Orgel, which appeared in the planetary science journal Icarus the following year, the two argued that, in particular, the protein synthesis machinery is so complex that it was very hard to understand how it could have been created by the slow, stepwise progression of evolution. This quandary was so serious, they proposed, that we must consider even the wildest alternative hypotheses. For example, they argued, a possible alternative solution would be that life on Earth, with its seemingly impossibly complex biochemistry, may have been artificially designed by intelligent aliens from some other planetary system in our galaxy who then purposefully sent it here by “space mail.” The aliens in question solved the problem of the difficulties associated with the origins of our complex biochemistry by themselves having a much simpler biochemistry. Simple enough, Crick and Orgel argued, that their biochemistry could have arisen spontaneously from nonlife more easily than our rather complicated biochemistry could have. The two further decorated their proposal—which built on earlier panspermia ideas discussed in chapter 5—with plenty of detail, including the design of the spaceship that might have delivered the first spores to Earth. It is a remarkable tribute to the complexity of contemporary Terrestrial biochemistry that, after decades spent deciphering some of its greatest mysteries, these two highly distinguished researchers still found many aspects of biochemistry so puzzling that they would seriously consider such a radical alternative (or at least semiseriously: Orgel admits that the paper was for him rather tongue-in-cheek, but he suspects “Francis took it somewhat more seriously”*).
Today, more than four decades later, few researchers working on the translation of DNA into protein would resort to such speculative explanations, but the evolution of protein biosynthesis still poses a serious conundrum. Protein synthesis as it occurs today in all cellular organisms (and, independently, in certain subcellular compartments, such as the mitochondria) requires an incredibly large tool kit, including ribosomes consisting of more than 50 proteins and at least three large strands of RNA, multiple tRNAs (the t stands for “transfer” because this RNA’s job is to transfer an amino acid to the growing polypeptide chain), and several dozen non-ribosomal proteins, including the tRNA synthetases (the enzymes that covalently attach the appropriate amino acid to each tRNA), as well as protein factors that initiate translation, ensure that elongation proceeds efficiently, and, ultimately, drive the release of the full-length protein. If any one of these components is removed, the whole process fails. How could such an “irreducibly complex” set of interacting pieces (i.e., a set in which removing any one piece eliminates all function) have arisen by the stepwise, random workings of evolution? How could the RNA world transform itself into a DNA-RNA-protein world? (And if we rewound and ran the film again, would the story unfold the same way? See sidebar 6.1.) Luckily, clues to this mystery are contained within the very complexity of the protein synthesis machinery itself.
My Name Is LUCA
Judging from the extraordinary degree to which the biochemistry of all Terrestrial life is similar, it seems that everything living on Earth today is related through some long-lost great-to-the-nth-power grandmother: the last universal common ancestor (LUCA) of all living things on Earth. Her descendants branched out into two of the major domains of life, the Archaea and the Bacteria, some of which later recombined to form the third, the Eukarya, which comprises the plants, animals, fungi, and protists.
Extrapolating backward from today’s biodiversity, we can look across all life on Earth to identify those things we share in common (that are homologous, i.e., have arisen from a common ancestor), under the economical assumption that any traits that are common across all life are shared because we all inherited them from LUCA, and thus she shared them too. Using this comparative approach, biochemists have been able to infer quite a bit about LUCA and her biochemistry. For example, we know that LUCA stored genetic information in DNA, produced a couple of hundred proteins working as enzymes, receptors, or transporters, and made use of the 20 amino acids that are now the standard components of proteins. Similarly, LUCA used the same genetic code that we do to translate DNA sequences into the amino acid sequences of proteins and performed this translation using more or less the same RNA-based protein synthesis machinery that all life on Earth employs.*
LUCA’s biochemistry was thus already quite complex; by the time LUCA was around, life had come a long way since the birth of the very first simple, self-replicating molecules. But because so much was lost in going through the bottleneck that was LUCA and, presumably, many earlier bottlenecks (we must remember that there may have been thousands of other species, contemporary with LUCA, whose descendants just weren’t lucky enough or fit enough to survive in competition with her and her relatives), we can only speculate about how the first cells came into being and which of the many compounds and functions that we now consider essential may have been absent in LUCA’s progenitors. But we do have constraints that can guide our speculations: we assume that the primordial soup was the starting point, and LUCA was the final product.
Back to the RNA World
One of the most widely accepted theories concerning the phase between primordial soup and ancestral cells is the RNA-world hypothesis, which we introduced in chapter 5. The discovery of ribozymes as potential relics of the RNA world was a major inspiration for RNA biochemists as it suggested that RNA could carry out the various functions considered essential for life. But the first ribozymes to be discovered were limited to the processing of other RNAs and, perhaps worse, to the processing of themselves (i.e., as we mentioned in chapter 5, they aren’t really catalysts in the true sense of the word). This is hardly the sort of diverse chemistry around which complex life can be built; for that, we’d expect at the very least to need reactions that convert small molecules that look nothing like RNA into the true precursors of RNA.
The first ribozyme-catalyzed reaction that does not involve the processing of RNA was observed by Thomas Cech’s group in 1992 with a genetically modified Tetrahymena ribozyme. The altered ribozyme could cleave the bond between the amino acid methionine and its matching tRNA; this is the reverse of the reaction catalyzed by the tRNA synthetases, which add amino acids to tRNAs as the first step in the synthesis of proteins. Three years later, Michael Yarus, a colleague of Cech’s at the University of Colorado in Boulder, and his team screened a random mixture of 1014 different RNA sequences and managed to select a sequence that catalyzed the attachment of an activated amino acid to itself. Following this, Peter Lohse and Jack Szostak demonstrated an RNA sequence that is able to transfer aminoacyl groups to a free amino acid to form a dipeptide—which is just what the peptidyltransferase center of the ribosome does when it elongates the polypeptide chain by one unit.
It thus seems that RNA can bind substrates and catalyze a range of reactions above and beyond the postulated ability of some RNA molecules to copy or edit themselves (as they might have done if the RNA world was not just an intermediate stage but the beginning of life). This chemical promiscuity might have made all the difference to the earliest organisms. The first self-replicating, evolving, and hence living thing would have been the only organism in the history of the planet that was not in competition with other organisms. That situation would have changed just a soon as it produced daughters. Immediately, there was competition for the precursors with which these organisms reproduced, and all too soon some molecule would have become hard to obtain. Then what? Then death. Unless, of course, one of these replicating RNA strands was error prone (or, put more positively, could evolve) and started to copy some different RNA sequence that catalyzed some reaction not directly tied up in replication. An example might be a reaction that converted some not-quite-right precursor into the correct, but now rare, precursor. This would provide a tremendous selective advantage for this organism: it could now outcompete its sisters by employing an alternative molecular source to replace the now rare precursor. It would also mark the invention of metabolism—the set of chemical reactions by which the various molecules that are available to an organism from its environment are converted into the precise molecules that the organism is built of.
It is possible that complex metabolisms arose during the era of RNA-based organisms. The present-day widespread use of ribonucleotides as cofactors in key metabolic pathways suggests that these pathways may have originated during the RNA-world era. Indeed, so compelling is this idea that, in 1976, a half dozen years before the discovery of ribozymes, Harold White used the widespread existence of ribonucleotide-containing cofactors to argue that “a metabolic system composed of nucleic acid enzymes … existed prior to the evolution of ribosomal protein synthesis.”* Examples of these cofactors include the ribonucleotide ATP (adenosine triphosphate), which is used as the major energy “currency” of the cell, the adenine-containing coenzyme A (CoA), used as a “handle” with which to carry acyl groups such as acetate (CH3C=O), and the ribonucleotides FAD (flavin adenine dinucleotide) and NAD (nicotine adenine dinucleotide), which accept high-energy electrons from reactions that liberate them and donate high-energy electrons to reactions that consume them. These potential remnants of the RNA world suggest that RNA-based organisms might have had a rich metabolism that included complex oxidation and reduction chemistries. And because the organism was enclosed by something, all this metabolic machinery, like the replicative machinery that evolved before it, was physically associated with the genes that encoded it, providing them a selective advantage.
But if our ancient ancestors had such rich RNA-based metabolisms, why don’t we see RNA-based metabolisms today? The presumed answer is that any RNA-based organism would have been driven to extinction, remorselessly outcompeted by its more fit cousins who had the good fortune to invent or inherit protein-based catalysts. This idea is not so far-fetched given that the catalytic efficiency of enzymes is typically orders of magnitude higher than that of comparable ribozymes. For example, while the so-called hammerhead ribozyme, which catalyzes the cleavage of RNA, accelerates the degradation reaction a millionfold over the rate of the uncatalyzed reaction, a similar-sized protein, the enzyme ribonuclease, is a hundred thousand times more catalytically active still. Proteins, made up of 20 different types of amino acids, are much more complex than RNA, with its four nucleobases, and with this increased complexity comes increased catalytical flexibility and efficiency. Thus, any RNA-based organism that evolved the ability to synthesize proteins gained a tremendous advantage over its protein-free competitors.
Of course, seeing a comparison between the exceptional catalytic ability of proteins and the rather paltry skills of RNA-based catalysts, skeptics might question whether the RNA world ever existed. There is always the possibility of an alternative explanation: the relatively rare ribozymes might be fairly recent, not very successful experiments of evolution rather than survivors of a principle that was once more generally applicable. This ribozymes-first versus ribozymes-later argument raged through much of the 1990s (among those of us who cared) until it was finally resolved in favor of the primordial role of ribozymes. The resolution came with the unraveling of the mysteries of the ribosome, the subcellular factory that churns out the cell’s proteins.
Even the bacterial ribosome (which is somewhat simpler than the version in the cytoplasm of eukaryotes, such as ourselves) consists of 57 different proteins and three RNA molecules folded together into an enormous macromolecular machine of several hundred thousand atoms in all (fig. 6.1). But which of these many components is responsible for the fundamental chemical reaction that the ribosome catalyzes: the synthesis of proteins? Long after the initial characterization of the ribosome, it was assumed that the catalyst must be one or more of the proteins (remember: until 1982, it was thought that all biocatalysts were proteins). Research throughout the 1980s and 1990s, though, had shown that each individual ribosomal protein was expendable—that is, after removal, in turn, of each of the 57 ribosomal proteins, the ribosome continued to function. But despite several well-publicized—and quite possibly successful—attempts, nobody had unequivocally succeeded in constructing a completely protein-free version of a ribosome that remained active. The RNA-world community had to wait for an atomic-resolution structure of the ribosome to find out whether the ribosome, at heart, is a protein-based enzyme or an RNA-based ribozyme.
When a string of high-resolution structures of ribosomal subunits and complete ribosomes started to appear, the answer was perhaps even clearer than expected. Reported by the research groups of crystallographer Tom Steitz (1940–2018) and “ribosomologist” Peter Moore, the structure of the 50S subunit from Haloarcula marismortui ribosomes made the cover of Science magazine in 2000 and won Steitz, along with Ada Yonath of the Weizmann Institute in Israel and Venkatraman Ramakrishnan of the MRC Laboratory of Molecular Biology in Cambridge, England, the 2009 Nobel Prize in Chemistry. The structure they published finally pulled back the curtain on the peptidyltransferase site of the ribosome, the spot at which new amino acids are added to the growing polypeptide chain. What must have delighted the RNA-world community more than any specific, mechanistic detail, however, was the observation that the peptidyltransferase active site is made up entirely of RNA: the nearest protein is 1.8 nm away (about 15 times the length of, say, a carbon-carbon bond) and thus clearly excluded from any participation in the catalytic activity. As RNA champion Tom Cech concluded in a commentary accompanying the structure paper, “The ribosome is a ribozyme.” It became abundantly clear that the original catalyst for the synthesis of proteins was an RNA molecule that was later surrounded by proteins that serve various supporting roles.
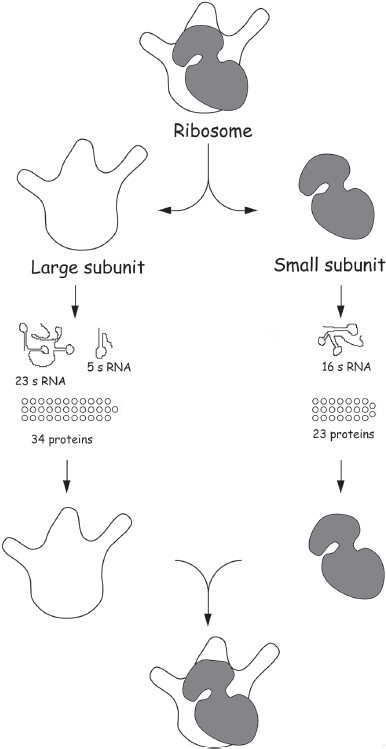
Figure 6.1 The bacterial protein-manufacturing machinery, the bacterial ribosome, can be separated in the test tube into the three strands of RNA and 57 different proteins from which it is made, and then put back together again. Using this approach, researchers have found that the resulting ribosomes are still active if any one of the proteins—no matter which one—is left out, showing that none of them are crucial for ribosome function.
Polypeptides Join the Fold
Proteins are long polymers each of a single, specific sequence, and thus, not surprisingly, the cellular machinery with which they are synthesized is quite complex. The question then naturally arises as to how such complex machinery could have arisen in one fell swoop. In short, it probably couldn’t. Instead, it is thought that the first polypeptides were homopolymers (polymers consisting of multiple copies of a single amino acid) or short, random-sequence polymers. But homopolymers and random polypeptides generally do not fold and are not catalytically active, and thus they lack the selective advantages we generally associate with true proteins. Given this, why would some previously peptide-less life-form evolve the ability to polymerize amino acids? Several suggestions have been put forth. The chemical strength of the peptide bond implies, for example, that even simple, short chains of amino acids could form stable structural elements for an early cell. Likewise, simple polymers of positively charged amino acids could help counteract the negatively charged phosphates in RNA and improve its ability to fold into functional structures (remember: the ribosome has more than 50 proteins, which are mostly there to help the catalytic RNA fold). Alternatively, the first (simple) polypeptides may have provided a selective advantage by improving transport across the cell membrane. Because membranes are hydrophobic, it is hard to imagine that a highly charged RNA molecule could insert within a membrane to support the transport of some important nutrient into the cell. Many simple polypeptides, in contrast, are quite hydrophobic and could easily serve this role. Indeed, David Deamer of the University of California, Santa Cruz, has demonstrated just this: short polypeptides consisting solely of alanine or leucine spontaneously insert into membranes and produce channels capable of transporting hydrogen ions (H+). Moreover, these channels are specific: they do not transport other positively charged ions, such as sodium or potassium. So perhaps the first polypeptides were employed to regulate the properties of the membrane, to facilitate the entry of vital nutrients into the cell.
The fact that even short polymers of one or two amino acid types might have provided a selective advantage simplifies the problem at hand. That is, rather than needing to develop the entire, exceedingly complex protein synthesis machinery from scratch, evolution could have generated each part piecemeal, starting with the (presumably less complex) machinery required to make simple homopolymers, which would provide a modest selective advantage, before moving on to translation as we know it today.
The start of this evolutionary journey probably involved a close association between amino acids and RNA, which over many millions of years culminated in the complex and well-conserved mechanisms we still observe in today’s protein biosynthesis. The first step, for example, might have been the use of amino acids to add functionality to RNA. Evolution could easily have invented an RNA molecule that “charged” itself—that is, autocatalytically attached an amino acid to itself to form a covalent complex. As described in chapter 5, such molecules have been created in the laboratory, so we know that RNA is capable of performing such chemistry. These mixed molecules could have provided a selective advantage for an originally RNA-only organism, say, by being more catalytic due to the addition of a new functional group. Similarly, even in contemporary Terrestrial biochemistry, we see examples of “aminoacylated” RNAs that are used to “donate” amino acids in metabolic processes. A glutamate attached to its tRNA is used, for example, in the synthesis of porphyrins, the type of organic carbon-and-nitrogen rings that hold the iron in hemoglobin and that date back to LUCA. Given this, it is quite possible that the first self-charging RNA resulted from a need to introduce amino acids (from Miller-Urey chemistry) into metabolic pathways aimed at making more RNA. Either way, it is easy to understand how the formation of the first RNA–amino acid complexes could have provided a selective advantage for RNA-based organisms. And if it existed, it seems likely that this amino acid–charged RNA might have been the progenitor of today’s tRNA (but without the need for today’s tRNA-charging enzymes).
The second step in the evolution of protein synthesis was probably the formation of a ribozyme that could use the RNA–amino acid complexes to synthesize homopolymers or random polymers of amino acids. Once again, ribozymes capable of synthesizing peptide bonds starting from activated amino acids (amino acids participating in high-energy bonds, such as those in aminoacylated RNAs) have been demonstrated in the laboratory, so we know that RNA is capable of performing this sort of chemistry. But is such a step a plausible intermediate in the origins and evolution of life? The products of this reaction, short random or homogeneous polymers of amino acids, may have provided a selective advantage due to their suitability for structural roles in the cell. Under the influence of this selective pressure, evolution could have quite readily produced a ribozyme capable of synthesizing polypeptides from charged tRNA precursors. This ribozyme would have been the ancestor of the modern ribosome.
Random-sequence polypeptides, though, are not proteins. How did sequence specificity enter the picture? Today the sequence specificity of protein synthesis arises because messenger RNA (mRNA) is used as a template to direct the incorporation of new amino acids into the growing polypeptide. Thus, the nascent ribosome must also have learned how to direct synthesis using such a template. Presumably this development occurred when the nascent ribosome found that it could bind its primitive tRNA substrates more tightly when they, in turn, had bound to yet another RNA, which would be the first messenger RNA. The precise sequence of this RNA would then determine the sequence of amino acids incorporated into newly synthesized polymer. The advent of sequence-specific synthesis would have provided a very significant selective advantage. Namely, it allowed the cell to make complex, highly efficient, protein-based catalysts and, because a protein’s sequence is encoded in a gene, to pass this selective advantage on to its offspring. With this, we have the first true ribosome.
The Genetic Code
The ribosome translates the sequence of nucleotides in a messenger RNA intermediate, which was itself generated using the sequence of a DNA-encoded gene, into the corresponding sequence of amino acids that makes up a given protein, following the rules contained in the genetic code. The genetic code is simply the conversion table that links the 43 = 64 possible ways of combining the four nucleotides into three-base codons to the 20 amino acids generally used in proteins, plus the chain termination or “stop” codons that tell the ribosome to halt synthesis when the job is done (table 6.1). When first deciphered in the late 1960s, the genetic code seemed to give no clues as to its early evolution. Indeed, when it was initially discovered that the same code applied in all the organisms studied so far, most researchers believed that it simply reflected a “frozen accident.” The thought was that the universal code that assigns a given set of three bases to each amino acid was not fundamentally different from any of the other approximately 1020 possible patterns that could map the codons to the amino acids, but that once the existing code was set down randomly, the cost of changing it would have been so prohibitive that it was essentially frozen. Exchanging the assignment of one codon, for instance, would alter the corresponding amino acid in hundreds of proteins simultaneously, almost certainly with fatal consequences.
A quarter of a century later, however, a slightly more dynamic view of the code began to take hold. For one thing, it is now clear that a small number of exceptions to the code exist,* illustrating the fact that the code can evolve. Specifically, codon frequency was found to differ slightly among organisms, offering a viable, though rare, route to code evolution. A rare codon in a small enough genome might become so rare that it was used in only one or a few genes, and at that point it could be reassigned to a different amino acid if the change benefited that protein without producing fatal changes in other proteins. Despite these counterexamples, though, in the vast majority of cases it would seem to be effectively impossible for the codon assignments to vary on a reasonable evolutionary timescale—hence the suggestion that the current codon pattern, which presumably was originally randomly assigned, has been frozen in its current form by the nearly always fatal consequences of changing it.
Table 6.1
The genetic code
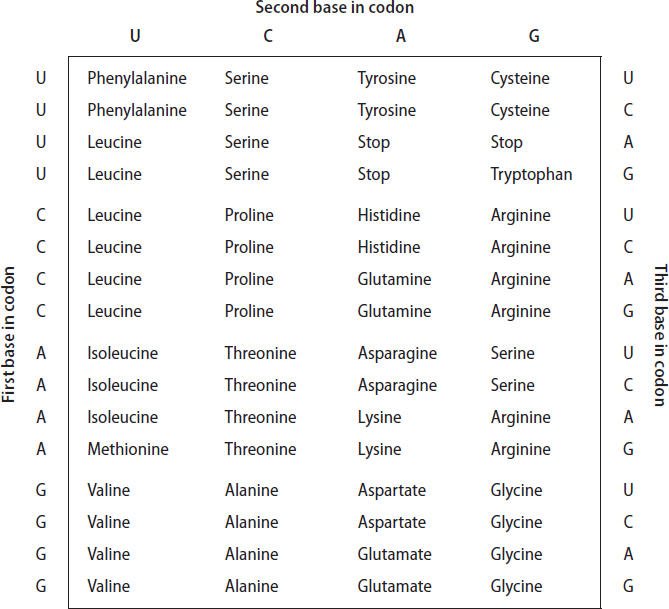
But there is a problem with this frozen accident hypothesis: the current genetic code appears to be far more highly optimized than one would expect were it simply an accident. That is, the current genetic code is set up such that a large fraction of mutations at the level of nucleic acid sequence are silent, or at least chemically conservative, at the amino acid level. This is easy to see by looking at the genetic code. For example, look closely at each of the 16 four-codon blocks in the table of codon assignments (see table 6.1). The second block in the first row represents the four codons with the sequence UCN, where N indicates any of the four nucleobases U, C, A, or G. All four of these codons encode the amino acid serine, and so any mutation of the third position in any of these codons will be silent! And it’s not just serine: this trait is shared by eight of the 20 amino acids, and partially by several others, so more than a quarter of all possible point (single-base) mutations are completely silent. That is, while they are changes in the DNA sequence, they do not produce changes in the sequence of amino acids that the DNA encodes. Moreover, many other mutations are conservative; mutation of the first base of many codons, for example, tends to swap chemically similar amino acids, such as leucine (CUN, where, again, N stands for any of the four nucleotides) for either isoleucine (AU followed by U, C, or A) or methionine (AUG).
The robustness against mutation that is captured in the current genetic code provides a significant advantage over alternative genetic codes that might not have this property. Keeping track of silent mutations and using various chemical scoring functions (such as hydrophobicity) to rank the impact of potentially conservative amino acid substitutions, theoreticians have found that the current genetic code is highly optimized in terms of suppressing the effects of mutation. In fact, the probability of picking by chance a genetic code as error proof as ours would be close to one in a billion, which suggests that the present-day code is, somehow, the product of intensive evolutionary optimization. But this finding seems highly paradoxical. If changes to the code are almost invariably fatal, how could the code evolve? Hints regarding the answer to this question are apparent in the structure of the code itself.
Look again at table 6.1. The amino acids in the first column, those with codons having the structure NUN, are the hydrophobic (water-hating) amino acids phenylalanine, leucine, isoleucine, methionine, and valine (see fig. 4.2 for their structures). Similarly, all the amino acids in the third column, those encoded by codons with the structure NAN, are hydrophilic. This has led to the suggestion that the first code was very simple; it may have used three nucleotides in a codon, but only the middle of the three mattered. If the middle nucleotide was U, a hydrophobic amino acid (perhaps the simplest, valine, but we don’t know for sure) was encoded; if the middle nucleotide was A, a hydrophilic amino acid (again, perhaps the simple amino acid aspartate, but we don’t know for sure) was encoded instead. The earliest code might thus have encoded only four different amino acids, and consistent with our earlier arguments about the origins of translation, the earliest proteins might have been of very simple composition.
How, then, did we go from this simple, four–amino acid, “only the middle position counts” code to the current 20–amino acid code? In time, selective pressures would ensure that new amino acids were recruited into the process of building proteins. When new amino acids were added, more complexity needed to be added to the genetic code to accommodate them. According to this hypothesis, this was done using the first position in the codon. Valine is differentiated from leucine by the first nucleotide in their GUN and CUN codon sets; the middle position encodes “hydrophobic” and the first distinguishes which of the several hydrophobic amino acids. Using just the first two codons, we can encode 4 × 4 = 16 amino acids. To enlarge the set beyond 16, we have to involve the third position. We see some examples of this in the current genetic code. For example, the amino acids glutamate and aspartate, which are chemically similar in that they are the only negatively charged amino acids (a glance back at fig 4.2 reveals how similar they are), are differentiated only by the third position in their codons. But for many codon sets, the third position is entirely redundant; all four GGN codons, for example, encode glycine. It thus seems that the genetic code did freeze. That is, sometime after the first two codon positions became important, but before all the third positions became distinct, organisms had become complex enough that any further changes (save the rare, limited exceptions described above) were prohibitive. The freeze occurred after only 20 amino acids had become encoded, presumably because this was the balance point between the selective pressures that pushed toward greater complexity (more diversity equals better ability to solve problems) and the increasing chance that any additional changes would prove fatal.
The near-universal spread of the standard code suggests that it was already in place in the time of LUCA. This, in turn, means that a full set of tRNAs—and the catalysts required to create them and charge them with the appropriate amino acids—were also in place. For example, all three domains of life process nascent tRNA into its final, functional length using the ribozyme ribonuclease P (RNase P), implying that we all inherited this catalyst from LUCA. Genomic comparisons likewise indicate that LUCA encoded between 40 and 45 tRNAs and 18 of the 20 tRNA synthetases in use by life today.*
Because LUCA was a bottleneck in evolution through which all life passed, it is often difficult to use evolutionary comparisons to peer any farther back. The complexity of the protein synthesis apparatus, however, allows researchers to study the evolution of the code beyond that time limit. In humans, for example, there are around 50 different tRNAs (not quite as many as there are codons since some can recognize several codons differing only in the third position, a phenomenon called “wobble”) all sharing a common L-shaped structure and a variety of specific peculiarities such as the occurrence at specific points in the molecule of rare nucleobases—that is, bases other than the four common ones (e.g., a base called pseudouracil, which differs slightly from uracil). The high degree of sequence similarity among the different tRNAs suggests that they originally evolved from a single, progenitor “adaptor molecule” invented by evolution long before LUCA, which ultimately duplicated and diverged to create the 40 to 45 tRNAs that LUCA appears to have employed.
The tRNA synthetases tell a similar tale about the pre-LUCA evolution of translation. Researchers have found that the 20 synthetases are evenly divided into two distinct classes, with the 10 members within each sharing a common three-dimensional structure as well as similarities in the chemical details of their catalytic sites. The two families, however, do not appear to be even remotely related to one another; their amino acid sequences and final folded structures are utterly dissimilar. The thinking is that evolution invented a protein to replace one of the 20 tRNA-charging ribozymes, and that through gene duplication and subsequent evolution, related protein sequences evolved that replaced more and more of the earlier synthetase ribozymes. But before evolution had succeeded in replacing all the ribozyme synthetases via duplications of the first synthetase protein, it developed a second, unrelated synthetase protein. Through gene duplication and drift, this, too, began to replace other ribozyme synthetases until, today, we find that all 20 synthetases belong to one of two unrelated families.
Archival Storage
In principle, RNA can serve as genetic material. In fact, it still does for many viruses, including HIV and the coronavirus that causes COVID-19. But the poor chemical stability of RNA limits the size that can be achieved using RNA genomes to a few thousand bases. Any longer, and the genome is too likely to suffer a fatal self-cleavage reaction via a mechanism described below. Thus, to achieve larger genomes—perhaps to accommodate a growing number of protein-coding genes—evolution had to invent a new archival storage material.
At first glance, RNA and DNA look very much alike (fig. 6.2). What is so special about the missing oxygen atom that puts the D into DNA (the D stands for “deoxy,” i.e., lacking an oxygen)? Textbooks of biochemistry tend to start from DNA and then mention in passing that RNA has a hydroxyl group (−OH) at position 2′. (In nucleotides, the prime distinguishes the numbering of atoms in the sugar—ribose or deoxyribose—from the numbering of those in the base.) But it seems that, in the history of life, RNA is the earlier version of the idea, and DNA the deluxe edition introduced later.
Considering the structure of the ribose and deoxyribose alone, removal of one of the five oxygen atoms doesn’t look like such a big deal (see fig. 6.2). But if you look at the ribose inside a nucleic acid polymer, you see that the 2′ oxygen is the only one that does not serve an immediate function in the primary structure. In RNA, the oxygen in position 1′ is replaced by the nitrogen of the nucleobase, and the 4′ oxygen is holding the ring together. Oxygens 3′ and 5′ link to the phosphate groups leading to neighboring nucleotides. This leaves the oxygen of the 2′ hydroxyl group as the sole survivor, a chemically reactive group that might get into all kinds of mischief, including additional (branched) polymerization, hydrogen bonding, and—worst of all—autocatalytic hydrolysis of the phosphate-sugar bonds that hold the RNA together: the 2′ oxygen is, in fact, in the perfect geometry to attack the phosphate linkage in the RNA backbone, cleaving it. Because of this, RNA polymers are relatively unstable and are prone to breakage under even mild conditions over the course of days or weeks. DNA lacks the 2′ hydroxyl group and thus is enormously more stable. So stable, in fact, that genome sequences have been obtained from the bones of hominins, the Neandertals and the Denisovans—although, sadly, not yet from dinosaurs—that became extinct more than 30,000 years ago. This enhanced stability renders DNA much better suited than RNA to the archiving of large amounts of genetic information. Moreover, as DNA is completely compatible with the RNA archives that presumably preceded it (DNA binds more strongly to a complementary strand made of RNA than to one made of DNA), it was presumably easy for this improved system of information storage to evolve from the RNA world. A vestige of DNA’s takeover as the genetic material may be found in the way DNA is made in the cell: the synthesis of DNA is initiated using a short RNA “primer.” The formation of RNA, in contrast, doesn’t generally require a primer, and thus RNA synthesis can “bootstrap” itself.

Figure 6.2 At first glance, RNA and DNA look very much alike: DNA is simply missing an oxygen atom at the 2′ position. (The carbon numbering system denotes atoms in the sugar with a “prime” in order to distinguish them from those in the nucleobase, which are denoted without primes.) This missing oxygen, however, makes a world of difference: the 2′ hydroxyl group in the RNA is well placed to attack the phosphate backbone, leading to a relatively rapid self-cleavage and putting a strong limit on the maximum size of an RNA-based genome.
As an additional bonus, DNA contains a new kind of nucleobase that facilitates the repair of damaged genetic material. Instead of uracil (U), DNA contains a methylated version of this base, known as thymine (T). The trouble with the nucleobases used in RNA is that cytosine sometimes spontaneously converts to uracil via a simple hydrolysis reaction that replaces an amino group on the nucleobase with oxygen. The additional methyl group in thymine allows the cell to distinguish this base from any uracil accidentally introduced into a DNA strand by the hydrolysis reaction. There is an entire tool kit of repair enzymes to fix this: they first cut off the uracil base, then open the damaged DNA strand, and finally restore the cytosine. Thus, the introduction of thymine and the associated set of quality controls is a valuable improvement over the RNA world in the fidelity of genetic inheritance, but it would be of much less value in “disposable” products, such as messenger RNA, which are therefore still made of RNA today.
Which Came First, Proteins or DNA?
With the advent of a more durable genetic material and the availability of highly efficient protein-based catalysts, the machinery that copied, repaired, and transcribed the cell’s genome evolved to levels of complexity that were simply not possible in an RNA world. This complexity included not only enzymes that copy DNA to make either new DNA or RNA transcripts, but also enzymes that unwind DNA, repair DNA damaged induced by UV light or other sources of radiation, untangle DNA when it’s all knotted up, cut DNA at specific sites and that regulate the length of the chromosome ends, and much, much more.
But this raises a question. Because of the obvious advantages that proteins and DNA possess, it is easy to rationalize why the protein-DNA world took over from the RNA world. But even if we accept that the RNA world begat the protein-DNA world, which of these new polymers came first? As yet, nobody knows whether the RNA world first recruited proteins or recruited proteins only after inventing DNA. A rather indirect argument in favor of DNA first is as follows: while we know LUCA used DNA, LUCA may not have contained the enzyme ribonucleotide reductase, which converts ribonucleotides to deoxyribonucleotides, because this enzyme is quite different in archaea, bacteria, and eukaryotes. Steven Benner has speculated that this is because LUCA’s ribonucleotide reductase was still a ribozyme. That is, it was a ribozyme that catalyzed the reaction that made DNA, not a protein—supporting the argument that DNA came before proteins. Still, the ribonucleotide reductase reaction is a very difficult one to perform (it is one of the few biochemical reactions that relies on radicals), so there is some question as to whether it could have been performed by a ribozyme, and no such ribozyme has been created in the laboratory. Given this, it is probably best to say that the jury is still out on the question of which came first. Or, more accurately, second, after RNA.
Enzymes and Metabolic Networks
At this point in our story, we’re talking about an organism with all the major molecular components of today’s life in place, including RNA, proteins, and DNA. So, having reached this point, several natural questions now arise. How many proteins did this early organism have? What were their likely tasks? And how did they link up into complex metabolic networks? In short, which of the metabolic pathways of today’s cell (fig. 6.3) would already be listed in a biochemistry textbook had it been written by visiting aliens a few billion years ago?
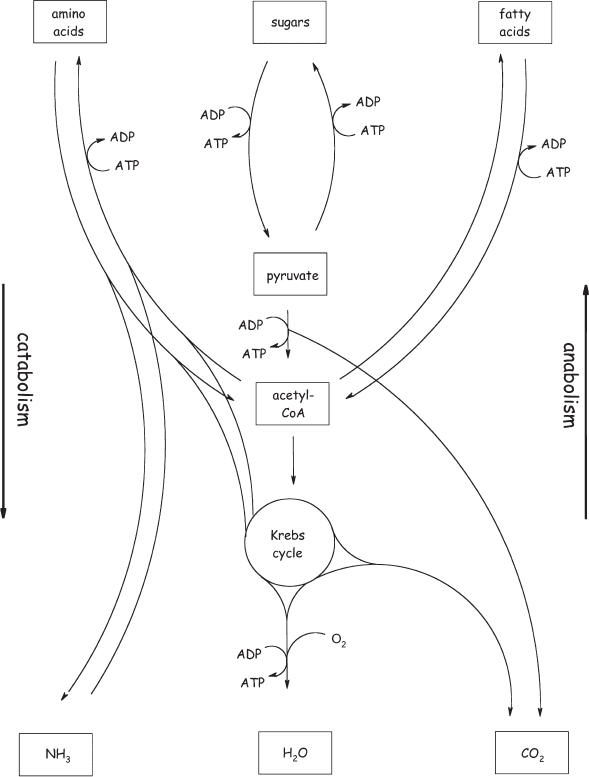
Figure 6.3 Even a minimalist Terrestrial genome encodes a very complex metabolic network. This includes catabolic pathways that break down large molecules, such as glucose, into smaller molecules, such as pyruvate, in order to generate energy; and anabolic pathways that use energy to synthesize amino acids, nucleobases, and the like from simpler precursors.
Since the sequencing of entire bacterial genomes became feasible in 1995, genomics (the study of the full complement of genes that an organism carries) has increasingly provided researchers with new tools to address all these questions. Obviously, the availability of unprecedented amounts of gene sequences has aided molecular phylogeny—the construction of family trees for groups of related organisms, or even groups of related proteins, which we’ll discuss in the next chapter. But on a higher organizational level, the comparison of complete genomes has made it possible to investigate the question of what makes up a minimal set of genes for a cellular organism.
The first two organisms to have their entire genomes sequenced, Haemophilus influenzae and Mycoplasma genitalium, were selected for these studies, in part, because their genomes are small. In fact, with just 480 genes, M. genitalium was assumed to contain precious little beyond the minimal set. Nonetheless, comparison of the genomes of these two organisms suggests that there is a shared set of around 260 genes that represent the minimum “essential” collection. Later studies focused on sequentially knocking out individual genes from the much larger genome (approximately 4,100 genes) of the bacterium Bacillus subtilis. These studies arrived at a list of just 271 essential genes. Still other studies have produced results ranging from 150 to 670 essential genes. But it is not so much the precise number that should interest us here. Instead, we should focus on the tasks that these genes fulfill, and their usefulness as a model for the simplest, and perhaps earliest, metabolisms.
And what do these simple, minimal genomes tell us? In the B. subtilis study, most of the 271 essential genes can be clearly grouped into the broad categories of information processing (DNA processing: 27 genes; RNA processing: 14; protein synthesis: 95), and the cell envelope (44), cell shape and division (10), and energetics (30). Not surprisingly, this suggests that DNA replication, protein synthesis, maintenance of the cell’s physical integrity, and the metabolism required for energy production are all critical elements of the simplest complete metabolism. Still, the question remains as to which of these metabolic networks we inherited from LUCA and which, if any, were invented after her. To answer this question, we have to look at the bigger picture.
Steven Benner has likened the evolution of metabolism to a palimpsest, the word used in archaeology for a parchment that has been used more than once and from which traces of the imperfectly erased, earlier inscriptions can still be read. For example, as we described in chapter 5, ribonucleotide cofactors (e.g., ATP) can be interpreted as vestiges of the RNA world. Benner argues that all of metabolism can be viewed in this way, for, as we argued above, any metabolic pathway that is shared across all life-forms was probably inherited by them from LUCA. Using this approach to map out LUCA’s biochemistry, Benner’s group postulated that LUCA not only used DNA as her genetic material, but that she also employed a fairly modern-looking DNA polymerase, the enzyme that synthesizes DNA by stringing together nucleotides on a DNA template. As described above, LUCA also contained the transcriptional machinery by which RNAs are made from a DNA template and a full set of machinery for translating messenger RNA into the appropriate protein sequences.
It appears current life on Earth also inherited a fair bit of its metabolism from LUCA. That is, beyond transcription and translation, current life inherited from LUCA many of the myriad of biochemical pathways that it uses to convert food into organisms (and into heat). Although we humans, for example, can synthesize only 12 of the 20 amino acids found in proteins (due to our rich diets, we could afford to lose some of the pathways through mutation without taking too hard a selective hit), most organisms are not similarly handicapped. Looking across the tree of life, we find, in fact, not only that most organisms can synthesize all 20 amino acids, but also that the biosynthetic pathways by which most amino acids are formed are closely related. The only notable exceptions to this rule are the biosynthetic pathways for the three aromatic amino acids (phenylalanine, tyrosine, and tryptophan, each of which contains a benzene-like group in its side chain; see fig. 4.2), which are synthesized via very different pathways in eukaryotes and bacteria. So it seems that LUCA had developed an ability to synthesize most of the amino acids herself, if perhaps not the aromatic amino acids. By a similar argument, LUCA probably could synthesize the nucleobases; the biosynthetic routes by which both the purine and pyrimidine bases are manufactured in the cell are closely related across all life. Finally, LUCA also employed pretty much all the nucleotide-containing cofactors, including ATP, FAD, vitamin B12, S-adenosyl methionine, and coenzyme A, as might be expected given the putative connection of these cofactors to the earlier RNA world.
But what about the mechanisms by which the cell derives its energy? Humans obtain most of their energy via two metabolic pathways. The first is called glycolysis and involves the nonoxidative breakdown of glucose into the smaller molecule pyruvate. Such nonoxidative, energy-producing reactions are called fermentation.* The 10 enzymes involved in glycolysis share close relatives across the three domains of life, suggesting once again that LUCA contained this key metabolic pathway. In our cells, the pyruvate is then oxidized to carbon dioxide in a cyclic metabolic pathway called the Krebs (citric acid) cycle (which we’ve already encountered but will learn more about in chapter 7). The enzymes of our Krebs cycle, however, are not present in archaea, suggesting that LUCA did not contain this oxidative metabolic reaction.
Although LUCA’s genome encoded the enzymes necessary to perform glycolysis, it is difficult to imagine that, by the time she was around, long after the origins of life itself, sugars like glucose were simply lying around like manna from heaven. Instead, she probably employed the enzymes of glycolysis in reverse, using them to synthesize sugars from simpler carbon compounds. Given this, though, what did she eat? That is, what was her source of these simpler carbon compounds? To answer this question, William Martin and coworkers at Heinrich-Heine-Universität in Dusseldorf, Germany, compared more than 6 million genes taken from 1,847 bacterial and 134 archaeal genomes to identify 355 genes that contributed to LUCA’s genome. From this, they deduced that LUCA employed the Wood-Ljungdahl pathway (fig. 6.4), a metabolic route by which carbon dioxide is reduced into more useful compounds using hydrogen gas, which, in LUCA’s case, would have been produced by the reaction of water with reduced iron compounds in the Earth’s crust. Their work indicates that LUCA’s genome also encoded nitrogenase, the enzyme that uses molecular hydrogen to reduce nitrogen gas to the more useful ammonia, and glutamine synthase, the enzyme that converts ammonia into more useful (and less toxic) nitrogen-containing compounds. This ability to fix atmospheric nitrogen was lost in most organisms, including all eukaryotes; it presumably would have been of value to us, but oxygen is a potent inhibitor of this enzyme, rendering it difficult to keep active after the advent of the oxic atmosphere.
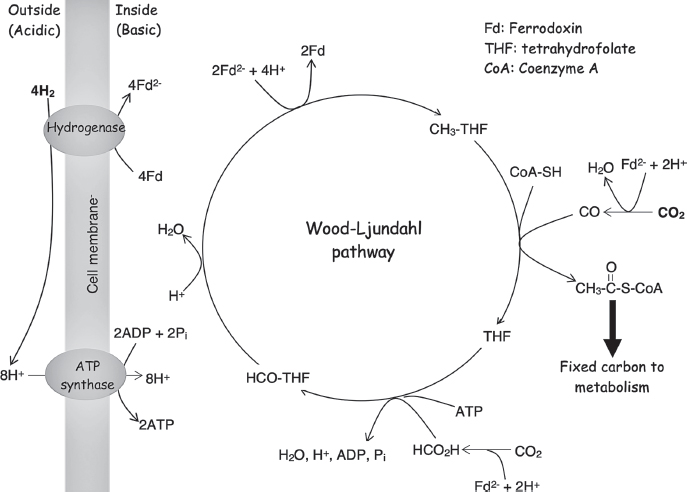
Figure 6.4 Comparative genomic studies indicate that LUCA encoded the Wood-Ljungdahl pathway (also known as the reductive acyl-CoA pathway), a metabolic route by which two molecules of carbon dioxide are reduced via the consumption of four hydrogen molecules to create one molecule of the central (see Figure 6.3) metabolite acetyl-CoA. The consumption of hydrogen takes place outside the cell, generating hydrogen ions there, and the reaction consumes hydrogen ions inside the cell. LUCA used the resulting hydrogen ion concentration gradient to produce metabolic energy in the form of ATP. Tetrahydrofolate and coenzyme A are small-molecule cofactors, and ferredoxin is a small, iron-and-sulfur-containing protein; these are used throughout biology to carry single-carbon units, acetyl groups, and electrons, respectively.
Membranes: Wrapping It All Up
The DNA-RNA-protein division of labor is, effectively, a universal feature of organisms living on our planet today. Another similarly near-universal feature is the barrier that separates the living from the nonliving world: the cell membrane. Life may have originated as a set of self-propagating chemical reactions on a solid surface, in liquid droplets, or in other kinds of media (as described in chapter 5), but it acquired the ability to grow and spread, independent of the medium, only when it succeeded in isolating itself from the environment by creating the cell membrane. In the RNA-world hypothesis, the membrane also serves the critical role of keeping the genetic material in physical association with the metabolic catalysts it encodes, without which, the metabolic networks of the cell would not provide a selective advantage for the organism (which is defined by its genes), and evolution would grind to a halt. In a sense, the membrane was the key step in creating cellular life as we know it today. (Note that viruses, many of which are also surrounded by a membrane, were a later development based on the DNA or RNA of already existing cellular organisms.)
But where did the membrane come from? The universality of the DNA-RNA-protein system strongly suggests that it predates the common ancestors of today’s organisms. Similarly, all cells are surrounded and defined by at least one double-layer lipid membrane, supporting the argument that LUCA must have had a membrane too. The chemical composition of the lipids making up the membrane, however, differs fairly significantly among the three domains of life. Specifically, both bacterial and eukaryotic membranes (including our own) are made of diacylglycerides, which are composed of a glycerol molecule to which two fatty acid tails are linked via an ester bond to a backbone comprised of glycerol-3-phosphate (fig. 6.5). Archaea, however, cannot synthesize fatty acids, and instead build their membranes from a class of lipids called terpenoids, which they link to the backbone glycerol-1-phosphate via a chemically distinct ester bond. Given that LUCA appears to have been able to make terpenoids (all three of the broadest branches of the tree of life can synthesize them), and given that archaea, and thus presumably LUCA, cannot synthesize fatty acids, the presumption is that LUCA employed terpenoids in her membranes and that these were later replaced with fatty acids in the bacterial and eukaryotic branches of the tree of life (see sidebar 6.2).
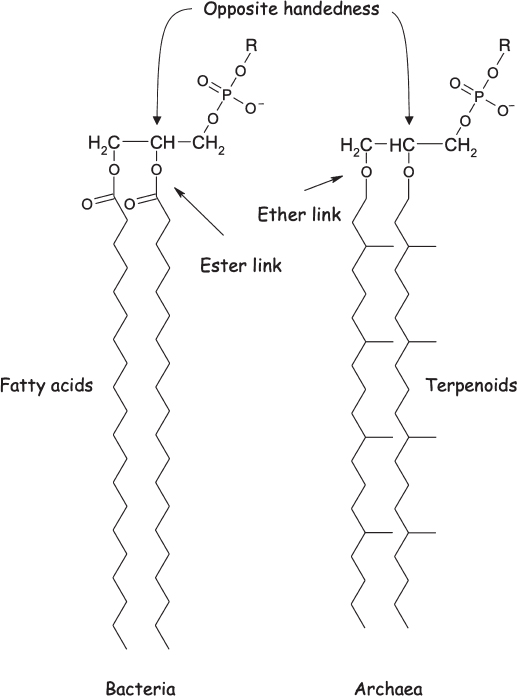
Figure 6.5 The cell membranes of most organisms, including bacteria, are composed largely of diacylglycerides, in which two water-hating fatty acid tails are linked by ester bonds to a glycerol, which in turn is connected to a water-loving “head group” comprised of modified phosphates (the “R” group denotes a family of molecules that vary in that position). The cell membranes of one large, microbial branch of the tree of life (the Archaea) are formed from branched hydrocarbons called terpenoids attached to glycerol by ether, rather than ester, linkages. A final, more subtle distinction is that the chirality (handedness) of the glycerol backbone is flipped between the two.
Conclusions
From the first simple, self-replicating molecules to protein- and DNA-based organisms of breathtaking metabolic complexity, it’s a fascinating story, the broadest sweep of which seems clear: the incessant push of selective pressure, fighting against the imperatives of chemical reactivity, guided the earliest, simplest life into the complex, robust life-forms we see around us.
As illustrated by the scientific biography of Francis Crick, the tale of how we came to understand the origins of cellular life is a similarly complex and fascinating story, one driven by episodes of startlingly original, outside-the-box thinking. And while we may be tempted to deride those wild ideas that turned out to be off the mark, at the frontiers of our knowledge many wild ideas turn out to be true. The origin and early evolution of life is one such frontier where this kind of unbridled creativity is still useful.
Further Reading
Directed Panspermia
Crick, F. H. C., and L. E. Orgel. “Directed Panspermia.” Icarus 19, no. 3 (1973): 341–46.
RNA Evolution
Joyce, Gerald F. “The Antiquity of RNA-Based Evolution.” Nature 418 (2002): 214–21.
Protein Biosynthesis
Ramakrishnan, Venki. Gene Machine: The Race to Decipher the Secrets of the Ribosome. London, UK: One World Publications, 2018.
LUCA’s Metabolism
Benner, S. A., A. D. Ellington, and A. Tauer. “Modern Metabolism as a Palimpsest of the RNA World.” Proceedings of the National Academy of Sciences USA 86, no. 18 (1989): 7054–58.
Weiss, Madeline C., Filipa L. Sousa, Natalia Mrnjavac, Sinje Neukirchen, Mayo Roettger, Shijulal Nelson-Sathi, and William F. Martin. “The Physiology and Habitat of the Last Universal Common Ancestor.” Nature Microbiology 1, no. 9 (2016): 16116.
- * Personal communication with the author (Plaxco).
- * This said, somewhere along the way the eukaryotic lineage added further complexity to its ribosomes, which contain far more components of archaeal or bacterial ribosomes.
- * Harold B. White III, “Coenzymes as Fossils of an Earlier Metabolic State,” Journal of Molecular Evolution 7, no. 2 (1976): 101–104.
- * These occur mainly in mitochondria, the energy-producing subcellular organelles that power our cells and contain their own DNA. In the mitochondria of starfish, for example, the codons AGA/AGG and UGA specify serine and tryptophan, respectively, whereas in the standard code they represent arginine and a stop codon, respectively. These substitutions are possible because the mitochondrial genome is quite small: it encodes only 13 proteins. But altered genetic codes have also been found in some nuclear genomes, including in some species of yeast.
- * Archaea lack the synthetase enzymes that charge the glutamine and asparagine tRNAs with these amino acids, suggesting that LUCA likewise lacked these. Instead archaea (and, presumably, LUCA) charge these tRNAs with the related amino acids glutamate and aspartate, then chemically convert them to glutamine and asparagine, respectively.
- * Under anaerobic conditions (such as in a champagne bottle), yeast obtain their energy from the glycolytic pathway. As a last step in the pathway, they convert the pyruvate to ethanol and carbon dioxide. Cheers!