These arguments have been developed substantially in subsequent years by ourselves along with John Kain and his students, Edward Glaeser, Richard Florida, and others. This is a relatively new interpretation. Much of the urban literature followed the so-called economic materialist interpretation until relatively recently (as evidenced by the widespread use of textbooks like those following the Muth tradition), which suggests that factors like jobs are the primary drivers of people’s decisions about where to live. There has been almost no serious research to extend the sort of studies initiated by Muth and Greenwood perhaps because of the intrinsic complexities we flag here.48
Despite the relative lack of research progress, in discussions about scenes we are frequently asked variations of this chicken-and-egg question. For example, does income cause a scene to change, or vice versa? The first simple answer is that these are classic processes throughout the social sciences and not specific to scenes. Thus the kinds of logical answers, the methodology and data that are used elsewhere, can be applied here. Some studies use cross-sectional data, others two or three periods, others large numbers of time periods. So have we.
The second main answer is that given the huge complexity of factors that generate scenes, for strategic reasons we have for the most part not sought to conceptualize and measure their constitution in this book. Rather we have mostly focused on the consequences of scenes for several widely used items in social science and policy discussions (like population change, rent, patents) to help establish scenes impacts in the same models as many others have developed.
Third, it is distinctly difficult to explore chicken-and-egg dynamics precisely. Since the scenes data are so extensive and draw from so many sources, it is exceedingly difficult to find comparable data across many years from all sources. Thus it is difficult to follow one systematic pattern and consistent model to test simple hypotheses. The YP data were collected at one time point only, since YP business directory services generally discard their historic data and update their categorizations in ways they refuse to report (we tried!). The US Census of Population is only completed every decade. The Economic Census collects data every few years. The exception to this is the BIZZIP data set, which is updated annually, but like (many, alas) other “series,” it changed coding schemes over time, reducing the quality of analyses using performance scores that attempt to combine data across time periods. Clearly, if we tried to make the sort of strong statistical and econometric assumptions logically necessary for the stronger statistical procedures, the data are too inconsistent to identify precise sequencing.
The Chicken and the Egg, Total Jobs and Arts Jobs
We investigated some distinct chicken-and-egg dynamics by examining arts jobs in relation to other jobs, contrasting patterns across all US zip codes. We explored changes over time and for selected subgroups of zip codes. We analyzed repeatedly mutual impacts of arts jobs on total jobs of all sorts at the zip code level. The total jobs item simply summed all jobs in all industries collected by the US Census of Business (BIZZIP), for each US zip code. Unfortunately the codes for job categories changed, such that the older Standard Industrial Classification (SIC) codes were replaced by a new set of NAICS categories in the 1990s. Then the NAICS categories were revised. Thus, for longer time periods, one confronts problems of consistency in classification.
We did many analyses using the data available for slightly different time periods. One solution to the problem posed by changes in job classifications was to simply sum all jobs in all categories to create a total jobs measure; for this, the definitions of job categories should be irrelevant. Then we looked at the subcategories of arts jobs and found that most subcategories were repeated with near identical labels from the 1980s until after 2000. Thus it seemed reasonable to estimate the impact (economic elasticity) of arts jobs on total jobs over the years from the 1980s to after 2000. This seemed important as one of our findings was that arts jobs were one of the most powerful predictors of job growth after 2000, even when controlling for our core variables. We wanted to see if this same strong relationship between arts jobs and (subsequent) growth in total jobs held over time—especially as there is virtually no systematic comparative analysis in the small literature on arts jobs as drivers of urban growth, and virtually none that confronts chicken-and-egg issues.
One interesting finding was that in the earlier years, 1980s and 1990s, arts jobs did not have a significant impact or relationship to growth in total jobs in subsequent years. But from 1998 to 2001, the arts job impact was strong, the strongest of all variables in a 10-variable model. We could not use data for each subperiod for all our other variables due to data availability, so these results are tentative.
Nevertheless the apparent rise in impact of arts jobs on general job growth over time is consistent with our more general interpretation that as a general indicator of consumption/lifestyle spaces, and specifically more self-expressively oriented scenes-related amenities, arts jobs may have increased in importance in the last few decades. These results fit with our discussions of shifts in a postindustrial society toward consumption and amenities as distinct opportunities to express personal values and styles of life. These last statements are based on assessment of many different sources of evidence in addition to those originally analyzed here, but the rise in the specific arts job to total job elasticity fits with the broader interpretation.
Cross-lagged regression permits further analysis of the relationships of total jobs and arts jobs. Figure 8.4 illustrates the general cross-lagged regression approach. We use this method as it takes advantage of the annual BIZZIP data for the large number of zip codes. The basic idea of cross-lagged regression is to allow for an analysis across different time periods, using data that is normally analyzed cross-sectionally. In our case, we analyze how much arts jobs influence total jobs, after we (statistically) remove the impact of total jobs from earlier years. The top and bottom horizontal lines in figure 8.4 are thus mostly “controls” of the same variable across time, while the two diagonal lines are the key items to contrast. The beta coefficients for the crossed lines show the relative impact of arts jobs compared to other (nonarts) jobs in explaining the change from 1998 to 2013. We explored many variations of this basic model, adding further variables, interaction terms, and so on. But the main results held strong.
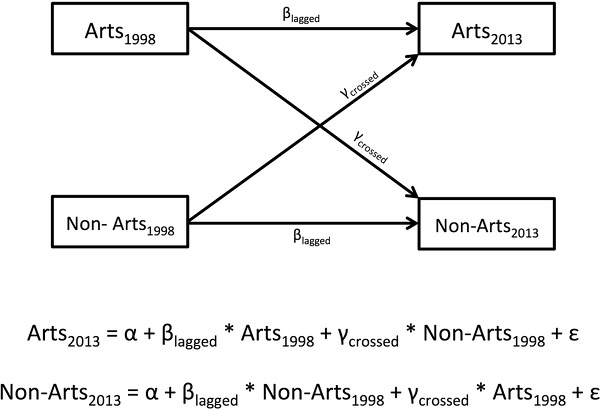
Figure 8.4 Cross-lagged regression, general model
The individual variables are simply levels of absolute numbers (not change or per capita). By including the absolute number of arts jobs in a zip code as both independent and dependent variables in the first equation, the first beta (with the subscript “lagged”) shows the direction and magnitude of change (growth or decline) in arts jobs from 1998 to 2013 for all US zip codes. The method does not require the strong assumptions demanded by other methods, such as “instrumental variables” in two-stage least squares regression.
A first analysis contrasted the diagonal coefficients (as in figure 8.4) and found them both significant, for changes in arts jobs and nonarts jobs from 1998 to 2013. This differs from earlier years when there was zero impact of arts jobs on later numbers of total jobs.
Our second analysis compared the relative impact of arts jobs in different types of zip codes. We hypothesized that there may be a stronger taste for the arts and often more diversification in locations with larger populations, and more educated and affluent residents. In such locations, arts jobs may have higher impacts (elasticities and multiplier effects) on the numbers of nonarts jobs in subsequent years. To test these simple hypotheses, we contrasted the impact of arts jobs in zip codes that varied in population, education, and income (see the note to figure 8.5). We found support for the hypotheses. The results depicted in figure 8.5 show that arts jobs spark other nonarts jobs more in the top 10 percent of zip codes in population, education, and income. By contrast, arts jobs have relatively weaker impact over time on nonarts jobs where population size, education, and income are lower. The other (nonarts) jobs show more impact on arts jobs and other jobs in locations in the bottom 10 percent. For all zip codes, by contrast, results were in between the top and bottom groups, as expected.
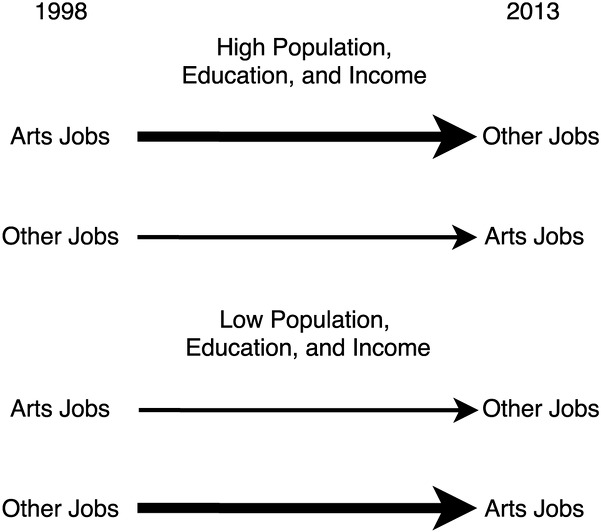
Figure 8.5 The impact of arts jobs on job growth varies across zip codes
The paths shown here are only the diagonal paths from the full model we estimated, shown in figure 8.4. We reestimated the full model three times for three sets of zip codes; the high and low 10 percent are summarized in the two sets of paths shown above. The high and low 10 percent were from an index of three items for all US zip codes: median household income, percentage residents with a BA or higher degree, and surrounding county population. The top 10 percent on all three items included 1,421 zip codes and the bottom 10 percent was 1,076 zip codes. The figure contrasts betas for the high and low zip codes; results for all US zip codes were in between in the cross-lagged regressions. The thickness of the arrows illustrates the relative strength of the relationships. For instance, in the top 10 percent, the impact of (1998) arts jobs on (2013) total jobs was greater than the impact of (1998) total jobs on (2013) arts jobs.
In sum, arts jobs do drive economic growth. Zip codes with more arts jobs often grow all kinds of jobs faster. This arts multiplier effect is largest in zip codes with higher population size, education, and income. So we find a chicken-and-egg pattern, but the magnitude of each effect varies by type of area. There is no general answer to the question about which comes first, arts jobs or total jobs, in the final analysis. Each feeds into the other. But arts jobs enhance local scenes and often encourage more general job growth.
The chicken-and-egg metaphor is useful for many complex social phenomena, scenes and others: it is futile, the metaphor suggests, to seek first causes or prime movers. Rather, if change in one factor occurs, in a highly interdependent system, it brings consequences that feed back on other factors in the next time period. And so on. Sometimes one factor leads and others follow; next it may be the other way around. Sometimes one can be more precise about specifics, such as how variables such as population, education, and income shift the impacts of arts jobs. But why seek to overgeneralize? We need both chickens and eggs.49
Scenes as Dependent Variables
That scenes are part of complex feedback mechanisms implies that it makes sense to analyze them as dependent variables and not only as independent variables, testing theories about not only the consequences but also the sources of scenes. Reversing in this way the typical approach of Scenescapes brings us immediately into closer conversation with studies more characteristic of “the sociology of culture.” Here one investigates, for instance, why one type of cultural practice, taste, sensibility is more likely to occur in a given place or group than another.
Many leading theories of culture in the social sciences work in this explanatory direction, with “cultural variables” as outcomes. In a similar way, throughout Scenescapes, we have often noted that many processes we consider can also be analyzed from this perspective. For instance, a neighborhood with a self-expressive scene may attract college graduates; but at an earlier point, the emergence of this scene may have been encouraged by college graduates as customers and residents. We have accordingly explored potential explanations for why some scenes are stronger or weaker in different places, in reference to leading theories from the sociology of culture.
Here as in the rest of Scenescapes, we begin with key variables posed by others to assess their impacts, in this case on our scene variables. A first example is a general proposition in the mode of Pierre Bourdieu or Thorstein Veblen—that class inequality and segregation should strongly determine differences in style and taste. This has been widely discussed in past literature. In Veblen’s version, elites undertake lavish and conspicuous consumption not for any physical need but to display their dominant social position and to inspire “pecuniary emulation” in others. In Bourdieu’s variant, high culture provides a suite of special knowledge, manners, and tastes that helps those at the top of the social hierarchy distinguish themselves from, and thereby exclude, those below.
We examined both of these claims separately but focus here on the more Veblenesque version.50 To do so, we used a measure of metropolitan income segregation from John Logan, a leading researcher on the topic, the “the rank-order information theory index H.”51 We then analyze the connection between income segregation and the five factor score combinations of scene dimensions from chapter 5: Communitarianism/Urbanity, LA-LA Land, Rossini’s Tour, City on a Hill, and Nerdistan. These focus on Veblenesque conspicuousness included in more flashy consumption styles, like glamour and exhibition, especially LA-LA Land.52
If we look first at simple bivariate Pearson correlations between metro income segregation and the five factor scores, we find that four out of five scenes are positively correlated with metro inequality (all but egalitarian City on a Hill). But if we add only three more variables (specifically metro total population along with zip code education and rent, since these types of variables are widely discussed in several overlapping literatures as major social drivers of differences in cultural tastes), the picture changes, as table 8.11 shows.
| Table 8.11. The relationship between metropolitan income segregation and scenes becomes insignificant or reverses after adjusting for other variables | ||
|---|---|---|
| Relationship with metropolitan income segregation, adjusting for four variables | ||
|
Communitarian vs. Urbanity |
0 |
|
|
LA-LA Land |
0 |
|
|
Rossini’s Tour |
− |
|
|
City on a Hill |
0 |
|
|
Nerdistan |
+ |
|
|
Note: This table shows the relationship between five scenes and metropolitan segregation, after we adjust for the metro total population, zip code rent, and zip code education. All five scenes are positively correlated with inequality in a simple bivariate relationship. After adding the other variables, three become insignificant and one shifts from positive to negative. Only Nerdistan remains positive. These scene variables are derived from factor analysis of the 15 dimensions. Factor weights for each dimension in the five scenes are summarized above, in table 8.4, and the factors are described in more detail in chapter 5. |
||
Table 8.11 summarizes relationships between the five factor scores and metro income segregation, after we include the other variables. It makes immediately clear how much the simple bivariate relationship with metro inequality leaves out. When we add these three basic controls, the positive relationship between metro inequality and the scenes either disappears or reverses sign.
Most notably, the link between metro inequality and LA-LA Land—perhaps our most conspicuous-consumption-oriented scene, in stressing glamour and exhibitionism—becomes insignificant, as does the association between metro inequality and Communitarianism/Urbanity. Rossini’s Tour, which combines local authenticity and self-expression, we now see, is typically found in less segregated metros once we adjust for these other variables. The negative association of inequality with City on a Hill has also become insignificant. The only scene to be positively linked with metro inequality is Nerdistan (Nerdistan is a complex scene stressing formality and rationality [see table 8.4], all weak measures of conspicuousness compared to glamour and exhibitionism). The Veblenesque theory—that variation in scenes should be traceable to variation in residential income segregation—does not find much support in these results. It may well be that Veblenesque ideas hold in some scenes for some groups of persons, and maybe more in the past or other countries, but they do not emerge readily or strongly here.
The general methodological point here is that many plausible and standard variables are starting points rather than stopping points for investigating the sources of scenes—we can begin with Veblen but cannot end there. Indeed, the variables in the models summarized in table 8.11 only account for a small amount of the variance in the scenescape: the adjusted R-squared for Nerdistan is the highest, around 0.14, and the rest are 0.1 or below. Pursuing other potential explanations, such as ethnicity, occupation, region, and much more, and slowly folding them into leading theories in the sociology of culture, is thus an active area of current scenes research.
Scenes in International Context
Scenescapes has mostly described and analyzed the American scenescape, sprinkling illustrative references to other countries throughout, and including somewhat more from our neighbor to the north, Canada, where our lead author is based. But scenes research is a truly international endeavor. Teams in Canada, France, Spain, Poland, Japan, Korea, and China are studying their countries’ scenes. These international efforts are exciting opportunities to extend, revise, and test the approach in Scenescapes, as well as challenging occasions to work out new ideas and methods for comparing and analyzing scenes cross-nationally.
Clemente Navarro’s team in Seville’s Universidad Pablo de Olavide has been an international leader in scenes research (see, for example, Navarro 2012). This is not surprising given Navarro’s crucial role in developing many scenes concepts and methods. Navarro and colleagues built a database of Spanish amenities similar to our own, applied the same type of scoring system, and computed performance scores for approximately 800 localities. Exploratory factor analysis of their performance scores reveals a first factor similar to the first factors in US and Canadian performance scores—Navarro and colleagues call it “conventional vs. unconventional,” with dimensions like neighborliness, locality, and tradition on one side and transgression, self-expression, and glamour on the other. And they have mapped this factor across all of Spain, revealing a strong concentration of “unconventional” scenes in the Northeast and around major cities, as in figure 8.6.

This map plots the relative Communitarianism versus Urbanity within Spain’s scenes. Darker is more Urbane. Source: Figure 2 (p. 309) from Clemente J. Navarro, Cristina Mateos, and Maria J. Rodriguez, “Cultural Scenes, the Creative Class and Development in Spanish Municipalities,” European Urban and Regional Studies 2, 3 (2014): 301–17.
Building on these scenes measures, Navarro and colleagues show that the unconventionality versus conventionality of the scene is a strong predictor of where Spain’s “creative class” is located. Moreover, unconventional scenes are strongly linked with higher relative incomes in Spanish localities and in fact enhance the connection between “the creative class” and income, which is also strong. These results are especially important in the European context, as they, together with other recent European work on amenities,53 provide grounds for doubting the claim that the links between scenes and economic growth are dependent on parochial features of North American countries, such as (sometimes) higher geographic mobility. Some of the Navarro team’s results are in Navarro, Mateos, and Rodríguez (2012).
Teams in France and Korea have created similar maps. In Paris, Stephen Sawyer’s (2011) group charted Parisian scenes, as a way to better understand the on-the-ground cultural styles that strongly differentiate Parisian neighborhoods. Using yellow pages and census data similar to ours, they mapped all Paris area communes and arrondissements, not only across all 15 dimensions, but also on combinations that capture key Parisian scenes, like “the art of living” and “the underground,” extending our initial approach to detecting scenes to capture some of the specific context of French culture (Clark and Sawyer 2009–2010). Work continues in all French communes.
Wonho Jang in Seoul led a team that produced two reports, mapping Seoul’s scenes and comparing them to scenes in Tokyo and Chicago. Others are pursuing comparable work, often with methods and data similar to those employed in Scenescapes, sometimes exploring new techniques, as in Chad Anderson’s studies of scenes in Seoul and China using photo ethnography. Links to much of this ongoing work can be found on our website.
In China, Wu (2013) analyzed 374 districts in 35 large Chinese cities. He and colleagues coded amenities using the basic 15 scenes dimensions and factor analyzed them. They found interesting age differences across neighborhoods. Areas with older residents more often featured state, corporate, and utilitarian dimensions, while those with younger residents featured more exhibitionism, self-expression, and charisma. He completed geographically weighted regressions and network analyses among amenities, which detailed how these differences affected rent prices across neighborhoods.
Jang, Clark, and Byun (2011) is especially important in the present context. It breaks new ground by explicitly comparing scenes cross-nationally, finding intriguing differences in conceptions of Bohemia—a concept unfamiliar to most Korean and Chinese social scientists and intellectuals. This led Jang et al. to deconstruct the concept of Bohemia into 10 distinct components and look for parallels in each cross-nationally. In this way Bohemian components were isolated and compared, showing different spatial distributions of Bohemian scenes in Seoul, Tokyo, and Chicago. Chicago shows more neighborhood segregation in such scenes; zoning is weaker in Tokyo and Seoul. The report also shows Asian challenges to the Tocqueville/Putnam proposition that civic participation generates trust in politics.
These differences raise important substantive questions about how and why Bohemianism, civic participation, and citizenship in Asia differ from their European and North American variants. But they also point toward the more general emerging frontier of scenes research coalescing around the comparison of scenes across nations. That is, rather than labeling a pattern by its nation or region like Asia, it leads us to drill down to identify counterparts to “Asian” patterns in the West, using more generalizable concepts like family strength, social integration, and the like. Then by comparing combinations of scenes dimensions we can show how patterns that may seem to be “Korean” recur in Western areas with stronger families, more local social integration, and other related components. Reanalyzed in Asia, our Gemeinschaft/Gesellschaft factor that looked quite similar in Spain captures elements that both differ and help interpret some Asian/Western differences (Jang, Clark, and Byun 2011). These international comparisons of democracy and development are extended via arts and culture in Clark (2007, 2014).
Methodological Challenges of International Scenes Research
Cross-national scenes research poses its own methodological challenges. A first challenge, seemingly trivial but in fact quite difficult, is simply merging and/or comparing data from so many sources, compiled in different languages, at different units of analysis. An initial international scenes database has been created (led by James Murdoch), but cross-national analysis is just beginning by the teams who contributed the basic data (from Spain, France, Korea, and more).
A potentially deeper challenge is the question of what exactly to compare and how. One option is to focus on a small subset of amenities for which data are available in many countries, like museums and restaurants and religious organizations. This restricted set of amenities could be used to calculate performance scores across countries in two relatively straightforward ways. One could then use the original US coding of amenities’ scenic meaning (e.g., to gain insight into how Americans would view the scenes in Germany). Or local teams could apply their own coding system (e.g., to gain insight into the relationships explored in Scenescapes within Germany). It is illuminating to do both and compare the results.
Another option is for national teams to collect whatever amenities data they believe best capture the character of their countries’ scenes, based on their local expertise, again either applying the US coding or their own. As we found that our approach to calculating performance scores minimized the effect of adding or removing individual amenities, we can see if this robustness holds true in other contexts, allowing other researchers to use their own judgment in terms of what constitutes the most informative amenities for inclusion. Further, teams could pose additional scene dimensions (as Stephen Sawyer has in France or Silver has in Canada), to capture ideal typical scenes that our US-based approach has missed, or discard dimensions that seem less salient. This flexibility is one of the most powerful aspects of our science of scenes.
Given potential variation in the meaning attributable to amenities, and even the scene dimensions they constitute, studying combinations of scenes such as via exploratory factor analysis becomes distinctly useful for international comparisons. All scenes are measured imperfectly, and cross-nationally even the meaning and/or makeup of our scene dimensions can vary.
Indeed, the possible existence of relatively consistent configurations of scenes cross-nationally opens up tantalizing directions for future research that make the world a smaller place culturally. There was no a priori reason why a similar factor number 1 should exist among scenes in the United States, Canada, Spain, and China. In fact, there is ample reason to believe that Spain should be more culturally dissimilar to North America than similar. Yet early results taking this approach are promising. For instance, the similarities in the first factors in the United States, Canada, and Spain suggest strong cross-national commonalities but at the same time reveal subtle differences as well.54 Then to find larger differences in Korea, for instance, is a step toward more precisely interpreting what “Asian” or “Korean” means in more generalizable, but precise, components.
Comparing the correlations of various scene dimensions with rent is also intriguing. Toronto and Montreal stand out in that their more formal scenes have higher rent, whereas in most other cities and countries, glamour and self-expression have higher rent. We would also expect some strikingly different national meanings of amenities to emerge through their different spatial distributions and relationships to other amenities (like the strong differences in the location of churches in France and the United States, noted in chapter 3). Further, comparing what constitutes a transgressive scene in the United States versus, for instance, Korea provides significant insight into larger cultural differences that are often lost in translation and therefore difficult to pinpoint.
We also stress that scenes analysis can inform many different overlapping theories, data, and methods, from multiuse and New Urbanism concepts to video and photo essays to the ethnographic to the historical to the architectural and more. Conferences and publications on scenes are multiplying in several disciplines and countries. We look forward to more.
The primary aim of this chapter was to provide an overview of our multiple ways of constructing a science of scenes. It builds on chapters 2 and 3 to summarize in more detail how we measured our core concepts and overviews the main analytical procedures employed throughout the book. We used many data sources and methods to assure ourselves and our readers that the key relations were being tested systematically, defined by adapting the best data and methods we could find in related fields and disciplines. The main strategy was to identify a core set of variables used in past work and to add our scenes measures to models used by others. “Systematically” here means seeking to assure ourselves that scenes are significant by specifying how they combine or complement other variables, like education and residential choice. This largely means measuring the size of scenes effects compared to other variables, assuring that they are not spurious, and detailing how relations among variables like education and voting vary by context.
Our more original contribution is to codify procedures for capturing and analyzing scenes. Our performance scores quantify the salience of each of our 15 scenes dimensions indicated by the amenities in that zip code. These measures provide a powerful way to capture the range and combinations of cultural meanings present across different localities and to integrate cultural analysis into comparative and quantitative studies of urban development. They bring the scene within the purview of a social scientific account of how and why our cities and communities are changing.