In this preliminary chapter, we introduce the problem of optimal transport, which is the main concept behind Wasserstein spaces. General references on this topic are the books by Rachev and Rüschendorf [107], Villani [124, 125], Ambrosio et al. [12], Ambrosio and Gigli [10], and Santambrogio [119]. This chapter includes only few proofs, when they are simple, informative, or are not easily found in one of the cited references.
1.1 The Monge and the Kantorovich Problems
 , a pit space
, a pit space  , and a cost function
, and a cost function  that encapsulates how costly it is to move a unit of sand at
that encapsulates how costly it is to move a unit of sand at  to a location
to a location  in the pit. The sand distribution is represented by a measure μ on
in the pit. The sand distribution is represented by a measure μ on  , and the shape of the pit is described by a measure ν on
, and the shape of the pit is described by a measure ν on  . Our decision where to put each unit of sand can be thought of as a function
. Our decision where to put each unit of sand can be thought of as a function  , and it incurs a total transport cost of
, and it incurs a total transport cost of 
 representing a region of the pit of volume ν(B), exactly that same volume of sand must go into B. The amount of sand allocated to B is
representing a region of the pit of volume ν(B), exactly that same volume of sand must go into B. The amount of sand allocated to B is  , so the mass preservation requirement is that μ(T
−1(B)) = ν(B) for all
, so the mass preservation requirement is that μ(T
−1(B)) = ν(B) for all  . This condition will be denoted by T#μ = ν and in words: ν is the push-forward of μ under T, or T pushes μ forward to ν. To make the discussion mathematically rigorous, we must assume that c and T are measurable maps, and that μ(T
−1(B)) = ν(B) for all measurable subsets of
. This condition will be denoted by T#μ = ν and in words: ν is the push-forward of μ under T, or T pushes μ forward to ν. To make the discussion mathematically rigorous, we must assume that c and T are measurable maps, and that μ(T
−1(B)) = ν(B) for all measurable subsets of  . When the underlying measures are understood from the context, we call T a transport map. Specifying
. When the underlying measures are understood from the context, we call T a transport map. Specifying  , we see that no such T can exist unless
, we see that no such T can exist unless  ; we shall assume that this quantity is finite, and by means of normalisation, that μ and ν are probability measures. In this setting, the Monge problem is to find the optimal transport map, that is, to solve
; we shall assume that this quantity is finite, and by means of normalisation, that μ and ν are probability measures. In this setting, the Monge problem is to find the optimal transport map, that is, to solve 
 and
and  are complete and separable metric spaces,1 endowed with their Borel σ-algebra, which, we recall, is defined as the smallest σ-algebra containing the open sets. Measures defined on the Borel σ-algebra of
are complete and separable metric spaces,1 endowed with their Borel σ-algebra, which, we recall, is defined as the smallest σ-algebra containing the open sets. Measures defined on the Borel σ-algebra of  are called Borel measures. Thus, if μ is a Borel measure on
are called Borel measures. Thus, if μ is a Borel measure on  , then μ(A) is defined for any A that is open, or closed, or a countable union of closed sets, etc., and any continuous map on
, then μ(A) is defined for any A that is open, or closed, or a countable union of closed sets, etc., and any continuous map on  is measurable. Similarly, we endow
is measurable. Similarly, we endow  with its Borel σ-algebra. The product space
with its Borel σ-algebra. The product space  is also complete and separable when endowed with its product topology; its Borel σ-algebra is generated by the product σ-algebra of those of
is also complete and separable when endowed with its product topology; its Borel σ-algebra is generated by the product σ-algebra of those of  and
and  ; thus, any continuous cost function
; thus, any continuous cost function  is measurable. It will henceforth always be assumed, without explicit further notice, that μ and ν are Borel measures on
is measurable. It will henceforth always be assumed, without explicit further notice, that μ and ν are Borel measures on  and
and  , respectively, and that the cost function is continuous and nonnegative.
, respectively, and that the cost function is continuous and nonnegative. is a complete and separable metric space with metric d, and
is a complete and separable metric space with metric d, and 
 is measurable in
is measurable in  . Particular focus will be put on the quadratic case p = 2 (Sect. 1.6) and the linear case p = 1 (Sect. 1.8.2).
. Particular focus will be put on the quadratic case p = 2 (Sect. 1.6) and the linear case p = 1 (Sect. 1.8.2). (meaning that μ(A) = 1 if x
0 ∈ A and 0 otherwise) but ν is not. Indeed, in that case the set B = {T(x
0)} satisfies μ(T
−1(B)) = 1 > ν(B), so no such T can exist. This also shows that the problem is asymmetric in μ and ν: in the Dirac example, there always exists a map T such that T#ν = μ—the constant map T(x) = x
0 for all x is the unique such map. A less extreme situation occurs in the case of absolutely continuous measures. If μ and ν have densities f and g on
(meaning that μ(A) = 1 if x
0 ∈ A and 0 otherwise) but ν is not. Indeed, in that case the set B = {T(x
0)} satisfies μ(T
−1(B)) = 1 > ν(B), so no such T can exist. This also shows that the problem is asymmetric in μ and ν: in the Dirac example, there always exists a map T such that T#ν = μ—the constant map T(x) = x
0 for all x is the unique such map. A less extreme situation occurs in the case of absolutely continuous measures. If μ and ν have densities f and g on  and T is continuously differentiable, then T#μ = ν if and only if for μ-almost all x
and T is continuously differentiable, then T#μ = ν if and only if for μ-almost all x 
 one constructs a probability measure μ
x that describes how the mass at x is split among different destinations. If μ
x is a Dirac measure at some y, then all the mass at x is sent to y. The formal mathematical object to represent this idea is a probability measure π on the product space
one constructs a probability measure μ
x that describes how the mass at x is split among different destinations. If μ
x is a Dirac measure at some y, then all the mass at x is sent to y. The formal mathematical object to represent this idea is a probability measure π on the product space  (which is
(which is  in our particular setting). Here π(A × B) is the amount of sand transported from the subset
in our particular setting). Here π(A × B) is the amount of sand transported from the subset  into the part of the pit represented by
into the part of the pit represented by  . The total mass sent from A is
. The total mass sent from A is  , and the total mass sent into B is
, and the total mass sent into B is  . Thus, π is mass-preserving if and only if
. Thus, π is mass-preserving if and only if 

 , one can represent π as a collection of probability measures
, one can represent π as a collection of probability measures  on
on  , in the sense that for all measurable nonnegative g
, in the sense that for all measurable nonnegative g ![$$\displaystyle \begin{aligned} {\int_{\mathcal X\times\mathcal Y} \! g(x,y) \, \mathrm{d}\pi(x,y)} ={{\int_{\mathcal X} \! {\left[{{\int_{\mathcal Y} \! {g(x,y)} \, \mathrm{d}{\pi_x(y)}}} \right]} \, \mathrm{d}{\mu(x)}}}. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Eque.png)

![$$\displaystyle \begin{aligned} C(\pi) {=}{\int_{\mathcal X\times\mathcal Y} \! c(x,y) \, \mathrm{d}\pi(x,y)} {=}{{\int_{\mathcal X} \! {\left[{{\int_{\mathcal Y} \! {c(x,y)} \, \mathrm{d}{\pi_x(y)}}} \right]} \, \mathrm{d}{\mu(x)}}} {=}{{\int_{\mathcal X} \! {c(x,T(x))} \, \mathrm{d}{\mu(x)}}} {=}C(T). \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equg.png)
 and
and  .
. of all finite signed Borel measures on
of all finite signed Borel measures on  . This is a vector space with (μ
1 + αμ
2)(A) = μ
1(A) + αμ
2(A) for
. This is a vector space with (μ
1 + αμ
2)(A) = μ
1(A) + αμ
2(A) for  ,
,  and
and  Borel. The set of probability measures on
Borel. The set of probability measures on  is denoted by
is denoted by  , and is a convex subset of
, and is a convex subset of  . The set Π(μ, ν) is then a convex subset of
. The set Π(μ, ν) is then a convex subset of  , and as C(π) is linear in π, the set of minimisers is a convex subset of Π(μ, ν). Thirdly, there is a natural symmetry between Π(μ, ν) and Π(ν, μ). If π belongs to the former and we define
, and as C(π) is linear in π, the set of minimisers is a convex subset of Π(μ, ν). Thirdly, there is a natural symmetry between Π(μ, ν) and Π(ν, μ). If π belongs to the former and we define  , then
, then  . If we set
. If we set  , then
, then 
 and
and  is symmetric (as in (1.1)),
is symmetric (as in (1.1)), 
 is optimal in Π(ν, μ). This symmetry will be fundamental in the definition of the Wasserstein distances in Chap. 2.
is optimal in Π(ν, μ). This symmetry will be fundamental in the definition of the Wasserstein distances in Chap. 2.Perhaps most importantly, a minimiser for the Kantorovich problem exists under weak conditions. In order to show this, we first recall some definitions. Let  be the space of real-valued, continuous bounded functions on
be the space of real-valued, continuous bounded functions on  . A sequence of probability measures
. A sequence of probability measures  is said to converge weakly
2 to
is said to converge weakly
2 to  if for all
if for all  ,
,  . To avoid confusion with other types of convergence, we will usually write μ
n → μ weakly; in the rare cases where a symbol is needed we shall use the notation
. To avoid confusion with other types of convergence, we will usually write μ
n → μ weakly; in the rare cases where a symbol is needed we shall use the notation  . Of course, if μ
n → μ weakly and
. Of course, if μ
n → μ weakly and  , then μ must be in
, then μ must be in  too (this is seen by taking f ≡ 1 and by observing that
too (this is seen by taking f ≡ 1 and by observing that  if f ≥ 0).
if f ≥ 0).
A collection of probability measures  is tight if for all 𝜖 > 0 there exists a compact set K such that
is tight if for all 𝜖 > 0 there exists a compact set K such that  . If
. If  is represented by a sequence {μ
n}, then Prokhorov’s theorem (Billingsley [24, Theorem 5.1]) states that a subsequence of {μ
n} must converge weakly to some probability measure μ.
is represented by a sequence {μ
n}, then Prokhorov’s theorem (Billingsley [24, Theorem 5.1]) states that a subsequence of {μ
n} must converge weakly to some probability measure μ.
 and
and  are complete separable metric spaces. Let {π
n} be a minimising sequence for C. Then, according to [24, Theorem 1.3], μ and ν must be tight. If K
1 and K
2 are compact with μ(K
1), ν(K
2) > 1 − 𝜖, then K
1 × K
2 is compact and for all π ∈ Π(μ, ν), π(K
1 × K
2) > 1 − 2𝜖. It follows that the entire collection Π(μ, ν) is tight, and by Prokhorov’s theorem π
n has a weak limit π after extraction of a subsequence. For any integer K,
are complete separable metric spaces. Let {π
n} be a minimising sequence for C. Then, according to [24, Theorem 1.3], μ and ν must be tight. If K
1 and K
2 are compact with μ(K
1), ν(K
2) > 1 − 𝜖, then K
1 × K
2 is compact and for all π ∈ Π(μ, ν), π(K
1 × K
2) > 1 − 2𝜖. It follows that the entire collection Π(μ, ν) is tight, and by Prokhorov’s theorem π
n has a weak limit π after extraction of a subsequence. For any integer K,  is a continuous bounded function, and
is a continuous bounded function, and 


A remark about terminology is in order. Many authors talk about the Monge–Kantorovich problem or the optimal transport(ation) problem. More often than not, they refer to what we call here the Kantorovich problem. When one of the scenarios presented in Sects. 1.3 and 1.6.1 is considered, this does not result in ambiguity.
1.2 Probabilistic Interpretation
The preceding section was an analytic presentation of the Monge and the Kantorovich problems. It is illuminating, however, to also recast things in probabilistic terms, and this is the topic of this section.
A random element on a complete separable metric space (or any topological space)  is simply a measurable function X from some (generic) probability space
is simply a measurable function X from some (generic) probability space  to
to  (with its Borel σ-algebra). The probability law (or probability distribution) is the probability measure
(with its Borel σ-algebra). The probability law (or probability distribution) is the probability measure  defined on the space
defined on the space  ; this is the Borel measure satisfying
; this is the Borel measure satisfying  for all Borel sets A.
for all Borel sets A.
 and
and  , respectively, and a cost function
, respectively, and a cost function  . The Monge problem is to find a measurable function T such that T(X) has the same distribution as Y , and such that the expectation
. The Monge problem is to find a measurable function T such that T(X) has the same distribution as Y , and such that the expectation ![$$\displaystyle \begin{aligned} C(T) ={{\int_{\mathcal X} \! {c(x,T(x))} \, \mathrm{d}{\mu(x)}}} ={{\int_{\varOmega} \! {c[X(\omega),T(X(\omega))]} \, \mathrm{d}{\mathbb{P}(\omega)}}} =\mathbb{E} c(X,T(X))\end{aligned} $$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equl.png)
 minimises the expectation
minimises the expectation ![$$\displaystyle \begin{aligned} C(\pi) ={\int_{\mathcal X\times\mathcal Y} \! c(x,y) \, \mathrm{d}\pi(x,y)} ={{\int_{\varOmega} \! {c[X(\omega),Y(\omega))]} \, \mathrm{d}{\mathbb{P}(\omega)}}} =\mathbb{E}_\pi c(X,Y). \end{aligned} $$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equm.png)
 , c(x, y) = ∥x − y∥2, and X and Y are square integrable random vectors (
, c(x, y) = ∥x − y∥2, and X and Y are square integrable random vectors ( ). Let A and B be the covariance matrices of X and Y , respectively, and notice that the covariance matrix of a coupling π must have the form
). Let A and B be the covariance matrices of X and Y , respectively, and notice that the covariance matrix of a coupling π must have the form  for a d × d matrix V . The covariance matrix of the difference X − Y is
for a d × d matrix V . The covariance matrix of the difference X − Y is 
![$$\displaystyle \begin{aligned} \mathbb{E}_\pi c(X,Y)= \mathbb{E}_\pi \|X-Y\|{}^2= \| \mathbb{E} X - \mathbb{E} Y\|{}^2 + {\mathrm{tr}}_\pi[A + B - V^t - V]. \end{aligned} $$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equo.png)
1.3 The Discrete Uniform Case
There is a special case in which the Monge–Kantorovich problem reduces to a finite combinatorial problem. Although it may seem at first hand as an oversimplification of the original problem, it is of importance in practice because arbitrary measures can be approximated by discrete measures by means of the strong law of large numbers. Moreover, the discrete case is important in theory as well, as a motivating example for the Kantorovich duality (Sect. 1.4) and the property of cyclical monotonicity (Sect. 1.7).

 . Transport maps T are associated with permutations in S
n, the set of all bijective functions from {1, …, n} to itself: given σ ∈ S
n, a transport map can be constructed by defining T(x
i) = y
σ(i). If σ is not a permutation, then T will not be a transport map from μ to ν. Transference plans π are equivalent to n × n matrices M with coordinates M
ij = π({(x
i, y
j)}) = M
ij; this is the amount of mass sent from x
i to y
j. In order for π to a be a transference plan, it must be that ∑jM
ij = 1∕n for all i and ∑iM
ij = 1∕n for all j, and in addition M must be nonnegative. In other words, the matrix M′ = nM belongs to B
n, the set of bistochastic matrices of order n, defined as n × n matrices M′ satisfying
. Transport maps T are associated with permutations in S
n, the set of all bijective functions from {1, …, n} to itself: given σ ∈ S
n, a transport map can be constructed by defining T(x
i) = y
σ(i). If σ is not a permutation, then T will not be a transport map from μ to ν. Transference plans π are equivalent to n × n matrices M with coordinates M
ij = π({(x
i, y
j)}) = M
ij; this is the amount of mass sent from x
i to y
j. In order for π to a be a transference plan, it must be that ∑jM
ij = 1∕n for all i and ∑iM
ij = 1∕n for all j, and in addition M must be nonnegative. In other words, the matrix M′ = nM belongs to B
n, the set of bistochastic matrices of order n, defined as n × n matrices M′ satisfying 


The Kantorovich problem is a linear program with n
2 variables and 2n constraints. It must have a solution because B
n (hence B
n∕n) is a compact (nonempty) set in  and the objective function is linear in the matrix elements, hence continuous. (This property is independent of the possibly infinite-dimensional spaces
and the objective function is linear in the matrix elements, hence continuous. (This property is independent of the possibly infinite-dimensional spaces  and
and  in which the points lie.) The Monge problem also admits a solution because S
n is a finite set. To see that the two problems are essentially the same, we need to introduce the following notion. If B is a convex set, then x ∈ B is an extremal point of B if it cannot be written as a convex combination tz + (1 − t)y for some distinct points y, z ∈ B. It is well known (Luenberger and Ye [89, Section 2.5]) that there exists an optimal solution that is extremal, so that it becomes relevant to identify the extremal points of B
n. It is fairly clear that each permutation matrix is extremal in B
n; the less obvious converse is known as Birkhoff’s theorem, a proof of which can be found, for instance, at the end of the introduction in Villani [124] or (in a different terminology) in Luenberger and Ye [89, Section 6.5]. Thus, we have:
in which the points lie.) The Monge problem also admits a solution because S
n is a finite set. To see that the two problems are essentially the same, we need to introduce the following notion. If B is a convex set, then x ∈ B is an extremal point of B if it cannot be written as a convex combination tz + (1 − t)y for some distinct points y, z ∈ B. It is well known (Luenberger and Ye [89, Section 2.5]) that there exists an optimal solution that is extremal, so that it becomes relevant to identify the extremal points of B
n. It is fairly clear that each permutation matrix is extremal in B
n; the less obvious converse is known as Birkhoff’s theorem, a proof of which can be found, for instance, at the end of the introduction in Villani [124] or (in a different terminology) in Luenberger and Ye [89, Section 6.5]. Thus, we have:
There exists σ ∈ S n such that M(σ) minimises C(M) over B n∕n. Furthermore, if {σ 1, …, σ k} is the set of optimal permutations, then the set of optimal matrices is the convex hull of {M(σ 1), …, M(σ k)}. In particular, if σ is the unique optimal permutation, then M(σ) is the unique optimal matrix.
Thus, in the discrete case, the Monge and the Kantorovich problems coincide. One can of course use the simplex method [89, Chapter 3] to solve the linear program, but there are n! vertices, and there is in principle no guarantee that the simplex method solves the problem efficiently. However, the constraints matrix has a very specific form (it contains only zeroes and ones, and is totally unimodular), so specialised algorithms for this problem exist. One of them is the Hungarian algorithm of Kuhn [85] or its variant of Munkres [96] that has a worst-case computational complexity of at most O(n
4). Another alternative is the class of net flow algorithms described in [89, Chapter 6]. In particular, the algorithm of Edmonds and Karp [50] has a complexity of at most  . This monograph does not focus on computational aspects for optimal transport. This is a fascinating and very active area of contemporary research, and readers are directed to Peyré and Cuturi [103].
. This monograph does not focus on computational aspects for optimal transport. This is a fascinating and very active area of contemporary research, and readers are directed to Peyré and Cuturi [103].
The special case described here could have been more precisely called “the discrete uniform case on the same number of points”, as “the discrete case” could refer to any two finitely supported measures μ and ν. In the Monge context, the setup discussed here is the most interesting case, see page 8 in the supplement for more details.
1.4 Kantorovich Duality
The discrete case of Sect. 1.3 is an example of a linear program and thus enjoys a rich duality theory (Luenberger and Ye [89, Chapter 4]). The general Kantorovich problem is an infinite-dimensional linear program, and under mild assumptions admits similar duality.
1.4.1 Duality in the Discrete Uniform Case
 , say
, say  , by enumeration of the elements row by row. If nM is bistochastic, i.e., M ∈ B
n∕n, then the 2n constraints can be represented in a (2n) × n
2 matrix A. For instance, if n = 3, then
, by enumeration of the elements row by row. If nM is bistochastic, i.e., M ∈ B
n∕n, then the 2n constraints can be represented in a (2n) × n
2 matrix A. For instance, if n = 3, then 
 and A takes the form
and A takes the form 

 and the constraints vector b = n
−1(1, …, 1). Call the new variables p
1, …, p
n and q
1, …, q
n, and notice that each column of A corresponds to exactly one p
i and one q
j, and that the n
2 columns exhaust all possibilities. Hence, the dual problem is
and the constraints vector b = n
−1(1, …, 1). Call the new variables p
1, …, p
n and q
1, …, q
n, and notice that each column of A corresponds to exactly one p
i and one q
j, and that the n
2 columns exhaust all possibilities. Hence, the dual problem is 
 and (p, q) satisfy the respective constraints, then
and (p, q) satisfy the respective constraints, then 
 is primal optimal and (p, q) is dual optimal. Strong duality is the nontrivial assertion that there exist
is primal optimal and (p, q) is dual optimal. Strong duality is the nontrivial assertion that there exist  and (p
∗, q
∗) satisfying
and (p
∗, q
∗) satisfying  .
.1.4.2 Duality in the General Case
 and
and  were obtained from the cost function c and the transference plan π as C
ij = c(x
i, y
j) and M
ij = π({(x
i, y
j)}). Similarly, we can view the vectors p and q as restrictions of functions
were obtained from the cost function c and the transference plan π as C
ij = c(x
i, y
j) and M
ij = π({(x
i, y
j)}). Similarly, we can view the vectors p and q as restrictions of functions  and
and  of the form p
i = φ(x
i) and q
j = ψ(y
j). The constraint vector b = (1
n, 1
n) can be written as b
i = μ({x
i}) and b
n+j = ν({y
j}). In this formulation, the constraint p
i + q
j ≤ c
ij writes (φ, ψ) ∈ Φ
c with
of the form p
i = φ(x
i) and q
j = ψ(y
j). The constraint vector b = (1
n, 1
n) can be written as b
i = μ({x
i}) and b
n+j = ν({y
j}). In this formulation, the constraint p
i + q
j ≤ c
ij writes (φ, ψ) ∈ Φ
c with 
![$$\displaystyle \begin{aligned} \sup_{(\varphi,\psi)\in L_1(\mu)\times L_1(\nu)} \left[{{\int_{\mathcal X} \! {\varphi(x)} \, \mathrm{d}{\mu(x)}}} +{{\int_{\mathcal Y} \! {\psi(y)} \, \mathrm{d}{\nu(y)}}}\right] \qquad \mathrm{subject to} \quad (\varphi,\psi)\in \varPhi_c. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equy.png)
![$$\displaystyle \begin{aligned} {\int_{\mathcal X\times\mathcal Y} \! [\varphi(x) + \psi(y)] \, \mathrm{d}\pi(x,y)} ={{\int_{\mathcal X} \! {\varphi(x)} \, \mathrm{d}{\mu(x)}}} +{{\int_{\mathcal Y} \! {\psi(y)} \, \mathrm{d}{\nu(y)}}}. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equz.png)
The proof follows from the fact that (1.2) yields the above equality when φ and ψ are indicator functions. One then uses linearity and approximations to deduce the result.
![$$\displaystyle \begin{aligned} {{\int_{\mathcal X} \! {\varphi(x)} \, \mathrm{d}{\mu(x)}}} +{{\int_{\mathcal Y} \! {\psi(y)} \, \mathrm{d}{\nu(y)}}} ={\int_{\mathcal X\times\mathcal Y} \! [\varphi(x) + \psi(y)] \, \mathrm{d}\pi(x,y)} \le C(\pi). \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equaa.png)
 and
and
 , respectively, and let
, respectively, and let
 be a measurable function. Then
be a measurable function. Then
![$$\displaystyle \begin{aligned} \inf_{\pi\in\varPi(\mu,\nu)} {{\int_{\mathcal X\times\mathcal Y} \! c \, \mathrm{d}\pi}} =\sup_{(\varphi,\psi)\in \varPhi_c} \left[{{\int_{\mathcal X} \! {\varphi} \, \mathrm{d}\mu}} +{{\int_{\mathcal Y} \! \psi \, \mathrm{d}\nu}} \right]. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equab.png)
See the Bibliographical Notes for other versions of the duality.
When the cost function is continuous, or more generally, a countable supremum of continuous functions, the infimum is attained (see (1.3)). The existence of maximisers (φ, ψ) is more delicate and requires a finiteness condition, as formulated in Proposition 1.8.1 below.
The next sections are dedicated to more concrete examples that will be used through the rest of the book.
1.5 The One-Dimensional Case
 , the Monge–Kantorovich problem has a particularly simple structure, because the class of “nice” transport maps contains at most a single element. Identify
, the Monge–Kantorovich problem has a particularly simple structure, because the class of “nice” transport maps contains at most a single element. Identify  with their cumulative distribution functions F and G defined by
with their cumulative distribution functions F and G defined by ![$$\displaystyle \begin{aligned} F(t)=\mu((-\infty,t]), \qquad G(t) = \nu((-\infty,t]) ,\qquad t\in\mathbb{R}. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equac.png)


![$$\displaystyle \begin{aligned} G(t) = \nu((-\infty,t]) =\mu((-\infty,T^{-1}(t)]) =F(T^{-1}(t)). \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equae.png)
![$$\displaystyle \begin{aligned} G^{-1}(u) =\inf G^{-1}([u,1]) =\inf\{x\in\mathbb{R}:G(x)\ge u\}, \qquad 0<u<1, \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equaf.png)

 such that π(Γ) = 1 and whenever (x
i, y
i) ∈ Γ,
such that π(Γ) = 1 and whenever (x
i, y
i) ∈ Γ, 

 .
.Since any distribution can be approximated by continuous distributions, in view of the above discussion, the following result from Villani [124, Theorem 2.18] should not be too surprising.
 )
) with distribution functions F and G, respectively, and let the cost function be of the form c(x, y) = h(|x − y|) with h convex and nonnegative. Then
with distribution functions F and G, respectively, and let the cost function be of the form c(x, y) = h(|x − y|) with h convex and nonnegative. Then 
If the infimum is finite and h is strictly convex, then the optimal transference plan is unique. Furthermore, if F is continuous, then the infimum is attained by the transport map T = G −1 ∘ F.
The prototypical choice for h is h(z) = |z|p with p > 1. This result allows in particular a direct evaluation of the Wasserstein distances for measures on the real line (see Chap. 2).
Note that no regularity is needed in order that the optimal transference plan be unique, unlike in higher dimensions (compare Theorem 1.8.2). The structure of solutions in the concave case (0 < p < 1) is more complicated, see McCann [94].
When p = 1, the cost function is convex but not strictly so, and solutions will not be unique. However, the total cost in Theorem 1.5.1 admits another representation that is often more convenient.

The proof is a simple application of Fubini’s theorem; see page 13 in the supplement.

1.6 Quadratic Cost

 is a separable Hilbert space. This cost is popular in applications, and leads to a lucid and elegant theory. The factor of 1∕2 does not affect the minimising coupling π and leads to cleaner expressions. (It does affect the optimal dual pair, but in an obvious way.)
is a separable Hilbert space. This cost is popular in applications, and leads to a lucid and elegant theory. The factor of 1∕2 does not affect the minimising coupling π and leads to cleaner expressions. (It does affect the optimal dual pair, but in an obvious way.)1.6.1 The Absolutely Continuous Case
We begin with the Euclidean case, where  is endowed with the Euclidean metric, and use the Kantorovich duality to obtain characterisations of optimal maps.
is endowed with the Euclidean metric, and use the Kantorovich duality to obtain characterisations of optimal maps.

![$$\displaystyle \begin{aligned} \psi(y) =\inf_{x\in\mathbb{R}^d}\left[\frac{\|x-y\|{}^2}2 - \varphi(x)\right] =\frac{\|y\|{}^2}2 + \inf_{x\in\mathbb{R}^d}\left[\frac{\|x\|{}^2}2-\varphi(x)-{\left\langle {x},{y}\right\rangle} \right]. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equao.png)
![$$\displaystyle \begin{aligned} \widetilde\psi(y) :=\frac{\|y\|{}^2}2 - \psi(y) =\sup_{x\in\mathbb{R}^d}\left[{\left\langle {x},{y}\right\rangle} - \widetilde\varphi(x)\right], \qquad \tilde\varphi(x) = \frac{\|x\|{}^2}2 - \varphi(x). \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equap.png)
 enjoys some useful properties. We remind the reader that a function
enjoys some useful properties. We remind the reader that a function  is convex if f(tx + (1 − t)y) ≤ tf(x) + (1 − t)f(y) for all
is convex if f(tx + (1 − t)y) ≤ tf(x) + (1 − t)f(y) for all  and t ∈ [0, 1]. It is lower semicontinuous if for all
and t ∈ [0, 1]. It is lower semicontinuous if for all  , f(x) ≤liminfy→xf(y). Affine functions are convex and lower semicontinuous, and it straightforward from the definitions that both convexity and lower semicontinuity are preserved under the supremum operation. Thus, the function
, f(x) ≤liminfy→xf(y). Affine functions are convex and lower semicontinuous, and it straightforward from the definitions that both convexity and lower semicontinuity are preserved under the supremum operation. Thus, the function  is convex and lower semicontinuous. In particular, it is Borel measurable due to the following characterisation: f is lower semicontinuous if and only if {x : f(x) ≤ α} is a closed set for all
is convex and lower semicontinuous. In particular, it is Borel measurable due to the following characterisation: f is lower semicontinuous if and only if {x : f(x) ≤ α} is a closed set for all  .
. and
and  , and to assume that
, and to assume that  , where
, where ![$$\displaystyle \begin{aligned} f^*(y) =\sup_{x\in\mathbb{R}^d}[{\left\langle {x},{y}\right\rangle} - f(x)], \qquad y\in\mathbb{R}^d \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equaq.png)
 by
by  , so it is reasonable to expect that an optimal dual pair should take the form
, so it is reasonable to expect that an optimal dual pair should take the form  , with
, with  convex and lower semicontinuous.
convex and lower semicontinuous.


![$$\displaystyle \begin{aligned} {\int_{\mathbb{R}^d\times\mathbb{R}^d} \! [\widetilde\varphi(x) + (\widetilde\varphi)^*(y) - {\left\langle {x},{y}\right\rangle} ] \, \mathrm{d}\pi(x,y)} =0. \end{aligned} $$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equ5.png)
 everywhere, the integrand is nonnegative. Hence, the integral vanishes if and only if π is concentrated on the set of (x, y) such that
everywhere, the integrand is nonnegative. Hence, the integral vanishes if and only if π is concentrated on the set of (x, y) such that  . By definition of the Legendre transform as a supremum, this happens if and only if the supremum defining
. By definition of the Legendre transform as a supremum, this happens if and only if the supremum defining  is attained at x; equivalently
is attained at x; equivalently 
 at x [113, Chapter 23]. When
at x [113, Chapter 23]. When  is differentiable at x, its unique subgradient is the gradient
is differentiable at x, its unique subgradient is the gradient  [113, Theorem 25.1]. If we are fortunate and
[113, Theorem 25.1]. If we are fortunate and  is differentiable everywhere, or even μ-almost everywhere, then the optimal transference plan π is unique, and in fact induced from the transport map
is differentiable everywhere, or even μ-almost everywhere, then the optimal transference plan π is unique, and in fact induced from the transport map  . The problem, of course, is that
. The problem, of course, is that  may fail to be differentiable μ-almost surely. This is remedied by assuming some regularity on the source measure μ in order to make sure that any convex function be differentiable μ-almost surely, and is done via the following regularity result, which, roughly speaking, states that convex functions are differentiable almost surely. A stronger version is given in Rockafellar [113, Theorem 2.25], with an alternative proof in Alberti and Ambrosio [6, Chapter 2]. One could also combine the local Lipschitz property of convex functions [113, Chapter 10] with Rademacher’s theorem (Villani [125, Theorem 10.8]).
may fail to be differentiable μ-almost surely. This is remedied by assuming some regularity on the source measure μ in order to make sure that any convex function be differentiable μ-almost surely, and is done via the following regularity result, which, roughly speaking, states that convex functions are differentiable almost surely. A stronger version is given in Rockafellar [113, Theorem 2.25], with an alternative proof in Alberti and Ambrosio [6, Chapter 2]. One could also combine the local Lipschitz property of convex functions [113, Chapter 10] with Rademacher’s theorem (Villani [125, Theorem 10.8]).Let
 be a convex function with domain
be a convex function with domain
 and let
and let
 be the set of points at which f is not differentiable. Then
be the set of points at which f is not differentiable. Then
 has Lebesgue measure 0.
has Lebesgue measure 0.
Theorem 1.6.1 is usually stated for the interior of domf, denoted int(domf), rather than the closure. But, since A = domf is convex, its boundary has Lebesgue measure zero. To see this assume first that A is bounded. If intA is empty, then A lies in a lower dimensional subspace [113, Theorem 2.4]. Otherwise, without loss of generality 0 ∈intA, and then by convexity of A, ∂A ⊆ (1 + 𝜖)A for all 𝜖 > 0. When A is unbounded, write it as ∪nA ∩ [−n, n]d.

![$$\displaystyle \begin{aligned} C(\pi) \le{\int_{\mathbb{R}^d\times\mathbb{R}^d} \! [\|x\|{}^2 + \|y\|{}^2] \, \mathrm{d}\pi(x,y)} ={\int_{\mathbb{R}^d} \! \|x\|{}^2 \, \mathrm{d}\mu(x)} +{\int_{\mathbb{R}^d} \! \|y\|{}^2 \, \mathrm{d}\nu(y)}<\infty. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equaw.png)
Let μ and ν be probability measures on  with finite second moments, and suppose that μ is absolutely continuous with respect to Lebesgue measure. Then the solution to the Kantorovich problem is unique, and is induced from a transport map T that equals μ-almost surely the gradient of a convex function ϕ. Furthermore, the pair (∥x∥2∕2 − ϕ, ∥y∥2∕2 − ϕ
∗) is optimal for the dual problem.
with finite second moments, and suppose that μ is absolutely continuous with respect to Lebesgue measure. Then the solution to the Kantorovich problem is unique, and is induced from a transport map T that equals μ-almost surely the gradient of a convex function ϕ. Furthermore, the pair (∥x∥2∕2 − ϕ, ∥y∥2∕2 − ϕ
∗) is optimal for the dual problem.
To alleviate the notation we write ϕ instead of  . By Proposition 1.8.1, there exists an optimal dual pair (φ, ψ) such that ϕ(x) = ∥x∥2∕2 − φ(x) is convex and lower semicontinuous, and by the discussion in Sect. 1.1, there exists an optimal π. Since ϕ is μ-integrable, it must be finite almost everywhere, i.e., μ(domϕ) = 1. By Theorem 1.6.1, if we define
. By Proposition 1.8.1, there exists an optimal dual pair (φ, ψ) such that ϕ(x) = ∥x∥2∕2 − φ(x) is convex and lower semicontinuous, and by the discussion in Sect. 1.1, there exists an optimal π. Since ϕ is μ-integrable, it must be finite almost everywhere, i.e., μ(domϕ) = 1. By Theorem 1.6.1, if we define  as the set of nondifferentiability points of ϕ, then
as the set of nondifferentiability points of ϕ, then  ; as μ is absolutely continuous, the same holds for μ. (Here Leb denotes Lebesgue measure.)
; as μ is absolutely continuous, the same holds for μ. (Here Leb denotes Lebesgue measure.)
We conclude that  . In other words, ϕ is differentiable μ-almost everywhere, and so for μ-almost any x, there exists a unique y such that
. In other words, ϕ is differentiable μ-almost everywhere, and so for μ-almost any x, there exists a unique y such that  , and y = ∇ϕ(x). This shows that π is unique and induced from the transport map ∇ϕ(x). The gradient ∇ϕ is Borel measurable, since each of its coordinates can be written as
, and y = ∇ϕ(x). This shows that π is unique and induced from the transport map ∇ϕ(x). The gradient ∇ϕ is Borel measurable, since each of its coordinates can be written as  for some vector v (the canonical basis of
for some vector v (the canonical basis of  ), which is Borel measurable because the limit superior is taken on countably many functions (and ϕ is measurable because it is lower semicontinuous).
), which is Borel measurable because the limit superior is taken on countably many functions (and ϕ is measurable because it is lower semicontinuous).
1.6.2 Separable Hilbert Spaces
The finite-dimensionality of  in the previous subsection was only used in order to apply Theorem 1.6.1, so one could hope to extend the results to infinite-dimensional separable Hilbert spaces.
in the previous subsection was only used in order to apply Theorem 1.6.1, so one could hope to extend the results to infinite-dimensional separable Hilbert spaces.
Although there is no obvious parallel for Lebesgue measure (i.e., translation invariant) on infinite-dimensional Banach spaces, one can still define absolute continuity via Gaussian measures. Indeed,  is absolutely continuous with respect to Lebesgue measure if and only if the following holds: if
is absolutely continuous with respect to Lebesgue measure if and only if the following holds: if  is such that
is such that  for any nondegenerate Gaussian measure ν, then
for any nondegenerate Gaussian measure ν, then  . This definition can be extended to any separable Banach space
. This definition can be extended to any separable Banach space  via projections, as follows. Let
via projections, as follows. Let  be the (topological) dual of
be the (topological) dual of  , consisting of all real-valued, continuous linear functionals on
, consisting of all real-valued, continuous linear functionals on  .
.
A probability measure
 is a nondegenerate Gaussian measure if for any
is a nondegenerate Gaussian measure if for any
 ,
,
 is a Gaussian measure with positive variance.
is a Gaussian measure with positive variance.
A subset
 is a Gaussian null set if whenever ν is a nondegenerate Gaussian measure,
is a Gaussian null set if whenever ν is a nondegenerate Gaussian measure,
 . A probability measure
. A probability measure
 is absolutely continuous if μ vanishes on all Gaussian null sets.
is absolutely continuous if μ vanishes on all Gaussian null sets.
Clearly, if ν is a nondegenerate Gaussian measure, then it is absolutely continuous.
As explained in Ambrosio et al. [12, Section 6.2], a version of Rademacher’s theorem holds in separable Hilbert spaces: a locally Lipschitz function is Gâteaux differentiable except on a Gaussian null set of  . Theorem 1.6.2 (and more generally, Theorem 1.8.2) extend to infinite dimensions; see [12, Theorem 6.2.10].
. Theorem 1.6.2 (and more generally, Theorem 1.8.2) extend to infinite dimensions; see [12, Theorem 6.2.10].
1.6.3 The Gaussian Case
Apart from the one-dimensional case of Sect. 1.5, there is another special case in which there is a unique and explicit solution to the Monge–Kantorovich problem.
Suppose that μ and ν are Gaussian measures on  with zero means and nonsingular covariance matrices A and B. By Theorem 1.6.2, we know that there exists a unique optimal map T such that T#μ = ν. Since linear push-forwards of Gaussians are Gaussian, it seems natural to guess that T should be linear, and this is indeed the case.
with zero means and nonsingular covariance matrices A and B. By Theorem 1.6.2, we know that there exists a unique optimal map T such that T#μ = ν. Since linear push-forwards of Gaussians are Gaussian, it seems natural to guess that T should be linear, and this is indeed the case.
Since T is a linear map that should be the gradient of a convex function ϕ, it must be that ϕ is quadratic, i.e.,  for
for  and some matrix Q. The gradient of ϕ at x is (Q + Q
t)x and the Hessian matrix is Q + Q
t. Thus, T = Q + Q
t and since ϕ is convex, T must be positive semidefinite.
and some matrix Q. The gradient of ϕ at x is (Q + Q
t)x and the Hessian matrix is Q + Q
t. Thus, T = Q + Q
t and since ϕ is convex, T must be positive semidefinite.
![$$\displaystyle \begin{aligned}{}[A^{1/2}TA^{1/2}][A^{1/2}TA^{1/2}] =A^{1/2}TATA^{1/2} =A^{1/2}BA^{1/2} =[A^{1/2}B^{1/2}][B^{1/2}A^{1/2}]. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equax.png)
![$$\displaystyle \begin{aligned} T=A^{-1/2}[A^{1/2}BA^{1/2}]^{1/2}A^{-1/2}. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equay.png)
![$$\displaystyle \begin{aligned} TAT -TA -AT +A =A+B -A^{1/2}[A^{1/2}BA^{1/2}]^{1/2}A^{-1/2} -A^{-1/2}[A^{1/2}BA^{1/2}]^{1/2}A^{1/2}. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equaz.png)
 , then
, then  equals the trace of C, denoted trC. Hence, by properties of the trace,
equals the trace of C, denoted trC. Hence, by properties of the trace, ![$$\displaystyle \begin{aligned} C(T) ={\mathrm{tr}}\left[A+B - 2(A^{1/2}BA^{1/2})^{1/2}\right]. \end{aligned} $$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equ6.png)
![$$\displaystyle \begin{aligned} T=B^{1/2}A^{-1/2} ,\qquad C(T)={\mathrm{tr}}\left[A+B - 2A^{1/2}B^{1/2}\right] =\|A^{1/2} - B^{1/2}\|{}^2_F, \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equba.png)
![$$\displaystyle \begin{aligned} Tx=n +A^{-1/2}[A^{1/2}BA^{1/2}]^{1/2}A^{-1/2}(x-m); \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equbb.png)
![$$\displaystyle \begin{aligned} C(T) =\|n - m\|{}^2 +{\mathrm{tr}}[A+B - 2(A^{1/2}BA^{1/2})^{1/2}]. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equbc.png)
 in terms of their second order structure. This is worth mentioning, because such lower bounds are not very common (the Monge–Kantorovich problem is defined by an infimum, and thus typically easier to bound from above).
in terms of their second order structure. This is worth mentioning, because such lower bounds are not very common (the Monge–Kantorovich problem is defined by an infimum, and thus typically easier to bound from above). have means m and n and covariance matrices A and B and let π be the optimal map. Then
have means m and n and covariance matrices A and B and let π be the optimal map. Then
![$$\displaystyle \begin{aligned} C(\pi) \ge \|n - m\|{}^2 +{\mathrm{tr}}[A+B - 2(A^{1/2}BA^{1/2})^{1/2}]. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equbd.png)
 for some matrix
for some matrix  , constrained so that C is positive semidefinite. This gives the lower bound
, constrained so that C is positive semidefinite. This gives the lower bound ![$$\displaystyle \begin{aligned} \inf_{\pi\in\varPi(\mu,\nu)} \mathbb{E}_\pi\|X{-}Y\|{}^2 =\|m {-} n\|{}^2 + \inf_{\pi\in\varPi(\mu,\nu)} {\mathrm{tr}}_\pi [A+B{-}2V] \ge \|m - n\|{}^2 + \inf_{V:C\ge0}{\mathrm{tr}} [A+B{-}2V]. \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Eqube.png)
1.6.4 Regularity of the Transport Maps
The optimal transport map T between Gaussian measures on  is linear, so it is of course very smooth (analytic). The densities of Gaussian measures are analytic too, so that T inherits the regularity of μ and ν. Using the formula for T, one can show that a similar phenomenon takes place in the one-dimensional case. Though we do not have a formula for T at our disposal when μ and ν are general absolutely continuous measures on
is linear, so it is of course very smooth (analytic). The densities of Gaussian measures are analytic too, so that T inherits the regularity of μ and ν. Using the formula for T, one can show that a similar phenomenon takes place in the one-dimensional case. Though we do not have a formula for T at our disposal when μ and ν are general absolutely continuous measures on  , d ≥ 2, it turns out that even in that case, T inherits the regularity of μ and ν if some convexity conditions are satisfied.
, d ≥ 2, it turns out that even in that case, T inherits the regularity of μ and ν if some convexity conditions are satisfied.
To guess what kind of results can be hoped for, let us first examine the case d = 1. Let F and G denote the distribution functions of μ and ν, respectively. Suppose that G is continuously differentiable and that G′ > 0 on some open interval (finite or not) I such that ν(I) = 1. Then the inverse function theorem says that G −1 is also continuously differentiable. Recall that the support of a (Borel) probability measure μ (denoted suppμ) is the smallest closed set K such that μ(K) = 1. A simple application of the chain rule (see page 19 in the supplement) gives:
 )
)Let  possess distribution functions F and G of class C
k, k ≥ 1. Suppose further that suppν is an interval I (possibly unbounded) and that G′ > 0 on the interior of I. Then the optimal map is of class C
k as well. If F, G ∈ C
0 are merely continuous, then so is the optimal map.
possess distribution functions F and G of class C
k, k ≥ 1. Suppose further that suppν is an interval I (possibly unbounded) and that G′ > 0 on the interior of I. Then the optimal map is of class C
k as well. If F, G ∈ C
0 are merely continuous, then so is the optimal map.
The assumption on the support of ν is important: if μ is Lebesgue measure on [0, 1] and the support of ν is disconnected, then T cannot even be continuous, no matter how smooth ν is.
 , d ≥ 2, because there is no explicit formula available for the optimal maps. As before, we cannot expect the optimal map to be continuous if the support of ν is disconnected. It turns out that the condition on the support of ν is not connectedness, but rather convexity. This was shown by Caffarelli, who was able to prove ( [32] and the references within) that the optimal maps have the same smoothness as the measures. To state the result, we recall the following notation for an open
, d ≥ 2, because there is no explicit formula available for the optimal maps. As before, we cannot expect the optimal map to be continuous if the support of ν is disconnected. It turns out that the condition on the support of ν is not connectedness, but rather convexity. This was shown by Caffarelli, who was able to prove ( [32] and the references within) that the optimal maps have the same smoothness as the measures. To state the result, we recall the following notation for an open  , k ≥ 0 and α ∈ (0, 1]. We say that f ∈ C
k, α(Ω) if all the partial derivatives of order k of f are locally α-Hölder on Ω. For example, if k = 1, this means that for any x ∈ Ω there exists a constant L and an open ball B containing x such that
, k ≥ 0 and α ∈ (0, 1]. We say that f ∈ C
k, α(Ω) if all the partial derivatives of order k of f are locally α-Hölder on Ω. For example, if k = 1, this means that for any x ∈ Ω there exists a constant L and an open ball B containing x such that 
 , with Ω
2 convex, and absolutely continuous measures
, with Ω
2 convex, and absolutely continuous measures  with finite second moments and bounded, strictly positive densities f, g, respectively, such that μ(Ω
1) = 1 = ν(Ω
2). Let ϕ be such that ∇ϕ#μ = ν.
with finite second moments and bounded, strictly positive densities f, g, respectively, such that μ(Ω
1) = 1 = ν(Ω
2). Let ϕ be such that ∇ϕ#μ = ν. - 1.
If Ω 1 and Ω 2 are bounded and f, g are bounded below, then ϕ is strictly convex and of class C 1, α(Ω 1) for some α > 0.
- 2.
If
 and f, g ∈ C
0, α, then ϕ ∈ C
2, α(Ω
1).
and f, g ∈ C
0, α, then ϕ ∈ C
2, α(Ω
1).
If in addition f, g ∈ C k, α, then ϕ ∈ C k+2, α(Ω 1).
In other words, the optimal map T = ∇ϕ ∈ C k+1, α(Ω 1) is one derivative smoother than the densities, so has the same smoothness as the measures μ, ν.
Theorem 1.6.7 will be used in two ways in this book. Firstly, it is used to derive criteria for a Karcher mean of a collection of measures to be the Fréchet mean of that collection (Theorem 3.1.15). Secondly, it allows one to obtain very smooth estimates for the transport maps. Indeed, any two measures μ and ν can be approximated by measures satisfying the second condition: one can approximate them by discrete measures using the law of large numbers and then employ a convolution with, e.g., a Gaussian measure (see, for instance, Theorem 2.2.7). It is not obvious that the transport maps between the approximations converge to the transport maps between the original measures, but we will see this to be true in the next section.
1.7 Stability of Solutions Under Weak Convergence
In this section, we discuss the behaviour of the solution to the Monge–Kantorovich problem when the measures μ and ν are replaced by approximations μ
n and ν
n. Since any measure can be approximated by discrete measures or by smooth measures, this allows us to benefit from both worlds. On the one hand, approximating μ and ν with discrete measures leads to the finite discrete problem of Sect. 1.3 that can be solved exactly. On the other hand, approximating μ and ν with Gaussian convolutions thereof leads to very smooth measures (at least on  ), and so the regularity results of the previous section imply that the respective optimal maps will also be smooth. Finally, in applications, one would almost always observe the measures of interest μ and ν with a certain amount of noise, and it is therefore of interest to control the error introduced by the noise. In image analysis, μ can represent an image that has undergone blurring, or some other perturbation (Amit et al. [13]). In other applications, the noise could be due to sampling variation, where instead of μ one observes a discrete measure μ
N obtained from realisations X
1, …, X
N of random elements with distribution μ as
), and so the regularity results of the previous section imply that the respective optimal maps will also be smooth. Finally, in applications, one would almost always observe the measures of interest μ and ν with a certain amount of noise, and it is therefore of interest to control the error introduced by the noise. In image analysis, μ can represent an image that has undergone blurring, or some other perturbation (Amit et al. [13]). In other applications, the noise could be due to sampling variation, where instead of μ one observes a discrete measure μ
N obtained from realisations X
1, …, X
N of random elements with distribution μ as  (see Chap. 4).
(see Chap. 4).
In Sect. 1.7.1, we will see that the optimal transference plan π depends continuously on μ and ν. With this result under one’s belt, one can then deduce an analogous property for the optimal map T from μ to ν given some regularity of μ, as will be seen in Sect. 1.7.2.
We shall assume throughout this section that μ
n → μ and ν
n → ν weakly, which, we recall, means that  for all continuous bounded
for all continuous bounded  . The following equivalent definitions for weak convergence will be used not only in this section, but elsewhere as well.
. The following equivalent definitions for weak convergence will be used not only in this section, but elsewhere as well.
 be a complete separable metric space and let
be a complete separable metric space and let
 . Then the following are equivalent:
. Then the following are equivalent:
μ n → μ weakly;
F n(x) → F(x) for any continuity point x of F. Here
 , F
n is the distribution function of μ
n and F is that of μ;
, F
n is the distribution function of μ
n and F is that of μ;for any open
 ,
,
 ;
;
for any closed
 ,
,
 ;
;
 for any bounded measurable h whose set of discontinuity points is a μ-null set.
for any bounded measurable h whose set of discontinuity points is a μ-null set.
For a proof, see, for instance, Billingsley [24, Theorem 2.1]. The equivalence with the last condition can be found in Pollard [104, Section III.2].
1.7.1 Stability of Transference Plans and Cyclical Monotonicity
In this subsection, we state and sketch the proof of the fact that if μ n → μ and ν n → ν weakly, then the optimal transference plans π n ∈ Π(μ n, ν n) converge to an optimal π ∈ Π(μ, ν). The result, as stated in Villani [125, Theorem 5.20], is valid on complete separate metric spaces with general cost functions, and reads as follows.
 and let
and let  be continuous. If π
n ∈ Π(μ
n, ν
n) are optimal transference plans and
be continuous. If π
n ∈ Π(μ
n, ν
n) are optimal transference plans and 
then (π n) is a tight sequence and each of its weak limits π ∈ Π(μ, ν) is optimal.
One can even let c vary with n under some conditions.
 and
and  . There exists an optimal transference plan π induced from a permutation σ
0 ∈ S
N. Since the ordering of {x
i} and {y
i} is irrelevant in the representations of μ and ν, we may assume without loss of generality that σ
0 is the identity permutation. Then, by definition of optimality,
. There exists an optimal transference plan π induced from a permutation σ
0 ∈ S
N. Since the ordering of {x
i} and {y
i} is irrelevant in the representations of μ and ν, we may assume without loss of generality that σ
0 is the identity permutation. Then, by definition of optimality, 


 is cyclically monotone if for any n and any (x
1, y
1), …, (x
n, y
n) ∈ Γ,
is cyclically monotone if for any n and any (x
1, y
1), …, (x
n, y
n) ∈ Γ, 
A probability measure π on  is cyclically monotone if there exists a monotone Borel set Γ such that π(Γ) = 1.
is cyclically monotone if there exists a monotone Borel set Γ such that π(Γ) = 1.
 is cyclically monotone. In fact, even if the optimal permutation is not unique, the set
is cyclically monotone. In fact, even if the optimal permutation is not unique, the set 
Let  and suppose that the cost function c is nonnegative and continuous. Assume that the optimal π ∈ Π(μ, ν) has a finite total cost. Then suppπ is cyclically monotone. In particular, π is cyclically monotone.
and suppose that the cost function c is nonnegative and continuous. Assume that the optimal π ∈ Π(μ, ν) has a finite total cost. Then suppπ is cyclically monotone. In particular, π is cyclically monotone.

Thus, optimal transference plans π solve infinitely many discrete Monge– Kantorovich problems emanating from their support. More precisely, for any finite collection (x
i, y
i) ∈suppπ, i = 1, …, N and any permutation σ ∈ S
N, (1.7) is satisfied. Therefore, the identity permutation is optimal between the measures  and
and  .
.
In the same spirit as Γ defined above for the discrete case, one can strengthen Proposition 1.7.4 and prove existence of a cyclically monotone set Γ that includes the support of any optimal transference plan π: take Γ = ∪supp(π) for π optimal.
The converse of Proposition 1.7.4 also holds.
Let  ,
,  continuous and π ∈ Π(μ, ν) a cyclically monotone measure with C(π) finite. Then π is optimal in Π(μ, ν).
continuous and π ∈ Π(μ, ν) a cyclically monotone measure with C(π) finite. Then π is optimal in Π(μ, ν).

 by
by 
 ; see (1.5) and the discussion around it.
; see (1.5) and the discussion around it.The argument for more general costs follows similar lines and is sketched at the end of this subsection.
Given these intermediary results, it is now instructive to prove Theorem 1.7.2.
 is continuous and bounded:
is continuous and bounded: 
 that converge to (x
k, y
k). Once this is established, we conclude from the cyclical monotonicity of suppπ
n and the continuity of c that
that converge to (x
k, y
k). Once this is established, we conclude from the cyclical monotonicity of suppπ
n and the continuity of c that 
 . Let 𝜖 = 1∕m, say, then for all n ≥ N
m we can find
. Let 𝜖 = 1∕m, say, then for all n ≥ N
m we can find  of distance 2∕m from (x
k, y
k). We can choose N
m+1 > N
m without loss of generality in order to complete the proof.
of distance 2∕m from (x
k, y
k). We can choose N
m+1 > N
m without loss of generality in order to complete the proof.
A nonempty
 is quadratic cyclically monotone if and only if it is included in the graph of the subdifferential of a lower semicontinuous convex function that is not identically infinite.
is quadratic cyclically monotone if and only if it is included in the graph of the subdifferential of a lower semicontinuous convex function that is not identically infinite.
Secondly, we have not used at all the Kantorovich duality, merely its weak form. The machinery of cyclical monotonicity can be used in order to prove the duality Theorem 1.4.2. This is indeed the strategy of Villani [125, Chapter 5], who explains its advantage with respect to Hahn–Banach-type duality proofs.

1.7.2 Stability of Transport Maps
We now extend the weak convergence of π
n to π of the previous subsection to convergence of optimal maps. Because of the applications we have in mind, we shall work exclusively in the Euclidean space  with the quadratic cost function; our results can most likely be extended to more general situations.
with the quadratic cost function; our results can most likely be extended to more general situations.
In this setting, we know that optimal plans are supported on graphs of subdifferentials of convex functions. Suppose that π n is induced by T n and π is induced by T. Then in some sense, the weak convergence of π n to π yields convergence of the graphs of T n to the graph of T. Our goal is to strengthen this to uniform convergence of T n to T. Roughly speaking, we show the following: there exists a set A with μ(A) = 1 and such that T n converge uniformly to T on every compact subset of A. For the reader’s convenience, we give a user-friendly version here; a more general statement is given in Proposition 1.7.11 below.
Let μ
n, μ be absolutely continuous measures with finite second moments on an open convex set  such that μ
n → μ weakly, and let ν
n → ν weakly with
such that μ
n → μ weakly, and let ν
n → ν weakly with  with finite second moments. If T
n and T are continuous on U and C(T
n) is bounded uniformly in n, then
with finite second moments. If T
n and T are continuous on U and C(T
n) is bounded uniformly in n, then

for any compact Ω ⊆ U.
Since T
n and T are only defined up to Lebesgue null sets, it will be more convenient to work directly with the subgradients. That is, we view T
n and T as set-valued functions that to each  assign a (possibly empty) subset of
assign a (possibly empty) subset of  . In other words, T
n and T take values in the power set of
. In other words, T
n and T take values in the power set of  , denoted by
, denoted by  .
.
 be convex, y
1 ∈ ∂ϕ(x
1) and y
2 ∈ ∂ϕ(x
2). Putting n = 2 in the definition of cyclical monotonicity (1.10) gives
be convex, y
1 ∈ ∂ϕ(x
1) and y
2 ∈ ∂ϕ(x
2). Putting n = 2 in the definition of cyclical monotonicity (1.10) gives 
 monotone if whenever y
i ∈ u(x
i), i = 1, 2,
monotone if whenever y
i ∈ u(x
i), i = 1, 2, 

Of course, if  is convex, then u = ∂ϕ is monotone. It follows from Theorem 1.7.6 that u is maximally cyclically monotone (no points can be added to its graph while preserving cyclical monotonicity). It can actually be shown that u is maximally monotone [6, Section 7]. In what follows, we will always work with subdifferentials of convex functions, so unless stated otherwise, u will always be assumed maximally monotone.
is convex, then u = ∂ϕ is monotone. It follows from Theorem 1.7.6 that u is maximally cyclically monotone (no points can be added to its graph while preserving cyclical monotonicity). It can actually be shown that u is maximally monotone [6, Section 7]. In what follows, we will always work with subdifferentials of convex functions, so unless stated otherwise, u will always be assumed maximally monotone.
Maximally monotone functions enjoy the following very useful continuity property. It is proven in [6, Corollary 1.3] and will be used extensively below.
Let  such that u(x) = {y} is a singleton. Then u is nonempty on some neighbourhood of x and it is continuous at x: if x
n → x and y
n ∈ u(x
n), then y
n → y.
such that u(x) = {y} is a singleton. Then u is nonempty on some neighbourhood of x and it is continuous at x: if x
n → x and y
n ∈ u(x
n), then y
n → y.
Notice that this result implies that if a convex function ϕ is differentiable on some open set  , then it is continuously differentiable there (Rockafellar [113, Corollary 25.5.1]).
, then it is continuously differentiable there (Rockafellar [113, Corollary 25.5.1]).
 is any function, one can define its subgradient at x locally as
is any function, one can define its subgradient at x locally as 
 ,
, 
 and y ∈ u(x). Then by maximality, y
∗ must equal y
0. By “local property”, we mean that the conclusion y
∗ = y
0 holds if the above inequality holds for x in a small neighbourhood of x
0 (an open set that includes x
0). We will need a more general version of this result, replacing neighbourhoods by a weaker condition that can be related to Lebesgue points. The strengthening is somewhat technical; the reader can skip directly to Lemma 1.7.10 and assume that G is open without losing much intuition.
and y ∈ u(x). Then by maximality, y
∗ must equal y
0. By “local property”, we mean that the conclusion y
∗ = y
0 holds if the above inequality holds for x in a small neighbourhood of x
0 (an open set that includes x
0). We will need a more general version of this result, replacing neighbourhoods by a weaker condition that can be related to Lebesgue points. The strengthening is somewhat technical; the reader can skip directly to Lemma 1.7.10 and assume that G is open without losing much intuition.Let B
r(x
0) = {x : ∥x − x
0∥ < r} for r ≥ 0 and  . The interior of a set
. The interior of a set  is denoted by intG and the closure by
is denoted by intG and the closure by  . If G is measurable, then LebG denotes the Lebesgue measure of G. Finally, convG denotes the convex hull of G.
. If G is measurable, then LebG denotes the Lebesgue measure of G. Finally, convG denotes the convex hull of G.
 if for any 𝜖 > 0 there exists t
𝜖 > 0 such that
if for any 𝜖 > 0 there exists t
𝜖 > 0 such that 
 in
in  (see Fig. 1.1). Since the “slope” of the square root is infinite, x
0 = (0, 0) is a Lebesgue point, but the fraction above is strictly smaller than one, for all t > 0.
(see Fig. 1.1). Since the “slope” of the square root is infinite, x
0 = (0, 0) is a Lebesgue point, but the fraction above is strictly smaller than one, for all t > 0.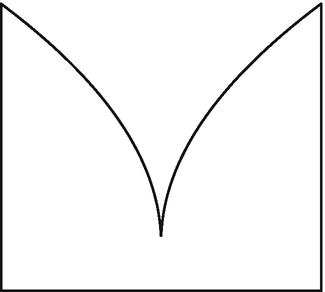
The set 
We denote the set of points of Lebesgue density of G by G
den. Here are some facts about G
den: clearly,  . Stein and Shakarchi [121, Chapter 3, Corollary 1.5] show that Leb(G ∖ G
den) = 0 (and Leb(G
den ∖ G) = 0, so G
den is very close to G). By the Hahn–Banach theorem, G
den ⊆int(conv(G)): indeed, if x is not in int(convG), then there is a separating hyperplane between x and convG ⊇ G, so the fraction above is at most 1∕2 for all t > 0.
. Stein and Shakarchi [121, Chapter 3, Corollary 1.5] show that Leb(G ∖ G
den) = 0 (and Leb(G
den ∖ G) = 0, so G
den is very close to G). By the Hahn–Banach theorem, G
den ⊆int(conv(G)): indeed, if x is not in int(convG), then there is a separating hyperplane between x and convG ⊇ G, so the fraction above is at most 1∕2 for all t > 0.
The “denseness” of Lebesgue points is materialised in the following result. It is given as exercise in [121] when d = 1, and the proof can be found on page 27 in the supplement.
 . Then
. Then

Of course, this result holds for any  if the little o is replaced by big O, since δ is Lipschitz. When x
0 ∈intG, this is trivial because δ vanishes on intG.
if the little o is replaced by big O, since δ is Lipschitz. When x
0 ∈intG, this is trivial because δ vanishes on intG.
The important part here is the following corollary: for almost all x ∈ G, δ(z) = o(∥z − x∥) as z → x. This can be seen in other ways: since δ is Lipschitz, it is differentiable almost everywhere. If  and δ is differentiable at x, then ∇δ(x) must be 0 (because δ is minimised there), and then δ(z) = o(∥z − x∥). We just showed that δ is differentiable with vanishing derivative at all Lebesgue points of x. The converse is not true:
and δ is differentiable at x, then ∇δ(x) must be 0 (because δ is minimised there), and then δ(z) = o(∥z − x∥). We just showed that δ is differentiable with vanishing derivative at all Lebesgue points of x. The converse is not true:  has no Lebesgue points, but δ(y) ≤ 4y
2 as y → 0.
has no Lebesgue points, but δ(y) ≤ 4y
2 as y → 0.
The locality of monotone functions can now be stated as follows. It is proven on page 27 of the supplement.
 such that u(x
0) = {y
0} and x
0 is a Lebesgue point of a set G satisfying
such that u(x
0) = {y
0} and x
0 is a Lebesgue point of a set G satisfying 
Then y
∗ = y
0. In particular, the result is true if the inequality holds on  with ∅≠O open and
with ∅≠O open and  Lebesgue negligible.
Lebesgue negligible.


With this background on monotone functions at our disposal, we are now ready to state the stability result for the optimal maps. We assume the following.
 with optimal couplings (with respect to quadratic cost) π
n ∈ Π(μ
n, ν
n), π ∈ Π(μ, ν) and convex potentials ϕ
n and ϕ, respectively, such that
with optimal couplings (with respect to quadratic cost) π
n ∈ Π(μ
n, ν
n), π ∈ Π(μ, ν) and convex potentials ϕ
n and ϕ, respectively, such that (convergence ) μ n → μ and ν n → ν weakly;
- (finiteness ) the optimal couplings π n ∈ Π(μ n, ν n) satisfy

(unique limit ) the optimal π ∈ Π(μ, ν) is unique.
We further denote the subgradients ∂ϕ nand ∂ϕ by u nand u, respectively.
These assumptions imply that π has a finite total cost. This can be shown by the  argument in the proof of Theorem 1.7.2 but also from the uniqueness of π. As a corollary of the uniqueness of π, it follows that π
n → π weakly; notice that this holds even if π
n is not unique for any n. We will now translate this weak convergence to convergence of the maximal monotone maps u
n to u, in the following form.
argument in the proof of Theorem 1.7.2 but also from the uniqueness of π. As a corollary of the uniqueness of π, it follows that π
n → π weakly; notice that this holds even if π
n is not unique for any n. We will now translate this weak convergence to convergence of the maximal monotone maps u
n to u, in the following form.

In particular, if u is univalued throughout int(E) (so that ϕ ∈ C 1 there), then uniform convergence holds for any compact Ω ⊂int(E).
if a sequence in the graph of u n converges, then the limit is in the graph of u;
sequences in the graph of u n are bounded if the domain is bounded.
If in addition μ is absolutely continuous, then u n(x) → u(x) μ-almost surely.
We first claim that  . Indeed, for any x ∈ E and any 𝜖 > 0, the ball B = B
𝜖(x) has positive measure. Consequently, u cannot be empty on the entire ball, because otherwise
. Indeed, for any x ∈ E and any 𝜖 > 0, the ball B = B
𝜖(x) has positive measure. Consequently, u cannot be empty on the entire ball, because otherwise  would be 0. Since domu is almost convex (see the discussion before Assumptions 1), this implies that actually int(convE) ⊆domu.
would be 0. Since domu is almost convex (see the discussion before Assumptions 1), this implies that actually int(convE) ⊆domu.

1.8 Complementary Slackness and More General Cost Functions
It is well-known (Luenberger and Ye [89, Section 4.4]) that the solutions to the primal and dual problems are related to each other via complementary slackness. In other words, solution of one problem provides a lot of information about the solution of the other problem. Here, we show that this idea remains true for the Kantorovich primal and dual problems, extending the discussion in Sect. 1.6.1 to more general cost functions.
Let  and
and  be complete separable metric spaces,
be complete separable metric spaces,  ,
,  , and
, and  be a measurable cost function.
be a measurable cost function.
![$$\displaystyle \begin{aligned} {\int_{\mathcal X\times\mathcal Y} \! [c(x,y)-\varphi(x) - \psi(y)] \, \mathrm{d}\pi(x,y)} =0 \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equcd.png)



1.8.1 Unconstrained Dual Kantorovich Problem

![$$\displaystyle \begin{aligned} \psi(y) =\inf_{x\in\mathcal X}[c(x,y) - \varphi(x)] :=\varphi^c(y).\end{aligned} $$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equci.png)
![$$\displaystyle \begin{aligned} \sup_{\psi\in L_1(\nu):(\varphi,\psi)\in\varPhi_c} \left[{{\int_{\mathcal X} \! {\varphi} \, \mathrm{d}{\mu}}} +{{\int_{\mathcal Y} \! {\psi} \, \mathrm{d}{\nu}}}\right] ={{\int_{\mathcal X} \! {\varphi} \, \mathrm{d}{\mu}}} +{{\int_{\mathcal Y} \! {\varphi^c} \, \mathrm{d}{\nu}}}.\end{aligned} $$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equcj.png)
![$$\displaystyle \begin{aligned} \sup_{\varphi\in L_1(\mu)} \left[{{\int_{\mathcal X} \! {\varphi} \, \mathrm{d}{\mu}}} +{{\int_{\mathcal Y} \! {\varphi^c} \, \mathrm{d}{\nu}}}\right].\end{aligned} $$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equck.png)
![$$\displaystyle \begin{aligned} \varphi^{cc}(x) =(\varphi^c)^c(x) =\inf_{y\in\mathcal Y}[c(x,y) - \varphi^c(y)] \ge \varphi(x), \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equcl.png)
 has a better objective value than (φ
1, ψ
1), and satisfies (φ, ψ) ∈ Φ
c. Moreover, φ
c = ψ and ψ
c = φ; in words, φ and ψ are c-conjugate. An optimal dual pair (φ, ψ) can be expected to be c-conjugate; this is indeed true almost surely:
has a better objective value than (φ
1, ψ
1), and satisfies (φ, ψ) ∈ Φ
c. Moreover, φ
c = ψ and ψ
c = φ; in words, φ and ψ are c-conjugate. An optimal dual pair (φ, ψ) can be expected to be c-conjugate; this is indeed true almost surely:Let μ and ν be probability measures on  and
and  such that the independent coupling with respect to the nonnegative and lower semicontinuous cost function is finite:
such that the independent coupling with respect to the nonnegative and lower semicontinuous cost function is finite:  . Then there exists an optimal pair (φ, ψ) for the dual Kantorovich problem. Furthermore, the pair can be chosen in a way that μ-almost surely, φ = ψ
c and ν-almost surely, ψ = φ
c.
. Then there exists an optimal pair (φ, ψ) for the dual Kantorovich problem. Furthermore, the pair can be chosen in a way that μ-almost surely, φ = ψ
c and ν-almost surely, ψ = φ
c.
 should be optimal. Combining Proposition 1.8.1 with the preceding subsection, we see that if φ is optimal (for the unconstrained dual problem), then any optimal transference plan π
∗ must be concentrated on the set
should be optimal. Combining Proposition 1.8.1 with the preceding subsection, we see that if φ is optimal (for the unconstrained dual problem), then any optimal transference plan π
∗ must be concentrated on the set 
We remark that at the level of generality of Proposition 1.8.1, the function φ c may fail to be Borel measurable; Ambrosio and Pratelli show that this pair can be modified up to null sets in order to be Borel measurable. If c is continuous, however, then φ c is an infimum of a collection of continuous functions (in y). Hence − φ c is lower semicontinuous, which yields that φ c is measurable. When c is uniformly continuous, measurability of φ c is established in a more lucid way, as exemplified in the next subsection.
1.8.2 The Kantorovich–Rubinstein Theorem
 , denote their metric by d, and let c(x, y) = d(x, y). If φ = ψ
c is c-concave, then it is 1-Lipschitz. Indeed, by definition and the triangle inequality
, denote their metric by d, and let c(x, y) = d(x, y). If φ = ψ
c is c-concave, then it is 1-Lipschitz. Indeed, by definition and the triangle inequality ![$$\displaystyle \begin{aligned} \varphi(z) =\inf_{y\in\mathcal Y} [d(z,y) - \psi(y)] \le \inf_{y\in\mathcal Y} [d(x,y) + d(x,z) - \psi(y)] =\varphi(x) + d(x,z). \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equcn.png)

 , x↦d(x, x
0) is in L
1(μ), then any Lipschitz function is μ-integrable. Otherwise one needs to restrict the supremum to, e.g., bounded Lipschitz φ.)
, x↦d(x, x
0) is in L
1(μ), then any Lipschitz function is μ-integrable. Otherwise one needs to restrict the supremum to, e.g., bounded Lipschitz φ.)1.8.3 Strictly Convex Cost Functions on Euclidean Spaces
 and explore the structure of c-transforms. When c is different than ∥x − y∥2∕2, we can no longer “open up the square” and relate the Monge–Kantorovich problem to convexity. However, we can still apply the idea that φ(x) + φ
c(y) = c(x, y) if and only if the infimum is attained at x. Indeed, recall that
and explore the structure of c-transforms. When c is different than ∥x − y∥2∕2, we can no longer “open up the square” and relate the Monge–Kantorovich problem to convexity. However, we can still apply the idea that φ(x) + φ
c(y) = c(x, y) if and only if the infimum is attained at x. Indeed, recall that ![$$\displaystyle \begin{aligned} \varphi^c(y) =\inf_{x\in\mathcal X}[c(x, y) - \varphi(x)], \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equco.png)

The following result generalises Theorem 1.6.2 to other powers p > 1 of the Euclidean norm. These cost functions define the Wasserstein distances of the next chapter.
 )
) with finite p-th moments such that μ is absolutely continuous with respect to Lebesgue measure. Then the solution to the Kantorovich problem with cost function c is unique and induced from a transport map T. Furthermore, there exists an optimal pair (φ, φ
c) of the dual problem, with φ c-concave. The solutions are related by
with finite p-th moments such that μ is absolutely continuous with respect to Lebesgue measure. Then the solution to the Kantorovich problem with cost function c is unique and induced from a transport map T. Furthermore, there exists an optimal pair (φ, φ
c) of the dual problem, with φ c-concave. The solutions are related by 
The existence of the optimal pair (φ, φ c) with the desired properties follows from Proposition 1.8.1 (they are Borel measurable because c is continuous). We shall now show that φ has a unique c-supergradient μ-almost surely.
Step 1: φ is c-superdifferentiable. Let π ∗ be an optimal coupling. By duality arguments, π is concentrated on the set of (x, y) such that y ∈ ∂ cφ(x). Consequently, for μ-almost any x, the c-superdifferential of φ at x is nonempty.
Step 2: φ is differentiable. Here, we impose the additional condition that ν is compactly supported. Then φ can be taken as a c-transform on the compact support of ν. Since h is locally Lipschitz (it is C 1 because p > 1) this implies that φ is locally Lipschitz. Hence, it is differentiable Lebesgue almost surely, and consequently μ-almost surely.


![$$\displaystyle \begin{aligned} y = T(x) := x- (\nabla h)^{-1}[\nabla\varphi(x)], \end{aligned}$$](../images/456556_1_En_1_Chapter/456556_1_En_1_Chapter_TeX_Equct.png)
The general result, without assuming compact support for ν, can be found in Gangbo and McCann [59]. It holds for a larger class of functions h, those that are strictly convex on  (this yields that ∇h is invertible), have superlinear growth (h(v)∕∥v∥→∞ as v →∞) and satisfying a technical geometric condition (which ∥v∥p∕p does when p > 1). Furthermore, if h is sufficiently smooth, namely h ∈ C
1, 1 locally (it is if p ≥ 2, but not if p ∈ (1, 2)), then μ does not need to be absolutely continuous; it suffices that it not give positive measure to any set of Hausdorff dimension smaller or equal than d − 1. When d = 1 this means that Theorem 1.8.2 is still valid as long as μ has no atoms (μ({x}) = 0 for all
(this yields that ∇h is invertible), have superlinear growth (h(v)∕∥v∥→∞ as v →∞) and satisfying a technical geometric condition (which ∥v∥p∕p does when p > 1). Furthermore, if h is sufficiently smooth, namely h ∈ C
1, 1 locally (it is if p ≥ 2, but not if p ∈ (1, 2)), then μ does not need to be absolutely continuous; it suffices that it not give positive measure to any set of Hausdorff dimension smaller or equal than d − 1. When d = 1 this means that Theorem 1.8.2 is still valid as long as μ has no atoms (μ({x}) = 0 for all  ), which is a weaker condition than μ being absolutely continuous.
), which is a weaker condition than μ being absolutely continuous.
It is also noteworthy that for strictly concave cost functions (e.g., p ∈ (0, 1)), the situation is similar when the supports of μ and ν are disjoint. The reason is that h may fail to be differentiable at 0, but it only needs to be differentiated at x − y with x ∈suppμ and y ∈suppν. If the supports are not disjoint, then one needs to leave all common mass in place until the supports become disjoint (Villani [124, Chapter 2]) and then the result of [59] applies. As a simple example, let μ be uniform on [0, 1] and ν be uniform on [0, 2]. After leaving common mass in place, we are left with uniforms on [0, 1] and [1, 2] (with total mass 1∕2) with essentially disjoint supports, for which the optimal transport map is the decreasing map T(x) = 2 − x. Thus, the unique optimal π is not induced from a map, but rather from an equal weight mixture of T and the identity. Informally, each point x in the support of μ needs to be split; half stays and x and the other half transported to 2 − x. The optimal coupling from ν to μ is unique and induced from the map S(x) = x if x ≤ 1 and 2 − x if x ≥ 1, which is neither increasing nor decreasing.
1.9 Bibliographical Notes
Many authors, including Villani [124, Theorem 1.3]; [125, Theorem 5.10], give the duality Theorem 1.4.2 for lower semicontinuous cost functions. The version given here is a simplification of Beiglböck and Schachermayer [17, Theorem 1]. The duality holds for functions that take values in [−∞, ∞] provided that they are finite on a sufficiently large subset of  , but there are simple counterexamples if c is infinite too often [17, Example 4.1]. For results outside the Polish space setup, see Kellerer [80] and Rachev and Rüschendorf [107, Chapter 4].
, but there are simple counterexamples if c is infinite too often [17, Example 4.1]. For results outside the Polish space setup, see Kellerer [80] and Rachev and Rüschendorf [107, Chapter 4].
Theorem 1.5.1 for the one-dimensional case is taken from [124], where it is proven using the general duality theorem. For direct proofs and the history of this result, one may consult Rachev [106] or Rachev and Rüschendorf [107, Section 3.1]. The concave case is carefully treated by McCann [94].
The results in the Gaussian case were obtained independently by Olkin and Pukelsheim [98] and Givens and Shortt [65]. The proof given here is from Bhatia [20, Exercise 1.2.13]. An extension to separable Hilbert spaces can be found in Gelbrich [62] or Cuesta-Albertos et al. [39].
The regularity theory of Sect. 1.6.4 is very delicate. Caffarelli [32] showed the first part of Theorem 1.6.7; the proof can also be found in Figalli’s book [52, Theorem 4.23]. Villani [124, Theorem 4.14] states the result without proof and refers to Alesker et al. [7] for a sketch of the second part of Theorem 1.6.7. Other regularity results exist, Villani [125, Chapter 12]; Santambrogio [119, Section 1.7.6]; Figalli [52].
Cuesta-Albertos et al. [40, Theorem 3.2] prove Theorem 1.7.2 for the quadratic case; the form given here is from Schachermayer and Teichmann [120, Theorem 3].
The definition of cyclical monotonicity depends on the cost function. It is typically referred to as c-cyclical monotonicity, with “cyclical monotonicity” reserved to the special case of quadratic cost. Since we focus on the quadratic case and for readability, we slightly deviate from the standard jargon. That cyclical monotonicity implies optimality (Proposition 1.7.5) was shown independently by Pratelli [105] (finite lower semicontinuous cost) and Schachermayer and Teichmann [120] (possibly infinite continuous cost). A joint generalisation is given by Beiglböck et al. [18].
Section 1.7.2 is taken from Zemel and Panaretos [134, Section 7.5]; a slightly weaker version was shown independently by Chernozhukov et al. [35]. Heinich and Lootgieter [68] establish almost sure pointwise convergence. If μ n = μ, then the optimal maps converge in μ-measure [125, Corollary 5.23] in a very general setup, but there are simple examples where this fails if μ n≠μ [125, Remark 5.25]. In the quadratic case, further stability results of a weaker flavour (focussing on the convex potential ϕ, rather than its derivative, which is the optimal map) can be found in del Barrio and Loubes [42].
The idea of using the c-transform (Sect. 1.8) is from Rüschendorf [116].

Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.