The Kantorovich problem described in the previous chapter gives rise to a metric structure, the Wasserstein distance, in the space of probability measures  on a space
on a space  . The resulting metric space, a subspace of
. The resulting metric space, a subspace of  , is commonly known as the Wasserstein space
, is commonly known as the Wasserstein space  (although, as Villani [125, pages 118–119] puts it, this terminology is “very questionable”; see also Bobkov and Ledoux [25, page 4]). In Chap. 4, we shall see that this metric is in a sense canonical when dealing with warpings, that is, deformations of the space
(although, as Villani [125, pages 118–119] puts it, this terminology is “very questionable”; see also Bobkov and Ledoux [25, page 4]). In Chap. 4, we shall see that this metric is in a sense canonical when dealing with warpings, that is, deformations of the space  (for example, in Theorem 4.2.4). In this chapter, we give the fundamental properties of the Wasserstein space. After some basic definitions, we describe the topological properties of that space in Sect. 2.2. It is then explained in Sect. 2.3 how
(for example, in Theorem 4.2.4). In this chapter, we give the fundamental properties of the Wasserstein space. After some basic definitions, we describe the topological properties of that space in Sect. 2.2. It is then explained in Sect. 2.3 how  can be endowed with a sort of infinite-dimensional Riemannian structure. Measurability issues are dealt with in the somewhat technical Sect. 2.4.
can be endowed with a sort of infinite-dimensional Riemannian structure. Measurability issues are dealt with in the somewhat technical Sect. 2.4.
2.1 Definition, Notation, and Basic Properties
 be a separable Banach space. The p-Wasserstein space on
be a separable Banach space. The p-Wasserstein space on  is defined as
is defined as 
 instead of
instead of  .
. , then Π(μ, ν) is defined to be the set of measures
, then Π(μ, ν) is defined to be the set of measures  having μ and ν as marginals in the sense of (1.2). The p-Wasserstein distance between μ and ν is defined as the minimal total transportation cost between μ and ν in the Kantorovich problem with respect to the cost function c
p(x, y) = ∥x − y∥p:
having μ and ν as marginals in the sense of (1.2). The p-Wasserstein distance between μ and ν is defined as the minimal total transportation cost between μ and ν in the Kantorovich problem with respect to the cost function c
p(x, y) = ∥x − y∥p: 
 , because
, because 
![$$[\mathcal W_p(\mathcal X)]^2=\mathcal W_p(\mathcal X)\times \mathcal W_p(\mathcal X)$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_IEq20.png) ; it is nonnegative and symmetric and it is easy to see that W
p(μ, ν) = 0 if and only if μ = ν. A proof that W
p is a metric (satisfies the triangle inequality) on
; it is nonnegative and symmetric and it is easy to see that W
p(μ, ν) = 0 if and only if μ = ν. A proof that W
p is a metric (satisfies the triangle inequality) on  can be found in Villani [124, Chapter 7].
can be found in Villani [124, Chapter 7].The aforementioned setting is by no means the most general one can consider. Firstly, one can define W
p and  for 0 < p < 1 by removing the power 1∕p from the infimum and the limit case p = 0 yields the total variation distance. Another limit case can be defined as W
∞(μ, ν) =limp→∞W
p(μ, ν). Moreover, W
p and
for 0 < p < 1 by removing the power 1∕p from the infimum and the limit case p = 0 yields the total variation distance. Another limit case can be defined as W
∞(μ, ν) =limp→∞W
p(μ, ν). Moreover, W
p and  can be defined whenever
can be defined whenever  is a complete and separable metric space (or even only separable; see Clément and Desch [36]): one fixes some x
0 in
is a complete and separable metric space (or even only separable; see Clément and Desch [36]): one fixes some x
0 in  and replaces ∥x∥ by d(x, x
0). Although the topological properties below still hold at that level of generality (except when p = 0 or p = ∞), for the sake of simplifying the notation we restrict the discussion to Banach spaces. It will always be assumed without explicit mention that 1 ≤ p < ∞.
and replaces ∥x∥ by d(x, x
0). Although the topological properties below still hold at that level of generality (except when p = 0 or p = ∞), for the sake of simplifying the notation we restrict the discussion to Banach spaces. It will always be assumed without explicit mention that 1 ≤ p < ∞.
 is defined as the collection of measures μ such that W
p(μ, δ
0) < ∞ with δ
x being a Dirac measure at x. Of course, W
p(μ, ν) can be finite even if
is defined as the collection of measures μ such that W
p(μ, δ
0) < ∞ with δ
x being a Dirac measure at x. Of course, W
p(μ, ν) can be finite even if  . But if
. But if  and
and  , then W
p(μ, ν) is always infinite. This can be seen from the triangle inequality
, then W
p(μ, ν) is always infinite. This can be seen from the triangle inequality 
 .
. . This property extends to the distances in the form:
. This property extends to the distances in the form: 




 . Situations where this inequality holds as equality and t and s are optimal maps are related to compatibility of the measures μ, ν = t#μ and ρ = s#μ (see Sect. 2.3.2) and will be of conceptual importance in the context of Fréchet means (see Sect. 3.1).
. Situations where this inequality holds as equality and t and s are optimal maps are related to compatibility of the measures μ, ν = t#μ and ρ = s#μ (see Sect. 2.3.2) and will be of conceptual importance in the context of Fréchet means (see Sect. 3.1).We also recall the notation B
R(x
0) = {x : ∥x − x
0∥ < R} and  for open and closed balls in
for open and closed balls in  .
.
2.2 Topological Properties
2.2.1 Convergence, Compact Subsets
The topology of a space is determined by the collection of its closed sets. Since  is a metric space, whether a set is closed or not depends on which sequences in
is a metric space, whether a set is closed or not depends on which sequences in  converge. The following characterisation from Villani [124, Theorem 7.12] will be very useful.
converge. The following characterisation from Villani [124, Theorem 7.12] will be very useful.
 . Then the following are equivalent:
. Then the following are equivalent:
- 1.
W p(μ n, μ) → 0 as n →∞;
- 2.
μ n → μ weakly and
 ;
; - 3.μ n → μ weakly and
 (2.4)
(2.4) - 4.for any C > 0 and any continuous
 such that |f(x)|≤ C(1 + ∥x∥p) for all x,
such that |f(x)|≤ C(1 + ∥x∥p) for all x, 
- 5.
(Le Gouic and Loubes [ 87, Lemma 14]) μ n → μ weakly and there exists
 such that W
p(μ
n, ν) → W
p(μ, ν).
such that W
p(μ
n, ν) → W
p(μ, ν).
Consequently, the Wasserstein topology is finer than the weak topology induced on  from
from  . Indeed, let
. Indeed, let  be weakly closed. If
be weakly closed. If  converge to μ in
converge to μ in  , then μ
n → μ weakly, so
, then μ
n → μ weakly, so  . In other words, the Wasserstein topology has more closed sets than the induced weak topology. Moreover, each
. In other words, the Wasserstein topology has more closed sets than the induced weak topology. Moreover, each  is a weakly closed subset of
is a weakly closed subset of  by the same arguments that lead to (1.3). In view of Theorem 2.2.1, a common strategy to establish Wasserstein convergence is to first show tightness and obtain weak convergence, hence a candidate limit, and then show that the stronger Wasserstein convergence actually holds. In some situations, the last part is automatic:
by the same arguments that lead to (1.3). In view of Theorem 2.2.1, a common strategy to establish Wasserstein convergence is to first show tightness and obtain weak convergence, hence a candidate limit, and then show that the stronger Wasserstein convergence actually holds. In some situations, the last part is automatic:
Let  be a bounded set and suppose that μ
n(K) = 1 for all n ≥ 1. Then W
p(μ
n, μ) → 0 if and only if μ
n → μ weakly.
be a bounded set and suppose that μ
n(K) = 1 for all n ≥ 1. Then W
p(μ
n, μ) → 0 if and only if μ
n → μ weakly.
This is immediate from (2.4).
 is stronger than weak convergence is exemplified in the following result. If μ
n → μ and ν
n → ν in
is stronger than weak convergence is exemplified in the following result. If μ
n → μ and ν
n → ν in  , then it is obvious that W
p(μ
n, ν
n) → W
p(μ, ν). But if the convergence is only weak, then the Wasserstein distance is still lower semicontinuous:
, then it is obvious that W
p(μ
n, ν
n) → W
p(μ, ν). But if the convergence is only weak, then the Wasserstein distance is still lower semicontinuous: 
Before giving some examples, it will be convenient to formulate Theorem 2.2.1 in probabilistic terms. Let X, X
n be random elements on  with laws
with laws  . Assume without loss of generality that X, X
n are defined on the same probability space
. Assume without loss of generality that X, X
n are defined on the same probability space  and write W
p(X
n, X) to denote W
p(μ
n, μ). Then W
p(X
n, X) → 0 if and only if X
n → X weakly and
and write W
p(X
n, X) to denote W
p(μ
n, μ). Then W
p(X
n, X) → 0 if and only if X
n → X weakly and  .
.
An early example of the use of Wasserstein metric in statistics is due to Bickel and Freedman [21]. Let X
n be independent and identically distributed random variables with mean zero and variance 1 and let Z be a standard normal random variable. Then  converge weakly to Z by the central limit theorem. But
converge weakly to Z by the central limit theorem. But  , so W
2(Z
n, Z) → 0. Let
, so W
2(Z
n, Z) → 0. Let  be a bootstrapped version of Z
n constructed by resampling the X
n’s. If
be a bootstrapped version of Z
n constructed by resampling the X
n’s. If  , then
, then  and in particular
and in particular  has the same asymptotic distribution as Z
n.
has the same asymptotic distribution as Z
n.
 for any p ≤ 2 by the last condition of the theorem. If in addition
for any p ≤ 2 by the last condition of the theorem. If in addition  , then
, then 
Condition (2.4) is called uniform integrability of the function x↦∥x∥p with respect to the collection (μ
n). Of course, it holds for a single measure  by the dominated convergence theorem. This condition allows us to characterise compact sets in the Wasserstein space. One should beware that when
by the dominated convergence theorem. This condition allows us to characterise compact sets in the Wasserstein space. One should beware that when  is infinite-dimensional, (2.4) alone is not sufficient in order to conclude that μ
n has a convergent subsequence: take μ
n to be Dirac measures at e
n with (e
n) an orthonormal basis of a Hilbert space
is infinite-dimensional, (2.4) alone is not sufficient in order to conclude that μ
n has a convergent subsequence: take μ
n to be Dirac measures at e
n with (e
n) an orthonormal basis of a Hilbert space  (or any sequence with ∥e
n∥ = 1 that has no convergent subsequence, if
(or any sequence with ∥e
n∥ = 1 that has no convergent subsequence, if  is a Banach space). The uniform integrability (2.4) must be accompanied with tightness, which is a consequence of (2.4) only when
is a Banach space). The uniform integrability (2.4) must be accompanied with tightness, which is a consequence of (2.4) only when  .
.
 )
) is Wasserstein-tight (has a compact closure in
is Wasserstein-tight (has a compact closure in
 ) if and only if
) if and only if



The proof is on page 41 of the supplement.
For any sequence (μ
n) in  (tight or not) there exists a monotonically divergent g with
(tight or not) there exists a monotonically divergent g with  for all n.
for all n.
 be a compact set. Then
be a compact set. Then

is compact.




2.2.2 Dense Subsets and Completeness
If we identify a measure  with a random variable X (having distribution μ), then X has a finite p-th moment in the sense that the real-valued random variable ∥X∥ is in L
p. In view of that, it should not come as a surprise that
with a random variable X (having distribution μ), then X has a finite p-th moment in the sense that the real-valued random variable ∥X∥ is in L
p. In view of that, it should not come as a surprise that  enjoys topological properties similar to L
p spaces. In this subsection, we give some examples of useful dense subsets of
enjoys topological properties similar to L
p spaces. In this subsection, we give some examples of useful dense subsets of  and then “show” that like
and then “show” that like  itself, it is a complete separable metric space. In the next subsection, we describe some of the negative properties that
itself, it is a complete separable metric space. In the next subsection, we describe some of the negative properties that  has, again in similarity with L
p spaces.
has, again in similarity with L
p spaces.
We first show that  is separable. The core idea of the proof is the feasibility of approximating any measure with discrete measures as follows.
is separable. The core idea of the proof is the feasibility of approximating any measure with discrete measures as follows.
 , and let X
1, X
2, … be a sequence of independent random elements in
, and let X
1, X
2, … be a sequence of independent random elements in  with probability distribution μ. Then the empirical measure μ
n is defined as the random measure
with probability distribution μ. Then the empirical measure μ
n is defined as the random measure  . The law of large numbers shows that for any (measurable) bounded or nonnegative
. The law of large numbers shows that for any (measurable) bounded or nonnegative  , almost surely
, almost surely 
 , then μ
n → μ in
, then μ
n → μ in  if and only if μ
n → μ weakly. We know that integrals of bounded functions converge with probability one, but the null set where convergence fails may depend on the chosen function and there are uncountably many such functions. When
if and only if μ
n → μ weakly. We know that integrals of bounded functions converge with probability one, but the null set where convergence fails may depend on the chosen function and there are uncountably many such functions. When  , by the portmanteau Lemma 1.7.1 we can replace the collection
, by the portmanteau Lemma 1.7.1 we can replace the collection  by indicator functions of rectangles of the form (−∞, a
1] ×⋯ × (−∞, a
d] for
by indicator functions of rectangles of the form (−∞, a
1] ×⋯ × (−∞, a
d] for  . It turns out that the countable collection provided by rational vectors a suffices (see the proof of Theorem 4.4.1 where this is done in a more complicated setting). For more general spaces
. It turns out that the countable collection provided by rational vectors a suffices (see the proof of Theorem 4.4.1 where this is done in a more complicated setting). For more general spaces  , we need to find another countable collection {f
j} such that convergence of the integrals of f
j for all j suffices for weak convergence. Such a collection exists, by using bounded Lipschitz functions (Dudley [47, Theorem 11.4.1]); an alternative construction can be found in Ambrosio et al. [12, Section 5.1]. Thus:
, we need to find another countable collection {f
j} such that convergence of the integrals of f
j for all j suffices for weak convergence. Such a collection exists, by using bounded Lipschitz functions (Dudley [47, Theorem 11.4.1]); an alternative construction can be found in Ambrosio et al. [12, Section 5.1]. Thus: )
)For any  and the corresponding sequence of empirical measures μ
n, W
p(μ
n, μ) → 0 almost surely if and only if
and the corresponding sequence of empirical measures μ
n, W
p(μ
n, μ) → 0 almost surely if and only if  .
.
Indeed, if  , then W
p(μ
n, μ) is infinite for all n, since μ
n is compactly supported, hence in
, then W
p(μ
n, μ) is infinite for all n, since μ
n is compactly supported, hence in  .
.
Proposition 2.2.6 is the basis for constructing dense subsets of the Wasserstein space.
 )
) :
:
- 1.
finitely supported measures with rational weights;
- 2.
compactly supported measures;
- 3.
finitely supported measures with rational weights on a dense subset
 ;
;
- 4.
if
 , the collection of absolutely continuous and compactly supported measures;
, the collection of absolutely continuous and compactly supported measures;
- 5.
if
 , the collection of absolutely continuous measures with strictly positive and bounded analytic densities.
, the collection of absolutely continuous measures with strictly positive and bounded analytic densities.
In particular,
 is separable (the third set is countable as
is separable (the third set is countable as
 is separable).
is separable).
This is a simple consequence of Proposition 2.2.6 and approximations, and the details are given on page 43 in the supplement.
The Wasserstein space
 is complete.
is complete.
One may find two different proofs in Villani [125, Theorem 6.18] and Ambrosio et al. [12, Proposition 7.1.5]. On page 43 of the supplement, we sketch an alternative argument based on completeness of the weak topology.
2.2.3 Negative Topological Properties
In the previous subsection, we have shown that  is separable and complete like L
p spaces. Just like them, however, the Wasserstein space is neither locally compact nor σ-compact. For this reason, existence proofs of Fréchet means in
is separable and complete like L
p spaces. Just like them, however, the Wasserstein space is neither locally compact nor σ-compact. For this reason, existence proofs of Fréchet means in  require tools that are more specific to this space, and do not rely upon local compactness (see Sect. 3.1).
require tools that are more specific to this space, and do not rely upon local compactness (see Sect. 3.1).
 is Not Locally Compact)
is Not Locally Compact) and let 𝜖 > 0. Then the Wasserstein ball
and let 𝜖 > 0. Then the Wasserstein ball 
is not compact.
Ambrosio et al. [12, Remark 7.1.9] show this when μ is a Dirac measure, and we extend their argument on page 43 of the supplement.
From this, we deduce:
The Wasserstein space
 is not σ-compact.
is not σ-compact.




2.2.4 Covering Numbers
 be compact and assume that
be compact and assume that  . Then for any 𝜖 > 0 the covering number
. Then for any 𝜖 > 0 the covering number 
 . Invoking Proposition 2.2.3, introduce a continuous monotone divergent f : [0, ∞) → [0, ∞] such that
. Invoking Proposition 2.2.3, introduce a continuous monotone divergent f : [0, ∞) → [0, ∞] such that 
 is. If
is. If  is the set of measures supported on a compact
is the set of measures supported on a compact  , then f(L) can be taken infinite for L large, and L can be treated as a constant in the theorem. Otherwise L increases as
, then f(L) can be taken infinite for L large, and L can be treated as a constant in the theorem. Otherwise L increases as 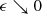 , at a speed that depends on f: the faster f diverges, the slower L grows with decreasing 𝜖 and the better the bound becomes.
, at a speed that depends on f: the faster f diverges, the slower L grows with decreasing 𝜖 and the better the bound becomes.![$$\displaystyle \begin{aligned} \log N(\epsilon) \le C_1(d)\left(\frac L\epsilon\right)^d\left[(p+d)\log \frac L\epsilon + C_2(d,p)\right], \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equp.png)
with C
1(d) = 3deθ
d,  and
and ![$$\theta _d=d[5+\log d+\log \log d]$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_IEq124.png) .
.
Since 𝜖 > 0 is small and L is increasing in 𝜖, the restriction that d𝜖 ≤ L is typically not binding. We provide some examples before giving the proof.

 have uniform exponential moments, then f(L) = e
L and
have uniform exponential moments, then f(L) = e
L and  is a constant times 𝜖
−d[log 1∕𝜖]d. The exponent p appears only in the constant.
is a constant times 𝜖
−d[log 1∕𝜖]d. The exponent p appears only in the constant. is a Wasserstein ball of order p + δ, that is, f(L) = L
δ. Then L ∼ 𝜖
−p∕δ and
is a Wasserstein ball of order p + δ, that is, f(L) = L
δ. Then L ∼ 𝜖
−p∕δ and ![$$\displaystyle \begin{aligned} \widetilde N(\epsilon) \le C_1(d)(p+d)(1+p/\delta)\epsilon^{-d[1+p/\delta]} \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equr.png)
 depends more strongly upon p: if p′ < p, then we can replace δ by δ′ = δ + p − p′ > δ, leading to a smaller magnitude of
depends more strongly upon p: if p′ < p, then we can replace δ by δ′ = δ + p − p′ > δ, leading to a smaller magnitude of  .
.Example 4: if f(L) is only  , then
, then  behaves like
behaves like  , so p has a very dominant effect.
, so p has a very dominant effect.
The proof is divided into four steps.
 be the projection onto
be the projection onto  and let
and let  . Then
. Then 
 . There exists a set
. There exists a set  such that B
L(0) ⊆∪B
𝜖(x
i). If
such that B
L(0) ⊆∪B
𝜖(x
i). If  , there exists a measure μ
n supported on the x
i’s and such that
, there exists a measure μ
n supported on the x
i’s and such that 

![$$\displaystyle \begin{aligned} n\le e\theta_d[L/\epsilon]^d, \qquad \theta_d=d[5+\log d+\log\log d], \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equv.png)
 and
and  , then
, then  . Let
. Let 
![$$\displaystyle \begin{aligned} N(3\epsilon) \le(2+1/\delta)^{n-1} \le\!\! \left[2{\kern-1pt}+\!\left(\!\frac L\epsilon\!\right)^{p+d}2^pe\theta_d\right]^{e\theta_d[L/\epsilon]^d} \le\!\! \left[\!\left(\!\frac L\epsilon\!\right)^{p+d}2^{p+2}\theta_d\right]^{e\theta_d[L/\epsilon]^d}, \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equx.png)
![$$\displaystyle \begin{aligned} N(\epsilon) \le \left[3^{p+d}\left(\frac L\epsilon\right)^{p+d}2^{p+2}\theta_d\right]^{3^de\theta_d[L/\epsilon]^d}. \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equy.png)
2.3 The Tangent Bundle
Although the Wasserstein space  is non-linear in terms of measures, it is linear in terms of maps. Indeed, if
is non-linear in terms of measures, it is linear in terms of maps. Indeed, if  and
and  are such that ∥T
i∥∈ L
p(μ), then
are such that ∥T
i∥∈ L
p(μ), then  for all
for all  . Later, in Sect. 2.4, we shall see that
. Later, in Sect. 2.4, we shall see that  is in fact homeomorphic to a subset of the space of such functions. The goal of this section is to exploit the linearity of the latter in order to define the tangent bundle of
is in fact homeomorphic to a subset of the space of such functions. The goal of this section is to exploit the linearity of the latter in order to define the tangent bundle of  . This in particular will be used for deriving differentiability properties of the Wasserstein distance in Sect. 3.1.6. However, the latter can be understood at a purely analytic level, and readers uncomfortable with differential geometry can access most of the rest of the monograph without reference to this section.
. This in particular will be used for deriving differentiability properties of the Wasserstein distance in Sect. 3.1.6. However, the latter can be understood at a purely analytic level, and readers uncomfortable with differential geometry can access most of the rest of the monograph without reference to this section.
We assume here that  is a Hilbert space and that p = 2; the results extend to any p > 1. Absolutely continuous measures are assumed to be so with respect to Lebesgue measure if
is a Hilbert space and that p = 2; the results extend to any p > 1. Absolutely continuous measures are assumed to be so with respect to Lebesgue measure if  and otherwise refer to Definition 1.6.4.
and otherwise refer to Definition 1.6.4.
2.3.1 Geodesics, the Log Map and the Exponential Map in 
 be absolutely continuous and
be absolutely continuous and  arbitrary. From Sect. 1.6.1, we know that there exists a unique solution to the Monge–Kantorovich problem, and that solution is given by a transport map that we denote by
arbitrary. From Sect. 1.6.1, we know that there exists a unique solution to the Monge–Kantorovich problem, and that solution is given by a transport map that we denote by  . Recalling that
. Recalling that  is the identity map, we can define a curve
is the identity map, we can define a curve ![$$\displaystyle \begin{aligned} \gamma_t=\left[\mathbf i +t({\mathbf{t}}_{\gamma}^{\mu} - \mathbf i)\right] \#\gamma,\qquad t\in[0,1]. \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equz.png)
 and the identity. Clearly γ
0 = γ, γ
1 = μ and from (2.3),
and the identity. Clearly γ
0 = γ, γ
1 = μ and from (2.3), ![$$\displaystyle \begin{aligned} \begin{array}{rcl} W_2(\gamma_t,\gamma) &\displaystyle &\displaystyle \le \sqrt{\int_{\mathcal{X}}{\left[t(\mathbf{ t}_{\gamma}^{\mu} - \mathbf{ i})\right]^2}\mathrm{d}\gamma} =tW_2(\gamma,\mu);\\ W_2(\gamma_t,\mu) &\displaystyle &\displaystyle \le \sqrt{\int_{\mathcal{X}}{\left[(1-t)(\mathbf{ t}_{\gamma}^{\mu} - \mathbf{ i})\right]^2}\mathrm{d}\gamma} =(1-t)W_2(\gamma,\mu). \end{array} \end{aligned} $$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equaa.png)
 that these inequalities must hold as equalities. Taking this one step further, we see that
that these inequalities must hold as equalities. Taking this one step further, we see that 
 .
. at μ as (Ambrosio et al. [12, Definition 8.5.1])
at μ as (Ambrosio et al. [12, Definition 8.5.1]) 
 such that ∥f∥∈ L
2(μ) rather than L
2(μ) itself, as in Definition 2.4.3, but we will write L
2 for simplicity.)
such that ∥f∥∈ L
2(μ) rather than L
2(μ) itself, as in Definition 2.4.3, but we will write L
2 for simplicity.) , Lipschitz functions are dense in L
2(μ), and for t Lipschitz the negative of a tangent element
, Lipschitz functions are dense in L
2(μ), and for t Lipschitz the negative of a tangent element 
 functions. We refer to [12, Definition 8.4.1 and Theorem 8.5.1] for the proof and extensions to other values of p > 1 and to infinite dimensions, using cylindrical functions that depend on finitely many coordinates [12, Definition 5.1.11]. The alternative definition highlights that it is essentially the inner product in Tanμ, but not the elements themselves, that depends on μ.
functions. We refer to [12, Definition 8.4.1 and Theorem 8.5.1] for the proof and extensions to other values of p > 1 and to infinite dimensions, using cylindrical functions that depend on finitely many coordinates [12, Definition 5.1.11]. The alternative definition highlights that it is essentially the inner product in Tanμ, but not the elements themselves, that depends on μ. . The exponential map at
. The exponential map at  is the restriction to Tanγ of the mapping that sends r ∈ L
2(γ) to
is the restriction to Tanγ of the mapping that sends r ∈ L
2(γ) to ![$$[\mathbf r+\mathbf i]\#\gamma \in \mathcal W_2(\mathcal X)$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_IEq165.png) . More explicitly,
. More explicitly,  takes the form
takes the form ![$$\displaystyle \begin{aligned} {\exp}_{\gamma}(t(\mathbf{t} - \mathbf i)) ={\exp}_{\gamma}([t\mathbf{t} + (1-t)\mathbf i] - \mathbf i) = [t\mathbf{t} + (1-t)\mathbf i]\#\gamma \quad (t\in\mathbb{R}). \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equae.png)

 (by virtue of Theorem 1.6.2). In symbols,
(by virtue of Theorem 1.6.2). In symbols, ![$$\displaystyle \begin{aligned} \exp_\gamma(\log_\gamma(\mu))=\mu ,\quad \mu\in \mathcal W_2, \quad \ \mathrm{and}\quad \ \log_\gamma(\exp_\gamma(t(\mathbf{t} - \mathbf i))) = t(\mathbf{t} - \mathbf i) \quad (t\in[0,1]), \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equag.png)
![$$\left [\mathbf i+t({\mathbf {t}}_{\gamma }^{\mu } - \mathbf i)\right ]\#\gamma $$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_IEq168.png) is mapped bijectively to the line segment
is mapped bijectively to the line segment  through the log map.
through the log map.![$$\displaystyle \begin{aligned}{}[tp_2+(1-t)p_1]\#\pi, \qquad p_1(x,y)=x, \quad p_2(x,y)=y, \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equah.png)
 are projections and π is any optimal transport plan between γ and μ. This is defined for arbitrary measures
are projections and π is any optimal transport plan between γ and μ. This is defined for arbitrary measures  , and reduces to the previous definition if γ is absolutely continuous. It is shown in Ambrosio et al. [12, Chapter 7] or Santambrogio [119, Proposition 5.32] that these are the only constant-speed geodesics in
, and reduces to the previous definition if γ is absolutely continuous. It is shown in Ambrosio et al. [12, Chapter 7] or Santambrogio [119, Proposition 5.32] that these are the only constant-speed geodesics in  .
.2.3.2 Curvature and Compatibility of Measures
 be absolutely continuous measures. Then by (2.3)
be absolutely continuous measures. Then by (2.3) 
 than the distance between the corresponding vectors logγ(μ) and logγ(ν) in the tangent space Tanγ. In the terminology of differential geometry, this means that the Wasserstein space has nonnegative sectional curvature at any absolutely continuous γ.
than the distance between the corresponding vectors logγ(μ) and logγ(ν) in the tangent space Tanγ. In the terminology of differential geometry, this means that the Wasserstein space has nonnegative sectional curvature at any absolutely continuous γ. , a change of variables gives
, a change of variables gives 
 pushes forward ν to μ, equality holds if and only if
pushes forward ν to μ, equality holds if and only if  . This motivates the following definition.
. This motivates the following definition.A collection of absolutely continuous measures  is compatible if for all
is compatible if for all  , we have
, we have  (in L
2(ν)).
(in L
2(ν)).
The absolute continuity is not necessary and was introduced for notational simplicity. A more general definition that applies to general measures is the following: every finite subcollection of  admits an optimal multicoupling whose relevant projections are simultaneously pairwise optimal; see the paragraph preceding Theorem 3.1.9.
admits an optimal multicoupling whose relevant projections are simultaneously pairwise optimal; see the paragraph preceding Theorem 3.1.9.
 , then the entire collection of absolutely continuous (or even just continuous) measures is compatible. This is because of the simple geometry of convex functions in
, then the entire collection of absolutely continuous (or even just continuous) measures is compatible. This is because of the simple geometry of convex functions in  : gradients of convex functions are nondecreasing, and this property is stable under composition. In a more probabilistic way of thinking, one can always push-forward μ to ν via the uniform distribution Leb|[0,1] (see Sect. 1.5). Letting
: gradients of convex functions are nondecreasing, and this property is stable under composition. In a more probabilistic way of thinking, one can always push-forward μ to ν via the uniform distribution Leb|[0,1] (see Sect. 1.5). Letting  and
and  denote the quantile functions, we have seen that
denote the quantile functions, we have seen that 
 is an isometry from
is an isometry from  to the subset of L
2(0, 1) formed by (equivalence classes of) left-continuous nondecreasing functions on (0, 1). Since this is a convex subset of a Hilbert space, this property provides a very simple way to evaluate Fréchet means in
to the subset of L
2(0, 1) formed by (equivalence classes of) left-continuous nondecreasing functions on (0, 1). Since this is a convex subset of a Hilbert space, this property provides a very simple way to evaluate Fréchet means in  (see Sect. 3.1). If γ = Leb|[0,1], then
(see Sect. 3.1). If γ = Leb|[0,1], then  for all μ, so we can write the above equality as
for all μ, so we can write the above equality as 
 , the Wasserstein space is essentially flat (has zero sectional curvature).
, the Wasserstein space is essentially flat (has zero sectional curvature). be compatible and fix
be compatible and fix  . Then for all
. Then for all 

 is an isometric embedding of
is an isometric embedding of  into L
2(γ). Generalising the one-dimensional case, we shall see that this allows for easy calculations of Fréchet means by means of averaging transport maps (Theorem 3.1.9).
into L
2(γ). Generalising the one-dimensional case, we shall see that this allows for easy calculations of Fréchet means by means of averaging transport maps (Theorem 3.1.9). be a standard Gaussian distribution with identity covariance matrix. Let Σ
μ denote the covariance matrix of a measure
be a standard Gaussian distribution with identity covariance matrix. Let Σ
μ denote the covariance matrix of a measure  . When μ and ν are centred nondegenerate Gaussian measures,
. When μ and ν are centred nondegenerate Gaussian measures, ![$$\displaystyle \begin{aligned} {\mathbf{t}}_{\gamma}^{\mu} =\varSigma_\mu^{1/2}; \qquad {\mathbf{t}}_{\gamma}^{\nu} =\varSigma_\nu^{1/2}; \qquad {\mathbf{t}}_{\mu}^{\nu} =\varSigma_\mu^{-1/2}[\varSigma_\mu^{1/2}\varSigma_\nu\varSigma_\mu^{1/2}]^{1/2}\varSigma_\mu^{-1/2}, \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equan.png)

 and
and  commute (if A and B are symmetric, then AB is symmetric if and only if AB = BA), or equivalently, if and only if Σ
ν and Σ
μ commute. We see that a collection
commute (if A and B are symmetric, then AB is symmetric if and only if AB = BA), or equivalently, if and only if Σ
ν and Σ
μ commute. We see that a collection  of Gaussian measures on
of Gaussian measures on  that includes the standard Gaussian distribution is compatible if and only if all the covariance matrices of the measures in
that includes the standard Gaussian distribution is compatible if and only if all the covariance matrices of the measures in  are simultaneously diagonalisable. In other words, there exists an orthogonal matrix U such that D
μ = UΣ
μU
t is diagonal for all
are simultaneously diagonalisable. In other words, there exists an orthogonal matrix U such that D
μ = UΣ
μU
t is diagonal for all  . In that case, formula (1.6)
. In that case, formula (1.6) ![$$\displaystyle \begin{aligned} \mathcal W_2^2(\mu,\nu) ={\mathrm{tr}}[\varSigma_\mu+\varSigma_\nu - 2(\varSigma_\mu^{1/2}\varSigma_\nu \varSigma_\mu^{1/2})^{1/2}] ={\mathrm{tr}}[\varSigma_\mu+\varSigma_\nu - 2\varSigma_\mu^{1/2}\varSigma_\nu^{1/2}] \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equap.png)
![$$\displaystyle \begin{aligned} \mathcal W^2_2(\mu,\nu) ={\mathrm{tr}}[D_\mu+D_\nu - 2D_\mu^{1/2}D_\nu^{1/2}] =\sum_{i=1}^d (\sqrt{\alpha_i} - \sqrt{\beta_i})^2, \ \ \alpha_i= [D_\mu]_{ii}; \ \ \beta_i= [D_\nu]_{ii}, \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equaq.png)
 with the map x↦ax on
with the map x↦ax on  , the optimal maps take the “orthogonal separable” form
, the optimal maps take the “orthogonal separable” form 
 gives
gives 
 and
and  for μ-almost all x. In the Gaussian case, the optimal maps are linear functions, so x does not appear in the matrices.
for μ-almost all x. In the Gaussian case, the optimal maps are linear functions, so x does not appear in the matrices.Here are some examples of compatible measures. It will be convenient to describe them using the optimal maps from a reference measure  . Define
. Define  with t belonging to one of the following families. The first imposes the one-dimensional structure by varying only the behaviour of the norm of x, while the second allows for separation of variables that splits the d-dimensional problem into d one-dimensional ones.
with t belonging to one of the following families. The first imposes the one-dimensional structure by varying only the behaviour of the norm of x, while the second allows for separation of variables that splits the d-dimensional problem into d one-dimensional ones.
 of the form t(x) = xG(∥x∥) with
of the form t(x) = xG(∥x∥) with  differentiable. Then a straightforward calculation shows that
differentiable. Then a straightforward calculation shows that ![$$\displaystyle \begin{aligned} \nabla\mathbf{t}(x) =G(\|x\|)I +[G'(\|x\|)/\|x\|] \ xx^t. \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equat.png)
![$$\displaystyle \begin{aligned} \nabla \mathbf{s}(\mathbf{t}(x)) =H\big[\|x\|G(\|x\|)\big]I + \Big[G(\|x\|) H'(\|x\|G(\|x\|))/\|x\|\Big] \ xx^t \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equau.png)


 of the form
of the form 
 for all a ∈ [0, 1] and all j = 1, …, d, and
for all a ∈ [0, 1] and all j = 1, …, d, and ![$$\displaystyle \begin{aligned} \mathbb{P}(V_1\le v_1,\dots,V_d\le v_d) =C(v_1,\dots,v_d), \qquad u_i\in[0,1]. \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equax.png)
![$$\displaystyle \begin{aligned} G(a_1,\dots,a_d) =\mu((-\infty,a_1]\times\dots\times (-\infty,a_d]) =C(G_1(a_1),\dots,G_d(a_d)). \end{aligned}$$](../images/456556_1_En_2_Chapter/456556_1_En_2_Chapter_TeX_Equay.png)
The copulae associated with absolutely continuous measures  are equal if and only if
are equal if and only if  takes the separable form (2.8).
takes the separable form (2.8).
 is convex with gradient t and A is a d × d matrix, then the gradient of the convex function x↦ϕ(Ax) at x is t
A = A
tt(Ax). Suppose ψ is another convex function with gradient s and that compatibility holds, i.e., ∇s(t(x)) commutes with ∇t(x) for all x. Then in order for
is convex with gradient t and A is a d × d matrix, then the gradient of the convex function x↦ϕ(Ax) at x is t
A = A
tt(Ax). Suppose ψ is another convex function with gradient s and that compatibility holds, i.e., ∇s(t(x)) commutes with ∇t(x) for all x. Then in order for 
2.4 Random Measures in Wasserstein Space
Let μ be a fixed absolutely continuous probability measure in  . If
. If  is another probability measure, then the transport map
is another probability measure, then the transport map  and the convex potential are functions of Λ. If Λ is now random, then we would like to be able to make probability statements about them. To this end, it needs to be shown that
and the convex potential are functions of Λ. If Λ is now random, then we would like to be able to make probability statements about them. To this end, it needs to be shown that  and the convex potential are measurable functions of Λ. The goal of this section is to develop a rigorous mathematical framework that justifies such probability statements. We show that all the relevant quantities are indeed measurable, and in particular establish a Fubini-type result in Proposition 2.4.9. This technical section may be skipped at first reading.
and the convex potential are measurable functions of Λ. The goal of this section is to develop a rigorous mathematical framework that justifies such probability statements. We show that all the relevant quantities are indeed measurable, and in particular establish a Fubini-type result in Proposition 2.4.9. This technical section may be skipped at first reading.
Here is an example of a measurability result (Villani [125, Corollary 5.22]). Recall that  is the space of Borel probability measures on
is the space of Borel probability measures on  , endowed with the topology of weak convergence that makes it a metric space. Let
, endowed with the topology of weak convergence that makes it a metric space. Let  be a complete separable metric space and
be a complete separable metric space and  a continuous cost function. Let
a continuous cost function. Let  be a probability space and
be a probability space and  be measurable maps. Then there exists a measurable selection of optimal transference plans. That is, a measurable
be measurable maps. Then there exists a measurable selection of optimal transference plans. That is, a measurable  such that π(ω) ∈ Π(Λ(ω), κ(ω)) is optimal for all ω ∈ Ω.
such that π(ω) ∈ Π(Λ(ω), κ(ω)) is optimal for all ω ∈ Ω.
Although this result is very general, it only provides information about π. If π is induced from a map T, it is not obvious how to construct T from π in a measurable way; we will therefore follow a different path. In order to (almost) have a self-contained exposition, we work in a somewhat simplified setting that nevertheless suffices for the sequel. At least in the Euclidean case  , more general measurability results in the flavour of this section can be found in Fontbona et al. [53]. On the other hand, we will not need to appeal to abstract measurable selection theorems as in [53, 125].
, more general measurability results in the flavour of this section can be found in Fontbona et al. [53]. On the other hand, we will not need to appeal to abstract measurable selection theorems as in [53, 125].
2.4.1 Measurability of Measures and of Optimal Maps
Let  be a separable Banach space. (Most of the results below hold for any complete separable metric space but we will avoid this generality for brevity and simpler notation). The Wasserstein space
be a separable Banach space. (Most of the results below hold for any complete separable metric space but we will avoid this generality for brevity and simpler notation). The Wasserstein space  is a metric space for any p ≥ 1. We can thus define:
is a metric space for any p ≥ 1. We can thus define:
A random measure Λ is any measurable map from a probability space
 to
to
 , endowed with its Borel σ-algebra.
, endowed with its Borel σ-algebra.
In what follows, whenever we call something random, we mean that it is measurable as a map from some generic unspecified probability space.
A random measure Λ is measurable if and only if it is measurable with respect to the induced weak topology.
Since both topologies are Polish, this follows from abstract measure-theoretic results (Fremlin [57, Paragraph 423F]). We give an elementary proof on page 53 of the supplement.
Optimal maps are functions from  to itself. In order to define random optimal maps, we need to define a topology and a σ-algebra on the space of such functions.
to itself. In order to define random optimal maps, we need to define a topology and a σ-algebra on the space of such functions.
 )
) be a Banach space and μ a Borel measure on
be a Banach space and μ a Borel measure on
 . Then the space
. Then the space
 is the space of measurable functions
is the space of measurable functions
 such that
such that

When  is separable,
is separable,  is an example of a Bochner space, though we will not use this terminology.
is an example of a Bochner space, though we will not use this terminology.
 is the L
p norm of the map
is the L
p norm of the map  from
from  to
to  :
: 
 is a normed vector space. It enjoys another property shared by L
p spaces—completeness:
is a normed vector space. It enjoys another property shared by L
p spaces—completeness:The space
 is a Banach space.
is a Banach space.
The proof, a simple variant of the classical one, is given on page 53 of the supplement.
Random maps lead naturally to random measures:
Let  and let t be a random map in
and let t be a random map in  . Then Λ = t#μ is a continuous mapping from
. Then Λ = t#μ is a continuous mapping from  to
to  , hence a random measure.
, hence a random measure.
 follows from a change of variables
follows from a change of variables 
 (see (2.3)), Λ is a continuous (in fact, 1-Lipschitz) function of t.
(see (2.3)), Λ is a continuous (in fact, 1-Lipschitz) function of t.Conversely, t is a continuous function of Λ:
Let Λ be a random measure in  and let
and let  such that
such that  is the unique optimal coupling of μ and Λ. Then
is the unique optimal coupling of μ and Λ. Then  is a continuous mapping from
is a continuous mapping from  to
to  , so
, so  is a random element in
is a random element in  . In particular, the result holds if
. In particular, the result holds if  is a separable Hilbert space, p > 1, and μ is absolutely continuous.
is a separable Hilbert space, p > 1, and μ is absolutely continuous.
This result is more subtle than Lemma 2.4.5, since  is not necessarily Lipschitz. We give here a self-contained proof for the Euclidean case with quadratic cost and μ absolutely continuous. The general case builds on Villani [125, Corollary 5.23] and is given on page 54 of the supplement.
is not necessarily Lipschitz. We give here a self-contained proof for the Euclidean case with quadratic cost and μ absolutely continuous. The general case builds on Villani [125, Corollary 5.23] and is given on page 54 of the supplement.
 and fix 𝜖 > 0. For any
and fix 𝜖 > 0. For any  ,
, 



In Proposition 5.3.7, we show under some conditions that  is a continuous function of μ.
is a continuous function of μ.
2.4.2 Random Optimal Maps and Fubini’s Theorem
From now on, we assume that  is a separable Hilbert space and that p = 2. The results can most likely be generalised to all p > 1 (see Ambrosio et al. [12, Section 10.2]), but we restrict to the quadratic case for simplicity.
is a separable Hilbert space and that p = 2. The results can most likely be generalised to all p > 1 (see Ambrosio et al. [12, Section 10.2]), but we restrict to the quadratic case for simplicity.

 and L
2(θ
0), both of which are Banach spaces. There are several (nonequivalent) definitions for integrals in such spaces (Hildebrant [69]); the one which will be the most convenient for our needs is the Bochner integral.
and L
2(θ
0), both of which are Banach spaces. There are several (nonequivalent) definitions for integrals in such spaces (Hildebrant [69]); the one which will be the most convenient for our needs is the Bochner integral. be a simple random element taking values in B:
be a simple random element taking values in B:


 , then the Bochner integral of f is defined as the limit
, then the Bochner integral of f is defined as the limit 
The space of functions for which the Bochner integral is defined is the Bochner space L
1(Ω;B), but we will use neither this terminology nor the notation. It is not difficult to see that Bochner integrals are well-defined: the expectations do not depend on the representation of the simple functions nor on the approximating sequence, and the limit exists in B (because it is complete). More on Bochner integrals can be found in Hsing and Eubank [71, Section 2.6] or Dunford et al. [48, Chapter III.6]. A major difference from the real case is that there is no clear notion of “infinity” here: the Bochner integral is always an element of B, whereas expectations of real-valued random variables can be defined in  . It turns out that separability is quite important in this setting:
. It turns out that separability is quite important in this setting:
Let f : Ω → B be measurable. Then there exists a sequence of simple functions f
n such that ∥f
n(ω) − f(ω)∥→ 0 for almost all ω if and only if  is separable for some
is separable for some  of probability zero. In that case, f
n can be chosen so that ∥f
n(ω)∥≤ 2∥f(ω)∥ for all ω ∈ Ω.
of probability zero. In that case, f
n can be chosen so that ∥f
n(ω)∥≤ 2∥f(ω)∥ for all ω ∈ Ω.
A proof can be found in [48, Lemma III.6.9], or on page 55 of the supplement. Functions satisfying this approximation condition are sometimes called strongly measurable or Bochner measurable. In view of the lemma, we will call them separately valued, since this is the condition that will need to be checked in order to define their integrals.
Two remarks are in order. Firstly, if B itself is separable, then f(Ω) will obviously be separable. Secondly, the set  on which
on which  does not converge to f may fail to be measurable, but must have outer probability zero (it is included in a measurable set of measure zero) [48, Lemma III.6.9]. This can be remedied by assuming that the probability space
does not converge to f may fail to be measurable, but must have outer probability zero (it is included in a measurable set of measure zero) [48, Lemma III.6.9]. This can be remedied by assuming that the probability space  is complete. It will not, however, be necessary to do so, since this measurability issue will not alter the Bochner expectation of f.
is complete. It will not, however, be necessary to do so, since this measurability issue will not alter the Bochner expectation of f.
 such that
such that
 and let
and let
 such that
such that
 and
and
 exist (and are unique) with probability one. (For example, if θ
0is absolutely continuous.) Then
exist (and are unique) with probability one. (For example, if θ
0is absolutely continuous.) Then

This holds by linearity when Λ is a simple random measure. The general case follows by approximation: the Wasserstein space is separable and so is the space of optimal maps, by Lemma 2.4.6, so we may apply Lemma 2.4.8 and approximate  by simple maps for which the equality holds by linearity. On page 56 of the supplement, we show that these simple maps can be assumed optimal, and give the full details.
by simple maps for which the equality holds by linearity. On page 56 of the supplement, we show that these simple maps can be assumed optimal, and give the full details.
2.5 Bibliographical Notes
Our proof of Theorem 2.2.11 borrows heavily from Bolley et al. [29]. A similar result was obtained by Kloeckner [81], who also provides a lower bound of a similar order.
The origins of Sect. 2.3 can be traced back to the seminal work of Jordan et al. [74], who interpret the Fokker–Planck equation as a gradient flow (where functionals defined on  can be differentiated) with respect to the 2-Wasserstein metric. The Riemannian interpretation was (formally) introduced by Otto [99], and rigorously established by Ambrosio et al. [12] and others; see Villani [125, Chapter 15] for further bibliography and more details.
can be differentiated) with respect to the 2-Wasserstein metric. The Riemannian interpretation was (formally) introduced by Otto [99], and rigorously established by Ambrosio et al. [12] and others; see Villani [125, Chapter 15] for further bibliography and more details.
Compatible measures (Definition 2.3.1) were implicitly introduced by Boissard et al. [28] in the context of admissible optimal maps where one defines families of gradients of convex functions (T
i) such that  is a gradient of a convex function for any i and j. For (any) fixed measure
is a gradient of a convex function for any i and j. For (any) fixed measure  , compatibility of
, compatibility of  is then equivalent to admissibility of the collection of maps
is then equivalent to admissibility of the collection of maps  . The examples we gave are also taken from [28].
. The examples we gave are also taken from [28].
Lemma 2.3.3 is from Cuesta-Albertos et al. [38, Theorem 2.9] (see also Zemel and Panaretos [135]).

Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.