Web pages are the basic unit of a Web site, and every Web site is a collection of one or more pages. The ideal Web page contains enough information to fill the width of a browser window, but not so much that readers need to scroll from morning until lunchtime to get to the page's end. In other words, the ideal page strikes a balance—it avoids the lonely feeling caused by too much white space, and the stress induced by an avalanche of information.
The best way to get a handle on what a Web page should hold is to look at your favorite sites. A news site like www.nytimes.com displays every news article on a separate page (and subdivides longer stories into several pages). At an e-commerce shop like www.amazon.com, every product has its own page. Similarly, a personal Web site like www.MyUndyingLoveForPigTrotters.com may be divided into separate Web pages with titles like "About Me," "Vacation Photos," "Résumé," and "Top Secret Recipes for Pig Parts."
For now, don't worry too much about how to divide your Web site into pages—that's a task you'll revisit in Chapter 8 when you start linking pages together. Instead, your first goal is to understand how a basic page works and how to create one of your own. In this chapter, you'll get a chance to build that first page. On the way, you'll learn the essential details of the most important standard in Web site design: XHTML.
Web pages are written in HTML (HyperText Markup Language) or the closely related XHTML (Extensible HyperText Markup Language) standard. Essentially, HTML is the original language of the Web, while XHTML is the modernized version. It doesn't matter whether your Web page contains a series of text-only blog entries, a dozen pictures of your pet lemur, or a heavily formatted screenplay—odds are that, if you're looking at it in a browser, it's an HTML or XHTML page.
Note
In this book, you'll focus all your attention on XHTML, which is the latest and greatest Web markup language. However, most of what you'll learn applies equally well to the older HTML standard. For more information about how the two stack up, see the box on Cracking Open an XHTML Document.
XHTML plays a key role in Web pages—it tells a Web browser how to display the contents of a page. Although plenty of computer programs can format text (take Microsoft Word, for instance), it's almost impossible to find a single standard that every type of computer, operating system, and Web-enabled device supports. XHTML fills the gap by supplying information that any browser can interpret. These formatting details include special instructions (called tags) that tell a browser when to start a paragraph, italicize a word, or display a picture. To create your own Web pages, you need to learn to use this family of tags.
XHTML is such an important standard that you'll spend a good portion of this book digging through most of its features, frills, and shortcomings. Every Web page you build along the way will be a bona fide XHTML document.
Note
The XHTML standard doesn't have anything to do with the way a Web browser accesses a page on the Web. Instead, HTTP (HyperText Transport Protocol) is the low-level communication system that lets two computers exchange data over the Internet. If you were to apply the analogy of a phone conversation, the telephone line is HTTP, and the juicy tidbits of gossip you're exchanging with Aunt Martha are the XHTML documents.
On the inside, an XHTML page is actually nothing more than a plain-vanilla text file. That means that every Web page consists entirely of letters, numbers, and a few special characters (like spaces, punctuation, and everything else you can spot on your keyboard). This file is quite different from what you'd find if you cracked open a typical binary file on your computer. A binary file contains genuine computer language—a series of 0s and 1s. If another program is foolish enough to try and convert this binary information into text, you end up with gibberish.
To understand the difference between a text file and a binary file, take a look at Figure 2-1, which examines a traditional Word document under the microscope. Compare that with what you see in Figure 2-2, which dissects an XHTML document with the same content.
To take a look at an XHTML document, all you need is an ordinary text editor, like Notepad, which is included on all Windows computers. To run Notepad, click the Start button, and then select All Programs → Accessories → Notepad (in Windows Vista) or Programs → Accessories → Notepad (in every other version of Windows). Choose File → Open, and then begin hunting around for the XHTML file you want. On the Mac, try TextEdit, which you can find at Applications → TextEdit. Choose File → Open, and then find the XHTML file. If you downloaded the companion content for this book (all of which you can find on the Missing CD page at www.missingmanuals.com), try opening the popsicles.htm file, which is shown in Figure 2-2.
Unfortunately, most text editors don't let you open a Web page directly from the Internet. To do that, they'd need to be able to send a request over the Internet to a Web server, which is a job best left to a Web browser. However, most browsers do give you the chance to look at the raw XHTML for a Web page. Here's what you need to do:
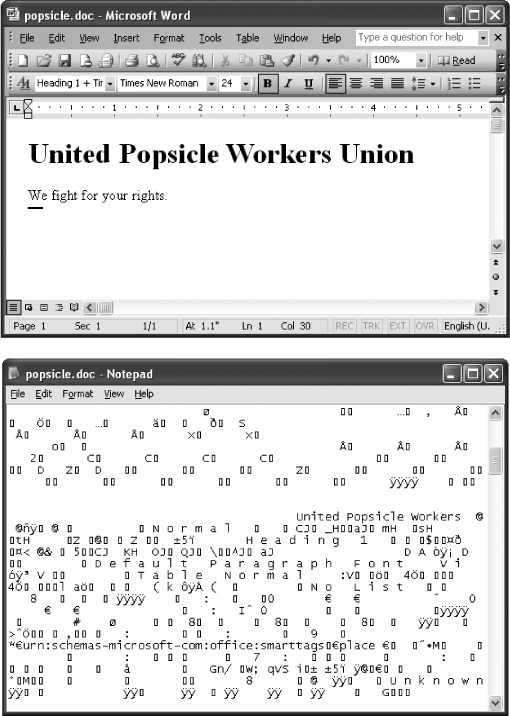
Figure 2-1. Your PC stores Word and most other documents as binary files (consisting of just 0s and 1s). Top: Even if your document looks relatively simple in Word, it doesn't look nearly as pretty when you bypass Word and open the file in an ordinary text editor like Notepad or TextEdit (bottom). Bottom: Text editors usually convert a file's string of 0s and 1s into a meaningless stream of intimidating gibberish. The actual text is there somewhere, but it's buried in computer gobbledygook.
Open your preferred browser.
Navigate to the Web page you want to examine.
In your browser, look for a menu command that lets you view the source content of the Web page. In Internet Explorer (or Opera), select View → Source. In Firefox and Netscape, use View → Page Source. In Safari, View → View Source does the trick. Isn't diversity a wonderful thing?
Once you make your selection, a new window appears showing you the XHTML used to create the Web page. This window may represent a built-in text viewer that's included with your browser, or it may just be Notepad or TextEdit. Either way, you'll see the raw XHTML.
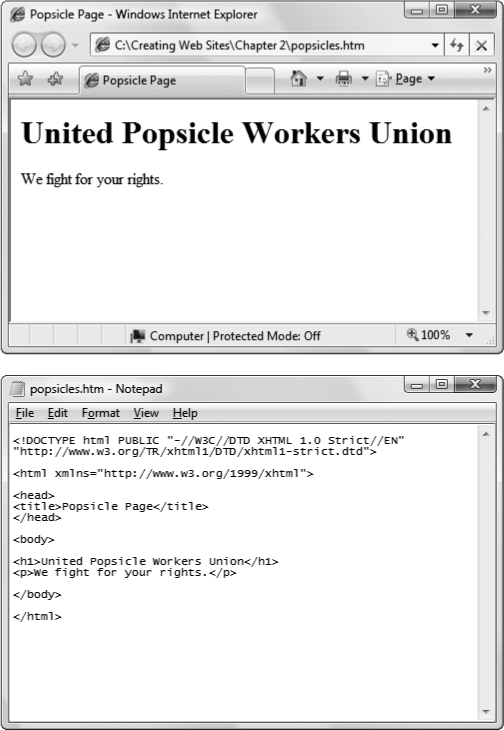
Figure 2-2. You store XHTML documents as ordinary text. Top: The Word document in rewritten as an XHTML document and displayed in a Web browser. Bottom: When you display an XHTML file in a text editor, you can easily spot all the text from the original document, along with a few extra pieces of information inside angle brackets (< >). These are XHTML tags.
Tip
Firefox has a handy feature that lets you home in on part of the XHTML in a complex page. Just select the text you're interested in on the Web page, right-click it, and then choose View Selection Source.
Most Web pages are considerably more complex than the popsicles.htm example shown in Figure 2-2, so you need to wade through many more XHTML tags. But once you acclimate yourself to the jumble of information, you'll have an extremely useful way to peer under the covers of any Web page. In fact, professional Web developers often use this trick to check out the work of their competitors.
Here's one of the best-kept secrets of Web page writing: You don't need a live Web site to start creating your own Web pages. That's because you can easily build and test Web pages using only your own computer. In fact, you don't even need an Internet connection.
The basic approach is simple:
Fire up your favorite text editor.
Start writing XHTML content.
Of course, this part is a little tricky because you haven't explored the XHTML standard yet. Hang on—help is on the way in the following sections.
When you finish your Web page, save the document (a simple File → Save usually does it).
By convention, XHTML documents typically have the file extension .htm or .html (which they inherit from the original HTML standard). For example, a typical XHTML file name is LimeGreenPyjamas.html. Strictly speaking, these extensions aren't necessary, because browsers are perfectly happy displaying Web pages with any file extension. You're free to choose any file extension you want for your Web pages. The only rule is that the file has to contain valid XHTML content. However, using the .htm or .html file extensions is still a good idea; not only does it save confusion, it also helps your PC recognize that the file contains a Web page. For example, when you double-click a file with the .htm or .html extension, your PC automatically opens it in your Web browser.
For the record, there's no difference between .htm and .html—which one you use is just a matter of preference.
To take a look at your work, open the file in a Web browser.
If you use the extension .htm or .html, it's usually as easy as double-clicking the file. If not, you may need to type in the full file path in your Web browser's address bar, as shown in Figure 2-3.
Remember, when you compose your XHTML document in a text editor, you won't be able to see the formatted document. All you'll see is the plain text and the XHTML formatting instructions.
Tip
If you change and save the file after you open it in your Web browser, you can take a look at your recent changes by hitting the browser's Refresh button.
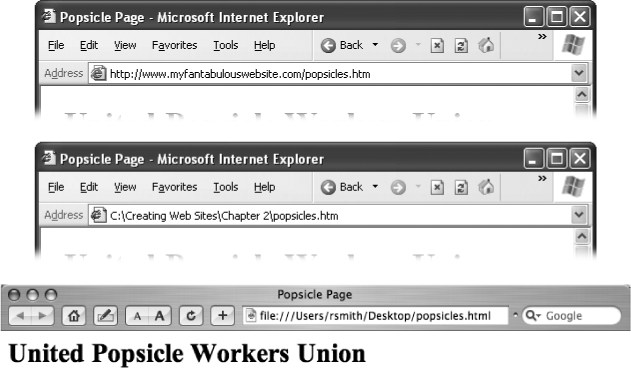
Figure 2-3. A browser's address bar identifies where the current Web page is really located. If you see http://, it comes from a Web server on the Internet (top). If you're looking at a Web page on your own computer, you'll just see an ordinary file path (middle, showing a Windows file location in Internet Explorer), or you'll see a URL that starts with the prefix "file:///" (bottom, showing a Mac file location in Safari). Local addresses depend on the browser and operating system you're using.
As you've already learned, Web browsers recognize two markup languages: old-school HTML and today's XHTML. When a browser examines a Web page, it needs to determine which language you wrote it in. To tell the browser what standard your page uses, you place something called a document type definition (DTD) at the very beginning of the page (see Figure 2-4). A DTD is also known as a doctype.
The doctype is cryptic code that looks like this:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
This doctype specifies that the Web page uses the strict version of the XHTML 1.0 standard. This is the most common XHTML choice, and it's the doctype you'll see in most of the examples in this book.
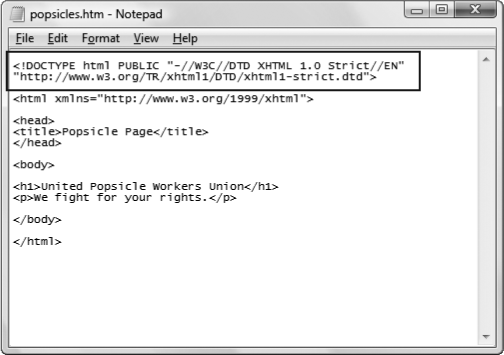
Figure 2-4. The document type definition (DTD) is the first piece of information you'll see in an XHTML file. It tells the browser what markup standard you used to write the page. If a Web page doesn't include a doctype, the browser assumes it contains HTML content rather than XHTML.
Alternatively, you can use a watered-down version of XHTML 1.0 called transitional. Transitional XHTML lets you use some HTML formatting features that are being phased out in XHTML. The word transitional hints at the fact that this HTML support is only temporary. Later versions of XHTML won't give you this option.
Here's the doctype for transitional XHTML:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
The best time to use transitional XHTML is when you're converting an old HTML page to XHTML, and you haven't yet met all the requirements of strict XHTML. Otherwise, strict XHTML is a better standard, because it keeps you on the high road of Web design. And don't worry about missing features. Serious Web designers don't need the cheap formatting hacks that HTML used—instead, they use a more powerful and better-organized style sheet standard, discussed in Chapter 6.
Tip
When looking at someone else's Web page, the doctype is the only reliable way for you to figure out if the page is written in HTML or XHTML.
At this point, you might wonder what happens if you create a Web page without a doctype. In this situation, the browser assumes you wrote your page in HTML. And because XHTML is really just a stricter form of HTML, the browser still displays your document successfully. However, all is not well. In many browsers, you'll also enter the dreaded quirks mode. For example, a missing doctype causes Internet Explorer to process your page in a way that's consistent with previous versions of Internet Explorer, but not with other browsers. As a result, the page looks subtly but annoyingly inconsistent on different browsers, often with differently sized text, inconsistent margins and borders, and improperly positioned content.