CHAPTER 8
In-Memory Computing in Hadoop Stack
By now you are familiar with the Hadoop platform, its broader ecosystem, and some of the computation engines on top of it. You have also learned about the benefits and shortcomings of the traditional MapReduce computational framework. One benefit is linear scalability and the ability to process data in parallel, which comes with the cost of over-reliance on the underlying distributed storage. Each stage of a MapReduce job needs to be written into a filesystem that increases fault tolerance. The process of sending data from the mappers to the reducers, or so-called shuffle stage, can take a heavy toll on the network bandwidth at the time when intermediate data gets copied between the nodes.
This chapter will get into more advanced topics of data processing. In it we explore some of the alternative compute engines and computing technologies, which, unlike traditional systems, open up a great number of beneficial breakthroughs and new ways of leveraging legacy platforms.
From the beginning of Hadoop's creation there have been attempts to make the MapReduce computation engine less complex and more available for non-programmer types. The commonly available system for this is Hive, described in Chapter 4. It adds a SQL engine on top of MapReduce, providing a subset of the SQL language (HQL) for analysis of non-structured data. Evidently, although MapReduce is the engine of the system, it is still a bottleneck.
For a few years developers have been working on improvements to this model. Apache Spark, described in Chapter 3, provides an alternative computation engine, commonly dubbed as MapReduce 2.0. In this system the query plans are calculated more efficiently, and data transformations happen primarily with in-memory. As a direct result, it is possible to achieve impressive performance gains with this new model. It isn't without its own contentions though. Separate Spark jobs cannot share a state, which has to be serialized to the disk to avoid data loss. The latter limitation hits particularly hard when different data processing pipelines, or ETLs, are in need of sharing results with each other. SQL processing on Spark seems like an obvious idea, and after a few trials the community seems to be converging to use Hive HQL on top of the Spark engine. The project is relatively new, but it's already showing interesting potential.
No conversation about Hadoop databases should go without a reference to HBase, which also uses HDFS as the storage, but relies on unique data organization to achieve very impressive, sometimes close to real-time, response SLAs. This system is adopted in the solutions where short reaction time and ability to make fast updates are needed.
With a slight exception in the case of HBase, the common theme for the systems referred to above, as well as many others, is how they deal with the data storage. Because these are using computer memory only for computation and always persisting the data to a slower disk storage, we call them “disk first.” But really, aren't all of the data processing systems like this? If this is the first time you are getting into the subject, you might benefit from reading some introductory materials starting with Hbase and following through with some of the links in the article. Or just simply proceed with this chapter.
INTRODUCTION TO IN-MEMORY COMPUTING
What is in-memory computing? Isn't the term overly confusing? After all, even the first generations of computers had to load the data into some sort of memory, connected to a CPU, in order to work on it. Thus, all of the computing is virtually done in memory. But the RAM is limited, making it difficult for a lot of programs trying to use it. In multi-tenant and shared operating systems, a number of processes might be competing to use RAM to keep their data objects and structures in it. Because of the physical limitations, the software usually loads and keeps in computer memory only what it needs right away, and pushes everything else to a disk system once the data isn't required anymore. However, this pattern has been a case mostly for economic reasons: The memory is quite expensive. And being a scarce resource of any computer system it is in high demand.
At the end of 1995 RAM was averaging at US$100 per Megabyte, or roughly US$100,000 for a Gigabyte. At the end of 2015, you can expect to pay about US$4–6 per Gigabyte of a consumer grade DIMM3 RAM. The price came down from US$100,000 to US$5 or so—a 20,000 times reduction. And over the same period of time the US dollar lost about 60% of its value: US$100 from 1995 could buy you $160 worth of goods today. Modern spin-drives now are going for about US$30 per Terabyte; and SSDs cost about ten times of that. What justifies the premium in the case of RAM is the performance. RAM is about 5,000 faster than a spin-drive, and it is still 2,500 times faster than an SSD.
In retrospect, paying under US$6,000 per Terabyte of RAM versus US$300 for an SSD of the same size looks like a great bargain. While it might be hard to find a single system with that much RAM, for the price of a new car you can build a multi-node computer cluster, delivering as much or even more combined memory. As with any distributed system, effectively addressing the memory shared by multiple computers is a challenge. The benefits, though, are overwhelming.
Today, more and more people are getting fixated on big data. However, “big” is subjective and isn't well defined. Leading analytical companies have done thorough research in an attempt to identify what “big” means in reality, rather than in a parallel universe of marketing white papers. The result is quite the opposite of what you might expect under the influence of big data hype. According to some surveys, in early 2015, the largest relevant dataset among nearly 800 companies was about 80TB. With a high probability, a dataset like this doesn't need to be in a cluster memory all at the same time. So, in all likelihood, an organization with a modest IT budget should even today be able to afford in-memory processing.
Apparently, there is a demand for these types of computation nodes. Amazon has just announced new high-performing X1 instances—virtual slices of physical servers—carrying up to 2TB of RAM. X1 instances will be also equipped with more than 100 vCPUs. While the pricing information isn't available yet, it is not so difficult to imagine where it will go in a year, considering the high stakes and creative competition in this space.
Modern computer architecture put forward by von Neumann and Alan Turing in 1945 is what we are likely to have for a while, unless quantum technology makes a leap. Until then, RAM seems to be the most promising medium of storage as both prices come down and non-volatile designs spring to life.
On the other hand, the development of the technologies that let you “connect” the RAM across multiple computers is extremely challenging. A quick look into the modern commercial market of these solutions reveals that less than a dozen companies have the expertise and are innovative to the point where they can embark on this path.
The vertical markets for the technology are huge and growing rapidly. Among typical uses of in-memory computing across different industries are:
- Investment and retail banking
- Medical imaging processing
- Natural language processing and cognitive computing
- Real-time sentiment analysis
- Insurance claim processing and modeling
- Real-time ad platforms
- Merchant platform for online games
- Hyper-local advertising
- Geospatial/GIS processing
- Real-time machine learning
- Complex event processing of streaming sensor data
So, how can in-memory computing be beneficial for the processing of massive amounts of data? Is it practical or even possible to deal with modern volumes of data in memory? Over the rest of this chapter we will dive deeper into a very interesting Apache Software Foundation top-level project called Apache Ignite™.
APACHE IGNITE: MEMORY FIRST
Here's what we consider to be a correct definition of in-memory computing: the middleware software that stores data in RAM, across a cluster of computers, and processes it in parallel. As it will immediately become evident, “stores data in RAM” is the key factor that puts IMC systems apart from what was referred to as “disk first.” In these systems RAM is considered to be the primary storage, not only for the software code, but also for the data the code is written to work with. The data of course needs to be somehow transferred into RAM, unless it is directly generated by the software. And this can be achieved by different means, starting with good old loading from disk storage, to streaming it over the network from external sources. However, once the data is in memory, it isn't off-loaded to the external storage to preserve the updates or changes in a state. Instead, it is retained there and it's immediately available to the software applications that might need it. Clearly, at some point, the data might not fit into the RAM anymore. In this case, part of it needs to be evicted from RAM to the secondary storage. As we'll see later in this chapter, Apache Ignite has some clever ways of dealing with this.
Wait, some might say, but how is this different from JVM memory management where the garbage collection deals with old and unused objects? First of all, the garbage collection is quite expensive for large heap sizes. For production systems configured with 128+ GB of JVM heap, it is indeed very tricky to make it work without long pauses where the memory needs to be swept from the stale data structures. Second, garbage collection (GC) lacks the fine granularity of eviction: If an object isn't referenced by anything, it gets collected. But what can you do in the case when a large collection fills the node's RAM completely? How do you automatically get rid of just some elements in it? GC won't address this use case because every element of the collection is at least referenced by the collection itself.
Let's consider a more elaborate example where a collection is spanning the memory of more than just one node. In this example, the collection is partitioned in a way that some elements are replicated on the first two nodes. Some other elements are replicated on the other two, and so on. In this particular case, GC will be completely helpless. Perhaps you can resort to a distributed garbage collection, but this is pretty much guaranteed to grind your system to a halt.
A more common solution is to provide a cache implementation as a way of loading/off-loading data between persistent storage and RAM. A commonly used API standard today is described in JSR107 or JCache, and is implemented by many vendors. JCache standardizes (among other things):
- In-memory key-value store
- Basic cache operations
- ConcurrentMap APIs
- Pluggable persistence
So, let's see how Apache Ignite deals with all of these complexities and what you can do better by adding an Ignite cluster into your data stack. But first, let's quickly revisit Ignite's architecture: what components it consists of and what functionality they have.
System Architecture of Apache Ignite
Apache Ignite has started as a data grid platform (see Figure 8.1). Data grids were a widely popular idea in the early 2000s. But it took a massive change in the economics of the computer industry, including the vast improvements in network hardware, as well as the dramatic drop in the prices of RAM, to make a data grid platform affordable. Modern Apache Ignite has overgrown its own crib and became a data fabric, combining together a data storage layer, computing and service layers, and many more.
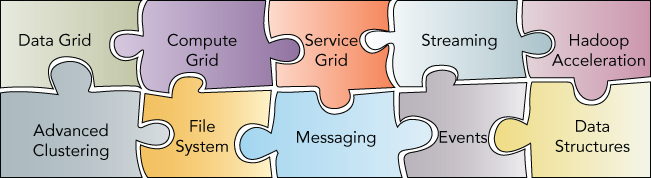
Each piece in the puzzle plays a different role. Some of them are convenience adapters allowing other applications and tools to be plugged into the core and take advantage of effective in-memory cache. Others, like data grid, provide the functionality core to the platform itself. Using a cluster RAM as the primary storage allows all of the components in the stack to collaboratively use it without expensive roundtrips to a filesystem.
Data Grid
The Ignite in-memory data grid is a key value in-memory store, which enables caching data within a distributed cluster memory (see Figure 8.2). It has been built from the ground up to linearly scale to hundreds of nodes with strong semantics of data locality and affinity data routing, thus reducing redundant data noise.
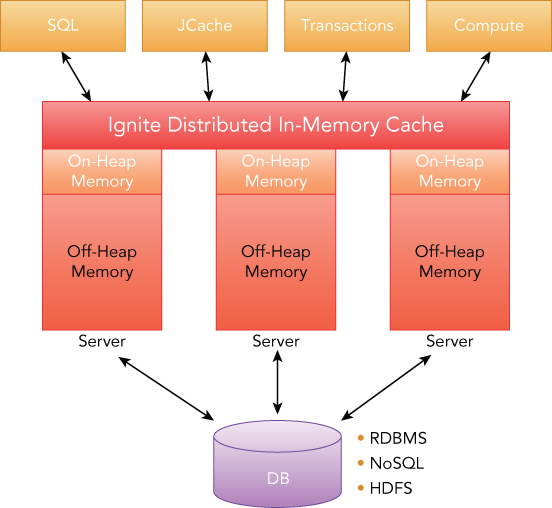
Generally speaking, this layer provides the storage facility with clever replication techniques and the ability to plug secondary storage systems for data persistence. And as you will see later in this chapter, this is the foundation for the rest of the platform. Ignite operates with essentially a cache or, more precisely, a distributed partitioned hash map. Every cluster node owns a portion of the data, thus supporting the linear scalability of the storage.
Users can create as many caches as needed. A cache can be created as PARTITIONED, REPLICATED, or LOCAL. As the name suggests, a PARTITIONED cache allows you to divide the data into partitions, and all partitions get equally split between participating nodes (see Figure 8.3). This allows you to store and work with multi-terabyte datasets across all cluster nodes. This type of cache fits well the situations with large datasets that need to be frequently updated.

The REPLICATED cache (see Figure 8.4) makes a copy of the data on every node in the cluster, so it provides the highest level of data availability. Clearly, such redundancy sacrifices performance and scalability. Under the hood, a replicated cache is a special variation of a partitioned cache, where every key has a primary copy and backups on all other cluster nodes.

And finally, the caches created in LOCAL mode have no data distribution property. As such, these are ideal for the situations where the data is read-only, or where data needs to be refreshed at intervals. Cluster singletons are discussed later, which can benefit from LOCAL caches.
A Discourse on High Availability
Like other key-value stores, Ignite operates with the notion of data locality or affinity. Unlike others, this hashing mechanism is pluggable. Every client can determine which node a key belongs to by plugging it into a hashing function, without a need for any special mapping servers or nodes serving and managing the metadata. This is quite important for a number of reasons. Let's review some of them.
The master-less property automatically removes the Single Point Of Failure (SPOF) scenarios, increasing the availability as well as the scalability of the fabric. SPOF is one of the common issues with HDFS. If a NameNode cannot be reached because of a network or hardware failure, or just over a long GC pause, the whole HDFS cluster becomes non-responsive. To deal with this Hadoop provides a special HA framework. In essence, it uses Apache Zookeeper for a leader reelection based on the ZAB protocol. When configured with HA support, HDFS runs active and standby NameNodes, which are kept in sync via the Zookeeper apparatus: Once the active master is down, the clients are forced to use a standby master that becomes active. The algorithm works well for the primary-backup use case. This is a very common problem for single-master distributed systems. The HDFS NameNode is a SPOF, so its high-availability framework is quite elaborate. It involves many moving parts and significantly increases the operational complexity and overall footprint of the file system.
Another common yet often overlooked issue of single master (or single-active master) distributed systems is their unfitness for global clustering. In the case of two or more clusters working over a WAN connection, a single master isolation leads to the loss of the service of the whole global system. The leader-reelection protocols like ZAB might also lead to a pretty bad complication called split-brain. Let's define split-brain: Say the clusterA has the leader node at the moment, and clusterB's nodes are the followers of it. In the case of network partitioning between the two clusters, clusterB will initiate the reelection of a new leader. However, clusterA still has a running master. Now, two parts of what earlier was a global cluster start diverging as the data modifications are not coordinated by one, but now two isolated masters.
The Ignite data grid is a master-less system, providing better availability guarantees, as well as protection against split-brain situations.
Compute Grid
Distributed computations are performed in parallel fashion to gain high performance, low latency, and linear scalability. The Ignite compute grid provides a set of simple APIs that allow users to distribute computations and data processing across multiple computers in the cluster. Distributed parallel processing is based on the ability to take any computation and execute it on any set of cluster nodes and return the results back. This layer of the fabric has properties for load balancing, fault tolerance, data and compute collocation, and many others.
The compute grid is what allows an application to take advantage of multiple computation nodes in the cluster, so the execution isn't hindered by resource contentions. Ignite lacks job scheduler in the traditional sense of the word. There is not one designated component that tracks the cluster resource utilization, job resources demands, and so on. All jobs are mapped to cluster nodes during the initial tasks split or client side closure execution. Once jobs arrive at the designated nodes, they are submitted to a thread pool, and are then executed at random. There are, however, mechanisms allowing you to change the execution order if necessary. We will talk about the efficiency of this approach in the section on in-memory MapReduce.
With jobs sent directly to compute nodes and getting executed in a thread pool, a need in a centralized job manager disappears. This once again improves the overall availability of the system. However, compute nodes still might get shut down or crashed or start running slow. For cases like this, Ignite supports automatic job failover. In case of a crash, jobs are automatically transferred to other available nodes and get re-executed. As a result, Ignite provides at least one guarantee, and until there's at least one running node, no job will be lost.
Please refer to the Ignite documentation for in-depth details on the topic.
Service Grid
The Service Grid allows for the deployment of arbitrary user-defined services on the cluster. You can implement and deploy any service, such as custom counters, ID generators, hierarchical maps, and more. This layer allows you to control the life-cycle and cardinality of the deployed services, and provides guarantees of continuous availability in the event of failures or topology changes. Singleton services are an especially interesting case of cardinality control. A user can deploy three types of singletons including:
- Node singletons
- Cluster singletons
- Key-affinity singletons, when a service is run depending on the presence of a key
Together with the advanced clustering layer, this functionality creates a very potent system to deploy and manage non-trivial topologies of distributed services in a cluster. Fundamentally, there are no practical obstacles to implementing a resource allocator similar to YARN using Ignite service grid, if anyone indeed needs yet another resource negotiator.
Memory Management
While memory management and the model used by Ignite should be discussed as a part of the Data grid layer, let's examine it a bit further here. As mentioned earlier, Apache Ignite provides an implementation of the JSR107 specification. It goes beyond JCache, however, and provides the facilities for data loading, querying, asynchronous mode, and many more. In order to achieve the best performance and low-latency results, the system needs to go outside of the traditional JVM-heap and disk storage ecosystem. We have briefly touched on the existing issues of GC pausing with larger heap sizes. For this particular reason the data grid adds the support for off-heap memory.
Ignite implements a multi-tiered memory management model. Generally, the following three types of memory are supported:
- On-heap memory (JVM heap with GC)
- Off-heap memory (not managed by JVM, no garbage collection)
- Swap memory
Each tier has a higher capacity with the payoff of a higher latency than the next. Depending on the data size and performance considerations, a user can create a cache in one of the tiers. Optionally, the data from lower tiers can be evicted to a higher tier. Table 8.1 described the modes of creating a cache.
Table 8.1 Cache creating modes
| Memory Mode | Description |
ONHEAP_TIERED |
Store entries on-heap and evict to off-heap and optionally to swap. |
OFFHEAP_TIERED |
Store entries off-heap, bypassing on-heap and optionally evicting to swap. |
OFFHEAP_VALUES |
Store keys on-heap and values off-heap. |
The following code snippet provides a quick look into the action:
CacheConfiguration cacheCfg = new CacheConfiguration();
cacheCfg.setMemoryMode(CacheMemoryMode.ONHEAP_TIERED);
// Set off-heap memory to 10GB (0 for unlimited)
cacheCfg.setOffHeapMaxMemory(10 * 1024L * 1024L * 1024L);
CacheFifoEvictionPolicy evctPolicy = new CacheFifoEvictionPolicy();
// Store only 100,000 entries on-heap.
evctPolicy.setMaxSize(100000);
cacheCfg.setEvictionPolicy(evctPolicy);
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setCacheConfiguration(cacheCfg);Eviction policies are pluggable. Ignite has a ready implementation for a number of policies like LRU, FIFO, sorted, and some others. Custom eviction policies also can be provided by the user.
The seamless up and down transitions between different memory tiers is beneficial for application developers. This complex logic is now available for any component via simple APIs, and better yet, the in-memory data can be shared between the applications via simple abstractions like a filesystem.
Persistence Store
This feature allows for data read/write through, from, and to a persistent storage. Persistent storage could be a relational database server like PostgreSQL, or a NOSQL system like Cassandra, or a distributed filesystem like HDFS. As an added benefit, the Ignite CacheStore interface that simplifies the work with JCache CacheLoader and CacheWriter is fully transactional. Ignite offers an option of asynchronous persistence, or write-behind for situations with a high rate of cache updates. The latter is likely to negatively impact the performance of the storage system with a high operational load. Write-behind is a fancy term for a batch operation, where updates are accumulated for a while and then asynchronously flushed into the persistent store.
Ignite also has a facility of automatic persistence to be used to retrieve and write-through domain models from and to a relational database. Ignite comes with its own DB schema mapping wizard supporting automatic integration with persistent stores. The utility automatically connects to an underlying database and generates all required OR-mapping configurations and POJO domain model classes. As the schema-less data formats gain more and more popularity, a similar functionality might soon be provided for data-interchange formats like JSON.
LEGACY HADOOP ACCELERATION WITH IGNITE
As demonstrated above, all parts of Apache Ignite are useful and have a huge value-add for application developers, both in the traditional enterprise environment, as well as for schema-on read and streaming architectures. What might be particularly interesting for the Hadoop audience, however, is an in-memory acceleration layer. Generally, it includes two parts:
- The in-memory filesystem, or the Ignite File System (IGFS), has a pluggable secondary filesystem for effective caching into a persistent storage.
- The in-memory high-performance MapReduce implementation that fully and transparently replaces one in Hadoop. With Ignite MapReduce you don't need JobTracker or ResourceManager, because all of the scheduling is done via Compute Grid.
Benefits of In-Memory Storage
Ever since the early days of computing, disk storage was considered to be slow. If a program had to work with a diskstore then it was viewed as a performance penalty. RAM disk was one of the earlies technologies providing an interface to store files in memory. It was introduced in 1980 for the CP/M operating system. Interestingly enough, even today this technology is available on pretty much any Linux distribution as a standard tool. Ubuntu, for example, creates a special tmpfs limited to half of the physical computer memory. The tmpfs can be mounted to the user space and used by anyone. Quick unscientific microbenchmarking shows that writing a 1GB file to ramdisk happens at the rate of 2.8 GB/s. Doing the same into a decent SSD drive is a way lengthier process averaging at 2.8 MB/s, or three orders of magnitude slower. But this is nothing new. We know that RAM is way faster than any secondary storage, as previously discussed.
RAM disk only provides a filesystem abstraction. The applications that need to share the data would have to resort to reading and writing files and directories, even if the data is represented by different structures. Eventually, the data would need to be serialized into something suitable for files, and then de-serialized when it's needed. Also, advanced processing-like transactions become tricky if possible at all in the frame of a pure file paradigm. And in a distributed environment, where the data needs to be replicated and shared across multiple actors, the block-level abstraction of a file system only adds to the complexity for the software system.
Evidently, while glorious, the RAM disk concept has its design limits, yet it serves its original goals and use cases pretty well. There were, mostly academic and without any notable industry adoption, attempts to find a solution for distributed RAM disk, or to devise an implementation of network RAM. The latter perhaps is least interesting considering its potentials for network congestions caused by over-the-LAN swaps.
With that in mind, we can pause for a moment and reminisce on what we know about Apache Ignite's distributed cache and its properties. It is a distributed key-value store, with strong consistency guarantees, and simple APIs allowing plug-in to a variety of adapters. Being essentially a distributed object store, it is well suited for block storage if needed. And this leads to an idea of using Ignite Data Grid to provide filesystem caching. We have already discussed the strong persistence support in Apache Ignite. The filesystem adapter discussed below is just one of the possible implementations.
Memory Filesystem: HDFS Caching
HDFS and other Hadoop Compatible File Systems (HCFS) seem to be a pretty common way of implementing a scalable distributed storage. But like any disk-based storage it will be a constant disadvantage compared to the RAM. We have covered the difficulties for attempting to cache distributed content using memory technologies that are only suitable for locally stored data. With this we will stop exploring any further the possibilities of speeding up local access via RAM caching, while facing performance and implementation challenges working with distributed content. Instead we will look into how the filesystem can be implemented as a side-property of distributed object storage.
Ignite File System (IGFS) is an in-memory filesystem allowing working with files and directories over existing cache infrastructure. IGFS can either work as a purely in-memory file system, or delegate to another filesystem (e.g., various Hadoop-like filesystem implementations) acting as a caching layer. In addition, IGFS provides an API to execute MapReduce tasks over the filesystem data. IGFS supports regular file and directory operations. And being a part of the middleware platform it could be configured and accessed directly from Java application code.
Apache Ignite is shipped with HCFS, like the IGFS subsystem called IgniteHadoopFileSystem. Any client capable of working with HCFS APIs will be able to take advantage of this implementation in plug-n-play fashion, and significantly reduce I/O and improve both latency and throughput. Figure 8.5 illustrates this architecture.
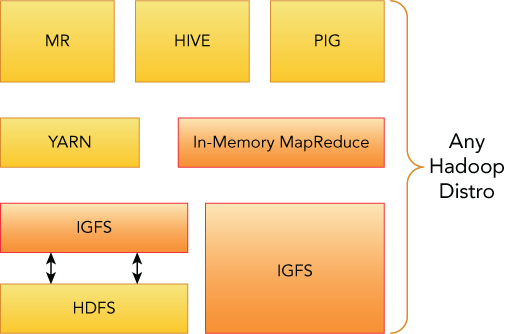
The configuration of the IGFS is quite simple, and if you're provisioning a cluster using Apache Bigtop deployment it will be readily done for you. From the operational standpoint, the Ignite process needs to have access to some of the Hadoop JAR files; a client needs to have a couple of Ignite JARs to be added in its classpath. A common way to do it is by adding them into the HADOOP_CLASSPATH environment variable. The IGFS can be accessed via its own filesystem URL. Here are some examples:
igfs://igfs@node2.my.domain/
igfs://igfs@localhost/When IGFS is configured to front an HCFS instance, a user can still access the latter. In this case all benefits of the in-memory caching won't be accessible.
In-Memory MapReduce
Ignite in-Memory MapReduce allows you to effectively parallelize the processing of the data stored in any HDFS-compatible filesystem. It eliminates the overhead associated with job tracker and task trackers in a standard Hadoop architecture, while providing low-latency, HPC-style distributed processing. The diagram in Figure 8.6 illustrates the difference between the two implementations.

While there are other alternatives to MapReduce (most notably Apache Spark), Ignite's component is:
- Non-intrusive: No changes need to be made in the Hadoop layer.
- Completely transparent and fully compatible with the existing MapReduce protocol: User applications don't need to be recompiled, redeployed, or changed in any way. A simple environment variable setting is enough to start using the new engine.
- Preserving legacy code: No development time needs to be spent on rewiring an application to a different library or API. Better yet—there's no need to learn a new programming language.
If you still have the cluster we've built and deployed in the last chapter, now is the time to dust it off, because we're going to use it. The way the cluster has been deployed was to include a distributed disk storage layer (HDFS), Hive, and Apache Ignite accelerator components. There's no trace of either JobTracker (MR1) or YARN (MR2) software bits in our cluster. We have done this for a more dramatic effect, because no MapReduce application would work without either of their components in place. This includes Hive with its reliance on the MapReduce computation engine. The stack, however, has mapred-app deployed, but it doesn't include anything beyond MapReduce application code examples.
Let's see how Apache Ignite helps. During the deployment exercise in Chapter 7, Bigtop orchestration provided a few client side configuration files allowing any Hadoop client to take advantage of Ignite accelerator. By default these are set under /etc/hadoop/ignite.client.conf/ on every node of the cluster where Ignite is deployed. There, you can find three files that should already look familiar to you: core-site.xml, mapred-site.xml, and hive-site.xml. But surprise! The files are way simpler than you might remember from the Hadoop documentation. For the first two essentially just set new values for fs.defaultFS and mapreduce.jobtracker.address locations. And the last one is even more trivial, so we won't bother talking about it.
If you look into core and mapred site files you'll notice that both NameNode and JobTracker addresses are set to a localhost, instead of some arbitrary hostname. We have already touched upon the reason in the “A Discourse on High-Availability section. Any of the nodes in a cluster can disappear for one reason or another. However, in the master-less environment (or rather in the multi-master environment) this should be of a little concern for a client application, because the request will simply go elsewhere and be served.
Okay, let's run a standard MapReduce job. There's no need to go a find some MapReduce code, because we already have some example archives from the mapred-app component. First, let's point clients to the accelerator layer instead of base Hadoop:
export HADOOP_CONF_DIR=/etc/hadoop/ignite.client.conf/
export HADOOP_CLASSPATH=/usr/lib/ignite-hadoop/libs/ignite-core-1.5.jar:\/usr/↵
lib/ignite-hadoop/libs/ignite-hadoop/ignite-hadoop-1.5.jarThe last export is required if your cluster is configured to use HDFS as a secondary filesystem. Our Bigtop cluster is. And that's it. You're all set to run legacy MapReduce code with the in-memory computation engine!
Let's run some PI estimations. Who likes to type if they don't have to, so we will set a variable to point to our example JAR, followed by a standard Hadoop command:
export \
MR_JAR=/usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar
hadoop jar $MR_JAR pi 20 20How was it? Pretty fast? How about wordcount—a traditional Hello, World for MapReduce? We'll grab The Adventures of Tom Sawyer by Mark Twain and count the words in it:
wget -O - https://www.gutenberg.org/ebooks/76.txt.utf-8 | \
hadoop fs -put – 76.txt
hadoop jar $MR_JAR wordcount 76.txt w-countAnd to check the results, run:
hadoop fs -cat w-count/part-r-00000You have probably noticed how the output of the jobs is different from what you would expect to see with Hadoop MapReduce. But this is perhaps the only difference in the user experience. However, performance and availability-wise, it works way faster and better without changing anything in the application.
You can experiment a little to measure the time differences that can be achieved with different jobs. By now you have an experience with the toolset, and using Bigtop deployment it is very easy to add, configure, and start YARN with MR2 on your cluster. Refer to Chapter 7 to see how it is done. Once ready, simply unset the HADOOP_CONF_DIR variable and re-run jobs with the Hadoop MapReduce framework. My own experiments show as much as 30 times performance improvements when switching to Apache Ignite in-Memory MapReduce.
Similarly, it is possible to dramatically speed up Hive queries without making any changes to the Hive or queries themselves. We will simply refer you to an article about doing this here: http://drcos.boudnik.org/2015/10/lets-speed-up-apache-hive-with-apache.html. It includes detailed instructions and explanations.
ADVANCED USE OF APACHE IGNITE
By now you have learned how to run existing MapReduce code with no changes or even recompilation while getting a huge performance boost. The MapReduce paradigm isn't the most sexy thing in the computing world. After all, only so many problems can be solved with massive parallel processing, which isn't the most common approach anymore, even in the Hadoop ecosystem.
With all of the free time you now have due to MapReduce acceleration, you're ready to go further. This section covers a few advanced topics, but before that we want to provide a clear demarcation between Apache Spark, a popular machine learning and computation engine, and Apache Ignite.
Spark and Ignite
On multiple occasions we've witnessed people being confused about alleged similarities between Apache Ignite and Apache Spark. While these two share some commonalities being distributed systems with computation capabilities and additional benefits like streaming, they are actually completely different. Initially, we called this section “Spark vs Ignite,” but then we realized that this was a false dichotomy. These systems aren't competing, but rather somewhat complementing each other. Let's review these differences in depth.
- Ignite is an in-memory computing system, e.g., the one that treats RAM as primary storage facility. Spark only uses RAM for processing. A memory-first approach is faster, because the system can do indexing, reduce the fetch time, and avoid (de)serializations.
- Ignite's MapReduce is fully compatible with Hadoop MR APIs, which let everyone simply reuse existing legacy MR code, yet run it with a greater than 30x performance improvement.
- The streaming in Ignite isn't quantified by the size of an RDD. In other words, you don't need to fill an RDD first before processing it; you can actually do the real streaming and CEP. This means there are no delays in a stream content processing in the case of Ignite.
- Spill-overs are a common issue for in-memory computing systems: After all, the RAM is limited. In Spark where RDDs are immutable, if an RDD was created with its size more than 1/2 node's RAM, then a transformation and generation of the consequent RDD is likely to fill all the node's memory, which will cause the spill-over, unless the new RDD is created on a different node. This will eat into network bandwidth. Ignite doesn't have this issue with data spill-overs, because its caches can be updated in an atomic or transactional manner. Spill-overs are still possible: The strategies to deal with it are explained in the off-heap memory chapter of Ignite documentation.
- As one of its components, Ignite provides the first-class citizen filesystem caching layer.
- Ignite uses off-heap memory to avoid GC pauses, and does it highly efficiently.
- Ignite guarantees a strong consistency.
- Ignite fully supports SQL99 as one of the ways to process the data with full support for ACID transactions.
- Ignite provides in-memory SQL indexes functionality, which lets you avoid full scans of datasets, directly leading to very significant performance improvements.
- Spark focuses on advanced use-cases of machine learning (ML) and analytical data processing. While training ML models, you might get into the situation where certain part of the training is incorrect. With Spark it should be trivial to quickly retrace all of the steps up to the point of divergence, as all inter-RDD transitions are already recorded for better fault tolerance.
While the potential use cases for both technologies don't seem to overlap at all, there are a few places where Ignite can help to significantly improve Spark work-flows.
Sharing the State
Apache Spark provides a strong property of data isolation. The prevalent design pattern around Spark is that SparkContext is only used inside of one process (or job). While there are legitimate reasons for it, a number of important cases exist where different jobs might need to share the context and/or state. The only way to do it in Spark is to use the secondary storage, either directly or via some sort of RAM disk layer. The former, obviously, is no good for the system performance. The latter doesn't help with sharing a state or context across node boundaries, and is also bound to a filesystem API.
Naturally, an efficient distributed cache could be the answer we are looking for. And fortunately, there's one right there. Apache Ignite provides an implementation of SparkRDD abstraction, which allows easily sharing a state in memory across Spark jobs. The main difference between native SparkRDD and IgniteRDD is that the latter provides a shared in-memory view on data across different Spark jobs, workers, or applications, while native SparkRDD cannot be seen by other Spark jobs or applications.
IgniteRDD is implemented as a live view over a distributed Ignite cache, which may be deployed either within the Spark job executing process, or on a worker, or in its own cluster (see Figure 8.7). Depending on the chosen deployment mode, either the shared state may exist only during the lifespan of a Spark application (embedded mode), or it may out-survive the Spark application (standalone mode), in which case the state can be shared across multiple Spark applications.
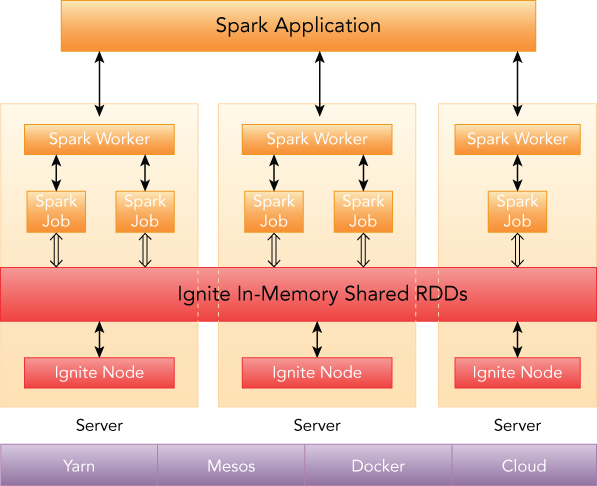
IgniteRDD isn't immutable, and all changes in the cache will be immediately visible to RDD users. Here's the best part: The cache content can be changed via another RDD or could come from other external sources, like different applications in the cluster. This is a very important characteristic, because it enables Spark to be deeply integrated with tools like Hive, BI front-ends, and many more without a smallest change to the Spark or tools in question. This is a real data collaboration made possible by in-memory computing platform.
IgniteRDD uses the partitioned nature of underlying caches, and provides partition information to a Spark executor. Affinity (or locality) of the data is also available. Reading and writing is easy with this new structure. Because IgniteRDD is a live view into a cache, the Spark application doesn't need to explicitly load the data, and all usual RDD API calls can be used immediately once the object is created.
The following code fragment shows these benefits in action. If you want to try it yourself, please add and deploy the spark component to the Apache Bigtop cluster from the last exercise. Then simply follow Section 8 from the training script that we have up on the Apache Bigtop wiki.
Because IgniteRDD is mutable, it is now possible to build and rebuild its indexes. Having an index speeds up the lookup and searches, because an application can avoid constant full scans of the data sets. This leads us to the next advanced use case for Apache Ignite.
In-Memory SQL on Hadoop
Traditionally, SQL is perhaps the most often used language for data processing. A lot of data professionals are very familiar with it. This book, and this very chapter, have already touched on Apache Hive. A very different approach and a good example of advanced SQL on Hadoop is a new Apache Incubator project called HAWQ. In essence, it is a variation of the PostgreSQL server using HDFS for the storage. It provides both SQL for Hadoop and the analytics MPP database. Postgres clustering has been around for a while, and now with linear scalability of HDFS storage it definitely has its time in the spotlight.
Perhaps a majority of the SQL-on-Hadoop difficulties are coming from the storage system. HDFS has been designed and built first and foremost with scalability and redundancy in mind. Data loss or corruption is a very serious issue for distributed storage, and it has been the main design goal for the development team. For this particular reason, the files are split into blocks. Multiple copies of the blocks, or replicas, then send to different data nodes. Two logically sequential blocks of the same file most likely won't end up on the same data node, assuming you have more than a single data node in the cluster. Query planning, especially an optimal one, becomes a real engineering and scientific hassle.
Another underwater stone waiting to be hit by Hadoop SQL engines is the lack of decent updates for HDFS files. HDFS initially was a write-once system. And if a file needs to get updated, a user has to simply write a new file. This would contain the content of the old one plus whatever had to be updated. Imagine how well it worked for big files. On a second try, HDFS was extended with a working append operation (HDFS-265). And a few months ago, five years after the second coming of append, a nice truncated implementation was added as well. Updates are still tough. There a few strategies for it, and perhaps the most interesting is implemented by HBase, yet it has its own inefficiencies.
But neither HDFS nor HBase are main topics, as fascinating as they might be. The mentioned limitations are jamming the Hadoop ecosystem into an Online Analytical Processing (OLAP) bucket, with the exception of HBase. There's also a couple of attempts to build transactional support using HDFS snapshots and HDFS truncate, but it isn't clear how much legs those have. Time will tell.
SQL with Ignite
Updates are important for a SQL engine, and critical for an Online Transaction Processing (OLTP) engine. As businesses start getting the taste of fast or near real-time OLAP flows, they often want to tap into the speed that OLTP provides. And that is where in-memory systems are coming to play with their unparalleled performance, ACID transaction support, and fast distributed queries. And Apache Ignite shines here.
To start with, the querying of the data is one of the fundamental functionalities of IgniteCache. A cache could be indexed to speed up the data lookups. If a cache sits in off-heap memory, the index will reside in off-heap as well, improving the performance even further. Several querying methods are provided including scan queries, SQL queries, and text-based queries based on Lucine indexing.
By now you might have noticed that most of the cool functionalities available from Ignite are merely clever crafted views into IgniteCache. But the data itself is managed by the same key-value distributed store without costly transformations or transitions between the format. SQL queries are no different. Ignite supports free-form SQL queries virtually without any limitations. SQL syntax is ANSI-99 compliant. You can use any SQL function, any aggregation, and any grouping, and Ignite will figure out where to fetch the results from. Ignite also supports distributed SQL joins. Moreover, if data resides in different caches, Ignite allows for cross-cache queries and joins as well.
There are two main ways that query is executed in Ignite:
- If you execute the query against the
REPLICATEDcache, then Ignite assumes that all data is available locally, and you can run a simple local SQL query in an H2 database engine. The same will happen forLOCALcaches. - If you execute the query against the
PARTITIONEDcache, it works like this: The query is first parsed and split into multiple map queries and a single reduce query. Then all of the map queries are executed on all data nodes of participating caches, providing results to the reduce node, which will in turn run the reduce query over the intermediate results.
Running a SQL query on a cache is as trivial as:
IgniteCache<Long, Person> cache = ignite.cache("mycache");
SqlQuery sql = new SqlQuery(Person.class, "salary > ?");
// Find only persons earning more than 1,000.
try (QueryCursor<Entry<Long, Person>> cursor = cache.query(sql.setArgs(1000))) {
for (Entry<Long, Person> e : cursor)
System.out.println(e.getValue().toString());
}While we cannot think of a place or occupation paying less than $1,000 as an example, the code is pretty clean and self-explanatory.
The data stored in a cache is an object, with its own structure. At some level, an object structure could be looked upon as a table schema in the relational world. But what if the object in question has an elaborate structure with complex rules about what fields can be exposed and what fields can't be exposed? Apache Ignite provides transparent access to object fields, further reducing the network overhead and traffic. In order to make the fields visible to SQL queries, they have to be annotated with @QuerySqlField. This adds an additional control for the data security. Building upon the example above, let's change it slightly:
// Select with join between Person and Organization.
SqlFieldsQuery sql = new SqlFieldsQuery(
"select concat(firstName, ' ', lastName), Organization.name "
+ "from Person, Organization where "
+ "Person.orgId = Organization.id and "
+ "Person.salary > ?");
// Only find persons with salary > 1000.
try (QueryCursor<List<?>> cursor = cache.query(sql.setArgs(1000))) {
for (List<?> row : cursor)
System.out.println("personName=" + row.get(0) +
", orgName=" + row.get(1));
}As we alluded to earlier, indexing the data is important if fast queries are required. Ignite has a few ways of creating the indexes for a single column, or a group index via annotations or API calls. The class Person we used above might look like this:
public class Person implements Serializable {
/** Indexed in a group index with "salary". */
@QuerySqlField(orderedGroups={@QuerySqlField.Group(
name = "age_salary_idx", order = 0, descending = true)})
private int age;
/** Indexed separately and in a group index with "age". */
@QuerySqlField(index = true,
orderedGroups={@QuerySqlField.Group(
name = "age_salary_idx", order = 3)})
private double salary;
}Running SQL from Java or any other language is a lot of fun, as we know. But sometimes it makes sense to be boring and simply use a good old SQL client. This is why Ignite has a way to run the H2 debug console out of the box. This powerful tool allows you to have a great introspection into the data structure, as well as to run SQL queries interactively right from the browser. To enable this, simply start a local Ignite node with the IGNITE_H2_DEBUG_CONSOLE system property.
If you have another favorite SQL client, you can use it directly via a standard JDBC connection. The Ignite JDBC driver is based on the Ignite Java client. As a result, all client specific configuration parameters, like SSL-security and others, can be used on a JDBC connection. To get connected specify the JDBC URL:
jdbc:ignite://<hostname>:<port>/<cache_name>Port numbers, as well as the cache name, could be omitted, in which case the defaults will be used. Everything we discussed above about exposing the object fields for querying and other topics is still relevant in the case of the JDBC connection to the Ignite caches.
Apache Bigtop adds out of the box integration between Apache Zeppelin (incubating) and Apache Ignite. Zeppelin is a project providing web-based notebooks for interactive data analytics.
Streaming with Apache Ignite
The last topic we want to touch on is streaming, which is very important for near- and real-time platforms to be able to work with streamed content. Because of the transient nature of a data stream, it is vital to be able to process the data as it goes through. There are a few very interesting open source systems in this field. As with in-memory, some of them are capable of conducting streams on the back of their fundamental data organization (like Spark); and some of them were made with streaming as the primary design goal (Apache Flink).
Ignite has its own streaming processing framework, and like everything else in this platform it's a clever layer on top of the Data Grid. A simple diagram is shown in Figure 8.8.
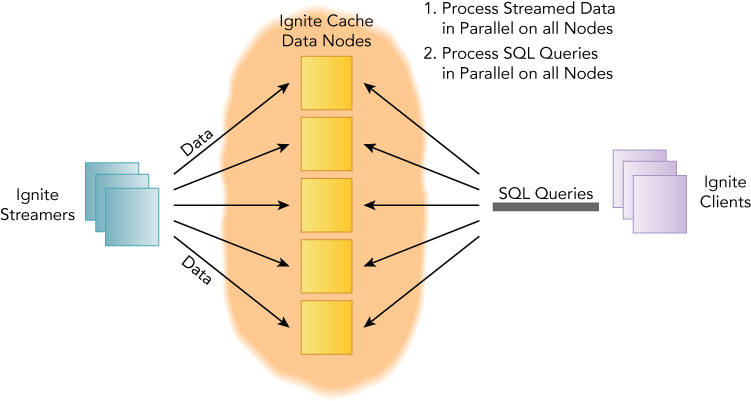
- Client nodes inject finite or continuous streams of data into Ignite caches using Ignite Data Streamers. Data streamers are fault tolerant and provide at-least-once semantic. Streamers are going hand-in-hand with
StreamReceiver, which could be used to introduce custom logic before adding new data.StreamTransformerallows you to perform data transformation and updates, andStreamVisorallows you to scan the tuples in stream and optionally execute a custom logic based on their values. - Data is automatically partitioned between Ignite data nodes, and each node receives an equal amount of it.
- Streamed data can be concurrently processed directly on the Ignite data nodes in a co-located fashion.
- Clients can also perform concurrent SQL queries on the streamed data. Ignite supports the full set of data indexing capabilities, together with Ignite SQL, TEXT, and Predicate based cache queries to query the streaming content.
Streamed data can be queried via sliding windows. A stream can literally be infinite, and trying to query the data from the beginning of time seems to be quite impractical. Instead, you might want to figure out certain properties of the dataset over a period of time. Something like “Which songs were listened to the most in the last 12 hours?” For this, a sliding data window works perfectly. Sliding windows are configured as Ignite cache eviction policies, and can be time-based, size-based, or batch-based. You can configure one sliding-window per cache. However, you can easily define more than one cache if you need different sliding windows for the same data.
SUMMARY
As has been demonstrated in this chapter, Apache Ignite is a very powerful data-processing platform providing a high-performance memory-first storage system as its foundation. The distrusted key-value store makes it extremely easy to have a variety of logic and functional live views into the data. And the efficient computation engine paradigm makes programmatic or SQL-based data processing a breeze. A computation layer can be used for the acceleration of legacy Hadoop MapReduce and tools like Hive, which uses it as the engine.
The Apache Ignite cluster can be easily scaled up and down and can seamlessly span heterogeneous hardware environments including on-premise datacenters, both virtual and hardware, as well as cloud deployments. This makes it ideal for quick expansion of the Ignite applications from a developer's laptop to a cloud data center without an interruption. Built-in a high degree of fault-tolerance and master-less architecture also makes the platform a great candidate for production systems in mission critical environments.
Full SQL99 capabilities effectively remove the learning barrier for business analysts and business intelligence professionals. Unlike other systems in the Hadoop ecosystem today, Apache Ignite fully supports data indexing, and high-performance ACID transaction.