Chapter 18
Blazing a Path to Data Science Career Success
IN THIS CHAPTER
 Finding your way on the data scientist career path
Finding your way on the data scientist career path
Becoming a data leader
Starting your own data science business
If you’re just starting out on your career path or you’re looking to break new ground career-wise and you’re intrigued by the possibilities of a career in data science, this chapter is for you. Here you’ll see some incredible examples of what’s possible for you in your future data science career. You’ll meet warm and inviting data science thought leaders, and you’ll come up with ideas for how to make your way up the data science career ladder — regardless of whether you feel called to become a data implementer, a data leader, or a data entrepreneur.
Navigating the Data Science Career Matrix
Data science careers are anything but straightforward. There’s no one-size-fits-all path to becoming a data science professional, but there are some well-trodden paths I’d like to share with you in this section. Figure 18-1 shows a wide variety of options you can take to move from entry-level to senior-level as a data implementation professional.
Of all the data science implementation career paths that can be taken, the most established, proven approach is this one:
Data analyst > Data scientist > Senior data scientist

FIGURE 18-1: Potential roles that can take you from entry-level to senior-level as a data implementer.
If data leadership is more aligned with your interests and personality, you have an equally diverse set of options to advance from entry-level to senior-level. Figure 18-2 shows you some of these options.

FIGURE 18-2: Potential roles that can take you from entry-level to senior-level as a data leader.
 To uncover which type of data path you should take, check out the fast, fun Data Superhero Quiz on the companion website,
To uncover which type of data path you should take, check out the fast, fun Data Superhero Quiz on the companion website, www.businessgrowth.ai.
Of all the data science leadership career paths that can be taken, the most common approach might look something like this:
Data analyst > Analytics manager > Head of data science
Lastly, if you’re looking to do some data science freelancing or to become a data science entrepreneur, the fastest way to get going is to offer data science services. Figure 18-3 shows options for moving from entry-level to senior-level.

FIGURE 18-3: Potential roles that can take you from entry-level to senior-level as a data entrepreneur.
Of all the data science services you can offer, the easiest path is this one:
Audit services > Data cleaning services > Machine learning services
When I say that this is the easiest path, I mean that it’s the easiest set of services to sell and deliver. That’s mostly because the demand for these services is high, and the structure would naturally create simplicity in your service delivery workflow.
Now suppose that you’ve decided you want to take the traditional path of the data scientist and seek employment in that role. In the next section, I show you some of the communities, resources, and actions that are available to help you land the job.
Landing Your Data Scientist Dream Job
When I talk about data science jobs and careers, what I’m really talking about is business. When I talk about business, what I’m really talking about is wealth-generating activities. Maybe you’ve amassed all the wealth you’ll ever need, but the primary reason that most people work is so that they can earn money to support themselves and their families, right? Make no mistake about it: When you set out to land a job in data science, what you’re really doing is looking to use your data skills to generate wealth for yourself (and maybe the people you love). Nothing wrong with that! Cash earnings are a basic necessity, but there’s so much more to wealth than just cash holdings, correct? Let’s look a little deeper into what wealth actually is, and then I’ll map it back to your quest for a dream job in data science.
When it comes right down to it, these four main types of currency can be used to generate wealth:
- Time: When you look for a job and when you secure that job, you’re exchanging your time for cash. Time is the most valuable currency of all four forms.
- Money: Do you know the saying “Cash is king”? Well, when it comes to currency, if you have ample cash, you can save all your time by spending your money to inspire someone else to spend their time helping you.
- Relationships: Does this saying sound familiar: “It’s not what you know — it’s who you know”? That age-old adage is as true now as ever. The more time, attention, and resources you can pour into building and maintaining relationships, the more those relationships pay off in the long run. Great relationships confer trust, which then confers influence.
- Audience: The audience type is similar to relationships in that the more you give, the more you get. But they have some crucial differences between them. Whereas a relationship is a 1-to-1 type of interaction, the audience is a 1-to-many interaction. With relationships, you can develop a real depth and intimacy with another person, but with an audience, you’re mostly looking to help people far and wide. You could equate the audience to what you see across the influencer industry, thought leadership industry, or, plainly, online creator space. These influencers, thought leaders, and creators amass an audience that they can then convert to money, time, or relationships. Ironic as it is, audience is more about reach than it is about influence. Influence comes from relationships.
For a graphical representation of the relationships between these four types of currencies, see Figure 18-4.
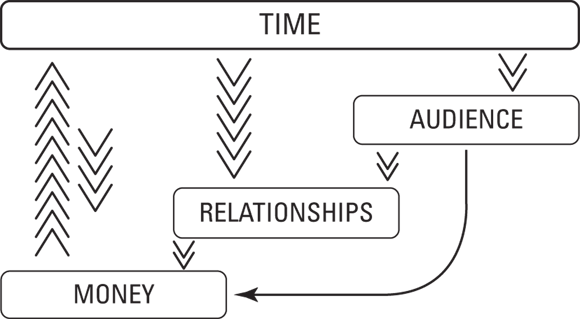
FIGURE 18-4: The four types of currency.
What does all this have to do with your landing a job in the ubercompetitive world of data science? A lot, actually! Here’s how it works: If you have some time and some data science skills, you can find a job in data science and earn money. If you take some of your time and spend it in developing meaningful relationships with other competent professionals in data science, at a later date those will likely convert to new professional opportunities for you and, hence, to more money. If you take your time and develop an audience, you will also later be able to convert it to money, in the form of new job opportunities or paid products and services in the case that you take the entrepreneurial route. As you can see in Figure 18-4, time is the scarcest form of currency because it’s required in order to create all the other forms.
With the data scientist topic covered, it’s time to direct your attention to my online peers in the data science space. Be prepared to have your mind blown by all the incredible things data science implementation professionals are doing within the communities they’re building online.
Leaning into data science implementation
Beyond the fact that all the creators I discuss in this section work to support data implementers in advancing their data careers, they have something else in common: They’re all relatively new to the online data science thought-leadership scene. All these creators have brought their data implementation expertise online and have built massive traction within their communities, in only the brief period since 2019!
Here are some community leaders I find particularly compelling:
- Danny Ma, founder of Sydney Data Science: After several years of working as a data scientist and machine learning engineer, in 2020 Danny Ma began coaching other data professionals to level up in their own data science implementation careers. His dynamic LinkedIn community, called Data with Danny, is a great place to go for real-life input on everything from data science interviews and fine-tuning resumes to fun data memes and everything in between. If you're new to the data science field and looking to work in an implementation capacity long-term, make sure to follow Danny on LinkedIn
https://au.linkedin.com/in/datawithdanny - Harpreet Sahota, founder and host of the Artists of Data Science podcast: Harpreet is the founder of Artists of Data Science — an online community and podcast that’s exclusively focused on the personal growth and development of data scientists. Outside of growing his podcast community and carrying out his day job as a lead data scientist, he has spent several years mentoring aspiring data scientists inside the Data Science Dream Job course. If you’re looking to land a job as a data scientist (and you want to enjoy that process, despite its rigors), Sahota and his community can help get you there in comfort. Take a listen to his podcast:
- Ken Jee, creator of Ken Jee on YouTube: Jee is a data scientist, based in Honolulu, Hawaii. He founded his YouTube channel in 2019 and grew it to 100,000 subscribers in just 12 months. He also has a podcast, cleverly named Ken’s Nearest Neighbors Podcast. His magnetic YouTube channel helps new-and-aspiring data scientists prepare for seeking and landing a job in the industry. His videos are dedicated to data science implementation topics, like how to do well in Kaggle, pick the best portfolio projects, study to become a data scientist, and perfect your data science resume. His podcast features data scientists from all over the world serving in a wide variety of capacities — from data science leaders to implementers to entrepreneurs and everything in between. If you’re looking to learn more about how to get started in your data science career, be sure to check out Jee’s YouTube channel:
- Zach Wilson, tech lead at Airbnb: If you’re thinking that data engineering is more your flavor, you’ll love the LinkedIn community that Wilson has built. After several high-profile software and data engineering jobs for companies as lovable as Netflix and Airbnb, he made up his mind to do something about the dreadful lack of online communities in data engineering. He regularly shares valuable insider perspectives about his work and the job of a data engineer in order to help new-and-aspiring data engineers level up in their own data careers. I appreciate his down-to-earth and encouraging approach to career development in data engineering and software development. You can follow his LinkedIn community:
Acing your accreditations
My advice to you: If you want to get a job as a data scientist, save yourself a lot of time and trouble by making sure you have a STEM degree first. Figures 18-5 and 18-6 show why.
I’ve stored all links to my research findings for this book over on the companion website, www.businessgrowth.ai. Make a visit if you want to check them out and learn more about these studies.
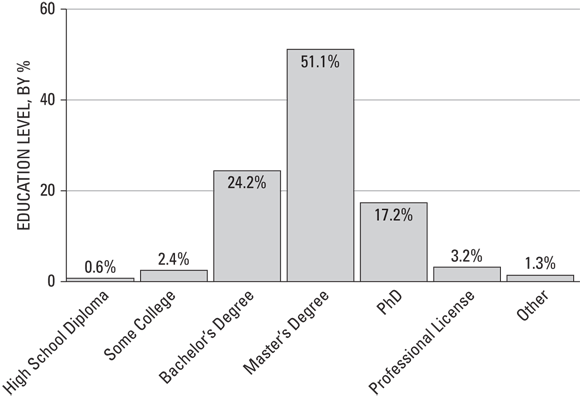
(Source: Kaggle State of Machine Learning and Data Science 2020)
FIGURE 18-5: Data scientists, broken down by degree types.
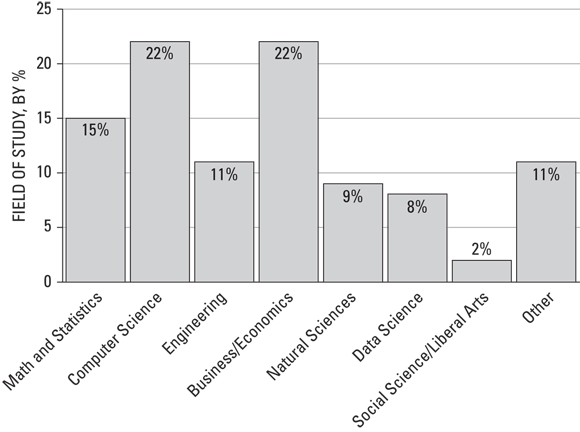
(Source: Where Do Data Scientists Come From? by Indeed Engineering)
FIGURE 18-6: Data scientists, broken down by field of study.
The fundamentals that go into earning a STEM degree are the same fundamentals that make up the basics involved in doing data science. And because most data scientists have these degrees, it puts you at a serious disadvantage if you don’t.
 STEM skills are the building blocks that form the foundation of data science.
STEM skills are the building blocks that form the foundation of data science.
Making the grade with coding bootcamps and data science career accelerators
If you have a STEM degree and don’t want to spend tens of thousands of dollars to earn an official data science degree when you don’t actually need one, another great option is to enroll in a data science boot camp. These programs tend to be more affordable than university degree programs, and they tend to evolve more quickly with changes in industry needs.
With a STEM degree, you can more or less teach yourself the extra skills you need to get into data science. If you take this path, invest some time in building out your own custom curriculum and making sure that the one you come up with is an appropriate fit for the job you’ll inevitably seek. One nice benefit of boot camps, though, is that you don't have to worry about designing your own curriculum or trying to hold yourself accountable. You can generally develop an entire set of data science skills in about 16 weeks, via any one of the ample online boot camp options.
 Boot camps have prerequisites that generally require all applicants to hold a STEM degree before applying. If the boot camp program you’re looking at doesn’t require a STEM degree as a prerequisite for admission, I would question the program’s validity.
Boot camps have prerequisites that generally require all applicants to hold a STEM degree before applying. If the boot camp program you’re looking at doesn’t require a STEM degree as a prerequisite for admission, I would question the program’s validity.
If I were to go back and learn data science all over again, today in 2021, I would take the faster, easier route by simply enrolling in a boot camp program. Data science boot camps not only provide training, mentoring, and accountability but also help you land a job in the data science field after you graduate. As far as which data science boot camp I would pursue, I’m sure as heck not paying $16,000 for a data science training experience. I don’t think any boot camp can provide enough value to compensate for that type of fee. After a modicum of research, I’ve identified these two data science boot camps that I’d consider joining if I were learning data science over again:
- UCLA Extension: 10-week data science intensive ($4,500): This 4-course (16-unit) certificate provides training and education for pursuing a career in data science, with courses that cover data development and management, machine learning and natural language processing, exploratory data analysis, statistical models, data visualization, and inference. The program also provides hands-on training for handling real-life data science problems.
- Guru Path of the Data Science Bootcamp at Data Science Dojo ($3,000): This program offers instructional support, career counseling, and a verified certificate from the University of New Mexico, on top of the 16-week data science boot camp learning experience:
I like both of these programs because, in addition to being reasonably priced, they’re robust. They don’t just rehash all the same old basics I’ve seen a hundred times. These programs are offered in a virtual environment, so I don’t need to leave the comfort of my island villa. Lastly, these programs both appear to highlight fun and interesting practice problems that you don’t see elsewhere on the Internet for free.
Networking and building authentic relationships
No question about it — diligent attention to professional networking and relationship-building affords you an unfair advantage when it comes to landing jobs in the data science field. Regardless, relationships don’t form overnight, and they certainly don’t form without concerted effort. If you haven’t yet started building relationships in the data science space, don’t worry: You can start today by joining, and actively contributing to, any of the professional networking associations listed here:
- Data Science Association (DSA): DSA promotes data science to improve life, business, and government. Its guiding principles are to establish standards for the ethical professional practice of data science, ensure a base-level data scientist competency, advance data science to serve core values of the scientific method, and help shape a better future — not just for the powerful but also for the majority of people. If this sounds like an organization you can get behind, you can learn more about it here:
- Research Data Alliance (RDA): RDA’s vision is to foster a safe and supportive community where researchers and innovators can openly share data and data expertise across technologies, disciplines, and countries to address the grand challenges of society. The Research Data Alliance (RDA) builds the social and technical bridges that enable the open sharing of data. Check them out:
- Women in Data: The international nonprofit organization Women in Data works to close the gender gap in technology and attract more women to the C-Suite — c-level roles within a company, such as CEO, COO, CFO, and so on. Rated as the number-one community for women in AI and tech, Women in Data is now in 17 countries with over 47 chapters and has a community of over 20,000 individuals. If you’re a female in the data space, consider yourself invited to join this amazing community:
I’ve included more professional networking options inside my Mini Black Book of Data Professional Organizations, available to you at businessgrowth.ai.
Developing your own thought leadership in data science
Thought leadership has become a bit of a buzzword lately, but don’t let that lead you to believe that it’s an ephemeral concept you can safely ignore. Thought leadership is real, and if you can put it to use for you, you can expand your audience and reach. Beyond wanting to make a positive impact on the world around them, there’s a reason the number of people who aspire to become online thought leaders in the data science space is increasing: Audience confers opportunity. Whether that opportunity comes in the form of new job offers or the ability to start your own data science business, a significant audience is a verifiable form of currency.
For example, let me share a little about how it worked for me. With the intention of starting my own data business, I started building my data science audience back in 2012, before data scientist was dubbed “the sexiest job of the 21st century” by Harvard Business Journal. Within six months, I’d already grown my community to several thousand members and — because of the audience and relationships I was building — I scored a few freelance contracts to supplement my day job. At that job, I worked on a proof-of-concept data analytics project and on more sophisticated data science projects for my local county government. Throughout the 22 months that I worked there, I continued growing my data science community as well as my freelance client base. By the end of 2013, I had grown my data science community by several tens of thousands of members, and I’d established enough freelancing income to quit that job and convert to full-time in my business, Data-Mania. It has been nine years since I started working in data science — and the company is still going strong.
If the ability to establish one’s financial independence in less than two years isn’t sufficient proof of the value of an audience, consider this: Twenty months into that journey, I was being actively recruited to interview with Facebook for a data position based in Menlo Park. Before this job at local government, I had only a few years of work experience as a project engineer with a low-key environmental engineering consulting firm. To have a company like Facebook recruiting someone like me back then for a data position in Silicon Valley is quite the testament to the power of community-building in data science.
I didn’t just build an audience, though. I actively contributed to the data science community, and I published the best data science portfolio I was capable of at that time. When you’re looking to land a job as a data scientist, a great way to demonstrate your chops is by building a public data science portfolio. I tell you more about that topic in the next section.
Building a public data science project portfolio
Back in the early days of my own data science career, I grew and nurtured my audience by creating and publishing coding demonstrations. The purpose of this task was many fold. Here are some benefits to publishing a data science coding portfolio:
- Helping others: Help other new and aspiring data scientists learn how to code and implement machine learning algorithms.
- Proving your competence: Demonstrate your data science skills.
- Future-proofing your online hub: Because coding demonstration content is extremely search-friendly, it will attract droves of traffic to your online hub for years to come.
- Growing your audience: Publish and share this form of content to inevitably help increase the audience size, which can then confer new and better job opportunities later.
- Reeling in new job offers: Hiring personnel often comb the Internet for coding demonstrations showing that the author has the specific skills and competencies required for a particular job. If your portfolio fits a company’s needs, someone will actively try to reach you to see whether you’re interested in the job. (That’s a good reason it’s important to publish a means by which they can contact you.)
Prospective employers are looking to hire data scientists who can generate monetary value for the business by either reducing wasteful spending or increasing revenues. Although a data science portfolio isn’t all you need to showcase the value of your skills, it can go a long way in terms of highlighting your valuable expertise and data science skills.
Showcasing your data science skills
Though each individual prospective employer is looking for something a little different, the good news is that skills in the following fundamental areas are common to most data science roles:
- Programming in Python and/or R
- Statistical programming
- Machine learning and deep learning
- SQL
- Data visualization
Additionally, you’ll want to find a way to show off your personality from within your coding portfolio. (Tough, I know!) Especially if you’re a team player, problem-solver, or tenacious individual, you’ll want to make those attributes shine. Just by taking the time to publish a coding portfolio, you’re already showing potential employers that you’re committed and passionate about the data science field. This dedication helps demonstrate that you have the personality attributes prospective employers are looking for.
Deciding which data science activities to publish
As far as what you should publish within your data science portfolio, you should build one that concisely demonstrates your ability to carry out all the essential data science tasks that’ll be required of you. A good portfolio should make clear that you’re quite capable of these activities:
- Data-wrangling: In other words, this term refers to being able to show folks how to clean, restructure, and reformat raw data into the form needed for use in modeling and analysis. (For more on data-wrangling, see Chapter 12.)
- Describing and inferring: Demonstrate how to use statistical methods to describe and make inferences from your cleaned datasets. (For more on this topic, see Chapter 4.)
- Data-showcasing and storytelling: Here’s where you show your proficiency at communicating data insights to different types of audiences. (For more on data showcasing and storytelling, see Chapter 8.)
- Predictive modeling and machine learning: Demonstrate how you’re able to use machine learning methods to make predictions (presumably, predictions that are relevant to business!). For more on these topics, check out Chapters 3 through 6.
You can put these activities together piecemeal or build an end-to-end project that walks you through each of the important components. The latter is probably the better bet.
Taking inspiration from the data science greats
When you’re building a data science portfolio, it’s always nice to look at some examples for inspiration. I have been quite impressed and inspired by Jake Vanderplas’ GitHub portfolio. You can take a look at it for yourself on his GitHub site at https://github.com/jakevdp. Figure 18-7 gives a taste of what he’s offering.
FIGURE 18-7: A map from within Jake Vanderplas’s instructional coding demonstrations on GitHub.
Jake Vanderplas is a long-standing software engineer at Google as well as the developer of a number of open-source Python projects. His portfolio stands out to me for many reasons. Right off the bat, having 12,000 followers on GitHub is awesome, but the real reason I admire the GitHub portfolio is the sentiment behind it. When you look over Jake’s coding portfolio, you can clearly see that he is driven by a deep desire to help data professionals and the data industry at-large — making the learning of these skills more accessible to people around the world with no monetary gain for himself (although he does get paid for his work at Google). He takes time in his explanations and makes them all freely available on GitHub along with all the code to support his free demos. His portfolio demonstrates all the data science skills, activities, and personality traits of a data professional that any hiring manager would jump through hoops to hire.
For more sample portfolios, as well as a brief but powerful video session I created called Doing Data Science Freelancing Portfolios Right, be sure to visit the companion website to this book at www.businessgrowth.ai.
Leading with Data Science
I highlighted some amazing data implementers earlier in this chapter, but now let me highlight some data science professionals who know what it is to lead:
- Eric Weber, head of Experimentation, Economic Insights, and Metrics at Yelp: Eric Weber is the perfect picture of what it looks like when you combine exceptional data science expertise, data leadership skills, and healthy dedication to a professional mindset. In his thriving LinkedIn community, he shares his insights about data science, data careers, interviews, hiring, and job opportunities. I most appreciate Eric’s emphasis on maintaining the right mindset as well as his product-driven approach to leading in data science. You can follow Eric Weber on LinkedIn:
- Cassie Kozyrkov, chief decision scientist at Google: Cassie Kozyrkov was instrumental in developing a decision intelligence approach at Google, and she's a passionate advocate of the field, especially on LinkedIn, where she consistently contributes to her community of over 350,000 followers. The main focus of her content centers around high-impact data science and the data driven decision-making I discuss in Chapter 12. Or, to put it in her words, she's all about “making data useful and turning information into better actions.” Join her community on LinkedIn to learn more about decision intelligence, machine learning, statistics, AI ethics, and the impact of data on society:
- Felipe Flores, founder and host of the Data Futurology Podcast: After 20 years of experience in data science implementation, consulting, and leadership, Felipe Flores started the Data Futurology Podcast back in 2018. As a fun and heartfelt host, Felipe uses this podcast as a means by which to help data enthusiasts, data scientists, and upcoming data science leaders advance their careers. He achieves this goal by inviting dynamic guests to share their stories and lessons learned with respect to data leadership, strategy, management, team building, stakeholder management, value delivery, and the skills required to be a truly great data scientist. If you’re looking to become a better data science leader, the Data Futurology Podcast is right up your alley. Take a listen here:
- Kirk Borne, chief science officer at DataPrime: Kirk Borne has been an esteemed data science thought leader since 2013. He’s most active over on Twitter, where he shares, for example, breaking news in AI and free data science learning resources. I am most appreciative of Kirk’s emphasis on community, as well as his generosity and consistency as a long-standing community leader in data science. In addition to the work he does as chief science officer at DataPrime, Kirk has authored introductory-level data science courses with a company called AI+ Training. Follow and learn from Kirk Borne at:
These individuals have created vibrant communities online where you can go to freely learn about what it takes to become a better data science leader. If you’re like most readers, though, you have no interest in investing the overwhelming amount of time and resources it takes to grow and maintain an online community. That’s great! You don’t have to. You can start becoming a better data science leader here and now, in your current work environment. The nearby sidebar “Becoming your company’s data science leader: A true story” shows you what it might look like.
Starting Up in Data Science
In this section, I share my insider perspective on how to go about starting your own data science business, without investors. This advice has limited applicability to funded start-ups, simply because investment money generally fast-tracks what is possible while also diverting the founder’s autonomy over to the investors. In this section, you can read all about the business models and revenue models for data businesses. Additionally, I provide some input about which one makes the most sense for you, given your specific situation.
Choosing a business model for your data science business
Before going into any of the business models that work best for data science businesses, let me explain what a business model is. A business model is just a conceptual model that explains how a business delivers value in exchange for money. Figure 18-8 shows the four best business models for remote, self-funded data businesses — data businesses that you can operate from anywhere in the world, without investors. These are service-based businesses, information products businesses, consulting and advising businesses, and Software as a Service (SaaS) businesses. Of course, these are not binary classifications, so natural areas of overlap will occur between each of these business models.

FIGURE 18-8: The four best business models for remote, self-funded data science businesses.
The most obvious of the business models is for service-based businesses, where the “services” I’m referring to are data implementation services. If you're already a data science freelancer, you already have a form of service-based business, but you’re probably the only employee delivering the services. Another way to deliver data science services sounds something like “freelancing with a team.” This strategy is akin to a data science services agency.
In terms of the pros of service-based data science businesses, service businesses are certainly the fastest way to start a data business. Additionally, you can easily make sales of high-dollar contracts with a data science services business because you're essentially selling your time, which is the most valuable resource you have to offer. Now, because you're a data science professional, you can sell your time for quite a bit of money. The base rate on that service? You need to sell your time for two times the amount of money you would make in take-home pay if you were doing the equivalent work as an in-house employee working within someone else’s business.
When it comes to the cons of the service-based business model for data business, for starters you have the liability to think of in terms of anything you built. If it breaks, you have to figure out who will own responsibility for its repercussions. This can potentially amount to a huge degree of financial liability, so tread carefully. And, honestly, a services-based data science business isn’t scalable in the long term. Though it's a great way to start your business and become profitable, you then need to start looking into how you shift your business model into one that’s more scalable.
One way you can make a services-based data business more scalable is to transform it into an agency or SaaS.
As far as information products businesses go, in this business model you’d sell items such as data courses, data books (like the one you’re reading now), and data digital products. The pros of starting an information products business is that it's generally easy to sell your products, and the business model is quite scalable. Looking at the drawbacks, however, most of your information products will generate a lower dollar amount per sale. To make sales in this type of business model, you must already have an audience that trusts you. That means if you haven't started to build up an audience, you shouldn’t start an information products data business. In this case, you’re better off starting by offering data science services and then making sure you go heavy on your thought leadership efforts in order to build up the audience you need to then sell information products.
When it comes to data businesses, trying to sell your data expertise to other data professionals is a bit like trying to sell blacksmithing expertise to a blacksmith. That’s usually the exact kind of help they do not need. It’s people from other industries, outside of the data professions, who need to hire out for the data expertise they don’t already have.
If you want to grow your data science business extremely quickly, specialize in supporting professionals or businesses in other industries, outside of the data science industry.
Now let's look at data science consulting and advising as a business model. This is essentially strategy-level advising work that you offer as a service via your data business. When it comes to the pros on this type of model, it's easy to set up this type of offer, and the hourly pay rates can be quite decent. As for the drawbacks, advising packages tend to produce lower dollar amounts per sale compared to selling a product like enterprise-grade subscriptions to a SaaS product. And because you’re still selling time here, you need to charge a relatively high rate — so it’s tougher to make the sale.
Lastly, let's look at the SaaS business model for data businesses. In terms of what your business would sell under this type of model, that’s some sort of data or AI software as a service that you deliver across a cloud environment. Now, the pros on this type of business model are, of course, that it can be very scalable and very profitable. The cons, however, are that SaaS generally has a long time-to-market, which means that it takes you a long time to build a software package as a service solution. It also requires a technical skillset, and that can get expensive. And, when you need to bring on other developers and data scientists to help you develop and maintain your product, you'll have even more capital, operational, and maintenance costs.
I created a mini training course, “The Secret to Building AI Software That Actually Sells,” and left it for you at this page: www.businessgrowth.ai.
As far as which of these business models you should use to start your data science business — it depends. If you have no audience, definitely start with a services-based business. If you have an audience but need to monetize fast, a services-based business also works best. If you have strong data science expertise already and an audience, and if you have no urgent need to monetize, you might combine the information products model and the consulting-and-advising model. SaaS is the best option for established data businesses or founders who’ve already secured investment money to fund their research and development.
Selecting a data science start-up revenue model
Revenue models are all about the best ways to use your data science experience to quickly monetize within your small data science business or start-up. In this section, you see the best ways to monetize fast in your data science business. Before discussing any of the revenue models, you should know the difference between a revenue model and a business model. Simply put, a revenue model is just the portion of the business model that’s responsible for bringing revenues into the business. Figure 18-9 illustrates some common revenue models.
FIGURE 18-9: The four best business models for remote, self-funded data science businesses.
The first revenue model I want to discuss is unit sales — the direct sale of ownership of a product. It might be the sale of merchandise or the sale of a license to use a digital product, like a course or an e-book. The pros to this type of revenue model are that it's scalable and it has a high earning capacity. Another nice aspect is that you can automate or delegate most of the client delivery work so that it's not occupying any of your personal time to deliver the data products. In terms of negatives, however, this type of revenue model requires that you have an audience. Yes, of course, you can make the product and try to sell it, but if you have no audience, it makes that task difficult. Another risk in this type of revenue model is the product development time: Make sure that you validate your offer before taking all the time required to build it and take it to market.
Another revenue model is licensing, where you essentially sell a license to someone in exchange for their right to use your intellectual property. In other words, you're selling a license to your customer in exchange for the right to use your intellectual property as if it were their own. You're probably familiar with these types of data products. They come under the guise of white label products like Klipfolio’s white label analytics dashboards (www.klipfolio.com/partner-features/white-label-reporting). The pros on this type of revenue model are that it can be easy to develop this type of product and you can use it to grow your audience as you make sales. The con to this type of revenue model is, of course, that this is no path to high ticket sales — it's a low-ticket earner.
I created a mini training course on how to implement these revenue models in your data business. It’s at www.businessgrowth.ai.
As for the subscriptions revenue model, this is when you sell the right to access your product or service or community on a subscription or pay-as-you-go basis. In some cases, it can be something like a service retainer package. Now, the pros on this type of revenue model are that they're generally easy to sell and they’re also a great way to get paid while you build out your product suite while testing it with users. It also has a small time-to-market — unless you're trying to sell SaaS subscriptions, of course.
Another benefit to the SaaS model is that it can be effective for making sales while you're growing your audience — simply because lower-priced versions would be an option that’s easier to sell. The drawback to this type of revenue model is, of course, that it can be high-maintenance in terms of your customers. If your membership grows, you have to bring in team members to help you administer it — for example, people join and cancel all the time, ask questions or want to help, or request service. You must be clear in the contract about what the membership includes — and doesn't include.
The next revenue model is the services revenue model, or fee-for-service, where you essentially either sell your services according to a fixed price, as with a lump sum, or on an hourly basis.
Never sell your time in exchange for money when you're doing implementation work — this is an easy way to get yourself a microboss. Then when you scale that offer, you'll attract many microbosses, all trying to micromanage the work you're doing on an hourly basis. (This is a good way to build a business that you detest.)
In terms of the positive aspects of fee-for-service, this is the fastest way to start a data business — or any other business, for that matter. Now, the negative aspect of fee-for-service is that it's not a scalable revenue model. You have only so many hours per day. At a certain point, if you start off with a fee-for-service revenue model and you want to keep rendering services, you have to switch to something like an agency or SaaS business model.
Taking inspiration from Kam Lee’s success story
Kam Lee revels in all the trappings of success: A multiple six-figure income as a data scientist. A posh apartment in New York City. A glorious reputation that precedes him. Long and illustrious tales about his traveling adventures across the far reaches of the planet. Lee’s work has been featured by media sites like Bloomberg and Foundr magazine. What’s more, he’s driven upward of $2 billion in revenue for his clients and has produced 40 percent year-over-year growth for some of the fastest-growing companies in financial technology, SaaS, e-commerce, and cloud security with econometrics, marketing mix modeling, lead scoring, and AI. In short, Lee’s data science career is more fabulous and exciting than most data scientists would ever dare to dream possible.
And yet, less than a decade ago, he too was new to the data science field. By taking the time to learn to do data science, Lee made a complete 180-degree turnaround in his career — he went from marketer to marketing data science leader. I want to briefly highlight how he did it and pass on the words of wisdom he has to offer to new-and-aspiring data science professionals.
It was 2015 when he first started reading the books and taking the online courses that helped him develop skills in statistics and machine learning. In fact, Lee is the exact prototype of the person I had in mind when I created The Self-Taught Data Scientist Curriculum back in 2017.
The Self-Taught Data Scientist Curriculum is part of my free, 52-page e-book, A Badass’s Guide to Breaking into Data, and I have left it for you to download at www.businessgrowth.ai.
So, how did Lee do it? I can tell you what he didn’t do. He didn't spend two or three years and tens of thousands of dollars to earn a master’s degree in data science. Nor did he devote a month’s worth of sleepless nights trying to land one of those competitive corporate jobs as a data scientist.
As for what Lee did do (according to him, anyway), he started by following these three steps:
-
Take online training courses on data science implementation.
For example, in 2018 he first took my LinkedIn Learning course on building a recommendation system with Python machine learning and AI. Because he was already working in e-commerce at the time, the course helped him adopt a more data-intensive approach to his marketing career. In other words, he became a marketing data scientist rather than the other clear option, which would have been to become a marketing strategist.
-
Start taking contract work as an independent data scientist in the marketing industry (otherwise known as a “marketing data scientist”).
In 2019, Lee began consulting on marketing analytics projects, delivering these services as an agency. After getting caught up in the low-budget hamster wheel, Lee could clearly see the error of his ways, which were these:
- His offers weren’t differentiated from market competitors.
- His ideal customer profiles weren’t clear.
- He wasn’t clearly presenting the monetary value of the results his services could generate.
-
He invested in taking his data business to the next level.
In 2020, Lee joined my group mentorship program. Since March 2020, he closed 15 business-to-business (B2B) contracts valued at $310,000. He also presold $60,000 worth of annual contracts for his upcoming marketing optimization SaaS company, which is expected to go live in the fourth quarter (Q4) of 2021. Of the sales he has generated since joining, 67 percent has been pure profit. With the optimization of new, custom internal tools, he estimates that by the end of Q4 2021 (when he launches his software), he should be able to drive even more automation which should earn Lee’s company anywhere between a 75 and 80 percent profit margin. Of all the work Lee did throughout the course of the mentorship, he attributes his remarkable success to the following core elements:
- Market research: He developed a concrete customer research study that helped him validate his minimum viable product. He built a competitor matrix and established clarity on his ideal customer profile and then used that profile to clearly define his circle of influence — in other words, the influencers, team members, and other close associates who have the ability to influence his outcomes. He also clarified the true Total Addressable Market (TAM) — the total market demand for his offers, expressed as an annual revenue estimate. After estimating the TAM, he crafted and executed a plan for meeting individuals wherever they are within that market.
- Offer development and positioning: He improved his offers with the help of his research findings and converted many of his previous services into products. He also made sure he was demonstrating the value of his marketing data science expertise to his growing online audience.
- Operations optimization: He came up with innovative ways to apply systems and technology such as Python, RPA, and data engineering to drive back-office operations for his company. As a result, he’s been able to keep costs down and drive a high profit margin.
In 2020, Lee successfully converted his deep marketing data science expertise into a SaaS product that delivers both lead scoring and marketing mix modeling. The signature framework around which he is developing this AI SaaS has already helped several clients realize over $120 million in opportunities for predictable ROI and cost savings. By developing this marketing mix modeling and marketing optimization software, what he’s doing is building clever ways to automate much of the existing successes he has already generated with data science services he offers in marketing attribution and marketing mix optimization, customer segmentation, customer lifetime value models, predictive models, cross-sell/upsell models (Buy-Till-You-Die for CLTV), market basket analysis, pricing and promo optimization, as well as web analytics and digital data.
I like to stress the importance of not trying to sell data expertise to fellow data experts. Lee’s story offers a perfect example of what’s possible when you avoid this mistake. When asked, “To which market factors do you most attribute your rapid success as a data entrepreneur?” he responded:
As a data entrepreneur, my thought leadership, case studies, and niche expertise have given me an edge against other marketers and data professionals in my industry because I apply statistical knowledge to solve complex marketing and business strategy problems. A major gap in contextual knowledge occurs when it comes to marketing analytics, data science, and technical expertise. Currently, teams typically rely on analysts who are not inherent marketers. This creates a knowledge gap between technical expertise, functional business knowledge, and being able to translate analysis into business results that truly add value. Moreover, I've invested a lot of time and effort into developing the essential people skills and communication skills that are synonymous with analytics success. These skills are proven difference-makers across all career levels but are especially relevant as you enter the management and leadership ranks with data strategy.
And, to new data science professionals, Lee recommends that you differentiate yourself from the pack of other aspiring data scientists by developing and exhibiting the following ancillary skills:
- Data engineering: These skills allow you to be useful in many dynamic ways.
- Business consulting: These skills help you show up and become a trusted business partner to stakeholders by quantifying the impact of their work. Additionally, as you develop your business consulting skills, you naturally improve in other aspects that are vital to your career success in data science — skills like communication, organization/project management, and research skills that will help you solve complex statistical and technical problems.
Following in the footsteps of the data science entrepreneurs
I’ve highlighted quite a few examples of data science professionals in this chapter who have built strong and enormously helpful communities that help data professionals of all shapes and sizes. Now I want to introduce you to a list of people that exemplify what happens when you combine an entrepreneurial spirit with a love of data science and community-building:
- Kate Strachnyi, founder and CEO of DATAcated: Strachnyi is the founder of the DATAcated community, whose powerful presence is predominantly active on LinkedIn. The vibrant DATAcated community is focused on helping data professionals improve both their data visualization and data storytelling skills. If you’re looking to improve your visual and verbal skills in communicating data insights, take a peek at what’s happening inside the DATAcated community, as well as the data storytelling courses offered at the DATAcated website. Personally, I’ve learned a lot from Strachnyi about the data community, and what it means to be a good steward of that community. Be sure to join her LinkedIn community at
www.linkedin.com/in/kate-strachnyi-data, and then listen and learn your way to data storytelling excellence. - Matt Dancho, founder and CEO of Business Science University: Dancho is an engineering leader turned data entrepreneur. Fueled by a mission to empower data scientists, he founded his online training company back in 2017. Since then, he’s helped educate over 2,000 data scientists. What I find particularly compelling about Dancho’s program is that he is fully cognizant of, and committed to, helping data scientists deliver projects that positively impact their company’s bottom line. His free social media community is a great place to go to learn more about technical details related to implementing data science solutions in business. If that sounds good to you, be sure to join his LinkedIn community at
www.linkedin.com/in/mattdancho. -
Sadie St. Lawrence, founder and CEO of Women in Data: St. Lawrence, a serial entrepreneur in the data science space, runs a data consulting company where she has been a data science instructor since 2017 for Coursera, where she has educated over 300,000 data professionals. She also serves as a board member for multiple start-ups. Her other business is Women in Data, the nonprofit which was introduced earlier in this chapter. St. Lawrence’s work has been featured in USA Today and the Dataversity website, and she is the recipient of the Outstanding Service award from UC Davis. She is most active on LinkedIn (
www.linkedin.com/in/sadiestlawrence), where she offers a female perspective on career development in the data science field. Not all successful data entrepreneurs started off as data professionals and then became business owners. In fact, some data entrepreneurs started off as entrepreneurs and then grew their data expertise as they grew their businesses, eventually morphing those businesses into full-fledged data businesses. Such is the case with our next leader here, Jennifer Grayeb. - Jennifer Grayeb, CEO of The Nimble Company & COO of Funnel Gorgeous: Back in just 2019, Jennifer left her senior HR strategy role at a Fortune 5 company where she held 5 roles in just 7 years. On the side of her work at that company, and in just 2 short years, she built a productivity blog that reached over 2 million pageviews per year. After selling that business, Jennifer founded The Nimble Company, a consulting group focused on helping online business owners better understand their marketing analytics so they can make data-driven and profit-generating marketing decisions. More recently, Jennifer has taken an advisory role on the C-Suite of another women-founded data-intensive marketing company called Funnel Gorgeous. Always generous with her analytics knowledge, Jennifer’s most active free online community is on Instagram, where she shares valuable, free content that helps entrepreneurs use data to generate greater revenues. Check her out at
www.instagram.com/jennifergrayeb/.
As you’ve probably already noticed, I myself fall into the data science entrepreneur camp. I started building my data science community in 2012 and grew it to 650,000 members as I worked as an independent data science consultant in my business, Data-Mania. After supporting 10 percent of Fortune 100 companies, after being featured in Forbes, The Guardian, and Fortune (and many more media outlets), and after helping educate over 1.2 million data professionals on data science and AI, I felt moved to switch the focus of my business away from data consulting to mentoring fellow data professionals. Our mission is to support data professionals in transforming to world-class data leaders and entrepreneurs. If that’s you, and if you’re thinking about ways to become a better data science leader, or even an entrepreneur, I invite you to join my LinkedIn community of over 350,000 like-minded data science professionals at www.linkedin.com/in/lillianpierson.