As already explained in the introduction, software is nowadays just about everywhere. For almost a full 24 hours a day we rely on software operating correctly, starting with the alarm clock in the morning, via proper functioning of car and train brakes, through to the management of our money in bank accounts.
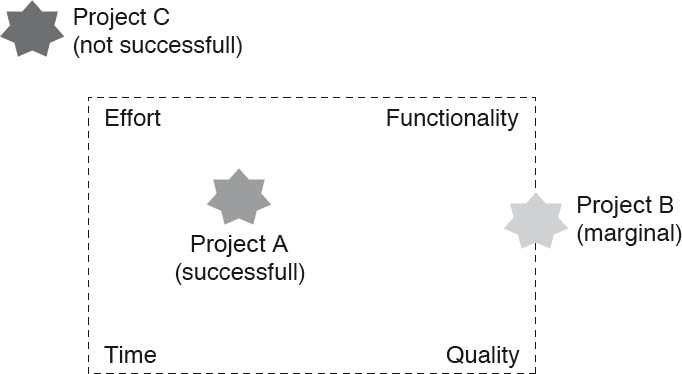
Despite this omnipresence and our dependence on software, we software engineers have still not understood in sufficient detail how to successfully construct software on a repeatable basis. Software projects take too long, cost too much, and fail too often. And even when a software project successfully goes into operational use, the result is often inadequate for those involved. This is confirmed time and time again on an annual basis in the CHAOS Report from the Standish Group [Sta99]. Despite all the criticism of the CHAOS Report, the fact can not be denied that other methods for evaluating success provide very similar, less than flattering results (see [EK08], [EV10]). The bottom line is that our ability to successfully manage software projects within the magic rectangle (see [Bal00], [Die00], [Dum01], [Lit05], [May05]), as shown in figure 2-1, is extremely limited. We are still not able to create high-quality software repeatably with the necessary functionality at affordable costs and within the specified timeframe.
Figure 2-1The magic rectangle of successful software projects
Two key factors for successfully developing software are requirements engineering and architecture design. With both of these disciplines the risk of serious undesirable developments is high, since decisions with far-reaching impacts (that in some cases can only be identified much later in the course of the project) have to be made at an early stage—in particular when the level of available knowledge is still limited (see [Nus01], [GEM04]).
For this reason, software architecture is one of the decisive success factors in software development, since it decides how to structure millions of lines of program code for large, software-intensive systems in such a way that the specified functionality is available in the end result with the desired quality, within budget, and on time (see fig. 2-1).
So what does software architecture actually involve? What are the central concepts in this decisive sub-discipline of software engineering? What procedures and approaches are available for successful architecture design?
Software architecture, like software engineering, is a young discipline. There are therefore many different opinions on the above issues, and we do not wish to decry these in any way or disqualify them as incorrect. In this chapter we instead wish to explain our fundamental understanding of software architecture, and thus provide the basis for the chapters that follow.
First we will present the term “software-intensive system” and its relevance to software architecture. Building on this, we then present and define the central fundamental terms of software architecture. Finally, we will introduce the fundamental procedures involved in architecture design and explain the interactions with other disciplines and roles.
An extract from the Fundamental terms used in the context of software architectures section of the iSAQB curriculum [isaqb-curriculum] is provided below.
 LG1-1:Discuss definitions of software architectureLG1-2:Understand and identify the benefits and objectives of software architectureLG1-3:Understand software architecture as part of the software lifecycleLG1-4:Understand software architects’ tasks and responsibilitiesLG1-5:Relate the role of software architects to other stakeholdersLG1-6:Ability to explain the correlation between development approaches and software architectureLG1-7:Differentiate between architecture and project objectivesLG1-8:Distinguish between explicit statements and implicit assumptionsLG1-9:Know roles and responsibilities of software architects in an organizational contextLG1-10:Understand the differences between types of IT systems
LG1-1:Discuss definitions of software architectureLG1-2:Understand and identify the benefits and objectives of software architectureLG1-3:Understand software architecture as part of the software lifecycleLG1-4:Understand software architects’ tasks and responsibilitiesLG1-5:Relate the role of software architects to other stakeholdersLG1-6:Ability to explain the correlation between development approaches and software architectureLG1-7:Differentiate between architecture and project objectivesLG1-8:Distinguish between explicit statements and implicit assumptionsLG1-9:Know roles and responsibilities of software architects in an organizational contextLG1-10:Understand the differences between types of IT systemsSoftware architecture always manifests itself in the associated system, irrespective of whether it was explicitly designed or has simply evolved. We must therefore first develop a clear understanding of what a software-intensive system really is, before we can take a more detailed look at the architecture of such systems. In the following sections we will therefore first define the term “software-intensive system” and discuss different types of software-intensive systems. Building on this, we can then establish the relationship to the software architecture of the addressed systems.
First of all there’s a fundamental question here: What is a system? We can find an answer to this question in IEEE Standard 610.12-1990, the IEEE Standard Glossary of Software Engineering Terminology. A system is defined there as follows:
System. A collection of components organized to accomplish a specific function or set of functions.
[IEEE 610.12-1990, p. 73]
That definition—which appears quite intuitive—appropriately characterizes the essential attributes of a system. A system consists of building blocks and components such as hardware, software or mechanical building blocks. This definition of a system also includes the concept that systems can be broken down into building blocks. In accordance with the definition above, a system must also serve a specific purpose. This reflects the fundamental understanding of engineering, namely to create things with a beneficial impact on the quality of people’s lives (see the NSPE Code of Ethics for Engineers [NSPE]).
The second essential element of a “software-intensive system” is the term “software”. In this case too, we find a definition in the IEEE Standard Glossary of Software Engineering Terminology:
Software. Computer programs, procedures, and possibly associated documentation and data pertaining to the operation of a computer system.
[IEEE 610.12-1990, p. 66]
Software is accordingly more than just a collection of program files. Software also includes additional procedures such as configuration scripts, associated documentation (e.g. an architectural description), and data (e.g. the initial filling of a database with the necessary metadata and master data).
In order to formulate a definition of a software-intensive system in the context of this chapter, we need to combine the two definitions above and also include the intensive role of the software in the system. Based on this approach, a software-intensive system is defined as follows:
A software-intensive system is a collection of building blocks that are organized in such a way that they together accomplish the purpose of the system. Building blocks of such a system that entirely or for the most part consist of software carry out essential tasks for achievement of the purpose of the system. The software element of the system consists of a collection of programs, procedures, data, and associated documentation.
Different approaches exist for categorizing software. Each of these approaches places emphasis on specific attributes, and is consequently not universally applicable. In its definition of the term “software”, the IEEE Standard Glossary of Software Engineering Terminology, for example, differentiates between application software, support software and system software:
Software. . . . See also: application software; support software; system software.
[IEEE 610.12-1990, p. 66]
This differentiation depends on the context in which the categorization takes place. The database of an insurance system is, from the customers’ point of view, system software. From the programmer’s point of view, however, it is support software. Or consider a web browser: From the point of view of a computer user who wants to surf on the Internet, the web browser is application software. From the viewpoint of the programmer whose task is to create a plug-in for it, the web browser is system software.
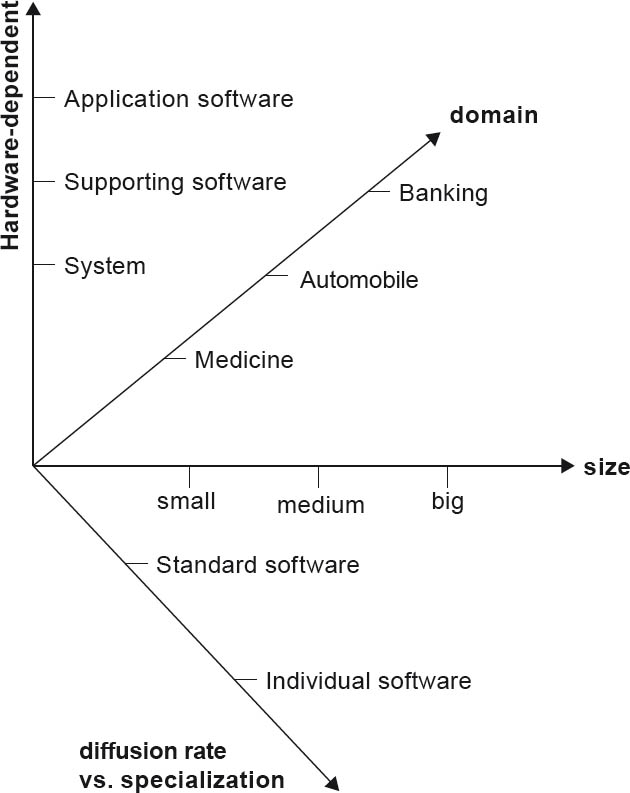
Another frequently encountered differentiation is the one between standard software and custom software [Sie04]. These and other attempts to categorize software (for example, on the basis of size or application domain) ultimately result in a multidimensional classification as shown in figure 2-2. The classification here is not always distinct, and in most cases depends on the viewer’s perception, as noted in the previous paragraph.
Figure 2-2Multi-dimensional categorization of software-intensive systems
Categorization of software is helpful to us, since it permits initial inferences to be made about the software architecture. In an ideal world, a series of architecture approaches and architecture-specific design problems could be predefined for each category of software. This predefinition would then reflect the collective design experience of the software architects. Software architects would then have an easy and reliable start to their design task.
Unfortunately neither a standardized categorization system for software nor a related and complete collection of design know-how exists. It is also not clear whether it will ever be possible to build up and use such a knowledge base in an environment as dynamic as the software industry. For this reason, each individual software architect and software organization has to compile and expand this for themselves.
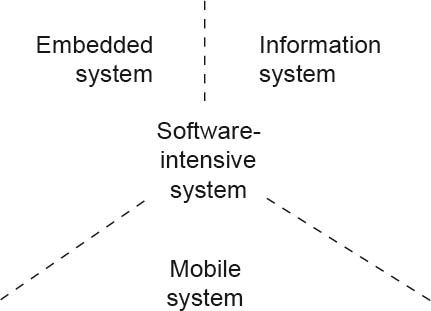
The fundamental approach and the goal are nonetheless worth following. For this reason, in this chapter we want to carry out a simple categorization and also, by way of an example, at least partially establish a link to software architecture. Figure 2-3 shows a possible classification into the following categories:
Figure 2-3Categories of software-intensive systems
With the increasing networking of systems, software-intensive systems exist that cannot be assigned to merely one category. An insurance system, for example, integrates an insurance broker directly into the system via an app on a smartphone. Via an Internet connection and a web browser, SAP evaluation reports can be analyzed directly in vehicles. Additionally, almost all of a factory’s production lines are nowadays already connected via the associated manufacturing execution system to the factory’s SAP system, and vice versa.
Despite the fact that many of today’s systems cannot be unambiguously assigned to one of the three categories defined above, each system nonetheless has its key focus. In cases of doubt, it is clear to all involved whether the system in question or the design task to be addressed should be categorized as an information system or an embedded system.
This is particularly important for software architects, since for each of these categories there are specific basic patterns and approaches in terms of software architecture and architecture design. With information systems, for example, one usually finds a layered architecture, whereas embedded systems involve architecture with active processes or modules that are loosely coupled but nonetheless interact with each other via networks (for example, via bus-based communication). With mobile systems one also has an architecture with active processes, but in this case the processes mainly communicate using shared memory, since they run on a single (possibly multicore) processor.
For each category there is also a specific set of architecture-relevant design problems, particularly with regard to specific, non-functional requirements. With information systems, for example, one has to consider the nature of data management and the associated transaction control. With embedded systems on the other hand, the scheduling of the active processes or the communication load on the network is more relevant. And with the mobile devices, it’s more a case of striking a balance between the required high-quality but resource-intensive graphical user interface and the sensor and actuator-specific functions at the hardware level.
As already explained in the introduction, designing software architecture is an important and critical step in software development. The software architecture has a direct impact on the parameters of the magic rectangle depicted in figure 2-1. These are the desired functionality, the associated quality characteristics, the effort necessary for creating the system, and the time required until the system can be deployed. Ultimately, the question is how to structure large systems so that the desired parameters of the magic rectangle can be achieved.
But does every software-intensive system actually have its own software architecture? In the same way as structures that came into being without the involvement of a building architect, each software-intensive system has an architecture, even if it wasn’t explicitly designed and implemented. In development projects one can, regrettably, too often see cases where the software architecture has not been explicitly designed. The consequences are often serious.
Software requirements change during the course of development, and also during the software’s entire lifecycle, regardless of how well they are documented. Changing requirements impact the development project. For example, project plans have to be changed or the budget adjusted. All of this is futile, however, if the already implemented software elements are incompatible with the desired changes. Good software architecture, however, makes it easy to change existing functionalities or introduce new functionalities without endangering the quality characteristics of the existing software.
Software architecture is thus of enormous importance for successful software development. What, however, is the reason for this? We will briefly address this question using two sub-questions: Why does all software have an architecture? Why is the software architecture a decisive factor for successful software development?
An essential element of good software architecture is the mainly hierarchical decomposition of the system into subsystems or building blocks. The existence of such a decomposed structure is also already part of the nature of software-intensive systems. As already mentioned in the definition above, a software-intensive system consists of a collection of building blocks that are organized so that they accomplish the purpose of the system. The birth of the architecture is thus inextricably linked to the definition of a system. Each (software-intensive) system thus has an implicit or explicit architecture.
This inherent dovetailing concept—that the software architecture decisively defines the system structure and vice versa—is also the reason why software architecture is a decisive factor for successful software development. The structure of buildings defines which components are crucial load-bearing elements and which are not. If you want to change part of a building without affecting its load-bearing elements, that is usually possible without any problems. If, however, load-bearing elements have to be modified, then it’s difficult to predict whether and how that can be achieved and how much it will cost.
This also applies analogously to software architecture, which defines the critical elements in the software via the definition of the system structure. The software architecture thus defines the framework for future changes. Should requests for change or new features arise during the course of the development project or the subsequent lifecycle of the software, these can be fulfilled without problems as long as the critical cornerstones of the software are retained. Otherwise the same applies as for buildings—in other words, costs, time, and the resulting quality are extremely difficult to estimate, and the relationship between costs and benefits is normally not acceptable.
This banal but fundamental relationship between the software-intensive system, the inherently existent software architecture, and the resulting limitations to the magic rectangle is the reason for the enormous significance and implications of software architecture in software development.
Software architecture defines the essential structures, overall technical concepts, and design decisions of a software system, and is the basis for the development of the entire system. It can thus be regarded as a construction plan that sustainably eases the development of complex and extensive software. The software architecture does not specify the detailed design, but instead describes a constructive path to a solution, starting from the requirements placed on the system from the outside, through to the fully constructed system that results—for example, in the form of program files. During this process, the reasons for the design decisions should be documented wherever possible, since the selection of a specific architecture has a significant influence on the quality attributes as well as non-functional characteristics such as maintainability, extendibility, and performance.
Despite its importance, software architecture is still a young discipline. For this reason, this chapter provides a general introduction to the fundamental concepts of software architectures. First we define our understanding of the term “software architecture” based on the terms “building block” and “interface”, which will also be introduced. This provides us with the basis for describing what software architectures are good for and what benefits they can generate. This is then rounded out with concepts for describing software architectures.
There is no single, universally accepted definition of software architecture. As an introduction to the many definitions of software architecture, here is a fairly exotic but nevertheless appropriate definition:
Software architecture is a framework for change.
(Andreas Rausch, see also [SEI Def])
The Software Engineering Institute at Carnegie Mellon University (SEI) has collected more than 150 definitions of software architecture on a website specially created for this purpose [SEI Def]. A consensus, which we endorse, can increasingly be identified among the formulated definitions. It is also reflected in the definition provided by IEEE Standard 42010:2011, Recommended Practice for Architectural Description for Software-Intensive Systems:
<system> fundamental concepts or properties of a system in its environment embodied in its elements, relationships, and in the principles of its design and evolution.
Rather than introducing a completely new definition for this central term within the scope of this chapter, we orient ourselves to this standard but supplement it in a few places, for example using the term “interface” and a reference to the development organization, since we regard these as fundamentally important for software architectures.
The software architecture defines the fundamental principles and rules for the organization of a system and its structure into building blocks and interfaces, and their relationships to each other and to the surrounding environment. It thus defines guidelines for the entire software lifecycle, the developer, and the software’s operator, from analysis via design and implementation to operation and enhancement.
This understanding of software architecture includes two significant aspects. Firstly the constructive aspect, which specifies the structure of a software-intensive system and its division into building blocks and interfaces, and their relationships to each other and the surrounding environment. The definition, however, also includes a second aspect with regard to procedures. Software architecture also influences the developer and the system lifecycle, and thus specifies which principles and rules have to be observed.
This also means that software architecture objectives can also be long-term objectives that extend beyond project objectives and their time horizon, which is usually coupled to the duration of the development project. Software architecture can thus also represent and include an investment in the entire system lifecycle, which possibly only amortizes itself following completion of the associated development project.
We will now take a look at the system construction aspect of software architecture. The terms “building block” and “interface” and the relationship between these elements will be introduced.
“Interface” and “building block” are fundamental engineering terms. They are also popular in information technology, but although they are used almost on a daily basis, there is no common, precise understanding of what an interface or a building block is.
The fact that interfaces and building blocks are not understood in the same way by everyone can be seen when, for example, electrical engineers, mechanical engineers, and computer scientists are simultaneously involved in a system development project. If you try to reach agreement with all parties involved on an interface for the machine tool to be developed, you will soon discover that completely different concepts exist regarding what an interface is and what it isn’t. So at this stage we wish to define the term “interface” as follows:
An interface represents a well-defined access point to the system or its building blocks. In this context, an interface describes the characteristics, (for example, attributes, data, and functions) of this access point. The objective is to define these characteristics as precisely as possible with all the necessary aspects, such as syntax, data structures, functional behavior, error behavior, non-functional characteristics, the interface usage log, technologies, protocols, access modifiers, file formats, conditions/constraints, and semantics.
This definition of an interface clearly shows that the comprehensive specification of interfaces can be extremely laborious. Programming languages such as Java or C# contain interface concepts with which one can normally define the syntax, (the name of the interface), the methods provided, and their arguments and return values. Other aspects of an interface—for example, its functional behavior—have to be recorded in additional documentation.
We often find only inadequate interface descriptions in the programs. If, for example, you look at the Collection interface in Java, it appears to be extremely well prepared and documented. On the other hand, there are no statements in regarding the performance of the Insert operation for inserting an element into a Collection (for example, the upper and lower limit, or the average time allowed for the insertion of an element).
For the use of this interface, however, this characteristic can be highly relevant, particularly in the case of processor-intensive tasks on a large number of elements. These characteristics are critical when it comes to deciding whether the Java Collection should be used, or an alternative solution has to be found.
In this special case, the programmer therefore has to be aware of the specific implementations of the interface and select the appropriate one. In this case he can choose either the ArrayList or the LinkedList, which have different performance characteristics. The interface thus doesn’t completely encapsulate the implementation, despite the fact that this is its defined task.
This example illustrates that it is generally not possible to create complete interface descriptions. It is more often left to the architect to decide which aspects of an interface have to be described and which can be neglected in cases of doubt. You should nonetheless attempt to create complete interface descriptions wherever possible, with relevant characteristics for the specific project context.
We can now address the term “building block”. The term “building block” is often used as a synonym for “component”. However, while “building block”, is a general term, “components” are a special form of building blocks. In this respect we have consciously decided against the term “component” since it is often understood to mean something else. Some people understand components to primarily mean UML components, while others associate components with programming constructs such as packages or JavaBeans.
We use the colloquial term “building block” to abstract component elements of a software architecture from the multitude of terms used in programming languages, modeling approaches, and design methods. A building block in our context is thus an abstraction of special programming constructs or descriptive elements.
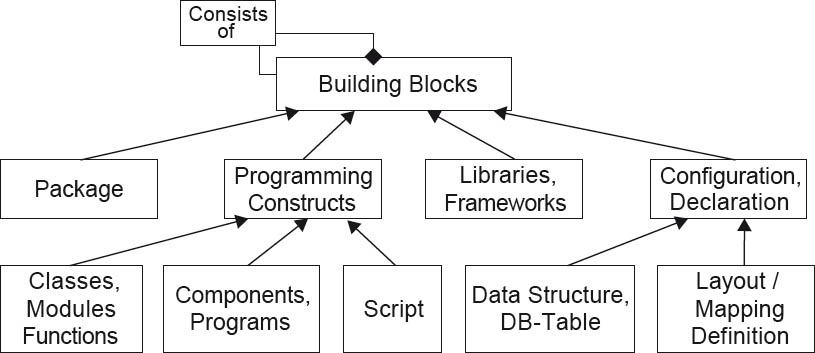
The building block is the central basic element from which the static structure of a software architecture is constructed. It includes all software or implementation artifacts that ultimately represent abstractions of source code. This ranges from small building blocks (such as functions or classes) via medium-sized building blocks (such as packages or libraries) through to large building blocks (such as subsystems, layers or frameworks). Building blocks can thus manifest themselves in different ways. Figure 2-4 shows some examples of specific types of building blocks. It should be noted here that building blocks can themselves consist of other building blocks.
Figure 2-4Examples of building blocks
The term “building block” is thus one of the most important terms in software architecture. It requires clear criteria, however, for the purposes of delimitation. What is a building block and what is not? Our definition of a building block includes the three essential characteristics specified below, and thus extensively subsumes the dominant definitions found in relevant literature ([Szy 98], [D’SW98], [RQ+12]).
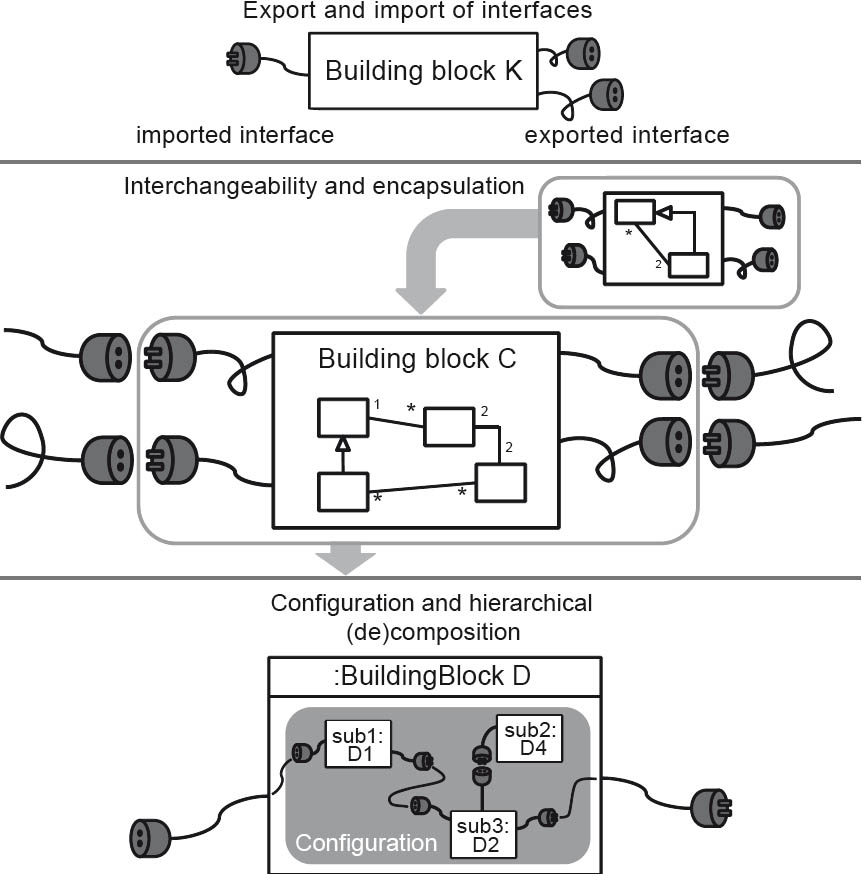
A building block provides interfaces that it guarantees in the sense of a contract. This guarantee, however, only applies when the interfaces that it requires are made available within the scope of a corresponding configuration. (Provided and required interfaces)
Via the provided and required interfaces, the building block encapsulates the implementation of these interfaces. It can thus be replaced by other building blocks that provide and, where appropriate, also require the same interfaces. (Encapsulation and interchangeability)
Building blocks are also the unit of hierarchical (de)composition of a software-intensive system. In other words, a building block can be implemented using an appropriate configuration of other (sub-)building blocks and their interrelationships. In this case, too, we say that this (super) building block encapsulates the (sub-) blocks. The building block can also delegate external interfaces to internal interfaces and vice versa. This is how relationships between building blocks are defined. (Configuration and hierarchical (de)composition)
Figure 2-5The relationships between building blocks and interfaces
Please note: Due to possible side effects, the required interfaces must also be taken into account when replacing building blocks. A building block is a reusable component. Further assumptions—for example, regarding the surrounding environment of the building blocks and the existence of the interfaces required by a building block—should be kept to a minimum and be explicitly documented.
The term “building block” has now been explained, and the possible relationships between building blocks and interfaces have been defined. The essential characteristics of building blocks have also been determined as follows: Provided and required interfaces, encapsulation and interchangeability, configuration and hierarchical (de)composition. Figure 2-5 illustrates these terms and their interrelationships.
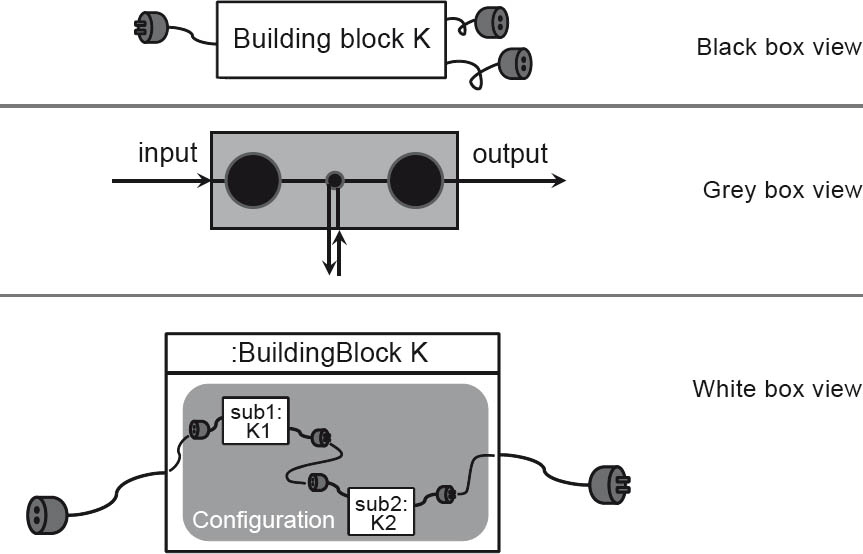
As shown in figure 2-6, we can differentiate between different views of a building block:
Figure 2-6Black box, gray box, and white box views
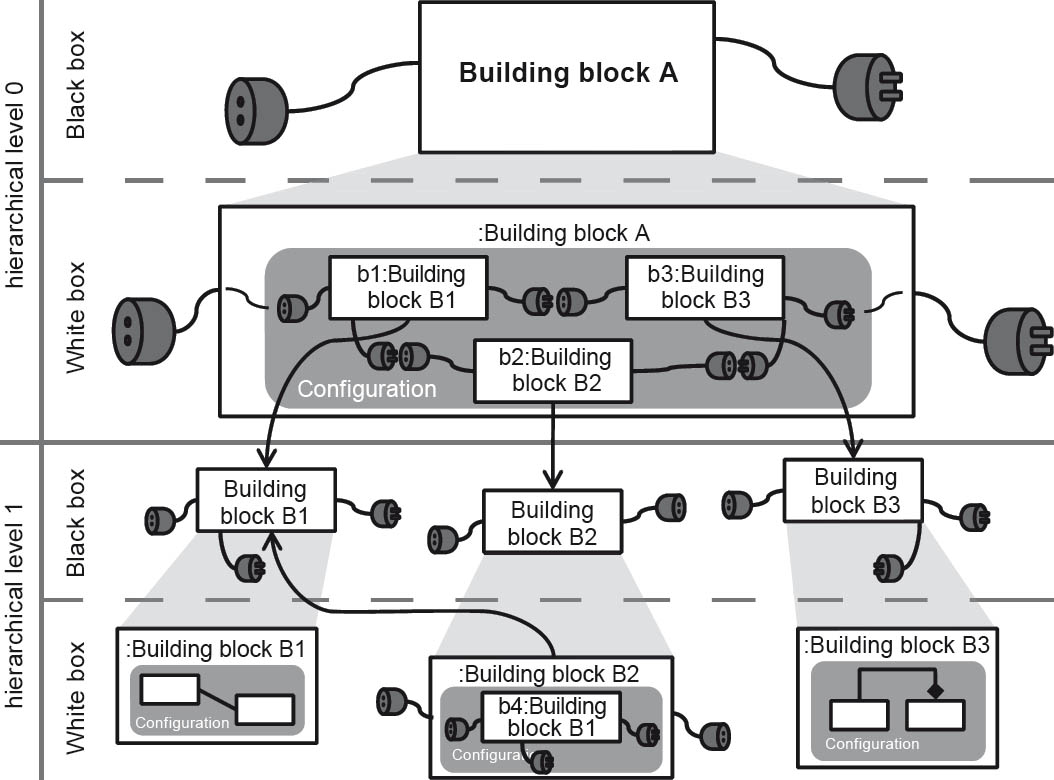
The hierarchical (de)composition of an architecture and its buildings blocks becomes particularly clear in the interaction between black box, gray box, and white box. As shown in figure 2-7, the black box view of a building block A can be hierarchically decomposed in the white box view below it. In this white box view, building block A is broken down into the component elements B1, B2 and B3.
Please note: The elements b1, b2 and b3 are not building blocks, but placeholders (also referred to as “parts” in UML) that use an instance of a building block. We also refer to these placeholders as building block instances, or simply building blocks if there is no important difference. For the sub-building block instances b1 to b3 there are also placeholders for building block instances in the configuration of building block A. Not all building block instances, however, can be used by the placeholders b1, b2 and b3, since the placeholders have specific types. Placeholders are comparable to variables in that they have a value (= building block instance) and a type (=building block). The placeholder “b1 : Building block B1” can thus only use an instance of building block B1.
Since this building block instance defines the building block type in the configuration, there is also a black box view for this building block.
It should be noted here that the diagram only shows one hierarchy in the context of the description of the architecture. Instances of a building block can thus be used in multiple configurations of other building blocks, viewable in their white box views. Building blocks may also be used at different hierarchical levels. In figure 2-7, building block B1 appears as a building block instance in the configuration of the white box view, both as a sub-building block instance of A and as a sub-building block instance of B2. B1 could be an XML parser building block that is used in a wide range of different building blocks at a number of different levels.
Figure 2-7Hierarchical (de)composition with black box and white box views
It should also be noted that this hierarchical decomposition applies not only to the building blocks, but also to their interfaces. In other words, if a building block has an interface to another building block in the gray box, a corresponding interface also exists at the black box and white box levels, and must naturally be implemented accordingly—for example, by delegating the interface to a sub-building block.
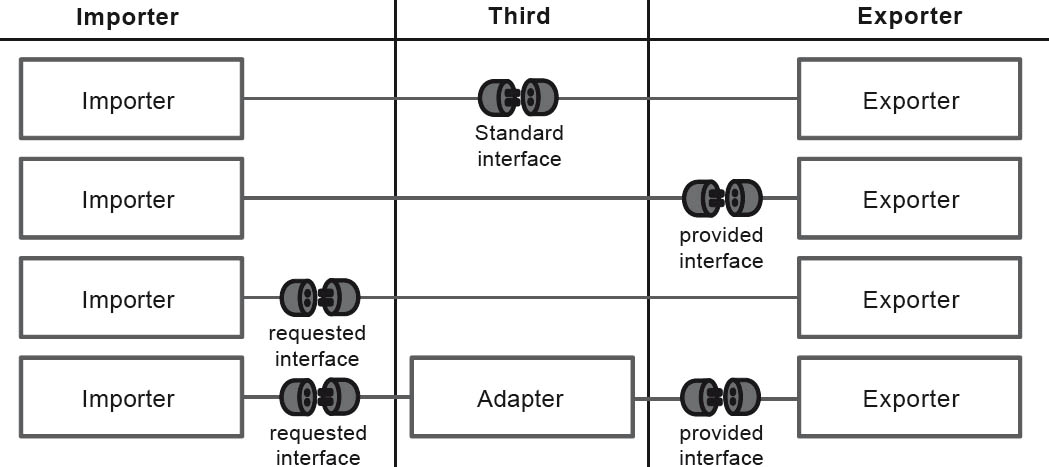
Interfaces are used to connect building blocks. Both building blocks must comply with the interface agreement, regardless of whether they provide or require the interface. This is defined in the interface itself. But who defines the interface? There are different possibilities here:
Figure 2-8Who defines the interface and the interface agreement?
This interface is defined by an external third party. Both the providing and requesting building blocks comply with it.
In this case the interface is defined by the building block that provided it. Apart from the standard interface, this is the type of interface that is most commonly used.
In this case the interface is defined by the building block that requires it. This configuration is often found within frameworks. With these types of interfaces you can incorporate building blocks with specific functionality into a program structure.
In this case both the building block that provides the interface and the building block that requires it define their own interfaces. This increases the decoupling of the building blocks, and they can be developed and tested independently. This, however, means that the interfaces do not remain identical over the course of time, and for this reason an adapter has to be placed between them.
Each interface definition type has its specific characteristics, and thus also advantages and disadvantages. The final variant of the interface definition type increases the decoupling of the building blocks, but has to be paid for with increased development effort and extended timescale. This variant can nonetheless be considered a reasonable long-term solution—for example, in the case of integration tasks.
On the other hand, this variant can also be used on a temporary basis to ensure maximum concurrency during development while uniting inconsistent developments. In this case, however, you need to budget additional time for refactoring and redesign of the architecture to enable removal of the adapter, with new common interface agreements. Otherwise, the temporary solution will unintentionally become a permanent solution.
Regardless of whether it has evolved explicitly or implicitly, an architecture is only of limited use if it is not documented. Only an appropriately documented architecture can be sustainably communicated, discussed, and further developed.
Software architecture is not only discussed with other architects. All aspects of the software architecture are presented to representatives of different interests (stakeholders), discussed with them, and jointly further developed. Customers and users, for example, can also become involved in architecture decisions that affect them. Developers should also become involved in the discussion, in particular for communication and discussion of aspects of the architecture that are relevant to the final implementation.
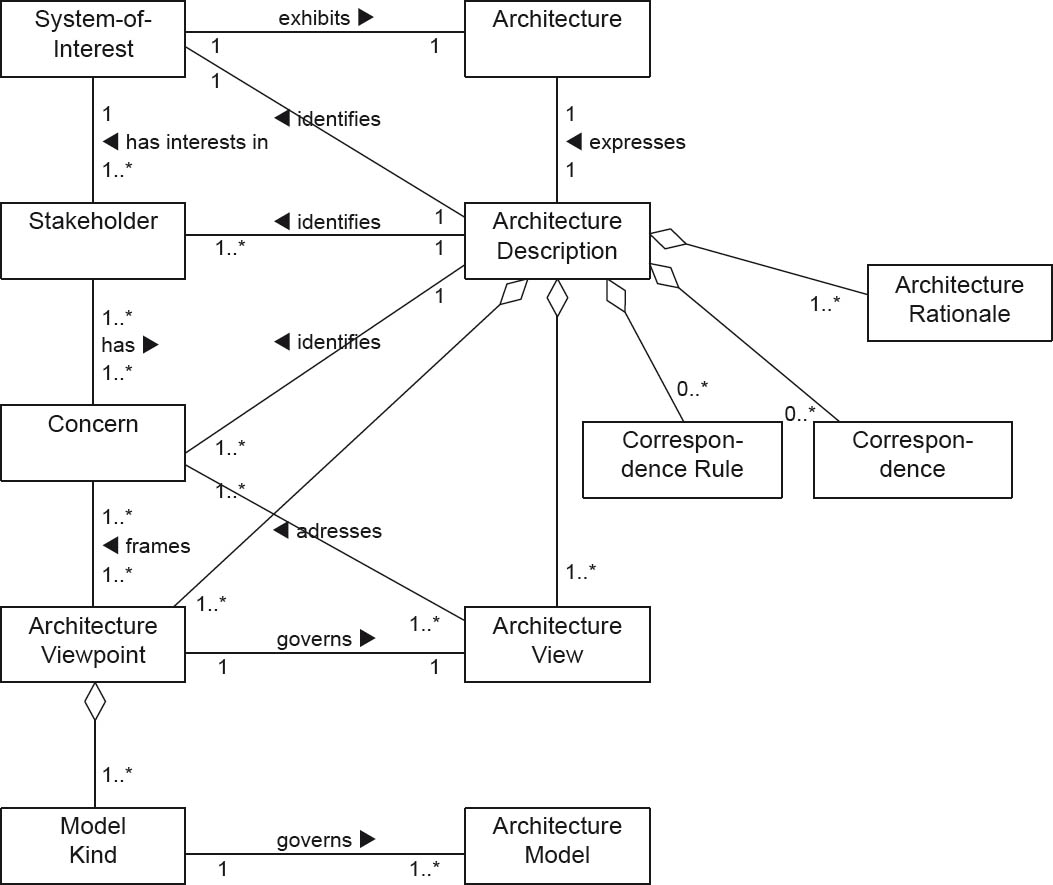
In accordance with IEEE Standard 42010:2011, Recommended Practice for Architectural Description for Software-Intensive Systems [IEEE 42010:2011], a software architecture description contains a collection of artifacts for depicting a software architecture. The corresponding standard defines a conceptual model for architectural descriptions. Figure 2-9 shows the part of the conceptual model that is of particular interest to us.
Figure 2-9Core elements of the conceptual model according to IEEE 42010:2011
In this excerpt from the model, a system is influenced by its environment and vice versa. Each system has an architecture. In accordance with the IEEE standard, this architecture is described by a single architectural description. At first glance this would appear to be a limitation. However, as explained above, the standard defines an architectural description as consisting of a collection of artifacts. This means that an architecture is documented by a collection of descriptions. This could (and should) be stated more clearly in the standard.
A system also has a number of stakeholders, and stakeholders in turn have a number of concerns. The architectural description addresses the stakeholders’ concerns and uses them to justify the architecture decisions made in the associated rationales.
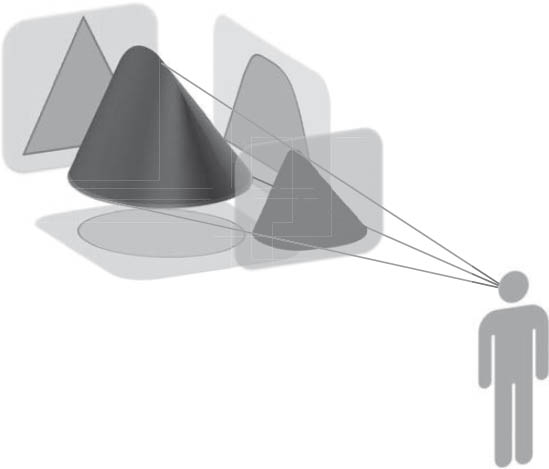
In this respect, the standard covers a widespread core concept of many software architecture approaches, namely: that architectural descriptions include views of the architecture. The concept of views is illustrated in figure 2-10. A stakeholder has a different view of the architecture depending on his viewpoint. These viewpoints are motivated by each stakeholder’s own particular concerns.
Figure 2-10Views are projections of the software architecture.
The IEEE standard describes multiple “views”, including a “functional view”, a “physical view”, and a “technical view”, which are often referred to as separate architectures or architectural levels—for example, as “functional architecture” or “functional levels”.
Architecture Viewpoint
An architecture viewpoint is a set of conventions for constructing, interpreting, using and analyzing one type of architecture view. A viewpoint includes model kinds, viewpoint languages and notations, modeling methods and analytical techniques to frame a specific set of concerns. Examples of viewpoints are: operational, systems, technical, logical, deployment, process, information.
Architecture View
An architecture view in an AD1 expresses the architecture of the system of interest from the perspective of one or more stakeholders to address specific concerns, using the conventions established by its viewpoint. An architecture view consists of one or more architecture models.
In other architecture approaches—for example, the 4+1 architecture model from Kruchten [Kru95], the views are motivated by the different descriptive elements in different diagrams. In Kruchten’s logical view, for example, the focus is on building blocks and their relationships, while the process view describes processes and the exchange of information between them.
In addition, relevant literature frequently refers to many different architectures or architecture levels. These include business process architectures, IT architectures, functional architecture levels, technical architectures, technical infrastructure architectures, deployment architecture levels, and many other terms (see for example [EH+08], [Sie03]).
A refreshingly original differentiation in this terminological muddle is provided by Siedersleben’s “Blood Groups” [SD00]. Take an application architecture layer (Blood Group A) and a technical architecture layer (Blood Group T). As with blood groups, mixing of the architecture layers is undesirable. Another type of differentiation can be found in the Zachmann Framework [O’RF+03], where architecture levels are differentiated in two dimensions according to roles and perspectives.
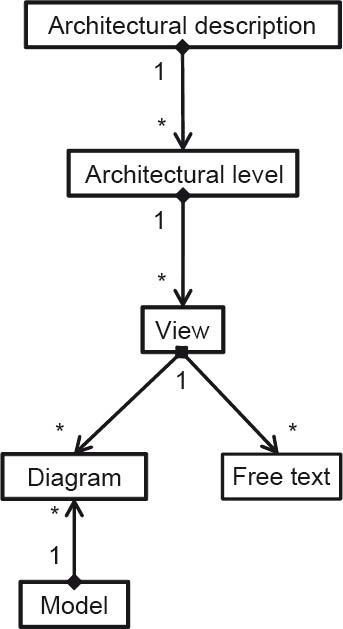
In summary, it can be stated that the terms architectures, architecture layers, and views are used all too frequently to describe architectures. Against this background, we define a simple conceptual model (see figure 2-11) for the description of software architectures.
Figure 2-11Conceptual model for descriptions of software architectures
In accordance with this definition, an architectural description consists of a collection of architectural levels. An architectural level combines a number of views to form a meaningful descriptive element. Views include both text and diagrams, which in turn are stored in models.
A functional architecture level can, for example, contain both a static view consisting of a collection of static diagrams (see the building block view in Section 4.3.5), and a dynamic view consisting of a collection of behavior diagrams (see the runtime view in Section 4.3.6). Additional free-text descriptions, however, are essential for documenting and understanding the architecture. Furthermore, the rationales already referred to for the architecture decisions form a part of this text. Some levels consist solely of free text.
As already explained, an architecture is described at different levels. The selection and organization of these levels provides an initial reference point for the associated design methodology. Architectural levels are often found at different levels of abstraction—for example, a high-level “service-oriented layered architecture” style, or a more specific functional architectural level that includes functional entities and services.
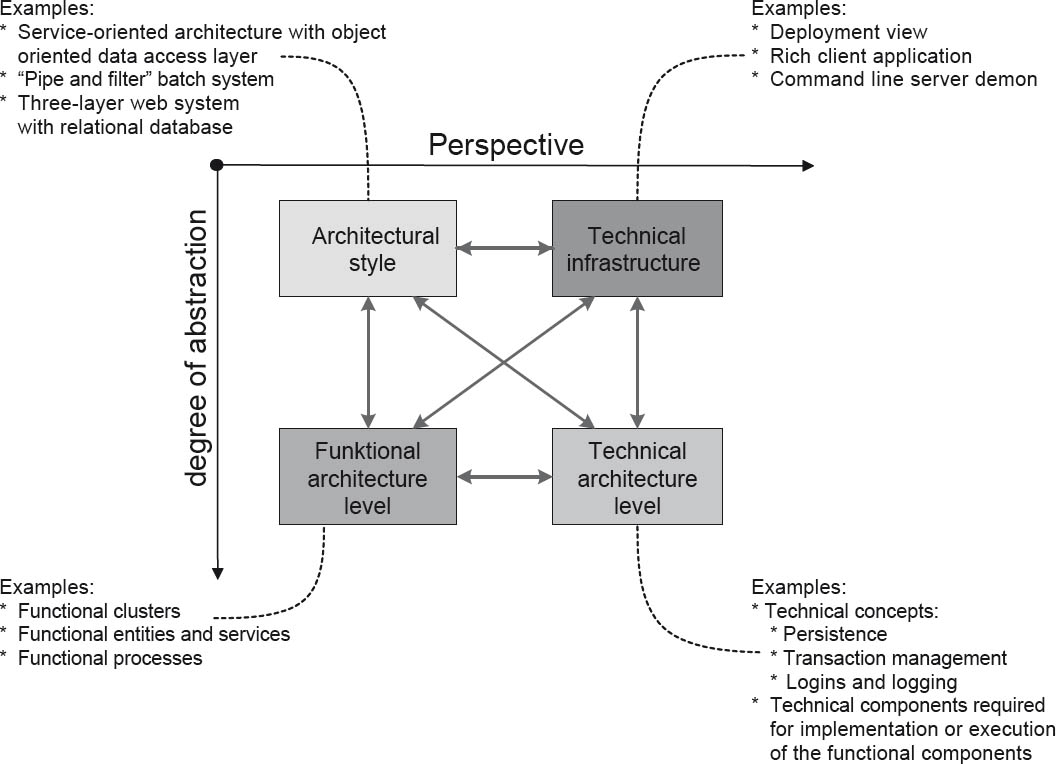
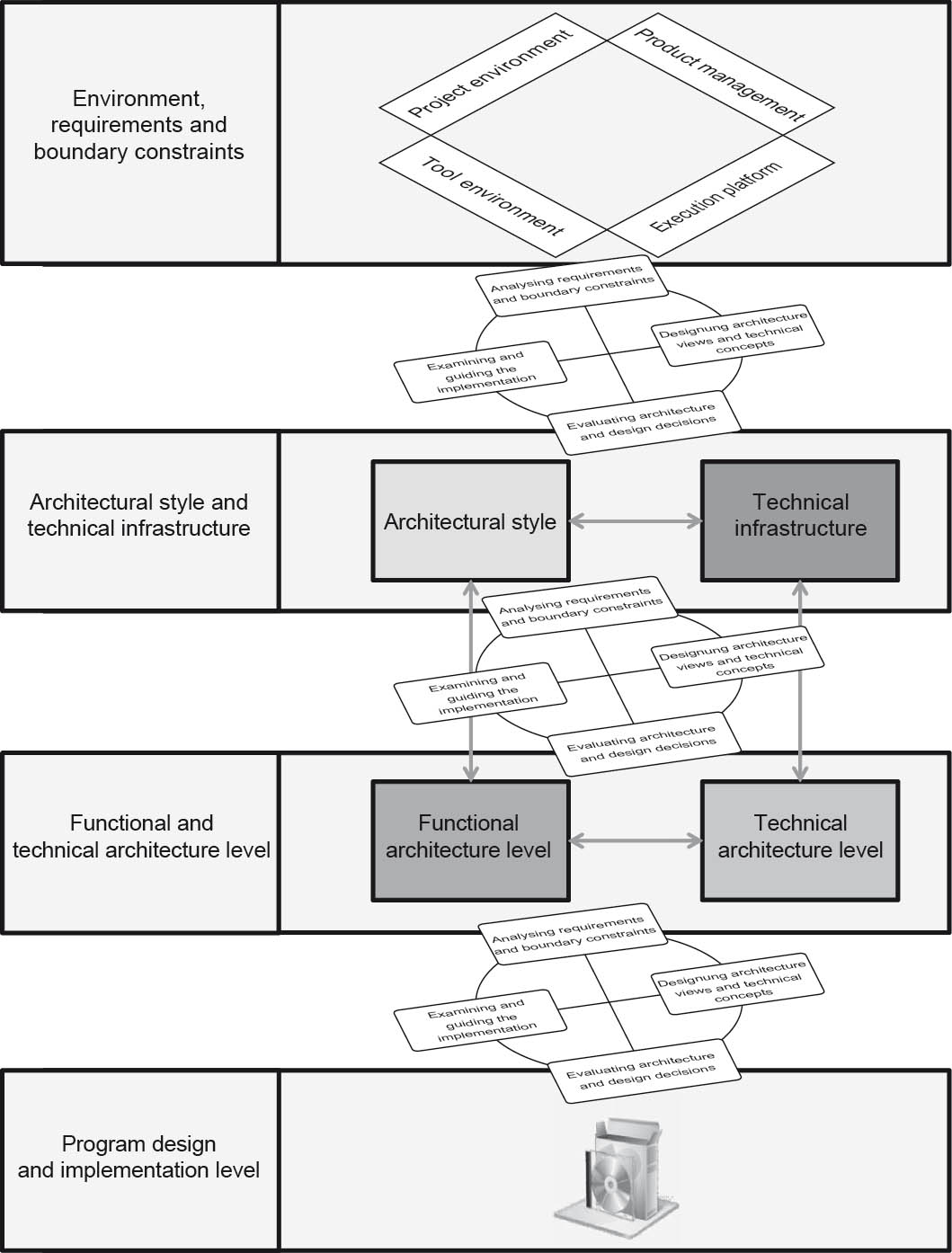
There are a large number of different approaches and standards for architecture methods and their associated description methods. Some of these—such as TOGAF®, RM-ODP, and the Zachman Framework—are introduced in Chapter 4. One fundamental principle however, shown in figure 2-12, is common to all of these methods. The methodology in all of these architecture approaches is based on a separation of the associated description and refinement approach into two dimensions. In the perspective dimension, different architectural areas (such as data, processes, services, and program organization) are addressed. In the degree-of-abstraction dimension, these different architectural areas are addressed and described step by step in increasing detail. Once you have understood this approach, it will be relatively easily to navigate your way around each of these architecture frameworks.
As an example, figure 2-12 shows a subdivision of the architectural description into four architectural levels: the architectural style, technical infrastructure, the functional application architecture level (also referred to as A-architecture), and the technical architecture level (T-architecture). As shown below, these four levels differ in two dimensions—in other words, in terms of both the level of abstraction and perspective (functional vs. technical).
Figure 2-12The different levels in an architectural description
As the arrows between the levels illustrate, the architectural levels can be addressed individually, although they mutually influence each other and are thus interdependent. The more specific functional and technical architectural levels naturally involve the requirements of the architectural style and the technical infrastructure. In the one direction, the specific designs of the functional and technical architectural levels influence the requirements on higher architectural levels. Analogous relationships can be found in the other dimension. For example, technical architecture provides specific concepts for persistence or transaction management, which in turn have to be included at the functional architectural level. In the other direction, the functional architectural level provides the inputs in terms of the required persistence concepts.
The architectural style here is the central architectural metaphor of the system. For example: “Our software system is structured as a three-layer architecture using a model view controller in the presentation layer and object-relational mapping in the data management layer.” On the other hand, the technical infrastructure defines the network profiles of the architecture. For example: “We have a thin client with a web and application container and a relational database.”
The view-based description of the functional and technical architectural levels takes place at the more detailed architectural levels (see also [SD00]). At the functional architectural level, appropriate application building blocks and their relationships are designed for the implementation of the functional requirements. For example, a design can be created here for a generic insurance product model that enables mapping of different insurance products in the application.
In contrast, at the technical architectural level cross-disciplinary solution building blocks are designed and documented for the relevant aspects based on non-functional requirements. For example, versioning of all functional entities may be necessary, and a solution for this is developed in the technical architecture. The functional entities on the application architecture level can then use this general solution from the technical architectural level.
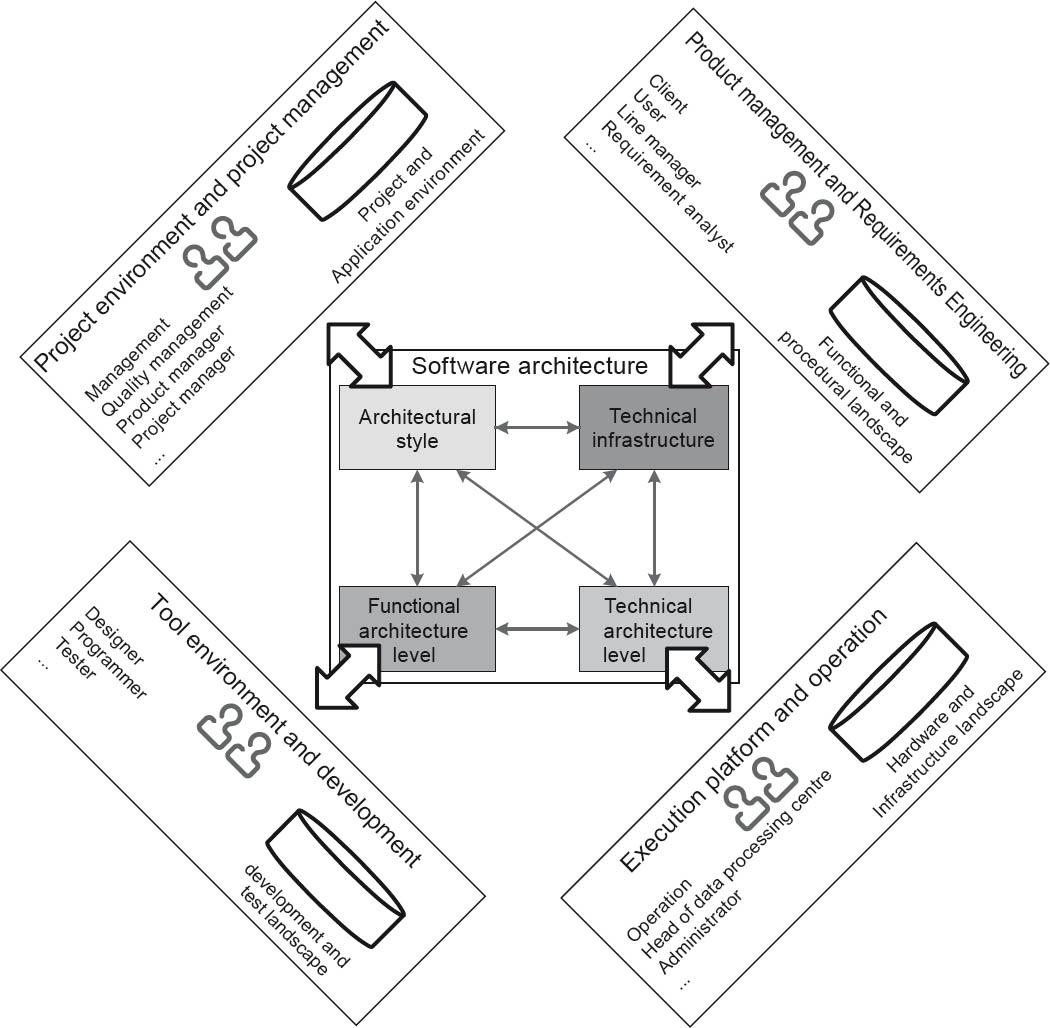
As figure 2-12 shows, the architecture of a system is not created in a vacuum, but is influenced by the surrounding environment and vice versa. The elements surrounding the actual software architecture are frequently also referred to as architectures—for example, a business process architecture. We wish to avoid the use of the term architecture here to avoid overloading it. Instead, we increasingly use the terms “environment” or “landscape”. Figure 2-13 shows the essential surrounding areas within the context of software architecture and the roles involved in them:
Project environment and project management provide a variety of constraints and project objectives that must be taken into account where they are relevant to the architecture. Budgets and the development approach, for example, can influence the software architecture, and vice versa. In the surrounding environment of a system there are usually a number of applications and projects. This existing (and continuously changing) project and application landscape often has significant impacts on the software architecture being developed. If additional projects or applications are initiated or suddenly terminated, this can have enormous impact on interfaces to the system for which a software architecture is to be developed.
Product Management and Requirements Engineering place functional and, in particular, non-functional requirements, quality objectives, and constraints on the system, all of which can change during the course of the project and thus affect the architecture. On the other hand, the architecture can also identify which requirements generate conflicts of interest with other requirements or project constraints. The architecture can thus also generate impulses for changes to requirements.
Generally, the execution platform and operations organization already exist within the organization. New systems should use existing systems where possible, and this should be taken into account during the architecture design. On the other hand, new platform and operations requirements can also result from the architecture.
Figure 2-13Software architecture is influenced by its environment and vice versa.
The architecture must ultimately be implemented. This requires appropriate tools and a development organization. Appropriate development environments also have to be provided for the selected programming languages, frameworks, and technologies. Equally, the architecture itself can also place new requirements on tools and the development organization. Expansion of the test infrastructure may, for example, be necessary, depending on the selected technology.
But when is a developed or provided software architecture a good software architecture? [BCK03] defines a good architecture as one that enables a project and the system to fulfill their objectives within the context of the magic rectangle (i.e., costs, time, functionality, and quality), while factoring in the lifecycle. As with all quality attributes, the quality of an architecture is subjective and depends on who is assessing it [ISO/IEC 25010].
In other words, a software architecture is only suitable for the specified objectives, constraints, requirements, and future challenges to a certain extent. The externally perceived quality of a software architecture can only be evaluated in the context of specific quality objectives. The required quality characteristics are derived from the current and future objectives, constraints, and requirements, and are thus specific to the individual software system in question.
However, current and future objectives, constraints, and functional requirements (and in particular non-functional requirements) are often not described sufficiently and completely. In this respect, it is worth taking a look at ISO Standard 25010 [ISO/IEC 25010], in which high-level quality characteristics are already defined:
These quality attributes are good starting points for deriving additional quality characteristics for the software architecture and the software system. In addition, the existing objectives, constraints, and requirements and the required quality characteristics derived from them can also be checked for completeness using the FURPS attributes (see also Section 2.4 and Chapter 5).
In addition to explicitly formulated objectives, constraints, and requirements, from which the required quality characteristics are derived, each project also has a variety of implicit objectives, constraints, and requirements. During checking of the completeness of the required quality characteristics, these implicit (and still hidden) quality characteristics must—where possible—be made completely explicit. For example, there may be an implicit condition that a specific database management system is to be used, since it is the standard system in the company, licenses have already been paid for, and the operation of the database is ensured. Non-explicit constraints with regard to time-to-market can also result in implicit architectural requirements in terms of incremental approach support. These implicit objectives, constraints, and requirements must be made explicit, and the quality characteristics that have to be implemented must be derived from them. This is the only way to ensure that they are taken into account and implemented in the designed architecture.
In addition to externally perceptible quality, quality not seen directly by the user also plays a role. In the product design of modern vehicles, for example, components are designed and installed to simplify future recycling of precious metals or rare earth. These quality characteristics are not obvious to the owner, but may be manifested indirectly in the vehicle’s price.
Quality objectives that are not immediately perceptible to the user are also inherently defined with the software architecture, independent of the specific software-intensive system. If the software architecture is defined as a central value during system development, a range of quality objectives implicitly results. For example, the software architecture must be easy to understand, transparent, have up-to-date documentation, and be implemented correctly. Ease of development and a structured project organization must be supported by the architecture. It should also ensure simple and economic system operation, extensibility, and maintainability. The greatest possible reuse of existing building blocks is desirable for both quality-related and economic reasons.
As already explained in the introduction, requirements engineering and architecture design are two key factors for successful software development. The risk of unwanted developments is particularly high in these areas, which is why they also offer the greatest potential for risk minimization and general optimization.
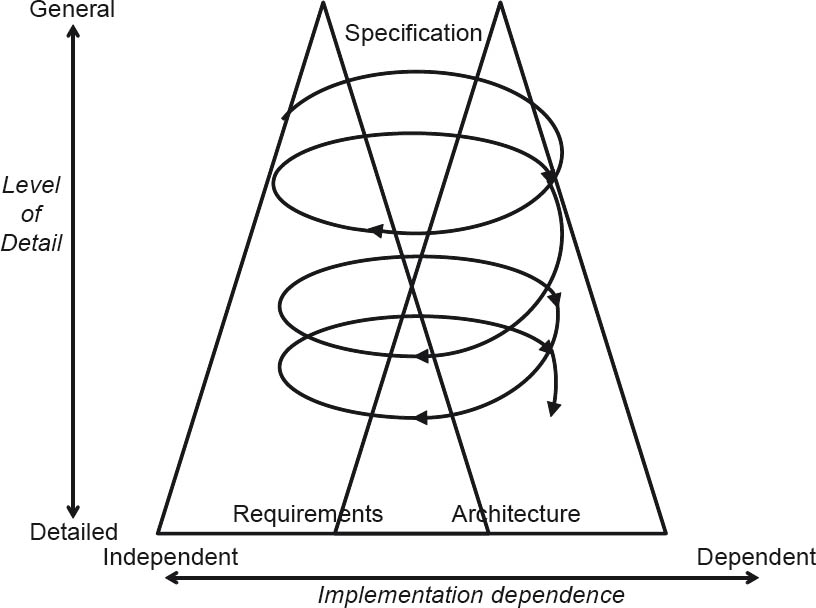
It is not sufficient to address these two areas in isolation. On the contrary, it is essential to ensure consistent integration of requirements engineering and architecture design if they are to influence each other positively. The so-called Twin Peaks Model (cf. [Nus01]) emphasizes this relationship, and requires iterative collaboration of requirements engineering and architecture design, as shown in figure 2-14.
Figure 2-14The Twin Peaks Model [Nus01]
The impacts of requirements in terms of the effort involved can only be realistically assessed when an initial high-level architecture design is available. If the efforts assessed on the basis of the high-level architecture design are then presented to the customer, it is not uncommon for them to waive certain requirements. However, existing design alternatives can indicate to those responsible for specifying the requirements that the requirements are not sufficiently precisely defined (see also [HM+07]).
The central task of software architecture design is to find a design approach with which the functional and non-functional requirements defined by requirements engineering are implemented in a fully designed solution. This approach, however, is not a one-way street, as indicated by the Twin Peaks Model shown in figure 2-14.
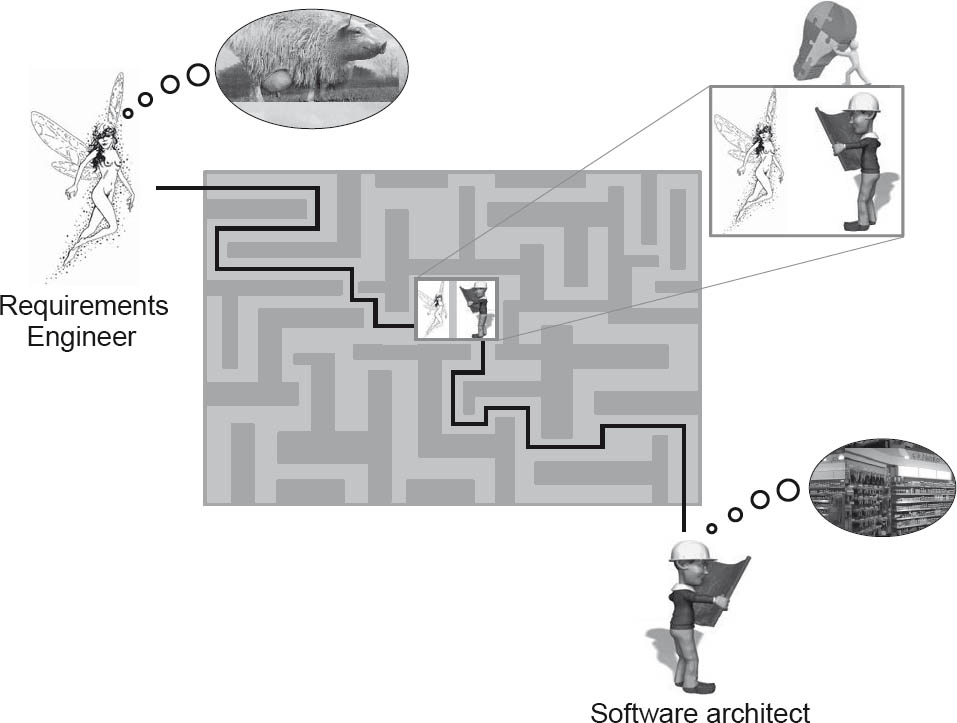
Instead, the process involves continual compromise between the “request list” from requirements engineering and the software architect’s inventory of existing solutions, building blocks, and other architecture artifacts. As figure 2-15 illustrates, this approach means the software architect develops the construction plan for the software system in coordination with relevant stakeholders (such as the requirements engineer, the customer, the user, the developer, the tester, or the administrator).
Figure 2-15The software architect’s long march
Since a new system or system enhancements should not be addressed in isolation, interfaces to other systems, affected organizations, execution platforms, and the implementation infrastructure also have to be taken into account. The interfaces, requirements, and constraints from the four adjacent areas (see fig. 2-13) must be considered and co-designed by the architect.
The architect must also take the entire lifecycle of the system and the adjacent areas referred to above into account. Architecture always means investment in supporting elements in order to achieve flexibility and extensibility elsewhere. This, however, demands consideration of the corresponding lifecycles; otherwise, these investments may not be secure.
Software architecture is not developed behind closed doors, and demands teamwork from the many parties involved in the project. It is therefore necessary to develop a common understanding of what forms part of a software architecture and what does not, both within the current project and in its surrounding environment. This includes a common nomenclature for the most important terms such as “interface” or “building block”.
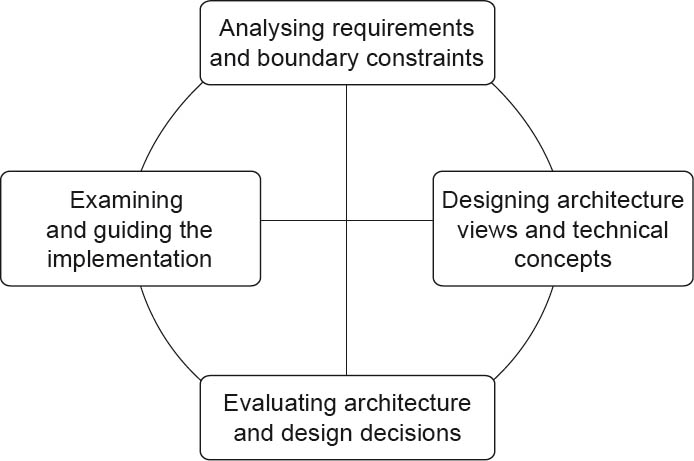
As shown in figure 2-13, the architect not only has to consider interfaces with requirements engineering, but also with other disciplines and roles involved in software development. A software architect designs an architecture starting from the conditions, constraints, and requirements of these surrounding areas, thus defining the essential aspects of the solution, such as the building block structure and interaction patterns. Viewed in isolation, the architecture design process is not sequential. Even the term “iterative approach” doesn’t sufficiently describe the nature of the architecture design process. The individual tasks involved in the process cannot be meaningfully brought into a linear sequence. Instead, as shown in figure 2-16, we subdivide architecture design into four activities of equal weighting:
Figure 2-16Iterative and incremental steps involved in software architecture design
The central task of architecture analysis is to analyze the objectives, constraints, and the functional (and in particular, non-functional requirements) that come from requirements engineering in the context of the other surrounding areas (cf. figure 2-13). This must include an analysis of quality, flexibility (the stakeholder is open to changes), and susceptibility to change (changes as a result of external influences over time) of the requirements. Gaps in the requirements must be identified (see [HNS99]). Particularly with regard to non-functional requirements, there is normally room for improvement since those responsible for specifying the requirements often regard them as being self-evident. All parties involved in the project—especially designers and developers—have to develop an initial understanding of the architecture style and the technical infrastructure. This is the central architectural metaphor of the system.
Here, the architecture is developed in more detail. In particular the view-based description of the different architectural levels (functional and technical levels—see figure 2-13) also takes place here. The objective is to break down the functional requirements to the corresponding functional architecture level, and for the relevant aspects of the non-functional requirements to design and document appropriate cross-cutting solution building blocks at the technical architecture level (see also Chapter 4). All the while, the fundamental solution framework given by the architecture style and the technical infrastructure must be taken into account.
The developed architecture must undergo quality assurance. Various methods can be used here, from diverse review techniques through technical prototypes and tests to analysis and evaluation. The critical aspect here is the derivation of specific scenarios from the requirements to ensure the quality of the resulting architecture (see also Chapter 5).
The importance of the communication of software architecture to all parties involved in the project is often underestimated. Only when all those involved—from the developer through to the customer—have understood and accepted the software architecture, can it be successfully implemented and achieve the desired effects. The software architecture must of course be communicated in such a way that it can be understood by the recipient. This means that the architecture is explained to the customer with a different level of detail than to the developer. This process is not a one-way street, but rather a process of learning from one another and understanding. During its implementation, the architecture continues to be discussed with the parties involved in the project and any open issues, potential for improvement, faults and errors, and approaches for further development continue to be identified.
Effective tool support should also be established on the basis of these concepts. This ensures optimal support for the individual areas of activity involved in the design of the software architecture—for example, analysis and management of requirements, handling of architecture models and documentation, quality assurance, and communication. Autonomous tool solutions already exist for these individual task areas (see Chapter 6). These stand-alone tools must be integrated as seamlessly as possible to ensure that the architect can use them effectively. Because the design process is not sequential but rather iterative and incremental (or even concurrent), it is especially important to close the gaps between the individual tools.
As already explained, the individual activities involved in the software architecture design process cannot be arranged linearly. They are areas of equal importance to which the software architect has to devote sufficient attention depending on the current project situation. The architecture design is a continuous interplay between the activities shown in figure 2-16:
During the architecture design process, the software architect carries out these four activities in a sequence that suits the needs and context of the project. This iterative and incremental interplay of activities is associated with a top-down and bottom-up change of the abstraction levels and perspectives shown in figure 2-13:
This way, we can switch from the topmost abstraction level of the conditions, constraints, and requirements of the surrounding areas via the abstraction levels in the software architecture (architecture style and technical infrastructure, plus the functional and technical architecture levels) through to the bottommost abstraction level, which consist of the software program itself, the program’s design and its implementation. The architecture design process is thus a continuous top-down and bottom-up flow within the abstraction levels along with a continuous change of activities that are performed interactively and incrementally. This is illustrated in figure 2-17.
Within this process, the project setting and constraints define the constraints of the architecture. In return, the architecture design provides data on technical project risks and planning information.
Requirements engineering describes the functional and non-functional requirements for the architecture design coming from those accountable for the system. As explained above, this is not a one-way street, and the architecture design also provides feedback on the feasibility of implementing the requirements, and their consequences for requirements engineering.
The partially or fully available technical infrastructure—for example, server infrastructure, operating systems, requirements for programming languages, and the operating organization—must also be taken into consideration during the architecture design process. Especially the interface with operations is far too often neglected, which can result in major problems during system deployment. And once again, this is not a one-way street. The architecture design can produce new technical infrastructure requirements—for example, further expansion of the server landscape or the integration of additional middleware.
Finally, the architecture design provides the specifications for detailed design and programming. However, return flows of information are also necessary here. Unforeseen problems can arise during the implementation of the software architecture and, if these are not communicated to the software architect and a supposedly simple solution is implemented instead, this can undermine the entire architecture. It is therefore important to discuss such problems with the software architect, and to jointly develop a solution that may result in changes to the architecture.
Figure 2-17Overview of the software architecture design process
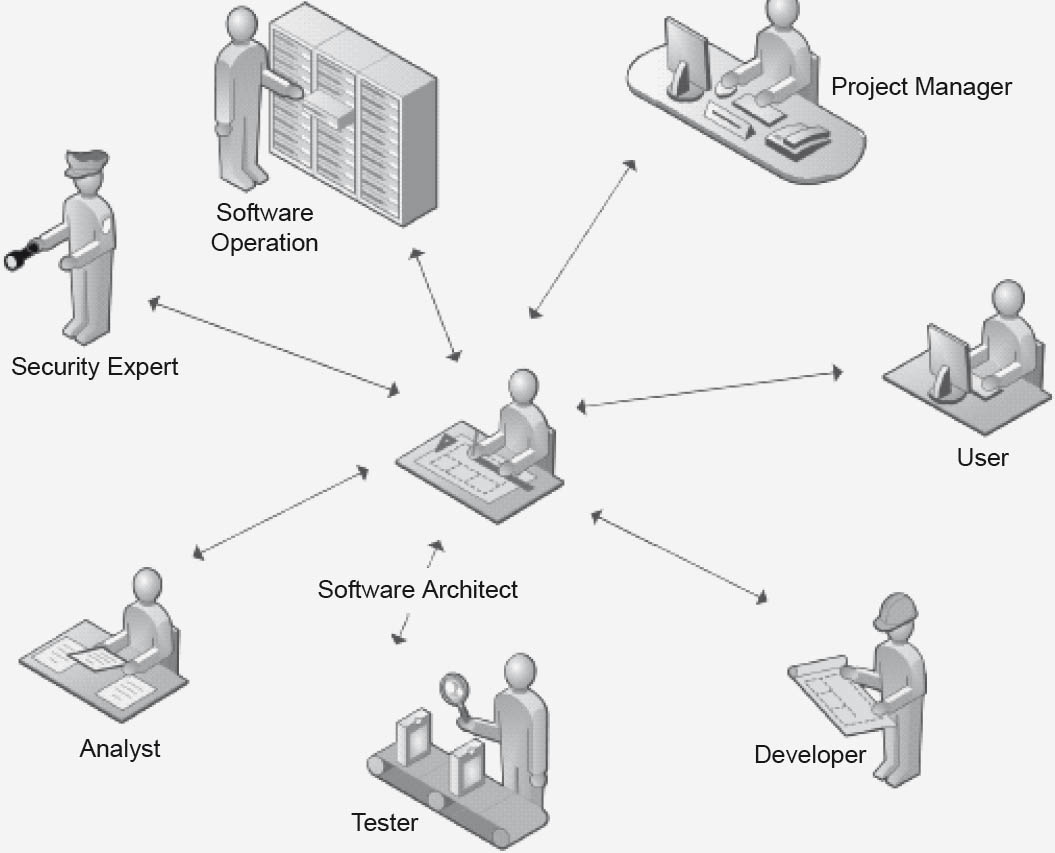
The task of the architect is to develop a blueprint for the system based on the functional and non-functional requirements, while taking requirements and constraints of the surrounding areas into account. The subsequent implementation, maintenance, support and enhancements are then based on this blueprint. This requires development of a complete and concise architectural description. The architectural description serves on the one hand as a communication and discussion platform, and on the other hand as a design and implementation plan. As shown in figure 2-18, the architect must provide a large number of interfaces to almost all of the roles involved in a software development project.
Figure 2-18The software architect in relation to the neighboring roles
Based on the architecture, the architect presents the feasibility of the requirements to the requirements engineer, the customer, and possibly the user too. During this process, the architect provides support by correlating, prioritizing, and reflecting on functional and non-functional requirements. He can identify contradictions and discrepancies, and ultimately ensures that the requirements can be implemented. The architect identifies ways of integrating existing solutions and systems, and aligns the requirements to the existing system architecture and hardware. He develops, evaluates, and assesses alternative solution approaches. Finally, based on the software architecture, the architect advises the project manager on project and iteration planning, and supports risk analysis and mitigation, thus providing support for the definition of work structure and assignment.
The architect is a central point of contact for the system’s developers. He defines the system’s building blocks as well as their interfaces and interaction patterns. He has to encourage the integration of new technologies and innovative solution approaches, and discuss them with the developers. He is in charge of the development, introduction, training, and reviewing of programming guidelines. He assists the developers in the development of prototypes and sample solutions, and accelerates reuse of existing (partial) implementations. He explains the architecture, provides development specifications, passes on his experience, and carries out code reviews. He also supports the testers. In an ideal situation, he even defines testing conditions and specific test cases for testing specific architecture objectives. He assists in the definition of test sequences and dependencies. Finally, he is the point of contact for fault and error reports that are relevant to the architecture. He is also the central point of contact for organizational roles such as operations staff, security experts, and the like.
Here are some detailed excerpts from the Fundamental terms used in the context of software architectures section of the iSAQB curriculum [isaqb-curriculum] to help you consolidate what you have learned.
LG1-1:Discuss definitions of software architecture
LG1-2:Understand and identify the benefits and objectives of software architecture
LG1-3:Understand software architecture as part of the software lifecycle
LG1-4:Understand a software architect’s tasks and responsibilities
LG1-5:Relate the role of software architects to other stakeholders
LG1-6:Ability to explain the correlation between development approaches and software architecture
LG1-7:Differentiate between architecture and project objectives
LG1-8:Distinguish between explicit statements and implicit assumptions
LG1-9:Know roles and responsibilities of software architects in an organizational context
LG1-10:Understanding the differences between types of IT systems
1AD = Architecture Description