Chapter 1 is useful to understand the reasons behind the selection of technologies such as Python and TensorFlow. It also helped us setting up our environments.
Chapter 2 makes a brief introduction to machine learning since deep learning is a subfield of machine learning.
In Chapter 3, we finally cover the basics of deep learning. These three chapters were conceptual and introductory chapters.
Chapter 4 summarizes all the technologies we use in our deep learning pipeline, except for one: TensorFlow.
In this chapter, we cover the basics of TensorFlow and the API references that we use in this book.
TensorFlow Basics
Eager execution vs. graph execution
TensorFlow constants
TensorFlow variables
Eager Execution
One of the novelties brought with TensorFlow 2.0 was to make the eager execution the default option. With eager execution, TensorFlow calculates the values of tensors as they occur in your code. Eager execution simplifies the model building experience in TensorFlow, and you can see the result of a TensorFlow operation instantly.
The main motivation behind this change of heart was PyTorch’s dynamic computational graph capability. With the dynamic computational graph capability, PyTorch users were able to follow define-by-run approach, in which you can see the result of an operation instantly.
However, with graph execution, TensorFlow 1.x followed a define-and-run approach, in which evaluation happens only after we’ve wrapped our code with tf.Session. Graph execution has advantages for distributed training, performance optimizations, and production deployment. But graph execution also drove the newcomers away to PyTorch due to the difficulty of implementation. Therefore, this difficulty for newcomers led the TensorFlow team to adopt eager execution, TensorFlow’s define-by-run approach, as the default execution method.
In this book, we only use the default eager execution for model building and training .
Tensor
Tensors are TensorFlow’s built-in multidimensional arrays with uniform type. They are very similar to NumPy arrays, and they are immutable, which means that once created, they cannot be altered, and you can only create a new copy with the edits.
Rank-0 (Scalar) Tensor: A tensor containing a single value and no axes
Rank-1 Tensor: A tensor containing a list of values in a single axis
Rank-2 Tensor: A tensor containing two axes
Rank-N Tensor: A tensor containing N-axis
Ragged Tensors : A tensor with variable numbers of elements along some axis
Sparse Tensors : A tensor where our data is sparse, like a very wide embedding space
Variable
A TensorFlow variable is the recommended way to represent a shared, persistent state that you can manipulate with a model. TensorFlow variables are recorded as a tf.Variable object. A tf.Variable object represents a tensor whose values can be changed, as opposed to plain TensorFlow constants. tf.Variable objects are used to store model parameters.
TensorFlow variables are very similar to TensorFlow constants, with one significant difference: variables are mutable. So, the values of a variable object can be altered (e.g., with assign() function) as well as the shape of the variable object (e.g., with reshape() function).
These are some of the fundamental concepts in TensorFlow. Now we can move on to the model building and data processing with TensorFlow .
TensorFlow Deep Learning Pipeline
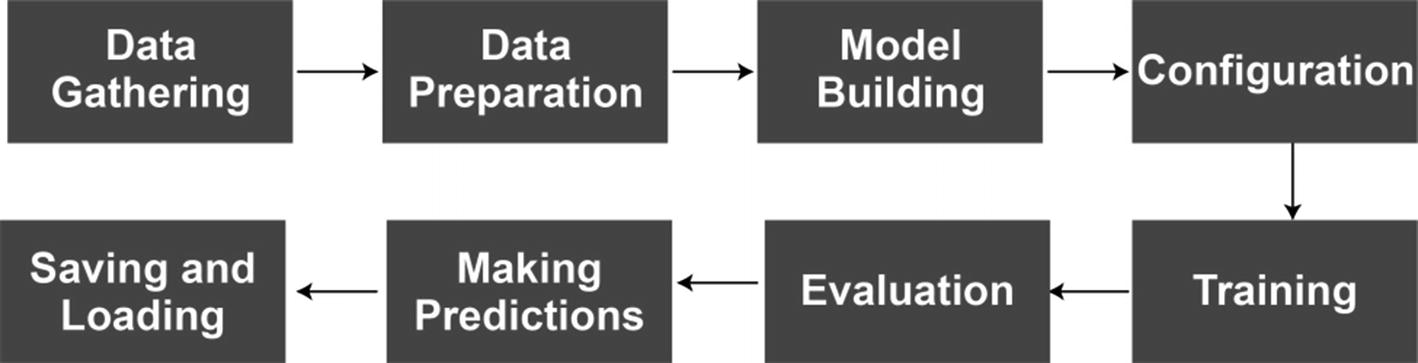
Deep Learning Pipeline Built with TensorFlow
In the next sections, we cover these steps with code examples. Please note that the data gathering step will be omitted since it is usually regarded as a separate task and not usually performed by machine learning experts.
Data Loading and Preparation
TensorFlow Dataset object
TensorFlow Datasets catalog
NumPy array object
Pandas DataFrame object
Let’s dive into how we can use them.
Dataset Object (tf.data.Dataset)
TensorFlow Dataset object represents a large set of elements (i.e., a dataset). tf.data.Dataset API is one of the objects TensorFlow accepts as model input used for training and specifically designed for input pipelines.
Create a dataset from the given data.
Transform the dataset with collective functions such as map.
Iterate over the dataset and process individual elements.
Dataset from a Python list, NumPy array, Pandas DataFrame with from_tensor_slices function
Dataset from a text file with TextLineDataset function
Dataset from TensorFlow’s TFRecord format with TFRecordDataset function
Dataset from CSV file with
Dataset from TensorFlow Datasets catalog: This will be covered in the next section.
TensorFlow Datasets Catalog
TensorFlow Datasets is a collection of popular datasets that are maintained by TensorFlow. They are usually clean and ready to use.
Installation
tensorflow-datasets: The stable version, updated every few months
tfds-nightly: The nightly released version, which contains the latest versions of the datasets
As you can understand from the names, you may use either the stable version, which updates less frequently but is more reliable, or the nightly released version, which gives access to the latest versions of the dataset. But beware that because of the frequent releases, tfds-nightly is more prone to breaking and, thus, is not recommended to be used in production-level projects.
Importing
Datasets Catalog
After the main library is imported, we can use load function to import one of the popular libraries listed in the TensorFlow Datasets catalog page, which is accessible on
www.tensorflow.org/datasets/catalog/overview
Audio
Image
Image classification
Object detection
Question answering
Structured
Summarization
Text
Translate
Video
Loading a Dataset
Download the dataset.
Save it as TFRecord files.
Load the TFRecord files to your notebook.
Create a tf.data.Dataset object, which can be used to train a model.
split: Controls which part of the dataset to load
shuffle_files: Controls whether to shuffle the files between each epoch
data_dir: Controls the location where the dataset is saved
with_info: Controls whether the DatasetInfo object will be loaded or not
In our upcoming sections, we take advantage of this catalog to a great extent.
Keras Datasets
MNIST
CIFAR10
CIFAR100
IMDB Movie Reviews
Reuters Newswire
Fashion MNIST
Boston Housing
As you can see, this catalog is very limited, but come in handy in your research projects.
One important difference of Keras’s datasets from TensorFlow’s datasets is that they are imported as NumPy array objects.
NumPy Array
You can create a NumPy array with np.array() function, which can be fed into the TensorFlow model. You can also use a function such as np.genfromtxt() to load a dataset from a CSV file.
In reality, we rarely use a NumPy function to load data. For this task, we often take advantage of the Pandas library, which acts almost as a NumPy extension.
Pandas DataFrame
Pandas DataFrame and Series objects are also accepted by TensorFlow as well as NumPy arrays. There is a strong connection between Pandas and NumPy. To process and clean our data, Pandas often provides more powerful functionalities. However, NumPy arrays are usually more efficient and recognized by other libraries to a greater extent. For example, you may need to use scikit-learn to preprocess your data. Scikit-learn would accept a Pandas DataFrame as well as a NumPy array, but only returns a NumPy array. Therefore, a machine learning expert must learn to use both libraries.
CSV Files: pd.read_csv("path/xyz.csv")
Excel Files: pd.read_excel("path/xyz.xlsx")
Text Files: pd.read_csv("path/xyz.txt")
HTML Files: pd.read_html("path/xyz.html") or pd.read_html('URL')
After loading your dataset from these different file formats, Pandas gives you an impressive number of different functionalities, and you can also check the result of your data processing operation with pandas.DataFrame.head() or pandas.DataFrame.tail() functions.
Other Objects
The number of supported file formats is increasing with the new versions of TensorFlow. In addition, TensorFlow I/O is an extension library that extends the number of supported libraries even further with its API. Although the supported objects and file formats we covered earlier are more than enough, if you are interested in other formats, you may visit TensorFlow I/O’s official GitHub repository at
TensorFlow I/O: https://github.com/tensorflow/io#tensorflow-io
Model Building
Keras API
Estimator API
In this book, we only use Keras API and, therefore, focus on the different ways of building models with Keras API.
Keras API
As mentioned in the earlier chapters, Keras acts as a complementary library to TensorFlow. Also, TensorFlow – with version 2.0 – adopted Keras as a built-in API to build models and for additional functionalities.
Sequential API
Functional API
Model Subclassing
Let’s take a look at each method in the following.
Sequential API
The Keras Sequential API allows you to build a neural network step-by-step fashion. You can create a Sequential() model object, and you can add a layer at each line.
Using the Keras Sequential API is the easiest method to build models which comes at a cost: limited customization . Although you can build a Sequential model within seconds, Sequential models do not provide some of the functionalities such as (i) layer sharing, (ii) multiple branches, (iii) multiple inputs, and (iv) multiple outputs. A Sequential model is the best option when we have a plain stack of layers with one input tensor and one output tensor.
Using the Keras Sequential API is the most basic method to build neural networks, which is sufficient for many of the upcoming chapters. But, to build more complex models, we need to use Keras Functional API and Model Subclassing options.
Once a Sequential model is built, it behaves like a Functional API model, which provides an input attribute and an output attribute for each layer.
During our case studies, we take advantage of other attributes and functions such as model.layers and model.summary() to understand the structure of our neural network.
Functional API
The Keras Functional API is a more robust and slightly more complex API to build powerful neural networks with TensorFlow. The models we create with the Keras Functional API is inherently more flexible than the models we create with the Keras Sequential API. They can handle nonlinear topology, share layers, and can have multiple branches, inputs, and outputs.
The Keras Functional API methodology stems from the fact that most neural networks are directed acyclic graph (DAG) of layers. Therefore, the Keras team develops Keras Functional API to design this structure. The Keras Functional API is a good way to build graphs of layers.
To create a neural network with the Keras Functional API, we create an input layer and connect it to the first layer. The next layer is connected to the previous one and so on and so forth. Finally, a Model object takes the input and the connected stack of layers as parameters.
Model and Layer Subclassing
Model Subclassing is the most advanced Keras method, which gives us unlimited flexibility to build a neural network from scratch. You can also use Layer Subclassing to build custom layers (i.e., the building blocks of a model) which you can use in a neural network model.
With Model Subclassing, we can build custom-made neural networks to train. Inside of Keras Model class is the root class used to define a model architecture.
The upside of the Model Subclassing is that it’s fully customizable, whereas its downside is the difficulty of implementation. Therefore, if you are trying to build exotic neural networks or conducting research-level studies, the Model Subclassing method is the way to go. However, if you can do your project with the Keras Sequential API or the Keras Functional API, you should not bother yourself with the Model Subclassing.
the __init__ function acts as a constructor. Thanks to __init__, we can initialize the attributes (e.g., layers) of our model.
the super function is used to call the parent constructor (tf.keras.Model).
the self object is used to refer to instance attributes (e.g., layers).
the call function is where the operations are defined after the layers are defined in the __init__ function.
In the preceding example, we defined our Dense layers under the __init__ function, then created them as objects, and built our model similar to how we build a neural network using the Keras Functional API. But note that you can build your model in Model Subclassing however you want.
Estimator API
Training
Evaluation
Prediction
Export for serving
We can take advantage of various premade Estimators as well as we can write our own model with the Estimator API. Estimator API has a few advantages over Keras APIs, such as parameter server-based training and full TFX integration. However, Keras APIs will soon become capable of these functionalities, which makes Estimator API optional.
This book does not cover the Estimator API in case studies. Therefore , we don’t go into the details. But, if you are interested in learning more about the Estimator API, please visit the TensorFlow’s Guide on Estimator API at www.tensorflow.org/guide/estimator.
Compiling, Training, and Evaluating the Model and Making Predictions
Compiling is an import part of the deep learning model training where we define our (i) optimizer, (ii) loss function, and other parameters such as (iii) callbacks. Training, on the other hand, is the step we start feeding input data into our model so that the model can learn to infer patterns hidden in our dataset. Evaluating is the step where we check our model for common deep learning issues such as overfitting.
Using the standard method
Writing a custom training loop
The Standard Method
model.compile()
model.fit()
model.evaluate()
model.predict()
model.compile( )
Option 1: Passing arguments as a string
Option 2: Passing arguments as a TensorFlow object
Passing loss function, metrics, and optimizer as object offers more flexibility than Option 1 since we can also set arguments within the object.
Optimizer
Adadelta
Adagrad
Adam
Adamax
Ftrl
Nadam
RMSProp
SGD
The up-to-date list can be found at this URL:
www.tensorflow.org/api_docs/python/tf/keras/optimizers
You may select an optimizer via tf.keras.optimizers module.
Loss Function
Another important argument, which must be set, before starting the training is the loss function. tf.keras.losses module supports a number of loss functions suitable for classification and regression tasks. The entire list can be found at this URL:
model.fit( )
model.evaluate( )
model.predict( )
Custom Training
Instead of following standard training options which allows you to use functions such as model.compile(), model.fit(), model.evaluate(), and model.predict(), you can fully customize this process.
To be able to define a custom training loop, you have to use a tf.GradientTape(). tf.GradientTape() records operations for automatic differentiation, which is very useful for implementing machine learning algorithms such as backpropagation during training. In other words, tf.GradientTape() allows us to track TensorFlow computations and calculate gradients.
Set optimizer, loss function, and metrics.
- Run a for loop for the number of epochs.
Run a nested loop for each batch of each epoch:
Work with tf.GradientTape() to calculate and record loss and to conduct backpropagation.
Run the optimizer.
Calculate, record, and print out metric results.
As you can see, it is much more complicated, and therefore, you should only use custom training when it is absolutely necessary. You may also customize the individual training step, model.evaluate() function , and even model.predict() function . Therefore, TensorFlow almost always provide enough flexibility for researchers and custom model developers. In this book, we take advantage of custom training in Chapter 12.
Saving and Loading the Model
We just learned how to build a neural network, and this information will be crucial for the case studies in the upcoming chapters. But we also would like to use the models we trained in real-world applications. Therefore, we need to save our model so that it can be reused.
The model’s architecture and configuration data
The model’s optimized weights
The model’s compilation information (model.compile() info)
The optimizer and its latest state
TensorFlow SavedModel Format
Keras HDF5 (or H5) Format
Although the old HDF5 format was quite popular previously, SavedModel has become the recommended format to save models in TensorFlow. The key difference between HDF5 and SavedModel is that HDF5 uses object configs to save the model architecture, while SavedModel saves the execution graph. The practical consequence of this difference is significant. SavedModels can save custom objects such as models that are built with Model Subclassing or custom-built layers without the original code. To be able to save the custom objects in HDF5 format, there are extra steps involved, which makes HDF5 less appealing.
Saving the Model
Saving the model in one of these formats is very easy. The desired format can be selected with an argument (save_format) passed in the model.save() function.
After saving the model, the files containing the model can be found in your temporary Google Colab directory.
Loading the Model
Conclusion
Now that we covered how we can use TensorFlow for our deep learning pipeline along with some TensorFlow basics, we can start covering different types of neural network concepts along with their corresponding case studies. Our first neural network type is feedforward neural networks or, in other words, multilayer perceptron.