Kapitel 20. Verbesserte Bibliotheken
Die verbesserten Bibliotheken in C++11 basieren auf bestehenden C++-Bibliotheken und runden diese ab. Das prominenteste Beispiel ist die neue Bibliothek zu Smart Pointern, die dem klassischen Smart Pointer std::auto ptr gleich drei neue Smart Pointer zur Seite stellt. Aber auch die Container std::tuple und std::array, die Hashtabellen, neue Algorithmen und die zwei funktionalen Bausteine std::bind und std::function machen C++11 zu einer moderneren und somit besseren Programmiersprache.
Smart Pointer
Die Anforderungen an Smart Pointer sind vielfältig. Daher verwundert es nicht, das C++11 drei neue Exemplare anbietet. So verfolgt der Smart Pointer std::shared_ptr das Konzept des geteilten Besitzverhältnisses und der std::unique_pt das des exklusiven Besitzverhältnisses. Für Zyklen von Smart Pointern hingegen ist der std::weak_ptr verantwortlich.
<memory>
unique_ptr
std::unique_ptr ersetzt std::auto_ptr, der in C++11 deprecated ist. Beides sind Smart Pointer, die exklusiv eine Ressource besitzen und den transparenten Zugriff auf diese erlauben. Beide bieten ein sehr ähnliches Interface an. Bevor es in die Details geht, stellt Listing 20.1 das Interface von std::unique_ptr vor.
uniquePtr.cpp
01 #include <iomanip>
02 #include <iostream>
03 #include <memory>
04 #include <utility>
05
06 struct MyStruct{
07 MyStruct(int v):val(v){
08 std::cout << std::setw(10) << std::left
<< (void*) this << " Hello: " << val
<< std::endl;
09 }
10 ~MyStruct(){
11 std::cout << std::setw(10) << std::left
<< (void*)this << " Good Bye: " << val
<< std::endl;
12 }
13 int val;
14 };
15
16 int main(){
17
18 std::cout << std::endl;
19
20 { // begin of scope
21
22 // Initialize with resource
23 std::unique_ptr<MyStruct> uniquePtr0{new MyStruct(0)};
24
25 // use an std::auto_ptr
26 std::auto_ptr<MyStruct> autoPtr{new MyStruct(1)};
27 std::unique_ptr<MyStruct> uniquePtr1{std::move(autoPtr)};
28
29 // Default Constructor
30 std::unique_ptr<MyStruct> uniquePtr2;
31
32 // Move Constructor
33 std::unique_ptr<MyStruct> uniquePtr4{new MyStruct(2)};
34 std::unique_ptr<MyStruct> uniquePtr5{std::move(uniquePtr4)};
35
36 // Move Assignment
37 std::unique_ptr<MyStruct> uniquePtr6{new MyStruct(3)};
38 std::unique_ptr<MyStruct> uniquePtr7= std::move(uniquePtr6);
39
40 // access the resource
41 std::cout << std::endl;
42 std::cout << "Address of resource of uniquePtr7"
<< (void*)uniquePtr7.get() << " " << std::endl;
43 std::cout << "Get val: uniquePtr7.get()->val: "
<< uniquePtr7.get()->val << std::endl;
44 std::cout << "Get val: uniquePtr7->val: "
<< uniquePtr7->val << std::endl;
45 std::cout << std::endl;
46
47 // release the resource
48 MyStruct* myStruct= uniquePtr7.release();
49 std::cout << "myStruct->val: " << myStruct->val
<< std::endl;
50 delete myStruct;
51
52 std::cout << std::endl;
53
54 // reset the resource
55 uniquePtr2.reset(new MyStruct(4));
56 std::unique_ptr<MyStruct> uniquePtr8{new MyStruct(5)};
57 uniquePtr8.reset(new MyStruct(6));
58
59 std::cout << std::endl;
60
61 // swap the std::unique_ptr
62 uniquePtr2.swap(uniquePtr1);
63 std::swap(uniquePtr2,uniquePtr1);
64
65 } // end of scope
66
67 std::cout << std::endl;
68
69 }In Listing 20.1 hat MyStruct (Zeile 6) die Aufgabe, den Wert der Instanzvariablen val, ihre Adresse und eine kurze Nachricht im Konstruktor und Destruktor auszugeben. Damit ist es leichter, die Lebenszeit der Objekte vom Typ MyStruct in Abbildung 20.1 zu verfolgen. Ein std::unique_ptr bietet verschiedene Varianten der Instanziierung an. Er kann über einen Zeiger auf eine Ressource (Zeile 23), einen std::auto_ptr (Zeile 27) oder auch den Aufruf des Standardkonstruktors (Zeile 30) instanziiert werden. Die Initialisierung über ein Rvalue (Zeilen 34 und 38) wird unterstützt, für einen Lvalue wird sie unterbunden. Ist der std::unique_ptr uniquePtr7 initialisiert, lässt sich durch uniquePtr7.get() (Zeilen 42 und 43) auf die Ressource und durch uniquePtr7-> (Zeile 44) auf die Elemente der Ressource zugreifen. Um die Ressource freizugeben, steht uniquePtr7.release() (Zeile 48) bereit. Durch das explizite Löschen der Ressource in Zeile 50 wird ein Speicherloch vermieden. Eine neue Ressource kann mit uniquePtr2.reset(new MyStruct(4)) (Zeile 55) gesetzt werden. Besitzt der std::unique_ptr bereits eine Ressource, wird die ursprüngliche Ressource gelöscht (Zeile 56). Dies lässt sich auch direkt in Abbildung 20.1 nachvollziehen. Über uniquePtr2.swap(uniquePtr1) oder auch std::swap(uniquePtr2,uniquePtr1) lassen sich zwei std::unique_ptr tauschen.
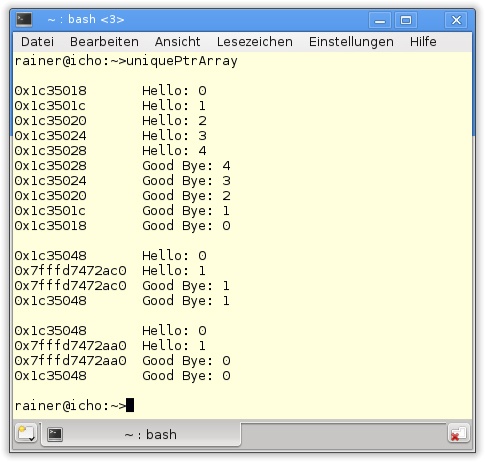
Der feine, aber entscheidende Unterschied zwischen std::unique_ptr und std::auto_ptr ist, dass beim Kopieren eines std::auto_ptr dessen Ressource verschoben wird. Was oberflächlich wie Copy-Semantik wirkt, ist unter der Decke Move-Semantik. In Kapitel 5 im Abschnitt „Smart Pointer“ wird das implizite Verschieben einer Ressource mit std::auto_ptr und das explizite Verschieben mit std::unique_ptr bildlich gegenübergestellt.
Wie wird nun verhindert, dass std::unique_ptr kopiert werden kann? Die Antwort gibt die Definition von std::unique_ptr in Listing 20.2.
template <typename _Tp, ... >
class unique_ptr{
public:
...
// Move constructors
unique_ptr(const unique_ptr&& __u) ...
// Assignment
unique_ptr&
operator=(unique_ptr&& __u) ...
...
// Disable copy from lvalue.
unique_ptr(const unique_ptr&) = delete;
unique_ptr& operator=(const unique_ptr&) = delete;
};In der Implementierung von std::unique_ptr (GCC 4.7, 2011) wird das C++11-Schlüsselwort delete angewandt, um die Copy-Semantik zu unterbinden. Sowohl den Move-Konstruktor unique_ptr(const unique_ptr&& __u) als auch den Move-Zuweisungsoperator unique_ptr& operator=(unique_ptr&& __u) bietet dieser Smart Pointer an. Soll ein std::unique_ptr kopiert werden, muss der Umweg über std::move gegangen werden.
std::unique_ptr<int> up1(new int(10)); std::unique_ptr<int> up2= up1; //ERROR: use of deleted function std::unique_ptr<int> up1(new int(10)); std::unique_ptr<int> up2= std::move(up1);
Sink and Source-Idiom
Das Sink and Source-Idiom beschreibt zwei Funktionen, die eine Ressource verwalten. Dabei ist die Quelle (source) die Funktion, die die Ressource bereitstellt und deren Besitz an die Funktion Senke (sink) auf Anfrage übergibt. Das definierte Zusammenspiel, und das ohne potenzielle Speicherlöcher, lässt sich elegant mit std::unique_ptr in Listing 20.4 formulieren.
sinkSource.cpp
01 #include <memory>
02 #include <iostream>
03
04 struct BigData{
05 BigData(int i):mySize(i),myData(new int[i]){}
06 int mySize;
07 int* myData;
08 ~BigData(){
09 std::cout << "deleting BigData of size: "
<< mySize << std::endl;
10 delete [] myData;
11 }
12 };
13
14 // allocate an array of size BigData
15 std::unique_ptr<BigData> source(int size)
16 {
17 return std::unique_ptr<BigData>(new BigData(size) );
18 }
19
20 // get an array of BigData
21 void sink(std::unique_ptr<BigData> bd){
22 std::cout << "get an array of size: "
<< bd->mySize << std::endl;
23 }
24
25 void dontUseBigData(){
26 source(1000);
27 }
28
29 int main(){
30
31 std::cout << std::endl;
32
33 source(123456789);
34
35 std::cout << std::endl;
36
37 sink(source(100000000));
38
39 std::cout << std::endl;
40
41 dontUseBigData();
42
43 std::cout << std::endl;
44
45 sink( std::unique_ptr<BigData>( new BigData(2011)));
46
47 std::cout << std::endl;
48
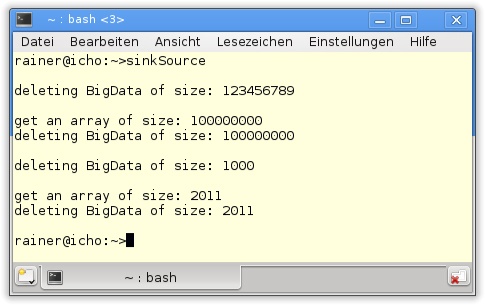
49 }Listing 20.4 dient nur der Illustration des Grundproblems, das mit dem Sink and Source-Idiom gelöst wird: Eine Funktion stellt die Ressource bereit und übergibt den Besitz einer anderen Funktion. Wer ist nun für das Freigeben der Ressource zuständig? Die kritische Ressource ist in diesem konkreten Fall BigData, das ein beliebig großes, dynamisch allokiertes Array myData besitzt. Betrachten wir zuerst den typischen Anwendungsfall in Zeile 37. Wird source(100000000) prozessiert, allokiert die Funktion source (Zeile 15) BigData und stellt es über seinen Rückgabewert zur Verfügung. Die Funktion sink in Zeile 21 verhält sich genau spiegelbildlich zur Funktion source, denn sie benötigt einen std::unique_ptr<BigData> als Eingabewert. Die Eleganz dieses Idioms ist, dass, wie auch immer die Funktionen sink und source verwendet werden, die Ressource automatisch freigegeben wird.
source(123456789):Der Rückgabewert verliert am Ende des Funktionskörpers von
sourceseine Gültigkeit und wird automatisch gelöscht.sink(source(100000000)):Der Rückgabewert von
sourceist ein Rvalue, sodass die Ressource zum Aufrufsink(Move-Semantik) verschoben wird. Am Ende des Funktionskörpers vonsinkverliert derstd::unique_ptrseine Gültigkeit und wird automatisch gelöscht.source(1000):Stellt eine Variation von
source(12345679)dar.sink( std::unique_ptr<BigData>( new BigData(2011))):Die Funktion
sinkfordert die Ressource direkt. Da diese Ressource ein Rvalue ist, wird sie verschoben.
Abbildung 20.2 zeigt den Programmlauf von Listing 20.4.
auto_ptr versus unique_ptr
Der explizite Übergang der Besitzverhältnisse beim std::unique_ptr gegenüber dem impliziten beim deprecated std::auto_ptr ist aber noch nicht das Ende der Geschichte. std::unique_ptr zeichnet sich in weiteren Punkten gegenüber std::auto_ptr aus. Er kann Arrays verwalten, über eine Löschfunktion parametrisiert und in der Standard Template Library verwendet werden. Zuerst die zusätzlichen Features von std::unique_ptr der Reihe nach.
std::unique_ptrkann in Containern und den Algorithmen der STL verwendet werden. Diese Aussage trifft mit der Einschränkung zu, dass diestd::unique_ptrin den STL-Containern und Algorithmen nur Move- und keine Copy-Semantik unterstützen. Wird jedoch einstd::unique_ptrin einem STL-Container kopiert, quittiert dies der Compiler mit einer Fehlermeldung.Der Konstruktor von
std::unique_ptrlässt sich über eine Löschfunktion parametrisieren, die automatisch verwendet wird. Fehlt dieser optionale Parameter, wird auf den Destruktor der Ressource zurückgegriffen. Im Abschnitt „shared_ptr“ werden wir die Anwendung der Löschfunktion in Aktion sehen.std::unique_ptrbesitzt eine Template-Spezialisierung für Arrays:class unique_ptr<T[]>. Optional kann er über eine Löschfunktion weiter parametrisiert werden. Damit sorgt diese Spezialisierung für das automatische Verwalten der Arrays. Mit dem Array lässt sich in gewohnter Weise interagieren, denn der Zugriff auf das Array wird durch dieget-Funktion, der Zugriff auf die Elemente des Arrays durch den Indexoperatoroperator[]unterstützt. Als Default-Löschfunktion wirddelete []angewandt.
Zum Abschluss zeigt Listing 20.5 den Umgang mit einem Array.
uniquePtrArray.cpp
01 #include <iomanip>
02 #include <iostream>
03 #include <memory>
04
05 class MyStruct{
06 public:
07 MyStruct():val(count){
08 std::cout << std::setw(15) << std::left
<< (void*) this << " Hello: " << val
<< std::endl;
09 MyStruct::count++;
10 }
11 ~MyStruct(){
12 std::cout << std::setw(15) << std::left
<< (void*)this << " Good Bye: " << val
<< std::endl;
13 MyStruct::count--;
14 }
15 private:
16 int val;
17 static int count;
18 };
19
20 int MyStruct::count= 0;
21
22 int main(){
23
24 std::cout << std::endl;
25
26 // create a myUniqueArray with five MyStructs
27 {
28
29 std::unique_ptr<MyStruct[]> myUniqueArray
{new MyStruct[5]};
30
31 }
32
33 std::cout << std::endl;
34
35 // create a myUniqueArray
36 // assign an myUnqiueArray element a new MyStruct
37 {
38
39 std::unique_ptr<MyStruct[]> myUniqueArray
{new MyStruct[1]};
40 MyStruct myStruct;
41 myUniqueArray[0]=myStruct;
42
43 }
44
45 std::cout << std::endl;
46
47 // create a myUniqueArray
48 // assign a new MyStruct an myUniqueArray element
49 {
50
51 std::unique_ptr<MyStruct[]> myUniqueArray
{new MyStruct[1]};
52 MyStruct myStruct;
53 myStruct= myUniqueArray[0];
54
55 }
56
57 std::cout << std::endl;
58
59 }Die Datenstruktur MyStruct (Zeile 5) in Listing 20.5 zählt über die statische Variable MyStruct::count mit, wie viele Instanzen der Struktur existieren. Dazu wird sie im Konstruktor in- und im De struktor dekrementiert. Neben ihrem Wert wird in den beiden Funktionen zusätzlich die Adresse der Instanz ausgegeben. Die einfache Verwendung eines std::unique_ptr<MyStruct[]> zeigt Zeile 29. Um den Lebenszyklus der Ressource MyStruct leichter zu verfolgen, wurde die Gültigkeit von std::unique_ptr<MyStruct[]> auf den Bereich (Zeilen 27 bis 31) eingeschränkt. In Abbildung 20.3 ist schön zu sehen, wie die Instanzen vom Typ MyStruct am Ende ihres Gültigkeitsbereichs (Zeile 31) in umgekehrter Reihenfolge ihrer Erzeugung automatisch gelöscht werden. In Zeile 41 wird dem ersten myUniqueArray-Element eine neue MyStruct-Instanz zugewiesen. Aber auch einer neuen MyStruct-Instanz kann ein myUniqueArray-Element in Zeile 53 zugewiesen werden.

vectorUniquePtr.cpp
Aufgabe 20-1
Verwenden Sie einen std::unique_ptr in einem std::vector.
Instanziieren Sie einen Vektor vom Typ std::vector<std::unique_ptr<int>>. Geben Sie seine Elemente ab- und aufsteigend sortiert aus.
shared_ptr
std::shared_ptr stellt den typischen Anwendungsfall für Smart Pointer in C++11 dar. Mit ihm lässt sich eine Ressource gemeinsam nutzen. Jeder std::shared_ptr hält einen Referenzzähler auf einen Zähler und auf eine gemeinsam genutzte Ressource. Wird nun der std::shared_ptr kopiert, wird der Referenzzähler erhöht. Beim Löschen des std::shared_ptr wird dieser dekrementiert. Erreicht der Referenzzähler den Wert 0, führt dies zur automatischen Löschung der Ressource. Der std::shared_ptr bietet ein ähnliches Interface wie der std::unique_ptr und der aus C++98 bekannte std::auto_ptr an. sharedPtr.cpp in Listing 20.6 sollte nach uniquePtr.cpp in Listing 20.1 vertraut wirken.
sharedPtr.cpp
01 #include <iomanip>
02 #include <iostream>
03 #include <memory>
04 #include <utility>
05
06 struct MyStruct{
07 MyStruct(int v):val(v){
08 std::cout << std::setw(10) << std::left
<< (void*) this << " Hello: " << val
<< std::endl;
09 }
10 ~MyStruct(){
11 std::cout << std::setw(10) << std::left
<< (void*)this << " Good Bye: " << val << std::endl;
12 }
13 int val;
14 };
15
16 int main(){
17
18 std::cout << std::endl;
19
20 { // begin of scope
21
22 // Initialize with resource
23 std::shared_ptr<MyStruct> sharedPtr{new MyStruct(0)};
24
25 // use an std::auto_ptr
26 std::auto_ptr<MyStruct> autoPtr{new MyStruct(1)};
27 std::shared_ptr<MyStruct> sharedPtr1{std::move(autoPtr)};
28
29 std::unique_ptr<MyStruct> uniquePtr{new MyStruct(2)};
30 std::shared_ptr<MyStruct> sharedPtr2{std::move(uniquePtr)};
31
32 // Default Constructor
33 std::shared_ptr<MyStruct> sharedPtr3;
34
35 // Move Constructor
36 std::unique_ptr<MyStruct> uniquePtr1{new MyStruct(3)};
37 std::shared_ptr<MyStruct> sharedPtr4{std::move(uniquePtr1)};
38
39 // Move Assignment
40 std::unique_ptr<MyStruct> uniquePtr2{new MyStruct(4)};
41 std::shared_ptr<MyStruct> sharedPtr5= std::move(uniquePtr2);
42
43 // test, if unique owner of the resource
44 std::cout << std::boolalpha << std::endl;
45 std::cout << "sharedPtr5.unique(): "
<< sharedPtr5.unique() << std::endl;
46 std::cout << std::endl;
47
48 // Copy Constructor form a std::shared_ptr
49 std::shared_ptr<MyStruct> sharedPtr6{new MyStruct(5)};
50 std::shared_ptr<MyStruct> sharedPtr7{sharedPtr6};
51
52 // Copy Assignment from a std::shared_ptr
53 std::shared_ptr<MyStruct> sharedPtr8= sharedPtr6;
54
55 // get the reference count
56 std::cout << std::endl;
57 std::cout << "sharedPtr8.use_count(): "
<< sharedPtr8.use_count() << std::endl;
58
59 // access the resource
60 std::cout << std::endl;
61 std::cout << "Address of resource of sharedPtr8"
<< (void*)sharedPtr8.get() << " " << std::endl;
62 std::cout << "Get val: sharedPtr8.get()->val: "
<< sharedPtr8.get()->val << std::endl;
63 std::cout << "Get val: sharedPtr8->val: "
<< sharedPtr8->val << std::endl;
64 std::cout << std::endl;
65
66 // reset the resource
67 sharedPtr8.reset(new MyStruct(8));
68
69 std::cout << std::endl;
70
71 // only sharedPtr8 will be reset
72 std::cout << "sharedPtr6.use_count(): "
<< sharedPtr6.use_count() << std::endl;
73 std::cout << "sharedPtr6.get->val: "
<< sharedPtr6.get()->val << std::endl;
74 std::cout << "sharedPtr7.use_count(): "
<< sharedPtr7.use_count() << std::endl;
75 std::cout << "sharedPtr7.get->val:"
<< sharedPtr7.get()->val << std::endl;
76
77 std::cout << std::endl;
78 std::cout << "sharedPtr8.use_count(): "
<< sharedPtr8.use_count() << std::endl;
79 {
80 std::shared_ptr<MyStruct> sharedPtr9{sharedPtr8};
81 std::shared_ptr<MyStruct> sharedPtr10= sharedPtr9;
82 std::cout << "sharedPtr8.use_count(): "
<< sharedPtr8.use_count() << std::endl;
83 sharedPtr10.reset();
84 std::cout << "sharedPtr8.use_count(): "
<< sharedPtr8.use_count() << std::endl;
85 }
86 std::cout << "sharedPtr8.use_count(): "
<< sharedPtr8.use_count() << std::endl;
87 sharedPtr8.reset();
88
89 std::cout << std::endl;
90
91 // swap the std::shared_ptr
92 sharedPtr2.swap(sharedPtr1);
93 std::swap(sharedPtr2,sharedPtr1);
94
95 } // end of scope
96
97 std::cout << std::endl;
98
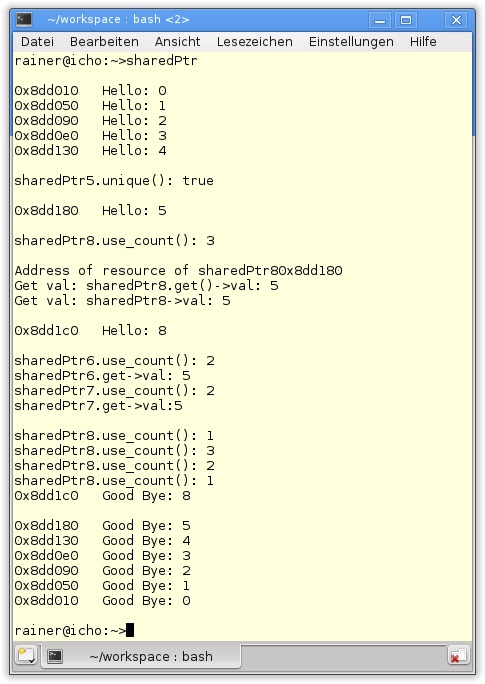
99 }Die einfache Datenstruktur MyStruct aus Listing 20.1 findet in Listing 20.6 ihre Wiederverwendung. Zuerst wird std::shared_ptr in verschiedenen Varianten instanziiert. Das findet in Zeile 23 durch eine Ressource, in Zeile 25 durch einen std::auto_ptr und in Zeile 40 durch ein std::unique_ptr statt. Entsprechend dem std::unique_ptr besitzt der std::shared_ptr auch einen Standardkonstruktor (Zeile 33). Ein std::shared_ptr kann über einen std::unique_ptr initialisiert werden (Zeilen 36 und 40). Mit der Elementfunktion unique lässt sich in Zeile 45 testen, ob der std::shared_ptr als einziger eine Ressource besitzt. Durch den Aufruf des Kopierkonstruktors in Zeile 50 und den Kopierzuweisungsoperator in Zeile 53 besitzt der Referenzzähler sharedPtr8.use_count() in Zeile 57 den Wert 3. std::shared_ptr ist eng verwandt mit std::unique_ptr. Dies ist einfach an den Aufrufen in Zeile 61 bis 63 zu sehen, denn durch sharedPtr8.get() kann auf die Ressource, durch sharedPtr8->val auf den Wert von MyStruct zugegriffen werden.
Erhält die Elementfunktion reset beim Aufruf eine Ressource (Zeile 68), bewirkt dies, dass sharedPtr8 der alleinige Besitzer der neuen Ressource ist. sharedPtr6 und sharedPtr7 teilen sich MyStruct5 aus Zeile 44. Ihr Referenzzähler besitzt jetzt den Wert 2. In dem Bereich zwischen Zeile 80 und Zeile 85 wird der Referenzzähler von sharedPtr8 zu Beginn wieder auf 3 erhöht. sharedPtr10.reset() ohne Argument bewirkt, dass sharedPtr10 zurückgesetzt wird. Der Referenzzähler von sharedPtr8 wird dekrementiert. Dekrementiert wird er nochmals beim Verlassen des Bereichs, denn sharedPtr9 verliert seine Gültigkeit. Ein letztes Mal sharedPtr8.reset() in Zeile 87, und die Ressource MyStruct(8) kann zerstört werden. Zum Abschluss folgt noch ein unspektakuläres Tauschen der std::shared_ptr. Diese lange Ausführung in Prosa lässt sich natürlich auch auf der Konsole in Abbildung 20.4 bewundern.
STL-konform
Praxistipp
Erzeugen Sie die Ressource im Konstruktoraufruf des Smart Pointer.
Die Ressource sollte im Konstruktoraufruf des Smart Pointer erzeugt werden.
Zum einen sorgt der Konstruktor dafür, dass der Speicher wieder freigegeben wird, wenn in einem Aufruf eine Ausnahme vom Typ std::bad_alloc geworfen wird, falls die Speicherzuweisung fehlschlägt. Wird die Ressource nicht im Konstruktor allokiert, sollte durch Ausnahmebehandlung die Freigabe des Speichers sichergestellt werden. Listing 20.7 stellte beide Varianten gegenüber.
01 std::shared_ptr<VeryBig> sp( new VeryBig() );
02
03 try{
04 VeryBig *veryBig= new VeryBig() ;
05 std::shared_ptr<VeryBig> sp1(veryBig);
06 }
07 catch( ... ){
08 // handle the exception
09 }Zum anderen wird dadurch das falsche wiederholte Löschen einer Ressource verhindert. Listing 20.8 zeigt die falsche Benutzung von std::shared_ptr. Um den Blick aufs Wesentliche zu richten, habe ich auf die Ausnahmebehandlung verzichtet.
sharedPtrDouDelete.cpp
01 #include <iomanip>
02 #include <iostream>
03 #include <memory>
04
05 struct MyStruct{
06 MyStruct(int v):val(new int(v)){
07 std::cout << std::setw(10) << std::left
<< (void*) this << " Hello: "
<< *val << std::endl;
08 }
09 ~MyStruct(){
10 std::cout << std::setw(10) << std::left
<< (void*)this << " Good Bye: "
<< *val << std::endl;
11 }
12 int* val;
13 };
14
15 int main(){
16
17 std::cout << std::endl;
18
19 std::cout << std::boolalpha;
20
21 MyStruct* myStruct1= new MyStruct(5);
22 MyStruct* myStruct2= myStruct1;
23
24 std::shared_ptr<MyStruct> sharedPtr1(myStruct1);
25 std::shared_ptr<MyStruct> sharedPtr2(myStruct2);
26
27 std::cout << "sharedPtr1.unique(): "
<< sharedPtr1.unique() << std::endl;
28 std::cout << "sharedPtr2.unique(): "
<< sharedPtr2.unique() << std::endl;
29
30 }Das Ausführen des Programms bringt es in Abbildung 20.5 auf den Punkt.
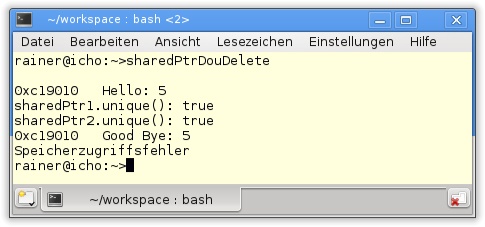
Die zwei
std::shared_ptr sharedPtr1undsharedPtr2in den Zeilen 24 und 25 glauben, alleiniger Besitzer der Ressource zu sein. Beide antworten auf die FragesharedPtr1.unique()bzw.sharedPtr2.unique()mit dem Wahrheitswerttrue. Dies führt dazu, dass beide den Speicher freigeben wollen. Das schlägt beim zweiten Versuch fehl und führt zu einem Speicherzugriffsfehler.
Löschfunktion
std::shared_ptr sowie std::unique_ptr lassen sich über sogenannte Löschfunktionen parametrisieren. In diesem Fall wird zum Löschen der Ressource die benutzerdefinierte Löschfunktion verwendet. Dabei sind die Forderungen an die Löschfunktion d, dass sie eine aufrufbare Einheit ist. Statt delete p für die Ressource p wird in diesem Fall d(p) aufgerufen, wenn die Ressource p destruiert wird. Listing 20.9 zeigt die Anwendung einer Löschfunktion, die darüber hinaus über die statische Variable count mitzählt, wie oft sie schon aufgerufen wurde.
sharedPtrDeleter.cpp
01 #include <iostream>
02 #include <memory>
03 #include <random>
04 #include <typeinfo>
05 #include <utility>
06
07 template <typename T>
08 class Deleter{
09 public:
10 void operator()(T *ptr){
11 ++Deleter::count;
12 // do the actual work
13 delete ptr;
14 }
15 void getInfo(){
16 std::string typeId{typeid(T).name()};
17 size_t sz= Deleter::count * sizeof(T);
18 std::cout << "Deleted " << Deleter::count
<< " objects of type: " << typeId
<< std::endl;
19 std::cout << "Freed size in bytes: " << sz << "."
<< std::endl;
20 std::cout << std::endl;
21
22 }
23 private:
24 static int count;
25 };
26
27 template <typename T>
28 int Deleter<T>::count=0;
29
30 typedef Deleter<int> IntDeleter;
31 typedef Deleter<double> DoubleDeleter;
32
33 void createRandomNumbers(){
34
35 std::random_device seed;
36
37 // generator
38 std::mt19937 engine(seed());
39
40 // distribution
41 std::uniform_int_distribution<int> thousand(1,1000);
42 int ranNumber= thousand(engine);
43 for ( int i=0 ; i <= ranNumber; ++i)
std::shared_ptr<int>(new int(i),IntDeleter());
44
45 }
46
47 int main(){
48
49 std::cout << std::endl;
50
51 // declare a local scope
52 {
53 std::shared_ptr<int> sharedPtr1( new int,IntDeleter() );
54 std::shared_ptr<int> sharedPtr2( new int,IntDeleter() );
55 auto intDeleter=
std::get_deleter<IntDeleter>(sharedPtr1);
56 intDeleter->getInfo();
57 sharedPtr2.reset();
58 intDeleter->getInfo();
59
60 }
61 // create up to 1000 std::shared_ptr of type int
62 createRandomNumbers();
63
64 // declare a local scope
65 {
66
67 // create three Smart pointer for doubles
68 std::unique_ptr<double,DoubleDeleter >
uniquePtr( new double, DoubleDeleter() );
69 std::unique_ptr<double,DoubleDeleter >
uniquePtr1( new double, DoubleDeleter() );
70 std::shared_ptr<double> sharedPtr( new double, DoubleDeleter() );
71
72 std::shared_ptr<double> sharedPtr4(std::move(uniquePtr));
73 std::shared_ptr<double> sharedPtr5= std::move(uniquePtr1);
74
75 }
76
77 IntDeleter().getInfo();
78 DoubleDeleter().getInfo();
79
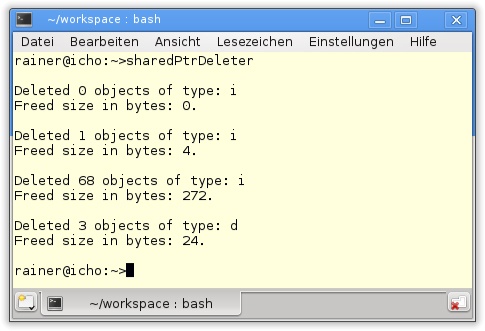
80 }Deleter (Zeile 7) in Listing 20.9 ist eine aufrufbare Einheit. Da sie kopierkonstruierbar ist, lässt sie sich als Löschfunktion anwenden. Tatsächlich ist es ein Klassen-Template, das seine statische Variable count (Zeile 24) im Aufrufoperator (Zeile 10) inkrementiert. Die gesammelte Information stellt das Template über die Funktion getInfo (Zeile 15) zur Verfügung. Die zwei Typsynonyme in Zeile 30 und 31 ersparen ein bisschen Tipparbeit.
Bevor ich das Hauptprogramm beschreibe, noch ein paar Worte zur Funktion createRandomNumbers. Mithilfe der neuen C++11-Zufallszahlen-Bibliothek (siehe Kapitel 19, Abschnitt „Zufallszahlen“) werden bis zu 1.000 verschiedene Zufallszahlen erzeugt und genauso viele std::shared_ptr in Zeile 43 instanziiert. In dem ersten lokalen Bereich in den Zeilen 52 bis 60 werden zwei std::shared_ptr erzeugt. Über den Aufruf std::get_deleter<IntDeleter>(sharedPtr1) steht die Löschfunktion von sharedPtr2 zur Verfügung. Dieser kann benutzt werden, um Information über die Anzahl der Löschaufrufe zu erhalten. Erst nach dem Aufruf von sharedPtr2.reset() wurde ein int-Datentyp gelöscht. Das ist in Abbildung 20.6 schön zu sehen. Genauso gut ist zu sehen, dass die Anzahl der Instanzen vom Typ std::shared_ptr<int> deutlich nach dem Aufruf von createRandom Numbers in Zeile 62 steigt. Deleter ist ein Klassen-Template, sodass sich Smart Pointer von double-Datentypen mit ihm parametrisieren lassen. In den Zeilen 68 und 69 wird dazu std::unique_ptr erzeugt. Durch den Move-Konstruktoraufruf in Zeile 72 und den Move-Zuweisungsaufruf in Zeile 73 werden die std::shared_ptr<double> die neuen Besitzer der Ressource und ihrer Löschfunktion. Dass die Löschfunktion ordentlich Buch führt, zeigt Abbildung 20.6.
shared_ptr von this
Die Funktion std::shared_from_this ist eine praktische Hilfsfunktion, um aus einem bestehenden Objekt einen std::shared_ptr auf dieses zurückzugeben. Dazu ist es lediglich notwendig, dass die Klasse von std::enable_shared_from_this abgeleitet ist.
Die Funktion std::shared_from_this ist einfacher mit dem Listing 20.10 erklärt, als mit vielen Worten beschrieben.
enabledShared.cpp
01 #include <iostream>
02 #include <memory>
03
04 class ShareMe: public std::enable_shared_from_this<ShareMe>{
05 public:
06 std::shared_ptr<ShareMe> getShared(){
07 return shared_from_this();
08 }
09 };
10
11 int main(){
12
13 std::cout << std::endl;
14
15 // share the same ShareMe object
16 std::shared_ptr<ShareMe> shareMe(new ShareMe);
17 std::shared_ptr<ShareMe> shareMe1= shareMe->getShared();
18
19 // both resources have the same address
20 std::cout << "Address of resource of shareMe "
<< (void*)shareMe.get() << " " << std::endl;
21 std::cout << "Address of resource of shareMe1 "
<< (void*)shareMe1.get() << " " << std::endl;
22
23 // the use_count is 2
24 std::cout << "shareMe.use_count(): "
<< shareMe.use_count() << std::endl;
25
26 std::cout << std::endl;
27
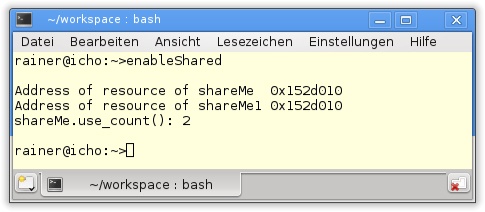
28 }Was in Listing 20.10 wie Magie wirkt, hat in C++ einen Namen: Curiously Recurring Template Pattern (CRTP). SharedMe in Zeile 4 ist solch ein Exemplar. Das Besondere daran ist, dass die abgeleitete Klasse SharedMe Template-Argument der Basisklasse std::enable_shared_from_this ist. Die Details zu diesem bekannten C++-Idiom lassen sich in dem Buch »C++ Templates« von David Vandevoorde und Nicolai Josuttis nachlesen (Vandevoorde & Josuttis, 2002). Das Entscheidende an SharedMe ist, dass die Elementfunktion getShared einen Smart Pointer vom Typ std::shared_ptr<SharedMe> in Zeile 7 zurückgibt. Dazu verwendet die Funktion den Aufruf shared_from_this. Das Hauptprogramm ist unspektakulär. Durch shareMe->getShared() in Zeile 17 wird eine Referenz auf ShareMe zurückgegeben. Dies ist einfach zu sehen. Denn einerseits besitzen die Ressourcen beider Smart Pointer die gleiche Adresse (Zeilen 20 und 21), und andererseits beträgt der shareMe.use_count()-Zähler 2. Beides lässt sich direkt von der Ausgabe in Abbildung 20.7 ablesen.
Konvertierung in Ableitungshierarchien
std::shared_ptr, std::unique_ptr und der im nächsten Abschnitt vorgestellte std::weak_ptr unterstützen die implizite Konvertierung in Ableitungshierarchien. Nur der deprecated std::auto_ptr macht die Ausnahme. So ist ein Konstruktoraufruf std::shared_ptr<Base> sp(new Der) zulässig, falls Der von Base öffentlich abgeleitet ist. Dies trifft nicht nur auf den Konstruktor, den Kopierkonstruktor und den Kopierzuweisungsoperator zu, sondern im Fall von std::shared_ptr auch auf die reset-Elementfunktion. Die gleiche Argumentation für die implizite Konvertierung einer Ressource lässt sich auch direkt auf die Smart Pointer selbst anwenden. Ob die implizite Konvertierung eines Smart Pointer std::shared_ptr<Base> sp(sp1) (sp1 ist vom Typ std::shared_ptr<Der>) zulässig ist, hängt davon ab, ob die Ressource Der von Base öffentlich abgeleitet ist.
dynamic_pointer_cast, static_pointer_cast und const_pointer_cast
std::dynamic_pointer_cast, std::static_pointer_cast und std::const_pointer_cast verhalten sich so wie ihre bekannten Namensverwandten std::dynamic_cast, std::static_cast und std::const_cast aus C++. Dies lässt sich leicht einsehen, denn ein std::dynamic_pointer_cast<Der>(p) setzt voraus, dass dynamic_cast<Der*>(p.get()) gültig ist. Semantisch ist std::dynamic_pointer_cast<Der>(p) äquivalent zu std::shared_ptr<Der>(std::dynamic_cast<Der*>(p.get())). Dies gilt natürlich auch für die Varianten std::static_pointer_cast und std::const_pointer_cast. std::reinterpret_pointer_cast habe ich nicht vergessen. Diese Variante existiert nicht in C++11.
Aufgabe 20-2
Hinterfragen Sie die Verwendung von std::auto_ptr in Ihrem Sourcecode.
std::auto_ptr ist deprecated in C++11. Dass std::auto_ptr deprecated ist und insbesondere die Tatsache, dass std::auto_ptr heimlich die Ressource verschiebt, ist Grund genug, den Sourcecode auf dessen Einsatz zu hinterfragen. Entscheiden Sie daher im Einzelfall, ob std::unique_ptr oder std::shared_ptr der Ersatz für std::auto_ptr ist. Die Umstellung sollte kurz und schmerzlos sein, denn die neuen std::unique_ptr und std::shared_ptr bieten ein sehr ähnliches Interface wie std::auto_ptr an. Lediglich das implizite Verschieben der Ressource ist mit std::unique_ptr nicht möglich und muss mit std::move explizit angefordert werden.
Aufgabe 20-3
Automatisches Speichermanagement mit Ganzzahlen
Variieren Sie das kleine Programm in Listing 20.11. Verwenden Sie einen std::unique_ptr und einen std::shared_ptr für das automatische Verwalten der Ressource und vergleichen Sie die Ausführungszeiten.
#include <chrono>
#include <iostream>
static const long long numInt= 100000000;
int main(){
auto start = std::chrono::system_clock::now();
for ( long long i=0 ; i < numInt; ++i){
int* tmp(new int(i));
delete tmp;
}
std::chrono::duration<double>
dur= std::chrono::system_clock::now() - start;
std::cout << "time native: " << dur.count()
<< " seconds" << std::endl;
}Mit dem GCC 4.7-Compiler und dem Optimierungsflag -03 übersetzt, erhalte ich die folgenden Zeitangaben.
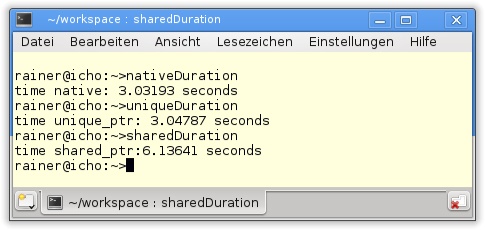
Damit ist std::unique_ptr genauso schnell wie das direkte Löschen der Ressource. std::shared_ptr benötigt ca. doppelt so lang.
nativeDuration.cpp
uniqueDuration.cpp
sharedDuration.cpp
Aufgabe 20-4
Verifizieren Sie die Aussagen zur Konvertierung in Ableitungshierarchien.
Leiten Sie eine Klasse public, protected und private von einer Klasse Base ab. Initialisieren Sie einen Smart Pointer std::shared_ptr<Base>, indem Sie die drei abgeleiteten Klassen von Base verwenden.
Entspricht das Ergebnis Ihren Erwartungen?
Aufgabe 20-5
Eine mögliche Implementierung von std::enable_shared_from_this.
Wem die Erläuterung zu std::enable_shared_from_this im Abschnitt „shared_ptr von this“ nicht ausreicht, der sei auf eine mögliche Implementierung aus dem Standardentwurf N3242 (Becker, Working Draft, Standard for Programming Language C++ (N3242), 2011) von Pete Becker verwiesen.
template<class T>
class enable_shared_from_this {
private:
weak_ptr<T> __weak_this;
protected:
constexpr enable_shared_from_this() : __weak_this() { }
enable_shared_from_this(enable_shared_from_this const &) { }
enable_shared_from_this& operator=(enable_shared_from_this
const &) { return *this; }
~enable_shared_from_this() { }
public:
shared_ptr<T> shared_from_this() { return
shared_ptr<T>(__weak_this); }
shared_ptr<T const> shared_from_this() const { return
shared_ptr<T const>(__weak_this); }
};weak_ptr
Der std::weak_ptr ist kein Smart Pointer im eigentlichen Sinn, denn er bietet keinen transparenten Zugriff auf seine Ressource. Er besitzt nicht einmal eine Ressource, er bekommt sie von einem std::shared_ptr geliehen. Da er nicht der Besitzer der Ressource ist, verändert er auch nicht den Referenzzähler auf diese. Die Existenzberechtigung für den std::weak_ptr ist es, zyklische Referenzen von std::shared_ptr aufzubrechen. Dazu reicht ihm ein einfaches Interface aus. Bevor zyklische Referenzen unser Thema sein werden, ein bewährter Blick auf die Schnittstelle von std::weak_ptr in Listing 20.12.
weakPtr.cpp
01 #include <iostream>
02 #include <memory>
03
04 class MyInt{
05 public:
06
07 MyInt(int i):i_(i){}
08 int get() const{ return i_; }
09
10 private:
11 int i_;
12 };
13
14 int main(){
15
16 std::cout << std::endl;
17
18 std::cout << std::boolalpha;
19
20 // default constructor
21 std::weak_ptr<MyInt> weakPtr;
22 std::cout << "weakPtr.use_count(): "
<< weakPtr.use_count() << std::endl;
23 std::cout << "weakPtr.expired(): " << weakPtr.expired()
<< std::endl;
24
25 std::cout << std::endl;
26
27 std::shared_ptr<MyInt> sharedPtr(new MyInt(2011));
28 std::cout << "sharedPtr.use_count(): "
<< sharedPtr.use_count() << std::endl;
29
30 // initialize weakPtr
31 weakPtr= sharedPtr;
32 std::cout << "weakPtr.use_count(): "
<< weakPtr.use_count() << std::endl;
33 std::cout << "weakPtr.expired(): " << weakPtr.expired()
<< std::endl;
34
35 std::weak_ptr<MyInt> weakPtr1(sharedPtr);
36
37 std::cout << std::endl;
38
39 // refer to the resource
40 std::cout << "sharedPtr->get(): " << sharedPtr->get()
<< std::endl;
41 // will not work with weakPtr
42 // std::cout << "weakPtr->get()" << weakPtr->get()
<< std::endl;
43
44 if(std::shared_ptr<MyInt> sharedPtr1 = weakPtr.lock()) {
45 std::cout << "sharedPtr->get(): " << sharedPtr->get()
<< std::endl;
46 }
47 else{
48 std::cout << "Don't get the resource!" << std::endl;
49 }
50
51 std::cout << std::endl;
52
53 // reset the weakPtr
54 weakPtr.reset();
55 if(std::shared_ptr<MyInt> sharedPtr1 = weakPtr.lock()) {
56 std::cout << "sharedPtr->get(): "
<< sharedPtr->get() << std::endl;
57 }
58 else{
59 std::cout << "Don't get the resource!" << std::endl;
60 }
61
62 // swap weakPtr2 and weakPtr3
63
64 std::cout << std::endl;
65 std::shared_ptr<MyInt> sharedPtr2(new MyInt(2));
66 std::shared_ptr<MyInt> sharedPtr3(new MyInt(3));
67 std::weak_ptr<MyInt> weakPtr2(sharedPtr2);
68 std::weak_ptr<MyInt> weakPtr3(sharedPtr3);
69
70 if(std::shared_ptr<MyInt> sharedFromWeak2 =
weakPtr2.lock()) {
71 std::cout << "sharedFromWeak2->get(): "
<< sharedFromWeak2->get() << std::endl;
72 }
73
74 std::cout << std::endl;
75
76 weakPtr2.swap(weakPtr3);
77 if(std::shared_ptr<MyInt> sharedFromWeak2 =
weakPtr2.lock()) {
78 std::cout << "sharedFromWeak2->get(): "
<< sharedFromWeak2->get() << std::endl;
79 }
80
81 std::cout << std::endl;
82
83 std::swap(weakPtr2,weakPtr3);
84 if(std::shared_ptr<MyInt> sharedFromWeak2 =
weakPtr2.lock()) {
85 std::cout << "sharedFromWeak2->get(): "
<< sharedFromWeak2->get() << std::endl;
86 }
87
88 std::cout << std::endl;
89
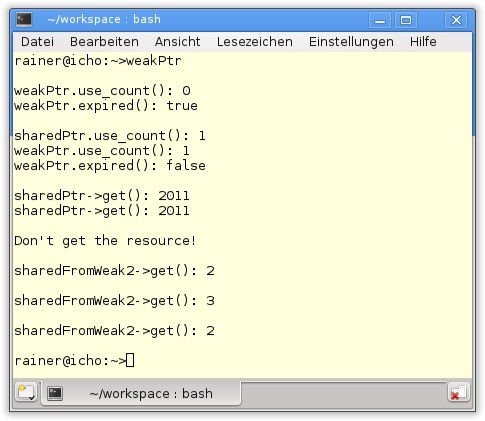
90 }Die Klasse MyInt (Zeile 4) in Listing 20.12 ist lediglich eine dünne Hülle um den Datentyp int. Mit ihm lässt sich der Zugriff auf die Ressource einfach demonstrieren. std::weak_ptr besitzt einen Default-Konstruktor. Ohne eine Ressource besitzt weakPtr.use_count() in Zeile 22 den Wert 0 und weakPtr.expired() in Zeile 23 den Wert true. Das ändert sich, nachdem sharedPtr in Zeile 27 eine Ressource erhält, mit der weakPtr in Zeile 31 initialisiert wird. Ich will aber nochmals explizit darauf hinweisen, dass durch den Ausdruck weakPtr= sharedPtr in Zeile 31 der Referenzzähler nicht erhöht wird. Ein std::weak_ptr lässt sich auch direkt über einen std::shared_ptr (Zeile 35) initialisieren. Der std::weak_ptr bietet keine Schnittstelle für die direkte Adressierung der Ressource an. Dazu muss der Umweg über einen weakPtr.lock()-Aufruf und den resultierenden std::shared_ptr gegangen werden. In den Zeilen 44 bis 49 ist der idiomatische Weg dargestellt. Wird std::weak_ptr zurückgesetzt (Zeile 54), gibt weakPtr.lock() einen std::shared_ptr<MyInt>() zurück. Dieser evaluiert in dem logischen Ausdruck zu false, sodass der else-Zweig in Zeile 59 ausgeführt wird. Das bisher Ausgeführte und die Anwendung der swap-Funktion in den folgenden Zeilen lässt sich auf bekannte Art und Weise bildlich in Abbildung 20.9 verfolgen.
Zyklische Referenzen
Nun zum eigentlichen Einsatzgebiet von std::weak_ptr, dem Aufbrechen von zyklischen Referenzen des std::shared_ptr. Bevor wir uns aber die Lösung anschauen, sollten wir zuerst eine zyklische Referenz bilden.
Die zyklische Referenz in Listing 20.14 ist nach folgendem Rezept gebaut.
Nehmen Sie zwei Knoten Node mit einem next-Zeiger vom Typ std::shared_ptr<Node>. Verbinden Sie die next-Zeiger der zwei Knoten miteinander, und Sie erhalten eine zyklische Referenz.

Das Listing 20.14 folgt der Struktur von Abbildung 20.10:
cycle.cpp
01 #include <iostream>
02 #include <memory>
03
04 class Node{
05 public:
06 Node(const std::string& n):name(n){}
07
08 ~Node(){
09 std::cout << "destructor invoked" << std::endl;
10 }
11
12 void setNext( std::shared_ptr<Node>n ){
13 next= n;
14 }
15
16 std::string getName() const { return name; }
17
18 void getCycle() const{
19 std::cout << "this" << std::endl;
20 std::cout << " (" << getName() << ":"
<< (void*)this << ")" << std::endl;
21 std::cout << "this->next" << std::endl;
22 std::cout << " (" << next->getName() << ":"
<< (void*)next.get() << ")" << std::endl;
23 std::cout << "this->next->next" << std::endl;
24 std::cout << " (" << next->next->getName()
<< ":" << (void*)next->next.get() << ")"
<< std::endl;
25
26 }
27
28 private:
29 std::string name;
30 std::shared_ptr<Node> next;
31 };
32
33
34
35 int main(){
36
37 std::cout << std::endl;
38
39 {
40
41 // create the Nodes and give them names
42 Node* head= new Node("head");
43 Node* tail= new Node("tail");
44 std::cout << "head->getName(): " << head->getName()
<< std::endl;
45 std::cout << "tail->getName(): " << tail->getName()
<< std::endl;
46
47 std::cout << std::endl;
48
49 // create the shared pointer
50 std::shared_ptr<Node> spForHead(head);
51 head->setNext(std::shared_ptr<Node>(tail));
52
53 // close the cycle
54 tail->setNext(spForHead);
55
56 // show the cycle
57 spForHead->getCycle();
58
59 }
60
61 std::cout << std::endl;
62
63 }Node (Zeile 4) in Listing 20.14 ist der im Rezept zitierte Knoten. Dieser enthält einen Namen, einen Destruktor in Zeile 8, der anzeigt, wann er aufgerufen wurde. Der Knoten erhält darüber hinaus eine Elementfunktion, um den std::shared_ptr<Node> in Zeile 12 zu setzen, und eine Elementfunktion getCycle, die die ganze zyklische Referenz ausgibt. Zuerst werden in den Zeilen 42 und 43 die zwei Knoten instanziiert, anschließend werden deren Namen ausgegeben. Der Knoten head wird in Zeile 50 in einen std::shared_ptr<Node> verpackt, und dessen next–Zeiger wird auf den ebenfalls frisch verpackten Knoten tail in Zeile 51 gesetzt. Die zyklische Referenz lässt sich in der Ausgabe des Programms in Abbildung 20.11 direkt und indirekt erkennen.
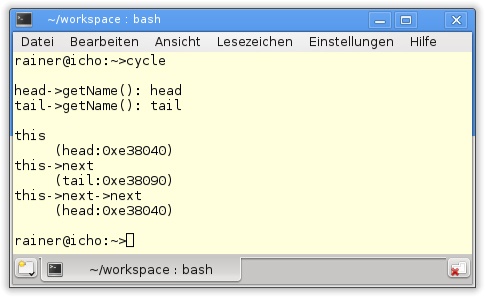
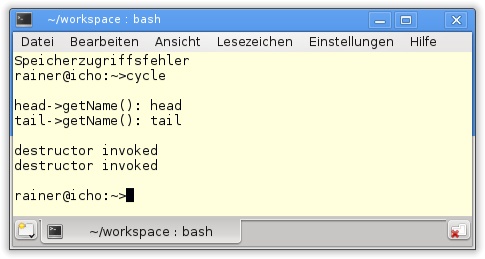
Direkt, denn die Ausgabe von getCycle zeigt in Abbildung 20.11 sehr schön, dass zweimaliges Verfolgen des next-Zeigers wieder zum Ursprungszeiger zurückführt. Der Name und die Adresse des Ursprungszeigers sind in Abbildung 20.11 (head:0x604040) dargestellt, und dieses Wertepaar taucht in identischer Form im übernächsten Knoten auf. Indirekt, denn der Destruktor des Knotens wird nicht aufgerufen. Dass der Destruktor aufgerufen wird, zeigt das Auskommentieren der Zeilen 52 bis 58. Dadurch wird der Zyklus nicht geschlossen, und das Programm verhält sich anständig (Abbildung 20.12).
Die Lösung der zyklischen Referenz ist relativ einfach. Ein next-Zeiger vom Typ std::shared_ptr<Node> wird durch einen std::weak_ptr<Node> ausgetauscht. Der Komfort eines echten Smart Pointer std::shared_ptr<Node> ist natürlich dahin, denn um auf den nächsten std::shared_ptr<Node> mittels next zuzugreifen, muss der std::weak_ptr<Node> in einen std::shared_ptr<Node> konvertiert werden. Damit wird die Funktion getCycle noch komplizierter zu implementieren.
In Listing 20.15 folgt die angepasste Implementierung.
cycleBreak.cpp
01 #include <iostream>
02 #include <memory>
03
04 class Node{
05 public:
06 Node(const std::string& n):name(n){}
07
08 ~Node(){
09 std::cout << "destructor invoked" << std::endl;
10 }
11
12 void setWeakNext( std::shared_ptr<Node> n ){
13 weak_next= n;
14 }
15
16 void setSharedNext( std::shared_ptr<Node> n ){
17 shared_next= n;
18 }
19
20 std::string getName() const { return name; }
21
22 void getCycle() const{
23 std::cout << "this" << std::endl;
24 std::cout << " (" << getName() << ":"
<< (void*)this << ")" << std::endl;
25 std::cout << "this->next" << std::endl;
26 std::cout << " (" << shared_next->getName()
<< ":" << (void*)shared_next.get() << ")"
<< std::endl;
27 if (std::shared_ptr<Node> next =
shared_next->weak_next.lock()) {
28 std::cout << "this->next->next" << std::endl;
29 std::cout << " (" << next->getName() << ":"
<< (void*)next.get() << ")" << std::endl;
30 }
31 }
32
33 private:
34 std::string name;
35 std::weak_ptr<Node> weak_next;
36 std::shared_ptr<Node> shared_next;
37 };
38
39
40
41 int main(){
42
43 std::cout << std::endl;
44
45 {
46
47 // create the Nodes and give them names
48 Node* head= new Node("head");
49 Node* tail= new Node("tail");
50 std::cout << "head->getName(): " << head->getName()
<< std::endl;
51 std::cout << "tail->getName(): " << tail->getName()
<< std::endl;
52
53 std::cout << std::endl;
54
55 // create the shared pointer
56 std::shared_ptr<Node> spForHead(head);
57 head->setSharedNext(std::shared_ptr<Node>(tail));
58
59 // close the cycle
60 tail->setWeakNext(spForHead);
61
62 // show the cycle
63 spForHead->getCycle();
64
65 std::cout << std::endl;
66
67 }
68
69 std::cout << std::endl;
70
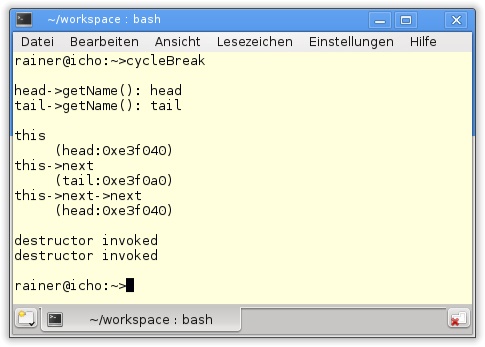
71 }Sowohl die zyklische Referenz als auch den Aufruf der beiden Konstruktoren zeigt Abbildung 20.13.
Aufgabe 20-6
Versuchen Sie, einen std::weak_ptr mehrmals zu locken.
Der Rückgabewert von weak.lock() für einen std::weak_ptr weak wird als
expired()? shared_ptr<T>(): shared_ptr<T>(*this)
beschrieben. Verifizieren Sie, dass das Locken eines std::weak_ptr nur dann einen Default-initialisierten std::shared_ptr<T>() zurückgibt, wenn der weak_ptr verfallen (expired) ist. Dies ist genau dann der Fall, wenn der use_count von std::weak_ptr 0 ist. Lange Rede, kurzer Sinn: Ein std::weak_ptr kann öfter gelockt werden.
Neue Container
Lange vermisst, gibt es in C++11 nun die Möglichkeit, Hashtabellen einzusetzen. Hashtabellen sind unverzichtbare Container, wenn die Performance im Vordergrund steht. Neben Hashtabellen bietet C++11 aber noch weitere mächtige Container an: std::tuple erweitert das C++-Paar std::pair, das std::array vereinigt das Beste aus dem C-Array mit dem C++-Vektor, und die einfache verkettete Liste std::forward_list ist auf minimale Speicheranforderungen getrimmt.
Tupel
<tuple>
std::tuple ist eine Verallgemeinerung des heterogenen STL-Containers std::pair. Beim std::tuple gilt die Einschränkung auf ein Paar nicht mehr, denn er kann beliebig viele Elemente annehmen. Leider ist es dem std::tuple anzusehen, dass er ein Template ist. Das zeigt sich beim Zugriff auf seine Elemente, und das zeigt auch die Iteration über das Tupel in Listing 20.16.
tupleInterface.cpp
01 #include <iostream>
02 #include <string>
03 #include <tuple>
04 #include <typeinfo>
05
06 class MyInt{
07 public:
08 MyInt(int i): val(i){}
09 int getVal() const{
10 return val;
11 }
12 private:
13 int val;
14 };
15
16 bool operator < (const MyInt& l, const MyInt& r){
17 return l.getVal() < r.getVal();
18 }
19
20 std::ostream& operator << (std::ostream& strm,
const MyInt& myIn){
21 strm << "MyInt(" << myIn.getVal() << ")";
22 return strm;
23 }
24
25
26 int main(){
27
28 std::cout << std::endl;
29
30 std::cout << std::boolalpha;
31
32 // creating tuples
33 std::tuple<int,double> tup0;
34 std::pair<int,int> pair(2011,2011.5);
35 tup0= pair;
36 std::tuple<std::string,int,float> tup1("tup1",3,4.17);
37 std::tuple<std::string,int,double> tup2("tup2",4,1.1);
38
39 // print the values
40 std::cout << "tup1: " << std::get<0>(tup1) << ","
<< std::get<1>(tup1) << ","
<< std::get<2>(tup1) << std::endl;
41 std::cout << "tup2: " << std::get<0>(tup2) << ","
<< std::get<1>(tup2) << ","
<< std::get<2>(tup2) << std::endl;
42
43 // compare them
44 std::cout << "tup1 < tup2: " << (tup1 < tup2)
<< std::endl;
45
46 std::cout << std::endl;
47
48 // modify a tuple value
49 std::get<0>(tup2)= "Tup2";
50
51 // print the values
52 std::cout << "tup1: " << std::get<0>(tup1) << ","
<< std::get<1>(tup1) << ","
<< std::get<2>(tup1) << std::endl;
53 std::cout << "tup2: " << std::get<0>(tup2) << ","
<< std::get<1>(tup2) << ","
<< std::get<2>(tup2) << std::endl;
54
55 // compare them
56 std::cout << "tup1 < tup2: " << (tup1 < tup2)
<< std::endl;
57
58 std::cout << std::endl;
59
60 // use MyInt
61 std::tuple<MyInt,int> tup3(MyInt(1),2011);
62 std::tuple<MyInt,int> tup4(MyInt(0),2011);
63
64 // print the values
65 std::cout << "tup3: " << std::get<0>(tup3) << ","
<< std::get<1>(tup3) << std::endl;
66 std::cout << "tup4: " << std::get<0>(tup4) << ","
<< std::get<1>(tup4) << std::endl;
67
68 std::cout << "tup3 < tup4: " << (tup3 < tup4)
<< std::endl;
69
70 std::cout << std::endl;
71
72 // modify a tuple value
73 std::get<0>(tup4)= MyInt(2011);
74
75 // print the values
76 std::cout << "tup3: " << std::get<0>(tup3) << ","
<< std::get<1>(tup3) << std::endl;
77 std::cout << "tup4: " << std::get<0>(tup4) << ","
<< std::get<1>(tup4) << std::endl;
78
79 std::cout << "tup3 < tup4: " << (tup3 < tup4)
<< std::endl;
80
81 std::cout << std::endl;
82
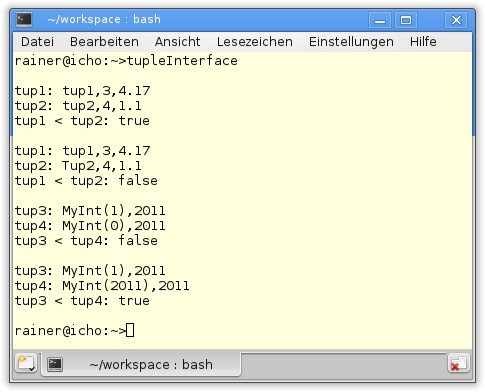
83 }Listing 20.16 zeigt eine kleine Tour durch die wichtigsten std::tuple-Funktionen. Die Klasse MyInt in Zeile 6 ist die bekannte Hülle um den Datentyp int. Um ihn auf kleiner (<) vergleichen und ausgeben zu können, sind sowohl der Vergleichsoperator für kleiner als auch der Ausgabeoperator überladen. Dazu aber am Ende des Programms mehr. Zuerst werden in verschiedenen Varianten std::tuple erzeugt. In Zeile 33 wird ein Default-konstruiertes Tupel definiert, das in Zeile 35 durch ein std::pair initialisiert wird. Dabei wird das zweite Argument von int nach double konvertiert. Die Elemente der zwei folgenden Tupel tup1 und tup2 werden anschließend ausgegeben, und die Tupel werden verglichen. Auf das erste Element des Tupels tup1 lässt sich mithilfe des Aufrufs std::get<0> (tup1) sowohl lesend (Zeile 40) als auch schreibend (Zeile 49) zugreifen. Nachdem das erste Element von tup1 modifiziert wurde, gibt der Vergleich in Zeile 56 false aus. Das gleiche Spiel ist mit dem eigenen Datentyp MyInt möglich, da für ihn der entsprechende Vergleichsoperator und der Ausgabeoperator definiert wurden. In den Zeilen 61 und 62 werden dazu die zwei std::tuple tup3 und tup4 definiert. Die aufwendige Ausgabe und der Vergleich der std::tuple sind in Abbildung 20.14 dargestellt.
Hilfsfunktionen
Die zwei Hilfsfunktionen std::make_tuple und std::tie vereinfachen den Umgang mit std::tuple. Werden diese praktischen Erzeugungsfunktionen mit dem neuen Schlüsselwort auto kombiniert, reduziert sich der Schreibaufwand auf das Notwendigste.
make_tuple
War std::make_pair in C++98 eine praktische Hilfsfunktion, um std::pair-Datentypen zu erzeugen, so ist es std::make_tuple für std::tuple. Diese Erzeugerfunktion ist ein Funktions-Template, das den Typ der Template-Parameter automatisch aus dem Argument ableitet. Vereinfacht gesagt, erzeugt ein Aufruf std::make_tuple(1,'a',3.14) dank automatischer Typableitung ein Tupel der Form std::tuple<type(1),type('a'),type(3.14)>(1,'a',3.14). Kommen die Refererenz-Wrapper std::ref oder std::cref für die Argumente der Tupel zum Einsatz, werden Referenzen oder konstante Referenzen erzeugt.
Deutlich einfacher ist dies mit der weiteren Hilfsfunktion std::tie, die ein Tupel erzeugt, das nur Referenzen auf Objekte hält. Wird der Rückgabewert von std::tie ignoriert, ist std::tie eine einfache Möglichkeit, ein bestehendes std::tuple in Variablen zu entpacken. Dabei können Argumente des zu entpackenden Tupels mit std::ignore ignoriert werden.
Genug der Worte. Listing 20.17 soll für Klarheit sorgen. Der Übersichtlichkeit halber werden in dem Beispiel nur Tupel von int-Datentypen verwendet.
helperTuple.cpp
01 #include <functional>
02 #include <iostream>
03 #include <tuple>
04
05 int main(){
06
07 std::cout << std::endl;
08
09 // make a tuple
10 auto tup1= std::make_tuple(1,2,3);
11
12 // print the values
13 std::cout << "std::tuple tup1: ("
<< std::get<0>(tup1) << ","
<< std::get<1>(tup1) << ","
<< std::get<2>(tup1) << ")" << std::endl;
14
15 std::cout << std::endl;
16
17 int first= 1;
18 int second= 2;
19 int third= 3;
20 int fourth= 4;
21
22 // create a tuple with references
23 auto tup2= std::make_tuple(
std::cref(first),std::ref(second),std::ref(third),fourth);
24
25 // print the values
26 std::cout << "std::tuple tup2: (" << std::get<0>(tup2)
<< "," << std::get<1>(tup2) << ","
<< std::get<2>(tup2) << ","
<< std::get<3>(tup2) << ")" << std::endl;
27
28 std::cout << std::endl;
29
30 //change the values
31 // will not work, because of std::cref(first)
32 // std::get<0>(tup2)= 1001;
33 first= 1001;
34 std::get<1>(tup2)=1002;
35 third= 1003;
36 fourth= 1004;
37
38 // print the values
39 std::cout << "std::tuple tup2: (" << std::get<0>(tup2)
<< "," << std::get<1>(tup2)
<< "," << std::get<2>(tup2)
<< "," << std::get<3>(tup2) << ")" << std::endl;
40 std::cout << "global variables: " << first
<< " " << second << " " << third
<< " " << fourth << std::endl;
41
42 std::cout << std::endl;
43
44 first= 1;
45 second= 2;
46 third= 3;
47 fourth= 4;
48
49 // create tup3 and set the variables
50 auto tup3= std::tie(first,second,third,fourth)=
std::make_tuple(1001,1002,1003,1004);
51
52 // print the values
53 std::cout << "std::tuple tup3: (" << std::get<0>(tup3)
<< "," << std::get<1>(tup3)
<< "," << std::get<2>(tup3)
<< "," << std::get<3>(tup3) << ")" << std::endl;
54 std::cout << "global variables: " << first << " "
<< second << " " << third << " "
<< fourth << std::endl;
55
56 std::cout << std::endl;
57
58 int a;
59 int b;
60
61 // bind the 2th and 4th argument to a and b
62 std::tie(std::ignore,a,std::ignore,b)= tup3;
63
64 // print the values
65 std::cout << "a: " << a << std::endl;
66 std::cout << "b: " << b << std::endl;
67
68 std::cout << std::endl;
69
70 // will also work for std::pair
71 std::tie(a,b)= std::make_pair(3001,3002);
72
73 // print the values
74 std::cout << "a: " << a << std::endl;
75 std::cout << "b: " << b << std::endl;
76
77 std::cout << std::endl;
78
79 }Das Erzeugen eines Tupels in Listing 20.17 geht in Zeile 10 dank std::make_pair und automatischer Typableitung mit auto schnell von der Hand. In Zeile 23 werden die Argumente von tup2 auf verschiedene Arten an die Variablen gebunden. first wird als konstante Referenz adressiert, second und third als Referenz. Lediglich fourth wird kopiert. Diese Bindungen bewirken, dass das erste Element nicht über das Tupel-Interface modifiziert werden kann (Zeile 32). Dagegen sind second und third sowohl über das Tupel-Interface std::get<1>(tup2)= 1001 in Zeile 33 als auch die Variable third modifizierbar. Die Ausgabe in Abbildung 20.15 zeigt, dass die Variablenzuweisung fourth=4 in Zeile 47 keine Auswirkung auf tup2 besitzt. Dies ist nicht verwunderlich, wurde das vierte Argument von tup2 in Zeile 23 doch mit Copy-Semantik versehen. std::tie in Zeile 50 erzeugt ein std::tuple aus Referenzen. Damit ist die Anwendung von std::ref auf die Tupel-Argumente nicht mehr notwendig. Zeile 50 hat mehr Aufmerksamkeit verdient. Durch std::make_tuple(1001,1002,1003,1004) lässt sich ein Tupel erzeugen. Dies wird std::tie(first,second,third,fourth) zugewiesen. std::tie erledigt zwei Aufgaben. Zuerst entpackt die Funktion das Tupel in die Variablen first, second, third und fourth. Anschließend gibt sie ein Tupel zurück, das Referenzen auf diese vier Variablen hält. Zuletzt wird das Tupel an die Variable tup3 gebunden.

Das von std::tie erzeugte Tupel muss aber an keine Variable gebunden werden. In Zeile 62 werden nur die Werte der Variablen a und b als reiner Seiteneffekt des Aufrufs des Funktions-Templates std::tie gesetzt. Da tup3 vier Argumente besitzt und nur zwei Argumente in dem Aufruf von std::tie verwendet werden, werden die überflüssigen Argumente durch std::ignore ignoriert. Dass std::tuple nur eine Verallgemeinerung von std::pair ist, zeigt ein weiteres Mal Zeile 71, denn std::tie kann den Rückgabewert von std::make_pair annehmen.
tuple_element und tuple_size
Einen kleinen Vorgeschmack auf Template-Metaprogramming liefert das Listing 20.18, denn in ihm wird alles zur Übersetzungszeit ausgewertet. Dabei hilft die Funktion std::tuple_element, denn durch den Aufruf std::tuple_element<i,tuple>::type steht der Typ des i-ten Elements des Tupels tuple zur Verfügung. Die Länge des Tupels tuple lässt sich durch die Funktion std::tuple_size<tuple> ermitteln.
tupleMeta.cpp
01 #include <iostream>
02 #include <tuple>
03
04 typedef std::tuple<std::string,double,bool> tup1;
05
06 template <int v>
07 struct Int2Type {
08 const static int value= v;
09 };
10
11 typedef std::tuple<Int2Type<2000>,Int2Type<10>,
Int2Type<1>> tup2;
12
13 int main(){
14
15 std::cout << std::endl;
16
17 std::cout << std::boolalpha;
18
19 std::tuple_element<0,tup1>::type fir= "meta-programming";
20 std::tuple_element<1,tup1>::type sec= 3.14;
21 std::tuple_element<2,tup1>::type thir= true;
22
23 std::cout << fir << std::endl;
24 std::cout << sec << std::endl;
25 std::cout << thir << std::endl;
26
27 std::cout << std::endl;
28
29 std::cout << "std::tuple_size<tup1>::value: "
<< std::tuple_size<tup1>::value << std::endl;
30
31 std::cout << std::endl;
32
33 typedef std::tuple_element<0,tup2>::type twoThousand;
34 typedef std::tuple_element<1,tup2>::type ten;
35 typedef std::tuple_element<2,tup2>::type one;
36
37 const int actYear= twoThousand::value + ten::value +
one::value;
38
39 static_assert(actYear == 2011 ,"Will be done at
compiletime");
40
41 std::cout << "The actual year: " << actYear << std::endl;
42
43 std::cout << std::endl;
44
45 }Zeile 4 in Listing 20.18 definiert das Typsynonym tup1. Dieses kann benutzt werden, um die Datentypen std::string fir, double sec oder auch bool thir zu erklären. In den Zeilen 19 bis 21 wird dazu std::tuple_element<0,tup1>::type auf die einzelnen Elemente von tup1 angewandt, um den entsprechenden Datentyp zu erhalten. Die Länge von tup1 steht in Zeile 29 durch std::tuple_size<tup1>::value zur Verfügung. Es ist eine Konvention in der Template-Metaprogrammierung, Typen über ::type und Werte über ::value anzubieten. Ein Typsynonym tup2 zu erklären, das unter der Decke einen Wert beinhaltet, das wird durch das bekannte Idiom Int2Type von Andrei Alexandrescu aus »Modern C++ Design« (Alexandrescu, 2001) erreicht. Der Datentyp Int2Typ ist eine dünne Hülle um eine natürliche Zahl v, die über die statische Variable value abgefragt werden kann. So ist Int2Type<2000> ein Typ, der die Zahl 2000 beherbergt. Um mit den Werten zu rechnen, werden die Datentypen in den Zeilen 33 bis 35 instanziiert, und in Zeile 37 wird ihr Wert referenziert. Das Ergebnis steht zur Übersetzungszeit zur Verfügung, denn die statische Zusicherung in Zeile 39 wird eingehalten. In Zeile 41 wird zuletzt das Ergebnis der Addition ausgegeben. Zugegeben, es gibt einfachere Arten, Zahlen zu addieren. In Abbildung 20.16 ist die Ausgabe des Programmlaufs zu sehen.

fourReturnValues.cpp
Aufgabe 20-7
Schreiben Sie eine Funktion, die vier heterogene Typen zurückgibt.
Die Funktion returnFourValues ist nicht vollständig implementiert. Vervollständigen Sie die Funktion und geben Sie ihre Werte aus.
??? returnFourValues(){
int a= 5;
double b= 10.1;
std::string c= "test";
bool c= true;
return ??? a, b, c, d
}Der klassische C++-Weg bestand darin, eine Struktur zu definieren, die die vier Typen bindet, und diese Struktur als Rückgabewert zu verwenden. In C++11 gibt es einen einfacheren und besseren Weg.
Aufgabe 20-8
Implementieren Sie die Funktion divmod, die für die Division von zwei Ganzzahlen den ganzen Anteil und den Rest der Division zurückgibt.
divmod ist eine bekannte Funktion aus Python. Aus der Dokumentation von Python: divmod(x, y) -> (div, mod). Sie können das Ergebnis der Operation als Tupel oder einfach nur als Paar zurückgeben.
tupleArrayComp.cpp
tupleArrayCompSolution.cpp
Aufgabe 20-9
std::array ist mit std::tuple verwandt.
Ist std::array ein sequenzieller Container, ist es auch entfernt verwandt mit std::tuple.
01 #include <iostream>
02 #include <tuple>
03
04 int main(){
05
06 std::cout << std::endl;
07
08 typedef std::tuple<int,int,int> IntTuple;
09
10 IntTuple intTuple(1,2,3);
11
12 std::cout << "std::tuple_size<IntTuple>::value: "
<< std::tuple_size<IntTuple>::value
<< std::endl;
13 typedef std::tuple_element<0,IntTuple>::type MyInt;
14 MyInt a= 5;
15
16 std::cout << "a: " << a << std::endl;
17
18 std::cout << "intTuple: "
19 << std::get<0>(intTuple) << ","
20 << std::get<1>(intTuple) << ","
21 << std::get<2>(intTuple) << std::endl;
22
23 std::cout << std::endl;
24
25 }Portieren Sie Listing 20.19 auf std::array<int,3> und führen Sie das Programm aus.
Array
std::array lässt sich kurz und knapp charakterisieren: std::array vereint die Speicher- und Laufzeitanforderungen des C-Arrays mit einem STL-konformen Interface. Das Beste aus beiden Welten.
<array>
Ein bisschen detaillierter soll es aber schon sein. Der neue Standardcontainer std::array ist ein sequenzieller Container fester Länge, der wahlfreien Zugriff erlaubt. Damit schließt er genau die Lücke zwischen dem C-Array und dem C++-std::vector. Mit dem C-Array hat er gemein, dass er keinen zusätzlichen Speicher benötigt, und mit std::vector, dass er STL-konform ist. Selbst mit dem std::tuple teilt sich std::array einige Eigenschaften. So lässt sich ein Element mit der get-Elementfunktion referenzieren. Dazu im Listing 20.20 mehr.
arrayInterface.cpp
01 #include <algorithm>
02 #include <array>
03 #include <iostream>
04 #include <iterator>
05
06 const int NUM= 10;
07
08 int main(){
09
10 std::cout << std::endl;
11
12 std::cout << std::boolalpha;
13
14 // not value initialized
15 std::array<int,NUM> arr1;
16 std::cout << "arr1: ";
17 std::copy(arr1.begin(),arr1.end(),
std::ostream_iterator<int>(std::cout, " "));
18
19 std::cout << std::endl;
20 std::cout << std::endl << "arr2: ";
21
22 // value-initialization
23 std::array<int,NUM> arr2= {};
24 std::array<int,NUM>::const_iterator arrIt;
25 for( arrIt= arr2.begin(); arrIt != arr2.end(); ++arrIt){
26 std::cout << *arrIt << " ";
27 }
28
29 std::cout << std::endl;
30
31 std::array<int,NUM> arr3({{1,2,3,4}});
32 std::cout << std::endl << "arr3: ";
33 for ( auto a: arr3){
34 std::cout << a << " " ;
35 }
36
37 std::cout << std::endl;
38
39 // initializer list
40 std::array<int,NUM> arr4({{1,2,3,4,5,6,7,8,9,10}});
41 std::cout << std::endl << "arr4: ";
42 std::copy(arr4.rbegin(),arr4.rend(),
std::ostream_iterator<int>(std::cout, " "));
43
44 std::cout << std::endl;
45
46 // get the size of arr4
47 double sum= std::accumulate(arr4.begin(),arr4.end(),0);
48 double mean= sum / arr4.size();
49 std::cout << "mean of a4: " << mean << std::endl;
50
51 // read and write
52 std::cout << "arr4[5]: " << arr4[5] << std::endl;
53 std::cout << "arr4.at(5): " << arr4.at(5) << std::endl;
54 arr4[5]= 2011;
55 std::cout << "arr4[5]: " << arr4[5] << std::endl;
56
57 // swap arrays
58 std::swap(arr1,arr4);
59 std::cout << std::endl << "arr4: ";
60 for ( auto a: arr4){
61 std::cout << a << " " ;
62 }
63
64 std::cout << std::endl;
65
66 // comparison
67 std::cout << "(arr1 < arr4): " << (arr1 < arr4 )
<< std::endl;
68
69 // tuple like
70 std::cout << "(arr4[0] == std::get<0>(arr4)): "
<< (arr4[0] == std::get<0>(arr4)) << std::endl;
71
72 std::cout << std::endl;
73
74 }Die Verwandtschaft von std::array und std::vector geht so weit, dass, sieht man von kleinen Modifikationen ab, in Listing 20.20 std::array mit std::vector getauscht werden könnten. Ein std::array als STL-Container lässt sich auf verschiedene Weisen instanziieren. arr1 in Zeile 15 wird mit zehn Werten instanziiert. Dabei werden die Werte nicht initialisiert. Dies steht im Gegensatz zu arr2 in Zeile 23, denn hier werden durch die leere Initialisiererliste alle Elemente auf 0 initialisiert. Ist die Initialisiererliste zu kurz gewählt, trifft die Initialisierung mit 0 auf die restlichen Elemente zu. Neben der Instanziierung der std::array-Objekte variiert in Listing 20.20 die Ausgabe der einzelnen Elemente. In Zeile 17 kommt der Algorithmus std::copy zum Einsatz. Deutlich umständlicher ist da schon die klassische Form mit Iteratoren in Zeile 25. Komfort pur stellt die for-Schleife in Zeile 33 dar. Die letzte Variation besteht darin, die Elemente in Zeile 42 in der umgekehrten Reihenfolge auszugeben. std::array kennt im Gegensatz zum C-Array seine Länge. Dies nutzt die Berechnung des Mittelwerts in Zeile 48 aus. Lesenden und schreibenden Indexzugriff unterstützt std::array natürlich als sequenzieller Container. Der Unterschied zwischen dem Indexzugriff in Zeile 52 und dem at-Zugriff in Zeile 53 ist, dass Letzterer die Array-Grenzen überprüft. Natürlich lassen sich std::array-Objekte tauschen (Zeile 58) und vergleichen (Zeile 67). Vertraut sollte der Aufruf von std::get<0>(arr4) aus Zeile 70 wirken. Mit der gleichen Syntax lassen sich auch die Elemente des Tupels (siehe Abschnitt „Tupel“) referenzieren. Abbildung 20.17 zeigt insbesondere, dass die Elemente von arr1 nicht initialisiert sind.
Praxistipp
Ein array ist ein Aggregat, das ein Aggregat enthält.
Gewöhnungsbedürftig sind die doppelten Klammern {{ bzw. }} in der Initialisierung der std::array arr3 und arr4 in Listing 20.20, Zeilen 31 und 40, durch eine Initialisiererliste. Der Grund liegt in der Implementierung des std::array.
Ein
std::arrayist ein Aggregat, das ein Aggregat enthält.
Mit dieser Merkregel im Kopf lässt sich ein std::array richtig über eine Initialisiererliste initialisieren.
arrayAggregate.cpp
#include <array>
#include <iostream>
#include <vector>
int main(){
std::vector<int> myVec({1,2,3,4,5});
for (auto v: myVec) std::cout << v << " ";
std::cout << std::endl;
std::array<int,5> myArr({{1,2,3,4,5}});
for (auto a: myArr) std::cout << a << " ";
std::cout << std::endl;
}
Praxistipp
Unterscheiden Sie die Einsatzgebiete von array und vector.
Die entscheidende Frage ist, welchen sequenziellen Datentyp der Anwender wählen sollte: das C-Array, das neue std::array oder den etablierten std::vector. Die Antwort zum C-Array fällt sehr leicht. Dieser C-Datentyp wird nicht mehr benötigt. Ist nun die Länge des sequenziellen Datentyps zur Übersetzungszeit bekannt, ist das neue std::array die erste Wahl. Soll die Länge des sequenziellen Datentyps dynamisch sein, führt kein Weg an std::vector vorbei. (Der Einfachheit halber berücksichtige ich nicht die weiteren sequenziellen Container std::list, std::deque und std::string aus C++98 und std::forward_list aus C++11.)
arrayViolation.cpp
Aufgabe 20-10
Greifen Sie über die Indexgrenzen des Arrays hinaus.
In bekannter Tradition mit std::vector und std::deque bietet std::array zwei Arten von Indexzugriffen an. Mit dem Indexoperator [] lassen sich die Elemente ohne Kontrolle der Containergrenzen referenzieren, mit der at-Elementfunktion werden die Containergrenzen zur Laufzeit überprüft. Schreiben Sie ein kleines Programm, das mit dem Indexoperator [] und der at-Elementfunktion über die Array-Grenzen hinaus auf Elemente zugreifen will.
Einfach verkettete Liste
<forward_list>
std::forward_list ist ein sequenzieller Container mit einem eingeschränkten Interface. Als einfach verkettete Liste benötigt sie nicht mehr Speicher als die entsprechende C-Datenstruktur. std::forward_list ist für den speziellen Einsatz konzipiert: Wenn die optimierte Speicheranforderung, das schnelle Einfügen oder Entfernen von Elementen gefragt ist und der wahlfreie Zugriff nicht benötigt wird, sollte die einfach verkettete Liste in Erwägung gezogen werden. Dabei unterstützt std::forward_list vertraute Operationen wie das Dekrementieren eines Iterators –-It oder das Hinzufügen eines neuen Elements mit push_back nicht. Ihre minimalen Speicheranforderungen drücken sich auch darin aus, dass sie nicht die Anzahl ihrer Elemente speichert und diese über eine Methode zur Verfügung stellt. Während das Hinzufügen zu oder auch das Entfernen von Elementen der einfach verketteten Liste an ihrem Anfang direkt möglich ist, wird für diese Operationen im allgemeinen Fall ein Iterator benötigt. Manipulationen der std::forward_list beziehen sich in diesem allgemeinen Fall auf die dem Iterator folgenden Positionen.
In Listing 20.22 ist das Interface der std::forward_list in Aktion zu sehen.
forwardListManipulate.cpp
01 #include <algorithm>
02 #include <forward_list>
03 #include <iostream>
04
05 int main(){
06
07 std::cout << std::boolalpha << std::endl;
08
09 std::forward_list<int> myForList;
10
11 std::cout << "myForList.empty(): "
<< myForList.empty() << std::endl;
12 myForList.push_front(7);
13 myForList.push_front(6);
14 myForList.push_front(5);
15 myForList.push_front(4);
16 myForList.push_front(3);
17 myForList.push_front(2);
18 myForList.push_front(1);
19
20 std::cout << std::endl;
21
22 std::cout << "myForList: " << std::endl;
23 for (auto It= myForList.cbegin();It != myForList.cend();
++It) std::cout << *It << " ";
24 std::cout << "\n\n";
25
26 std::cout <<
"myForList.erase_after(myForList.before_begin()): "
<< std::endl;
27 myForList.erase_after(myForList.before_begin());
28 std::cout<< "myForList.front(): " << myForList.front()
<< "\n\n";
29
30 std::forward_list<int>myForList2;
31 myForList2.insert_after(myForList2.before_begin(),1);
32 myForList2.insert_after(myForList2.before_begin()++,2);
33 myForList2.insert_after(
(myForList2.before_begin()++)++,3);
34 myForList2.push_front(1000);
35
36 std::cout << "myForList2: " << std::endl;
37 for (auto It= myForList2.cbegin();It != myForList2.cend();
++It) std::cout << *It << " ";
38 std::cout << "\n\n";
39 auto IteratorTo5=
std::find(myForList.begin(),myForList.end(),5);
40 myForList.splice_after(IteratorTo5,std::move(myForList2));
41
42 std::cout << "myForList.splice_after(IteratorTo5,
std::move(myForList2)): "
<< std::endl;
43 for (auto It= myForList.cbegin();It != myForList.cend();
++It) std::cout << *It << " ";
44 std::cout << "\n\n";
45
46 myForList.sort();
47
48 std::cout << "myForList.sort(): " << std::endl;
49 for (auto It= myForList.cbegin();It != myForList.cend();
++It) std::cout << *It << " ";
50 std::cout << "\n\n";
51
52 myForList.reverse();
53
54 std::cout << "myForList.reverse(): " << std::endl;
55 for (auto It= myForList.cbegin();It != myForList.cend();
++It) std::cout << *It << " ";
56 std::cout << "\n\n";
57
58 myForList.unique();
59
60 std::cout << "myForList.unique(): " << std::endl;
61 for (auto It= myForList.cbegin();It != myForList.cend();
++It) std::cout << *It << " ";
62 std::cout << "\n";
63
64 std::cout << std::endl;
65
66 }Ein paar Anmerkungen noch zu Listing 20.22, bevor in Abbildung 20.18 die Ausgabe des Programms folgt. Vertraut sollten die ersten Zeilen des Listings wirken. In Zeile 40 wird durch den Ausdruck myForList.splice_after(IteratorTo5,std::move(myForList2)) myForList2 an myForList nach der Position IteratorTo5 angehängt. Die Elemente von myForList2 werden transferiert. Das Sortieren (Zeile 46), Umkehren der Reihenfolge (Zeile 52) oder das Entfernen von Duplikaten (Zeile 58) der Elemente einer verketteten Liste sind Elementfunktionen von std::forward_list. Bei unique gilt es zu beachten, dass nur Duplikate entfernt werden, die aufeinanderfolgen.

Aufgabe 20-11
Bestimmen Sie die Anzahl der Elemente einer std::forward_list.
forwardListRemoveIf.cpp
Aufgabe 20-12
Entfernen Sie Elemente, die ein Prädikat erfüllen, aus einer std::forward_list.
Füllen Sie eine std::forward_list<int> mit den Ganzzahlen von 0 bis 9. Entfernen Sie im ersten Schritt das Element, das den Wert 8 besitzt. Entfernen Sie im zweiten Schritt alle Elemente, die kleiner als 3 oder größer als 5 sind. Geben Sie jeweils die Ergebnisse zur Kontrolle aus.
Ohne die Elementfunktionen remove und remove_if (std::forward_list, 2011) ist die Aufgabe relativ umständlich zu lösen.
Hashtabellen
<unordered_set>
<unordered_map>
Hashtabellen, auch bekannt unter den Namen Dictionary oder assoziatives Array, sind aus dem Leben eines Programmierers nicht wegzudenken – erlauben sie es doch, einfach und performant Werte über assoziierte Schlüssel abzufragen. Dass C++ keine Hashtabellen besaß, wog nicht so schwer, denn mit der Datenstruktur std::map stand ein Container zur Verfügung, der einer Hashtabelle sehr ähnlich ist. Einerseits ist std::map mächtiger als eine Hashtabelle, da seine Schlüssel geordnet sind, andererseits hängt seine Zugriffszeit auf die Schlüssel logarithmisch von der Anzahl der Schlüssel ab. Hier spielt aber die neue Hashtabelle ihre wahre Stärke aus, denn ihre Zugriffszeit auf die Schlüssel ist unabhängig von der Anzahl der Schlüssel. Den bekannten assoziativen Containern std::set, std::multiset, std::map und std::multimap stellt C++11 die ungeordneten assoziativen Container std::unordered_set, std::unordered_multiset, std::unordered_map und std::unordered_multimap gegenüber. Die Tabellen in Kapitel 5 im Abschnitt „Hashtabellen“ helfen, Ordnung in die verschiedenen assoziativen Container zu bringen. Wer mit den bekannten assoziativen Containern aus C++98 vertraut ist, kann Listing 20.23 und Listing 20.24 gern überspringen, denn die neuen ungeordneten assoziativen Container bieten nahezu das gleiche Interface wie die bekannten geordneten assoziativen Container an.
unordSet.cpp
01 #include <iostream>
02 #include <set>
03 #include <unordered_set>
04
05 int main(){
06
07 std::cout << std::endl;
08
09 // constructor
10 std::unordered_multiset<int>multiSet
{1,2,3,4,5,6,7,8,9,8,7,6,5,4,3,2,1};
11 std::unordered_set<int> uniqSet
(multiSet.begin(),multiSet.end());
12
13 // show the difference
14 std::cout << "multiSet: ";
15 for(auto m : multiSet) std::cout << m << " ";
16
17 std::cout << std::endl;
18
19 std::cout << "uniqSet: ";
20 for(auto s : uniqSet) std::cout << s << " ";
21
22 std::cout << std::endl << std::endl;
23
24 // insert elements
25 multiSet.insert(-1000);
26 uniqSet.insert(-1000);
27
28 std::set<int> mySet{-5,-4,-3,-2,-1};
29 multiSet.insert(mySet.begin(),mySet.end());
30 uniqSet.insert(mySet.begin(),mySet.end());
31
32 // show the difference
33 std::cout << "multiSet: ";
34 for(auto m : multiSet) std::cout << m << " ";
35
36 std::cout << std::endl;
37
38 std::cout << "uniqSet: ";
39 for(auto s : uniqSet) std::cout << s << " ";
40
41 std::cout << std::endl << std::endl;
42
43 // search for elements
44 auto it= uniqSet.find(5);
45 if ( it != uniqSet.end()){
46 std::cout << "uniqSet.find(5): " << *it << std::endl;
47 }
48
49 std::cout << "multiSet.count(5): " << multiSet.count(5)
<< std::endl;
50
51 std::cout << std::endl;
52
53 // remove
54 int numMulti= multiSet.erase(5);
55 int numUniq= uniqSet.erase(5);
56
57 std::cout << "Erased " << numMulti
<< " times 5 from multiSet." << std::endl;
58 std::cout << "Erased " << numUniq
<< " times 5 from uniqSet." << std::endl;
59
60 // all
61 multiSet.clear();
62 uniqSet.clear();
63
64 std::cout << std::endl;
65
66 std::cout << "multiSet.size(): " << multiSet.size()
<< std::endl;
67 std::cout << "uniqSet.size(): " << uniqSet.size()
<< std::endl;
68
69 std::cout << std::endl;
70
71 }In Listing 20.23 werden zwei ungeordnete assoziative Container instanziiert, deren Schlüssel kein Wert zugeordnet ist. Dabei kann multiSet in Zeile 10 mehrere gleiche Schlüssel besitzen, uniqSet in Zeile 11 dagegen nicht. Das zeigt die Ausgabe in Abbildung 20.19, denn alle Duplikate in uniqSet sind nicht mehr vorhanden. Dass die Elemente in den beiden Containern sortiert sind, ist rein zufällig. Dies ist in der nächsten Ausgabe zu sehen, nachdem ein paar weitere Zahlen mit der Elementfunktion insert in den Zeilen 25 bis 30 hinzugefügt wurden. Die Elementfunktion find in Zeile 44 gibt im Erfolgsfall einen Iterator auf das zu suchende Element zurück und einen Iterator auf uniqSet.end() im Misserfolgsfall. Wer es genauer wissen will, kann sich mit der Elementfunktion count in Zeile 49 die Anzahl der Elemente ermitteln lassen. Durch die Elementfunktion erase in Zeile 54 werden alle adressierten Elemente entfernt. Dies schließt die mehrfach vorkommenden Schlüssel im Fall von muliSet.erase(5) in Zeile 54 ein. Die Funktion clear löscht alle Schlüssel, sodass die Länge der beiden ungeordneten assoziativen Arrays danach 0 beträgt.

std::map ist im klassischen C++ der mit Abstand am häufigsten eingesetzte assoziative Container, verhält er sich doch fast wie eine Hashtabelle. std::unordered_map hingegen ist eine Hashtabelle. Seine Schlüssel sind nicht sortiert, und jedem Schlüssel ist ein Wert zugeordnet. Der entscheidende Punkt ist aber, dass die Suche nach einem Schlüssel in der Hashtabelle unabhängig von der Anzahl der Schlüssel ist.
Listing 20.24 zeigt die Anwendung von std::unordered_map zusammen mit dem std::unordered_multimap, der mehrere gleiche Schlüssel unterstützt.
unordMap.cpp
01 #include <iostream>
02 #include <map>
03 #include <unordered_map>
04
05 int main(){
06
07 std::cout << std::endl;
08
09 long long home= 497074123456;
10 long long mobile= 4916046123356;
11
12 // constructor
13 std::unordered_multimap<std::string,long long> multiMap
{{"grimm",home},{"grimm",mobile},{"jaud-grimm",home}};
14 std::unordered_map<std::string,int> uniqMap
{{"bin",1},{"root",0},{"nobody",65834},{"rainer",1000}};
15
16 // show the unordered maps
17 std::cout << "multiMap: ";
18 for(auto m : multiMap) std::cout << '{' << m.first
<< ',' << m.second << '}';
19
20 std::cout << std::endl;
21
22 std::cout << "uniqMap: ";
23 for(auto u : uniqMap) std::cout << '{' << u.first
<< ',' << u.second << '}';
24 std::cout << std::endl;
25
26 std::cout << std::endl;
27
28 // insert elements
29 long long work= 4970719754513;
30
31 multiMap.insert({"grimm",work});
32 // will not work
33 // multiMap["grimm-jaud"]=4916012323356;
34
35 uniqMap["lp"]=4;
36 uniqMap.insert({"sshd",71});
37
38 std::map<std::string,int> myMap
{{"ftp",40},{"rainer",999}};
39 uniqMap.insert(myMap.begin(),myMap.end());
40
41 // show the unordered maps
42 std::cout << "multiMap: ";
43 for(auto m : multiMap) std::cout << '{' << m.first
<< ',' << m.second << '}';
44
45 std::cout << std::endl;
46
47 std::cout << "uniqMap: ";
48 for(auto u : uniqMap) std::cout << '{' << u.first
<< ',' << u.second << '}';
49 std::cout << std::endl;
50
51
52 std::cout << std::endl;
53 // search for elements
54
55 // only grimm
56 auto iter= multiMap.equal_range("grimm");
57 std::cout << "grimm: ";
58 for(auto itVal= iter.first; itVal !=iter.second;++itVal){
59 std::cout << itVal->second << " ";
60 }
61
62 std::cout << std::endl;
63
64 std::cout << "multiMap.count(grimm): "
<< multiMap.count("grimm") << std::endl;
65
66 auto it= uniqMap.find("root");
67 if ( it != uniqMap.end()){
68 std::cout << "uniqMap.find(root): " << it->second
<< std::endl;
69 std::cout << "uniqMap[root]: " << uniqMap["root"]
<< std::endl;
70 }
71
72 // will create a new entry
73 std::cout << "uniqMap[notAvailable]: "
<< uniqMap["notAvailable"] << std::endl;
74
75 std::cout << std::endl;
76
77 // remove
78 int numMulti= multiMap.erase("grimm");
79 int numUniq= uniqMap.erase("rainer");
80
81 std::cout << "Erased " << numMulti
<< " times grimm from multiMap." << std::endl;
82 std::cout << "Erased " << numUniq
<< " times rainer from uniqMap." << std::endl;
83
84 // all
85 multiMap.clear();
86 uniqMap.clear();
87
88 std::cout << std::endl;
89
90 std::cout << "multiMap.size(): " << multiMap.size()
<< std::endl;
91 std::cout << "uniqMap.size(): " << uniqMap.size()
<< std::endl;
92
93 std::cout << std::endl;
94
95 }Listing 20.24 folgt einer ähnlichen Struktur wie Listing 20.23. In den Zeilen 13 und 14 werden zwei Hashtabellen deklariert. Dabei kann multiMap mit mehreren identischen Schlüsseln umgehen, uniqMap hingegen nicht. Dies ergibt durchaus Sinn, soll doch multiMap zu einer Person alle Telefonnummern speichern und uniqMap die eindeutige Beziehung zwischen einem Benutzer und seiner ID zur Verfügung stellen. Beide Datenstrukturen lassen sich auf gewohnte Weise als Pärchen ausgeben. Dabei wird mit m.first der Schlüssel und mit m.second der Wert in Zeile 18 referenziert. Auch das Hinzufügen neuer Paare fühlt sich wie bei allen assoziativen Containern an. Für eine Hashtabelle typisch, ist der Zugriff auf uniqMap über den Indexoperator in Zeile 35 möglich. Dies gilt natürlich auch für den lesenden Zugriff. Ein std::map kann dazu verwendet werden, einem std::unorderd_map neue Elemente hinzuzufügen. Da der Schlüssel "rainer" in Zeile 38 in uniqMap vorhanden ist, wird dessen ursprünglicher Wert überschrieben. Dies zeigt am besten die Ausgabe in Abbildung 20.20. Das Suchen nach Schlüsseln und deren assoziierten Werten ist die Stärke von Hashtabellen. In den Zeilen 56 bis 60 werden alle Werte ausgegeben, die den Schlüssel "grimm" besitzen. Das ist zugegeben ein bisschen umständlich. Durch auto iter= multiMap.equal_range("grimm") wird ein Iterator zurückgegeben, der in Zeile 58 benutzt wird, um über alle Werte zu iterieren. Dabei erleichtert auto das Leben des Anwenders enorm. Tatsächlich ist iter vom Typ
std::pair<
std::unordered_map<std::string,long long>::iterator,
std::unordered_map<std::string,long long>::iterator>.Deutlich einfacher in der Anwendung ist das Zählen der Telefonnummern in Zeile 64, die dem Schlüssel "grimm" zugeordnet sind. Ob ein Schlüssel existiert, lässt sich in Zeile 66 mit der Elementfunktion find ermitteln. Mit it->second (Zeile 68) oder dem Indexoperator (Zeile 69) kann anschließend auf den Wert zugegriffen werden. Ist der Schlüssel nicht vorhanden, wird ein Schlüssel/Wert-Paar erzeugt und der Hashtabelle hinzugefügt. Für den Wert wird der Standardkonstruktor ausgeführt. Genau dieses Verhalten ist in Zeile 73 zu sehen, sodass uniqMap um das Paar (std::string("notAvailable"),int()) erweitert wird. Der Rest des Listings sollte keine Überraschungen beinhalten. Durch multiMap.erase("grimm") bzw. uniqueMap.erase("rainer") werden alle Paare aus den Hashtabellen mit den angegebenen Schlüsseln entfernt. Die Elementfunktion clear entfernt in bekannter Manier alle Schlüssel/Wert-Paare.
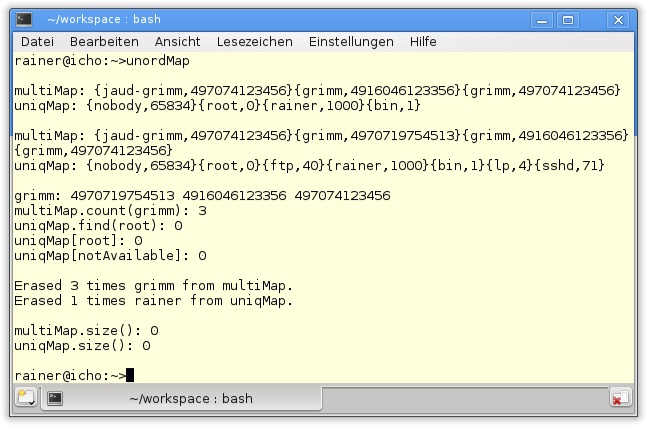
Hashfunktion
Die zentrale Komponente einer Hashtabelle ist die sogenannte Hashfunktion. Diese Funktion bildet die Schlüssel auf einen Index, den sogenannten Hashwert, ab. Der wesentliche Unterschied zwischen einem Array und einem assoziativen Array ist, das Letzterer nicht nur natürliche Zahlen als Indizes erlaubt. Andersherum betrachtet, verhält sich ein assoziatives Array, das natürliche Zahlen als Indizes erlaubt und deren Hashfunktion die Identität ist, wie ein Array.
Eine Frage bleibt aber noch offen. Welche Datentypen können als Schlüssel verwendet werden? C++11 unterstützt von Hause aus die folgenden Datentypen:
boolGanzzahlen:
char,signed char,unsigned char,short,unsigned short,int,unsigned int,long,unsigned longFließkommazahlen:
float,double,long doubleZeiger
Strings:
std::string,std::wstring
Soll ein eigener Datentyp als Schlüssel verwendet werden, haben die Objekte dieses Datentyps zwei Charakteristiken zu erfüllen. Zum einen muss der Hashwert zur Verfügung stehen, zum anderen müssen die Objekte auf Gleichheit == vergleichbar sein. Der alte Bekannte MyInt wird in Listing 20.25 als Schlüssel verwendet.
hashClass.cpp
01 #include <iostream>
02 #include <ostream>
03 #include <unordered_map>
04
05 struct MyInt{
06 MyInt(int v):val(v){}
07 bool operator== (const MyInt& other) const {
08 return val == other.val;
09 }
10 int val;
11 };
12
13 struct MyHash{
14 std::size_t operator()(MyInt m) const {
15 std::hash<int> hashVal;
16 return hashVal(m.val);
17 }
18 };
19
20 struct MyAbsHash{
21 std::size_t operator()(MyInt m) const {
22 std::hash<int> hashVal;
23 return hashVal(abs(m.val));
24 }
25 };
26
27 struct MyEq{
28 bool operator() (const MyInt& l, const MyInt& r) const {
29 return abs(l.val) == abs(r.val);
30 }
31 };
32
33 std::ostream& operator << (std::ostream& strm,
const MyInt& myIn){
34 strm << "MyInt(" << myIn.val << ")";
35 return strm;
36 }
37
38 int main(){
39
40 std::cout << std::endl;
41
42 std::hash<int> hashVal;
43
44 // a few hash values
45 for ( int i= -2; i <= 1 ; ++i){
46 std::cout << "hashVal(" << i << "): " << hashVal(i)
<< std::endl;
47 }
48
49 std::cout << std::endl;
50
51 typedef std::unordered_map<MyInt,int,MyHash> MyIntMap;
52
53 std::cout << "MyIntMap: ";
54 MyIntMap myMap{{MyInt(-2),-2},{MyInt(-1),-1},
{MyInt(0),0},{MyInt(1),1}};
55
56 for(auto m : myMap) std::cout << '{' << m.first << ','
<< m.second << '}';
57
58 std::cout << std::endl << std::endl;
59
60 typedef std::unordered_map<MyInt,int,MyAbsHash,MyEq>
MyAbsMap;
61 std::cout << "MyAbsMap: ";
62 MyAbsMap myAbsMap{{MyInt(-2),-2},{MyInt(-1),-1},
{MyInt(0),0},{MyInt(1),1}};
63
64 for(auto m : myAbsMap) std::cout << '{' << m.first
<< ',' << m.second << '}';
65
66 std::cout << std::endl << std::endl;
67
68 std::cout << "myAbsMap[MyInt(-2)]: "
<< myAbsMap[MyInt(-2)] << std::endl;
69 std::cout << "myAbsMap[MyInt(2)]: "
<< myAbsMap[MyInt(2)] << std::endl;
70 std::cout << "myAbsMap[MyInt(3)]: "
<< myAbsMap[MyInt(3)] << std::endl;
71
72 std::cout << std::endl << std::endl;
73
74 }Für den Datentyp MyInt (Zeile 5) in Listing 20.25 ist die Gleichheit über seinen Datentyp val definiert. Dieser einfache Ansatz wird auch auf die Hashfunktion von MyInt angewandt. Aber zuerst der Reihe nach. In der main-Funktion wird in Zeile 42 ein Klassen-Template hashVal definiert, das sich wie eine Funktion benutzen lässt. Dies ist in der Zeile 46 sehr schön zu sehen, da diese Funktion zu jeder Zahl ihren Hashwert ausgibt. In Abbildung 20.21 sind die numerischen Werte dargestellt. Interessant ist, dass die natürlichen Zahlen 0 und 1 auf sich selbst abgebildet werden. Dies trifft nicht auf negative Ganzzahlen zu. Der Typ MyIntMap in Zeile 51 verwendet MyInt als Schlüssel. Als drittes Template-Argument erhält MyIntMap die Hashfunktion. Diese Klasse MyHash in Zeile 13 ist ein aufrufbares Objekt, denn der operator() ist implementiert. Dabei nimmt dieser einen Typ MyInt an und gibt als Hashwert den Hashwert der Variablen val zurück. Auch die zweite Bedingung erfüllt MyInt. Durch das Überladen des Operators == in Zeile 7 sind seine Objekte auf Gleichheit vergleichbar. Der Instanziierung von myMap und deren Ausgabe (Abbildung 20.21) steht nichts mehr entgegen.
MyAbsMap in Zeile 60 erhält ein viertes Template-Argument. Das Funktionsobjekt MyEq ist in MyAbsMap für den Vergleich auf Gleichheit zuständig. Das Besondere von MyIntMap gegenüber MyAbsMap ist, dass in MyAbsMap der absolute Wert von val für die Berechnung des Hashwerts und den Gleichheitsvergleich verwendet werden soll. Dies ist der Grund dafür, dass in dem Funktionsobjekt MyAbsHash der Hashwert von hash(abs(m.val))) in Zeile 23 zurückgegeben wird und dass in Zeile 29 der Gleichheitsvergleich abs(l.val) == abs(r.val) lautet. Für die einfache Ausgabe der assoziativen Arrays ist noch der Ausgabeoperator in Zeile 33 definiert. Betrachten wir nun Abbildung 20.21, fällt auf, dass MyAbsMap ein Wertepaar weniger besitzt. Was ist der Grund? Da der Hashwert von MyInt(1) identisch mit dem von MyInt(-1) ist, wenn der absolute Wert verwendet wird, tritt das bekannte Verhalten von Hashtabellen auf. Das Wertepaar (MyInt(1),1) wird durch (MyInt(-1),-1) überschrieben.
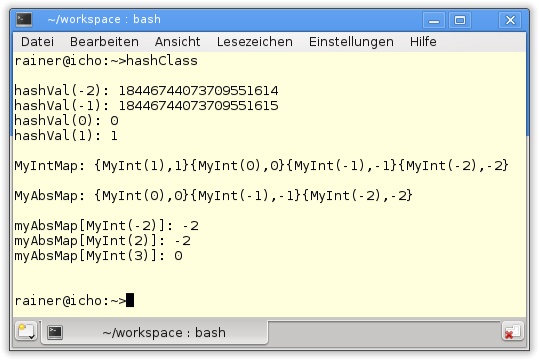
Aber nicht nur die Hashfunktion, auch der Test auf Gleichheit ignoriert das Vorzeichen. In den Zeilen 68 und 69 ergibt die Abfrage an myAbsMap[MyInt(-2)] und MyAbsMap[MyInt(2)] jeweils den Wert 2. Das Bemerkenswerte ist, dass der Hashwert von MyInt(-2) gleich dem von MyInt(2) ist. Dies bewirkt, dass kein neues Element (MyInt(2),2) zu myAbsMap hinzugefügt wird. Den feinen Unterschied zeigt die Abfrage myAbsMap[MyInt(3)] in Zeile 70. MyInt(3) ist kein Element von myAbsMap, sodass der assoziative Container um ein neues Paar (MyInt(3),int()) erweitert wird.
Für den Anwender ist die Geschichte zu Hashtabellen in C++11 hier zu Ende. C++11 erlaubt es aber, wie so oft, seine Datenstrukturen weiter zu tunen. Die Hashtabelle macht da keine Ausnahme. Dazu ist ein tieferes Verständnis von Hashtabellen notwendig.
Buckets, Kapazität und Ladefaktor
Die Hashtabelle speichert ihre Schlüssel in den sogenannten Buckets. In welchem Bucket ein Eintrag landet, entscheidet dessen Hashwert. Dieser wird durch die Hashfunktion gebildet. Die Hashfunktion ermittelt aus dem Schlüssel einen Index in das Bucket. Für eine Hashtabelle, die den Familiennamen als Schlüssel verwendet und die Telefonnummer als Wert, ist dies exemplarisch in Abbildung 20.22 dargestellt. Damit ist der Zugriff auf ein Bucket immer konstant, da lediglich die Hashfunktion angewandt werden muss.
Dies trifft natürlich auch für das Hinzufügen eines neuen Elements zu einer Hashtabelle zu. Komplizierter ist der Schlüsselzugriff auf ein Element einer Hashtabelle. Befindet sich ein einziges Element in einem Bukket, den die Hashfunktion ermittelt hat, ist die Zugriffszeit auf das Element konstant. Andererseits kann es natürlich vorkommen, dass sich mehrere Elemente in einem Bucket befinden. Mit dieser Situation, Kollision genannt, muss die Hashtabelle umgehen können. Ziel einer Hashtabelle und insbesondere der Hashfunktion ist es, Kollisionen zu vermeiden. Für den Umgang mit Kollisionen gibt es mehrere Strategien. Eine einfache Strategie kann darin bestehen, die Elemente in einem Bucket als verlinkte Liste zu repräsentieren. Nun wird es kompliziert. Der Zugriff auf das Bucket ist konstant, die Suche im Bucket ist linear. Zu Hashtabellen im Allgemeinen und Kollisionen im Besonderen möchte ich gern auf den ausgezeichneten Wiki-Artikel zu Hashtabellen verweisen (hash table, 2011).
Zwei Begriffe, Kapazität und Ladefaktor, fehlen noch, um die in C++11 angebotenen Elementfunktionen verstehen und nutzen zu können. Kapazität bezeichnet die Anzahl der Buckets und Ladefaktor die durchschnittliche Anzahl der Elemente je Bucket. Ist B die Anzahl der Buckets und n die Anzahl der Elemente einer Hashtabelle hash, so ist L = n / B der Ladefaktor der Hashtabelle. Übersteigt der Ladefaktor der Hashtabelle deren maximalen Ladefaktor, der in der Regel 1 ist, werden in der Regel neue Buckets erzeugt und die Elemente auf diese neu verteilt. Dieser Vorgang wird als rehashing bezeichnet und automatisch von der Hashtabelle ausgeführt. Mit der Elementfunktion hash.max_load_factor(L) kann der Anwender den maximalen Ladefaktor L einer Hashtabelle setzen, sodass ein Überschreiten dieses Werts zum automatischen rehashing der Hashtabelle führt. Dieses rehashing ist auch direkt möglich. Denn durch einen Aufruf der Elementfunktion hash.rehash(B) wird die Anzahl der Buckets der Hashtabelle hash auf mindestens B gesetzt. Listing 20.26 zeigt die Theorie in der Praxis.
hashInfo.cpp
01 #include <iostream>
02 #include <random>
03 #include <unordered_set>
04
05 void getInfo(const std::unordered_set<int>& hash){
06
07 std::cout << "hash.bucket_count(): "
<< hash.bucket_count() << std::endl;
08 std::cout << "hash.load_factor(): "
<< hash.load_factor() << std::endl;
09
10 }
11
12 void fillHash(std::unordered_set<int>& h,int n){
13
14 std::random_device seed;
15 // default generator
16 std::mt19937 engine(seed());
17 // get random numbers 0 - 1000
18 std::uniform_int_distribution<> uniformDist(0,1000);
19
20 for ( int i=1; i<= n; ++i){
21 h.insert(uniformDist(engine));
22 }
23
24 }
25
26 int main(){
27
28 std::cout << std::endl;
29
30 std::unordered_set<int> hash;
31 std::cout << "hash.max_load_factor(): "
<< hash.max_load_factor() << std::endl;
32
33 std::cout << std::endl;
34
35 getInfo(hash);
36
37 std::cout << std::endl;
38
39 // only to be sure
40 hash.insert(500);
41 // get the bucket of 500
42 std::cout << "hash.bucket(500): " << hash.bucket(500)
<< std::endl;
43
44 std::cout << std::endl;
45
46 // add 100 elements
47 fillHash(hash,100);
48 getInfo(hash);
49
50 std::cout << std::endl;
51
52 // at least 500 buckets
53 std::cout << "hash.rehash(500): " << std::endl;
54 hash.rehash(500);
55
56 std::cout << std::endl;
57
58 getInfo(hash);
59
60 std::cout << std::endl;
61
62 // get the bucket of 500
63 std::cout << "hash.bucket(500): " << hash.bucket(500)
<< std::endl;
64
65 std::cout << std::endl;
66
67 }Auch wenn ein std::unordered_set<int> in Zeile 30 eine degenerierte Hashtabelle ist, da ihrem Schlüssel kein Wert zugeordnet ist, gelten die in Listing 20.26 gewonnenen Erkenntnisse für alle ungeordneten assoziativen Container. In der Hilfsfunktion getInfo in Zeile 5 wird die Information zur Kapazität (Zeile 7) und zum Ladefaktor (Zeile 8) ausgegeben. Die weitere Hilfsfunktion fillHash in Zeile 12 fügt n neue Elemente, zufällig aus 0 bis 1000 ausgewählt, zu std::unordered_set<int> hinzu. Die Ausgabe des Programmlaufs lässt sich in Abbildung 20.23 verfolgen. Für die leere Hashtabelle ergibt der maximale Ladefaktor in Zeile 31 1. In diesem Fall werden elf Buckets auf Verdacht angelegt, und der durchschnittliche Ladefaktor ist 0 (Zeile 35). In Zeile 40 wird die 500 der Hashtabelle hinzugefügt. Der Wert landet im fünften Bucket (Zeile 42). Nun wird es interessanter. In die Hashtabelle werden 100 weitere Elemente in Zeile 47 eingefügt. Das ändert drastisch die Kapazität und den Ladefaktor. Während nun 199 Buckets zur Verfügung stehen, steigt der Ladefaktor auf fast 0,5. Dies ist immer noch deutlich niedriger als der maximale Ladefaktor von 1. So schnell ist daher kein rehashing der Hashtabelle notwendig. Genau dieses rehashing wird in Zeile 54 erzwungen, indem die Anzahl der Buckets auf mindestens 500 gesetzt wird. Die Auswirkung zeigt die Ausgabe von getInfo(hash) in Zeile 58. Die Kapazität beträgt nun 503, der Ladefaktor knapp 0,2. Was ist mit dem Schlüssel 500 passiert? Dieser ist jetzt im 500sten Bucket.
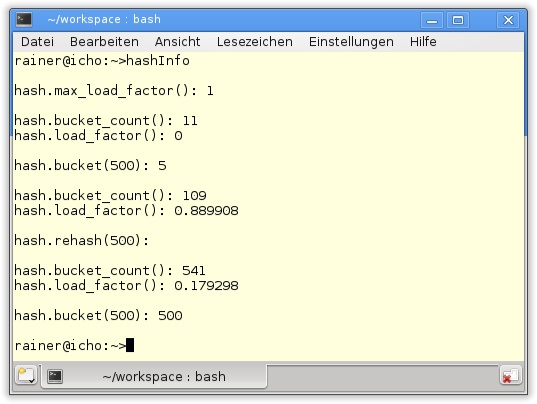
Aufgabe 20-13
Vergleichen Sie die Zugriffszeit von std::map und std::unordered_map.
Legen Sie zwei große assoziative Container vom Datentyp std::map<int,int> und std::unordered_map<int,int> an und greifen Sie mit dem Indexoperator auf ein Zehntel der bestehenden Elemente zufällig zu. Vergrößern Sie sukzessive die Größe der assoziativen Container. Vergleichen Sie die Zugriffszeiten auf die Elemente. Entspricht das Ergebnis Ihren Erwartungen?
Bei 10.000.000 Elementen und 1.000.000 Zugriffen ist der Zugriff auf meiner Plattform für std::unordered_map um den Faktor 15 schneller als der für std::map.
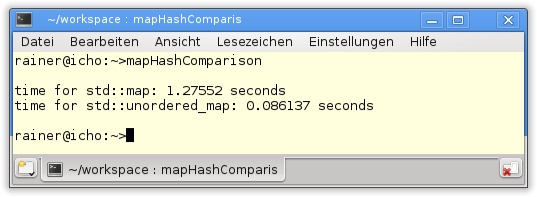
bucketInfo.cpp
Aufgabe 20-14
Geben Sie den Inhalt jedes Bucket aus.
Ein std::unordered_map<int,std::string> myDict verrät viel über sich. Neben der Anzahl der Buckets mit myDict.bucket_count() lässt sich die Anzahl der Elemente in einem Bucket mit myDict.bucket_size(b) für das b-te Bucket ermitteln. Darüber hinaus lassen sich die Elemente des b-ten Bucket mit den zwei Iteratoren myDict.begin(b) und myDict.end(b) ausgeben.
Definieren Sie eine Hashtabelle std::unordered_map<int,std::string> myDict und füllen Sie sie mit ein paar Schlüssel/Wert-Paaren. Bestimmen Sie für myDict die Anzahl der Buckets, die Anzahl der Elemente jedes Bucket und iterieren Sie zum Abschluss über jedes Bucket.
Neue Algorithmen
Die Algorithmen std::all_of, std::any_of und std::none_of prüfen logische Zusicherungen auf Bereichen.
std::copy_if und std::copy_n sind weitere Kopieralgorithmen auf Bereichen.
std::iota hilft beim schnellen Erzeugen von Werten.
Es geht weiter mit std::partition_copy, std::is_partitioned und std::partition_point für den Umgang mit Partitionen sowie std::is_heap und std::is_heap_until für den Umgang mit der Datenstruktur Heap (Heap, 2011).
Auch zum Sortieren gibt es zwei neue Algorithmen: std::is_sorted und std::is_sorted_until.
Praktisch sind auch die zwei Algorithmen std::minmax und std::minmax_element, die ein Paar (min,max) zurückgeben. Während std::minmax auf einem Wertepaar oder einer std::initializer_list aufgerufen werden kann und das Minimum/Maximum-Wertepaar ermittelt, wirkt std::minmax_element auf einem Bereich und ermittelt ein Minimum/Maximum-Iteratorenpaar.
Viele der Algorithmen sind in Listing 20.27 im Einsatz zu sehen.
newAlgorithm.cpp
01 #include <algorithm>
02 #include <array>
03 #include <deque>
04 #include <iostream>
05 #include <iterator>
06 #include <list>
07 #include <vector>
08
09 bool even_(const int& i){
10 return ((i % 2) == 0);
11 }
12
13 int main() {
14
15 std::cout << std::endl;
16
17 std::cout << std::boolalpha;
18
19 // increase each element by 1
20 std::vector<int> myVec(20);
21 std::iota(myVec.begin(),myVec.end(),1);
22
23 std::cout << "myVec:";
24 for (auto i: myVec) std::cout << i << " ";
25 std::cout << std::endl << std::endl;
26
27 // test a predicate on a range
28 std::cout << "one even in myVec: "
<< std::any_of(myVec.begin(),myVec.end(),even_)
<< std::endl;
29 std::cout << "all even in myVec: "
<< std::all_of(myVec.begin(),myVec.end(),even_)
<< std::endl;
30 std::cout << "all even in myVec with lambda: "
<< std::all_of(myVec.begin(),myVec.end(),
[](int i){ return (i % 2) == 0; })
<< std::endl;
31 std::cout << "none even in myVec with lambda: "
<< std::none_of(myVec.begin(),myVec.end(),
[](int i){ return (i % 2) == 0; })
<< std::endl;
32
33 std::cout << std::endl;
34
35 // copying all odd element to std::cout
36 std::cout << "all odd elements: ";
37 std::copy_if(myVec.begin(), myVec.end(),
std::ostream_iterator<int>(std::cout, " "),
[](int a){ return a % 2;} );
38
39 std::cout << std::endl;
40
41 // copying the first 10 element
42 std::cout << "The first 10 elements: ";
43 std::copy_n(myVec.begin(),10,
std::ostream_iterator<int>(std::cout, " "));
44
45 std::cout << std::endl << std::endl;
46
47 std::list<int> allOdd;
48 std::deque<int> allEven;
49
50 // odd ints to list allOdd
51 // even ints to deque allEven
52 std::partition_copy(myVec.begin(),myVec.end(),
std::back_inserter(allEven),std::back_inserter(allOdd),
even_);
53
54 std::cout << "allOdd: ";
55 for (auto o: allOdd) std::cout << o << " ";
56
57 std::cout << std::endl;
58
59 std::cout << "allEven: ";
60 for (auto e: allEven) std::cout << e << " ";
61
62 std::cout << std::endl;
63
64 // test, if partitioned
65 std::cout << "Partition a < 10: "
<< std::is_partitioned(myVec.begin(),myVec.end(),
[](int a){ return a < 10;}) << std::endl;
66
67 std::cout << std::endl;
68
69 // get the partition point
70 std::cout << "Partition Point for a < 10: " <<
*(std::partition_point(myVec.begin(),myVec.end(),
[](int a){ return a < 10;})) << std::endl;
71
72 std::cout << std::endl;
73
74 // test, if sorted
75 std::cout << "Is sorted (ascending): "
<< std::is_sorted(myVec.begin(),myVec.end())
<< std::endl;
76
77 std::cout << "Is sorted (descending): "
<< std::is_sorted(myVec.begin(),myVec.end(),
[](int a, int b ){return a > b;})
<< std::endl;
78
79 myVec.push_back(-10);
80 myVec.push_back(100);
81 myVec.push_back(2011);
82
83 std::cout << std::endl;
84
85 std::cout << "myVec:";
86 for (auto i: myVec) std::cout << i << " ";
87 std::cout << std::endl << std::endl;
88
89 std::cout << "Is sorted until: "
<< *(std::is_sorted_until(myVec.begin(),myVec.end()))
<< std::endl;
90
91 std::cout << std::endl;
92
93 }Die Funktion even_ (Zeile 9) in Listing 20.27 ist ein einfaches Prädikat, das auf Anfrage ermittelt, ob das Argument gerade ist. Der Vektor myVec wird durch den neuen Algorithmus std::iota in Zeile 21 initialisiert. Das erste Element des Vektors erhält den Wert des Funktionsarguments 1, jedes weitere Element wird um 1 inkrementiert. Anschließend wird auf myVec bestimmt, ob ein Element std::any_of gerade ist (Zeile 28), ob alle Elemente std::all_of gerade sind (Zeilen 29 und 30) und ob kein Element std::none_of gerade ist (Zeile 31). Neben dem Prädikat kommt eine Lambda-Funktion in den Zeilen 30 und 31 zum Einsatz. Die drei praktischen Funktionen sollten dem einen oder anderen aus Haskell oder auch Python vertraut sein. Praktisch ist auch der Algorithmus std::copy_if in Zeile 37, der es erlaubt, nur die Elemente auf std::cout zu kopieren, die das Prädikat in Form einer anonymen Funktion erfüllen. std::copy_n erlaubt es hingegen, eine feste Anzahl von Elementen zu kopieren. Das Kopieren wird mit std::partition_copy in Zeile 52 noch mächtiger. Diesmal ist das Ziel der Kopieraktion nicht std::cout, sondern zwei Container vom Typ std::list und std::deque. Vollkommen generisch lassen sich die Elemente, die das Prädikat erfüllen, auf den Container allEven schieben. Der Rest landet in allOdd. Generisch ist, dass es weder dem Container noch der for-Schleife anzusehen ist, welcher Containertyp der Operation zugrunde liegt. Generisch ist, dass durch den Iterator-Adapter std::back_inserter in Zeile 52 die Elemente direkt auf den Container geschoben werden können.
Ob ein Bereich partitioniert ist, lässt sich leicht durch std::is_partitioned in Zeile 65 ermitteln. std::partition_point liefert darüber hinaus noch den Iterator iter auf das erste Element der zweiten Teilmenge. Durch *iter lässt sich auf sein Element zugreifen. std::is_sorted beantwortet die Frage, ob ein Bereich aufsteigend sortiert ist. Durch die Parametrisierung des Algorithmus mit der Vergleichsfunktion [](int a, int b) {return a>b;} ist schnell getestet, ob ein Bereich absteigend sortiert ist. Nachdem in Zeile 79 das Element -10 auf den Container geschoben wurde, ist dieser nicht mehr aufsteigend sortiert. Bis zu welcher Stelle dieser sortiert ist, das beantwortet der neue Algorithmus std::is_sorted. std::is_sorted gibt wieder einen Iterator zurück, der auf das erste Element zeigt, das der Sortierreihenfolge widerspricht. In Abbildung 20.25 lässt sich der Programmlauf auf der Konsole nachvollziehen.
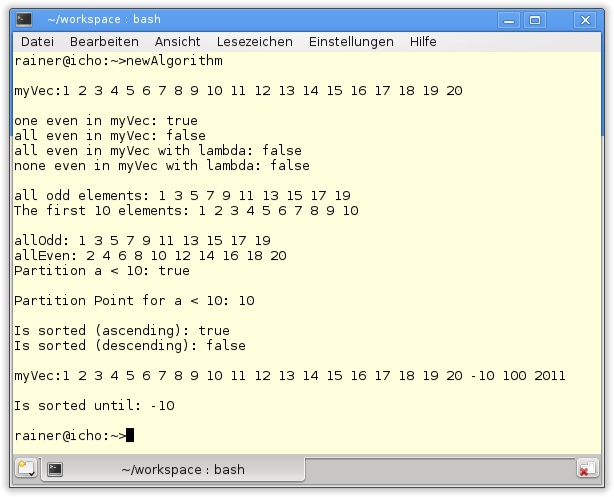
Praktische Helferlein
C++11 bringt noch ein paar weitere praktische Algorithmen mit, die den Umgang mit den Containern der STL vereinfachen. Die Container in C++11 können mit Initialisiererlisten initialisiert werden, unterstützen die Move-Semantik und erzeugen auf Anfrage einen konstanten Iterator mit den Methoden cbegin und cend bzw. einen reversen konstanten Iterator mit crbegin und crend.
emplace, emplace_back und emplace_front
Das direkte Erzeugen eines neuen Datentyps in einem Container ist mit emplace, emplace_back und emplace_front, die sich im Wesentlichen wie die bekannten insert, push_back und push_front verhalten, direkt möglich. Der feine Unterschied ist, dass bei emplace_back im Gegensatz zu push_back kein unnötiges Konstruieren eines temporären Objekts und das anschließende Kopieren notwendig sind. Listing 20.28 zeigt die Methoden im Einsatz.
emplace.cpp
01 #include <deque>
02 #include <iostream>
03 #include <map>
04 #include <utility>
05
06 class MyVal{
07 public:
08 MyVal(){};
09 MyVal(int i):val(i){}
10 int getVal() const{
11 return val;
12 }
13 private:
14 int val;
15 };
16
17 int main(){
18
19 std::cout << std::endl;
20
21 std::deque<MyVal> myDeq;
22 myDeq.push_back(MyVal(10));
23 myDeq.push_front(MyVal(11));
24 myDeq.emplace_back(12);
25 myDeq.emplace_front(13);
26
27 std::cout << "myDeq: ";
28 for ( auto it= myDeq.cbegin(); it != myDeq.cend(); ++it){
29 std::cout << it->getVal() << " ";
30 }
31
32 std::cout << std::endl;
33
34 std::map<int,MyVal> myMap;
35 myMap.insert(std::make_pair(1,MyVal(14)));
36 myMap.insert(std::make_pair(2,15));
37
38 std::cout << "myMap: ";
39 std::cout << myMap[1].getVal() << " ";
40 std::cout << myMap[2].getVal();
41
42 std::cout << std::endl;
43
44 }In Listing 20.28 ist die ressourcenschonende Anwendung der emplace- Funktionen zu sehen. In den Zeilen 24 und 25 werden die Argumente direkt an den Konstruktor von MyVal durchgereicht. Entsprechend wird in Zeile 36 der Wert MyVal(15) für den Schlüssel 2 in myMap eingefügt. In Abbildung 20.26 ist die Ausführung des Programms zu sehen.

shrink_to_fit
Die Verbesserungen gehen weiter. In C++ gibt es das bekannte Idiom »shrink-to-fit«, um einen Vektor std::vector<int> vecInt auf seine tatsächlich benötigte Größe zu reduzieren: std::vector<int>(vecInt).swap(vecInt). Der Name dieses Tricks stand Pate für die neuen shrink_to_fit-Algorithmen, die für std::string, std::deque und std::vector zur Verfügung stehen. Der Aufruf ist aber nicht bindend.
at
Wird in einer Map std::map<int,std::string> myMap nach einem Element myMap[2011] gefragt, das es nicht gibt, erzeugt die C++-Laufzeit implizit ein neues Paar (2011,std::string()) und fügt dieses in myMap ein. Für den Wert wird der Standardkonstruktor aufgerufen.
Ein Aufruf myMap.at(2012) in C++11 wirft eine Ausnahme, falls der Schlüssel 2012 in myMap nicht vorhanden ist.
Aufgabe 20-15
Was ist ein Heap?
In Listing 20.27 findet sich kein Beispiel zu den neuen C++11-Algorithmen std::is_heap und std::is_heap_until. Die erste Frage ist natürlich: Was ist ein Heap? Die kurze Antwort lautet: Ein Heap ist ein binärer Baum, bei dem das Vaterelement immer größer ist als seine Kindelemente. In Abbildung 20.27 ist ein Heap in Baumstruktur dargestellt.
Die lange Antwort lässt sich im Wikipedia-Artikel zur Heap-Datenstruktur (Heap, 2011) nachlesen.
Aufgabe 20-16
Erzeugen Sie einen Heap.
Durch die C++-Algorithmen std::make_heap wird ein Heap erzeugt. Mit std::sort_heap lassen sich die Elemente des Heap sortiert ausgeben. Die C++11-Algorithmen std::is_heap und std::is_heap_until beantworten die Frage, ob eine Sequenz ein Heap ist.
minMax.cpp
Aufgabe 20-17
Ermitteln Sie den minimalen und den maximalen Wert des sequenziellen Containers std::deque.
std::minmax_element lässt sich über eine Vergleichsfunktion parametrisieren. Ermitteln Sie das minimale und das maximale Element eines std::deque<std::string>. Variieren Sie im zweiten Schritt die Aufgabenstellung, indem Sie die Länge des Strings als Vergleichskriterium verwenden.
shrinkToFit.cpp
Aufgabe 20-18
Wenden Sie die neue Methode shrink_to_fit auf einem std::vector an.
In (Becker, Working Draft, Standard for Programming Language C++ (N3242), 2011) ist über shrink_to_fit für std::vector zu lesen: »... shrink_to_fit is a non-binding request to reduce capacity() to size().« Legen Sie einen std::vector an, dessen Kapazität größer als seine tatsächliche Größe ist. Geben Sie die Kapazität und seine tatsächliche Größe vor und nach shrink_to_fit aus. Besitzt der Aufruf von shrink_to_fit auf Ihrer Plattform eine Auswirkung?
bind und function
Der Anwendungsbereich von std::bind ist die Definition von aufrufbaren Einheiten aus Funktionsobjekten oder Funktionen. Diese aufrufbaren Einheiten können direkt ausgeführt oder in einem Funktionsobjekt gespeichert werden. Hier tritt std::function in Aktion, denn sie nimmt die Funktionsobjekte von std::bind an. std::function-Objekte fühlen sich wie Daten an. Sie können kopiert oder als Ein- oder Ausgabe einer Funktion verwendet werden. Da std::bind es erlaubt, Funktionen teilweise zu evaluieren, ist die beliebte Technik der funktionalen Programmierung nun auch in C++11 zu Hause: Evaluieren Sie eine Funktion teilweise mit std::bind und binden Sie das Ergebnis an eine neue Funktion mit std::function.
bind
Das C++11-std::bind erweitert die beiden C++98-Templates std::bind1st und std::bind2nd, die nur ein Argument binden können und dann auch nur das erste oder das zweite. Ein Ausdruck der Form
std::remove_if(con.begin(),con.end(),
std::bind2nd(std::greater<int>(), 8));entfernt alle Elemente aus dem Container con, die größer als 8 sind. Dabei wird das binäre Funktionsobjekt std::greater<int> in ein unäres Funktionsobjekt transformiert, da 8 an das zweite Argument gebunden wird. Das kann std::bind auch.
std::remove_if(con.begin(),con.end(), std::bind(std::greater<int>(),std::placeholders::_1,8));
Praxistipp
Verwenden Sie erase nach remove_if.
std::remove_if entfernt keine Elemente aus con, sondern gibt einen Iterator pos= remove_if( ... ) auf das neue logische Ende des Containers con zurück. Dieser Iterator con kann im nächsten Schritt verwendet werden, um die Elemente tatsächlich zu entfernen:
std::erase(pos,con.end());
Natürlich kann std::bind noch viel mehr, denn es erlaubt:
die Argumente an beliebige Positionen zu binden,
die Reihenfolge der Argumente umzustellen,
Platzhalter für Argumente einzuführen,
Funktionen nur teilweise zu evaluieren,
das resultierende Funktionsobjekt direkt aufzurufen, in den Algorithmen der STL zu verwenden oder in
std::functionzu speichern.
function
std::function nimmt die Funktionsobjekte von std::bind an und bindet sie unter einem neuen Namen. Der Funktionstyp der anzunehmenden Funktion wird durch das Template-Argument tempArg von std::function <tempArg> spezifiziert. Tabelle 20.1 stellt ein paar Funktionstypen tempArg dar.
Funktionstyp | Argumente | Rückgabetyp |
|
| |
|
|
|
|
|
|
|
std::function-Objekte können wie gewöhnliche Werte kopiert oder auch als Callback verwendet werden. In Listing 20.29 ist die perfekte Zusammenarbeit von std::bind und std::function zu sehen.
bindAndFunction.cpp
01 #include <algorithm>
02 #include <functional>
03 #include <iostream>
04 #include <iterator>
05 #include <vector>
06
07 double divMe(double a, double b){
08 return double(a/b);
09 }
10
11 using namespace std::placeholders;
12
13 int main(){
14
15 std::cout << std::endl;
16
17 // invoking the function object directly
18 std::cout << "1/2.0= " << std::bind(divMe,1,2.0)()
<< std::endl;
19
20 // placeholders for both arguments
21 std::function<double(double,double)> myDivBindPlaceholder=
std::bind(divMe,_1,_2);
22 std::cout << "1/2.0= " << myDivBindPlaceholder(1,2.0)
<< std::endl;
23
24 // placeholders for both arguments, swap the arguments
25 std::function<double(double,double)>
myDivBindPlaceholderSwap= std::bind(divMe,_2,_1);
26 std::cout << "1/2.0= " << myDivBindPlaceholderSwap(2.0,1)
<< std::endl;
27
28 // placeholder for the first argument
29 std::function<double(double)> myDivBind1St=
std::bind(divMe,_1,2.0);
30 std::cout<< "1/2.0= " << myDivBind1St(1) << std::endl;
31
32 // placeholder for the second argument
33 std::function<double(double)> myDivBind2Nd=
std::bind(divMe,1.0,_1);
34 std::cout << "1/2.0= " << myDivBind2Nd(2.0) << std::endl;
35
36 // copy all element to std::cout, which are bigger than 10
37 std::vector<int>
myVec{5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20};
38 std::copy_if(myVec.begin(),myVec.end(),
std::ostream_iterator<int>( std::cout," "),
std::bind( std::greater <int>(),_1,10));
39
40 std::cout << std::endl;
41 std::cout << std::endl;
42
43 }std::bind in Listing 20.29 definiert in verschiedenen Variationen ein Funktionsobjekt. In Zeile 18 werden die Argumente direkt an divMe gebunden, und die abschließenden Klammern rufen das Funktionsobjekt auf. Im Gegensatz hierzu sind die Ausdrücke _1 und _2 in den std::bind-Ausdrücken (Zeilen 21, 25, 29 und 33) Platzhalter, die ihre Argumente erst beim Aufruf in der jeweils nächsten Zeile erhalten. Durch diese Platzhalter wird erreicht (Zeile 29), dass aus einer Funktion, die zwei Argumente erwartet, eine Funktion erzeugt wird, die nur noch ein Argument benötigt. Diese Technik ist unter dem Namen Currying (siehe Exkurs: Currying) aus der funktionalen Programmierung sehr bekannt. Der std::function-Aufruf gibt dem neu erzeugten Funktionsobjekt einen Namen. Dabei definiert das Template-Argument <double(double)> den Funktionstyp des Arguments – eine Funktion, die ein double annimmt und ein double zurückgibt. Relativ schwierig zu lesen ist der Ausdruck std::bind( std::greater <int>(),_1,10), denn hier wird ein spezielles Funktionsobjekt erklärt, ein Prädikat. Ein Prädikat gibt nur true oder false zurück. In diesem Fall gibt es genau dann true zurück, wenn die Zahl größer als 10 ist. Die Zahlen aus myVec, die größer als 10 sind, werden direkt nach std::cout kopiert. Genau diese Ausgabe ist in Abbildung 20.28 zu sehen.
Dies waren schon die wesentlichen Punkte zum Zusammenspiel von std::bind und std::function. Ein paar Details folgen noch.
Platzhalter
Auf den ersten Blick wirken die Platzhalter in Listing 20.29 nicht vertraut. Voll ausgeschrieben sind sie ein bisschen sperrig: std::placeholders::_1. Dabei bezeichnen sie die Argumente, die das aus std::bind resultierende Funktionsobjekt erhält. Das erste Argument des resultierenden Funktionsobjekts wird an std::placeholders::_1 gegeben, das zweite an std::placeholders::_2, das dritte an ... Ich denke, das Prinzip ist klar. Es hängt von der Implementierung ab, wie viele Platzhalter sie definiert. Ein Blick in die Implementierung verrät: Der GCC 4.7 (GCC 4.7, 2011) definiert 29 Platzhalter, der Microsoft-Visual C++-Compiler VC10 zehn Platzhalter.
Elementfunktionen
Nicht nur Funktionen und Funktionsobjekte, auch Methoden lassen sich mit std::bind extrahieren und als freie Funktionen anbieten. Dieses Extrahieren gilt nicht nur für die Methoden, sondern auch für den Zustand des Objekts. Listing 20.30 zeigt diese Magie in der Anwendung.
bindFuncObject.cpp
01 #include <functional>
02 #include <iomanip>
03 #include <iostream>
04
05 class Family{
06 public:
07 Family(const std::string& s):family(s){}
08
09 std::string getName(const std::string& first){
10 return family + ", " + first;
11 }
12 private:
13 std::string family;
14 };
15
16 int main(){
17
18 std::cout << std::endl;
19 int len= 23;
20
21 // using methods
22 Family grimm("Grimm");
23 std::cout << std::setw(len) << std::left
<< "grimm.getName(Rainer): "
<< grimm.getName("Rainer") << std::endl;
24
25 std::cout << std::endl;
26
27 // using std::bind with objects
28 Family mann("Mann");
29 std::function<std::string(const std::string&)> mannCrea=
std::bind(&Family::getName,mann,std::placeholders::_1);
30
31 std::cout << std::setw(len) << std::left
<< "mannCrea(Heinrich): "
<< mannCrea("Heinrich") << std::endl;
32 std::cout << std::setw(len) << std::left
<< "mannCrea(Golo): "
<< mannCrea("Golo") << std::endl;
33 std::cout << std::setw(len) << std::left
<< "mannCrea(thomas): "
<< mannCrea("Thomas") << std::endl;
34
35 std::cout << std::endl;
36
37 }Family (Zeile 5) in Listing 20.30 stellt Familienobjekte zur Verfügung. Im Konstruktor wird der Familienname gesetzt, die Methode getName (Zeile 9) fügt zum Familiennamen den Vornamen hinzu und gibt ihn aus. Das Objekt grimm in Zeile 22 gibt den vollständigen Namen in der folgenden Zeile aus. Bis hierher nichts Besonderes. Das beginnt mit Zeile 28. Hier wird das Objekt mann vom Typ Family erzeugt. Das Objekt mann besitzt einen Zustand, denn der Familienname wurde im Konstruktoraufruf gesetzt. Dieses Objekt wird in Zeile 29 an mannCrea gebunden. Die Argumente von std::bind sind nicht ganz einfach zu lesen. Auf den Zeiger auf die Methode &Family::getName folgen das Objekt mann und der Platzhalter std::placeholders::_1. Das Template-Argument std::string <(const std::string&)> entspricht dabei der Signatur der Methode getName. Damit steht der Objektzustand in der freien Funktion mannCrea zur Verfügung und kann in den Funktionsaufrufen in den Zeilen 31, 32 und 33 angewandt werden. Die Ausgabe des Programms folgt in Abbildung 20.29.
Praxistipp
Ziehen Sie auto und Lambda-Funktionen bind und function vor.
Für das einfache Erzeugen von neuen Funktionsobjekten aus bestehenden Funktionen oder auch das Kopieren von Funktionsobjekten bietet C++11 zwei Wege an. Der eine Weg führt über die Bibliotheksfunktionen std::bind und std::function, der andere über auto und Lambda-Funktionen. Da stellt sich natürlich die Frage: Welchen Weg soll man wählen? Meist sind die Erweiterungen der Kernsprache einfacher zu schreiben und zu lesen. Ein paar Codeschnipsel sollen dies veranschaulichen.
Beide Funktionsobjekte beschreiben Prädikate, die für einen Eingabewert entscheiden, ob dieser größer als 10 ist.
01 std::bind(std::greater<int> (),
std::placeholders::_1,10)
02 [](int a){return a > 10;}Wird das resultierende Funktionsobjekt an eine Variable gebunden, wird der Unterschied noch deutlicher.
01 std:function<double(double)>func=
std::bind(divMe,1.0,std::placeholders::_1)
02 auto func= [](double b){return divMe(1.0,b);}Beim nächsten Beispiel ist die Implementierung mit Funktionen der Standard Template Library meines Erachtens sehr verständnisresistent. Dabei lässt sich der Algorithmus einfach beschreiben: Kopiere alle Elemente von myVec nach std::cout, die größer als 9 und kleiner als 16 sind.
std::copy_if( myVec.begin(), myVec.end(),
std::ostream_iterator<int>( std::cout, ", " ),
std::bind( std::logical_and<bool>(),
std::bind( std::greater <int>(),
std::placeholders::_1,9 ),
std::bind( std::less <int>(),
std::placeholders::_1,16 )))
std::copy_if( myVec.begin(), myVec.end(),
std::ostream_iterator<int>( std::cout, ", " ),
[](int a){return (a>9)&&(a<16);})Der entscheidende Punkt in Listing 20.33 ist, dass sich das Prädikat mit einer Lambda-Funktion in einem Ausdruck beschreiben lässt, während mehrere Funktionsobjekte bei der STL-Implementierung ineinander verschachtelt werden müssen.
Insbesondere Programmierer, die mit den funktionalen Ideen vertraut sind, werden sich bei automatischer Typableitung und Lambda-Funktionen sofort zu Hause fühlen.
bindLamdaComparison.cpp
Aufgabe 20-19
Löschen Sie alle Elemente aus einem Vektor, die das Prädikat aus Listing 20.33 erfüllen.
Der Vektor soll vom Typ std::vector<int> sein. Lösen Sie die Aufgabe in zwei Variationen.
Definieren Sie das Prädikat durch
std::bindund speichern Sie es instd::function.eine Lambda-Funktion und verwenden Sie
auto, um es zu speichern.
Wenden Sie anschließend das Prädikat mit den Algorithmen der Standard Template Library an und geben Sie den reduzierten Vektor zur Kontrolle aus.
countAlphabetFunctional.cpp
Aufgabe 20-20
Bestimmen Sie, wie oft ein Buchstabe in einem Text vorkommt.
Zählen Sie die Häufigkeit der Buchstaben des Alphabets in einem Text, und dies ohne Berücksichtigung der Klein- oder Großschreibung. Geben Sie die Buchstaben nach ihrer Häufigkeit sortiert aus.
Das war eine Aufgabenstellung im Kapitel zu regulären Ausdrücken, aber das hier ist eine neue Aufgabe, die es gilt, mithilfe von std::function und std::bind zu lösen. Der Algorithmus std::for_each aus der Standard Template Library hilft Ihnen, das Problem zu lösen.
Lösen Sie die Aufgabe und vergleichen Sie die Lösung mit der Lösung in Kapitel 19 im Abschnitt „regex_iterator“ die auf regulären Ausdrücken aufbaut.