All data and code for this book are available for download at http://www.malwaredatascience.com/. Be warned: there is Windows malware in the data. If you unzip the data on a machine with an antivirus engine running on it, many of the malware examples will likely get deleted or quarantined.
NOTE
We have modified a few bytes in each malware executable so as to disable it from executing. That being said, you can’t be too careful about where you store it. We recommend storing it on a non-Windows machine that’s isolated from your home or business network.
Ideally, you should only experiment with the code and data within an isolated virtual machine. For convenience, we’ve provided a VirtualBox Ubuntu instance at http://www.malwaredatascience.com/ that has the data and code preloaded onto it, along with all the necessary open source libraries.
Now let’s walk through the datasets that accompany each chapter of this book.
Recall that in Chapter 1 we walk through basic static analysis of a malware binary called ircbot.exe. This malware is an implant, meaning it hides on users’ systems and waits for commands from an attacker, allowing the attacker to collect private data from a victim’s computer or achieve malicious ends like erasing the victim’s hard drive. This binary is available in the data accompanying this book at ch1/ircbot.exe.
We also use an example of fakepdfmalware.exe in this chapter (located at ch1/fakepdfmalware.exe). This is a malware program that has an Adobe Acrobat/PDF desktop icon to trick users into thinking they’re opening a PDF document when they’re actually running the malicious program and infecting their systems.
In this chapter we explore a deeper topic in malware reverse engineering: analyzing x86 disassembly. We reuse the ircbot.exe example from Chapter 1 in this chapter.
For our discussion of dynamic malware analysis in Chapter 3, we experiment with a ransomware example stored in the path ch3/d676d9dfab6a4242258362b8ff579cfe6e5e6db3f0cdd3e0069ace50f80af1c5 in the data accompanying this book. The filename corresponds to the file’s SHA256 cryptographic hash. There’s nothing particularly special about this ransomware, which we got by searching VirusTotal.com’s malware database for examples of ransomware.
Chapter 4 introduces the application of network analysis and visualization to malware. To demonstrate these techniques, we use a set of high-quality malware samples used in high-profile attacks, focusing our analysis on a set of malware samples likely produced by a group within the Chinese military known to the security community as Advanced Persistent Threat 1 (or APT1 for short).
These samples and the APT1 group that generated them were discovered and made public by cybersecurity firm Mandiant. In its report (excerpted here) titled “APT1: Exposing One of China’s Cyber Espionage Units” (https://www.fireeye.com/content/dam/fireeye-www/services/pdfs/mandiant-apt1-report.pdf), Mandiant found the following:
As this excerpt of the report shows, the APT1 samples were used for high-stakes, nation state–level espionage. These samples are available in the data accompanying this book at ch4/data/APT1_MALWARE_FAMILIES.
Chapter 5 reuses the APT1 samples used in Chapter 4. For convenience, these samples are also located in the Chapter 5 directory, at ch5/data/APT1_MALWARE_FAMILIES.
These conceptual chapters don’t require any sample data.
Chapter 8 explores building machine learning–based malware detectors and uses 1,419 sample binaries as a sample dataset for training your own machine learning detection system. These binaries are located at ch8/data/benignware for the benign samples and ch8/data/malware for the malware samples.
The dataset contains 991 benignware samples and 428 malware samples, and we got this data from VirusTotal.com. These samples are representative, in the malware case, of the kind of malware observed on the internet in 2017 and, in the benignware case, of the kind of binaries users uploaded to VirusTotal.com in 2017.
Chapter 9 explores data visualization and uses the sample data in the file ch9/code/malware_data.csv. Of the 37,511 data rows in the file, each row shows a record of an individual malware file, when it was first seen, how many antivirus products detected it, and what kind of malware it is (for example, Trojan horse, ransomware, and so on). This data was collected from VirusTotal.com.
This chapter introduces deep neural networks and doesn’t use any sample data.
This chapter walks through building a neural network malware detector for detecting malicious and benign HTML files. Benign HTML files are from legitimate web pages, and the malicious web pages are from websites that attempt to infect victims via their web browsers. We got both of these datasets from VirusTotal.com using a paid subscription that allows access to millions of sample malicious and benign HTML pages.
All the data is stored at the root directory ch11/data/html. The benignware is stored at ch11/data/html/benign_files, and the malware is stored at ch11/data/html/malicious_files. Additionally, within each of these directories are the subdirectories training and validation. The training directories contain the files we train the neural network on in the chapter, and the validation directories contain the files we test the neural network on to assess its accuracy.
Chapter 12 discusses how to become a data scientist and doesn’t use any sample data.
Although all the code in this book is sample code, intended to demonstrate the ideas in the book and not be taken whole cloth and used in the real world, some of the code we provide can be used as a tool in your own malware analysis work, particularly if you’re willing to extend it for your own purposes.
NOTE
Intended as examples and starting places for full-fledged malware data science tools, these tools are not robustly implemented. They have been tested on Ubuntu 17 and are expected to work on this platform, but with a bit of work around installing the right requirements, you should be able to get the tools to work on other platforms like macOS and other flavors of Linux fairly easily.
In this section, we walk through the nascent tools provided in this book in the order in which they appear.
A shared hostname network visualization tool is given in Chapter 4 and is located at ch4/code/listing-4-8.py. This tool extracts hostnames from target malware files and then shows connections between the files based on common hostnames contained in them.
The tool takes a directory of malware as its input and then outputs three GraphViz files that you can then visualize. To install the requirements for this tool, run the command run bash install_requirements.sh in the ch4/code directory. Listing A-1 shows the “help” output from the tool, after which we discuss what the parameters mean.
usage: Visualize shared hostnames between a directory of malware samples
[-h] target_path output_file malware_projection hostname_projection
positional arguments:
➊ target_path directory with malware samples
➋ output_file file to write DOT file to
➌ malware_projection file to write DOT file to
➍ hostname_projection file to write DOT file to
optional arguments:
-h, --help show this help message and exit
Listing A-1: Help output from the shared hostname network visualization tool given in Chapter 4
As shown in Listing A-1, the shared hostname visualization tool requires four command line arguments: target_path ➊, output_file ➋, malware_projection ➌, and hostname_projection ➍. The parameter target_path is the path to the directory of malware samples you’d like to analyze. The output_file parameter is a path to the file where the program will write a GraphViz .dot file representing the network that links malware samples to the hostnames they contain.
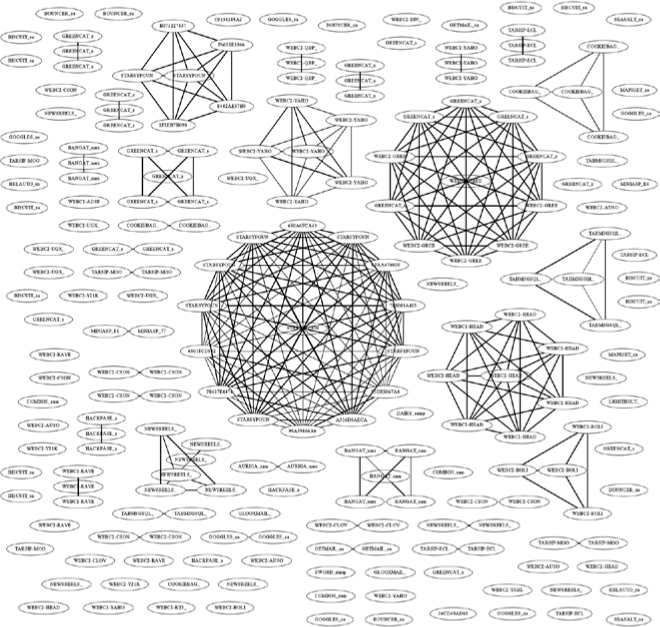
The malware_projection and hostname_projection parameters are also file paths and specify the locations where the program will write .dot files that represent these derived networks (for more on network projections, see Chapter 4). Once you’ve run the program, you can use the GraphViz suite discussed in Chapters 4 and 5 to visualize the networks. For example, you could use the command fdp malware_projection.dot -Tpng -o malware_projection.png to generate a file like the .png file rendered in Figure A-1 on your own malware datasets.
Figure A-1: Sample output from the shared hostname visualization tool given in Chapter 4
We present a shared image network visualization tool in Chapter 4, which is located at ch4/code/listing-4-12.py. This program shows network relationships between malware samples based on embedded images they share.
The tool takes a directory of malware as its input and then outputs three GraphViz files that you can then visualize. To install the requirements for this tool, run the command run bash install_requirements.sh in the ch4/code directory. Let’s discuss the parameters in the “help” output from the tool (see Listing A-2).
usage: Visualize shared image relationships between a directory of malware samples
[-h] target_path output_file malware_projection resource_projection
positional arguments:
➊ target_path directory with malware samples
➋ output_file file to write DOT file to
➌ malware_projection file to write DOT file to
➍ resource_projection file to write DOT file to
optional arguments:
-h, --help show this help message and exit
Listing A-2: Help output from the shared resource network visualization tool given in Chapter 4
As shown in Listing A-2, the shared image relationships visualization tool requires four command line arguments: target_path ➊, output_file ➋, malware_projection ➌, and resource_projection ➍. Much like in the shared hostname program, here target_path is the path to the directory of malware samples you’d like to analyze, and output_file is a path to the file where the program will write a GraphViz .dot file representing the bipartite graph that links malware samples to the images they contain (bipartite graphs are discussed in Chapter 4). The malware_projection and resource_projection parameters are also file paths and specify the locations where the program will write .dot files that represent these networks.
As with the shared hostname program, once you’ve run the program, you can use the GraphViz suite to visualize the networks. For example, you could use the command fdp resource_projection.dot -Tpng -o resource_projection.png on your own malware datasets to generate a file like the .png file rendered in Figure 4-12 on page 55.
In Chapter 5, we discuss malware similarity and shared code analysis and visualization. The first sample tool we provide is given in ch5/code/listing_5_1.py. This tool takes a directory containing malware as its input and then visualizes shared code relationships between the malware samples in the directory. To install the requirements for this tool, run the command run bash install_requirements.sh in the ch5/code directory. Listing A-3 shows the help output for the tool.
usage: listing_5_1.py [-h] [--jaccard_index_threshold THRESHOLD]
target_directory output_dot_file
Identify similarities between malware samples and build similarity graph
positional arguments:
➊ target_directory Directory containing malware
➋ output_dot_file Where to save the output graph DOT file
optional arguments:
-h, --help show this help message and exit
➌ --jaccard_index_threshold THRESHOLD, -j THRESHOLD
Threshold above which to create an 'edge' between
samples
Listing A-3: Help output from the malware similarity visualization tool given in Chapter 5
When you run this shared code analysis tool from the command line, you need to pass in two command line arguments: target_directory ➊ and output_dot_file ➋. You can use the optional argument, jaccard_index_threshold ➌, to set the threshold the program uses with the Jaccard index similarity between two samples to determine whether or not to create an edge between those samples. The Jaccard index is discussed in detail in Chapter 5.
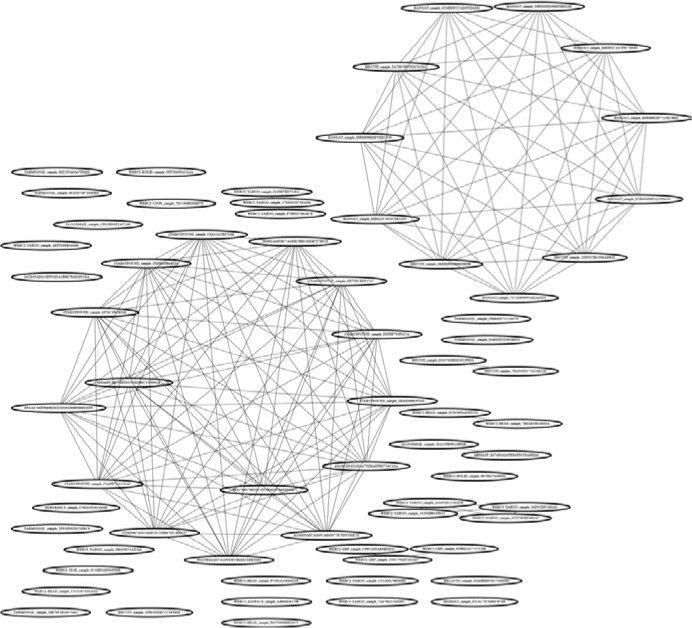
Figure A-2 shows sample output from this tool once you’ve rendered the output_dot_file with the command fdp output_dot_file.dot -Tpng -o similarity_network.png. This is the shared code network inferred by the tool for the APT1 malware samples we just described.
Figure A-2: Sample output from the malware similarity analysis tool given in Chapter 5
The second code-sharing estimation tool we provide in Chapter 5 is given in ch5/code/listing_5_2.py. This tool allows you to index thousands of samples in a database and then perform a similarity search on them with a query malware sample, which lets you find malware samples that likely share code with that sample. To install the requirements for this tool, run the command run bash install_requirements.sh in the ch5/code directory. Listing A-4 shows the help output for the tool.
usage: listing_5_2.py [-h] [-l LOAD] [-s SEARCH] [-c COMMENT] [-w]
Simple code-sharing search system which allows you to build up a database of
malware samples (indexed by file paths) and then search for similar samples
given some new sample
optional arguments:
-h, --help show this help message and exit
➊ -l LOAD, --load LOAD Path to directory containing malware, or individual
malware file, to store in database
➋ -s SEARCH, --search SEARCH
Individual malware file to perform similarity search
on
➌ -c COMMENT, --comment COMMENT
Comment on a malware sample path
➍ -w, --wipe Wipe sample database
Listing A-4: Help output from the malware similarity search system given in Chapter 5
This tool has four modes in which it can be run. The first mode, LOAD ➊, loads malware into the similarity search database and takes a path as its parameter, which should point to a directory with malware in it. You can run LOAD multiple times and add new malware to the database each time.
The second mode, SEARCH ➋, takes the path to an individual malware file as its parameter and then searches for similar samples in the database. The third mode, COMMENT ➌, takes a malware sample path as its argument and then prompts you to enter a short textual comment about that sample. The advantage of using the COMMENT feature is that when you search for samples similar to a query malware sample, you see the comments corresponding to the similar sample, thus enriching your knowledge of the query sample.
The fourth mode, wipe ➍, deletes all the data in the similarity search database, in case you want to start over and index a different malware dataset. Listing A-5 shows some sample output from a SEARCH query, giving you a flavor for what the output from this tool looks like. Here we’ve indexed the APT1 samples described previously using the LOAD command and have subsequently searched the database for samples similar to one of the APT1 samples.
Showing samples similar to WEBC2-GREENCAT_sample_E54CE5F0112C9FDFE86DB17E85A5E2C5
Sample name Shared code
[*] WEBC2-GREENCAT_sample_55FB1409170C91740359D1D96364F17B 0.9921875
[*] GREENCAT_sample_55FB1409170C91740359D1D96364F17B 0.9921875
[*] WEBC2-GREENCAT_sample_E83F60FB0E0396EA309FAF0AED64E53F 0.984375
[comment] This sample was determined to definitely have come from the advanced persistent
threat group observed last July on our West Coast network
[*] GREENCAT_sample_E83F60FB0E0396EA309FAF0AED64E53F 0.984375
Listing A-5: Sample output for the malware similarity search system given in Chapter 5
The final tool you can use in your own malware analysis work is the machine learning malware detector used in Chapter 8, which can be found at ch8/code/complete_detector.py. This tool allows you to train a malware detection system on malware and benignware and then use this system to detect whether a new sample is malicious or benign. You can install the requirements for this tool by running the command bash install.sh in the ch8/code directory. Listing A-6 shows the help output for this tool.
usage: Machine learning malware detection system [-h]
[--malware_paths MALWARE_PATHS]
[--benignware_paths BENIGNWARE_PATHS]
[--scan_file_path SCAN_FILE_PATH]
[--evaluate]
optional arguments:
-h, --help show this help message and exit
➊ --malware_paths MALWARE_PATHS
Path to malware training files
➋ --benignware_paths BENIGNWARE_PATHS
Path to benignware training files
➌ --scan_file_path SCAN_FILE_PATH
File to scan
➍ --evaluate Perform cross-validation
Listing A-6: Help output for the machine learning malware detection tool given in Chapter 8
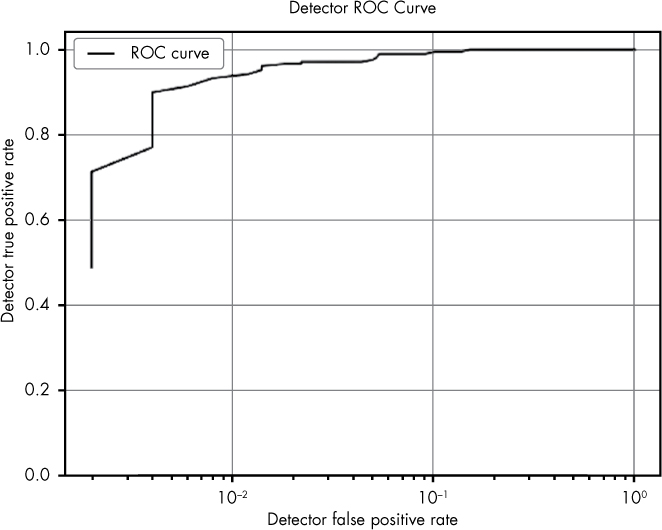
This tool has three modes in which it can be run. The evaluate mode ➍, tests the accuracy of the system on the data you select for training and evaluating the system. You can invoke this mode by running python complete_detector.py –malware_paths <path to directory with malware in it> --benignware_paths <path to directory with benignware in it> --evaluate. This command will invoke a matplotlib window showing your detector’s ROC curve (ROC curves are discussed in Chapter 7). Figure A-3 shows some sample output from evaluate mode.
Figure A-3: Sample output from the malware detection tool provided in Chapter 8, run in evaluate mode
Training mode trains a malware detection model and saves it to disk. You can invoke this mode by running python complete_detector.py –malware_paths ➊ <path to directory with malware in it> --benignware_paths ➋ <path to directory with benignware in it>. Note that the only difference between this command invocation and the invocation of evaluate mode is that we’ve left off the --evaluate flag. The result of this command is that it generates a model that it saves to a file called saved_detector.pkl, which is saved in your current working directory.
The third mode, scan ➌, loads saved_detector.pkl and then scans a target file, predicting whether it’s malicious or not. Make sure you have run training mode before running a scan. You can run a scan by running python complete_detector.py –scan_file_path <PE EXE file> in the directory where you trained the system. The output will be a probability that the target file is malicious.