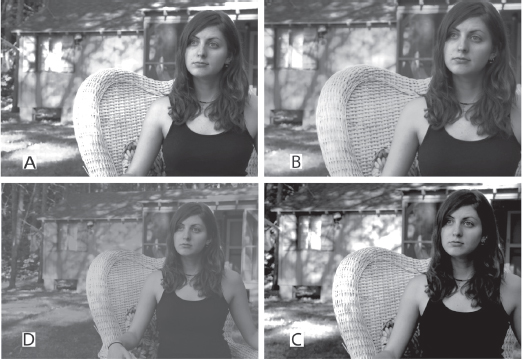
This chapter provides more technical information about digital video recording in production and postproduction. For the basics of video formats, cameras, and editing, see Chapters 1, 2, 3, and 14.
FORMING THE VIDEO IMAGE
THE DIGITAL VIDEO CAMERA’S RESPONSE TO LIGHT
You’ll find simplified instructions for setting the exposure of a video camera on p. 107. Let’s look more closely at how the camera responds to light so you’ll have a better understanding of exposure and how to achieve the look you want from your images.
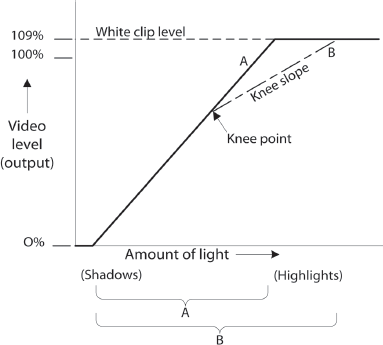
The camera’s sensor converts an image made of light into an electrical signal (see p. 5). Generally speaking, the more light that strikes the sensor, the higher the level of the signal. To look more closely at the relationship between light and the resulting video level, we can draw a simplified graph like the one in Fig. 5-1. The amount of light striking the sensor increases as we move from left to right.1 The vertical axis shows the resulting video signal level.
This relationship between light input and video signal output is called a sensor’s transfer characteristic. It resembles a characteristic curve for film (see Fig. 7-3, with the exception that it is a straight line: both CCD and CMOS sensors produce signals directly proportional to the light falling on them.
Look at the line marked “A.” Note that below a certain amount of light (the far left side of the graph), the system doesn’t respond at all. These are dark shadow areas; the light here is so dim that the photons (light energy) that strike the sensor from these areas simply disappear into the noise of the sensor. Then, as the amount of light increases, there is a corresponding increase in the video level. Above a certain amount of exposure, the system again stops responding. This is the white clip level. You can keep adding light, but the video level won’t get any higher. Video signals have a fixed upper limit, which is restricted by legacy broadcast standards, despite the fact that sensors today can deliver significantly more stops of highlight detail than in the past.
When the exposure for any part of the scene is too low, that area in the image will be undifferentiated black shadows. And anything higher than the white clip will be flat and washed-out white. For objects in the scene to be rendered with some detail, they need to be exposed between the two.
Fig. 5-1. The video sensor’s response to light. The horizontal axis represents increasing exposure (light) from the scene. The vertical axis is the level of the resulting video signal that the camera produces. Line A shows that as the light increases, so does the video level—until the white clip is reached, at which point increases in light produce no further increase in video level (the line becomes horizontal). With some cameras, a knee point can be introduced that creates a less steep knee slope to the right of that point (Line B). Note how this extends the camera’s ability to capture bright highlights compared to A. This graph is deliberately simplified. (Steven Ascher)
The limits of the video signal help explain why the world looks very different to the naked eye than it does through a video camera. Your eye is more sensitive to low light levels than most video cameras are—with a little time to adjust, you can see detail outdoors at night or in other situations that may be too dark for a camera. Also, your eye can accommodate an enormous range of brightness. For example, you can stand inside a house and, in a single glance, see detail in the relatively dark interior and the relatively bright exterior. By some estimates, if you include that our pupils open and close for changing light, our eyes can see a range of about twenty-four f-stops.
Digital video and film are both much more limited in the range of usable detail they can capture from bright to dark (called the exposure range or dynamic range). When shooting, you may have to choose between showing good detail in the dark areas or showing detail in the bright areas, but not both at the same time (see Fig. 7-16). Kodak estimates that many of its color negative film stocks can capture about a ten-stop range of brightness (a contrast ratio of about 1,000:1 between the brightest and darkest value), although color negative’s S-shaped characteristic curve can accommodate several additional stops of information at either end of the curve.2 Historically, analog video cameras were able to handle a much more limited range, sometimes as low as about five stops (40:1), but new high-end digital cameras capture an exposure range of around ten stops, and the latest digital cinematography cameras like the ARRI Alexa and Sony F65 claim fourteen stops. RED says its Epic camera can capture eighteen stops when using its high dynamic range function.
The image in Fig. 7-17 was shot with film; the middle shot shows a “compromise” exposure that balances the bright exterior and dark interior. With typical video cameras it is often harder to find a compromise that can capture both; instead you may need to expose for one or the other (more on this below).
To truly evaluate exposure range we need to look at the film or video system as a whole, which includes the camera, the recording format, and the monitor or projection system—all of which play a part. For example, a digital camera’s sensor may be capable of capturing a greater range than can be recorded on tape or in a digital file, and what is recorded may have a greater range than can be displayed by a particular monitor.
Measuring Digital Video Levels
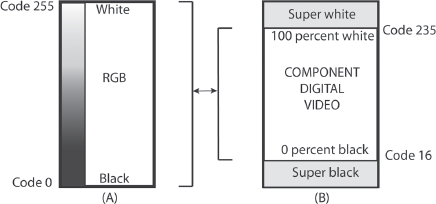
We’ve seen that the digital video camera records a range of video levels from darkest black to brightest white. This range is determined in part by what is considered “legal” by broadcast standards. We can think of the darkest legal black as 0 percent digital video level and the brightest legal white as 100 percent (sometimes called full white or peak white).
The actual range a digital video camera is capable of capturing always goes beyond what is broadcast legal. On most cameras today, the point at which bright whites are clipped off is 109 percent. The range above 100 is called super white or illegal white and can be useful for recording bright values as long as they’re brought down before the finished video is broadcast. If you’re not broadcasting—say, you’re creating a short for YouTube or doing a film-out—you don’t need to bring the super white levels down at all.
Professional video cameras have a viewfinder display called a zebra indicator (or just “zebra” or “zebras”) that superimposes a striped pattern on the picture wherever the video signal exceeds a preset level (see Fig. 3-3). A zebra set to 100 percent will show you where video levels are close to or above maximum and may be clipped. Some people like to set the zebra lower (at 85 to 90 percent) to give some warning before highlights reach 100 percent. If you use the zebra on a camera that’s not your own, always check what level it’s set for.3
Fig. 5-2. Histograms. The normally exposed shot (top) produces a histogram with pixels distributed from dark tones to light. In this case, the distribution is a “mountain in the middle,” with the most pixels in the midtones, and relatively few in the darkest shadows or brightest highlights. The underexposed shot (bottom left) creates a histogram with the pixels piled up against the left side, showing that blacks are being crushed and shadow detail is lost. The overexposed shot (bottom right) shows pixels concentrated in the bright tones on the right, with details lost due to clipped highlights. (Steven Ascher)
Many newer digital cameras and all DSLRs use a histogram to display the distribution of brightness levels in the image (see Fig. 5-2). A histogram is a dynamically changing bar graph that displays video levels from 0 to 100 percent along the horizontal axis and a pixel count along the vertical axis. In a dark scene, the histogram will show a cluster of tall bars toward the left, which represents a high number of dark pixels in the image. A bright highlight will cause a tall bar to appear on the right side. By opening and closing the iris, the distribution of pixels will shift right or left. For typical scenes, some people use the “mountain in the middle” approach, which keeps the majority of the pixels safely in the middle and away from the sides where they may be clipped.

Fig. 5-3. A waveform monitor displays video levels in the image. In this case, you can see that the brightest parts of the bed sheet on the right side of the frame are exceeding 100 percent video level. (Steven Ascher)
A waveform monitor gives a more complete picture of video levels (see Fig. 5-3). On waveform monitors used for digital video formats, 0 percent represents absolute black and, at the top of the scale, 100 percent represents peak legal white level. (For analog video, waveform monitors were marked in IRE—from Institute of Radio Engineers—units of measurement. Absolute black was 0 IRE units and peak white was 100 IRE units. The units of percentage used for today’s digital video signal directly parallel the old system of IRE units.)
Waveform monitors are commonly used in postproduction to ensure that video levels are legal. But a waveform monitor is also a valuable tool on any shoot. With a waveform monitor, unlike a histogram, if there is a shiny nose or forehead creating highlights above 100 percent signal level, you’ll notice it easily—and know what’s causing it (when a subject in a close-up moves from left to right, you can see the signal levels shift left to right on the waveform monitor). It’s like having a light meter that can read every point in a scene simultaneously. Some picture monitors and camera viewfinders can display a waveform monitor on screen.
Fig. 5-4. By looking at the waveform display of a single horizontal line of pixels, you can more clearly see how luminance values in the image are represented in the waveform monitor. (Robert Brun)
USING A LIGHT METER. Some cinematographers like to use a handheld light meter when shooting digital, much as they would when shooting film. For any particular camera it will take some experimentation to find the best ISO setting for the meter (with digital video cameras that have ISO settings, you can’t assume those will match the meter’s ISO). Point the camera at a standard 18 percent gray card (see p. 307) and make sure the card fills most of the frame. Lock the shutter speed and the gain or ISO, and set the camera’s auto-iris so it sets the f-stop automatically (shutter priority in DSLRs). Note the f-stop of the lens. Now, with the light meter, take a reflected reading of the gray card (or an incident reading in the same light) and adjust the meter’s ISO until it has the same f-stop. If you have a waveform monitor, and are using a manual iris, set the iris so the gray card reads about 50 percent video level.
The fact is, in a digital video camera, no aspect of the digital video signal goes unprocessed (with such adjustments as gamma, black stretch, and so on) so there isn’t an easily measured sensitivity, as there is for film or digital cinema cameras capturing RAW files directly from the sensor. For this reason, experienced video camera operators rarely use light meters to set exposure. They may, however, use light meters to speed up lighting, particularly if they know the light levels best suited to a particular scene and how to adjust key-to-fill ratios with a light meter alone.
Setting Exposure—Revisited
See Setting the Exposure on p. 107 before reading this. Setting exposure by eye—that is, by the way the picture looks in the viewfinder or monitor—is the primary way many videographers operate. But to be able to trust what you’re seeing, you need a good monitor, properly set up, and there shouldn’t be too much ambient light falling on the screen (see Appendix A).
By using the camera’s zebra indicator, a histogram, or a waveform monitor (described above) you can get more precise information to help you set the level.
The goal is to adjust the iris so the picture is as pleasing as possible, with good detail in the most important parts of the frame. If you close the iris too much, the picture will look too dark and blacks will be crushed and show no detail. If you open the iris too much, the highlights will be compressed and the brightest parts of the scene will be blown out (see Fig. 5-2). As noted above, there is a white clip circuit that prevents the signal from going above about 109 percent on many cameras.4 Say you were shooting a landscape, and exposing the sky around 100 percent. If a bright cloud, which would otherwise read at 140 percent, came by, the white clip will cut off (clip) the brightness level of the cloud somewhere between 100 and 109 percent, making it nearly indistinguishable from the sky. In Fig. 5-8A, the edge of the white chair is being clipped.
In most video productions, you have an opportunity to try to correct for picture exposure in postproduction when doing color correction. Given the choice, it’s better to underexpose slightly than overexpose when shooting since it’s easier in post to brighten and get more detail out of underexposed video than to try to reclaim images that were overexposed on the shoot. Once details are blown out, you can’t recover them.
One method for setting exposure is to use the zebra indicator to protect against overexposing. If you have the zebra set at 100 percent, you’ll know that any areas where the zebra stripes appear are being clipped or are right on the edge. You might open the iris until the zebra stripes appear in the brightest areas and then close it slightly until the stripes just disappear. In this way, you are basing the exposure on the highlights (ensuring that they’re not overexposed) and letting the exposure of other parts of the frame fall where it may. If you’re shooting a close-up of a face, as a general rule no part of the face should read above 100 percent (or even close) or else the skin in those areas will appear washed out in a harsh, unflattering way.
When using a camera with a histogram, you can do a similar thing by opening the iris until the pixels pile over to the right side of the display, then close it until they are better centered or at least so there isn’t a large spike of pixels at the right-hand edge (see Fig. 5-2).
Even so, sometimes to get proper exposure on an important part of the scene you must allow highlights elsewhere in the frame to be clipped. If you’re exposing properly for a face, the window in the background may be “hot.” The zebra stripes warn you where you’re losing detail. In this situation you may be able to “cheat” the facial tones a little darker, or you may need to add light (a lot of it) or shade the window (see Fig. 7-17). Or, if seeing into shadow areas is important, you may want to ensure they’re not too dark (because they may look noisy) and let other parts of the frame overexpose somewhat.
It’s an old cliché of “video lighting” that it’s necessary to expose flesh tones consistently from shot to shot, for example at 65–70 percent on a waveform monitor. This approach is outmoded (if not racist). First, skin tone varies a lot from person to person, from pale white to dark black. If you use auto-iris on close-ups of people’s faces, it will tend to expose everyone the same. However, “average” white skin—which is a stop brighter than the 18 percent gray card that auto-iris circuits aim for—may end up looking too dark, and black skin may end up too light. (See Understanding the Reflected Reading, p. 292.) But, even more important, exposure should serve the needs of dramatic or graphic expression. The reality is that people move through scenes, in and out of lighting, and the exposure of skin tones changes as they do. In a nighttime scene, for instance, having faces exposed barely above shadow level may be exactly the look you want (See Fig. 5-10). For sit-down interviews with light-skinned people, a video level of 50–55 percent on a waveform monitor is usually a safe bet. Momentary use of auto-iris is always a good way to spot-check what the camera thinks the best average exposure should be, but don’t neglect to use your eyes and creative common sense too.
As a rule of thumb when using a standard video gamma alone (see below for more on gamma), changing the exposure of a scene by a stop will cause the digital video level of a midtone to rise or fall by about 20 percent. If a digital video signal is defined by a range of 0 to 100 percent, does this imply that the latitude of broadcast video is five stops? It would seem so, but through the use of special gammas, digital video cameras can actually pack many more stops of scene detail into the fixed container that is the video signal. With today’s digital video cameras, you have around ten stops of dynamic range. Use ’em.
For inspiration regarding the creative limits to which digital video exposure—particularly HD—can be pushed these days, watch the newest dramatic series on network or cable television for the latest trends in lighting. You may be in for some surprises.
UNDERSTANDING AND CONTROLLING CONTRAST
As we’ve seen, the world is naturally a very contrasty place—often too contrasty to be captured fully in a single video exposure. For moviemakers, contrast is a key concern, and it comes into play in two main areas:

Fig. 5-5. Thinking about contrast. (A) This image was captured with enough latitude or dynamic range to bring out details in the shadow areas (under the roadway) and in the highlights like the water. (B) This image has compressed shadow areas (crushed blacks), which can happen when you set the exposure for the highlights and your camera has insufficient dynamic range to reach into the shadows. (C) This shot has increased overall contrast; shadows are crushed and the highlights are compressed (note that details in the water are blown out). Notice also the greater separation of midtones (the two types of paving stones in the sidewalk look more similar in B and more different in C). Though increasing the contrast may result in loss of detail in dark and/or light areas, it can also make images look bolder or sharper. (D) If we display image C without a bright white or dark black, it will seem murky and flat despite its high original contrast. Thus the overall feeling of contrast depends both on how the image is captured and how it is displayed. (Steven Ascher)
Contrast is important because it’s both about information (are the details visible?) and emotion (high-contrast images have a very different feel and mood than low-contrast images). Contrast can be thought of as the separation of tones (lights and darks) in an image. Tonal values range from the dark shadow areas to the bright highlights, with the midtones in the middle. The greater the contrast, the greater the separation between the tones.
Low-contrast images—images without good tonal separation—are called flat or soft (soft is also used to mean “not sharp” and often low-contrast images look unsharp as well, even if they’re in focus). Low-contrast images are sometimes described as “mellow.” High-contrast images are called contrasty or hard. An image with good contrast range is sometimes called snappy.
Contrast is determined partly by the scene itself and partly by how the camera records the image and how you compose your shots. For example, if you compose your shots so that everything in the frame is within a narrow tonal scale, the image can sometimes look murky or flat. When shooting a dark night shot, say, it can help to have something bright in the picture (a streetlight, a streak of moonlight) to provide the eye with a range of brightness that, in this case, can actually make the darks look darker (see Fig. 5-10).
Let’s look at some of the factors that affect contrast and how you can work with them.
WHAT IS GAMMA?
Gamma in Film and Analog Video
In photography and motion picture film, gamma () is a number that expresses the contrast of a recorded image as compared to the actual scene. A photographic image that perfectly matches its original scene in contrast is said to have 1:1 contrast or a “unity” gamma equal to 1.
A film negative’s gamma is the slope of the straight line section of its characteristic curve (see Fig. 7-3). The steeper the characteristic curve, the greater the increase in density with each successive unit of exposure, and the greater the resulting image contrast. Actually, a negative and the print made from that negative each has its own separate gamma value, which when multiplied together yield the gamma of the final image. The average gamma for motion picture color negatives is 0.55 (which is why they’re so flat looking), while the gamma for print film is far higher, closer to four.6 When these two gamma values are multiplied (for example, 0.55 × 3.8 = 2), the result is an image projected on the screen with a contrast twice that of nature. We perceive this enhanced contrast as looking normal, however, because viewing conditions in a dark theater are anything but normal, and in the dark our visual system requires additional contrast for the sensation of normal contrast.
In analog video, the term “gamma” has a different meaning. This has caused endless confusion among those who shoot both film and video, which continues in today’s digital era.
TV was designed to be watched in living rooms, not in dark theaters, and therefore there was no need to create any unnatural contrast in the final image. Video images are meant to reproduce a 1:1 contrast ratio compared to the real world. But the cathode ray tubes (CRTs; see Fig. 5-6) used for decades in TVs were incapable of linear image reproduction (in which output brightness is a straight line that’s directly proportional to input signal level). Instead, a gamma correction was needed so that shadow detail wouldn’t appear too dark and bright areas wouldn’t wash out (see Fig. 5-7).7
In analog video, “gamma” is shorthand for this gamma correction needed to offset the distortions of an analog CRT display. When a gamma-corrected signal from an analog video camera is displayed on a CRT, the resulting image has a gamma of 1 and looks normal.

Fig. 5-6. For decades analog CRTs were the only kind of TV. Now no one makes them, though many are still in use. CRT monitors are recognizable because they’re big and boxy (definitely not flat panel). (Sony Electronics, Inc.)
Digital Video Gamma
CRTs are a thing of the past. The video images you shoot will be viewed on plasma, LCD, LCOS, OLED, or laser displays or projectors that are not affected by the nonlinearity of CRT vacuum tubes. So why do digital video cameras still need gamma correction?
In theory we could create a digital camcorder and TV each with a gamma of 1. In fact, as shown in Fig. 5-1, digital video sensors natively produce a straight line response, and digital TVs and displays are capable of reproducing the image in a linear way, with output directly proportional to input. The problem is that this equipment would be incompatible with millions of existing televisions and cameras. So, new cameras and displays are stuck with gamma correction—let’s return to the shorthand “gamma”—as a legacy of the analog era. However, in today’s professional digital video cameras, gamma curves can be used as a creative tool to capture a greater range of scene brightness than was possible in analog.

Fig. 5-7. Gamma correction. CRT monitors have a response curve that bows downward (darkening shadows and midtones), so cameras were designed to compensate by applying a gamma correction that bows upward. When we combine the camera’s gamma-corrected video signal with the monitor’s gamma, we get a straight line (linear) response, which appears to the TV viewer as normal contrast.
Altering the gamma has a noticeable effect on which parts of the scene show detail and on the overall mood and feel of the picture. A high gamma setting can create an image that looks crisp and harsh by compressing the highlights (crushing the detail in the bright areas), stretching the blacks, and rendering colors that appear more saturated and intense (see Fig. 5-8A). A low gamma setting can create a picture that looks flat and muted, allowing you to see more gradations and detail in the bright areas that would otherwise overexpose, while compressing shadow detail and desaturating colors (see Fig. 5-8D).
Some people choose to use various gamma settings on location, while others prefer to alter the look of the image in post under more controlled conditions. If contrast can be fully adjusted in post, why bother with gamma correction in the camera at all? When you adjust gamma in a camera—or any picture parameter, such as color or sharpness—what is being adjusted is the full video signal in the camera’s DSP (digital signal processing) section prior to any compression. If you adjust the image after it’s been compressed and recorded with typical camera codecs, quality can suffer (which is why some people go to the trouble of using external recorders with little or no compression).
Gamma or contrast adjustments in post can achieve only so much. Whether you record compressed or uncompressed, if you didn’t capture adequate highlight detail in the first place by using an appropriate gamma (see the next section) you’re out of luck. There is no way in post to invent missing highlight detail.
GAMMA OPTIONS WHEN SHOOTING
Standard Gamma
All digital video cameras out of the box offer a default or “factory setting” gamma meant to make that camera look good. In some cameras this is called standard gamma. In professional cameras, a camera’s standard gamma will be the internationally standardized gamma for that video format. In high definition, the international standard for gamma is the ITU-R 709 video standard (also known as Rec. 709, CCIR 709, or just 709). Standard definition’s international standard is ITU-R 601. The 709 and 601 standards apply to both gamma (contrast) and the range of legal colors (the color gamut), and they look quite similar to each other in these respects.
Fig. 5-8. Picture profiles. Many cameras offer a variety of preset or user-adjustable settings for gamma and other types of image control. (A) Standard gamma. (B) By adding a knee point (here at 82 percent) highlight detail can be captured without affecting other tonalities—note increased detail in the bright edge of the chair. (C) Some cameras offer a profile that emulates the look of a film print stock, with darker shadows for added contrast (note crushed blacks and loss of detail in dark areas like the woman’s hair). You might use this setting if you like the look and aren’t planning to do color correction in post. However, if you shoot with a standard gamma like A, it’s very easy to achieve the look of C in post, and you don’t risk throwing away shadow detail that can’t be reclaimed later. (D) Some cameras can produce an extended dynamic range image that contains greater detail in highlights and shadows but looks too dark and flat for direct viewing. Different cameras may accomplish this kind of look using a cine gamma, or log or RAW capture. The flat image can be corrected to normal contrast in post, while retaining more detail in bright and dark areas than if it had been shot with standard gamma. All the images here are for illustration; your particular camera or settings may produce different results. (Steven Ascher)
ITU-R 709 and ITU-R 601 are designed to reproduce well without much correction in postproduction. They produce an overall bright, intense feel with relatively rich, saturated colors. For sports and news, this traditional video look makes for a vibrant image. At the same time, these are relatively high gammas that also result in a limited exposure range—extreme highlight detail is lost. These standardized gammas used alone don’t allow you to capture all the dynamic range your camera is capable of, or that a high-quality professional monitor or projector can display.
The curve marked “Standard” in Figure 5-9 is not precisely Rec. 709, but it shares a basic shape. Notice that it rises quickly in the shadows, providing good separation of tones (good detail) in the dark parts of the scene. However, it rises at such a steep slope that it reaches 109 percent quite quickly compared to the other curves; thus it captures a more limited range of brightness in the scene.
Standard gammas like Rec. 709, which are based on the characteristics of conventional TV displays, not only limit dynamic range, they also fall short of the wider color gamut found in today’s digital cinema projectors. To address this fact, some digital video cameras offer a gamma that incorporates DCI P3 (also called SMPTE 431-2), a new color standard established by Hollywood’s Digital Cinema Initiatives for commercial digital video projectors. As a camera gamma, DCI P3 combines the dynamic range of Rec. 709 with an expanded color gamut modeled after 35mm print film. The advantage of using DCI P3 gamma is that what you see in the field will closely resemble what you see on the big screen. Note that LCD monitors must be DCI P3 compliant to accurately view color when using this gamma.
Standard Gamma with Knee Correction
As we’ve just seen, using a standardized gamma produces a snappy, fairly contrasty image at the expense of highlight detail. When the camera’s sensitivity reaches maximum white, highlights are clipped. But there is a way to extend a camera’s dynamic range to improve the handling of highlight detail when using Rec. 709 or Rec. 601.
On a professional digital video camera, you can manually introduce a knee point to the sensor’s transfer characteristic (see Fig. 5-1). Normally, with no knee, the camera’s response curve is a relatively straight line that clips abruptly at 100 or 109 percent. However, using menu settings, if you add a knee point at, say, 85 percent, the straight line can be made to bend at that point, sloping more gently and intersecting the white clip level further to the right along the horizontal axis, which corresponds to higher exposure values. This technique compresses highlights above 85 percent (in this example), so that parts of the scene that would otherwise be overexposed can be retained with some detail.8
When highlights are compressed by use of a knee point, their contrast and sharpness are compressed as well. They can appear less saturated. To correct for this, professional cameras also offer menu settings for “knee aperture” (to boost sharpness and contrast in highlights) and “knee saturation level” (to adjust color saturation in highlights). These are usually located next to the knee point settings in the camera’s menu tree.
It is possible to set the knee point too low, say below 80 percent, where the knee slope can become too flat, with the result that highlights may seem too compressed, normally bright whites may seem dull, and light-skin faces may look pasty.
In addition to a knee point setting, most professional video cameras have an automatic knee function that, when engaged, introduces highlight compression on the fly. When no extreme highlights exist, this function places the knee point near the white clip level, but when highlights exceed the white clip level, it automatically lowers the knee point to accommodate the intensity of the brightest levels. Called Dynamic Contrast Control (DCC) in Sony cameras and Dynamic Range Stretch (DRS) in Panasonic cameras, automatic knee helps to preserve highlight details in high-contrast images, although sometimes the outcome is subtle to the eye. Some camera operators leave it on all the time; others feel that the manual knee is preferable. As with all knee point functions, you can experiment by shooting a high-contrast image and inspecting the results on a professional monitor. Everything you need to know will be visible on the screen.

Fig. 5-9. Gamma curves. Standard gamma rises quickly in the shadows, creates relatively bright midtones, and reaches the white clip level relatively soon. By comparison, the Cine A curve provides darker shadows and midtones but continues to rise to the right of the point at which the standard curve has stopped responding, so it’s able to capture brighter highlights. The Cine B curve is similar to Cine A, but tops out at 100 percent video level, so the picture is legal for broadcast without correction in post. These curves are for illustration only; the names and specific gamma curves in your camera may be different. (Steven Ascher)
“Cine” Gamma in Video Cameras
The technique just discussed of setting a knee point to control highlight reproduction has been with us for a while. Today’s digital video cameras accomplish a similar but more sophisticated effect using special “cine” gamma curves that remap the sensor’s output to better fit the limited dynamic range of the video signal.
All professional digital video cameras offer reduced gamma modes said to simulate the look of film negative or film print. These gamma curves typically darken midtones and compress highlight contrast, thereby extending reproducible dynamic range and allowing you to capture detail in extremely bright areas that would otherwise overexpose. The goal is to capture highlights more like the soft shoulder of a film negative’s characteristic curve does. The cine curves in Fig. 5-9 represent such filmlike video gammas. Note that they continue to rise to the right of the standard video gamma curve, capturing bright highlights where the standard gamma has stopped responding.
The principle of most cine gammas is similar, but they come in two categories: (1) display cine gammas, whose images are meant to be viewed directly on a video monitor, and (2) intermediate cine gammas not meant for direct viewing, whose dark, contrast-flattened images need to be corrected in post.
Examples of the first type include Panasonic’s CineGamma (called Cine-Like and Film-Like in some camcorders), Sony’s CinemaTone (found in low-cost pro cameras), Canon’s Cine, and JVC’s Cinema gamma. Typically they come in gradations like Canon’s Cine 1 and 2 or Sony’s CinemaTone 1 and 2.9 A more sophisticated cine gamma called HyperGamma, which extends the camera’s dynamic range without the use of a knee point, is found in high-end Sony CineAlta cameras (it’s also called CINE gamma in some Sony cameras, although it’s exactly the same thing). HyperGamma features a parabolic curve and comes in four gradations.
Some of these cine gammas cut off at 100 percent, and keep the level legal for broadcast. Some reach up to 109 percent, which extends the ability to capture extreme highlights, but the maximum level must be brought down if the video will be televised.10
The second type of cine gammas are the intermediate gammas including Panasonic’s FILM-REC (found in VariCams) and JVC’s Film Out gamma. Both produce flat-contrast images with extended dynamic range, which need to be punched up in post for normal viewing. Both were a product of the 2000s, a decade in which independent filmmakers sometimes shot low-cost digital video for transfer to 35mm film for the film festival circuit.
Camcorder manuals invariably do a poor job describing what each cine gamma actually does, and the charts, if there are any, often use different scales (making them hard to compare) or are fudged. Cine gammas can be confusing if not misleading because their very name implies a result equal to film. Color negative film possesses a very wide dynamic range (up to sixteen stops), while digital video signals must fall inside a fixed range of 0–100 percent (for broadcast) or 0–109 percent (for everything else). Cine gamma curves must shoehorn several additional stops of highlight detail into these strict signal limits, regardless of the sensor’s inherent dynamic range. It’s no easy task.
Some people prefer cine gamma settings; others think that display cine gammas look disagreeably flat and desaturated. (In some cases, whites don’t look very bright.) Many who do use cine gammas add contrast correction in postproduction to achieve a more normal-looking scene. At the end of the day, the main advantage to using a cine gamma is that you can capture extended highlights that would be unavailable in post if you hadn’t.
As in the case of adding a knee point, you can experiment with cine gammas by shooting a variety of scenes and inspecting the results on a professional monitor or calibrated computer screen like an Apple Cinema Display. Watch the image on the monitor as you open the iris. Highlight areas that might otherwise clearly overexpose may take on a flat, compressed look as you increase the exposure. You may wish to underexpose by a half stop or more to further protect these areas. You may also want to experiment with contrast and color correction in post in order to discover what impact a cine gamma has on dark detail and low-light noise levels.
In summary, most cine gammas attempt to capture the look of film for viewing on a video monitor or TV. To attempt to capture the latitude of film from a digital sensor requires something beyond the conventional video signal. To do this requires a more extreme approach, even a new kind of signal, which we will discuss next.

Fig. 5-10. This shot might be considered underexposed, but as a night shot it feels appropriate. The lights in the background accentuate the cigarette smoke and create a range of contrast that helps the scene feel natural by giving the eye a bright reference point that can make the blacks seem darker. (Steven Ascher)
Log and RAW Capture in Digital Cinema Cameras
High-end digital cinematography cameras offer two methods of capturing a much larger dynamic range, allowing you to record details in deeper shadows and brighter highlights.
LOG CAPTURE. Logarithmic transfer characteristic, or log for short, is one way to extract even more of a sensor’s dynamic range from an uncompressed RGB video signal. Think of it as a super gamma curve.
In a typical linear scale, each increment represents adding a fixed amount (for example, 1, 2, 3, 4, 5…). Along a logarithmic scale, however, each point is related by a ratio. In other words, each point on a logarithmic scale, although an equal distance apart, might be twice the value of the preceding point (for example, 1, 2, 4, 8, 16, 32).
Digital video is intrinsically linear, from sensors to signals (before gamma is applied), while both film and human vision capture values of light logarithmically.11 So, for example, imagine you had a light fixture with thirty-two lightbulbs; you might think that turning on all the bulbs would appear to the eye thirty-two times as bright as one bulb. However, following a logarithmic scale, the eye only sees that as five times as bright (five steps along the 1, 2, 4, 8, 16, 32 progression).12 At low light levels, the eye is very sensitive to small increases in light. At high light levels, the same small increases are imperceptible. The change in brightness you see when you go from one light to two lights (a one-light difference) is the same as going from sixteen lights to thirty-two lights (a sixteen-light difference).
Where the sampling of digital images is concerned, the advantage of a nonlinear logarithmic scale is that many more samples, and therefore bits, can be assigned to the gradations of image brightness we perceive best—namely, dark tones—and fewer bits to brightness levels we are less sensitive to, meaning whites and bright tones. Digital video with its linear capture of brightness levels can’t do this; it assigns the same number of samples and precious digital bits to highlights as to shadows, without distinction. This is particularly disadvantageous in postproduction, where vastly more samples are needed in the dark half of the tonal scale for clean image manipulation.
The logarithmic mapping of image brightness levels originated in film scanning for effects and digital intermediate work using full-bandwidth RGB signals (no color subsampling or component video encoding), 10-bit quantization for 1024 bits per sample (compared to 8-bit quantization and 256 bits per sample of most digital video), and capture to an RGB bitmap file format pioneered by Kodak known as DPX (Digital Picture Exchange).
One of the first digital cinematography cameras to output a log transfer characteristic was Panavision’s Genesis, a PL-mount, single-CCD camera introduced in 2005. Panavision was motivated to use what it called PANALOG because standard Rec. 709 gamma for HD could accommodate only 17 percent of the CCD’s saturation level (the maximum exposure a sensor can handle). By dramatically remapping the video signal using a 10-bit log function to preserve the CCD’s entire highlight range, a filmlike latitude of ten stops was achieved.13
PANALOG is output as uncompressed RGB (4:4:4) via dual-link HD-SDI cables and typically recorded to a Sony SSR-1 solid-state recorder or an HDCAM SR tape using a portable Sony field recorder.14
The equipment needed to capture and record uncompressed 10-bit log signals is expensive. The data flow is enormous: nearly 200 megabytes (not bits) per second at 24 fps. Cameras must be capable of dual-link HD-SDI output. Hard-disk recording systems used on location must incorporate a lot of bandwidth and fast RAID performance. Don’t forget you have to transfer it all, and back it up at some point too.
For its F35, F23, and F3 digital cinematography cameras, Sony has its own version of log output, called S-Log. ARRI’s Alexa uses a third type of log output, a SMPTE standard called Log C.15 Each company might boast that its version contains the best secret sauce, but in fact with the proper LUT (lookup table), it’s relatively easy to convert S-Log to Log C or PANALOG, or the other way around. In other words, they’re easily intercut, just as they’re also easily captured to standard 10-bit DPX files on hard disks.
Because a log transfer characteristic radically remaps the brightness values generated by the sensor, the video image that results is flat, milky, and virtually unwatchable in its raw state. In effect, you’ve committed your production to extensive D.I.-like color correction of every scene in post. On the upside, you’ll obtain a video image that comes closest to film negative in its latitude and handling of color grading without quality loss. Don’t forget, not only is there no color subsampling (full 4:4:4), but 10-bit log sampling of the individual RGB components also better captures the wide color gamut produced by the sensor, which is not reproducible by conventional video. All of this favors more accurate keying and pulling of mattes in effects work. With some cameras, such as the Sony F3, it is also possible to record log in 4:2:2 at a lower data rate internally or to more affordable external recorders such as the Ki Pro Mini or Atomos Ninja (see Figs. 2-19 and 5-11).
Each camera capable of log output has its own solution for displaying usable contrast in its viewfinder, as well as for providing viewing LUTs for monitoring the image on location. LUTs, simply put, convert the log image into something that looks normal. They are nondestructive, meaning they translate only the image for viewing but don’t change the image in any way. LUTs created and used on location can be stored and sent to color correction as guides to a DP’s or director’s intent. When shooting log, it’s recommended to not underexpose.

Fig. 5-11. The AJA Ki Pro Mini field recorder can be mounted on a camera. Records 10-bit HD and SD Apple ProRes files to CF cards. Inputs include SDI, HD-SDI, and HDMI. Files are ready to edit without transcoding. (AJA Video Systems)
Canon’s EOS C300 brings a new wrinkle to log output, an 8-bit gamma curve called Canon Log. (Echoes of the Technicolor CineStyle gamma curves found in Canon DSLRs.) This high-dynamic-range gamma is invoked when the C300 is switched into “cinema lock” mode. A built-in LUT permits viewing of normal contrast in the C300’s LCD screen only. (Unavailable over HDMI or HD-SDI outputs—so you can’t see it on an external monitor.) Since the C300 records compressed 50 Mbps, long-GOP MPEG-2 to CF cards and outputs uncompressed HD from a single HD-SDI connection—both only 8 bit, 4:2:2—it does not belong in the same class as the digital cinematography cameras described above.
RAW CAPTURE. For those who need the utmost in dynamic range from a digital cinematography camera, recording RAW files is the alternative to using a log transfer characteristic. RAW files are signals captured directly from a single CMOS sensor that uses a Bayer pattern filter to interpret color (see Fig. 1-13). Before being captured directly to disk, flash memory, or solid-state drive, the sensor’s analog signals are first digitized—yes, linearly—but no other processing takes place, including video encoding or gamma curves. As a result, RAW is not video. Nor is it standardized.
RAW recording first gained popularity among professional still photographers, because it provides them with a “digital negative” that can be endlessly manipulated. As a result, it is the gold standard in that world. RAW recording of motion pictures works the same way, only at 24 frames per second.
It’s called RAW for a reason. Upon recording, each frame has to be demosaicked or “debayered.” Among CMOS sensors with Bayer filters, there are different types of relationships between the number of pixels that make up the final image (for instance, 1920 x 1080) and the number of photosites on that sensor that gather light for each individual pixel. The simplest arrangement is 1:1, where each photosite equals one pixel. In this case, a Bayer filter means that there will be twice as many green pixels/photosites as either red and blue. In the final image, the color of each pixel is represented by a full RGB value (a combination of red, green, and blue signals) but each photosite on the sensor captures only one of those signals (either red, green, or blue). Debayering involves averaging together (interpolating) the color values of neighboring photosites to essentially invent the missing data for each pixel. It’s more art than science.
Next a transfer characteristic or gamma curve must be applied; otherwise, the image would appear flat and milky. White balance, color correction, sharpening—every image adjustment is made in postproduction. All of this consumes time, personnel, and computer processing power and storage, and none of it will satisfy those with a need for instant gratification. But the ultimate images can be glorious. It’s like having a film lab and video post house in your video editing workstation.
RED pioneered the recording and use of RAW motion picture images with the RED One camera and its clever if proprietary REDCODE RAW, a file format for recording of compressed 4K Bayer images (compression ratios from 8:1 to 12:1). In this instance 4K means true 4K, an image with the digital cinema standard of 4,096 pixels across, like a film scan (instead of 3,840 pixels, sometimes called Quad HD by the video industry). REDCODE’s wavelet compression enables instant viewing of lower-resolution images in Final Cut Pro and other NLEs by use of a QuickTime component, and full resolution playback or transcoding when using the RED ROCKET card (see Fig. 3-8).
Both ARRI’s D-21 and Alexa can output uncompressed 2K ARRIRAW by dual-link HD-SDI, usually to a Codex Digital or S.two disk recorder. Uniquely, it is 12 bit and log encoded. ARRI says that 12-bit log is the best way to transport the Alexa’s wide dynamic range. Actually, an ARRIRAW image is captured at 2,880 pixels across and remains that size until downscaled to 2,048 pixels (2K) upon postproduction and completion of effects.
The Sony F65 digital cinema camera captures 4K, 16-bit linear RAW with a unique 8K sensor (20 million photosites) that provides each 4K pixel with a unique RGB sample—no interpolation needed. Onboard demosaicking provides real-time RGB output files to a small docking SRMASTER field recorder that carries one-terabyte SRMemory cards.
More within reach for independent filmmakers is Silicon Imaging’s SI-2K Mini with its 2⁄3-inch sensor and 2K RAW output captured using the CineForm RAW codec, a lossless wavelet compression similar to REDCODE. The Blackmagic Cinema Camera is an even-more affordable option (see p. 29).
Like video cameras that provide log output, motion picture cameras that output RAW files let you monitor a viewable image during production. By means of a LUT, they typically output an image close to standard ITU-R 709 gamma so you can get a rough sense of how the image will look after processing.
A wide latitude is always more flexible and forgiving. A side benefit to the filmlike latitude provided by cameras with log and RAW output is that DPs can once again use their light meters for setting scene exposure, just as in film, using the camera’s ISO rating.
Other Ways to Extend Dynamic Range
When you go into the world with a camera, you’re constantly dealing with situations in which the contrast range is too great. You’re shooting in the shade of a tree, and the sunlit building in the background is just too bright. You’re shooting someone in a car, and the windows are so blown out you can’t see the street. When the lighting contrast of a scene exceeds the camera’s ability to capture it, there are a number of things you can do (see Controlling Lighting Contrast, p. 512).
Altering the gamma and adjusting the knee point and slope as discussed above are important tools in allowing you to capture greater dynamic range. Here are some other methods or factors.
USE MORE BITS, LESS COMPRESSION. When you can record video using 10 bits or 12 bits instead of the 8 bits common to consumer and many professional camcorders, you will be able to capture greater dynamic range and subtler differences between tones. With greater bit depth comes a more robust image better able to withstand color and contrast adjustment in postproduction. Often an external recording device is the answer. Convergent Design’s nanoFlash records uncompressed HD to CompactFlash cards using Sony XDCAM HD422 compression up to 280 Mbps (see Fig. 1-27). The Atomos Ninja records uncompressed HD to a bare solid-state drive (SSD) via HDMI using 10-bit ProRes (see Fig. 2-19). For no compression, Convergent Design’s Gemini 4:4:4 recorder records uncompressed HD and 2K via HD-SDI, and Blackmagic Design’s HyperDeck Shuttle records 10-bit uncompressed HD, both to SSDs (see Fig. 5-30).
HIGHLIGHTS AND ISO. Video sensors have a fixed sensitivity, and changing the ISO or gain doesn’t make the sensor more or less sensitive, it only affects how the image is processed after the sensor. Changing the ISO when shooting effectively rebalances how much dynamic range extends above and below middle gray. If you shoot with a high ISO (essentially underexposing the sensor), there’s more potential latitude above middle gray, so you actually increase the camera’s ability to capture highlights. If you decrease the ISO (overexposing), dynamic range below neutral gray increases, so you improve the camera’s ability to reach into shadows. This is counterintuitive for anyone familiar with film, where using a faster, more sensitive stock usually means curtailing highlights (because a faster negative is genuinely more light sensitive).
HIGH DYNAMIC RANGE MODE. The RED Epic camera has a mode called HDRx (high dynamic range) in which it essentially captures two exposures of each frame, one exposed normally and one with a much shorter exposure time to capture highlights that would otherwise be overexposed. The two image streams can be combined in the camera or stored separately and mixed together in post. This extends the camera’s latitude up to eighteen stops, allowing you to capture very dark and very bright areas in the same shot.
Black Level
The level of the darkest tones in the image is called the black level. The darkest black the camera puts out when the lens cap is on is known as reference black. Black level is important because it anchors the bottom of the contrast range. If the black level is elevated, instead of a rich black you may get a milky, grayish tone (see Fig. 5-5D).16 Without a good black, the overall contrast of the image is diminished and the picture may lack snap. Having a dark black can also contribute to the apparent focus—without it, sometimes images don’t look as sharp. In some scenes, blacks are intentionally elevated, for example, by the use of a smoke or fog machine. In some scenes, nothing even approaches black to begin with (for example, a close shot of a blank piece of white paper).
In all digital video, the world over, reference black is 0 percent video, also known as zero setup.17 When you’re recording digitally, or transferring from one digital format to another, the nominal (standard) black level is zero. Some systems can create black levels below the legal minimum, known as super blacks.
Fig. 5-12. Video levels in RGB and component color systems. (A) In RGB color, used in computer systems, digital still cameras, and some digital cinema cameras, the darkest black is represented by digital code 0 and the brightest white by code 255 (this is for an 8-bit system). (B) In component digital video (also called YCBCR or YUV), used in most digital video cameras, 100 percent white is at code 235. Video levels higher than 100 percent are considered “super white”; these levels can be used to capture bright highlights in shooting and are acceptable for nonbroadcast distribution (for example, on the Web), but the maximum level must be brought down to 100 percent for television. Darkest legal black is at 0 percent level, represented by code 16. RGB has a wider range of digital codes from white to black and can display a wider range of tonal values than component. Problems can sometimes result when translating between the two systems. For example, bright tones or vibrant colors that look fine in an RGB graphics application like Photoshop may be too bright or saturated when imported to component video. Or video footage that looks fine in component may appear dull or dark when displayed on an RGB computer monitor or converted to RGB for the Web. Fortunately, when moving between RGB and component, some systems automatically remap tonal values (by adjusting white and black levels and tweaking gamma for midtones).

Fig. 5-13. Most editing systems operate in component video color space. When you import a file, the system needs to know if the source is an RGB file that needs to be converted to component, or one that is already component (either standard definition Rec. 601 or high definition Rec. 709). Shown here, some options in Avid Media Composer. Compare the code numbers here and in Fig. 5-12. (Avid Technology, Inc.)
BLACK STRETCH/COMPRESS. Some cameras have a black stretch adjustment that can be set to increase or decrease contrast in the shadow areas. Increasing the black stretch a little brings out details in the shadows and softens overall contrast. On some cameras, the darkest black can be a bit noisy, and adding some black stretch helps elevate dark areas up out of the noise. Some cameras also provide a black compress setting, which you can use to darken and crush shadow areas. Since stretching or compressing blacks alters the shape of the gamma curve, some cameras simply call these settings black gamma.
Because you can always crush blacks in post, it’s a good idea not to throw away shadow detail in shooting.
Storing Picture Settings for Reuse
Professional cameras provide extensive preset and user-adjustable settings for gamma and many other types of image control. Generally, after you turn off a digital camera, your latest settings are retained in memory, available again when the camera is powered up.
Most cameras permit gathering together various image-control settings and storing them internally, to be called up as needed. These collections of settings are called scene files in Panasonic cameras, picture profiles in Sony cameras, custom picture files in Canon cameras, and camera process in JVC cameras. Typically you are able to store five to eight of these preprogrammed collections.
Many cameras also permit convenient storage of your settings on setup cards (usually inexpensive SD cards), allowing you to transfer settings from one camera to another or later restore the same settings for different scenes. These settings pertain only to the exact same model of camera.
Scene files or picture profiles make it easy to experiment with different looks. If you want to experiment with a particular gamma, for instance, hook up your digital video camera to a large video monitor (set to display standard color and brightness) and look carefully at how the image changes as you adjust various parameters of that gamma. Aim the camera at bright scenes with harsh contrast and also low-key scenes with underexposed areas. Inspect extremes of highlight and shadow detail. Often one size doesn’t fit all, but with the ability to save and instantly call up several collections of settings, you can determine what works best for you before you shoot. It’s a great way to get to know a digital video camera intimately.
VIDEO COLOR SYSTEMS
Color Systems
Be sure to read How Color Is Recorded, p. 16, and Thinking About Camera Choices, Compression, and Workflow, p. 94, before reading this section.
All digital camcorders accomplish the same basic set of tasks: (1) capture an image to a sensor; (2) measure the amounts of red, green, and blue light at photosites across the sensor; (3) process and store that data; and (4) provide a means to play back the recording, re-creating the relative values of red, green, and blue so a monitor can display the image.
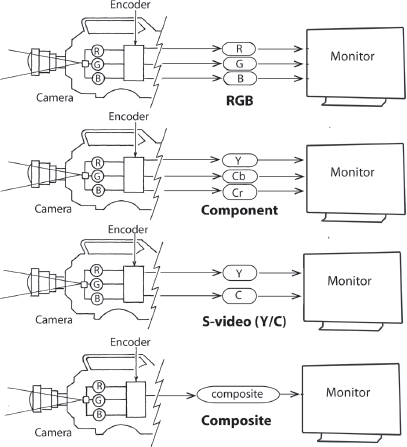
Fig. 5-14. RGB, component, S-video, and composite video systems vary in the paths they use to convey the video signal from one piece of equipment to another. For systems that use multiple paths, the signal is sometimes sent on multiple cables, but often the various paths are part of one cable. See text. (Robert Brun)
Different cameras use different methods, particularly when it comes to steps 2 and 3. As noted earlier, each photosite in a digital camera sensor can measure only brightness, but we can create color values in the image by placing a microscopic red, green, or blue filter over individual photosites (a technique used for single-sensor cameras; see Fig. 1-13) or by splitting the light from the lens into three paths using a prism and recording with three sensors (the technique used in three-chip cameras; see Fig. 1-14).
Let’s briefly review how digital cameras acquire and process color; one or more of these methods may be employed by your camera.
RGB. All digital cameras internally process raw data from the sensor(s) to generate three distinct color signals—red, green, and blue (RGB). RGB (also called 4:4:4; see below) is a full-bandwidth, uncompressed signal that offers a wide gamut of hues and is capable of very high image quality. RGB output can be found in high-end cameras, including some digital cinematography cameras, and is usually recorded to a high-end format like HDCAM SR. RGB requires high bandwidth and storage space; it is particularly useful for visual effects. RGB handles brightness values differently than component video, so there may be translation issues, for instance, when moving between the RGB color of a computer graphics program and the component color of a video editing program (see Fig. 5-12).18
COMPONENT VIDEO. Most digital cameras today record component video. They acquire the three RGB signals from the sensor(s), digitize them, process them, then throw away either half or three-quarters of the color data to make a video signal that’s easier to store and transmit. Prior to output, the three color signals (R, G, and B) are encoded into a monochrome luminance (sometimes called luma) signal, represented with the letter Y, which corresponds to the brightness of the picture, as well as two “color difference” signals (R minus Y, B minus Y), which are called chrominance (or sometimes chroma). Your color TV later decodes the luma and chroma signals and reconstructs the original RGB signals. Prominent examples of this type of video are the world standards for standard definition, ITU-R 601, and high definition, ITU-R 709.
Shorthand for component video is variously Y’CBCR, YCbCr, or Y,B-Y,R-Y. Though historically inaccurate, it’s also widely referred to as YUV. Analog component is Y’PBPR.
S-VIDEO. S-video (separate video) is also called Y/C. This is for analog video only, and it’s not so much a video system as a two-path method of routing the luminance signal separately from the two chrominance signals. It provides poorer color and detail than true component video, but is noticeably better than composite. If a camera or monitor has an S-video input or output, this is a superior choice over a composite input or output.
COMPOSITE VIDEO. Analog television, the original form of video, was broadcast as a single signal. What was uploaded to the airwaves was composite video, in which the luminance and two chrominance signals were encoded together. As a result, composite video could be sent down any single path, such as an RCA cable. Many different types of gear today still have analog composite inputs and outputs, often labeled simply “video in” and “video out” (see Fig. 14-13). These can be handy for, say, monitoring a camera on a shoot. Composite video was used for decades for analog broadcast PAL and NTSC, but it delivered the lowest-quality image of all the color systems, with many sacrifices in color reproduction due to technical compromises. No digital cameras today record composite video.
Color Sampling
See Reducing Color Data, p. 17, before reading this.
When we look at the world or a picture, our eyes (assuming we have good eyesight) can perceive subtle distinctions in brightness in small details. However, the eye is much less sensitive to color gradations in those same fine details. Because of this, smart engineers realized that if a video system records less information about color than brightness, the picture can still look very good, while cutting down the amount of data. This can be thought of as a form of compression.
As discussed above, most digital camcorders record component color. In this system there are three components: Y (luma) and CB and CR (both chroma). When the signal from the camera’s sensor is processed, some of the color resolution is thrown away in a step called subsampling or chroma subsampling; how much depends on the format.
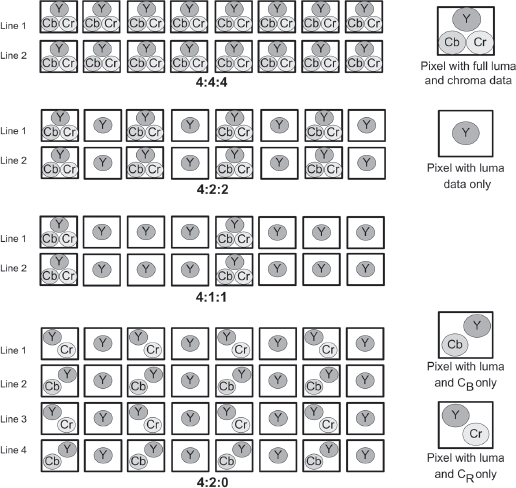
To see how this works, look at a small group of pixels, four across (see Fig. 5-15). In a 4:4:4 (“four-four-four”) digital video system there are four pixels each of Y, CB, and CR. This provides full-color resolution. Component 4:4:4 is used mostly in high-end video systems like film scanners. (RGB video, described above, is always 4:4:4, meaning that each pixel is fully represented by red, green, and blue signals.)19
In 4:2:2 systems, a pair of adjacent CB pixels is averaged together and a pair of CR pixels is averaged together. This results in half as much resolution in color as brightness. Many high-quality component digital formats in both standard and high definition are 4:2:2. This reduction in color information is virtually undetectable to the eye.
Some formats reduce the color sampling even further. In a 4:1:1 system, there are four luma samples for every CB and CR, resulting in one-quarter the color resolution. This is used in the NTSC version of DV. While the color rendering of 4:1:1 is technically inferior to 4:2:2, and the difference may sometimes be detectable in side-by-side comparisons, the typical viewer may see little or no difference. Another type of chroma sampling is 4:2:0, used in HDV and PAL DV. Here, the resolution of the chroma samples is reduced both horizontally and vertically. Like 4:1:1, the color resolution in 4:2:0 is one-quarter that of brightness.
Some people get very wrapped up in comparing cameras and formats in terms of chroma sampling, praising one system for having a higher resolution than another. Take these numbers with a grain of salt: the proof is in how the picture looks. Even low numbers may look very good. Also, bear in mind that chroma sampling applies only to resolution. The actual color gamut—the range of colors—is not affected.
The main problems with 4:1:1 and 4:2:0 formats have to do with the fact that after we’ve thrown away resolution to record the image, we then have to re-create the full 4:4:4 pixel array when we want to view the picture. During playback this involves interpolating between the recorded pixels (essentially averaging two or more together) to fill in pixels that weren’t recorded. As a result, previously sharp borders between colored areas can become somewhat fuzzy or diffuse. This makes 4:1:1 and 4:2:0 less than ideal for titles and graphics, special effects, and blue- or green-screen work (though many people successful do green-screen work with 4:2:0 HD formats). Often projects that are shot in a 4:1:1 format like DV are finished on a 4:2:2 system that has less compression.
Fig. 5-15. Color sampling. In a 4:4:4 system, every pixel contains a full set of data about brightness (Y) and color (CB and CR). In 4:2:2 and 4:1:1 systems, increasing amounts of color data are thrown away, resulting in more pixels that have only brightness (luma) information. In 4:2:0 systems, pixels with Y and CR alternate on adjacent lines with ones that have Y and CB (shown here is PAL DV; other 4:2:0 systems use slightly different layouts).
SOME IMAGE MANIPULATIONS AND ARTIFACTS
Green Screen and Chroma Keys
There are digital graphic images, and scenes in movies and TV shows, that involve placing a person or object over a graphic background or a scene shot elsewhere. A common example is a weather forecaster who appears on TV in front of a weather map. This is done by shooting the forecaster in front of a special green background, called a green screen. A chroma key is used to target areas in the frame that have that particular green and “key them out”—make them transparent—which leaves the person on a transparent background. The forecaster, minus the background, is then layered (composited) over a digital weather map. The green color is a special hue not otherwise found in nature, so you don’t accidentally key out, say, a green tie. In some cases a blue background is used instead, which may work better with subjects that are green; blue is also used for traditional film opticals.
This technique is called a green-screen or blue-screen shot or, more generically, a process or matte shot. For situations other than live television, the chroma key is usually done in postproduction, and the keyer is part of the editing system. Ultimatte is a common professional chroma key system and is available as a plug-in for various applications.
Green-screen shots are not hard to do, but they need to be lit and framed carefully. Green background material is available in several forms, including cloth that can be hung on a frame, pop-up panels for close shots, and paint for covering a large background wall. When using a small screen, keep the camera back and shoot with a long lens to maximize coverage. It’s important that the green background be evenly lit with no dark shadows or creases in the material, though some keying programs are more forgiving than others of background irregularities. For typical green-screen work shot on video, lighting the background with tungsten-balanced light should work fine, but for film and blue-screen work, filters or bulbs better matched to the screen color are often used. Don’t underexpose the background, since you want the color to be vivid.
Avoid getting any of the green background color on the subject, since that may become transparent after the key. Keep as much separation as possible between the subject and the background and avoid green light from the background reflecting on the subject (called spill—most keying software includes some spill suppression). If you see green tones in someone’s skin, reposition him or set a flag. If objects are reflecting the background, try dulling spray or soap. Fine details, like frizzy hair, feathers, and anything with small holes can sometimes be hard to key. Make sure your subject isn’t wearing green (or blue for a blue screen) or jewelry or shiny fabrics that may pick up the background. Don’t use smoke or diffusion that would soften edges. Using a backlight to put a bright rim on the subject can help define his edges.
The Chromatte system uses a special screen that reflects back light from an LED light ring around the lens. This is fast to set up (since you don’t need other light for the background) and works in situations where the subject is very close to the screen (but keep the camera back). Get your white balance before turning up the light ring.
Locked-down shots with no camera movement are the easiest to do. You can put actors on a treadmill, stationary bike, or turntable to simulate camera or subject movement. Footage shot to be superimposed behind the subject is called a background plate. If the camera moves you’ll want the background to move also, which may require motion tracking. Orange tape marks are put on the green screen for reference points for tracking. Do digital mockups or storyboards to plan your shots.
As a rule, keys work best with HD and with 4:2:2 color sampling (or even better, 4:4:4). That said, many successful keys have been done in SD, and even with formats like DV that are 4:1:1 or 4:2:0 (for more, see the previous section). Make sure the detail/enhancement on the camera isn’t set too high. Bring a laptop with keying software to the set to see how the chroma key looks.

Fig. 5-16. Chroma key. The subject is shot in front of a green or blue background, which is then keyed out. The subject can then be composited on any background. NLEs usually include a chroma key effect or you may get better results with specialized software or plug-ins such as this Serious Magic product. (Serious Magic)
Deinterlacing
See Progressive and Interlace Scanning on p. 11 before reading this section.
It’s very easy to convert from progressive to interlace. One frame is simply divided into two fields (this is PsF; see p. 602). This is done when you’ve shot using a progressive format but are distributing the movie in an interlaced one, such as 50i or 60i.
Creating progressive footage from interlace is more complex. This may be done when distributing interlaced material on the Web, for example, or when extracting still frames. Static images aren’t a problem—you can just combine the two fields. But when there’s any movement between fields they will show edge tear when you combine them (see Figs. 1-11 and 5-17). Some deinterlacing methods just throw away one of the fields and double the other (line doubling), which lowers resolution and can result in unsmooth motion. Some use field blending to interpolate between the two fields (averaging them), which may also lower resolution. “Smart” deinterlacers can do field blending when there’s motion between two fields but leave static images unchanged. For more, see p. 600.
Moiré
In terms of video, moiré (pronounced “mwa-ray”) is a type of visual artifact that can appear as weird rippling lines or unnatural color fringes. Sometimes you’ll see moiré in video when people wear clothing that has a finely spaced checked, striped, or herringbone pattern. Moiré patterns often show up on brick walls, along with odd-colored areas that may seem to move. When you convert from a higher definition format to a lower definition one, various types of aliasing can result, including moiré and “jaggies” (stair steps on diagonal lines).
With the explosion of DSLRs, moiré is often showing up in scenes that would look fine if shot with traditional video cameras. Even hair, or clothing that has no visible pattern, may end up with moiré when shot with a DSLR. This happens in part because the DSLR’s sensor is designed to shoot stills at a much higher resolution than HD or SD video. To create the video image, instead of doing a high-quality downconversion, as you might do in postproduction with specialized software or hardware, many DSLRs simply skip some of the sensor’s horizontal lines of pixels. The resulting image forces together pixels that should have been separated by some distance, causing artifacts.

Fig. 5-17. Interlace and deinterlace. (A, B) Two consecutive fields from 60i footage of a basketball being thrown. (C) Here we see both fields together as one frame. You can clearly see that each field has half the resolution (half the horizontal lines), and that the ball has moved between the two fields. Makes for an ugly frame. (D) This deinterlaced frame was made by deleting the first field and filling in the gap it left. We can create new pixels for the gap by “interpolating” (essentially averaging) the lines on either side of each missing line. Though this creates a single frame that could be used for a progressive display, it’s not as clean or sharp as true progressive footage shot in a progressive format. Deinterlacing works best when there’s relatively little camera or subject movement. See also Fig. 1-11.
Though it may seem counterintuitive, the way to minimize this problem is essentially to lower the resolution of the picture at the sensor. With a DSLR, be sure that any sharpness settings are turned down. The camera may have a picture profile for a softer, mellower look. Sometimes you have to shoot a shot slightly out of focus to get rid of a particularly bothersome pattern. True video cameras avoid moiré by using an optical low pass filter (OLPF), which softens the image, removing very fine details that can cause artifacts (if you’re shooting with a Canon EOS 5D Mark II DSLR, you could use Mosaic Engineering’s VAF-5D2 Optical Anti-Aliasing filter). Higher-end cameras that shoot both stills and video, like the RED Epic, avoid artifacts by not doing line skipping when they downconvert.
If you’re on a shoot and you’re seeing moiré in the viewfinder, it may be in the image or it may just be in the viewfinder. Try a different monitor to check. If it’s in the image, to minimize the artifacts try shooting from a different angle and not moving the camera. You may also need to change wardrobe or other items that are causing issues.
Footage that has moiré in it can be massaged in post to try to soften the most objectionable parts, but it’s a cumbersome process that usually delivers mixed results. Along with poor audio, moiré is one of the chief drawbacks of shooting with DSLRs.

Fig. 5-18. Moiré. The metal gate on the storefront has only horizontal slats, but this video image shot with a DSLR (Canon EOS 5D Mark II with full-frame sensor) shows a fan pattern of moving dark lines. This is one of several types of moiré that can occur in video, particularly with footage from DSLRs. (David Leitner)
Rolling Shutter
As described on p. 11, interlace involves scanning the picture from top to bottom, capturing each frame in two parts: one field (half of the frame) first, and the second field fractions of a second later. Progressive formats, on the other hand, capture the entire frame at the same instant in time.
Actually, the part about progressive is not entirely true. CCD sensors can capture an entire progressive frame at once, as can CMOS cameras equipped with global shutters. However, many CMOS cameras have rolling shutters, which scan from top to bottom. There’s still only one field—it’s truly progressive—but the scan starts at the top of the frame and takes a certain amount of time to get to the bottom. The result is that fast pans and movements can seem to wobble or distort. Straight vertical lines may seem to bend during a fast pan (sometimes called skew; see Fig. 5-19). Some people call the overall effect “jello-cam.”
Some sensors scan faster than others, so you may not have a problem. To avoid rolling shutter issues, do relatively slow camera movements. Avoid whip pans. Keep in mind that fast events, like a strobe light, lightning, or photographer’s flash may happen faster than the sensor’s scan, leaving the top or the bottom of the frame dark.
Various software solutions minimize rolling shutter artifacts in postproduction, including Adobe After Effects, the Foundry’s RollingShutter plug-in, and CoreMelt’s Lock & Load.
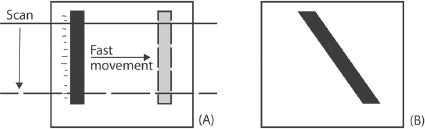
Fig. 5-19. Rolling shutter and skew. (A) On cameras that have a rolling shutter, the sensor scans from top to bottom. If the camera or an object moves quickly, the top of an object may be in one part of the frame at the beginning of the scan, with the bottom of the object in a different place by the time the scan finishes. (B) The recorded frame shows the object tilted or skewed, even though it was in fact vertical. The slower a particular camera scans, the worse the problem.
Video Noise
As discussed elsewhere, different types of video noise can become apparent in the image when it is underexposed, enlarged, processed at a low bit depth, etc. Sometimes you can reduce the appearance of noise simply by darkening blacks in postproduction. Various types of noise-reducing software are available either as part of your NLE or as a plug-in, such as Neat Video.
VIDEO MONITORS AND PROJECTORS
See Camera and Recorder Basics, p. 5, and Viewfinder and Monitor Setup, p. 105, before reading this section.
On many productions, a lot of attention and money go into finding the best camera, doing good lighting, creating artful production design, etc. All in the service of creating a picture that looks great and captures the intent of the filmmakers.
But when showing the work in video, all that care can be undone by a display device that’s not up to the task. There are numerous reasons why a given monitor or projector may not show the picture the way it should (see below). As a moviemaker, you can control some aspects of the viewing experience (such as what type of equipment you use yourself and how you set it up). In screening situations, always do a “tech check” beforehand to make sure anything adjustable is set correctly. Unfortunately, once your movie goes out into the world, you have no control over how it looks and viewers will see something that may or may not look the way you intended it.
These days, video displays are everywhere and there are many different types. The following are some of the main varieties available. Many of these technologies come in different forms: as flat-panel screens (except CRT) and video projectors (which shine on a screen like a film projector). CRTs are analog; the rest are digital.

Fig. 5-20. Sony’s Luma series of professional LCD video monitors. (Sony Electronics, Inc.)
CRT. Cathode ray tube (CRT) technology is what’s behind the traditional TV set dating back to the beginning of broadcasting (see Fig. 5-6). For decades CRTs were the only game in town; now they’re no longer made. Even so, high-quality CRTs continue to offer some of the best color and contrast reproduction of any monitors. Color and brightness are formed by a coating of phosphors on the inside of the tube that glows when struck from behind by a scanning electron beam. CRTs, as a result, are a direct light source.
LCD. Liquid crystal display (LCD) monitors use a fluorescent or LED backlight to project through a screen of liquid crystal molecules sandwiched together with tiny RGB filters. The brightness of a pixel is controlled by sending a voltage to it, which darkens it to prevent light from shining through. LCDs are very thin and can offer good color reproduction; good blacks are a problem, though, and shadow detail may be crushed. Contrast, however, is constantly improving and major broadcast manufacturers are beginning to introduce reference-quality LCD video monitors (see below).
LCDs are often limited in their viewing angle: if you sit off axis (to the side, above, or below) the image may grow lighter or darker. LCDs have no burn-in effect (see Plasma, below).
PLASMA. Plasma screens are flat-panel displays that use tiny red, green, and blue pixels filled with a rare gas that gives off light when excited with electricity (similar to fluorescent light). Plasma screens can be very large, with a wide viewing angle. They have good contrast, color, and black levels. They use the same types of phosphors as CRTs and share a similar color reproduction. They are heavier than LCDs.
Some plasmas can suffer from screen burn-in, which causes the screen to retain brightness values from static images held for a long time.
OLED. Organic light-emitting diode (OLED) displays are another newer thin-film display technology that may someday replace LCDs. When an electrical current is applied, OLEDs phosphoresce (glow), providing their own illumination. They offer excellent color and contrast and have perfect blacks, since black is simply the absence of illumination. (Nothing is backlit.) Their image-forming surface is paper-thin, and they can be remarkably light in weight.
DLP. Digital light processing (DLP) displays use millions of microscopic mirrors to direct light through colored filters. The mirrors switch on and off thousands of times a second. DLP projectors are capable of excellent color, contrast, and resolution; some are very affordable and compact. Many digital cinema projectors in commercial theaters are DLP.

Fig. 5-21. Panasonic 3D home theater projector with 1080p resolution. The PT-AE7000U uses transparent LCD panel technology. (Panasonic Broadcast)
OTHERS. LCOS (liquid crystal on silicon) is similar to LCD technology and is used for video projectors as well as camera viewfinders. JVC calls its version D-ILA and Sony calls its SXRD. LCOS eliminates the screen door effect created by visible pixels. (On some LCDs, the pixel grid is obvious in the image, as though viewing through a screen door.) Sony has a 4K SXRD projector popular for digital cinema use. Laser-based projectors are under development.
Computer and Video Monitors
Clearly there are numerous display technologies in use. As a moviemaker, you need to be aware that, even within one type of technology, all monitors are not created equal and you need the right type for the job you’re doing.
Computer monitors are designed to show the output of a laptop or desktop computer. Depending on the system, computer monitors may be connected with a DVI (Digital Video Interface) cable, DisplayPort cable, Thunderbolt cable, or HDMI cable (see p. 237 for more on these connections). You’ll be using a computer monitor as part of your nonlinear editing system (either built into a laptop or connected to a desktop). Computer monitors operate in RGB color space (see above) and are fine for viewing the editing interface and controls. However, when it comes to evaluating the color and contrast of the actual video you’re making, other considerations come into play. Almost all broadcast video formats produced by HD and SD cameras are in component video color space (also called Y’CBCR or YUV; see p. 209). So if you edit your movie with an NLE and output the component signal to a typical computer monitor, the picture will often look flat (low contrast) and too dark, because the color and tonal values are not properly converted from component to RGB (see Fig. 5-12). This problem can be addressed in a number of ways.

Fig. 5-22. When editing video, it’s important that tonal values be correctly translated from the editing system any built-in or external monitors. Shown here, Avid Nitris DX input/output and monitoring interface. (Avid Technology, Inc.)
First, if you’re producing something that will be seen only on the Web, cell phones, iPods, or computer monitors, then your computer monitor can serve as a picture reference, since your audience will be watching on RGB screens themselves. If you’re using a good-quality monitor and the picture looks okay to you, it will hopefully look somewhat similar for your viewers. You may need to color-correct your material in the NLE for proper contrast and color.
However, if you’re doing something for television or distribution in video (for example, on DVD or Blu-ray), you need to view the picture with proper component color values (for HD, the monitor should be compliant with Rec. 709). This is usually done with a monitor designed and calibrated for video use. A broadcast monitor is essentially a professional-quality video monitor capable of reproducing the full range of color to meet broadcast standards, with the kinds of controls and settings necessary to adjust the image properly. One particularly helpful control is the blue-only switch for accurate color adjustments (see Appendix A). Consumer TVs generally do not deliver consistent, controlled results; only with a broadcast monitor can you make the most realistic and accurate assessment of what the picture actually looks like. When doing critical tasks like color correction, a high-end reference monitor is even better.
You can feed a video monitor with the output from a camera, a deck, or a computer input/output (I/O) device. For example, you can output component video from an NLE using products such as Blackmagic Design’s DeckLink or Intensity cards, AJA’s Kona cards or Io boxes (see Fig. 14-4), or Matrox’s MXO2 I/O devices (see Fig. 5-23). Some of these can be used with a desktop computer via a PCI card, or connected to a laptop via Thunderbolt or ExpressCard. The MXO2 units have a calibration utility that can help you set up a consumer TV that lacks the ability to display color bars with blue-only (see Appendix A). This utility also allows you to calibrate an RGB computer monitor to emulate the look of a YUV video monitor. Matrox promotes this as an affordable alternative to a broadcast monitor for HD color correction.
Newer versions of some NLEs, such as Adobe Premiere Pro CS6, claim to display HD video properly on the NLE’s computer monitor (the desktop), so you may be able to view the picture with correct tonalities for TV without the need of an I/O device. However, I/O devices with dedicated video monitors may still offer better motion or quality, as well as larger full-screen playback.
Maddeningly, even if everything is set up correctly, you’ll find that your video often looks quite different on different systems.
Some Monitor Issues
RESOLUTION AND SCANNING. Flat-panel displays have a fixed number of pixels, which is their native resolution, and they are at their best when playing video that has the same number of pixels (sometimes called pixel-for-pixel, or 1:1): for example, a 720p monitor displaying a 720p picture from a Blu-ray player. Check your monitor’s manual for its native resolution; when working in HD, try to get one capable of “Full HD” (1920 x 1080).
If the video source has fewer pixels than the monitor, the picture may be displayed pixel-for-pixel, using only part of the screen and appearing as a smaller box within the frame. Or the monitor may scale up (enlarge) the picture to the monitor’s size. Sometimes you have to do this manually (by pressing the zoom button on the remote). Scaling up an image will result in a less sharp picture.
If the video source has a higher resolution (more pixels), some detail will be lost and some of the picture area may actually be cut off. There are various devices that can convert from one format or resolution to another for monitoring. For example, if you’re editing HD video and only have an SD monitor, you can use capture cards or external boxes that can downconvert to SD in real time (see p. 550), though editing HD in SD is not optimal.
Flat-panel displays and digital projectors are progressive by nature. If you input interlaced video, the player or monitor will deinterlace, which may cause artifacts (see above). The other side of that coin is that if you shoot in an interlaced format, there can be interlace artifacts (such as twitter), or errors in field order (due to mismatched cameras or improper NLE setups) that appear only on an interlaced CRT display. So if you have only a progressive LCD or plasma screen there could be image issues you won’t see but others with CRTs may.
Newer flat-panel displays may offer high scanning rates, such as 120 Hz or 240 Hz in NTSC countries, which may reduce motion artifacts (see p. 86). Be aware that sometimes these have settings that create new, interpolated frames between existing frames (essentially increasing the frame rate), which can change the look of the video.
COLOR. Getting accurate color reproduction is one of the trickiest aspects of monitors and projectors. There are two aspects you need to be concerned with. One is hue, technically called phase, which is like dialing into place all the colors on a color wheel. The other aspect is saturation—how pale or rich the colors are—which is controlled by the chroma setting. See Appendix A for setup.
If you’re working in HD, you’ll want the monitor set up to Rec. 709 standards for color and contrast (see p. 195). Many consumer monitors come from the factory set too bright and with oversaturated colors because consumers are thought to like a punchy image. In some types of video or connections there is no need for phase adjustments, such as when using HDMI, HD-SDI, component analog RGB, or PAL. However, small errors in hue adjustment will throw off analog NTSC colors in a big way. Also, when using an NTSC standard definition monitor to display HD downconverted to SD, phase should be adjusted.
Some devices, such as the Matrox MXO2 boxes, can help you calibrate a monitor, especially helpful with a consumer monitor that lacks a blue-only mode.
Some newer, high-end digital reference monitors claim to be able to reproduce colors accurately and consistently over time and from monitor to monitor without adjustment. The need for this kind of standardization can’t be overstated. As things stand now, many monitors and projectors you encounter will be poorly adjusted, and many aren’t even capable of reproducing all the colors in your video. But until the world is brimming with perfect digital monitors, keep those color bars handy.

Fig. 5-23. Matrox’s MXO2 family offers a range of input/output (I/O) and monitoring options to use with editing apps like Adobe Premiere Pro, Apple Final Cut Pro, and Avid Media Composer. Various models offer I/O via HDMI (RGB or Y’CBCR), HD-SDI, SDI, and other connectors. The HDMI calibration utility lets an RGB monitor perform like a broadcast HD video monitor with proper display of Rec. 709 component color space so it can be used for color grading. (Matrox Electronic Systems, Ltd.)
CONTRAST RATIO. The range from the darkest black to the brightest white that a monitor can reproduce is critical (see Understanding and Controlling Contrast, p. 191). Manufacturers express this as a contrast ratio, such as 800:1. The higher the better, but be skeptical of the numbers in the ads; they are often fudged.
Be sure to set black level (brightness) and contrast as described in Appendix A. The screening environment also plays a role in contrast. If there’s too much light in the room (and on the screen), you won’t get a good black. If the room is totally dark, contrast may seem harsh. A dim ambient light often works best with consumer monitors.
ASPECT RATIO. Playing widescreen video on a nonwidescreen monitor, and vice versa, can cause issues. This is affected by the monitor and how the video itself is prepared (see p. 74). Another consideration is whether the video and the monitor both use square or nonsquare pixels (see p. 232). Sometimes consumers choose to stretch the width of an SD 4:3 image on an HD 16:9 monitor, so it “fills the frame,” but this results in a distorted picture. Don’t do it!
CONNECTIONS. Often video recorders and players offer a variety of output options through different connectors. For example, a player might have both composite and component outputs. Always use the highest-quality signal path possible. See Video Color Systems, p. 207, for a ranking of some of the options you may have. If the monitor has digital inputs, it’s preferable to go digital out from the player to the monitor rather than using analog connections. For example, use a DVI connection or an HDMI connection, which supports uncompressed video and audio between player and monitor or other gear. However, with some equipment, direct digital connections are not available. See p. 237 for more on digital connections.
Professional monitors often allow you to loop through the signal—going into the monitor and out to another monitor or recorder.

Fig. 5-24. Timecode. Shown here burned in on screen (also called a window burn).
The idea of timecode is simple: to assign a timestamp to every frame of picture or sound. Timecode is a running twenty-four-hour “clock” that counts hours, minutes, seconds, and frames (see Fig. 5-24). Timecode enables many different aspects of production and postproduction and is pretty much essential for serious video and audio work. Timecode comes in a few different flavors, which can sometimes be confusing.
Types of Timecode
In all types of video timecode the frame count depends on the frame rate you’re working in.
For example, when shooting at 30 fps (either 30p or 60i), timecode can advance as high as 23:59:59:29 (twenty-three hours, fifty-nine minutes, fifty-nine seconds, and twenty-nine frames). One frame later it returns to 00:00:00:00. Note that since there are 30 frames per second, the frame counter only goes up to :29. This timecode system is called SMPTE nondrop timecode. Many people just refer to it as SMPTE (pronounced “simpty”) or nondrop (often written ND or NDF). This is the standard, basic timecode often used in North America and places where NTSC has been standard.
In Europe and other parts of the world where PAL video has been standard, video is often shot at 25 fps (25p or 50i). Here, EBU timecode is used, which has a similar twenty-four-hour clock, except the frame counter runs up to :24 instead of :29.
DROP FRAME TIMECODE. One of the joys of video in NTSC countries is that with several formats, the frame rate is just slightly slower than what you might think it is (by 0.1 percent). For example, 30 fps video is actually 29.97 fps (which is to say, 60i is really 59.94i). When you shoot 24p video, that usually means 23.976p. This is described on p. 14.
You can’t see the 0.1 percent reduction in speed, but it affects the overall running time of the video. Say you watch a movie shot at 29.97 fps that has nondrop timecode, and click a stopwatch just as it begins. If you stop the stopwatch when the video timecode indicates one hour, you’d see that actually one hour and 3.6 seconds has gone by. The nondrop timecode is not keeping real time. This discrepancy is no big deal if the movie is not intended for broadcast. Nondrop timecode is often used for production.
Because broadcasters need to know program length very exactly, drop frame (DF) timecode was developed. This system drops two timecode numbers every minute so that the timecode reflects real time.20 A program that finishes at one hour drop frame timecode is indeed exactly one hour long. With drop frame timecode, no actual frames of video are dropped and the frame rate doesn’t change. The only thing that’s affected is the way the frames are counted (numbered). This is a point that confuses many people. Switching a camera from ND to DF has no affect on the picture or on the number of frames that are recorded every second. The only thing that changes is the way the digits in the timecode counter advance over time.
Television-bound programs in NTSC countries are usually shot with DF code (though see note about 24p below). Even if you shot NDF you can edit in DF (most editing systems can display whichever you choose) and broadcasters will require that you deliver in DF because program length must be precise. DF timecode is usually indicated with semicolons instead of colons between the numbers (00;14;25;15) or with a semicolon just before the frame count (01:22:16;04).
24p TIMECODE. If you’re shooting and editing at 24p frame rate, you may be using 24-frame timecode (the frame counter goes up to :23).
When shooting, you generally want to avoid drop frame timecode in 24p mode because the dropped timecode numbers can make it harder to do pulldown removal in the editing system. Cameras that use pulldown to achieve 24p often will not record DF for this reason.
How Timecode Is Recorded
Most digital video cameras generate timecode in some form. The timecode may be embedded in the video recording, or it may be included with the digital video file as metadata (see p. 242).
One way to record timecode is to embed the data in each video frame, outside the picture area. This is vertical interval timecode (VITC, pronounced “vit-see”). One advantage of VITC for tape recording is that it can be read by the VTR even when the tape is not moving (useful for editing). VITC does not use up any audio tracks but must be recorded at the same time as the video and cannot be added later (except during dubbing to another tape).
On some videotape formats, there is a longitudinal track (LTC) just for timecode. With some video decks, the LTC is readable during high-speed shuttle but VITC isn’t. Some formats allow you to record timecode on one of the audio tracks.
Timecode in Consumer Camcorders
Consumer digital camcorders don’t offer professional SMPTE timecode but they do record a nondrop record run (see below) HOUR:MINUTE:SECONDS:FRAME for each frame of video, located in the data section of video tracks on tape or as metadata in the case of files. Fortunately, NLEs can read and manipulate this timecode as if it were SMPTE timecode. Mostly there is no way to preset anything. In the case of tape, like HDV, timecode in a consumer camcorder resets to 00:00:00:00 whenever a tape is changed or ejected. In the case of file recording, run a few tests with your consumer camcorder and import them into your NLE. It’s the only way to know if the native timecode is adequate to your needs.
Late-model DSLRs popular for HD work may also have timecode capabilities.
Using Timecode in Production
While digital consumer cameras offer no control over timecode, all professional cameras and many prosumer models allow you to preset the starting code and may offer a choice of timecode options. Different productions call for different choices, and methods can be somewhat different with tape-based or file-based recording.
RECORD RUN MODE. The simplest timecode mode is called record run, which advances whenever the camera is recording. When shooting in record run mode, you can stop and start the camera as much as you want, but the code should advance on the tape or memory card uninterrupted from beginning to end.21
On most professional and prosumer cameras you can preset timecode to select the starting code. If you are using tapes or memory cards that store less than an hour of material, you might start the first at one hour (1:00:00:00), then start the second at two hours (2:00:00:00), and so on until you reach hour twenty, then start at hour one again. That way, the timecode on each tape and card is different, which helps keep things organized in editing. However, as long as you keep track of each tape or memory card, having two with the same code isn’t a big problem (and it’s unavoidable if you shoot a lot of material on a project). Many cameras allow you to set user bits (U-bits), which are a separate set of data recorded with the timecode and can be used to identify camera roll numbers, the date, or other information. It helps to use U-bits if the timecode on any two tapes is the same.
TIME-OF-DAY AND FREE RUN MODES. On some cameras, you can shoot with a time-of-day (TOD) clock recorded as timecode. TOD code can be useful if you need to identify when things were filmed or when more than one camera is shooting at the same time. A similar system is sometimes called free run mode, which advances every second whether the camera is running or not, but can be set to start at whatever number you preset.
TOD code can create a number of issues, which are explained below in Avoiding Timecode Problems. One issue is that TOD code is discontinuous whenever you stop the camera (because when you start up again, it will jump to the new time of day). Another problem can occur if you’re shooting tape and you record the same tape on different days. Say you finish the first day at four in the afternoon (16:00:00:00 code). You start the next day at eleven in the morning (11:00:00:00 code). When you edit this tape, the edit controller will find the lower code number after the high number, causing problems. Using TOD code will likely result in several tapes having the same code numbers, so try to put the date or tape number in the U-bits. You can avoid some of these problems with camcorders that have a real time mode that puts the time of day in the user bits (if you need it for reference) but uses record run mode for the regular timecode.
RED cameras can record two independent timecode tracks: “edge code” is SMPTE code that starts at 1:00:00 at the first frame of each piece of digital media (and is continuous between clips); “time code” is TOD code (or external free run code from another source) that is discontinuous between clips.
DOUBLE-SYSTEM AND MULTICAMERA SHOOTS. On productions when a separate audio recorder is being used, it will facilitate editing if the camera and recorder have the same timecode. For more on this, see p. 464.
On shoots when more than one video camera is being used at the same time, it’s also helpful if they’re operating with the same timecode. With cameras that can generate and accept an external timecode source, one technique is to run a cable from the timecode-out connector of one camera (the master) to the timecode-in on the second camera (the slave). Some cameras can import timecode via the FireWire connector. The master camera should be started first, then the slave. Make sure the two are running identical code before starting the take. Usually TOD code is used.
If you don’t want the cameras wired together, you may be able to jam-sync one camera with the code from another or from a separate timecode source (such as Ambient’s Lockit box or Denecke’s Syncbox; see Fig. 11-20). The cameras are then used in free run mode and should maintain the same timecode. However, timecode may drift slightly over time, so you may need to rejam the cameras every few hours to keep their timecode identical.
Even with the same timecode, two or more cameras may not be perfectly in sync with each other for editing or live switching. For perfectly matched editing from one to the other, the cameras should be genlocked together. This can be done on professional cameras by running a cable from the video-out connector on one camera (or from a separate sync source) to the genlock-in connector on the other. With HD cameras, genlock is properly called trilevel sync. There are Lockit boxes and Syncboxes that can generate trilevel sync and timecode, to permit genlocked shooting with cameras not tethered by a wire.
Avoiding Timecode Problems
You can think of timecode as an organizational tool for keeping track of your material and locating it later. If you plan to do any editing, timecode is more than that: it’s a crucial part of how the editing system retrieves video and audio data when needed. When using a camera that records to videotape, there are certain ground rules to follow (that are not an issue with file-based cameras).
REPEATING TIMECODE. You never want to have a situation in which the same timecode number occurs on a single tape in more than one place. A common way this can happen is with some DV and HDV cameras that reset the code to 00:00:00:00 every time you remove or insert a tape. You shoot part of a tape, take it out, then put it back in to finish recording it. When you’re later searching for that great shot of a guitar player that starts at timecode 00:12:12:00, you find instead a shot of a drummer with the same code. This can create nightmares in editing.
With most tape camcorders you can avoid this whenever there’s an interruption in code by rewinding the tape into the last previously recorded shot and playing to the end of it (record review or end search on the camera may do this automatically). Then when you start the new recording it will pick up where the timecode ended before (see Operating the Camcorder, p. 125). Some cameras have a regen (regenerate) timecode setting; this will continue the timecode already recorded on tape (as opposed to using “preset,” which will usually start where you have it set). Regen should be used when shooting with a tape that was partially recorded before.
TIMECODE BREAKS. As discussed above, if you shoot carefully in record run mode you can record a whole tape with continuous, ascending timecode. However, wherever there are breaks in the timecode, when you bring the material into the editing system a new clip will be created at the break (see p. 571). When using time-of-day code, timecode breaks happen whenever you stop the camera (because the timecode jumps to a new time when you start recording again). Another way to cause a break is if you aren’t careful and leave a gap after, say, rewinding the tape to check a take.
Timecode breaks aren’t necessarily a big problem, but they can be annoying, especially if you’re shooting a lot of short shots. If you know there’s a break in code, be sure to leave five to ten seconds of preroll time after you start recording before calling “action.” One solution for a tape that has timecode breaks or many short shots is to dub it to a new tape with continuous timecode before editing.
TIMECODE OUT OF ORDER. You want to avoid a situation in which a higher number timecode precedes a lower number on the same tape. This can happen when using time-of-day code (see above) or if you preset the code for an hour tape to start at 23:30:00:00 (because it would finish at 00:30:00:00). Editing systems expect the numbers on a tape to be ascending and get confused if a high number comes before a low number.
If you absolutely can’t avoid this happening, make sure you note it carefully on the tape box or in the log for later reference.
DIGITAL VIDEO RECORDING—HOW IT WORKS
The Basic Idea
Before digital recording existed, there was analog. In analog recording, changes in light or sound are represented by a changing electrical signal. When a singer holds a microphone and starts to sing louder, the electrical voltage in the wire coming from the microphone increases. We can say that changes in the electrical signal are analogous to changes in the sound. If we use an analog tape deck to record the singer, those electrical changes are translated yet again into changes in magnetism on the tape. All these translations introduce small distortions and reduce the quality of the recording. When you copy an analog recording (and then make a copy of the copy) yet more distortions are introduced and the quality is reduced further.
The idea of digital recording is to express changes in light or sound as a set of binary numbers, ones and zeros, that represent those changes as precisely as possible. We can then transmit, record, and copy those basic digits with no translation errors. The copy is then a perfect clone of the original.
As a very simplistic idea of how digital transmission can be superior to analog, think of the “telephone” game kids sometimes play. A group of people sit in a circle and the first person whispers a phrase to the person on the right. Then that person whispers it to the next, and so on around the circle. Say, in this particular game, we use a musical tone instead: A woman plays a note on a piano, a B flat. The man next to her hears it, then tries to hum it to the next person. His pitch isn’t perfect and neither is the next person’s, and by the time you get around the circle the note sounds a lot different from what came out of the piano. This is the “analog” version of the game.
In the “digital” version, the woman doesn’t play the note, but writes “B flat” on a piece of paper. The man copies what she’s written (and checks that it’s the same as the original); then the guy next to him copies and checks it again; and so on down the line. By passing along this written version of the note, when it comes fully around the circle, we can still know exactly what that note is and play it again on the piano.
Digital recording works by sampling the audio or video signal at regular intervals of time; each sample is a measurement of the voltage at that one slice in time. That measurement is converted to a number that can be recorded on tape or on disk (converting the voltage to a number is called quantizing). Once the number is recorded, we can pass it along, much like the written B flat in the game, and reproduce it exactly even after many copies have been made.
In digital systems, all numbers are expressed in binary code, which uses a series of ones and zeros. (The number 5 would be 101 in binary.) Each digit in a binary number is a bit (101 is thus a three-bit number). By convention, eight bits together make a byte. The entire process of converting a video or audio signal to digital form is called digitizing and is done by an analog-to-digital (A/D) converter, which is usually an internal chip or card. To view the picture or hear the sound, we need to convert it back from digital to analog form using a digital-to-analog (D/A) converter, because our eyes and ears are analog, not digital.
The process of digitally recording video shares a lot with digitally recording audio, but there are differences. Let’s look at video first. Digital audio recording is described on p. 405.
Digital Video Recording—With Buckets
See Camera and Recorder Basics, p. 5, before reading this section.
Let’s look at how a digital video camera converts light to a digital recording. The camera’s sensor is a grid of thousands or millions of photosites that are sensitive to light. We’ll assume here that each photosite equals one pixel, or picture element in the image (which is not always the case). For the rest of this discussion, we’ll use the more common term, pixels, instead of photosites.
Each pixel is a receptor that collects light (photons) when the camera shutter is open. To use a simple analogy, we can think of each pixel as a tiny bucket that collects raindrops (see Fig. 5-25). We put out a large number of buckets in a grid and uncover them (opening the shutter), and rain falls into the buckets. Then we cover them again (close the shutter) and measure exactly how much fell into each bucket.
In the actual camera sensor, each pixel gets a different amount of light depending on whether it’s in a bright area of the picture or in shadow. The sampling aspect of digital video takes place both in space (light is measured only where the pixels are) and in time (light is collected only during the time the shutter is open).
Returning to the water buckets, let’s imagine that along the side of each one there’s a numbered scale, with 0 at the bottom and 4 at the top. We can walk from bucket to bucket, writing down the water level in each according to that scale: for a half-full bucket we’d record a number 2; a full bucket would be a 4. We now have a list of numbers that describes how much water is in every bucket in this large array of buckets. We’ve converted the pattern of rainfall to numbers. This is quantizing.

Fig. 5-25. Digital video recording—the bucket version. (left) Buckets placed on the ground in a grid pattern collect different amounts of rainwater depending on where they are in the scene. This is akin to how pixels in the camera’s sensor collect different amounts of electric charge after being struck by light from the scene. (right) These two buckets have the same amount of water. The measurement scale on the upper bucket has only four levels, so the water level would be considered either 2 or 3, introducing a half-unit error (there’s no such thing as 21⁄2 in digital). The scale on the lower bucket has eight levels, so we can say the water level is precisely 5 units with no error. In the digital equivalent, the scale on the lower bucket can be thought of as having greater bit depth or precision. (Steven Ascher)
If we wanted to, we could set up an identical set of buckets somewhere else, fill them with water according to our list of numbers, and reproduce the original pattern of rain.
This is essentially how digital imaging works. The pixels are struck by different amounts of light and respond by creating different amounts of electrical charge. The A/D converter measures the charge at each pixel and converts it to a number.22 That digital number (after a lot of digital signal processing) can then be sent to a video monitor and converted back into light.
For a high-fidelity recording, we want to be able to reproduce the original scene as closely as possible. One key factor is how many pixels (buckets) we use; more on that below. Another factor is how precisely we measure the level of each one. In our rainwater example, the scale on the side of each bucket has four levels. But what if the level of water in one bucket were exactly halfway between level 2 and level 3? In digital systems, you can only record whole numbers, so we’d have to score what was actually a 21⁄2 as either a 2 or a 3—introducing a rounding error that makes our recording inaccurate (see Figs. 5-25 and 10-3). In technical terms, this is a quantizing error.
For more precision, we could use buckets that had a finer scale, say from 0 to 8. Now we could score that same water level as precisely a 5, with no error. This is the concept of bit depth or precision. A two-bit system gives us four levels on the scale; a three-bit system gives us eight levels. The more levels (bits) we have, the more precisely and accurately we can measure the water in each bucket.
It’s also important to think about what happens with buckets if they get too little or too much rain. If only a few drops fall in a bucket we can’t measure it, because it’s below our lowest level on the scale. In digital terms, that amount of light will be lost in the noise. And if too much rain falls, our bucket will overflow and stop collecting rain. When a pixel has absorbed all the photons it can handle, it becomes overexposed and stops responding. This is what happens when the sensor becomes saturated, and the light exceeds the exposure range of the camera (see p. 185).
PIXELS AND RESOLUTION
The Pixel Array
The digital video frame is made up of a lattice or grid of pixels. As discussed in Chapter 1, video formats differ in their number of pixels and in the number of horizontal lines the pixels are arranged in (see p. 8). Take a look at Fig. 5-26. The top image is divided into a lattice of fairly large pixels in relatively few horizontal lines. The middle image has far more pixels in the same area and more horizontal lines. The middle image is capable of capturing finer detail—its resolution is higher.
If the number of pixels is too low, the image will look unsharp, and other artifacts may be introduced. One such defect is aliasing, which can produce a moiré pattern (see Fig. 5-18) or cause diagonal lines in the frame to look like jagged stair steps (see Fig. 1-11).
If the number of pixels is high enough, the eye can’t even discern that the image is divided into pixels at all. Compare Fig. 12-33, which is the same image with yet more (and smaller) pixels. HD video formats have higher resolution than SD formats in part because they have more horizontal lines and more pixels.
Interestingly, our ability to judge resolution in an image is directly related to how large the image appears. You can hold Fig. 12-33 fairly close to your face and it looks fine. With Fig. 5-26, which is a lower-resolution version, it looks pretty bad from close up, but if you view it from several feet away, it looks sharper. As you step back, the pixels start to disappear and the image begins to look continuous. In the ongoing debate about how much resolution we really need in our cameras and video formats, key questions are: How big is the screen? From how far away are you viewing it? For example, many people argue that in typical living room viewing conditions consumers can’t see the difference between 1080p (1920 x 1080 pixels) and 720p (1280 x 720 pixels). When it comes to theatrical distribution, people debate how much difference audiences can detect between 1080p, 2K (about 2048 x 1080), and 4K (4096 x 2160); for more, see p. 71. It depends on screen size and how far back you sit in the theater.
We’ve seen that resolution can be increased by increasing the number of pixels. We can also improve resolution by measuring the brightness of each pixel more precisely. Remember the buckets and how we could measure the water level more precisely with a finer scale?

Fig. 5-26. (top) A relatively low number of pixels forms a coarse, low-resolution image. (middle) Using more pixels in a finer grid produces a higher-resolution image. (bottom) This image has the same number of pixels as the middle image but the bit depth is only three bits per pixel instead of eight. Note the discontinuous tonalities. Try viewing these images from a distance to see how they appear sharper. Compare with Fig. 12-33. Also see Fig. 1-8.
Eight-bit video systems can distinguish between 256 different brightness values for each pixel—which really means, if you think about it, 256 different shades of red, 256 different shades of green, and 256 shades of blue. For a total number of color combinations of 2563. In the millions.
Sixteen-bit systems yield 65,536 gradations of each color. Or 65,5363 combinations of colors. That’s a lot more colors. In the millions of millions.
The more gradations, the finer the detail you can render. Greater bit depth particularly facilitates any manipulation like color correction or recovering shadow detail that involves stretching image tones.
In Fig. 5-26, the middle image uses 8 bits, while the bottom image (which has the same number of pixels) has only 3 bits per pixel. Notice how the shading on the wall and on the man’s face is relatively continuous in the middle picture and is blocky and discontinuous in the lower picture (this discontinuity is called banding or posterization).
The bottom image in Fig. 5-26 has no more than eight levels of brightness from black to white—you can actually count each level on the wall. Clearly, this is very unlike the way the scene appeared in reality. Unsurprisingly, you won’t find any 3-bit camcorders on the market.
Many video formats use 8 bits, a few have 10- or 12-bit precision, and some high-quality HD systems use 16 bits. Increasing the number of bits beyond a certain point isn’t necessarily directly visible to the eye. However, there are various types of digital processing (such as effects work and color correction) where any errors get multiplied, so having more precision helps prevent visible artifacts. The downside of using more bits is that it means more data to process, store, and transmit.
Pixel Shape
Not all pixels are created equal: the shape (proportions) depends on the format. The pixels in computer video systems and most HD video formats are square (see Fig. 5-27). However, the pixels used in SD video formats, and in 1080 HDV (but not 720p HDV), are rectangular (nonsquare). NTSC 601 nonwidescreen video uses pixels that are slightly taller than they are wide. PAL 601 nonwidescreen video has pixels that are slightly wider than they are tall.
Pixel shape can be described as a number: the pixel aspect ratio (PAR). It’s the ratio of pixel width to height, like the way display aspect ratio is expressed (see Fig. 1-12). Nonwidescreen 601 and NTSC DV have a pixel aspect ratio of 0.9; for wide-screen it’s 1.2. PAL nonwidescreen is 1.066; widescreen is 1.42. Both 1080 HDV and DVCPRO HD are 1.33.
If you work in only one format, pixel aspect ratio is usually not a major concern. Most editing systems make the necessary adjustments when you input video from the camera. However, if you are working with a mix of formats that have different PARs, or you’re creating graphics in an application like Photoshop, you need to be aware of it. Figure 5-27 shows that a ball originating in a square pixel format looks horizontally squished when shown in a format with narrower pixels. Similarly, if you create titles in a graphics program and import them into your SD video they could become distorted if not built and converted correctly. To avoid image distortions, consult the manuals of your graphics and editing software when combining material with different pixel aspect ratios.
Fig. 5-27. Pixel aspect ratio. When converting between formats or systems that have different-shaped pixels, the image can become distorted if adjustments aren’t made. (A) An image created in a square pixel format (such as HD or any computer graphics application) can look horizontally squeezed when imported into standard definition NTSC-based formats, which use tall, nonsquare pixels. (B) An image created in an NTSC-based format can look horizontally stretched when shown on a computer monitor (which displays square pixels) or imported into a computer graphics application. Note that settings vary, and some apps compensate automatically, so your results may not be distorted or may be distorted in different ways. The NTSC and PAL pixel aspect ratios indicated on the right are for nonwidescreen formats.
Resolution and Sharpness
The resolution of a video image refers to its ability to reproduce fine detail. When fine detail is rendered clearly, an image will often look sharp to the eye. But sharpness is a complicated topic. There are many factors that play a part in apparent sharpness. These include the measurable fine detail of the image (resolution), the contrast of the picture (higher-contrast images tend to look sharper than low), and the distance from which we are viewing it (the farther away and smaller an image is, the sharper it looks). In the end, audiences care about the subjective perception of sharpness and not about resolution per se.
Particularly when comparing video formats or cameras, people look for numerical ways to express resolution and sharpness. All of them are useful to some extent, but none of them perfectly correlates to the actual experience of looking at video footage. If camera X has 10 percent better numbers than camera Y, it won’t necessarily look that way on screen.23
When talking about resolution, the first thing to consider is the frame size, particularly the number of horizontal lines. Standard definition DV has 480 horizontal lines of pixels; high definition HDCAM has 1080. HDCAM is thus a higher resolution format. Even so, you could have two formats that have the same number of lines, but different resolution due to one being interlaced and the other progressive (the latter is higher resolution). Bit depth or precision plays a part too: a 10-bit format has a higher resolution than an 8-bit format with the same pixel count. When comparing two cameras that record the same frame size, there can be differences in resolution due to the particular sensor, compression, or lens, or factors like frame rate (higher frame rates look sharper due to less motion blur).
Various methods are used to evaluate images.
One technique is to look closely at a test pattern of finely spaced vertical lines. The higher the resolution of the format, the smaller and more tightly packed the lines can be and still be distinguishable. If you were shooting a picket fence, how small could the fence be and still have individual slats visible? This can be measured in TV lines per picture height (TVL/ph). “Per picture height” means that instead of counting lines all the way across the frame, we measure only the same distance as the height of the picture. This allows comparisons between widescreen and nonwidescreen images.
Don’t confuse TV lines with the horizontal scan lines described above, or with the line-pairs-per-millimeter measurement used to evaluate film stocks. If someone says, “DV has a resolution of 500 lines,” that person is referring to TV lines per picture height. TV lines are a rather inexact, simplified way to discuss resolution.
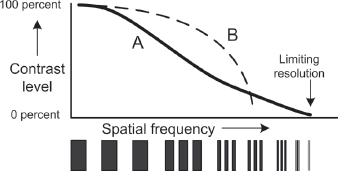
Fig. 5-28. An MTF (modulation transfer function) chart shows how well an imaging device (such as a lens) or a combined system (such as a lens plus a video camera, or a lens plus a film stock) can reproduce the contrast between black and white bars. On the left, the bars are far apart and the contrast is 100 percent. As we move to the right, the bars are thinner and more closely spaced; eventually they appear to blend together into gray (0 percent contrast). This point is the limiting resolution. System A can distinguish finer details than System B and has higher resolving power. However, B has better contrast in the middle range, which, for audiences viewing images from a distance, may make it look sharper.
A perhaps more useful measurement system is MTF (modulation transfer function), which looks at contrast as well as resolution. MTF examines a pattern of alternating black and white lines, specifically measuring the contrast between them. While TV lines per picture height measures only the top limit of resolution (which represents fine details that may not be that critical when images are viewed from far away), MTF looks at how the image holds up across a whole range of lines, from thick, widely spaced bars (low frequencies) to the finest lines (high frequencies). When the lines are relatively wide, any video system can recognize that the black lines are deep black and the white lines are bright white. (This is high contrast or “100 percent modulation.”) But as the lines get very narrow, blurring across the borders between the lines makes the black bars lighter and the white bars darker, which reduces contrast. If the lines are so narrow that they exceed the resolution of the system (this is the TVL/ph limit) they all appear as gray. MTF can be used to compare lenses, cameras, film stocks, recording format, displays, or all together as a complete imaging system.
Bear in mind that even if a format or camera is theoretically capable of a certain resolution, many things can conspire to reduce resolution, including a low-quality lens, poor focus, or an unsharp monitor. Also note that sometimes a less sharp image looks better than an apparently sharp one (see p. 71).
Still Images and Video
If you’re familiar with digital still photography or printing still images, you probably have a number of concepts in your head that don’t apply to digital video. For example, the idea of talking about an image file’s resolution in terms of dots per inch (DPI) or pixels per inch (PPI), which refer to the relationship of a digital image to how large it will eventually be printed on paper. This is irrelevant in digital video or images used on the Web.24 In video, the size of the picture is simply its dimensions in pixels: how many pixels wide by how many pixels high. Sometimes people talk about video having a “resolution of 72 PPI,” but that’s merely a way to estimate how large an image will look on a monitor using numbers some people are familiar with.
Say you want to have a shot in your movie in which you zoom in on a still image. When you go to import the digital still or scan a photograph, all you care about is its dimensions in pixels. PPI or DPI numbers, which you may see in Photoshop or in a digital file’s metadata, mean nothing in this context.25 A still image with a lot of pixels relative to the video format you’re working in may allow you to move in close and see details; an image with relatively fewer pixels will usually look soft or reveal individual pixels if you go in too close. If the image is too small to do a zoom with high quality, you can sometimes help yourself a little by scaling up the image to a larger size with a high-quality scaler (even so, you can’t truly add resolution). Experiment with resizing settings in Photoshop or an application like PhotoZoom Pro that has sophisticated scaling algorithms. Sometimes sharpening the image helps too. For more on using stills in your movie, see p. 594.
While movies are about characters and stories, the tools of moviemaking are increasingly about creating, moving, and storing digital data. Even if you don’t consider yourself a computer wiz, a little knowledge of basic concepts and common equipment can help you navigate this world.
You can think of digital audio and video as a stream of digits: ones and zeros. Different formats create different-sized streams. If data were water, imagine that the data stream produced by standard definition DV could flow through a thin garden hose. By comparison, uncompressed high definition 1080p might need a thick fire hose to move the data fast enough. The amount of information flowing every second is the data rate. The term bandwidth is also used to talk about data rate. Bandwidth is like the diameter of the hose. A high bandwidth connection can pass a lot of data quickly (high-speed Internet connections are called broadband). A connection with low bandwidth, or low throughput, has a relatively narrow hose.
In Appendix B, you can see a comparison of different formats and how much data they generate. Data rates are often expressed in megabits per second (Mbps). You will also see them as megabytes per second (MBps—note the capital B). There are eight bits in a byte, so a megabyte is eight times bigger. To review basic digital quantities: a kilobyte (KB) is 1,000 bytes; a megabyte (MB) is 1,000 KB and is often referred to as a “meg”; a gigabyte (GB) is 1,000 MB and is called a “gig”; and a terabyte (TB) is 1,000 GB.

Fig. 5-29. Data and video connectors. (A) USB 2.0 male A connector. (B) USB 2.0 Mini B connector. (C) USB 3.0 male A connector (USB 3.0 is faster than 2.0 but this connector is backward compatible with 2.0 ports). (D) USB 3.0 male B connector. (E) FireWire 800 (IEEE 1394). (F) FireWire 400 four-pin connector. (G) FireWire 400 six-pin (the two extra pins supply power). (H) DVI connector. (I) HDMI connector. For other common connectors see Figs. 3-14, 10-13, and 10-32. (Belkin Corporation)
When you work with cameras, monitors, computers, and editing systems you’ll have many situations where you need to connect pieces of gear together. You may have several options depending on the equipment, the video format, and what you’re trying to do. It’s easy to get confused when talking about these connections because several factors can be involved:
As for the first item, you’ll find a listing of some widely used formats starting on p. 21. For the second item, you find the video color systems and how they compare on p. 207. Regarding number three, here are the main types of connection technologies.
USB. Universal Serial Bus is a common, low-cost connector found on all computers. USB 2.0, with data rates up to 480 Mbps, has some video uses (like backing up data) but is usually not fast enough for video editing. Newer USB 3.0 connectors support data transfer up to about 3 to 5 Gbps, though not all machines have them, and not all are compatible with one another.
FIREWIRE (ALSO CALLED IEEE 1394 OR i.LINK). FireWire connections have been a mainstay of many consumer and prosumer cameras and computers since the late 1990s. FireWire is an Apple term for what’s defined officially as IEEE 1394. Sony’s name for the same thing is i.Link. Avid calls it simply 1394.
People originally used FireWire cables to connect DV equipment, but many other formats can be used with FireWire, including HDV, DVCPRO HD, and uncompressed SD. The original FireWire system is capable of 400 Mbps and is called FW400. FW800 is twice as fast and is found on many computers and hard drives. FW400 connectors come in four-pin and six-pin styles (the six-pin has two pins to carry power); the FW800 connector has nine pins. FireWire devices can be daisy-chained and with the right cable or adapter you can connect FW400 devices to FW800 devices. However, if you do this the speed of all devices on that bus will only be 400 Mbps.
THUNDERBOLT. Apple and Intel have introduced an exciting connection technology called Thunderbolt that supports two channels of data transfer on the same connector, each up to 10 Gbps. It has the potential to make many other types of high-speed connections obsolete. Thunderbolt is compatible with PCI Express and DisplayPort devices and allows monitors, computers, drives, and other devices to be daisy-chained from one to another. Thunderbolt uses a small connector (see Fig. 14-5) and can supply power to hard drives. As of this writing, Thunderbolt exists on late-model Apple computers and a growing number of hard drives, RAIDs, monitors, and peripherals from various manufacturers. Converters, like AJA’s T-Tap, allow you to output video from a Thunderbolt port to a monitor’s HDMI or SDI input.
HDMI. High Definition Multimedia Interface is a single-cable connection technology for uncompressed high definition, including audio and metadata, that is finding wide use in connecting cameras, monitors, Blu-ray players, and many other devices (see Fig. 5-29). HDMI version 1.3 supports all HDTV standards as well as RGB 4:4:4, and eight channels of audio at up to 10 Gbps. The newer HDMI 1.4 version also supports 3D formats and digital cinema 4K formats. Some Sony cameras like the NEX-FS100 can embed 30p or 24p SMPTE timecode along with 2:3 pulldown markers in HDMI 1.3.
SDI, HD-SDI, AND DUAL LINK. Serial Digital Interface (SDI) is used widely in professional video equipment. SDI can carry 8- and 10-bit 4:2:2 standard definition video with up to eight channels of digital audio. Sometimes referred to as SMPTE 259M, this connection is capable of a data rate up to 270 Mbps and uses BNC cables (see Fig. 3-14).
HD-SDI is a faster version, up to 1.485 Gbps, capable of carrying component HD video. Also known as SMPTE 292M.
For higher speeds, both SDI and HD-SDI can be used in dual-link configurations (sometimes with two cables but there is a dual-link 3 Gbps HD-SDI standard that uses one cable). When a Sony F35 outputs uncompressed 4:4:4 high definition video, it uses a dual-link HD-SDI connection to a HDCAM-SRW1 field recorder, as does an ARRI Alexa when it outputs RAW to a Codex Digital or S.two digital disk recorder.
When you require SDI or HD-SDI, use real SDI cables, and not standard coax composite cables that also use BNC connectors and look similar. This is especially important for long cable runs.
ETHERNET. Some recorders and playback decks have the ability to communicate and send files over the Internet through direct Ethernet connections to a camera or computer. If you have a wired computer network in your home, you’re probably familiar with the Cat. 5 Ethernet cable and connector. Some cameras have a gigabit Ethernet connection that can handle data rates up to 1,000 Mbps.
HARD DRIVE STORAGE
There are lots of ways to store digital data, including flash memory cards, SSDs (solid-state drives that use a form of flash memory), hard drives, videotape, optical discs (like DVDs and Blu-rays), and LTO linear tape cassettes. The choice between them depends on cost, speed, convenience, and other considerations. Memory card, tape, and drive systems used primarily for shooting and archiving are discussed in earlier chapters. In postproduction and editing, hard drive storage systems are most commonly used, though SSDs (much more expensive) are gaining popularity due to their high data transfer speed and robustness.
Fig. 5-30. Blackmagic Design’s HyperDeck Shuttle is a compact video recorder that can capture uncompressed 10-bit HD or SD files to removable flash media SSDs. Connects to a camera via HDMI, HD-SDI, or SDI. Uncompressed files in a QuickTime wrapper are compatible with most editing systems, and material can be edited directly from the SSD. (Blackmagic Design)
Though editing can be done on a computer with only one drive (such as a laptop), it’s generally recommended that video and audio media not be stored on the same physical hard drive on which the OS (operating system) and NLE application are installed.26 If your computer has open bays, you can add additional internal drives, which provide fast data flow. External drives have the advantage that you can bring them from system to system as needed.
Hard drive systems vary in terms of the type of interface between the drive and the computer, and in terms of how the drives are configured: Are they independent disks or grouped together into RAIDs? Are they part of a shared-storage network? Do they provide redundancy in case some of the data is lost or corrupted?
As we’ve seen, video formats vary widely in their data rates. When you choose a hard drive system, make sure it’s up to your needs in terms of throughput (data transfer rate) and seek time (how fast data can be accessed). A utility or application on your computer can show you how fast data is being written and read from the drive. In editing, hard drives should be able to handle not just the basic data rate of the format you’re working in, but multiple streams of video for situations when you’re compositing more than one image at a time (see Appendix B for data rates).
When buying individual hard drives, check their rotational speed (faster is better for video, usually at least 7200 rpm). Some drives are formatted for Mac systems, others for Windows. You can easily reformat a drive to work on your system (use Drive Utility in Macs; use Disk Management in Windows).
Be sure to consult knowledgeable people before choosing drives or setting up a system.
Hard Drive Interfaces
Hard drives can be installed in or attached to a computer using various technologies. The interface or bus that connects the drive(s) and the computer determines in part how fast the connection is, how long cables can be, and how many drives can be grouped together. The following are some of the main interface types as of this writing.
RAIDs
Several drives can be operated together as a single unit in a RAID (redundant array of independent disks). RAIDs can be made up of hard drives or SSD flash memory drives. Drives can be configured in different types of RAIDs for different purposes. Whichever type of RAID is used, the drives work together and are treated as one giant drive or “volume” by the computer.
A RAID system can be controlled with just software, or with a dedicated hardware controller attached to the computer. The latter is faster and reduces the load on the CPU. Be sure to get a RAID designed specifically to handle video.
Sometimes several drives are housed in the same enclosure, but are independent and not in a RAID configuration, so the computer just sees them as separate drives. They may be called JBOD—Just a Bunch of Disks.

Fig. 5-31. A RAID is several drives grouped together to improve performance and/or data security. In the rear view of this Mercury Elite Pro Qx2 unit you can see four hot-swappable hard drive bays. (Other World Computing)
Networks
There are many situations in which it’s helpful for several users to access stored video and audio from different workstations or locations. For example, in a postproduction facility, an editor could be cutting a movie while special effects work is done on the same files, while the sound editor is using the same material to prep for the mix.
Many technologies are used to network computers and storage devices together. A local area network (LAN) can be used to transfer files between systems, and sometimes it’s fast enough for editing. A storage area network (SAN) is a more versatile and expensive solution that allows multiple users to work from the same files. Apple’s Xsan and Avid’s Unity systems both use fibre channel and are complex systems requiring expert setup.
The least expensive but often sufficient method is to physically carry portable drives (such as FireWire drives) from machine to machine as needed. This low-tech solution is known affectionately as “sneakernet.”
Hard Drive Storage Tips
When estimating how much hard drive storage you’ll need during production, consult Appendix B to see the storage requirements per hour of material for the format you’re working in (AJA makes a handy calculator, which can be found at AJA.com and as a mobile app). Don’t forget to include extra drives for backup storage. If you’re just starting a project and trying to estimate your future storage needs, you could multiply the number of shooting days by how much material you plan to shoot each day or you could guess based on the length of the finished piece and the shooting ratio (see p. 360).
When estimating how much storage you’ll need during editing and postproduction, don’t forget to include space for graphics, music, and other files you’ll add during editing (such as outputs of the movie for the Web or finishing) and for the render files and timeline archiving that the NLE will create on its own.
Keep in mind that due to hard drive formatting and the way binary numbers are counted, you get less storage on a drive than the advertised capacity suggests (for example, a “1 TB” drive usually only has about 930 GB available storage). Also, many people feel you should leave 10 to 25 percent of a drive unused (filling a drive too full can result in slow data transfer).
Cleaning up unneeded files and doing maintenance can make a big difference. When using a Mac system, DiskWarrior is highly recommended to rebuild directories on a regular basis, which can help with performance and prevent crashes and data loss.
Generally speaking, all hard drives crash eventually. Your data is not secure if it’s on only one drive. Back up your data and don’t leave your backups in one location (see pp. 92 and 117).
FILE FORMATS AND DATA EXCHANGE
The digital systems we use to make movies involve lots of data. To exchange files between different systems, the data has to be packaged so it can be correctly interpreted. For example, when a digital video camera makes a recording, it doesn’t just record the pixels that make up each frame, but also lots of data about things like the frame rate, timecode, audio, and sampling rate. As another example, a digital editing system doesn’t simply play one shot after another, but works with all sorts of associated information, including how to transition from one shot to the next, how loud to play the audio, and what shape the frame should be.
We can divide all this information into two groups. The pictures and sounds themselves are the media (sometimes called the essence). The metadata is all the other information about how to play or edit the media, including things like the name of the file and the date it was created. Metadata is data about data. If making a movie were like baking a cake, the media files would be the ingredients and the metadata would be the nutrition label and/or the recipe.
To make movies, we need ways to transfer both the media and the metadata from a camera to an editing system, from one editing system to another, or from a disc to a video player. There are several file formats that serve as containers (also called wrappers) to bundle the media and metadata together and describe how they’re stored, which makes it easier to work with them (see Fig. 5-32).
When you shoot video with a digital camera, the video is compressed with a codec (see Digital Compression, p. 245). For example, you might record using the AVCHD or DV codecs. The audio may be uncompressed or recorded with a different codec (for example, Dolby Digital). The movie file your camera records to a memory card or hard drive is made by wrapping the video and audio and metadata inside a container file format.

Fig. 5-32. A digital movie file is made up of video, audio, and metadata packaged inside a container or wrapper. The video may be uncompressed or it may be compressed with one of many possible codecs (such as H.264, DV, DVCPRO HD, etc.). Similarly, the audio may be uncompressed (PCM) or compressed with a codec such as Dolby Digital, MP3, AAC, and so on. Common container formats include QuickTime (.mov), MXF (.mxf), and MPEG-4 (.mp4). When sharing files, it’s important to know the video and audio codecs (if any) as well as the container format.
Container formats vary. Some are designed to be open exchange formats, allowing you to conveniently transfer media and metadata from one platform to another. Other wrappers are proprietary and work only on certain systems or with certain applications. In some cases, you might have video wrapped in one format, and you need to unwrap it and convert it to another wrapper format in order to work with it on your system.
File name extensions including .mov, .avi, .mxf, .flv, and .f4v are container formats that may contain different audio, video, or image formats. Your NLE may be able to import a given container file, but to work with the data it contains, the NLE needs to have installed the codec(s) that were used to compress the video and audio when the file was made.
This issue often comes up when people share footage or a movie that they’re working on. When exchanging files, keep in mind that it’s not just the container that matters. If someone says, “I sent you a QuickTime of the scene,” you need to know what codec she used to make the QuickTime file, because if you don’t have that codec on your machine, you may not be able to play the file. All of the wrappers listed below can contain a wide range of codecs. Often, instead of directly passing files back and forth, a production team will share material by posting to a website or a video-sharing site like YouTube or Vimeo. This has several advantages, including not having to exchange large files and usually not having to worry about whether the person you’re sharing with can handle a particular codec or wrapper, since the sharing site will convert to commonly used formats. For more on making a movie file to share, see Exporting a File, p. 614.
Wrappers are used in both production and postproduction. In an ideal world, projects could be edited on any system in any format, then have the video, audio, and metadata wrapped so that the project could be transferred to any other system for display or for further work. That level of universal, seamless interchange is not yet here.
QUICKTIME. QuickTime was developed by Apple and is supported by a wide range of applications. Software from Apple is available for compatibility in Windows, though not all codecs may be supported. QuickTime files normally have the extension .mov.
MPEG-4. The newer MPEG-4 container file format (.mp4 or .m4v extension) was adapted from QuickTime. (Creating an .mp4 file from your video may still be called “QuickTime conversion.”) What can get confusing is that while MPEG-4 is a container format, there are also codecs that are part of the MPEG-4 family. An MP4 file, for example, can contain MPEG-4 video in the form of H.264, but it can also contain MPEG-2 video. You have to open it up to find out what’s inside.
WINDOWS MEDIA. Microsoft’s container format has evolved and had various names, including Video for Windows and Windows Media. Like Apple, Microsoft has built a large media creation and distribution system around Windows Media formats and wrappers. Some files have the extension .wmv.
MXF. MXF (Material Exchange Format) is a wrapper used in cameras and editing systems to facilitate transfer of a wide range of media files and metadata from one system to another. It can be used at all stages of content creation, including acquisition, editing, and distribution. As one example, Sony’s XDCAM EX wraps MPEG-2 files in the MXF format and offers the potential to include such metadata as voice notes from the cameraperson, or GPS location information.
AAF AND OMF. AAF (Advanced Authoring Format) shares many aspects of MXF and is also an open format for exchanging media and metadata between different applications or systems. AAF grew out of an Avid format called OMFI (Open Media Framework Interchange), which is often referred to just as OMF.
AAF is often used in postproduction as a way to transfer project elements such as video, audio, graphics, animation, and effects from one application to another. For example, AAF can be used to export sound files from a nonlinear editing system to a digital audio workstation in preparation for a sound mix. For more on this process, see Chapters 14 and 15.
XML. The XML Interchange Format is not a wrapper or a way to move media exactly, but it’s a tool used to describe data in one application using plain text so it can easily be understood by another. As one example, XML is sometimes used to transfer an editing project from one NLE to another, and it provides information about the sequence, the video and audio settings, and so on. One NLE translates the project from its proprietary system into XML and the other reads the XML and translates that to its own proprietary system. Often, not all aspects of the project survive the translation. XML can be used to generate other types of files, like OMFs or AAFs, which help move files from one app to another.
DPX. Digital Picture Exchange is a nonproprietary container file for uncompressed images; it was originally derived from the Cineon (.cin) files of Kodak motion picture film scanners. DPX supports multiple resolutions—HD, 2K, 4K—as well as timecode, metadata, and embedded audio. Files can be log or linear, and restored on a per-frame basis to reduce the amount of storage required when conforming. DPX is used extensively in Hollywood for effects work.
DIGITAL COMPRESSION
See What Is Compression?, p. 19, before reading this section.
Though digital compression is a complex topic, the idea behind it is simple: take some video or audio, use a codec to compress it into a smaller package, then decompress it again when you want to view or hear it. Ideally, after going through this process, the material looks and sounds as good as it did originally.
Starting from the camera’s sensor, there is a long chain of events from recording to editing to broadcast. Forms of compression can happen at every stage.27 One of the first things that happens in most cameras is that the RGB data from the sensor is processed into component video, reducing the color information in a way that normally isn’t noticeable to the viewer (see Video Color Systems, p. 207). Different formats throw away different amounts of color data.
At this point, we have what’s called uncompressed video.28 Uncompressed video uses a lot of data; how much depends on the format (see Appendix B). Uncompressed is the top quality the format is capable of. However, uncompressed video requires so much storage and processing power that it just isn’t practical in most digital cameras. Uncompressed video is often used in editing and finishing, however.
To compress the video prior to recording, a codec (compression/decompression algorithm) is used. Some codecs are standardized for an entire format. For example, the DV codec is employed in all DV cameras; no matter which manufacturer made your camera, the video it records should be playable with DV from other cameras (even so, some cameras do a better job of compressing than others). Other codecs are proprietary to one company or a group of companies and, if they’re good codecs, are intended to get you to buy that company’s gear (for example, you won’t find Panasonic’s DVCPRO HD on a Sony camera). Codecs can be hardware—a chip, for example—or they can exist wholly in software.
Some codecs don’t degrade the image at all. With lossless compression, you can decompress the video and get a picture that has perfect fidelity to the original before you compressed it. Lossy compression, on the other hand, throws away information that can never be restored. In practical use, almost all codecs are lossy but can still look great to viewers. Some codecs can be used at different levels of compression, so the same codec could look very good at a light compression setting, and worse with heavier compression. If you’ve worked with digital stills, you may be familiar with the JPEG file format (with the file name extension .jpg), which allows you to select how much compression you want: the greater the compression, the smaller the file, and the lower the quality. Several video codecs are based on JPEG.
COMPRESSION METHODS
Different codecs use different techniques to compress video. These are some of the main methods.
Compressing Within a Frame
All codecs compress individual frames. In other words, they take each video frame one at a time, and delete some of the data while trying to preserve image quality.29 This is called intraframe compression or spatial compression. Intraframe means “within the frame.”
Many intraframe codecs use a process called DCT (discrete cosine transform). Versions of DCT are used in DV, DigiBeta, HDCAM, and other formats. Basically, DCT involves analyzing the picture in 8 x 8 blocks of pixels called macroblocks. It then uses sophisticated formulas to delete repetitive information and compact the data.
Another intraframe compression process, called wavelet, used for both video and audio, is gaining popularity. Hollywood’s Digital Cinema Initiatives adopted wavelet-based JPEG 2000 for theatrical distribution partly because any dropouts cause the affected area to turn soft in focus instead of blocky, as DCT codecs do.
Different codecs compress the data by different amounts. For example, standard definition DigiBeta compresses about 2:1; DV uses heavier compression, about 5:1. The more compression, the greater the chance of artifacts, such as the “mosquito noise” that can sometimes be seen in DV images as dark or light pixels around sharp edges and text.
With intraframe compression, each frame stands on its own, independent of the others. This speeds up the compression/decompression process and makes editing much simpler. Apple’s ProRes and Avid’s DNxHD editing codecs are examples of this idea. However, intraframe compression alone creates files that are larger than if interframe compression is also used (see below).
Compressing a Group of Frames
Video images can be thought of as existing in the horizontal and vertical dimensions of the frame, as well as another dimension: time. The intraframe compression we just looked at compresses data in the first two dimensions. Interframe compression analyzes a string of frames over time and finds ways to delete repetitive information from one to the next (interframe meaning “between frames”). This method is also called temporal (relating to time) compression.
To get the idea of interframe compression, try looking at some video footage in slow motion. You’ll notice that very often, not much changes from frame to frame. An extreme example is a “locked off” (nonmoving) shot of an empty, windowless room. You could shoot for an hour and the first frame you recorded and the thousands that follow would be identical. Rather than record each of these individually, we could save a lot of space if we could somehow record just one frame with instructions to keep repeating it for an hour.
Obviously, most video footage has some movement, and some has a great deal, so we can’t just repeat frames. However, codecs that use interframe compression look for anything that stays the same from frame to frame—even if it moves somewhat—and finds ways to reuse the data it already has stored rather than trying to store a whole new frame every time. Interframe compression works by looking at a group of frames together (referred to as a group of pictures, or GOP). The first frame in the group is recorded normally. But for several of the frames that follow, instead of storing a whole picture, the codec only records the differences between the frame and its neighboring frames. Recording only the differences between frames takes a lot less data than recording the actual frames themselves.
Interframe codecs are used for an impressive number of production, distribution, and transmission systems, including formats used in cameras, DVDs, and cable, satellite, and broadcast TV. Interframe codecs include those based on MPEG-2, such as HDV, XDCAM, and XDCAM HD, and those based on MPEG-4, such as AVCHD and H.264 used in DSLRs. In these codecs, each GOP has three types of frames (see Fig. 5-33).
Different interframe formats use a different-length GOP. The length of the GOP affects how the compressor handles motion and complexity: the longer the GOP, the more you can compress the data, but that means more processing power is needed to keep up with the calculations. The 720p version of HDV, for instance, uses a 6-frame GOP; the 1080i version uses a longer, 15-frame GOP.
As a filmmaker, what does all this mean for you? Well, the upside of interframe compression is that it results in more efficient compression and more convenient storage. It makes low-cost HD formats like XDCAM and AVCHD possible in the first place.
The downside is that it can create problems in shooting, editing, and distribution. Different versions of MPEG-2, MPEG-4, and other codecs that use interframe compression behave differently, so these problems may or may not apply to the system you’re using. But it helps to understand some of the potential underlying issues, discussed below.
Fig. 5-33. Interframe compression means compressing several frames in a group (a group of pictures, or GOP). Only the I-frame is independently and completely stored; the P- and B-frames are calculated based on neighboring frames. The P-frame has about half as much data as the I-frame and the B-frames have one-quarter; compared to I-frames, they require more computing time to generate or view them. Pictured here is a 6-frame GOP used in the 720p version of HDV. The 1080i version uses a 15-frame “long GOP.” The longer the GOP, the greater the compression, and the more computing time and power that’s required to work with the material.
SHOOTING AND EDITING WITH INTERFRAME CODECS. In shooting, problems may result from the way interframe codecs handle footage that has a lot of complexity or action. As discussed, the codec is always looking for redundancy (repetition) between frames. When things don’t change much (remember the locked-off shot of the room?) the codec has very little to do. But when things change a lot, the compressor can get overwhelmed by all the data (the more change, the harder it is for the codec to generate all those P- and B-frames). A shot that has a lot of detail and motion—for example, a tree branch with fluttering leaves or a panning wide shot of a stadium full of cheering fans—could cause the picture to momentarily break up: MPEG-2 may break into blocky, noisy artifacts; MPEG-4 may create less conspicuous artifacts because it uses smaller macroblocks than MPEG-2. On the whole, though, both codecs make excellent HD images with few obvious flaws.
In editing, a long GOP creates other challenges. In a certain sense, the P- and B-frames don’t fully exist (at least they aren’t completely stored); they have to be generated every time you want to look at one. This puts a lot of demand on the editing system when you view or edit individual frames. If you make a cut within a group of pictures, the system has to insert a new I-frame and build a new sequence of I-, P-, and B-frames before the footage can be output (you can’t start a GOP with just P- and B-frames; you always need an I-frame to begin the group).
While editing long-GOP formats is not as straightforward as intraframe formats like DV, most professional and prosumer NLEs, including Final Cut and Avid, can handle them well as long as you have a reasonably fast computer. If you plan to do a lot of effects or have many streams of video, the system can slow down. With some NLEs, you can choose to edit natively with the interframe codec from your camera, but let the system create any effects with an intraframe codec like ProRes or DNxHD.
Another issue arises when you’ve edited the movie and you’re ready to export it from the NLE to a file or on tape. To export an HDV sequence, for example, the NLE must first reestablish the 15-frame GOP structure along the entire length of the project. Depending upon the muscle of your computer’s CPU and the amount of RAM you have, this begins a rendering process (also called conforming) that can take hours (or much longer if the work is feature length or contains many effects layers). Heaven forbid you have a crash in the meantime.
There are a few workarounds to this obstacle. One is to convert all your material to an intraframe codec either while importing it into the NLE or before editing. Many filmmakers shooting with DSLRs will transcode their H.264 camera files to ProRes or DNxHD when ingesting to the NLE. The transcoded files are then used from that point forward. This increases storage requirements, but working with ProRes or DNxHD often makes the NLE more responsive and can help maintain image quality.
Another possibility when editing HDV with Final Cut Pro is to use one of Matrox’s MXO2 family of devices (see Fig. 5-23) or their Mojito card. These can accelerate HDV playback without requiring conforming. Several Matrox products are available with MAX technology that can accelerate the creation of H.264 files, which may allow you to encode H.264 files in real time when using compatible software.
Compared to HDV, the intraframe compressions used in formats such as DV and DigiBeta are very simple and straightforward. They only have I-frames, and their codecs make no attempt to take into account what happens before or after each frame. They’re also longer in the tooth, dating back further in time. MPEG codecs are more sophisticated and therefore more efficient. So is there a way to have our cake and eat it too? The answer is that there are indeed forms of MPEG-2 (including Sony’s 50 Mbps MPEG IMX) and MPEG-4 (such as Panasonic’s AVC-Intra for P2) that use a one-frame GOP, which is sometimes called I-frame only. The advantages of I-frame only include fewer artifacts and much simpler editing and processing. H.264, part of the MPEG-4 standard, is considered to be twice as efficient as MPEG-2, taking up half the storage for the same quality of image, even in I-frame-only mode (see AVC-Intra and AVC Ultra, p. 26).
Constant and Variable Bit Rates
We’ve seen that shots with a lot of detail or motion require more data to process than ones that are relatively simple or static. With some codecs, the same amount of data is recorded for every frame, regardless of how complex it is. For example, the data rate of DV is 36 Mbps no matter what you’re recording. This is a constant bit rate (CBR) format.
Some formats, however, allow for a higher data rate on shots that are complex or active, and reduce the data rate for scenes that are less demanding. These are variable bit rate (VBR) formats. VBR encoding is more efficient: it provides more data when you need it, less when you don’t. It can result in fewer artifacts and smaller file sizes. The problem with VBR is that it requires more processing power and time to accomplish. In postproduction (for example, when creating DVDs) VBR compression is often done in a two-pass process: in the first pass, the system analyzes the entire movie to gauge where high and low data rates are called for; in the second pass the codec actually does the compressing.
An interesting example of a camcorder design that exploits both CBR and VBR is found in Sony’s XDCAM HD camcorders, the PDW-F330 and PDW-F350, which record 1080i/60 and 1080p/24 using long-GOP MPEG-2 with a choice of 18 Mbps (variable), 25 Mbps (constant, functionally equivalent to HDV), and 35 Mbps (variable).
A FEW COMMON CODECS
There are numerous codecs, and new ones are always being developed. Some are employed in camera formats, some are used primarily in editing, and others are used mostly for distribution. Some codecs are used in all three areas.
See Comparing Video Formats, p. 21, for camera formats and the codecs they employ, including DV, DVCPRO, DVCPRO HD, H.264, and others. Below are just a few other codecs used in video production and postproduction.
MPEG-2
MPEG-2 has been around since the early 1990s and is widely used. (See Compressing a Group of Frames, above, for a basic idea of how MPEG-2 compression works.) MPEG-2 provides superb picture quality, all the way up to HD, and supports widescreen. It comes in a number of flavors (there are different profiles, each of which have various levels), which may behave differently and may not be compatible (a system that can play one may not be able to play another). As mentioned above, it is the codec used in standard definition DVDs and it’s also one of the codecs used with Blu-ray. It is the basis for ATSC digital broadcasting in the U.S. and DBV digital broadcasting in Europe, as well as cable and satellite transmission.
Many professional camcorder systems use MPEG-2 to record HD, particularly Sony camcorders. Sony HDV cameras record MPEG-2 at 25 Mbps (constant bit rate) and Sony XDCAM EX cameras record up to 35 Mbps (variable bit rate), while XDCAM HD cameras record up to 50 Mbps (CBR).
One aspect of MPEG-2 that is generally misunderstood—and this goes equally for MPEG-4 codecs like H.264 below—is that although the decompression algorithms are standardized, the compression algorithms are not. What this means is that while any device that can play back MPEG-2 or MPEG-4 is expecting a standard type of video essence, how the camera gets there in creating a compressed recording is left up to the camera and codec designers. This has huge implications. It means that even though MPEG-2 has been around since the early 1990s, the MPEG-2 codecs of today are vastly superior and will continue to improve. It also means that even though two camcorders from difference manufacturers claim to use the same MPEG-2 or H.264 compression, the results can be quite different depending on the performance capabilities of the particular codec in each camera.
H.264
Versatile H.264 is found extensively in today’s consumer camcorders and DSLRs under the brand name AVCHD. It’s also used in postproduction and across the Web for streaming, for example in YouTube HD videos. Also known as AVC and MPEG-4, Part 10, this codec is twice as efficient as MPEG-2 (which means you can get the same quality with as little as half the data). H.264 is very scalable, which means you can use the same codec for high-quality needs like HD projection and for very low-resolution cell phones. Like MPEG-2, H.264 has several profiles; higher profiles offer better quality at smaller file sizes, take longer to encode, and need more processing to decode in real time. Because of the considerable processing power needed to encode and decode H.264, it can sometimes create bottlenecks when editing on an NLE.
H.264 is supported by many newer systems, including European digital broadcasting and Apple’s QuickTime. It is the basis of Sony’s HDCAM SR and also one of the three mandatory codecs for Blu-ray. To simplify editing while taking advantage of H.264’s great efficiency, Panasonic created an I-frame-only version, which it calls AVC-Intra, for use with its P2 cards (see p. 26).
The successor to H.264, called High Efficiency Video Coding (HEVC) or H.265, is already on the horizon. H.265 is said to achieve the same or better image quality as H.264 at half the data rate.
Windows Media Video
Microsoft’s WMV (Windows Media Video) is a competitor of MPEG-4 and offers many of the same advantages. Like MPEG-4, it has different profiles that can be used for high- and low-quality applications. WMV is sometimes called VC-1. As of this writing, Windows Media 9 is the most recent version and one of the three mandatory codecs for Blu-ray.
Apple ProRes
Apple introduced ProRes compression for editing with Final Cut Pro, originally positioning it as a kind of universal codec into which many other formats can be converted for editing and finishing. It has been so popular, and offers such good quality, that cameras like the ARRI Alexa and external digital recorders like the AJA Ki Pro and Atomos Ninja offer it as a recording codec, allowing you to go directly to editing with no transcoding or processing necessary (see Figs. 2-19 and 5-11). ProRes is stored in a QuickTime container (files have the extension .mov) and can be edited with Final Cut or NLEs made by other companies.
ProRes is really a family of codecs, all of which are I-frame only (intraframe compression) and offer fast encoding and decoding at data rates much lower than uncompressed video. All ProRes versions use variable bit rate (VBR) encoding.
ProRes 422 supports SD and full-resolution HD (both 1920 x 1080 and 1280 x 720) at 4:2:2 color sampling with 10-bit precision. Normal quality is targeted at 145 Mbps, and there is the high-quality ProRes 422 (HQ) version at 220 Mbps. To streamline editing of interframe codecs like H.264 and HDV you can transcode to ProRes, which increases file sizes but can speed up processing while maintaining quality.
For projects such as news or sports that require smaller file sizes at broadcast quality, there is ProRes 4:2:2 (LT). For very small file sizes, ProRes 422 (Proxy) can be used for offline editing, followed by online editing with another ProRes version or another codec. At the top end of the quality scale, there is ProRes 4:4:4:4, which is 12 bit and uses 4:4:4 chroma sampling and includes support for an alpha channel (see p. 59).
An older format that can be used for similar purposes is Apple Intermediate Codec (AIC); this is sometimes used with systems that don’t support ProRes.
Avid DNxHD
DNxHD is much like ProRes, but designed by Avid.30 It works seamlessly with the Avid family of products and is also intended as an open standard to be used with applications and equipment by different manufacturers. DNxHD is I-frame only and typically stored in an MXF container, but it can be wrapped in QuickTime as well.
Like ProRes, it has different levels of compression. There is a 220 Mbps version at 10 or 8 bits as well as 8-bit versions at 145 and 36 Mbps. DNxHD 36 is often used for offline editing. DNxHD supports all common SD and HD frame sizes.
JPEG 2000
As noted above, JPEG 2000 is based on wavelet compression and used by Hollywood’s Digital Cinema Initiatives for theatrical projection. It’s scalable and capable of a very high-quality image.
CineForm
CineForm makes a range of compression products based on its wavelet-based CineForm codec. Silicon Imaging’s SI-2K Mini records 2K RAW files to CineForm’s RAW codec. Mostly, however, CineForm’s workflow is based on transcoding any camera format, including AVCHD, XDCAM, P2, or large 2K or 4K RAW files, to CineForm as an “intermediate codec” used for editing, finishing, and archiving. It offers high image quality up to 12-bit precision in various color spaces and wrappers. CineForm can be used with Windows or Mac NLEs and applications; you don’t need any particular NLE installed to take advantage of it.
Cineform is owned by GoPro and can be used in the postproduction workflow for footage from GoPro cameras (see Fig. 2-8).