La audición: la recepción de la onda sonora
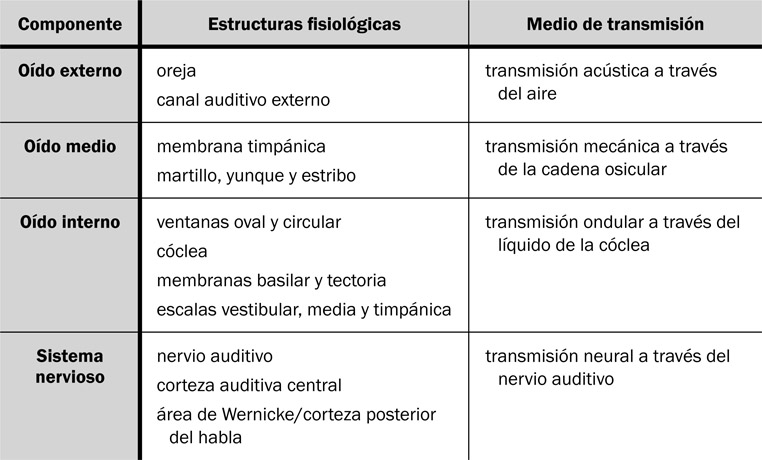
La audición, cuyo órgano principal es el oído, resulta ser el más complejo de los cinco sentidos del ser humano debido al número de componentes fisiológicos del oído mismo y al número de transformaciones físicas que sufre la energía acústica recibida. El oído se divide inicialmente en tres partes: el oído externo, el oído medio y el oído interno. El proceso auditivo concluye con el componente del sistema nervioso auditivo que transmite la información recogida por el oído al cerebro. La Fig. 7.1 indica la ubicación de esas tres partes del oído.
El oído externo
Las partes principales del oído externo son la oreja (también llamado el lóbulo o pabellón de la oreja) y el canal auditivo externo, como se ve en la Fig. 7.2. La oreja misma sirve como una antena para capturar la onda sonora. Su diseño favorece la recepción de sonidos producidos delante del receptor. El trago, la pequeña prominencia saliente a la entrada del canal auditivo externo, sirve de protección para el oído.

7.1
Las regiones principales del oído.
El canal auditivo externo en sí es un tubo de aire con una extensión de entre 2,5 cm. y 3,5 cm. y un diámetro de aproximadamente 0,7 cm., por el que pasa la onda sonora. El tubo, abierto en el extremo exterior, está cerrado en su extremo interior por la membrana timpánica. Esa conformación permite que se amplifique un poco la amplitud de la onda sonora, sobre todo en las frecuencias más altas. El canal está forrado de pelitos y de cerilla que protegen el oído de objetos forasteros.
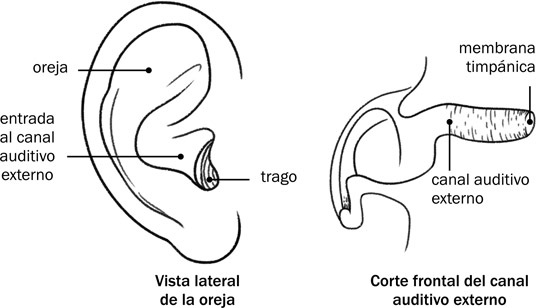
7.2 Los componentes principales del oído externo.
El oído medio
El oído medio es más complicado y tiene más componentes que el oído externo. Se compone principalmente de la membrana timpánica y de los llamados huesecillos, que se ven en la Fig. 7.3. Al llegar al final del canal auditivo exterior, la onda sonora transfiere sus patrones de vibración a la membrana timpánica, una membrana ovalada de tejido fibroso extremadamente sensible a las vibraciones del aire. Las frecuencias bajas hacen vibrar toda la extensión de la membrana, mientras que las frecuencias más altas hacen vibrar distintas regiones de la membrana.
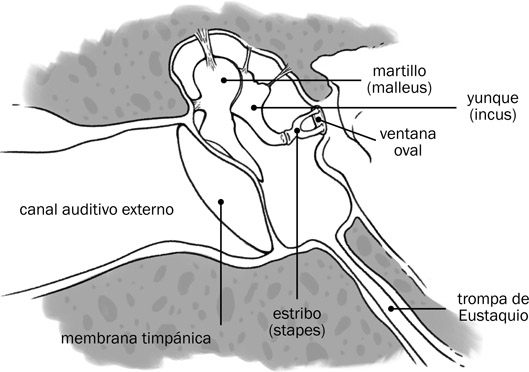
7.3
Los componentes principales del oído medio.
De la membrana timpánica, la energía se transfiere a una cadena osicular formada por los tres huesos más pequeños del cuerpo: el martillo (malleus), el yunque (incus) y el estribo (stapes). Específicamente, la super-ficie interior de la membrana timpánica se conecta al mango del martillo que recibe la energía vibratoria. Con eso, la transmisión de energía cambia de un sistema acústico a un sistema mecánico. El mango del martillo funciona como una palanca que amplifica la energía transmitida a la cabeza del martillo. La cabeza del martillo encadena con el cuerpo del yunque que sirve de fulcro entre el martillo y el estribo, amplificando de nuevo la energía transmitida. El proceso inferior del yunque enlaza con el estribo, pasándole su energía. El estribo, el último elemento de la cadena osicular, contiene dos procesos cilíndricos que terminan en un asiento que se encaja en la ventana oval, que es el comienzo del oído interno.
El estribo sufre dos tipos de movimiento. En primer lugar, actúa como un pistón, pasándole en dirección horizontal la energía sonora a la ventana oval. En segundo lugar, puede sufrir un movimiento perpendicular, el llamado reflejo auditivo, cuando el oído medio siente un sonido de volumen muy alto. Ese reflejo tiene como motivo el proteger el oído interno de sonidos de volumen tan alto que podrían dañar su frágil mecanismo.
La cadena osicular se asienta en una cámara de aire, pero el aire no interviene en la transmisión de energía. El aire ambiental de la cámara del oído medio proviene de la trompa de Eustaquio, que conecta con la faringe nasal. Ese aire es necesario para que funcione la membrana timpánica, que no puede responder adecuadamente a la onda sonora acústica en el canal auditivo externo sin que haya un equilibrio de presión de aire por los dos lados de la membrana timpánica. La transmisión de la energía sonora a través del sistema mecánico de los huesos permite que la energía se amplifique para que la presión de energía sonora contra la ventana oval sea de treinta a cuarenta veces mayor que la presión contra la membrana timpánica.
El oído interno
El sistema auditivo del oído interno empieza donde el estribo conecta con la ventana oval que da entrada a la cóclea, el órgano principal del oído interno. Como se ve en la Fig. 7.4, el oído interno también contiene tres canales semicirculares, llenos de líquido, que se responsabilizan por el sentido de equilibrio y de posicionamiento corporal. Esas estructuras, junto con la cóclea, se conocen como el laberinto membranoso.
La cóclea es de forma fija y se encaja en el hueso más denso del cuerpo humano. La cóclea en sí tiene forma de caracol de dos vueltas y tres cuartos. Dentro de la cóclea hay tres canales, dos de ellos (uno superior y otro inferior) transmiten la energía sonora y el tercero (en el medio de los otros dos) convierte la energía en impulsos nerviosos. La ventana oval se conecta al canal superior, llamado la scala vestibuli. Cuando el estribo empuja contra la ventana oval, el estribo funciona como pistón, creando una ondulación en el líquido perilinfático del canal vestibular. Como se ve en la Fig. 7.5, la ondulación viaja a lo largo de la escala vestibular y pasa por el helicotrema, que queda al extremo de la cóclea, y la energía entra en el canal inferior o scala tympani. La ondulación sigue por la escala timpánica hasta llegar a la ventana redonda, que se distiende hacia el oído medio en compensación del movimiento de la ventana oval.
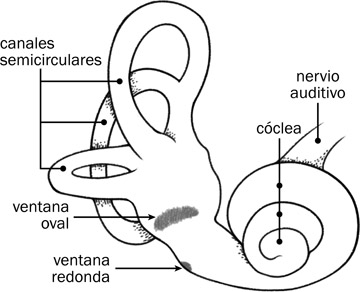
7.4
Los componentes principales del oído interno.
La ondulación del líquido en las escalas vestibular y timpánica causa un movimiento de una membrana que divide la escala timpánica del canal medio. El canal medio se llama la scala media o canal coclear. Ese canal, por su parte lleno de líquido endolinfático, contiene el llamado órgano de Corti o el órgano de audición, como se ve en la Fig. 7.6. La membrana inferior que divide la escala timpánica de la escala media se llama la membrana basilar. La membrana basilar está forrada en su superficie superior de fibras ciliadas, que son pelitos muy finos en patrones organizados. La membrana basilar varía en su grosor a lo largo de su extensión por la cóclea. Debido a la graduación de su grosor, la membrana basilar responde a frecuencias acústicas distintas. Cuando la membrana se distiende hacia arriba en la región que corresponde a determinada frecuencia, las fibras ciliadas se levantan y entran en contacto con el techo o membrana tectoria. Cuando las fibras ciliadas entran en contacto con la membrana tectoria, se excitan los sensores neurales que registran la existencia de energía sonora en su determinada frecuencia. El mecanismo auditivo del ser humano es tan preciso que responde a ocho frecuencias entre dos semitonos musicales, o sea puede precisar ocho niveles distintos entre dos notas consecutivas del piano.
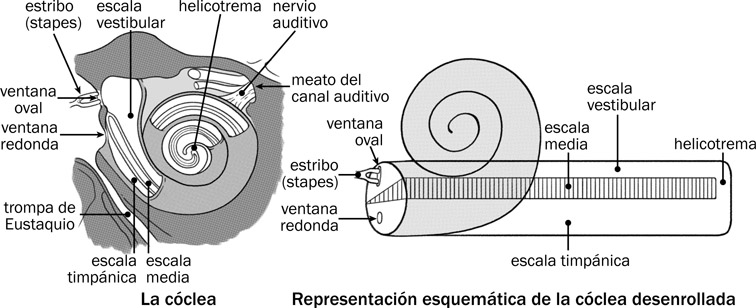
7.5 Corte transversal parcial de la cóclea y una representación esquemática de la cóclea desenrollada.
Al transmitirse la onda compuesta por el líquido perilinfático de la cóclea, se registran las distintas frecuencias desde las bajas hasta las altas a lo largo de las vueltas de la cóclea. La Fig. 7.7 indica el lugar relativo de la percepción de las frecuencias reconocidas por el oído humano desde 20 cps hasta 20.000 cps.
El sistema nervioso auditivo

7.6
Corte transversal de una vuelta del caracol de la cóclea y una corte transversal ampliada de la escala media.
Los sensores neurales se excitan al reconocer la presencia de energía acústica en la frecuencia que les corresponde. Los nervios que provienen de cada una de estas posiciones se combinan hasta unirse todos en el nervio auditivo, o el octavo nervio craneal. En el sistema auditivo humano hay como 30.000 fibras en cada uno de los dos nervios auditivos.
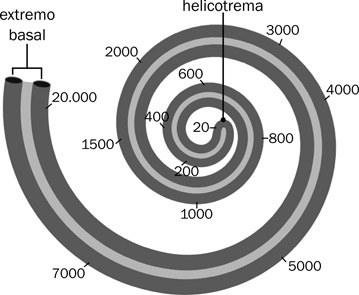
7.7 Representación esquemática de las frecuencias en hertzios reconocidas por la membrana basilar.
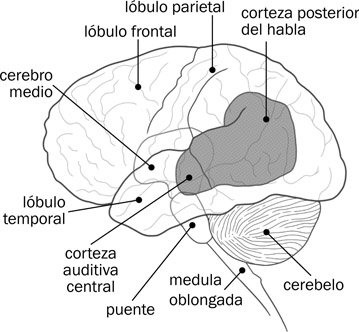
El nervio auditivo, como se ve en la Fig. 7.5, sale de la cóclea y pasa por un hueco (el meato del canal auditivo) en el hueso temporal a la médula oblongada. En esta región a donde llegan los dos nervios auditivos se comparan las señales de los dos para localizar la fuente del sonido producido. Los nervios aquí se entrecruzan; el nervio auditivo izquierdo pasa por el cerebro medio y sigue al lóbulo temporal derecho mientras el nervio auditivo derecho pasa por el cerebro medio y sigue al lóbulo temporal izquierdo, como se ve en la Fig. 7.8. De esa forma toda la información sobre las frecuencias y amplitudes percibidas a través del tiempo por la cóclea se transmite a la región del lóbulo temporal que se denomina la corteza auditiva central como se ve en la Fig. 7.9. Una vez comunicada esa información a la corteza auditiva, la información pasa a la región del cerebro denominada el área de Wernicke o coreteza posterior del habla, donde comienza el proceso de reconocimiento e identificación de los sonidos del mensaje transmitido.
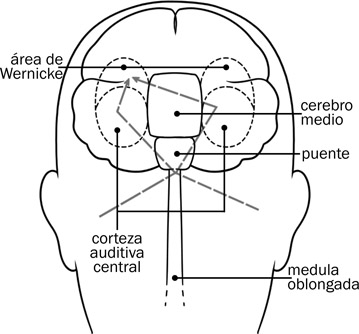
7.8
Las flechas con líneas en puntos representan la trayectoria de los impulsos acústico-neurales desde la cóclea hasta el área de Wernicke.