
This chapter includes contributions from Alex Bentley (IBM), Marco De Angelis (IBM), Marc Fiammante (IBM), Arild Kristensen (IBM), Frode Myren (IBM), and Grégory Neuvéglise (IBM).
Machine-to-machine (M2M) refers to technologies that allow both wireless and wired systems to communicate with other devices. M2M uses a device such as a sensor or meter to capture an event such as speed, temperature, pressure, flow, or salinity. The device then relays this data through a wireless, wired, or hybrid network to an application that translates the captured event into meaningful information. For example, a utility might install smart meters at customers’ premises that wirelessly communicate electrical usage.
The expansion of wireless networks across the world has made it far easier for M2M communication to take place and has lessened the amount of power and time necessary for information to be communicated between machines. These networks also allow an array of new business opportunities and connections between consumers and producers, in terms of the products being sold.1 All this creates the so-called “internet of things”—billions of things like materials, products, pharmaceuticals, machinery, mobile phones, and vehicles that are represented with Internet addresses and interconnected in a vast network. Each thing is attached to an RFID tag or GPS chip that can keep track of its location.
This chapter deals with the critical issues associated with governing the vast amounts of M2M data within an organization. The big data governance program needs to adopt the following best practices to govern the usage of M2M data:
14.1 Assess the types of geolocation data that are currently available.
14.2 Establish policies regarding the acceptable use of geolocation data pertaining to customers.
14.3 Establish policies regarding the acceptable use of geolocation data pertaining to employees.
14.4 Ensure the privacy of RFID data.
14.5 Define policies relating to the privacy of other types of M2M data.
14.6 Address the metadata and quality of M2M data.
14.7 Establish policies regarding the retention period for M2M data.
14.8 Improve the quality of master data to support M2M initiatives.
14.9 Secure the SCADA infrastructure from vulnerability to cyber attacks.
These sub-steps are discussed in detail in the rest of this chapter.
With the advent of smartphones, sensors, and RFID-enabled devices, an entirely new class of geolocation-enabled applications is emerging. Geolocation is the identification of the geographic location of a person or object based on the transmission of signals from an RFID-enabled device, such as a smartphone or another similar device. These devices transmit information such as the phone number, current location, and MAC address even when the device is not in use. There are a number of legitimate uses for geolocation data. Indeed, a number of social media companies, such as Foursquare®, would not exist without access to geolocation data.
The big data governance program needs to assess the types of geolocation data that are currently collected by the organization. The following is a short primer on the different types of geolocation infrastructures.
Telecommunication operators divide their coverage territories into areas known as cells. To be able to use a mobile phone or connect to the Internet using 3G communications, the mobile device has to connect to the antenna (base station) that covers that cell. Each cell covers areas of different sizes, depending on interference from structures such as mountains and high buildings. When a mobile device is switched on, the device is linked to a specific base station. The telecom operator continuously registers these links. Every base station has a unique ID and is registered with a specific location. Both the telecom operator and many mobile devices use a technique called triangulation that uses signals from overlapping cells (neighboring base stations) to estimate the position of the mobile device with increased accuracy.
Base station data can be used in innovative ways, such as for the detection of traffic jams. Each road has an average speed for each segment of the day, but when handovers to the next base station take longer than expected, there apparently is a traffic jam. Base station data provides a rough indication of location, but is not very accurate compared to GPS and WiFi data. The accuracy is approximately 50 meters in densely populated city areas, but up to several kilometers in rural areas.
Global Positioning System (GPS) Technology
Smart mobile devices have onboard chipsets with GPS-receivers that determine their location. GPS technology uses a network of United States military satellites. Each one transmits a very precise radio signal. The mobile device can determine its location when the GPS sensor captures at least four of those signals. GPS technology provides accurate positioning, to between four and 15 meters.
WiFi
A relatively new source of geolocation information is the use of WiFi access points. The technology is similar to the use of base stations. They both rely on a unique ID (from the base station or the WiFi access point) that can be detected by a mobile device and sent to a service that has a location for each unique ID.
The unique ID for each WiFi access point is its Medium Access Control (MAC) address. A MAC address is a unique identifier attributed to a network interface. It is usually recorded in hardware such as memory chips, network cards in computers, telephones, laptops, or access points. WiFi access points can be used as a source of geolocation information because they continuously announce their existence.
Radio Frequency Identification (RFID)3
RFID is a technology that allows automatic identification of objects, animals, or people by incorporating a small electronic microchip on its “host.” Data is stored on this chip, which can be read by wireless devices, called RFID readers. The concept is similar to traditional barcodes. A barcode represents information in a condensed format that takes little space and can be read by a machine.
Compared to barcodes, RFID tags are “smarter.” The information on the microchip can be read automatically, at a distance, by another wireless machine. This means RFID is easier to use and more efficient than a barcode; there is no need to pass each individual object, animal, or person in front of a scanner to retrieve the information contained in each tag. Linked to databases and communication networks such as the Internet, RFID tags can detect counterfeit pharmaceuticals, track the lifecycle of dangerous chemicals, identify the location of a container, track retail apparel, locate assets, and sort pallets in a warehouse.
A smart mobile device is very intimately linked to a specific individual. Most people tend to keep their mobile devices very close to themselves, from their pockets or bags to the night tables next to their beds. A person seldom lends such a device to another person. Most people are aware that their mobile devices contain a range of highly intimate information, from emails to private pictures, and from browsing histories to contact lists. All of this information allows the providers of geolocation-based services to gain an intimate overview of habits and patterns of the owner of such a device and build extensive profiles. For example, from a pattern of inactivity at night, the sleeping place can be deduced, and from a regular travel pattern in the morning, the location of an employer can be deduced. The pattern may also include data derived from the movement patterns of friends, based on the so-called “social graph”—a term indicating the visibility of friends on social networking sites and the capacity to deduce behavioral traits from data about those friends. A behavioral pattern may also include special categories of data. For example, it can reveal visits to hospitals and religious places, or presence at political demonstrations. These profiles can be used to take decisions that significantly affect the owner.
At the time this book was published, the United States had a number of conflicting rules and regulations regarding the use of geolocation data from smart devices. The Location Privacy Protection Act of 2011 was introduced to bring some legislative clarity to this murky area. Although the bill has not yet become law as we write this, Case Study 14.1 covers some key aspects that should be addressed by organizations looking to leverage location data from smart devices in the United States. Organizations within the United States and elsewhere would be well-served to establish robust guidelines that account for the local regulatory environment, the risk of lawsuits, and the potential for public embarrassment.
In January 2009, a special report by the Department of Justice revealed that approximately 26,000 persons were victims of GPS stalking annually, including by cell phone. In December 2010, an investigation by The Wall Street Journal revealed that of the top 101 applications for Apple iPhones and Google Android smartphones, 47 disclosed a user’s location to third parties without the user’s consent.5
These events have raised serious concerns among the American public about their location privacy on cell phones and smartphones. Most Americans do not understand that current federal laws allow many of the companies that obtain location information from their customers’ cell phones and smartphones to give that information to almost anyone they please—without their customers’ consent. While the Cable Act and the Communications Act prohibit cable and phone companies offering telephone service from freely disclosing their customers’ whereabouts, an obscure section of the Electronic Communications Privacy Act (ECPA) allows smartphone companies, app companies, and even phone companies offering wireless Internet service to freely share their customers’ location information with third parties without first obtaining their consent.
This legal landscape creates a confusing hodgepodge of regulation. Thus, when a person uses a smartphone to place a phone call to a business, that person’s wireless company cannot disclose his or her location information to third parties without first getting express consent. However, when that same person uses that same phone to look up that business on the Internet, because of ECPA, the wireless company is legally free to disclose his or her location to anyone other than the government.
The Location Privacy Protection Act of 2011 (S. 1223) seeks to close current loopholes in U.S. federal law to require any company that might obtain a customer’s location information from his or her smartphone or other mobile device to do the following:
The bill also includes the following provisions:
Let’s now consider the regulatory environment for the privacy of geolocation data within the European Union. As discussed in Case Study 14.2, the legal framework for the use of geolocation data from smart mobile devices within the European Union is primarily the Data Protection Directive (95/46/EC).
Legal Framework
Legitimate Ground
The big data governance program needs to work with human resources to establish robust policies around the use of geolocation data pertaining to employees. Case Study 14.3 describes the guidelines that govern the use of employee-related geolocation data within the European Union.
RFID data that can be tied to a specific person needs to be treated as personally identifiable information (PII). As a result, organizations need to treat such RFID data with the same care as they would any other PII. In May 2009, the European Commission issued a recommendation that established a requirement to develop a framework so that RFID applications would be subject to a privacy impact assessment (PIA). A PIA is a process whereby a conscious and systematic effort is made to assess the privacy and data protection impact of a specific RFID application, to prevent or at least minimize those impacts. The Article 29 Data Protection Working Party of the European Commission endorsed the PIA framework in February 2011.
Based on these regulatory requirements, an RFID operator in the European Union needs to follow the decision tree depicted in Figure 14.1. A full-scale PIA is required for applications that are determined to be level 2 or level 3. Examples of applications requiring a full-scale PIA include those that process personal information (level 2) or where the RFID tag contains personal data (level 3).
Figure 14.1: A decision tree on whether and at what level of detail to conduct a PIA. (Source: “Privacy and Data Protection Impact Assessment Framework for RFID Applications.” European Union, January 12, 2011.)
As part of the PIA process, the RFID operator needs to identify certain risks that might threaten or compromise personal data. We discuss a few such risks below, in the context of retail and healthcare.
RFID tags can potentially be used to profile and track individuals. Retailers who pass RFID tags onto customers without automatically deactivating or removing them at the checkout might unintentionally enable this risk.
The European Union highlights secret data collection by RFID operators as another privacy risk. An RFID operator might surreptitiously tailor marketing messages to an individual by reading all tags carried by an individual, including tags provided by another merchant. Consider the example of a customer who purchased a pair of shoes at a retail outlet. The shoes carry an RFID tag that was not deactivated when the customer left the store. When the customer walks into another store, it is possible for the merchant to surreptitiously read the RFID and offer a pair of socks at 20 percent off.
A key question, though, is whether the privacy risk is likely, and whether it actually materializes into an undismissable risk. According to European guidelines, retailers should deactivate or remove RFID tags at the point of sale unless consumers, after being informed of the policy, give their consent to keep the tags operational. Retailers are also not required to deactivate or remove tags if the PIA report concludes that tags do not represent a likely threat to privacy or the protection of personal data.
Hospitals
Hospitals have increasingly deployed RFID over the past five years, primarily for tracking assets and patients. Hospitals use RFID to track assets, to manage inventory levels, and to avoid fraud, waste, and abuse. Many hospitals are now also using RFID bracelets to facilitate the treatment of patients. In that case, however, they have to deal with the following privacy issues:
Although no specific legislation has been passed in the United States to address these issues, governments and health care organizations need to explore the appropriate balance between patient health and privacy.
Other types of M2M data can also create significant privacy issues. Case Study 14.4 discusses the privacy framework for smart meters in the European Union. (Chapter 19 includes a primer on smart meters.)
The European Union Article 29 Data Protection Working Party issued opinion 12/2011 on smart metering. It was adopted on April 4, 2011. Some of the key provisions of this opinion are listed here.
Due to the presence of a unique identifier that is tied to a specific property, smart meter readings are considered personal data under the European Data Protection Directive 95/46/EC. Privacy is particularly important because detailed smart meter readings can be used to profile the energy consumption and household patterns of customers.
Utilities must meet one or more of five possible grounds for the processing of personal data relating to smart meters:
Smart meter implementations should have privacy built in at the start, not just in terms of security measures, but also in terms of minimizing the amount of personal data processed. The Working Party states that any data should remain within the household network unless transmission is necessary, or unless the customer consents to the transmission.
The opinion highlights a utility that collects real-time data every 10 to 60 minutes to create load graphs. The load graph is stored inside the meter, with a two-month history, and is collected by the utility only when needed.
Finally, the Working Party recommends privacy impact assessments regarding the use of smart meters.
The Working Party states that smart meter data should be retained only for as long as necessary. For example, utilities might make smart meter readings available to customers so that they can improve their energy efficiency. In this case, the Working Party states that a retention period of 13 months might be suitable to provide year-to-year comparisons, provided the customer has agreed to take advantage of this functionality. However, a shorter retention period would be appropriate for other services. In many instances, it is conceivable that customers could hold much of the data on the smart meter itself.
Smart meter data can also be used to identify suspicious activities, such as indoor marijuana growers who use large amounts of electricity. The Working Party states that the mere fact that such a possibility exists does not automatically legitimize the wide-scale processing of data to identify potential wrongdoers.
Case Study 14.5 discusses the privacy framework for smart meters in California.
The California Public Utility Commission has issued decision 11-07-056, adopting rules to protect the privacy and security of the electricity usage data of utility customers. In March 2012, San Diego Gas & Electric (SDG&E) and the Information and Privacy Commissioner of Ontario, Canada released a white paper entitled “Applying Privacy by Design: Best Practices to SDG&E’s Smart Pricing Program.” It details the best practices to apply privacy by design to the smart meter pricing program at SDG&E.
SDG&E has a chief customer privacy officer as well as a working group that oversees privacy compliance. The chief customer privacy officer is also the vice president of customer services and serves as a member of the executive management team. The chief customer privacy officer is responsible for the completion of privacy impact assessments.
A key feature of SDG&E’s privacy by design program is “privacy by default.” Said differently, SDG&E’s policy is that no action is required by customers, who need to opt-in rather than opt-out of default privacy settings.
The big data governance program has to address a number of biases, such as “The data is coming from machines, so it must be correct.” Here are some examples of data quality and metadata issues relating to M2M data:
RFID readers create large volumes of data that might contain errors, such as duplicates and missed readings. RFID data generally follows a standard such as Application Level Events (ALE). Consider a situation where RFID data shows that a product has been lost. There might be several explanations for this situation. For example, the RFID tag might not be readable from certain angles or in high-moisture environments. Alternatively, the RFID tag itself might have been corrupted.
The big data platform might use streaming technologies to read large quantities of ALE-compliant RFID data that must be de-duplicated in real time. In the case of missed readings, the big data platform can use business rules to determine if the item was missing, or to initiate a workflow that alerts the security system.
An insurance company offers lower rates to automobile policyholders who agree to install sensors on their vehicles that measure factors such as speed. Due to sensor errors, the telematics application registers a car speed of 600 miles per hour.
Electric voltage monitoring registers a measurement of 1,000 volts in a home.
A spike in customer usage confounded the business intelligence team at a telecommunications operator, until granular details revealed that a network switch had erroneously recorded a call with a duration of 20 million minutes.
The marketing team at a cable television provider had this to say, “We use channel-surfing data so that we can understand granular details, such as the shows that were watched by our subscribers and whether they switched channels during commercials. We want to use the data that we receive at our cable headends in different neighborhoods. However, we cannot easily compare this data to the Nielsen data. Nielsen derives its data based on rigorous statistical sampling techniques, but the data from our bi-directional set-top boxes is skewed because these boxes have only been installed in more affluent neighborhoods.”
An application that tracks the location of trucks in a fleet might have to normalize inconsistent GPS data in hours, minutes, and seconds versus degrees.
Two detailed case studies provide additional details about these issues. Case Study 14.6 describes the data quality issues at a public transport awareness solution in a European city.
A European city wanted to better understand the performance of its public transportation network. The city deployed GPS sensors on more than 1,000 buses across its entire fleet. The city’s command center received real-time GPS data at the rate of 3,000 readings per minute, in addition to feeds from more than 200 closed-circuit television sets. By combining this data with geospatial information and streaming analytics, the personnel in the command center were able to monitor the location, status, speed, and predicted time of arrival of the buses in the fleet. As a result, traffic managers were able to answer questions such as these:
The traffic monitoring solution faced some interesting data quality issues, however. Due to inaccuracies introduced into the GPS signal data when roads converged, the system pinpointed several instances where a bus was in a river. The traffic management system addressed these issues with algorithms such as, “If the bus was on the street in road segment 32 and again in road segment 34, then the fact that it is in the river in road segment 33 is probably due to inaccuracies in the quality of GPS data.”
Case Study 14.7 describes the data quality issues relating to the calculation of electricity outages in Italy.
The Italian Electrical Authority has issued decree number 333/07 to increase the national quality of electricity service, in terms of voltage quality and continuity of service. As a result, Italian electricity distribution companies are subject to incentives and penalties based on the duration of interruptions lasting more than one second.
It’s necessary to understand a few specific elements of the utility network before delving into further details:
Utilities have to deal with these issues around governing meter data relating to their outages for regulatory compliance:
The European Union Article 29 Data Protection Working Party states that providers of geolocation applications or services should implement retention policies that ensure that geolocation data, or profiles derived from such data, are deleted after a “justified” period of time. Chapter 12, on managing the lifecycle of big data, discusses this topic in more detail.
M2M data initiatives also depend on high-quality master data. Case Study 14.8 describes the impact of inconsistent asset nomenclature on the preventive maintenance program at a railroad. The case study also addresses other concepts, including data quality, metadata, and information lifecycle management.
Figure 14.2 describes a simple process for advanced condition monitoring at a railroad.

Figure 14.2: The process for advanced condition monitoring at a railroad.
These processes are described below:8
Sensors on a modern train record more than 1,000 different types of mechanical and electrical events. These include operational events such as “opening door” or “train is braking,” warning events such as “line voltage frequency is out of range” or “compression is low in compressor X,” and failure events such as “pantograph is out of order” or “inverter lockout.”
The data analysis team then determines events that are highly correlated with preceding events. Consider an example where failure event 1245 is preceded by warning event 2389 in 90 percent of the cases. In that example, the operations team needs to issue a work order for preventive maintenance whenever warning event 2389 is logged in the system.
The operations department conducts preventive maintenance to reduce the need for emergency repairs and to keep the trains running smoothly.
The railroad had to deal with the following big data governance issues:
The railroad had different trains in its fleet from different manufacturers. As a result, sensors on different trains often generated different numerical codes for the same event. For example, the failure event “pantograph out of order” would generate code A3785 on one train, and code A7865 on another. The analytics team had to standardize the sensor events across the different trains before further analysis.
Because the service process triggered sensors in ways that did not reflect the actual behavior of the trains, the analytics team had to eliminate data that was recorded while the trains were in a repair shop. The analytics team combined the GPS data from the trains with the pre-existing geolocation data about the railroad’s repair shops to eliminate these false positive readings.
If a particular part failed on one train, the operations department wanted to inspect similar parts on other trains. However, that was difficult when the same part might be named differently across trains.
Retention of sensor data is driven by business and regulatory requirements. From a business standpoint, the railroad might need to review data over several months to discern trends regarding equipment failure. On the other hand, local regulations also govern the retention period for sensor data. For example, the United States Federal Railroad Administration has issued Rule 49 CFR Part 229, requiring that locomotive event recorders (similar to flight safety recorders) be fitted on trains operating above 30 miles per hour. The regulations require that locomotive event recorders store the last 48 hours of safety-critical event data.
Next, let’s consider RFID data moving through a manufacturer’s supply chain. Figure 14.3 provides an example of RFID data relating to pharmaceuticals that move through a manufacturer’s supply chain. The RFID tag on a pallet might include information such as the product name and identifier. The product’s RFID tag is scanned as it moves through the supply chain. When the RFID tag is scanned at each location along the supply chain, the product record is updated with location-specific data, such as the address and temperature.
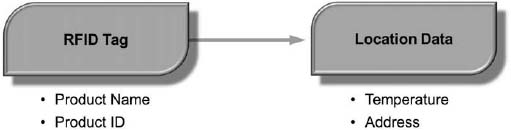
Figure 14.3: RFID data relating to pharmaceuticals.
The enterprise might use this RFID data to answer the following questions:
The supply chain depends on consistent master data relating to materials. All points in the supply chain need to work off consistent master data relating to product name, identifier, and temperature requirements.
Supervisory Control and Data Acquisition (SCADA) are computer systems that monitor and control industrial, infrastructure, and facility-based processes. They are used in processes such as the following:9
SCADA systems have become increasingly vulnerable to cyber attacks, due to open standards and increasing interconnectivity with the Internet. Case Study 14.9 discusses the Stuxnet worm that hit Siemens SCADA systems.
In June 2010, researchers discovered a worm, called Stuxnet, in SCADA systems from Siemens at 14 plants in Iran. The worm was designed to steal industrial secrets and to disrupt operations. The worm leveraged a previously unknown Windows® vulnerability that has since been fixed.
Once installed on a computer, Stuxnet was designed to use Siemens’ default passwords to gain access to systems that run WinCC and PCS7 programs—programmable logic controller (PLC) programs that manage large-scale industrial systems on factory floors, military installations, and chemical plants. The Stuxnet worm was designed to allow the attackers to reprogram the way a system works, with potentially disastrous consequences. However, experts believe that Stuxnet caused minimal damage before it was discovered.
The big data governance program needs to assess the vulnerabilities of the SCADA systems and implement the appropriate security measures. Case Study 14.10 discusses how utilities need to improve the security of the smart grid.
Because smart grids use the Internet Protocol (IP) and other open standards for operations, they need to be secured at multiple points. To address the diverse threats to the smart grid, the security architecture team must perform an assessment to identify Information and Communications Technology (ICT) security vulnerabilities and risks. To be successful, all utility business units and support organizations must participate, allowing access to their ICT infrastructure and providing the transparency needed to uncover all known and potential security attack vectors.
Each security assessment must also consider evolving legal and regulatory security requirements. For example, utilities in the United States need to prove compliance with the North American Electricity Reliability Corporation Critical Infrastructure Protection (NERC-CIP) regulations regarding critical security measures relating to the electric grid. The NERC-CIP regulations call out a set of documents that must be created and actively maintained, and produced when requested by NERC. To comply with NERC-CIP regulations, the big data governance program needs to identify the critical assets that must be monitored and protected from outside intrusions, and establish records retention periods for specific documents and plans.
We conclude this chapter with Case Study 14.11, which discusses the governance of sensor data within the oil and gas industry.
Figure 14.4 describes a simple process to manage oilfield sensor data, including key activities and milestones. Table 14.1 provides an overall description of these milestones and activities.

Figure 14.4: The process for monitoring oilfield sensor data.
| Table 14.1: Key Milestones and Activities to Manage Oilfield Sensor Data | ||
| Seq. | Milestone/Activity | Description |
| 1.1 | Sensors installed | Oil and gas companies install sensors on facilities as well as the seabed to monitor production, the state of the facility, health and safety, and adherence to environmental regulations. The sensor control systems typically support the OPC protocol, a standard that specifi es the communication of real-time plant data between SCADA systems from different manufacturers. |
| 1.1 | Install sensors on facility | The modern oil facility might have more than 30,000 sensors that capture numerous types of real-time data from the exploration process such as flows, revolutions per minute (RPM), voltage, watts, temperature, and pressure. |
| 1.2 | Install sensors on seabed | Companies might also install sensors on the seabed to monitor environmental conditions such as flow, temperature, and turbidity. Turbidity is a measurement of water quality based on the cloudiness of water caused by individual particles that might not be visible to the naked eye. |
| 2. | Production monitored | Organizations need to monitor production of oil and gas. The oil company, acting as the operator, also calculates the production allocation to each owner of the facility. |
| 2.1 | Monitor production at facility | Operators install sensors to monitor oil and gas production at each facility. |
| 2.2 | Create production dashboards | Oil and gas companies also create dashboards to monitor energy production across facilities. Oil and gas companies create common operations centers so that they can monitor production from a central location. |
| 3. | Equipment monitored | Facilities use sensors to monitor equipment. |
| 3.1 | Monitor equipment on facility | Operations departments monitor equipment such as pumps and valves on each rig. Typical questions include the following:12 • “Given a brand of turbine, what is the expected time to failure when the equipment starts to vibrate in the manner now detected?” • “Given an alarm on a well, how much time do we have to take corrective action, based on the historical behavior of the well?” • “How do we detect weather events from the observation data?” • “Which sensors have observed a blizzard within a 100-mile radius of a given location?” |
| 3.2 | Conduct preventive maintenance | Operators conduct preventive maintenance if their predictive models indicate that a particular piece of equipment is likely to fail. |
| 4. | Environment monitored | Oil and gas companies use sensors to monitor the environment. |
| 4.1 | Monitor environment on seabed around facility | Environmental sensors may be in operation before, during, and after the operating life of the platform. |
| 4.2 | Monitor environmental pollution over time | Companies need to answer questions such as, “Do the levels of salinity and turbidity in the water around the facility indicate an oil spill?” |
Table 14.2 summarizes the key big data governance policies associated with managing oilfield sensor data.
| Table 14.2: Key Big Data Governance Policies Relating to Oilfield Sensors | ||
| Seq. | Milestone/ Activity | Big Data Governance Policy |
| 1.1 | Install sensors on facility | The big data governance program should ensure that the SCADA systems are properly secured against the possibility of cyber attacks. |
| 2.2 | Create production dashboards | The big data governance program needs to ensure consistency of the business terms within production reports. As discussed in Case Study 6.2 in chapter 6, the program needs to establish consistent definitions for key business terms such as “well,” in addition to associated child terms such as “well origin,” “well completion,” “wellbore,” and “wellbore completion.”The big data governance program should leverage standard models such as the Professional Petroleum Data Management (PPDM) Association model for well data and definitions. |
| 3.1 | Monitor equipment on facility | In the past, a rig might have had only about 1,000 sensors, of which only about 10 fed databases that would be purged every two weeks due to capacity limitations. Today, oil and gas companies need to retain sensor data for a much longer period. For example, the HSE (health, safety, and environment) department might need to recreate a picture using three-month old information to explain why a particular decision was made in the field.The big data governance program should leverage standard models such as ISO 15926 for systems and equipment on oil and gas production facilities, and associated definitions. The big data governance program also needs to play a key role in determining how much information needs to be retained, and for how long, to satisfy both internal needs and the regulators. It is important to note that the rig might generate a lot of unstructured information, such as video, pictures, and sound. |
| 3.2 | Conduct preventive maintenance |
If a specific type of equipment failed on one rig, the oil company needs to quickly pinpoint where else the same equipment has been deployed so that it can initiate the appropriate preventive maintenance. However, if the same asset has different names on different rigs, it will be difficult to locate the asset in a timely manner. As a result, big data governance has a critical role to ensure consistent naming and nomenclature for asset data.The Institute of Asset Management and the British Standards Institute have worked together to develop strategies to help reduce risks to business-critical assets. This project resulted in the Publicly Available Specification (PAS) 55, which embodies the latest thinking in terms of best practices in asset management systems. Oil and gas companies are increasingly adopting PAS 55 as the industry standard for quality asset management. |
| 4.1 | Monitor environment on seabed around facility |
As discussed earlier, oil exploration and production activities generate a lot of structured and unstructured environmental information. This information needs to be maintained well after the lifetime of the facility itself, to demonstrate adherence to environmental regulations. This information might need to be stored for 50 to 70 years, or even up to 100 years in some cases.While storage is cheap, it is not free. The big data governance program needs to establish retention schedules for specific types of information and establish the appropriate archiving policies to move information onto cheaper storage, if possible. |
M2M data includes information from RFID tags, smart meters, and sensors. M2M data needs to be governed based on best practices relating to organization, metadata, privacy, data quality, business process integration, master data integration, and information lifecycle management.

1. http://en.wikipedia.org/wiki/Machine-to-Machine#cite_note-4.
2. This section includes content from “Opinion 13/2011 on Geolocation services on smart mobile devices,” European Union Article 29, Data Protection Working Party.
3. http://ec.europa.eu/information_society/policy/rfid/about_rfid/index_en.htm.
4. This section includes content from “Opinion 13/2011 on Geolocation services on smart mobile devices,” European Union Article 29, Data Protection Working Party.
5. Thurm, Scott and Kane, Yukari Iwatani. “Your Apps are Watching You.” The Wall Street Journal, December 17, 2010.
6. This section includes content from the “Privacy and Data Protection Impact Assessment Framework for RFID Applications,” European Union, January 12, 2011.
7. De Angelis, Marco. “Guidelines for Proper Data Collection about Electric Outage Quality of Service: Automated Meter Management.” IBM, 2011.
8. Fiammante, Marc and Neuvéglise, Grégory. “Modeling Trains with SPSS.” IBM Data Management Magazine, July 15, 2011.
9. http://en.wikipedia.org/wiki/SCADA.
10. McMillan, Robert. “Siemens: Stuxnet worm hit industrial systems.” IDG News Service, September 15, 2010.http://www.pcworld.idg.com.au/article/360645/siemens_stuxnet_worm_hit_industrial_systems/.
11. “Smart Grid Reference Architecture.” SCE-Cisco-IBM SGRA, March 31, 2011.
12. Della Valle, Emanuele and Carenini, Alessio. “Supporting Environmental Information Systems and Services Realization with the Geospatial and Streaming Dimensions of the Semantic Web.” Workshop at EnviroInfo2010. http://ceur-ws.org/Vol-679/paper9.pdf