Hadoop offers a great deal of potential in enabling enterprises to harness the data that was, until now, difficult to manage and analyze. Specifically, Hadoop makes it possible to process extremely large volumes of data with varying structures (or no structure at all). That said, with all the promise of Ha-doop, it’s still a relatively young technology. The Apache Hadoop top-level project was started in 2006, and although adoption rates are increasing—along with the number of open source code contributors—Hadoop still has a number of known shortcomings (in fairness, it’s not even at version 1.0 yet). From an enterprise perspective, these shortcomings could either prevent companies from using Hadoop in a production setting, or impede its adoption, because certain operational qualities are always expected in production, such as performance, administrative capabilities, and robustness. For example, as we discussed in Chapter 4, the Hadoop Distributed File System (HDFS) has a centralized metadata store (referred to as the NameNode), which represents a single point of failure (SPOF) without availability (a cold standby is added in version 0.21). When the NameNode is recovered, it can take a long time to get the Hadoop cluster running again, because the metadata it tracks has to be loaded into the NameNode’s memory structures, which all need to be rebuilt and repopulated. In addition, Hadoop can be complex to install, configure, and administer, and there isn’t yet a significant number of people with Hadoop skills. Similarly, there is a limited pool of developers who have MapReduce skills. Programming traditional analytic algorithms (such as statistical or text analysis) to work in Hadoop is difficult, and it requires analysts to become skilled Java programmers with the ability to apply MapReduce techniques to their analytics algorithms. (Higher level languages, such as Pig and Jaql, make MapReduce programming easier, but still have a learning curve.) There’s more, but you get the point: not only is Hadoop in need of some enterprise hardening, but also tools and features that help round out the possibilities of what the Hadoop platform offers (for example, visualization, text analytics, and graphical administration tools).
IBM InfoSphere BigInsights (BigInsights) addresses all of these issues, and more, through IBM’s focus on two primary product goals:
• Deliver a Hadoop platform that’s hardened for enterprise use with deep consideration for high availability, scalability, performance, ease-of-use, and other things you’ve come to expect from any solution you’ll deploy in your enterprise.
• Flatten the time-to-value curve associated with Big Data analytics by providing the development and runtime environments for developers to build advanced analytical applications, and providing tools for business users to analyze Big Data.
In this chapter, we’ll talk about how IBM readies Hadoop for enterprise usage. As you can imagine, IBM has a long history of understanding enterprise needs. By embracing new technologies such as Hadoop (and its open source ecosystem) and extending them with the deep experience and intellectual capital that IBM has built over its century of existence, you gain a winning combination that lets you explore Hadoop with a platform you can trust that also yields results more quickly.
The BigInsights installer was designed with simplicity in mind. IBM’s development teams asked themselves, “How can IBM cut the time-to-Hadoop curve without the effort and technical skills normally required to get open source software up and running?” They answered this question with the BigInsights installer.
The main objective of the BigInsights installer is to insulate you from complexity. As such, you don’t need to worry about software prerequisites or determining which Apache Hadoop components to download, the configuration between these components, and the overall setup of the Hadoop cluster. The BigInsights installer does all of this for you, and all you need to do is click a button. Hadoop startup complexity is all but eliminated with BigInsights. Quite simply, your experience is going to be much like installing any commercial software.
To prepare for the writing of this book, we created three different Hadoop clusters:
• One from scratch, using just open source software, which we call the roll your own (RYO) Hadoop approach
• One from a competitor who solely offers an installation program, some operational tooling, and a Hadoop support contract
• One with BigInsights
The “roll your own” Hadoop approach had us going directly to the Apache web site and downloading the Hadoop projects, which ended up involving a lot of work. Specifically, we had to do the following:
1. Choose which Hadoop components, and which versions of those components, to download. We found many components, and it wasn’t immediately obvious to us which ones we needed in order to start our implementation, so that required some preliminary research.
2. Create and set up a Hadoop user account.
3. Download each of the Hadoop components we decided we needed and install them on our cluster of machines.
4. Configure Secure Shell (SSH) for the Hadoop user account, and copy the keys to each machine in the cluster.
5. Configure Hadoop to define how we wanted it to run; for example, we specified I/O settings, JobTracker, and TaskTracker-level details.
6. Configure HDFS—specifically, we set up and formatted the NameNode and Secondary NameNode.
7. Define all of the global variables (for example, HADOOP_CLASSPATH, HADOOP_PID_DIR, HADOOP_HEAPSIZE, JAVA_HOME).
As you can imagine, getting the Hadoop cluster up and running from the open source components was complex and somewhat laborious. We got through it, but with some effort. Then again, we have an army of experienced Hadoop developers ready to answer questions. If you’re taking the RYO route, you’ll need a good understanding of the whole Hadoop ecosystem, along with basic Hadoop administration and configuration skills. You need to do all this before you can even begin to think about running simple MapReduce jobs, let alone running any kind of meaningful analytics applications.
Next, we tried installing a competitor’s Hadoop distribution (notice it’s a distribution, not a platform like BigInsights). This competitor’s installation did indeed represent an improvement over the no-frills open source approach because it has a nifty graphical installer. However, it doesn’t install and configure additional Hadoop ecosystem components such as Pig, Hive, and Flume, among others, which you need to install manually.
These two experiences stand in contrast to the BigInsights approach of simply laying down and configuring the entire set of required components using a single installer. With BigInsights, installation requires only a few button clicks, eliminating any worry about all the Hadoop-related components and versions. Very little configuration is needed and no extra prerequisites need to be downloaded. What’s more, you can use IBM’s installation program to graphically build a response file, which you can subsequently use to deploy BigInsights on all the nodes in your cluster in an automated fashion.
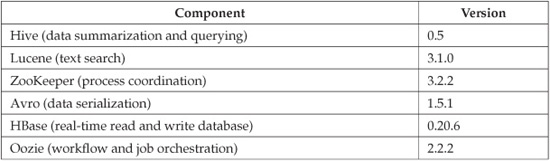
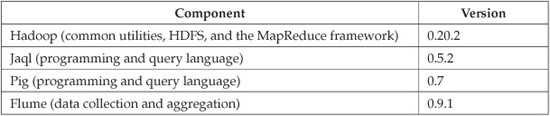
BigInsights features Apache Hadoop and its related open source projects as a core component. IBM remains committed to the integrity of the open source projects, and will not fork or otherwise deviate from their code. The following table lists the open source projects (and their versions) included in BigInsights 1.2, which was the most current version available at the time of writing:
With each release of BigInsights, updates to the open source components and IBM components go through a series of testing cycles to ensure that they work together. That’s another pretty special point we want to clarify: You can’t just drop new code into production. Some backward-compatibility issues are always present in our experience with open source projects. BigInsights takes away all of the risk and guesswork for your Hadoop components. It goes through the same rigorous regression and quality assurance testing processes used for other IBM software. So ask yourself this: Would you rather be your own systems integrator, testing all of the Hadoop components repeatedly to ensure compatibility? Or would you rather let IBM find a stable stack that you can deploy and be assured of a reliable working environment?
Finally, the BigInsights installer also lays down additional infrastructure, including analytics tooling and components that provide enterprise stability and quality to Hadoop, which is what makes BigInsights a platform instead of a distribution. We’ll discuss those in the remainder of this chapter.
The General Parallel File System (GPFS) was developed by IBM Research in the 1990s for High-Performance Computing (HPC) applications. Since its first release in 1998, GPFS has been used in many of the world’s fastest supercomputers, including Blue Gene, Watson (the Jeopardy! supercomputer), and ASC Purple. (The GPFS installation in the ASC Purple supercomputer supported data throughput at a staggering 120 GB per second!) In addition to HPC, GPFS is commonly found in thousands of other mission-critical installations worldwide. GPFS is also the file system that’s part of DB2 pureScale and is even found standing up many Oracle RAC installations; you’ll also find GPFS underpinning highly scalable web and file servers, other databases, applications in the finance and engineering sectors, and more. Needless to say, GPFS has earned an enterprise-grade reputation and pedigree for extreme scalability, high performance, and reliability.
One barrier to the widespread adoption of Hadoop in some enterprises today is HDFS. It’s a relatively new file system with some design-oriented limitations. The principles guiding the development of HDFS were defined by use cases, which assumed Hadoop workloads would involve sequential reads of very large file sets (and no random writes to files already in the cluster—just append writes). In contrast, GPFS has been designed for a wide variety of workloads and for a multitude of uses, which we’ll talk about in this section.
GPFS was originally available only as a storage area network (SAN) file system, which isn’t suitable for a Hadoop cluster since these clusters use locally attached disks. The reason why SAN technology isn’t optimal for Hadoop is because MapReduce jobs perform better when data is stored on the node where it’s processed (which requires locality awareness for the data). In a SAN, the location of the data is transparent, which results in a high degree of network bandwidth and disk I/O, especially in clusters with many nodes.
In 2009, IBM extended GPFS to work with Hadoop with GPFS-SNC (Shared Nothing Cluster). The following are the key additions IBM made to GPFS that allows it to be a suitable file system for Hadoop, thereby hardening Hadoop for the enterprise:
• Locality awareness A key feature of Hadoop is that it strives to process data at the node where the data is stored. This minimizes network traffic and improves performance. To support this, GPFS-SNC provides location information for all files stored in the cluster. The Hadoop JobTracker uses this location information to pick a replica that is local to the task that needs to be run, which helps increase performance.
• Meta-blocks The typical GPFS block size is 256 KB, while in a Hadoop cluster, the block size is much larger. For instance, recommended block size for BigInsights is 128 MB. In GPFS-SNC, a collection of many standard GPFS blocks are put together to create the concept of a meta-block. Individual map tasks execute against meta-blocks, while file operations outside Hadoop will still use the normal smaller block size, which is more efficient for other kinds of applications. This flexibility enables a variety of applications to work on the same cluster, while maintaining optimal performance. HDFS doesn’t share these benefits, as its storage is restricted to Hadoop and Hadoop alone. For example, you can’t host a Lucene text index on HDFS. In GPFS-SNC, however, you can store a Lucene text index alongside the text data in your cluster (this co-location has performance benefits). Although Lucene uses the GPFS block size of 256 KB for its operations, any Hadoop data is stored in the cluster and read in meta-blocks.
• Write affinity and configurable replication GPFS-SNC allows you to define a placement strategy for your files, including the approach taken during file replication. The normal replication policy is for the first copy to be local, the second copy to be local to the rack (which is different than HDFS), and the third copy to be striped across other racks in the cluster. GPFS-SNC lets you customize this replication strategy. For instance, you might decide that a specific set of files should always be stored together to allow an application to access the data from the same location. This is something you can’t do in HDFS, which can lead to higher performance for specific workloads such as large sequential reads. The strategy for the second replica could also be to keep this same data together. In case the primary node fails, it would be easy to switch to another node without seeing any degradation in application performance. The third copy of the data is typically stored striped, in case one of the first two copies must be rebuilt. Restoring files is much faster to do when files are striped. In HDFS, there is no data striping, and you cannot customize write affinity or replication behavior (except to change the replication factor).
• Configurable recovery policy When a disk fails, any files with lost blocks become under-replicated. GPFS-SNC will automatically copy the missing files in the cluster to maintain the replication level. GPFS-SNC lets you customize the policy of what to do in the event of a disk failure. For example, one approach could be to restripe the disk when a failure occurs. Since one of the replicated copies of a file is typically striped, the rebuilding of missing blocks is very fast as reads are done in parallel. Alternatively, you could specify a policy to rebuild the disk—perhaps, for example, when the disk is replaced. These recovery policies don’t need to be automatic; you could decide to use manual recovery in the case of a maintenance task, such as swapping a set of disks or nodes. You could also configure recovery to work incrementally. For example, if a disk was offline and was brought online later, GPFS-SNC knows to copy only its missing blocks, as it maintains the list of files on each disk. In HDFS, the NameNode will initiate replication for files that are under-replicated, but recovery is not customizable.
All of the characteristics that make GPFS the file system of choice for large-scale mission-critical IT installations are applicable to GPFS-SNC. After all, this is still GPFS, but with the Hadoop-friendly extensions. You get the same stability, flexibility, and performance in GPFS-SNC, as well as all of the utilities that you’re used to. GPFS-SNC also provides hierarchical storage management (HSM) capabilities, where it can manage and use disk drives with different retrieval speeds efficiently. This enables you to manage multi-temperature data, keeping your hot data on your best performing hardware. HDFS doesn’t have this ability.
GPFS-SNC is such a game changer that it won the prestigious Supercom-puting Storage Challenge award in 2010 for being the “most innovative storage solution” submitted to this competition.
GPFS-SNC is a distributed storage cluster with a shared-nothing architecture. There is no central store for metadata because it’s shared across multiple nodes in the cluster. Additionally, file system management tasks are distributed between the data nodes in the cluster, such that if a failure occurs, replacement nodes are nominated to assume these tasks automatically.
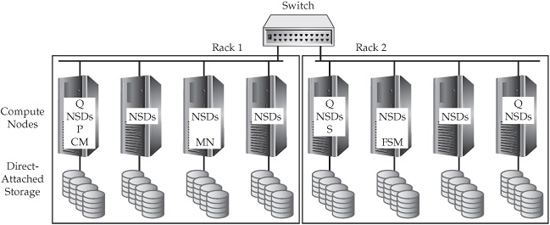
As you can see in Figure 5-1, a GPFS-SNC cluster consists of multiple racks of commodity hardware, where the storage is attached to the compute nodes. If you’re familiar with HDFS, you’ll notice that Figure 5-1 doesn’t include a NameNode, a Secondary NameNode, or anything that acts as a centralized metadata store. This is a significant benefit of GPFS-SNC over HDFS.
The cluster design in Figure 5-1 is a simple example and assumes that each compute node has the same CPU, RAM, and storage specifications (in reality there might be hardware differences with the Quorum Nodes and Primary Cluster Configuration Server to harden them so that they are less likely to undergo an outage). To ensure smooth management of the cluster, different compute nodes in a GPFS-SNC cluster assume different management roles, which deserve some discussion.
Figure 5-1 An example of a GPFS-SNC cluster
The figure shows that each compute node in a GPFS-SNC cluster has a Network Shared Disk (NSD) server service that can access the local disks. When one node in a GPFS-SNC cluster needs to access data on a different node, the request goes through the NSD server. As such, NSD servers help move data between the nodes in the cluster.
A Quorum Node (Q) works together with other Quorum Nodes in a GPFS-SNC cluster to determine whether the cluster is running and available for incoming client requests. A Quorum Node is also used to ensure data consistency across a cluster in the event of a node failure. A cluster administrator designates the Quorum Node service to a selected set of nodes during cluster creation or while adding nodes to the cluster. Typically, you’ll find one Quorum Node per rack, with the maximum recommended number of Quorum Nodes being seven. When setting up a GPFS-SNC cluster, an administrator should define an odd number of nodes and, if you don’t have a homogeneous cluster, assign the Quorum Node role to a machine that is least likely to fail. If one of the Quorum Nodes is lost, the remaining Quorum Nodes will talk to each other to verify that quorum is still intact.
There’s a single Cluster Manager (CM) node per GPFS-SNC cluster, and it’s selected by the Quorum Nodes (as opposed to being designated by the cluster administrator). The Cluster Manager determines quorum, manages disk leases, detects failures, manages recovery, and selects the File System Manager Node. If the Cluster Manager node fails, the Quorum Nodes immediately detect the outage and designate a replacement.
A GPFS-SNC cluster also has a Primary Cluster Configuration Server (P), which is used to maintain the cluster’s configuration files (this role is designated to a single node during cluster creation). If this node goes down, automated recovery protocols are engaged to designate another node to assume this responsibility. The Secondary Configuration Server (S) is optional, but we highly recommend that production clusters include one because it removes an SPOF in the GPFS-SNC cluster by taking over the Primary Cluster Configuration Server role in the event of a failure. If the Primary Cluster Configuration Server and the Secondary Cluster Configuration Server both fail, the cluster configuration data will still be intact (since cluster configuration data is replicated on all nodes), but manual intervention will be required to revive the cluster.
Each GPFS-SNC cluster has one or more File System Manager (FSM) nodes that are chosen dynamically by the Cluster Manager node (although a cluster administrator can define a pool of available nodes for this role). The File System Manager is responsible for file system configuration, usage, disk space allocation, and quota management. This node can have higher memory and CPU demands than other nodes in the cluster; generally, we recommend that larger GPFS-SNC clusters have multiple File System Managers.
The final service in Figure 5-1 is the Metanode (MN). There’s a Metanode for each open file in a GPFS-SNC cluster, and it’s responsible for maintaining file metadata integrity. In almost all cases, the Metanode service will run on the node where the particular file was open for the longest continuous period of time. All nodes accessing a file can read and write data directly, but updates to metadata are written only by the Metanode. The Metanode for each file is independent of that for any other file, and can move to any node to meet application requirements.
A Failure Group is defined as a set of disks that share a common point of failure that could cause them all to become unavailable at the same time. For example, all the disks in an individual node in a cluster form a failure group, because if this node fails, all disks in the node immediately become unavailable. The GPFS-SNC approach to replication reflects the concept of a Failure Group, as the cluster will ensure that there is a copy of each block of replicated data and metadata on disks belonging to different failure groups. Should a set of disks become unavailable, GPFS-SNC will retrieve the data from the other replicated locations.
If you select the GPFS-SNC component for installation, the BigInsights graphical installer will handle the creation and configuration of the GPFS-SNC cluster for you. The installer prompts you for input on the nodes where it should assign the Cluster Manager and Quorum Node services. This installation approach uses default configurations that are typical for BigIn-sights workloads. GPFS-SNC is highly customizable, so for specialized installations, you can install and configure it outside of the graphical installer by modifying the template scripts and configuration files (although some customization is available within the installer itself).
Regardless of whether you’re using GPFS-SNC or HDFS for your cluster, the Hadoop MapReduce framework is running on top of the file system layer. A running Hadoop cluster depends on the TaskTracker and JobTracker services, which run on the GPFS-SNC or HDFS storage layers to support MapReduce workloads. Although these servers are not specific to the file system layer, they do represent an SPOF in a Hadoop cluster. This is because if the JobTracker node fails, all executing jobs fail as well; however, this kind of failure is rare and is easily recoverable. A NameNode failure in HDFS is far more serious and has the potential to result in data loss if its disks are corrupted and not backed up. In addition, for clusters with many terabytes of storage, restarting the NameNode can take hours, as the cluster’s metadata needs to be fetched from disk and read into memory, and all the changes from the previous checkpoint must be replayed. In the case of GPFS-SNC, there is no need for a NameNode (it is solely an HDFS component).
Different kinds of failures can occur in a cluster, and we describe how GPFS-SNC handles each of these failure scenarios:
• Cluster Manager Failure When the Cluster Manager fails, Quorum Nodes detect this condition and will elect a new Cluster Manager (from the pool of Quorum Nodes). Cluster operations will continue with a very small interruption in overall cluster performance.
• File System Manager Node Failure Quorum Nodes detect this condition and ask the Cluster Manager to pick a new File System Manager Node from among any of the nodes in the cluster. This kind of failure results in a very small interruption in overall cluster performance.
• Secondary Cluster Configuration Server Failure Quorum Nodes will detect the failure, but the cluster administrator will be required to designate a new node manually as the Secondary Cluster Configuration Server. Cluster operations will continue even if this node is in a failure state, but some administrative commands that require both the primary and secondary servers might not work.
• Rack Failure The remaining Quorum Nodes will decide which part of the cluster is still operational and which nodes went down with it. If the Cluster Manager was on the rack that went down, Quorum Nodes will elect a new Cluster Manager in the healthy part of the cluster. Similarly, the Cluster Manager will pick a File System Manager Node in case the old one was on the failed rack. The cluster will employ standard recovery strategies for each of the individual data nodes lost on the failed rack.
A significant architectural difference between GPFS-SNC and HDFS is that GPFS-SNC is a kernel-level file system, while HDFS runs on top of the operating system. As a result, HDFS inherently has a number of restrictions and inefficiencies. Most of these limitations stem from the fact that HDFS is not fully POSIX-compliant. On the other hand, GPFS-SNC is 100 percent POSIX-compliant. This makes your Hadoop cluster more stable, more secure, and more flexible.
Files stored in GPFS-SNC are visible to all applications, just like any other files stored on a computer. For instance, when copying files, any authorized user can use traditional operating system commands to list, copy, and move files in GPFS-SNC. This isn’t the case in HDFS, where users need to log into Hadoop to see the files in the cluster. In addition, if you want to perform any file manipulations in HDFS, you need to understand how the Hadoop command shell environment works and know specific Hadoop file system commands. All of this results in extra training for IT staff. Experienced administrators can get used to it, but it’s a learning curve nevertheless. As for replication or backups, the only mechanism available for HDFS is to copy files manually through the Hadoop command shell.
The full POSIX compliance of BigInsights’ GPFS-SNC enables you to manage your Hadoop storage just as you would any other computer in your IT environment. That’s going to give you economies of scale when it comes to building Hadoop skills and just making life easier. For example, your traditional file administration utilities will work, as will your backup and restore tooling and procedures. GPFS-SNC will actually extend your backup capabilities as it includes point-in-time (PiT) snapshot backup, off-site replication, and other utilities.
With GPFS-SNC, other applications can even share the same storage resources with Hadoop. This is not possible in HDFS, where you need to define disk space dedicated to the Hadoop cluster up front. Not only must you estimate how much data you need to store in HDFS, but you must also guess how much storage you’ll need for the output of MapReduce jobs, which can vary widely by workload; don’t forget you need to account for space that will be taken up by log files created by the Hadoop system too! With GPFS-SNC, you only need to worry about the disks themselves filling up; there is no need to dedicate storage for Hadoop.
An added benefit of GPFS-SNC’s POSIX compliance is that it gives your MapReduce applications—or any other application, for that matter—the ability to update existing files in the cluster without simply appending to them. In addition, GPFS-SNC enables multiple applications to concurrently write to the same file in the Hadoop cluster. Again, neither of these capabilities is possible with HDFS, and these file-write restrictions limit what HDFS can do for your Big Data ecosystem. For example, BigIndex, or a Lucene text index (which is an important component for any kind of meaningful text processing and analytics), can readily be used in GPFS-SNC. As we discussed before, you are using HDFS, Lucene needs to maintain its indexes in the local file system, and not in HDFS, because Lucene needs to update existing files continually, and all of this (you guessed it) adds complexity and performance overhead.
As previously mentioned, unlike HDFS, GPFS-SNC is a kernel-level file system, which means it can take advantage of operating system–level security. Extended permissions through POSIX Access Control Lists (ACLs) are also possible, which enables fine-grained user-specific permissions that just aren’t possible in HDFS.
With the current Hadoop release (0.20 as of the time this book was written), HDFS is not aware of operating system–level security, which means anyone with access to the cluster can read its data. Although Hadoop 0.21 and 0.22 will integrate security capabilities into HDFS (which will require users to be authenticated and authorized to use the cluster), this new security model is more complex to administer and is less flexible than what’s offered in GPFS-SNC. (We talk more about security later in this chapter.)
The initial purpose for GPFS was to be a storage system for high-performance supercomputers. With this high-performance lineage, GPFS-SNC has three key features that give it the flexibility and power that enable it to consistently outperform HDFS.
The first feature is data striping. In GPFS-SNC, the cluster stripes and mirrors everything (SAME) so data is striped across the disks in the cluster. The striping enables sequential reads to be faster than when performed on HDFS because this data can be read and processed in parallel. This greatly aids operations such as sorts, which require high sequential throughputs. In HDFS, the files are replicated across the cluster according to the replication factor, but there is no striping of individual blocks across multiple disks.
Another performance booster for GPFS-SNC is distributed metadata. In GPFS-SNC, file metadata is distributed across the cluster, which improves the performance of workloads with many random block reads. In HDFS, metadata is stored centrally on the NameNode, which is not only a single point of failure, but also a performance bottleneck for random access workloads.
Random access workloads in a GPFS-SNC cluster get an additional performance boost because of client-side caching. There’s just no caching like this in HDFS. Good random access performance is important for Hadoop workloads, in spite of the underlying design, which favors sequential access. For example, exploratory analysis activities with Pig and Jaql applications benefit greatly from good random I/O performance.
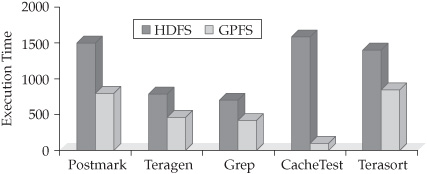
Figure 5-2 Performance benchmark comparing GPFS to HDFS
IBM Research performed benchmark testing of GPFS-SNC and HDFS using standard Hadoop workloads on the same clusters (one with GPFS-SNC and one running HDFS). The impressive performance boost (and our lawyers wouldn’t let us go to print without this standard disclaimer: your results may vary) is shown in Figure 5-2.
As you can see, GPFS-SNC gives a significant performance boost for Ha-doop workloads, when compared to the default HDFS file system. With these results, and within our own internal tests, we estimated that a 10-node Hadoop cluster running on GPFS-SNC will perform at the same level as a Hadoop cluster running on HDFS with approximately 16 of the same nodes.
We’ve spent a lot of time detailing all of the benefits that GPFS-SNC provides a Hadoop cluster because of their importance. These benefits showcase how IBM’s assets, experiences, and research can harden and simultaneously complement the innovations from the Hadoop open source community, thereby creating the foundation for an enterprise-grade Big Data platform. In summary, there are availability, security, performance, and manageability advantages to leveraging GPFS-SNC in your Hadoop cluster.
When dealing with the large volumes of data expected in a Hadoop setting, the idea of compression is appealing. On the one hand, you can save a great deal of space (especially when considering that every storage block is replicated three times by default in Hadoop); on the other hand, data transfer speeds are improved because of lower data volumes on the wire. You should consider two important items before choosing a compression scheme: split-table compression and the compression and decompression speeds of the compression algorithm you’re using.
In Hadoop, files are split (divided) if they are larger than the cluster’s block size setting (normally one split for each block). For uncompressed files, this means individual file splits can be processed in parallel by different mappers. Figure 5-3 shows an uncompressed file with the vertical lines representing the split and block boundaries (in this case, the split and block size are the same).
When files, especially text files, are compressed, complications arise. For most compression algorithms, individual file splits cannot be decompressed independently from the other splits from the same file. More specifically, these compression algorithms are not splittable (remember this key term when discussing compression and Hadoop). In the current release of Ha-doop (0.20.2 at the time of writing), no support is provided for splitting compressed text files. For files in which the Sequence or Avro formats are applied, this is not an issue, because these formats have built-in synchronization points, and are therefore splittable. For unsplittable compressed text files, MapReduce processing is limited to a single mapper.
For example, suppose the file in Figure 5-3 is a 1 GB text file in your Ha-doop cluster, and your block size is set at the BigInsights default of 128 MB, which means your file spans eight blocks. When this file is compressed using the conventional algorithms available in Hadoop, it’s no longer possible to parallelize the processing for each of the compressed file splits, because the file can be decompressed only as a whole, and not as individual parts based on the splits. Figure 5-4 depicts this file in a compressed (and binary) state, with the splits being impossible to decompress individually. Note that the split boundaries are dotted lines, and the block boundaries are solid lines.
![]()
Figure 5-3 An uncompressed splittable file in Hadoop
Figure 5-4 A compressed nonsplittable file
Because Hadoop 0.20.2 doesn’t support splittable text compression natively, all the splits for a compressed text file will be processed by only a single mapper. For many workloads, this would cause such a significant performance hit that it wouldn’t be a viable option. However, Jaql is configured to understand splittable compression for text files and will process them automatically with parallel mappers. You can do this manually for other environments (such as Pig and MapReduce programs) by using the TextInput - Format input format instead of the Hadoop standard.
The old saying “nothing in this world is free” is surely true when it comes to compression. There’s no magic going on; in essence, you are simply consuming CPU cycles to save disk space. So let’s start with this assumption: There could be a performance penalty for compressing data in your Hadoop cluster, because when data is written to the cluster, the compression algorithms (which are CPU-intensive) need CPU cycles and time to compress the data. Likewise, when reading data, any MapReduce workloads against compressed data can incur a performance penalty because of the CPU cycles and the time required to decompress the compressed data. This creates a conundrum: You need to balance priorities between storage savings and additional performance overhead.
NOTE If you’ve got an application that’s I/O bound (typical for many warehouse-style applications), you might see a performance gain in your application, because I/O-bound systems typically have spare CPU cycles (found as idle I/O wait in the CPU) that can be utilized to run the compression and decompression algorithms. For example, if you use idle I/O wait CPU cycles to do the compression, and you get good compression rates, you could end up with more data flowing through the I/O pipe, and that means faster performance for those applications that need to fetch a lot of data from disk.
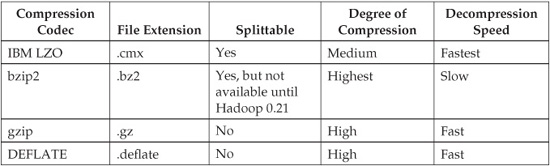
BigInsights includes the IBM LZO compression codec, which supports splitting compressed files and enabling individual compressed splits to be processed in parallel by your MapReduce jobs.
Some Hadoop online forums describe how to use the GNU version of LZO to enable splittable compression, so why did IBM create a version of it, and why not use the GNU LZO alternative? First, the IBM LZO compression codec does not create an index while compressing a file, because it uses fixed-length compression blocks. In contrast, the GNU LZO algorithm uses variable-length compression blocks, which leads to the added complexity of needing an index file that tells the mapper where it can safely split a compressed file. (For GNU LZO compression, this means mappers would need to perform index lookups during decompress and read operations. With this index, there is administrative overhead, because if you move the compressed file, you will need to move the corresponding index file as well.) Second, many companies, including IBM, have legal policies that prevent them from purchasing or releasing software that includes GNU Public License (GPL) components. This means that the approach described in online Hadoop forums requires additional administrative overhead and configuration work. In addition, there are businesses with policies restricting the deployment of GPL code. The IBM LZO compression is fully integrated with BigInsights and under the same enterprise-friendly license agreement as the rest of BigInsights, which means you can use it with less hassle and none of the complications associated with the GPL alternative.
In the next release of Hadoop (version 0.21), the bzip2 algorithm will support splitting. However, decompression speed for bzip2 is much slower than for IBM LZO, so bzip2 is not a desirable compression algorithm for workloads where performance is important.
Figure 5-5 shows the compressed text file from the earlier examples, but in a splittable state, where individual splits can be decompressed by their own mappers. Note that the split sizes are equal, indicating the fixed-length compression blocks.

Figure 5-5 A splittable compressed text file
In the previous table you can see the four compression algorithms available on the BigInsights platform (IBM LZO, bzip2, gzip, and DEFLATE) and some of their characteristics.
Finally, the following table shows some benchmark comparison results for the three most popular compression algorithms commonly used in Hadoop (original source: http://stephane.lesimple.fr/wiki/blog/lzop_vs_compress_vs_gzip_vs_bzip2_vs_lzma_vs_lzma2-xz_benchmark_reloaded). In this benchmark, a 96 MB file is used as the test case. Note that the performance and compression ratio for the IBM LZO algorithm is on par with the LZO algorithm tested in this benchmark, but with the benefit of being splittable without having to use indexes, and being released under an enterprise-friendly license.

To aid in the administration of your cluster, BigInsights includes a web-based administration console that provides a real-time, interactive view of your cluster. The BigInsights console provides a graphical tool for examining the health of your BigInsights environment, including the nodes in your cluster, the status of your jobs (applications), and the contents of your HDFS or GPFS-SNC file system. It’s automatically included in the BigInsights installation and by default runs on port 8080, although you can specify a different port during the installation process.
Apache Hadoop is composed of many disparate components, and each has its own configuration and administration considerations. In addition, Hadoop clusters are often large and impose a variety of administration challenges. The BigInsights administration console provides a single, harmonized view of your cluster that simplifies your work. Through this console, you can add and remove nodes, start and stop nodes, assess an application’s status, inspect the status of MapReduce jobs, review log records, assess the overall health of your platform (storage, nodes, and servers), start and stop optional components (for example, ZooKeeper), navigate files in the BigIn-sights cluster, and more.
Figure 5-6 shows a snippet of the console’s main page. As you can see, the administration console focuses on tasks required for administering your Ha-doop cluster. A dashboard summarizes the health of your system, and you can drill down to get details about individual components.
In Figure 5-6, you can also see a tab for HDFS, which allows you to navigate through an HDFS directory structure to see what files have been stored and create new directories. You can also upload files to HDFS through this tool, although it’s not well suited for large files. For uploading large files to your Hadoop cluster, we recommend using other mechanisms, such as Flume. The BigInsights console features a GPFS tab (if you are using GPFS-SNC as opposed to HDFS) which provides the same capability to browse and exchange data with the GPFS-SNC file system.
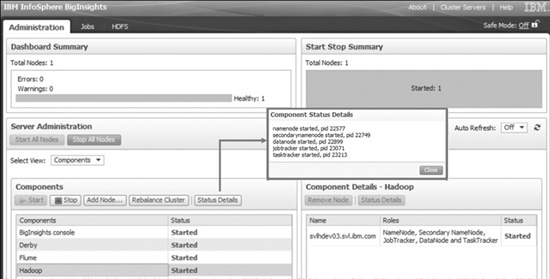
Figure 5-6 An example of the BigInsights administration console
The main page of this web console also allows you to link to the Cluster Server tools provided by the underlying open source components. This comes in handy for administrators, because it easily allows them to access a variety of built-in tools from a single console.
Figure 5-7 shows a couple of screens from the administration console. On the top is the Job Status page, where you can view summary information for your cluster, such as status, the number of nodes that make up the cluster, task capacity, jobs in progress, and so on. If a job is in progress, and you have the appropriate authorizations, you can cancel the running job as shown at the bottom of this figure. To view details about a specific job, select a job from the list and view its details in the Job Summary section of the page. You can drill down even further to get more granular details about your jobs. For example, you can view the job configuration (shown as XML) and counter information, which explains how many mappers were used at execution time and the number of bytes read from/written to complete the job.
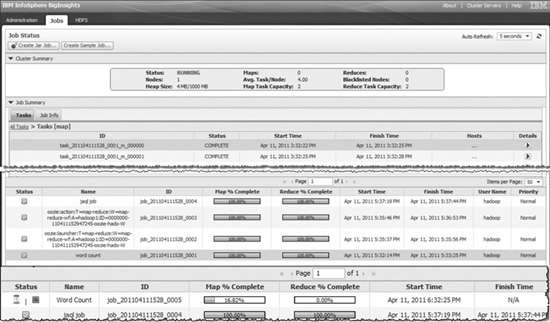
Figure 5-7 Job Status and Jobs in Progress windows in the BigInsights administration console
A number of other tooling benefits are provided in BigInsights that aren’t available in a regular Hadoop environment. For example, interfaces used to track jobs and tasks have colorization for status correlation, automatic refresh intervals, and more.
Security is an important concern for enterprise software, and in the case of open source Hadoop, you need to be aware of some definite shortcomings when you put Hadoop into action. The good news is that BigInsights addresses these issues by securing access to the administrative interfaces and key Hadoop services.
The BigInsights administration console has been structured to act as a gateway to the cluster. It features enhanced security by supporting LDAP authentication. LDAP and reverse-proxy support help administrators restrict access to authorized users. In addition, clients outside the cluster must use REST HTTP access. In contrast, Apache Hadoop has open ports on every node in the cluster. The more ports you have to have open (and there are a lot of them in open source Hadoop), the less secure the environment, because the surface area isn’t minimized.
BigInsights can be configured to communicate with a Lightweight Directory Access Protocol (LDAP) credentials server for authentication. All communication between the console and the LDAP server occurs using LDAP (by default) or both LDAP and LDAPS (LDAP over HTTPS). The BigInsights installer helps you to define mappings between your LDAP users and groups and the four BigInsights roles (System Administrator, Data Administrator, Application Administrator, and User). After BigInsights has been installed, you can add or remove users from the LDAP groups to grant or revoke access to various console functions.
Kerberos security is integrated in a competing Hadoop vendor that merely offers services and some operational tooling, but does not support alternative authentication protocols (other than Active Directory). BigInsights uses LDAP as the default authentication protocol. The development team has emphasized the use of LDAP because, as compared to Kerberos and other alternatives, it’s a much simpler protocol to install and configure. That said, BigInsights does provide pluggable authentication support, enabling alternatives such as Kerberos.
BigInsights, with the use of GPFS-SNC, offers security that is less complex and inherently more secure than HDFS-based alternatives. Again, because GPFS-SNC is a kernel-level file system, it’s naturally aware of users and groups defined in the operating system.
Upcoming changes to Apache Hadoop have improved security for HDFS, but because HDFS is not a kernel-level file system, this still will require additional complexity and processing overhead. As such, the experience IBM has with locking down the enterprise, which is baked into BigInsights, allows you to build a more secure, robust, and more easily maintained multi-tenant solution.
A key component of IBM’s vision for Big Data is the importance of integrating any relevant data sources; you’re not suddenly going to have a Hadoop engine meet all your storage and processing needs. You have other investments in the enterprise, and being able leverage your assets (the whole left hand-right hand baseball analogy from Chapter 2 in this book) is going to be key. Enterprise integration is another area IBM understands very well. As such, BigInsights supports data exchange with a number of sources, including Netezza; DB2 for Linux, UNIX, and Windows; other relational data stores via a Java Database Connectivity (JDBC) interface; InfoSphere Streams; Info-Sphere Information Server (specifically, Data Stage); R Statistical Analysis Applications; and more.
BigInsights includes a connector that enables bidirectional data exchange between a BigInsights cluster and Netezza appliance. The Netezza Adapter is implemented as a Jaql module, which lets you leverage the simplicity and flexibility of Jaql in your database interactions.
The Netezza Adapter supports splitting tables (a concept similar to splitting files). This entails partitioning the table and assigning each divided portion to a specific mapper. This way, your SQL statements can be processed in parallel.
The Netezza Adapter leverages Netezza’s external table feature, which you can think of as a materialized external UNIX pipe. External tables use JDBC. In this scenario, each mapper acts as a database client. Basically, a mapper (as a client) will connect to the Netezza database and start a read from a UNIX file that’s created by the Netezza infrastructure.
You can exchange data between BigInsights and DB2 for Linux, UNIX, and Windows in two ways: from your DB2 server through a set of BigInsights user defined functions (UDFs) or from your BigInsights cluster through the JDBC module (described in the next section).
The integration between BigInsights and DB2 has two main components: a set of DB2 UDFs and a Jaql server (to listen for requests from DB2) on the BigInsights cluster. The Jaql server is a middleware component that can accept Jaql query processing requests from a DB2 9.5 server or later. Specifically, the Jaql server can accept the following kinds of Jaql queries from a DB2 server:
• Read data from the BigInsights cluster.
• Upload (or remove) modules of Jaql code in the BigInsights cluster.
• Submit Jaql jobs (which can refer to modules you previously uploaded from DB2) to be run on the BigInsights cluster.
Running these BigInsights functions from a DB2 server gives you an easy way to integrate with Hadoop from your traditional application framework. With these functions, database applications (which are otherwise Hadoop-unaware) can access data in a BigInsights cluster using the same SQL interface they use to get relational data out of DB2. Such applications can now leverage the parallelism and scale of a BigInsights cluster without requiring extra configuration or other overhead. Although this approach incurs additional performance overhead as compared to a conventional Hadoop application, it is a very useful way to integrate Big Data processing into your existing IT application infrastructure.
The Jaql JDBC module enables you to read and write data from any relational database that has a standard JDBC driver. This means you can easily exchange data and issue SQL statements with every major database warehouse product in the market today.
With Jaql’s MapReduce integration, each map task can access a specific part of a table, enabling SQL statements to be processed in parallel for partitioned databases.
As you’ll discover in Chapter 6, Streams is the IBM solution for real-time analytics on streaming data. Streams includes a sink adapter for BigInsights, which lets you store streaming data directly into your BigInsights cluster. Streams also includes a source adapter for BigInsights, which lets Streams applications read data from the cluster. The integration between BigInsights and Streams raises a number of interesting possibilities. At a high level, you would be able to create an infrastructure to respond to events in real time (as the data is being processed by Streams), while using a wealth of existing data (stored and analyzed by BigInsights) to inform the response. You could also use Streams as a large-scale data ingest engine to filter, decorate, or otherwise manipulate a stream of data to be stored in the BigInsights cluster.
Using the BigInsights sink adapter, a Streams application can write a control file to the BigInsights cluster. BigInsights can be configured to respond to the appearance of such a file so that it would trigger a deeper analytics operation to be run in the cluster. For more advanced scenarios, the trigger file from Streams could also contain query parameters to customize the analysis in BigInsights.
Streams and BigInsights share the same text analytics capabilities through the Advanced Text Analytics Toolkit (known initially by its IBM Research codename, SystemT). In addition, both products share a common end user web interface for parameterizing and running workloads. Future releases will feature additional alignment in analytic tooling.
DataStage is an extract, transform, and load (ETL) platform that is capable of integrating high volumes of data across a wide variety of data sources and target applications. Expanding its role as a data integration agent, DataStage has been extended to work with BigInsights and can push and pull data to and from BigInsights clusters.
The DataStage connector to BigInsights integrates with both the HDFS and GPFS-SNC file systems, taking advantage of the clustered architecture so that any bulk writes to the same file are done in parallel. In the case of GPFS-SNC, bulk writes can be done in parallel as well (because GPFS-SNC, unlike HDFS, is fully POSIX-compliant).
The result of DataStage integration is that BigInsights can now quickly exchange data with any other software product able to connect with DataStage. Plans are in place for even tighter connections between Information Server and BigInsights, such as the ability to choreograph BigInsights jobs from DataStage, making powerful and flexible ETL scenarios possible. In addition, designs are in place to extend Information Server information profiling and governance capabilities to include BigInsights.
BigInsights includes an R module for Jaql, which enables you to integrate the R Project (see www.r-project.org for more information) for Statistical Computing into your Jaql queries. Your R queries can then benefit from Jaql’s MapReduce capabilities and run R computations in parallel.
Open source Hadoop ships with a rudimentary first in first out (FIFO) scheduler and a pluggable architecture supporting alternative scheduling options. Two pluggable scheduling tools are available through the Apache Hadoop project: the Fair Scheduler and the Capacity Scheduler. These schedulers are similar in that they enable a minimum level of resources to be available for smaller jobs to avoid starvation. (The Fair Scheduler is included in BigInsights while the Capacity Scheduler is not.) These schedulers do not provide adequate controls to ensure optimal cluster performance or offer administrators the flexibility they need to implement customizable workload management requirements. For example, FAIR is pretty good at ensuring resources are applied to workloads, but it doesn’t give you SLA-like granular controls.
Performance experts in IBM Research have studied the workload scheduling problems in Hadoop and have crafted a solution called the Intelligent Scheduler (previously known as the FLEX scheduler). This scheduler extends the Fair Scheduler and manipulates it by constantly altering the minimum number of slots assigned to jobs. The Intelligent Scheduler includes a variety of metrics you can use to optimize your workloads. These metrics can be chosen by an administrator on a cluster-wide basis, or by individual users on a job-specific basis. You can optionally weight these metrics to balance competing priorities, minimize the sum of all the individual job metrics, or maximize the sum of all of them.
The following are examples of the Intelligent Scheduler controls you can use to tune your workloads:

IBM Research workload management and performance experts have been working with Hadoop extensively, identifying opportunities for performance optimizations. IBM Research has developed a concept called Adaptive MapReduce, which extends Hadoop by making individual mappers self-aware and aware of other mappers. This approach enables individual map tasks to adapt to their environment and make efficient decisions.
When a MapReduce job is about to begin, Hadoop divides the data into many pieces, called splits. Each split is assigned a single mapper. To ensure a balanced workload, these mappers are deployed in waves, and new mappers start once old mappers finish processing their splits. In this model, a small split size means more mappers, which helps ensure balanced workloads and minimizes failure costs. However, smaller splits also result in increased cluster overhead due to the higher volumes of startup costs for each map task. For workloads with high startup costs for map tasks, larger split sizes tend to be more efficient. An adaptive approach to running map tasks gives BigInsights the best of both worlds.
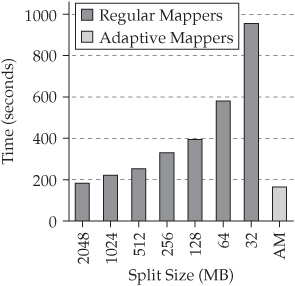
One implementation of Adaptive MapReduce is the concept of an adaptive mapper. Adaptive Mappers extend the capabilities of conventional Hadoop mappers by tracking the state of file splits in a central repository. Each time an Adaptive Mapper finishes processing a split, it consults this central repository and locks another split for processing until the job is completed. This means that for Adaptive Mappers, only a single wave of mappers is deployed, since the individual mappers remain open to consume additional splits. The performance cost of locking a new split is far less than the startup cost for a new mapper, which accounts for a significant increase in performance. Figure 5-8 shows the benchmark results for a set-similarity join workload, which had high map task startup costs that were mitigated by the use of Adaptive Mappers. The Adaptive Mappers result (see the AM bar) was based on a low split size of 32 MB. Only a single wave of mappers was used, so there were significant performance savings based on avoiding the startup costs for additional mappers.
Figure 5-8 Benchmarking a set-similarity join workload with high-map and task startup costs with Adaptive Mappers.
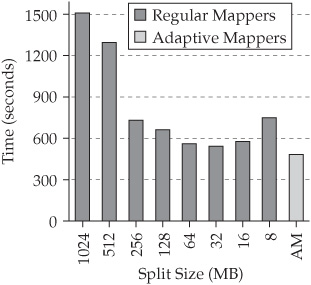
For some workloads, any lack of balance could get magnified with larger split sizes, which would cause additional performance problems. When using Adaptive Mappers, you can, without penalty, avoid imbalanced workloads by tuning jobs to use a lower split size. Since there will only be a single wave of mappers, your workload will not be crippled by the mapper startup costs of many additional mappers. Figure 5-9 shows the benchmark results for a join query on TERASORT records, where an imbalance occurred between individual map tasks that led to an imbalanced workload for the higher split sizes. The Adaptive Mappers result (again, see the AM bar) was based on a low split size of 32 MB. Only a single wave of mappers was used, so there were significant performance savings based on the startup costs for additional mappers.
A number of additional Adaptive MapReduce performance optimization techniques are in development and will be released in future versions of BigInsights.
Figure 5-9 Benchmark results for a join query on TERASORT records.
Up until now in this chapter, we have been discussing foundational infrastructure aspects of BigInsights. Those are important features, which make Hadoop faster, more reliable, and more flexible for use in your enterprise. But the end goal of storing data is to get value out of it, which brings us to the BigInsights analytics capabilities. This is another major distinguishing feature of BigInsights, which makes it far more than just a Hadoop distribution—it is a platform for Big Data analytics. Unlike the core Apache Hadoop components or competitive bundled Hadoop distributions, BigInsights includes tooling for visualizing and performing analytics on large sets of varied data. Through all of its analytics capabilities, BigInsights hides the complexity of MapReduce, which enables your analysts to focus on analysis, not the intricacies of programming parallel applications.
Although Hadoop makes analyzing Big Data possible, you need to be a programmer with a good understanding of the MapReduce paradigm to explore the data. BigInsights includes a browser-based visualization tool called Big-Sheets, which enables line of business users to harness the power of Hadoop using a familiar spreadsheet interface. BigSheets requires no programming or special administration. If you can use a spreadsheet, you can use BigSheets to perform analysis on vast amounts of data, in any structure.
Three easy steps are involved in using BigSheets to perform Big Data analysis:
1. Collect data. You can collect data from multiple sources, including crawling the Web, local files, or files on your network. Multiple protocols and formats are supported, including HTTP, HDFS, Amazon S3 Native File System (s3n), and Amazon S3 Block File System (s3). When crawling the Web, you can specify the web pages you want to crawl and the crawl depth (for instance, a crawl depth of two gathers data from the starting web page and also the pages linked from the starting page). There is also a facility for extending BigSheets with custom plug-ins for importing data. For example, you could build a plug-in to harvest Twitter data and include it in your BigSheets collections.
2. Extract and analyze data. Once you have collected your information, you can see a sample of it in the spreadsheet interface, such as that shown in Figure 5-10. At this point, you can manipulate your data using the spreadsheet-type tools available in BigSheets. For example, you can combine columns from different collections, run formulas, or filter data. You can also include custom plug-ins for macros that you use against your data collections. While you build your sheets and refine your analysis, you can see the interim results in the sample data. It is only when you click the Run button that your analysis is applied to your complete data collection. Since your data could range from gigabytes to terabytes to petabytes, working iteratively with a small data set is the best approach.
3. Explore and visualize data. After running the analysis from your sheets against your data, you can apply visualizations to help you make sense of your data. BigSheets provides the following visualization tools:
• Tag Cloud Shows word frequencies; the bigger the word, the more frequently it exists in the sheet. See Figure 5-11 for an example.
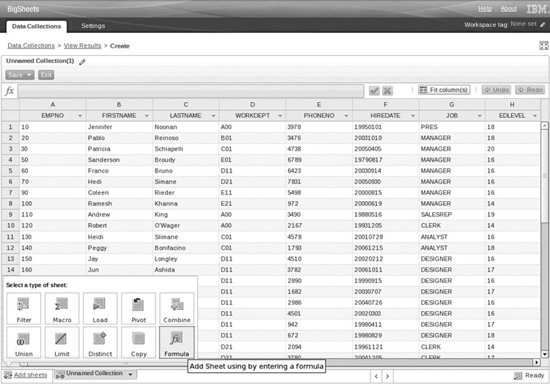
Figure 5-10 Analyze data in BigSheets
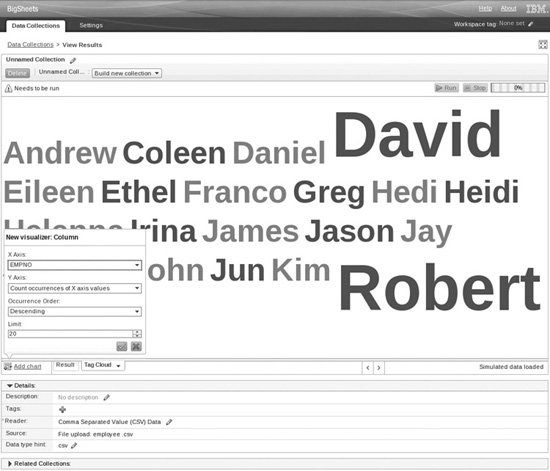
Figure 5-11 Analyze data in BigSheets
• Pie Chart Shows proportional relationships, where the relative size of the slice represents its proportion of the data.
• Map Shows data values overlaid onto either a map of the world or a map of the United States.
• Heat Map Similar to the Map, but with the additional dimension of showing the relative intensity of the data values overlaid onto the Map.
• Bar Chart Shows the frequency of values for a specified column.
BigSheets is fully extensible with its visualization tools. As such, you can include custom plug-ins for specialized renderings for your data.
While BigSheets is geared for the line-of-business user, BigInsights includes capabilities for much deeper analysis, such as text analytics.
Text analytics is growing in importance as businesses strive to gain insight from their vast repositories of text data. This can involve looking for customer web browsing patterns in clickstream log files, finding fraud indicators through email analytics, or assessing customer sentiment from social media messages. To meet these challenges, and more, BigInsights includes the Advanced Text Analytics Toolkit, which features a text analytics engine that was developed by IBM Research starting in 2004 under the codename SystemT. Since then, the Advanced Text Analytics Toolkit has been under continual development and its engine has been included in many IBM products, including Lotus Notes, IBM eDiscovery Analyzer, Cognos Consumer Insight, InfoSphere Warehouse, and more. Up to this point, the Advanced Text Analytics Toolkit has been released only as an embedded text analytics engine, hidden from end users. In BigInsights, the Advanced Text Analytics Toolkit is being made available as a text analytics platform that includes developer tools, an easy-to-use text analytics language, a MapReduce-ready text analytics processing engine, and prebuilt text extractors. The Advanced Text Analytics Toolkit also includes multilingual support, including support for double-byte character languages.
The goal of text analysis is to read unstructured text and distill insights. For example, a text analysis application can read a paragraph of text and derive structured information based on various rules. These rules are defined in extractors, which can, for instance, identify a person’s name within a text field. Consider the following text:
In the 2010 World Cup of Soccer, the team from the Netherlands distinguished themselves well, losing to Spain 1-0 in the Final. Early in the second half, Dutch striker Arjen Robben almost changed the tide of the game on a breakaway, only to have the ball deflected by Spanish keeper, Iker Casillas. Near the end of regulation time, winger Andres Iniesta scored, winning Spain the World Cup.
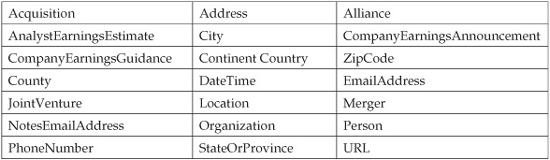
The product of these extractors is a set of annotated text, as shown in the underlined text in this passage.
Following is the structured data derived from this example text:

In the development of extractors and applications where the extractors work together, the challenge is to ensure the accuracy of the results. Accuracy can be broken down into two factors: precision, which is the percentage of items in the result set that are relevant (are the results you’re getting valid?), and recall, which is the percentage of relevant results that are retrieved from the text (are all the valid strings from the original text showing up?). As analysts develop their extractors and applications, they iteratively make refinements to fine-tune their precision and recall rates.
Current alternative approaches and infrastructure for text analytics present challenges for analysts, as they tend to perform poorly (in terms of both accuracy and speed) and they are difficult to use. These alternative approaches rely on the raw text flowing only forward through a system of extractors and filters. This is an inflexible and inefficient approach, often resulting in redundant processing. This is because extractors applied later in the workflow might have done some processing already completed earlier. Existing toolkits are also limited in their expressiveness (specifically, the degree of granularity that’s possible with their queries), which results in analysts having to develop custom code. This, in turn, leads to more delays, complexity, and difficulty in refining the accuracy of your result set (precision and recall).
The BigInsights Advanced Text Analytics Toolkit offers a robust and flexible approach for text analytics. The core of the Advanced Text Analytics Toolkit is its Annotator Query Language (AQL), a fully declarative text analytics language, which means there are no “black boxes” or modules that can’t be customized. In other words, everything is coded using the same semantics and is subject to the same optimization rules. This results in a text analytics language that is both highly expressive and very fast. To the best of our knowledge, there are no other fully declarative text analytics languages available on the market today. You’ll find high-level and medium-level declarative languages, but they all make use of locked-up black-box modules that cannot be customized, which restricts flexibility and are difficult to optimize for performance.
AQL provides an SQL-like language for building extractors. It’s highly expressive and flexible, while providing familiar syntax. For example, the following AQL code defines rules to extract a person’s name and telephone number.

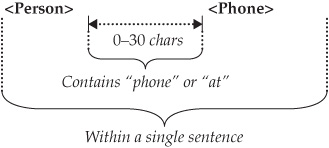
Figure 5-12 Visual expression of extractor rules
Figure 5-12 shows a visual representation of the extractor defined in the previous code block.
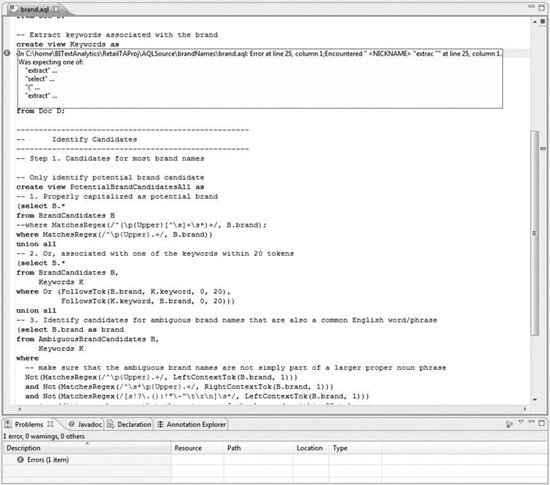
The Advanced Text Analytics Toolkit includes Eclipse plug-ins to enhance analyst productivity. When writing AQL code, the editor features syntax highlighting and automatic detection of syntax errors (see Figure 5-13).
Also included is a facility to test extractors against a subset of data. This is important for analysts as they refine the precision and recall of their extractors. Testing their logic against the complete data sets, which could range up to petabytes of volume, would be highly inefficient and wasteful.
A major challenge for analysts is determining the lineage of changes that have been applied to text. It can be difficult to discern which extractors need to be adjusted to tweak the resulting annotations. To aid in this, the Provenance viewer, shown in Figure 5-14, features an interactive visualization, displaying exactly which rules influence the resulting annotations.
An additional productivity tool to aid analysts to get up and running quickly is the inclusion of a prebuilt extractor library with the Advanced Text Analytics Toolkit. Included are extractors for the following:
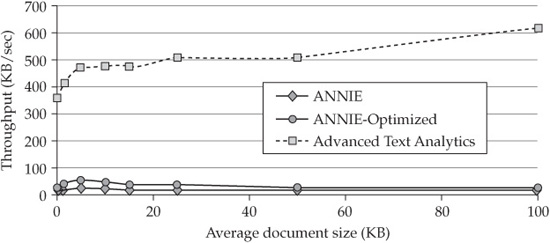
The fully declarative nature of AQL enables its code to be highly optimized. In contrast with the more rigid approaches to text analytics frameworks described earlier, the AQL optimizer determines order of execution of the extractor instructions for maximum efficiency. As a result, the Advanced Text Analytics Toolkit has delivered benchmark results up to ten times faster than leading alternative frameworks (see Figure 5-15).
When coupled with the speed and enterprise stability of BigInsights, the Advanced Text Analytics Toolkit represents an unparalleled value proposition. The details of the integration with BigInsights (described in Figure 5-16) are transparent to the text analytics developer. Once the finished AQL is compiled and then optimized for performance, the result is an Analytics Operator Graph (AOG) file. This AOG can be submitted to BigInsights as an analytics job through the BigInsights web console. Once submitted, this AOG is distributed with every mapper to be executed on the BigInsights cluster. Once the job starts, each mapper then executes Jaql code to instantiate its own Advanced Text Analytics Toolkit runtime and applies the AOG file. The text from each mapper’s file split is run through the toolkit’s runtime, and an annotated document stream is passed back as a result set.
Figure 5-15 Advanced Text Analytics Toolkit performance benchmark
When you add up all its capabilities, the BigInsights Advanced Text Analytics Toolkit gives you everything you need to develop text analytics applications to help you get value out of extreme volumes of text data. Not only is there extensive tooling to support large-scale text analytics development, but the resulting code is highly optimized and easily deployable on a Hadoop cluster.
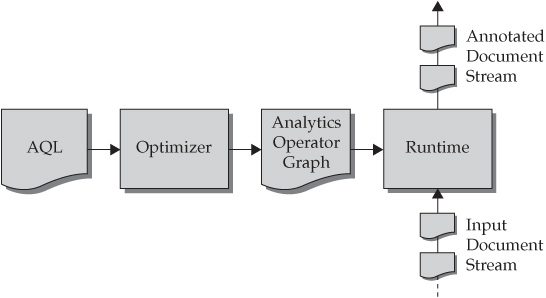
Figure 5-16 Integration of Advanced Text Analytics Toolkit with BigInsights
In 2012, we believe BigInsights will include a Machine Learning Toolkit, which was developed by IBM Research under the codename SystemML. (Disclaimer: there is no guarantee that this feature will debut in 2012, but if we had to bet, we’d say you will see it sooner than later.) This provides a platform for statisticians and mathematicians to conduct high-performance statistical and predictive analysis on data in a BigInsights Hadoop cluster. It includes a high-level machine learning language, which is semantically similar to R (the open source language for statistical computing) and can be used by analysts to apply statistical models to their data processing. A wealth of precanned data mining algorithms and statistical models are included as well and are ready for customization.
The Machine Learning Toolkit includes an engine that converts the statistical workloads expressed in machine learning language into parallelized MapReduce code, so it hides this complexity from analysts. In short, analysts don’t need to be Java programmers, and they don’t need to factor MapReduce into their analytics applications.
The Machine Learning Toolkit was developed in IBM Research by a team of performance experts, PhD statisticians, and PhD mathematicians. Their primary goals were high performance and ease of use for analysts needing to perform complex statistical analysis in a Hadoop context. As such, this toolkit features optimization techniques for the generation of low-level MapReduce execution plans. This enables statistical jobs to feature orders of magnitude performance improvements, as compared to algorithms directly implemented in MapReduce. Not only do analysts not need to apply MapReduce coding techniques to their analytics applications, but the machine learning code they write is highly optimized for excellent Hadoop performance.
To support its analytics toolkits, BigInsights includes a framework for building large-scale indexing and search solutions, called Biglndex. The indexing component includes modules for indexing over Hadoop, as well as optimizing, merging, and replicating indexes. The search component includes modules for programmable search, faceted search, and searching an index in local and distributed deployments. Especially in the case of text analytics, a robust index is vital to ensure good performance of analytics workloads.
BigIndex is built on top of the open source Apache Lucene search library and the IBM Lucene Extension Library (ILEL). IBM is a leading contributor to the Lucene project and has committed a number of Lucene enhancements through ILEL. Because of its versatile nature as an indexing engine, the technologies used in BigIndex are deployed in a number of products. In addition to BigIn-sights, it’s included in Lotus Connections, IBM Content Analyzer, and Cognos Consumer Insight, to name a few. IBM also uses BigIndex to drive its Intranet search engine. (This project, known as Gumshoe, is documented heavily in the book Hadoop in Action, by Chuck Lam [Manning Publications, 2010].)
The goals for BigIndex are to provide large-scale indexing and search capabilities that leverage and integrate with BigInsights. For Big Data analytics applications, this means being able to search through hundreds of terabytes of data, while maintaining subsecond search response times. One key way BigIndex accomplishes this is by using various targeted search distribution architectures to support the different kinds of search activities demanded in a Big Data context. BigIndex can build the following types of indexes:
• Partitioned index This kind of index is partitioned into separate indices by a metadata field (for example, a customer ID or date). A search is usually performed only on one of these indices, so the query can be routed to the appropriate index by a runtime query dispatcher.
• Distributed index The index is distributed into shards, where the collection of shards together represents one logical index. Each search is evaluated against all shards, which effectively parallelizes the index key lookups.
• Real-time index Data from real-time sources (for example, Twitter) is added to an index in near real time. The data is analyzed in parallel, and the index is updated when analysis is complete.
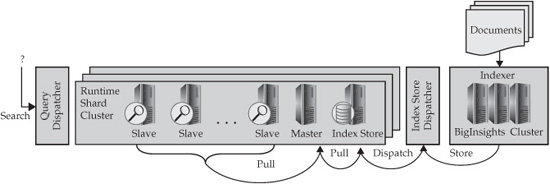
Figure 5-17 depicts a deployment of BigIndex, where indexing is done using a BigInsights cluster and search is done in its own shard cluster.
Figure 5-17 Distributed Biglndex deployment
The following steps are involved in generating and deploying an index for the kind of distributed environment shown in Figure 5-17:
1. Data ingest Documents are ingested into the BigInsights cluster. This can be done through any available means—for instance, a flow of log files ingested through Flume, diagnostic data processed by Streams, or a Twitter feed stored in HDFS or GPFS-SNC.
2. Data parsing Parse the documents to select fields that need to be indexed. It is important for the parsing algorithms to be selective: there needs to be a balance between good coverage (indexing fields on which users will search) and quantity (as more fields are indexed, performance slows). Text analytics can be used here, if needed.
3. Data faceting Identify how the current documents relate to others by isolating and extracting the facets (such as categories) that users might want to use to narrow and drill down into their search results—for example, year, month, date; or country, state, city.
4. Data indexing This indexing is based on a Lucene text index, but with many extensions. The documents are indexed using Hadoop by an Indexer, which is deployed as a MapReduce job. Two kinds of indexes are generated: a single Lucene index and a distributed index (which is composed of multiple Lucene indexes representing individual indices). Faceted indexing capability is integrated with both the single Lucene index and the distributed index.
5. Index merging Once generated, the index is dispatched to the Runtime Shard Cluster for storage. The Master pulls the indexes from the Index Store and merges them with its local index. This is not like a regular database index, where you can insert or delete values as needed. This index is an optimized data structure. As a result, incremental changes need to be merged into this structure.
6. Index replication The slave processors replicate the index updates from the Master and are ready to serve search queries from users.
7. Index searching BigIndex exposes its distributed search functionality through multiple interfaces, including a Java API, a scripting language using Jaql, and REST-like HTTP APIs.
As the sum of the many parts described in this chapter, BigInsights represents a fast, robust, and easy-to-use platform for analytics on Big Data at rest. With our graphical installation, configuration, and administrative tools, management of the cluster is easy. By storing your data using GPFS-SNC, you gain performance improvements, but also high availability and flexibility in maintaining your data. The inclusion of the IBM LZO compression module enables you to compress your data with a high-performance algorithm, without licensing hassles. There are additional performance features, such as Adaptive MapReduce, and the Intelligent Scheduler, which helps you maintain reliable service level agreements with a user base that will come to depend on your Big Data analytics. And speaking of analytics, BigInsights provides capabilities for a wide range of users. For line-of-business users, BigSheets is a simple tool geared to create visualizations on large volumes of data. And for deeper analytics, BigInsights provides an industry-leading text analytics tookit and engine. And in the near future, the IBM Research Machine Learning Analytics Toolkit will be available as well. We think this represents an incredible story, which is unparalleled in the IT industry. Through BigInsights, you get a complete analytics solution, supported by the world’s largest corporate research organization, a deep development team, and IBM’s global support network.