4
Program Input and the Software Design Process
KNOWLEDGE GOALS
 To understand the value of appropriate prompting messages for interactive programs.
To understand the value of appropriate prompting messages for interactive programs.
To know when noninteractive input/output is appropriate and how it differs from interactive input/output.
To understand the distinction between functional decomposition and object-oriented design.
SKILL GOALS
To be able to:
Construct input statements to read values into a program.
Determine the contents of variables assigned values by input statements.
Write programs that use data files for input and output.
Apply the functional decomposition methodology to solve a simple problem.
Take a functional decomposition and code it in C++, using self-documenting code.
A program needs data on which to operate. Up to this point, we have been writing data values in the program itself, in literal and named constants. If this were the only way we could enter data, we would have to rewrite a program for each different set of values. In this chapter, we look at ways of entering data into a program while it is running.
Once we know how to input data, process it, and output results, we can begin to think about designing more complicated programs. We have talked about general problem-solving strategies and writing simple programs. For a simple problem, it’s easy to choose a strategy, write the algorithm, and code the program. As problems become more complex, however, we have to use a more organized approach. In the second part of this chapter, we look at two general methodologies for developing software: object-oriented design and functional decomposition.
4.1 Getting Data into Programs
One of the major advantages offered by computers is that a program can be used with many different sets of data. To do so, we must keep the data separate from the program until the program is executed. Then instructions in the program copy values from the data set into variables in the program. After storing these values into the variables, the program can perform calculations with them (see FIGURE 4.1).
The process of placing values from an outside data set into variables in a program is called input. We say that the computer reads data into the variables. Data can come from an input device or from a file on an auxiliary storage device. We look at file input later in this chapter; here we consider the standard input device, the keyboard.
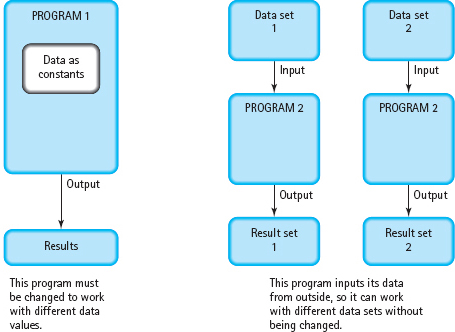
FIGURE 4.1 Separating the Data from the Program
Input Streams and the Extraction Operator (>>)
The concept of a stream is fundamental to input and output in C++. Similar to how we have described an output stream, you can think of an input stream as a doorway through which characters come into your program from an input device.
As we saw in Chapter 2, to use stream input/output (I/O), we write the preprocessor directive
#include <iostream>
The header file iostream contains, among other things, the definitions of two data types: istream and ostream. These data types represent input streams and output streams, respectively. The header file also contains declarations that look like this:
istream cin;
ostream cout;
The first declaration says that cin (pronounced “see-in”) is a variable of type istream. The second says that our old friend cout is a variable of type ostream. The stream cin is associated with the standard input device (the keyboard).
As you have already seen, you can output values to cout by using the insertion operator (<<), which is sometimes pronounced “put to”:
cout << 3 * price;
In a similar fashion, you can input data from cin by using the extraction operator (>>), sometimes pronounced “get from”:
cin >> cost;
When the computer executes this statement, it inputs the next number you type on the keyboard (425, for example) and stores it into the variable cost.
The extraction operator >> takes two operands. Its left-hand operand is a stream expression (in the simplest case, just the variable cin). Its right-hand operand is a variable into which we store the input data. For now, let’s assume the variable is of a simple type (char, int, float, and so forth). Later in the chapter we discuss the input of string data.
You can use the >> operator several times in a single input statement. Each occurrence extracts (inputs) the next data item from the input stream. For example, there is no difference between the statement
cin >> length >> width;
and the pair of statements
cin >> length;
cin >> width;
Using a sequence of extractions in one statement is very convenient for the programmer.
When you are new to C++, you may confuse the extraction operator (>>) with the insertion operator (<<). Here is an easy way to remember which is which: Always begin the statement with either cin or cout, and use the operator that points in the direction in which the data is going. The statement
cout << someInt;
sends data from the variable someInt to the output stream. The statement
cin >> someInt;
sends data from the input stream to the variable someInt. The following program demonstrates the use of cin and cout.
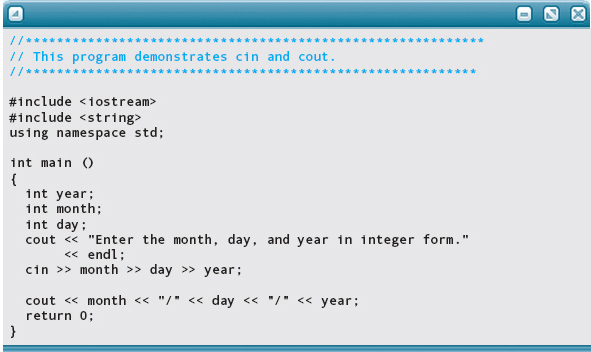
Here is the output, with the data entered by the user highlighted:
Here’s the syntax template for an input statement:
InputStatement

Unlike the items specified in an output statement, which can be constants, variables, or complicated expressions, the items specified in an input statement can only be variable names. Why? Because an input statement indicates where input data values should be stored. Only variable names refer to memory locations where we can store values while a program is running.
When you enter input data at the keyboard, you must be sure that each data value is appropriate for the data type of the variable in the input statement.
Data Type of Variable in an >> Operation |
Valid Input Data |
char |
A single printable character other than a blank |
int |
An int literal constant, optionally preceded by a sign |
float |
An int or float literal constant (possibly in scientific, or E, notation), optionally preceded by a plus or minus sign |
When you input a number into a float variable, the input value doesn’t need a decimal point. That’s because the integer value is automatically coerced to a float value. Any other mismatches, such as trying to input a float value into an int variable or a char value into a float variable, can lead to unexpected and sometimes serious results. Later in this chapter we discuss what might happen.
When looking for the next input value in the stream, the >> operator skips any leading whitespace characters. Whitespace characters are blanks and certain nonprintable characters, such as the character that marks the end of a line. (We talk about this end-of-line character in the next section.) After skipping any whitespace characters, the >> operator proceeds to extract the desired data value from the input stream. If this data value is a char value, input stops as soon as a single character is input. If the data value is an int or float, input of the number stops at the first character that is inappropriate for the data type, such as a whitespace character. Here are some examples, where i, j, and k are int variables, ch is a char variable, and x is a float variable:
Statement |
Data |
Contents After Input |
1. cin >> i; |
32 |
i = 32 |
2. cin >> i >> j; |
4 60 |
i = 4, j = 60 |
3. cin >> i >> ch >> x; |
25 A 16.9 |
i = 25, ch = ‘A’, x = 16.9 |
4. cin >> i >> ch >> x; |
25 |
|
|
A |
|
|
16.9 |
i = 25, ch = ‘A’, x = 16.9 |
5. cin >> i >> ch >> x; |
25A16.9 |
i = 25, ch = ‘A’, x = 16.9 |
6. cin >> i >> j >> x; |
12 8 |
i = 12, j = 8 (Computer waits for a third number) |
7. cin >> i >> x; |
46 32.4 15 |
i = 46, x = 32.4 (15 is held for later input) |
Examples 1 and 2 are straightforward examples of integer input. Example 3 shows that you do not use quotes around character data values when they are input (quotes around character constants are needed in a program, though, to distinguish them from identifiers). Example 4 demonstrates how the process of skipping whitespace characters includes going on to the next line of input if necessary. Example 5 shows that the first character encountered that is inappropriate for a numeric data type ends the number. Input for the variable i stops at the input character A, after which the A is stored into ch, and then input for x stops at the end of the input line. Example 6 shows that if you are at the keyboard and haven’t entered enough values to satisfy the input statement, the computer waits (and waits and waits …) for more data. Example 7 shows that if you enter more values than there are variables in the input statement, the extra values remain waiting in the input stream until they can be read by the next input statement. If extra values are left over when the program ends, the computer disregards them.
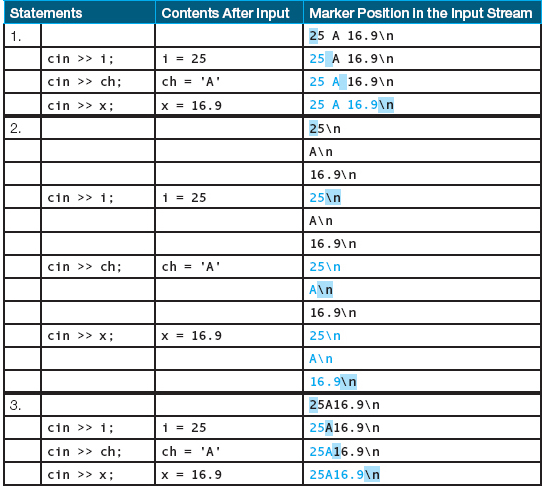
The Reading Marker and the Newline Character
To help explain stream input in more detail, we introduce the concept of the reading marker. The reading marker works like a bookmark, but instead of marking a place in a book, it keeps track of the point in the input stream where the computer should continue reading. In other words, the reading marker indicates the next character waiting to be read. The extraction operator >> leaves the reading marker on the character following the last piece of data that was input.
Each input line has an invisible end-of-line character (the newline character) that tells the computer where one line ends and the next begins. To find the next input value, the >> operator crosses line boundaries (newline characters) if necessary.
Where does the newline character come from? What is it? The answer to the first question is easy. When you are working at a keyboard, you generate a newline character each time you press the Return or Enter key. Your program also generates a newline character when it uses the endl manipulator in an output statement. The endl manipulator outputs a newline, telling the screen cursor to go to the next line. The answer to the second question varies from computer system to computer system. The newline character is a nonprintable control character that the system recognizes as meaning the end of a line, whether it’s an input line or an output line.
As we saw in Chapter 3, you can also refer directly to the newline character by using the symbols \n, consisting of a backslash and an n with no space between them.
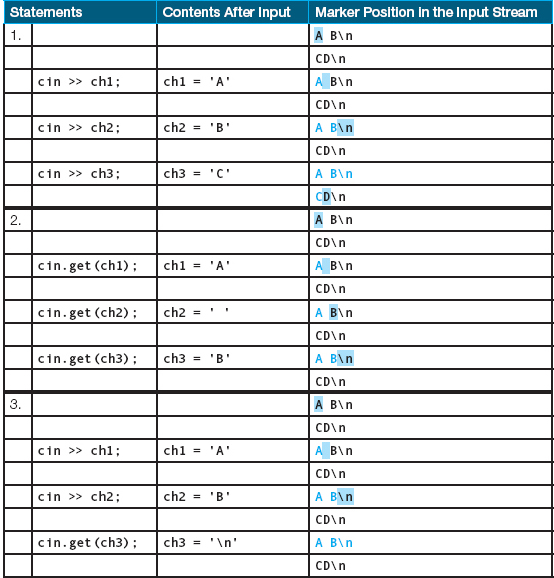
Let’s look at some examples of input using the reading marker and the newline character. In the following table, i is an int variable, ch is a char variable, and x is a float variable. The input statements produce the results shown. The part of the input stream printed in color is what has been extracted by input statements. The reading marker, denoted by the shaded block, indicates the next character waiting to be read. The \n denotes the newline character.
Reading Character Data with the get Function
As we have discussed, the >> operator skips any leading whitespace characters (such as blanks and newline characters) while looking for the next data value in the input stream. Suppose that ch1 and ch2 are char variables and the program executes the following statement
cin >> ch1 >> ch2;
If the input stream consists of
R 1
then the extraction operator stores 'R' into ch1, skips the blank, and stores '1' into ch2. (Note that the char value '1' is not the same as the int value 1. The two are stored in completely different ways in a computer’s memory. The extraction operator interprets the same data in different ways, depending on the data type of the variable that’s being filled.)
What if we had wanted to input three characters from the input line, where one was a blank? With the extraction operator, it’s not possible. Whitespace characters such as blanks are skipped over.
The istream data type provides a second way in which to read character data, in addition to the >> operator. You can use the get function, which inputs the very next character in the input stream without skipping any whitespace characters. The function call looks like this:
cin.get(someChar);
The get function is associated with the istream data type, and you must use dot notation to make a function call. (Recall that we used dot notation in Chapter 3 to invoke certain functions associated with the string type. Later in this chapter we explain the reason for dot notation.) To use the get function, you give the name of an istream variable (here, cin), then a dot (period), and then the function name and argument list. Notice that the call to get uses the syntax for calling a void function, not a value-returning function. The function call is a complete statement; it is not part of a larger expression.
The effect of this function call is to input the next character waiting in the stream—even if it is a whitespace character like a blank—and store it into the variable someChar. The argument to the get function must be a variable, not a constant or arbitrary expression; we must tell the function where we want it to store the input character.
The following program demonstrates the use of the get function to read three characters and store them in three different places.
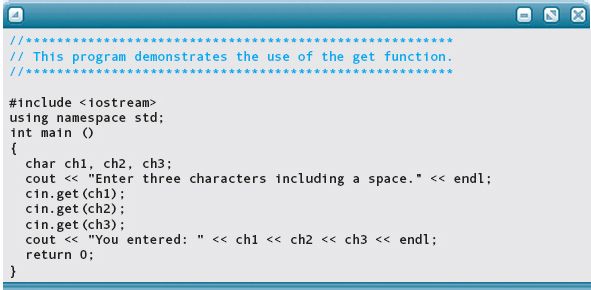
Here is the output, with user input highlighted:

Because the middle character is a blank, we could have used the following three lines to input the data.
cin >> ch1;
cin.get(ch2);
cin >> ch3;
However, the first version always works.
Here are some more examples of character input using both the >> operator and the get function. ch1, ch2, and ch3 are all char variables. As before, \n denotes the newline character.
THEORETICAL FOUNDATIONS
More About Functions and Arguments

When your main function tells the computer to go off and follow the instructions in another function, SomeFunc, the main function is calling SomeFunc. In the call to SomeFunc, the arguments in the argument list are passed to the function. When SomeFunc finishes, the computer returns to the main function.
With some functions you have seen, such as sqrt and abs, you can pass constants, variables, and arbitrary expressions to the function. The get function for reading character data, however, accepts only a variable as an argument. The get function stores a value into its argument when it returns, and only variables can have values stored into them while a program is running. Even though get is called as a void function—not a value-returning function—it returns or passes back a value through its argument list. The point to remember is that you can use arguments both to send data into a function and to get results back out.
Skipping Characters with the ignore Function
Most of us have a specialized tool lying in a kitchen drawer or in a toolbox. It gathers dust and cobwebs because we almost never use it. Of course, when we suddenly need it, we’re glad we have it. The ignore function associated with the istream type is like this specialized tool. You rarely have occasion to use ignore; but when you need it, you’re glad it’s available.
The ignore function is used to skip (read and discard) characters in the input stream. It is a function with two arguments, called like this:
cin.ignore(200, '\n');
The first argument is an int expression; the second, a char value. This particular function call tells the computer to skip the next 200 input characters or to skip characters until a newline character is read, whichever comes first.
Here are some examples that use a char variable ch and three int variables, i, j, and k:
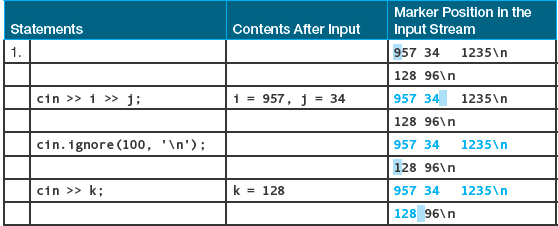
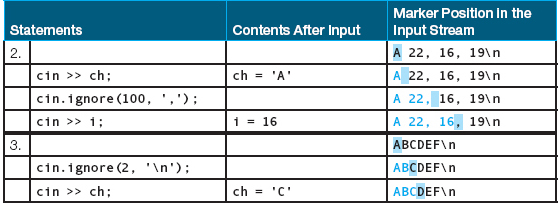
Example 1 shows the most common use of the ignore function, which is to skip the rest of the data on the current input line. Example 2 demonstrates the use of a character other than \n as the second argument. We skip over all input characters until a comma has been found, and then read the next input number into i. In both Example 1 and Example 2, we are focusing on the second argument to the ignore function, and we arbitrarily choose any large number, such as 100, for the first argument. In Example 3, we change our focus and concentrate on the first argument. Our intention is to skip the next two input characters on the current line.
Reading String Data
To input a character string into a string variable, we have two options. First, we can use the extraction operator (>>). When reading input characters into a string variable, the >> operator skips any leading whitespace characters such as blanks and newlines. It then reads successive characters into the variable, stopping at the first trailing whitespace character (which is not consumed, but remains as the first character waiting in the input stream). For example, assume we have the following code:
string firstName;
string lastName;
cin >> firstName >> lastName;
If the input stream initially looks like this (where  denotes a blank):
denotes a blank):
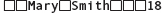
then our input statement stores the four characters Mary into firstName, stores the five characters Smith into lastName, and leaves the input stream as

Although the >> operator is widely used for string input purposes, it has a potential drawback: It cannot be used to input a string that has blanks within it. (Remember that it stops reading as soon as it encounters a whitespace character.) This fact leads us to the second option for performing string input: the getline function. A call to this function looks like this:
getline(cin, myString);
This function call, which does not use dot notation, requires two arguments: an input stream variable (here, cin) and a string variable. The getline function does not skip leading whitespace characters and continues until it reaches the newline character \n. That is, getline reads and stores an entire input line, embedded blanks and all. Note that with getline, the newline character is consumed (but is not stored into the string variable). Given the code segment
string inputStr;
getline(cin, inputStr);
and the input line
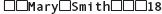
the result of the call to getline is that all 17 characters on the input line (including blanks) are stored into inputStr, and the reading marker is positioned at the beginning of the next input line.
The following table summarizes the differences between the >> operator and the getline function when reading string data into string variables.
Statement |
Skips Leading Whitespace? |
Stops Reading When? |
cin >> inputStr; |
Yes |
When a trailing whitespace character is encountered (which is not consumed) |
getline(cin, inputStr); |
No |
When \n is encountered (which is consumed) |
The following program demonstrates the use of getline and cin.

Here is a sample run of the program. The data entered by the user are highlighted, and are followed by the output.

QUICK CHECK

4.1.1 Write an input statement that reads three integer values into variables a, b, and c. (pp. 139–142)
4.1.2 If an input line contains
Jones, Walker Thomas
what will be the values in the string variables first, middle, and last when the following statement is executed? (pp. 147–149)
cin >> first >> middle >> last;
4.1.3 What do we call the process of placing values from an outside data set into variables in a program? (p. 138)
4.1.4 Which operator do you use for program input, >> or <<? (p. 139)
4.1.5 Why can an input statement specify only variables as its operands? (p. 141)
4.1.6 What is a reading marker used for? (p. 142)
4.1.7 The << operator skips spaces when reading input from the console. What function can we use to read characters into a char variable ch and not skip spaces? (p. 144)
4.1.8 Write a C++ statement that invokes a function to skip 10 characters or skip characters until a space is encountered? (p. 146)
4.2 Interactive Input/Output
In Chapter 1, we defined an interactive program as one in which the user communicates directly with the computer. Many of the programs that we write are interactive. There is a certain “etiquette” involved in writing interactive programs that has to do with instructions for the user to follow.
To get data into an interactive program, we begin with input prompts—that is, printed messages explaining what the user should enter. Without these messages, the user has no idea which data values to type. In many cases, a program also should print out all of the data values typed in by the user so that the user can verify that they were entered correctly. Printing out the input values is called echo printing.
Here’s a program showing the proper use of prompts:


Here is the output, with user input highlighted:
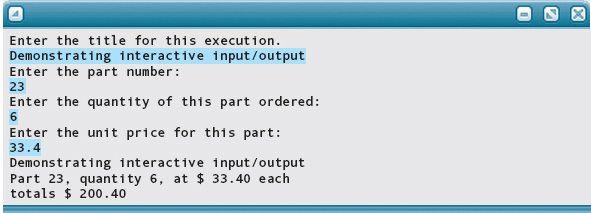
Go back and look at the program in the previous section. It is the same program with no prompts and no formatting. If you were the person entering the information, which program would you prefer to use? If your job required you to read the output, which version would you find more usable?
The amount of information you should put into your prompts depends on who will use the program. If you are writing a program for people who are not familiar with computers, your messages should be more detailed. For example, the prompt might read, “Type a four-digit part number, then press the key marked Enter.” If the program will be used frequently by the same people, you might shorten the prompts: “Enter PN” and “Enter Qty.” If the program is intended for very experienced users, you can prompt for several values at once and have them type all of the values on one input line:
Enter PN, Qty, Unit Price:
In programs that use large amounts of data, this method saves the user keystrokes and time. Of course, it also makes it easier for the user to enter values in the wrong order. In such situations, echo printing the data is especially important.
The decision about whether a program should echo print its input or not also depends on how experienced the users are and on which task the program is to perform. If the users are experienced and the prompts are clear, as in the first example, then echo printing is probably not required. If the users are novices or multiple values can be input at once, echo printing should be used. If the program takes a large quantity of data as input and the users are experienced, rather than echo print the data, the data may be stored in a separate file that can be checked after all of the data is input. We discuss how to store data into a file later in this chapter.
Prompts are not the only way in which programs interact with users. It can be helpful to have a program print out some general instructions at the beginning (“Press Enter after typing each data value. Enter a negative number when done.”). When data are not entered in the correct form, a message that indicates the problem should be printed. For users who haven’t worked much with computers, it’s important that these messages be informative and “friendly.” The message

is likely to upset an inexperienced user. Moreover, it doesn’t offer any constructive information. A much better message would be

In Chapter 5, we introduce the statements that allow us to test for erroneous data.
QUICK CHECK
4.2.1 Why do we need to use prompts for interactive I/O? (pp. 147–148)
4.2.2 What is an input prompt? (p. 149)
4.3 Noninteractive Input/Output
Although we tend to use examples of interactive I/O in this text, many programs are written using noninteractive I/O. A common example of noninteractive I/O on large computer systems is batch processing (see Chapter 1). In batch processing, the user and the computer do not interact while the program is running. This method is most effective when a program will have large amounts of data as input or output. An example of batch processing is a program that takes as input a file containing semester grades for thousands of students and prints grade reports to be mailed out to those students.
When a program must read in many data values, the usual practice is to prepare the data ahead of time, storing them into a file. This allows the user to go back and make changes or corrections to the data as necessary before running the program. When a program is designed to print lots of data, the output can be sent directly to a high-speed printer or another disk file. After the program has been run, the user can examine the data at leisure. In the next section, we discuss input and output with disk files.
Programs designed for noninteractive I/O do not print prompting messages for input. It is a good idea, however, to echo print each data value that is read. Echo printing allows the person reading the output to verify that the input values were prepared correctly. Because noninteractive programs tend to print large amounts of data, their output often takes the form of a table—columns with descriptive headings.
Most C++ programs are written for interactive use. The flexibility of the language allows you to write noninteractive programs as well. The biggest difference is in the input/output requirements. Noninteractive programs are generally more rigid about the organization and format of the input and output data.
4.4 File Input and Output
In everything we’ve done so far, we’ve assumed that the input to our programs comes from the keyboard and that the output from our programs goes to the screen. We look now at input/output from and to files.
Files
Earlier we defined a file as a named area in secondary storage that holds a collection of information (for example, the program code we have typed into the editor). The information in a file usually is stored on an auxiliary storage device, such as a disk. Our programs can read data from a file in the same way they read data from the keyboard, and they can write output to a disk file in the same way they write output to the screen.
Why would we want a program to read data from a file instead of the keyboard? If a program will read a large quantity of data, it is easier to enter the data into a file with an editor than to enter it while the program is running. When we are working in the editor, we can easily go back and correct mistakes. Also, we do not have to enter the data all at once; we can take a break and come back later. Finally, if we want to rerun the program, having the data stored in a file allows us to do so without retyping the data.
Why would we want the output from a program to be written to a file? The contents of a file can be displayed on a screen or printed. This gives us the option of looking at the output over and over again without having to rerun the program. Also, the output stored in a file can be read into another program as input.
Using Files
If we want a program to use file I/O, we have to do four things:
1. Request the preprocessor to include the header file fstream.
2. Use declaration statements to declare the file streams we will use.
3. Prepare each file for reading or writing by using a function named open.
4. Specify the name of the file stream in each input or output statement.
Including the Header File fstream
Suppose we want Chapter 3’s Mortgage program (p. 126) to read data from a file and to write its output to a file. The first thing we must do is use the following preprocessor directive:
#include <fstream>
Through the header file fstream, the C++ standard library defines two data types, ifstream and ofstream (standing for input file stream and output file stream, respectively). Consistent with the general idea of streams in C++, the ifstream data type represents a stream of characters coming from an input file, whereas ofstream represents a stream of characters going to an output file.
All of the istream operations you have learned about—the extraction operator (>>), the get function, and the ignore function—are also valid for the ifstream type. Likewise, all of the ostream operations, such as the insertion operator (<<) and the endl, setw, and setprecision manipulators, apply to the ofstream type. To these basic operations, the ifstream and ofstream types add some more operations designed specifically for file I/O.
Declaring File Streams
In a program, you declare stream variables the same way that you declare any variable—you specify the data type and then the variable name:

(You don’t have to declare the stream variables cin and cout. The header file iostream already does so for you.)
For our Mortgage program, let’s name the input and output file streams inData and outData. We declare them like this:

Note that the ifstream type is for input files only, and the ofstream type is for output files only. With these data types, you cannot read from and write to the same file.
Opening Files
The third thing we have to do is prepare each file for reading or writing, an act called opening a file. Opening a file causes the computer’s operating system to perform certain actions that allow us to proceed with file I/O.
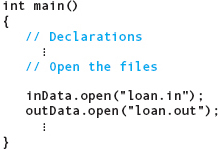
In our example, we want to read from the file stream inData and write to the file stream outData. We open the relevant files by using these statements:
inData.open("loan.in");
outData.open("loan.out");
Both of these statements are function calls (notice the telltale arguments—the mark of a function). In each function call, the argument is a literal string enclosed by quotes. The first statement is a call to a function named open, which is associated with the ifstream data type. The second statement is a call to another function (also named open) associated with the ofstream data type. As we have seen earlier, we use dot notation (as in inData.open) to call certain library functions that are tightly associated with data types.
Exactly what does an open function do? First, it associates a stream variable used in your program with a physical file on disk. Our first function call creates a connection between the stream variable inData and the actual disk file, named loan.in. (Names of file streams must be identifiers; they are variables in your program. But some computer systems do not use this syntax for file names on disk. For example, many systems allow or even require a dot within a file name.) Similarly, the second function call associates the stream variable outData with the disk file loan.out. Associating a program’s name for a file (outData) with the actual name for the file (loan.out) is much the same as associating a program’s name for the standard output device (cout) with the actual device (the screen).1
The next thing the open function does depends on whether the file is an input file or an output file. With an input file, the open function sets the file’s reading marker to the first piece of data in the file. (Each input file has its own reading marker.)
With an output file, the open function checks whether the file already exists. If the file doesn’t exist, open creates a new, empty file for you. If the file already exists, open erases the old contents of the file. Then the writing marker is set at the beginning of the empty file (see FIGURE 4.2). As output proceeds, each successive output operation advances the writing marker to add data to the end of the file.
Because the reason for opening files is to prepare the files for reading or writing, you must open the files before using any input or output statements that refer to the files. In a program, it’s a good idea to open files right away to be sure that the files are prepared before the program attempts any file I/O.
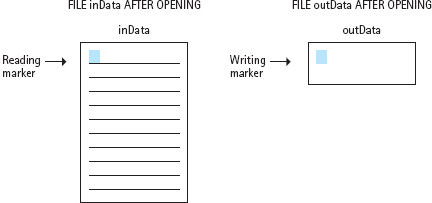
FIGURE 4.2 The Effect of Opening a File
In addition to the open function, a close function is associated with both the ifstream and ofstream types. This function has no arguments and may be used as follows:

Closing a file causes the operating system to perform certain wrap-up activities on it and to break the connection between the stream variable and the file.
Should you always call the close function when you’re finished reading or writing a file? In some programming languages, it’s extremely important that you remember to do so. In C++, however, a file is automatically closed when program control leaves the block (compound statement) in which the stream variable is declared. (Until we get to Chapter 8, this block is assumed to be the body of the main function.) When control leaves this block, a special function associated with each of ifstream and ofstream called a destructor is implicitly executed; this destructor function closes the file for you. Consequently, C++ programs rarely call the close function explicitly. Conversely, many programmers make it a regular habit to call the close function explicitly, and you may wish to do so yourself.
Specifying File Streams in Input/Output Statements
There is just one more thing we have to do to use files. As we said earlier, all istream operations also are valid for the ifstream type, and all ostream operations are valid for the ofstream type. So, to read from or write to a file, all we need to do in our input and output statements is substitute the appropriate file stream variable for cin or cout. In our Mortgage program, we would use a statement like
inData >> loanAmount >> yearlyInterest >> numberOfYears;
to instruct the computer to read data from the file inData. Similarly, all of the output statements that write to the file outData would specify outData, not cout, as the destination:

What is nice about C++ stream I/O is that we have a uniform syntax for performing I/O operations, regardless of whether we’re working with the keyboard and screen, with files, or with other I/O devices.
SOFTWARE MAINTENANCE CASE STUDY: Adding File Input/Output to a Program
We have used the Mortgage program as an example to demonstrate file input and output. In this maintenance case study, we rework the complete program to use files.
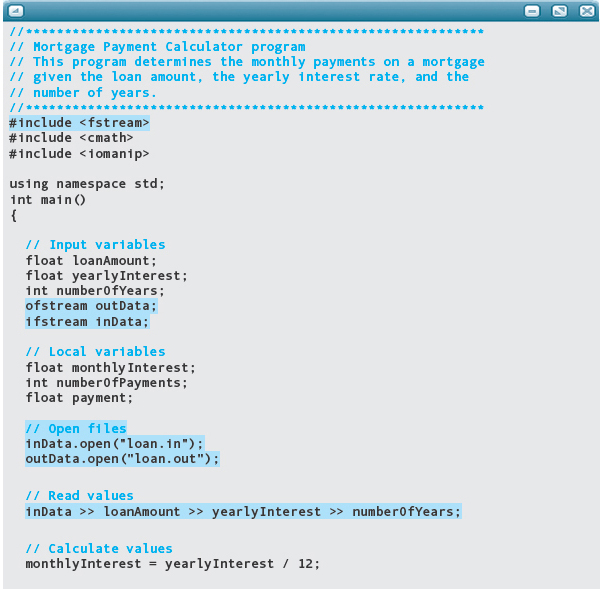
The first steps in any maintenance project involve examining the original program, understanding how the code works, and creating a copy of the original code with which to work. Here is a listing of the original program with comments interspersed as we examine the code.

These first four lines remain the same for any program that uses screen input/output, math functions, and formatting manipulators. Now, however, we will use file input/output. Thus the first line must be changed to include fstream rather than iostream.
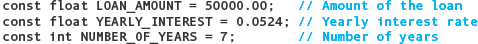
These constants must be removed, and variable declarations inserted for loanAmount, yearlyInterest, and numberOfYears. These declarations should be placed within the function main along with the other declarations.

These declarations should remain the same, followed by the declarations for the values that were previously constants.

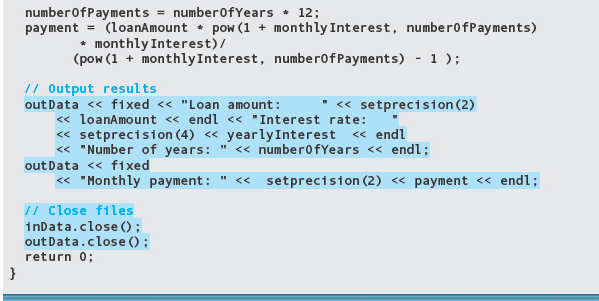
These assignment statements must have the names of the constants replaced with the corresponding variable names. But before we do that, we must enter the values for the variables from the files.

The constants need to be replaced by the variable names in these output statements. While we are making the changes, let’s change the output to be in tabular form rather than sentence form.
return 0;
}
Let’s list the tasks necessary to make the changes.
 Remove constants and insert variable declarations.
Remove constants and insert variable declarations.
Read in the values for the variables.
Change assignments to use variables instead of constants.
Change output statements from constants to appropriate variables.
Make the output in table form.
Have we forgotten anything? Yes: We must declare the file variables, which in turn means we must include fstream, and open the files. Although it isn’t required, we also close the files so that you can see an example of doing this.
Here is a listing of the revised program with the changes highlighted.
Before running the program, you would use the editor to create and save a file loan.in to serve as input. The contents of loan.in and loan.out are shown here:
loan.in

loan.out

In writing the new Mortgage program, what happens if you mistakenly specify cout instead of outData in one of the output statements? Nothing disastrous—the output of that one statement merely goes to the screen instead of the output file. And what if, by mistake, you specify cin instead of inData in the input statement? The consequences are not as pleasant: When you run the program, the computer will appear to go dead (to hang). Here’s the reason: Execution reaches the input statement and the computer waits for you to enter the data from the keyboard. Of course, you don’t know that the computer is waiting, because no message on the screen prompts you for input, and you are assuming (wrongly) that the program is getting its input from a data file. So the computer waits, and you wait, and the computer waits, and you wait. Every programmer at one time or another has had the experience of thinking the computer has hung, when, in fact, it is working just fine, silently waiting for keyboard input.
Run-Time Input of File Names
Until now, our examples of opening a file for input have included code similar to the following:
ifstream inFile;
inFile.open("datafile.dat");
The open function associated with the ifstream data type requires an argument that specifies the name of the actual data file. By using a literal string, as in the preceding example, the file name is fixed at compile time. Therefore, the program works for only this particular file.
We often want to make a program more flexible by allowing the file name to be determined at run time. A common technique is to prompt the user for the name of the file, read the user’s response into a variable, and pass the variable as an argument to the open function. In principle, the following code should accomplish what we want. Unfortunately, the compiler does not allow it.

The problem is that the open function does not expect an argument of type string. Instead, it expects a C string. A C string (so named because it originated in the C language, the forerunner of C++) is a limited form of string whose properties we discuss much later in this book. A literal string, such as "datafile.dat", happens to be a C string and thus is acceptable as an argument to the open function.
To make this code work correctly, we need to convert a string variable to a C string. The string data type provides a value-returning function named c_str that is applied to a string variable as follows:
fileName.c_str()
This function returns the C string that is equivalent to the one contained in the fileName variable. (The original string contained in fileName is not changed by the function call.) The primary purpose of the c_str function is to allow programmers to call library functions that expect C strings, not string strings, as arguments.
The following program reads in a file name and prints the first line on the file. The file and output are shown following the program.

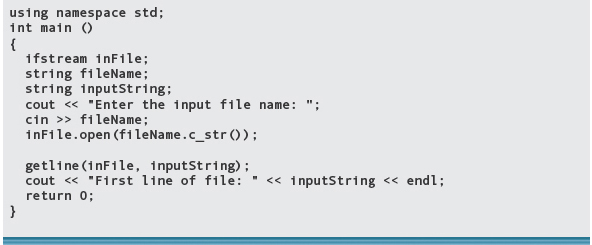
File testData.in:

Output:

QUICK CHECK
4.4.1 What is a file? (p. 152)
4.4.2 Why might we want a program to read from a file instead of the keyboard? (p. 152)
4.4.3 Why might we want a program to write output to a file instead of the console? (p. 152)
4.4.4 What are the four things we must do to have a program use file I/O? (p. 153)
4.4.5 Which data type is used for a file input stream? (p. 153)
4.4.6 Which data type is used for a file output stream? (p. 153)
4.4.7 What is wrong with the following code: (p. 160)

4.4.8 What conditions would you look for in a problem to decide whether interactive or noninteractive input is appropriate? (p. 152)
4.4.9 After including the header file fstream and declaring a file stream, what is the next step in using a file I/O? (p. 153)
4.5 Input Failure
When a program inputs data from the keyboard or an input file, things can go wrong. Suppose that we’re executing a program. It prompts us to enter an integer value, but we absentmindedly type some letters of the alphabet. The input operation fails because of the invalid data. In C++ terminology, the cin stream has entered the fail state. Once a stream has entered the fail state, any further I/O operations using that stream are considered to be null operations—that is, they have no effect at all. Unfortunately for us, the computer does not halt the program or display any error message. The computer just continues executing the program, silently ignoring each additional attempt to use that stream.
Invalid data is the most common reason for input failure. When your program takes an int value as input, it expects to find only digits in the input stream, possibly preceded by a plus or minus sign. If there is a decimal point somewhere within the digits, does the input operation fail? Not necessarily—it depends on where the reading marker is. Let’s look at an example.
Assume that a program has int variables i, j, and k, whose contents are currently 10, 20, and 30, respectively. The program now executes the following two statements:
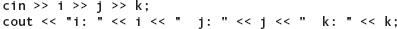
If we type these characters for the input data:
1234.56 7 89
then the program produces this output:
i: 1234 j: 20 k: 30
Let’s see why.
Remember that when reading int or float data, the extraction operator >> stops reading at the first character that is inappropriate for the data type (whitespace or otherwise). In our example, the input operation for i succeeds. The computer extracts the first four characters from the input stream and stores the integer value 1234 into i. The reading marker is now on the decimal point:
1234.56 7 89
The next input operation (for j) fails; an int value cannot begin with a decimal point. The cin stream is now in the fail state, and the current value of j (20) remains unchanged. The third input operation (for k) is ignored, as are all the rest of the statements in our program that read from cin.
Another way to make a stream enter the fail state is to try to open an input file that doesn’t exist. Suppose that you have a data file named myfile.dat. Your program includes the following statements:

In the call to the open function, you misspelled the name of your file. At run time, the attempt to open the file fails, so the stream inFile enters the fail state. The next three input operations (for i, j, and k) are null operations. Without issuing any error message, the program proceeds to use the (unknown) contents of i, j, and k in calculations. The results of these calculations are certain to be puzzling.
The point of this discussion is not to make you nervous about I/O but rather to make you aware of its limitations. The “Testing and Debugging” section at the end of this chapter offers suggestions for avoiding input failure, and Chapters 5 and 6 introduce program statements that let you test the state of a stream.
4.6 Software Design Methodologies
Over the last two chapters and the first part of this one, we have introduced elements of the C++ language that let us input data, perform calculations, and output results. The programs we have written so far were short and straightforward because the problems to be solved were simple. We are now ready to write programs for more complicated problems—but first we need to step back and look at the overall process of programming.
As you learned in Chapter 1, the programming process consists of a problem-solving phase and an implementation phase. The problem-solving phase includes analysis (analyzing and understanding the problem to be solved) and design (designing a solution to the problem). Given a complex problem—one that results in a 10,000-line program, for example—it’s simply not reasonable to skip the design process and go directly to writing C++ code. What we need is a systematic way of designing a solution to a problem, no matter how complicated the problem is.
In the remainder of this chapter, we describe two important methodologies for designing solutions to more complex problems: functional decomposition and object-oriented design. These methodologies will help you create solutions that can be easily implemented as C++ programs. The resulting programs are readable, understandable, and easy to debug and modify.
One software design methodology that is in widespread use is known as object-oriented design (OOD). C++ evolved from the C language primarily to facilitate the use of the OOD methodology. Here we present the essential concepts of OOD; we expand our treatment of the approach later in the book. OOD is often used in conjunction with the other methodology that we discuss more fully in this chapter, functional decomposition.
Object-oriented design (OOD) A technique for developing software in which the solution is expressed in terms of objects—self-contained entities composed of data and operations on that data.
Functional decomposition A technique for developing software in which the problem is divided into more easily handled subproblems, the solutions of which create a solution to the overall problem.
OOD focuses on entities (objects) consisting of data and operations on the data. In OOD, we solve a problem by identifying the components that make up a solution and identifying how those components interact with one another through operations on the data that they contain. The result is a design for a set of objects that can be assembled to form a solution to a problem. In contrast, functional decomposition views the solution to a problem as a task to be accomplished. It focuses on the sequence of operations that are required to complete the task. When the problem requires a sequence of steps that is long or complex, we divide it into subproblems that are easier to solve.
The choice of which methodology to use depends on the problem at hand. For example, a large problem might involve several sequential phases of processing, such as gathering data and verifying its correctness with noninteractive processing, analyzing the data interactively, and printing reports noninteractively at the conclusion of the analysis. This process has a natural functional decomposition. Each of the phases, however, may best be solved by a set of objects that represent the data and the operations that can be applied to it. Some of the individual operations may be sufficiently complex that they require further decomposition, either into a sequence of operations or into another set of objects.
If you look at a problem and see that it is natural to think about it in terms of a collection of component parts, then you should use OOD to solve it. For example, a banking problem may require a checkingAccount object with associated operations OpenAccount, WriteCheck, MakeDeposit, and IsOverdrawn. The checkingAccount object might consist of both data (the account number and current balance, for example) and these operations, all bound together into one unit.
By contrast, if you find that it is natural to think of the solution to the problem as a series of steps, you should use functional decomposition. For example, when computing some statistical measures on a large set of real numbers, it is natural to decompose the problem into a sequence of steps that read a value, perform calculations, and then repeat the sequence. The C++ language and the standard library supply all of the operations that we need, and we simply write a sequence of those operations to solve the problem.
To summarize, top-down design methods focus on the process of transforming the input into the output, resulting in a hierarchy of tasks. Object-oriented design focuses on the data objects that are to be transformed, resulting in a hierarchy of objects. In reality, these design methods are often combined, with functional decomposition used to describe the actions of the objects specified in an object-oriented design.
QUICK CHECK
4.6.1 What is the first step in the object-oriented design process? (p. 163)
4.7 Functional Decomposition
In functional decomposition (also called structured design, top-down design, stepwise refinement, and modular programming), we work from the abstract (a list of the major steps in our solution) to the particular (algorithmic steps that can be translated directly into C++ code). You can also think of this methodology as working from a high-level solution, leaving the details of the implementation unspecified, down to a fully detailed solution.
The easiest way to solve a problem is to give it to someone else and say, “Solve this problem.” This is the most abstract level of a problem solution: a single-statement solution that encompasses the entire problem without specifying any of the details of implementation. It’s at this point that we programmers are called in. Our job is to turn the abstract solution into a concrete solution, a program.
If the solution clearly involves a series of major steps, we break it down (decompose it) into pieces. In the process, we move to a lower level of abstraction—that is, some of the implementation details (but not too many) are now specified. Each of the major steps becomes an independent subproblem that we can work on separately. In a large project, one person (the chief architect or team leader) formulates the subproblems for other members of the team, saying to each one, “Solve this problem.” In the case of a small project, we give the subproblems to ourselves. Then we choose one subproblem at a time to solve. We may break the subproblem into another series of steps that, in turn, become smaller subproblems. Or we may identify components that are naturally represented as objects. The process continues until each subproblem cannot be divided further or has an obvious solution.
Why do we work this way? Why not simply write out all of the details? Because it is much easier to focus on one problem at a time. For example, suppose you are working on a program and discover that you need a complex formula to calculate an appropriate fieldwidth for printing a value. Calculating fieldwidths is not the purpose of this part of the program. If you shift your focus to the calculation, you are likely to forget some detail of the overall process. So you write down an abstract step—“Calculate the fieldwidth”—and go on. Once you’ve written out the major steps, you can go back to working out the calculation.
By subdividing the problem, you create a hierarchical structure called a tree structure. Each level of the tree is a complete solution to the problem that is less abstract (more detailed) than the level above it. FIGURE 4.3 shows a generic solution tree for a problem. Steps that are shaded have enough detail to be translated directly into C++ statements; these are concrete steps. Those that are not shaded are abstract steps; they reappear as subproblems in the next level down. Each box in the figure represents a module. Modules are the basic building blocks in a functional decomposition. The diagram in Figure 4.3 is also called a module structure chart.
Concrete step A step for which the implementation details are fully specified.
Abstract step A step for which some implementation details remain unspecified.
Module A self-contained collection of steps that solves a problem or subproblem; can contain both concrete and abstract steps.
Functional decomposition uses the divide-and-conquer approach to problem solving. In other words, it breaks up large problems into smaller units that are easier to handle. OOD does this, too, but in OOD the units are objects, whereas the units in functional decomposition are modules.
Modules
A module begins life as an abstract step in the next-higher level of the solution tree. It is completed when it solves a given subproblem—that is, when it specifies a series of steps that does the same thing as the higher-level abstract step. At this stage, a module is functionally equivalent to the abstract step. (Don’t confuse our use of function here with C++ functions. Here we use the term to refer to the specific role that the module or step plays in an algorithmic solution.)
Functional equivalence A property of a module that performs exactly the same operation as the abstract step it defines. A pair of modules are also functionally equivalent to each other when they perform exactly the same operation.
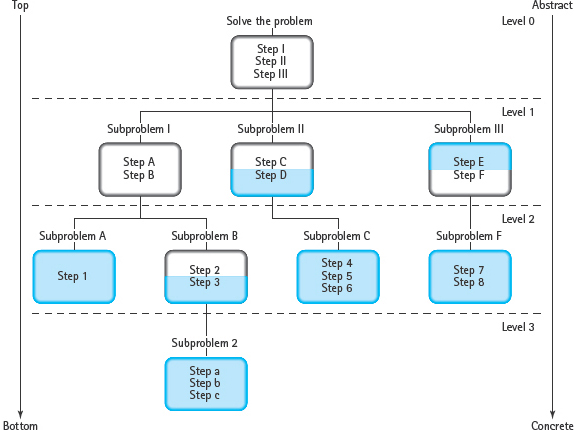
FIGURE 4.3 Hierarchical Solution Tree
In a properly written module, the only steps that directly address the given subproblem are concrete steps; abstract steps are used for significant new subproblems. This is called functional cohesion.
Functional cohesion A property of a module in which all concrete steps are directed toward solving just one problem, and any significant subproblems are written as abstract steps.
The idea behind functional cohesion is that each module should do just one thing and do it well. Functional cohesion is not a well-defined property; there is no quantitative measure of cohesion. Rather, it is a product of the human need to organize things into neat chunks that are easy to understand and remember. Knowing which details to make concrete and which to leave abstract is a matter of experience, circumstance, and personal style. For example, you might decide to include a fieldwidth calculation in a printing module if there isn’t so much detail in the rest of the module that it becomes confusing. In contrast, if the calculation is performed several times, it makes sense to write it as a separate module and just refer to it each time you need it.
Writing Cohesive Modules
Here’s one approach to writing modules that are cohesive:
1. Think about how you would solve the subproblem by hand.
2. Write down the major steps.
3. If a step is simple enough that you can see how to implement it directly in C++, it is at the concrete level; it doesn’t need any further refinement.
4. If you have to think about implementing a step as a series of smaller steps or as several C++ statements, it is still at an abstract level.
5. If you are trying to write a series of steps and start to feel overwhelmed by details, you probably are bypassing one or more levels of abstraction. Stand back and look for pieces that you can write as more abstract steps.
We could call this the “procrastinator’s technique.” If a step is cumbersome or difficult, put it off to a lower level; don’t think about it today, think about it tomorrow. Of course, tomorrow does come, but the whole process can be applied again to the subproblem. A trouble spot often seems much simpler when you can focus on it. And eventually the whole problem is broken up into manageable units.
As you work your way down the solution tree, you make a series of design decisions. If a decision proves awkward or wrong (and many times it does!), you can backtrack (go back up the tree to a higher-level module) and try something else. You don’t have to scrap your whole design—only the small part you are working on. You may explore many intermediate steps and trial solutions before you reach a final design.
Pseudocode
You’ll find it easier to implement a design if you write the steps in pseudocode. Pseudocode is a mixture of English statements and C++-like control structures that can be translated easily into C++. (We’ve been using pseudocode in the algorithms in the Problem-Solving Case Studies.) When a concrete step is written in pseudocode, it should be possible to rewrite it directly as a C++ statement in a program.
Implementing the Design
The product of functional decomposition is a hierarchical solution to a problem with multiple levels of abstraction. FIGURE 4.4 shows a functional decomposition for the revised Mortgage program. This kind of solution forms the basis for the implementation phase of programming.
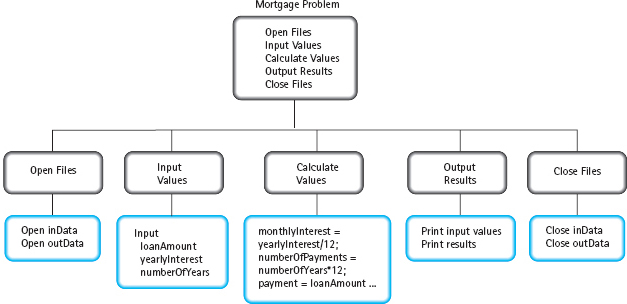
FIGURE 4.4 Solution Tree of Mortgage Program
How do we translate a functional decomposition into a C++ program? If you look closely at Figure 4.4, you can see that the concrete steps (which are shaded) can be assembled into a complete algorithm for solving the problem. The order in which they are assembled is determined by their position in the tree. We start at the top of the tree, at level 0, with the first step, “Open Files.” Because it is abstract, we must go to the next level, level 1. There we find a series of concrete steps that correspond to this step; this series of steps becomes the first part of our algorithm. Because the conversion process is now concrete, we can go back to level 0 and go on to the next step, “Input Values.” Because it is abstract, we go to level 1 and find a series of concrete steps that correspond to this step; this series of steps becomes the next part of our algorithm. Returning to level 0, we go on to the next step, “Calculate Values.” Finally we return to level 0 for the last time and complete the last steps, “Output Results” and “Close Files.”
Open inData
Open outData
Input loanAmount, yearlyInterest, numberOfYears
Set monthlyInterest to yearlyInterest divided by 12
Set numberOfPayments to numberOfYears times 12
Set payment to (loanAmount * pow(1 + monthlyInterest, numberOfPayments) * monthlyInterest) / (pow(1 + monthlyInterest, numberOfPayments) – 1)
Print “For a loan amount of” loanAmount “with an interest rate of” yearlyInterest “and a” numberOfYears “year mortgage,”
Print “your monthly payments are $” payment “.”
Close inData
Close outData
From this algorithm we can construct a table of the variables required, and then write the declarations and executable statements of the program.
In practice, you write your design not as a tree diagram, but rather as a series of modules grouped by levels of abstraction.
Main
Level 0
Open Files
Input Values
Calculate Values
Output Results
Close Files
Open Files
Level 1
Open inData
Open outData
Input Values
Input loanAmount
Input yearlyInterest
Input numberOfyears
Calculate Values
Set monthlyInterest to yearlyInterest divided by 12
Set numberOfPayments to numberOfYears times 12
Set payment to (loanAmount * pow(1 + monthlyInterest, numberrOfPayments)
* monthlyInterest) / (pow(1 + monthlyInterest, numberOfPayments) – 1)
Output
Print “Loan amount:” loanAmount
Print “Interest rate:” yearlyInterest
Print “Number of years:” numberOfYears
Print “Monthly payment:” payment
Close Files
Close inData
Close outData
If you look at the C++ program for Mortgage, you can see that it closely resembles this solution. The names of the modules are also paraphrased as comments in the code.
The type of implementation that we’ve introduced here is called a flat or inline implementation. We are flattening the two-dimensional, hierarchical structure of the solution by writing all of the steps as one long sequence. This kind of implementation is adequate when a solution is short and has only a few levels of abstraction. The programs it produces are clear and easy to understand, assuming appropriate comments and good style.
Longer programs, with more levels of abstraction, are difficult to work with as flat implementations. In Chapter 8, you’ll see that it is preferable to implement a hierarchical solution by using a hierarchical implementation. There we implement many of the modules by writing them as separate C++ functions, and the abstract steps in the design are then replaced with calls to those functions.
One advantage of implementing modules as functions is that they can be called from different places in a program. For example, if a problem requires that the volume of a cylinder be computed in several places, we could write a single function to perform this calculation and simply call it in each place. This gives us a semihierarchical implementation. Such an implementation does not preserve a pure hierarchy because abstract steps at various levels of the solution tree share one implementation of a module (see FIGURE 4.5). A shared module actually falls outside the hierarchy because it doesn’t really belong at any one level.
Another advantage of implementing modules as functions is that you can pick them up and use them in other programs. Over time, you will build a library of your own functions to complement those that are supplied by the C++ standard library.
We will postpone a detailed discussion of hierarchical implementations until Chapter 8. For now, our programs remain short enough for flat implementations to suffice. Chapters 5 and 6 examine topics such as flow of control, preconditions and postconditions, interface design, and side effects that you’ll need to develop hierarchical implementations.
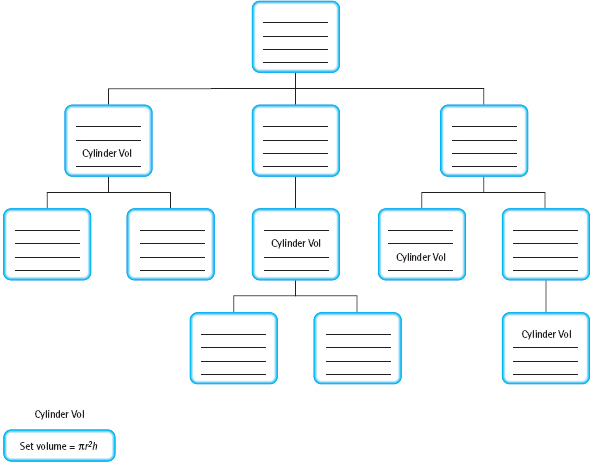
FIGURE 4.5 A Semihierarchical Module Structure Chart with a Shared Module
From now on, we use the following outline for the functional decompositions in our case studies, and we recommend that you adopt a similar outline in solving your own programming problems:
Problem statement
Input description
Output description
Discussion
Assumptions (if any)
Main module
Remaining modules by levels
Module structure chart
In some of our case studies, this outline is reorganized a bit, so that the input and output descriptions follow the discussion. In later chapters, we also expand the outline with additional sections. Don’t think of this outline as a rigid prescription—it is more like a “to-do list.” We want to be sure to do everything on the list, but the individual circumstances of each problem guide the order in which we do them.
A Perspective on Design
We have looked at two design methodologies, object-oriented design and functional decomposition. Until we learn about additional C++ language features that support OOD, we will use functional decomposition in the next several chapters to come up with our problem solutions.
An important perspective to keep in mind is that functional decomposition and OOD are not separate, disjoint techniques. OOD decomposes a problem into objects. Objects not only contain data but also have associated operations. The operations on objects require algorithms. Sometimes the algorithms are complicated and must be decomposed into subalgorithms by using functional decomposition. Experienced programmers are familiar with both methodologies and know when to use one or the other, or a combination of the two.
Remember that the problem-solving phase of the programming process takes time. If you spend the bulk of your time analyzing and designing a solution, then coding and implementing the program should take relatively little time.
SOFTWARE ENGINEERING TIP Documentation

As you create your functional decomposition or object-oriented design, you are developing documentation for your program. Documentation includes the written problem specifications, design, development history, and actual code of a program.
Good documentation helps other programmers read and understand a program and is invaluable when software is being debugged and modified (maintained). If you haven’t looked at your program for six months and need to change it, you’ll be happy that you documented it well. Of course, if someone else has to use and modify your program, documentation is indispensable.
Documentation is both external and internal to the program. External documentation includes the specifications, the development history, and the design documents. Internal documentation includes the program format and self-documenting code—meaningful identifiers and comments. You can use the pseudocode from the design process as comments in your programs.
Self-documenting code Program code containing meaningful identifiers as well as judiciously used clarifying comments.
This kind of documentation may be sufficient for someone reading or maintaining your programs. However, if a program will be used by people who are not programmers, you must provide a user’s manual as well.
Be sure to keep documentation up to date. Indicate any changes you make in a program in all of the pertinent documentation. Use self-documenting code to make your programs more readable.
QUICK CHECK
4.7.1 What characterizes a concrete step in a functional decomposition design? (pp. 164–166)
4.7.2 If you are given a functional decomposition design, how do you implement it? (pp. 166–167)
4.7.3 In functional decomposition we work from the _______________ to the _______________. (p. 164)
4.7.4 If a solution clearly involves a series of major steps, what must we do? (p. 164)
4.7.5 What is a module? (p. 165)
4.7.6 What is functional cohesion? (p. 166)
4.7.7 What is pseudocode? (p. 166)
4.7.8 Where do we start when translating a functional decomposition into a C++ program? (p. 167)
Now let’s look at a case study that demonstrates functional decomposition.
Problem-Solving Case Study
Displaying a Name in Multiple Formats
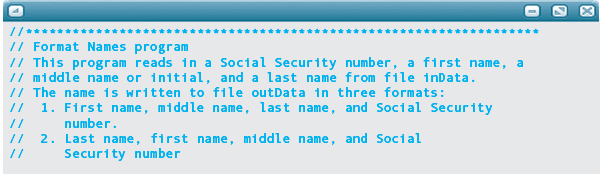
PROBLEM: You are beginning to work on a problem that needs to output names in several formats along with the corresponding Social Security number. As a start, you decide to write a short C++ program that takes a Social Security number as input and a single name and displays them in the different formats so you can be certain that all of your string expressions are correct.
INPUT: The Social Security number and a name in three parts, on file name.dat, each separated by one or more whitespace characters.
OUTPUT: The name is to be written in four different formats on file name.out:
1. First name, middle name, last name, Social Security number
2. Last name, first name, middle name, Social Security number
3. Last name, first name, middle initial, Social Security number
4. First name, middle initial, last name
DISCUSSION: You could easily type the Social Security number and the name in the four formats as string literals in the code, but the purpose of this exercise is to develop and test the string expressions that you need for the larger problem. The problem statement doesn’t say in which order the parts of the name are entered on the file, but it does say that they are separated by whitespace. You assume that they are in first name, middle name or initial, and last name order. Because the data are on a file, you don’t need to prompt for the values. Once you have the Social Security number and the name, you just write them out in the various formats.
ASSUMPTION: The name is in first, middle, and last order on the file.
Main Module
Level 0
Open files
Get Social Security number
Get name
Write data in proper formats
Close files
Open Files
Level 0
Open inData
Open outData
The “Get Social Security number” step can be directly implemented by reading into the string variable. Thus it doesn’t require expansion at Level 1 of our design.
Get Name
Get first name
Get middle name or initial
Get last name
Does reading the middle name present a problem if the file contains an initial rather than a middle name? Not really. You just assume that a middle name is entered and extract the initial from the middle name when you need it for the third and fourth formats. If the initial was entered for the middle name, then the second and third output forms will be the same.
What about punctuation in the output? If the last name comes first, it should be followed by a comma, and the middle initial should be followed by a period. Thus, if an initial is entered rather than a middle name, it must be followed by a period. This must be added to the assumptions.
ASSUMPTION: The name is in first, middle, and last order, and a period must follow the middle initial if it is entered instead of a middle name.
Write Data in Proper Formats
Write first name, blank, middle name, blank, last name, blank, Social Security number
Write last name, comma, blank first name, blank, middle name, blank, Social Security number
Write last name, comma, blank, first name, blank, middle initial, period, blank, Social Security number
Write first name, blank, middle initial, period, blank, last name
The only thing left to define is the middle initial. We can directly access the first character in the middle name.
Middle Initial
Level 2
Set initial to middleName.at(0)
Close Files
Close inData
Close outData
MODULE STRUCTURE CHART

Below is the program. The input data and the output follow the program.

Input file:

Output:

Testing and Debugging
An important part of implementing a program is testing it (checking the results). By now you should realize that there is nothing magical about the computer. It is infallible only if the person writing the instructions and entering the data is infallible. Don’t trust the computer to give you the correct answers until you’ve verified enough of them by hand to convince yourself that the program is working.
From here on, these “Testing and Debugging” sections offer tips on how to test your programs and what to do if a program doesn’t work the way you expect it to work. But don’t wait until you’ve found a bug to read the “Testing and Debugging” sections—it’s much easier to prevent bugs than to fix them.
When testing programs that receive data values from a file as input, it’s possible for input operations to fail. And when input fails in C++, the computer doesn’t issue a warning message or terminate the program. Instead, the program simply continues executing, ignoring any further input operations on that file. The two most common reasons for input failure are invalid data and the end-of-file error.
An end-of-file error occurs when the program has read all of the input data available in the file and needs more data to fill the variables in its input statements. It might be that the data file simply was not prepared properly. Perhaps it contains fewer data items than the program requires. Or perhaps the format of the input data is wrong. Leaving out whitespace between numeric values, for instance, is guaranteed to cause trouble.
As an example, suppose we want a data file to contain three integer values: 25, 16, and 42. Look what happens with this data:
2516 42
and this code:
inFile >> i >> j >> k;
The first two input operations use up the data in the file, leaving the third with no data to read. The stream inFile enters the fail state, so k isn’t assigned a new value and the computer quietly continues executing at the next statement in the program.
If the data file is prepared correctly and an end-of-file error still occurs, the problem lies in the program logic. For some reason, the program is attempting too many input operations. In this case, the error could be a simple oversight such as specifying too many variables in a particular input statement. It could be a misuse of the ignore function, causing values to be skipped inadvertently. Or it could be a serious flaw in the algorithm. You should check all of these possibilities.
The other major source of input failure—invalid data—has several possible causes. The most common is an error in the preparation or entry of the data. Numeric and character data mixed inappropriately in the input can cause the input stream to fail if it is supposed to read a numeric value but the reading marker is positioned at a character that isn’t allowed in the number. Another cause is using the wrong variable name (which happens to be of the wrong data type) in an input statement. Declaring a variable to be of the wrong data type is a variation on the problem. Finally, leaving out a variable (or including an extra one) in an input statement can cause the reading marker to end up positioned on the wrong type of data.
Another oversight, which doesn’t cause input failure but does cause programmer frustration, is to use cin or cout in an I/O statement when you meant to specify a file stream. If you mistakenly use cin instead of an input file stream, the program stops and waits for input from the keyboard. If you mistakenly use cout instead of an output file stream, you get unexpected output on the screen.
By giving you a framework that can help you organize and keep track of the details involved in designing and implementing a program, functional decomposition (and, later, object-oriented design) should help you avoid many of these errors in the first place.
In later chapters, you’ll see that you can test modules separately. If you make sure that each module works by itself, your program should work when you put all the modules together. Testing modules separately is less work than trying to test an entire program. In a smaller section of code, it’s less likely that multiple errors will combine to produce behavior that is difficult to analyze.
Testing and Debugging Hints
1. Input and output statements always begin with the name of a stream object, and the >> and << operators point in the direction in which the data is going. The statement
cout << n;
sends data to the output stream cout, and the statement
cin >> n;
sends data to the variable n.
2. When a program takes input from or sends output to a file, each I/O statement from or to the file should use the name of the file stream, not cin or cout.
3. The open function associated with an ifstream or ofstream object requires a C string as an argument. The argument cannot be a string object. At this point in the book, the argument can only be (a) a literal string or (b) the C string returned by the function call myString.c_str(), where myString is of type string.
4. When you open a data file for input, make sure that the argument to the open function supplies the correct name of the file.
5. When reading a character string into a string object, the >> operator stops at, but does not consume, the first trailing whitespace character.
6. Each input statement must specify the correct number of variables, and each of those variables must be of the correct data type.
7. If your input data is mixed (character and numeric values), be sure to deal with intervening blanks.
8. Echo print the input data to verify that each value is where it belongs and is in the proper format. (This is crucial, because an input failure in C++ doesn’t produce an error message or terminate the program.)
 Summary
Summary
Programs operate on data. If data and programs are kept separate, the data is available to use with other programs, and the same program can be run with different sets of input data.
The extraction operator (>>) inputs data from the keyboard or a file, storing the data into the variable specified as its right-hand operand. The extraction operator skips any leading whitespace characters and finds the next data value in the input stream. The get function does not skip leading whitespace characters; instead, it takes the very next character and stores it into the char variable specified in its argument list. Both the >> operator and the get function leave the reading marker positioned at the next character to be read. The next input operation begins reading at the point indicated by the marker.
The newline character (denoted by \n in a C++ program) marks the end of a data line. You create a newline character each time you press the Return or Enter key. Your program generates a newline each time you use the endl manipulator or explicitly output the \n character. Newline is a control character, so it is not a printable character. It controls the movement of the screen cursor.
Interactive programs prompt the user for each data entry and directly inform the user of results and errors. Designing interactive dialog through use of prompts is an exercise in the art of communication.
Noninteractive input/output allows data to be prepared before a program is run and allows the program to run again with the same data in the event that a problem crops up during processing.
Data files often are used for noninteractive processing and to permit the output from one program to be used as input to another program. To use these files, you must do four things: (1) include the header file fstream, (2) declare the file streams along with your other variable declarations, (3) prepare the files for reading or writing by calling the open function, and (4) specify the name of the file stream in each input or output statement that uses it.
Object-oriented design and functional decomposition are methodologies for tackling nontrivial programming problems. Object-oriented design produces a problem solution by focusing on objects and their associated operations. Functional decomposition begins with an abstract solution that then is divided into major steps. Each step becomes a subproblem that is analyzed and subdivided further. A concrete step is one that can be translated directly into C++; those steps that need more refining are called abstract steps. A module is a collection of concrete and abstract steps that solves a subproblem. Programs can be built out of modules using a flat implementation, a hierarchical implementation, or a semihierarchical implementation.
Careful attention to program design, program formatting, and documentation produces highly structured and readable programs.
Quick Check Answers

4.1.3 input. 4.1.4 << 4.1.5 Because an input statement indicates where input data values should be stored. 4.1.6 To keep track of the point in the input stream where the computer should continue reading. 4.1.7 cin.get(ch) 4.1.8 cin.ignore(10, ' '); 4.2.1 To tell the user how and when to enter values as input. 4.2.2 A printed message explaining what the user should enter. 4.4.1 A named area in secondary storage that holds a collection of information. 4.4.2 If a program will read a large quantity of data, it is easier to enter the data into a file with an editor than to enter it while the program is running. 4.4.3 The contents of a file can be displayed on a screen, printed, or used as input to another program. 4.4.4 1. Include the fstream library, 2. Declare the file streams we will use, 3. Use the open function to open a file, 4. Use the file stream in each input or output statement. 4.4.5 ifstream 4.4.6 ofstream 4.4.7 we must use the filename.c_str function to return a C string because that is what the inFile.open function expects as its argument type. 4.4.8 The amount of data to be input, and whether the data can be prepared for entry before the program is run. 4.4.9 Preparing the file for reading or writing with the open function. 4.6.1 To identify the major objects in the problem. 4.7.1 It is a step that can be implemented directly in a programming language. 4.7.2 By identifying all of the concrete steps, starting from the top of the tree, and arranging them in the proper order. The sequence of steps is then converted step-by-step into code. 4.7.3 Abstract, particular. 4.7.4 We break the problem down into pieces. 4.7.5 A module is an abstract step in the next-higher level of the solution tree. 4.7.6 A property of a module in which all concrete steps are directed toward solving just one problem, and any significant subproblems are written as abstract. 4.7.7 A mixture of English statements and C++-like control structures that can be translated easily into C++. 4.7.8 We start with the concrete steps at the bottom of the decomposition tree.
Exam Preparation Exercises
1. The statement
cin >> maximum >> minimum;
is equivalent to the two statements:
cin >> minimum;
cin >> maximum;
True or false?
2. What is wrong with each of the following statements?
a. cin << score;
b. cout >> maximum;
c. cin >> "Enter data";
d. cin.ignore('Y', 35);
e. getline(someString, cin);
3. Suppose the input data are entered as follows:
10 20
30 40
50 60
70 80
The input statements that read it are
cin >> a >> b >> c;
cin >> d >> e >> f;
cin >> a >> b;
What are the contents of the variables a, b, c, d, e, and f after the statements have executed?
4. Suppose the input data are entered as follows:

The input statements that read it are

What are the contents of the variables a, b, c, d, e, and f after the statements have executed?
5. Given the input data
January 25, 2005
and the input statement
cin >> string1 >> string2;
a. What is contained in each of the string variables after the statement is executed?
b. Where is the reading marker after the statement is executed?
6. Given the input data
January 25, 2005
and the input statement
getline(cin, string1);
a. What is contained in the string variable after the statement is executed?
b. Where is the reading marker after the statement is executed?
7. Given the input data
January 25, 2005
and the input statement (where the type of each variable is given by its name)
cin >> string1 >> int1 >> char1 >> string2;
a. What is contained in each of the variables after the statement is executed?
b. Where is the reading marker after the statement is executed?
8. If the reading marker is on the newline character at the end of a line, and you call the get function, what value does it return in its argument?
9. What do the two arguments to the ignore function specify?
10. You are writing a program whose input is a date in the form of mm/dd/yyyy.
a. Write an output statement to prompt an inexperienced user to enter a date.
b. Write an output statement to prompt an experienced user to input a date.
11. What are the four steps necessary to use a file for input or output?
12. What are the two file stream data types discussed in this chapter?
13. What is the purpose of the following statements?

14. Correct the following code segment so that it opens the file whose name is entered via the input statement.

15. What happens when an input operation is performed on a file that is in the fail state?
16. When you try to open a file that doesn’t exist, C++ outputs an error message and terminates execution of the program. True or false?
17. Just opening an input file stream cannot cause it to enter the fail state. True or false?
18. You’re writing a program for a rental car company that keeps track of vehicles. What are the major objects in this problem?
19. Define the following terms:
a. Concrete step
b. Abstract step
c. Module
d. Functional equivalence
e. Functional cohesion
20. Which C++ construct do we use to implement modules?
21. Which of the following are member functions of the istream class?
a. >>
b. ignore
c. get
d. getline
e. cin
22. The open function is associated with both the ifstream and the ofstream data types. True or false?
Programming Warm-Up Exercises
1. Write a C++ input statement that reads three integer values into the variables int1, int2, and int3, in that order.
2. Write a prompting output statement and then an input statement that reads a name into three string variables: first, middle, and last. The name is to be entered in the following format: first middle last.
3. Write a prompting output statement and then an input statement that reads a name into a single string variable, name. The name is to be entered on one line, in the following format: first middle last.
4. Write the statements necessary to prompt for and input three floating-point values, and then output their average. For this exercise, assume that the user has no prior experience with computers and needs very detailed instructions. To help avoid errors, the user should enter each value separately.
5. Write the statements necessary to prompt for and input three floating-point values, and then output their average. For this exercise, assume that the user has plenty of experience with computers and needs minimal instructions. The user should enter all three values on one line.
6. Write the declarations and input statements necessary to read each of the following sets of data values into variables of the appropriate types. You choose the names of the variables. In some cases, punctuation marks or special symbols must be skipped.
a. 100 A 98.6
b. February 23 March 19
c. 19, 25, 103.876
d. A a B b
e. $56.45
7. Write a single input statement that reads the following lines of data into the variables streetNum, street1, street2, town, state, and zip.
782 Maple Avenue
Blithe, CO 56103
8. Write the statements necessary to prepare a file called temperatures.dat for reading as an ifstream called temps.
9. The file temperatures.dat contains a list of six temperatures, arranged one per line. Assuming that the file has already been prepared for reading, as described in Exercise 8, write the statements to read in the data from the file and print out the average temperature. You will also need to declare the necessary float variables to accomplish this task.
10. Fill in the blanks in the following program:

11. Modify the program in Exercise 10 so that it allows the user to enter the name of the output file instead of having the program use outData.dat.
12. The file stream inFile contains two integer values. Write an input statement that will cause it to enter the fail state.
13. Write a code segment that prompts the user for a file name, reads the file name into a string called filename, and then opens the file stream userFile using the supplied name.
14. Use functional decomposition to write an algorithm for writing and mailing a business letter.
Programming Problems
1. Write a C++ program that computes a student’s grade for an assignment as a percentage given the student’s score and the total points. The final score should be rounded up to the nearest whole value using the ceil function in the <cmath> header file. You should also display the floating-point result up to 5 decimal places. The input to the program must come from a file containing a single line with the score and total separated by a space.
2. Write a program that reads a line from a file called quote.txt containing the text,
a b c d e f
And writes the uppercase version of that line in reverse to the output file named upquote.txt.
3. Write an interactive C++ program that inputs a name from the user in the following format:
last, first middle
The program should then output the name in the following format:
first middle last
The program will have to use string operations to remove the comma from the end of the last name. Be sure to use proper formatting and appropriate comments in your code. The input should have an appropriate prompt, and the output should be labeled clearly and formatted neatly.
4. Write an interactive C++ program whose input is a series of 12 temperatures from the user. It should write out on file tempdata.dat each temperature as well as the difference between the current temperature and the one preceding it. The difference is not output for the first temperature that is input. At the end of the program, the average temperature should be displayed for the user via cout. For example, given the input data
34.5 38.6 42.4 46.8 51.3 63.1 60.2 55.9 60.3 56.7 50.3 42.2
file tempdata.dat would contain
34.5 |
|
38.6 |
4.1 |
42.4 |
3.8 |
46.8 |
4.4 |
51.3 |
4.5 |
63.1 |
11.8 |
60.2 |
–2.9 |
55.9 |
–4.3 |
60.3 |
4.4 |
56.7 |
–3.6 |
50.3 |
–6.4 |
42.2 |
–8.1 |
Be sure to use proper formatting and appropriate comments in your code. The input should be collected through appropriate prompts, and the output should be labeled clearly and formatted neatly.
5. Write an interactive C++ program that computes and outputs the mean and standard deviation of a set of four integer values that are input by the user. (If you did Programming Problem 2 in Chapter 3, then you can reuse much of that code here.) The mean is the sum of the four values divided by 4, and the formula for the standard deviation is
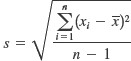
where n = 4, xi refers to each of the four values, and  is the mean. Although the individual values are integers, the results are floating-point values. Be sure to use proper formatting and appropriate comments in your code. Provide appropriate prompts to the user. The output should be labeled clearly and formatted neatly.
is the mean. Although the individual values are integers, the results are floating-point values. Be sure to use proper formatting and appropriate comments in your code. Provide appropriate prompts to the user. The output should be labeled clearly and formatted neatly.
6. Write a C++ program that reads data from a file whose name is input by the user, and that outputs the first word following each of the first three commas in the file. For example, if the file contains the text of this problem, then the program would output
and
if
then
Assume that a comma appears within at least every 200 characters in the file. Be sure to use proper formatting and appropriate comments in your code. Provide appropriate prompts to the user. The output should be labeled clearly and formatted neatly.
7. Write a C++ program that allows the user to enter the percentage of the moon’s face that appears illuminated, and that outputs the surface area of that portion of the moon. The formula for the surface area of a segment of a sphere is
S = 2R2θ
where R is the radius of the sphere (the moon’s radius is 1738.3 km) and θ is the angle of the wedge in radians. There are 2π radians in a circle, so the hemisphere of the moon that we see accounts for at most π radians. Thus, if the user enters 100% (full moon), the angle of the wedge is π and the formula can be evaluated as follows:
S = 2 × 1738.32 × 3.14159 = 18985818.672 square kilometers
If the user enters 50% (first or last quarter), then the angle of the wedge is π × 0.5, and so on. Be sure to use proper formatting and appropriate comments in your code. Provide appropriate prompts to the user. The output should be labeled clearly and formatted neatly (limit the decimal precision to three places as in the example above).
Case Study Follow-Up
1. Replace Clara Jones Jacobey’s information with your own name as input to the Format Names program.
2. Change this program so that the Social Security number is written on a line by itself with the various name formats indented five spaces on the next four lines.
3. Change the program so that the name of the input file name is read from the keyboard.
4. Change the program so that the names of both the input file and the output file are read from the keyboard.
5. Rewrite the Mortgage program, prompting for and reading the variables from the keyboard.