KNOWLEDGE GOALS
 To know how functions can be used to reflect the structure of a functional decomposition.
To know how functions can be used to reflect the structure of a functional decomposition.
To understand the difference between value and reference parameters.
To know how to use arguments and parameters.
Functions
KNOWLEDGE GOALS
To know how functions can be used to reflect the structure of a functional decomposition.
To understand the difference between value and reference parameters.
To know how to use arguments and parameters.
SKILL GOALS
To be able to:
Write a module of your own design as a void function.
Design the parameter list for each module of a functional decomposition.
Code a program using functions.
Define and use local variables correctly.
Write a program that uses multiple calls to a single function.
You have been using C++ functions since we introduced standard library routines such as sqrt and abs in Chapter 3. By now, you should be quite comfortable with the idea of calling these subprograms to perform a task. So far, however, we have not considered how the programmer can create his or her own functions other than main. That is the topic of this chapter and the next.
You might wonder why we waited until now to look at user-defined subprograms. The reason—and the major purpose for using subprograms—is that we write our own functions to help organize and simplify larger programs. Until now, our programs have been relatively small and simple, so we didn’t need to write subprograms. Now that we’ve covered the basic control structures, we are ready to introduce subprograms so that we can begin writing larger and more complex programs.
8.1 Functional Decomposition with Void Functions
As a brief refresher, let’s review the two kinds of subprograms with which the C++ language works: value-returning functions and void functions. A value-returning function receives some data through its argument list, computes a single function value, and returns this function value to the calling code. The caller invokes (calls) a value-returning function by using its name and argument list in an expression:
y = 3.8 * sqrt(x);
In contrast, a void function does not return a value, nor is it called from within an expression. Instead, the call appears as a complete, standalone statement. An example is the get function associated with the istream and ifstream classes:
cin.get(inputChar);
In this chapter, we concentrate exclusively on creating our own void functions. In Chapter 9, we examine how to write value-returning functions.
From the early chapters on, you have been designing your programs as collections of modules. Many of these modules are naturally implemented as user-defined void functions. We now look at how to do this explicitly in C++
When to Use Functions
In general, you can code any module as a function, although some are so simple that this step really is unnecessary. In designing a program, then, we frequently need to decide which modules should be implemented as functions. The decision should be based on whether the overall program is easier to understand as a result. Other factors can affect this decision, but for now this is the simplest heuristic (strategy) to use.
If a module is a single line only, it is usually best to write it directly in the program. Turning it into a function merely complicates the code, which defeats the purpose of using functions. Conversely, if a module is many lines long, it is natural to turn it into a function.
One case where we might implement a short module as a function is when the module is used in several places within the program. Coding the module in one place and calling it from many places yields a better design for two reasons. First, if we code the module directly in multiple places, there are more opportunities for us to make a mistake. We are less likely to introduce an error if we code the module once and just call it where it’s needed. Second, if we later must change the module algorithm, we would need to search the code for every place that it was directly inserted. But given a function implementation, we need make the change only once within the function, and it affects every place that the function is called.
Keep in mind that implementing a module as a function should affect only the readability of the program and may make it more or less convenient to change the program later. It should not alter the functioning of the program. We say should because whether this is true depends on what we call the module’s interface. We have not yet examined this aspect of module design, which we now consider.
Why Do Modules Need an Interface Design?
Before we look at how to convert a module to a function, we need to revisit how we design a module. Until now, our modules have simply been groups of statements that have access to all of the values in a program. That’s fine for small problems, but it doesn’t work when we have big problems with lots of modules.
To see why allowing every module to access every value is a bad idea, consider an analogy. At home, people tend to keep their doors open, and they share most of their belongings. Now suppose that you check into a hotel that’s based on the same principle—none of the rooms have doors. There would be no privacy or security. Everyone would have free access to everyone else’s things. (And the snoring would be terrible!) To make the hotel safe, we need to have a lockable door on each room.
Modules in larger problems need to be designed with the equivalent of doors. They should not have direct access to each other’s values, and information should enter and leave them via just one carefully controlled route. We call this aspect of a module’s design its interface. There are two views that we can take of the interface: external and internal. In our hotel room analogy, from outside you can see just the door to the room. From inside, you can see the door and the contents of the room. We start the interface design process with the external view.
Designing Interfaces
From now on, we consider a module as a separate block within a design whose implementation details are “hidden” (walled-off) from view.
How can we work with such a module? From the external perspective, as long as you know what a module does and how to call it, you can use the module without knowing how it accomplishes its task. For example, you don’t know how the code for a library function like sqrt is written (its implementation is hidden from view), yet you still can use it effectively.
FIGURE 8.1 Module Interface (Visible) and Implementation (Hidden)
The specification of what a module does and how it is invoked defines its interface (see FIGURE 8.1). Hiding a module implementation is called encapsulation. When a module is encapsulated, we don’t have to worry that it will accidentally access the values in other modules, or that other modules will be able to change its values.
Interface The formal description of what a subprogram does and how we communicate with it.
Encapsulation Hiding a module implementation in a separate block with a formally specified interface.
Another advantage of encapsulation is that we can make internal changes to a module, as long as the interface remains the same. For example, you can rewrite the body of an encapsulated module using a more efficient algorithm.
One way to specify the interface to a module is to write down its purpose, its precondition and postcondition, and the information it takes and returns. If the specification is sufficiently complete, we could hand it to someone else, and that person could then implement the module for us. Interfaces and encapsulation are the basis for team programming, in which a group of programmers work together to solve a large problem.
Thus designing a module can (and should) be divided into two tasks: designing the external interface and designing the internal implementation. For the external interface, we focus on the what, not the how. We define the behavior of the module (what it does) and the mechanism for communicating with it.
To define the mechanism for communicating with the module, we make a list of the following items:
1. Incoming values that the module receives from the caller.
2. Outgoing values that the module produces and returns to the caller.
3. Incoming/outgoing values—values the caller has that the module changes (receives and returns).
Next, we turn to the internal view of the interface as the starting point for our implementation. We choose names for identifiers that will exist as variables inside the module, each of which matches a value in our list. These identifiers become what we call the parameter list for the module.
Module parameter list A set of variables within a module that hold values that are either incoming to the module or outgoing to the caller, or both.
Henceforth, we write the parameters in the module heading. Any other variables that the module needs are said to be local and we declare them within its body. We do this for any module that we anticipate implementing as a function. As part of the module interface, we also document the direction of data flow for each parameter.
Data flow The direction of flow of information between the caller and a module through each parameter.
Now that we’ve seen how to design a module for implementation as a function, we are ready to start coding modules in C++.
Writing Modules as Void Functions
It is quite a simple matter to turn a module into a void function in C++. Basically, a void function looks like the main function except that the function heading uses void rather than int as the data type of the function. Additionally, the body of a void function does not contain a statement like
return 0;
as does main. That’s because a void function doesn’t return a value to its caller.
Let’s look at a program using void functions. We’ll start with a very simple example that doesn’t have any parameters. A friend of yours is returning from a long trip, and you want to write a program that prints the following message:

Here is a design for the program:
Main
Level 0
Print two lines of asterisks
Print “Welcome Home!”
Print four lines of asterisks
Print 2 Lines
Level 1
Print “***************”
Print “***************”
Print 4 Lines
Level 1
Print “***************”
Print “***************”
Print “***************”
Print “***************”
If we write the two first-level modules as void functions, the main function is simply this:

Notice how similar this code is to the main module of our functional decomposition. It contains two function calls—one to a function named Print2Lines and another to a function named Print4Lines. Both of these functions have empty argument lists.
The following code should look familiar to you, but look carefully at the function heading.

This segment is a function definition. A function definition is the code that extends from the function heading to the end of the block that is the body of the function. The function heading begins with the word void, signaling the compiler that this is not a value-returning function. The body of the function executes some ordinary statements and does not contain a return statement.
Now look again at the function heading. Just like any other identifier in C++, the name of a function cannot include blanks, even though our paper-and-pencil module names do. Following the function name is an empty parameter list—that is, there is nothing between the parentheses. Later we will see what goes inside the parentheses if a function uses arguments.
Now let’s put main and the other two functions together to form a complete program.
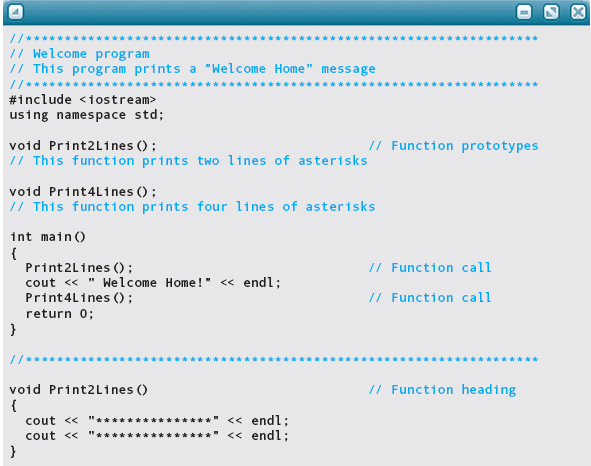
C++ function definitions can appear in any order. We could have chosen to place the main function last instead of first, but C++ programmers typically put main first and any supporting functions after it.
In the Welcome program, the two statements just before the main function are called function prototypes. These declarations are necessary because C++ requires you to declare an identifier before you can use it. Our main function calls functions Print2Lines and Print-4Lines, but their definitions don’t appear until later. We supply the function prototypes to inform the compiler in advance that Print2Lines and Print4Lines are void functions that have no arguments. In addition, we include comments describing these two functions for the reader so that the main function makes sense. We say more about function prototypes later in the chapter.
Because the Welcome program is so simple initially, it may seem more complicated with its modules written as functions. Upon closer inspection, however, it is clear that it much more closely resembles our functional decomposition. If you handed this code to someone, the person could look at the main function and tell you immediately what the program does—it prints two lines of something, prints “Welcome Home!”, and prints four lines of something. If you asked the person to be more specific, he or she could then look up the details in the other function definitions. The person is able to begin with a top-level view of the program and then study the lower-level modules as necessary, without having to read the entire program or look at a module structure chart. As our programs grow to include many modules nested several levels deep, the ability to read a program in the same manner as a functional decomposition aids greatly in the development and debugging process.
MAY WE INTRODUCE
Charles Babbage

The British mathematician Charles Babbage (1791–1871) is generally credited with designing the world’s first computer. Unlike today’s electronic computers, however, Babbage’s machine was mechanical. It was made of gears and levers, the predominant technology of the 1820s and 1830s.
Babbage actually designed two different machines. The first, called the Difference Engine, was to be used in computing mathematical tables. For example, the Difference Engine could produce a table of squares:
x |
x2 |
1 |
1 |
2 |
4 |
3 |
9 |
4 |
16 |
· |
· |
· |
· |
· |
· |
Babbage’s Difference Engine was essentially a complex calculator that could not be programmed. It was designed to improve the accuracy of the computation of similar mathematical tables, not the speed. At that time, all tables were produced by hand, a tedious and error-prone job. Because much of science and engineering in Babbage’s day depended on accurate tables of information, an error could have serious consequences. Even though the Difference Engine could perform the calculations only a little faster than a human could, it did so without error. In fact, one of its most important features was that the device would stamp its output directly onto copper plates, which could then be placed into a printing press, thereby avoiding even typographical errors.
By 1833, the project to build the Difference Engine had run into financial trouble. The engineer whom Babbage had hired to do the construction was dishonest and had drawn the project out as long as possible to extract more money from Babbage’s sponsors in the British government. Eventually the sponsors became tired of waiting for the machine and withdrew their support. At about the same time, Babbage lost interest in the project because he had developed the idea for a much more powerful machine, which he called the Analytical Engine—a truly programmable computer.
The idea for the Analytical Engine came to Babbage as he toured Europe to survey the best technology of the time in preparation for constructing the Difference Engine. One of the technologies that he saw was the Jacquard automatic loom, in which a series of paper cards with punched holes was fed through the machine to produce a woven cloth pattern. The pattern of holes constituted a program for the loom and made it possible to weave patterns of arbitrary complexity automatically. In fact, its inventor even had a detailed portrait of himself woven by one of his machines.
Babbage realized that this sort of device could be used to control the operation of a computing machine. Instead of calculating just one type of formula, such a machine could be programmed to perform arbitrarily complex computations, including the manipulation of algebraic symbols. As his associate, Ada Lovelace (the world’s first computer programmer), elegantly put it, “We may say most aptly that the Analytical Engine weaves algebraical patterns.” It is clear that Babbage and Lovelace fully understood the power of a programmable computer and even contemplated the notion that someday such machines could achieve artificial thought.
Unfortunately, Babbage never completed construction of either of his machines. Some historians believe that he never finished them because the technology of the period could not support such complex machinery. But most feel that Babbage’s failure was his own doing. He was both brilliant and somewhat eccentric (it is known that he was afraid of Italian organ grinders, for example). As a consequence, he had a tendency to abandon projects midstream so that he could concentrate on newer and better ideas. He always believed that his new approaches would enable him to complete a machine in less time than his old ideas would.
When he died, Babbage had many pieces of computing machines and partial drawings of designs, but none of the plans were complete enough to produce a single working computer. After his death, his ideas were dismissed and his inventions ignored. Only after modern computers were developed did historians realize the true importance of his contributions. Babbage recognized the potential of the computer an entire century before one was fully developed. Today, we can only imagine how different the world would be if he had succeeded in constructing his Analytical Engine.
QUICK CHECK

8.1.1 Which elements of a functional decomposition correspond to functions in C++? (pp. 346–347)
8.1.2 If the same module appears in multiple places in a functional decomposition, how do you convert it into code in a program? (pp. 349–351)
8.1.3 What items define the mechanism for communicating with a module? (p. 348)
8.1.4 What is the name of the specification of what a module does and how it is invoked? (p. 348)
8.1.5 Write a void function called PrintName that prints your name. (pp. 349–351)
8.2 An Overview of User-Defined Functions
Now that we’ve seen an example of how a program is written with functions, let’s look briefly and informally at some of the more important points of function construction and use.
Flow of Control in Function Calls
We said that C++ function definitions may be arranged in any order. During compilation, the functions are translated in the order in which they physically appear. When the program is executed, however, control begins at the first statement in main, and the program proceeds in logical order (recall that the flow of control is normally sequential, unless it is altered by a control structure statement).1
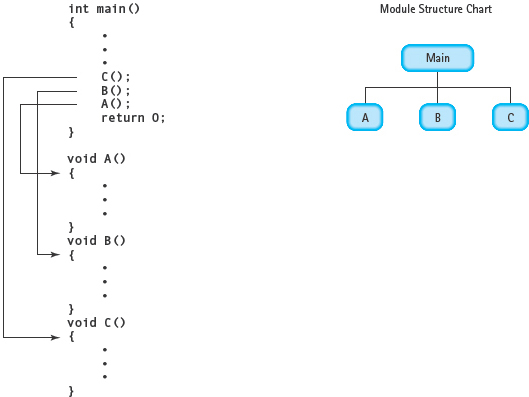
When a function call is encountered, control passes to the first statement in that function’s body, with its remaining statements being executed in logical order. After the last statement is executed, control returns to the point immediately following the function call. Because function calls alter the order of execution, functions are considered control structures. FIGURE 8.2 illustrates this physical versus logical ordering of functions. In the figure, functions A, B, and C are written in the physical order A, B, C but are executed in the order C, B, A.
In the Welcome program, execution begins with the first executable statement in the main function (the call to Print2Lines). When Print2Lines is called, control passes to its first statement and subsequent statements in its body. After the last statement in Print2Lines has executed, control returns to main at the point following the call (the output statement that prints “Welcome Home!”).
FIGURE 8.2 Physical Versus Logical Order of Functions
Function Parameters
Looking at the Welcome program, you can see that Print2Lines and Print4Lines are very similar functions. They differ only in the number of lines that they print. Do we really need two different functions in this program? Maybe we should write just one function that prints any number of lines, where the “any number of lines” is passed as an argument by the caller (main). Deciding to use only one function changes the design.
Main
Level 0
Print lines (2)
Print “Welcome Home!”
Print lines (4)
Print Lines (In: numLines)
Level 1
FOR count going from 1 to numLines
Print “***************”
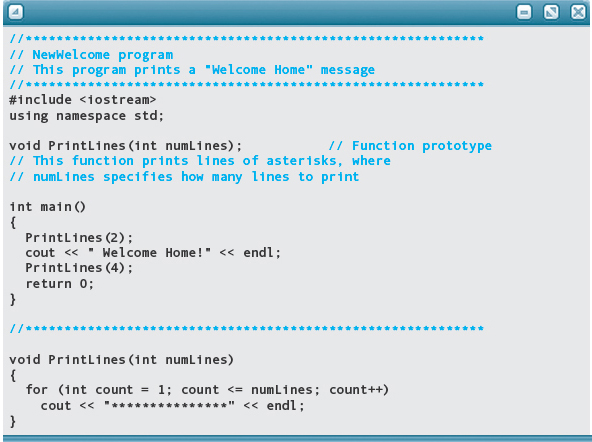
Here is a second version of the program, which uses just one function to do the printing. We call it NewWelcome.
In the function heading of PrintLines, you see some code between the parentheses that looks like a variable declaration. This code is a parameter declaration.
As you learned in earlier chapters, the items listed in the call to a function are the arguments. We have been using arguments, which constitute the external view of a function interface, for some time now.
Argument A variable or expression listed in a call to a function.
The variables declared in the function heading are parameters. They provide identifiers within the function by which we can refer to the values supplied through the arguments. Parameters are the internal view of the function interface.
Parameter A variable declared in a function heading.
In the NewWelcome program, the arguments in the two function calls are the constants 2 and 4, and the parameter in the PrintLines function is named numLines. The main function first calls PrintLines with an argument of 2. When control is turned over to PrintLines, the parameter numLines is initialized to 2. Within PrintLines, the count-controlled loop executes twice and the function returns. The second time PrintLines is called, the parameter numLines is initialized to the value of the argument, 4. The loop executes four times, after which the function returns.
Here is another version of the main function, just to show that the arguments can be variables instead of constants:

In this version, each time main calls PrintLines, a copy of the value in lineCount is passed to the function to initialize the parameter numLines. As you can see, the argument and the parameter can have different names.
NewWelcome illustrates that a function can be called from many places in main (or from other functions). If a task must be done in more than one place in a program, we can avoid repetitive coding by writing it as a function and then calling it wherever we need it.
If more than one argument is passed to a function, the arguments and parameters are matched by their relative positions in the two lists. For example, if you want PrintLines to print lines consisting of any selected character, not only asterisks, you could rewrite the function so that its heading is
void PrintLines(int numLines, char whichChar)
A call to this function might look like this:
PrintLines(3, '#');
The first argument, 3, is matched with numLines because numLines is the first parameter. Likewise, the second argument, '#', is matched with the second parameter, whichChar.
QUICK CHECK
8.2.1 When a function call is encountered where does control pass to? (p. 353)
8.2.2 When a function returns where is control passed to? (p. 353)
8.2.3 What is the difference between a function argument and a function parameter? (p. 355)
8.2.4 If more than one argument is passed to a function, in what order are they matched with the parameters? (p. 356)
8.3 Syntax and Semantics of Void Functions
Function Call (Invocation)
As we’ve seen, to call (or invoke) a void function, we use its name as a statement, with the arguments in parentheses following the name. Here is the syntax template of a function call to a void function:
FunctionCall (to a void function)

Note that the argument list is optional, but the parentheses are required even if the list is empty.
If the list includes two or more arguments, you must separate them with commas. Here is the syntax template for ArgumentList:
ArgumentList

When a function call is executed, the arguments are passed to the parameters according to their positions, left to right, and control is then transferred to the first executable statement in the function body. When the last statement in the function has executed, control returns to the point from which the function was called.
Function Declarations and Definitions
In C++, a function’s declaration must physically precede any function call. The declaration gives the compiler the name of the function, the form of the function’s return value (either void or a data type like int or float), and the data types of the parameters.
The NewWelcome program contains three function declarations. The first one (the statement labeled “Function prototype”) does not include the body of the function. The remaining two—for main and PrintLines—include bodies for the functions.
In C++ terminology, a function declaration that omits the body is called a function prototype, and a declaration that does include the body is called a function definition. We can use a Venn diagram to illustrate that all definitions are declarations, but not all declarations are definitions:
Function prototype A function declaration without the body of the function.
Function definition A function declaration that includes the body of the function.
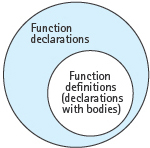
In general, C++ distinguishes declarations from definitions by whether memory space is allocated for the item. For example, a function prototype is merely a declaration—that is, it specifies only the unique properties of a function. By comparison, a function definition does more: it causes the compiler to allocate memory for the instructions in the body of the function.2
The rule throughout C++ is that you can declare an item as many times as you wish, but you can define it only once. In the NewWelcome program, we could include many function prototypes for PrintLines (though we have no reason to do so), but only one function definition is allowed.
Function Prototypes
Function prototypes allow us to declare functions before they are defined, so that we can arrange their definitions in any order. As we’ve noted, C++ programmers typically define main first, followed by all other functions.
Aside from style, there is a situation in C++ where function prototypes are essential. Suppose that two functions, A and B, call each other. If we write the definition of A followed by the definition of B, then within A the call to B generates a message that identifier B is undeclared. Of course, reversing the order of the definitions won’t solve the problem. The solution is to write a prototype for B preceding the definition of A, so that B is declared before it is used in A. Because the prototype for B omits the function body, it doesn’t contain a call to A. As a result, it avoids referring to A before it is declared. Notice that this special case is automatically covered when we adopt the style of writing prototypes for all of our functions preceding main.
A prototype for a void function has the following syntax:
FunctionPrototype (for a void function)

As you can see in the template, no body is included for the function, and a semicolon terminates the declaration. The parameter list is optional, to allow for parameterless functions. If the parameter list is present, it has the following form:
ParameterList (in a function prototype)

The ampersand (&) attached to the name of a data type is optional and has a special significance that we cover later in the chapter.
In a function prototype, the parameter list must specify the data types of the parameters, but their names are optional. You could write either
void DoSomething(int, float);
or
void DoSomething(int velocity, float angle);
Sometimes it’s useful for documentation purposes to supply names for the parameters, but be aware that the compiler ignores them.
Function Definitions
You learned in Chapter 2 that a function definition consists of two parts: the function heading and the function body, which is syntactically a block (compound statement). Here’s the syntax template for a function definition—specifically, for a void function:
FunctionDefinition (for a void function)

Notice that the function heading does not end in a semicolon the way a function prototype does. Putting a semicolon at the end of the line will generate a syntax error.
The syntax of the parameter list differs slightly from that of a function prototype in that you must specify the names of all the parameters. Also, it’s our style preference (but not a C++ language requirement) to declare each parameter on a separate line:
ParameterList (in a function definition)

Local Variables
Because a function body is a block, any function—not just main—can include variable declarations. These variables are called local variables because they are accessible only within the block in which they are declared. As far as the calling code is concerned, they don’t exist. If you tried to print the contents of a local variable from another function, a compile-time error such as UNDECLARED IDENTIFIER would occur. You saw an example of a local variable in the NewWelcome program—the count variable declared within the PrintLines function.
Local variable A variable declared within a block and not accessible outside of that block.
In contrast to local variables, variables declared outside of all the functions in a program are called global variables. We return to the topic of global variables in Chapter 9.
Local variables occupy memory space only while the function is executing. At the moment the function is called, memory space is created for its local variables. When the function returns, its local variables are destroyed.3 Therefore, every time the function is called, its local variables start out with their values undefined. Because every call to a function is independent of every other call to that same function, you must initialize the local variables within the function itself. Also, because local variables are destroyed when the function returns, you cannot use them to store values between calls to the function.
The following code segment illustrates each of the parts of the function declaration and calling mechanism that we have discussed.

The Return Statement
The main function uses the statement
return 0;
to return the value 0 to its caller, the operating system.
As we’ve seen, a void function does not return a function value. Control returns from the function when it “falls off” the end of the body—that is, after the final statement has executed. As you saw in the NewWelcome program, the PrintLines function simply prints some lines of asterisks and then returns.
Alternatively, you can use a second form of the Return statement. It looks like this:
return;
This statement is valid only for void functions. It can appear anywhere in the body of the function; it causes control to exit the function immediately and return to the caller. Here’s an example:

In this (nonsense) example, there are two ways for control to exit the function. At function entry, the value of n is tested. If it is greater than 50, the function prints a message and returns immediately without executing any more statements. If n is less than or equal to 50, the If statement’s then-clause is skipped and control proceeds to the assignment statement. After the last statement, control returns to the caller.
Another way of writing this function is to use an If-Then-Else structure:

If you asked different programmers about these two versions of the function, you would get differing opinions. Some prefer the first version, saying that it is most straightforward to use Return statements whenever it logically makes sense to do so. Others insist on a single-entry, single-exit approach. With this philosophy, control enters a function at one point only (the first executable statement) and exits at one point only (the end of the body). These programmers argue that multiple exits from a function make the program logic hard to follow and difficult to debug. Other programmers take a position somewhere between the two extremes, allowing occasional use of the Return statement when the logic is clear. Our advice is to use the Return statement sparingly; overuse can lead to confusing code.
Matters of style
Naming Void Functions

When you choose a name for a void function, keep in mind how calls to it will look. A call is written as a statement; therefore, it should sound like a command or an instruction to the computer. For this reason, it is a good idea to choose a name that is an imperative verb or has an imperative verb as part of it. (In English, an imperative verb is one representing a command: Listen! Look! Do something!) For example, the statement
Lines(3);
has no verb to suggest that it’s a command. Adding the verb Print makes the name sound like an action:
PrintLines(3);
When you are picking a name for a void function, write down sample calls with different names until you come up with one that sounds like a command to the computer.
QUICK CHECK
8.3.1 Where do declarations of functions that are called by main appear in the program with respect to main? (pp. 356–359)
8.3.2 Which parts of a program can access a local variable declared within a function’s block? (pp. 359–360)
8.3.3 What is a function prototype? (p. 357)
8.3.4 Why are function prototypes useful? (p. 357)
8.3.5 Write a void function prototype for a function called UpdateRace that takes an integer and floating-point parameter in that order. (pp. 357–359)
8.3.6 What is a variable called when it is declared within a block and not accessible outside of that block? (p. 359)
8.4 Parameters
When a function is executed, it uses the arguments given to it in the function call. How is this done? The answer to this question depends on the nature of the parameters. C++ supports two kinds of parameters: value parameters and reference parameters. With a value parameter, which is declared without an ampersand (&) at the end of the data type name, the function receives a copy of the argument’s value. With a reference parameter, which is declared by adding an ampersand (&) to the data type name, the function receives the location (memory address) of the caller’s argument. Before we examine in detail the difference between these two kinds of parameters, let’s look at an example of a function heading with a mixture of reference and value parameter declarations:
Value parameter A parameter that receives a copy of the value of the corresponding argument.
Reference parameter A parameter that receives the location (memory address) of the caller’s argument.
With simple data types—int, char, float, and so on—a value parameter is the default (assumed) kind of parameter. In other words, if you don’t do anything special (add an ampersand), a parameter is assumed to be a value parameter. To specify a reference parameter, you have to do something extra (attach an ampersand).
Now let’s look at both kinds of parameters, starting with value parameters.
Value Parameters
In the NewWelcome program, the PrintLines function heading is
void PrintLines(int numLines)
The parameter numLines is a value parameter because its data type name doesn’t end in &. If the function is called using an argument lineCount,
PrintLines(lineCount);
then the parameter numLines receives a copy of the value of lineCount. At this moment, there are two copies of the data—one in the argument lineCount and one in the parameter numLines. If a statement inside the PrintLines function were to change the value of numLines, this change would not affect the argument lineCount (remember, there are two copies of the data). As you can see, using value parameters helps us avoid unintentional changes to arguments.
Because value parameters are passed copies of their arguments, anything that has a value may be passed to a value parameter. This includes constants, variables, and even arbitrarily complicated expressions. (The expression is simply evaluated and a copy of the result is sent to the corresponding value parameter.) For the PrintLines function, the following function calls are all valid:

There must be the same number of arguments in a function call as there are parameters in the function heading.4 Also, each argument should have the same data type as the parameter in the same position. Notice how each parameter in the following example is matched to the argument in the same position (the data type of each argument is what you would assume from its name):

If the matched items are not of the same data type, implicit type coercion takes place. For example, if a parameter is of type int, an argument that is a float expression is coerced to an int value before it is passed to the function. As usual in C++, you can avoid unintended type coercion by using an explicit type cast or, better yet, by not mixing data types at all.
As we have stressed, a value parameter receives a copy of the argument and, therefore, the caller’s argument cannot be accessed directly or changed. When a function returns, the contents of its value parameters are destroyed, along with the contents of its local variables. The difference between value parameters and local variables is that the values of local variables are undefined when a function starts to execute, whereas value parameters are automatically initialized to the values of the corresponding arguments.
Because the contents of value parameters are destroyed when the function returns, they cannot be used to return information to the calling code. What if we do want to return information by modifying the caller’s arguments? We must use the second kind of parameter available in C++: reference parameters. Let’s look at these in more detail now.
Reference Parameters
A reference parameter is one that you declare by attaching an ampersand to the name of its data type. It is called a reference parameter because the called function can refer to the corresponding argument directly. Specifically, the function is allowed to inspect and modify the caller’s argument.
When a function is invoked using a reference parameter, it is the location (memory address) of the argument—not its value—that is passed to the function. Only one copy of the information exists, and it is used by both the caller and the called function. When a function is called, the argument and the parameter become synonyms for the same location in memory. When a function returns control to its caller, the link between the argument and the parameter is broken. They are synonymous only during a particular call to the function. The only evidence that a matchup between the two ever occurred is that the contents of the argument may have changed (see FIGURE 8.3).
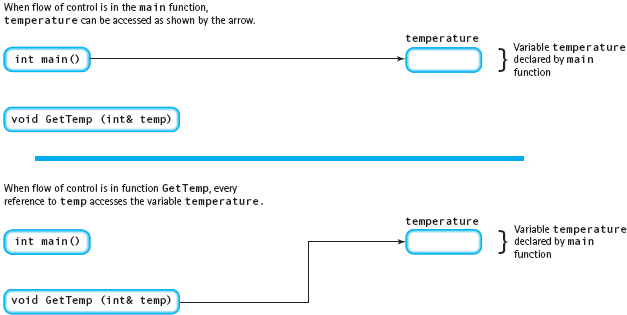
FIGURE 8.3 Using a Reference Parameter to Access an Argument
Whatever value is left by the called function in this location is the value that the caller will find there. You must be careful when using a reference parameter, because any change made to it affects the argument in the calling code. Here is an example of a heading and a call:
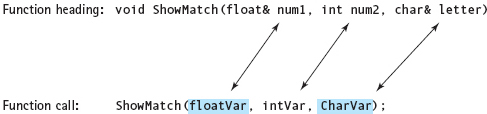
For the highlighted arguments, the addresses of floatVar and charVar are passed to num1 and letter, respectively. Because num2 is a value parameter, it receives the value stored in intVar.
Another important difference between value and reference parameters relates to matching arguments with parameters. With value parameters, we said that implicit type coercion occurs (the value of the argument is coerced, if possible, to the data type of the parameter). In contrast, reference parameters require that the matched items must have exactly the same data type.
Earlier in this chapter, we discussed documenting data flow direction in modules. Function parameters corresponding to Out and In/out module parameters must have an ampersand attached to their type when converting them to C++ code. We do not attach an ampersand to In parameters.
The following table summarizes the usage of arguments and parameters.
Item |
Usage |
Argument |
Appears in a function call. The corresponding parameter may be either a reference parameter or a value parameter. |
Value parameter |
Appears in a function heading. Receives a copy of the value of the corresponding argument, which will be coerced if necessary. |
Reference parameter |
Appears in a function heading. Receives the address of the corresponding argument. Its corresponding type must have an ampersand (&) appended to it. The type of an argument must exactly match the type of the parameter. |
SOFTWARE MAINTENANCE CASE STUDY: Refactoring a Program
MAINTENANCE TASK: For the Problem-Solving Case Study in Chapter 3, we wrote a mortgage payment calculator. In the Software Maintenance Case Study in Chapter 4, we changed it to use file I/O. In Chapter 5, we revised the input to allow interest to be entered either as a decimal or as a percentage. In Chapter 6, we expanded the program’s capabilities, including calculation of the total interest paid over the period of the loan, and allowing entry of data for multiple loans in one run. Needless to say, by now this program has gotten quite long and complicated. It’s time to refactor it.
When the goal of a maintenance project is to improve the maintainability of a program without changing its functionality, the process is called refactoring. Because this program has been changed so often, let’s start over with a problem statement and a functional decomposition. In a refactoring situation, however, our functional decomposition is done in light of the known solution to the problem. In many cases, the process involves arranging existing statements into encapsulated functions so that the code is easier to understand and to modify.
Refactoring Modifying code to improve its quality without changing its functionality.
PROBLEM STATEMENT: Write a program that calculates the monthly payment for a loan, given the loan amount, the length of the loan in years, and the interest rate either in decimal or percentage form. The input values, the monthly payment, and the total interest paid should be printed on the standard input device.
The loop that we added was based on a loan payment: A negative loan payment ended the processing. We do the same here. The main module can be written from this problem statement with no further discussion.
Main
Level 0
Get loan amount
WHILE loan amount is greater than zero
Get rest of input (interest and number of years)
Set numberOfPayments to numberOfYears * 12
Determine payment
Set totalInterest to payment * numberOfPayments - loanAmount
Print results
Get loan amount
GetLoanAmt(Out: loanAmount)
Level 1
In the original design, we printed all the prompts together, and printed them all again at the end of the loop. A better design is to separate the prompt for the loan amount from the prompts for the other values, and to issue each kind of prompt just before the respective value is to be read.
Print “Input loan amount. A negative loan amount ends the processing.”
Read loanAmount
GetInterest(Out: monthlyInterest)
Level 2
Remember that the yearly interest can be entered either as a percentage or as a decimal value. The GetInterest module can decide which form was used for input and send the appropriate value back to the calling module.
Print “Input interest rate. An interest rate of less than 0.25 is assumed to be”
“a decimal rather than a percentage.”
Read yearlyInterest
IF (yearlyInterest greater than or equal to 0.25)
Set yearlyInterest to yearlyInterest / 100
Set monthlyInterest to yearlyInterest / 12
GetYears(Out: numberOfYears)
Level 2
Print “Enter number of years of the loan.”
Read numberOfYears
DeterminePayment(Out: payment; In: loanAmount, monthlyInterest, numberOfPayments)
Level 1
Set payment to (loanAmount * pow(1 + monthlyInterest, numberOfPayments)
* monthlyInterest)/(pow(1 + monthlyInterest, numberOfPayments) − 1);
PrintResults(In: loanAmount, yearlyInterest, numberOfPayments, payment, totalInterest)
Level 1
In the original versions, we computed the total amount of interest in the output statement because the calculation was an add-on feature. Here we have put it where it belongs in the main module. However, we leave the conversion of the interest rate to a percentage as part of the output.
Print “Loan amount:” loanAmount
Print “Interest rate:” interestRate * 100, “%”
Print “Number of payments:” numberOfPayments
Print “Monthly payments:” payment
Print “Total interest:” totalInterest
There are several things to note about this decomposition. First, issuing the prompts when they are needed keeps us from repeating an extra request for the interest rate and length of the loan. Second, one module—GetLoanAmt—is called from two different places in the design. Third, module PrintResults has no formatting information. At the design stage, we can specify what the output should look like, but not how the formatting is done, which is specific to the C++ implementation. If there are specific formatting requirements, they would appear in the problem statement.
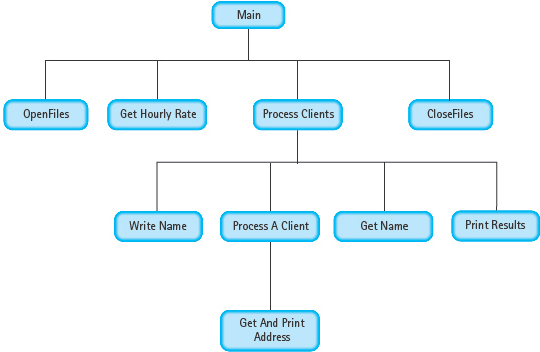
MODULE STRUCTURE CHART
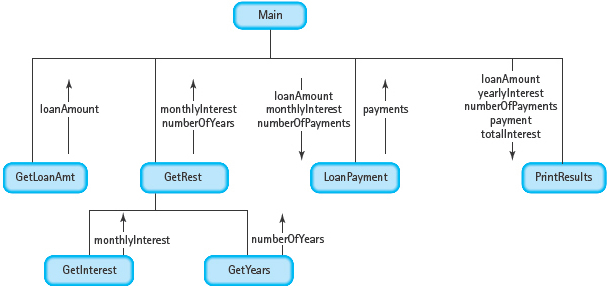
This looks like a very complicated design for such a simple problem. Do we really need to represent each module as a C++ function? The answer depends on your programming style. Some modules definitely should be functions—for example, PrintResults. Other modules probably should not be functions—for example, GetYears. Whether to implement the remaining modules as functions is up to the programmer. As we stated earlier, the key question is whether using a function makes the program easier to understand. “Easier to understand” is open to individual interpretation.
Here, we choose to turn all of the modules except GetYears into functions. Although GetLoanAmt is only two lines long, it is called from two places and, therefore, should be a function. Module DeterminePayment is only one statement long, but it is a complicated statement. It is appropriate to push the formula to a lower level. The reader does not need to know how the payment amount is calculated.
The first step is to create the function prototypes, being sure that all Out and In/out parameters have ampersands attached to the respective data types. Notice that we include the parameter names in the prototypes because our use of meaningful identifiers helps to automatically document what each parameter does.

We have suggested documenting modules with a descriptive comment beside each parameter, and marking the direction of flow. We do show the direction of flow on each module parameter, but it is necessary to document (comment) a parameter only when the name isn’t self-explanatory.
In C++, the absence of an ampersand on the type indicates that its direction of flow is In. If the parameter has an ampersand, it is either an Out or an In/out parameter. Out is more common, so we do not explicitly document this case. When the value is both used and changed, then adding a comment identifying it as In/out would be useful. There is no such example in this problem.
Sample output:
Argument-Passing Mechanisms

There are two major ways of passing arguments to and from subprograms. C++ supports both mechanisms. Some languages, such as Java, support just one.
C++ reference parameters employ a mechanism called pass by address or pass by location, in which a memory address is passed to the function. Another name for this technique is pass by reference, so called because the function can refer directly to the caller’s variable that is specified in the argument list.
C++ value parameters are an example of the pass by value mechanism. The function receives a copy of the value of the caller’s argument. Passing by value can be less efficient than passing by address because the value of an argument may occupy many memory locations (as we see in Chapter 11), whereas an address usually occupies only a single location. For the simple data types int, char, bool, and float, the efficiency of either mechanism is about the same. Java supports only pass by value, although many of its data types are represented by an address that references the actual information, so in practice it passes arguments with efficiency comparable to C++.
A third method of passing arguments is called pass by name. With this mechanism, the argument is passed to the function as a character string that must be interpreted by special run-time support software called a thunk. Passing by name is less efficient than the other two argument-passing mechanisms. It is supported by the older ALGOL and LISP programming languages, but not by C++. More recently, a research language called Haskell has implemented a variation of pass by name, called pass by need, which remembers the interpretation of the string between calls so that subsequent calls can be more efficient.
There are two different ways of matching arguments with parameters, although C++ supports only one of them. Most programming languages (C++ among them) match arguments and parameters based on their relative positions in the argument and parameter lists. This technique is called positional matching, relative matching, or implicit matching. A few languages, such as Ada, also support explicit or named matching. In explicit matching, the argument list specifies the name of the parameter to be associated with each argument. Explicit matching allows arguments to be written in any order in the function call. The real advantage is that each call documents precisely which values are being passed to which parameters.
Using Expressions with Parameters
Only a variable should be passed as an argument to a reference parameter because a function can assign a new value to the argument.5 (In contrast, an arbitrarily complicated expression can be passed to a value parameter.) Suppose that we have a function with the following heading:
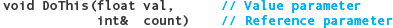
Then the following function calls are all valid:

In the DoThis function, the first parameter is a value parameter, so any expression is allowed as the argument. The second parameter is a reference parameter, so the argument must be a variable name. The statement
DoThis(y, 3);
generates a compile-time error because the second argument isn’t a variable name. Earlier we said the syntax template for an argument list is
ArgumentList

Keep in mind, however, that Expression is restricted to a variable name if the corresponding parameter is a reference parameter.
The following table summarizes the appropriate forms of arguments.
Parameter |
Argument |
Value parameter |
A variable, constant, or arbitrary expression (type coercion may take place) |
Reference parameter (&) |
A variable only, of exactly the same data type as the parameter |
A Last Word of Caution About Argument and Parameter Lists
It is the programmer’s responsibility to make sure that the argument list and parameter list match up semantically as well as syntactically. For example, suppose we had written the modification to the LoanCalculator program as follows. Can you spot the error?

The argument list in the last function call matches the corresponding parameter list in its number and type of arguments, so no syntax error message would be generated. However, the output would be wrong because the first two arguments are switched. If a function has two parameters of the same data type, you must be careful that the arguments appear in the correct order.
SOFTWARE ENGINEERING TIP
Conceptual Versus Physical Hiding of a Function Implementation

In many programming languages, the encapsulation of an implementation is purely conceptual. If you want to know how a function is implemented, you simply look at the function body. C++, however, permits function implementations to be written and stored separately from main.
Larger C++ programs are usually split into separate files. One file might contain just the source for main; another file, the source for two functions invoked by main; and so on. This organization is called a multifile program. To translate the source code into object code, the compiler is invoked for each file. A program called the linker then collects all the resulting object code into a single executable program.
When you write a program that invokes a function located in another file, it isn’t necessary for that function’s source code to be available. You just need to include a function prototype so that the compiler can check the syntax of the call. After the compiler finishes its work, the linker finds the object code for that function and links it with your main function’s object code. We do this kind of thing all the time when we invoke library functions. C++ systems supply only the object code—not the source code—for library functions like sqrt. The source code for their implementations is physically hidden from view.
One advantage of physical hiding is that it helps the programmer avoid the temptation to take advantage of any unusual features of a function’s implementation. For example, suppose we want a program to read temperatures and output activities repeatedly. Knowing that the GetTemp function that reads the data doesn’t perform range checking on the input value, we might be tempted to use −1000 as a sentinel for the loop reading temperatures:

This code works fine for now, but later another programmer decides to improve GetTemp so that it checks for a valid temperature range (as it should):

Unfortunately, this improvement causes main to become stuck in an infinite loop because GetTemp won’t let us enter the value −1000. If the original implementation of GetTemp had been physically hidden, we would not have relied on the knowledge that it does not perform error checking.
Later in the book, you will learn how to write multifile programs and hide implementations physically. In the meantime, conscientiously avoid writing code that depends on the internal workings of a function.
Writing Assertions as Function Documentation
We have been talking informally about preconditions and postconditions. From now on, we include preconditions and postconditions as comments to document function interfaces. Here’s an example:

The precondition is an assertion describing everything that the function requires to be true at the moment when the caller invokes the function. The postcondition describes the state of the program at the moment when the function finishes executing.
You can think of the precondition and the postcondition as forming a contract. The contract states that if the precondition is true at function entry, then the postcondition must be true at function exit. The caller is responsible for ensuring the precondition, and the function body must ensure the postcondition. If the caller fails to satisfy its part of the contract (the precondition), the contract is off; the function cannot guarantee that the postcondition will be true.
In the preceding example, the precondition warns the caller to make sure that sum has been assigned a meaningful value and that count is positive. If this precondition is true, the function guarantees it will satisfy the postcondition. If count isn’t positive when PrintAverage is invoked, the effect of the module is undefined. (For example, if count equals 0, the postcondition surely isn’t satisfied—any code that implements this module crashes!)
Sometimes the caller doesn’t need to satisfy any precondition before calling a function. In this case, the precondition can be written as the value true or simply omitted. In the following example, no precondition is necessary:

MATTERS OF STYLE
Function Documentation

Preconditions and postconditions, when well written, provide a concise but accurate description of the behavior of a function. A person reading your function should be able to see at a glance how to use the function simply by looking at its interface (the heading and the precondition and postcondition). The reader should never have to look into the function body to understand its purpose or use.
A function interface describes what the function does, not the details of how it works its magic. For this reason, the postcondition should mention (by name) each outgoing parameter and its value but should not mention any local variables. Local variables are implementation details; they are irrelevant to the module’s interface.
In this book, we write pre/postconditions informally. However, some programmers use a very formal notation to express them. For example, function Get2Ints might be documented as follows:

Some programmers place comments next to the parameters to explain how each parameter is used and use embedded comments to indicate which of the data flow categories each parameter belongs to.

To write a postcondition that refers to parameter values that existed at the moment the function was invoked, you can attach the symbol @entry to the end of the variable name. An example of the use of this notation follows. The Swap function exchanges, or swaps, the contents of its two parameters.

QUICK CHECK
8.4.1 Why does C++ mostly allow only variables to be passed as an argument to a reference parameter? (p. 371)
8.4.2 Why is it important for a programmer to not only make sure that the argument list and parameter list match up syntactically but also semantically? (p. 372)
8.4.3 Which character do we use to indicate a reference parameter, and where does it appear in the parameter’s declaration? (pp. 361–365)
8.4.4 Where do arguments appear, and where do parameters appear? (pp. 361–366)
8.4.5 You are writing a function to return the first name from a string containing a full name. How many parameters does the function have, and which of them are reference parameters and which are value parameters? (pp. 361–366)
8.4.6 Which kind of parameter would you use for an incoming value from an argument? For an outgoing value? For a value that comes in, is changed, and returns to the argument? (pp. 361–366)
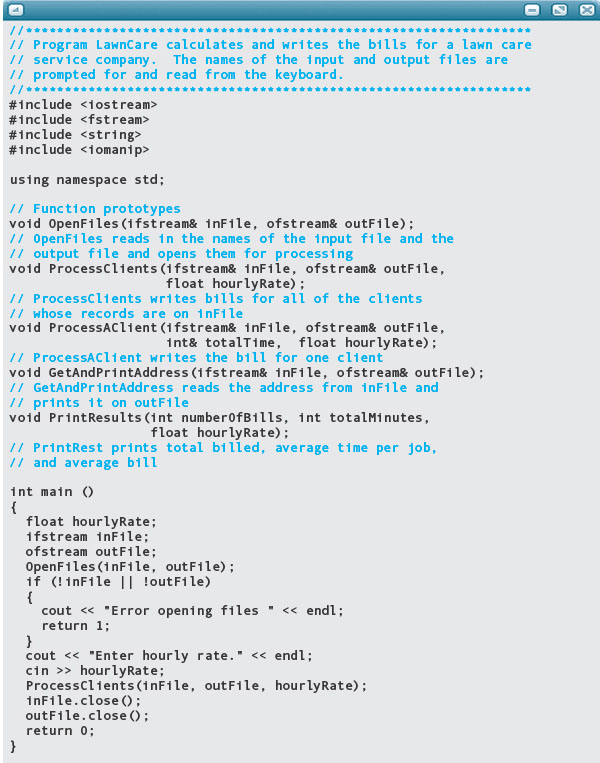
Lawn Care Company Billing
PROBLEM: A lawn care company has hired you to write a program to help with monthly billing. The company works for each client several times a month. Customers are billed by the number of hours spent on each job. The monthly record for a client consists of a sheet with the client’s name, address, and a series of times in hours and minutes. Your program will read this information from a file, print a bill for each client, and output the monthly total and average of the time and charges for the company.
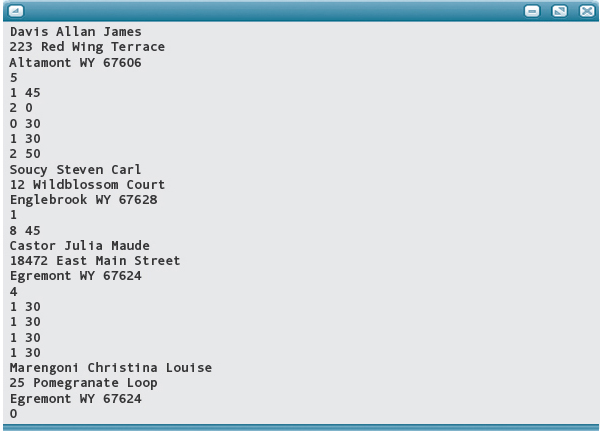
INPUT: A file contains a series of client records. Each client record begins with the customer’s name and address. On the following line is a number indicating how many jobs were done for the client that month. Following that number are a series of times, one on each line, made up of a pair of integer values (hours and minutes). The name is written in last, first, middle format, with blanks separating the three parts. An address consists of a street address, a city, a state, and a ZIP code. The street address is on one line, and the city, state, and ZIP code are on the next line, separated by blanks. Here’s an example of a client record:

The input file name may change, so the user should be prompted to enter the input file name.
OUTPUT
File: A file made up of each client’s bill, which contains a labeled echo-print of the input record, the total hours worked, and the payment amount. The output file name may change, so the user must be prompted to enter the output file’s name. The file on which the output is based (the input file’s name) must be written on the output file.
Screen: A summary statement showing the monthly total of all charges and the average time and charges for the company.
DISCUSSION: The processing takes place in two parts: producing the client’s bill and calculating the summary statistics. The input file doesn’t contain the number of records, so the processing must be based on reaching the end-of-file condition. What about the hourly rate? We should ask the user to input the hourly rate at the beginning of each run.
Main
Level 0
Open files
IF files don’t open properly
Print “Error opening files”
Quit
Get hourly rate
Process Clients
Close files
OpenFiles(In/out: inFile, outFile)
Level 1
We have marked the files as In/out. Although we only read from the input file, it must be marked In/out because the reading pointer in the file changes during the reading process. Likewise, we only write to the output file, but the file itself is input to the module, which then changes the file’s contents.
Print “Enter the name of the input file.”
Read inFileName
Open inFile with inFileName
Print “Enter the name of the output file.”
Read outFileName
Open outFile with outFileName
Write on outFile “Billing for clients on file” inFileName
GetHourlyRate(Out: hourlyRate)
Level 1
Print “Enter hourly rate.”
Read hourlyRate
ProcessClients(In/out: inFile, outFile; In: hourlyRate)
Level 1
Module ProcessClients reads and processes all the bills. The loop is an end-of-file loop, so we need a priming read before the loop. We read the name before the loop and again at the end of each iteration of the loop. We then print the name as the first step in the loop body. We do not need to keep a running total of the charges, because we can calculate it given the total time and the hourly rate. We do, however, have to keep a count of the number of clients so that we can calculate the averages.
Set totalTime to 0
Set numberOfBills to 0
Get name
WHILE inFile
Write name
ProcessAClient
Increment numberOfBills
Get name
Print results
Before we continue with the decomposition, we need to think more about printing the bills. The client’s name is written in last, first, middle format on the file. Is it okay to print the bills with the name still in this format? If so, the name can simply be kept as a string; it doesn’t have to be broken up into first, last, and middle parts. There is nothing in the instructions that gives us any information about what the format of the name should be on the bill, so we call the customer. She says that any format is fine for the output. Thus modules GetName and WriteName do not need further decomposition.
ProcessAClient(In/out: inFile, outFile, totalTme; In: hourlyWages)
Level 2
The number of jobs follows the client address. This value can be used to control a loop that reads and sums hours and minutes. For calculating purposes, we would prefer to have the time in a form that can be multiplied by the hourly rate. We can convert the time either to a float, representing hours and the fraction of an hour, or to an int, representing minutes. For calculating the individual charges, it makes no difference which way we represent the time. In summing up the total time, however, it will be more accurate to add up a series of int values than float values. As we noted in Chapter 5, float values can have small errors in their least significant digits. The more of them we add up, the greater this total error will be. Thus we change the time to minutes, divide it by 3600 (the number of minutes in an hour), and multiply that value by the hourly rate. We’ll also keep totalTime in minutes. We can convert the minutes back to hours and minutes before printing the final summary.
Set time to 0
Read numberOfJobs
Write “Number of jobs:” numberOfJobs
Get Address
Print Address
FOR count going from 1 through numberOfJobs
Read hours
Read minutes
Set time to hours * 60 + minutes + time
Write “Job”, count, “:”, hours, “and”, minutes, “minutes”
Set cost to totalTime / 60 * hourlyRate
Write “Amount of bill: $” cost
Set totalTime to totalTime + time
The address is formatted in the file as it should be on the bill, so the address can just be written to the output file as it is read. Thus GetAddress and WriteAddress should be combined into one module.
GetAndPrintAddress(In/out: inFile, outFile)
Level 3
Read street line
Write street line
Read city line
Write city line
PrintResults(In: numberOfBills, totalMinutes)
Level 2
Print “Total amount billed this month is” totalMinutes/60 * hourlyRate
Print “Average time worked per job is” totalMinutes / numberOfBills / 60
Print “Average customer bill is” totalMinutes/60 * hourlyRate / numberOfBills
The only module that is simple enough to code directly is GetHourlyRate. All of the other modules should be coded as functions. However, before we start to code these functions, we need to consider whether any problems might come up in the translation from pseudocode to C++. Two popular places where errors often lurk are complex input and mixed-mode arithmetic; both occur here.
Let’s first look at the input, which occurs across several modules. The following table shows the variables in the order in which they are read, the function in which the reads occur, the types of input statement to use, and the positions in which the reads leave the file. Recall that the stream input operator (>>) cannot be used with strings that might contain blanks.

We input hourlyRate from the keyboard, and the remaining input comes from the file. The name and address (two lines) are read, leaving the file pointer positioned at the beginning of the line following the address, ready to read the integer numberOfJobs. The three integer values (numberOfJobs, hours, and minutes) are read, skipping any extra blanks or lines that might be there. There is, however, a problem. Look at where the input operator leaves the file pointer after the last numeric read: at the blank or end of line (eoln) that ended the numeric read. Thus the input statement that should read the name reads the eoln and stores it into name. How can we get around this problem? We issue a getline command immediately after the minutes are read. This moves the file pointer to the beginning of the next line.
What about mixed-mode arithmetic? Let’s examine the variables, their types, and the expressions in which they occur. Here is a table listing the variables, the places where they are declared, and their data types.
Variable |
Location Declared |
Type |
hourlyRate |
main |
float |
totalTime |
ProcessClients |
int |
time |
ProcessAClient |
int |
hours |
ProcessAClient |
int |
minutes |
ProcessAClient |
int |
cost |
ProcessAClient |
float |
numberOfJobs |
ProcessAClient |
int |
Now let’s look at the types of the variables in the context of the expressions in which they are used. We show each expression rewritten as a comment where we’ve replaced the variable names with their types. Here’s ProcessAClient:

The calculations of time and totalTime are okay, but the calculation of cost will give the wrong answer. The first int value (time) must be cast to a float for the calculations to be accurate. We should also change the int constant 60 to the float constant 60.0.
Next we look at PrintResults:
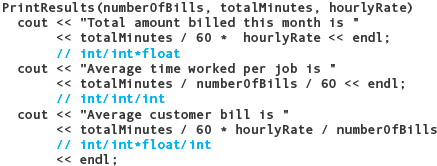
There are problems in all three of these expressions. For starters, totalMinutes is an int parameter. The first statement in the function should declare a local float variable and set it to the argument cast as a float. The expressions should all be written using this local variable. We should also use 60.0 instead of 60, and explicitly cast numberOfBills to float.
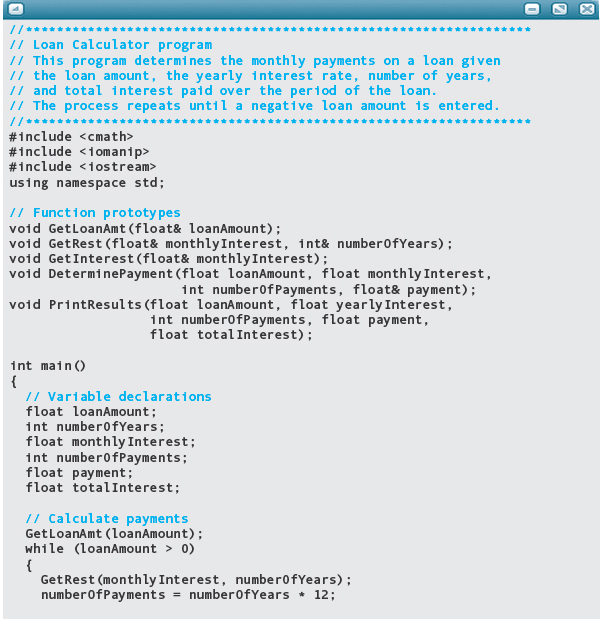
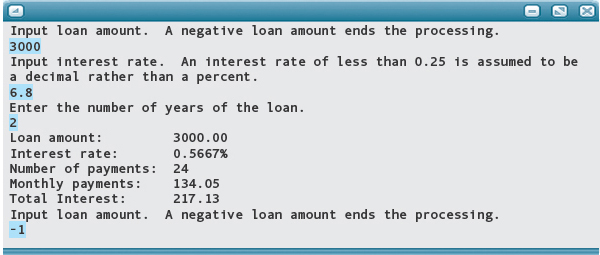
Now the modules can be converted to C++ and the program tested. If we had not looked at these two possible problem areas in advance, we would have spent much time trying to decipher why the output was wrong. Here is the code:
TESTING: Devising a test plan for this program brings up an interesting question: Whose responsibility is it to check for errors in the input file? That is, should the application program include tests to confirm that the input file is correctly formatted or should a correctly formatted file be a precondition for the program? In this case, we included no tests for formatting because the billing program is given a task to process a file with a certain format. If we had decided to include some checks, how would the program recognize errors? For example, how would the application recognize that an address contains only one line? It might check that the second line of the address contains both numbers and letters—but what if the name line is missing? And if the program did check for correct formatting, what should it do in the case of errors? When checking the formatting of the input becomes more complicated than the required calculations, make the correct format a precondition.
Given that the program assumes correct input, which cases do we need to check for during testing? In testing the LawnCare application we need to have customers who have no jobs, one job, and more than one job. We also need runs with no customers, one customer, and more than one customer.
The following input file contains multiple customers with varying numbers of jobs. You are asked to test the program with no customers and one customer in the Case Study Follow-Up exercises.
Input File LawnCare.txt
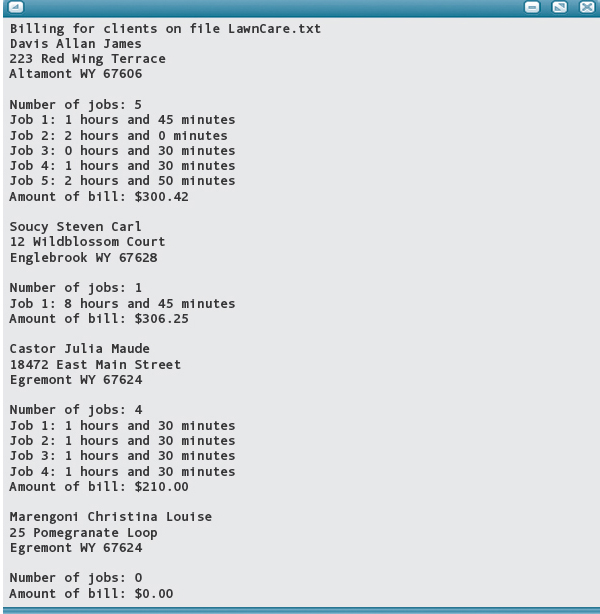
The parameters declared by a function and the arguments that are passed to the function by the caller must satisfy the interface to the function. Errors that occur with the use of functions often are due to incorrect use of the interface between the calling code and the called function.
One source of errors is mismatched argument and parameter lists. The C++ compiler ensures that the lists have the same number of items and that they are compatible in type. It is the programmer’s responsibility, however, to verify that each argument list contains the correct items. This task is a matter of comparing the parameter declarations to the argument list in every call to the function. This job becomes much easier if the function heading gives each parameter a distinct name and further describes its purpose in a comment, if necessary. You can avoid mistakes in writing an argument list by using descriptive variable names in the calling code to suggest exactly which information is being passed to the function.
Another source of errors is failure to ensure that the precondition for a function is met before it is called. For example, if a function assumes that the input file is not at EOF when it is called, then the calling code must ensure that this assumption holds before making the call to the function. If a function behaves incorrectly, review its precondition, then trace the program execution up to the point of the call to verify the precondition. You can waste a lot of time trying to locate an error in a correct function when the error is really in the part of the program prior to the call.
If the arguments match the parameters and the precondition is correctly established, then the source of the error is most likely in the function itself. Trace the function to verify that it transforms the precondition into the proper postcondition. Determine whether all local variables are initialized properly. Parameters that are supposed to return data to the caller must be declared as reference parameters (with an & symbol attached to the data type name).
An important technique for debugging a function is to use your system’s debugger, if one is available, to step through the execution of the function. If a debugger is not available, you can insert debug output statements to print the values of the arguments immediately before and after calls to the function. It also may help to print the values of all local variables at the end of the function. This information provides a snapshot of the function (a picture of its status at a particular moment in time) at its two most critical points, which is useful in verifying hand traces.
To test a function thoroughly, you must arrange the incoming values so that the precondition is pushed to its limits; then the postcondition must be verified. For example, if a function requires a parameter to be within a certain range, try calling the function with values in the middle of that range and at its extremes.
The assert Library Function
We have discussed how function preconditions and postconditions are useful for debugging (by checking that the precondition of each function is true prior to a function call, and by verifying that each function correctly transforms the precondition into the postcondition) and for testing (by pushing the precondition to its limits and even violating it). To state the preconditions and postconditions for our functions, we’ve been writing the assertions as program comments:

Of course, the compiler ignores all comments. They are not executable statements; they are for humans to examine.
The C++ standard library also gives us a way to write executable assertions. Through the header file cassert, the library provides a void function named assert. This function takes a logical (Boolean) expression as an argument and halts the program if the expression is false. Here’s an example:
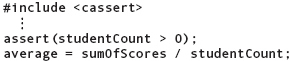
The argument to the assert function must be a valid C++ logical expression. If its value is true, nothing happens; execution continues on to the next statement. If its value is false, execution of the program terminates immediately with a message stating (1) the assertion as it appears in the argument list, (2) the name of the file containing the program source code, and (3) the line number in the program. In the preceding example, if the value of studentCount is less than or equal to 0, the program halts after printing a message like this:
Assertion failed: studentCount > 0, file myprog.cpp, line 48
(This message is potentially confusing. It doesn’t mean that studentCount is greater than 0. In fact, it’s just the opposite. The message tells you that the assertion studentCount > 0 is false.)
Executable assertions have a profound advantage over assertions expressed as comments: The effect of a false assertion is highly visible (the program terminates with an error message). The assert function is, therefore, valuable in software testing. A program under development might be filled with calls to the assert function to help identify where errors are occurring. If an assertion is false, the error message gives the precise line number of the failed assertion.
There is also a way to “remove” the assertions without really removing them. Suppose you use the preprocessor directive #define NDEBUG before including the header file cassert, like this:

Then all calls to the assert function are ignored when you run the program. (NDEBUG stands for “No debug,” and a #define directive is a preprocessor feature that we won’t discuss right now.) After program testing and debugging, programmers often like to “turn off” debugging statements yet leave them physically present in the source code in case they might need the statements later. Inserting the line #define NDEBUG turns off assertion checking without having to remove the assertions.
As useful as the assert function is, it has two limitations. First, the argument to the function must be expressed as a C++ logical expression. We can turn a comment such as

into an executable assertion with the following statement:
assert(0.0 <= yearlyInterest && numberOfYears <= 30);
Conversely, there is no easy way to turn the comment

into a C++ logical expression.
The second limitation is that the assert function is appropriate only for testing a program that is under development. A production program (one that has been completed and released to the public) must be robust and must furnish helpful error messages to the user of the program. You can imagine how baffled a user would be if the program suddenly quit and displayed an error message such as this:
Assertion failed: sysRes <= resCount, file newproj.cpp, line 298
Despite these limitations, you should consider using the assert function as a regular tool for testing and debugging your programs.
Testing and Debugging Hints
1. Follow documentation guidelines carefully when writing functions (see Appendix F). As your programs become more complex and, therefore, prone to errors, it becomes increasingly important to adhere to documentation and formatting standards. Include comments that state the function precondition (if any) and postcondition and that explain the purposes of all parameters and local variables whose roles are not obvious.
2. Provide a function prototype near the top of your program for each function you’ve written. Make sure that the prototype and its corresponding function heading are an exact match (except for the absence of parameter names in the prototype).
3. Be sure to put a semicolon at the end of a function prototype, but do not put a semicolon at the end of the function heading in a function definition. Because function prototypes look so much like function headings, it’s a common mistake to get one of them wrong.
4. Make sure the parameter list gives the data type of each parameter.
5. Use value parameters unless a result is to be returned through a parameter. Reference parameters can change the contents of the caller’s argument; value parameters cannot. However, file names must be reference parameters.
6. In a parameter list, make sure the data type of each reference parameter ends with an ampersand (&). Without the ampersand, the parameter is a value parameter.
7. Make sure that the argument list of every function call matches the parameter list in terms of number and order of items, and be very careful with their data types. The compiler will trap any mismatch in the number of arguments. If a mismatch in data types occurs, however, there may be no compile-time error message generated. Specifically, with the pass by value mechanism, a type mismatch can lead to implicit type coercion rather than a compile-time error.
8. Remember that an argument matching a reference parameter must be a variable, whereas an argument matching a value parameter can be any expression that supplies a value of the same data type (except as noted above in Hint 7).
9. Become familiar with all the tools available to you when you’re trying to locate the sources of errors—the algorithm walk-through, hand tracing, the system’s debugger program, the assert function, and debug output statements.
C++ allows us to write programs in modules expressed as functions. The structure of a program, therefore, can parallel its functional decomposition even when the program is complicated. To make your main function look exactly like Level 0 of your functional decomposition, simply write each lower-level module as a function. The main function then executes these other functions in logical sequence.
Functions communicate by means of two lists: the parameter list (which specifies the data type of each identifier) in the function heading, and the argument list in the calling code. The items in these lists must agree in number and position, and they should agree in data type.
Part of the functional decomposition process involves determining which data must be received by a lower-level module and which information must be returned from it. The names of these data items, together with the precondition and postcondition of a module, define its interface. The names of the data items become the parameter list, and the module name becomes the name of the function. With void functions, a call to the function is accomplished by writing the function’s name as a statement, enclosing the appropriate arguments in parentheses.
C++ supports two kinds of parameters: reference and value. Reference parameters have data types ending in & in the parameter list, whereas value parameters do not. Parameters that return values from a function must be reference parameters. All others should be value parameters. This practice minimizes the risk of errors, because only a copy of the value of an argument is passed to a value parameter, which protects the argument from change.
In addition to the variables declared in its parameter list, a function may have local variables declared within it. These variables are accessible only within the block in which they are declared. Local variables must be initialized each time the function containing them is called because their values are destroyed when the function returns.
You may call functions from more than one place in a program. The positional matching mechanism allows the use of different variables as arguments to the same function. Multiple calls to a function, from different places and with different arguments, can simplify greatly the coding of many complex programs.
 Quick Check Answers
Quick Check Answers
8.1.1 Modules. 8.1.2 You code the module once, placing it, or its prototype, before any reference to it in the rest of the program. You then call the module from each place in the program that corresponds to its appearance in the functional decomposition. 8.1.3 1. Incoming values, 2. Outgoing values, 3. Incoming/outgoing values.
8.1.4 interface

8.2.1 To the first statement in that function’s body, with its remaining statements executed in logical order. 8.2.2 To the statement immediately following the function call. 8.2.3 An argument is a variable or expression listed in a call to a function, whereas a parameter is a variable declared in a function heading. 8.2.4 Arguments and parameters are matched by their relative ordering in the two lists. 8.3.1 They must be declared before they are used, so they appear before main. However, the declaration may simply be a function prototype and the actual definition can then appear anywhere. 8.3.2 Only the statements within the block, following the declaration. 8.3.3 A function declaration without the body of the function. 8.3.4 They allow you to declare a function before they are defined so that we can arrange function definitions in any order. 8.3.5 void UpdateRace(int, float); 8.3.6 local variable 8.4.1 Because a function can assign a new value to the argument. 8.4.2 Because a function could possibly have two or more parameters of the same data type. 8.4.3 The & character appears at the end of the type name of the parameter. 8.4.4 Arguments appear in function calls; parameters appear in function headings. 8.4.5 It should have two parameters, one for each string. The full name parameter should be a value parameter, and the first name parameter should be a reference parameter. 8.4.6 Incoming values use value parameters. Values that return to the argument (Out or In/out) must be passed through reference parameters.
Exam Preparation Exercises
1. What three things distinguish a void function from main?
2. A function prototype must specify the name of a function and the name and type of each of its parameters. True or false?
3. When and to where does control return from a void function?
4. Match the following terms with the definitions given below.
a. Argument
b. Parameter
c. Function call
d. Function prototype
e. Function definition
f. Local variable
g. Value parameter
h. Reference parameter
i. A function declaration without a body.
ii. A parameter that receives a copy of the argument’s value.
iii. A variable declared in a function heading.
iv. A function declaration with a body.
v. A variable or expression listed in a call to a function.
vi. A statement that transfers control to a function.
vii. A parameter that receives the location of the argument.
viii. A variable declared within a block.
5. In the following function heading, which parameters are value parameters and which are reference parameters?
void ExamPrep (string& name, int age, float& salary, char level)
6. If a function has six parameters, how many arguments must appear in a call to the function?
7. What happens if a function assigns a new value to a value parameter? What happens if it assigns a new value to a reference parameter?
8. What’s wrong with this function prototype?
void ExamPrep (phone& int, name string, age& int)
9. Arguments can appear in any order as long as they have the correct types and C++ will figure out the correspondence. True or false?
10. Define encapsulation.
11. For which direction(s) of data flow do you use reference parameters?
12. What is wrong with the following function?

13. What is wrong with the following function?

14. What is wrong with the following function?

15. What is wrong with the following function?

16. A local variable can be referenced anywhere within the block in which it is declared. True or false?
17. Functions can be called from other functions in addition to main. True or false?
18. What would be the precondition for a function that reads a file of integers and returns their mean?
Programming Warm-Up Exercises
1. Write the heading for a void function called Max that has three int parameters: num1, num2, and greatest. The first two parameters receive data from the caller, and greatest returns a value. Document the data flow of the parameters with appropriate comments.
2. Write the function prototype for the function in Exercise 1.
3. Write the function definition of the function in Exercise 1 so that it returns the greatest of the two input parameters.
4. Write the heading for a void function called GetLeast that takes an ifstream parameter called infile as an input parameter that is changed, and that has an int parameter called lowest that returns a value. Document the data flow of the parameters with appropriate comments.
5. Write the function prototype for the function in Exercise 4.
6. Write the function definition for the function in Exercise 4 so that it reads all of infile as a series of int values and returns the lowest integer input from infile.
7. Add comments to the function definition you wrote in Exercise 6 that state its precondition and postcondition.
8. Write the heading for a function called Reverse that takes two string parameters. In the second parameter, the function returns a string that is the character-by-character reverse of the string in the first parameter. The parameters are called original and lanigiro. Document the data flow of the parameters with appropriate comments.
9. Write the function prototype for the function in Exercise 8.
10. Write the function definition for the function in Exercise 8.
11. Add comments to the function definition you wrote in Exercise 10 that state its precondition and postcondition.
12. Write a void function called LowerCount that reads a line from cin, and that returns an int (count) containing the number of lowercase letters in the line. In Appendix C, you will find the description of function islower, which returns true if its char parameter is a lowercase character. Document the data flow of the parameters with appropriate comments.
13. Add comments to the function definition you wrote in Exercise 12 that state its precondition and postcondition.
14. Write a void function called GetNonemptyLine that takes an ifstream (infile) as an In/out parameter, and that reads lines from the file until it finds a line that contains characters. It should then return the line via a string parameter called line. Document the data flow of the parameters with appropriate comments.
15. Write a void function called SkipToEmptyLine that takes an ifstream (infile) as an In/out parameter, and that reads lines from the file until it finds a line that contains no characters. It should then return the number of lines skipped via an int parameter called skipped. Document the data flow of the parameters with appropriate comments.
16. Write a void function called TimeAdd that takes parameters representing two times in days, hours, and minutes, and then adds those parameters to get a new time. Each part of the time is an int. Hours range from 0 to 23, while minutes range from 0 to 59. There is no limit on the range of days. We assume that the time to be added is positive. The values in the parameters representing the first time are replaced by the result of adding the two times.
Here is an example call in which 3 days, 17 hours, and 49 minutes is added to 12 days, 22 hours, and 14 minutes:

After the call, the values in the variables are as follows:

17. Extend function TimeAdd in Exercise 16 to include seconds.
18. Write a void function called SeasonPrint that takes int parameters representing a month and a day and that outputs to cout the name of the season. For the purposes of this exercise, spring begins on March 21, summer begins June 21, fall begins September 21, and winter begins December 21. Note that the year begins and ends during winter. The function can assume that the values in the month and day parameters have been validated before it is called.
Programming Problems
1. Write a C++ program that computes student grades for an assignment as a percentage given each student’s score and the total points. The final score should be rounded up to the nearest whole value using the ceil function in the <cmath> header file. You should also display the floating-point result up to 5 decimal places. You should have a function to print the last name of the student and another function to compute and print the percentage as well as “Excellent” if the grade is greater than 90, “Well Done” if the grade is greater than 80, “Good” if the grade is greater than 70, “Need Improvement” if the grade is greater than or equal to 60, and “Fail” if the grade is less than 50. The main function is responsible for reading the input file and passing the appropriate arguments to your functions. Here is an example of what the input file might look like:
The output of your program should look like this:

2. ROT13 (rotate by 13 places) is a simple letter substitution cipher that is an instance of a Caesar cipher developed in ancient Rome and used by Julius Caesar who used it in his private correspondence. ROT13 replaces a letter with the letter 13 letters after it in the alphabet. The following table demonstrates the translation in ROT13:
Thus, the translation of the word JULIUS using ROT13 would be WHYVHF. Write a C++ program that asks the user for the name of an input file and translates the contents of that input file using ROT13. Your main function should be responsible for reading the input file and coordinating calls to a function named Rot13 that will do the translation for each character and WriteTranslatedChar that will write the translated character to a secondary file. The Rot13 function should be defined with a reference parameter that will be the initial character as input and the translated character as output. The second function named WriteTranslatedChar will have two parameters, the translated character and a reference to an ifstream data type for a secondary file named “output.rot13”, and write that translated character to this file.
3. In mathematics, the Fibonacci numbers are the series of numbers that exhibit the following pattern:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
In mathematical notation the sequence Fn of Fibonacci numbers is defined by the following recurrence relation:
Fn = Fn−1 + Fn−2
With the initial values of F0 = 0 and F1 = 1. Thus, the next number in the series is the sum of the previous two numbers. Write a program that asks the user for a positive integer N and generates the Nth Fibonacci number. Your main function should handle user input and pass that data to a function called Fib that takes an integer value N as input and a reference parameter that is assigned the Nth Fibonacci number.
4. Consider the following maze:
The maze begins at S and ends at E. We represent the current position in the maze using two integer variables named posX and posY. The starting location (S) is thus represented as posX = 0 and posY = 0. Movement through the maze is defined by the following rules:
1. MoveRight(spaces): posY = posY + spaces
2. MoveLeft(spaces): posY = posY – spaces
3. MoveDown(spaces): posX = posX + spaces
4. MoveUp(spaces): posX = posX – spaces
Define functions for each of the above rules such that each function has an integer reference parameter. Use these function declarations to write a C++ program that defines posX and posY, initialized to 0, and the corresponding calls to your functions that will correctly move your position in the maze from S to E ending at posX = 0, posY = 11. Print out the value of posX and posY after each function call.
5. Rewrite the program from Programming Problem 3 of Chapter 6 using functions. The program is to print a bar chart of the hourly temperatures for one day, given the data on a file. You should have a function to print the chart’s heading, and another function that prints the bar of stars for a given temperature value. Note that the second function does not print the value to the left of the bar graph. The main program coordinates the process of inputting values and calling these functions as necessary. Now that your programs are becoming more complex, it is even more important for you to use proper indentation and style, meaningful identifiers, and appropriate comments.
6. You’re working for a company that lays ceramic floor tile, and its employees need a program that estimates the number of boxes of tile for a job. A job is estimated by taking the dimensions of each room in feet and inches, and converting these dimensions into a multiple of the tile size (rounding up any partial multiple) before multiplying to get the number of tiles for the room. A box contains 20 tiles, so the total number needed should be divided by 20 and rounded up to get the number of boxes. The tiles are assumed to be square.
The program should initially prompt the user for the size of the tile in inches and the number of rooms to be covered with tile. It should then input the dimensions for each room and output the number of tiles needed for that room. After data for the last room is input, the program should output the total number of tiles needed, the number of boxes of tile needed, and how many extra tiles will be left over.
Here is an example of how a run might appear:
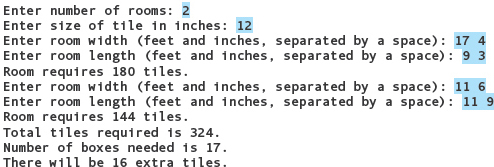
Use functional decomposition to solve this problem, and code the solution using functions wherever it makes sense to do so. Your program should check for invalid data such as nonpositive dimensions, number of rooms less than 1, number of inches greater than 11, and so on. It should prompt the user for corrected input whenever it detects invalid input. Now that your programs are becoming more complex, it is even more important for you to use proper indentation and style, meaningful identifiers, and appropriate comments.
7. Programming Problem 8 in Chapter 5 asked you to write a program to compute the score for one frame in a game of tenpin bowling. In this exercise, you will extend this algorithm to compute the score for an entire game for one player. A game consists of 10 frames, but the tenth frame has some special cases that were not described in Chapter 5.
A frame is played by first setting up the 10 pins. The player then rolls the ball to knock them down. If all 10 are knocked down on the first throw, it is called a strike, and the frame is over. If fewer than 10 are knocked down on the first throw, the number knocked down is recorded and the player gets a second throw. If the remaining pins are all knocked down on the second throw, it is called a spare. The frame ends after the second throw, even if there are pins left standing. If the second throw fails to knock all of the pins down, then the number that it knocked down is recorded, and the score for the frame is just the number of pins knocked down by the two throws. However, in the case of a strike or a spare, the score for the frame depends on throws in the next frame and possibly the frame after that.
If the frame is a strike, then the score is equal to 10 points plus the number of pins knocked down in the next two throws. Thus the maximum score for a frame is 30, which occurs when the frame is a strike and the two following frames are also strikes. If the frame is a spare, then the score is those 10 points plus the number of pins knocked down on the next throw.
The last frame is played somewhat differently. If the player gets a strike, then he or she gets two more throws so that the score for the strike can be computed. Similarly, if it is a spare, then one extra throw is given. If the first two throws fail to knock down all of the pins, then the score for the last frame is just the number knocked down, and there is no extra throw. Here is an example of how the I/O might appear for the start of a run:
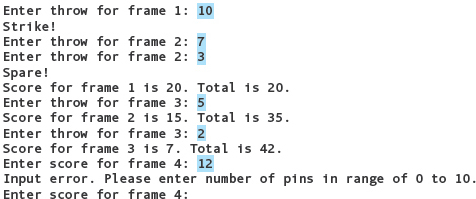
Your program should take as input the number of pins knocked down by each throw, and output the score for each frame as it is computed. The program must recognize when a frame has ended (due to either a strike or a second throw). The program also should check for erroneous input. For example, a throw may be in the range of 0 through 10 pins, and the total of the two throws in any of the first nine frames must be less than or equal to 10.
Use functional decomposition to solve this problem and code the solution using functions as appropriate. Be sure to use proper formatting and appropriate comments in your code. The output should be labeled clearly and formatted neatly, and the error messages should be informative.
8. Write a simple telephone directory program in C++ that looks up phone numbers in a file containing a list of names and phone numbers. The user should be prompted to enter a first and last name, and the program should then either output the corresponding number or indicate that the name isn’t present in the directory. After each lookup, the program should ask the user whether he or she wants to look up another number, and then either repeat the process or exit the program. The data on the file should be organized so that each line contains a first name, a last name, and a phone number, separated by blanks. You can return to the beginning of the file by closing it and opening it again.
Use functional decomposition to solve this problem and code the solution using functions as appropriate. Be sure to use proper formatting and appropriate comments in your code. The output should be labeled clearly and formatted neatly, and the error messages should be informative.
9. Extend the program in Problem 8 to look up addresses as well as phone numbers. Change the file format so that the name and phone number appear on one line, and the address appears on the following line for each entry. The program should ask the user whether he or she wants to look up a phone number, an address, or both, and then perform the lookup and output the requested information. The program should recognize an invalid request and prompt the user to enter the request again. As in Problem 8, the program should allow the user to keep entering queries until the user indicates that he or she is finished.
10. Programming Problem 3 in Chapter 5 asked you to write a program that inputs a letter and outputs the corresponding word in the International Civil Aviation Organization (ICAO) phonetic alphabet. This problem asks you to turn that program into a function, and use it to convert a string input by the user into the series of words that would be used to spell it out phonetically. For example:

For ease of reference, the ICAO alphabet is repeated here:
A |
Alpha |
B |
Bravo |
C |
Charlie |
D |
Delta |
E |
Echo |
F |
Foxtrot |
G |
Golf |
H |
Hotel |
I |
India |
J |
Juliet |
K |
Kilo |
Lima |
|
M |
Mike |
N |
November |
O |
Oscar |
P |
Papa |
Q |
Quebec |
R |
Romeo |
S |
Sierra |
T |
Tango |
U |
Uniform |
V |
Victor |
W |
Whiskey |
X |
X-ray |
Y |
Yankee |
Z |
Zulu |
Be sure to use proper formatting and appropriate comments in your code. Provide appropriate prompts to the user. The output should be labeled clearly and formatted neatly.
11. You’ve been asked to write a program to grade a multiple-choice exam. The exam has 20 questions, each answered with a letter in the range of 'a' through 'f'. The data are stored on a file (exams.dat) where the first line is the key, consisting of a string of 20 characters. The remaining lines on the file are exam answers; each consists of a student ID number, a space, and a string of 20 characters. The program should read the key, read each exam, and output the ID number and score to file scores.dat. Erroneous input should result in an error message. For example, given the data

the program would output the following data on scores.dat:

Use functional decomposition to solve the problem and code the solution using functions as appropriate. Be sure to use proper formatting and appropriate comments in your code. The output should be formatted neatly, and the error messages should be informative.
1. Test the LawnCare application using a file with no data. What happens? If this input causes an error, rewrite the program to handle this situation.
2. Test the LawnCare application using a file with only one customer. What happens? If this input causes an error, rewrite the program to handle this situation.
3. The current version writes a bill with a zero amount due if there are no jobs. Rewrite the application so that no bill is written if there are no jobs.
1. Actually, some parts of a C++ program execute prior to main, such as the initialization of cin and cout. For the programs we are writing, however, it is simplest to think of execution as starting with main.
2. Technically, all of the variable declarations we’ve used so far have been variable definitions as well as declarations—they allocate memory for the variable. In Chapter 9, we see examples of variable declarations that aren’t variable definitions.
3. We’ll see an exception to this rule in Chapter 9.
4. This statement is not the whole truth. C++ has a special language feature—called default parameters—that lets you call a function with fewer arguments than parameters. We do not cover default parameters in this book.
5. C++ does allow some special cases of expressions that can be arguments to reference parameters, but their definition is beyond the scope of this text.