Distance doesn’t exist, in fact, and neither does time. Vibrations from love or music can be felt everywhere, at all times.
Yoko Ono (1933- ) Japanese multimedia artist, singer, and peace activist, and widow of John Lennon of The Beatles.
Covering a hypercube in  , with side length L, by boxes of side length s requires (L∕s)E boxes. This complexity, exponential in E, makes d
B expensive to compute for sets in a high-dimensional space. The correlation dimension was introduced in 1983 by Grassberger and Procaccia [Grassberger 83a, Grassberger 83b] and by Hentschel and Procaccia [Hentschel 83] as a computationally attractive alternative to d
B. The correlation dimension has been enormously important to physicists [Baker 90], and even by 1999 the literature on the computation of the correlation dimension was huge [Hegger 99, Lai 98]. The Grassberger and Procaccia papers introducing the correlation dimension were motivated by the study of strange attractors,
a topic in dynamical systems. Although this book is not focused on chaos and dynamical systems, so much of the literature on the correlation dimension is motivated by these topics that a very short review, based on [Ruelle 80, Ruelle 90] will provide a foundation for our discussion of the correlation dimension of a geometric object (in this chapter and in the next chapter) and of a network (in Chap. 11).
, with side length L, by boxes of side length s requires (L∕s)E boxes. This complexity, exponential in E, makes d
B expensive to compute for sets in a high-dimensional space. The correlation dimension was introduced in 1983 by Grassberger and Procaccia [Grassberger 83a, Grassberger 83b] and by Hentschel and Procaccia [Hentschel 83] as a computationally attractive alternative to d
B. The correlation dimension has been enormously important to physicists [Baker 90], and even by 1999 the literature on the computation of the correlation dimension was huge [Hegger 99, Lai 98]. The Grassberger and Procaccia papers introducing the correlation dimension were motivated by the study of strange attractors,
a topic in dynamical systems. Although this book is not focused on chaos and dynamical systems, so much of the literature on the correlation dimension is motivated by these topics that a very short review, based on [Ruelle 80, Ruelle 90] will provide a foundation for our discussion of the correlation dimension of a geometric object (in this chapter and in the next chapter) and of a network (in Chap. 11).
9.1 Dynamical Systems
 , for some function F, while a discrete time dynamical system has the form
, for some function F, while a discrete time dynamical system has the form  for some function F. A physical system can be described using its phase space,
so that each point in phase space represents an instantaneous description of the system at a given point in time. We will be concerned only with finite dimensional systems for which the phase space is
for some function F. A physical system can be described using its phase space,
so that each point in phase space represents an instantaneous description of the system at a given point in time. We will be concerned only with finite dimensional systems for which the phase space is  , and the state of the system is specified by x = (x
1, x
2, …, x
E). For example, for a physical system the state might be the coordinates on a grid, and for a chemical system the state might be temperature,
pressure, and concentration of the reactants. The E coordinates of x are assumed to vary with time, and their values at time t are x(t) = (x
1(t), x
2(t), …, x
E(t)). We assume [Ruelle 80] the state at time t + 1 depends only on the state at time t:
, and the state of the system is specified by x = (x
1, x
2, …, x
E). For example, for a physical system the state might be the coordinates on a grid, and for a chemical system the state might be temperature,
pressure, and concentration of the reactants. The E coordinates of x are assumed to vary with time, and their values at time t are x(t) = (x
1(t), x
2(t), …, x
E(t)). We assume [Ruelle 80] the state at time t + 1 depends only on the state at time t: 
 . Given x(0), we can determine x(t) for each time t.
. Given x(0), we can determine x(t) for each time t.If an infinitesimal change δx(0) is made to the initial conditions (at time t = 0), there will be a corresponding change δx(t) at time t. If for some λ > 0 we have |δx(t)|∝|δx(0)|e λt (i.e., if δx(t) grows exponentially with t), then the system is said to exhibit sensitive dependence on initial conditions. This means that small changes in the initial state become magnified, eventually becoming distinct trajectories [Mizrach 92]. The exponent λ is called a Lyapunov exponent.

There are two types of dynamical physical systems. When the system loses energy due to friction, as happens in most natural physical systems, the system is dissipative.
If there is no loss of energy due to friction, the system is conservative.
A dissipative system always approaches, as t →∞, an asymptotic state [Chatterjee 92]. Consider a dissipative dynamical system  , and suppose that at time 0, all possible states of the system lie in a set Ω
0 having positive volume (i.e., positive Lebesgue measure, as defined in Sect. 5.1). Since the system is dissipative, Ω
0 must be compressed due to loss of energy, and Ω
0 converges to a compact set Ω as t →∞. The set Ω lives in a lower dimensional subspace of the phase space, and thus has Lebesgue measure zero in the phase space. The set Ω satisfies F(Ω) = Ω, and Ω can be extremely complicated, often possessing a fractal structure [Hegger 99]. Interestingly, Benford’s Law (Sect. 3.2) has been shown to apply to one-dimensional dynamical systems [Fewster 09].
, and suppose that at time 0, all possible states of the system lie in a set Ω
0 having positive volume (i.e., positive Lebesgue measure, as defined in Sect. 5.1). Since the system is dissipative, Ω
0 must be compressed due to loss of energy, and Ω
0 converges to a compact set Ω as t →∞. The set Ω lives in a lower dimensional subspace of the phase space, and thus has Lebesgue measure zero in the phase space. The set Ω satisfies F(Ω) = Ω, and Ω can be extremely complicated, often possessing a fractal structure [Hegger 99]. Interestingly, Benford’s Law (Sect. 3.2) has been shown to apply to one-dimensional dynamical systems [Fewster 09].
 , with infinitely many points, is a strange attractor for the map
, with infinitely many points, is a strange attractor for the map  if there is a set U with the following four properties [Ruelle 80]:
if there is a set U with the following four properties [Ruelle 80]: - 1.
U is an E-dimensional neighborhood of Ω, i.e., for each point x ∈ Ω, there is a ball centered at x and entirely contained in U. In particular, Ω ⊂ U.
- 2.
For each initial point x(0) ∈ U, the point x(t) ∈ U for all t > 0, and x(t) is arbitrarily close to Ω for all sufficiently large t. (This means that Ω is attracting.)
- 3.
There is a sensitive dependence on initial condition whenever x(0) ∈ U. (This makes Ω is strange attractor.)
- 4.
One can choose a point x(0) in Ω such that, for each other point y in Ω, there is a point x(t) that is arbitrarily close to y for some positive t. (This indecomposability condition says that Ω cannot be split into two different attractors.)
To see how a strange attractor arises in dissipative systems, imagine we begin with a small sphere. After a small time increment, the sphere may evolve into an ellipsoid, such that the ellipsoid volume is less than the sphere volume. However, the length of longest principle axis of the ellipsoid can exceed the sphere diameter. Thus, over time, the sphere may compress in some directions and expand in other directions. For the system to remain bounded, expansion in a given direction cannot continue indefinitely, so folding occurs. If the pattern of compressing, expansion, and folding continues, trajectories that are initially close can diverge rapidly over time, thus creating the sensitive dependence on initial conditions. The amounts of compression or stretching in the various dimensions are quantified by the Lyapunov exponents [Chatterjee 92].
A well-known example of a discrete time dynamical system was introduced by Hénon. For this two-dimensional system, we have x 1(t + 1) = x 2(t) + 1 − ax 1(t)2 and x 2(t + 1) = bx 2(t). With a = 1.4 and b = 0.3, the first 104 points distribute themselves on a complex system of lines that are a strange attractor (see [Ruelle 80] for pictures); for a = 1.3 and b = 0.3 the lines disappear and instead we obtain 7 points of a periodic attractor.
Chaos in human physiology was studied in many papers by Goldberger, e.g., [Goldberger 90]. In the early 1980s, when investigators began to apply chaos theory to psychological systems, they expected that chaos would be most apparent in diseased or aging systems (e.g., [Ruelle 80] stated that the normal cardiac regime is periodic). Later research found instead that the phase-space representation of the normal heartbeat contains a strange attractor, suggesting that the dynamics of the normal heartbeat may be chaotic. There are advantages to such dynamics [Goldberger 90]: “Chaotic systems operate under a wide range of conditions and are therefore adaptable and flexible. This plasticity allows systems to cope with the exigencies of an unpredictable and changing environment.”
Several other examples of strange attractors were provided in [Ruelle 80]. Strange attractors arise in studies of the earth’s magnetic field, which reverses itself at irregular intervals, with at least 16 reversals in the last 4 million years. Geophysicists have developed dynamo equations,
which possess chaotic solutions, to describe this behavior. The Belousov–Zhabotinski chemical reaction
turns ferroin from blue to purple to red; simultaneously the cerium ion changes from pale yellow to colorless, so all kinds of hues are produced (this reaction caused astonishment and some disbelief when it was discovered). For a biological example, discrete dynamical models of the population of multiple species yield strange attractors. Even for a single species, the equation  , where R > 0, gives rise to non-periodic behavior. Ruelle observed that the non-periodic fluctuations of a dynamical system do not necessarily indicate an experiment that was spoiled by mysterious random forces, but rather may indicate the presence of a strange attractor. Chaos in ecology was studied in [Hastings 93].
, where R > 0, gives rise to non-periodic behavior. Ruelle observed that the non-periodic fluctuations of a dynamical system do not necessarily indicate an experiment that was spoiled by mysterious random forces, but rather may indicate the presence of a strange attractor. Chaos in ecology was studied in [Hastings 93].
In a system with F degrees of freedom, an attractor is a subset of F-dimensional phase space toward which almost all sufficiently close trajectories get “attracted” asymptotically. Since volume is contracted in dissipative flows, the volume of an attractor is always zero, but this leaves still room for extremely complex structures.
Typically, a strange attractor arises when the flow does not contract a volume element in all directions, but stretches it in some. In order to remain confined to a bounded domain, the volume element gets folded at the same time, so that it has after some time a multisheeted structure. A closer study shows that it finally becomes (locally) Cantor-set like in some directions, and is accordingly a fractal in the sense of Mandelbrot [Mandelbrot 77].
We could determine the fractal dimension of an attractor by applying box counting. However, a major limitation of box counting is that it counts only the number of occupied boxes, and is insensitive to the number of points in an occupied box. Thus d
B is more of a geometrical measure, and provides very limited information about the clumpiness of a distribution. Moreover, if the box size s is small enough to investigate the small-scale structure of a strange attractor, the relation  (assuming diameter-based boxes) implies that the number B
D(s) of occupied boxes becomes very large. The most interesting cases of dynamical systems occur when the dimension of the attractor exceeds 3. As observed in [Farmer 82], when d
B = 3 and s = 10−2 from
(assuming diameter-based boxes) implies that the number B
D(s) of occupied boxes becomes very large. The most interesting cases of dynamical systems occur when the dimension of the attractor exceeds 3. As observed in [Farmer 82], when d
B = 3 and s = 10−2 from  we obtain one million boxes, which in 1982 taxed the memory
of a computer. While such a requirement would today be no burden, the point remains: box-counting methods in their basic form have time and space complexity exponential in d
B. Moreover, for a dynamical system, some regions of the attractor have a very low probability, and it may be necessary to wait a very long time for a trajectory to visit all of the very low probability regions. These concerns were echoed in [Eckmann 85], who noted that the population of boxes is usually very uneven, so that it may take a long time for boxes that should be occupied to actually become occupied. For these reasons, box counting was not (as of 1985) used to study dynamical systems [Eckmann 85]. Nine years later, [Strogatz 94] also noted that d
B is rarely used for studying high-dimensional dynamical processes.
we obtain one million boxes, which in 1982 taxed the memory
of a computer. While such a requirement would today be no burden, the point remains: box-counting methods in their basic form have time and space complexity exponential in d
B. Moreover, for a dynamical system, some regions of the attractor have a very low probability, and it may be necessary to wait a very long time for a trajectory to visit all of the very low probability regions. These concerns were echoed in [Eckmann 85], who noted that the population of boxes is usually very uneven, so that it may take a long time for boxes that should be occupied to actually become occupied. For these reasons, box counting was not (as of 1985) used to study dynamical systems [Eckmann 85]. Nine years later, [Strogatz 94] also noted that d
B is rarely used for studying high-dimensional dynamical processes.
An early (1981) alternative to box counting was proposed in [Froehling 81]. Given a set of points in  , use regression to find the best hyperplane
of dimension m that fits the data, where m is an integer in the range 1 ≤ m ≤ E − 1. The goodness of fit of a given hyperplane is measured by χ
2, the sum of deviations from the hyperplane divided by the number of degrees of freedom. If m is too small, the fit will typically be poor, and χ
2 will be large. As m is increased, χ
2 will drop sharply. The m for which χ
2 is lowest is the approximate fractal dimension. A better approach, proposed two years later in 1983, is the correlation dimension. Our discussion of the correlation dimension begins with the natural invariant measure and the pointwise mass dimension.
, use regression to find the best hyperplane
of dimension m that fits the data, where m is an integer in the range 1 ≤ m ≤ E − 1. The goodness of fit of a given hyperplane is measured by χ
2, the sum of deviations from the hyperplane divided by the number of degrees of freedom. If m is too small, the fit will typically be poor, and χ
2 will be large. As m is increased, χ
2 will drop sharply. The m for which χ
2 is lowest is the approximate fractal dimension. A better approach, proposed two years later in 1983, is the correlation dimension. Our discussion of the correlation dimension begins with the natural invariant measure and the pointwise mass dimension.
9.2 Pointwise Mass Dimension
 . The study of measures of sizes of sets dates at least as far back as Borel (1885), and was continued by Lebesgue (1904), Carathéodory (1914), and Hausdorff (1919) [Chatterjee 92]. Recall that the Lebesgue measure μ
L was defined in Chap. 5. Formalizing the qualitative definition of “dissipative” provided above, we say that a dynamical physical system g
t, t = 1, 2, …, where
. The study of measures of sizes of sets dates at least as far back as Borel (1885), and was continued by Lebesgue (1904), Carathéodory (1914), and Hausdorff (1919) [Chatterjee 92]. Recall that the Lebesgue measure μ
L was defined in Chap. 5. Formalizing the qualitative definition of “dissipative” provided above, we say that a dynamical physical system g
t, t = 1, 2, …, where  , is dissipative if
the Lebesgue measure μ
L
of a bounded subset tends to 0 as t →∞, i.e., if for each bounded
, is dissipative if
the Lebesgue measure μ
L
of a bounded subset tends to 0 as t →∞, i.e., if for each bounded  we have
we have ![$$\displaystyle \begin{aligned} \begin{array}{rcl} \lim_{t \rightarrow \infty} \mu_{{\, L}} [g_t(B)] = 0 \, . {} \end{array} \end{aligned} $$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_Equ3.png)
![$$\displaystyle \begin{aligned} \begin{array}{rcl} \mu(B) \equiv \lim_{t \rightarrow \infty} \frac {1}{t} \int_0^t I_{B}[g_t(x_0)] \mathrm{d} t \, , {} \end{array} \end{aligned} $$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_Equ4.png)
 is the starting point of the system g
t, and I
B[x] is the indicator function whose value is 1 if x ∈ B and 0 otherwise [Theiler 90]. The measure defined by (9.2) is the natural measure for almost all x
0.
For a discrete dynamical system, the natural measure of B is [Peitgen 92]
is the starting point of the system g
t, and I
B[x] is the indicator function whose value is 1 if x ∈ B and 0 otherwise [Theiler 90]. The measure defined by (9.2) is the natural measure for almost all x
0.
For a discrete dynamical system, the natural measure of B is [Peitgen 92] ![$$\displaystyle \begin{aligned} \mu(B) = \lim_{t \rightarrow \infty} \frac{1}{t+1} \sum_{i = 0}^t I_{B}[x(t)] \, . \end{aligned}$$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_Equa.png)



9.3 The Correlation Sum
 , and suppose we have determined N points in Ω. Denote these points by x(n) for n = 1, 2, …, N. Denote the E coordinates of x(n) by x
1(n), x
2(n), …, x
E(n). We can approximate the average pointwise dimension 〈d〉 defined by (9.4) by averaging d(x) over these points, that is, by computing
, and suppose we have determined N points in Ω. Denote these points by x(n) for n = 1, 2, …, N. Denote the E coordinates of x(n) by x
1(n), x
2(n), …, x
E(n). We can approximate the average pointwise dimension 〈d〉 defined by (9.4) by averaging d(x) over these points, that is, by computing  . Since by (9.3) each
. Since by (9.3) each  is a limit, then
is a limit, then  is an average of N limits. An alternative method of estimating (9.4) is to first compute, for each r, the average
is an average of N limits. An alternative method of estimating (9.4) is to first compute, for each r, the average 

 be the Heaviside step function,
defined by
be the Heaviside step function,
defined by 

 [Frank 89]. Define
[Frank 89]. Define 




Grassberger stressed the importance of excluding i = j from the double sum defining C(r); see [Theiler 90]. However, taking the opposite viewpoint, [Smith 88] wrote that it is essential that the i = j terms be included in the correlation sum, “in order to distinguish the scaling of true noise at small r from fluctuations due to finite N”. The argument in [Smith 88] is that, when the i = j terms are omitted,  is not bounded as r → 0, and steep descents in
is not bounded as r → 0, and steep descents in  may result in large estimates of d
C, which may exceed E. In this chapter, we will use definition (9.9).
may result in large estimates of d
C, which may exceed E. In this chapter, we will use definition (9.9).
Given the set of N points, for  , the distance between each pair of distinct points does not exceed
, the distance between each pair of distinct points does not exceed  , so C(r) = 1. For
, so C(r) = 1. For  , the distance between each pair of distinct points is less than
, the distance between each pair of distinct points is less than  , so C(r) = 0. Hence the useful range of r is the interval
, so C(r) = 0. Hence the useful range of r is the interval ![$$[r_{\min }, r_{\max }]$$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_IEq34.png) . If there is a single pair of points at distance
. If there is a single pair of points at distance  , then
, then ![$$C(r_{\min }) = 2/[N(N-1)]$$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_IEq36.png) , and
, and  . Since
. Since  , the range of
, the range of  over the interval
over the interval ![$$[r_{\min }, r_{\max }]$$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_IEq40.png) is approximately
is approximately  . However, for box counting with N points, the number of non-empty boxes (i.e., B
R(r) for radius-based boxes and B
D(s) for diameter-based boxes) ranges from 1 to N, so the range of
. However, for box counting with N points, the number of non-empty boxes (i.e., B
R(r) for radius-based boxes and B
D(s) for diameter-based boxes) ranges from 1 to N, so the range of  or
or  is
is  , which is only half the range of
, which is only half the range of  . Similarly, for a single point x, over its useful range the pointwise mass dimension estimate (9.10) ranges from 1∕(N − 1) to 1, so the range of its logarithm is also approximately
. Similarly, for a single point x, over its useful range the pointwise mass dimension estimate (9.10) ranges from 1∕(N − 1) to 1, so the range of its logarithm is also approximately  , half the range for
, half the range for  . The greater range, by a factor of 2, for
. The greater range, by a factor of 2, for  is “the one advantage” the correlation sum has over the average pointwise dimension [Theiler 90].
is “the one advantage” the correlation sum has over the average pointwise dimension [Theiler 90].
 of the correlation sum, now using the double summation
of the correlation sum, now using the double summation  which does not exclude the case i = j. With this alternative definition, each of the N pairs (x(i), x(i)) contributes 1 to the double summation. Following [Yadav 10],
which does not exclude the case i = j. With this alternative definition, each of the N pairs (x(i), x(i)) contributes 1 to the double summation. Following [Yadav 10], 
 . In (9.13), we can interpret N
n(r)∕N as the expected fraction of points whose distance from n does not exceed r. Suppose this fraction is independent of n, and suppose we have a probability distribution P(k, r) providing the probability that k of N points are within a distance r from a random point. The expected value (with respect to k) of this probability distribution is the expected fraction of the N points within distance r of a random point, so
. In (9.13), we can interpret N
n(r)∕N as the expected fraction of points whose distance from n does not exceed r. Suppose this fraction is independent of n, and suppose we have a probability distribution P(k, r) providing the probability that k of N points are within a distance r from a random point. The expected value (with respect to k) of this probability distribution is the expected fraction of the N points within distance r of a random point, so 
 :
: 
 define the generalized correlation sum
define the generalized correlation sum 
 for −∞ < q < ∞ provides information about regions containing many points as well as regions with few points. We will explore this further in Chap. 16 on multifractals.
for −∞ < q < ∞ provides information about regions containing many points as well as regions with few points. We will explore this further in Chap. 16 on multifractals.9.4 The Correlation Dimension

 as r → 0, where “∼” means “tends to be approximately proportional to” (see Sect. 1.2 for a discussion of this symbol). However, the existence of d
C does not imply that
as r → 0, where “∼” means “tends to be approximately proportional to” (see Sect. 1.2 for a discussion of this symbol). However, the existence of d
C does not imply that  , since this proportionality may fail to hold, even as r → 0. For r > 0, define the function
, since this proportionality may fail to hold, even as r → 0. For r > 0, define the function  by
by 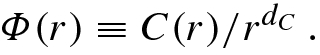
 [Theiler 88].
[Theiler 88].One great advantage of computing d
C rather than d
B is that memory
requirements are greatly reduced, since there is no need to construct boxes covering Ω. With box counting it is also necessary to examine each box to determine if it contains any points; this may be impractical, particularly if r is very small. Another advantage, mentioned in Sect. 9.3 above, is that the range of  is twice the range of
is twice the range of  or
or  . In [Eckmann 85], the correlation dimension was deemed a “quite sound” and “highly successful” means of determining the dimension of a strange attractor,
and it was observed that the method “is not entirely justified mathematically, but nevertheless quite sound”.5 In [Ruelle 90] it was noted that “... this algorithm has played a very important role in allowing us to say something about systems that otherwise defied analysis”. The importance of d
C was echoed in [Schroeder 91], which noted that the correlation dimension is one of the most widely used fractal dimensions, especially if the fractal comes as “dust”, meaning isolated points, sparsely distributed over some region. Lastly, [Mizrach 92] observed that, in the physical sciences, the correlation dimension has become the preferred dimension to use with experimental data.
. In [Eckmann 85], the correlation dimension was deemed a “quite sound” and “highly successful” means of determining the dimension of a strange attractor,
and it was observed that the method “is not entirely justified mathematically, but nevertheless quite sound”.5 In [Ruelle 90] it was noted that “... this algorithm has played a very important role in allowing us to say something about systems that otherwise defied analysis”. The importance of d
C was echoed in [Schroeder 91], which noted that the correlation dimension is one of the most widely used fractal dimensions, especially if the fractal comes as “dust”, meaning isolated points, sparsely distributed over some region. Lastly, [Mizrach 92] observed that, in the physical sciences, the correlation dimension has become the preferred dimension to use with experimental data.
 . The problem with this approach is that the convergence of
. The problem with this approach is that the convergence of  to d
C is very slow [Theiler 90]; this is the same problem identified in Sect. 4.2 in picking the smallest s value available to estimate d
B. A second possible approach [Theiler 88] is to take the local slope of the
to d
C is very slow [Theiler 90]; this is the same problem identified in Sect. 4.2 in picking the smallest s value available to estimate d
B. A second possible approach [Theiler 88] is to take the local slope of the  versus
versus  curve, using
curve, using 

By far, the most popular method for estimating d
C is the Grassberger–Procaccia method.
The steps are (i) compute C(r) for a set of positive radii r
m, m = 1, 2, …, M, (i) determine a subset of these M values of r
m over which the  versus
versus  curve is roughly linear, and (iii) estimate d
C as the slope of the best fit line through the points
curve is roughly linear, and (iii) estimate d
C as the slope of the best fit line through the points  over this subset of the M points. As observed in [Theiler 88], there is no clear criterion for how to determine the slope through the chosen subset of the M points. Finding the slope that minimizes the unweighted sum of squares has two drawbacks. First, the least squares model assumes a uniform error in the calculated
over this subset of the M points. As observed in [Theiler 88], there is no clear criterion for how to determine the slope through the chosen subset of the M points. Finding the slope that minimizes the unweighted sum of squares has two drawbacks. First, the least squares model assumes a uniform error in the calculated  , which is incorrect since the statistics get worse as r decreases. Second, the least squares model assumes that errors in
, which is incorrect since the statistics get worse as r decreases. Second, the least squares model assumes that errors in  are independent of each other, which is incorrect since C(r + 𝜖) is equal to C(r) plus the fraction of distances between r and 𝜖; hence for small 𝜖 the error at
are independent of each other, which is incorrect since C(r + 𝜖) is equal to C(r) plus the fraction of distances between r and 𝜖; hence for small 𝜖 the error at  is strongly correlated with the error at
is strongly correlated with the error at  .
.
Suppose C(r
m) has been computed for m = 1, 2, …, M, where r
m < r
m+1. In studying the orbits of celestial bodies, [Freistetter 00] used the following iterative procedure to determine the range of r values over which the slope of the  versus
versus  curve should be computed. Since the
curve should be computed. Since the  versus
versus  curve is not linear in the region of very small and very large r, we trim the ends of the interval as follows. In each iteration we first temporarily remove the leftmost r value (which in the first iteration is r
1) and use linear least squares to obtain d
R, the slope corresponding to {r
2, r
3, …, r
M}, and the associated correlation coefficient c
R. (Here the correlation coefficient, not to be confused with the correlation dimension, is a byproduct of the regression indicating the goodness of fit.) Next we temporarily remove the rightmost r value (which in the first iteration is r
M) and use linear least squares to obtain d
L, the slope corresponding to {r
1, r
2, …, r
M−1}, and the associated correlation coefficient c
L. Since a higher correlation coefficient indicates a better fit (where c = 1 is a perfect linear relationship), if c
R > c
L we delete r
L while if c
L > c
R we delete r
M. We begin the next iteration with either {r
2, r
3, …, r
M} or {r
1, r
2, …, r
M−1}. The iterations stop when we obtain a correlation coefficient higher than a desired value.
curve is not linear in the region of very small and very large r, we trim the ends of the interval as follows. In each iteration we first temporarily remove the leftmost r value (which in the first iteration is r
1) and use linear least squares to obtain d
R, the slope corresponding to {r
2, r
3, …, r
M}, and the associated correlation coefficient c
R. (Here the correlation coefficient, not to be confused with the correlation dimension, is a byproduct of the regression indicating the goodness of fit.) Next we temporarily remove the rightmost r value (which in the first iteration is r
M) and use linear least squares to obtain d
L, the slope corresponding to {r
1, r
2, …, r
M−1}, and the associated correlation coefficient c
L. Since a higher correlation coefficient indicates a better fit (where c = 1 is a perfect linear relationship), if c
R > c
L we delete r
L while if c
L > c
R we delete r
M. We begin the next iteration with either {r
2, r
3, …, r
M} or {r
1, r
2, …, r
M−1}. The iterations stop when we obtain a correlation coefficient higher than a desired value.
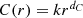 . Assume also that the distances between pairs of randomly selected points are independent and randomly distributed such that the probability P(x ≤ r) that the distance x between a random pair of points does not exceed r is given by
. Assume also that the distances between pairs of randomly selected points are independent and randomly distributed such that the probability P(x ≤ r) that the distance x between a random pair of points does not exceed r is given by 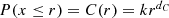 . Let X(r) be the number of pairwise distances less than r, and denote these X(r) distance values by r
i for 1 ≤ i ≤ X(r). The value of d
C that maximizes the probability of finding the X(r) observed distances {r
i} is given by the unbiased minimal variance Takens estimator
. Let X(r) be the number of pairwise distances less than r, and denote these X(r) distance values by r
i for 1 ≤ i ≤ X(r). The value of d
C that maximizes the probability of finding the X(r) observed distances {r
i} is given by the unbiased minimal variance Takens estimator  ,
defined by Guerrero and Smith [Guerrero 03]
,
defined by Guerrero and Smith [Guerrero 03] ![$$\displaystyle \begin{aligned} \begin{array}{rcl} \widetilde{T}(r) \equiv \biggl[ \frac{-1}{X(r)-1} \sum_{i=1}^{X(r)} \log \left( \frac{r_{{i}}}{r} \right) \biggr]^{-1} \, , {} \end{array} \end{aligned} $$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_Equ23.png)
 uses all distances less than a specified upper bound r, but there is no lower bound on distances. As r → 0 and X(r) →∞ we have
uses all distances less than a specified upper bound r, but there is no lower bound on distances. As r → 0 and X(r) →∞ we have  . If we replace X(r) − 1 by X(r) (which introduces a slight bias [Guerrero 03]), we can write (9.21) more compactly as
. If we replace X(r) − 1 by X(r) (which introduces a slight bias [Guerrero 03]), we can write (9.21) more compactly as 


 . However, for some fractal sets T(r) does not converge [Theiler 90]. The non-convergence is explained by considering the function Φ(r) defined by (9.18). A fractal has “periodic lacunarity” if for some positive number L
we have Φ(r) = Φ(Lr). For example, the middle-thirds Cantor set exhibits periodic lacunarity with L = 1∕3. The Takens estimate T(r) does not converge for fractals with periodic lacunarity. Theiler also supplied a condition on Φ(r) under which T(r) does converge.
. However, for some fractal sets T(r) does not converge [Theiler 90]. The non-convergence is explained by considering the function Φ(r) defined by (9.18). A fractal has “periodic lacunarity” if for some positive number L
we have Φ(r) = Φ(Lr). For example, the middle-thirds Cantor set exhibits periodic lacunarity with L = 1∕3. The Takens estimate T(r) does not converge for fractals with periodic lacunarity. Theiler also supplied a condition on Φ(r) under which T(r) does converge.Exercise 9.1 Show that the middle-thirds Cantor set exhibits periodic lacunarity with L = 1∕3. □
 by the linear function
by the linear function  for r ∈ [r
i−1, r
i], which implies C(r) is approximated by the exponential function
for r ∈ [r
i−1, r
i], which implies C(r) is approximated by the exponential function  for r ∈ [r
i−1, r
i]. The values a
i and b
i can be computed from the M points
for r ∈ [r
i−1, r
i]. The values a
i and b
i can be computed from the M points  . Assume r
i ≤ r for 1 ≤ i ≤ M. Since the integral of a linear function is trivial,
. Assume r
i ≤ r for 1 ≤ i ≤ M. Since the integral of a linear function is trivial, 
 for i = 1, 2, …, M, suppose there are indices L and U, where 1 ≤ L < U ≤ M, such that a straight line is a good fit to the points
for i = 1, 2, …, M, suppose there are indices L and U, where 1 ≤ L < U ≤ M, such that a straight line is a good fit to the points  for L ≤ i ≤ U. Then, using (9.23) and (9.24), a reasonable estimate of d
C is
for L ≤ i ≤ U. Then, using (9.23) and (9.24), a reasonable estimate of d
C is 
Exercise 9.2 Use (9.24) to estimate d C for the middle-thirds Cantor set for r ∈ [0.001, 1]. □


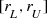 , where
, where 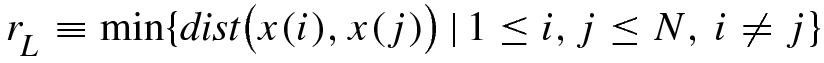
 . For time series
applications, only part of this range is usable, since the lower part of the range suffers from statistical fluctuations, and the upper part suffers from nonlinearities. Let r
min be the smallest usable r for which we evaluate f(r), and let r
max be the largest usable r, where
. For time series
applications, only part of this range is usable, since the lower part of the range suffers from statistical fluctuations, and the upper part suffers from nonlinearities. Let r
min be the smallest usable r for which we evaluate f(r), and let r
max be the largest usable r, where 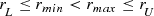 . Suppose r
max∕r
min ≥ 10, so the range is at least one decade. The correlation dimension d
C is approximately the slope m, where
. Suppose r
max∕r
min ≥ 10, so the range is at least one decade. The correlation dimension d
C is approximately the slope m, where 

This bound was used in [Boon 08] to study the visual evoked potential. Unfortunately, numerous studies do violate this bound [Ruelle 90]. If the inequality r max∕r min ≥ 10 is replaced by the more general bound r max∕r min ≥ k, then we obtain d C ≤ 2logkN. Ruelle observed that it seems unreasonable to have the ratio r max∕r min be much less than 10.
… dimensions characterize a set or an invariant measure whose support is the set, whereas any data set contains only a finite number of points representing the set or the measure. By definition, the dimension of a finite set of points is zero. When we determine the dimension of an attractor numerically, we extrapolate from finite length scales … to the infinitesimal scales, where the concept of dimensions is defined. This extrapolation can fail for many reasons …
9.5 Comparison with the Box Counting Dimension
In this section we present the proof of [Grassberger 83a, Grassberger 83b] that d C ≤ d B for a geometric object Ω.6 We first discuss notation. The pointwise mass measure μ(Ω(r)) was defined in Sect. 9.2 in terms of the box radius r. The correlation sum C(r) given by (9.11), and the correlation dimension d C given by (9.17), were similarly defined using r. Since C(r) counts pairs of points whose distance is less than r, we could equally well have defined the correlation sum and d C using using the variable s, rather than r, to represent distance. The motivation for using s rather than r in this section is that we will compute d C by first covering Ω with diameter-based boxes, and we always denote the linear size of a diameter-based box by s. Therefore, in this section we will denote the correlation sum by C(s); its definition is unchanged.
For a given positive s ≪ 1, let  be a minimal covering of Ω
by diameter-based boxes of size s, so the distance between any two points in a given box does not exceed s. Let N points be drawn randomly from Ω according to its natural measure and let N
j be the number of points in box
be a minimal covering of Ω
by diameter-based boxes of size s, so the distance between any two points in a given box does not exceed s. Let N points be drawn randomly from Ω according to its natural measure and let N
j be the number of points in box  . Discard from
. Discard from  each box for which N
j = 0, and, as usual, let B
D(s) be the number of non-empty boxes in
each box for which N
j = 0, and, as usual, let B
D(s) be the number of non-empty boxes in  .
.
 counts all ordered pairs (x(i), x(j)) of points, separated by a distance not exceeding s, such that x(i) and x(j) lie in the same box. Since a given pair (x(i), x(j)) of points satisfying dist(x(i), x(j)) ≤ s may lie within some box B
j, or x(i) and x(j) may lie in different boxes, from (9.9) and (9.11),
counts all ordered pairs (x(i), x(j)) of points, separated by a distance not exceeding s, such that x(i) and x(j) lie in the same box. Since a given pair (x(i), x(j)) of points satisfying dist(x(i), x(j)) ≤ s may lie within some box B
j, or x(i) and x(j) may lie in different boxes, from (9.9) and (9.11), 

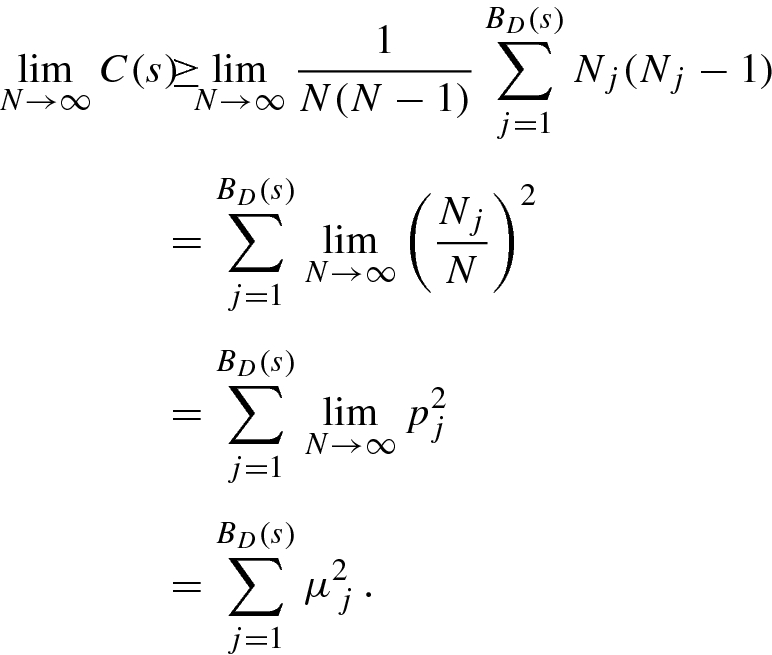
 , and B
D(s) as defined as in the previous paragraph, let Q(N, s, q) be the number of q-tuples of the N points such that the pairwise distance condition holds. Then
, and B
D(s) as defined as in the previous paragraph, let Q(N, s, q) be the number of q-tuples of the N points such that the pairwise distance condition holds. Then 
Having shown that we can lower bound the correlation sum by covering Ω with boxes, we now present the proof [Grassberger 83a, Grassberger 83b] that d
C ≤ d
B. The proof in [Grassberger 83b] assumes  and
and  . Since the symbol ∼ is ambiguous, we recast these assumptions as Assumptions 9.1 and 9.2 below.
. Since the symbol ∼ is ambiguous, we recast these assumptions as Assumptions 9.1 and 9.2 below.
 satisfying
satisfying 

 satisfying
satisfying 

 is a random variable, and
is a random variable, and  denotes expectation, then
denotes expectation, then  . In particular, for a random variable taking a finite set of values, if
. In particular, for a random variable taking a finite set of values, if  are nonnegative weights summing to 1, if
are nonnegative weights summing to 1, if  are positive numbers, and if f(z) = z
2 then
are positive numbers, and if f(z) = z
2 then 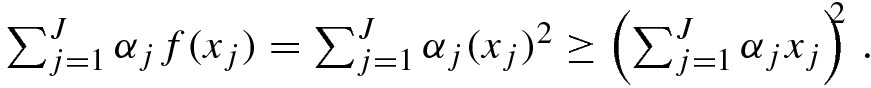
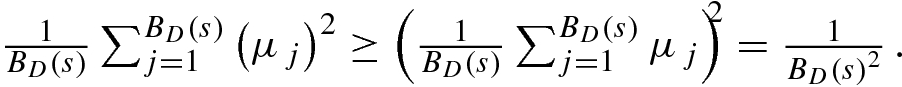
Theorem 9.1 If Assumptions 9.1 and 9.2 hold then d C ≤ d B.
 be a minimal s-covering of Ω and let B
D(s) be the number of boxes in
be a minimal s-covering of Ω and let B
D(s) be the number of boxes in  . Randomly select from Ω, according to its natural measure, the N points x(1), x(2), …, x(N). Let
. Randomly select from Ω, according to its natural measure, the N points x(1), x(2), …, x(N). Let  be the set of these N points. For box
be the set of these N points. For box  , let N
j(s) be the number of points of
, let N
j(s) be the number of points of  that are contained in B
j, so
that are contained in B
j, so  . From (9.29),
. From (9.29), ![$$\displaystyle \begin{aligned} \begin{array}{rcl} \lim_{N \rightarrow \infty} {C}(s) {\kern-1pt}\geq{\kern-1pt} \sum_{j=1}^{B_{{D}} (s)} {\mu_{{\, j}}^2} {\kern-1pt}= {\kern-1pt}B_{{D}} (s) \left( \frac{1}{B_{{D}} (s)} \sum_{j=1}^{ B_{{D}} (s)} {\mu_{{\, j}}^2} \right) {\kern-1pt}\geq{\kern-1pt} B_{{D}} (s) \left( \frac{1}{[ B_{{D}} (s) ]^2} \right) {\kern-1pt}={\kern-1pt} \frac{1}{B_{{D}} (s)} \, , \quad {} \end{array} \end{aligned} $$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_Equ38.png)
 . By Assumption 9.2, for s ≪ 1 we have
. By Assumption 9.2, for s ≪ 1 we have  , so
, so ![$$1/B_{{D}} (s) = [\varPhi _B(s)]^{-1} s^{{d_{{B}}}}$$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_IEq115.png) . Hence, from (9.35) for s ≪ 1 we have
. Hence, from (9.35) for s ≪ 1 we have ![$$\displaystyle \begin{aligned} \lim_{N \rightarrow \infty} C(s) = \varPhi_C(s) s^{{d_{{C}}}} \geq 1/B_{{D}} (s) = [ \varPhi_B(s) ]^{-1} s^{{d_{{B}}}} \, . \end{aligned}$$](../images/487758_1_En_9_Chapter/487758_1_En_9_Chapter_TeX_Equj.png)

 , which is negative, and letting s → 0 yields d
C ≤ d
B. □
, which is negative, and letting s → 0 yields d
C ≤ d
B. □For strictly self-similar fractals such as the Sierpiński gasket, the correlation dimension d C, the Hausdorff dimension d H, and the similarity dimension d S are all equal ( [Schroeder 91], p. 216).7