Design
The preceding chapters laid the groundwork and developed the background to let you start designing your own APIs. I have analyzed the various qualities that contribute to good API design and looked at standard design patterns that apply to the design of maintainable APIs.
This chapter puts all of this information together and covers the specifics of high-quality API design, from overall architecture planning down to class design and individual function calls. However, good design is worth little if the API doesn’t give your users the features they need. I will therefore also talk about defining functional requirements to specify what an API should do. I’ll also specifically cover the creation of use cases and user stories as a way to describe the behavior of the API from the user’s point of view. These different analysis techniques can be used individually or together, but they should always precede any attempt to design the API: you can’t design what you don’t understand.
Figure 4.1 shows the basic workflow for designing an API. This starts with an analysis of the problem, from which you can design a solution and then implement that design. This is a continual and iterative process: new requirements should trigger a reassessment of the design, as should changes from other sources such as major bug fixes. This chapter focuses on the first two stages of this process: analysis and design. The following chapters deal with the remaining implementation issues such as C++ usage, documentation, and testing.
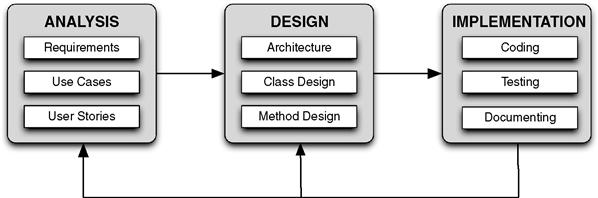
Figure 4.1 Stages of API development from analysis to design to implementation.
Before I jump into these design topics, however, I will spend a little bit of time looking at why good design is so important. This opening section is drawn from experience working on large code bases that have persisted for many years and have had dozens or hundreds of engineers working on them. Lessons learned from witnessing code bases evolve, or devolve, over many years offer compelling motivation to design it well from the start and—just as importantly—to maintain high standards from then on. The consequences of not doing so can be very costly. To mix metaphors: good API design is a journey, not a first step.
4.1 A Case for Good Design
This chapter focuses on the techniques that result in elegant API design. However, it’s likely that you’ve worked on projects with code that does not live up to these grand ideals. You’ve probably worked with legacy systems that have weak cohesion, expose internal details, have no tests, are poorly documented, and exhibit non-orthogonal behavior. Despite this, some of these systems were probably well designed when they were originally conceived. However, over time, the software has decayed, becoming difficult to extend and requiring constant maintenance.
4.1.1 Accruing Technical Debt
All large successful companies grew from meager beginnings. A classic example of this is Hewlett-Packard, which began with two electrical engineers in a Palo Alto garage in 1939 and eventually grew to become the first technology company in the world to post revenues exceeding $100 billion. The qualities that make a successful startup company are very different from those needed to maintain a multibillion dollar publicly traded corporation. Companies often go through several large organizational changes as they grow, and the same thing is true of their software practices.
A small software startup needs to get its product out as soon as possible to avoid being beaten to market by a competitor or running out of capital. The pressure on a software engineer in this environment is to produce a lot of software, and quickly. Under these conditions, the extra effort required to design and implement long-term APIs is often seen as an unaffordable luxury. This is a fair decision when the options are between getting to market quickly or your company perishing. I once spoke with a software architect for a small startup who forbade the writing of any comments, documentation, or tests because he felt that it would slow the development down too much.
However, if a piece of software becomes successful, then the pressure turns toward providing a stable, easy-to-use, and well-documented product. New requirements start appearing that necessitate the software being extended in ways it was never meant to support. All of this must be built upon the core of a product that was not designed to last for the long term. The result, in the words of Ward Cunningham, is the accrual of technical debt (Cunningham, 1992):
Shipping first time code is like going into debt. A little debt speeds development so long as it is paid back promptly with a rewrite. […] The danger occurs when the debt is not repaid. Every minute spent on not-quite-right code counts as interest on that debt. Entire engineering organizations can be brought to a stand-still under the debt load of an unconsolidated implementation.
Steve McConnell expands on this definition to note that there are two types of debt: unintentional and intentional. The former is when software designed with the best of intentions turns out to be error prone, when a junior engineer writes low-quality code, or when your company buys another company whose software turns out to be a mess. The latter is when a conscious strategic decision is made to cut corners due to time, cost, or resource constraints, with the intention that the “right” solution will be put in place after the deadline.
The problem, of course, is that there is always another important deadline, so it’s perceived that there’s never enough time to go back and do the right fix. As a result, the technical debt gradually accrues: short-term glue code between systems lives on and becomes more deeply embedded, last-minute hacks remain in the code and turn into features that clients depend upon, coding conventions and documentation are ignored, and ultimately the original clean design degrades and becomes obfuscated. Robert C. Martin defined four warning signs that a code base is reaching this point (Martin, 2000). Here is a slightly modified version of those indicators.
• Fragility. Software becomes fragile when it has unexpected side effects or when implementation details are exposed to the point that apparently unconnected parts of the system depend on the internals of other parts of the system. The result is that changes to one part of the system can cause unexpected failures in seemingly unrelated parts of the code. Engineers are therefore afraid to touch the code and it becomes a burden to maintain.
• Rigidity. A rigid piece of software is one that is resistant to change. In effect, the design becomes brittle to the point that even simple changes cannot be implemented without great effort, normally requiring extensive, time-consuming, and risky refactoring. The result is a viscous code base where efforts to make new changes are slowed significantly.
• Immobility. A good engineer will spot cases where code can be reused to improve the maintainability and stability of the software. Immobile code is software that is immune to these efforts, making it difficult to be reused elsewhere. For example, the implementation may be too entangled with its surrounding code or it may be hardcoded with domain-specific knowledge.
• Non-transferability. If only a single engineer in your organization can work on certain parts of the code then it can be described as non-transferable. Often the owner will be the developer who originally wrote the code or the last unfortunate person who attempted to clean it up. For many large code bases, it’s not possible for every engineer to understand every part of the code deeply, so having areas that engineers cannot easily dive into and work with effectively is a bad situation for your project.
The result of these problems is that dependencies between components grow, causing conceptually unrelated parts of the code to rely upon each other’s internal implementation details. Over time, this culminates in most program state and logic becoming global or duplicated (see Figure 4.2). This is often called spaghetti code or the big ball of mud (Foote and Yoder, 1997).
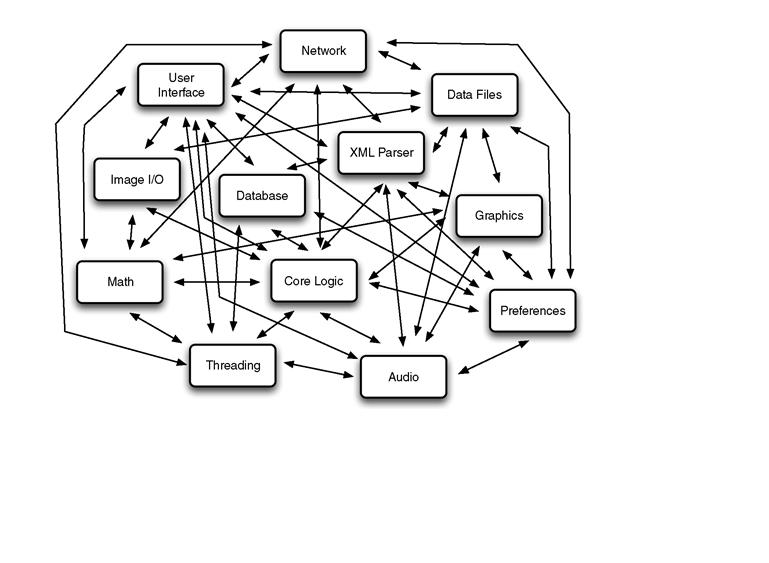
Figure 4.2 A decayed tightly coupled system that has devolved into a big ball of mud.
4.1.2 Paying Back the Debt
Ultimately, a company will reach the point where they have accrued so much technical debt that they spend more time maintaining and containing their legacy code base than adding new features for their customers. This often results in a “next-generation” project to fix the problems with the old system. For example, when I met the software architect mentioned a few paragraphs back, the company had since grown and become successful, and his team was busily rewriting all of the code that he had originally designed.
In terms of strategy, there are two extremes for such a next-generation project to consider:
1. Evolution: Design a system that incorporates all of the new requirements and then iteratively refactor the existing system until it reaches that point.
2. Revolution: Throw away the old code and then design and implement a completely new system from scratch.
Both of these options have their pros and cons, and both are difficult. I’ve heard the problem described as having to change the engine in a car, but the car is traveling at 100 mph, and you can’t stop the car.
In the evolution case, you always have a functional system that can be released. However, you still have to work within the framework of the legacy design, which may no longer be the best way to express the problem. New requirements may have fundamentally changed the optimal workflow for key use cases. A good way to go about the evolution approach is to hide old ugly code behind new well-designed APIs (e.g., by using the wrapper patterns presented in Chapter 3, such as Façade), incrementally update all clients to go through these cleaner APIs, and put the code under automated testing (Feathers, 2004; Fowler et al., 1999).
In the revolution case, you are freed from the shackles of old technology and can design a new tool with all the knowledge you’ve learned from the old one (although as a pragmatic step, you may still harvest a few key classes from the old system to preserve critical behavior). You can also put new processes in place, such as requiring extensive unit test coverage for all new code, and use the opportunity to switch tools, such as adopting a new bug tracking system or source control management system. However, this option requires a lot more time and effort (i.e., money) to get to the point of a usable system, and in the meantime you either stop all development on the old tool or continue delivering new features in the old system, which keeps raising the bar for the new system to reach in order to be successful. You must also be mindful of the second-system syndrome, where the new system fails because it is overengineered and overambitious in its goal (Brooks, 1995).
In both of these cases, the need for a next-generation project introduces team dynamic issues and planning complexities. For example, do you keep a single team focused on both new and old systems? This is desirable from a personnel point of view. However, short-term tactical needs tend to trump long-term strategic development so it may be hard to sustain the next-generation project in the face of critical bug fixes and maintenance for the old one. Alternatively, if you split the development team in two, then this can create a morale problem, where developers working on the old system feel that they’ve been classed as second-rate developers and left behind to support a code base with no future.
Furthermore, the need for a technical restart can often instigate a business and company reorganization as well. This causes team structures and relationships to be reassessed and reshaped. It can also materially affect people’s livelihoods, particularly when companies decide to downsize as part of refocusing the business. And all of this happens because of poor API design? Well, perhaps that’s being a little dramatic. Reorganizations are a natural process in the growth of a company and can happen for many reasons: a structure that works for a startup with 10 people doesn’t work for a successful business of 10,000. However, the failure of software to react to the needs of the business is certainly one way that reorganizations can be triggered. For instance, in June 2010, Linden Lab laid off 30% of its workforce and underwent a company-wide reorganization, primarily because the software couldn’t be evolved fast enough to meet the company’s revenue targets.
4.1.3 Design for the Long Term
Investing in a large next-generation effort to replace a decayed code base can cost a company millions of dollars. For example, just to pay the salary for a team of 20 developers, testers, writers, and managers for 1 year at an average salary of $100,000 would cost $2,000,000. However, the adoption of good design principles can help avoid this drastic course of action. Let’s start by enumerating some of the reasons why this scenario can arise.
1. A company simply doesn’t create a good software design in the first place because of a belief that it will cost valuable time and money early on.
2. The engineers on the project are ignorant of good design techniques or believe that they don’t apply to their project.
3. The code was never intended to last very long, for example, it was written hastily for a demo or it was meant to be throw-away prototype code.
4. The development process for the software project doesn’t make technical debt visible so knowledge of all the parts of the system that need to be fixed gets lost or forgotten over time. (Agile processes such as Scrum attempt to keep debt visible through the use of a product backlog.)
5. The system was well designed at first, but its design gradually degraded over time due to unregulated growth. For example, letting poor changes be added to the code even if they compromised the design of the system. In the words of Fred Brooks, the system loses its conceptual integrity (Brooks, 1995).
6. Changing requirements often necessitate the design to evolve too, but the company continually postpones this refactoring work, either intentionally or unintentionally, in preference to short-term fixes, hacks, and glue code.
7. Bugs are allowed to exist for long periods of time. This is often caused by a drive to continually add new functionality without a focus on the overall quality of the end product.
8. The code has no tests so regressions creep into the system as engineers modify functionality and parts of the code base ultimately turn into scary wastelands where engineers fear to make changes.
Let’s tackle a few of these problems. First, the perception that good design slows you down too much. Truthfully, it may actually be the least expensive overall decision to write haphazardly structured software that gets you to market quicker and then to rewrite the code completely once you have a hold on the market. Also, certain aspects of writing good software can indeed appear to be more time-consuming, such as writing the extra code to pimpl your classes or writing automated tests to verify the behavior of your APIs. However, good design doesn’t take as long as you might think, and it always pays off in the long run. Keeping a strong separation between interface and implementation pays dividends in the maintainability of your code, even in the short term, and writing automated tests gives you the confidence to change functionality rapidly without breaking existing behavior. It’s noteworthy that Michael Feathers defines legacy code as code without tests, making the point that legacy doesn’t have to mean old; you could be writing legacy code today (Feathers, 2004).
The beauty of APIs is that the underlying implementation can be as quick and dirty or as complete and elegant as you need. Good API design is about putting in place a stable logical interface to solve a problem. However, the code behind that API can be simple and inefficient at first. Then you can add more implementation complexity later, without breaking that logical design. Related to this, APIs let you isolate problems to specific components. By managing the dependencies between components you can limit the extent of problems. Conversely, in spaghetti code, where each component depends on the internals of other components, behavior becomes non-orthogonal and bugs in one component can affect other components in non-obvious ways. The important message is therefore to take the time to put a good high-level design in place first—to focus on the dependencies and relationships between components. That is the primary focus of this chapter.
Another aspect of the problem is that if you don’t continue to keep a high bar for your code quality then the original design decays gradually as the code evolves. Cutting corners to meet a deadline is okay, as long as you go back and do it right afterward. Remember to keep paying back your technical debt. Code has a tendency to live much longer than you think it will. It’s good to remember this fact when you weaken an API because you may have to support the consequences for a long time to come. It’s therefore important to realize the impact of new requirements on the design of the API and to refactor your code to maintain a consistent and up-to-date design. It’s equally important to enforce change control over your API so that it doesn’t evolve in an unsupervised or chaotic fashion. I will discuss ways to achieve these goals in Chapter 8 when I talk about API versioning.
4.2 Gathering Functional Requirements
The first step in producing a good design for a piece of software is to understand what it actually needs to do. It’s amazing how much development time is wasted by engineers building the wrong thing. It’s also quite eye opening to see how often two engineers can hear the same informal description of a piece of work and come away with two completely different ideas about what it involves. This is not necessarily a bad thing: it’s good to have minds that work differently to provide alternative perspectives and solutions. The problem is that the work was not specified in enough detail such that everyone involved could form a shared understanding and work toward the same goal. This is where requirements come in. There are several different types of requirements in the software industry, including the following.
• Business requirements: describe the value of the software in business terms, that is, how it advances the needs of the organization.
• Functional requirements: describe the behavior of the software, that is, what the software is supposed to accomplish.
• Non-functional requirements: describe the quality standards that the software must achieve, that is, how well the software works for users.
I will concentrate primarily on functional and non-functional requirements in the following sections. However, it is still extremely important to ensure that the functionality of your software aligns with the strategic goals of your business, as otherwise you run the risk of harming the long-term success of your API.
4.2.1 What Are Functional Requirements?
Functional requirements are simply a way to understand what to build so that you don’t waste time and money building the wrong thing. It also gives you the necessary up front information to devise an elegant design that implements these requirements. In our diagram of the phases of software development (Figure 4.1), functional requirements sit squarely in the analysis phase.
In terms of API development, functional requirements define the intended functionality for the API. These should be developed in collaboration with the clients of the API so that they represent the voice and needs of the user (Wiegers, 2003). Explicitly capturing requirements also lets you agree upon the scope of functionality with the intended users. Of course, the users of an API are also developers, but that doesn’t mean that you should assume that you know what they want just because you are a developer too. At times it may be necessary to second-guess or research requirements yourself. Nevertheless, you should still identify target users of your API, experts in the domain of your API, and drive the functional requirements from their input. For example, you can hold interviews, meetings, or use questionnaires to ask users:
• What tasks they expect to achieve with the API?
• What an optimal workflow would be from their perspective?
• What are all the potential inputs, including their types and valid ranges?
• What are all the expected outputs, including type, format, and ranges?
• What file formats or protocols must be supported?
• What (if any) mental models do they have for the problem domain?
If you are revising or refactoring an existing API, you can also ask developers to comment on the code that they currently must write to use the API. This can help identify cumbersome workflows and unused parts of an API. You can also ask them how they would prefer to use the API in an ideal world (Stylos, 2008).
Functional requirements can also be supported by non-functional requirements. These are requirements that judge the operational constraints of an API rather than how it actually behaves. These qualities can be just as critical to a user as the functionality provided by the API. Examples of non-functional requirements include aspects such as:
• Performance. Are there constraints on the speed of certain operations?
• Platform compatibility. Which platforms must the code run on?
• Security. Are there data security, access, or privacy concerns?
• Scalability. Can the system handle real-world data inputs?
• Flexibility. Will the system need to be extended after release?
• Usability. Can the user easily understand, learn, and use the API?
• Concurrency. Does the system need to utilize multiple processors?
4.2.2 Example Functional Requirements
Functional requirements are normally managed in a requirements document where each requirement is given a unique identifier and a description. A rationale for the requirement may also be provided to explain why it is necessary. It’s typical to present the requirements as a concise list of bullet points and to organize the document into different themed sections so that requirements relating to the same part of the system can be colocated.
Good functional requirements should be simple, easy to read, unambiguous, verifiable, and free of jargon. It’s important that they do not over-specify the technical implementation: functional requirements should document what an API should do and not how it does it.
To illustrate these points, here’s an example list of functional requirements for a user interacting with an Automated Teller Machine (ATM).
REQ 1.1. The system shall prevent further interaction if it’s out of cash or is unable to communicate with the financial institution.
REQ 1.2. The system shall validate that the inserted card is valid for financial transactions on this ATM.
REQ 1.3. The system shall validate that the PIN number entered by the user is correct.
REQ 1.4. The system shall dispense the requested amount of money, if it is available, and debit the user’s account by the same amount.
REQ 1.5. The system shall notify the user if the transaction could not be completed. In that case, no money shall be taken from the user’s account.
4.2.3 Maintaining the Requirements
There is no such thing as stable requirements; you should always expect them to change over time. This happens for a variety of reasons, but the most common reason is that users (and you) will have a clearer idea of how the system should function as you start building it. You should therefore make sure that you version and date your requirements so that you can refer to a specific version of the document and you know how old it is.
On average, 25% of a project’s functional requirements will change during development, accounting for 70–85% of the code that needs to be reworked (McConnell, 2004). While it’s good to stay in sync with the evolving needs of your clients, you should also make sure that everyone understands the cost of changing requirements. Adding new requirements will cause the project to take longer to deliver. It may also require significant changes to the design, causing a lot of code to be rewritten.
In particular, you should be wary of falling into the trap of requirement creep. Any major changes to the functional requirements should trigger a revision of the schedule and costing for the project. In general, any new additions to the requirements should be evaluated against the incremental business value that they deliver. Assessing a new requirement from this pragmatic viewpoint should help weigh the benefit of the change against the cost of implementing it.
4.3 Creating Use Cases
A use case describes the behavior of an API based on interactions of a user or another piece of software (Jacobson, 1992). Use cases are essentially a form of functional requirement that specifically captures who does what with an API and for what purpose rather than simply providing a list of features, behaviors, or implementation notes. Focusing on use cases helps you design an API from the perspective of the client.
It’s not uncommon to produce a functional requirement document as well as a set of use cases. For example, use cases can be used to describe an API from the user’s point of view, whereas functional requirements can be used to describe a list of features or the details of an algorithm. However, concentrating on just one of these techniques can often be sufficient, too. In which case, I recommend creating use cases because these resonate most closely with the way a user wants to interact with a system. When using both methods, you can either derive functional requirements from the use cases or vice versa, although it’s more typical to work with your users to produce use cases first and then derive a list of functional requirements from these use cases.
Ken Arnold uses the analogy of driving a car to illustrate the importance of designing an interface based on its usage rather than its implementation details. He notes that you are more likely to come up with a good experience for drivers by asking the question “How does the user control the car?” instead of “How can the user adjust the rate of fuel pumped into each of the pistons?” (Arnold, 2005).
4.3.1 Developing Use Cases
Every use case describes a goal that an “actor” is trying to achieve. An actor is an entity external to the system that initiates interactions, such as a human user, a device, or another piece of software. Each actor may play different roles when interacting with the system. For example, a single actor for a database may take on the role of administrator, developer, or database user. A good way to approach the process of creating use cases is therefore (1) identify all of the actors of the system and the roles that each plays, (2) identify all of the goals that each role needs to accomplish, and (3) create use cases for each goal.
Each use case should be written in plain English using the vocabulary of the problem domain. It should be named to describe the outcome of value to the actor. Each step of the use case should start with the role followed by an active verb. For example, continuing our ATM example, the following steps describe how to validate a user’s PIN number.
4.3.2 Use Case Templates
A good use case represents a goal-oriented narrative description of a single unit of behavior. It includes a distinct sequence of steps that describes the workflow to achieve the goal of the use case. It can also provide clear pre- and postconditions to specify the state of the system before and after the use case, that is, to explicitly state the dependencies between use cases, as well as the trigger event that causes a use case to be initiated.
Use cases can be recorded with different degrees of formality and verbosity. For example, they can be as simple as a few sentences or they can be as formal as structured, cross-referenced specifications that conform to a particular template. They can even be described visually, such as with the UML Use Case Diagram (Cockburn, 2000).
In the more formal instance, there are many different template formats and styles for representing use cases textually. These templates tend to be very project specific and can be as short or extensive as appropriate for that project. Don’t get hung up on the details of your template: it’s more important to communicate the requirements clearly than to conform to a rigid notation (Alexander, 2003). Nonetheless, a few common elements of a use case template include the following.
Name: A unique identifier for the use case, often in verb–noun format such as Withdraw Cash or Buy Stamps.
Version: A number to differentiate different versions of the use case.
Description: A brief overview that summarizes the use case in one or two sentences.
Goal: A description of what the user wants to accomplish.
Actors: The actor roles that want to achieve the goal.
Stakeholder: The individual or organization that has a vested interest in the outcome of the use case, for example, an ATM User or the Bank.
Basic Course: A sequence of steps that describe the typical course of events. This should avoid conditional logic where possible.
Extensions: A list of conditions that cause alternative steps to be taken. This describes what to do if the goal fails, for example, an invalid PIN number was entered.
Trigger: The event that causes the use case to be initiated.
Precondition: A list of conditions required for the trigger to execute successfully.
Postcondition: Describes the state of the system after the successful execution of the use case.
Notes: Additional information that doesn’t fit well into any other category.
4.3.3 Writing Good Use Cases
Writing use cases should be an intuitive process. They are written in plain easy-to-read language to capture the user’s perspective on how the API should be used. However, even supposedly intuitive tasks can benefit from general guidelines and words of advice.
• Use domain terminology. Use cases should be described in terms that are natural to the clients of an API. The terms that are used should be familiar to users and should come from the domain being targeted. In effect, users should be able to read use cases and understand the scenarios easily without them appearing too contrived.
• Don’t over-specify use cases. Use cases should describe the black-box functionality of a system, that is, you should avoid specifying implementation details. You should also avoid including too much detail in your use cases. Alistair Cockburn uses the example of inserting coins into a candy machine. Instead of trying to specify different combinations of inserting the correct quantity, such as “person inserts three quarters, or 15 nickels or a quarter followed by 10 nickels,” you just need to write “person inserts money.”
• Use cases don’t define all requirements. Use cases do not encompass all possible forms of requirements gathering. For example, they do not represent system design, lists of features, algorithm specifics, or any other parts of the system that are not user oriented. Use cases concentrate on behavioral requirements for how the user should interact with the API. You may still wish to compile functional and non-functional requirements in addition to use cases.
• Use cases don’t define a design. While you can often create a high-level preliminary design from your use cases, you should not fall into the trap of believing that use cases directly define the best design. The fact that they don’t define all requirements is one reason. For example, they don’t define performance, security, or network aspects of the API, which can affect the particular design greatly. Also, use cases are written from the perspective of users. You may therefore need to reinterpret their feedback in light of conflicting or imprecise goals rather than treating them too literally (Meyer, 1997).
• Don’t specify design in use cases. It is generally accepted that you should avoid describing user interfaces in use cases because UI is a design, not a requirement, and because UI designs are more changeable (Cockburn, 2000). While this axiom is not directly applicable to UI-less API design, it can be extrapolated to our circumstances by stating that you should keep API design specifics out of your use cases. Users may try to propose a particular solution for you to implement, but better solutions to the problem may exist. API design should therefore follow from your use case analysis. In other words, use cases define how a user wants to achieve a goal regardless of the actual design.
• Use cases can direct testing. Use cases are not test plans in themselves because they don’t specify specific input and output values. However, they do specify the key workflows that your users expect to be able to achieve. As such, they are a great source to direct automated testing efforts for your API. Writing a suite of tests that verify these key workflows will give you the confidence that you have reached the needs of your users, and that you don’t break this functionality as you evolve the API in the future.
• Expect to iterate. Don’t be too concerned about getting all of your use cases perfect the first time. Use case analysis is a process of discovery; it helps you learn more about the system you want to build. You should therefore look upon it as an iterative process where you can refine existing use cases as you expand your knowledge of the entire system (Alexander, 2003). However, it is well known that errors in requirements can impact a project significantly, causing major redesign and reimplementation efforts. This is why the first piece of advice I gave was to avoid making your use cases too detailed.
• Don’t insist on complete coverage. For the same reasons that use cases do not encompass all forms of requirements, you should not expect your use cases to express all aspects of your API. However, you also don’t need them to cover everything. Some parts of the system may already be well understood or do not need a user-directed perspective. There’s also the logistical concern that because you will not have unlimited time and resources to compile exhaustive use cases, you should focus the effort on the most important user-oriented goals and workflows (Alexander, 2003).
Putting all of this information together, I will complete our ATM example by presenting a sample use case for entering a PIN number and use our template described earlier to format the use case.
Description: User enters PIN number to validate her Bank account information.
Goal: System validates User’s PIN number.
1. User wants to use ATM services
2. Bank wants to validate the User’s account.
1. System validates that ATM card is valid for use with the ATM machine.
2. System prompts the user to enter PIN number.
4. System checks that the PIN number is correct.
a. System failure to recognize ATM card:
a-1. System displays error message and aborts operation.
b-1. System displays error message and lets User retry.
Trigger: User inserts card into ATM.
Postcondition: User’s PIN number is validated for financial transactions.
4.3.4 Requirements and Agile Development
Agile development is a general term for software development methods that align with the principles of the Agile Manifesto. Examples include Extreme Programming (XP), Scrum, and Dynamic Systems Development Method (DSDM). The Agile Manifesto (http://agilemanifesto.org/) was written in February 2001 by 17 contributors who wanted to find more lightweight and nimble alternatives to the traditional development processes of the time. It states that the following qualities should be valued when developing software:
• Individuals and interactions over processes and tools.
• Working software over comprehensive documentation.
Agile methodologies therefore deemphasize document-centric processes, instead preferring to iterate on working code. However, this does not mean that they are without any form of requirements. What it means is that the requirements are lightweight and easily changed. Maintaining a large, wordy, formal requirements document would not be considered agile. However, the general concept of use cases is very much a part of agile processes, such as Scrum and XP, which emphasize the creation of user stories.
A user story is a high-level requirement that contains just enough information for a developer to provide a reasonable estimate of the effort required to implement it. It is conceptually very similar to a use case, except that the goal is to keep them very short, normally just a single sentence. As a result, the brief informal use case is more similar to a user story than the formal template-driven or UML use case. Another important distinction is that user stories are not all completed up front. Many user stories will be added incrementally as the working code evolves. That is, you start writing code for your design early to avoid throwing away specifications that become invalid after you try to implement them.
Another important aspect of user stories is that they are written by project stakeholders, not developers, that is, the customers, vendors, business owners, or support personnel interested in the product being developed. Keeping the user story short allows stakeholders to write them in a few minutes. Mike Cohn suggests the use of a simple format to describe user stories (Cohn, 2004):
As a [role] I want [something] so that [benefit].
For instance, referring back to our ATM example, here’s an example of five different user stories for interacting with a cash machine:
• As a customer I want to withdraw cash so that I can buy things.
• As a customer I want to transfer money from my savings account to my checking account so I can write checks.
• As a customer I want to deposit money into my account so I can increase my account balance.
• As a bank business owner I want the customer’s identity to be verified securely so that the ATM can protect against fraudulent activities.
• As an ATM operator I want to restock the ATM with money so the ATM will have cash for customers to withdraw.
Given a set of well-written user stories, engineers can estimate the scale of the development effort involved, usually in terms of an abstract quantity such as story points, and work on implementing these stories. Stakeholders will also often provide an indication of the priority of a user story to help prioritize the order of work from the backlog of all stories. Stakeholders then assess the state of the software at regular intervals, such as during a sprint review, and can provide further user stories to focus the next iteration of development. In other words, this implies active user involvement and favors an iterative development style over the creation of large up-front requirements documents.
Cohn also presents an easy-to-remember acronym to help you create good user stories. The acronym is INVEST, where each letter stands for a quality of a well-written user story (Cohn, 2004):
In addition, all of the advice offered earlier for writing good use cases applies equally well to user stories. For example, because agile processes such as Scrum and XP do not tell you how to design your API, you must not forget that once you have built up your backlog of user stories, you still have to go through a separate design process to work out how best to implement those stories. This is the topic that I will concentrate on for the remainder of this chapter.
4.4 Elements of Api Design
At last, we can talk about design! The secret to producing a good API design lies in coming up with an appropriate abstraction for the problem domain and then devising appropriate object and class hierarchies to represent that abstraction.
An abstraction is just a simplified description of something that can be understood without any knowledge of how it will be implemented programmatically. It tends to emphasize the important characteristics and responsibilities of that thing while ignoring details that are not important to understanding its basic nature. Furthermore, you often find that complex problems exhibit hierarchies, or layers, of abstractions (Henning, 2009).
For example, you could describe how a car works at a very high level with six basic components: a fuel system, engine, transmission, driveshaft, axle, and wheels. The fuel system provides the energy to turn the engine, which causes the transmission to rotate, while the driveshaft connects the transmission to the axle, allowing the power to reach the wheels and ultimately cause the vehicle to move forward. This is one level of abstraction that is useful to understand the most general principles of how a car achieves forward motion. However, you could also offer another level of abstraction that provides more detail for one or more of these components. For example, an internal combustion engine could be described with several interconnected components, including a piston, crankshaft, camshaft, distributor, flywheel, and timing belt. Furthermore, an engine can be categorized as one of several different types, such as an internal combustion engine, an electric engine, a gas/electric hybrid, or a hydrogen fuel cell.
Similarly, most designs for complex software systems exhibit structure at multiple levels of detail, and those hierarchies can also be viewed in different ways. Grady Booch suggests that there are two important hierarchical views of any complex system (Booch et al., 2007):
1. Object Hierarchy: Describes how different objects cooperate in the system. This represents a structural grouping based on a “part of” relationship between objects (e.g., a piston is part of an engine, which is part of a car).
2. Class Hierarchy: Describes the common structure and behavior shared between related objects. It deals with the generalization and specialization of object properties. This can be thought of as an “is a” hierarchy between objects (e.g., a hybrid engine is a type of car engine).
Both of these views are equally important when producing the design for a software system. Figure 4.3 attempts to illustrate these two concepts, showing a hierarchy of related objects and a hierarchy of classes that inherit behavior and properties.
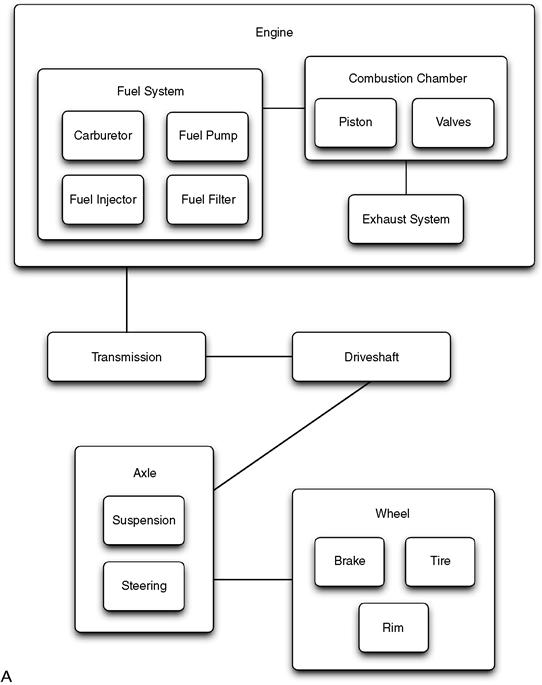
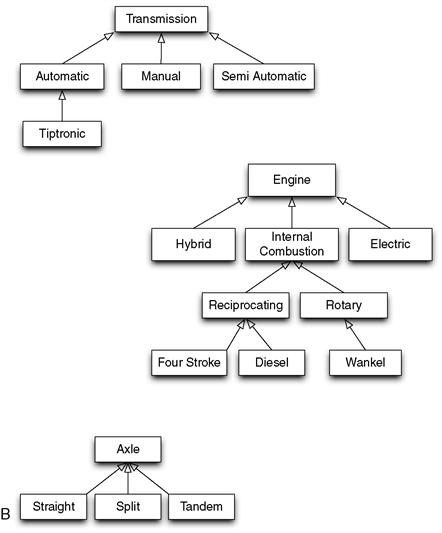
Figure 4.3 A car design shown as (a) a “part of” object hierarchy and (b) an “is a” class hierarchy. Arrows point from more specific to more general classes.
Related to this, it is generally agreed that the design phase of software construction consists of two major activities (Bourque et al., 2004):
1. Architecture design: Describes the top-level structure and organization of a piece of software.
2. Detailed design: Describes individual components of the design to a sufficient level that they can be implemented.
Therefore, as a general approach, I suggest defining an object hierarchy to delineate the top-level conceptual structure (or architecture) of your system and then refine this with class hierarchies that specify concrete C++ classes for your clients to use. The latter process of defining the classes of your API also involves thinking about the individual functions and arguments that they provide. The rest of this chapter will therefore focus on each of these topics in turn:
4.5 Architecture Design
Software architecture describes the coarse structure of an entire system: the collection of top-level objects in the API and their relationships to each other. By developing an architecture, you gain an understanding of the different components of the system in the abstract, as well as how they communicate and cooperate with each other.
It’s important to spend time thinking about the top-level architecture for your API because problems in your architecture can have a far-reaching and extensive impact on your system. Consequently, this section details the process of producing an architecture for your API and provides insight into how you can decompose a problem domain into an appropriate collection of abstract objects.
4.5.1 Developing an Architecture
There’s no right or wrong architecture for any given problem. If you give the same set of requirements to two different architects then you’ll undoubtedly end up with two different solutions. The important aspect is to produce a well-thought-out purposeful design that delivers a framework to implement the system and resolves trade-offs between the various conflicting requirements and constraints (Bass et al., 2003). At a high level, the process of creating an architecture for an API resolves to four basic steps.
1. Analyze the functional requirements that affect the architecture.
2. Identify and account for the constraints on the architecture.
3. Invent the primary objects in the system and their relationships.
The first of these steps is fed by the earlier requirements gathering stage (refer back to Figure 4.1), be it based on a formal functional requirements document, a set of goal-oriented use cases, or a collection of informal user stories. The second step involves capturing and accounting for all of the factors that place a constraint on the architecture you design. The third step involves defining the high-level object model for the system: key objects and how they relate to each other. Finally, the architecture should be communicated to the engineers who must implement it. Figure 4.4 illustrates each of these steps.
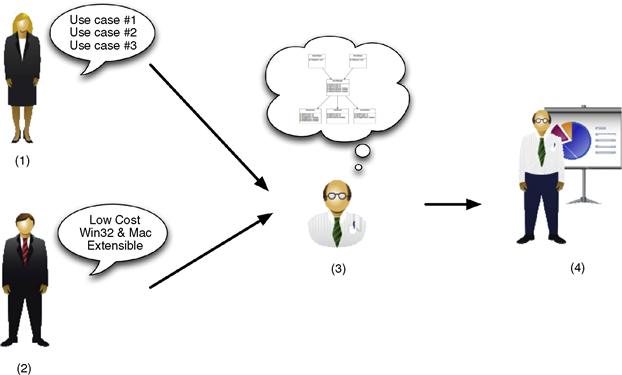
Figure 4.4 Steps to develop an API architecture: (1) gather user requirements, (2) identify constraints, (3) invent key objects, and (4) communicate design.
It’s important to stress that the aforementioned sequence of steps is not a recipe that you perform only once and magically arrive at the perfect architecture. As stated already, software design is an iterative process. You will rarely get each step right the first time. However, the first release of your API is critical because changes after that point will incur higher cost. It’s therefore important to try out your design early on and improve it incrementally before releasing it to clients who will then start to build upon it in their own programs.
4.5.2 Architecture Constraints
APIs aren’t designed in a vacuum. There will always be factors that influence and constrain the architecture. Before the design process can proceed in earnest you must therefore identify and accommodate for these factors. Christine Hofmeister and her coauthors refer to this phase as global analysis (Hofmeister et al., 2009). The term global in this respect connotes that the factors impact the system holistically and that as a group they are often interdependent and contradictory. These factors fall into three basic categories.
1. Organizational factors, such as
d. Software development process
e. Build versus buy decision on subsystems
f. Management focus (e.g., date versus feature versus quality).
2. Environmental factors, such as
a. Hardware (e.g., set-top box or mobile device)
b. Platform (e.g., Windows, Mac, and Linux)
c. Software constraints (e.g., use of other APIs)
d. Client/server constraints (e.g., building a Web service)
e. Protocol constraints (e.g., POP vs IMAP for a mail client)
f. File format constraints (e.g., must support GIF and JPEG images)
g. Database dependencies (e.g., must connect to a remote database)
h. Expose versus wrap decision on subsystems
It’s the job of the software architect to prioritize these factors, combined with the user constraints contained within the functional requirements, and to find the best compromises that produce a flexible and efficient design. Designing an API carefully for its intended audience can only serve to improve its usability and success. However, there’s no such thing as a perfect design; it’s all about trade-offs for the given set of organizational, environmental, and operational constraints. For example, if you are forced to deliver results under an aggressive schedule then you may have to focus on a simpler design that leverages third-party APIs as much as possible and restricts the number of supported platforms.
Some constraints can be negotiated. For example, if one of the client’s requirements places undue complexity on the system, the client may be willing to accept an alternative solution that costs less money or can be delivered sooner.
In addition to identifying the factors that will impact your initial architecture, you should also assess which of these are susceptible to change during development. For example, the first version of the software may not be very extensible, but you know that you will eventually want to move to a plugin model that lets users add their own functionality. Another common example is internationalization. You may not care about supporting more than one language at first, but later on this may become a new requirement, and one that can have a deep impact on the code. Your design should therefore anticipate the constraints that you reasonably expect to change in the future. You may be able to come up with a design that can support change or, if that’s not feasible, you may need to think about contingency plans. This is often referred to as “design for change” (Parnas, 1979).
It’s also worth thinking about how you can isolate your design from changes in any APIs that your project will depend upon. If your use of another API is completely internal, then there’s no problem. However, if you need to expose the concepts of a dependent API in your own public interface, then you should consider whether it’s possible to limit the degree to which it is made visible. In some cases this simply may not be practical. For example, if you use boost::shared_ptr to return smart pointers from your API, then your clients will also need to depend on the Boost headers. However, in other cases you may be able to provide wrappers for the dependent API so that you do not force your clients to depend directly on that API. For example, the KDE API is built on top of the Qt library. However, KDE uses a thin wrapper over the Qt API so that users are not directly dependent on the Qt API. As a specific example, KDE offers classes such as KApplication, KObject, and KPushButton instead of exposing Qt’s QApplication, QObject, and QPushButton classes directly. Wrapping dependent APIs in this way gives you an extra layer of indirection to protect against changes in a dependent API and to work around bugs or platform-specific limitations.
4.5.3 Identifying Major Abstractions
Once you have analyzed the requirements and constraints of the system, you are ready to start building a high-level object model. Essentially, this means identifying major abstractions in the problem domain and decomposing these into a hierarchy of interconnected objects. Figure 4.5 presents an example of this process. It shows a top-level architecture for the OpenSceneGraph API, an open source 3D graphics toolkit for visual simulation applications (http://www.openscenegraph.org/).
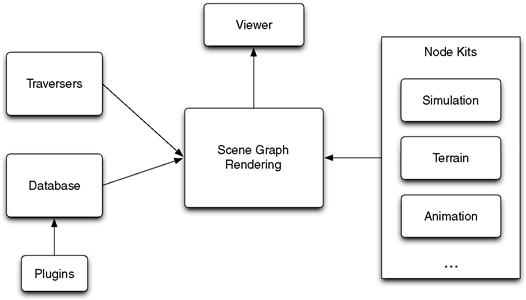
Figure 4.5 Example top-level architecture for the OpenSceneGraph API.
By basing the architecture on actual concepts in the problem domain, your design should remain general and robust to future changes in requirements. Recall that I listed this as the first API quality in Chapter 2: a good API should model the problem domain. However, decomposing a problem into a set of good abstractions is not an easy task. For well-understood problems, such as writing a compiler or a Web server, you can take advantage of the collective knowledge that has been distilled and published by many other designers over time. However, for new problems that have had little or no previous research applied to them, the task of inventing a good classification can be far from obvious.
This is not a problem that is unique to computer science. Classification of the biology of our planet into a logical taxonomy has been an area of debate ever since the days of Aristotle. In the 18th century, Carolus Linnaeus proposed a two-kingdom model for life, composed of vegetables and animals. This was later refined to include microscopic life forms in the 19th century. Modern advances in electron microscopy have increased the number of kingdoms to five or six. However, research in the 21st century has contested the traditional view of kingdoms and proposed an alternative “supergroup” model. Additionally, the topic of deciding which characteristics should be used to create classifications has received much debate. Aristotle classified animals according to their method of reproduction, the binomial system groups organisms by their morphology (similar structure or appearance), while Darwinian-inspired taxonomies favor classification by common descent (whether organisms have a common ancestor).
4.5.4 Inventing Key Objects
Despite the difficulty of classifying the major abstractions in a system, I can still offer some advice on how to tackle the problem. Accordingly, here are a number of techniques that you can draw upon to decompose a system into a set of key objects and identify their relationship to each other (Booch et al., 2007).
• Natural Language. Using the analogy to natural language, it has been observed that (in general) nouns tend to represent objects, verbs represent functions, and adjectives and possessive nouns represent attributes (Bourque et al., 2004). I can illustrate this by returning to our address book API from Chapter 2. Real-world concepts of an address book and a person are both nouns and make sense to represent key objects in the API, whereas actions such as adding a person to the address book or adding a telephone number for a person are verbs and should be represented as function calls on the objects that they modify. However, a person’s name is a possessive noun and makes more sense to be an attribute of the Person object rather than a high-level object in its own right.
• Properties. This technique involves grouping objects that have similar properties or qualities. This can be done using discrete categories that each object is unambiguously either a member of or not, such as red objects versus blue objects, or can involve a probabilistic grouping of objects that depends on how closely each object matches some fuzzy criterion or concept, such as whether a film is categorized as an action or romance story.
• Behaviors. This method groups objects by the dynamic behaviors that they share. This involves determining the set of behaviors in the system and assigning these behaviors to different parts of the system. You can then derive the set of objects by identifying the initiators and participants of these behaviors.
• Prototypes. In this approach, you attempt to discover more general prototypes for the objects that were initially identified. For example, a beanbag, bar stool, and recliner are all types of chairs, despite having very different forms and appearance. However, you can classify each of them based on the degree to which they exhibit affordances of a prototypical chair.
• Domains (Shlaer–Mellor). The Shlaer–Mellor method first partitions a system horizontally to create generic “domains” and then partitions these vertically by applying a separate analysis to each domain (Shlaer and Mellor, 1988). One of the benefits of this divide-and-conquer approach is that domains tend to form reusable concepts that can be applied to other design problems. For instance, using our earlier ATM example, a domain could be one of the following:
- Tangible domains, such as an ATM machine or a bank note.
- Role domains, such as an ATM user or a bank owner.
- Event domains, such as a financial transaction.
- Security domains, such as authentication and encryption.
- Interaction domains, such as PIN entry or a cash withdrawal.
- Logging domains, for the system to log information.
• Domains (Neighbors). James Neighbors coined the term domain analysis as the technique of uncovering classes and objects shared by all applications in the problem domain (Neighbors, 1980). This is done by analyzing related systems in the problem domain to discover areas of commonality and distinctiveness, such as identifying the common elements in all bug tracking systems or general features of all genealogy programs.
• Domains (Evans). A related issue to Neighbors’ domain analysis is the term domain-driven design. This was introduced by Eric Evans and seeks to produce designs for complex systems using an evolving model of the core business concepts (Evans, 2003).
Most of these techniques work best when you have a well-organized and structured set of use cases to work from. For example, use cases are normally constructed as sentences where a thing performs some action, often to or on another thing. You can therefore use these as input for a simple natural language analysis by taking the steps of each use case and identifying the subject or object nouns and use these to develop an initial candidate list of objects.
Each of the aforementioned techniques can also involve different degrees of formal methods. For example, natural language analysis it not a very rigorous technique and is often discouraged by proponents of formal design methodologies. That’s because natural language is intrinsically ambiguous and may express important concepts of the problem domain imprecisely or neglect significant architectural features. You should therefore be wary of naively translating all nouns in your use cases to key objects. At best, you should treat the result of this analysis as an initial candidate list from which to apply further careful analysis and refinement (Alexander, 2003). This refinement can involve identifying any gaps in the model, considering whether there are more general concepts that can be extracted from the list, and attempting to classify similar concepts.
In contrast, there are several formal techniques for producing a software design, including textual and graphical notations. One particularly widespread technique is the Universal Modeling Language (UML)(Booch et al., 2005). Using a set of graphical diagrams, UML can be used to specify and maintain a software design visually. For instance, UML 2.3 includes 14 distinct types of diagrams to represent the various structural and behavioral aspects of a design (see Figure 4.6). As a specific example, UML sequence diagrams portray the sequence of function calls between objects. These can be used during the analysis phase to represent use cases graphically. Then, during the design phase, the architect can use these formal diagrams to explore object interactions within the system and flesh out the top-level object model.

Figure 4.6 The 14 diagram types of UML 2.3.
Formal design notations can also be used to generate actual code. This ranges from the simple translation of class diagrams into their direct source code equivalents to the more comprehensive notion of an “executable architecture.” The latter is a sufficiently detailed description of an architecture that can be translated into executable software and run on a target platform. For example, the Shlaer–Mellor notation was eventually evolved into a profile of UML called Executable UML (Mellor and Balcer, 2002), which itself became a cornerstone of Model Driven Architecture. The basic principle behind this approach is that a model compiler takes several executable UML models, each of which defines a different crosscutting concern or domain, and combines these to produce high-level executable code. Proponents of executable architectures note the two-language problem that this entails: having a modeling language (e.g., UML) that gets translated into a separate programming language (e.g., C++, C#, or Java). Many of these proponents therefore posit the need for a single language that can bridge both of these concerns.
4.5.5 Architectural Patterns
Chapter 2 covered various design patterns that can be used to solve recurring problems in software design, such as Singleton, Factory Method, and Observer. These tend to provide solutions that can be implemented at the component level. However, a class of software patterns called architectural patterns describe larger scale structures and organizations for entire systems. As such, some of these solutions may be useful to you when you are building an API that maps well to a particular architectural pattern. The following list classifies a number of the more popular architectural patterns (Bourque et al., 2004).
- Structural patterns: Layers, Pipes and Filters, and Blackboard
- Interactive systems: Model–View–Controller (MVC), Model–View–Presenter, and Presentation–Abstraction–Control
- Distributed systems: Client/Server, Three Tier, Peer to Peer, and Broker
Many of these architectural patterns present elegant designs to avoid dependency problems between different parts of your system, such as the MVC pattern discussed in detail in Chapter 2. At this point, it’s worth noting that another important view of a system’s architecture is the physical view of library files and their dependencies. I presented an example of this view back in Figure 1.3, where I showed the layers of APIs that make up a complex end-user application. Even within a single API you will likely have different layers of physical architecture, such as those that follow and are illustrated in Figure 4.7.
1. API-neutral low-level routines, such as string manipulation routines, math functions, or your threading model.
2. Core business logic that implements the primary function of your API.
3. Plugin or Scripting APIs to allow users to extend the base functionality of the API.
4. Convenience APIs built on top of the core API functionality.
5. A presentation layer to provide a visual display of your API results.
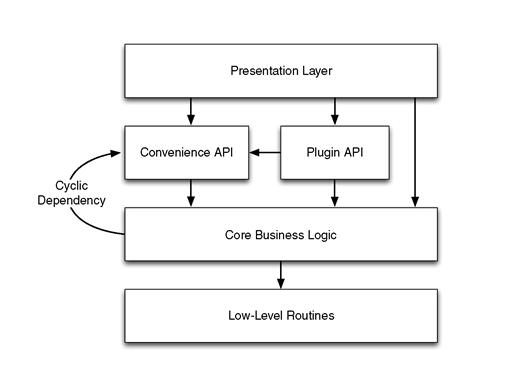
Figure 4.7 Example architectural layers of an API showing a cyclic, or circular, dependency between two components.
In this case, it’s important to impose a strict dependency hierarchy on the different architectural layers of your system, as otherwise you will end up with cyclic dependencies between layers (see Figure 4.7). The same is true for individual components within those layers. The general observation is that lower-level components should not depend on higher-level components of your architecture. For example, your core business logic cannot depend on your convenience API as this would introduce a cycle between the two (assuming that your convenience API also calls down into the core business logic). Referring back to the MVC architectural pattern, you will note that View depends on Model, but not vice versa. David L. Parnas referred to this concept as loop-free hierarchies (Parnas, 1979).
Cyclic dependencies are bad for many reasons. For example, they mean that you cannot test each component independently and you cannot reuse one component without also pulling in the other. Basically, it’s necessary to understand both components in order to understand either one (Lakos, 1996). This can also impact the speed of your development if you are forced to merge several components into one big über component, as described in the accompanying side bar. Chapters 1 and 2 presented various techniques to decouple dependencies, such as callbacks, observers, and notification systems. Fundamentally, an API should be an acyclic hierarchy of logically related components.
4.5.6 Communicating the Architecture
Once an architecture has been developed, it can be documented in various ways. This can range from simple drawings or wiki pages to various formal methods that provide modeling notations for architectures, such as UML or the set of Architecture Description Languages (Medvidovic and Taylor, 2000).
Whichever approach you adopt, documenting the architecture is an important factor in communicating the design to engineers. Doing so gives them more information to implement the system according to your vision and also ensures that future changes continue to preserve the intent and integrity of the architecture. This is particularly important if the development team is large or distributed geographically.
One of the elements you should include in your architecture documentation is a rationale for the overall design. That is, which alternative designs and trade-offs were considered and why the final structure was judged to be superior. This design rationale can be very important for the long-term maintenance of the design and to save future designers from revisiting the same dead ends that you did. In fact, Martin Robillard notes that users of an API often find it difficult to learn and use an API if they don’t understand its high-level architecture and design intents (Robillard, 2009).
Communication also allows for peer review of the design and for feedback and improvements to be received before the API is released. In fact, implementing design reviews early in the process to facilitate communication among architects, developers, and clients will help you produce a more comprehensive and durable design. If the API architect also writes some of the code then this can be an excellent way to communicate design principles through practical hands-on contribution.
Even though modern agile development methods deemphasize document heavy processes, because the design documents are frequently out of date, there is still a place for providing as much documentation about the system architecture as necessary, but no more. Augmenting any documentation with direct communication can be even more productive. This allows for a dialogue between the designer and the implementer and can avoid misunderstandings that can happen when reading specifications. Ultimately, it’s the job of the architect to be a passionate communicator, to be available to answer engineer questions, and to ensure that the most efficient channels are used to keep architectural communication constantly stimulated (Faber, 2010).
4.6 Class Design
With a high-level architecture in place, you can start refining the design to describe specific C++ classes and their relationship to other classes. This is the detailed design, in contrast to the top-level architecture design. It involves identifying actual classes that clients will use, how these classes relate to each other, and their major functions and attributes. For sufficiently large systems, this can also involve describing how classes are organized into subsystems.
Designing every single class in your API would be overkill for anything but the most trivial system. Instead, you should focus on the major classes that define the most important functionality. A good rule of thumb is the so-called “80/20 rule,” that is, you should concentrate on 20% of the classes that define 80% of your system’s behavior (McConnell, 2004).
4.6.1 Object-Oriented Concepts
Before I talk more about the details of object-oriented design, let’s take a moment to review some of the major object-oriented principles and their representation in C++. It is likely that you’re already very familiar with these concepts, but let’s summarize them here briefly in the interests of completeness and to ensure that we’re on the same page.
• Class: A class is the abstract description, or specification, of an object. It defines the data members and member functions of the object.
• Object: An object is an entity that has state, behavior, and identity (Booch et al., 2007). It is an instance of a concrete class created at run time using the new operator or on the stack. A concrete class is one that can be instantiated, for example, it has no undefined pure virtual member functions.
• Encapsulation: This concept describes the compartmentalization of data and methods as a single object with access control specifications such as public, protected, and private to support hiding of implementation details.
• Inheritance: This allows for objects to inherit attributes and behaviors from a parent class and to introduce their own additional data members and methods. A class defined in this way is said to be a derived (or sub) class of the parent (or base) class. A subclass can override any base class method, although normally you only want to do this when that base class method is declared to be virtual. A pure virtual method (indicated by appending it’s declaration with “= 0”) is one where a subclass must provide an implementation of the method in order for it to be concrete (i.e., to allow instances of it to be created). C++ supports multiple inheritance, meaning that a subclass can inherit from more than one base class. Public inheritance is generally referred to as an “is-a” relationship between two objects, whereas private inheritance represents a “was-a” relationship (Lakos, 1996).
• Composition: This is an alternative technique to inheritance where one or more simple objects are combined to create more complex ones. This is done by declaring the simpler objects as member variables inside of the more complex object. The “has-a” relationship is used to describe the case where a class holds an instance of another type. The “holds-a” relationship describes a class holding a pointer or reference to the other type.
• Polymorphism: This is the ability of one type to appear as, and to be used like, another type. This allows objects of different types to be used interchangeably as long as they conform to the same interface. This is possible because the C++ compiler can delay checking the type of an object until run time, a technique known as late or dynamic binding. The use of templates in C++ can also be used to provide static (compile-time) polymorphism.
4.6.2 Class Design Options
When considering the creation of a class, there are many factors to be considered. As Scott Meyers notes, creating a new class involves defining a new type. You should therefore treat class design as type design and approach the task with the same thoughtfulness and attention that the designers of C++ put into the built-in types of the language (Meyers, 2005).
Here is a list of a few major questions that you should ask yourself when you embark upon designing a new class. This is not meant to be an exhaustive list, but it should provide a good starting point and help you define the major constraints on your design.
• Use of inheritance. Is it appropriate to add the class to an existing inheritance hierarchy? Should you use public or private inheritance? Should you support multiple inheritance? This affects which member functions should be virtual.
• Use of composition. Is it more appropriate to hold a related object as a data member rather than inheriting from it directly?
• Use of abstract interfaces. Is the class meant to be an abstract base class, where subclasses must override various pure virtual member functions?
• Use of standard design patterns. Can you employ a known design pattern to the class design? Doing so lets you benefit from well-thought-out and refined design methodologies and makes your design easier to use by other engineers.
• Initialization and destruction model. Will clients use new and delete or will you use a factory method? Will you override new and delete for your class to customize the memory allocation behavior? Will you use smart pointers?
• Defining a copy constructor and assignment operator. If the class allocates any resource such as memory, you should define both of these (as well as a destructor of course). This will impact how your objects will be copied and passed by value. (You can also declare these functions as private to prevent copying.)
• Use of templates. Does your class define a family of types rather than a single type? If so, then you may consider the use of templates to generalize your design.
• Use of const and explicit. Define arguments, return results, and methods as const wherever you can. Use the explicit keyword to avoid unexpected type conversions for single-parameter constructors.
• Defining operators. Define any operators that you need for your class, such as +, *=, [], ==, or <<.
• Defining type coercions. Consider whether you want your class to be automatically coercible to different types and declare the appropriate conversion operators.
• Use of friends. Friends breach the encapsulation of your class and are generally an indication of bad design. Use them as a last resort.
• Non-functional constraints. Issues such as performance and memory usage can place constraints on the design of your classes.
4.6.3 Using Inheritance
By far the biggest design decision that you will face when designing your classes is when and how to use inheritance, For example, should you use public inheritance, private inheritance, or composition to associate related classes in your API? Because inheritance is such an important topic, and one that is often misused or overused, I will focus on this part of class design over the next few sections. Let’s begin with some general design recommendations.
• Design for inheritance or prohibit it. The most important decision you can make is to decide whether a class should support subclasses. If it should, then you must think deeply about which methods should be declared as virtual and document their behavior. If the class should not support inheritance, a good way to convey this is to declare a non-virtual destructor. See also the section called Prohibiting Subclassing in Chapter 12.
• Only use inheritance where appropriate. Deciding whether a class should inherit from another class is a difficult design task. In fact, this is perhaps the most difficult part of software design. I will present some guidance on this topic in the next section when I talk about the Liskov Substitution Principle (LSP).
• Avoid deep inheritance trees. Deep inheritance hierarchies increase complexity and invariably result in designs that are difficult to understand and software that is more prone to failure. The absolute limit of hierarchy depth is obviously subjective, but any more than two or three levels is already getting too complex (McConnell, 2004).
• Use pure virtual member functions to force subclasses to provide an implementation. A virtual member function can be used to define an interface that includes an optional implementation, whereas a pure virtual member function is used to define only an interface, with no implementation (although it is actually possible to provide a fallback implementation for a pure virtual method). Of course, a non-virtual method is used to provide behavior that cannot be changed by subclasses.
• Don’t add new pure virtual functions to an existing interface. You should certainly design appropriate abstract interfaces with pure virtual member functions. However, be aware that after you release this interface to users, if you then add a new pure virtual method to the interface then you will break all of your clients’ code. That’s because clients’ classes that inherit from the abstract interface will not be concrete until an implementation for the new pure virtual function is defined.
• Don’t overdesign. In Chapter 2, I stated that a good API should be minimally complete. In other words, you should resist the temptation to add extra levels of abstraction that are currently unnecessary. For example, if you have a base class that is inherited by only a single class in your entire API, this is an indication that you have overdesigned the solution for the current needs of the system.
Another important consideration is whether to utilize multiple inheritance, that is, designing classes that inherit from more than one base class. Bjarne Stroustrup argued for the addition of multiple inheritance to C++ using the example of a TemporarySecretary class, where this inherits from both a Secretary and a Temporary class (Alexandrescu, 2001). However, opinion is divided in the C++ community on whether multiple inheritance is a good thing. On the one hand, it offers the flexibilty to define composite relationships, such as the TemporarySecretary example. On the other hand, this can come at the cost of subtle semantics and ambiguities, such as the need to use virtual inheritance to deal with the “diamond problem” (where a class inherits ambiguously from two or more base classes that themselves inherit from a single common base class).
Most languages that allow inheriting from only a single base class still support inheriting from multiple, more constrained, types. For example, Java lets you inherit from multiple interface classes, and Ruby lets you inherit from multiple mixins. These are classes that let you inherit an interface (and implementation in the case of a mixin); however, they cannot be instantiated on their own.
Multiple inheritance can be a powerful tool if used correctly (see the STL iostreams classes for a good example). However, in the interest of robust and easy-to-use interfaces, I generally concur with Steve McConnell who recommends that you should avoid the use of multiple inheritance, except to use abstract interfaces or mixin classes (McConnell, 2004).
As a point of interest, the new C++11 specification includes a number of improvements relating to inheritance. One of particular note is the ability to specify explicitly your intent to override or hide a virtual method from a base class. This is done using the [[override]] and [[hiding]] attributes, respectively. This new functionality will be extremely helpful in avoiding mistakes such as misspelling the name of a virtual method in a derived class.
4.6.4 Liskov Substitution Principle
This principle, introduced by Barbara Liskov in 1987, provides guidance on whether a class should be designed as a subclass of another class (Liskov, 1987). The LSP states that if S is a subclass of T, then objects of type T can be replaced by objects of type S without any change in behavior.
At first glance, this may seem to be a simple restatement of the “is-a” inheritance relationship, where a class S may be considered a subtype of T if S is a more specific kind of T. However, the LSP is a more restrictive definition than “is-a.”
Let’s demonstrate this with the classic example of an ellipse shape type:
Ellipse(float major, float minor);
void SetMajorRadius(float major);
You then decide to add support for a circle class. From a mathematical perspective, a circle is a more specific form of an ellipse, where the two axes are constrained to be equal. It is therefore tempting to declare a Circle class to be a subclass of Ellipse. For example,
The implementation of SetRadius() can then set major and minor radii of the underlying ellipse to the same value to enforce the properties of a circle.
However, this poses a number of problems. The most obvious is that Circle will also inherit and expose the SetMajorRadius() and SetMinorRadius() methods of Ellipse. These could be used to break the self-consistency of our circle by letting users change one radius without also changing the other. You could deal with this by overriding the SetMajorRadius() and SetMinorRadius() methods so that each sets both major and minor radii. However, this also poses several issues. First, you must go back and declare Ellipse::SetMajorRadius() and Ellipse::SetMinorRadius() to be virtual so that you can override them in the Circle class. This in itself should alert you that you’re doing something wrong. Second, you have now created a non-orthogonal API: changing one property has the side effect of changing another property. Third, you have broken the Liskov Substitution Principle because you cannot replace uses of Ellipse with Circle without breaking behavior, as the following code demonstrates:
The problem resolves to the fact that you have changed the behavior of functions inherited from the base class.
So if you shouldn’t use public inheritance to model a circle as a kind of ellipse, how should you represent it? There are two main ways that you can correctly build your Circle class upon the functionality of the Ellipse class: private inheritance and composition.
Private Inheritance
Private inheritance lets you inherit the functionality, but not the public interface, of another class. In essence, all public members of the base class become private members of the derived class. I refer to this as a “was-a” relationship in contrast to the “is-a” relationship of public inheritance. For example, you can redefine your Circle class to inherit privately from Ellipse as follows.
In this case, Circle does not expose any of the member functions of Ellipse, that is, there is no public Circle::SetMajorRadius() method. This solution therefore does not suffer from the same problems as the public inheritance approach discussed earlier. In fact, objects of type Circle cannot be passed to code that accepts an Ellipse because the Ellipse base type is not publicly accessible.
Note that if you do want to expose a public or protected method of Ellipse in Circle then you can do this as follows.
Composition
Private inheritance is a quick way to fix an interface that violates the LSP if it already uses public inheritance. However, the preferred solution is to use composition. This simply means that instead of class S inheriting from T, S declares T as a private data member (“has-a”) or S declares a pointer or reference to T as a member variable (“holds-a”). For example,
Then the definition of the SetRadius() and GetRadius() methods might look like
In this case, the interface for Ellipse is not exposed in the interface for Circle. However, Circle still builds upon the functionality of Ellipse by creating a private instance of Ellipse. Composition therefore provides the functional equivalent of private inheritance. However, there is wide agreement by object-oriented design experts that you should prefer composition over inheritance (Sutter and Alexandrescu, 2004).
The main reason for this preference is that inheritance produces a more tightly coupled design. When a class inherits from another type—be it public, protected, or private inheritance—the subclass gains access to all public and protected members of the base class, whereas with composition, the class is only coupled to the public members of the other class. Furthermore, if you only hold a pointer to the other object, then your interface can use a forward declaration of the class rather than #include its full definition. This results in greater compile-time insulation and improves the time it takes to compile your code. Finally, you should not force an inheritance relationship when it is not appropriate. The preceding discussion told us that a circle should not be treated as an ellipse for purposes of type inheritance. Note that there may still be a good case for a general Shape type that all shapes, including Circle and Ellipse, inherit from. However, a Circle should not inherit from Ellipse because it actually exhibits different behavior.
4.6.5 The Open/Closed Principle
Bertrand Meyer introduced the Open/Closed Principle (OCP) to state the goal that a class should be open for extension but closed for modification (Meyer, 1997). Essentially this means that the behavior of a class can be modified without changing its source code. This is a particularly relevant principle for API design because it focuses on the creation of stable interfaces that can last for the long term.
The principal idea behind the OCP is that once a class has been completed and released to users, it should only be modified to fix bugs. However, new features or changed functionality should be implemented by creating a new class. This is often achieved by extending the original class, either through inheritance or composition, although, as covered later in this book, you can also provide a plugin system to allow users of your API to extend its basic functionality.
As an example of the OCP used to practical effect, the simple factory method presented in Chapter 3 is not closed to modification or open for extensibility. That’s because adding new types to the system requires changing the factory method implementation. As a reminder, here’s the code for that simple renderer factory method.
In contrast, the extensible renderer factory that was presented later in Chapter 3 allows for the system to be extended without modifying the factory method. This is done by allowing clients to register new types with the system at run time. This second implementation therefore demonstrates the Open/Closed Principle: the original code does not need to be changed in order to extend its functionality.
However, when adhered to strictly, the OCP can be difficult to achieve in real-world software projects and even contradicts some of the principles of good API design that have been advanced here. The constraint to never change the source code of a class after it is released is often impractical in large-scale complex systems, and the stipulation that any changes in behavior should trigger the creation of new classes can cause the original clean and minimal design to be diluted and fractured. In these cases, the OCP may be considered more of a guiding heuristic rather than a hard-and-fast rule. Also, while a good API should be as extensible as possible, there is tension between the OCP and the specific advice in this book that you should declare member functions to be virtual in a judicious and restrained manner.
Nevertheless, if I restate the OCP to mean that the interface of a class should be closed to change rather than considering the precise implementation behind that interface to be immutable, then you have a principle that aligns reasonably well with the focus of this book. That is, maintenance of a stable interface gives you the flexibility to change the underlying implementation without unduly affecting your client’s code. Furthermore, the use of extensive regression testing can allow you to make internal code changes without impacting existing behavior that your users rely upon. Also, use of an appropriate plugin architecture (see Chapter 12) can provide your clients with a versatile point of extensibility.
4.6.6 The Law of Demeter
The Law of Demeter (LoD), also known as the Principle of Least Knowledge, is a guideline for producing loosely coupled designs. The rule was proposed by Ian Holland based on experiences developing the Demeter Project at Northeastern University in the late 1980s (Lieberherr and Holland, 1989). It states that each component should have only limited knowledge about other components, and even then only closely related components. This can be expressed more concisely as only talk to your immediate friends.
When applied to object-oriented design, the LoD means that a function can:
• Call other functions in the same class.
• Call functions on data members of the same class.
• Call functions on any parameters that it accepts.
• Call functions on any local objects that it creates.
• Call functions on a global object (but you should never have globals).
By corollary, you should never call a function on an object that you obtained via another function call. For example, you should avoid chaining function calls such as
One way to avoid this practice involves refactoring object A so that it provides direct access to the functionality in object B, thus allowing you to do the following:
Alternatively, you could refactor the calling code so that it has an actual object B to invoke the required function directly. This can be done either by storing an instance or reference to object B in MyClass or by passing object B into the function that needs it, for example,
The downside of this technique is that you introduce lots of thin wrapper methods into your classes, increase the parameter count of your functions, or increase the size of your objects. However, the benefit is that you end up with more loosely coupled classes where the dependencies on other objects are made explicit. This makes the code much easier to refactor or evolve in the future. In fact, the latter solution of explicitly passing an object into a function has clear parallels with the modern practice of dependency injection (discussed in Chapter 3). Also, another application of the LoD involves creating a single method in object A that aggregates calls to multiple methods of object B, which resonates well with the Façade design pattern.
4.6.7 Class Naming
While I have been largely concerned with the details of object-oriented design in these latest sections, once you have developed an appropriate collection of classes, an equally critical task is the development of expressive and consistent names for these classes. Accordingly, here are some guidelines for naming your classes.
• Simple class names should be powerful, descriptive, and self-explanatory. Moreover, they should make sense in the problem domain being modeled and should be named after the thing they are modeling, for example, Customer, Bookmark, or Document. As already noted, class names tend to form the nouns of your system: the principal objects of your design.
• Joshua Bloch states that good names drive good designs. Therefore, a class should do one thing and do it well, and a class name should instantly convey its purpose (Bloch, 2008). If a class is difficult to name, that’s usually a sign that your design is lacking. Kent Beck offers the example that he originally used the generic compound name DrawingObject for an object in a graphical drawing system, but later refined this to the more expressive term Figure by referring to the field of typography (Beck, 2007).
• Sometimes it is necessary to use a compound name to convey greater specificity and precision, such as TextStyle, SelectionManager, or LevelEditor. However, if you are using any more than two or three words then this can indicate that your design is too confusing or complex.
• Interfaces (abstract base classes) tend to represent adjectives in your object model. They can therefore be named in this way, for example, Renderable, Clonable, or Observable. Alternatively, it’s common to prefix interface classes with the uppercase letter “I,” for example, IRenderer and IObserver.
• Avoid cryptic abbreviations. Good class names should be obvious and consistent. Don’t force your users to try and remember which names you’ve abbreviated and which you have not. I will revisit this point later when I discuss function naming.
• You should include some form of namespace for your top-level symbols, such as classes and free functions, so that your names do not clash with those in other APIs that your clients may be using. This can be done either via the C++ namespace keyword or through the use of a short prefix. For example, all OpenGL function calls start with “gl” and all Qt classes begin with “Q.”
4.7 Function Design
The lowest granularity of API design is how you represent individual function calls. While this may seem like an obvious exercise and not worth covering in much detail, there are actually many function-level issues that affect good API design. After all, function calls are the most commonly used part of an API: they are how your clients access the API’s behavior.
4.7.1 Function Design Options
There are many interface options you can control when designing a function call (Lakos, 1996). First of all, for free functions you should consider the following alternatives:
• Static versus non-static function.
• Pass arguments by value, reference, or pointer.
• Pass arguments as const or non-const.
• Use of optional arguments with default values.
• Return result by value, reference, or pointer.
• Return result as const or non-const.
For member functions, you should consider all of these free function options as well as the following:
• Virtual versus non-virtual member function.
• Pure virtual versus non-pure virtual member function.
• Const versus non-const member function.
In addition to these options that control the logical interface of a function, there are a couple of organizational attributes that you can specify for a function, such as
The proper application of these options can make a large impact on the quality of your API. For example, you should declare member functions as const wherever possible to advertise that they do not modify the object (see Chapter 6 on C++ usage for more details). Passing objects as const references can reduce the amount of memory copying that your API causes (see Chapter 7 on performance). Use of the explicit keyword can avoid unexpected side effects for non-default constructors (see Chapter 6). Also, inlining your functions can sometimes offer a performance advantage at the cost of exposing implementation details and breaking binary compatibility (see Chapters 7 and 8).
4.7.2 Function Naming
Function names tend to form the verbs of your system, describing actions to be performed or values to be returned. Here are some guidelines for naming your free and member functions.
• Functions used to set or return some value should fully describe that quantity using standard prefixes such as Get and Set. For example, a function that returns the zoom factor for a Web view might be called GetZoomFactor() or, less expressively, just ZoomFactor().
• Functions that answer yes or no queries should use an appropriate prefix to indicate this behavior, such as Is, Are, or Has, and should return a bool result, for example, IsEnabled(), ArePerpendicular(), or HasChildren(). As an alternative, the STL tends to drop the initial verb, as can be seen in functions such as empty() instead of IsEmpty(). However, while terser, this naming style is ambiguous because it could also be interpreted as an operation that empties the container (unless you’re astute enough to notice the const method decorator). The STL scheme therefore fails the qualities of discoverability and difficulty to misuse.
• Functions used to perform some action should be named with a strong verb, for example, Enable(), Print(), or Save(). If you are naming a free function, rather than a method of a class, then you should include the name of the object that the action will be applied to, for example, FileOpen(), FormatString(), MakeVector3d().
• Use positive concepts to name your functions rather than framing them in the negative. For example, use the name IsConnected() instead of IsUnconnected(). This can help to avoid user confusion when faced with double negatives like !IsUnconnected().
• Function names should describe everything that the routine does. For example, if a routine in an image processing library performs a sharpening filter on an image and saves it to disk, the method should be called something like SharpenAndSaveImage() instead of just SharpenImage(). If this makes your function names too long, then this may indicate that they are performing too many tasks and should be split up (McConnell, 2004).
• You should avoid abbreviations. Names should be self-explanatory and memorable, but the use of abbreviations can introduce confusing or obscure terminology. For example, the user has to remember if you are using GetCurrentValue(), GetCurrValue(), GetCurValue(), or GetCurVal(). Some software projects specify an explicit list of accepted abbreviations that must be conformed to, but in general it’s simply easier for your users if they don’t have to remember lists such as these.
• Functions should not begin with an underscore character (_). The C++ standard states that global symbols starting with an underscore are reserved for internal compiler use. The same is true for all symbols that begin with two underscores followed by a capital letter. While you can find legal combinations of leading underscore names that navigate these rules, it is generally best simply to avoid this practice in your function names (some developers use this convention to indicate a private member).
• Functions that form natural pairs should use the correct complementary terminology. For example, OpenWindow() should be paired with CloseWindow(), not DismissWindow(). The use of precise opposite terms makes it clearer to the user that one function performs the opposite function of another function (McConnell, 2004). The following list provides some common complementary terms.
| Add/Remove | Begin/End | Create/Destroy |
| Enable/Disable | Insert/Delete | Lock/Unlock |
| Next/Previous | Open/Close | Push/Pop |
| Send/Receive | Show/Hide | Source/Target |
4.7.3 Function Parameters
Use of good parameter names can also have a big impact on the discoverability of your API. For example, compare these two signatures for the standard C function strstr(), which searches for the first occurrence of a substring within another string:
and
I think you’ll agree that the second signature gives a much better indication of how to use the function simply through the use of descriptive parameter names.
Another factor is to make sure that you use the right data type for your parameters. For example, when you have methods that perform linear algebra calculations, you should prefer using double-precision floats to avoid loss of precision errors that are inherent in single-precision operations. Similarly, you should never use a floating-point data type to represent monetary values because of the potential for rounding errors (Beck, 2002).
There is also a balance to be sought in terms of the number of parameters that you specify for each function. Too many parameters can make the call more difficult to understand and to maintain. It can also imply greater coupling and may suggest that it is time to refactor the function. Therefore, wherever possible you should try to minimize the number of parameters to your public functions. In this regard, we have the often-cited research from the field of cognitive science, which states that the number of items we can hold in our short-term working memory is seven plus or minus two (Miller, 1956). This may suggest that you should not exceed around five to seven parameters, as otherwise the user will find it difficult to remember all of the options. Indeed, Joshua Bloch suggests that five or more parameters are too many (Bloch, 2008).
For functions that accept many optional parameters, you may consider passing the arguments using a Plain Old Data (POD) struct or map instead. For example,
This technique is also a good way to deal with argument lists that may change over the life of the API. A newer version of the API can simply add new fields to the end of the structure without changing the signature of the OpenWindow() function. You can also add a version field (set by the constructor) to allow binary compatible changes to the structure: the OpenWindow() function can then check the version field to determine what information is included in the structure. Other options include using a field that records the size of the structure in bytes or simply using a different structure.
Taking this one step further, you can hide all of the public member variables and only allow the values to be accessed via getter/setter functions. The Qt API refers to this as a property-based API. For example,
This lets you reduce the number of parameters required for functions; in this case, the start() function requires no parameters at all. The use of functions to set parameter values also offers the following benefits:
• Values can be specified in any order because function calls are order independent.
• The purpose of each value is more evident because you must use a named function to set the value, for example, setInterval().
• Optional parameters are supported by simply not calling the appropriate function.
• The constructor can define reasonable default values for all settings.
• Adding new parameters is backward compatible because no existing functions need to change signature. Only new functions are added.
Taking this even further, we could make each of the setter methods return a reference to its object instance (return *this;) so that you can chain a number of these methods together. This is called the Named Parameter Idiom (NPI). It offers the same benefits that I just enumerated while also letting your clients write less code. For instance, you could rewrite the QTimer example using the NPI as follows:
4.7.4 Error Handling
A large amount of the code that application developers write is purely there to handle error conditions. The actual amount of error handling code that is written will depend greatly on the particular application. However, it has been estimated that up to 90% of an application’s code is related to handling exceptional or error conditions (McConnell, 2004). This is therefore an important area of API design that will be used frequently by your clients. In fact, it is included in Ken Pugh’s Three Laws of Interfaces (Pugh, 2006):
1. An interface’s implementation shall do what its methods say it does.
2. An interface’s implementation shall do no harm.
3. If an interface’s implementation is unable to perform its responsibilities, it shall notify its caller.
Accordingly, the three main ways of dealing with error conditions in your API are
The last of these is an extreme course of action that should be avoided at all costs—and indeed it violates the third of Pugh’s three laws—although there are far too many examples of libraries out there that call abort() or exit(). As for the first two cases, different engineers have different proclivities toward each of these techniques. I will not take a side on the exceptions versus error code debate here, but rather I’ll attempt to present impartially the arguments and drawbacks for each option. Whichever technique you select for your API, the most important issues are that you use a consistent error reporting scheme and that it is well documented.
The error codes approach involves returning a numeric code to indicate the success or failure of a function. Normally this error code is returned as the direct result of a function. For example, many Win32 functions return errors using the HRESULT data type. This is a single 32-bit value that encodes the severity of the failure, the subsystem responsible for the error, and an actual error code. The C standard library also provides examples of non-orthogonal error reporting design, such as the functions read(), waitpid(), and ioctl() that set the value of the errno global variable as a side effect. OpenGL provides a similar error reporting mechanism via an error checking function called glGetError().
The use of error codes produces client code that looks like
As an alternative, you can use C++’s exception capabilities to signal a failure in your implementation code. This is done by throwing an object for your clients to catch in their code. For example, several of the Boost libraries throw exceptions to communicate error conditions to the client, such as the boost::iostreams and boost::program_options libraries. The use of exceptions in your API results in client code such as
The error codes technique provides a simple, explicit, and robust way to report errors for individual function calls. It’s also the only option if you’re developing an API that must be accessible from plain C programs. The main dilemma comes when you wish to return a result as well as an error code. The typical way to deal with this is to return the error code as the function result and use an out parameter to fill in the result value. For example,
Dynamic scripting languages such as Python handle this more elegantly by making it easy to return multiple values as a tuple. This is still an option with C++, however. For example, you could use boost::tuple to return multiple results from your function (or the C++11 version, std::tuple), as the following example demonstrates:
boost::tuple<int, std::string> FindName();
boost::tuple<int, std::string> result = FindName();
By comparison, exceptions let your clients separate their error handling code from the normal flow of control, making for more readable code. They offer the benefit of being able to catch one or more errors in a sequence of several function calls, without having to check every single return code, and they let you handle an error higher up in the call stack instead of at the exact point of failure. An exception can also carry more information than a simple error code. For example, standard C++ exceptions include a human-readable description of the failure, accessible via a what() method. Also, most debuggers provide a way to break if an exception is thrown, making it easier to debug problems. Finally, exceptions are the only way to report failures in a constructor.
However, this flexibility does come with a cost. Handling an exception can be an expensive operation due to the run-time stack unwinding behavior. Also, an uncaught exception can cause your clients’ programs to abort, resulting in data loss and frustration for their end users. Writing exception safe code is difficult and can lead to resource leaks if not done correctly. Typically the use of exceptions is an all-or-nothing proposition, meaning that if any part of an application uses exceptions then the entire application must be prepared to handle exceptions correctly. This means that the use of exceptions in your API also requires your clients to write exception safe code. It’s noteworthy that Google forbids the use of exceptions in their C++ coding conventions because most of their existing code is not tolerant of exceptions.
If you do opt to use exceptions to signal unexpected situations in your code, here are some best practices to observe.
• Derive your own exceptions from std::exception and override the what() method to describe the failure.
• Consider using RAII techniques to maintain exception safety, that is, to ensure that resources get cleaned up correctly when an exception is thrown.
• Make sure that you document all of the exceptions that can be thrown by a function in its comments.
• You might be tempted to use exception specifications to document the exceptions that a function may throw. However, be aware that these constraints will be enforced by the compiler at run time, if at all, and that they can impact optimizations, such as the ability to inline a function. As a result, most C++ engineers steer clear of exception specifications such as the following:
void MyFunction1() throw(); // throws no exceptions
void MyFunction2() throw(A, B); // throws either A or B
• Create exceptions for the set of logical errors that can be encountered, not a unique exception for every individual physical error that you raise.
• If you handle exceptions in your own code, then you should catch the exception by reference (as in the aforementioned example) to avoid calling the copy constructor for the thrown object. Also, try to avoid the catch(…) syntax because some compilers also throw an exception when a programming error arises, such as an assert() or segmentation fault.
• If you have an exception that multiply inherits from more than one base exception class, you should use virtual inheritance to avoid ambiguities and subtle errors in your client’s code where they attempt to catch your exceptions.
In terms of error reporting best practices, your API should fail as fast as possible once an error occurs and it should clean up any intermediate state, such as releasing resources that were allocated immediately before the error. However, you should also try to avoid returning an exceptional value, such as NULL, where it is not necessary. Doing so causes your clients to write more code to check for these cases. For example, if you have a function that returns a list of items, consider returning an empty list instead of NULL in exceptional cases. This requires your clients to write less code and reduces the chance that your clients will dereference a NULL pointer.
Also, any error code or exception description should represent the actual failure. Invent a new error code or exception if existing ones do not describe the error accurately. You will infuriate your users if they waste time trying to debug the wrong problem because your error reporting was inaccurate or plain wrong. You should also give them as much information as possible to track down the error. For example, if a file cannot be opened, then include the filename in the error description and the cause of the failure, for example, lack of permissions, file not found, or out of disk space.