Upon completion of this chapter, you should understand the following:
the dimension of sources of data with respect to the overall goals of understanding data systems,
the basic characteristics of each of the data sources of:
local files,
local and remote relational database systems,
web servers, and
provider APIs.
the idea of the forms of data being realized by specific formats, and those formats being the means of providing data from the various sources.
The purpose of this chapter is to introduce Part III of the textbook by giving an overview of the data system sources . We begin by reviewing the architecture originally described in Chap. 1, which characterizes the client application and the set of data system sources through which the application may obtain data. This review and the relationship between the sources and the data forms and formats are explored in Sect. 18.1. The remainder of the chapter discusses each of the data system source types.
18.1 Architecture

Data sources
Data forms for data sources
Format : The translation from a logical structure into a sequence of characters (or bytes) that allows interpretation/parsing, so that one endpoint, the provider, can translate a structure from a data model into a format for receipt and appropriate interpretation back into its structure by a client.
Encoding : The translation from a sequence of characters (provided by the format) into the bytes that represent those characters. Bytes are the unit of information storage used within files and carried by network messages.
Carrier : For local files, this is the operating system, which stores the data as named files on a physical storage medium. For providers over the network, the carrier is the network protocol used by both ends of the network communication. This could be a specialized protocol, like that used by MySQL or Postgres, or could be a general network protocol, like the HyperText Transfer Protocol (HTTP) used in Internet communication.
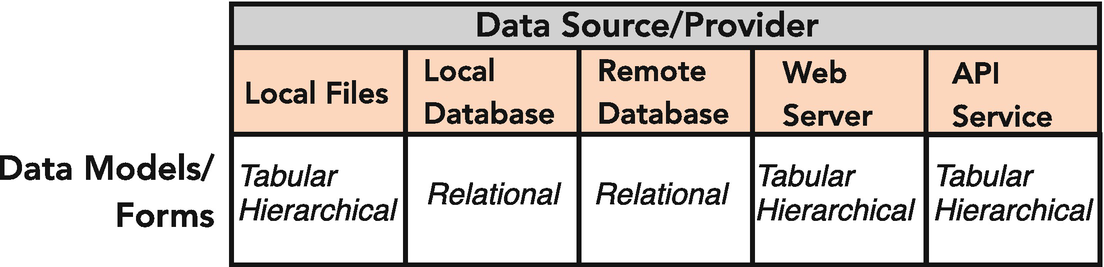
We can broadly partition providers into those whose data is provided locally and those whose data is provided over a network. Through the coverage of the data models, we have already seen the data sources of local files and relational database systems, both local and remote. We include them in this overview for completeness, but most of the emphasis in Part III of the book is on data sources over the network, and, in particular, data sources of web servers and API services.
18.2 Data Sources
We start with an overview of the data sources in data systems. Two of our data sources have already received attention—in the tabular and hierarchical models, we have used local files as a convenient source of our data; in the relational model, we used databases managed through a database system as our source of data.
The remaining two data sources, web servers and API services, both involve our clients formulating requests, communicating those requests over a network, and then building corresponding in-memory structure from the network response. For these data sources, the carrier, as described above, is a network protocol.
18.2.1 Local Files
Local files may be used to store data for the tabular model and for the hierarchical model.1 The access to local files is achieved through the operating system. That interaction is covered in Chap. 2, where we discuss direct manipulation of files through open( ) , close( ) , and a variety of read( ) operations. Libraries and packages may be layered above the underlying operating system operations, can parse and interpret a format, and can return a structure based on a path to a local file.
When we use local files for the data of the tabular model, the format involved must support representation of rows and columns. We learned in Sect. 6.2 about CSV and other delimited formats (e.g., tab-delimited files) for doing just that. Our choices for interacting with local files supporting this data model include:
direct processing with file open( ) , close( ) , and read( ) /readline( ) operations and controlling the construction of the data structures (e.g., column- and row-centric structures like the dictionary of column lists, or lists of row lists) to represent the two-dimensional data structures,
use of the Python csv module to facilitate the processing of CSV-formatted files, while maintaining control of the data structures, and
use of pandas and its read_csv( ) function, which automates the interaction through the operating system and construction of the DataFrame objects of the module, as described in Sect. 6.3.
For the hierarchical model, our client applications rarely manipulate files directly. The parsing and construction of tree data structures is more complex, and we rely on packages to facilitate our interaction with the local files.
If we have local files that are formatted as XML or HTML, we use the lxml package for reading and parsing the files, and the result is an Element tree. These interactions with local files are described in Chaps. 15 and 16.
When local files are formatted as JSON, we use the json package for reading and parsing the files. The top level local-file-based introduction to this format is given in Sect. 2.4, and more detail on structure and operations is then covered in Sects. 15.3 and 16.2
While using local files as a data source is often convenient, we should also consider some drawbacks:
The data still must originate from some external source, and in order to make a file local, we typically have to “download” from a source and place the data file(s) in our local file system.
Management becomes an issue; the data must be organized and maintained within the file system, and we run the risks of multiple copies of the data, and having different versions of the same data.
Because of different versions of the same data, and the possibility of local modifications, consistent and reproducible client execution and analysis becomes problematic.
It can be difficult for multiple people to work on the same data, without introducing local modifications.
18.2.2 Database Systems

Database source
The connection string described in Sect. 13.1.1 is our means of understanding the two data source variations. The connection string is a Uniform Resource Locator (URL that allows both local and remote resources to by uniquely identified. When the protocol scheme of the URL is, for instance, sqlite, the resource is a local one, and its location within the file system identified by a file system path. When the protocol scheme denotes a network protocol, for example, the protocol with prefix mysql, the resource is located over the network, and the other elements of the URL provide the necessary information for accessing the remote database system.
Once a connection is established, be it local or remote, the programmatic execution of SQL requests can proceed in similar fashion.
As a data source, a local database has the same drawbacks as local files, with versions and management of the database in the file system presenting problems. The remote database system as a data source can solve many of these problems. In this case, the data is shared and centralized, and so there is truly only one resource to be managed. As a result, research and analysis can be more robust and reproducible.
Need to manage user/password credentials for client users of the database.
As a shared resource, the database needs management and supervision. Too many client connections and the efficiency of client requests can affect the performance seen by users of the system.
Database systems and their operations are, by design, strongly consistent when multiple concurrent access occurs. But this consistency comes at a cost, with synchronization communication needed to resolve a set of operations into a consistent sequence. The end result is that database systems have a scalability problem as the size of the data, the number of clients, and the frequency of update operations increase.
18.2.3 Web Servers

Web server source
- 1.
The ability to make requests of a web server and receive and interpret the replies is not limited to web browsers. We can construct client applications that “speak the same language” as a web browser and can thus make our own requests.
- 2.
The remote information server by a web server is not limited to HTML and image files but can include files of any type. Thus we can have CSV, XML, JSON, text, and any other files as part of the resource tree provided by the web server.
- 3.
Many web pages in HTML carry useful data in the form of displayed tables of data and lists of items, and our clients may repurpose this data for analysis.
For constructing client applications such as these, we need to understand general topics of networking in the client–server model, and these are addressed in Chap. 19. Building on that understanding of networking, we can then learn details about the primary protocol of the Internet, used by web browsers and web servers, HTTP, in Chap. 20. In the terminology introduced in Sect. 18.1, HTTP is the carrier; the format, encoded into bytes, is encapsulated in the carrier protocol, and so we show, for our various formats, how to extract data and rebuild structure in Chap. 21.
When the HTML carries useful data, we need to understand the typical ways that data might be represented within a rendering language like HTML. The process of extracting useful data from HTML web pages is known as web scraping, and we will look into that further in Chap. 22.
18.2.4 API Service

API service source
In this book, we consider REpresentational State Transfer (REST or RESTful ) APIs . These have become the most common form of network-based data-providing API. Their popularity comes, in part, from being built upon HTTP, adding conventions for providing arguments serving as the parameters of requests. In Chap. 21 in the introduction, we list some of the many providers in this category.
One of the interesting aspects of an API service as a data source is that it makes opaque the design choices of how to manage the data on the server machines. As shown in the figure, a typical API provider has a middle tier that can, in some sense, translate between the HTTP based requests coming from the client and then use back end data sources, like a database system or combinations of tabular and hierarchical data, and can dynamically create responses to those requests.
The coverage of this textbook in the areas of networking, HTTP, and building structure from the HTTP carrier, as covered in Chaps. 19 through 21, is applicable and needed in understanding this data source. We address topics specific to client programming for REST-based API service as a data source in Chap. 23.
18.2.5 Reading Questions
Please give examples of formats, encodings, and carriers, to illustrate the layering of functionality in a data system architecture.
There will be an entire chapter on the HyperText Transfer Protocol (HTTP), but to get a sense of some of the subtleties that arise in the “Carrier” part of a data system, please Google “https vs http” and write a sentence to describe the difference. Hopefully by now in your life you have experienced this difference first hand through a web browser. If so, please write another sentence describing a time in your life when the difference mattered.
Please give an example from your own experience of a time you struggled with a local file. This could have to do with locating the file and writing code to extract data from it, or needing to share the file with a partner, or cleaning the file in some way that was not reproducible (e.g., not documented in your code).
Please give an example of a real-world situation where a database system might face scalability problems as described in the reading.
Please give an example of a web browser, and of other ways to obtain data from web pages.
Please give an example of a web page you know that has a displayed table of data, and then give a different example of a web page hosting a csv file you can download.
Please give an example of an API and its use. Even better if your example is RESTful.