Chapter 2. Tools for Artificial Intelligence
This chapter is the first of two that explores the tools that you’re likely to encounter when building artificial intelligence (AI) features using Swift. We’re taking a top-down approach to AI, which means that you’re probably going to be picking a tool based on the practical problem you want to address, rather than for a more esoteric or academic reason.
Note
We have nothing against a more esoteric academic approach. All of your authors come from an academic background. And there are plenty of fabulous books and other content out there that explores the theoretical as well as algorithm- and science-focused side of AI. You can find our recommendations on our website. As we said earlier, in “A Typical Task-Based Approach”, the book isn’t called Interesting but Divorced from the Reality of Using Such a System in the Real World AI with Swift.
Our discussion of the tools for practical AI takes the same perspective: we care about what the tool can do more than we care about how it works. We also care about where it fits into a potential pipeline that you’d be using to perform a given task. In Chapter 3, we look at finding or building a dataset from the same perspective.
Why Top Down?
AI has shifted toward implementing rather than exploring the problem. This book is part of that shift. We want to help you build great Swift apps, with deeply practical implementations of AI–powered features. Although it’s really interesting how, for example, a convolutional neural network is assembled, layer by layer, it’s not necessary to grok that to make use of a convolutional neural network.
Tip
There are some great posts on O’Reilly Radar about this topic. If you’re interested in exploring the shift from bottom-up AI to top-down AI in more detail, see this article on model governance.
This chapter is not particularly concerned with using and consuming models. That’s what…well…the rest of the book is about. We do touch on it at the very end, though.
Note
Later in the book, in Part III, we do look at things from a bottom-up approach by covering the underlying methods for AI, revisiting some of the top-down tasks we explored to see what makes them tick, and making a neural net from scratch.
Great Tools for Great AI
Many experts are acknowledging that we’re in the implementation phase for AI technologies. The past decade of consistently applied research, innovation, and development has resulted in a healthy ecosystem of amazing AI tools.
Amazing tools means that we’re now in an era in which we can focus on building experiences using AI, instead of nitpicking the details of how it is working. A great bellwether for this is the fact that the technology giants, such as Google, Amazon, and Apple, have all begun putting their might behind polished developer ecosystems for AI.
To complement Swift, Apple has developed a suite of amazing practical, polished, and evolving AI tools such as CoreML, CreateML, and Turi Create. Alongside Apple’s AI tools, the community and other interested parties such as Google have developed even more complementary tools for the world of Swift and AI.
In this chapter, we give you the lay of the land and survey the tools that we work with to create AI features in our Swift apps. These are the tools that we use every day to add practical AI features to the software we build for iOS, macOS, watchOS, tvOS, and beyond, using Swift.
Broadly, there are three categories of tools, each of decreasing Swift-connectedness (but they’re all pretty important) to our daily work building Swift-powered AI-driven apps:
- Tools from Apple
-
Tools for doing AI things built by Apple or acquired by Apple (and now built by Apple) and tightly embedded in Apple’s ecosystem of Swift and iOS (and macOS and so on).
These tools are the core of our work with practical AI using Swift, and the vast majority of this book will focus on using the output of these tools from Apple in Swift applications.
We explore these tools in “Tools from Apple” and use them throughout the book. The centerpiece of these tools is CoreML.
- Tools from others
-
Tools for doing AI things that are built by companies and individuals other than Apple. These are either strongly coupled to Apple’s ecosystem of Swift and iOS (and so on) or incredibly useful for building practical artificial intelligence using Swift.
This book touches on using some of these tools and provides you with pointers to others and explains where they fit in. We don’t use these tools as often as we use the first category of tools, not because they’re not as good, but because in this era of polished AI tools, we often don’t need them. Apple’s provided tools are pretty incredible on their own.
We explore these tools in “Tools from Others” and touch on their use throughout the book.
- AI-adjacent tools
-
By “AI-adjacent tools” we really mean Python and the tools surrounding it. Although this book is focused on Swift, and we try to use Swift wherever possible, it’s genuinely difficult to avoid Python if you’re serious about working with AI and machine learning.
Python is completely dominant as the programming language du jour of the AI, machine learning, and data science communities. Python was at the forefront of the advances in tooling that we mentioned earlier in “Great Tools for Great AI”.
These tools are often not explicitly for AI or are only tangentially related to the world of AI or Apple’s Swift ecosystem, and we wouldn’t mention them unless we wanted to present a really complete picture of practical AI with Swift. Some of these tools go without saying (for example, it’s DIFFICULT to avoid the Python programming language when you’re doing AI), and some of them seem to not rate a mention (e.g., a spreadsheet).
We touch on some of these tools in “AI-Adjacent Tools” and use them occasionally throughout the book.
The remainder of this chapter looks at each of these categories, and the tools therein.
Tools from Apple
Apple ships a lot of useful tools for AI. The ones that you’re likely to encounter and use are CreateML, CoreML, Turi Create, the CoreML Community Tools, and Apple’s domain-specific machine-learning frameworks for vision, speech, natural language, and other specific areas. Apple’s tools are shown in Figure 2-1.
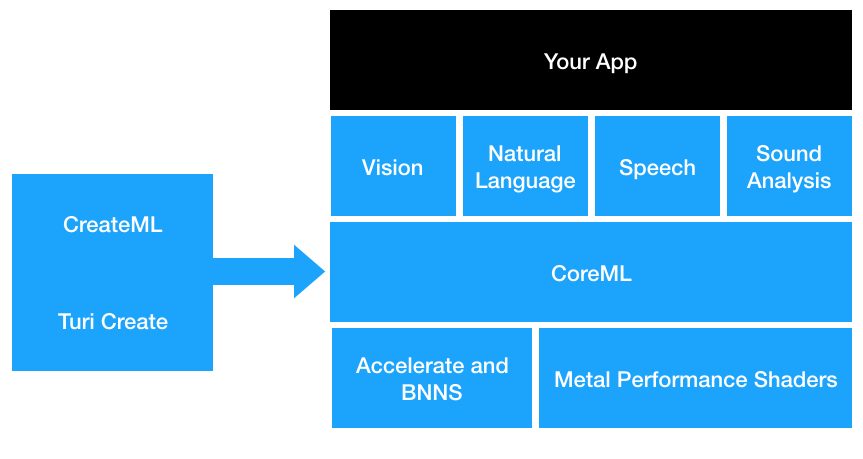
Figure 2-1. Apple’s AI tools and how they relate to one another
CoreML and CreateML are both Swift frameworks that allow you to do things with AI. Figure 2-2 shows how CoreML and CreateML relate to each other and your app.
Turi Create is a Python framework for creating models. It’s very similar to CreateML, but it lives in the world of Python instead of Swift.
Broadly, CoreML is for using models, and CreateML and Turi Create are for making models. It’s a little bit more nuanced than that, though.
CoreML
CoreML is your framework for using machine-learning models in your apps “Tools from Apple”, which essentially means asking the model for predictions, but you can also use CoreML to perform on-device training to update the model on the fly. CoreML will be used by your apps, from within your Swift code, to access and use your machine-learning models to provide AI features.

Figure 2-2. What CoreML does
Tip
If you come from the world of Android development, you might be familiar with Google’s MLKit. CoreML is kind of the equivalent to MLKit for iOS. VentureBeat has a good summary of this.
CoreML is also the basis for domain-specific Apple frameworks for working with AI, such as Vision, Natural Language, Speech, and Sound Analysis, as well as the lower-level mathematics- or graphics-related frameworks like Accelerate, BNNS, and Metal. CoreML exists on macOS and on iOS.
Note
In this book, we use CoreML constantly. We also use Vision, Natural Language, Speech, and Sound Analysis throughout the practical tasks that we build in Part II. We also touch on, very briefly, Accelerate and BNNS in Part III.
CoreML does…what?
CoreML is Apple’s framework for running pretrained machine-learning models on its devices. CoreML handles the loading of a model and creates interfaces to the model, providing you with a standardized way to give the model input and receive output regardless of the model being used in your apps.
Along with being able to use CoreML directly with your own custom models, CoreML is also used in other libraries such as in Apple’s Vision framework, where it is used to provide image analysis and detection.
CoreML itself is built upon other Apple technologies such as the Accelerate framework and Metal Performance Shaders. You can use these libraries yourself if you’d like and achieve the same results as CoreML, but you need to do more work to get the same result.
Tip
If you are interested in seeing how you can use the underlying technology that makes up CoreML, check out Chapter 12, in Part III, where we build up a neural net one layer at a time.
Rarely will you ever need to dive into the lower-level libraries like Accelerate because CoreML is just the easier way. Likewise, when you can use the more-specific libraries that use CoreML, such as Vision or Natural Language, you will generally be better off doing so rather than trying to put it all together yourself.
There will be plenty of cases, though, for which Apple hasn’t provided a library for a specific domain, and that is where CoreML comes in on its own. You’re always using CoreML underneath when you use Vision and other Apple frameworks.
Tip
We talk about Apple’s other frameworks later in “Apple’s Other Frameworks”.
CoreML presents you with a standard approach to machine learning for Apple’s platforms, which means that after you have a grip on CoreML, you can add a huge variety of new functionality into your apps following the same process regardless of the model.
The general approach for any machine learning with CoreML is always the same:
-
Add your model to your project.
-
Load the model file in your app.
-
Provide the necessary input to the model for it to make a prediction.
-
Use the prediction output in your app.
In addition to providing a standard interface, CoreML also handles all the running of the model using device-specific hardware features where possible. This means that you don’t need to worry about how the model will run or add in support for device-specific hardware features. CoreML takes care of that for you.
Note
Training a machine-learning model has a well-deserved reputation for taking a lot of time and resources. However, even running machine-learning models can result in quite a performance and battery hit to devices.
In general this means you need to really think about when you need to use machine learning and when you don’t. CoreML does its best to use hardware features and run the model as efficently as possible, but you should always make sure you aren’t wasting your users’ precious device resources unless you have to.
When using CoreML, the machine-learning components of your app shouldn’t slow down the rest of the app too much, take up too much memory, or eat up too much of the battery life, although this will fluctuate on a model-by-model basis.
No system is perfect, though, so you will always need to test your apps to make sure they are integrated correctly with the machine-learning aspects and that they aren’t taxing too many resources of your devices.
The CoreML model
So far in this chapter, we’ve been speaking a fair amount about the machine-learning models, but we haven’t really spoken about what they are in the context of CoreML, so let’s do that now.
At the very high level, the model is anything that fully represents the machine-learning approach. It describes everything necessary for reproduction of the machine learning contained within the model.
So, for example, in the case of a neural net (which is just one type of thing that a model could represent), it would need to describe the different layers, their weights and biases, layer connectivity, and the inputs and outputs.
Note
Although neural nets are definitely the hype of machine learning, CoreML supports much more than just neural nets. We talk more about what a neural net actually is later in “Neural network”.
At the time of this book’s publication, CoreML supports the following:
-
Neural nets
-
Regressors
-
Classifiers
-
Feature engineering
-
Pipelines
-
Custom models for which Apple has specific support
This is true regardless of the machine-learning tools you are using. In the case of CoreML, this all gets neatly packaged up into a single object that then can be easily stored, shared, and integrated into your apps, in an .mlmodel file (Figure 2-3).

Figure 2-3. The MobileNet image detection CoreML model
Tip
Apple has provided a few different popular machine-learning models converted into the CoreML model for you to explore at its Working with Core ML Models page.
The MobileNet .mlmodel file shown in Figure 2-3 was downloaded from that site.
CoreML models are supported with Xcode and can be added to any project. After opening an .mlmodel file in Xcode, the editor view will change to something like that shown in Figure 2-4. It’s magic.

Figure 2-4. The MobileNet .mlmodel inside Xcode
In this case, we’ve opened the MobileNet model shown earlier inside Xcode so that we can take a look at how Xcode interfaces with this file. The file is broken up into three main sections.
The first is the metadata section, which shows the name, type, and size of the model. In our case, the model is a 17.1 MB Neural Net Classifier called MobileNet. This section also contains any additional metadata inside the model; in this case, we have author, description, and license, but you can put almost anything you like in this section when making a model.
The next section shows any model classes Xcode automatically generated for you. This is one of the strengths of CoreML—after reading through the .mlmodel file, Xcode generates any files necessary to interface with it. You shouldn’t ever need to touch these files; however, if you are curious, you can inspect the generated file or build your own if you don’t trust Xcode or want more direct control.
We go into more detail with these generated files a little bit later, but for now you can think of them as black boxes that give you a class to instantiate that has a prediction method that you can call to handle all interfacing with the .mlmodel file.
The final section shows the inputs and outputs of the model. In the case of MobileNet it has a single input, a color image that is 224 pixels wide and high; and two outputs, a string called classLabel and a dictionary called classLabelProbs.
Now in the case of MobileNet, which is designed for object detection, these outputs give you the most likely object and the probability of the other objects. In your own models, the inputs and outputs will be different, but the concept is the same: Xcode is showing you the interface that you’ll need to give the model data, and the output you can expect.
The MLModel format
Unless you are building custom models, you won’t need to worry about exactly what an .mlmodel file is, and even then, often the tools Apple has built to help create and convert models will have you covered.
Tip
By custom models, we don’t mean models that you train yourself; we mean models for which you’ve defined each component yourself.
There are, however, always going to be times when you need to dive inside and make some changes or custom tools; in that case, you need to know the model format.
The MLmodel format is based on the protocol buffers (often called protobufs) serialized data format created by Google. Protobuf is a serialization format like any other (such as JSON or XML), but unlike many serialization formats it is not designed to be human readable and isn’t a textual format. However, much like many serialization formats, protobuf is extensible and can store almost any data you need.
Protobuf was designed for efficiency, multiple language support, and forward and backward compatibility. Model formats will need much iteration as they improve and gain new features over time, but they will also be expected to hang around for a long time. Additionally, most training of machine learning currently happens in Python.
All of these reasons and more make protobuf an excellent choice as the format for the MLmodel.
Tip
If you are interested in playing around with protobuf in your apps, Apple has made a Swift library available that might be worth checking out.
The MLmodel format comprises various messages (protobuf’s term for bundled information, which can be thought of as similar to classes or structs ) that fully describe the information necessary to build any number of different machine-learning models.
The most important message in the specification is the Model format, which you can think of as the high-level container that describes every model. This has a version, a description of the model (itself a message), and one Type.
The Type of the model is another message that contains all the information necessary to describe that model. Each different machine-learning approach CoreML supports has its own custom Type message in the file format that encapsulates the data that approach needs.
Going back to the example of a neural net, our Type would be NeuralNetwork, and within that it has a repeating number of NeuralNetworkLayer and NeuralNetworkPreprocessing messages. These hold the data necessary for the neural net, with each NeuralNetworkLayer having a layer type (such as convolution, pooling, or custom), inputs, outputs, weights, biases, and activation functions.
All of this bundled up becomes an .mlmodel file, which CoreML can later read.
Note
If you are after the nitty-gritty details on the CoreML model formats and how you can build and interface with them, Apple has provided a full specification that you can read here.
This information is provided specifically for the creation of custom models and tools and is the best place to go if you are doing so.
Most of the time you can get by thinking of a CoreML model as information that describes the complete model without having to worry about the specifics of how it stores that information.
Why offline?
Apple makes a very big deal about how CoreML is all done offline, on-device, with all processing happening locally at all times.
This is quite a bit different than how some other systems approach machine learning, with another popular way being to take the data off the device and upload it to another computer that can crunch through it, and then returning the results to the device.
Apple’s decision to make CoreML work this way has some advantages and some disadvantages. Here are the main advantages:
-
It’s always available. The machine learning and data necessary are on the user’s device, so in areas with no signal, it can still perform any machine learning.
-
It prevents data use. If it’s done locally, there is no need to download or upload anything. This saves precious mobile data.
-
It needs no infrastructure. Running models yourself means that you need to provide a machine to do so as well as handle the transference of data.
-
It preserves privacy. If everything is done locally, so unless a device is broken into (which is very tricky to achieve), there is no chance for anyone to extract information.
Here are the disadvantages:
-
It’s more difficult to update models. If you update or make a new model, you either need to send it out to your users or make a new build or use Apple’s on-device personalization (“On-Device Model Updates”), which has a lot of limitations.
-
It increases app size. With the models stored on device, your apps are bigger than if they just sent the data over to another computer.
Tip
Depending on what you are doing with machine learning, the models can grow to gigantic proportions.
For this reason, Apple has published some information on how you can shrink down your .mlmodel files before deployment.
Apple has taken the view that the advantages to doing everything on-device outweighs the disadvantages, and we tend to agree, especially in the case of privacy. Machine learning has the capability to provide—at times terrifying—insight and functionality, but the potential risks are likewise staggeringly huge.
A computer can’t care about privacy, so we have to ensure that we do the thinking for it and keep the privacy of our users in mind at all times.
Understanding the pieces of CoreML
CoreML contains a whole bunch of things, and we’re not here to reproduce Apple’s API reference for CoreML.
The central part of CoreML is MLModel. MLModel encapsulates and represents a machine-learning model, and provides features to predict from a model and read the metadata of a model.
CoreML also provides MLFeatureProvider, which we talk about more in “A Look Inside CoreML”. MLFeatureProvider exists as a convenient way to get data into and out of CoreML models. Closely related to this, CoreML provides MLMultiArray. MLMultiArray is is a multidimensional array that can be used as feature input and feature output for a model.
Tip
Multidimensional arrays are common in AI. They’re great for representing all sorts of things from images to just plain numbers. CoreML uses MLMultiArrays to represent images; the channels, width, and height of the image are each their own dimension of the array.
There are a lot more bits and pieces in CoreML. We recommend working your way through the book and then checking out the documentation from Apple to fill in any gaps that are of interest to you.
Now that we clearly understand everything that there is to know about CoreML (right?), we might as well put our newfound knowledge to the test. That’s what Part II of the book is. The next section covers CreateML, the most likely way that you will create CoreML models.
CreateML
CreateML “CreateML” is Apple’s Swift-based toolkit for creating and training machine-learning models. It has has two primary components: a framework and an app (see Figure 2-5). It primarily exists on macOS, and is designed to be the framework on which to base your workflow.
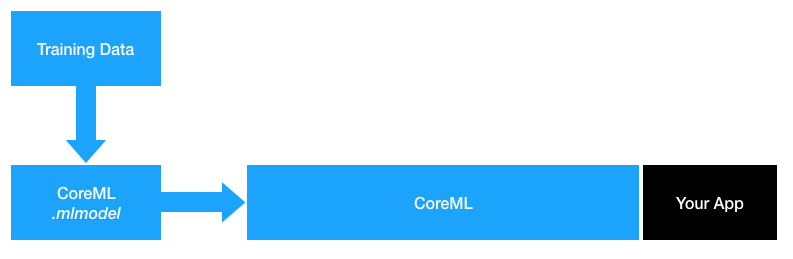
Figure 2-5. CreateML
CreateML is also a macOS app that Apple ships as part of its developer tools, as shown in Figure 2-6. The app lets you create and train machine-learning models in a graphical environment and uses the same underlying machine-learning subsystem that the CreateML framework provides access to, packaged into a user interface.

Figure 2-6. The CreateML app icon
The CreateML framework was the original incarnation of CreateML and was announced by Apple at its WWDC conference in 2018. It was originally designed to allow you to create machine-learning models within Xcode Playgrounds. Since then, it has evolved to be a more general-use machine-learning framework that’s not solely designed for building models, but also for working with and manipulating models in general.
Tip
There’s nothing magic about CreateML. It’s just a framework provided by Apple that has helper functions to create, work with, and manipulate models. It’s the manipulation counterpart to CoreML. Other platforms, such as TensorFlow, for example, have bundled this into one framework (e.g., “TensorFlow”). If it helps, you can think of Apple’s primary machine-learning stack as CreateML+CoreML.
Figure 2-7 shows the template chooser for CreateML.

Figure 2-7. The CreateML application’s template chooser
When you create a new project in the CreateML appliction, you can supply some metadata that will be visible in Xcode when you use the model you’ve generated, as shown in Figure 2-8.
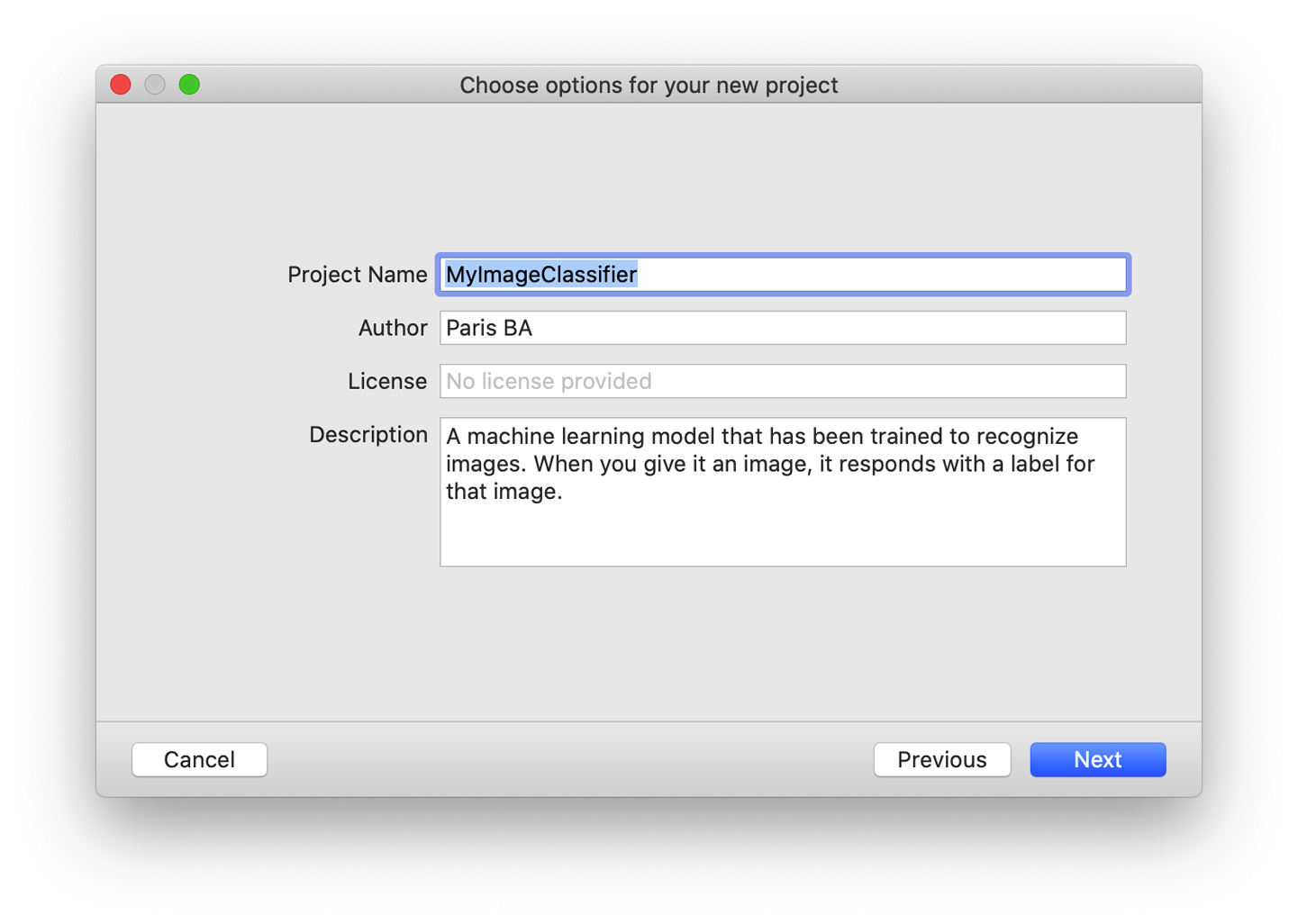
Figure 2-8. The CreateML new project options
Note
We step through actually using the CreateML application to train a model in Chapter 4, when we build an app that can classify images.
CreateML makes the training process as simple as it can be because it even splits the training data you provide into a training set and a validation set.
Warning
Because CreateML randomly chooses which data goes into a training set and which goes into a validation set, you might get slightly different results if you use the same data to train a model more than once.
Almost everything you can do with the CreateML application you also can do by using the CreateML framework directly, with Swift code. We’ll note where this is relevant later, when we’re working with CreateML.
At the time of writing, the CreateML application supports training the following types of models:
-
image classifier
-
sound classifier
-
object detector
-
activity classifier
-
text classifier
-
word tagger
-
tabular regressor
-
tabular classifier
The CreateML framework has the following broad features:
-
Image classification
-
Object detection within images
-
Text classification
-
Word tagging models
-
Word embedding, for comparing strings
-
Sound classification
-
Activity classification
-
Recommendation systems
-
Data structures for storing classified data (
MLClassifier), continuous values (MLRegressor), and tables of data (MLDataTable) -
Model accuracy metrics
-
Error handling for machine learning
-
Metadata storage for machine learning
We touch on many of these CreateML framework features as we work through the examples in Part II.
Tip
Accuracy, evaluation, and validation are a little out of scope for this book, but if you’re interested in learning more, Apple’s documentation is a good starting point.
Understanding the pieces of CreateML
We were going to write a big, long chapter that unpacked every piece of CreateML until we realized that we’d basically be duplicating Apple’s CreateML API reference and documentation.
Instead of doing that, we’re going to summarize the useful bits of CreateML and hope that you explore it yourself as you encounter it through our practical tasks in Part II.
CreateML has a whole bunch of things that will train models, such as these:
-
MLImageClassifierfor classifying images -
MLObjectDetectorfor detecting objects within an image -
MLTextClassifierfor classifying natural language text -
MLWordTaggerfor classifying text at a word level -
MLSoundClassifierfor classifying audio -
MLActivityClassifierfor classifying motion data -
MLClassifierfor classifying tabular data -
MLRegressorfor estimating (continuous) values using regression (as opposed to classification) -
MLRecommenderfor making recommendations
And a few things to help out when using or training models:
-
MLGazeteerfor defining terms and labels, to augment anMLWordTagger -
MLWordEmbeddingfor mapping strings to vectors, so you find neighboring strings -
MLClassifierMetricsfor metrics on classifier performance -
MLRegressorMetricsfor metrics on regressor performance -
MLCreateErrorfor storing errors that occur when using CreateML
And storing data:
-
MLDataTablefor storing tables of data -
MLDataValuefor storing a cell of data from anMLDataTable -
MLModelMetadatafor storing metadata about a model (such as creator and licensing information)
You can learn about all of these things in the CreateML documentation, but we do touch on almost all of them as part of the practical tasks that we look at throughout the book.
Unless you have a really good reason to go spelunking through Apple’s documentation, we recommend that you work through our tasks and then go back and look at the bits of CreateML that interest you. This book really tries its best to stay practical, and to that end, we’re focused on what you can do with CreateML, not the ins-and-outs of CreateML for interest’s sake.
Turi Create
Turi Create is an open source collection of task-based tools for training machine-learning models, manipulating data, and exporting models in the CoreML model format Python library. It runs on anything that supports Python, and is maintained and supported by Apple.
Note
If we were betting types, we’d put money on Apple eventually combining all of the functionality of CreateML and Turi Create into one tool. That day isn’t here yet, though.
Apple acquired a startup called Turi in 2016 and open sourced its software a year later (Figure 2-9). Apple’s task-focused approach to machine learning and AI is very much rooted in the philosophy espoused by Turi Create, but Turi Create is Python software and doesn’t quite fit in, or work the same way, as the rest of Apple’s ecosystem.
Note
Turi Create is available on GitHub; however, you probably don’t need to download or clone the GitHub repository to work with Turi Create because it’s available as a Python package. Later in this chapter, we show you how we set up our preferred Python distribution and environment in “Python”.
Turi Create is a task-focused (“A Typical Task-Based Approach”) AI toolkit, with most of its functionality separated into scenarios designed to tackle specific practical tasks. For a refresher on task-focused AI, check back to “Using This Book”.

Figure 2-9. The Turi Create project on GitHub
At the time of writing, the task-focused toolkits that Turi Create supplies are as follows:
-
Recommender systems
-
Image classification
-
Drawing classification
-
Sound classification
-
Image similarity
-
Object detection
-
Style transfer
-
Activity classification
-
Text classification
We cover the majority of these in the chapters in Part II, so we won’t be exploring them in detail here. We also use Turi Create—even though it’s Python and not Swift (we have nothing against Python, but this book does say “Swift” on the cover in large, friendly letters)—for the following tasks:
-
Image style transfer, in Chapter 8
-
Drawing identification, in Chapter 11
-
Activity classification, in Chapter 7
Understanding the pieces of Turi Create
As with CreateML (discussed in “Understanding the pieces of CreateML”), Turi Create comes with a lot of useful bits and pieces separate from the task-focused toolkits we mentioned in “Turi Create”. The other features provided by Turi Create are broader and not so task focused. Turi Create’s manual does a good job of covering most of these, but in general Turi Create’s less task-focused bits are useful for manipulating data, including plotting and showing collections of data in an interactive way.
The parts of Turi Create that allow you to perform general tabular classification, regression, and clustering are really useful, but we’re not going to deep-dive into them right now (we do touch on them throughout the book, though).
We think the most useful bit of Turi Create, other than the task-focused toolkits, are its tools for working with data:
-
SArrayis an array that can store data that exceeds your machine’s main memory capacity. This is really useful when you’re working with enormous datasets and need to manipulate them before you can train a model. -
SFrameis a tabular data object (similar to CreateML’sMLDataTable) that lets you store enormous amounts of data in columns and rows in a persistent way (on disk, instead of in memory). Each column in anSFrameis anSArray. AnSArraycan be trivially constructed from a comma-separated values (CSV) file, a text file, a Python dictionary, a DataFrame from the Pandas framework, JSON, or a previously savedSFrameon disk. It’s basically magic. -
SGraphis a graph structure withSFrames underneath. It allows you to store complicated networks of relationships and items (vertices and edges) and explore the data.
Additionally (and we think this is probably the most underrated bit), Turi Create comes with a suite of visualization tools:
-
SArrayandSFrameboth have ashowmethod, which displays a plot of the data structure. This is also basically magic. It works using a native GUI, or in a Jupyter Notebook. -
SArrayandSFrameboth also support anexploremethod, which opens an interactive view of the data structure.
You can learn more about Turi Create’s visualization tools in the documentation.
Turi Create also comes with a C++ API, which is useful if you want to embed Turi Create features into other applications.
Tip
There are too many third-party frameworks that can be used to supplement Turi Create for us to explore them all here, but one of our favorites is “turi-annotate-od,” which allows you to prepare images for use with Turi Create’s Object Detection task-focused toolkit. You can learn more about it on the project GitHub.
Apple’s Other Frameworks
Apple also supplies a lot of useful frameworks that provide AI features, without any training required. These are part of Apple’s collection of libraries that you can use when building for its platforms. There are more frameworks than we have time to cover in this book, but we use some of them quite a bit for our tasks in Part II, specifically:
-
Vision, for applying computer vision algorithms
-
Natural Language, for analyzing natural language text
-
Sound Analysis, for analyzing audio streams and files
-
Speech, for recognizing human speech and turning it into text
We’re not going to unpack the specifics of these frameworks here, because we look at them in the context of our tasks later in the book. For now, suffice it to say that sometimes you’ll make a machine-learning model (say, using CreateML or Turi Create) and access it directly using CoreML, and sometimes you’ll access it via (for example) Vision and CoreML (if it was an image-related task). Figure 2-10 shows the tools.
Figure 2-10. Apple’s AI tools and how they relate to one another
Sometimes, you won’t need to build your own model at all, and you’ll be able to implement powerful AI-driven features using Apple’s frameworks; for example, if you needed to perform speech recognition in your apps.
This book is broad minded: we discuss what we think is the most straightforward way to implement AI features regardless of whether that involves creating and training a model from scratch, using someone else’s model, or using one of Apple’s frameworks (which, somewhere under the hood, involves using a trained model that Apple made).
Note
You might be wondering where Apple’s BNNS and Accelerate frameworks fit in. If you’ve read through Apple’s documentation, you’d be forgiven for assuming that we were trying to pretend these two frameworks didn’t exist. We kind of were. However, they’re both very useful, and both very (in our humble opinions) unrelated to practical AI (practical being the operative word here). Chapter 12 looks into this, but please wait until you’ve read the rest of the book.
CoreML Community Tools
The final tool from Apple that we’re going to cover here is the CoreML Community Tools, a suite of Python scripts that allow you to manipulate other machine-learning model formats and convert them to the CoreML format. You can find the CoreML Community Tools on Apple’s GitHub, as shown in Figure 2-11.

Figure 2-11. CoreML Community Tools
You can use CoreML Community Tools to do the following:
-
Convert models from Keras, Caffe, scikit-learn, libsvm, and XGBoost into the CoreML format
-
Write the resulting CoreML model out as a file in the .mlmodel format following the conversion process
-
Perform basic inferences, using a converted model via the CoreML framework, to validate and verify a model conversion
-
Build a neural network from scratch, layer by layer
-
Create models that an be updated on-device
-
Work with TensorFlow models using other packages
Tip
If you’re already working with machine-learning tools, you might notice that TensorFlow is a big glaring omission from this list. You’d be right, and we cover what you can do about that in “Tools from Others”.
CoreML Tools exists so that people who perform significant work using one of the myriad other machine-learning and AI platforms can bring their work into CoreML. It serves to legitimize CoreML, and bring the wider machine-learning ecosystem into the Apple world.
You won’t always need to use CoreML Tools—in fact, when you take a predominantly task-based practical approach, as this book does, you’ll rarely need them at all—but it’s important that we cover them because they’re a key part of what makes the Apple- and Swift-based AI ecosystem so powerful.
To install the CoreML Community Tools, use your preferred Python package manager to fetch and install coremltools. Later in this chapter, in “Python”, we discuss our preferred Python distribution and environment setup. If you like to keep your Python installations neat, you can install coremltools inside a virtualenv or similar. We outline our approach to this in “Python”.
We’re not going to provide a complete guide, or even a full practical example (at this point in the book anyway) on using the CoreML Tools, because the documentation covers that pretty well. We’re just here to tell you what CoreML Tools can do and how it fits into the workflow that we’re using for the practical examples in this book.
Tip
If you’d prefer to manually download, you can grab the CoreML Community Tools from Apple's GitHub. After you’ve downloaded it, you can learn how to build it from source. We don’t recommend that you do this, because there is no benefit to be gained.
If you’re not already doing machine-learning work with another set of tools, the biggest purpose the CoreML Tools serves for you is as a way to get other people’s models into a format you can use in your apps.
Tip
Check out the giant list of Caffe models and the giant list of MXNet models for some food for thought and inspiration on what you might be able to achieve with models from other formats.
We work through some small examples of using CoreML Tools later, in Chapter 9, as part of “Task: Using the CoreML Community Tools”, and in “Task: Image Generation with a GAN”.
Tools from Others
The two biggest and most important tools that are of interest for Swift and practical AI that aren’t created or distributed by Apple are the TensorFlow to CoreML Model Converter and Swift for TensorFlow, both from Google.
There are also a few useful third-party tools that don’t originate with a giant company, which we look at shortly.
Swift for TensorFlow
Swift for TensorFlow is an entirely new suite of machine-learning tools that are designed around Swift. Swift for TensorFlow integrates TensorFlow-inspired features directly into the Swift programming language. It is a very large and complex project, and it takes a different approach than the regular TensorFlow project (which is a Python thing).
Warning
At the time of writing, Swift for TensorFlow’s current version is not yet 1.0, and it’s under heavy development. It’s an early-stage project that isn’t feature complete. We’d love to write a book on Swift for TensorFlow, but it’s going to change constantly and we’d just have to rewrite it every month, so the best we can offer is a broad, big-picture chapter, exploring what’s possible. That’s Chapter 9.
You can find Swift for TensorFlow on GitHub, as shown in Figure 2-12, but we don’t recommend you clone or download the repository just yet.

Figure 2-12. Swift for TensorFlow on GitHub
We look at how you can use Swift for TensorFlow for a practical task-based AI problem in Chapter 9, as part of “Task: Training a Classifier Using Swift for TensorFlow”.
TensorFlow to CoreML Model Converter
The TensorFlow to CoreML Model Converter does what it says on the box: it lets you convert TensorFlow models to CoreML using Python. It requires that you have the CoreML Tools installed and available from your preferred Python package manager as tfcoreml.
It works much as you’d expect:
importtfcoremlastf_convertertf_converter.convert(tf_model_path='my_model.pb',mlmodel_path='my_model.mlmodel',output_feature_names=['softmax'],input_name_shape_dict={'input':[1,227,227,3]},use_coreml_3=True)
Using the TensorFlow to CoreML Model Converter is outside the scope of this book, but if you’re interested, you can learn more on the project’s GitHub page.
Other Converters
Other converters exist, such as the following:
-
MMdnn, from Microsoft, which supports a range of conversions to and from CoreML
-
torch2coreml, which supports converting models from PyTorch to CoreML
-
mxnet-to-coreml, which supports converting from MXNet to CoreML
We don’t have the space to go into these, but they’re all useful. After you’ve learned how to use one, they’re all more or less the same, too!
AI-Adjacent Tools
Python and Swift are actually surprisingly similar languages, but there also are a lot of important differences. As we’ve mentioned, we use Python a fair bit more than you’d expect in this book, but because this book is about Swift, we gloss over the details of what we’re doing in Python more often than not.
Tip
We recommend picking up one of the many fabulous Python books that our lovely publisher offers. Our personal favorites are the Machine Learning with Python Cookbook and Thoughtful Machine Learning with Python.
Python
As we’ve indicated, it’s incredibly out of scope for this book to dive into the depths of Python for practical AI. Not only is it not what this book’s about, it’s not our area of expertise! That said, you’re going to need to use Python occasionally as you work through this book, and we’re going to recommend a specific way of getting Python set up on your macOS machine.
We’ll remind you about this section later on in the book each time we need you to use a Python environment. Fold a corner of the page back here, if that’s your thing (you probably want to avoid doing that if you’re reading this as an ebook, but that’s just us.)
Warning
Python came preinstalled on macOS prior to macOS 10.15 Catalina (which is the version of macOS you’ll need to be running to follow along with this book). Older documentation, articles, and books might assume that macOS has Python installed. It doesn’t come with it anymore unless you upgraded to Catalina from an older version of macOS (in which case any installations of Python you had are likely to be preserved).
To use Python for AI, machine learning, and data science, we recommend using the Anaconda Python Distribution. It’s an open source package of tools, including a straightforward package manager and all the bits and pieces you need to do AI with Python.
The general steps for setting up Python—which will be useful to you every time we suggest you use Python throughout this book—are as follows:
-
Download the Python 3.7 distribution of Anaconda for macOS.
Tip
Anaconda also comes with some graphical tools for managing environments. We prefer to use the command-line tools, and think it’s easier to explain and make it part of your workflow, but if you prefer a graphical user interface, it’s available for you. Launch “Anaconda Navigator” and explore. You can learn more about Anaconda Navigator at http://bit.ly/2IIPdrm.
-
Install Anaconda, as shown in Figure 2-13. The “Preparing Anaconda” stage, as shown in Figure 2-14, might take a little while.

Figure 2-13. Installing Anaconda on macOS
Figure 2-14. Preparing Anaconda might take a while
-
Open a Terminal, and execute the following command:
conda create -n MyEnvironment1This creates an empty, new environment for you to work in. You can repeat this command using a different name instead of
MyEnvironment1for each specific set of tasks that you want to do with Python. -
To activate
MyEnvironment1, you can execute the following command:conda activate MyEnvironment1To deactivate (leave the Anaconda environment you’re currently in), execute the following:
conda deactivate
You can see this process in Figure 2-15.
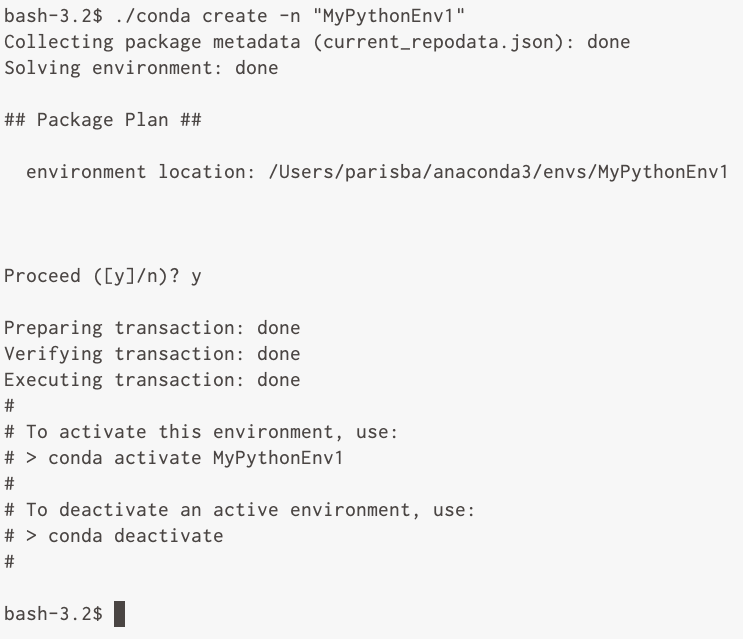
Figure 2-15. Creating a new Anaconda environment
-
Many AI and machine-learning tools require you to use Python 3.6. You can force Anaconda to create a Python 3.6 environment for you by using the following command:
conda create -n "MyPythonEnv2" python=3.6 -
After you’ve activated an Anaconda Python environment that you created with a specific Python verison, you can verify you’re running the right version of Python by executing the following from within your Anaconda environment:
python --versionYou should see Python print its version number, as shown in Figure 2-16.
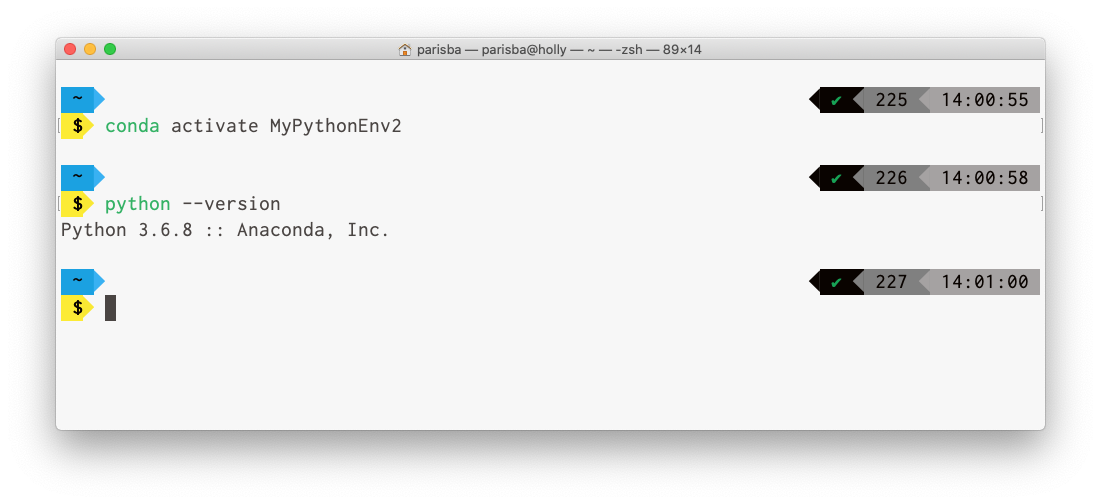
Figure 2-16. Python showing its version
-
You can always check which Anaconda environment you’re currently working in, or check on all your environments, by executing the following command:
conda info --envsAnaconda will display an asterisk (*) next to the environment in which you’re currently working, as shown in Figure 2-17.

Figure 2-17. Listing your Anaconda environments; the active environment has an asterisk
-
You can duplicate an existing Anaconda environment by executing the following command:
conda create --name NewEnvironment --clone OldEnvironmentReplace
NewEnvironmentwith the name of the new copy that you’d like to create, andOldEnvironmentwith the name of environment you’re cloning.
Tip
There are a lot of other environment-managing features available in Anaconda. Check out the Anaconda Documentation for more information. O’Reilly also has some great books that address the subject, such as Introducing Python, Second Edition.
-
You can install packages within your Anaconda environment using Anaconda’s built-in package manager. To search for packages that are available, you can execute the following command while you’re within an environment:
conda search scipyThis command searches the Anaconda package manager for the
scipypackage. -
To install a package using the Anaconda package manager, execute the following command:
conda install scipy
Warning
The install command installs the specified package into the currently active environment. To install a package to a specific environment, use a command like conda install --name MyEnvironment1 scipy, instead.
-
You can also install multiple packages at once, as follows:
conda install curl scipy -
If the package you need is not available in the Anaconda package manager, you can use
pipinstead.pipis the de facto standard package manager for the broader Python community. To install a package usingpip, activate the environment to which you want to install the package and execute the following command:pip install turicreateOf course, you’ll need to replace
turicreatewith the name of the package you want to install.
Note
We strongly recommend installing packages from the Anaconda package manager. Only turn to pip if a package is not available via Anaconda.
When we suggest that you make a new Python environment, at various points throughout this book, our recommendation is to make a new Anaconda environment for the specific project or task you’re working on, following the process we just outlined.
For each task for which we use Python (and therefore Anaconda), we indicate which packages we recommend installing within the environment you make for that task as we go. We also indicate whether those packags are available in the Anaconda package manager, or in pip.
Keras, Pandas, Jupyter, Colaboratory, Docker, Oh My!
Other than Python, the tools you’re likely to encounter when working with Swift and AI are diverse and unpredictable. When you’re concocting scripts, particularly in Python, there are all sorts of useful frameworks, ranging from Keras (a framework that’s designed to provide a range of useful functions for machine learning in a human-friendly way, shown in Figure 2-18), to Pandas (a framework for manipulating data, among other things, shown in Figure 2-19).

Figure 2-18. Keras GitHub
You can also try the useful Python framework’s NumPy and scikit-learn, which allow you to work with and manipulate data in all sorts of useful ways.
We occasionally use these Python frameworks as we work with data to apply it in the book’s tasks. We do refrain from going too in depth; they’re well covered online and in O’Reilly Online Learning.
Figure 2-19. Pandas
We think the final three tools that you’re likely to encounter, or want to use, are Jupyter, Google’s Colaboratory, and Docker.
Jupyter Notebooks are an online browser-based Python (or any language theoretically, assuming there’s a plug-in for it) environment that lets you share, write, and run Python code in a browser.
Jupyter is incredibly popular in the data science world as a great way to share code with integrated explanations, and has been used both as a means of distribution and documentation to explain concepts and ideas. Google’s Colaboratory (commonly called just Colab) is a free online hosted and slightly tweaked version of Jupyter Notebooks.
It has all of the same features (and a few more), but you don’t need to worry about running Jupyter yourself with Colab; you can let Google run it on its gigantic cloud infrastructure. Figure 2-20 shows Colab, and you can find it online at https://colab.research.google.com.

Figure 2-20. Colab, from Google
Colab is a great place to run the Python scripts that you’ll inevitably need to write when you’re working on AI, especially if you don’t want to install Python on your own machine.
Docker is a virtualization system that lets you package up software in a way that allows you distribute it without having to install it all over the underlying host operating system. Docker is a useful way to distribute large, unwieldly installations of things. We use Docker later when we install Swift for TensorFlow in “Task: Installing Swift for TensorFlow”. You can learn more about Docker here.
Other People’s Tools
One of our favorite tiny but useful things is Matthijs Hollemans’ CoreMLHelpers repository. It has a bunch of useful features (and more on the way), including these:
-
Convert images to CVPixelBuffer objects and back
-
An
MLMultiArray-to-image conversion -
Useful functions to get top-five predictions, argmax, and so on
-
Nonmaximum suppression for bounding boxes
-
A more Swift-friendly version of
MLMultiArray
Many of these things might not mean much to you right now, but trust us, they’re super useful. And we hope that they’ll mean something to you by the end of this book..
Tip
If you want to learn more about these tools, we highly recommend Matthijs Holleman’s book CoreML Survival Guide.
We’re also big fans of Fritz AI and their tutorials, documentation, and projects that make mobile on-device AI a lot easier. Check out their blog and Code Examples particularly.
What’s Next?
This chapter is not an exhaustive summary of every conceivable tool you could be using for AI with Swift. There’s no such guide that covers that. We’ve explored the tools that you’re most likely to encounter when you’re aiming to work with Swift from a top-down, task-focused, deeply practical perspective.
Almost every tool that we mentioned in this chapter is explored further, in some way small or large, in Part II or Part III.
You might be wondering how you use the models that could be created, manipulated, or explored using the tools we’ve discussed in this chapter. That’s a great question, and we’re really glad you asked it. We answer that question, chapter by chapter, in Part II.
Note
We were originally going to write a chapter all about consuming models using CoreML, but then we realized that we were straying from our original goal for this book: a guide to practical AI. The focus is on creating features and experiences using AI, not on exploring tools. This chapter is our only concession, and is by necessity. You can visit our website for articles, tutorials, and code samples covering this material from other perspectives.