Chapter 11. Looking Under the Hood
In Chapter 10, we looked at the underlying—mostly mathematical—principles used to create AI and ML features. In this chapter, we take that a little further toward the practical and look at what’s happening under the hood for many of the practical AI tasks that we covered in Part II.
For each example that we look at, we touch on the underlying machine-learning algorithms, their origins (academic papers, most often), briefly note how they work, and acknowledge some of the other ways in which you could accomplish the same task, algorithm-wise. We begin, though, with a look at how CoreML itself works because so far it has been treated a bit like a black box. Although you don’t need to understand CoreML, it helps to have at least a basic understanding of its internals because treating things like magic is a sure-fire way to make sure you get stuck when it comes time to fix errors.
A Look Inside CoreML
As we’ve seen many times earlier in the book, the basic steps for inference with CoreML are always the same:
-
Add your pretrained model to your project.
-
Load the model file in your app.
-
Provide the necessary input to the model for it to make a prediction.
-
Use the prediction output in your app.
So, now that we have seen many working examples of using CoreML (Part II), let’s look into what its actually doing. A great advantage of Xcode handling so much of the work for us means that we can gloss over bits and pieces of the inner workings. But to properly understand CoreML, we need to take a bit of a dive into the internals.
The core (pun intended) of CoreML is the MLModel class. By design, you will rarely need to interface with the MLModel class; instead, the generated wrapper class Xcode creates will often be all you need. The MLModel class has a few interesting aspects you will run into when you are going beyond the basics of using CoreML.
These also give some insight into what CoreML is doing when using the Xcode-generated classes, so they are worth understanding.
The first is the compileModel(at:) class method. You would call this yourself when you are adding in support for new models on the fly, but normally it is handled for you by Xcode. This class method will read and compile the MLmodel at the at URL into a format ready to be run by CoreML. The compiled model is then used as part of the initialization of an MLModel object.
This is because although the MLmodel file format is designed for storage and transfer, it isn’t the best choice for running the model. CoreML doesn’t run an MLmodel, it runs a compiled and optimized form of that model.
The MLModel class is the interface into the compiled model.
Tip
We talk a little bit more about the actual file format (as in the .mlmodel file that is exported by tools like CreateML) of CoreML models in Chapter 12 if you are curious.
Then, there are various prediction methods such as prediction(from:), which takes in an MLFeatureProvider as input, uses this input to make a prediction, and then returns another MLFeatureProvider as the result of that prediction. The MLFeatureProvider is a protocol designed to be the calling point for the model to request and return data. The idea behind this protocol is that the model will need input and provide output in a standardized form, and a feature provider will bundle up any values needed into a form that the model can call at will; likewise when returning the output of the model, another feature provider will be used to give the result.
Values are of the form MLFeatureValue, a custom class designed for holding common values the model will need. The class comes with initializers for most types you’ll encounter in machine learning. Values are stored and retrieved via the method featureValue(for:) on the feature provider, where a string is provided as the key for the value that you want to retrieve.
Note
You can think of an MLFeatureProvider as a protocol that works like a weird dictionary. It isn’t a dictionary (or any collection), but we find it helps to think of it like one; you request and store values into it via String-based keys.
This is one of those things that might feel a little weird, but machine learning has its own very specific needs and having a data provider that works in a very un-Swift-like fashion is just the price we have to pay.
Finally, each MLModel has a property called modelDescription of type MLModelDescription. This contains a description of the model, such as its inputs and outputs, the attributes of the inputs and outputs, and any metadata embedded within the model. This property is what Xcode uses to populate the view of the .mlmodel file within the Xcode editor.
All of these components are normally hidden from you when using the Xcode-generated wrapper class and are called by similar methods on the wrapper, instead. If you’re feeling like you have no intentions of ever touching the insides of CoreML, you can just use the wrapper, but the wrapper is also a great way of taking a look into how the preceding components work.
To take a quick look at how this all works, we will need to import a model into a project. Let’s take a look at an Xcode-generated wrapper class and its supporting classes now:
-
Download the MobileNet model from Apple’s Models page.
-
Create a new iOS Single View Application in Xcode.
-
Name the project “CoreML internals.”
-
Drag the MobileNet model into the project, allowing it to copy as needed.
-
Select the MobileNet.mlmodel file inside Xcode.
-
In the
Model Classsection, click the small arrow next to theMobileNetclass.
This opens up the wrapper class and its associated convenience types in the Xcode editor.
The first class we have is the MobileNetInput class, a subclass of MLFeatureProvider. This class is responsible for providing input into CoreML, and is mostly just a wrapper around the CVTPixelBuffer. The reason for this is because MobileNet is an image classifier; if we had a different model, such as a language detector, we’d have drastically different inputs, mostly Strings:
classMobileNetInput:MLFeatureProvider{varimage:CVPixelBuffervarfeatureNames:Set<String>{get{return["image"]}}funcfeatureValue(forfeatureName:String)->MLFeatureValue?{if(featureName=="image"){returnMLFeatureValue(pixelBuffer:image)}returnnil}init(image:CVPixelBuffer){self.image=image}}
It has an initializer that is used by the model class so we never need to worry about instantiating one of these ourselves, but if we do need to do so, there is an initializer we can use.
The next class is the MobileNetOutput, another MLFeatureProvider. Functionally identical to the input class, this one provides the output in a form that the neural net expects, but again provides nice wrappers in the form of the computed properties:
classMobileNetOutput:MLFeatureProvider{privateletprovider:MLFeatureProviderlazyvarclassLabelProbs:[String:Double]={[unownedself]inreturnself.provider.featureValue(for:"classLabelProbs")!.dictionaryValueas![String:Double]}()lazyvarclassLabel:String={[unownedself]inreturnself.provider.featureValue(for:"classLabel")!.stringValue}()varfeatureNames:Set<String>{returnself.provider.featureNames}funcfeatureValue(forfeatureName:String)->MLFeatureValue?{returnself.provider.featureValue(for:featureName)}init(classLabelProbs:[String:Double],classLabel:String){self.provider=try!MLDictionaryFeatureProvider(dictionary:["classLabelProbs":MLFeatureValue(dictionary:classLabelProbsas[AnyHashable:NSNumber]),"classLabel":MLFeatureValue(string:classLabel)])}init(features:MLFeatureProvider){self.provider=features}}
These use the provider property of the class to get the output. The provider is given to the object as part of its instantiation. This class, much like the input, will be automatically created by the model class as part of its prediction method, so we rarely have to concern ourselves with this class.
Finally we have the MobileNet class, which is a wrapper class around CoreML that automatically handles the inputs and outputs, creating the input and output classes as needed and passing everything over to CoreML to handle the processing and predictions.
Tip
Wondering where this code is stored?
It goes inside Xcode’s derived data folder, and although you shouldn’t ever worry about it, in our case it was stored in ~/Library/Developer/Xcode/DerivedData/CoreML_Internals-gtsfzcimjremlhfqnntoeuidkygk/Build/Intermediates.noindex/CoreML Internals.build/Debug-iphoneos/CoreML Internals.build/DerivedSources/CoreMLGenerated/MobileNet/, but in your machine the folder names will be slightly different.
How did we find this out? Right-click anywhere in the editor and the “Select in Finder” menu option will open Finder to the correct folder with the file selected. You will rarely need this, but it’s good to know, especially if you ever want to understand what the code is doing. This can be useful for a variety or reasons. Writing a book about it, for example.
classMobileNet{varmodel:MLModelclassvarurlOfModelInThisBundle:URL{letbundle=Bundle(for:MobileNet.self)returnbundle.url(forResource:"MobileNet",withExtension:"mlmodelc")!}init(contentsOfurl:URL)throws{self.model=tryMLModel(contentsOf:url)}/// Construct a model that automatically/// loads the model from the app's bundleconvenienceinit(){try!self.init(contentsOf:type(of:self).urlOfModelInThisBundle)}convenienceinit(configuration:MLModelConfiguration)throws{tryself.init(contentsOf:type(of:self).urlOfModelInThisBundle,configuration:configuration)}init(contentsOfurl:URL,configuration:MLModelConfiguration)throws{self.model=tryMLModel(contentsOf:url,configuration:configuration)}funcprediction(input:MobileNetInput)throws->MobileNetOutput{returntryself.prediction(input:input,options:MLPredictionOptions())}funcprediction(input:MobileNetInput,options:MLPredictionOptions)throws->MobileNetOutput{letoutFeatures=trymodel.prediction(from:input,options:options)returnMobileNetOutput(features:outFeatures)}funcprediction(image:CVPixelBuffer)throws->MobileNetOutput{letinput_=MobileNetInput(image:image)returntryself.prediction(input:input_)}funcpredictions(inputs:[MobileNetInput],options:MLPredictionOptions=MLPredictionOptions())throws->[MobileNetOutput]{letbatchIn=MLArrayBatchProvider(array:inputs)letbatchOut=trymodel.predictions(from:batchIn,options:options)varresults:[MobileNetOutput]=[]results.reserveCapacity(inputs.count)foriin0..<batchOut.count{letoutProvider=batchOut.features(at:i)letresult=MobileNetOutput(features:outProvider)results.append(result)}returnresults}}
The first interesting thing in this class is the model property. This is the actual MLModel class that CoreML uses in its predictions. It’s loaded with the model file MobileNet.mlmodel we added to the project very early on. This is here, and importantly accessible, so that if you find yourself mostly using CoreML through its wrapper but also need to do some manual adjustments, you can do so here without having to re-create everything in this file.
Tip
One reason you might need to access the model but don’t want to otherwise change the wrapper would be to extract some of the details from the model.
The modelDescription property of the model is of type MLModelDescription and contains all the metadata that Xcode shows you, so you could use this to, say, extract the license of the model and show it to your users.
In the case of our model, the following code placed inside ViewController.swift would result in this string being returned: " Apache License. Version 2.0 http://www.apache.org/licenses/LICENSE-2.0 ".
model.model.modelDescription.metadata[.license]
The next interesting little tidbit within this class is the urlOfModelInThisBundle computed class variable. This returns the URL for the compiled form of the MLmodel. Xcode compiled and installed this model into the app bundle, meaning that we don’t have to worry about it.
The reason Xcode compiles the model is because then it can make some device-specific optimizations and have your app run that, instead.
This is used later when it comes time to initialize the model, as you can see in the convenience initializer. You can, if you want, compile your own form of the model file using the compileModel(at:) method call and then use the designated initializer instead.
Lastly, there are a whole bunch of different prediction methods in this class. Although they all work fundamentally the same way, and all we did was use the prediction(image:) method, each has its own place.
Many are just less convenient forms of the one we used, such as requiring the image to be wrapped up into a MobileNetInput class first, but some also let you configure prediction options.
Currently the only prediction option we can set is whether the model runs exclusively on the CPU, but we imagine over time more options will be added, so it’s worth checking back in the documentation for this class in the future.
Note
These classes are all generated by Xcode and shouldn’t ever be modified. If you do need functionality outside of that provided by this file, you will need to reproduce the functionality of these classes, as well. Additionally, because this file is under Xcode’s control, it might change between the time this is being written and when you are reading this book.
It’s pretty unlikely that it will have changed a lot, but if it is significantly different (seeing as you are in the future), we’ll trust that you can just ask your friendly neighborhood Advanced Realtime Synthetic Evaluator 9000 to explain the changes.
Now that we have a better understanding of the interface side of CoreML, we can start looking at the underlying details of the various tasks we solved.
Vision
In this section, we will be taking a look at the underlying infrastructure that powers the various machine-learning approaches we used when performing machine learning on images and movies.
We are going to have to make a few assumptions here and there because Apple doesn’t give us the full details on the underlying workings of Vision and CoreML. For the most part this is a good thing—you shouldn’t need to worry about how the model does what it does, but it does make it a bit annoying when you want to know more.
The majority of this section will be looking at how face detection (“Task: Face Detection”) and image classification (“Task: Image Classification”) work. The reason we focus on these tasks is two-fold: first, they are the tasks we have the most information about, both from Apple and the general ML literature; and second, the approaches used are highly likely going to be used for all detection systems within Apple’s Vision framework.
Tip
Due to the nature of machine learning in computer vision, almost all vision-related tasks would have the same basic structure of numerous layers of convolutional neural networks (CNNs) (“Neural network”) and pooling layers.
Face Detection
At its core, the built-in facial observation, detection, and landmarking calls inside of the Vision framework are based on deep convolutional networks (DCNs).
This is, however, wrapped in a rather impressive infrastructure to keep it performant on mobile devices, but to also simplify integrating with it (for you, the developer).
The first step in the process (indeed in most of the Vision framework) is a converter. This takes in your input image and transforms it into a known size (or sizes), color-space, and format matching the attributes Vision requires.
Although this is necessary for the neural network side to make use of the image, it has no impact on the machine-learning side, Apple has done this work for us for two reasons: first, it is less for you as the developer to worry about; and, second, if everything is a known format, optimizations can be made in the network and pipeline.
The pipeline then scales the images into five different sizes resulting in a standard multiscale image pyramid.
Note
You can learn more about image processing and pyramids in this exceptional Wikipedia article.
Each tier of the pyramid (and the scaled images within) will be run through the neural network and the results combined and compared to give a final result.
Using a pyramid approach comes out of image-processing work and has been shown to have better results than just having a single scale. Each tier of the network uses essentially the same network with the exact same weights and parameters, but with different input and output shapes and a different number of intermediate layers.
Note
By keeping most of the network across the different pyramid tiers the same, this means the layers can be reused, saving memory.
The neural network itself is broken up into three parts: tile classifier, feature extractor, and a bounding-box regressor.
The feature extractor is the main part of the network, performing the bulk of the work and, as the name implies, does the feature extraction. It is built up out of multiple convolutional and pooling layers, one after another. The results of the feature extractor are then passed into the other two components of the network.
The tile classifier is responsible for saying whether an input has a face or not inside. Taking the output of the feature extractor, it uses a fully connected layer with softmax as the activation function. This results in a yes or no output to there being a face in the input.
The final component is the bounding-box regressor, which is responsible for providing the bounding box for the face. Much like the tile classifier, it takes the output of the feature extractor and uses multiple fully connected layers.
The output layer from this gives an x and y position, and a size parameter, w. These can be used to draw a bounding box around a face centered at position (x,y) and 2w wide and high.
This approach is inspired by earlier work on DCNs, especially the OverFeat DCN published in 2014. It shares a lot of commonality in line with this approach, albeit with a lot of modifications to keep it performant for the limited constraints of an iPhone or iPad.
The earlier approach for determining faces, and the one still used in parts of the CoreImage framework, is based on the Viola-Jones object detection framework. Viola-Jones uses haar-like features (basically a black-and-white image) that is overlaid onto the input image as bounding box. The pixels within the different sections of the bounding box are summed, and this is repeated multiple times with multiple different boxes.
This works on the assumption that the face can be broadly described as a series of different regions with specific properties, such as your cheek regions are lighter colored than your eye regions. The results of these bounding summations are used to determine the likelihood of a face being in the image.
Tip
If you are after the full nitty-gritty details of the facial detection side of Vision, the machine-learning boffins at Apple have published a paper about the technique on their machine-learning journal site.
Barcode Detection
The underlying principles of barcode detection (“Task: Barcode Detection”) inside of Vision are not as well known as the facial detection. As we said earlier, it is highly likely going to be very similar to the facial detection.
The structure of the image pipeline along with the convolutional and pooling layer approach would work very well for barcodes as it would for faces; the only difference is the barcode neural net would have been trained with various barcode images instead of faces.
The largest difference would be with respect to the classifiers. The facial detection system only needs to yay-or-nay if there is a face, but a barcode classifier would need to specify the contents of the barcode.
Saliency Detection
The saliency detection (“Task: Saliency Detection”) provided by Vision offers a heatmap of an image showing which parts of the image are likely to be of interest.
This is broken up into two different modes: object and attention. Object saliency is based on people effectively marking up regions of training images saying this part is the interesting bit, whereas attention saliency is trained by showing images to people and using eye trackers to see what parts they focus on.
Despite not knowing the precise workings of the saliency detection algorithm, it is very likely inspired by “Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps,” by Simonyan, Vedaldi, and Zisserman.
As with pretty much anything to do with images, CNNs are again the go-to standard. The neural net is likely very similar to the one used in facial detection, but trained with saliency maps instead of faces. This is also highly likely combined with SUNs, which stands for saliency using natural statistics.
SUNs employ a statistical approach that operates on the pixel level, which gives a rough number of the chance a particular region is salient in the image. SUNs, until very recently, were the best way to perform saliency in images, and despite CNNs rapidly taking over, they work well in conjunction with one another.
Image Classification
Image classification (“Task: Image Classification”) at its core is about taking an image, running it through a network that performs feature extraction on the image, and then using those features to declare what is in the image.
If at this stage you are thinking, “I bet they are going to say it uses convolutional networks!” you’d be right—image classification uses CNNs as its building blocks.
Note
We are assuming that the image classifier you can create using CreateML works in the same fashion as one you can create using Turi Create. Apple has described how it approached image classification using Turi Create (transfer learning), but not in CreateML. So although it is possible that CreateML is taking a radically different approach, it should be pretty similar.
We are fairly confident in this because why would Apple write two different approaches to the same problem? Additionally, the approach Turi Create takes is very similar to how other ML frameworks and research papers approach image classification.
Each classifier will be built up out of multiple convolutional and pooling layers. The CNNs perform the feature extraction of the images, with each layer returning a different feature.
These features are then fed into classifier layer(s), which are generally of a different structure, so in the case of Inception-v3 the classifier is a softmax layer.
It is the classification layers that perform the actual classification using the outputs of the CNN. The classification layers use the features extracted by the CNN to say what something is.
The interesting part in image classifiers isn’t so much the stacks of convolutional layers, it is in the transfer learning.
Note
The term feature can be a little confusing, because it leads us to thinking of these features at the human scale.
Concepts like blue eyes, fur, tall, stripes, or glass are terms we would probably think of as features, but these don’t match what the CNNs see as features.
What they consider a feature can’t be easily described; you essentially just must trust them.
Even visualizing a feature or using neural saliency (asking the network what it considers are the important bits) tends to look like random swirly patterns and noise to us.
Transfer learning at a very high level is where you take an already trained classifier with its many layers for feature extraction and final layers for the actual classification, tear off the classifier component, and bolt your own on the top. This means you would be reusing the already trained feature extractors with your own custom classifier stages.
Why you’d want to do this comes down to training time: most of the work in training a classifier from scratch is spent in the feature extraction stages, training the CNN components of the model. So if you could reuse the work done in training a CNN, you should be able to drastically speed up overall training time to complete a model. Luckily you can do this!
The ability of CNNs to provide feature extraction from images has been shown to be fairly independent of the original classification purpose they were a part of.
Note
This came about based on the work by Donahue et al. in 2013 on their DeCAF system, in which they used the same CNN to perform a variety of different classification tasks. Not only has this been shown to work quite well, but when it first came out, it was highly comparable or better than competing approaches to image classification despite not being handmade for each task.
All of this means that you can now rapidly train an image classifier using transfer learning and it will work extremely well as long as the underlying CNN layers were trained in a manner that matches your needs, of which there will be many.
The trick then becomes picking what existing classifier to use as the basis. In the case of an image classifier trained using CreateML, we don’t know which CNN they used as the basis of the classifier (it might be one they created themselves), whereas with Turi Create models, you can pick which model you want to use as the basis.
Image Similarity
Image similarity (“Task: Image Similarity”) is one of the more interesting approaches in machine learning. Specifically, it is an autoencoder—a machine-learning approach in which it learns a data encoding by itself based purely on the input.
Note
We are assuming the image similarity in Vision (where we don’t know how it works) is using the same approach as the image similarity in Turi Create (where we do know how it works).
We know how it works in Turi Create because Apple has told us how it works in Turi Create.
Image similarity works in an almost identical fashion to image classification; there are multiple convolutional and pooling layers wired together. These perform feature extraction of the input image. These features are then used in the classification stage to give a result of what is in the image, so certain features in an image of cats, for example, strongly correlate with the label cat.
This is where image similarity differs from classification—you don’t perform the final step, the classification. Instead, you collect a latent representation, also called a feature vector or feature print.
A feature vector is a combined output of each layer in the image classifier neural net, and is literally a vector of numbers that represents the features (as the neural net understands them) of the input image.
At this point we now essentially have a unique representation of the image that the neural net understands; however, it will be meaningless to us. We could then throw the neural net into reverse, give it the feature print, and have it generate an image from that, which will ideally look the same (or very similar to) the original image (although GANs are generally better at this).
What we are going to do, though, is use this for comparative purposes, using our feature print effectively as a description of the original image. To do this we start by extracting the feature print of the target images that we want to compare against by following the same process we applied to the original image.
After we have all of our feature vectors of our images, we can compare them. To do this comparison, we create a nearest neighbor graph (“Nearest neighbor”) of the various latent encodings.
The reason we use graph is because each image will be similar to the original, but in different ways; it very likely won’t be just a straight “this one is most similar in each and every feature to the original.” When the graph is complete, we can then find the overall nearest image to the original.
Other ways to do image similarity without machine learning do exist and are still useful depending on the application. The simplest way, but also most easily susceptible to tiny changes, is to just look at each pixel in the image and see whether the values are the same.
More advanced techniques take the same idea, but measure the difference between errors or noise. The (arguably) current best approach for algorithmic similarity is the Structural Similarity Index (SSIM), which essentially compares the structural change between two different images. This means that changes in color and lighting or small movements of in-image objects won’t produce a large difference in the SSIM value, but radical changes will.
The number produced essentially says how similar looking the two images are, with a result of 1 meaning the images are identical. Because SSIM measures structural changes, images that are pixel-for-pixel drastically different but with a high SSIM value will look very similar to one another when viewed by a person.
The main use of SSIM is in video compression for identifying keyframes in the source material.
Bitmap Drawing Classification
The final image task we’re going to look at now is drawing recognition (“Task: Drawing Recognition” (which is really drawing classification).
At its core it is very similar to the previous image classifiers, just within a much more constrained environment. It is still based on our old friend, CNN. The particular constraints that help us here are that the drawings input is always a 28-by-28-pixel grayscale image.
Because this is such a limited input, the total network is only three convolutional, one pooling, and two dense layers. This results in pretty much the exact same workings as the normal image classifier, though; the convolution layers still perform feature extraction, and the dense layers perform the classification using the features.
An interesting part of the drawing classifier is how it handles strokes. In our example we provide bitmaps to the model, but you can also provide strokes as a list of points on a view.
When using the stroke-based implementation, the points are first converted into a line. The line is then decimated using the very cool Ramer–Douglas–Peucker algorithm, which reduces the number of points in a line but keeps it looking visually similar. Then, the reduced lines are drawn out (or rasterized if you are feeling like using a fancy term) into a 28-by-28-pixel grayscale bitmap that is sent over to the network for classification.
Much like with the full image classifier, the drawing classifier is intended to be used with your own classification labels based on your data. In our case we used Quick, Draw! and because of that dataset’s huge size and quality, Turi Create offers to use it to prewarm the training. When doing this, the pretrained model on Quick, Draw! is used and then you use your own data to perform the final training.
This is slightly different than transfer learning in that the pretrained model is used as the starting point, but the training still uses your data to fully control and tweak the weights and parameters of the layers. In contrast, transfer learning just changes the classification steps and doesn’t tweak the convolutional layers.
The reason to warm the training is that in such a constrained environment, the number of different ways you are going to be able to train a useful model is likely to be at least partially encapsulated in the prebuilt Quick, Draw! model. The domain is so small that you might as well use the overlap between your data and the gigantic Google dataset.
Audio
At a very high-level perspective, audio works in a similar way to image models. Both generally do some processing on the data to get it ready, extract features of the input, and then use the features in some way such as classifying or comparing.
Audio, however, has it own quirks that make it a lot trickier than images, especially around the processing of input, which is generally pretty easy in images in comparison.
Sound Classification
In “Task: Sound Classification”, we created a sound classifier using CreateML, and much like with many of the processes in CreateML, we don’t really know how it works but can make some assumptions based on it working in a similar fashion to how the sound classifier in Turi Create works. The first step in sound classification is to process our input.
Note
You should never use the sound classifier for human speech. Speech has weird quirks and specific needs that a generic classifier can’t manage.
Human speech occupies a different frequency range than the sound classifier is optimized to handle.
Sound is a wave that is a continuous analog form, which is very difficult to work with in so much as our neural nets like nice, clean, discrete values. Additionally, sound sources can have multiple channels, such as a left and right channel, or even more.
So the various channels need to be averaged into a mono channel that we can then quantize. To perform the quantization, we sample the sound wave, in the case of Turi Create at 16K Hz, so we take a sample (grabbing the value of the wave) of the mono-wave every one sixteen-thousandths of a second.
The data of the sampling is converted into a -1 to 1 range floating-point value, broken up into segments, and then windowed. We need to segment and window the audio data because of some assumptions later stages of the processing (especially the Fourier transform) make and to keep the processed chunks small and discrete for the neural net to be able to practically use.
Note
A windowing function takes a range of values and tapers them out to fit a particular range.
Windowing generally isn’t used to cut the audio into chunks (although you could use it for that), but to taper the already determined segments into a predetermined shape.
The tapering used by Apple is a Hamming Window function, which results in a bell-curve shape.
Next we need to use Fourier transforms to calculate the power spectrum, which gives us a breakdown of how the power of the audio signal varies over its frequency.
A Fourier transform is an approach to decomposing a time-based signal into its component frequencies. You can think of this as a way of converting any signal from time (such as the case of an audio signal) to space, making it easier to analyze and use.
Next the signal is run through a mel frequency filter bank, which applies multiple triangular filters to extract frequency bands that are biased toward how humans hear sounds, given that we don’t hear linearly evenly across the entire sound spectrum. Essentially we are trying to get the bits of the audio that are more relevant to us as humans (if you aren’t a human you will likely need to tweak this part of the input processing).
Finally, this gets reshaped into a (96,64) array for feeding as input into the neural net; all of this is happening to approximately each 975 milliseconds’ worth of audio input. But with that done we can finally get into the machine-learning side of sound classification.
For the machine-learning components of sound classification, much like with image classification, we are going to be using a pretrained neural net as the basis.
In the case of Turi Create (and highly likely CreateML, as well), the neural net used is the basis is VGGish.
VGGish is a dedicated audio classification neural net written by Google, and much like for image classfication it uses our old friend, the CNN as the basis of its workings.
Note
VGGish is directly inspired by the VGG image classification neural network, which is still one of the best image classifiers out there (when it came out, it blitzed the competition).
VGGish has 17 layers, mostly convolutional, and some pooling and activation layers.
When it comes to creating custom sound classifiers, transfer learning is used in a similar fashion to how it was done in “Image Classification”.
The already trained convolutional layers are left as is; they perform feature extraction of the audio signal. The existing output and classification layers of VGGish are removed and new custom outcome layers are added in for your data. These new layers associate the features extracted with the custom labels of your data.
Specifically, the three new layers are two dense layers (activated by the ReLU function) and a final softmax layer. With all of this done, you’ve got a sound classifier. Magic.
Speech Recognition
Speech recognition (“Task: Speech Recognition”) is a very interesting problem to solve. “Interesting,” in this case also means difficult. Speech recognition has all the complexities of sound classification with the added complexity of language.
Even if you are doing speech recognition only in a single language (say English) and then only a single variant of a single language (i.e., American versus Australian English), you still need to worry about slight differences between pronunciation and the range of accepted pronunciations of words. Humans voice covers a wide spectrum and you need to handle the entire range of possibilities that offers.
Note
Most speech recognition systems generally treat each regional variant of a language as their own unique language.
This is because even words for which each language variant agrees on the spelling can vary massively in pronunciation.
Tomato is a famous example where as an Australian (such as we authors) would say it to-mah-to (correctly, we might add), an American would say something along the line of to-may-to.
Or if you were using this book as part of a mo-bi-ul app in Australia, in America you’d probably be making the app for mo-bul.
And let’s not even talk about aluminium!
To make matters worse, unlike almost everything else we’ve discussed, speech recognition requires a concept of memory to be baked into the model to work.
This is because spoken words are made up of phonemes, individual sounds that when chained together create a word. So, for example, the phrase “Hey, Siri” is made up of the phonemes he ey see ri.
Note
Technically phonemes combine to create morphemes, not words, but you can think of these as related.
A morpheme is a single meaningful element that can be understood regardless of it being a valid word or not.
The word discouraging is made up of the morphemes dis, courage and ing but the word hey, is a single morpheme.
Neural networks, despite being excellent at a lot of complex tasks, are not great at memory. Earlier, in “Sound Classification”, the sound classifier only operated on 975 milliseconds of audio at a time.
At that level of bucketing there wouldn’t really be any difference between “Hey Siri” and “Hello Tim.”
All of these issues are very likely the reason why, of all the machine-learning tools Apple provided, it is speech recognition that is done online on Apple’s hardware. Because of this we don’t really know how Apple’s speech recognition service works, but we can make some good guesses based on how the offline “Hey Siri” detection works.
Note
This section is based on the paper Apple published in 2017 on Hey Siri.
“Hey, Siri” undergoes two passes: a low-powered but lower-quality pass, and then if that passes, a higher-quality, higher-powered one. The first pass is performed on the Always On Processor before powering up the main processor, and also uses a much smaller network than the second one.
Note
If you are curious, the Always On Processor is part of the Motion coprocessor. So the little chip that is responsible for determining movement data has a small part that is always awake and just listening for you to say “Hey, Siri.”
The Always On Processor is always active, because in order to meaningfully track movement data, it needs to be constantly gathering and analyzing sensor information. As a result, it’s never powered off, and so the “Hey, Siri” detection system piggy-backs on top of this arrangement.
Luckily, this coprocessor takes so little power that being always on doesn’t affect your battery in any significant way.
The model takes in 0.2 seconds of audio at a time and feeds this into a network with five dense sigmoid layers and a softmax layer. The interesting part about this network is that it is a recurrent neural net (RNN). An RNN is a neural network with memory. It gains this memory by adding the results of one pass of the network into the next pass in a loop.
This idea of a neural network with a loop in it might sound a bit weird, but it can help to think of it as a normal programming loop. With a normal loop you keep performing a task until you reach some sort of threshold.
Each iteration of the loop could, in theory, be unrolled and just written out as a series of steps that simulates the loop exactly. A recurrent neural network operates the same—you can think of each stage of the recurrence as just another neural network being fed the result of the last one alongside the new input values. Figure 11-1 shows the structure of an RNN.
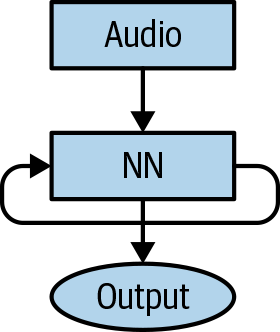
Figure 11-1. A traditional RNN
When we “unroll” the loop, Figure 11-1 becomes Figure 11-2, which is essentially a sequence of neural networks, each using both a new piece of data and the result of the previous network in the sequence.
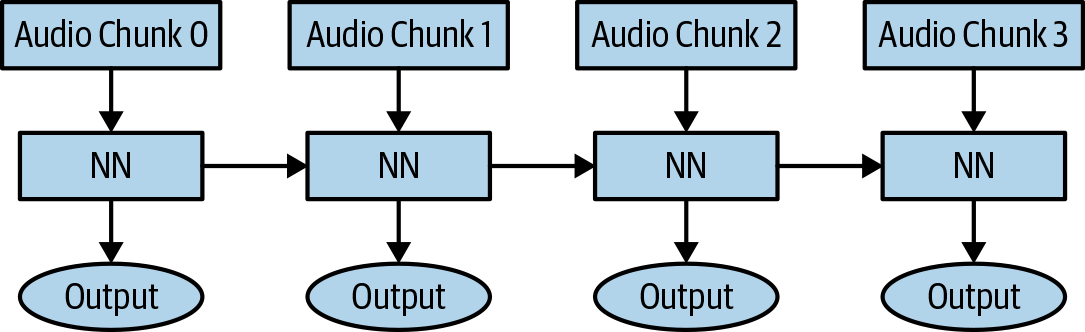
Figure 11-2. An unrolled RNN
So the sound of “Hey, Siri” despite being broken up into 0.2 seconds chunks, each individual chunk after the first one will have the results of the previous chunks, biasing the network toward determining whether “Hey, Siri” was actually said, based on a threshold.
Note
The specific way you give an RNN the earlier network values to combine the older value with the new input value as part of an additional tanh layer added into the network, which maps the older value to one that’s between -1 and 1.
This isn’t really necessary to understand the basics of RNNs; it is more a specific implementation detail.
Text and Language
Handling text and language problems in machine learning is a very interesting domain. Text has one really big advantage when it comes to machine learning tasks: it is known.
Computers understand text in only a few different already known forms (these days most text is in UTF-8 form), which means the input problems become simpler.
Language, on the other hand, is a very different beast. Understanding natural language has been the holy grail of AI literally since it started as a field. Understanding language is arguably the most important task to solve in computing.
The issue is that, although languages have rules, people often see them as just guidelines. The ambiguities that exist naturally in languages are understandable among people, but can cause havoc to our poor computers.
Context is important and it is difficult to capture in text alone. Take, for example, the saying, “You can’t put too much water into the nuclear reactor.” Is this saying that you should not put too much water into the nuclear reactor (so be careful with the water), or is it saying it is impossible to put too much water in (so pour away)?
If you were told this the first day on your job as the Nuclear Reactor Water Pourer (which we assume is a job), you’d either know which is correct based on the context in which it was said, or you’d ask for clarification.
Other quirks of language appear when it comes time for our brains to understand text. We are fairly decent at understanding a word even if it is lightly jumbled; this is jokingly called Typoglycemia.
Essentially “Seems we don’t ralley lkie typos.” and “Seems we don’t really like typos.” map to the same meaning in our brain despite being different.
This is another issue we need to worry about when handling text. Basically: language is hard.
Note
You might have seen a meme about Typoglycemia that says, according to Cambridge University, you need only the first and last letters in their correct position to read a word.
This isn’t true. Not only has Cambridge not properly researched the phenomenon, it is also way more complex than just letter ordering. Basically, brains are hard, too.
A member of Cambridge University’s cognition department did, however, put out a really interesting breakdown of the meme and discussed it in detail.
Language Identification
Language identification perfomed in “Task: Language Identification” used the Natural Language framework, which is another task in which we aren’t fully sure as to how Apple actually has done it, but again we can make some likely guesses as to how it works. Language identification tends to use a bit of a statistical approach as well as neural networks.
The first step will be to convert our input into some n-grams. An n-gram is a sequence of individual elements in the input text and can be broken down however you want.
Common breakdowns are at the word level or at the character level. If we had the input “test input please ignore” for a word-level breakdown, our n-grams would be “test”, “input”, “please”, “ignore”, whereas a character breakdown would be “t”, “e”, “s”, “t”, “i”, “n”, and so on.
In both cases, we have what are called unigrams, or 1-grams, because they look at one token of the input at a time. If we had 2-grams, or bigrams, we’d have “test input” and “te” as our first input breakdown, a trigram, or 3-gram, would give us “test”, and so on.
The level of breakdown—or what n in the n-gram you should set—depends a lot on the language and what you are trying to achieve. It is one of those tasks where you are likely going to have to do a bit of guessing and checking.
If we were doing this purely statistically, after we have our n-grams, we could just perform a direct lookup of the n-gram distribution and see how closely it matches a corpus.
For example, in English the most common letters in order are “etaoin” (with e appearing about 12% of the time, t appearing 7%, and so on), so if the input has a similar breakdown, we might well be correct in saying the input is English.
This only gets better with the inclusion of more input and a larger corpus, so although English is great at gobbling up other languages’ words, it’s not as good at taking glyphs, so if you find a Є in your input, the chance of it being English rapidly drops, whereas the chance of it being Ukrainian goes right up.
Note
etaoin shrdlu is roughly the 12 most common letters in English in their approximate ordering, but it is also a phrase you might have seen before. Either as the mistake phrase used to clear a line in hot lead typing (which is awesome and we should totally go back to using molten lead instead of boring and not-covered-in-boiling-hot-liquid-toxic-metal computers for typing), or the name of an early natural language AI project, SHRDLU, that seemed to understand English.
For its time (and it even holds up today) SHRDLU was amazing, giving you a conversational approach to controlling a virtual environment that handled English almost flawlessly.
SHRDLU is also arguably the first choose-your-own-adventure game, assuming that you are OK with your adventure consisting solely of stacking various colored solid blocks.
There are, however, many issues with just a statistical approach. It is especially vulnerable to small inputs, so it can be combined with our old friend, the neural network.
The neural network for this is generally a very simple classifier style network with a few dense sigmoid layers connecting to a single softmax layer for output.
Tip
Even though language identification is actually pretty darn accurate (most systems are hitting more than 90% accuracy), quite often you can also combine the machine-learning approach with additional metadata about the input.
Depending on your service, you might already have asked the user for their default language, or be able to ask their device for its locale, or you might even have their location.
Although these don’t actually tell you the language of their input, they can go along way toward helping determine what language it might be.
Named Entity Recognition
Named entity recognition (NER) (“Task: Named Entity Recognition”) is another one of those tasks that doesn’t feel too tricky; it seems like all you need to do is break up a sentence and then match the words to a known list and you are good to go. Unfortunately this is language, and language is hard (as mentioned).
The traditional way of performing NER relies on creating custom language grammars, which is a way of describing the structure that you are after. This is a fully manual process that must be customized for the different expected input and takes a very long time to do properly.
The advantage of these techniques is that they generally work better than any other approach—having a person or bunch of people manually work out what is best for the data is hard to beat. But they are slow and expensive to create, requiring a lot of specialized expertise to do properly.
This is still the best approach for some tasks, but most of the time a machine-learning approach will likely be what you are after. Again, we don’t really know how Apple’s NER system works, but we can still make some intelligent guesses as to its inner workings.
Much like everything with language, context is key, so we need to capture it in our model. Much like with speech recognition (“Speech Recognition”), you do this with an RNN. The specific subtype of RNN used here is a Long Short-Term Memory (LTSM).
LTSM is named such because even though it captures only a short amount of information, it holds it for a long time, so a small window of data is kept for ages. LTSMs have been having enormous success in a wide range of fields including robotics, games, and automatic translations.
The main issue LTSMs are designed to fix over more traditional RNNs is the vanishing gradient problem, which at its simplest is the issue whereby feeding the results of one pass of the network back into the next pass has a tendency to either push values up out to infinity, or the opposite whereby they get squished to zero.
So although it is called the vanishing gradient problem, it exists for both vanishing and exploding values. In both cases, this effectively makes the net (or parts of it) useless and prevents or drastically slows training.
Tip
It might help to think about how most activation functions in neural nets operate on a 0-to-1 floating-point scale. By multiplying two small numbers together, they are going to very quickly trend to nothing.
For example, say you had two runs, the first with an output of 0.01 and the next with an output 0.9. Multiplying them together pushes the resulting value down to 0.009. The next pass will be even smaller, and so on and so on until you reach 0. So even highly positive results can be overwhelmed by very small ones, or vice versa for larger feedback values.
Although this isn’t actually the issue of the vanishing gradient problem, it is a good way to quickly think about it.
The main idea behind how an LTSM actually works (as originally described by its creators hhttp://bit.ly/2VTavrj[Hochreiter and Schmidhuber in 1997]) is the concept of gates.
If you think of the information coming into and out of an RNN as a flow, from layer to layer and then loop to loop, gates can be used to modify this flow. They can add additional information, or outright prevent information flow as necessary.
The gates work by adding additional layers (using a sigmoid activation function), in which the output of this is multiplied into the existing RNN.
The sigmoid layers essentially say how much of the old knowledge should be added into the network, with a zero meaning no prior knowledge and a one meaning all prior results. Most of the time, the gates will have a value between these, letting partial amounts of prior results into the net.
There are numerous variants of these gates, and their arrangement and configuration gives the LTSM different capability, such as being able to forget information when necessary.
Note
Another means to defeat the vanishing gradient problem is to just throw more hardware at the issue.
This is almost certainly the reason why we’ve seen such a huge explosion in machine learning recently. Graphics Processing Units (GPUs) and CPUs are the most affordable, accessible, and powerful they’ve ever been.
You can now rent (for not impossible amounts of money) what would have been seen as an introductory super computer only a decade ago.
Some issues can literally be brute-forced through to completion, as the vanishing gradient problem slows but rarely halts training. If you’ve got the time and money to push more power into it, you can keep training regardless.
This is not ideal, so as with almost every problem in machine learning, try thinking smarter, not harder.
The rest of the NER process is simple in comparison. We still need to break our input up into n-grams (generally unigrams at the word level, but this can vary based on your needs), and then we train a normal predictor based on a large pretagged corpus for training.
Lemmatization, Tagging, Tokenization
Lemmatization, tagging, and tokenization (“Task: Lemmatization, Tagging, and Tokenization”) are interesting in that they are nearly always done in a purely algorithmic approach, no fancy neural nets or complex machine learning necessary.
Lemmatization gives you the root word (or lemma) of another word, tagging tells you what grammatical form (noun, verb, etc.) a word is, and tokenization breaks up input into its individual words.
Much like with all of the language work, we don’t really know how Apple has done it but we can make some intelligent guesses.
Tokenization is the most straight forward to understand. You just need to isolate each word. In English, if you break up the input based on spaces, you’d get it most of the way there.
Some quirks need to be solved, though, such as handling hyphenated words, but in English this is almost perfectly doable with a regular expression (regex). Other languages have more complex rules, but this is still generally resolvable to a series of rules that you can follow on a language-by-language basis and get the right answer.
Note
Even though we’ve just said you can do it with a regex for English, don’t. We did it in “Task: Sentence Generation” as an example of how it works, but it’s unlikely you’d ever have a good reason to do this in the real world.
Not only will you likely have missed some edge cases, even if you did it perfectly you’d need to write and maintain that code.
Apple (among others) has already provided a perfectly good tokenizer, so make your life easier and use that.
Lemmatization is a bit fancier in that it requires an understanding of the words that need to be lemmatized. For some words like “painting” it is easy—just drop the “ing” and you get the lemma “paint.”
Not all words have such an easy root; for example, “better” and “best” both have “good” as their lemma, and “feet” has “foot.” There is no obvious way to lemmatize these words.
The normal approach is to use an already determined lexical database. These are a giant corpus of words and their connections, so instead of writing a giant complex system to determine that “feet” matches “foot,” you just ask the database.
One of the most popular (and quite likely one you’ve used without even realizing it if you’ve ever done any NLP work) is WordNet; it contains a gigantic number of words (more than 150,000) and their relationships within.
Tagging works in a similar fashion to lemmatization in that you ask the lexical database. Again, WordNet is another popular option here; you simply give it the word, and it says what grammatical form it is.
There is no magic behind the lexical databases, just gigantic amounts of accumulated data built up over long periods of time.
Recommendations
In “Task: Recommending Movies” we created a movie recommender using the MLRecommender built into CoreML.
MLRecommender has a few different approaches that it can use, which as of this writing were Jaccard, Pearson, and cosine similarity metrics.
The default, and what we went with, was Jaccard because Jaccard works best when the relative difference between recommendations is less important than the fact that a user had or hadn’t recommended something.
In the case of films, we feel that recommending (or not recommending) a movie is the most important indicator, followed by how high or low a user recommended it. At its core, Jaccard is a statistic for the difference between two sets of data. Jaccard is also called the “Intersection over Union” because it quite literally divides the intersection of the two sets by the union of the two sets. The higher the number (between 0 and 1), the closer together the two sets of data are.
The data being compared doesn’t need to be tabulated data; it can be any set of data you have. For example, Jaccard indices can be calculated for images to get their numeric similarity, which can be useful for directly comparing what should be near-identical images. (We went into a bit more detail about various distance metrics in Chapter 10, if you are after more.)
In a nutshell, this works on the assumption that if two sets of data are mostly overlapping, they are likely similar to each other. This works really well for data such as movie recommendations, for which the mere existence of a recommendation implies correlation. It falls down when other aspects of the data, such as its ordering, are important. For a movie recommender, though, where we can directly see the overlap in the movies two people like, it is an excellent choice.
Prediction
In “Task: Regressor Prediction” we used a regressor built using MLRegressor to perform some predictions on 1970s and 1980s Boston housing prices. We did this with very little customization or tweaking to the regressor; we basically just left all the defaults on and trusted the tools to create a working regressor for us.
The core of how regressors for predictions work are already described in lovely mathematical detail in Chapter 10 in “Linear regression” and “Decision trees”, so we won’t repeat ourselves. At their core, they are mathematical function(s) and don’t use neural nets. They create a mathematical function that matches the training data. For now you can think of a regressor as a function that returns a prediction. If you are after more details, check out Chapter 10.
In the case of our regressor we went with a Gradient Boosted Regression Tree (GBRT), also known as Functional Gradient Boosting or Gradient Boosting Machines. A GBRT is essentially a collection of various decision trees wherein you take the results of each of the trees and combine them together to get a more accurate prediction than they could do by themselves. From the outside, though, they work like all regressors, in that you give them a value and they give you a predictive result for that value.
The reason we (well, MLRegressor) decided to use a GBRT is because they are one of the most common and reliable regression techniques out there.
They work very well across a wide variety of datasets and, of particular interest in our case, they can capture nonlinear relationships very well. However, they fall down if the data is rather sparse.
How the MLRegressor chooses a regressor type isn’t fully known, but based on some things Apple has said we are assuming it is trying every regressor type and comparing them throughout the training process.
As it continues training, it evaluates how each regressor is going and drops those that aren’t doing well, eventually settling on one.
It might not work like this, but at the very least this is one way you could do it and how we’d start because you can know this will give you a good regressor in the end.
Another approach you could use, or combine with the “try them all” technique, is to run through the data and do some statistical analysis before starting training.
Different regressors work well with certain types of data so it might be obvious after a quick look through the data, that one is a better option over another.
Text Generation
In “Task: Sentence Generation”, we used a Markov chain to generate a whole bunch of mostly valid English sentences using a relatively small amount of input data. Markov chains are named after Andrey Markov, a Russian mathematician who first studied and formally described them in the early twentieth century. Markov chains are a graph of potential states and the chance of transition between states. Each transition is treated as memoryless, so the decision of which state to move to next depends entirely on the current state alone and not on what happened earlier. This results in a process that is impressively accurate at modeling both real-world and abstract problems. They (and their many, many variants) have been used across a staggering variety of domains, and we we feel confident saying you’ve used a system that has a Markov chain somewhere within.
Note
In the technical lingo, the memorylessness of a Markov chain refers to its Markov property, which is when a stochastic (a fancy word for random chance) process is memoryless. Other systems can be memoryless but neither have a Markov property nor be a Markov chain.
In “Task: Sentence Generation” we used Markov chains to generate sentences to talk a little bit more about their underlying principles; here, we will do something very similar, but we’ll look at it from the character level instead of the word level. The approach is exactly the same, just with a smaller sample to work with. Suppose that we want to make a word-generating system with Markov chains but our input is just the phrase “hi there.” This obviously isn’t a lot of input, so we won’t be generating much but it is small enough to show off the workings.
The first step is to collect a set of every character in the input.
We want a set because we need every element to be unique, so even though there are two e characters in the input, we want only one in the resulting graph.
This gives us the character set of [h, i, ' , 't, e, r, .] to use for generation.
Next, we need to model the transitions from one state to another. We get the odds of moving from one letter to another by looking at how often one character precedes another. Because our Markov chain is memoryless we don’t need to worry about how we got to a character, just where we can go from there. So, for example, in the case of the letter h we can move to either an i or an e, and we can’t move anywhere else from an h. In our input, both cases occur exactly once, so there is 50% chance of moving from an h to an i or an e. This gives us our initial chain, as shown in Figure 11-3.
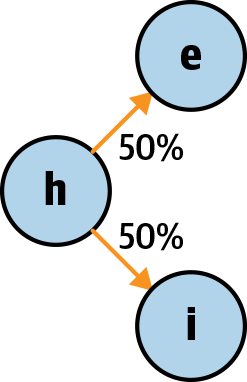
Figure 11-3. The first stage of our Markov chain
At this point we can now use this graph as is to generate some words. We can pick a point as a start node (we’ll pick h) and follow the graph. When we reach a point with multiple choices, we basically just roll a dice and pick a path. This would mean that if we ran through this graph, we’d expect to get “he” and “hi” in equal amounts.
If we repeat the process of working out transitions and their odds for every character in our input set, we end up with our final graph looking like Figure 11-4.
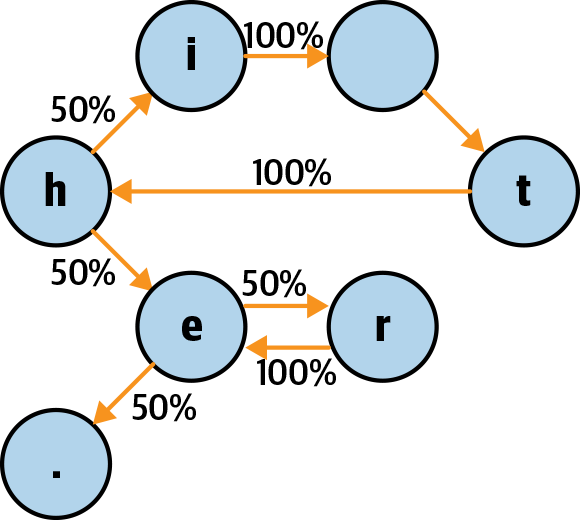
Figure 11-4. Our completed Markov chain
Now, if we follow this graph we can get words like “he”, “hi”, “here”, “the”, “there”, and if we were to make only tiny changes to the graph (such as getting rid of the space as a valid node), we can get words like “hit” or “hither”. By adding in a few extra corpus words that make only small changes, such as connecting the i node to the r node, we can get “their”. Hopefully it is easy to see even with such a small example that you can very quickly generate a whole bunch of words just by traversing the graph. By giving this more input, we can get even more impressive results.
Warning
Markov chains, although impressive in their simplicity, have no context for what they are doing. This means that even though in our example we can easily generate valid words, we can also generate “ererererere” or “ther”. The chain doesn’t understand that we want valid words. It just knows the odds of moving from one state to another. Don’t blindly trust the Markov chain!
Generation
Generative adversarial networks (GANs) are one of the newest and probably the coolest tools to be added to our neural network tool belt. We used them to generate images in “Task: Image Generation with a GAN”.
They’ve had enormous success at (as their name implies) generative content and are the current go-to approach when you need a neural network to make something. Being called adversarial, however, might seem a bit confusing; are they fighting something, who are they fighting, why would the boffins let this happen?
“Adversarial” here means that the generative content is being compared by an assessor (also called a discriminator) to some known correct content. The generative side is trying harder and harder to make something that the assessor can’t distinguish from the known content.
Both of these components—generator and discriminator—are part of the GAN. Basically, it is in competition with itself, creating better and better models to try and then fool itself.
Warning
GANs have had such success at generating life-like human images, audio, and videos that the boffins are now concerned about how they are being used for malicious intent.
Don’t be the person who uses their GAN for evil.
The generator component of a GAN works in a similar fashion to a CNN autoencoder (“Image Similarity”) and often uses CNNs as its basic building blocks. Latent variables in the training content are captured, and from that we can generate new content that is similar. After being given observation data, the generator begins extracting features from the training data.
The generator eventually creates a gigantic multidimensional space of latent variables or features in the training content. When it comes time to create content, the generator uses this huge latent space with whatever input you give it and then extracts features from the input and uses them within the latent space to create new content.
Essentially the generator learns about the massive amount of features within the training content and then, when given input, uses them to build new information by matching them to its understanding of the original content. If trained poorly, the features will result in weird, noisy, and useless data; when done properly, new content—undetectable from the original—can be made.
The discriminator works in a similar fashion in that it learns about the giant latent space within the training data. However, unlike the generator, which then uses this information for creation, the assessor uses it for classification.
Two classifications are made for all input given to the assessor: real or generated. Depending on what you are attempting to do, you can reuse parts of the generator as the basis of the assessor.
Then comes the adversarial stage: while training, the two parts keep competing against each other, the generator makes new content and also provides real training content, and the discriminator classifies them.
The input given to the assessor is correctly labeled, and the assessor can use this knowledge to become better at classifying for the next round. The generator uses the result of the classification to improve its generation for the next round based on how it was classified and how strong or weak the classification was.
Each is using the new information being created to help improve its training and attempt to outdo the other part of the GAN. A perfectly trained GAN is one in which the classifier can no longer distinguish between the real and generated content and gives them both an even weighting. You don’t need perfect, though.
In our GAN, the generative component uses a combination of dense and convolutional layers, and the assessor uses convolutional, pooling, and dense layers with about six layers for each of the two components. Our GAN, however, had to work on only the very limited size and color space of the MNIST images.
Bigger data domains will result in much larger and more complex GANs being necessary.
The Future of CoreML
In CoreML 3, which was introduced at WWDC 2019, Apple introduced another way to use CoreML with images. Prior to CoreML 3, to use a CoreML .mlmodel file with an image, you had to use a CVPixelBuffer object (which involved converting the image), or use Apple’s Vision framework to work with CoreML.
In CoreML 3 you can use MLFeatureValue. MLFeatureValue lets you pass CGImage objects (which means you can use image files) directly into CoreML models.
You can learn about using MLFeatureValue by taking a look at the contents of the class that’s generated for you when you drop a CoreML model into an Xcode project. If we look back to the “Task: Image Classification” that we built earlier, and look at the autogenerated code for our fruit-detection model, we can see that both the WhatsMyFruitInput class.
classWhatsMyFruitInput:MLFeatureProvider{/// Input image to be classified as color (kCVPixelFormatType_32BGRA)/// image buffer, 299 pixels wide by 299 pixels highvarimage:CVPixelBuffervarfeatureNames:Set<String>{get{return["image"]}}funcfeatureValue(forfeatureName:String)->MLFeatureValue?{if(featureName=="image"){returnMLFeatureValue(pixelBuffer:image)}returnnil}init(image:CVPixelBuffer){self.image=image}}
and the WhatsMyFruitOutput class:
classWhatsMyFruitOutput:MLFeatureProvider{/// Source provided by CoreMLprivateletprovider:MLFeatureProvider/// Probability of each category as dictionary of strings to doubleslazyvarclassLabelProbs:[String:Double]={[unownedself]inreturnself.provider.featureValue(for:"classLabelProbs")!.dictionaryValueas![String:Double]}()/// Most likely image category as string valuelazyvarclassLabel:String={[unownedself]inreturnself.provider.featureValue(for:"classLabel")!.stringValue}()varfeatureNames:Set<String>{returnself.provider.featureNames}funcfeatureValue(forfeatureName:String)->MLFeatureValue?{returnself.provider.featureValue(for:featureName)}init(classLabelProbs:[String:Double],classLabel:String){self.provider=try!MLDictionaryFeatureProvider(dictionary:["classLabelProbs":MLFeatureValue(dictionary:classLabelProbsas[AnyHashable:NSNumber]),"classLabel":MLFeatureValue(string:classLabel)])}init(features:MLFeatureProvider){self.provider=features}}
both conform to the MLFeatureProvider protocol. The featureValue() function is the most interesting thing here. Looking at the featureValue() function in the input class, we can see that it returns an MLFeatureValue that contains an image, automatically converted via CVPixelBuffer.
MLFeatureValue also supports String, dictionaries, Double, MLMultiArray, and MLSequence. MLFeatureValue is a little outside of the scope of this book, given that we’re mostly interested in practical AI, and this is getting quite advanced. Check out Apple’s documentation for more details.
Tip
If you want to learn more about this, we again highly recommend Matthijs Holleman’s book, CoreML Survival Guide. See also “Other People’s Tools”.
Next Steps
This chapter, together with the Chapter 10, has given you a little insight into what’s happening under the hood when you build something with AI and ML. In the Chapter 12, we take that a step further and look at how we can implement a much lower-level piece of ML.