Kapitel 15
Verzerrtes Bild der Wirklichkeit?
IN DIESEM KAPITEL
Fehler: zufällig oder systematisch?
Bevölkerungen richtig auswählen
Verzerrungen durch falsche Informationen
Störgrößen, die die Sicht vernebeln: Confounder
Wenn Risikofaktoren erst gemeinsam richtig stark sind: Effektmodifikation
Epidemiologische Studien sind in allen Stadien von der Planung bis zur Interpretation der Ergebnisse fehleranfällig. Im Grundsatz gilt das auch für Studien in anderen Wissenschaftsfeldern. Epidemiologen haben aber weit weniger Möglichkeiten, alle Störfaktoren in ihren Studien unter Kontrolle zu bringen als etwa Physiker. Denn sie beobachten ja Menschen im Alltagsleben mit allen ihren Unberechenbarkeiten, während Physiker unter den genau überwachten Bedingungen eines Labors experimentieren.
Gute Epidemiologen sind sich dessen bewusst. Natürlich versuchen sie, Fehler zu vermeiden oder klein zu halten. Sie wissen aber, dass das nie vollständig gelingen kann. Daher legen sie mögliche Fehlerquellen offen und diskutieren deren Auswirkungen auf die Studienergebnisse und die Schlussfolgerungen. Wenn Sie epidemiologische Studien kritisch lesen wollen, müssen Sie neben den wichtigsten Studiendesigns auch häufige Fehlerquellen und ihre Auswirkungen kennen. Vor allem müssen Sie überlegen, ob Fehler zufällig oder systematisch sind: Die jeweiligen Folgen können nämlich ganz unterschiedlich sein.
Keine Wissenschaft ohne Fehler (leider)
In epidemiologischen Studien treten verschiedene Arten von Fehlern auf, die ganz unterschiedliche Konsequenzen haben. Das zeigen wir Ihnen an einem praktischen Beispiel: Unser junger Assistent soll für eine epidemiologische Studie eine Bevölkerung (in der epidemiologischen Bedeutung des Wortes) wiegen – der Reihe nach und immer morgens, wenn die Menschen noch nüchtern sind.
 Die meisten Beispiele und die zugehörigen Zahlen in diesem Kapitel haben wir uns ausgedacht. Auf diese Weise können wir Ihnen besonders gut typische Fehler in Reinform demonstrieren. Im epidemiologischen Alltag treten oft mehrere Fehler gleichzeitig auf und sind dann schwerer zu durchschauen.
Die meisten Beispiele und die zugehörigen Zahlen in diesem Kapitel haben wir uns ausgedacht. Auf diese Weise können wir Ihnen besonders gut typische Fehler in Reinform demonstrieren. Im epidemiologischen Alltag treten oft mehrere Fehler gleichzeitig auf und sind dann schwerer zu durchschauen.
Situation Nummer eins: Wir haben unserem Assistenten eine präzise Balkenwaage besorgt (so eine hat auch Ihr Arzt in seiner Praxis). Aber der junge Mann ist morgens immer noch ziemlich verschlafen und hat zudem seine Brille nicht auf. Daher liest er beim Wiegen manchmal ein oder zwei Kilo zu viel ab, dann wieder ein Kilo zu wenig und so weiter. Jede einzelne Messung ist zwar nicht optimal genau, die Messwerte streuen also stark. Die Fehler sind aber zufällig, gehen in beide Richtungen und gleichen sich – sofern er eine große Zahl von Menschen wiegt – insgesamt in etwa aus. Daher stimmt das auf diese Weise ermittelte durchschnittliche Körpergewicht in der Bevölkerung recht genau mit dem wahren Wert überein. Die Messungen sind aber unpräzise.
Situation Nummer zwei: Einer von uns hat den jungen Mann wegen der Zufallsfehler beim Wiegen zur Schnecke gemacht (so was tun wir im wirklichen Leben nur ungern – wie gesagt, das Beispiel ist ausgedacht). Die Folge: Er ist jetzt auch morgens hellwach und mit einem Adlerblick oder jedenfalls mit einer Brille ausgestattet. Aber leider benutzt er nun zum Wiegen seine alte Badezimmerwaage statt der Balkenwaage, vielleicht um Zeit zu sparen oder um sich an uns zu rächen.
Diese Badezimmerwaage hat nämlich ein Problem. Die Mechanik ist ausgeleiert, daher zeigt sie das Gewicht einer jeden Person fünf Kilogramm höher an als es in Wirklichkeit ist (viele Menschen glauben, genau so eine Waage in ihrem Badezimmer stehen zu haben). Dabei spielt es keine Rolle, wer sich auf diese Waage stellt (oder auf wie viele Gummibärchen derjenige im Lauf der letzten Wochen verzichtet hat), sie zeigt stur fünf Kilogramm zu viel an. Es leuchtet ein, dass eine solche Waage die Wissenschaft nicht wirklich voranbringen kann, denn sie führt zu einem systematischen Fehler: Jede einzelne Messung mag noch so präzise sein, sie ist dennoch in immer gleicher Weise falsch. Und genauso systematisch falsch ist auch das auf diese Weise ermittelte durchschnittliche Körpergewicht der Bevölkerung.
Fehler treten nicht nur bei Messungen auf. Sie können auch entstehen, wenn eine Störgröße den Zusammenhang zwischen einer Exposition und einem Outcome verschleiert. Epidemiologen sprechen dann von »Confounding«. Auch über diese Fehlerquelle erfahren Sie gleich mehr.
Zufällige Fehler: Heute so, morgen so
Epidemiologen sprechen von einem zufälligen Fehler (auch Zufallsfehler genannt), wenn ein Wert, den sie gemessen haben, zufallsbedingt um den tatsächlichen Wert schwankt. Eine Ursache von Zufallsfehlern sind Messungenauigkeiten, die durch unpräzise Messinstrumente auftreten können. (Unter »Messinstrumenten« verstehen Epidemiologen übrigens nicht nur Waagen wie im Beispiel unseres armen Assistenten, sondern auch Befragungs-»Instrumente« wie Fragebogen.) Wenn Sie genügend Messungen durchführen, halten sich die negativen Folgen der ungenauen Messung in Grenzen: Die Streuung der einzelnen Messungen ist zwar groß, ihr Durchschnittswert nähert sich aber an einen Wert an, wie ihn auch ein sehr genaues Instrument gemessen hätte.
Doch der Zufall kann uns noch auf eine andere Weise einen Streich spielen, auch wenn die Messung sehr genau ist. Stellen Sie sich zum Beispiel einen Münzwurf vor: Sie werfen drei Mal und es kommt jedes Mal Kopf. Ist die Münze gezinkt? Höchstwahrscheinlich nicht, denn rein zufallsbedingt landet die Münze drei Mal auf der gleichen Seite. Epidemiologen sprechen hier von einem sogenannten Stichprobenfehler. Je größer die Stichprobe ist (im Münzbeispiel heißt das, je öfter Sie die Münze werfen), desto geringer schlägt der Stichprobenfehler zu Buche. Um Stichprobenfehler weitestgehend auszuschließen, müssen Stichproben ausreichend groß sein. Mehr darüber erfahren Sie in Kapitel 17.
 Englischsprachige Epidemiologen bezeichnen Zufallsfehler als »random error« und Stichprobenfehler als »sampling error«.
Englischsprachige Epidemiologen bezeichnen Zufallsfehler als »random error« und Stichprobenfehler als »sampling error«.
Systematische Fehler: Immer gleich falsch
Ein Fehler im Design, in der Durchführung oder in der Auswertung einer Studie, der regelmäßig und immer in gleicher Weise auftritt, heißt systematischer Fehler oder Bias. Er kann entweder zu einer Unterschätzung oder einer Überschätzung des tatsächlichen Zusammenhangs zwischen Exposition und Outcome führen. Dadurch können die Ergebnisse der Studie systematisch vom wahren Wert abweichen. Systematische Fehler lassen sich anders als Stichprobenfehler nicht von der Größe der Stichprobe beeindrucken, das heißt, ein systematischer Fehler wird mit zunehmender Stichprobengröße nicht kleiner.
Alle epidemiologischen Studientypen sind für systematische Fehler anfällig, manche mehr (zum Beispiel Beobachtungsstudien), andere weniger (zum Beispiel randomisierte kontrollierte Studien).
Epidemiologen haben keine Mühen gescheut, die unterschiedlichen Typen von systematischen Fehlern zu identifizieren und ihnen mehr oder weniger sprechende Namen zu verleihen. Das Ergebnis ist ein Sammelsurium verschiedener Bezeichnungen, die selbst erfahrene Epidemiologen manchmal in Erklärungsnöte bringen und über die auch keine einhellige Meinung besteht.
Englischsprachige Epidemiologen bezeichnen systematische Fehler als »systematic error« oder eben als »bias«.
Folgende wichtige systematische Fehler bei der Auswahl von Studienteilnehmern (Selektionsbias) und bei der Erhebung von Informationen (Informationsbias) stellen wir Ihnen in diesem Kapitel vor:
- Selektionsbias (Verzerrung durch ungeeignete Auswahl der Teilnehmer)
- Nonresponse-Bias (bestimmte Befragte antworten nicht)
- Freiwilligen-Bias (bestimmte Menschen nehmen bevorzugt an Studien teil)
- Bias durch Ausfälle (bestimmte Studienteilnehmer springen ab)
- Publikationsbias (manche Ergebnisse bleiben unveröffentlicht)
- Informationsbias (Verzerrung durch unzutreffende Informationen)
- Missklassifikation (falsche Kategorisierung von Exposition oder Outcome), darunter »Recall-Bias« (unterschiedliches Erinnerungsvermögen, beispielsweise von Fällen und Kontrollen in Fall-Kontroll-Studien)
Die falsche Bevölkerung ausgewählt: Selektionsbias
Auch Epidemiologen kommen um die Tatsache nicht herum, dass Ressourcen nur in begrenztem Maße zur Verfügung stehen. Die wichtigsten davon sind Zeit und Geld, zwei Dinge, von denen Epidemiologen stets zu wenig haben. Da kommt es schon einmal vor, dass nur wenige finanzielle Mittel für die Rekrutierung von Studienteilnehmern zur Verfügung stehen, die darüber hinaus in einem kurzen Zeitraum befragt werden müssen.
Epidemiologen möchten daher manchmal Menschen in ihre Studien einschließen, die sie ohne viel Mühe und Zeitaufwand erreichen können. Dazu gehören Schüler, Studierende oder Patienten in Krankenhäusern. Das kann jedoch zu Problemen führen. Denn während zum Beispiel Grundschulkinder recht repräsentativ für ihre Altersgruppe sind (schließlich gibt es ja eine Schulpflicht), ist dieses bei Studenten nicht der Fall. Sie unterscheiden sich in ihrem Gesundheitszustand, ihrem Verhalten und ihrer sozialen Herkunft von der Gesamtbevölkerung ihrer Altersgruppe – allesamt Faktoren, die selbst im Zusammenhang mit einem untersuchten Outcome stehen können.
 Ein Selektionsbias (auch »Selektionsfehler« genannt) bezeichnet einen Fehler in der Auswahl von Studienteilnehmern. Er führt dazu, dass sich die für die Studie ausgewählten Menschen systematisch von der Bevölkerung unterscheiden, aus der die Auswahl erfolgte.
Ein Selektionsbias (auch »Selektionsfehler« genannt) bezeichnet einen Fehler in der Auswahl von Studienteilnehmern. Er führt dazu, dass sich die für die Studie ausgewählten Menschen systematisch von der Bevölkerung unterscheiden, aus der die Auswahl erfolgte.
Selektionsfehler können unterschiedliche Ursachen haben. Epidemiologen versehen sie mit passenden Namen – aber meist auf Englisch. Die wichtigsten Arten von Selektionsfehlern stellen wir Ihnen im Folgenden vor.
Antwort verweigert: Nonresponse-Bias
Wenn Epidemiologen eine bestimmte Bevölkerung für eine Studie befragen wollen, nehmen in der Regel nicht alle teil. Abhängig von der Art der Fragen und der Länge des Fragebogens kommt es vor, dass sie nur 60 Prozent oder weniger derjenigen, die sie kontaktieren, von einer Teilnahme überzeugen können. Das heißt, dass 40 Prozent der ursprünglich kontaktierten Personen von vornherein eine Teilnahme ablehnen oder einen per Post zugeschickten Fragebogen nicht zurücksenden.
Die Wahrscheinlichkeit ist groß, dass sich diese sogenannten Non-Responder von den Studienteilnehmern unterscheiden. Mögliche Gründe:
- Sie sind nicht an gesundheitlichen Fragen interessiert.
- Sie fühlen sich zu alt, um den Fragebogen auszufüllen.
- Sie sind zu krank, um den Fragebogen auszufüllen.
- Sie können nicht gut genug Deutsch, um den Fragebogen zu verstehen.
Nehmen Sie an, Sie wollen mithilfe eines Fragebogens ermitteln, welcher Anteil der Frauen über 50 Jahre an der Krebsvorsorge teilnimmt (siehe das Kapitel 22 zum Thema Screening). Zu Ihrer Überraschung nehmen über 90 Prozent der Frauen, die den Fragebogen zurückschickten, am Screening teil. Aber nur 20 Prozent der angeschriebenen Frauen haben den Fragebogen zurückgeschickt – vermutlich all diejenigen, die besonders gesundheitsbewusst sind und daher auch am Screening teilnehmen. Die Non-Responder unterscheiden sich von den Teilnehmerinnen: Sie nehmen nicht am Screening teil und beantworten den Fragebogen nicht. Daher ist das Ergebnis Ihrer Befragung verzerrt.
Bildungsniveau, Alter und Gesundheitszustand sind Beispiele für Faktoren, die mit der Exposition oder mit dem Outcome einer Studie in Verbindung stehen können. Falls sich Non-Responder hinsichtlich dieser oder anderer für die Studie bedeutsamer Faktoren von den Studienteilnehmern unterscheiden (aber auch nur dann!), kommt es zu einer systematischen Verzerrung der Ergebnisse.
Um einschätzen zu können, wie groß der Nonresponse-Bias ist, versuchen Epidemiologen, von den Non-Respondern zumindest grundlegende Informationen zu erhalten und sie mit denen der Responder zu vergleichen. Dazu gehören zum Beispiel Alter, Bildung und möglichst auch Gründe für die Nichtteilnahme.
Nehmt lieber mich: Freiwilligen-Bias
Genau andersherum verhält es sich beim Freiwilligen-Bias. Menschen, die sich freiwillig für eine Studie melden, unterscheiden sich mit großer Wahrscheinlichkeit vom Rest der Bevölkerung. Freiwillige Teilnehmer einer Studie zum Zusammenhang zwischen Rauchen und chronischen Erkrankungen der Atemwege (Bronchitis) setzen sich wahrscheinlich kritisch mit ihrem Rauchverhalten auseinander und beobachten ihren Gesundheitszustand genauer als Teilnehmer, die Sie mühsam zur Teilnahme überreden mussten. Freiwillige Teilnehmer sind daher nicht repräsentativ für Raucher im Allgemeinen. Machen sie einen großen Teil der Studienpopulation aus, wird der negative Effekt des Rauchens geringer ausfallen, als dieses in einer unverzerrten Stichprobe der Fall wäre.
Für immer verschwunden: Ausfälle
Ein Mensch, der Ihnen am Herzen liegt, verschwindet plötzlich – eine schreckliche Vorstellung, die bei uns in Deutschland zum Glück nur selten Wirklichkeit wird. Den Epidemiologen, die Kohortenstudien durchführen (also Bevölkerungsgruppen über einen langen Zeitraum beobachten), passiert das öfter: Ihnen gehen über die Jahre trotz aller Bemühungen Studienteilnehmer verloren. Solche Teilnehmer nehmen das Telefon nicht mehr ab, beantworten keine Briefe oder öffnen die Tür nicht. Die Epidemiologen wissen dann nicht, ob die betreffenden Menschen verzogen oder verstorben sind oder ob sie einfach nicht mehr an der Studie teilnehmen wollen. Diese Teilnehmer sind »Ausfälle« und damit für die Studie und für die spätere Berechnung des Zusammenhangs zwischen Exposition und Outcome verloren.
Englischsprachige Epidemiologen bezeichnen Ausfälle aus laufenden Studien als »loss to follow-up«.
Sind die Ausfälle rein zufällig bedingt, also weder abhängig von der untersuchten Exposition noch vom Outcome, so entsprechen die Folgen denen eines Zufallsfehlers (siehe weiter vorn in diesem Kapitel).
Ausfälle können aber auch zu starken Verzerrungen der Studienergebnisse führen. Das ist der Fall, wenn sich die Ausfälle von den Teilnehmern, die in der Studie verbleiben, hinsichtlich Exposition und Outcome deutlich unterscheiden. Diese Verzerrung kann zu einer Unterschätzung oder zu einer Überschätzung des Zusammenhangs führen.
Nehmen Sie an, Sie führen eine Kohortenstudie zum Zusammenhang zwischen Rauchen und Lungenkrebs durch. Sie beobachten eine Gruppe von Rauchern (exponiert) und eine Gruppe von Nichtrauchern (nicht exponiert) über einen Zeitraum von zehn Jahren. Jedes halbe Jahr interviewen Sie alle Teilnehmer und erkundigen sich nach ihrem Gesundheitszustand. Einige Teilnehmer allerdings brechen im Verlauf der Beobachtungszeit den Kontakt zu Ihnen ab und melden sich auf Ihre Anfragen nicht mehr zurück. Erfahrungen aus der Praxis zeigen, dass insbesondere unverheiratete Männer dazu neigen, in Studien »verloren zu gehen«. Könnte das ein Problem darstellen und Ihre Ergebnisse beeinflussen?
In der Tat, denn unverheiratete Männer sind dafür bekannt, tendenziell stärker zu rauchen als der Rest der Bevölkerung. Dadurch haben sie auch ein überdurchschnittlich hohes Risiko, im Verlauf der Jahre an Lungenkrebs zu erkranken. Wenn Ihnen viele dieser Männer verloren gehen, befinden sich nach einer Weile in Ihrer exponierten Gruppe überwiegend Personen, die weniger stark rauchen (und daher ein geringeres Risiko für Lungenkrebs haben). Vergleichen Sie nun am Ende der Beobachtungszeit das Lungenkrebsrisiko aller verbliebenen Raucher mit dem der Nichtraucher, so unterschätzen Sie das tatsächliche Risiko des Rauchens.
 Sie können diese Unterschätzung vermeiden, indem Sie ein besonders intensives Follow-up Ihrer Studienteilnehmer betreiben. Gelingt Ihnen das nicht, sollten Sie eine stratifizierte Analyse durchführen. Sie berechnen dann statt eines Relativen Risikos für die gesamte Studienbevölkerung jeweils gesonderte Relative Risiken für schwache, mittelstarke und starke Raucher.
Sie können diese Unterschätzung vermeiden, indem Sie ein besonders intensives Follow-up Ihrer Studienteilnehmer betreiben. Gelingt Ihnen das nicht, sollten Sie eine stratifizierte Analyse durchführen. Sie berechnen dann statt eines Relativen Risikos für die gesamte Studienbevölkerung jeweils gesonderte Relative Risiken für schwache, mittelstarke und starke Raucher.
Verzerrung der besonderen Art: Publikationsbias
Wissenschaftler publizieren ihre Ergebnisse am liebsten in angesehenen wissenschaftlichen Fachzeitschriften mit einer großen Leserschaft. Damit beeinflussen sie die wissenschaftliche Diskussion (und verbessern vielleicht sogar das Leben ihrer Mitmenschen), heimsen Anerkennung ein und erleichtern sich so die Beschaffung von Forschungsgeldern. Das gilt auch für Epidemiologen und motiviert uns zum Schreiben.
Manchmal aber bringen wir unsere Artikel nicht unter, obwohl sie fachlich korrekt sind. Angesehene Fachzeitschriften drucken eher Artikel, die neue oder unerwartete Ergebnisse enthalten oder die zeigen, dass ein bestimmter Risikofaktor eine Krankheit auslöst. Wenn wir aber in unserer Studie keine Zusammenhänge zwischen der untersuchten Exposition und dem Outcome finden, nimmt vielleicht nur eine Nischen-Zeitschrift den Artikel. Dann wird er in keiner Zeitschriftendatenbank verzeichnet und kaum jemand nimmt ihn wahr. Oder, noch schlimmer: Wir schreiben den Artikel erst gar nicht.
Studienergebnisse, die nicht statistisch signifikant sind (mehr dazu erfahren Sie in Kapitel 17) oder einen Nulleffekt zeigen (so nennen Epidemiologen ein Relatives Risiko oder eine Odds Ratio von 1), werden systematisch vernachlässigt. Durch diesen sogenannten Publikationsbias bekommen andere Wissenschaftler und die Öffentlichkeit die Ergebnisse vielleicht nie zu Gesicht, obwohl sie wichtig sein können. Der Publikationsbias ist somit ein spezieller Selektionsbias.
Sie führen eine Literatursuche in einer wissenschaftlichen Datenbank durch. Dabei finden Sie zwei publizierte Studien, die zeigen, dass ein Joghurt mit bestimmten Inhaltsstoffen gesundheitsförderlich ist. Sie können nicht wissen, ob ein Publikationsbias vorliegt. Vielleicht gibt es mehrere andere Studien mit gegenteiligen Ergebnissen, die nie in einer Fachzeitschrift veröffentlicht wurden.
Informationsbias – oder: Missklassifizierte Menschen
Sie untersuchen den Einfluss häufiger Sonnenstudiobesuche (mindestens einmal pro Monat) auf das Hautkrebsrisiko in einer Kohortenstudie mit 10.000 Personen (jeweils die Hälfte exponiert und nicht exponiert) über einen Zeitraum von zehn Jahren. Sie interessieren sich dabei für die neu aufgetretenen Hautkrebsfälle (Outcome). Nach Ende der Beobachtungszeit tabellieren Sie Erkrankte und Nichterkrankte in einer Vier-Felder-Tafel (siehe Tabelle 15.1; die Zahlen haben wir uns ausgedacht).
Tabelle 15.1: Zusammenhang zwischen häufigen Sonnenstudiobesuchen und Hautkrebs (ausgedachte Hautkrebs-Kohortenstudie)
An Hautkrebs erkrankt |
Nicht an Hautkrebs erkrankt |
Gesamt |
|
Sonnenstudionutzung mindestens einmal pro Monat (exponiert) |
200 |
4.800 |
5.000 |
Sonnenstudionutzung seltener als einmal pro Monat (nicht exponiert) |
50 |
4.950 |
5.000 |
Gesamt |
250 |
9.750 |
10.000 |
Aus der Vier-Felder-Tafel berechnen Sie das Relative Risiko als
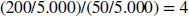
Das heißt: Menschen, die häufig Sonnenstudios nutzen, haben ein viermal so hohes Risiko, innerhalb von zehn Jahren an Hautkrebs zu erkranken, wie diejenigen, die selten oder nie ein Sonnenstudio aufsuchen.
Exposition oder Outcome falsch erfasst?
Bisher sind Sie davon ausgegangen, dass Ihre Studienteilnehmer zutreffende Informationen zur Häufigkeit von Sonnenstudiobesuchen und zum Auftreten von Hautkrebs gegeben haben. Was aber, wenn die Angaben falsch sind? Vielleicht haben einige Teilnehmer eine Frage falsch verstanden. Andere erinnern sich nicht genau, wie häufig sie wirklich ins Sonnenstudio gehen.
Wenn Sie falsche Informationen zum Expositions- oder Outcomestatus erheben, klassifizieren Sie die betreffenden Studienteilnehmer falsch. Einen Vielnutzer beispielsweise, der aber nur von fünf Besuchen pro Jahr im Sonnenstudio berichtet, sortieren Sie so fälschlicherweise unter die Wenignutzer – eine Missklassifikation.
Epidemiologen sprechen von Missklassifikationen, wenn Personen aufgrund fehlerhafter Messungen oder unzutreffender Informationen falsch kategorisiert werden. Diese falsche Kategorisierung kann sowohl den Expositionsstatus (exponiert oder nicht exponiert) als auch den Outcomestatus (zum Beispiel krank oder nicht krank) betreffen.
Missklassifikationen aufgrund unzutreffender Informationen können zu einer Verzerrung führen. Epidemiologen sprechen dann von einem Informationsbias.
Ein Informationsbias ist eine Verzerrung des Studienergebnisses durch unzutreffende Informationen, die zu einer Missklassifikation des Expositions- oder des Outcomestatus von Studienteilnehmern führen.
Ein Informationsbias kann die Studienergebnisse in unterschiedlicher Weise verzerren, abhängig von der Art der Missklassifikation. Epidemiologen unterscheiden zwischen einer nicht-differenziellen Missklassifikation (die alle Untergruppen in ähnlicher Weise betrifft) und einer differenziellen Missklassifikation (die bestimmte Untergruppen stärker betrifft).
Nicht-differenzielle Missklassifikation: Alle Gruppen betroffen
Nehmen wir nun an, dass Sie sowohl in der Gruppe der Erkrankten als auch in der Gruppe der Nichterkrankten zehn Prozent aller Personen fälschlicherweise als seltene Nutzer identifiziert (missklassifiziert) haben, obwohl sie in Wirklichkeit häufig ins Sonnenstudio gehen. Das Ergebnis dieser zehnprozentigen Missklassifikation innerhalb der Exposition sehen Sie in Tabelle 15.2. (Das Layout der Vier-Felder-Tafeln in Tabelle 15.1 und 15.2 entspricht übrigens der Darstellung, die Sie häufig in epidemiologischen Fachzeitschriften finden.)
Tabelle 15.2: Zusammenhang zwischen häufigen Sonnenstudiobesuchen und Hautkrebs, zehnprozentige Missklassifikation (ausgedachte Hautkrebs-Kohortenstudie)
An Hautkrebs erkrankt |
Nicht an Hautkrebs erkrankt |
Gesamt |
|
Sonnenstudionutzung mindestens einmal pro Monat (exponiert) |
180 |
4.320 |
4.500 |
Sonnenstudionutzung seltener als einmal pro Monat (nicht exponiert) |
70 |
5.430 |
5.500 |
Gesamt |
250 |
9.750 |
10.000 |
Wenn Sie nun das Relative Risiko berechnen, werden Sie feststellen, dass es nicht mehr 4, sondern nur noch 3,1 beträgt.
Ein ähnlich erniedrigtes Relatives Risiko erhalten Sie, wenn Sie sowohl bei den Exponierten als auch den Nichtexponierten zehn Prozent aller Hautkrebsfälle falsch diagnostizieren. Probieren Sie es aus! Durch eine Missklassifikation, die beide Gruppen (entweder Exponierte und Nichtexponierte oder Erkrankte und Nichterkrankte) gleichermaßen betrifft, unterschätzen Sie die wahre Stärke einer Assoziation.
Wenn eine Missklassifikation unabhängig vom Expositions- oder Outcomestatus ist, sprechen Epidemiologen von einer nicht-differenziellen Missklassifikation. Sie führt in der Regel dazu, dass die Stärke einer vorhandenen Assoziation unterschätzt wird.
Da steckt System dahinter: Differenzielle Missklassifikation
Wenn sich das Ausmaß der Missklassifikation in den Gruppen der Exponierten und Nichtexponierten oder in den Gruppen der Erkrankten und Nichterkrankten unterscheidet, sprechen Epidemiologen von einer differenziellen Missklassifikation.
Bei einer differenziellen Missklassifikation ist der Anteil der falsch kategorisierten Personen zwischen der Gruppe der Exponierten und der Gruppe der Nichtexponierten oder zwischen den Erkrankten und Nichterkrankten unterschiedlich. Das heißt, die Missklassifikation hängt vom Expositions- oder Outcomestatus ab. Differenzielle Missklassifikation kann sowohl zu einer Unter- als auch zu einer Überschätzung des tatsächlichen Zusammenhangs führen.
Differenzielle Missklassifikationen können durch einen Informationsbias auftreten. Ein besonders wichtiges Beispiel ist der sogenannte Recall-Bias in Fall-Kontroll-Studien. Menschen, die erkranken, grübeln oft intensiv nach, was denn dazu geführt haben könnte, dass gerade sie erkrankt sind. Bei Fragen nach zurückliegenden Expositionen erinnern sie sich daher anders als Nichterkrankte (denken Sie an das Beispiel zu Verletzungen der Hoden und Hodenkrebs aus Kapitel 11). Epidemiologen bezeichnen diese spezielle Form des Recall-Bias daher auch scherzhaft als Grübel-Bias.
Auch Forscher können Missklassifikationen provozieren: Wenn Ärzte in einer klinischen Studie wissen, wer das Placebo erhält, kann es sein, dass sie diese Gruppe besonders gründlich auf den Outcome untersuchen, während sie bei der Gruppe mit dem neuen Medikament nachlässiger vorgehen. Epidemiologen nennen das einen Untersucher- oder Beobachter-Bias. Er lässt sich am leichtesten verhindern, wenn die Untersucher gegenüber der Exposition verblindet sind. Mehr darüber erfahren Sie in Kapitel 12.
Confounding – oder: Leben auf großem Fuße
Kernstück einer jeden epidemiologischen Ausbildung ist es, so früh wie möglich praktische Erfahrungen mit der Durchführung von Studien zu sammeln. Von Ihrem Dozenten erhalten Sie daher den Arbeitsauftrag, mittels einer kleinen Querschnittstudie den Zusammenhang zwischen der Schuhgröße und dem monatlichen Einkommen zu untersuchen.
Schuhgröße und Einkommen: Die Schuh-Studie
Sie gehen also eines schönen Samstagnachmittags in die Einkaufszone der Innenstadt, suchen sich ein gemütliches Plätzchen und befragen 100 vorbeikommende Shopper.
Falls Sie Ihren Dozenten beeindrucken wollen: Englischsprachige Epidemiologen nennen eine Studie mit dieser Art der Rekrutierung »pedestrian intercept survey«.
Von jedem abgefangenen Fußgänger notieren Sie die Schuhgröße in den Kategorien »unter 40«, »40 bis 44« und »über 44« sowie das monatliche Nettoeinkommen, das Sie in die Kategorien: »bis 1500 €« und »über 1500 €« einteilen.
Das durchschnittliche Einkommen eines Berufsanfängers im Bereich Epidemiologie an einer Uni fällt eher in die niedrigere Kategorie. Überlegen Sie sich daher gut, ob Sie dieses Buch nicht lieber weglegen und sich stattdessen einen lukrativeren Titel wie Management für Dummies besorgen wollen.
Sie tabellieren Ihre Ergebnisse (siehe Tabelle 15.3) und stellen fest, dass die Chance auf ein Einkommen über 1500 € im Vergleich zu der Gruppe mit den kleinsten Füßen (Referenzgruppe) mit zunehmender Schuhgröße ansteigt.
Tabelle 15.3: Zusammenhang zwischen Schuhgröße und Einkommen (ausgedachte Schuh-Studie)
Schuhgröße |
Odds Ratio für ein Einkommen über 1500 € |
Über 44 |
2,1 |
40 bis 44 |
1,4 |
Unter 40 (Referenz) |
1,0 |
Confounding heißt Verschleierung
Wie kann das denn sein? Die Schuhgröße mag ja Aussagen über so manche Qualitäten erlauben, aber das Einkommen gehörte bisher nicht dazu. Da diese Assoziation nicht sehr plausibel ist, liegt hier womöglich eine Verschleierung des wirklichen Zusammenhangs durch einen anderen Faktor, einen Confounder, vor.
Epidemiologen sprechen von Verschleierung oder Confounding, wenn die Assoziation zwischen einer Exposition und einem Outcome durch eine Störgröße (in Form einer anderen Exposition) überlagert oder verzerrt wird. Diese Störgröße heißt Confounder.
Ein Confounder hat folgende Eigenschaften, die Sie auch aus Abbildung 15.1 herauslesen können:
- Der Confounder ist mit dem Outcome (hier: hohes Einkommen) assoziiert.
- Der Confounder ist auch mit der untersuchten Exposition (hier: Schuhgröße) assoziiert.
- Ein Confounder ist auch dann noch mit dem Outcome (hier: hohes Einkommen) assoziiert, wenn die ursprünglich untersuchte Exposition (hier: Schuhgröße) nicht vorliegt.
Sie machen sich auf die Suche nach möglichen Übeltätern, auf die der Steckbrief zutrifft und die das unerwartete Ergebnis erklären könnten. Sie erkennen schnell das Geschlecht als möglichen Schuldigen: Männer haben im Durchschnitt größere Füße als Frauen. Und Männer verdienen im Vergleich zu Frauen trotz vieler Gleichstellungsbemühungen in unserer Gesellschaft im Durchschnitt mehr für die gleiche Arbeit.
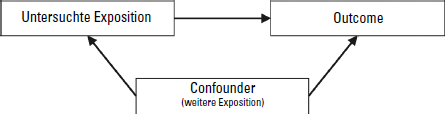
Abbildung 15.1: Schematische Darstellung des Confounding
Wie lässt sich diese Überlagerung des tatsächlichen Zusammenhangs zwischen Schuhgröße und Einkommen durch das Geschlecht bei der Auswertung berücksichtigen?
Der Umgang mit Confounding
Sie haben bereits unterschiedliche Techniken kennengelernt, mit denen Epidemiologen Confounding auf die Schliche kommen und ihre Ergebnisse »bereinigen« können. Bei der Planung einer Studie sind das:
- Randomisierung, durch die mögliche Confounder gleichmäßig zwischen den Fällen und Kontrollen verteilt werden (siehe Kapitel 12)
- Matching für mögliche Confounder (in Fall-Kontroll-Studien, siehe Kapitel 11)
- Einschränkung der Studienbevölkerung auf eine bestimmte Teilgruppe (in der Schuh-Studie zum Beispiel auf Männer)
Doch selbst wenn das Kind schon in den Brunnen gefallen und die Erhebung abgeschlossen ist, gibt es noch Hoffnung, Confounding zu identifizieren – vorausgesetzt, Sie hatten den Confounder gemessen. Epidemiologen stehen in dieser Situation zwei Verfahren zur Verfügung:
- Stratifikation, das heißt die separate Analyse für einzelne Untergruppen (in der Schuh-Studie zum Beispiel die Berechnung des Zusammenhangs zwischen Schuhgröße und Einkommen einzeln für Männer und Frauen, siehe Kapitel 7)
- Multivariate Verfahren, die dazu dienen, durch statistische Modelle den Einfluss einzelner Confounder herauszurechnen (siehe Kapitel 17 sowie den Band Weiterführende Statistik für Dummies).
Zum Glück haben Sie in Ihrer Erhebung neben der Schuhgröße und dem Einkommen auch das Geschlecht aller befragten Personen notiert. Um herauszufinden, ob die Ergebnisse Ihrer Schuh-Studie durch das Geschlecht verschleiert (konfundiert) sind, führen Sie die Analyse getrennt (stratifiziert) für Männer und Frauen durch. Damit kontrollieren Sie für das Geschlecht, wie es Epidemiologen ausdrücken würden. Das Ergebnis der stratifizierten Analyse finden Sie in Tabelle 15.4.
Tabelle 15.4: Zusammenhang zwischen Schuhgröße und Einkommen, stratifiziert nach Geschlecht (ausgedachte Schuh-Studie)
Männer |
Frauen |
||
Schuhgröße |
Odds Ratio für Einkommen über 1500 € |
Schuhgröße |
Odds Ratio für Einkommen über 1500 € |
über 44 |
1,0 |
über 44 |
1,0 |
40 bis 44 |
1,0 |
40 bis 44 |
1,0 |
unter 40 (Referenz) |
1,0 |
unter 40 (Referenz) |
1,0 |
Siehe da, innerhalb der beiden Gruppen findet sich kein Zusammenhang mehr zwischen der Schuhgröße und dem Einkommen. Die Schuhgröße hat also keinen Einfluss auf das Einkommen. Stattdessen scheint ein Zusammenhang zwischen dem Geschlecht und dem Einkommen zu bestehen. Um diesen zu quantifizieren, erstellen Sie eine weitere Tabelle (siehe Tabelle 15.5), diesmal zum Zusammenhang von Geschlecht und Einkommen, geschichtet (stratifiziert) nach Schuhgröße.
Tabelle 15.5: Zusammenhang zwischen Geschlecht und Einkommen, stratifiziert nach Schuhgröße (ausgedachte Schuh-Studie)
Schuhgröße unter 40 |
Schuhgröße 40 bis 44 |
Schuhgröße über 44 |
|||
Geschlecht |
Odds Ratio für Einkommen über 1500 € |
Geschlecht |
Odds Ratio für Einkommen über 1500 € |
Geschlecht |
Odds Ratio für Einkommen über 1500 € |
Männer |
1,7 |
Männer |
1,7 |
Männer |
1,7 |
Frauen |
1,0 |
Frauen |
1,0 |
Frauen |
1,0 |
Das Ergebnis zeigt, dass Männer eine 70 Prozent höhere Chance haben, zur Gruppe der Großverdiener zu gehören, deren Lohntüte am Ende des Monats mehr als 1500 € beherbergt. Erwartungsgemäß ist die Assoziation unabhängig von der Schuhgröße, was Sie daran erkennen, dass die Odds Ratios in allen drei Schichten (Strata) gleich sind.
Mit Ihrer Studie haben Sie also festgestellt, dass es keinen echten Zusammenhang zwischen der Schuhgröße und dem monatlichen Einkommen gibt. Darüber hinaus konnten Sie eine Ungleichheit in unserer Gesellschaft aufzeigen: Auch im 21. Jahrhundert werden Frauen im Vergleich zu Männern geringer entlohnt. Tatsächlich belegt eine Studie der Europäischen Union, dass Frauen für die gleiche Arbeit im Durchschnitt aller Mitgliedsstaaten 16 Prozent weniger verdienen als Männer. In Deutschland ist der Unterschied mit 22 Prozent besonders groß.
Die Schuh-Studie haben wir uns nur ausgedacht. Tatsächlich zeigen Studien, dass Männer mit steigender Körpergröße durchschnittlich mehr verdienen. Wir vermuten, dass große Männer auch große Füße haben. Vielleicht besteht bei Männern also doch ein wirklicher Zusammenhang zwischen Schuhgröße und Einkommen …
Typische Confounder
Confounder beschäftigen Epidemiologen in nahezu jeder Untersuchung. Übliche Verdächtige für ein Confounding sind:
- Geschlecht
- Alter
- Sozioökonomischer Status (beispielsweise Bildungsniveau oder Berufstätigkeit)
- Tabak- und Alkoholkonsum
Aus diesem Grund erheben Epidemiologen in ihren Studien nahezu reflexartig diese sowie weitere Faktoren, die bei einer bestimmten Fragestellung Zusammenhänge verschleiern könnten. Das ermöglicht es ihnen, bei Verdacht auf Confounding zusätzliche Auswertungen durchzuführen. Confounding wird Ihnen in Kapitel 16 wieder über den Weg laufen. Dann geht es um den Zusammenhang zwischen Kaffeekonsum und Bauchspeicheldrüsenkrebs – ein spannendes Thema für uns Kaffee-Vieltrinker.
Manche Epidemiologen betrachten Confounding als eine Form des Bias. Wir finden es jedoch wichtig, beide Begriffe getrennt zu behandeln. Ein Bias ist ein systematischer Fehler, der nachträglich kaum zu beheben ist. Confounding dagegen beruht auf einem Fehler in der Interpretation der Daten, den Sie auch nachträglich erkennen und in der Datenauswertung berücksichtigen können. Voraussetzung ist allerdings, dass Sie den Confounder in der Studie gemessen haben.
Auch Nichtwissenschaftler werden mit Confounding konfrontiert: »Wahrscheinlich bin ich gegen Leder allergisch, denn jedes Mal, wenn ich mit angezogenen Schuhen ins Bett gehe, wache ich am nächsten Morgen mit Kopfschmerzen auf«, so die Äußerung eines Komikers. In dieser Anekdote ist Alkoholkonsum der Confounder. Er ist sowohl mit der Exposition (Tragen von Schuhen im Bett) als auch mit dem Outcome (Kopfschmerz) assoziiert. Der Outcome verschwindet auch nicht, wenn Sie nach einer durchzechten Nacht die Schuhe ablegen, bevor Sie schlafen gehen.
Nehmen Sie zwei Aspirin und trinken Sie ein großes Glas Wasser dazu, bevor Sie mit Schuhen ins Bett gehen. Das vermindert die Folgen der »Lederallergie« am nächsten Morgen.
Zwischenstufen sind keine Confounder
Von zu vielen durchzechten Nächten mit Hochprozentigem raten wir Ihnen allerdings nachdrücklich ab. Sonst teilt Ihnen Ihr Zahnarzt vielleicht eines Tages mit, dass er in Ihrem Mund eine weiße Verdickung entdeckt hat, eine sogenannte Leukoplakie (Weißschwiele). Das ist die Vorstufe einer Krebserkrankung des Mundes (Mundhöhlenkarzinom).
Die Exposition »Alkoholkonsum« ist mit dem Outcome Mundhöhlenkarzinom assoziiert. Aber was ist mit der Leukoplakie? Sie ist ebenfalls ein Risikofaktor für ein Mundhöhlenkarzinom, und zudem mit der Exposition »Alkoholkonsum« assoziiert. Ist die Leukoplakie also ein Confounder?
Nein. Eine Leukoplakie ist kein Confounder für die Assoziation zwischen Alkoholkonsum und Mundhöhlenkarzinom, sondern eine Zwischenstufe. Das zeigt Ihnen Abbildung 15.2. Epidemiologen nennen solche Zwischenstufen »Intermediärvariablen«.

Abbildung 15.2: Der Zusammenhang zwischen Alkoholkonsum und Mundhöhlenkarzinom
Eine Exposition ist kein Confounder, wenn sie eine Zwischenstufe in einer Kette ursächlicher Zusammenhänge zwischen der ursprünglich untersuchten Exposition und dem Outcome ist.
Im richtigen Leben ist es nicht immer leicht, Intermediärvariablen von Confoundern zu unterscheiden. Epidemiologen müssen aber möglichst sicherstellen, dass sie Intermediärvariablen in ihren Analysen nicht wie Confounder behandeln. Tun sie es doch, so können sie verzerrte Ergebnisse erhalten.
Effektmodifikation
Dass sich Raucher vielen gesundheitlichen Gefahren aussetzen, wissen Sie bereits. Raucher haben nicht nur ein höheres Risiko für Lungenkrebs als Nichtraucher, sondern auch ein erhöhtes Risiko für Krebserkrankungen im Mund (Mundhöhlenkarzinome). Wie verändert sich das Risiko für diese Erkrankung, wenn die Raucher zusätzlich noch Alkohol trinken?
Tabelle 15.6 zeigt Ihnen Relative Risiken für Krebserkrankungen im Mund in Abhängigkeit von Rauchen und Alkoholkonsum. Vergleichsgruppe (Referenz) sind nicht trinkende Nichtraucher.
Tabelle 15.6: Relatives Risiko für Mundhöhlenkarzinome in Abhängigkeit von Rauchen und Alkoholkonsum
Nichtraucher |
Raucher |
|
Kein Alkoholkonsum |
1,0 (Referenz) |
1,5 |
Alkoholkonsum |
1,2 |
5,7 |
Aus der Tabelle können Sie erkennen: Raucher, die keinen Alkohol trinken, haben ein 1,5-mal so hohes Risiko einer Krebserkrankung in der Mundhöhle wie Nichtraucher, die ebenfalls auf Alkohol verzichten. Bei trinkenden Nichtrauchern ist das Risiko 1,2-mal so hoch. Wirken Alkohol und Rauchen zusammen, steigt das Risiko ungleich stärker an: Im Vergleich zu abstinenten Nichtrauchern haben trinkende Raucher ein 5,7-mal so hohes Risiko für Mundhöhlenkrebs. Die Wirkungen des Rauchens und des Alkoholkonsums verstärken sich gegenseitig. Es liegt eine Effektmodifikation vor (viele Epidemiologen sprechen auch von Interaktion).
Bei einer Effektmodifikation ändert sich die Stärke des Effekts einer Variablen, wenn eine oder mehrere weitere Variablen hinzukommen. Mit anderen Worten: Die Stärke der Assoziation zwischen einer Exposition und einem Outcome ist nicht stabil, sondern verändert sich in Abhängigkeit von einer oder mehreren anderen Expositionen.
Um Effektmodifikationen aufzuspüren, können Sie wie in Tabelle 15.6 stratifizieren. In der Praxis setzen die Epidemiologen meist multivariate Verfahren ein, ähnlich wie zur Kontrolle von Confounding (siehe den Band Weiterführende Statistik für Dummies).
Je nachdem, wie stark der kombinierte Effekt zweier Variablen ausfällt, sprechen Epidemiologen von einem additiven oder einem multiplikativen Modell. Beim additiven Modell entspricht der kombinierte Effekt ungefähr der Summe der Effektmaße (also der Odds Ratios oder der Relativen Risiken). Beim multiplikativen Modell entspricht der kombinierte Effekt (mindestens) ihrem Produkt. Viele Epidemiologen sprechen erst dann von Interaktion, wenn der kombinierte Effekt größer ist als die Summe der Effektmaße nach dem additiven Modell.
Die Untersuchung von Effektmodifikationen hat für Epidemiologen große praktische Bedeutung: Finden sie heraus, dass eine Exposition das Risiko für eine bestimmte Krankheit nicht erhöht, können sie noch lange keine Entwarnung geben. Es könnte nämlich sein, dass sich ein Zusammenhang zwischen Exposition und Outcome nur bei einer bestimmten Untergruppe ihrer Studienbevölkerung zeigt.
Wenn Epidemiologen mögliche Effektmodifikationen zwischen Expositionsvariablen nicht untersuchen, laufen sie Gefahr, einen möglichen Zusammenhang zu übersehen oder falsch zu beurteilen.
Auch aus einem weiteren Grund ist es für Epidemiologen wichtig, Effektmodifikationen zu identifizieren: Stellen sie zum Beispiel fest, dass ein Risikofaktor eine bestimmte Bevölkerungsgruppe besonders stark belastet, können sie sich für gezielte Präventionsprogramme einsetzen.
Jetzt kommt’s ganz dicke: Mehrere Fehler
Oft müssen wir Epidemiologen uns mit mehreren Quälgeistern gleichzeitig herumplagen (nein, wir meinen nicht unsere Kinder, die sind außergewöhnlich wohlerzogen). Was wir meinen: In jeder Studie können mehrere Fehler gleichzeitig auftreten. Wir erläutern an einem ausgedachten Beispiel, woran Sie denken müssen.
Sie möchten untersuchen, ob gestillte Kinder im ersten Lebensjahr häufiger an Durchfall erkranken als Kinder, die nicht gestillt werden. Sie werten dazu bei einem Kinderarzt jeweils 50 Patientenakten von gestillten und von nicht gestillten Kindern aus (dieses Studiendesign nennt sich historische Kohortenstudie, siehe Kapitel 10). Sie finden heraus, dass die Inzidenz der Erkrankung bei gestillten Kindern niedriger ist. Zweifelsfrei ein plausibler Befund, denn viele Studien zeigen, dass gestillte Kinder im Vergleich zu nicht gestillten in den ersten Lebensjahren ein geringeres Infektionsrisiko haben.
Das Relative Risiko, das Sie berechnen, fällt mit 10 allerdings ungewöhnlich hoch aus. Als kritischer Epidemiologe hinterfragen Sie natürlich das Ergebnis. Welche potenziellen Fehlerquellen könnten es verzerrt haben?
- Aufgrund der geringen Fallzahl ist es möglich, dass es in der Gruppe der nicht gestillten Kinder zufallsbedingt mehr Fälle von Magen-Darm-Grippe gab als in der gestillten Gruppe.
- Möglicherweise bringen stillende Mütter ihre Kinder seltener zum Arzt, selbst dann, wenn sie krank sind. Die Patientenakten sind dann bei gestillten Kindern unvollständiger als bei nicht gestillten, wodurch es zu einem Informationsbias kommt.
In beiden Fällen hätten Sie das Risiko des Nichtstillens überschätzt. Aber mal angenommen, beides wäre nicht der Fall: Bedeutet das dann, dass Nichtstillen das Risiko für Durchfall tatsächlich so stark erhöht? Nicht unbedingt, denn wir haben den dritten Übeltäter im Bunde bisher noch außer Acht gelassen:
- Der soziale Status von stillenden Müttern ist im Durchschnitt höher als der von nicht stillenden Müttern. Die Umgebung, in der gestillte Kinder aufwachsen, ist daher hygienischer und die Menschen wohnen weniger dicht beieinander. Mangelnde Hygiene und enges Zusammenleben sind Risikofaktoren für Durchfall. In Ihrer Studie sind sie möglicherweise Confounder für die Assoziation zwischen Durchfall und Stillen.
Das bringt uns direkt zum Thema von Kapitel 16: Wie können wir uns sicher sein, dass eine Exposition, die mit einem Outcome assoziiert ist, auch wirklich dessen Ursache ist?