Kapitel 17
Spielt uns der Zufall einen Streich? Schließende Statistik
IN DIESEM KAPITEL
Die Sache mit der Stichprobe
Von Hypothesen und Signifikanzniveaus
Vertrauen in die Ergebnisse: Konfidenzintervalle
Große oder kleine Stichprobe ziehen?
Was statistische Berechnungen über die Wirklichkeit aussagen
Epidemiologen benötigen statistische Kenntnisse nicht nur, um Daten korrekt darzustellen und zu interpretieren. Bei ihren Studien haben sie häufig ein Problem, das sie nur mithilfe der Statistik lösen können: Sie möchten Aussagen über die ganze Bevölkerung machen, aber dazu nicht jeden einzelnen Menschen befragen oder untersuchen – der dafür notwendige Aufwand wäre schlicht zu groß. Stattdessen ziehen Epidemiologen repräsentative Stichproben aus der Bevölkerung.
Je kleiner eine Stichprobe ist, desto schneller und kostengünstiger können sie die Studie durchführen. Gleichzeitig steigt aber die Gefahr, dass Zufall das Ergebnis beeinflusst. Dann zeigen die Studienergebnisse etwas anderes, als in Wirklichkeit geschieht. Wie Sie mit Stichproben umgehen und wie sicher die Schlussfolgerungen sind, die Sie aus einer Stichprobe ziehen können, erfahren Sie in diesem Kapitel.
Warum wir Sie mit schließender Statistik quälen
Die schließende oder induktive Statistik hilft Ihnen, von einer Stichprobe auf die Bevölkerung zu schließen, aus der die Stichprobe stammt. Wichtigster Aspekt dabei ist abzuschätzen, inwieweit der Zufall einen Einfluss auf die Ergebnisse nimmt.
Von der Stichprobe zur Bevölkerung
Mithilfe der deskriptiven Statistik beschreiben Sie Ihre Stichprobe (Näheres dazu finden Sie in Kapitel 8). Anschließend möchten Sie aus der Stichprobe Rückschlüsse auf die Grundgesamtheit ziehen.
 Die Grundgesamtheit ist die Bevölkerung (oder der Teil einer Bevölkerung, etwa alle Frauen ab 50 Jahren), aus der Sie die Stichprobe ziehen und über die Sie eine Aussage machen möchten.
Die Grundgesamtheit ist die Bevölkerung (oder der Teil einer Bevölkerung, etwa alle Frauen ab 50 Jahren), aus der Sie die Stichprobe ziehen und über die Sie eine Aussage machen möchten.
Das demonstrieren wir Ihnen wieder am Beispiel des Gummibärchenkonsums. Zur Erinnerung: In Kapitel 8 hatten wir uns eine Studie ausgedacht, in der Forscher 1.000 Personen befragt und einen durchschnittlichen Pro-Kopf-Verbrauch von 15 Tüten im Jahr ermittelt hatten. Wie sicher können Sie sein, dass die 15 Tüten den tatsächlichen Pro-Kopf-Verbrauch in der Bevölkerung wiedergeben? Anders gefragt: Wie stark könnte das Ergebnis durch Zufall bei der Stichprobenziehung beeinflusst sein?
Auf den Punkt gebracht – der Punktschätzer
Der Mittelwert des Verbrauchs von Gummibärchen liegt in der Stichprobe bei 15 Tüten. Die 15 Tüten sind eine punktgenau angegebene Schätzung des Verbrauchs in der Bevölkerung (im Gegensatz zur Schätzung eines Intervalls, beispielsweise zwischen 12 und 18 Tüten). Der Punktschätzer macht eine Aussage über den wahren, aber nicht bekannten Wert in der Bevölkerung, aus der Sie die Stichprobe gezogen haben (Statistiker nennen diese Bevölkerung auch Grundgesamtheit).
Eines der Ergebnisse, die Sie aus einer Stichprobe berechnen können, heißt Punktschätzer. Damit schätzen Sie den (Ihnen ja nicht bekannten) Wert in der Grundgesamtheit – etwa den Mittelwert oder ein Maß für die Stärke der Assoziation wie die Odds Ratio.
Der Punktschätzer für den Mittelwert in einer Grundgesamtheit schwankt von Stichprobe zu Stichprobe, weil die Ziehung von Stichproben vom Zufall beeinflusst ist. An einer Stichprobenziehung von Gummibärchen aus einer Schale demonstrieren wir Ihnen die Rolle des Zufalls:
- Wenn Sie zwei Stichproben ziehen, sind diese im Allgemeinen nicht gleich.
- Die gezogenen Stichproben weichen mehr oder weniger stark von der Grundgesamtheit ab.
Wir laden Sie zu einem kleinen Experiment ein: Geben Sie 50 rote und 50 weiße Gummibärchen in eine Schale und mischen Sie sie gut. Vergessen Sie nun für die Dauer des Versuchs, dass Sie die genaue Zahl der roten und weißen Bärchen kennen. Wenn Sie als Forscher eine Studie durchführen, dann deshalb, weil Sie die Verhältnisse in der Grundgesamtheit nicht kennen.
Nun nehmen Sie mit geschlossenen Augen (mogeln gilt nicht) zehn Bärchen aus der Schale und legen sie auf den Tisch. Das ist eine Zufallsstichprobe. Sie sollte die Anteile von roten und weißen Gummibärchen in der Schale widerspiegeln. Sie notieren sich die Anzahl der roten und weißen Bärchen. Nun legen Sie die Bärchen in die Schale zurück, ziehen erneut zehn Bärchen und notieren das Ergebnis. Wiederholen Sie den Versuch noch ein paar Mal.
Wenn die Stichprobe stets die tatsächlichen Verhältnisse in der Schale wiedergeben würde, müssten eigentlich jedes Mal fünf rote und fünf weiße Bärchen vor Ihnen liegen. Das ist aber nicht bei jedem Ihrer Versuche der Fall. Einmal befinden sich unter den zehn entnommenen Gummibärchen sechs oder sogar acht rote Exemplare, ein anderes Mal nur drei oder vier.
Die Variationen (die Unterschiede), die sich bei der Anzahl der roten Bärchen ergeben (und damit natürlich auch bei den weißen), haben Sie nicht systematisch beeinflusst, sie sind vielmehr zufällig zustande gekommen. Statistiker und Epidemiologen bezeichnen dies als »sampling variation«. Genauso kann der mithilfe einer Stichprobe geschätzte Wert in einer epidemiologischen Studie vom tatsächlichen Wert in der Bevölkerung abweichen.
 Während der Versuche hat einer der Autoren immer nur die roten Gummibärchen zurückgelegt und die weißen aufgegessen. Das verändert zwar ebenfalls die Ergebnisse der Stichprobenziehungen, hat aber nichts mit Zufall zu tun.
Während der Versuche hat einer der Autoren immer nur die roten Gummibärchen zurückgelegt und die weißen aufgegessen. Das verändert zwar ebenfalls die Ergebnisse der Stichprobenziehungen, hat aber nichts mit Zufall zu tun.
Präzision von Schätzungen
Je größer Sie Ihre Stichprobe wählen, desto präziser ist die Schätzung über das Vorkommen einer Eigenschaft in der gesamten Bevölkerung. Je kleiner die Stichprobe, desto größer die Wahrscheinlichkeit, dass das Ergebnis durch Zufall beeinflusst ist.
Sie machen weitere Versuche mit den 50 roten und 50 weißen Gummibärchen. Bei einer Versuchsreihe ziehen Sie mehrmals jeweils sechs Bärchen aus der Schale. In einer anderen Versuchsreihe entnehmen Sie stattdessen jedes Mal 40 Bärchen. Es leuchtet unmittelbar ein, dass Sie mit der Stichprobe von sechs Gummibärchen das Verhältnis von roten und weißen Gummibärchen schlechter treffen als mit der Stichprobe von 40 Bärchen.
 Die erforderliche Größe der Stichprobe ist unabhängig von der Größe der Grundgesamtheit. Wovon die erforderliche Größe einer Stichprobe abhängt, erfahren Sie weiter hinten in diesem Kapitel.
Die erforderliche Größe der Stichprobe ist unabhängig von der Größe der Grundgesamtheit. Wovon die erforderliche Größe einer Stichprobe abhängt, erfahren Sie weiter hinten in diesem Kapitel.
Zufall oder doch nicht? Statistisches Testen
In einer deutschen Großstadt (falsch geraten, es handelt sich diesmal nicht um Bielefeld) steht die Stichwahl für das Bürgermeisteramt bevor. Bei den Kandidaten handelt es sich um Erna Edel und Fritz Fies. Frau Edel will mehr Kindergartenplätze einrichten (gähn, unsere Kinder sind schon groß), Herr Fies eine schicke Autobahn auf Stelzen durch die Innenstadt bauen. Dann kommen die Käufer schneller in die Geschäfte und die Wirtschaft brummt.
Wenn Sie zukünftig sonntagnachmittags die Balkontür öffnen, brummen allerdings die eleganten Limousinen direkt vor Ihrer Nase vorbei. Sie können sich das nicht vorstellen? Wir laden Sie zum Probewohnen nach Bielefeld ein. Wir haben nämlich schon eine Autobahn auf Stelzen in der Stadt.
 Falls Ihnen Bielefeld zu provinziell erscheint, besuchen Sie Kobe oder Osaka, zwei Großstädte in Japan. Dort führen die Autobahnen sogar auf mehreren Etagen durch die Städte – der Ausblick von dort oben ist eindrucksvoll.
Falls Ihnen Bielefeld zu provinziell erscheint, besuchen Sie Kobe oder Osaka, zwei Großstädte in Japan. Dort führen die Autobahnen sogar auf mehreren Etagen durch die Städte – der Ausblick von dort oben ist eindrucksvoll.
Bleiben oder fortziehen, das ist jetzt die Frage. Passenderweise hat ein Meinungsforschungsinstitut einer Stichprobe der wahlberechtigten Bevölkerung die sogenannte Sonntagsfrage gestellt: »Wen würden Sie wählen, wenn am Sonntag Stichwahl für das Bürgermeisteramt wäre?« Sie interessieren sich brennend für das Ergebnis. Lieber auswandern als die fiese Autobahn vor dem Wohnzimmerfenster. 48,5 Prozent der Befragten geben an, dass sie Frau Edel wählen würden, und 51,5 Prozent Herrn Fies.
Schlechte Nachrichten. Aber bevor Sie Ihre Umzugsentscheidung treffen, müssen Sie noch eines klären: Beruht der Unterschied von 3 Prozentpunkten auf Zufall bei der Stichprobenziehung oder handelt es sich um einen wirklichen Unterschied? Um das einschätzen zu können, müssen Sie statistisch denken und dabei einen kleinen Umweg über die Nullhypothese machen.
Nullhypothese: In Wirklichkeit kein Unterschied
Zunächst müssen Sie zwei Hypothesen formulieren, in denen Sie gegenteilige Annahmen treffen (das machen Sie bei jeder analytischen epidemiologischen Untersuchung so). Statistiker bezeichnen sie als Nullhypothese und Alternativhypothese:
- Die Nullhypothese, abgekürzt als H0, lautet in der Regel, dass in der Bevölkerung, aus der die Stichprobe stammt, kein wirklicher Unterschied zwischen den untersuchten Gruppen besteht (allgemeiner formuliert: es liegt kein Effekt vor).
- Die Alternativhypothese, abgekürzt HA oder H1, unterstellt dann einen wirklichen Unterschied zwischen den untersuchten Gruppen. Die Alternativhypothese ist Ihre Arbeitshypothese, denn sie beschreibt die Annahme, für die Sie sich interessieren.
Sie formulieren als Nullhypothese: Es werden am Sonntag gleich viele Wähler Frau Edel und Herrn Fies wählen. Als Alternativhypothese formulieren Sie: Es werden am Sonntag unterschiedlich viele Wähler Frau Edel oder Herrn Fies wählen.
Die Studie, mit der Sie Ihre Hypothese prüfen, hat das Meinungsforschungsinstitut ja schon durchgeführt. Jetzt geht es ans statistische Testen. Ein passender statistischer Test ermöglicht es Ihnen herauszufinden, wie wahrscheinlich es ist, einen Unterschied von (in unserem Beispiel) mindestens 3 Prozent zu messen, wenn in Wirklichkeit gar kein Unterschied besteht – wenn also die Nullhypothese zutrifft. Als Ergebnis des Tests erhalten Sie den sogenannten p-Wert.
Sie sollten statistische Tests nicht mit diagnostischen Test verwechseln, wie sie in der Medizin vorkommen. Epidemiologen nennen letztere auch Schnelltests. Näheres darüber erfahren Sie in Kapitel 22.
Der p-Wert – je größer, desto Zufall
Der p-Wert gibt Ihnen an, mit welcher Wahrscheinlichkeit Sie den in der Stichprobe gefundenen Unterschied oder einen extremeren Unterschied messen würden, wenn in der Bevölkerung kein wirklicher Unterschied vorhanden wäre, wenn also die Nullhypothese zutrifft. Ist diese Wahrscheinlichkeit klein, interpretieren Sie das als Beleg, dass die Alternativhypothese zutreffen könnte.
Wir erläutern das an einem Beispiel aus dem epidemiologischen Alltag. Uns interessiert, ob in Deutschland lebende Ausländer häufiger oder seltener zum Arzt gehen als Deutsche. Wir untersuchen das mit Befragungsdaten aus dem Sozio-oekonomischen Panel, einer regelmäßigen Haushaltsbefragung. In Tabelle 17.1 haben wir die durchschnittliche Zahl der Arztbesuche von Deutschen und Ausländern in den letzten drei Wochen vor dem Befragungszeitpunkt im Jahre 2006 aufgelistet, stratifiziert nach Alter und Geschlecht.
Tabelle 17.1: Durchschnittliche Zahl der Arztbesuche in den letzten drei Wochen vor der Befragung, nach Alter und Geschlecht, Deutsche und Ausländer, 2006
Durchschnittliche Zahl der Arztbesuche |
|||||
Alter (Jahre) |
Geschlecht |
Deutsche |
Ausländer |
Differenz der Zahl der Arztbesuche |
p-Wert |
18 – 39 |
weiblich |
2,13 |
2,21 |
-0,08 |
0,637 |
männlich |
1,31 |
1,07 |
-0,24 |
0,155 |
|
40 – 59 |
weiblich |
2,43 |
3,29 |
-0,86 |
0,005 |
männlich |
1,94 |
2,16 |
-0,22 |
0,367 |
|
60+ |
weiblich |
3,59 |
4,13 |
-0,54 |
0,173 |
männlich |
3,21 |
3,25 |
-0,03 |
0,923 |
|
Die Unterschiede in der Zahl der Arztbesuche zwischen Deutschen und Ausländern sind gering. Einzig zwischen den 40- bis 59-jährigen Frauen besteht ein deutlicher Unterschied von 0,86 Arztbesuchen (also fast einem) innerhalb der letzten drei Wochen vor der Befragung. Die Interpretation des zugehörigen p-Wertes lautet:
- Die Wahrscheinlichkeit beträgt lediglich 0,005 (0,5 Prozent), diesen Unterschied (oder einen noch größeren) in der Stichprobe zu messen, wenn in Wirklichkeit gar kein Unterschied zwischen deutschen und ausländischen Frauen von 40 bis 59 Jahren besteht.
- Anders gesagt: Sie können ziemlich sicher sein, dass der beobachtete Unterschied nicht allein auf Zufallseinflüssen bei der Stichprobenziehung beruht. Sie haben einen Beleg dafür erhalten, dass deutsche Frauen dieser Altersgruppe tatsächlich seltener zum Arzt gehen als ausländische Frauen. (Das ist zwar statistisch nicht ganz korrekt formuliert, aber leichter verständlich).
Die Zahl der Arztbesuche von 18- bis 39-jährigen ausländischen Frauen unterscheidet sich kaum von der Zahl der Besuche deutscher Frauen gleichen Alters. Der dazugehörige p-Wert ist 0,637. Interpretation:
- Die Wahrscheinlichkeit beträgt 0,637 oder 63,7 Prozent, diesen (kleinen!) Unterschied von 0,08 oder einen größeren in der Stichprobe zu messen, wenn in Wirklichkeit gar kein Unterschied zwischen deutschen und ausländischen Frauen im Alter von 18 bis 39 Jahren besteht.
- Wenn Sie in 100 Bevölkerungsstichproben, in denen es zwischen Deutschen und Ausländern keinen Unterschied gibt, dieselbe Frage zu den Arztbesuchen stellen, würden Sie rund 64-mal einen Unterschied von 0,08 Arztbesuchen oder mehr finden.
- Hier können Sie ziemlich sicher sein, dass der beobachtete Unterschied lediglich auf Zufallseinflüssen bei der Stichprobenziehung beruht (das ist wiederum statistisch nicht ganz korrekt formuliert, aber leichter verständlich).
Den p-Wert berechnen Sie mit einem geeigneten Signifikanztest: Für kategorische Variablen, wie im Beispiel der Bürgermeisterwahl, verwenden Sie den Chi-Quadrat-Test (X2-Test), für den Vergleich von Mittelwerten bei kontinuierlichen Variablen dagegen den t-Test. Falls Ihr Computer das nicht für Sie erledigt, werfen Sie doch einen Blick in das Buch Statistik für Dummies.
Signifikanzniveau – dem Zufall eine Grenze setzen
Das Signifikanzniveau ist eine von den Statistikern recht willkürlich als Grenze festgelegte Wahrscheinlichkeit (die auch als Irrtumswahrscheinlichkeit bezeichnet wird), in der Regel von 5 Prozent. Anhand dieser Grenze treffen Sie die Entscheidung, ob Sie die Nullhypothese zurückweisen oder nicht. Bei einem Signifikanzniveau von 5 Prozent
- weisen Sie die Nullhypothese zurück, wenn der p-Wert 0,05 beziehungsweise 5 Prozent nicht überschreitet. Auf gut Statistisch können Sie dann sagen: Das Ergebnis ist statistisch signifikant.
- können Sie die Nullhypothese nicht zurückweisen, wenn der p-Wert größer als 0,05 beziehungsweise 5 Prozent ist. Das Ergebnis gilt dann als statistisch nicht signifikant.
Zurück zu den Bürgermeisterwahlen: Sie besorgen sich vom Meinungsforschungsinstitut Informationen über die Größe der befragten Stichprobe. Dann füttern Sie alle Daten in Ihren Computer und führen den passenden Signifikanztest durch (in diesem Fall einen Chi-Quadrat-Test). Da das Meinungsforschungsinstitut sehr viele Wahlberechtigte befragt hatte, vermeldet Ihr Computer: Der beobachtete Unterschied von 3 Prozentpunkten in den abgegebenen Stimmen für Frau Edel und Herrn Fies ist statistisch signifikant. Der p-Wert ist kleiner als 0,05.
Sie können also die Nullhypothese (kein Unterschied im Stimmenanteil der beiden Kandidaten) zurückweisen und mit der Wohnungssuche in einer anderen Stadt beginnen. Denn die Wahrscheinlichkeit, einen so großen Unterschied zu messen, wenn in Wirklichkeit gar keiner besteht, ist kleiner als 5 Prozent.
Bedenken Sie, dass die Wahl trotzdem einen anderen Ausgang als den durch die Sonntagsfrage vorhergesagten nehmen kann: Die Wähler überlegen es sich vielleicht noch anders (dafür gibt es keine statistischen Tests). Zudem besteht immer noch eine geringe Wahrscheinlichkeit (die genau dem p-Wert entspricht), dass der Unterschied im Umfrageergebnis doch nur auf Zufall beruht.
Das Signifikanzniveau von 5 Prozent ist nichts Unumstößliches, sondern basiert auf einer Vereinbarung unter Statistikern. Manchmal verwenden sie ein anderes Signifikanzniveau, beispielsweise 1 Prozent.
p-Wert und Nullhypothese – eine enge Beziehung
Liegt der p-Wert oberhalb des Signifikanzniveaus von 5 Prozent, ist er also größer als 0,05, können Sie die Nullhypothese nicht ablehnen: Es ist also möglich, dass kein wirklicher Unterschied zwischen den Gruppen in der Grundgesamtheit besteht. Statistiker sagen dann: Die Nullhypothese kann nicht zurückgewiesen werden. Das Ergebnis ist statistisch nicht signifikant. Das bedeutet aber nicht, dass die Nullhypothese notwendigerweise richtig ist. Wir können lediglich keinen Unterschied nachweisen.
Liegt der p-Wert unterhalb des Signifikanzniveaus, ist er also kleiner oder gleich 0,05, spricht dies gegen die Nullhypothese. Sie weisen die Nullhypothese zurück und nehmen die Alternativhypothese an.
Es ist im wissenschaftlichen Denken grundsätzlich nicht möglich, eine Hypothese zu beweisen – Sie können eine Hypothese lediglich widerlegen. Mit anderen Worten: Wenn der p-Wert kleiner oder gleich 0,05 ist, akzeptieren Sie die Alternativhypothese als die wahrscheinlichere der beiden Hypothesen. Sie haben ihre Richtigkeit damit aber nicht bewiesen.
Ein statistisch signifikantes Ergebnis muss kein bedeutsames Ergebnis sein. Unglücklicherweise wird das Wort »signifikant« auch in der Umgangssprache im Sinne von »bedeutsam, wesentlich« verwendet. Ein statistisch signifikantes Ergebnis sagt nichts über die tatsächliche Größe des Unterschieds (allgemeiner: die Größe des Effekts) aus. Die Relevanz, das heißt der praktische Nutzen, den Sie aus einem solchen Ergebnis ziehen, kann daher gering sein.
Konfidenzintervalle – der Bereich Ihres Vertrauens
Sie haben eine weitere Möglichkeit, den Einfluss des Zufalls bei der Stichprobenziehung deutlich zu machen, indem Sie das zum Punktschätzer gehörige Konfidenzintervall berechnen. Konfidenz heißt Vertrauen. Das Konfidenzintervall beschreibt die Präzision Ihrer Schätzung, die Sie auf Basis der Stichprobe durchgeführt haben. Der Vorteil eines Konfidenzintervalls ist, dass es den sogenannten Vertrauensbereich auf derselben Skala abbildet wie den Schätzwert, beispielsweise bei Wahlumfragen den Anteil der Wähler eines Kandidaten in Prozent.
Während Sie mit dem p-Wert die statistische Unsicherheit durch den Einfluss von Zufall bei der Stichprobenziehung beschreiben, grenzen Sie mit dem Konfidenzintervall den Vertrauensbereich ein, der mit einer festgelegten Wahrscheinlichkeit die Lage des tatsächlichen Wertes in der Bevölkerung einschließt.
Das 95 %-Konfidenzintervall enthält mit einer Wahrscheinlichkeit von 95 Prozent den wahren (aber nicht bekannten) Wert in der Bevölkerung, aus der die Stichprobe stammt (Grundgesamtheit). Mit einer Wahrscheinlichkeit von 5 Prozent liegt der wahre Wert außerhalb dieses Bereichs.
Sie können vom Konfidenzintervall grob orientierend auf die statistische Signifikanz schließen, aber nicht den präzisen p-Wert ableiten. Nehmen wir an, Sie haben mithilfe Ihres Computers das 95 %-Konfidenzintervall für den Punktschätzer für Frau Edels Wahlergebnis (48,5 Prozent) mit 47,5 Prozent bis 49,5 Prozent bestimmt (wie eng oder weit das Intervall ist, hängt von der Stichprobengröße ab; mehr dazu weiter hinten in diesem Kapitel). Das Konfidenzintervall überschneidet sich nicht mit dem Intervall für Herrn Fies (50,5 Prozent bis 52,5 Prozent), der bei 51,5 Prozent der Stimmen liegt. Der Unterschied der Punktschätzer ist – das hatten Sie bereits ermittelt – statistisch signifikant.
Wenn sich die Konfidenzintervalle zweier Punktschätzer überschneiden, ist der Unterschied zwischen den Schätzern meist nicht statistisch signifikant.
Auch für Maße der Assoziation wie das Relative Risiko und die Odds Ratio können Sie Konfidenzintervalle berechnen. Wenn das 95 %-Konfidenzintervall um den Punktschätzer eines Relativen Risikos den Wert 1 (also den Nulleffekt) nicht einschließt, ist dies ein statistisch signifikantes Ergebnis. Den genauen p-Wert können Sie aus dem Intervall nicht ableiten. Sie müssen ihn mithilfe eines Statistikprogramms berechnen. Die meisten aktuellen Programme geben sowohl das Konfidenzintervall als auch den p-Wert an – in unseren Augen die beste Lösung.
Je enger das Konfidenzintervall, desto präziser ist die Schätzung.
Wenn das 95 %-Konfidenzintervall den Nulleffekt (Odds Ratio = 1,0) einschließt, ist der p-Wert größer als 0,05 oder 5 Prozent. Ihr Ergebnis ist dann statistisch nicht signifikant. Das beweist aber nicht, dass kein Effekt vorliegt – achten Sie darauf, dass Ihnen kein TypII-Fehler unterläuft.
Fehlertypen: Falscher Alarm oder Aufdeckung verpasst
Wenn Sie aufgrund Ihrer Stichprobenergebnisse die Nullhypothese ablehnen, obwohl sie in Wirklichkeit zutrifft, sprechen Statistiker von einem Fehler erster Art (Typ-I-Fehler oder ß-Fehler). Deborah Rumsey bezeichnet dies in dem Buch Statistik für Dummies als »falschen Alarm schlagen«.
Wenn Sie die Nullhypothese nicht ablehnen, obwohl sie in Wirklichkeit falsch ist, ist dies ein Fehler zweiter Art (Typ-II-Fehler oder ß-Fehler). Sie haben, mit Deborah Rumseys Worten, »die Aufdeckung verpasst«.
Eine Übersicht der Fehlertypen finden Sie in Tabelle 17.2.
Tabelle 17.2: Fehler erster Art (α-Fehler) und Fehler zweiter Art (β-Fehler)
In der Grundgesamtheit besteht in Wirklichkeit … |
|||
kein Unterschied |
ein tatsächlicher Unterschied |
||
Sie entscheiden sich auf Basis der Stichprobe für die … |
Nullhypothese (die keinen Unterschied annimmt) |
Kein Unterschied: richtige Entscheidung |
Tatsächlichen Unterschied fälschlich nicht erkannt: Aufdeckung verpasst Fehler zweiter Art) |
Alternativhypothese (die einen Unterschied annimmt) |
Unterschied besteht nicht wirklich: falscher Alarm (Fehler erster Art) |
Tatsächlichen Unterschied erkannt: richtige Entscheidung |
|
Power – die Macht eines statistischen Tests
Die statistische Power (Teststärke) beschreibt die Güte eines Tests. Sie macht eine Aussage über die Wahrscheinlichkeit, mit der ein Signifikanztest für die Alternativhypothese (»Da ist doch was!«) spricht, falls die Alternativhypothese richtig ist. Die Power ist abhängig von drei Größen:
- Stichprobengröße: Je größer Ihre Stichprobe ist, desto höher wird die Power. Auf die erforderliche Größe einer Studie gehen wir auf den nächsten Seiten näher ein.
- Effekt: Je größer der angenommene Effekt ist, also je weiter entfernt die Alternativhypothese vom Nulleffekt ist, desto höher ist die Power. Das können Sie auch anders herum und mithilfe eines Beispiels formulieren: Die Wahrscheinlichkeit, einen vorhandenen Effekt mit einer Odds Ratio von 1,2 zu übersehen, ist größer, als einen Effekt mit einer Odds Ratio von 2,5 zu übersehen.
- Signifikanzniveau: Je kleiner das gewählte Signifikanzniveau ist, das heißt, je geringer Sie die Wahrscheinlichkeit für einen falschen Alarm halten wollen, desto geringer wird die Power eines Tests. Das Signifikanzniveau belassen Sie aber in der Regel unverändert bei 5 Prozent.
Während Sie mit dem Signifikanzniveau den Fehler erster Art festlegen, nutzen Sie die Power, um den Fehler zweiter Art zu kontrollieren. Epidemiologen wählen ihre Stichprobengröße gerne so, dass die Power des Tests bei 80 Prozent liegt (das ist wieder einmal eine Vereinbarung).
Hinter der Powerberechnung steht ein kompliziertes Konzept, da jede der drei Größen wechselseitig die Power beeinflusst. Alle, die mehr dazu wissen wollen, verweisen wir daher auf die einschlägigen Statistiklehrbücher.
Wie groß muss eine Studie sein?
Auf die Frage, wie groß eine Studie sein muss, gibt es keine pauschale Antwort. Die Genauigkeit der Ergebnisse wird durch die Größe Ihrer Stichprobe (mit-)bestimmt. Je größer die Stichprobe ist, desto geringer wird der Einfluss des Zufalls. Die Streuung der Ergebnisse wird kleiner, die Power der Studie steigt (genau genommen steigt die Power der statistischen Tests, die Sie in Ihrer Studie durchführen). Allerdings werden Sie schon aus Kostengründen keine Stichprobe ziehen, die wesentlich größer ist als erforderlich.
Nehmen Sie an, Sie möchten das Risiko eines Gehirntumors in zwei Gruppen vergleichen: unter Menschen, die ihr Handy intensiv nutzen, im Vergleich zu Menschen, die es nur selten nutzen. Sie müssen sich Gedanken darüber machen, welchen Unterschied in den Chancen, einen Gehirntumor zu bekommen, Sie als relevant ansehen. Ist erst eine zweifache Chance oder schon eine 1,2-fache Chance ein wichtiger Unterschied? Je kleiner der Unterschied ist, den Sie als relevant ansehen und daher aufdecken wollen (etwa beim Gehirntumorrisiko), desto größer muss Ihre Stichprobe sein.
Sie benötigen auch dann eine große Stichprobe, wenn der Anteil der Gesunden oder derjenigen ohne Risikofaktor in der Bevölkerung sehr klein ist und nur aus wenigen Personen besteht. Ist eine der zwei Teilstichproben sehr klein, steigt der Einfluss des Zufalls.
In Studien mit großen Stichproben können Unterschiede statistisch signifikant werden, die keinerlei praktische oder klinische Bedeutung haben. Beispiel: Wenn der durchschnittliche systolische Blutdruckwert (das ist der höhere der beiden Blutdruckwerte) in der Referenzgruppe bei 134 mm Hg liegt und in der Interventionsgruppe bei 133 mm Hg, so kann der Unterschied bei einer großen Stichprobe statistisch signifikant sein. Eine klinische Relevanz ist dem Unterschied aber nicht beizumessen.
Umgekehrt können bei zu kleiner Stichprobe bedeutsame Unterschiede statistisch nicht signifikant werden. Sie müssen daher vor jeder (epidemiologischen) Untersuchung die erforderliche Stichprobengröße berechnen.
In Tabelle 17.3 zeigen wir Ihnen exemplarisch die erforderliche Stichprobengröße je Gruppe für eine Fall-Kontroll-Studie. Das Verhältnis von Fällen und Kontrollen setzen Sie auf 1 zu 1 fest (mehr dazu finden Sie in Kapitel 11).
Tabelle 17.3: Erforderliche Stichprobengröße je Gruppe für eine Fall-Kontroll-Studie mit 1:1-Matching und einem Signifikanzniveau von 5 Prozent sowie einer Power von 80 Prozent
Prävalenz der Exposition bei den Kontrollen |
Stärke der Assoziation, die Sie für Ihre Studie als relevant ansehen (Odds Ratio) |
|||
3,0 |
2,0 |
1,5 |
1,2 |
|
50 % |
50 |
110 |
311 |
1.521 |
30 % |
55 |
113 |
340 |
1.745 |
10 % |
80 |
227 |
731 |
3.923 |
Dazu ein Beispiel: Sie möchten die Stichprobengröße für eine geplante Fall-Kontroll-Studie zu intensiver Handynutzung (50 und mehr Telefonate pro Woche gegenüber 5 und weniger) und Gehirntumoren bestimmen. Sie möchten eine 20 Prozent höhere Chance unter den Exponierten (entsprechend einer Odds Ratio von 1,2) aufdecken können, wenn sie denn besteht. Und Sie wissen, dass rund 30 Prozent der Personen in der tumorfreien Kontrollgruppe das Handy intensiv nutzen (das ist die Prävalenz der Exposition).
Das Signifikanzniveau legen Sie wie üblich auf 5 Prozent fest, die Power auf 80 Prozent. Das bedeutet, dass Sie mit einer Power (Wahrscheinlichkeit) von 80 Prozent bei einer Odds Ratio von 1,2 oder höher die richtige Entscheidung (»Da ist doch was!«) treffen, wenn es in der Grundgesamtheit tatsächlich einen Unterschied gibt.
Die entsprechenden Zahlen geben Sie in ein Computerprogramm zur Fallzahlkalkulation ein. Als Ergebnis erhalten Sie die in Tabelle 17.3 genannte Stichprobengröße. Die dort angegebenen Zahlen müssen Sie verdoppeln. Bei einer Prävalenz von 30 Prozent und einer Odds Ratio von 1,2 benötigen Sie 1.745 Fälle und 1.745 Kontrollen, also 3.490 Personen. Das ist eine gewaltige Studie!
Es gibt viele kostenlose und kommerzielle Programme zur Stichprobenkalkulation. Auch die gängigen Statistiksoftwarepakete enthalten Module zur Stichprobenberechnung. In jedem Fall sollten Sie aber einen Statistiker zurate ziehen.
Statistische Modelle und die Wirklichkeit
Die Aussagekraft statistischer Berechnungen (Statistiker nennen sie lieber »Modelle«) über die Wirklichkeit ist begrenzt. Statistische Modelle bilden in der Regel nur einen Ausschnitt aus der Wirklichkeit ab. Sie sind notwendige Vereinfachungen unserer komplizierten Welt. Statistische Modelle sind »reduktionistisch« (beschränkend), sie können nicht alle Faktoren berücksichtigen, die einen Einfluss auf das Ergebnis haben. Mit anderen Worten: Die Ergebnisse hängen stark von den Annahmen ab, die Statistiker bei den Berechnungen machen müssen. Das sollten Sie in Rechnung stellen, wenn Sie die Ergebnisse statistischer Modellierungen interpretieren.
Die Gefahr von Vereinfachungen ist, dass Sie falsche Schlussfolgerungen aus einem Modell ziehen. Eine Exposition kann in Wirklichkeit einen höheren oder einen geringeren Einfluss auf den Outcome haben. Oder Sie haben eine wichtige Exposition in Ihrem Modell gar nicht berücksichtigt.
Beispiel: Bluthochdruck und Herzinfarkt
Wenn Sie nur den Einfluss von Bluthochdruck auf das Herzinfarktgeschehen untersuchen, werden Sie ein anderes Bild vom Einfluss des Hochdrucks bekommen, als wenn Sie weitere Faktoren hinzunehmen. Warum das so ist, erklären wir Ihnen in Kapitel 15 unter »Confounding«.
Ein Beispiel finden Sie in Tabelle 17.4. Dort ist nur der Blutdruck als Risikofaktor eines Herzinfarkts bei 40- bis 59-jährigen Männern und Frauen berücksichtigt. Die Odds Ratio liegt bei 2,4. Die Chance, einen Herzinfarkt zu erleiden, ist für Bluthochdruckpatienten demnach fast zweieinhalbmal so hoch wie für Menschen mit normalem Blutdruck.
Tabelle 17.4: Bluthochdruck und Herzinfarktrisiko
Odds Ratio |
95 %-Konfidenzintervall |
p-Wert |
|
Bluthochdruck (Referenz: normaler Blutdruck) |
2,4 |
2,0 – 2,8 |
<0,001 |
Blättern Sie nun ein paar Seiten weiter. Im Abschnitt »Mehrere mögliche Risikofaktoren: Was tun?« haben wir Tabelle 17.4 um die Faktoren »Alter« und »Geschlecht« erweitert – zwei weitere Expositionen, die Einfluss auf das Herzinfarktrisiko haben. Wenn Sie diese zusätzlichen Expositionen in Ihr statistisches Modell aufnehmen, beträgt die Chance eines Herzinfarkts bei Bluthochdruck nur noch 1,4.
Beispiel: Übergewicht und Sterblichkeit
In der Presse finden Sie immer wieder Meldungen über die Zunahme von Übergewicht in der Bevölkerung und die gesundheitlichen Folgen. Zudem, so behaupten die Nachrichten, haben Übergewichtige ein erhöhtes Sterblichkeitsrisiko. Eine solche Behauptung enthält unausgesprochen ein einfaches statistisches Modell: Je höher das Gewicht, desto größer das Risiko, vorzeitig zu sterben. Das Modell beruht auf der Annahme, dass ein geradliniger (linearer) Zusammenhang zwischen Körpergewicht und Sterblichkeit besteht.
Aber eine solche Vereinfachung ist problematisch, denn hier werden alle Übergewichtigen als eine Gruppe angesehen. Zunächst sollten Sie die Exposition (Körpergewicht) genauer beschreiben. Dazu verwenden Sie den Body-Mass-Index.
Der Body-Mass-Index (BMI) ist das Körpergewicht in Kilogramm dividiert durch die Körpergröße in Metern zum Quadrat (BMI = kg/m2).
Nun bilden Sie Kategorien nach dem Body-Mass-Index (BMI):
- untergewichtig: weniger als 18,5 kg/m2
- normalgewichtig: zwischen 18,5 und weniger als 25 kg/m2
- übergewichtig: zwischen 25 und weniger als 30 kg/m2
- adipös (fettsüchtig): 30 kg/m2 und mehr
Wenn Sie die Übergewichtigen nach übergewichtigen und adipösen (fettleibigen) Menschen gruppieren und neben den Normalgewichtigen auch Untergewichtige in die Betrachtung einbeziehen, erhalten Sie ein anderes Bild:
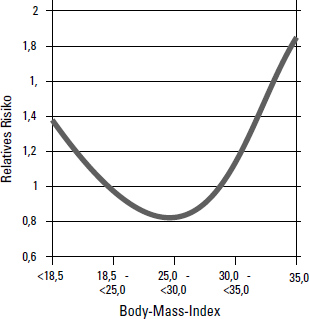
Epidemiologische Studien zeigen, dass Übergewichtige kein höheres, möglicherweise sogar ein geringeres Sterblichkeitsrisiko als Normalgewichtige haben. Erst für adipöse Menschen besteht ein erhöhtes Sterblichkeitsrisiko. Aber auch Untergewicht ist mit einem höheren Sterblichkeitsrisiko verbunden. In Abbildung 16.1 sehen Sie diese sogenannte J-förmige Abhängigkeit des Sterblichkeitsrisikos vom Body-Mass-Index.
Das ursprüngliche Modell einer direkten (linearen) Abhängigkeit von Körpergewicht und Sterblichkeit gibt ein viel zu stark vereinfachtes – und daher nicht zutreffendes – Abbild der Wirklichkeit. Wenn Sie die Sterblichkeit in Abhängigkeit vom Body-Mass-Index untersuchen, können Sie ein verbessertes Modell entwickeln: Es besteht ein J-förmiger Zusammenhang.
Die Wirklichkeit ist noch komplizierter: Der Body-Mass-Index unterscheidet nicht, ob ein zu hohes Körpergewicht durch einen übermäßigen Anteil an Körperfett oder durch große Muskelmasse (Leistungssportler, Bodybuilder) zustande kommt. Er gibt daher nur eine grobe Einschätzung von möglichem Übergewicht.
Mehrere mögliche Risikofaktoren: Was tun?
Im epidemiologischen Alltag haben Sie es selten mit nur einem Risikofaktor zu tun. Entweder ist für chronische Krankheiten schon ein Bündel von Faktoren bekannt und wurde durch viele Studien bestätigt. Oder eine aktuelle Untersuchung hat einen bisher unbekannten Risikofaktor für eine Erkrankung entdeckt, den Sie in einer weiteren Studie prüfen wollen.
Epidemiologen setzen in solchen Fällen sogenannte multivariate statistische Modelle ein. Das sind Verfahren, mit denen sie das Zusammenwirken mehrerer Variablen, zum Beispiel Risikofaktoren einer Erkrankung, gleichzeitig untersuchen. Sie können mit diesen Verfahren herauszufinden, welcher Faktor ein größeres und welcher Faktor ein kleineres Risiko für eine Erkrankung ist oder ob sich ein neu entdeckter Risikofaktor im Rahmen eigener Auswertungen unter Berücksichtigung weiterer Faktoren bestätigen lässt.
Es gibt verschiedene multivariate Verfahren, wie die lineare Regressionsanalyse für kontinuierliche Variablen und die logistische Regression für dichotome Variablen. Mehr Informationen dazu finden Sie im Band Weiterführende Statistik für Dummies.
Bluthochdruck ist ein Risikofaktor für den Herzinfarkt. Eine Hochdruckerkrankung kommt bei älteren Menschen häufiger vor. Aber auch ein Herzinfarkt kommt bei älteren Menschen häufiger vor – auch bei Älteren, die keinen Bluthochdruck haben. Welchen Effekt hat also der Blutdruck und welchen Effekt hat das Alter auf das Herzinfarktgeschehen?
Mit multivariaten Verfahren kontrollieren Sie für diese wechselseitige Beeinflussung (mehr dazu in Kapitel 15 unter Confounding) und beschreiben nur den tatsächlichen Effekt, den ein Risikofaktor auf die Erkrankung hat.
Wenn Sie mehrere Variablen untersuchen und Ihnen das Stratifizieren zu umständlich wird, können Sie stattdessen auf die Methoden der multiplen Regressionsanalysen zurückgreifen. Mehr dazu finden Sie im Band Weiterführende Statistik für Dummies.
Das Ergebnis einer solchen Analyse mit Daten aus der Deutschen Herz-Kreislauf-Präventionsstudie (DHP) zeigen wir in Tabelle 17.5. Der Outcome ist Herzinfarkt (»ja« oder »nein«) bei 40- bis 59-jährigen Männern und Frauen. Die Expositionen sind das Alter, das Geschlecht und der Blutdruck. Die Altersangaben der Teilnehmer haben wir in zwei Altersgruppen (40 bis 49 Jahre, 50 bis 59 Jahre) zusammengefasst und die gemessenen Blutdruckwerte ebenfalls gruppiert (normale Blutdruckwerte, Bluthochdruck). Zusätzlich haben wir das Geschlecht in das Modell aufgenommen.
Die Referenzgruppe ist jeweils in der Tabelle angegeben. Die Odds Ratios geben an, wievielmal so hoch die Chance der Älteren, der Frauen und der Teilnehmer mit Bluthochdruck im Vergleich zur Referenzgruppe ist, einen Herzinfarkt zu erleiden.
Tabelle 17.5: Risikofaktoren des Herzinfarkts, nach Alter, Geschlecht und Blutdruck
Odds Ratio |
95 %-Konfidenzintervall |
p-Wert |
|
Altersgruppe (Referenz: unter 50 Jahre) |
3,6 |
2,6 – 4,9 |
< 0,001 |
Geschlecht (Referenz: Männer) |
0,7 |
0,5 – 0,9 |
0,002 |
Bluthochdruck (Referenz: nein) |
1,4 |
1,1 – 1,8 |
0,016 |
Der Effekt von höherem gegenüber niedrigerem Alter ist deutlich (Odds Ratio = 3,6). Da das 95 %-Konfidenzintervall den Nulleffekt (Odds Ratio = 1) nicht einschließt, ist der Effekt mit einem Signifikanzniveau von 5 Prozent statistisch signifikant. Dies bestätigt auch der p-Wert in der rechten Spalte. Er liegt weit unterhalb des Signifikanzniveaus von 0,05 beziehungsweise 5 Prozent.
Die Ergebnisse zeigen einen schützenden (protektiven) Effekt für Frauen. Ihre Chance, einen Herzinfarkt zu erleiden, liegt beim 0,7-Fachen der Chance von Männern. Der schützende Effekt ist statistisch signifikant. Das können Sie am p-Wert ablesen, der mit 0,002 deutlich kleiner ist als die erforderlichen 0,05 beim festgelegten Signifikanzniveau von 5 Prozent. Zudem geht das Konfidenzintervall von 0,5 bis 0,9 und schließt die 1,0 nicht ein.
Die Chance, einen Herzinfarkt zu erleiden, ist bei Menschen mit Bluthochdruck 1,4-mal so hoch wie bei Menschen mit normalen Blutdruckwerten. Auch beim Bluthochdruck schließt das Konfidenzintervall den Nulleffekt nicht ein, das heißt, Bluthochdruck erhöht das Risiko, einen Herzinfarkt zu erleiden, signifikant.
Vergleichen Sie dieses Ergebnis mit dem aus Tabelle 17.4: Der Effekt des Bluthochdrucks wird deutlich geringer (Odds Ratio 1,4 gegenüber 2,4), wenn Sie in einem multivariaten Modell weitere Faktoren berücksichtigen.
Statistische Modelle, die nur den Effekt einer einzigen Exposition berücksichtigen, vereinfachen die Wirklichkeit meist zu stark.