Chapter 2. The Art of Building Abstractions
Abstractions play a vital role in software design and software architecture. In other words, good abstractions are the key to managing complexity. Without them, good design and proper architecture are hard to imagine. Still, building good abstractions and using them well is surprisingly difficult. As it turns out, building and using abstractions comes with a lot of subtleties, and therefore feels more like an art than a science. This chapter goes into detail about the meaning of abstractions and the art of building them.
In “Guideline 6: Adhere to the Expected Behavior of Abstractions”, we will talk about the purpose of abstractions. We will also talk about the fact that abstractions represent a set of requirements and expectations and why it is so important to adhere to the expected behavior of abstractions. In that context I will introduce another design principle, the Liskov Substitution Principle (LSP).
In “Guideline 7: Understand the Similarities Between Base Classes and Concepts”, we will compare the two most commonly used abstractions: base classes and concepts. You will understand that from a semantic point of view both approaches are very similar since both are able to express expected behavior.
In “Guideline 8: Understand the Semantic Requirements of Overload Sets”, I will extend the discussion about semantic requirements and talk about a third kind of abstraction: function overloading. You will understand that all functions, being part of an overload set, also have an expected behavior and thus also have to adhere to the LSP.
In “Guideline 9: Pay Attention to the Ownership of Abstractions”, I will focus on the architectural meaning of abstractions. I will explain what an architecture is and what we expect from the high and low levels of an architecture. I will also show you that from an architectural point of view, it is not enough to just introduce an abstraction to resolve dependencies. To explain this, I will introduce the Dependency Inversion Principle (DIP), vital advice on how to build an architecture by means of abstractions.
In “Guideline 10: Consider Creating an Architectural Document”, we will talk about the benefits of an architectural document. Hopefully, this will be an incentive to create one in case this wasn’t already on your radar.
Guideline 6: Adhere to the Expected Behavior of Abstractions
One of the key aspects of decoupling software, and thus one of the key aspects of software design, is the introduction of abstractions. For that reason, you would expect that this is a relatively straightforward, easy thing to do. Unfortunately, as it turns out, building abstractions is difficult.
To demonstrate what I mean, let’s take a look at an example. I have selected the classic example for that purpose. Chances are, you might already know this example. If so, please feel free to skip it. However, if you’re not familiar with the example, then this may serve as an eye-opener.
An Example of Violating Expectations
Let’s start with a Rectangle base class:
classRectangle{public:// ...virtual~Rectangle()=default;intgetWidth()const;intgetHeight()const;virtualvoidsetWidth(int);virtualvoidsetHeight(int);virtualintgetArea()const;// ...private:intwidth;intheight;};
First of all, this class is designed as a base class, since it provides
a virtual destructor
(![]() ).
Semantically, a
).
Semantically, a Rectangle represents an abstraction for different
kinds of rectangles. And technically, you can properly destroy an
object of derived type via a pointer to Rectangle.
Second, the Rectangle class comes with two data members: width and height
(![]() ).
That is to be expected, since a rectangle has two side lengths, which are
represented by
).
That is to be expected, since a rectangle has two side lengths, which are
represented by width and height. The getWidth() and getHeight() member
functions can be used to query the two side lengths
(![]() ),
and via the
),
and via the setWidth() and setHeight() member functions, we can set the width
and height
(![]() ).
It’s important to note that I can set these two independently; i.e., I can set the
).
It’s important to note that I can set these two independently; i.e., I can set the
width without having to modify the height.
Finally, there is a getArea() member function
(![]() ).
).
getArea() computes the area of the rectangle, which is of course implemented by
returning the product of width and height.
Of course there may be more functionality, but the given members are the ones
that are important for this example. As it is, this seems to be a pretty
nice Rectangle class. Obviously, we’re off to a good start. But, of
course there’s more. For instance, there is the Square class:
classSquare:publicRectangle{public:// ...voidsetWidth(int)override;voidsetHeight(int)override;intgetArea()constoverride;// ...};
The Square class publicly inherits from the Rectangle class
(![]() ).
And that seems pretty reasonable: from a mathematical perspective, a square
appears to be a special kind of rectangle.1
).
And that seems pretty reasonable: from a mathematical perspective, a square
appears to be a special kind of rectangle.1
A Square is special, in the sense that it has only one side length.
But the Rectangle base class comes with two lengths: width and height. For
that reason, we have to make sure that the invariants
of the Square are always preserved. In this given implementation
with two data members and two getter functions, we have to make sure that
both data members always have the same value. Therefore, we override the
setWidth() member function to set both width and height
(![]() ).
We also override the
).
We also override the setHeight() member function to set both
width and height
(![]() ).
).
Once we have done that, a Square will always have equal side lengths,
and the getArea() function will always return the correct area of a Square
(![]() ).
Nice!
).
Nice!
Let’s put these two classes to good use. For instance, we could think about a function that transforms different kinds of rectangles:
voidtransform(Rectangle&rectangle){rectangle.setWidth(7);rectangle.setHeight(4);assert(rectangle.getArea()==28);// ...}
The transform() function takes any kind of Rectangle by means of a
reference to non-const
(![]() ).
That’s reasonable, because we want to change the given rectangle. A first
possible way to change the rectangle is to set the
).
That’s reasonable, because we want to change the given rectangle. A first
possible way to change the rectangle is to set the width via the setWidth()
member function to 7
(![]() ).
Then we could change the
).
Then we could change the height of the rectangle to 4 via the setHeight()
member function
(![]() ).
).
At this point, I would argue that you have an implicit assumption. I am pretty
certain that you assume that the area of the rectangle is 28, because, of
course, 7 times 4 is 28. That is an assumption we can test via an
assertion
(![]() ).
).
The only thing missing is to actually call the transform()
function. That’s what we do in the main() function:
intmain(){Squares{};s.setWidth(6);transform(s);returnEXIT_SUCCESS;}
In the main() function, we create a special kind of rectangle: a Square
(![]() ).2 This square is passed to the
).2 This square is passed to the
transform() function, which of course
works, since a reference to a Square can be implicitly converted to a
reference to a Rectangle
(![]() ).
).
If I were to ask you, “What happens?” I’m pretty sure you would
answer, “The assert() fails!” Yes, indeed, the assert() will fail.
The expression passed to the assert() will evaluate to false, and assert()
will crash the process with a SIGKILL signal. Well, that’s
certainly unfortunate. So let’s do a postmortem analysis: why does the
assert() fail? Our expectation in the transform() function is that
we can change the width and height of a rectangle independently. This
expectation is explicitly expressed with the two function calls
to setWidth() and setHeight(). However, unexpectedly, this special
kind of rectangle does not allow that: to preserve its own
invariants, the Square class must always make sure that both side
lengths are equal. Thus, the Square class has to violate this
expectation. This violation of the expectation in an abstraction is
a violation of the LSP.
The Liskov Substitution Principle
The LSP is the third of the SOLID principles and is concerned with behavioral subtyping, i.e., with the expected behavior of an abstraction. This design principle is named after Barbara Liskov, who initially introduced it in 1988 and clarified it with Jeannette Wing in 1994:3
Subtype Requirement: Let be a property provable about objects of type T. Then should be true for objects of type S where S is a subtype of T.
This principle formulates what we commonly call an IS-A relationship. This relationship, i.e., the expectations in an abstraction, must be adhered to in a subtype. That includes the following properties:
-
Preconditions cannot be strengthened in a subtype: a subtype cannot expect more in a function than what the super type expresses. That would violate the expectations in the abstraction:
structX{virtual~X()=default;// Precondition: the function accepts all 'i' greater than 0virtualvoidf(inti)const{assert(i>0);// ...}};structY:publicX{// Precondition: the function accepts all 'i' greater than 10.// This would strengthen the precondition; numbers between 1 and 10// would no longer be allowed. This is a LSP violation!voidf(inti)constoverride{assert(i>10);// ...}};
-
Postconditions cannot be weakened in a subtype: a subtype cannot promise less when leaving a function than the super type promises. Again, that would violate the expectations in the abstraction:
structX{virtual~X()=default;// Postcondition: the function will only return values larger than 0virtualintf()const{inti;// ...assert(i>0);returni;}};structY:publicX{// Postcondition: the function may return any value.// This would weaken the postcondition; negative numbers and 0 would// be allowed. This is a LSP violation!intf(inti)constoverride{inti;// ...returni;}};
-
Function return types in a subtype must be covariant: member functions of the subtype can return a type that is itself a subtype of the return type of the corresponding member function in the super type. This property has direct language support in C++. However, the subtype cannot return any super type of the return type of the corresponding function in the super type:
structBase{/*...some virtual functions, including destructor...*/};structDerived:publicBase{/*...*/};structX{virtual~X()=default;virtualBase*f();};structY:publicX{Derived*f()override;// Covariant return type};
-
Function parameters in a subtype must be contravariant: in a member function, the subtype can accept a super type of the function parameter in the corresponding member function of the super type. This property does not have direct language support in C++:
structBase{/*...some virtual functions, including destructor...*/};structDerived:publicBase{/*...*/};structX{virtual~X()=default;virtualvoidf(Derived*);};structY:publicX{voidf(Base*)override;// Contravariant function parameter; Not// supported in C++. Therefore the function// does not override, but fails to compile.};
-
Invariants of the super type must be preserved in a subtype: any expectation about the state of a super type must always be valid before and after all calls to any member function, including the member functions of the subtype:
structX{explicitX(intv=1):value_(v){if(v<1||v>10)throwstd::invalid_argument(/*...*/);}virtual~X()=default;intget()const{returnvalue_;}protected:intvalue_;// Invariant: must be within the range [1..10]};structY:publicX{public:Y():X(){value_=11;// Broken invariant: After the constructor, 'value_'// is out of expected range. One good reason to// properly encapsulate invariants and to follow// Core Guideline C.133: Avoid protected data.}};
In our example, the expectation in a Rectangle is that we can change
the two side lengths independently, or, more formally, that the result
of getWidth() does not change after setHeight() is called. This
expectation is intuitive for any kind of rectangle. However, the Square
class itself introduces the invariant that all sides must always
be equal, or else the Square would not properly express our idea of a
square. But by protecting its own invariants, the Square unfortunately
violates the expectations in the base class. Thus, the Square class doesn’t fulfill the expectations in the Rectangle class, and the hierarchy
in this example doesn’t express an IS-A relationship. Therefore, a Square cannot be used in all the places a Rectangle is expected.
“But isn’t a square a rectangle?” you ask. “Isn’t that properly
expressing the geometrical relation?”4 Yes, there
may be a geometrical relation between squares and rectangles, but in
this example the inheritance relationship is broken. This example
demonstrates that the mathematical IS-A relationship is indeed different
from the LSP
IS-A relationship. While in geometry a square is always a
rectangle, in computer science it really depends on the actual interface
and thus the expectations. As long as there are the two independent
setWidth() and setHeight() functions, a Square will always violate
the expectations. “I understand,” you say. “Nobody would claim that,
geometrically, a square is still a square after changing its width, right?”
Exactly.
The example also demonstrates that inheritance is not a natural or intuitive feature, but a hard feature. As stated in the beginning, building abstractions is hard. Whenever you use inheritance, you must make sure that all expectations in the base class are fulfilled and that the derived type behaves as expected.
Criticism of the Liskov Substitution Principle
Some people argue that the LSP, as explained earlier, is in fact not what is described in the conference paper “Data Abstraction and Hierarchy” by Barbara Liskov and that the notion of subtyping is flawed. And that is correct: we usually do not substitute derived objects for base objects, but we use a derived object as a base object. However, this literal and strict interpretation of Liskov’s statements does not play any role in the kinds of abstractions that we build on a daily basis. In their 1994 paper “A Behavioral Notion of Subtyping,” Barbara Liskov and Jeannette Wing proposed the term behavioral subtyping, which is the common understanding of the LSP today.
Other people argue that because of potential violations of the LSP, a base class does not serve the purpose of an abstraction. The rationale is that using code would also depend on the (mis-)behavior of derived types. This argument unfortunately turns the world upside down. A base class does represent an abstraction, because calling code can and should only and exclusively depend on the expected behavior of this abstraction. It’s that dependency that makes LSP violations programming errors. Unfortunately, sometimes people try to fix LSP violations by introducing special workarounds:
classBase{/*...*/};classDerived:publicBase{/*...*/};classSpecial:publicBase{/*...*/};// ... Potentially more derived classesvoidf(Baseconst&b){if(dynamic_cast<Specialconst*>(&b)){// ... do something "special," knowing that 'Special' behaves differently}else{// ... do the expected thing}}
This kind of workaround will indeed introduce a dependency in the behavior of the derived types. And a very unfortunate dependency, indeed! This should always be considered an LSP violation and very bad practice.5 It doesn’t serve as a general argument against the abstracting properties of a base class.
The Need for Good and Meaningful Abstractions
To properly decouple software entities, it is fundamentally important that we can count on our abstractions. Without meaningful abstractions that we, the human readers of code, fully understand, we cannot write robust and reliable software. Therefore, adherence to the LSP is essential for the purpose of software design. However, a vital part is also the clear and unambiguous communication of the expectations of an abstraction. In the best case, this happens by means of software itself (self-documenting code), but it also entails a proper documentation of abstractions. As a good example, I recommend the iterator concepts documentation in the C++ standard, which clearly lists the expected behavior, including pre- and post-conditions.
Guideline 7: Understand the Similarities Between Base Classes and Concepts
In “Guideline 6: Adhere to the Expected Behavior of Abstractions”, I may have created the impression that the LSP is concerned only with inheritance hierarchies and base classes. To make sure that this impression doesn’t stick, allow me to explicitly state that the LSP is not limited to dynamic (runtime) polymorphism and inheritance hierarchies. On the contrary, we can apply the LSP just as well to static (compile-time) polymorphism and templated code.
To make the point, let me ask you a question: what’s the difference between the following two code snippets?
//==== Code Snippet 1 ====classDocument{public:// ...virtual~Document()=default;virtualvoidexportToJSON(/*...*/)const=0;virtualvoidserialize(ByteStream&,/*...*/)const=0;// ...};voiduseDocument(Documentconst&doc){// ...doc.exportToJSON(/*...*/);// ...}//==== Code Snippet 2 ====template<typenameT>conceptDocument=requires(Tt,ByteStreamb){t.exportToJSON(/*...*/);t.serialize(b,/*...*/);};template<DocumentT>voiduseDocument(Tconst&doc){// ...doc.exportToJSON(/*...*/);// ...}
I’m pretty sure your first answer is that the first code snippet shows a solution using dynamic polymorphism, and the second one shows static polymorphism. Yes, great! What else? OK, yes, of course, the syntax is different, too. OK, I see, I should ask my question a little more precisely: in which way do these two solutions differ semantically?
Well, if you think about it, then you might find that from a
semantic point of view the two solutions are very similar indeed. In the first
code snippet, the
useDocument() function works only with classes derived from
the Document base class. Thus, we can say that the function works only with
classes adhering to the expectations of the Document abstraction. In the second
code snippet, the useDocument() function works only with classes that implement
the Document concept. In other words, the function works only with classes
adhering to the expectations of the Document abstraction.
If you now have the feeling of déjà vu, then my choice of words hopefully
struck a chord. Yes, in both code snippets, the useDocument() function
works only with classes adhering to the expectations of the Document abstraction.
So despite the fact that the first code snippet is based on a runtime
abstraction and the second function represents a compile-time abstraction,
these two functions are very similar from a semantic point of view.
Both the base class and the concept represent a set of requirements (syntactic requirements, but also semantic requirements). As such, both represent a formal description of the expected behavior and thus are the means to express and communicate expectations for calling code. Thus, concepts can be considered the equivalent, the static counterpart, of base classes. And from this point of view, it makes perfect sense to also consider the LSP for template code.
“I’m not buying that,” you say. “I’ve heard that C++20
concepts cannot express semantics!”6
Well, to this I can only respond with a definitive yes and no. Yes,
C++20
concepts cannot fully express semantics, that’s correct. But on the other hand,
concepts still express expected behavior. Consider, for instance, the C++20
form of the std::copy() algorithm:7
template<typenameInputIt,typenameOutputIt>constexprOutputItcopy(InputItfirst,InputItlast,OutputItd_first){while(first!=last){*d_first++=*first++;}returnd_first;}
The std::copy() algorithm expects three arguments. The first two arguments
represent the range of elements that need to be copied (the input range).
The third argument represents the first element we need to copy to (the
output range). A general expectation is that the output range is big
enough that all the elements from the input range can be copied to
it.
There are more expectations that are implicitly
expressed via the names for the iterator types: InputIt and
OutputIt. InputIt represents a type of input iterator. The
C++ standard states all the expectations of such
iterator types, such as the availability of an (in-)equality
comparison, the ability to traverse a range with a prefix and postfix
increment (operator++() and operator++(int)),
and the ability to access elements with the dereference operator (operator*()).
OutputIt, on the other hand,
represents a type of output iterator.
Here, the C++ standard also explicitly states all expected
operations.
InputIt and OutputIt may not be C++20 concepts, but they represent the same idea: these named template parameters don’t just
give you an idea about what kind of type is required; they also express
expected behavior. For instance, we expect that subsequent
increments of first will eventually yield last. If any given
concrete iterator type does not behave this way, std::copy() will
not work as expected. This would be a violation of the expected behavior,
and as such, a violation of the LSP.8 Therefore, both InputIt and
OutputIt represent LSP abstractions.
Note that since concepts represent an LSP abstraction, i.e., a set of requirements and expectations, they are subject to the Interface Segregation Principle (ISP) as well (see “Guideline 3: Separate Interfaces to Avoid Artificial Coupling”). Just as you should separate concerns in the definition of requirements in the form of base classes (say, “interface” classes), you should separate concerns when defining a concept. The Standard Library iterators do that by building on one another, thus allowing you to select the desired level of requirements:
template<typenameI>conceptinput_or_output_iterator=/* ... */;template<typenameI>conceptinput_iterator=std::input_or_output_iterator<I>&&/* ... */;template<typenameI>conceptforward_iterator=std::input_iterator<I>&&/* ... */;
Since both named template parameters and C++20 concepts serve the same purpose and since both represent LSP abstractions, from now on, in all subsequent guidelines, I will use the term concept to refer to both of them. Thus, with the term concept, I will refer to any way to represent a set of requirements (in most cases for template arguments, but sometimes even more generally). If I want to refer to either of these two specifically, I will make it explicitly clear.
In summary, any kind of abstraction (dynamic and static) represents a set of requirements with that expected behavior. These expectations need to be fulfilled by concrete implementations. Thus, the LSP clearly represents essential guidance for all kinds of IS-A relationships.
Guideline 8: Understand the Semantic Requirements of Overload Sets
In “Guideline 6: Adhere to the Expected Behavior of Abstractions”, I introduced you to the LSP and hopefully made a strong argument: every abstraction represents a set of semantic requirements! In other words, an abstraction expresses expected behavior, which needs to be fulfilled. Otherwise, you (very likely) will have a problem. In “Guideline 7: Understand the Similarities Between Base Classes and Concepts”, I extended the LSP discussion to concepts and demonstrated that the LSP can and should also be applied to static abstractions.
That’s not the end of the story, though. As stated before: every abstraction represents
a set of requirements. There is one more kind of abstraction that we have not yet taken into
account, one that’s unfortunately often overlooked, despite its power, and hence one that we
should not forget in the discussion: function overloading. “Function overloading? You mean
the fact that a class can have several functions with the same name?”
Yes, absolutely. You probably have experienced that this is indeed a pretty powerful
feature. Think, for instance, about the two overloads of the begin() member function inside
the std::vector: depending on whether you have a const or a non-const vector, the
corresponding overload is picked. Without you even noticing. Pretty powerful! But honestly,
this isn’t really much of an abstraction. While it’s convenient and helpful to overload
member functions, I have a different kind of function overloading in mind, the kind that
truly represents a form of abstraction: free functions.
The Power of Free Functions: A Compile-Time Abstraction Mechanism
Next to concepts, function overloading by means of free functions represents a second
compile-time abstraction: based on some given types, the compiler figures out which function
to call from a set of identically named functions. This is what we call an overload set. This is an extremely versatile and powerful abstraction mechanism with many, many great design
characteristics. First of all, you can add a free function to any type: you can add one to
an int, to std::string, and to any other type. Nonintrusively. Try that with a member
function, and you will realize that this just does not work. Adding a member function is
intrusive. You can’t add anything to a type that cannot have a member function or to a type
that you cannot modify. Thus, a free function perfectly lives up to the spirit of the
Open-Closed Principle (OCP): you can extend the functionality by simply adding code,
without the need to modify already existing code.
This gives you a significant design advantage. Consider, for instance, the following code example:
template<typenameRange>voidtraverseRange(Rangeconst&range){for(autopos=range.begin();pos!=range.end();++pos){// ...}}
The traverseRange() function performs a traditional, iterator-based loop over the given
range. To acquire iterators, it calls the begin() and end() member functions
on the range. While this code will work for a large number of container types, it will
not work for a built-in array:
#include<cstdlib>intmain(){intarray[6]={4,8,15,16,23,42};traverseRange(array);// Compilation error!returnEXIT_SUCCESS;}
This code will not compile, as the compiler will complain about the missing begin() and
end() member functions for the given array type. “Isn’t that why we should avoid using
built-in arrays and use std::array instead?” I completely agree: you should use
std::array instead. This is also very nicely explained by Core Guideline SL.con.1:
Prefer using STL
arrayorvectorinstead of a C array.
However, while this is good practice, let’s not lose sight of the design issues of the
traverseRange() function: traverseRange() is restricting itself by depending on the
begin() and end() member functions. Thus, it creates an artificial requirement on the
Range type to support a member begin() and a member end() function and, by that, limits
its own applicability. There is a simple solution, however, a simple way to make the function
much more widely applicable: build on the overload set of free begin() and end()
functions:9
template<typenameRange>voidtraverseRange(Rangeconst&range){usingstd::begin;// using declarations for the purpose of callingusingstd::end;// 'begin()' and 'end()' unqualified to enable ADLfor(autopos=begin(range);pos!=end(range);++pos){// ...}}
This function is still doing the same thing as before, but in this form it doesn’t restrict
itself by any artificial requirement. And indeed, there is no restriction: any type can
have a free begin() and end() function or, if it is missing, can be equipped with one.
Nonintrusively. Thus, this function works with any kind of Range and doesn’t have to
be modified or overloaded if some type does not meet the requirement. It is more widely
applicable. It is truly generic.10
Free functions have more advantages, though. As already discussed in
“Guideline 4: Design for Testability”, free functions are a very elegant technique to separate concerns,
fulfilling the Single-Responsibility Principle (SRP). By implementing an operation
outside a class, you automatically reduce the dependencies of that class to the operation.
Technically, this becomes immediately clear, since in contrast to member functions, free
functions don’t have an implicit first argument, the this pointer. At the same time,
this promotes the function to become a separate, isolated service, which can be used by
many other classes as well. Thus, you promote reuse and reduce duplication. This very,
very nicely adheres to the idea of the Don’t Repeat Yourself (DRY) principle.
The beauty of this is wonderfully demonstrated in Alexander Stepanov’s brainchild, the Standard Template Library (STL).11 One part of the STL philosophy is to loosely couple the different pieces of functionality and promote reuse by separating concerns as free functions. That’s why containers and algorithms are two separate concepts within the STL: conceptually, containers don’t know about the algorithms, and algorithms don’t know about containers. The abstraction between them is accomplished via iterators that allow you to combine the two in seemingly endless ways. A truly remarkable design. Or to say it in the words of Scott Meyers:12
There was never any question that the [standard template] library represented a breakthrough in efficient and extensible design.
“But what about std::string? std::string comes with dozens of member functions,
including many algorithms.” You’re making a good point, but more in the sense of a counter
example. Today the community agrees that the design of std::string is not great. Its design
promotes coupling, duplication, and growth: in every new C++ standard, there are a
couple of new, additional member functions. And growth means modifications and subsequently
the risk of accidentally changing something. This is a risk that you want to avoid in your
design. However, in its defense, std::string was not part of the original STL. It
was not designed alongside the STL containers (std::vector, std::list, std::set, etc.)
and was adapted to the STL design only later. That explains why it’s different from the other
STL containers and does not completely share their beautiful design goal.
The Problem of Free Functions: Expectations on the Behavior
Apparently, free functions are remarkably powerful and seriously important for generic programming. They play a vital role in the design of the STL and the design of the C++ Standard Library as a whole, which builds on the power of this abstraction mechanism.13 However, all of this power can only work if a set of overload functions adheres to a set of rules and certain expectations. It can only work if it adheres to the LSP.
For instance, let’s imagine that you have written your own Widget type and want to
provide a custom swap() operation for it:
//---- <Widget.h> ----------------structWidget{inti;intj;};voidswap(Widget&w1,Widget&w2){usingstd::swap;swap(w1.i,w2.i);}
Your Widget only needs to be a simple wrapper for int values, called i and
j. You provide the corresponding swap() function as an accompanying free function. And
you implement swap() by swapping only the i value, not the j value. Further imagine
that your Widget type is used by some other developer, maybe a kind coworker.
At some point, this coworker calls the swap() function:
#include<Widget.h>#include<cstdlib>intmain(){Widgetw1{1,11};Widgetw2{2,22};swap(w1,w2);// Widget w1 contains (2,11)// Widget w2 contains (1,22)returnEXIT_SUCCESS;}
Can you imagine the surprise of your coworker when after the swap() operation the
content of w1 is not (2,22) but (2,11) instead? How unexpected is it that
only part of the object is swapped? Can you imagine how frustrated your coworker must
be after an hour of debugging? And what would happen if this wasn’t a kind coworker?
Clearly, the implementation of swap() doesn’t fulfill the expectations of a swap()
function. Clearly, anyone would expect that the entire observable
state of the object is swapped. Clearly, there are behavioral expectations. Thus, if you buy
into an overload set, you’re immediately and inevitably subject to fulfill the expected
behavior of the overload set. In other words, you have to adhere to the LSP.
“I see the problem, I get that. I promise to adhere to the LSP,” you say. That’s great, and this is an honorable intention. The problem is that it might not always be entirely clear what the expected behavior is, especially for an overload set that is scattered across a big codebase. You might not know about all the expectations and all the details. Thus sometimes, even if you’re aware of this problem and pay attention, you might still not do the “right” thing. This is what several people in the community are worried about: the unrestricted ability to add potentially LSP-violating functionality into an overload set.14 And as stated before, it’s easy to do. Anyone, anywhere, can add free functions.
As always, every approach and every solution has advantages, and also disadvantages. On the one hand, it is enormously beneficial to exploit the power of overload sets, but on the other hand, it is potentially very difficult to do the right thing. These two sides of the same coin are also expressed by Core Guideline C.162 and Core Guideline C.163:
Overload operations that are roughly equivalent.
Core Guideline C.162
Overload only for operations that are roughly equivalent.
Core Guideline C.163
Whereas C.162 expresses the advantages of having the same name for semantically equivalent
functions, C.163 expresses the problem of having the same name
for semantically different
functions. Every C++ developer should be aware of the tension between these two
guidelines. Additionally, to adhere to the expected
behavior, every C++ developer is well advised to be aware of existing overload
sets (std::swap(), std::begin(), std::cbegin(), std::end(), std::cend(), std::data(),
std::size(), etc.) and to know about common naming conventions. For instance, the name
find() should be used only for a function that performs a linear search over a range of
elements. For any function that performs a binary search, the name find() would raise
the wrong expectations and would not communicate the precondition that the range needs to
be sorted. And then, of course, the names begin() and end() should always fulfill the
expectation to return a pair of iterators that can be used to traverse a range. They should
not start or end some kind of process. This task would be better performed by a start()
and a stop() function.15
“Well, I agree with all these points,” you say. “However, I’m primarily using virtual functions, and since these cannot be implemented in terms of free functions, I can’t really use all of this advice on overload sets, right?” It may surprise you, but this advice still applies to you. Since the ultimate goal is to reduce dependencies, and since virtual functions may cause quite a significant amount of coupling, one of the goals will be to “free” these, too. In fact, in many of the subsequent guidelines, and perhaps most prominently in “Guideline 19: Use Strategy to Isolate How Things Are Done” and “Guideline 31: Use External Polymorphism for Nonintrusive Runtime Polymorphism”, I will tell the story of how to extract and separate virtual functions in the form of, but not limited to, free functions.
In summary, function overloading is a powerful compile-time abstraction mechanism that you should not underestimate. In particular, generic programming heavily exploits this power. However, don’t take this power too lightly: remember that just as with base classes and concepts, an overload set represents a set of semantic requirements and thus is subject to the LSP. The expected behavior of an overload set must be adhered to, or things will not work well.
Guideline 9: Pay Attention to the Ownership of Abstractions
As stated in “Guideline 2: Design for Change”, change is the one constant in software development. Your software should be prepared for change. One of the essential ingredients for dealing with change is the introduction of abstractions (see also “Guideline 6: Adhere to the Expected Behavior of Abstractions”). Abstractions help reduce dependencies and thus make it easier to change details in isolation. However, there is more to introducing abstractions than just adding base classes or templates.
The Dependency Inversion Principle
The need for abstractions is also expressed by Robert Martin:16
The most flexible systems are those in which source code dependencies refer only to abstractions, not to concretions.
This piece of wisdom is commonly known as the Dependency Inversion Principle (DIP), which is the fifth of the SOLID principles. Simply stated, it advises that for the sake of dependencies, you should depend on abstractions instead of concrete types or implementation details. Note that this statement doesn’t say anything about inheritance hierarchies but only mentions abstractions in general.
Let’s take a look at the situation illustrated in Figure 2-1.17 Imagine you are implementing the logic
for an automated teller machine (ATM). An ATM provides several kinds of
operations: you can withdraw money,
deposit money, and transfer money. Since all of these operations deal
with real money, they should either run to full completion or, in case of any
kind of error, be aborted and all changes rolled back. This kind
of behavior (either 100% success or a complete rollback) is what we commonly call
a transaction. Consequently, we can introduce an abstraction named
Transaction.
All abstractions (Deposit, Withdrawal, and Transfer) inherit from the
Transaction class (depicted by the UML inheritance arrow).
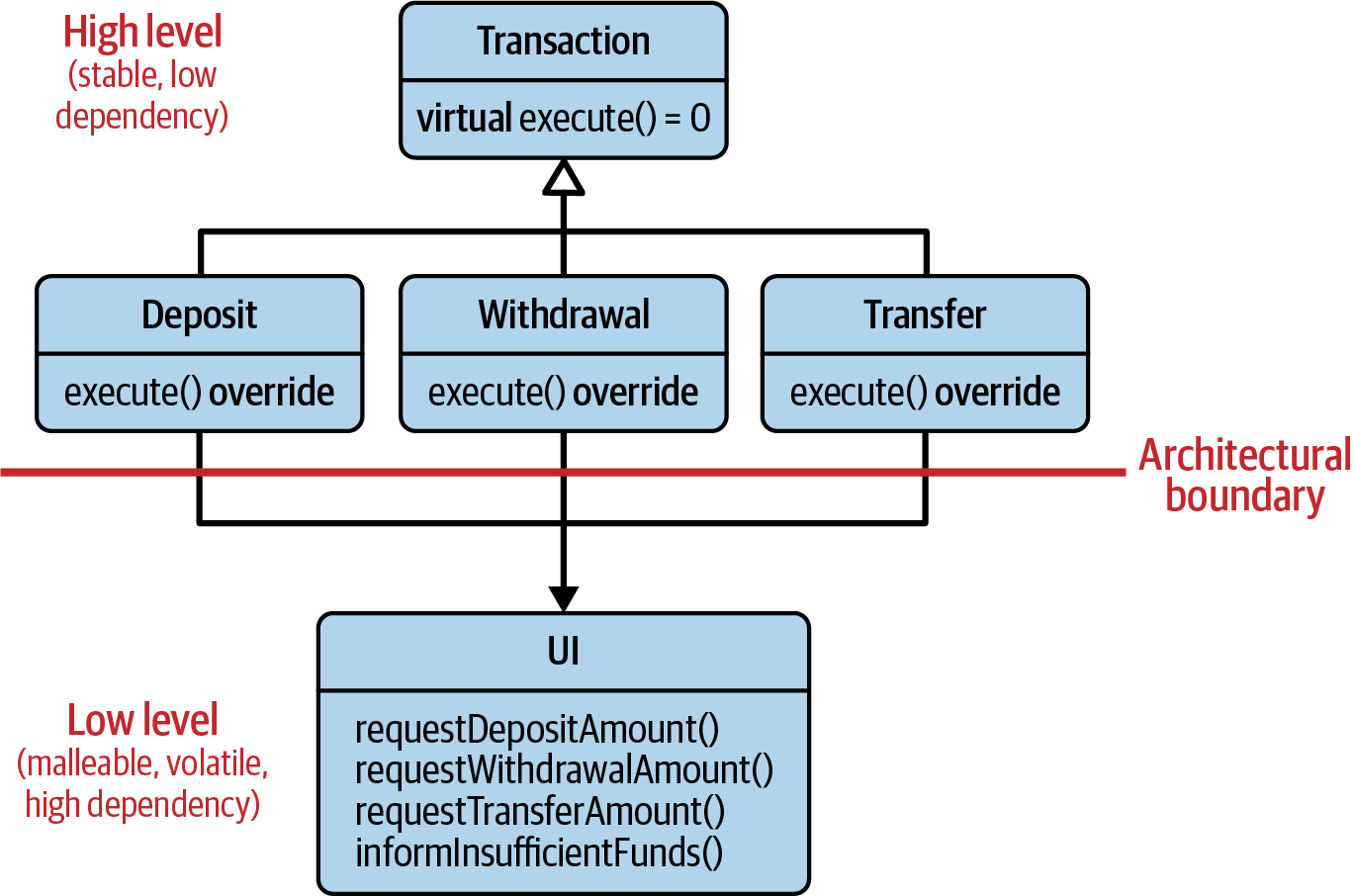
Figure 2-1. Initial strong dependency relationship between several transactions and a UI
All transactions are in need of input data entered by a bank customer via
the
user interface. This user interface is provided by the UI class, which
provides many different functions to query for the entered data:
requestDepositAmount(), requestWithdrawalAmount(), requestTransferAmount(),
informInsufficientFunds(), and potentially more functions. All three abstractions
directly call these functions whenever they need information. This
relationship is depicted by the little solid arrow, which indicates
that the abstractions depend on the UI class.
While this setup may work for some time, your trained eye might have already spotted a potential problem: what happens if something changes? For instance, what happens if a new transaction is added to the system?
Let’s assume that we must add a SpeedTransfer transaction for
VIP customers. This might require us to change and extend the UI class with
a couple of new functions (for instance, requestSpeedTransferAmount() and
requestVIPNumber()). That, in turn, also affects all of the other
transactions, since they directly depend on the UI class. In the best
case, these transactions simply have to be recompiled and retested (still,
this takes time!); in the worst case, they might have to be redeployed in
case they are delivered in separate shared libraries.
The underlying reason for all of that extra effort is a broken architecture.
All transactions indirectly depend on one another via the concrete dependency
on the UI class. And that is a very unfortunate situation from an architectural
point of view: the transaction classes reside at the high level of our
architecture, while the UI class resides at the low level. In this
example, the high level depends on the low level. And that is just wrong:
in a proper architecture, this dependency should be inverted.18
All transactions indirectly depend on one another due
to the dependency on the UI class. Furthermore, the high level of our
architecture depends on the low level. This is a pretty unfortunate situation
indeed, a situation that we should resolve properly. “But that’s simple!”
you say. “We just introduce an abstraction!” That’s exactly what Robert
Martin expressed in his statement: we need to introduce an abstraction
in order not to depend on the concrete implementation in the UI class.
However, a single abstraction wouldn’t solve the problem. The three kinds of transactions would still be indirectly coupled. No, as Figure 2-2 illustrates, we need three abstractions: one for each transaction.19
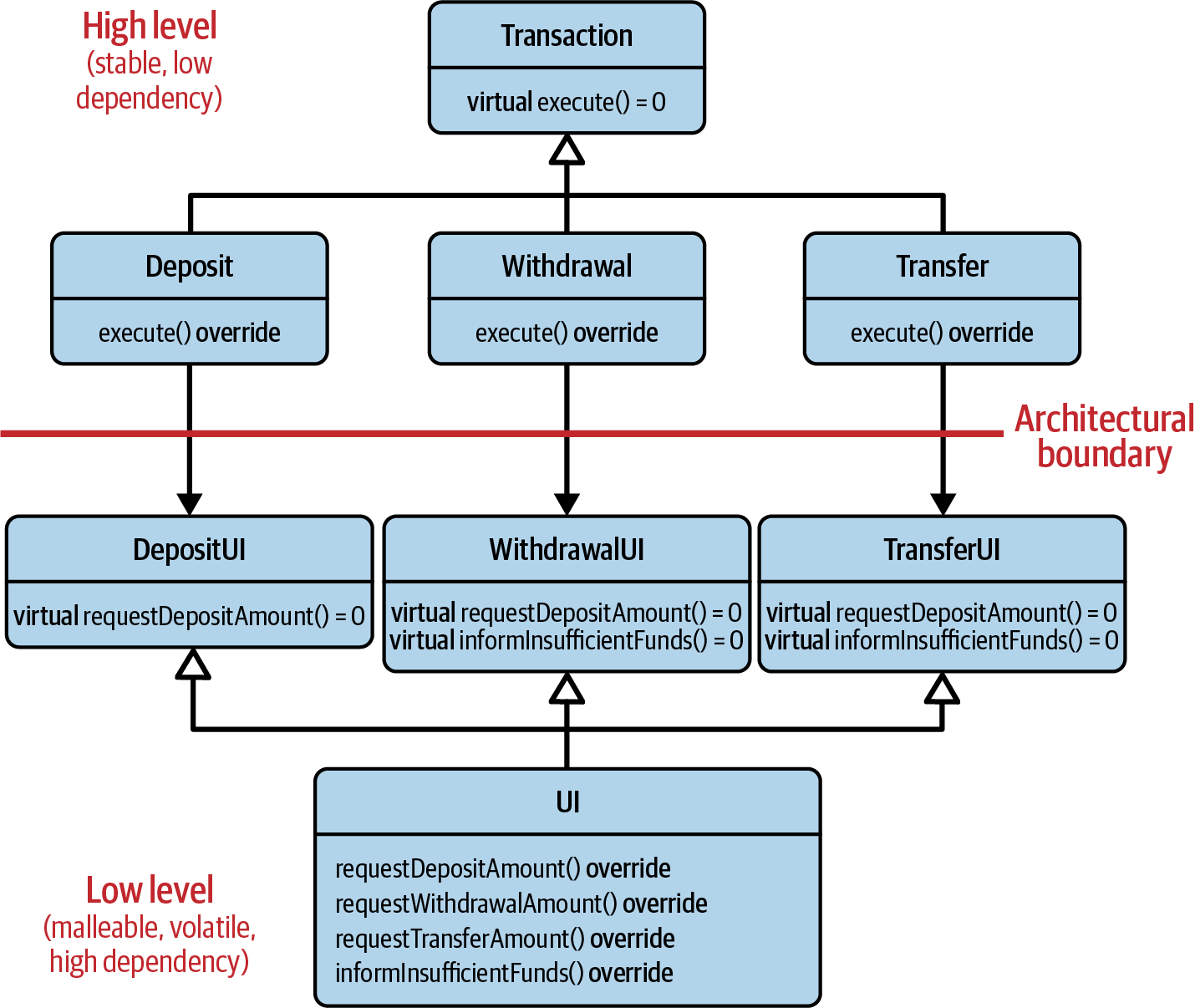
Figure 2-2. The relaxed dependency relationship between several transactions and a UI
By introducing the DepositUI, WithdrawalUI, and
TransferUI classes, we’ve broken the dependency among the three
transactions. The three transactions are no longer dependent on the
concrete UI class, but on a lightweight abstraction that
represents only those operations that the relevant transaction truly
requires. If we now introduce the SpeedTransfer transaction,
we can also introduce the
SpeedTransferUI abstraction, so none
of the other transactions will be affected by the changes introduced
in the UI class.
“Oh, yes, I get it! This way we have fulfilled three design principles!” You sound impressed. “We’ve introduced an abstraction to cut the dependency on the implementation details of the user interface. That must be the DIP. And we’ve followed the ISP and removed the dependencies among the different transactions. And as a bonus, we have also nicely grouped the things that truly belong together. That’s the SRP, right? That’s amazing! Let’s celebrate!”
Wait, wait, wait…Before you go off to uncork your best bottle of
champagne to celebrate solving this dependency problem, let’s take a
closer look at the problem. So yes, you are correct, we follow the ISP
by separating the concerns of the UI class. By segregating it into three
client-specific interfaces, we’ve resolved the dependency situation
among the three transactions. This is indeed the ISP. Very nice!
Unfortunately, we haven’t resolved our architectural problem yet, so no,
we do not follow the DIP (yet). But I get the misunderstanding:
it does appear as if we have inverted the dependencies. Figure 2-3
shows that we have really introduced an inversion of dependencies: instead
of depending on the concrete UI class, we now depend on abstractions.
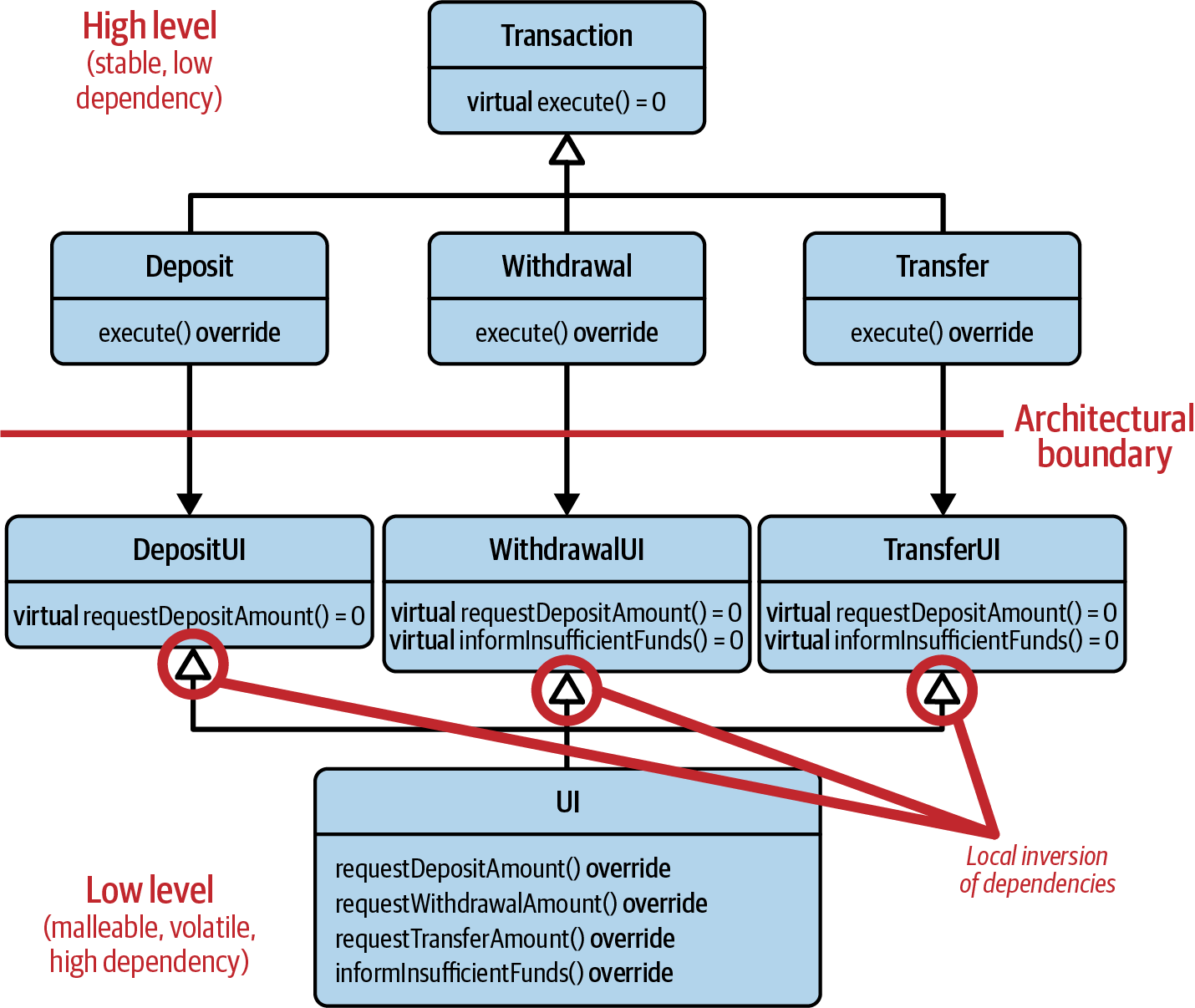
Figure 2-3. The local inversion of dependencies by introduction of three abstract UI classes
However, what we have introduced is a local inversion of dependencies. Yes, a local inversion only, not a global inversion. From an architectural point of view, we still have a dependency from the high level (our transaction classes) to the low level (our UI functionality). So no, it is not enough to just introduce an abstraction. It’s also important to consider where to introduce the abstraction. Robert Martin expressed this with the following two points:20
High-level modules should not depend on low-level modules. Both should depend on abstractions.
Abstractions should not depend on details. Details should depend on abstractions.
The first point clearly expresses an essential property of an architecture: the high level, i.e., the stable part(s) of our software, should not depend on the low level, i.e., the implementation details. That dependency should be inverted, meaning that the low level should depend on the high level. Luckily, the second point gives us an idea how to achieve that: we assign the three abstractions to the high level. Figure 2-4 illustrates the dependencies when we consider abstractions part of the high level.
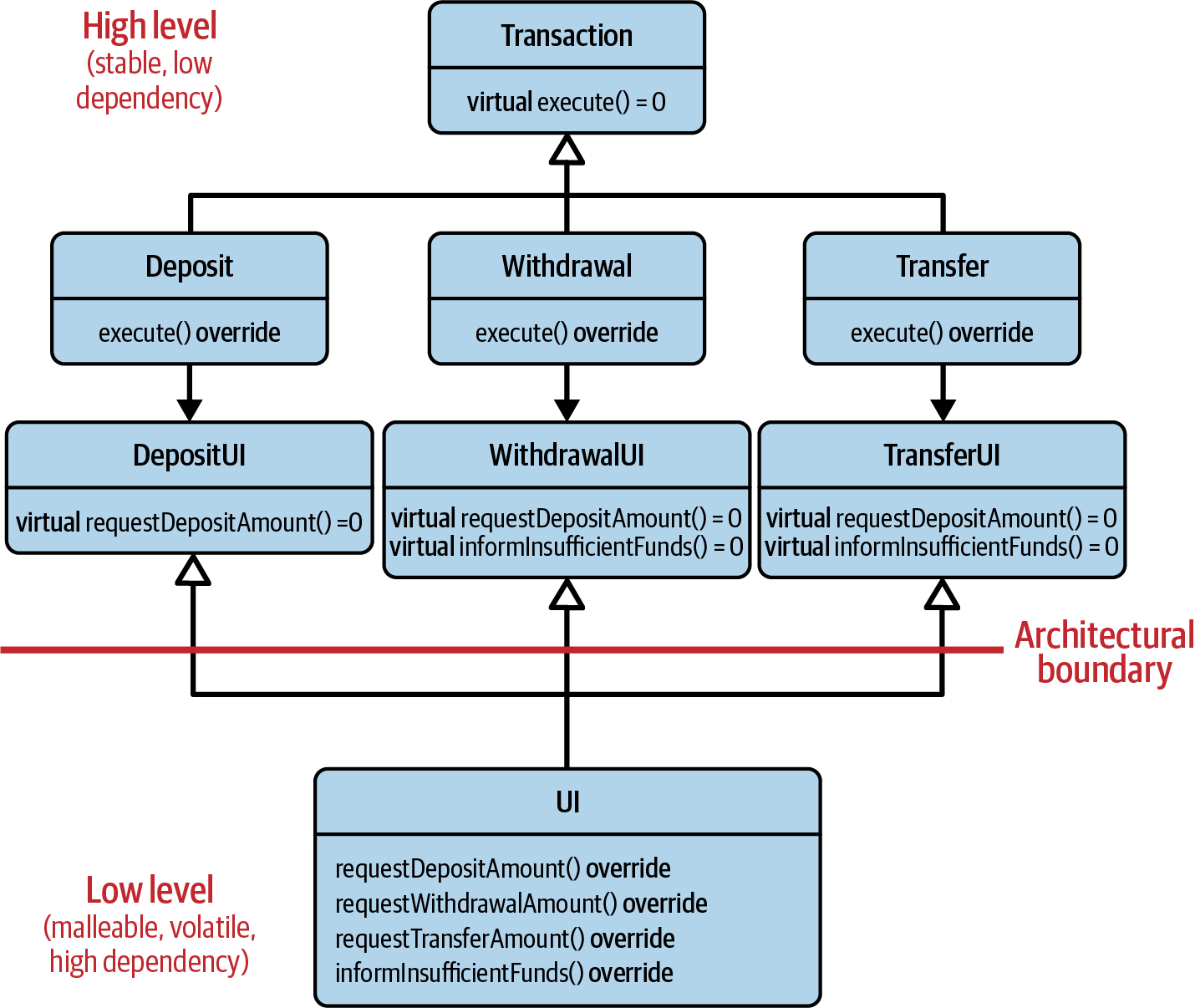
Figure 2-4. Inversion of dependencies by assigning the abstractions to the high level
By assigning the abstractions to the high level and by making the high level the owner of the abstractions, we truly follow the DIP: all arrows now run from the low level to the high level. Now we do have a proper architecture.
“Wait a second!” You look a little confused. “That’s it? All we need is to perform a mental shift of the architectural boundary?” Well, it may very well be more than just a mental shift. This may result in moving the dependent header files for the UI classes from one module to another and also completely rearranging the dependent include statements. It’s not just a mental shift—it is a reassignment of ownership.
“But now we no longer group the things that belong together,” you argue. “The
user interface functionality is now spread across both levels. Isn’t that a
violation of the SRP?” No, it isn’t. On
the contrary, only after assigning the abstractions to the high level do we
now properly follow the SRP. It’s not the UI classes that belong together;
it’s the transaction classes and the dependent UI abstractions that
should be grouped together. Only in this way can we steer the dependency in
the right direction; only in this way do we have an architecture. Thus, for a proper
dependency inversion, the abstraction must be owned by the high level.
Dependency Inversion in a Plug-In Architecture
Perhaps this fact makes more sense if we consider the situation depicted in
Figure 2-5. Imagine you have created the next-generation text editor. The
core of this new text editor is represented by the Editor class on the
lefthand side. To ensure that this text editor will be successful,
you want to make sure that the fan community can participate in the
development. Therefore, one vital ingredient for your success is the ability of
the community to add new functionality in the form of plug-ins. However,
the initial setting is pretty flawed from an architectural point of view and
will hardly satisfy your fan community: the Editor directly depends on the
concrete VimModePlugin class. Since the Editor class is part of the high level
of the architecture, which you should consider as your own realm, the VimModePlugin
is part of the low level of the architecture, which is the realm of your fan
community. Since the Editor directly depends on the VimModePlugin, and because
that essentially means that your community can define their interfaces as
they please, you would have to change the editor for every new plug-in. As
much as you love to work on your brainchild, there’s only so much time
you can devote to adapting to different kinds of plug-ins.
Unfortunately, your fan community will soon be disappointed and move on to
another text editor.
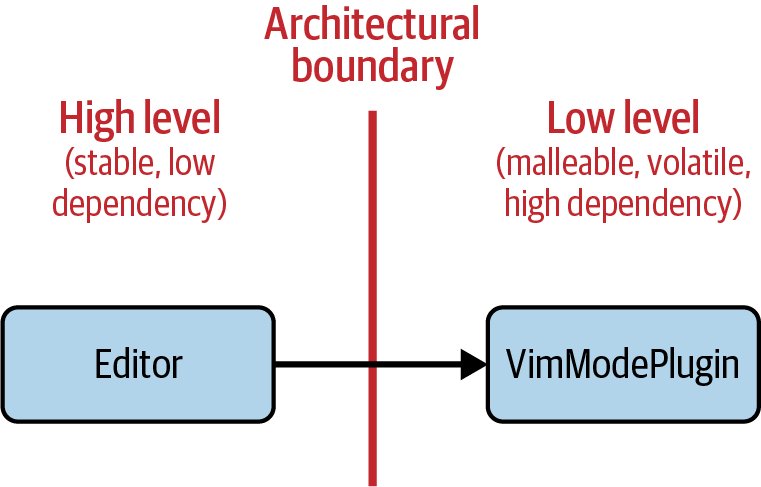
Figure 2-5. Broken plug-in architecture: the high-level Editor class depends on the low-level VimModePlugin class
Of course, that shouldn’t happen. In the given Editor example, it certainly
isn’t a good idea to make the Editor class depend on all the concrete plug-ins.
Instead, you should reach for an abstraction, for instance, in the form of a
Plugin base class. The Plugin class now represents the abstraction for
all kinds of plug-ins. However, it doesn’t make sense to introduce the abstraction
in the low level of the architecture (see Figure 2-6). Your Editor would
still depend on the whims of your fan
community.
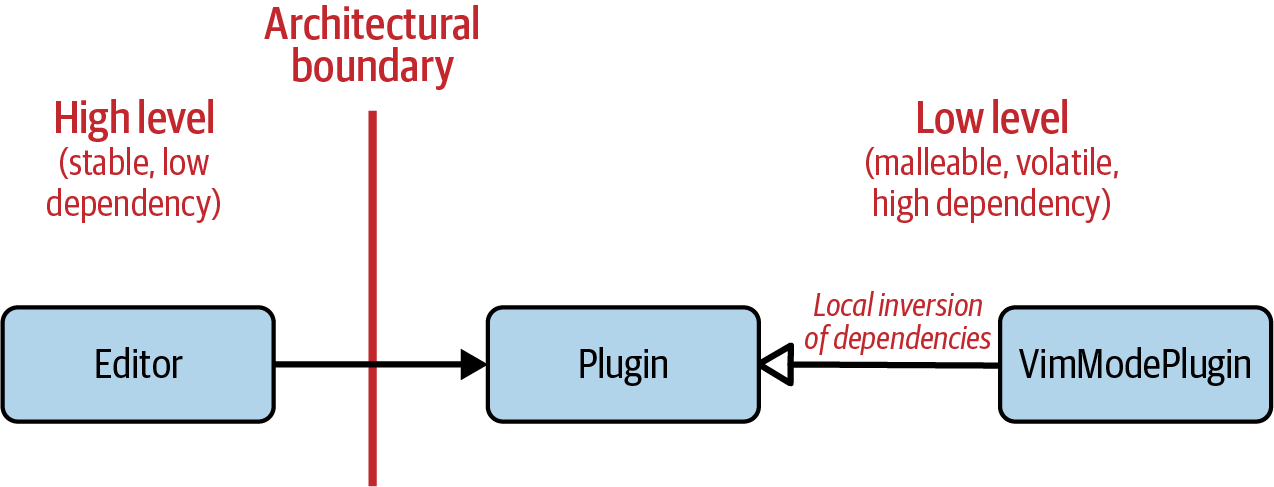
Figure 2-6. Broken plug-in architecture: the high-level Editor class depends on the low-level Plugin class
This misdirected dependency also becomes apparent when looking at the source code:
//---- <thirdparty/Plugin.h> ----------------classPlugin{/*...*/};// Defines the requirements for plugins//---- <thirdparty/VimModePlugin.h> ----------------#include<thirdparty/Plugin.h>classVimModePlugin:publicPlugin{/*...*/};//---- <yourcode/Editor.h> ----------------#include<thirdparty/Plugin.h>// Wrong direction of dependencies!classEditor{/*...*/};
The only way to build a proper plug-in architecture is to assign the abstraction
to the high level. The abstraction must belong to you, not to
your fan community. Figure 2-7 demonstrates that this resolves the architectural
dependency and frees your Editor class from the dependencies on plug-ins. This
resolves both the DIP, because the dependency is properly inverted, and
the SRP, because the abstraction belongs to the high level.
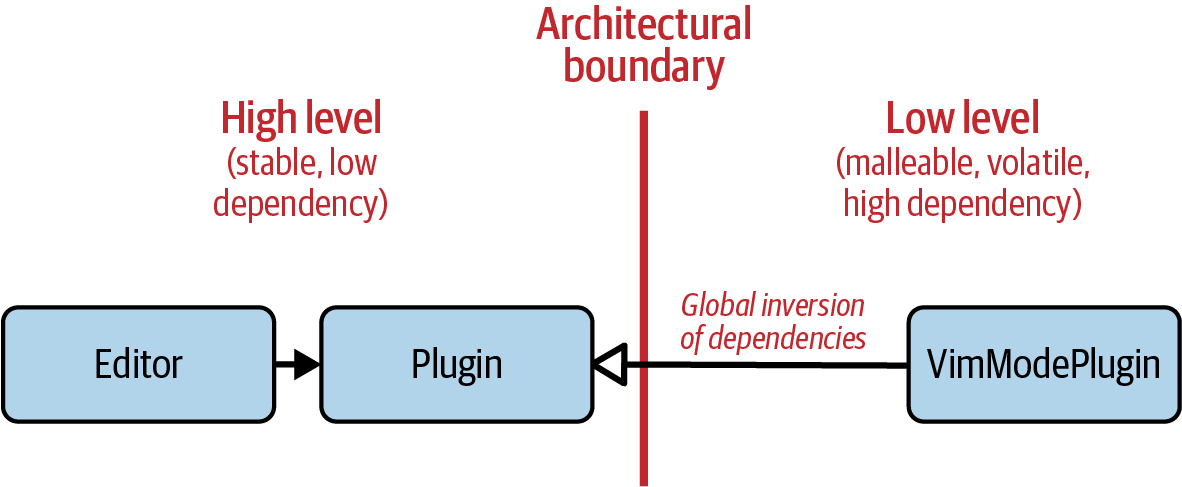
Figure 2-7. Correct plug-in architecture: the low-level VimModePlugin class depends on the high-level Plugin class
A look at the source code reveals that the direction of dependencies has been
fixed: the VimModePlugin depends on your code, and not vice versa:
//---- <yourcode/Plugin.h> ----------------classPlugin{/*...*/};// Defines the requirements for plugins//---- <yourcode/Editor.h> ----------------#include<yourcode/Plugin.h>classEditor{/*...*/};//---- <thirdparty/VimModePlugin.h> ----------------#include<yourcode/Plugin.h>// Correct direction of dependenciesclassVimModePlugin:publicPlugin{/*...*/};
Again, to get a proper dependency inversion, the abstraction must be
owned by the high level. In this context, the Plugin class represents the
set of requirements that needs to be fulfilled by all plug-ins (see again
“Guideline 6: Adhere to the Expected Behavior of Abstractions”). The Editor defines
and thus owns these requirements. It doesn’t depend on them. Instead, the
different plug-ins depend on the requirements. That is dependency inversion.
Hence, the DIP is not just about the introduction of an abstraction but also
about the ownership of that abstraction.
Dependency Inversion via Templates
So far I might have given you the impression that the DIP is concerned with only inheritance hierarchies and base classes.
However, dependency inversion is also achieved with templates. In
that context, however, the question of ownership is resolved automatically.
As an example, let’s consider the std::copy_if() algorithm:
template<typenameInputIt,typenameOutputIt,typenameUnaryPredicate>OutputItcopy_if(InputItfirst,InputItlast,OutputItd_first,UnaryPredicatepred);
This copy_if() algorithm also adheres to the DIP. The dependency inversion is
achieved with the concepts InputIt, OutputIt, and UnaryPredicate.
These three concepts represent the requirements on the passed iterators and
predicates that need to be fulfilled by calling code. By specifying these
requirements through concepts, i.e., by owning these concepts, std::copy_if()
makes other code depend on itself and does not itself depend on other code. This
dependency structure is depicted in Figure 2-8: both containers and
predicates depend on the requirements expressed by the corresponding algorithm. Thus,
if we consider the architecture within the Standard Library, then std::copy_if()
is part of the high level of the architecture, and containers and predicates (function objects, lambdas, etc.) are part of the low level of the architecture.
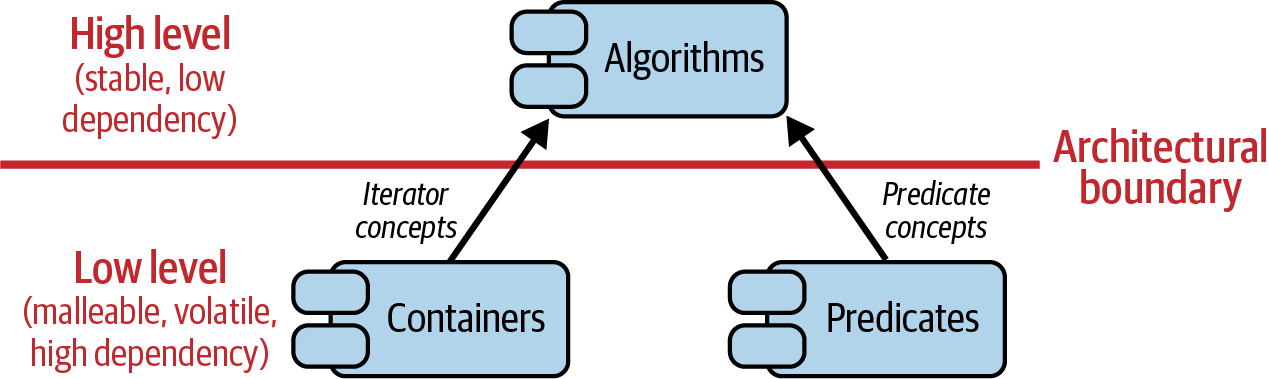
Figure 2-8. Dependency structure of the STL algorithms
Dependency Inversion via Overload Sets
Inheritance hierarchies and concepts are not the only means to invert dependencies.
Any kind of abstraction is able to do so. Therefore, it shouldn’t come as
a surprise that overload sets also enable you to follow the DIP. As you have seen
in “Guideline 8: Understand the Semantic Requirements of Overload Sets”, overload sets
represent an abstraction and, as such, a set of semantic requirements and expectations.
In comparison to base classes and concepts, though, there is unfortunately no code
that explicitly describes the requirements. But if these requirements are owned by
a higher level in your architecture, you can achieve dependency inversion. Consider,
for instance, the following Widget class template:
//---- <Widget.h> ----------------#include<utility>template<typenameT>structWidget{Tvalue;};template<typenameT>voidswap(Widget<T>&lhs,Widget<T>&rhs){usingstd::swap;swap(lhs.value,rhs.value);}
Widget owns a data member of an unknown type T. Despite the fact that
T is unknown, it is possible to implement a custom swap() function for Widget
by building on the semantic expectations of the swap() function. This
implementation works, as long as the swap() function for T adheres to all
expectations for swap() and follows the LSP:21
#include<Widget.h>#include<assert>#include<cstdlib>#include<string>intmain(){Widget<std::string>w1{"Hello"};Widget<std::string>w2{"World"};swap(w1,w2);assert(w1.value=="World");assert(w2.value=="Hello");returnEXIT_SUCCESS;}
In consequence, the Widget swap() function itself follows the expectations and
adds to the overload set, similar to what a derived class would do. The dependency
structure for the swap() overload set is shown in Figure 2-9. Since the
requirements, or the expectations, for the overload set are part of the high level
of the architecture, and since any implementation of swap() depends on these
expectations, the dependency runs from the low level toward the high level. The
dependency is therefore properly inverted.
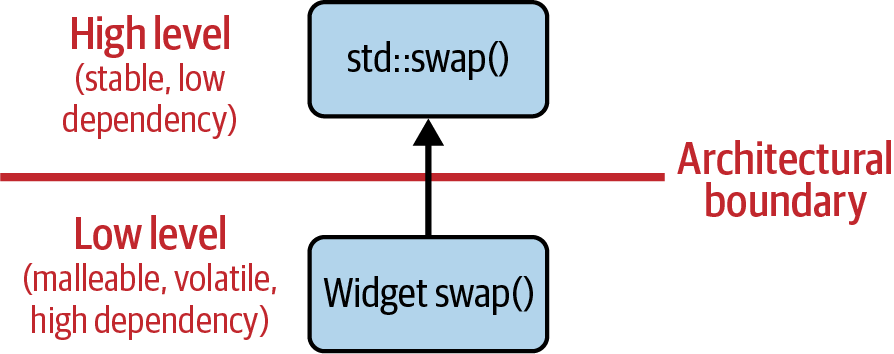
Figure 2-9. Dependency structure of the swap() overload set
Dependency Inversion Principle Versus Single-Responsibility Principle
As we have seen, the DIP is fulfilled by properly assigning ownership and by properly grouping the things that truly belong. From that perspective, it sounds plausible to consider the DIP as just another special case of the SRP (similar to the ISP). However, hopefully you see that the DIP is more than that. As the DIP, in contrast to the SRP, is very much concerned with the architectural point of view, I consider it a vital piece of advice to build proper global dependency structures.
To summarize, in order to build a proper architecture with a proper dependency structure, it’s essential to pay attention to the ownership of abstractions. Since abstractions represent requirements on the implementations, they should be part of the high level to steer all dependencies toward the high level.
Guideline 10: Consider Creating an Architectural Document
Let’s chat a little about your architecture. Let me start with a very simple question: do you have an architectural document? Any plan or description that summarizes the major points and fundamental decisions of your architecture and that shows the high levels, the low levels, and the dependencies between them? If your answer is yes, then you’re free to skip this guideline and continue with the next one. If your answer is no, however, then let me ask a few follow-up questions. Do you have a Continuous Integration (CI) environment? Do you use automated tests? Do you apply static code analysis tools? All yes? Good, there’s still hope. The only remaining question is: why don’t you have an architectural document?
“Oh, come on, don’t turn a mosquito into an elephant. A missing architectural document is not the end of the world! After all, we are Agile, we can change things quickly!” Imagine my completely blank expression, followed by a long sigh. Well, honestly, I was afraid this would be your explanation. It’s unfortunately what I hear far too often. There may be a misunderstanding: the ability to quickly change things is not the point of an Agile methodology. Sadly, I also have to tell you that your answer doesn’t make any sense. You could just as well have answered with “After all, we like chocolate!” or “After all, we wear carrots around our necks!” To explain what I mean, I will quickly summarize the point of the Agile methodology and then subsequently explain why you should invest in an architectural document.
The expectation that Agile methods help to change things quickly is pretty widespread. However, as several authors in the recent past have clarified, the major, and probably only, point of the Agile methodology is to get quick feedback.22 In Agile methods, the entire software development process is built around it: quick feedback due to business practices (such as planning, small releases, and acceptance tests), quick feedback due to team practices (e.g., collective ownership, CI, and stand-up meetings), and quick feedback due to technical practices (such as test-driven development, refactoring, and pair programming). However, contrary to popular belief, the quick feedback does not mean that you can change your software quickly and easily. Though quick feedback is, of course, key to quickly knowing that something has to be done, you gain the ability to quickly change your software only with good software design and architecture. These two save you the Herculean effort to change things; quick feedback only tells you something is broken.
“OK, you’re right. I get your point—it is important to pay attention to good software design and architecture. But what’s the point of an architectural document?” I’m glad we agree. And that is an excellent question. I see we are making progress. To explain the purpose of an architectural document, let me give you another definition of architecture:23
In most successful software projects, the expert developers working on that project have a shared understanding of the system design. This shared understanding is called ‘architecture.’
Ralph Johnson
Ralph Johnson describes architecture as the shared understanding of a codebase—the global vision. Let’s assume that there is no architectural document, nothing that summarizes the global picture—the global vision of your codebase. Let’s also assume that you believe you have a very clear idea of the architecture of your codebase. Then here are a few more questions: how many developers are on your team? Are you certain that all of these developers are familiar with the architecture in your head? Are you certain that all of them share the same vision? Are you certain that they all help you move forward in the same direction?
If your answers are yes, then you might not have gotten the point yet. It is fairly certain that every developer has different experiences and a slightly different terminology. It is also fairly certain that every developer sees the code differently and has a slightly different idea of the current architecture. And this slightly different view of the current state of affairs may lead to a slightly different vision for the future. While this might not be immediately evident over a short period of time, there is a good chance that surprises will happen in the long run. Misunderstandings. Misinterpretations. This is exactly the point of an architectural document: one common document that unifies the ideas, visions, and essential decisions in one place; helps maintain and communicate the state of the architecture; and helps avoid any misunderstandings.
This document also preserves ideas, visions, and decisions. Imagine that one of your leading software architects, one of the brains behind the architecture of your codebase, leaves the organization. Without a document with the fundamental decisions, this loss of manpower will also cause a loss of essential information about your codebase. As a consequence, you will lose consistency in the vision of your architecture and also, more importantly, some confidence to adapt or change architectural decisions. No new hire will ever be able to replace that knowledge and experience, and no one will be able to extract all that information from the code. Thus, the code will become more rigid, more “legacy.” This promotes decisions to rewrite large parts of the code, with questionable outcomes, as the new code will initially lack a lot of the wisdom of the old code.24 Thus, without an architectural document, your long-term success is at stake.
The value in such an architectural document becomes obvious if we take a look at how seriously architecture is taken at construction sites. Construction is not even going to start without a plan. A plan that everyone agrees to. Or let’s imagine what would happen if there was no plan: “Hey, I said the garage should be to the left of the house!” “But I built it to the left of the house.” “Yes, but I meant my left, not your left!”
This is exactly the kind of problem that can be avoided by investing time in an architectural document. “Yes, yes, you’re right,” you admit, “but such a document is soooo much work. And all of this information is in the code anyway. It adapts with the code, while the document goes out of date soooo quickly!” Well, not if you’re doing it properly. An architectural document shouldn’t go out of date quickly because it should primarily reflect the big picture of your codebase. It shouldn’t contain the little details that indeed can change very often; instead, it should contain the overall structure, the connections between key players, and the major technological decisions. All these things are not expected to change (although we all agree that “not expected to change” doesn’t mean that they won’t change; after all, software is expected to change). And yes, you are correct: these details are, of course, also part of the code. After all, the code contains all the details and thus can be said to represent the ultimate truth. However, it doesn’t help if the information is not easy to come by, is hidden from plain sight, and requires an archaeological effort to extract.
I am also aware that, in the beginning, the endeavor to create an architectural document does sound like a lot of work. An enormous amount of work. All I can do is encourage you to get started somehow. Initially, you do not have to document your architecture in all its glory, but maybe you start with only the most fundamental structural decisions. Some tools can already use this information to compare your assumed architectural state and its actual state.25 Over time, more and more architectural information can be added, documented, and maybe even tested by tools, which leads to more and more commonly available, established wisdom for your entire team.
“But how do I keep this document up to date?” you ask. Of course, you’ll have to maintain this document, integrate new decisions, update old decisions, etc. However, since this document should only contain information about the aspects that do not often change, there should be no need to constantly touch and refactor it. It should be enough to schedule a short meeting of the senior developers every one or two weeks to discuss if and how the architecture has evolved. Thus, it is hard to imagine this document becoming a bottleneck in the development process. In this regard, consider this document a bank deposit safe: it is invaluable to have all of the accumulated decisions of the past when you need them and to keep the information secure, but you wouldn’t open it every single day.
In summary, the benefits of having an architectural document by far outweigh the risks and efforts. The architectural document should be considered an essential part of any project and an integral part of the maintenance and communication efforts. It should be considered equally important as a CI environment or automated tests.
1 In one of my training classes several years ago, I was “gently” reminded that from a mathematical perspective, a square is not a rectangle but a rhombus. My knees still shake when I think about that lecture. Therefore, I specifically say “appears to be” instead of “is” to denote the naive impression that unaware people like me might have had.
2 Not mathematically, but in this implementation.
3 The LSP was first introduced by Barbara Liskov in the paper “Data Abstraction and Hierarchy” in 1988. In 1994, it was reformulated in the paper “A Behavioral Notion of Subtyping” by Barbara Liskov and Jeannette Wing. For her work, Barbara Liskov received the Turing Award in 2008.
4 If you have a strong opinion about a square being a rhombus, please forgive me!
5 And yet, in a sufficiently large codebase, there’s a good chance that you’ll find at least one example of this kind of malpractice. In my experience, it’s often the result of too little time to rethink and adapt the abstraction.
6 This is indeed a very often discussed topic. You’ll find a very good summary of this in foonathan’s blog.
7 In C++20, std::copy() is finally constexpr but does not yet use the std::input_iterator and std::output_iterator concepts. It is still based on the formal description of input and output iterators; see LegacyInputIterator and LegacyOutputIterator.
8 And no, it wouldn’t be a compile-time error, unfortunately.
9 The free begin() and end() functions are an example of the Adapter design pattern; see “Guideline 24: Use Adapters to Standardize Interfaces” for more details.
10 That is why range-based for loops build on the free begin() and end() functions.
11 Alexander Stepanov and Meng Lee, “The Standard Template Library”, October 1995.
12 Scott Meyers, Effective STL: 50 Specific Ways to Improve Your Use of the Standard Template Library (Addison-Wesley Professional, 2001).
13 Free functions are indeed a seriously valuable design tool. To give one example of this, allow me to tell a short war story. You might know Martin Fowler’s book Refactoring: Improving the Design of Existing Code (Addison-Wesley), which may be considered one of the classics for professional software development. The first edition of the book was published in 2012 and provided programming examples in Java. The second edition of the book was released in 2018, but interestingly rewritten with JavaScript. One of the reasons for that choice was the fact that any language having a C-like syntax was considered easier to digest for a majority of readers. However, another important reason was the fact that JavaScript, unlike Java, provides free functions, which Martin Fowler considers a very important tool for decoupling and separating concerns. Without this feature, you would be limited in your flexibility to achieve the refactoring goal.
14 A great discussion of this can be found in episode 83 of Cpp.Chat, where Jon Kalb, Phil Nash, and Dave Abrahams discuss the lessons learned from C++ and how they were applied in the development of the Swift programming language.
15 As Kate Gregory would say, “Naming Is Hard: Let’s Do Better.” This is the title of her highly recommended talk from CppCon 2019.
16 Robert C. Martin, Clean Architecture (Addison-Wesley, 2017).
17 This example is taken from Robert Martin’s book Agile Software Development: Principles, Patterns, and Practices (Prentice Hall, 2002). Martin used this example to explain the Interface Segregation Principle (ISP), and for that reason, he didn’t go into detail about the question of ownership of abstractions. I will try to fill this gap.
18 If you argue that the Transaction base class could be on an even higher level, you are correct. You’ve earned yourself a bonus point! But for the remainder of the example we won’t need this extra level, and therefore I will ignore it.
19 If you’re wondering about the two informInsufficientFunds() functions: yes, it is possible to implement both virtual functions (i.e., the one from the WithdrawalUI and the one from the TransferUI) by means of a single implementation in the UI class. Of course, this works well only as long as these two functions represent the same expectations and thus can be implemented as one. However, if they represent different expectations, then you’re facing a Siamese Twin Problem (see Item 26 in Herb Sutter’s More Exceptional C++: 40 New Engineering Puzzles, Programming Problems, and Solutions (Addison-Wesley). For our example, let’s assume that we can deal with these two virtual functions the easy way.
20 Martin, Clean Architecture.
21 I know what you’re thinking. However, it was just a matter of time until you encountered a “Hello World” example.
22 The point is, for instance, made by Robert C. Martin, one of the signees of the Agile manifesto, in his book Clean Agile: Back to Basics (Pearson). A second good summary is given by Bertrand Meyer in Agile! The Good, the Hype and the Ugly (Springer). Finally, you can also consult the second edition of James Shore’s book The Art of Agile Development (O’Reilly). A good talk on the misuse of the term Agile is Dave Thomas’s “Agile Is Dead” presentation from GOTO 2015.
23 Quoted in Martin Fowler, “Who Needs an Architect?” IEEE Software 20, no. 5 (2003), 11–13, https://doi.org/10.1109/MS.2003.1231144.
24 Joel Spolsky, whom you may know as the author of the Joel on Software blog, and also as one of the creators of Stack Overflow, named the decision to rewrite a large piece of code from scratch “the single worst strategic mistake that any company can make”.
25 One possible tool for this purpose is the Axivion Suite. You start by defining architectural boundaries between your modules, which can be used by the tool to check if the architectural dependencies are upheld. Another tool with such capabilities is the Sparx Systems Enterprise Architect.