Chapter 5. The Strategy and Command Design Patterns
This chapter is devoted to two of the most commonly used design patterns: the Strategy design pattern and the Command design pattern. Most commonly used indeed: the C++ Standard Library itself uses both of them dozens of times, and it’s very likely that you have used them many times yourself. Both of these can be considered fundamental tools for every developer.
In “Guideline 19: Use Strategy to Isolate How Things Are Done”, I will introduce you to the Strategy design pattern. I will demonstrate why this is one of the most useful and most important design patterns and why you will find it useful in many situations.
In “Guideline 20: Favor Composition over Inheritance”, we will take a look at inheritance and why so many people complain about it. You will see that it’s not bad per se, but like everything else, it has its benefits as well as limitations. Most importantly, however, I will explain that many of the classic design patterns do not draw their power from inheritance but rather from composition.
In “Guideline 21: Use Command to Isolate What Things Are Done”, I will introduce you to the Command design pattern. I will show you how to use that design pattern productively, and also give you an idea of how Command and Strategy compare.
In “Guideline 22: Prefer Value Semantics over Reference Semantics”, we take a trip into the realm of reference semantics. However, we will find that this realm is not particularly friendly and hospitable and makes us worry about the quality of our code. Thus, we will resettle into the realm of value semantics, which will welcome us with many benefits for our codebase.
In “Guideline 23: Prefer a Value-Based Implementation of Strategy and Command”,
we will revisit the Strategy and Command patterns. I will demonstrate
how we can
apply the insight we gained in the realm of value semantics and implement both design
patterns based on std::function.
Guideline 19: Use Strategy to Isolate How Things Are Done
Let’s imagine that you and your team are about to implement a new 2D graphics tool. Among other requirements, it needs to deal with simple geometric primitives, such as circles, squares, and so on, which need to be drawn (see Figure 5-1).
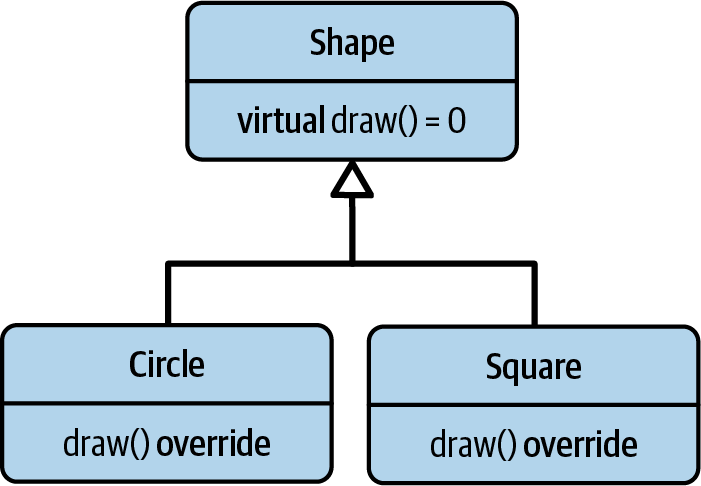
Figure 5-1. The initial Shape inheritance hierarchy
A couple of classes have already been implemented, such as a Shape base class, a
Circle class,
and a Square class:
//---- <Shape.h> ----------------classShape{public:virtual~Shape()=default;virtualvoiddraw(/*some arguments*/)const=0;};//---- <Circle.h> ----------------#include<Point.h>#include<Shape.h>classCircle:publicShape{public:explicitCircle(doubleradius):radius_(radius){/* Checking that the given radius is valid */}doubleradius()const{returnradius_;}Pointcenter()const{returncenter_;}voiddraw(/*some arguments*/)constoverride;private:doubleradius_;Pointcenter_{};};//---- <Circle.cpp> ----------------#include<Circle.h>#include/* some graphics library */voidCircle::draw(/*some arguments*/)const{// ... Implementing the logic for drawing a circle}//---- <Square.h> ----------------#include<Point.h>#include<Shape.h>classSquare:publicShape{public:explicitSquare(doubleside):side_(side){/* Checking that the given side length is valid */}doubleside()const{returnside_;}Pointcenter()const{returncenter_;}voiddraw(/*some arguments*/)constoverride;private:doubleside_;Pointcenter_{};};//---- <Square.cpp> ----------------#include<Square.h>#include/* some graphics library */voidSquare::draw(/*some arguments*/)const{// ... Implementing the logic for drawing a square}
The most important aspect is the pure virtual draw() member function of the Shape base class
(![]() ).
While you were on vacation, one of your team members already implemented this
).
While you were on vacation, one of your team members already implemented this draw()
member function for both the Circle and the Square classes using OpenGL
(![]() and
and ![]() ).
The tool is already able to draw circles and squares, and the entire team agrees
that the resulting graphics look pretty neat. Everyone is happy!
).
The tool is already able to draw circles and squares, and the entire team agrees
that the resulting graphics look pretty neat. Everyone is happy!
Analyzing the Design Issues
Everyone, except you, that is. Returning from your vacation, you of course immediately
realize that the implemented solution violates the Single-Responsibility Principle
(SRP).1 As it is, the Shape hierarchy is not designed
for change. First, it’s not easy to change the way a shape is drawn. In the current
implementation, there is only one fixed way of drawing shapes, and it’s not possible to change
these details nonintrusively. Since you already predict that the tool will have to support
multiple graphic libraries, this is definitely a problem.2
And second, if you eventually perform the change, you need to change the behavior
in multiple, unrelated places.
But there is more. Since the drawing functionality is implemented inside Circle
and Square, the Circle and Square classes depend on the implementation details of
draw(), meaning they depend on OpenGL. Despite the fact that circles and squares should
primarily be some simple geometric primitives, these two classes now carry the burden of
having to use OpenGL everywhere they are used.
When pointing this out to your colleagues, they are, at first, a little dumbfounded. And also a little annoyed, since they didn’t expect you to point out any flaws in their beautiful solution. However, you have a very nice way of explaining the problem, and eventually they agree with you and start to think about a better solution.
It doesn’t take them long to come up with a better approach. In the next team meeting a few days later, they present their new idea: another layer in the inheritance hierarchy (see Figure 5-2).
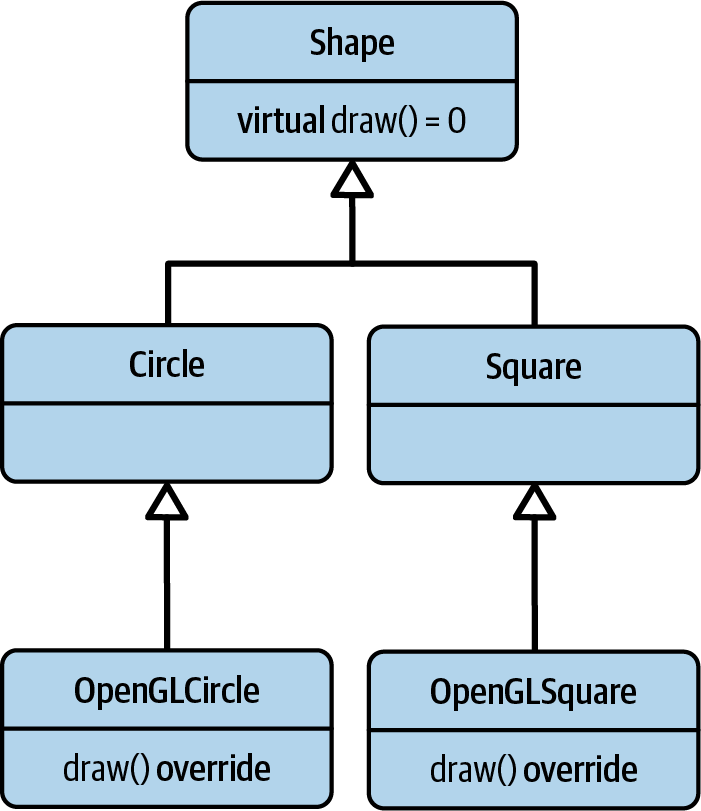
Figure 5-2. The extended Shape inheritance hierarchy
To demonstrate the idea, they have already implemented the OpenGLCircle and
OpenGLSquare classes:
//---- <Circle.h> ----------------#include<Shape.h>classCircle:publicShape{public:// ... No implementation of the draw() member function anymore};//---- <OpenGLCircle.h> ----------------#include<Circle.h>classOpenGLCircle:publicCircle{public:explicitOpenGLCircle(doubleradius):Circle(radius){}voiddraw(/*some arguments*/)constoverride;};//---- <OpenGLCircle.cpp> ----------------#include<OpenGLCircle.h>#include/* OpenGL graphics library headers */voidOpenGLCircle::draw(/*some arguments*/)const{// ... Implementing the logic for drawing a circle by means of OpenGL}//---- <Square.h> ----------------#include<Shape.h>classSquare:publicShape{public:// ... No implementation of the draw() member function anymore};//---- <OpenGLSquare.h> ----------------#include<Square.h>classOpenGLSquare:publicSquare{public:explicitOpenGLSquare(doubleside):Square(side){}voiddraw(/*some arguments*/)constoverride;};//---- <OpenGLSquare.cpp> ----------------#include<OpenGLSquare.h>#include/* OpenGL graphics library headers */voidOpenGLSquare::draw(/*some arguments*/)const{// ... Implementing the logic for drawing a square by means of OpenGL}
Inheritance! Of course! By simply deriving from Circle and Square, and by moving the
implementation of the draw() function further down the hierarchy, it is easily possible
to implement the drawing in different ways. For instance, there could be a MetalCircle
and a VulkanCircle, assuming that the Metal and
Vulkan libraries need to be supported. Suddenly, change is easy,
right?
While your colleagues are still very proud about their new solution, you already realize
that this approach will not work well for long. And it is easy to demonstrate the
shortcomings: all you have to do is consider another requirement, for instance, a
serialize() member
function:
classShape{public:virtual~Shape()=default;virtualvoiddraw(/*some arguments*/)const=0;virtualvoidserialize(/*some arguments*/)const=0;};
The serialize() member function
(![]() )
is supposed to transform a shape into a byte sequence, which can be stored in a file or a
database. From there, it’s possible to deserialize the byte sequence to re-create the
exact same shape. And just like the
)
is supposed to transform a shape into a byte sequence, which can be stored in a file or a
database. From there, it’s possible to deserialize the byte sequence to re-create the
exact same shape. And just like the draw() member function, the serialize() member function
can be implemented in various ways. For instance, you could reach for the
protobuf or
Boost.serialization
libraries.
Using the same strategy of moving the implementation details down the inheritance hierarchy,
this will quickly lead to a pretty complex and rather artificial hierarchy (see
Figure 5-3). Consider the class names: OpenGLProtobufCircle,
MetalBoostSerialSquare, and so on. Ridiculous, right? And how should we structure this: should
we add another layer in the hierarchy (see the Square branch)? That approach would quickly
lead to a deep and complex hierarchy. Or should we rather flatten the hierarchy out (as in
the Circle branch of the hierarchy)? And what about reusing implementation details? For
instance, how would it be possible to reuse the OpenGL code between the OpenGLProtobufCircle
and the OpenGLBoostSerialCircle classes?
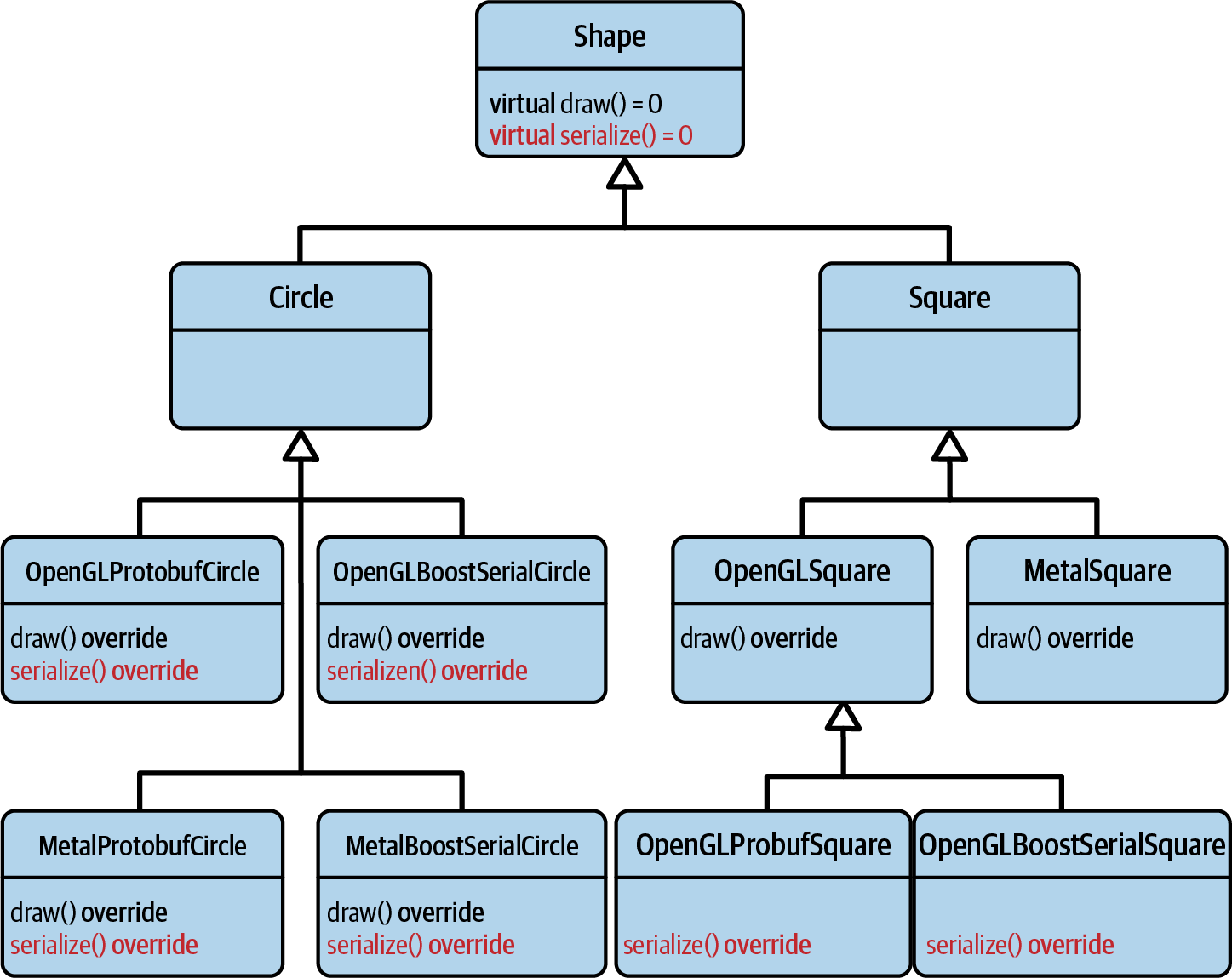
Figure 5-3. Adding the serialize() member function results in a deep and complex inheritance hierarchy
The Strategy Design Pattern Explained
You realize that your colleagues are just too enamored with inheritance, and that it’s up to you to save the day. They appear to need someone to show them how to properly design for this kind of change and present them a proper solution to the problem. As the two pragmatic programmers remarked:3
Inheritance is rarely the answer.
The problem is still the violation of the SRP. Since you have to plan for changing how the different shapes are drawn, you should identify the drawing aspect as a variation point. With this realization, the correct approach is to design for change, follow the SRP, and thus extract the variation point. That is the intent of the Strategy design pattern, one of the classic GoF design patterns.
The Strategy Design Pattern
Intent: “Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.”4
Instead of implementing the virtual draw() function in a derived class, you introduce another
class for the purpose of drawing shapes. In the case of the classic, object-oriented (OO) form of
the Strategy design pattern, this is achieved by introducing the DrawStrategy base class (see
Figure 5-4).
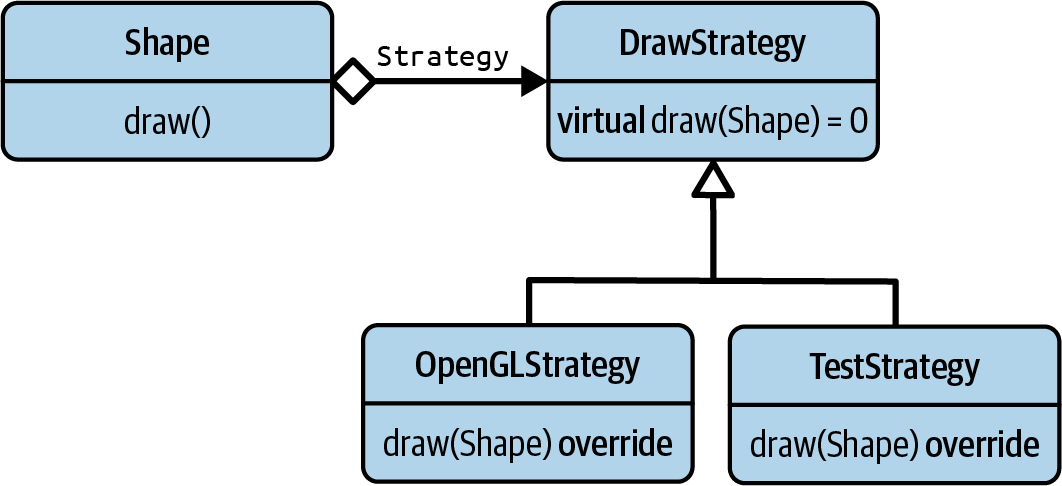
Figure 5-4. The UML representation of the Strategy design pattern
The isolation of the drawing aspect now allows us to change the implementation of drawing
without having to modify the shape classes. This fulfills the idea of the SRP. You are
now also able to introduce new implementations of draw() without modification of any
other code. That fulfills the Open-Closed Principle (OCP). Once again, in this OO setting,
SRP is the enabler of the OCP.
The following code snippet shows a naive implementation of the DrawStrategy base
class:5
//---- <DrawStrategy.h> ----------------classCircle;classSquare;classDrawStrategy{public:virtual~DrawStrategy()=default;virtualvoiddraw(Circleconst&circle,/*some arguments*/)const=0;virtualvoiddraw(Squareconst&square,/*some arguments*/)const=0;};
The DrawStrategy class comes with a virtual destructor and two pure virtual draw()
functions, one for circles
(![]() )
and one for squares
(
)
and one for squares
(![]() ).
For this base class to compile, you need to forward declare the
).
For this base class to compile, you need to forward declare the Circle and the
Square classes.
The Shape base class does not change due to the Strategy design pattern. It still
represents an abstraction for all shapes and thus offers a pure virtual draw() member
function. Strategy aims at extracting implementation details and thus affects only the
derived classes:6
//---- <Shape.h> ----------------classShape{public:virtual~Shape()=default;virtualvoiddraw(/*some arguments*/)const=0;// ... Potentially other functions, e.g. a 'serialize()' member function};
While the Shape base class does not change due to Strategy, the Circle and Square
classes are affected:
//---- <Circle.h> ----------------#include<Shape.h>#include<DrawStrategy.h>#include<memory>#include<utility>classCircle:publicShape{public:explicitCircle(doubleradius,std::unique_ptr<DrawStrategy>drawer):radius_(radius),drawer_(std::move(drawer)){/* Checking that the given radius is valid and that the given std::unique_ptr instance is not nullptr */}voiddraw(/*some arguments*/)constoverride{drawer_->draw(*this,/*some arguments*/);}doubleradius()const{returnradius_;}private:doubleradius_;std::unique_ptr<DrawStrategy>drawer_;};//---- <Square.h> ----------------#include<Shape.h>#include<DrawStrategy.h>#include<memory>#include<utility>classSquare:publicShape{public:explicitSquare(doubleside,std::unique_ptr<DrawStrategy>drawer):side_(side),drawer_(std::move(drawer)){/* Checking that the given side length is valid and that the given std::unique_ptr instance is not nullptr */}voiddraw(/*some arguments*/)constoverride{drawer_->draw(*this,/*some arguments*/);}doubleside()const{returnside_;}private:doubleside_;std::unique_ptr<DrawStrategy>drawer_;};
Both Circle and Square are now expecting a unique_ptr to a DrawStrategy in their
constructors
(![]() ).
This allows us to configure the drawing behavior from the outside, commonly called dependency injection. The
).
This allows us to configure the drawing behavior from the outside, commonly called dependency injection. The unique_ptr is moved
(![]() )
into a new data member of the same type
(
)
into a new data member of the same type
(![]() ).
It is also possible to provide corresponding setter
functions, which would allow
you to change the drawing behavior at a later point. The
).
It is also possible to provide corresponding setter
functions, which would allow
you to change the drawing behavior at a later point. The draw() member function now doesn’t have to implement the drawing itself but simply has to call the draw() function for
the given DrawStrategy
(![]() ).7
).7
Analyzing the Shortcomings of the Naive Solution
Wonderful! With this implementation in place, you are now able to locally, in isolation,
change the behavior of how shapes are drawn, and you enable everyone to implement the new
drawing behavior. However, as it is right now, our Strategy implementation has a serious
design flaw. To analyze this flaw, let’s assume that you have to add a new kind
of shape, maybe a Triangle. This should be easy, because, as we have discussed in
“Guideline 15: Design for the Addition of
Types or Operations”, the strength of OOP is the addition of new types.
As you’re starting to introduce this Triangle, you realize that it’s not as easy to add
the new kind of shape as expected. First, you need to write the new class. That is to be
expected and not a problem at all. But then you have to update the DrawStrategy base class to also enable the drawing of triangles. This, in turn, will have an unfortunate impact
on circles and squares: both the Circle and Square classes need to be recompiled, retested,
and potentially redeployed. More generally speaking, all shapes are affected in this way.
And that should strike you as problematic. Why should circles and squares have to recompile
if you add a Triangle class?
The technical reason is that via the DrawStrategy base class, all shapes implicitly
know about one another. Adding a new shape therefore affects all other shapes.
The underlying design reason is a violation of the Interface Segregation Principle (ISP)
(see “Guideline 3: Separate Interfaces to Avoid
Artificial Coupling”). By defining a single
DrawStrategy base class, you have artificially coupled circles,
squares, and triangles together. Due to this coupling, you have made it more difficult
to add new types and thus have limited the strength of OOP. In comparison, you
have created a very similar situation as we had when we talked about a procedural
solution for the drawing of shapes (see “Guideline 15: Design for the Addition of
Types or Operations”).
“Didn’t we unintentionally reimplement the Visitor design pattern?” you are wondering.
I see your point: the DrawStrategy looks very similar to a Visitor indeed. But
unfortunately, it does not fulfill the intent of a Visitor, since you cannot easily
add other operations. To do so, you would have to intrusively add a virtual
member
function in the Shape hierarchy. “And it is not a Strategy either, because
we cannot add types, right?” Yes, correct. You see, from a design perspective, this is
the worst kind of situation.
To properly implement the Strategy design pattern, you have to extract the
implementation details of each shape separately. You have to introduce
one DrawStrategy class for each kind of shape:
//---- <DrawCircleStrategy.h> ----------------classCircle;classDrawCircleStrategy{public:virtual~DrawCircleStrategy()=default;virtualvoiddraw(Circleconst&circle,/*some arguments*/)const=0;};//---- <Circle.h> ----------------#include<Shape.h>#include<DrawCircleStrategy.h>#include<memory>#include<utility>classCircle:publicShape{public:explicitCircle(doubleradius,std::unique_ptr<DrawCircleStrategy>drawer):radius_(radius),drawer_(std::move(drawer)){/* Checking that the given radius is valid and that the given 'std::unique_ptr' is not a nullptr */}voiddraw(/*some arguments*/)constoverride{drawer_->draw(*this,/*some arguments*/);}doubleradius()const{returnradius_;}private:doubleradius_;std::unique_ptr<DrawCircleStrategy>drawer_;};//---- <DrawSquareStrategy.h> ----------------classSquare;classDrawSquareStrategy{public:virtual~DrawSquareStrategy()=default;virtualvoiddraw(Squareconst&square,/*some arguments*/)const=0;};//---- <Square.h> ----------------#include<Shape.h>#include<DrawSquareStrategy.h>#include<memory>#include<utility>classSquare:publicShape{public:explicitSquare(doubleside,std::unique_ptr<DrawSquareStrategy>drawer):side_(side),drawer_(std::move(drawer)){/* Checking that the given side length is valid and that the given 'std::unique_ptr' is not a nullptr */}voiddraw(/*some arguments*/)constoverride{drawer_->draw(*this,/*some arguments*/);}doubleside()const{returnside_;}private:doubleside_;std::unique_ptr<DrawSquareStrategy>drawer_;};
For the Circle class, you have to introduce the DrawCircleStrategy base class
(![]() ),
and for the
),
and for the Square class, it is the DrawSquareStrategy
(![]() )
base class. And with the addition of a
)
base class. And with the addition of a Triangle class,
you will also have to add a DrawTriangleStrategy base class. Only in this way can you properly separate concerns and still allow everyone to add new types and new
implementations for the drawing of shapes.
With this functionality in place, you can easily implement new Strategy classes
for drawing circles, squares, and eventually triangles. As an example, consider the
OpenGLCircleStrategy, which implements the DrawCircleStrategy interface:
//---- <OpenGLCircleStrategy.h> ----------------#include<Circle.h>#include<DrawCircleStrategy.h>#include/* OpenGL graphics library */classOpenGLCircleStrategy:publicDrawCircleStrategy{public:explicitOpenGLCircleStrategy(/* Drawing related arguments */);voiddraw(Circleconst&circle,/*...*/)constoverride;private:/* Drawing related data members, e.g. colors, textures, ... */};
In Figure 5-5 you can see the dependency graph for the Circle
class. Note that the Circle and DrawCircleStrategy classes are on the same
architectural level. Even more noteworthy is the cyclic dependency between them: Circle
depends on the DrawCircleStrategy, but the DrawCircleStrategy also depends on Circle.
But don’t worry: although this may look like a problem at first sight, it isn’t. It is
a necessary relationship that shows that Circle really owns the DrawCircleStrategy
and by that creates the desired dependency inversion, as discussed in
“Guideline 9: Pay Attention to the Ownership of Abstractions”.
“Wouldn’t it be possible to implement the different draw Strategy classes using a class template? I’m imagining something similar to the Visitor class used for the Acyclic Visitor”:8
//---- <DrawStrategy.h> ----------------template<typenameT>classDrawStrategy{public:virtual~DrawStrategy()=default;virtualvoiddraw(Tconst&)const=0;};
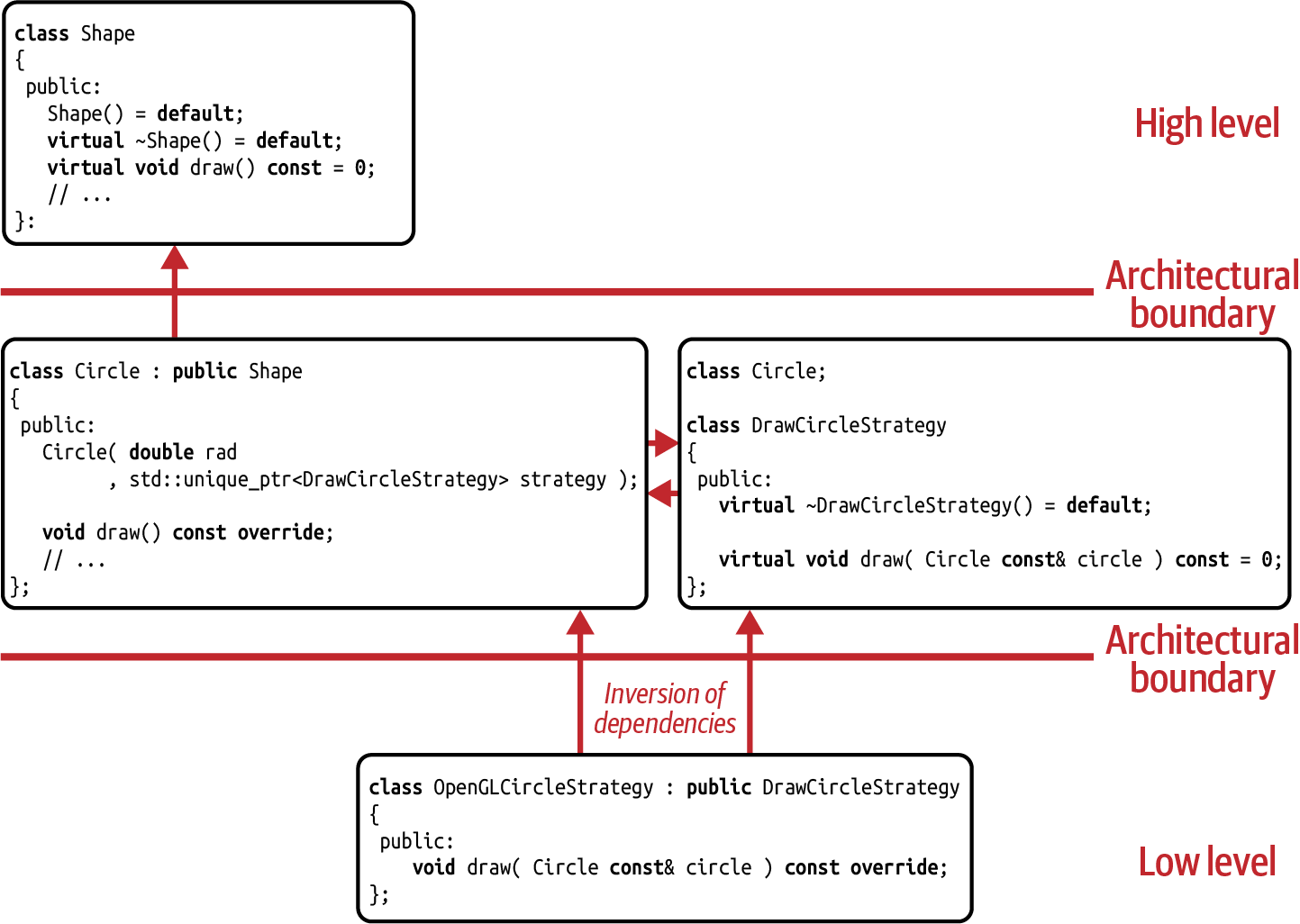
Figure 5-5. Dependency graph for the Strategy design pattern
This is a great idea and exactly what you should do. By means of this class template,
you can lift the DrawStrategy up into a higher architectural level, reuse code, and
follow the DRY principle (see Figure 5-6). Additionally,
if we would have used this approach from the start, we would not have fallen into
the trap of artificially coupling the different shape types. Yes, I really like that!
Although this is how we would implement such a Strategy class, you still should
not expect that this will reduce the number of base classes (it’s still the same, just
generated) or that it will save you a lot of work. The implementations of DrawStrategy, such as the OpenGLCircleStrategy class, represent most of the work and will hardly change:
//---- <OpenGLCircleStrategy.h> ----------------#include<Circle.h>#include<DrawStrategy.h>#include/* OpenGL graphics library */classOpenGLCircleStrategy:publicDrawStrategy<Circle>{// ...};
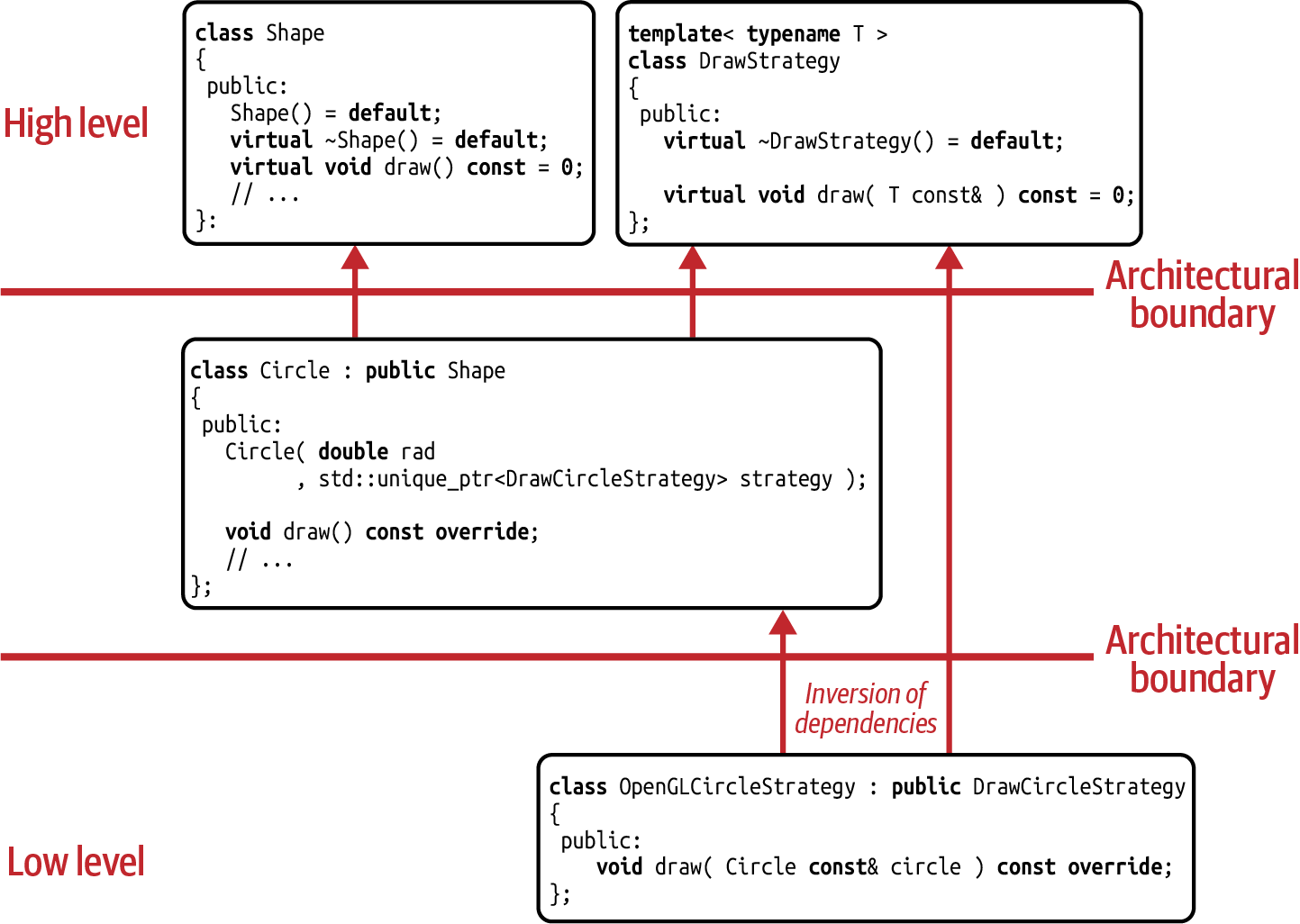
Figure 5-6. Updated dependency graph for the Strategy design pattern
Assuming a similar implementation for the OpenGLSquareStrategy, we can now put
everything together and draw shapes again but this time properly decoupled with the Strategy design pattern:
#include<Circle.h>#include<Square.h>#include<OpenGLCircleStrategy.h>#include<OpenGLSquareStrategy.h>#include<memory>#include<vector>intmain(){usingShapes=std::vector<std::unique_ptr<Shape>>;Shapesshapes{};// Creating some shapes, each one// equipped with the corresponding OpenGL drawing strategyshapes.emplace_back(std::make_unique<Circle>(2.3,std::make_unique<OpenGLCircleStrategy>(/*...red...*/)));shapes.emplace_back(std::make_unique<Square>(1.2,std::make_unique<OpenGLSquareStrategy>(/*...green...*/)));shapes.emplace_back(std::make_unique<Circle>(4.1,std::make_unique<OpenGLCircleStrategy>(/*...blue...*/)));// Drawing all shapesfor(autoconst&shape:shapes){shape->draw(/*some arguments*/);}returnEXIT_SUCCESS;}
Comparison Between Visitor and Strategy
As you have now learned about both the Visitor and Strategy design patterns, you might wonder what the difference between the two is. After all, the implementation looks fairly similar. But while there are parallels in implementation, the properties of the two design patterns are very different. With the Visitor design pattern, we have identified the general addition of operations as the variation point. Therefore, we created an abstraction for operations in general, which in turn allowed everyone to add operations. The unfortunate side effect was that it was no longer easy to add new shape types.
With the Strategy design pattern, we have identified the implementation details of a single function as a variation point. After introducing an abstraction for these implementation details, we’re still able to easily add new types of shapes, but we are not able to easily add new operations. Adding an operation would still require you to intrusively add a virtual member function. Hence, the intent of the Strategy design pattern is the opposite of the intent of the Visitor design pattern.
It may sound promising to combine the two design patterns to gain the advantages of both ideas (making it easy to add both types and operations). Unfortunately, this does not work: whichever of the two design patterns you apply first will fix one of the two axes of freedom.9 Therefore, you should just remember the strengths and weaknesses of these two design patterns and apply them based on your expectations of how your codebase will evolve.
Analyzing the Shortcomings of the Strategy Design Pattern
I have shown you the advantages of the Strategy design pattern: it allows you to reduce the dependencies on a particular implementation detail by introducing an abstraction for that detail. However, there is no silver bullet in software design, and every design comes with a number of drawbacks. The Strategy design pattern is no exception, and it’s important to also take potential disadvantages into account.
First, while the implementation details of a certain operation have been extracted and isolated, the operation itself is still part of the concrete type. This fact is evidence of the aforementioned limitation that we are still not able to easily add operations. Strategy, in contrast to Visitor, preserves the strength of OOP and enables you to easily add new types.
Second, it pays off to identify such variation points early. Otherwise a large refactoring is required. Of course, this doesn’t mean you should implement everything with Strategy up front, just in case, to avoid a refactoring. This could quickly result in overengineering. But at the first indication that an implementation detail might change, or that there is a desire to have multiple implementations, you should rather quickly implement the necessary modifications. The best, but of course a little insubstantial, advice is to keep things as simple as possible (the KISS principle; Keep It Simple, Stupid).
Third, if you implement Strategy by means of a base class, the performance will
certainly take a hit by the additional runtime indirection. The performance is also
affected by the many manual allocations (the std::make_unique() calls), the
resulting memory fragmentation, and the various indirections due to numerous pointers.
This is to be expected, yet the flexibility of your implementation and the opportunity
for everyone to add new implementations may outweigh this performance penalty. Of course,
it depends, and you will have to decide on a case-by-case basis. If you implement
Strategy using templates (see the discussion about “Policy-Based Design”),
this disadvantage is of no concern.
Last but not least, the major disadvantage of the Strategy design pattern is that
a single Strategy should deal with either a single operation or a small group of
cohesive functions. Otherwise you would again violate the SRP. If the implementation details of multiple operations need to be extracted, there
will have to be multiple Strategy base classes and multiple data members, which can
be set via dependency injection. Consider, for instance, the situation with an
additional serialize() member
function:
//---- <DrawCircleStrategy.h> ----------------classCircle;classDrawCircleStrategy{public:virtual~DrawCircleStrategy()=default;virtualvoiddraw(Circleconst&circle,/*some arguments*/)const=0;};//---- <SerializeCircleStrategy.h> ----------------classCircle;classSerializeCircleStrategy{public:virtual~SerializeCircleStrategy()=default;virtualvoidserialize(Circleconst&circle,/*some arguments*/)const=0;};//---- <Circle.h> ----------------#include<Shape.h>#include<DrawCircleStrategy.h>#include<SerializeCircleStrategy.h>#include<memory>#include<utility>classCircle:publicShape{public:explicitCircle(doubleradius,std::unique_ptr<DrawCircleStrategy>drawer,std::unique_ptr<SerializeCircleStrategy>serializer/* potentially more strategy-related arguments */):radius_(radius),drawer_(std::move(drawer)),serializer_(std::move(serializer))// ...{/* Checking that the given radius is valid and thatthe given std::unique_ptrs are not nullptrs */}voiddraw(/*some arguments*/)constoverride{drawer_->draw(*this,/*some arguments*/);}voidserialize(/*some arguments*/)constoverride{serializer_->serialize(*this,/*some arguments*/);}doubleradius()const{returnradius_;}private:doubleradius_;std::unique_ptr<DrawCircleStrategy>drawer_;std::unique_ptr<SerializeCircleStrategy>serializer_;// ... Potentially more strategy-related data members};
While this leads to a very unfortunate proliferation of base classes and larger instances due to multiple pointers, it also raises the question of how to design the class so that it’s possible to conveniently assign multiple different strategies. Therefore, the Strategy design pattern appears to be strongest in situations where you need to isolate a small number of implementation details. If you encounter a situation where you need to extract the details of many operations, it might be better to consider other approaches (see, for instance, the External Polymorphism design pattern in Chapter 7 or the Type Erasure design pattern in Chapter 8).
Policy-Based Design
As already demonstrated in previous chapters, the Strategy design pattern is not limited to dynamic polymorphism. On the contrary, the intent of Strategy can be implemented perfectly in static polymorphism using templates. Consider, for instance, the following two algorithms from the Standard Library:
namespacestd{template<typenameForwardIt,typenameUnaryPredicate>constexprForwardItpartition(ForwardItfirst,ForwardItlast,UnaryPredicatep);template<typenameRandomIt,typenameCompare>constexprvoidsort(RandomItfirst,RandomItlast,Comparecomp);}// namespace std
Both the std::partition() and the std::sort() algorithm make use of the
Strategy design pattern. The UnaryPredicate argument of std::partition()
(![]() )
and the
)
and the
Compare argument of std::sort()
(![]() )
represent a means to inject part of the behavior from outside. More specifically,
both arguments allow you to specify how elements are ordered. Hence, both algorithms
extract a specific part of their behavior and provide an abstraction for it in the
form of a concept (see “Guideline 7: Understand the Similarities Between
Base Classes and Concepts”).
This, in contrast to the OO form of Strategy, does not incur any runtime performance
penalty.
)
represent a means to inject part of the behavior from outside. More specifically,
both arguments allow you to specify how elements are ordered. Hence, both algorithms
extract a specific part of their behavior and provide an abstraction for it in the
form of a concept (see “Guideline 7: Understand the Similarities Between
Base Classes and Concepts”).
This, in contrast to the OO form of Strategy, does not incur any runtime performance
penalty.
A similar approach can be seen in the std::unique_ptr class template:
namespacestd{template<typenameT,typenameDeleter=std::default_delete<T>>classunique_ptr;template<typenameT,typenameDeleter>classunique_ptr<T[],Deleter>;}// namespace std
For both the base template
(![]() )
and its specialization for arrays
(
)
and its specialization for arrays
(![]() ),
it is possible to specify an explicit
),
it is possible to specify an explicit Deleter as the second template argument. With
this argument, you can decide whether you want to free the resource by means of delete,
free(), or any other deallocation function. It’s even possible to “abuse”
std::unique_ptr to perform a completely different kind of cleanup.
This flexibility is also evidence for the Strategy design pattern. The template argument allows you to inject some cleanup behavior into the class. This form of Strategy is also called policy-based design, based on a design philosophy introduced by Andrei Alexandrescu in 2001.10 The idea is the same: extract and isolate specific behavior of class templates to improve changeability, extensibility, testability, and reusability. Thus, policy-based design can be considered the static polymorphism form of the Strategy design pattern. And evidently, the design works really well, as the many applications of this idea in the Standard Library demonstrate.
You can also apply policy-based design to the shape-drawing example. Consider
the following implementation of the Circle class:
//---- <Circle.h> ----------------#include<Shape.h>#include<DrawCircleStrategy.h>#include<memory>#include<utility>template<typenameDrawCircleStrategy>classCircle:publicShape{public:explicitCircle(doubleradius,DrawCircleStrategydrawer):radius_(radius),drawer_(std::move(drawer)){/* Checking that the given radius is valid */}voiddraw(/*some arguments*/)constoverride{drawer_(*this,/*some arguments*/);}doubleradius()const{returnradius_;}private:doubleradius_;DrawCircleStrategydrawer_;// Could possibly be omitted, if the given// strategy is presumed to be stateless.};
Instead of passing std::unique_ptr to a DrawCircleStrategy base class in the
constructor, you could specify the Strategy with a template argument
(![]() ).
The biggest advantage would be the performance improvement due to fewer pointer
indirections: instead of calling through
).
The biggest advantage would be the performance improvement due to fewer pointer
indirections: instead of calling through std::unique_ptr, you could directly call to
the concrete implementation provided by the DrawCircleStrategy
(![]() ).
On the downside, you would lose the flexibility to adapt the drawing Strategy of a
specific
).
On the downside, you would lose the flexibility to adapt the drawing Strategy of a
specific Circle instance at runtime. Also, you wouldn’t have a single Circle class
anymore. You would have one instantiation of Circle for every drawing strategy. And
last but not least, you should keep in mind that class templates usually completely reside
in header files. You could therefore lose the opportunity to hide implementation details
in a source file. As always, there is no perfect solution, and the choice of the “right”
solution depends on the actual context.
In summary, the Strategy design pattern is one of the most versatile examples in the catalog of design patterns. You will find it useful in many situations in the realm of dynamic as well as static polymorphism. However, it is not the ultimate solution for every problem—be aware of its potential disadvantages.
Guideline 20: Favor Composition over Inheritance
After the enormous surge of enthusiasm for OOP in the 90s and early 2000s, OOP today is on the defensive. The voices that argue against OOP and highlight its disadvantages grow stronger and louder. This is not limited to the C++ communities but is also in other programming language communities. While OOP in its entirety indeed has some limitations, let’s focus on the one feature that appears to generate most of the heat: inheritance. As Sean Parent remarked:11
Inheritance is the base class of evil.
While inheritance is sold as a very natural and intuitive way of modeling real-world relations, it turns out to be much harder to use than promised. You have already seen the subtle failures of using inheritance when we talked about the Liskov Substitution Principle (LSP) in “Guideline 6: Adhere to the Expected Behavior of Abstractions”. But there are other aspects of inheritance that are often misunderstood.
First and foremost, inheritance is always described as simplifying reusability. This
seems intuitive, since it appears obvious that you can reuse code
easily if you just inherit from another class. Unfortunately, that’s not the kind of
reuse inheritance brings to you. Inheritance is not about reusing code in a base
class; instead, it is about being reused by other code that uses the base class
polymorphically. For instance, assuming a slightly extended Shape base class,
the following functions work for all kinds of shapes and thus can be reused by all
implementations of the Shape base class:
classShape{public:virtual~Shape()=default;virtualvoidtranslate(/*some arguments*/)=0;virtualvoidrotate(/*some arguments*/)=0;virtualvoiddraw(/*some arguments*/)const=0;virtualvoidserialize(/*some arguments*/)const=0;// ... Potentially other member functions ...};voidrotateAroundPoint(Shape&shape);voidmergeShapes(Shape&s1,Shape&s2);voidwriteToFile(Shapeconst&shape);voidsendViaRPC(Shapeconst&shape);// ...
All four functions
(![]() ,
,
![]() ,
,
![]() , and
, and
![]() )
are built on the
)
are built on the Shape abstraction. All of these functions are coupled only to
the common interface of all kinds of shapes but not to any specific shape.
All kinds of shapes can be rotated around a point, merged,
written to file, and sent via RPC. Every shape “reuses” this functionality.
It is the ability to express functionality by means of an abstraction that creates the opportunity to reuse code. This functionality is expected to create a vast amount of code, in comparison to the small amount of code the base class contains. Real reusability, therefore, is created by the polymorphic use of a type, not by polymorphic types.12
Second, inheritance is said to help in decoupling software entities. While that is
most certainly true (remember, for instance, the discussion about the Dependency
Inversion Principle (DIP) in “Guideline 9: Pay Attention to the Ownership of Abstractions”),
it’s often not explained that inheritance also creates
coupling. You’ve seen evidence of that before. While implementing the Visitor
design pattern, you experienced that inheritance forces certain implementation
details on you. In a classic Visitor, you have to implement the pure virtual
functions of a Visitor base class as they are required, even if this is not
optimal for your application. You also don’t have a lot of choices
with respect to the function arguments or return types. These things are
fixed.13
You also experienced this coupling at the beginning of the discussion on the Strategy design pattern. In this case, inheritance forced a structural coupling that caused a deep(er) inheritance hierarchy, resulted in questionable naming of classes, and impaired reuse.
At this point, you might get the impression that I’m trying to discredit inheritance completely. Well, to be honest, I am trying to make it look just a little bad, but only as much as necessary. To state it clearly: inheritance is not bad, nor is it wrong to use it. On the contrary: inheritance is a very powerful feature, and if used properly you can do incredible things with it. However, of course you remember the Peter Parker Principle:
With great power comes great responsibility.
Peter Parker, aka Spider-Man
The problem is the “if used properly” part. Inheritance has proven to be hard to use properly (definitely harder than we are led to believe; see my previous reasonings), and thus is misused unintentionally. It is also overused, as many developers have the habit of using it for every kind of problem.14 This overuse appears to be the source of many problems, as Michael Feathers remarks:15
[Programming by difference]16 fell out of favor in the 1990s when many people in the OO community noticed that inheritance can be rather problematic if it is overused.
In many situations, inheritance is neither the right approach nor the right tool. Most of the time it is preferable to use composition instead. You should not be surprised by that revelation, though, because you have already seen it to be true. Composition is the reason the OO form of the Strategy design pattern works so well, not inheritance. It is the introduction of an abstraction and the aggregation of corresponding data members that make the Strategy design pattern so powerful, not the inheritance-based implementation of different strategies. In fact, you will find that many design patterns are firmly based on composition, not on inheritance.17 All of these enable extension by means of inheritance but are themselves enabled by means of composition.
Delegate to Services: Has-A Trumps Is-A.
Andrew Hunt and David Thomas, The Pragmatic Programmer
This is a general takeaway for many design patterns. I suggest you keep this insight close at hand, as it will prove very useful in understanding the design patterns that you will see in the remainder of this book, and will improve the quality of your implementations.
Guideline 21: Use Command to Isolate What Things Are Done
Before we get started with this guideline, let’s try an experiment. Open your preferred
email client and write an email to me. Add the following content: “I love your book! It
keeps me up all night and makes me forget all my troubles.” OK, great. Now click Send.
Good job! Give me a second to check my emails…No, it’s not here yet…No, still not
here…Let’s try again: Click Resend. No, nothing. Hmm, I guess some server must
be down. Or all of my Commands simply failed: the WriteCommand, the
SendCommand,
the ResendCommand, and so on. How unfortunate. But despite this failed experiment, you now have
a pretty good idea of another GoF design pattern: the Command design pattern.
The Command Design Pattern Explained
The Command design pattern focuses on the abstraction and isolation of work packages that (most often) are executed once and (usually) immediately. For that purpose, it recognizes the existence of different kinds of work packages as variation points and introduces the corresponding abstraction that allows the easy implementation of new kinds of work packages.
The Command Design Pattern
Intent: “Encapsulate a request as an object, thereby letting you parameterize clients with different requests, queue or log requests, and support undoable operations.”18
Figure 5-7 shows the original UML formulation, taken from the GoF book.
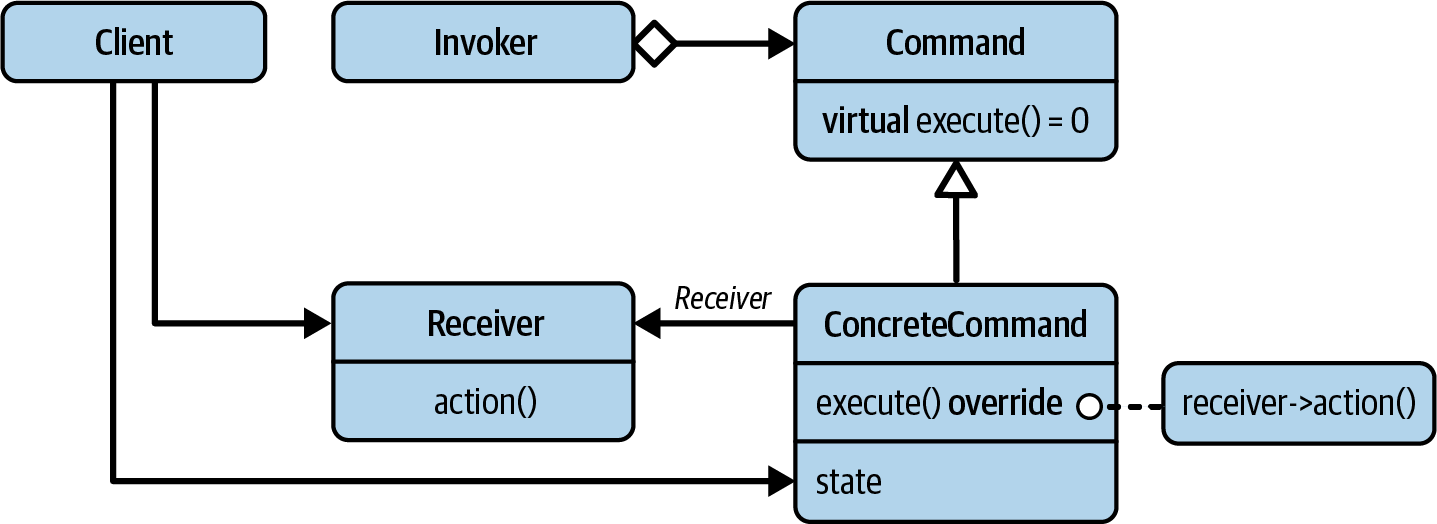
Figure 5-7. The UML representation of the Command design pattern
In this OO-based form, the Command pattern introduces an abstraction in the form
of the Command base class. This enables anyone to implement a new kind of
ConcreteCommand. That ConcreteCommand can do anything, even perform an action
on some kind of Receiver. The effect of a command is triggered via the abstract
base class by a particular kind of Invoker.
As a concrete example of the Command design pattern, let’s consider the following
implementation of a calculator. The first code snippet shows the implementation of a
CalculatorCommand base class, which represents the abstraction of a mathematical
operation on a given integer:
//---- <CalculatorCommand.h> ----------------classCalculatorCommand{public:virtual~CalculatorCommand()=default;virtualintexecute(inti)const=0;virtualintundo(inti)const=0;};
The CalculatorCommand class expects derived classes to implement both the pure virtual
execute() function
(![]() )
and the pure virtual
)
and the pure virtual undo() function
(![]() ).
The expectation for
).
The expectation for undo() is that it implements the necessary actions to reverse the
effect of the execute() function.
The Add and Subtract classes both represent possible commands for a
calculator and therefore implement the CalculatorCommand base class:
//---- <Add.h> ----------------#include<CalculatorCommand.h>classAdd:publicCalculatorCommand{public:explicitAdd(intoperand):operand_(operand){}intexecute(inti)constoverride{returni+operand_;}intundo(inti)constoverride{returni-operand_;}private:intoperand_{};};//---- <Subtract.h> ----------------#include<CalculatorCommand.h>classSubtract:publicCalculatorCommand{public:explicitSubtract(intoperand):operand_(operand){}intexecute(inti)constoverride{returni-operand_;}intundo(inti)constoverride{returni+operand_;}private:intoperand_{};};
Add implements the execute() function using an addition operation
(![]() )
and the
)
and the undo() function using a subtraction operation
(![]() ).
).
Subtract implements the inverse
(![]() and
and ![]() ).
).
Thanks to the CalculatorCommand hierarchy, the Calculator class itself can be kept
rather simple:
//---- <Calculator.h> ----------------#include<CalculatorCommand.h>#include<stack>classCalculator{public:voidcompute(std::unique_ptr<CalculatorCommand>command);voidundoLast();intresult()const;voidclear();private:usingCommandStack=std::stack<std::unique_ptr<CalculatorCommand>>;intcurrent_{};CommandStackstack_;};//---- <Calculator.cpp> ----------------#include<Calculator.h>voidCalculator::compute(std::unique_ptr<CalculatorCommand>command){current_=command->execute(current_);stack_.push(std::move(command));}voidCalculator::undoLast(){if(stack_.empty())return;autocommand=std::move(stack_.top());stack_.pop();current_=command->undo(current_);}intCalculator::result()const{returncurrent_;}voidCalculator::clear(){current_=0;CommandStack{}.swap(stack_);// Clearing the stack}
The only functions we need for the computing activities are compute()
(![]() )
and
)
and undoLast()
(![]() ).
The
).
The compute() function is passed a CalculatorCommand instance, immediately executes
it to update the current value
(![]() ),
and stores it on the stack
(
),
and stores it on the stack
(![]() ).
The
).
The undoLast() function reverts the last executed command by popping it from the stack
and calling undo().
The main() function combines all of the pieces:
//---- <Main.cpp> ----------------#include<Calculator.h>#include<Add.h>#include<Subtract.h>#include<cstdlib>intmain(){Calculatorcalculator{};autoop1=std::make_unique<Add>(3);autoop2=std::make_unique<Add>(7);autoop3=std::make_unique<Subtract>(4);autoop4=std::make_unique<Subtract>(2);calculator.compute(std::move(op1));// Computes 0 + 3, stores and returns 3calculator.compute(std::move(op2));// Computes 3 + 7, stores and returns 10calculator.compute(std::move(op3));// Computes 10 - 4, stores and returns 6calculator.compute(std::move(op4));// Computes 6 - 2, stores and returns 4calculator.undoLast();// Reverts the last operation,// stores and returns 6intconstres=calculator.result();// Get the final result: 6// ...returnEXIT_SUCCESS;}
We first create a calculator
(![]() )
and a series of operations
(
)
and a series of operations
(![]() ,
,
![]() ,
,
![]() , and
, and
![]() ),
which we apply one after another. After that, we revert
),
which we apply one after another. After that, we revert op4 by means of the
undo() operation before we query the final result.
This design very nicely follows the SOLID principles.19 It adheres to the SRP since the variation point has already
been extracted by means of the Command design pattern. As a result, both
compute() and undo() do not have to be virtual functions. The SRP also
acts as an enabler for the OCP, which allows us to add
new operations without having to modify any existing code. Last, but not least,
if the ownership for the
Command base class is properly assigned to the high
level, then the design also adheres to the DIP (see Figure 5-8).
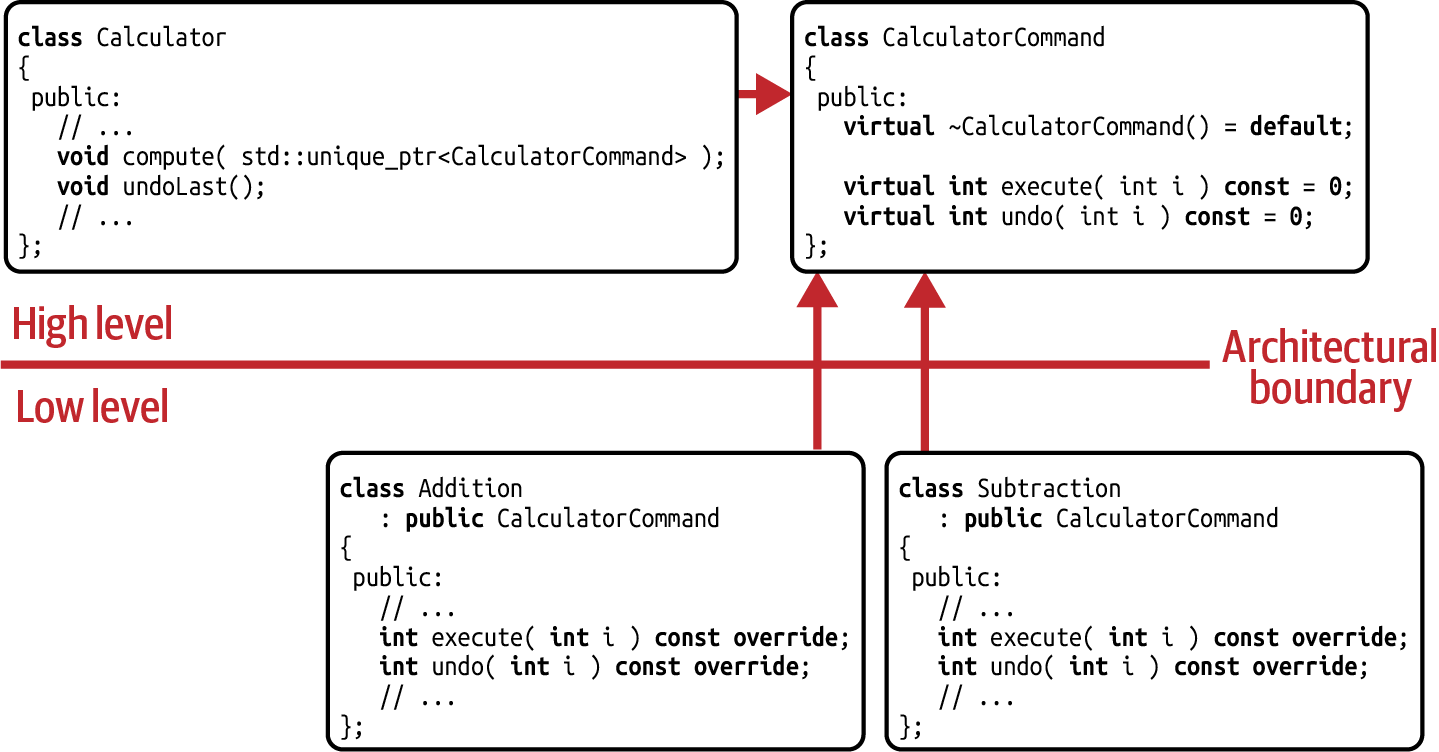
Figure 5-8. Dependency graph for the Command design pattern
There is a second example of the Command design pattern that belongs in the
category of classic examples: a thread pool.
The purpose of a thread pool is to maintain multiple threads waiting for tasks to be
executed in parallel. This idea is implemented by the following ThreadPool class:
it provides a couple of member functions to offload certain tasks to a specific
number of available threads:20
classCommand{/* Abstract interface to perform and undo any kind of action. */};classThreadPool{public:explicitThreadPool(size_tnumThreads);inlineboolisEmpty()const;inlinesize_tsize()const;inlinesize_tactive()const;inlinesize_tready()const;voidschedule(std::unique_ptr<Command>command);voidwait();// ...};
Most importantly, the ThreadPool allows you to schedule a task via the schedule()
function
(![]() ).
This can be any task: the
).
This can be any task: the ThreadPool is not at all concerned about what kind of work
its threads will have to perform. With the Command base class, it is completely
decoupled from the actual kind of task you schedule
(![]() ).
).
By simply deriving from Command, you can formulate arbitrary tasks:
classFormattingCommand:publicCommand{/* Implementation of formatting a disk */};classPrintCommand:publicCommand{/* Implementation of performing a printer job */}intmain(){// Creating a thread pool with initially two working threadsThreadPoolthreadpool(2);// Scheduling two concurrent tasksthreadpool.schedule(std::make_unique<FormattingCommand>(/*some arguments*/));threadpool.schedule(std::make_unique<PrintCommand>(/*some arguments*/));// Waiting for the thread pool to complete both commandsthreadpool.wait();returnEXIT_SUCCESS;}
One possible example of such a task is a FormattingCommand
(![]() ).
This task would get the necessary information to trigger the formatting of a disk via
the operating system. Alternatively, you can imagine a
).
This task would get the necessary information to trigger the formatting of a disk via
the operating system. Alternatively, you can imagine a PrintCommand that receives all
data to trigger a printer job
(![]() ).
).
Also in this ThreadPool example, you recognize the effect of the Command design pattern: the
different kinds of tasks are identified as a variation point and are extracted (which again follows
the SRP), which enables you to implement different kinds of tasks without the need to modify
existing code (adherence to the OCP).
Of course, there are also some examples from the Standard Library. For instance, you will
see the Command design pattern in action in the std::for_each()
(![]() )
algorithm:
)
algorithm:
namespacestd{template<typenameInputIt,typenameUnaryFunction>constexprUnaryFunctionfor_each(InputItfirst,InputItlast,UnaryFunctionf);}// namespace std
With the third argument, you can specify what task the algorithm is supposed to perform on all of the given elements. This can be any action, ranging from manipulating the elements to printing them, and can be specified by something as simple as a function pointer to something as powerful as a lambda:
#include<algorithms>#include<cstdlib>voidmultBy10(int&i){i*=10;}intmain(){std::vector<int>v{1,2,3,4,5};// Multiplying all integers with 10std::for_each(begin(v),end(v),multBy10);// Printing all integersstd::for_each(begin(v),end(v),[](int&i){std::cout<<i<<'\n';});returnEXIT_SUCCESS;}
The Command Design Pattern Versus the Strategy Design Pattern
“Wait a second!” I can hear you cry out. “Didn’t you just explain that the algorithms
of the Standard Library are implemented by means of the Strategy design pattern?
Isn’t this a complete contradiction of the previous statement?” Yes, you are
correct. Just a few pages back, I did explain that the std::partition()
and std::sort() algorithms are implemented by means of the Strategy design pattern.
And therefore, I admit that it appears as if I am now contradicting myself. However,
I did not claim that all the algorithms are based on Strategy. So let me explain.
From a structural point of view, the Strategy and Command design patterns are
identical: whether you’re using dynamic or static polymorphism, from an implementation
point of view, there is no difference between Strategy and Command.21 The difference
lies entirely in the intent of the two design patterns. Whereas the Strategy
design
pattern specifies how something should be done, the Command design
pattern specifies what should be done. Consider, for instance, the std::partition()
and std::for_each() algorithms:
namespacestd{template<typenameForwardIt,typenameUnaryPredicate>constexprForwardItpartition(ForwardItfirst,ForwardItlast,UnaryPredicatep);template<typenameInputIt,typenameUnaryFunction>constexprUnaryFunctionfor_each(InputItfirst,InputItlast,UnaryFunctionf);}// namespace std
Whereas you can only control how to select elements in the std::partition() algorithm
(![]() ),
the
),
the std::for_each() algorithm gives you control over what operation is applied
to each element in the given range
(![]() ).
And whereas in the shapes example you could only specify how to draw a certain kind of
shape, in the
).
And whereas in the shapes example you could only specify how to draw a certain kind of
shape, in the ThreadPool example you are completely in charge of deciding what
operation is scheduled.22
There are two other indicators for the two design patterns you have applied. First,
if you have an object and configure it using an action (you perform
dependency injection), then you are (most likely) using the Strategy design pattern.
If you don’t use the action to configure an object, but if instead the action is
performed directly, then you are (most likely) using the Command design pattern.
In our Calculator example, we did not pass an action to configure the Calculator,
but instead the action was evaluated immediately. Therefore, we built on the
Command pattern.
Alternatively, we could also implement Calculator by means of Strategy:
//---- <CalculatorStrategy.h> ----------------classCalculatorStrategy{public:virtual~CalculatorStrategy()=default;virtualintcompute(inti)const=0;};//---- <Calculator.h> ----------------#include<CalculatorStrategy.h>classCalculator{public:voidset(std::unique_ptr<CalculatorStrategy>operation);voidcompute(intvalue);// ...private:intcurrent_{};std::unique_ptr<CalculatorStrategy>operation_;// Requires a default!};//---- <Calculator.cpp> ----------------#include<Calculator.h>voidset(std::unique_ptr<CalculatorStrategy>operation){operation_=std::move(operation);}voidCalculator::compute(intvalue){current_=operation_.compute(value);}
In this implementation of a Calculator, the Strategy is injected by means of a set()
function
(![]() ).
The
).
The compute() function uses the injected Strategy to perform a computation
(![]() ).
Note, however, that this approach makes it more difficult to implement a reasonable
undo mechanism.
).
Note, however, that this approach makes it more difficult to implement a reasonable
undo mechanism.
The second indicator to see whether you are using Command or Strategy is the
undo() operation. If your action provides an undo() operation
to roll back what it has done and encapsulates everything that is needed to perform
the undo(), then you are—most likely—dealing with the Command design pattern.
If your action doesn’t provide an undo() operation, because it’s focused on how
something is done or because it lacks the information to roll back the operation, then
you are—most
likely—dealing with the Strategy design pattern. However, I should
explicitly point out that the lack of an undo() operation is not conclusive evidence
of Strategy. It could still be an implementation of Command if the intent is to
specify what should be done. For instance, the std::for_each() algorithm still
expects a Command, despite the fact that there is no need for
an undo() operation. The undo() operation should be considered an optional feature
of the Command design pattern, not a defining one. In my opinion,
undo() is not a strength of the Command design pattern but a pure necessity: if
an action has complete freedom to do whatever it desires, then only this action alone
will be able to roll the operation back (of course, assuming that you don’t want to
store a complete copy of everything for every call to a Command).
I admit there is no clear separation between these two patterns and that there is a gray area between them. However, there’s no point in arguing about whether something is a Command or a Strategy and losing a couple of friends in the process. More important than agreeing on which one of the two you are using is exploiting their ability to extract implementation details and separate concerns. Both design patterns help you isolate changes and extensions and thus help you follow the SRP and OCP. After all, this ability may be the reason why there are so many examples of these two design patterns in the C++ Standard Library.
Analyzing the Shortcomings of the Command Design Pattern
The advantages of the Command design pattern are similar to those of the Strategy design pattern: Command helps you decouple from the implementation details of concrete tasks by introducing some form of abstraction (for instance, a base class or a concept). This abstraction allows you to easily add new tasks. Thus, Command satisfies both the SRP and the OCP.
However, the Command design pattern also has its disadvantages. In comparison to the Strategy design pattern, the list of disadvantages is pretty short, though. The only real disadvantage is the added runtime performance overhead due to the additional indirection if you implement Command by means of a base class (the classic GoF style). Again, it’s up to you to decide whether the increased flexibility outweighs the loss of runtime performance.
In summary, just like the Strategy design pattern, the Command design pattern is one of the most basic and useful ones in the catalog of design patterns. You will encounter implementations of Command in many different situations, both static and dynamic. Thus, understanding the intent, advantages, and disadvantages of Command will prove useful many times.
Guideline 22: Prefer Value Semantics over Reference Semantics
In “Guideline 19: Use Strategy to Isolate How Things Are Done” and “Guideline 21: Use Command to Isolate What Things Are Done”, I introduced you to the Strategy and Command design pattern, respectively. In both cases, the examples were firmly built on the classic GoF style: they used dynamic polymorphism by means of an inheritance hierarchy. With that classic object-oriented style lacking a modern touch, I imagine that by now all your nail-biting has gotten you in trouble with your manicurist. And you might be wondering: “Isn’t there another, better way to implement Strategy and Command? A more ‘modern’ approach?” Yes, rest assured; there is. And this approach is so important for the philosophy of what we commonly call “Modern C++” that it definitely justifies a separate guideline to explain the advantages. I’m pretty sure your manicurist will understand the reason for this little detour.
The Shortcomings of the GoF Style: Reference Semantics
The design patterns collected by the Gang of Four and presented in their book were introduced as object-oriented design patterns. Almost all of the 23 design patterns described in their book are using at least one inheritance hierarchy and thus are firmly rooted in the realm of OO programming. Templates, the obvious second choice, did not play any part in the GoF book. This pure OO style is what I refer to as the GoF style. From today’s perspective, that style may appear to be an old, outdated way of doing things in C++, but of course we need to remember that the book was released in October 1994. At that time, templates may already have been a part of the language (at least they were officially described in the Annotated Reference Manual (ARM)), but we didn’t have template-related idioms, and C++ was still commonly perceived as an OO programming language.23 Hence, the common way to use C++ was to primarily use inheritance.
Today we know that the GoF style comes with a number of disadvantages. One of the most important, and usually one of the most-often mentioned, is performance:24
-
Virtual functions increase the runtime overhead and diminish the compiler’s opportunities to optimize.
-
Many allocations of small polymorphic objects cost extra runtime, fragment the memory, and lead to suboptimal cache usage.
-
The way data is arranged is often counterproductive with respect to data access schemes.25
Performance truly is not one of the strong aspects of the GoF style. Without
going into a complete discussion about all the possible shortcomings of the GoF
style, let’s instead focus on one other disadvantage that I consider of
particular interest: the GoF style falls into what we today call reference
semantics (or sometimes also pointer semantics). This style got its name
because it works primarily with pointers and references. To demonstrate term reference semantics means and why it usually comes with a rather
negative connotation, let’s take a look at the following code example using
the C++20 std::span class template:
#include<cstdlib>#include<iostream>#include<span>#include<vector>void(std::span<int>s){std::cout<<"(";for(inti:s){std::cout<<''<<i;}std::cout<<")\n";}intmain(){std::vector<int>v{1,2,3,4};std::vector<int>constw{v};std::span<int>consts{v};w[2]=99;// Compilation error!s[2]=99;// Works!// Prints ( 1 2 99 4 );(s);v={5,6,7,8,9};s[2]=99;// Works!// Prints ?(s);returnEXIT_SUCCESS;}
The print() function
(![]() )
demonstrates the purpose of
)
demonstrates the purpose of std::span. The std::span class template
represents an abstraction for an array. The print() function can be called
with any kind of array
(built-in arrays, std::array, std::vector, etc.) without coupling to any
specific type of array. In the demonstrated example of std::span with a
dynamic extent (no second template argument representing the size of
the array), a typical implementation of std::span contains two data members:
a pointer to the first element of the array, and the size of the array. For
that reason, std::span is considered easy to copy and is usually
passed by value. Apart from that, print() simply traverses the elements
of the std::span (in our case, integers) and prints them via std::cout.
In the main() function, we first create the std::vector<int> v and
immediately fill it with the integers 1, 2, 3, and 4
(![]() ).
Then we create another
).
Then we create another std::vector w as a copy of v
(![]() )
and the
)
and the std::span s
(![]() ).
Both
).
Both w and s are qualified with const. Directly after that, we try to
modify both w and s at index 2. The attempt to change w fails with
a compilation error: w is declared const, and for that reason it’s not
possible to change the contained elements
(![]() ).
The attempt to change
).
The attempt to change s, however, works fine. There will be no compilation
error, despite the fact that s is declared const
(![]() ).
).
The reason for this is that s is not a copy of v and does not represent a
value. Instead, it represents a reference to v. It essentially acts as a pointer
to the first element of v. Thus, the const qualifier semantically has
the same effect as declaring a pointer const:
std::span<int>consts{v};// s acts as pointer to the first element of vint*constptr{v.data()};// Equivalent semantical meaning
While the pointer ptr cannot be changed and will refer to the first
element of v throughout its lifetime, the referenced integer can be easily
modified. To prevent an assignment to the integer, you would need
to add an additional const qualifier for the int:
std::span<intconst>consts{v};// s represents a const pointer to a const intintconst*constptr{v.data()};// Equivalent semantical meaning
Since the semantics of a pointer and std::span are equivalent,
std::span obviously falls into the category of reference semantics.
And this comes with a number of additional dangers, as demonstrated in
the remainder of the main() function. As a next step, we print the
elements referred to by s
(![]() ).
Note that instead, you could also pass the vector
).
Note that instead, you could also pass the vector v directly, as the
std::span provides the necessary conversion constructors to accept std::vector. The print() function will correctly result in the following
output:
( 1 2 99 4 )
Because we can (and because by now, the numbers 1 through 4 probably start
to sound a little boring), we now assign a new set of numbers to the vector v
(![]() ).
Admittedly, the choice of
).
Admittedly, the choice of 5, 6, 7, 8, and 9 is neither particularly
creative nor entertaining, but it will serve its purpose. Directly afterward,
we again write to the second index by means of s
(![]() )
and again print the elements referred to by
)
and again print the elements referred to by s
(![]() ).
Of course, we expect the output to be
).
Of course, we expect the output to be ( 5 6 99 8 9 ), but unfortunately that
is not the case. We might get the following output:26
( 1 2 99 4 )
Maybe this completely shocks you and you end up with a few more gray
hairs.27 Perhaps you are merely surprised. Or you knowingly smile and
nod: yes, of course, undefined behavior! When assigning new values to the
std::vector v, we haven’t just changed the values but also the size
of the vector. Instead of four values, it now needs to store five elements.
For that reason, the vector has (possibly) performed a reallocation
and has thus changed the address of its first element. Unfortunately, the
std::span s didn’t get the note and still firmly holds onto the
address of the previous first element. Hence, when we try to write to v
by means of s, we do not write into the current array of v but to
an already discarded piece of memory that used to be the internal array
of v. Classic undefined behavior, and a classic problem of reference
semantics.
“Hey, are you trying to discredit std::span?” you ask. No,
I am not trying to suggest that std::span, and also std::string_view,
are bad. On the contrary, I actually like these two a lot since they
provide remarkably simple and cheap abstractions from all kinds of arrays
and strings, respectively. However, remember that every tool has advantages
and disadvantages. When I use them, I use them consciously, fully aware that
any nonowning reference type requires careful attention to the lifetime
of the value it references. For instance, while I consider both to be very
useful tools for function arguments, I tend to not use them as data members.
The danger of lifetime issues is just too high.
Reference Semantics: A Second Example
“Well, of course I knew that,” you argue. “I also wouldn’t store std::span
for a longer period of time. However, I’m still not convinced that references
and pointers are a problem.” OK, if that first example wasn’t startling enough,
I have a second example. This time I use one of the STL algorithms, std::remove().
The std::remove() algorithm takes three arguments: a pair of iterators for
the range that is traversed to remove all elements of a particular value,
and a third argument that represents the value to be removed. In particular,
note that the third argument is passed by a reference-to-const:
template<typenameForwardIt,typenameT>constexprForwardItremove(ForwardItfirst,ForwardItlast,Tconst&value);
Let’s take a look at the following code example:
std::vector<int>vec{1,-3,27,42,4,-8,22,42,37,4,18,9};autoconstpos=std::max_element(begin(vec),end(vec));vec.erase(std::remove(begin(vec),end(vec),*pos),end(vec));
We start with the std::vector v, which is initialized with a few random numbers
(![]() ).
Now we are interested in removing all the elements that represent the greatest value
stored in the vector. In our example, that is the value
).
Now we are interested in removing all the elements that represent the greatest value
stored in the vector. In our example, that is the value 42, which is stored
in the vector twice. The first step in performing the removal is to determine the
greatest value using the std::max_element() algorithm. std::max_element()
returns an iterator to the greatest value. If several elements in the range are
equivalent to the greatest element, it returns the iterator to the first such element
(![]() ).
).
The second step in removing the greatest values is a call to std::remove()
(![]() ).
We pass the range of elements using
).
We pass the range of elements using begin(vec) and end(vec), and the
greatest value by dereferencing the pos iterator. Last but not least,
we finish the operation with a call to the erase() member function:
we erase all the values between the position returned by the std::remove()
algorithm and the end of the vector. This sequence of operations is commonly known as the erase-remove idiom.
We expect that both 42 values are removed from the vector, and therefore we expect
to get the following result:
( 1 -3 27 4 -8 22 37 4 18 9 )
Unfortunately, this expectation does not hold. Instead, the vector now contains the following values:
( 1 -3 27 4 -8 22 42 37 18 9 )
Note that the vector still contains a 42 but is now missing a 4
instead. The underlying reason for this misbehavior is, again, reference
semantics: by passing the dereferenced iterator to the remove()
algorithm, we implicitly state that the value stored in that location
should be removed. However, after removing the first 42, this location holds the value 4. The
remove() algorithm removes all elements with the value
4. Hence, the next value that is removed is not the next 42 but the
next 4, and so on.28
“OK, I got it! But that problem is history! Today we don’t use the
erase-remove idiom anymore. C++20 finally provided us with
the free std::erase() function!” Well, I would love to agree with that
statement, but unfortunately I can only acknowledge the existence
of the std::erase() function:
template<typenameT,typenameAlloc,typenameU>constexprtypenamestd::vector<T,Alloc>::size_typeerase(std::vector<T,Alloc>&c,Uconst&value);
The std::erase() function also takes its second argument, the value that is to be
removed, by means of a reference-to-const. Therefore, the problem that I just described
remains. The only way to resolve this problem is to explicitly determine the greatest
element and pass it to the std::remove() algorithm
(![]() ):
):
std::vector<int>vec{1,-3,27,42,4,-8,22,42,37,4,18,9};autoconstpos=std::max_element(begin(vec),end(vec));autoconstgreatest=*pos;vec.erase(std::remove(begin(vec),end(vec),greatest),end(vec));
“Are you seriously suggesting that we shouldn’t use reference parameters
anymore?” No, absolutely not! Of course you should use reference parameters,
for instance, for performance reasons. However, I hope to have raised a
certain awareness. Hopefully, you now understand the problem:
references, and especially pointers, make our life so much harder.
It’s harder to understand the code, and therefore it is easier to
introduce bugs into our code. And pointers in particular raise so
many more questions: is it a valid pointer or a nullptr? Who owns
the resource behind the pointer and manages the lifetime? Of course,
lifetime issues are not much of an issue since we have
expanded our toolbox and have smart pointers at our disposal. As
Core Guideline R.3
clearly states:
A raw pointer (a T*) is non-owning.
In combination with knowing that smart pointers are taking on the responsibility of ownership, this cleans up the semantics of pointers quite significantly. But still, despite the fact that smart pointers are of course an immensely valuable tool and, for good reasons, are celebrated as a huge achievement of “Modern C++,” in the end they are only a fix for the holes that reference semantics has torn in the fabric of our ability to reason about code. Yes, reference semantics makes it harder to understand code and to reason about the important details, and thus is something we would like to avoid.
The Modern C++ Philosophy: Value Semantics
“But wait,” I can hear you object, “what other choice do we have? What should we do? And how else should we cope with inheritance hierarchies? We can’t avoid pointers there, right?” If you’re thinking something along these lines, then I have very good news for you: yes, there is a better solution. A solution that makes your code easier to understand and easier to reason about, and might even have a positive impact on its performance (remember we also talked about the negative performance aspects of reference semantics). The solution is value semantics.
Value semantics is nothing new in C++. The idea was already
part of the original STL. Let’s consider the most famous of the STL
containers, std::vector:
std::vector<int>v1{1,2,3,4,5};autov2{v1};assert(v1==v2);assert(v1.data()!=v2.data());v2[2]=99;assert(v1!=v2);autoconstv3{v1};v3[2]=99;// Compilation error!
We start with a std::vector called v1, filled with five integers. In the
next line, we create a copy of v1, called v2
(![]() ).
Vector
).
Vector v2 is a real copy, sometimes also referred to as a deep copy, which now contains its own chunk of memory and its own integers, and doesn’t refer to the integers in v1.29 We can assert
that by comparing the two vectors (they prove to be equal; see
![]() ),
but the addresses of the first elements are
different
(
),
but the addresses of the first elements are
different
(![]() ).
And changing one element in
).
And changing one element in v2 (![]() )
has the effect that the two vectors are not equal anymore
(
)
has the effect that the two vectors are not equal anymore
(![]() ).
Yes, both vectors have their own arrays. They do not share their content, i.e.,
they do not try to “optimize” the copy operation. You might have heard about
such techniques, for instance, the
copy-on-write
technique. And yes, you might even be aware that this was a common implementation
for
).
Yes, both vectors have their own arrays. They do not share their content, i.e.,
they do not try to “optimize” the copy operation. You might have heard about
such techniques, for instance, the
copy-on-write
technique. And yes, you might even be aware that this was a common implementation
for std::string prior to C++11. Since C++11, however,
std::string is
no longer allowed to use copy-on-write
due to its requirements
formulated in the C++ standard. The reason is that this
“optimization” easily proves to be a pessimization in a multithreaded world.
Hence, we can count on the fact that copy construction creates a real copy.
Last but not least, we create another copy called v3, which we declare as
const
(![]() ).
If we now try to change a value of
).
If we now try to change a value of v3, we will get a compilation error. This
shows that a const vector does not just prevent adding and removing elements
but that all elements are also considered to be const.
From a semantic perspective, this means that std::vector, just as any
container in the STL, is considered to be a value. Yes, a value, like an int. If we copy a value, we don’t copy just a part of the
value but the entire value. If we make a value const, it is not just
partially const but completely const. That is the rationale of value
semantics. And we’ve seen a couple of advantages already: values are
easier to reason about than pointers and references. For instance, changing
a value does not have an impact on some other value. The change happens
locally, not somewhere else. This is an advantage that compilers heavily
exploit for their optimization efforts. Also, values don’t make us think
about ownership. A value is in charge of its own content. A value also makes
it (much) easier to think about threading issues. That does not mean that
there are no problems anymore (you wish!), but the code is definitely easier
to understand. Values just don’t leave us with a lot of questions.
“OK, I get the point about code clarity,” you argue, “but what about performance?
Isn’t it super expensive to deal with copy operations all the time?” Well,
you are correct; copy operations can be expensive. However, they are only
expensive if they really happen. In real code, we can often rely on
copy elision, move
semantics, and well…pass-by-reference.30 Also, we have already
seen that, from a performance point of view, value semantics might give us a
performance boost. Yes, of course I am referring to the std::variant example
in “Guideline 17: Consider std::variant for
Implementing Visitor”. In
that example, the use of values of type std::variant has significantly
improved our performance because of fewer indirections due to pointers and a
much better memory layout and access pattern.
Value Semantics: A Second Example
Let’s take a look at a second example. This time we consider the following
to_int() function:31
intto_int(std::string_view);
This function parses the given string (and yes, I am using std::string_view
for the purpose of performance) and converts it to an int. The most interesting
question for us now is how the function should deal with errors, or in other
words, what the function should do if the string cannot be converted to an int.
The first option would be to return 0 for that case. This approach, however,
is questionable, because 0 is a valid return from the to_int() function. We
would not be able to distinguish success from failure.32 Another possible approach would be to throw an exception. Although
exceptions may be the C++ native tool to signal error cases, for this
particular problem, depending on your personal style and preferences, this may
appear as overkill to you. Also, knowing that exceptions cannot be used in a large
fraction of the C++ community, that choice might limit the usability
of the function.33
A third possibility is change the signature by a little bit:
boolto_int(std::string_views,int&);
Now the function takes a reference to a mutable int as the second parameter
and returns a bool. If it succeeds, the function returns true and sets
the passed integer; if it fails, the function returns false and leaves
the int alone. While this may seem like a reasonable compromise to you, I
would argue that we have now strayed further into the realm of reference
semantics (including all potential misuse). At the same time, the clarity of
the code has diminished: the most natural way to return a result is via the
return value, but now the result is produced by an output value. This,
for instance, prevents us from assigning the result to a const value. Therefore,
I would rate this as the least favorable approach so far.
The fourth approach is to return by pointer:
std::unique_ptr<int>to_int(std::string_view);
Semantically, this approach is pretty attractive: if it succeeds, the
function returns a valid pointer to an int; if it fails, it returns
a nullptr. Hence, code clarity is improved, as we can clearly distinguish
between these two cases. However, we gain this advantage at the cost of a
dynamic memory allocation, the need to deal with lifetime management using std::unique_ptr, and we’re still lingering in the realm of
reference semantics. So the question is: how can we leverage the
semantic advantages but stick to value semantics? The solution comes
in the form of std::optional:34
std::optional<int>to_int(std::string_view);
std::optional is a
value type, which represents any other value, in our example, an int.
Therefore, std::optional can take all the values that an int can take.
The specialty of std::optional, however, is that it adds one more state
to the wrapped value, a state that represents no value. Thus, our
std::optional is an int that may or may not be present:
#include<charconv>#include<cstdlib>#include<optional>#include<sstream>#include<string>#include<string_view>std::optional<int>to_int(std::string_viewsv){std::optional<int>oi{};inti{};autoconstresult=std::from_chars(sv.data(),sv.data()+sv.size(),i);if(result.ec!=std::errc::invalid_argument){oi=i;}returnoi;}intmain(){std::stringvalue="42";if(autooptional_int=to_int(value)){// ... Success: the returned std::optional contains an integer value}else{// ... Failure: the returned std::optional does not contain a value}}
Semantically, this is equivalent to the pointer approach, but we don’t pay the cost of dynamic memory allocation, and we don’t have to deal with lifetime management.35 This solution is semantically clear, understandable, and efficient.
Prefer to Use Value Semantics to Implement Design Patterns
“And what about design patterns?” you ask. “Almost all GoF patterns are based on inheritance hierarchies and therefore reference semantics. How should we deal with this?” That is an excellent question. And it provides us with a perfect bridge to the next guideline. To give a short answer here: you should prefer to implement design patterns using a value semantics solution. Yes, seriously! These solutions usually lead to more comprehensive, maintainable code and (often) better performance.
Guideline 23: Prefer a Value-Based Implementation of Strategy and Command
In “Guideline 19: Use Strategy to Isolate How Things Are Done”, I introduced you to the Strategy design pattern, and in
“Guideline 21: Use Command to Isolate What Things
Are Done”, I introduced you to the Command design pattern. I demonstrated that
these two design patterns are essential decoupling tools in your daily toolbox. However, in “Guideline 22: Prefer Value Semantics over
Reference Semantics”, I gave you the idea that it’s preferable to use value semantics instead
of reference semantics. And this of course raises the question: how can you
apply that wisdom for the Strategy and Command design patterns? Well, here
is one possible value semantics solution: draw on the abstracting
power of std::function.
Introduction to std::function
In case you have not yet heard about std::function, allow me to introduce you.
std::function represents an
abstraction for a callable (e.g., a function pointer,
function object, or lambda).
The only requirement is that the callable satisfies a specific function type,
which is passed as the only template parameter to std::function. The
following code gives an impression:
#include<cstdlib>#include<functional>voidfoo(inti){std::cout<<"foo:"<<i<<'\n';}intmain(){// Create a default std::function instance. Calling it results// in a std::bad_function_call exceptionstd::function<void(int)>f{};f=[](inti){// Assigning a callable to 'f'std::cout<<"lambda:"<<i<<'\n';};f(1);// Calling 'f' with the integer '1'autog=f;// Copying 'f' into 'g'f=foo;// Assigning a different callable to 'f'f(2);// Calling 'f' with the integer '2'g(3);// Calling 'g' with the integer '3'returnEXIT_SUCCESS;}
In the main() function, we create an instance of std::function, called f
(![]() ).
The template parameter specifies the required function type. In our example, this
is
).
The template parameter specifies the required function type. In our example, this
is void(int). “Function type…” you say. “Don’t you mean function pointer
type?” Well, since this is indeed something that you might have rarely seen
before, allow me to explain what a function type is and contrast it
with the thing you’ve probably seen more often: function pointers. The
following example uses both a function type and a function pointer type:
usingFunctionType=double(double);usingFunctionPointerType=double(*)(double);// Alternatively:// using FunctionPointerType = FunctionType*;
The first line shows a function type. This type represents any function that
takes a double and returns a double. Examples for this function type are
the corresponding overloads of
std::sin,
std::cos,
std::log, or
std::sqrt.
The second line shows a function pointer type. Note the little asterisk in
parentheses—that makes it a pointer type. This type represents the address
of one function of function type FunctionType. Hence, the relationship between
function types and function pointer types is pretty much like the relationship between
an int and a pointer to an int: while there are many int values, a pointer
to an int stores the address of exactly one int.
Back to the std::function example: initially, the instance is empty, therefore
you cannot call it. If you still try to do so, the std::function instance
will throw the std::bad_function_call exception at you. Better not provoke
it. Let’s rather assign some callable that fulfills the function type
requirements, for instance, a (possibly stateful) lambda
(![]() ).
The lambda takes an
).
The lambda takes an int and doesn’t return anything. Instead, it prints that
it has been called by means of a descriptive output message
(![]() ):
):
lambda: 1
OK, that worked well. Let’s try something else: we now create another
std::function instance g by means of f
(![]() ).
Then we assign another callable to
).
Then we assign another callable to f
(![]() ).
This time, we assign a pointer to the function
).
This time, we assign a pointer to the function foo(). Again, this callable
fulfills the requirements of the std::function instance: it takes an int
and returns nothing. Directly after the assignment, you call f with the
int 2, which triggers the expected output
(![]() ):
):
foo: 2
That was probably an easy one. However, the next function call is much more
interesting. If you call g with the integer 3
(![]() ),
the output demonstrates that
),
the output demonstrates that
std::function is firmly based on value semantics:
lambda: 3
During the initialization of g, the instance f was copied. And it was
copied as a value should be copied: it does not perform a “shallow copy,”
which would result in g being affected when f is subsequently changed,
but it performs a complete copy (deep copy), which includes a copy of
the lambda.36 Thus, changing f does not affect g. That’s the benefit of value semantics: the code is easy and intuitive, and you don’t have to be afraid that you are accidentally breaking something anywhere else.
At this point, the functionality of std::function may feel a little
like magic: how is it possible that the std::function instance can take
any kind of callable, including things like lambdas? How can it store
any possible type, even types that it can’t know, and even though these
types apparently have nothing in common? Don’t worry: in Chapter 8,
I will give you a thorough introduction to a technique called Type Erasure,
which is the magic behind std::function.
Refactoring the Drawing of Shapes
std::function provides everything we need to refactor our shape-drawing
example from “Guideline 19: Use Strategy to Isolate How Things Are Done”:
it represents the abstraction of a single callable, which is pretty much exactly
what we need to replace the DrawCircleStrategy and DrawSquareStrategy
hierarchies, which each contain a single virtual function. Hence, we rely on the
abstracting power of std::function:
//---- <Shape.h> ----------------classShape{public:virtual~Shape()=default;virtualvoiddraw(/*some arguments*/)const=0;};//---- <Circle.h> ----------------#include<Shape.h>#include<functional>#include<utility>classCircle:publicShape{public:usingDrawStrategy=std::function<void(Circleconst&,/*...*/)>;explicitCircle(doubleradius,DrawStrategydrawer):radius_(radius),drawer_(std::move(drawer)){/* Checking that the given radius is valid and that the given 'std::function' instance is not empty */}voiddraw(/*some arguments*/)constoverride{drawer_(*this,/*some arguments*/);}doubleradius()const{returnradius_;}private:doubleradius_;DrawStrategydrawer_;};//---- <Square.h> ----------------#include<Shape.h>#include<functional>#include<utility>classSquare:publicShape{public:usingDrawStrategy=std::function<void(Squareconst&,/*...*/)>;explicitSquare(doubleside,DrawStrategydrawer):side_(side),drawer_(std::move(drawer)){/* Checking that the given side length is valid and that the given 'std::function' instance is not empty */}voiddraw(/*some arguments*/)constoverride{drawer_(*this,/*some arguments*/);}doubleside()const{returnside_;}private:doubleside_;DrawStrategydrawer_;};
First, in the Circle class, we add a type alias for the expected type of
std::function
(![]() ).
This
).
This std::function type represents any callable that can take a Circle, and
potentially several more drawing-related arguments, and does not return
anything. Of course, we also add the corresponding type alias in the Square class
(![]() ).
In the constructors of both
).
In the constructors of both Circle and Square, we now take an instance of
type
std::function
(![]() )
as a replacement for the pointer to a Strategy base class (
)
as a replacement for the pointer to a Strategy base class (DrawCircleStrategy
or DrawSquareStrategy). This instance is immediately moved
(![]() )
into the data member
)
into the data member drawer_, which is also of type DrawStrategy
(![]() ).
).
“Hey, why are you taking the std::function instance by value? Isn’t that
terribly inefficient? Shouldn’t we prefer to pass by reference-to-const?”
In short: no, passing by value is not inefficient, but an elegant compromise
to the alternatives. I admit, though, that this may be surprising. Since this
is definitely an implementation detail worth noting, let’s take a closer
look.
If we used a reference-to-const, we would experience the disadvantage that
rvalues would be unnecessarily copied. If we were passed an rvalue, this
rvalue would bind to the (lvalue) reference-to-const. However, when passing this
reference-to-const to the data member, it would be copied. Which is
not our intention: naturally we want it to be moved. The simple reason is that
we cannot move from const objects (even when using std::move). So, to efficiently deal with rvalues, we would have to provide
overloads of the Circle and Square constructors that would take a
DrawStrategy by means of an rvalue reference (DrawStrategy&&).
For the sake of performance, we would provide two constructors for both Circle
and Square.37
The approach to provide two constructors (one for lvalues, one for rvalues) does
work and is efficient, but I would not necessarily call it elegant. Also, we
should probably save our colleagues the trouble of having to deal with
that.38 For this reason,
we exploit the implementation of std::function. std::function provides both a
copy constructor and a move constructor, and so we know that it can be moved
efficiently. When we pass a std::function by value, either the copy constructor
or the move constructor will be called. If we are passed an lvalue, the
copy constructor is called, copying the lvalue. Then we would move that copy into
the data member. In total, we would perform one copy and one move to initialize the
drawer_ data member. If we are passed an rvalue, the move constructor is
called, moving the rvalue. The resulting argument strategy is then moved into
the data member drawer_. In total, we would perform two move operations to
initialize the drawer_ data member. Therefore, this form represents a great
compromise: it is elegant, and there is hardly any difference in efficiency.
Once we’ve refactored the Circle and Square classes, we can implement
different drawing strategies in any form we like (in the form of a function,
a function object, or a lambda). For instance, we can implement the following
OpenGLCircleStrategy as a function object:
//---- <OpenGLCircleStrategy.h> ----------------#include<Circle.h>classOpenGLCircleStrategy{public:explicitOpenGLCircleStrategy(/* Drawing related arguments */);voidoperator()(Circleconst&circle,/*...*/)const;private:/* Drawing related data members, e.g. colors, textures, ... */};
The only convention we need to follow is that we need to provide a call operator
that takes a Circle and potentially several more drawing-related arguments, and doesn’t return anything (fulfill the function type void(Circle const&, /*…*/))
(![]() ).
).
Assuming a similar implementation for an OpenGLSquareStrategy, we can now create
different kinds of shapes, configure them with the desired drawing behavior, and
finally draw them:
#include<Circle.h>#include<Square.h>#include<OpenGLCircleStrategy.h>#include<OpenGLSquareStrategy.h>#include<memory>#include<vector>intmain(){usingShapes=std::vector<std::unique_ptr<Shape>>;Shapesshapes{};// Creating some shapes, each one// equipped with the corresponding OpenGL drawing strategyshapes.emplace_back(std::make_unique<Circle>(2.3,OpenGLCircleStrategy(/*...red...*/)));shapes.emplace_back(std::make_unique<Square>(1.2,OpenGLSquareStrategy(/*...green...*/)));shapes.emplace_back(std::make_unique<Circle>(4.1,OpenGLCircleStrategy(/*...blue...*/)));// Drawing all shapesfor(autoconst&shape:shapes){shape->draw();}returnEXIT_SUCCESS;}
The main() function is very similar to the original implementation using the
classic Strategy implementation (see
“Guideline 19: Use Strategy to Isolate How Things Are Done”). However,
this nonintrusive, base class–free approach with std::function further
reduces the coupling. This becomes evident in the
dependency graph for this
solution (see Figure 5-9): we can implement the drawing
functionality in any form we want (as a free function, a function object, or a
lambda) and we don’t have to abide by the requirements of a base class. Also, by
means of
std::function we have automatically inverted the dependencies
(see “Guideline 9: Pay Attention to the Ownership of Abstractions”).
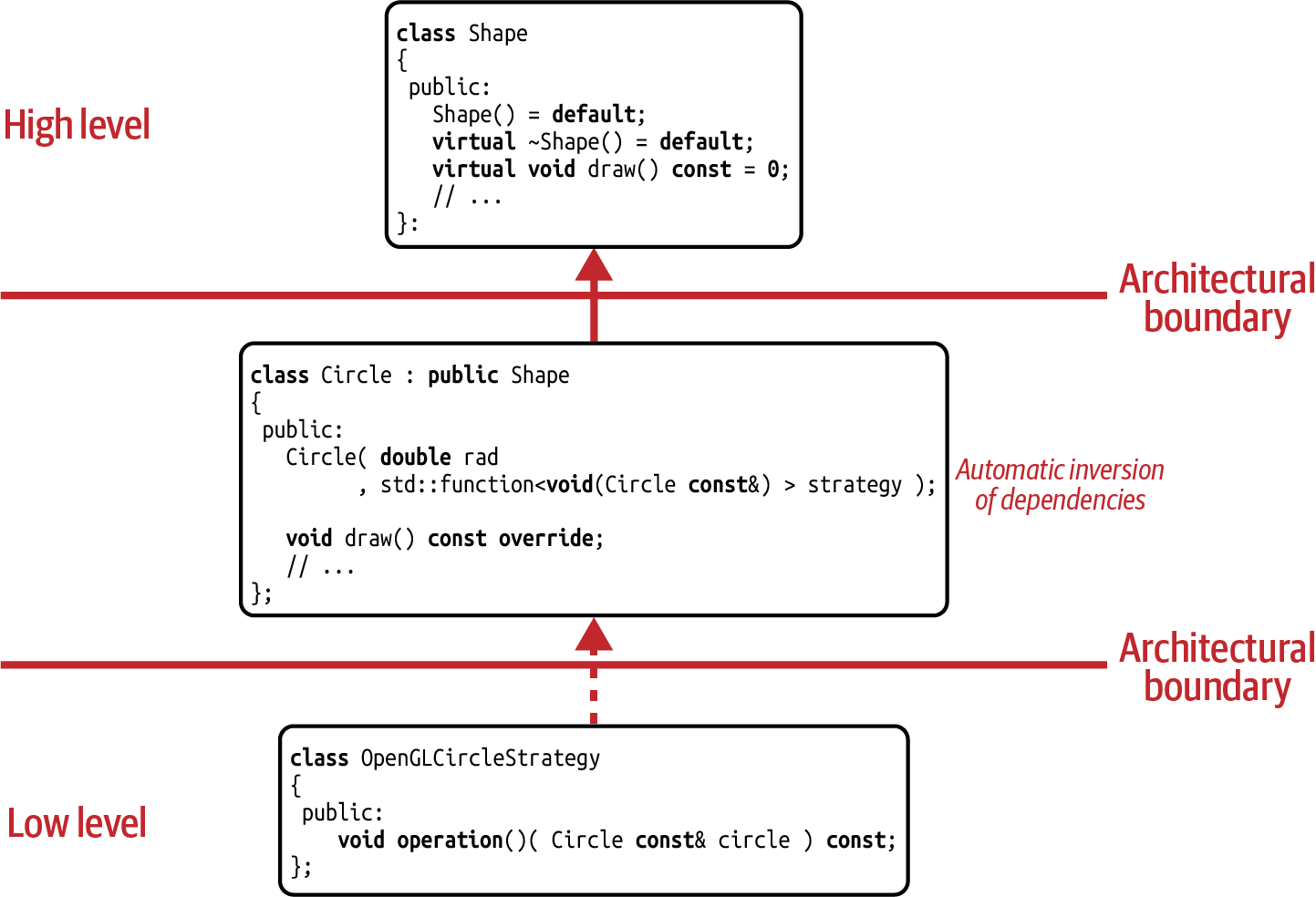
Figure 5-9. Dependency graph for the std::function solution
Performance Benchmarks
“I like the flexibility, the freedom. This is great! But what about
performance?” Yes, spoken like a true C++ developer. Of course
performance is important. Before showing you the performance results, though,
let me remind you of the benchmark scenario that we also used to
get the numbers for Table 4-2 in
“Guideline 16: Use Visitor to Extend Operations”. For the benchmark,
I have implemented four different kinds of shapes (circles, squares, ellipses,
and rectangles). Again, I’m running 25,000 translate operations on 10,000
randomly created shapes. I use both GCC 11.1 and Clang 11.1, and for both
compilers I’m adding only the -O3 and -DNDEBUG compilation flags. The
platform I’m using is macOS Big Sur (version 11.4) on an 8-Core Intel Core i7
with 3.8 GHz, 64 GB of main memory.
With this information in mind, you are ready for the performance results.
Table 5-1 shows the performance numbers for the
Strategy-based implementation of the drawing example and the resulting
solution using std::function.
| Strategy implementations | GCC 11.1 | Clang 11.1 |
|---|---|---|
Object-oriented solution |
1.5205 s |
1.1480 s |
|
2.1782 s |
1.4884 s |
Manual implementation of |
1.6354 s |
1.4465 s |
Classic Strategy |
1.6372 s |
1.4046 s |
For reference purposes, the first line shows the performance of the object-oriented solution from “Guideline 15: Design for the Addition of Types or Operations”. As you can see, this solution gives the best performance. This is not unexpected, however: since the Strategy design pattern, irrespective of the actual implementation, introduces additional overhead, the performance is anticipated to be reduced.
What is not expected, though, is that the std::function implementation
incurs a performance overhead (even a significant one in case of GCC). But
wait, before you throw this approach into your mental trash can, consider the
third line. It shows a manual implementation of std::function using
Type Erasure, the technique I will explain in Chapter 8. This
implementation performs much
better, in fact as good (or nearly as good for Clang) as a classic implementation
of the Strategy design pattern (see the fourth line). This result
demonstrates that the problem is not value semantics but the specific
implementation details of std::function.39 In summary, a value semantics approach is not worse in terms of performance than the classic approach, but
instead, as shown before, it improves many important aspects of your code.
Analyzing the Shortcomings of the std::function Solution
Overall, the std::function implementation of the Strategy design pattern
provides a number of benefits. First, your code gets cleaner and more readable
since you don’t have to deal with pointers and the associated lifetime management
(for instance, using std::unique_ptr), and since you don’t experience
the usual problems with
reference semantics (see
“Guideline 22: Prefer Value Semantics over
Reference Semantics”). Second, you promote loose
coupling. Very loose coupling, actually. In this context, std::function acts like
a compilation firewall, which protects you from the implementation details of the
different Strategy implementations but at the same time provides enormous
flexibility for developers on how to implement the different Strategy solutions.
Despite these upsides, no solution comes without downsides—even the
std::function approach has its disadvantages. I have already
pointed out the potential performance disadvantage if you rely on the standard
implementation. While there are solutions to minimize this effect (see
Chapter 8), it’s still something to consider in your codebase.
There is also a design-related issue. std::function can
replace only a single virtual function. If you need to abstract multiple virtual
functions, which could occur if you want to configure multiple aspects
using the Strategy design pattern, or if you need an undo() function
in the Command design pattern, you would have to use multiple std::function
instances. This would not only increase the size of a class due to the multiple data
members, but also incur an interface burden due to the question of how to
elegantly handle passing multiple std::function instances. For this reason, the
std::function approach works best for replacing a single or a very small
number of virtual functions. Still, this does not mean that you can’t use a
value-based approach for multiple virtual functions: if you encounter that
situation, consider generalizing the approach by applying the technique used for
std::function directly to your type. I will explain how to do that in
Chapter 8.
Despite these shortcomings, the value semantics approach proves to be a terrific choice for the Strategy design pattern. The same is true for the Command design pattern. Therefore, keep this guideline in mind as an essential step towards modern C++.
1 See “Guideline 2: Design for Change”.
2 You may correctly argue that there are multiple solutions for this problem: you could have one source file per graphics library, you could rely on the preprocessor by sprinkling a couple of #ifdefs across the code, or you could implement an abstraction layer around the graphics libraries. The first two options feel like technical workarounds to a flawed design. The latter option, however, is a reasonable, alternative solution to the one that I will propose. It’s a solution based on the Facade design pattern, which, unfortunately, I don’t cover in this book.
3 David Thomas and Andrew Hunt, The Pragmatic Programmer.
4 Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software.
5 Please explicitly note that I said naive. Although the code example is didactically a little questionable, I will show a common misconception before showing a proper implementation. My hope is that this way you will never fall into this common trap.
6 Although this is not a book about implementation details, please allow me to highlight one implementation detail that I find to be the source of many questions in my training classes. I’m certain you’ve heard about the Rule of 5—if not, please see the C++ Core Guidelines. Hence, you realize that the declaration of a virtual destructor disables the move operations. Strictly speaking, this is a violation of the Rule of 5. However, as Core Guideline C.21 explains, for base classes this is not considered to be a problem, as long as the base class does not contain any data members.
7 As I have referenced Core Guideline C.21 before, it is also worth mentioning that both the Circle and Square classes fulfill the Rule of 0; see Core Guideline C.20. By not falling into the habit of adding a destructor, the compiler itself generates all special member functions for both classes. And yes, worry not—the destructor is still virtual since the base class destructor is virtual.
8 See “Guideline 18: Beware the Performance of Acyclic Visitor” for a discussion about the Acyclic Visitor design pattern.
9 I should explicitly state that it does not work in dynamic polymorphism. It does work in static polymorphism, even quite well. Consider, for instance, templates and function overloading.
10 Andrei Alexandrescu, Modern C++ Design: Generic Programming and Design Patterns Applied (Addison-Wesley, 2001).
11 Sean Parent, “Inheritance Is the Base Class Of Evil”, GoingNative, 2013.
12 According to Sean Parent, there are no polymorphic types, only polymorphic usage of similar types; see “Better Code: Runtime Polymorphism” from the NDC London conference in 2017. My statement supports that opinion.
13 Another example of inheritance creating coupling is discussed in Herb Sutter’s Exceptional C++: 47 Engineering Puzzles, Programming Problems, and Exception-Safety Solutions (Pearson Education).
14 Are they really to blame for this habit? Since they’ve been taught that this is the way to go for decades, who can blame them for thinking this way?
15 Michael C. Feathers, Working Effectively with Legacy Code.
16 Programming by difference is a rather extreme form of inheritance-based programming, where even small differences are expressed by introducing a new derived class. See Michael’s book for more details.
17 See, for instance, the Strategy design pattern in “Guideline 19: Use Strategy to Isolate How Things Are Done”, the Observer design pattern in “Guideline 25: Apply Observers as an Abstract Notification Mechanism”, the Adapter design pattern in “Guideline 24: Use Adapters to Standardize Interfaces”, the Decorator design pattern in “Guideline 35: Use Decorators to Add Customization Hierarchically”, or the Bridge design pattern in “Guideline 28: Build Bridges to Remove Physical Dependencies”.
18 Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software.
19 Yes, it follows the SOLID principles, although of course by means of the classic form of the Command design pattern. If you are right now biting your fingernails in frustration or simply wondering if there isn’t a better way, then please be patient. I will demonstrate a much nicer, much more “modern” solution in “Guideline 22: Prefer Value Semantics over Reference Semantics”.
20 The given ThreadPool class is far from being complete and primarily serves as an illustration for the Command design pattern. For a working, professional implementation of a thread pool, please refer to Anthony William’s book C++ Concurrency in Action, 2nd ed. (Manning).
21 This is another example of my statement that design patterns are not about implementation details; see “Guideline 12: Beware of Design Pattern Misconceptions”.
22 For the complete shape example, see “Guideline 19: Use Strategy to Isolate How Things Are Done”.
23 Margaret A. Ellis and Bjarne Stroustrup, The Annotated C++ Reference Manual (Addison-Wesley, 1990).
24 To get an overview of C++ performance aspects in general and performance-related issues with inheritance hierarchies in particular, refer to Kurt Guntheroth’s book, Optimized C{plus}{plus} (O’Reilly).
25 A possible solution for that is to employ techniques from data-oriented design; see Richard Fabian, Data-Oriented Design: Software Engineering for Limited Resources and Short Schedules.
26 Mark my choice of words: “We might get the following output.” Indeed, we might get this output but also something else. It depends, as we have inadvertently entered the realm of undefined behavior. Therefore, this output is my best guess, not a guarantee.
27 Now not only your manicurist but also your hairdresser has work to do…
28 More gray hairs, more work for your hairdresser.
29 I should explicitly point out that the notion of a “deep copy” depends on the type T of elements in the vector: if T performs a deep copy, then so does the std::vector, but if T performs a shallow copy, then semantically std::vector also performs a shallow copy.
30 The best and most complete introduction to move semantics is Nicolai Josuttis’s book on the subject, C++ Move Semantics - The Complete Guide (NicoJosuttis, 2020).
31 See Patrice Roy’s CppCon 2016 talk, “The Exception Situation”, for a similar example and discussion.
32 Yet this is exactly the approach taken by the std::atoi() function.
33 In his standard proposal P0709, Herb Sutter explains that 52% of C++ developers have no or limited access to exceptions.
34 The experienced C++ developer also knows that C++23 will bless us with a very similar type called std::expected. In a few years, this might be the appropriate way to write the to_int() function.
35 From a functional programming point of view, std::optional represents a monad. You’ll find much more valuable information on monads and functional programming in general in Ivan Čukić’s book, Functional Programming in C++.
36 In this example, the std::function object performs a deep copy, but generally speaking, std::function copies the contained callable according to its copy semantics (“deep” or “shallow”). std::function has no way of forcing a deep copy.
37 This implementation detail is explained thoroughly by Nicolai Josuttis in this CppCon 2017 talk, “The Nightmare of Move Semantics for Trivial Classes”.
38 One more example of the KISS principle.
39 A discussion about the reasons for the performance deficiencies of some std::function implementations would go beyond the scope and purpose of this book. Still, please keep this detail in mind for performance-critical sections of your code.