Chapter 7. The Bridge, Prototype, and External Polymorphism Design Patterns
In this chapter, we will focus on two classic GoF design patterns: the Bridge design pattern and the Prototype design pattern. Additionally, we will study the External Polymorphism design pattern. At first glance, this selection may appear as an illustrious, almost random choice of design patterns. However, I picked these patterns for two reasons: first, in my experience, these three are among the most useful in the catalog of design patterns. For that reason, you should have a pretty good idea about their intent, advantages, and disadvantages. Second and equally important: they will all play a vital role in Chapter 8.
In “Guideline 28: Build Bridges to Remove Physical Dependencies”, I will acquaint you with the Bridge design pattern and its simplest form, the Pimpl idiom. Most importantly, I will demonstrate how you can use Bridges to reduce physical coupling by decoupling an interface from implementation details.
In “Guideline 29: Be Aware of Bridge Performance Gains and Losses”, we will take an explicit look at the performance impact of Bridges. We will run benchmarks for an implementation without Bridge, a Bridge-based implementation, and a “partial” Bridge.
In “Guideline 30: Apply Prototype for Abstract Copy Operations”, I will introduce you to the art of cloning. That is to say, that we will talk about copy operations and, in particular, abstract copy operations. The pattern of choice for this intent will be the Prototype design pattern.
In “Guideline 31: Use External Polymorphism for Nonintrusive Runtime Polymorphism”, we continue the journey of separating concerns by extracting the implementation details of a function from a class. To further reduce dependencies, however, we will take this separation of concerns to a whole new level: we will extract not only the implementation details of virtual functions but also the complete functions themselves, with the External Polymorphism design pattern.
Guideline 28: Build Bridges to Remove Physical Dependencies
According to dictionaries, the term bridge expresses a time, a place, or a means of connection or transition. If I were to ask what the term bridge means to you, I’m pretty certain you would have a similar definition. You might implicitly think about connecting two things, and thus bringing these things closer together. For instance, you might think about a city divided by a river. A bridge would connect the two sides of the city, bring them closer together, and save people a lot of time. You might also think about electronics, where a bridge connects two independent parts of a circuit. There are bridges in music and many more examples from the real world, where bridges help connect things. Yes, intuitively the term bridge suggests an increase in closeness and proximity. So naturally, the Bridge design pattern is about the polar opposite: it supports you in reducing physical dependencies and helps to decouple, i.e., it keeps two pieces of functionality that need to work together but shouldn’t know too many details about each other, at arm’s length.
A Motivating Example
To explain what I have in mind, consider the following ElectricCar class:
//---- <ElectricEngine.h> ----------------classElectricEngine{public:voidstart();voidstop();private:// ...};//---- <ElectricCar.h> ----------------#include<ElectricEngine.h>// ...classElectricCar{public:ElectricCar(/*maybe some engine arguments*/);voiddrive();// ...private:ElectricEngineengine_;// ... more car-specific data members (wheels, drivetrain, ...)};//---- <ElectricCar.cpp> ----------------#include<ElectricCar.h>ElectricCar::ElectricCar(/*maybe some engine arguments*/):engine_{/*engine arguments*/}// ... Initialization of the other data members{}// ...
As the name suggests, the ElectricCar class is equipped with an ElectricEngine
(![]() ).
However, while in reality such a car may be pretty attractive, the current implementation
details are concerning: because of the
).
However, while in reality such a car may be pretty attractive, the current implementation
details are concerning: because of the engine_ data member, the
<ElectricCar.h>
header file needs to include the <ElectricEngine.h> header. The compiler needs to
see the class definition of ElectricEngine, because otherwise it would not be
able to determine the size of an ElectricCar instance. Including the <ElectricEngine.h>
header, however, easily results in transitive, physical coupling: every file that includes
the <ElectricCar.h> header will physically depend on the <ElectricEngine.h> header.
Thus, whenever something in the header changes, the ElectricCar class and potentially many
more classes are affected. They might have to be recompiled, retested, and, in the worst
case, even redeployed…sigh.
On top of that, this design reveals all implementation details to everyone. “What do you
mean? Isn’t it the point of the private section of the class to hide and to encapsulate
implementation details?” Yes, it may be private, but the private label is merely an
access label. It is not a visibility label. Therefore, everything in your class definition
(and I mean everything) is visible to everyone who sees the ElectricCar class
definition. This means that you cannot change the implementation details of this class
without anyone noticing. In particular, this may be a problem if you need to provide ABI
stability, i.e., if the in-memory representation of your class must not change.1
A slightly better approach would be to only store a pointer to ElectricEngine
(![]() ):2
):2
//---- <ElectricCar.h> ----------------#include<memory>// ...structElectricEngine;// Forward declarationclassElectricCar{public:ElectricCar(/*maybe some engine arguments*/);voiddrive();// ...private:std::unique_ptr<ElectricEngine>engine_;// ... more car-specific data members (wheels, drivetrain, ...)};//---- <ElectricCar.cpp> ----------------#include<ElectricCar.h>#include<ElectricEngine.h>ElectricCar::ElectricCar(/*maybe some engine arguments*/):engine_{std::make_unique<ElectricEngine>(/*engine arguments*/)}// ... Initialization of the other data members{}// ... Other 'ElectricCar' member functions, using the pointer to an// 'ElectricEngine'.
In this case, it is sufficient to provide only a forward declaration to the
ElectricEngine
class, since the compiler doesn’t need to know the class definition to be able to determine
the size of an ElectricCar instance. Also, the physical dependency is gone, since the
<ElectricEngine.h> header has been moved into the source file
(![]() ).
Hence, from a dependency point of view, this solution is much better. What still remains is
the visibility of the implementation details. Everyone is still able to see that the
).
Hence, from a dependency point of view, this solution is much better. What still remains is
the visibility of the implementation details. Everyone is still able to see that the ElectricCar
builds on an ElectricEngine, and thus everyone is still implicitly depending on these
implementation details. Consequently, any change to these details, such as an upgrade
to the new PowerEngine, would affect any class that works with the <ElectricCar.h> header
file. “And that’s bad, right?” Indeed it is, because change is to be expected (see
“Guideline 2: Design for Change”). To get rid of this dependency and gain the luxury of being able to easily change the implementation details at any
time without anyone noticing, we have to introduce an abstraction. The classic form of
abstraction is the introduction of an abstract class:
//---- <Engine.h> ----------------classEngine{public:virtual~Engine()=default;virtualvoidstart()=0;virtualvoidstop()=0;// ... more engine-specific functionsprivate:// ...};//---- <ElectricCar.h> ----------------#include<Engine.h>#include<memory>classElectricCar{public:voiddrive();// ...private:std::unique_ptr<Engine>engine_;// ... more car-specific data members (wheels, drivetrain, ...)};//---- <ElectricEngine.h> ----------------#include<Engine.h>classElectricEngine:publicEngine{public:voidstart()override;voidstop()override;private:// ...};//---- <ElectricCar.cpp> ----------------#include<ElectricCar.h>#include<ElectricEngine.h>ElectricCar::ElectricCar(/*maybe some engine arguments*/):engine_{std::make_unique<ElectricEngine>(/*engine arguments*/)}// ... Initialization of the other data members{}// ... Other 'ElectricCar' member functions, primarily using the 'Engine'// abstraction, but potentially also explicitly dealing with an// 'ElectricEngine'.
With the Engine base class in place
(![]() ),
we can implement our
),
we can implement our ElectricCar class using this abstraction
(![]() ).
No one needs to be aware of the actual type of engine that we use. And no one needs to
know when we upgrade our engine. With this implementation, we can easily change
the implementation details at any time by only modifying the source file
(
).
No one needs to be aware of the actual type of engine that we use. And no one needs to
know when we upgrade our engine. With this implementation, we can easily change
the implementation details at any time by only modifying the source file
(![]() ).
Therefore, with this approach, we’ve truly
minimized dependencies on the
).
Therefore, with this approach, we’ve truly
minimized dependencies on the ElectricEngine implementation. We have made the
knowledge about this detail our own, secret implementation detail. And by doing that,
we have built ourselves a Bridge.
Note
As stated in the introduction, counterintuitively, this Bridge isn’t about bringing
the ElectricCar and Engine classes closer together. On the contrary, it’s about
separating concerns and about loose coupling. Another example that shows that
naming is hard comes from Kate Gregory’s talk at CppCon.
The Bridge Design Pattern Explained
The Bridge design pattern is yet another one of the classic GoF design patterns introduced in 1994. The purpose of a Bridge is to minimize physical dependencies by encapsulating some implementation details behind an abstraction. In C++, it acts as a compilation firewall, which enables easy change:
The Bridge Design Pattern
Intent: “Decouple an abstraction from its implementation so that the two can vary independently.”3
In this formulation of the intent, the Gang of Four talks about an “abstraction” and an
“implementation.” In our example, the ElectricCar class represents the “abstraction,”
while the Engine class represents the “implementation” (see Figure 7-1).
Both of these should be able to vary independently; i.e., changes to either one should
have no effect on the other. The impediments to easy change are the physical dependencies
between the ElectricCar class and its engines. Thus, the idea is to extract and isolate
these dependencies. By isolating them in the form of the Engine abstraction, separating
concerns, and fulfilling the SRP, you gain the flexibility
to change, tune, or upgrade the engine any way you want (see “Guideline 2: Design for Change”). The
change is no longer visible in the ElectricCar class. As a consequence, it is now easily
possible to add new kinds of engines without the “abstraction” noticing. This adheres to
the idea of the OCP (see “Guideline 5: Design for Extension”).
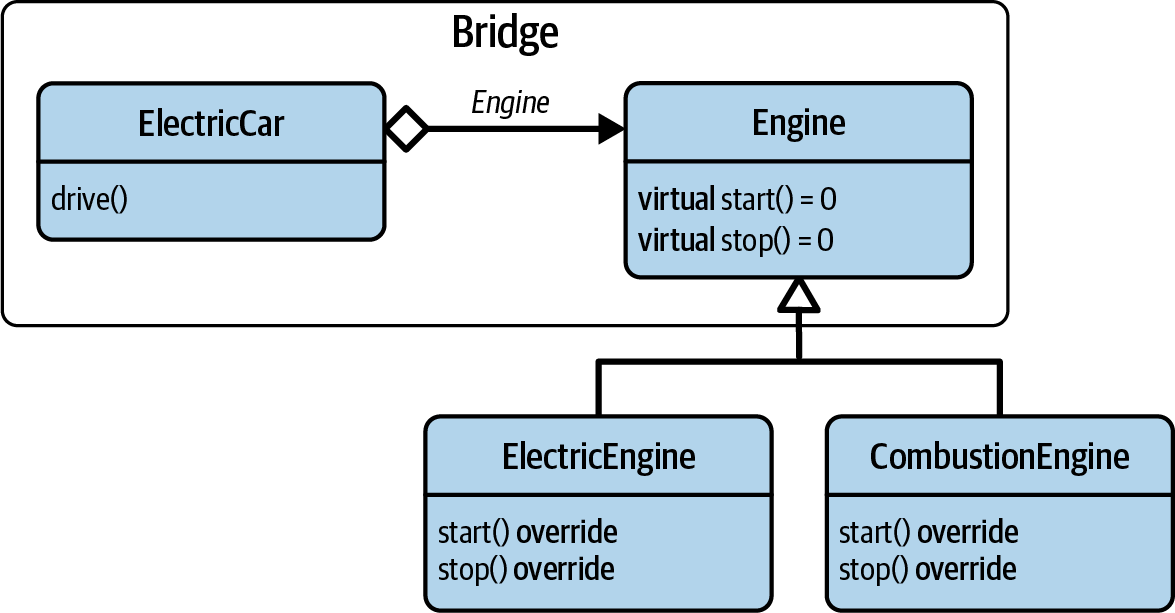
Figure 7-1. The UML representation of the basic Bridge design pattern
While this provides us the ability to easily apply changes, and implements the idea of a Bridge, there is one more step that we can take to
further decouple and reduce duplication. Let’s assume that we are not just interested
in electric cars but also in cars with combustion engines. So for
every kind of car that we plan to implement, we are interested in introducing the same kind
of decoupling from engine details, i.e., the same kind of Bridge. To reduce
the duplication and follow the DRY principle, we can extract
the Bridge-related implementation details into the Car base class (see
Figure 7-2).
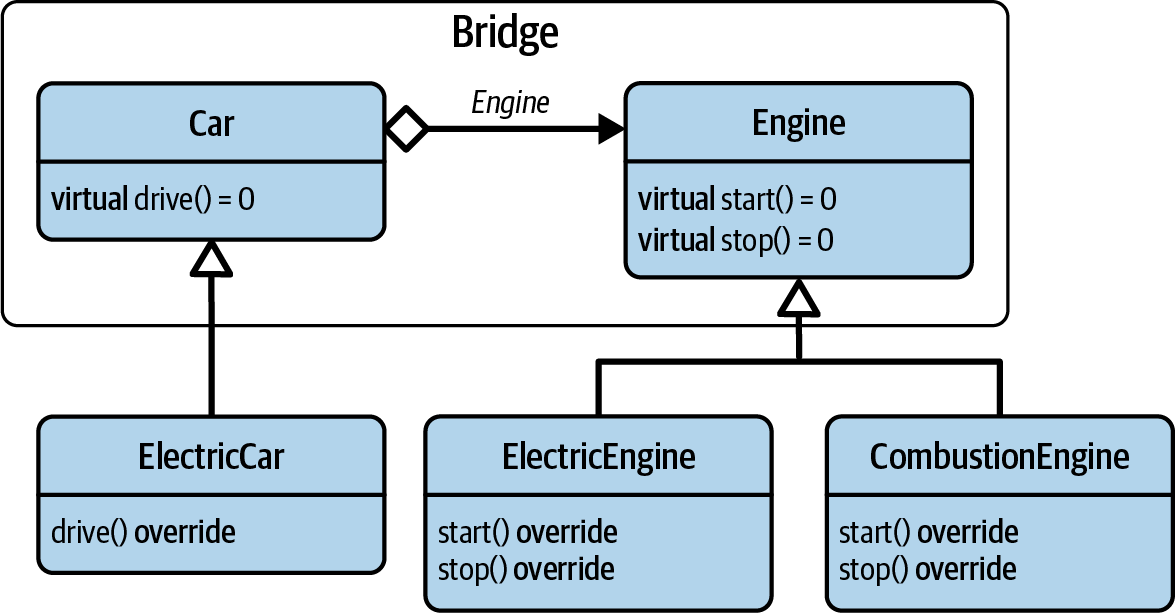
Figure 7-2. The UML representation of the full Bridge design pattern
The Car base class encapsulates the Bridge to the associated Engine:
//---- <Car.h> ----------------#include<Engine.h>#include<memory>#include<utility>classCar{protected:explicitCar(std::unique_ptr<Engine>engine):pimpl_(std::move(engine)){}public:virtual~Car()=default;virtualvoiddrive()=0;// ... more car-specific functionsprotected:Engine*getEngine(){returnpimpl_.get();}Engineconst*getEngine()const{returnpimpl_.get();}private:std::unique_ptr<Engine>pimpl_;// Pointer-to-implementation (pimpl)// ... more car-specific data members (wheels, drivetrain, ...)};
With the addition of the Car class, both the “abstraction” and the “implementation”
offer the opportunity for easy extension and can vary independently. While the Engine
base class still represents the “implementation” in this Bridge relation, the Car
class now plays the role of the “abstraction.” The first noteworthy detail about the
Car class is the protected constructor
(![]() ).
This choice makes sure that only derived classes are able to specify the kind of engine.
The constructor takes
).
This choice makes sure that only derived classes are able to specify the kind of engine.
The constructor takes std::unique_ptr to an Engine and moves it to its pimpl_
data member
(![]() ).
This pointer data member is the one pointer-to-implementation for all kinds of
).
This pointer data member is the one pointer-to-implementation for all kinds of
Cars and is commonly called the pimpl. This opaque pointer represents the Bridge
to the encapsulated implementation details and essentially represents the Bridge
design pattern as a whole. For this reason, it’s a good idea to use the name pimpl in
the code as an indication of your intentions (remember
“Guideline 14: Use a Design Pattern’s Name to Communicate Intent”).
Note that pimpl_ is declared in the private section of the class, despite the fact
that derived classes will have to use it. This choice is motivated by
Core Guideline C.133:
Avoid
protecteddata.
Indeed, experience shows that protected data members are barely better than
public
data members. Therefore, to grant access to the pimpl, the Car class instead
provides the protected getEngine() member functions
(![]() ).
).
The ElectricCar class is adapted accordingly:
//---- <ElectricCar.h> ----------------#include<Engine.h>#include<memory>classElectricCar:publicCar{public:explicitElectricCar(/*maybe some engine arguments*/);voiddrive()override;// ...};//---- <ElectricCar.cpp> ----------------#include<ElectricCar.h>#include<ElectricEngine.h>ElectricCar::ElectricCar(/*maybe some engine arguments*/):Car(std::make_unique<ElectricEngine>(/*engine arguments*/)){}// ...
Rather than implementing the Bridge itself, the ElectricCar class now inherits from the
Car base class
(![]() ).
This inheritance relationship introduces the requirement of initializing the
).
This inheritance relationship introduces the requirement of initializing the Car base
by specifying an Engine. This task is performed in the
ElectricCar constructor
(![]() ).
).
The Pimpl Idiom
There is a much simpler form of the Bridge design pattern that has been very commonly
and successfully used in both C and C++ for decades. To see an example, let’s
consider the following Person class:
classPerson{public:// ...intyear_of_birth()const;// ... Many more access functionsprivate:std::stringforename_;std::stringsurname_;std::stringaddress_;std::stringcity_;std::stringcountry_;std::stringzip_;intyear_of_birth_;// ... Potentially many more data members};
A person consists of a lot of data members: forename, surname, the complete postal
address, year_of_birth, and potentially many more. There may be the need to add
further data members in the future: a mobile phone number, a Twitter account, or the account
information for the next social media fad. In other words, it stands to reason that
the Person class needs to be extended or changed over time, potentially even frequently.
This may come with a whole lot of inconveniences for users of this class: whenever Person
changes, the users of Person have to recompile their code. Not to mention ABI stability:
the size of a Person instance is going to change!
To hide all changes to the implementation details of Person and gain ABI stability, you can use the Bridge design pattern. In this particular case,
however, there is no need to provide an abstraction in the form of a base class: there is
one, and exactly one, implementation for Person. Therefore, all we do is introduce a
private, nested class called Impl
(![]() ):
):
//---- <Person.h> ----------------#include<memory>classPerson{public:// ...private:structImpl;std::unique_ptr<Impl>constpimpl_;};//---- <Person.cpp> ----------------#include<Person.h>#include<string>structPerson::Impl{std::stringforename;std::stringsurname;std::stringaddress;std::stringcity;std::stringcountry;std::stringzip;intyear_of_birth;// ... Potentially many more data members};
The sole task of the nested Impl class is to encapsulate the implementation details
of Person. Thus, the only data member remaining in the Person class is the std::unique_ptr
to an Impl instance
(![]() ).
All other data members, and potentially some non-
).
All other data members, and potentially some non-virtual helper functions, are moved from
the Person class into the Impl class. Note that the Impl class is only declared in
the Person class but not defined. Instead, it is defined in the corresponding source file
(![]() ).
Only due to this, all details and all changes that you apply to the details, such as adding or
removing data members, changing the type of data members, etc., are hidden from the users
of
).
Only due to this, all details and all changes that you apply to the details, such as adding or
removing data members, changing the type of data members, etc., are hidden from the users
of Person.
This implementation of Person uses the Bridge design pattern in its simplest form:
this local, nonpolymorphic form of Bridge is called the
Pimpl idiom. It comes with all the
decoupling advantages of the Bridge pattern but, despite its simplicity, it still results
in a bit more complex implementation of the
Person class:
//---- <Person.h> ----------------//#include <memory>classPerson{public:// ...Person();~Person();Person(Personconst&other);Person&operator=(Personconst&other);Person(Person&&other);Person&operator=(Person&&other);intyear_of_birth()const;// ... Many more access functionsprivate:structImpl;std::unique_ptr<Impl>constpimpl_;};//---- <Person.cpp> ----------------//#include <Person.h>//#include <string>structPerson::Impl{// ...};Person::Person():pimpl_{std::make_unique<Impl>()}{}Person::~Person()=default;Person::Person(Personconst&other):pimpl_{std::make_unique<Impl>(*other.pimpl_)}{}Person&Person::operator=(Personconst&other){*pimpl_=*other.pimpl_;return*this;}Person::Person(Person&&other):pimpl_{std::make_unique<Impl>(std::move(*other.pimpl_))}{}Person&Person::operator=(Person&&other){*pimpl_=std::move(*other.pimpl_);return*this;}intPerson::year_of_birth()const{returnpimpl_->year_of_birth;}// ... Many more Person member functions
The Person constructor initializes the pimpl_ data member by std::make_unique()
(![]() ).
This, of course, involves a dynamic memory allocation, which means that the dynamic memory
needs to be cleaned up again. “And that is why we use
).
This, of course, involves a dynamic memory allocation, which means that the dynamic memory
needs to be cleaned up again. “And that is why we use std::unique_ptr,” you say.
Correct. But perhaps surprisingly, although we use std::unique_ptr for that purpose, it’s still necessary to manually deal with the destructor
(![]() ).
).
“Why on earth do we have to do this? Isn’t the point of std::unique_ptr that we don’t
have to deal with cleanup?” Well, we still have to. Let me explain: if you don’t write
the destructor, the compiler feels obliged to generate the destructor for you. Unfortunately,
it would generate the destructor in the <Person.h> header file. The destructor of Person
would trigger the instantiation of the destructor of
the std::unique_ptr data member,
which in turn would require the definition of the destructor of the Impl class. The
definition of Impl, however, is not available in the header file. On the contrary, it
needs to be defined in the source file or it would defeat the purpose of the Bridge. Thus,
the compiler emits an error about the incomplete type Impl. Fortunately, you do not have
to let go of the std::unique_ptr to resolve the issue (and in fact you should not let go
of it). The problem is rather simple to solve. All you have to do is move the definition
of the Person destructor to the source file: you declare the destructor in the class
definition and define it via =default in the source file.
Since std::unique_ptr cannot be copied, you will have to implement the copy constructor
to preserve the copy semantics of the Person class
(![]() ).
The same is true for the copy assignment operator
(
).
The same is true for the copy assignment operator
(![]() ).
Note that this operator is implemented under the assumption that every instance of
).
Note that this operator is implemented under the assumption that every instance of Person
will always have a valid pimpl_. This assumption explains the implementation of the move
constructor: instead of simply moving std::unique_ptr, it performs a potentially
failing, or throwing, dynamic memory allocation with std::make_unique(). For
that reason, it is not declared as noexcept
(![]() ).4 This assumption also explains why
the
).4 This assumption also explains why
the pimpl_ data member is declared as const. Once it’s initialized, the pointer will
not be changed anymore, not even in the move operations, including the move assignment
operator
(![]() ).
).
The last detail worth noting is that the definition of the year_of_birth() member
function is located in the source file
(![]() ).
Despite the fact that this simple getter function is a great
).
Despite the fact that this simple getter function is a great
inline candidate, the definition has to be moved to the source file. The reason is that
in the header file, Impl is an
incomplete type.
Which means that within the header file, you are not able to access any members (both data
and functions). This is possible only in the source file, or generally speaking, as soon as
the compiler knows the definition of Impl.
Comparison Between Bridge and Strategy
“I have a question,” you say. “I see a strong resemblance between the Bridge and the Strategy design pattern. I know you said that design patterns are sometimes structurally very similar and that the only difference is their intent. But what exactly is the distinction between these two?”5 I understand your question. The similarity between these two is truly a little confusing. However, there is something you can use to tell them apart: how the corresponding data member is initialized is a strong indicator about which one you’re using.
If a class does not want to know about some implementation detail, and if for that reason
it provides the opportunity to configure the behavior by passing in details from the outside
(for instance, via a constructor or via a setter function), then you are most likely dealing with
the Strategy design pattern. Because the flexible configuration of behavior, i.e., the
reduction of logical dependencies, is its primary focus, Strategy falls into the category
of a behavioral design pattern. For instance, in the following code snippet, the constructor
of the Database class is a telltale sign:
classDatabaseEngine{public:virtual~DatabaseEngine()=default;// ... Many database-specific functions};classDatabase{public:explicitDatabase(std::unique_ptr<DatabaseEngine>engine);// ... Many database-specific functionsprivate:std::unique_ptr<DatabaseEngine>engine_;};// The database is unaware of any implementation details and requests them// via its constructor from outside -> Strategy design patternDatabase::Database(std::unique_ptr<DatabaseEngine>engine):engine_{std::move(engine)}{}
The actual type of DatabaseEngine is passed in from the outside
(![]() ),
making this a good example of the Strategy design pattern.
),
making this a good example of the Strategy design pattern.
Figure 7-3 shows the dependency graph for this example.
Most importantly, the
Database class is on the same architectural level as the DatabaseEngine
abstraction, thus providing others with the opportunity to implement the behavior (e.g.,
in the form of the ConcreteDatabaseEngine). Since Database is depending only on the
abstraction, there is no dependency on any specific implementation.

Figure 7-3. Dependency graph for the Strategy design pattern
If, however, a class knows about the implementation details but primarily wants to reduce the physical dependencies on these details, then you’re most likely dealing with the Bridge design pattern. In that case, the class does not provide any opportunity to set the pointer from outside, i.e., the pointer is an implementation detail and set internally. Since the Bridge design pattern primarily focuses on the physical dependencies of the implementation details, not the logical dependencies, Bridge falls into the category of structural design patterns. As an example, consider the following code snippet:
classDatabase{public:explicitDatabase();// ...private:std::unique_ptr<DatabaseEngine>pimpl_;};// The database knows about the required implementation details, but does// not want to depend too strongly on it -> Bridge design patternDatabase::Database():pimpl_{std::make_unique<ConcreteDatabaseEngine>(/*some arguments*/)}{}
Again, there is a telltale sign for the application of the Bridge design pattern: instead
of accepting an engine from outside, the constructor of the Database class is aware of the
ConcreteDatabaseEngine and sets it internally
(![]() ).
).
Figure 7-4 shows the dependency graph for the Bridge
implementation of the
Database example. Most notably, the Database class is on the
same architectural level as the ConcreteDatabaseEngine class and does not leave
any opportunity for others to provide different implementations. This shows that in
contrast to the Strategy design pattern, a Bridge is logically coupled to a specific
implementation but only physically decoupled via the DatabaseEngine abstraction.
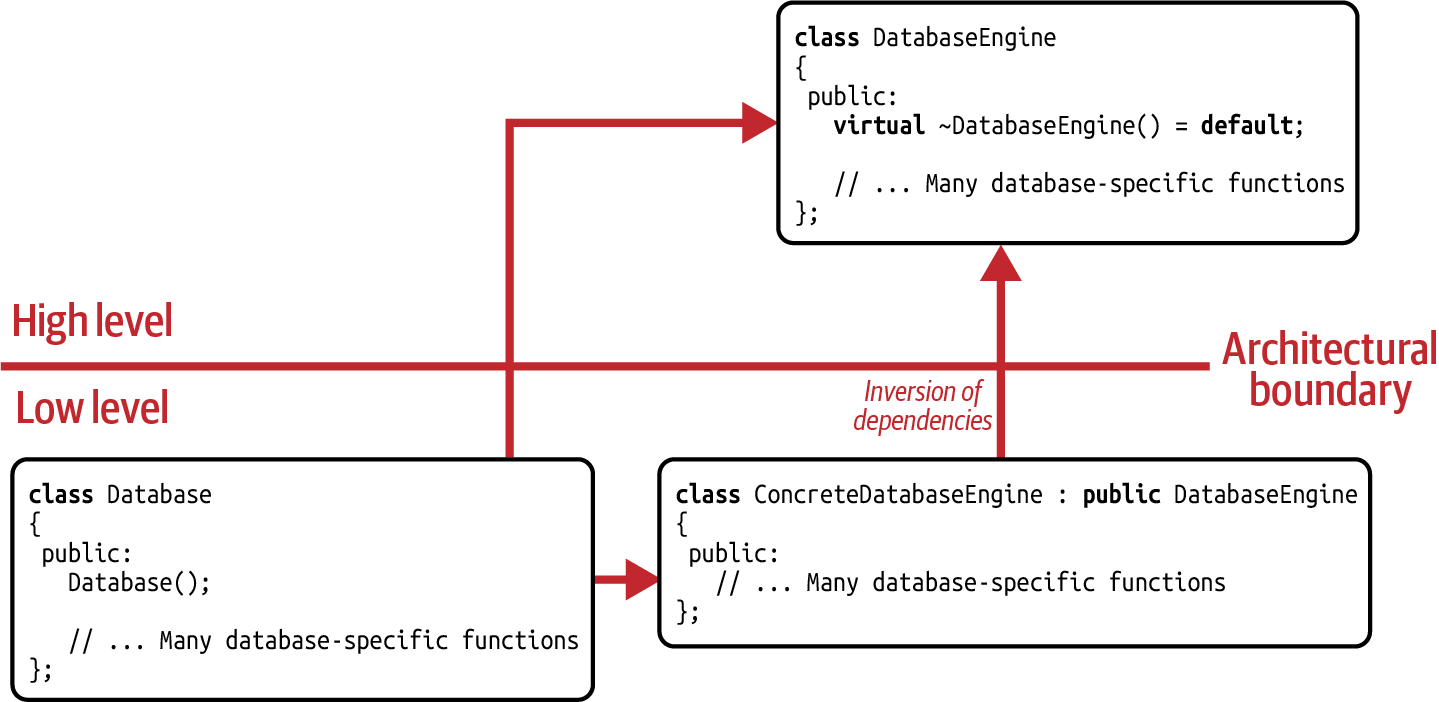
Figure 7-4. Dependency graph for the Bridge design pattern
Analyzing the Shortcomings of the Bridge Design Pattern
“I can totally see why the Bridge design pattern is so popular in the community. The decoupling properties are really great!” you exclaim. “However, you keep telling me that every design has its pros and cons. I expect there is a performance penalty?” Good, you remember that there are always some disadvantages. And of course this includes the Bridge design pattern, although it proves to be very useful. And yes, you’re correct to assume that there is some performance overhead involved.
The first of five types of overhead results from the fact that Bridge introduces an additional indirection: the pimpl pointer making all access to the implementation details more expensive. However, how much of the performance penalty this pointer causes is an issue that I will discuss separately in “Guideline 29: Be Aware of Bridge Performance Gains and Losses”. This is not the only source of performance overhead, though; there are more. Depending on whether you use an abstraction, you also might have to pay for the virtual function call overhead. Additionally, you’ll have to pay more due to the lack of inlining of even the simplest function accessing data members. And, of course, you will have to pay for an additional dynamic memory allocation whenever you create a new instance of a class implemented in terms of Bridge.6 Last but not least, you should also take into account the memory overhead caused by introducing the pimpl pointer. So, yes, isolating the physical dependencies and hiding implementation details is not free but results in a considerable overhead. Still, this shouldn’t be a reason to generally discard the Bridge solution: it always depends. For instance, if the underlying implementation performs slow, expensive tasks, such as system calls, then this overhead might not be measurable at all. In other words, whether or not to use a Bridge should be decided on a case-by-case basis and backed up with performance benchmarks.
Furthermore, you have seen the implementation details and realized that the code complexity has increased. Since simplicity and readability of code are a virtue, this should be considered a downside. It’s true that this affects only the internals of a class, not the user code. But still, some of the details (e.g., the need to define the destructor in the source file) might be confusing for less-experienced developers.
In summary, the Bridge design pattern is one of the most valuable and most commonly used solutions for reducing physical dependencies. Still, you should be aware of the overhead and the complexity that a Bridge introduces.
Guideline 29: Be Aware of Bridge Performance Gains and Losses
In “Guideline 28: Build Bridges to Remove Physical Dependencies”, we took a detailed look at the Bridge design pattern. While I imagine the design and decoupling aspect of Bridge left a positive impression on you, I must make you aware that using this pattern may introduce a performance penalty. “Yes, and that worries me. Performance is important to me, and it sounds like a Bridge will create a massive performance overhead,” you say. And this is a pretty common expectation. Since performance matters, I really should give you an idea of how much overhead you have to expect when using a Bridge. However, I should also demonstrate how to use Bridges wisely to improve the performance of your code. Sounds unbelievable? Well, let me show you how.
The Performance Impact of Bridges
As discussed in “Guideline 28: Build Bridges to Remove Physical Dependencies”, the performance of a Bridge implementation is influenced by many factors: access through an indirection, virtual function calls, inlining, dynamic memory allocations, etc. Because of these factors and the huge amount of possible combinations, there is no definitive answer to how much performance a Bridge will cost you. There simply is no shortcut, no substitute for assembling a couple of benchmarks for your own code and running them to evaluate a definitive answer. What I want to demonstrate, though, is that there is indeed a performance penalty of accessing through an indirection, but you can still use a Bridge to actually improve performance.
Let’s get started with giving you an idea about the benchmark. To form an
opinion on how costly the pointer indirection is, let’s compare the following two
implementations of a Person class:
#include<string>//---- <Person1.h> ----------------classPerson1{public:// ...privatestd::stringforename_;std::stringsurname_;std::stringaddress_;std::stringcity_;std::stringcountry_;std::stringzip_;intyear_of_birth_;};
The Person1 struct represents a type that is not implemented in terms of a Bridge. All
seven data members (six std::strings and one int) are directly part of the struct
itself. Altogether, and assuming a 64-bit machine, the total size of one instance of Person1
is 152 bytes with Clang 11.1 and 200 bytes with GCC 11.1.7
The Person2 struct, on the other hand, is implemented with the Pimpl idiom:
//---- <Person2.h> ----------------#include<memory>classPerson2{public:explicitPerson2(/*...various person arguments...*/);~Person2();// ...private:structImpl;std::unique_ptr<Impl>pimpl_;};//---- <Person2.cpp> ----------------#include<Person2.h>#include<string>structPerson2::Impl{std::stringforename;std::stringsurname;std::stringaddress;std::stringcity;std::stringcountry;std::stringzip;intyear_of_birth;};Person2::Person2(/*...various person arguments...*/):pimpl{std::make_unique<Impl>(/*...various person arguments...*/)}{}Person2::~Person2()=default;
All seven data members have been moved into the nested Impl struct and can
be accessed only via the pimpl pointer. While the total size of the nested Impl struct is
identical to the size of Person1, the size of the Person2 struct is only 8 bytes
(again, assuming a 64-bit machine).
Note
Via the Bridge design, you can reduce the size of a type, sometimes even significantly.
This can prove to be very valuable, for instance, if you want to use the type as an
alternative in std::variant (see
“Guideline 17: Consider std::variant for
Implementing Visitor”).
So let me outline the benchmark: I will create two std::vectors of 25,000 persons, one
for each of the two Person implementations. This number of elements will make certain
that we work beyond the size of the inner caches of the underlying CPU (i.e., we will use
a total of 3.2 MB with Clang 11.1 and 4.2 MB with GCC 11.1). All of these persons are given
arbitrary names and addresses and a year of birth between 1957 and 2004 (at the
time of writing, this would represent a reasonable range of ages of employees in an
organization). Then we will traverse both person vectors five thousand times, and each time determine
the oldest person with std::min_element(). The result will be
fairly uninteresting due to the repetitive nature of the benchmark. After one hundred
iterations, you’ll be too bored to watch. The only thing that matters is seeing the performance
difference between accessing a data member directly (Person1) or indirectly (Person2).
Table 7-1 shows the performance results, normalized to the
performance of the Person1 implementation.
| Person implementation | GCC 11.1 | Clang 11.1 |
|---|---|---|
Person1 (no pimpl) |
1.0 |
1.0 |
Person2 (complete Pimpl idiom) |
1.1099 |
1.1312 |
It’s fairly obvious that in this particular benchmark, the Bridge implementation incurs a pretty significant performance penalty: 11.0% for GCC and 13.1% for Clang. This sounds like a lot! However, don’t take these numbers too seriously: clearly, the result heavily depends on the actual number of elements, the actual number and type of data members, the system we’re running on, and the actual computation we perform in the benchmark. If you change any of these details, the numbers will change as well. Thus, these numbers only demonstrate that there is some, and potentially even some more, overhead due to the indirect access to data members.
Improving Performance with Partial Bridges
“OK, but this is an expected result, right? What should I learn from that?” you ask.
Well, I admit that this benchmark is fairly specific and does not answer all questions. However,
it does provide us with the opportunity to actually use a Bridge to improve performance.
If you take a closer look at the implementation of Person1, you might realize that for the
given benchmark, the achievable performance is pretty limited: while the total size of Person1
is 152 bytes (Clang 11.1) or 200 bytes (GCC 11.1), respectively, we use only 4 bytes, i.e.,
a single int, out of the total data structure. This proves to be rather wasteful and
inefficient: since in cache-based architectures memory is always loaded as cache
lines, a lot of the data that we load from memory is actually not used at all. In fact,
almost all of the data that we load from memory is not used at all: assuming a cache line
length of 64 bytes, we only use approximately 6% of the loaded data. Hence, despite the
fact that we determine the oldest person based on the year of birth of all persons, which
sounds like a compute-bound operation, we are in fact completely memory bound: the machine
simply cannot deliver data fast enough, and the integer unit will idle most of the time.
This setting gives us the opportunity to improve the performance with a Bridge.
Let’s assume that we can distinguish between data that is used often (such as forename, surname, and year_of_birth) and data that is used infrequently (for instance, the
postal address). Based on this distinction, we now arrange the data members accordingly:
all data members that are used often are stored directly in the Person class. All
data members that are used infrequently are stored inside the Impl struct. This leads
to the Person3 implementation:
//---- <Person3.h> ----------------#include<memory>#include<string>classPerson3{public:explicitPerson3(/*...various person arguments...*/);~Person3();// ...private:std::stringforename_;std::stringsurname_;intyear_of_birth_;structImpl;std::unique_ptr<Pimpl>pimpl_;};//---- <Person3.cpp> ----------------#include<Person3.h>structPerson3::Impl{std::stringaddress;std::stringcity;std::stringcountry;std::stringzip;};Person3::Person3(/*...various person arguments...*/):forename_{/*...*/},surname_{/*...*/},year_of_birth_{/*...*/},pimpl_{std::make_unique<Impl>(/*...address-related arguments...*/)}{}Person3::~Person3()=default;
The total size of a Person3 instance is 64 bytes for Clang 11.1 (two 24-byte
std::strings, one integer, one pointer, and four padding bytes due to alignment
restrictions) and 80 bytes on GCC 11.1 (two 32-byte std::strings, one integer,
one pointer, and some padding). Thus, a Person3 instance is only approximately half
as big as a Person1 instance. This difference in size is measurable:
Table 7-2 shows the performance result for all Person
implementations, including Person3. Again, the results are normalized to the
performance of the Person1 implementation.
| Person implementation | GCC 10.3 | Clang 12.0 |
|---|---|---|
Person1 (no pimpl) |
1.0 |
1.0 |
Person2 (complete Pimpl idiom) |
1.1099 |
1.1312 |
Person3 (partial Pimpl idiom) |
0.8597 |
0.9353 |
In comparison to the Person1 implementation, the performance for Person3 is improved by
14.0% for GCC 11.1 and 6.5% for Clang 11.1. And, as stated before, this is only because we
reduced the size of the Person3 implementation. “Wow, this was unexpected. I see, a Bridge
is not necessarily all bad for performance,” you say. Yes, indeed. Of course, it always
depends on the specific setup, but distinguishing between data members that are used frequently
and those that are used infrequently, and reducing the size of a data structure by implementing a “partial” Bridge
may have a very positive impact on performance.8
“The performance gain is huge, that’s great, but isn’t that running against the intention of a Bridge?” you ask. Indeed, you realize that there is a dichotomy between hiding implementation details and “inlining” data members for the sake of performance. As always, it depends: you will have to decide from case to case which aspect to favor. You hopefully also realize that there is an entire range of solutions in between the two extremes: it is not necessary to hide all data members behind a Bridge. In the end, you are the one to find the optimum for a given problem.
In summary, while Bridges in general will very likely incur a performance penalty, given the right circumstances, implementing a partial Bridge may have a very positive effect on your performance. However, this is only one of many aspects that influence performance. Therefore, you should always check to see if a Bridge results in a performance bottleneck or if a partial Bridge is addressing a performance issue. The best way to confirm this is with a representative benchmark, based on the actual code and actual data as much as possible.
Guideline 30: Apply Prototype for Abstract Copy Operations
Imagine yourself sitting in a fancy Italian restaurant and studying the menu. Oh my, they offer so many great things; the lasagna sounds great. But the selection of pizza they offer is also amazing. So hard to choose…However, your thoughts are interrupted as the waiter walks by carrying this incredible-looking dish. Unfortunately, it’s not meant for you but for someone at another table. Oh wow, the smell…At this moment, you know that you no longer have to think about what you want to eat: you want the same thing, no matter what it is. And so you order: “Ah, waiter, I’ll have whatever they are having.”
The same problem may occur in your code. In C++ terms, what you are asking the
waiter for is a copy of the other person’s dish. Copying an object, i.e., creating an
exact replica of an instance, is a fundamentally important operation in C++.
So important that classes are, by default, equipped with a copy constructor
and a copy assignment operator—two of the so-called special member
functions.9 However, when asking for a copy of the dish, you
are unfortunately not aware what dish it is. In C++ terms, all you have is a
pointer-to-base (say, a Dish*). And unfortunately, trying to copy via Dish* with the copy constructor or copy assignment operator usually doesn’t work. Still,
you want an exact copy. The solution to this problem is another classic GoF design
pattern: the Prototype design pattern.
A Sheep-ish Example: Copying Animals
As an example, let’s consider the following Animal base class:
//---- <Animal.h> ----------------classAnimal{public:virtual~Animal()=default;virtualvoidmakeSound()const=0;// ... more animal-specific functions};
Apart from the virtual destructor, which indicates that Animal is supposed to be
a base class, the class provides only the makeSound() function,
which deals with printing cute animal sounds. One example of such an animal is the
Sheep class:
//---- <Sheep.h> ----------------#include<Animal.h>#include<string>classSheep:publicAnimal{public:explicitSheep(std::stringname):name_{std::move(name)}{}voidmakeSound()constoverride;// ... more animal-specific functionsprivate:std::stringname_;};//---- <Sheep.cpp> ----------------#include<Sheep.h>#include<iostream>voidSheep::makeSound()const{std::cout<<"baa\n";}
In the main() function, we can now create a sheep and have it make sounds:
#include<Sheep.h>#include<cstdlib>#include<memory>intmain(){// Creating the one and only Dollystd::unique_ptr<Animal>constdolly=std::make_unique<Sheep>("Dolly");// Triggers Dolly's beastly sounddolly->makeSound();returnEXIT_SUCCESS;}
Dolly is great, right? And so cute! In fact, she’s so much fun that we want another
Dolly. However, all we have is a pointer-to-base—an Animal*.
We can’t copy via the Sheep copy constructor or the copy assignment operator, because
we (technically) don’t even know that we are dealing with a Sheep. It could be any
kind of animal (e.g., dog, cat, sheep, etc.). And we don’t want to copy just the Animal
part of Sheep, as this is what we call slicing.
Oh my, I just realized that this may be a particularly bad example for explaining the
Prototype design pattern. Slicing animals. This sounds bad. So let’s swiftly move
on. Where were we? Ah yes, we want a copy of Dolly, but we only have an Animal*. This
is where the Prototype design pattern comes into play.
The Prototype Design Pattern Explained
The Prototype design pattern is one of the five creational design patterns collected by the Gang of Four. It is focused on providing an abstract way of creating copies of some abstract entity.
The Prototype Design Pattern
Intent: “Specify the kind of objects to create using a prototypical instance, and create new objects by copying this prototype.”10
Figure 7-5 shows the original UML formulation, taken from the GoF book.
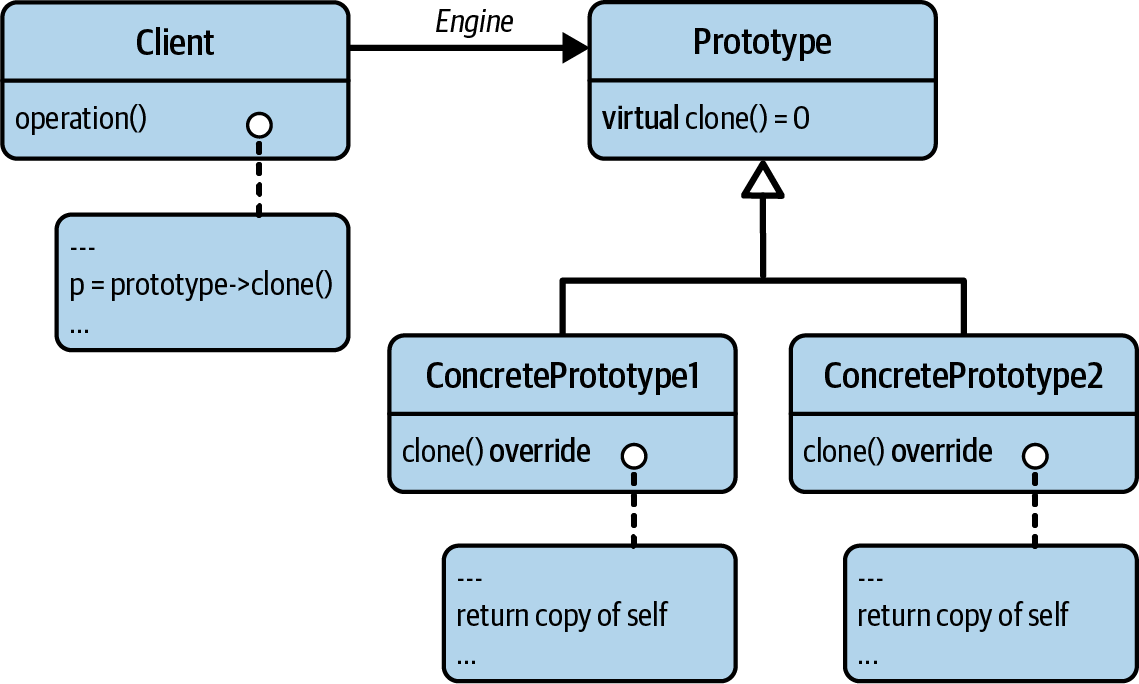
Figure 7-5. The UML representation of the Prototype design pattern
The Prototype design pattern is commonly implemented by a virtual clone()
function in the base class. Consider the updated Animal base class:
//---- <Animal.h> ----------------classAnimal{public:virtual~Animal()=default;virtualvoidmakeSound()const=0;virtualstd::unique_ptr<Animal>clone()const=0;// Prototype design pattern};
Via this clone() function, anyone can ask for an abstract copy of the given (prototype)
animal, without having to know about any specific type of animal (Dog, Cat, or Sheep).
When the Animal base class is properly assigned to the high level of your architecture,
it follows the DIP (see Figure 7-6).
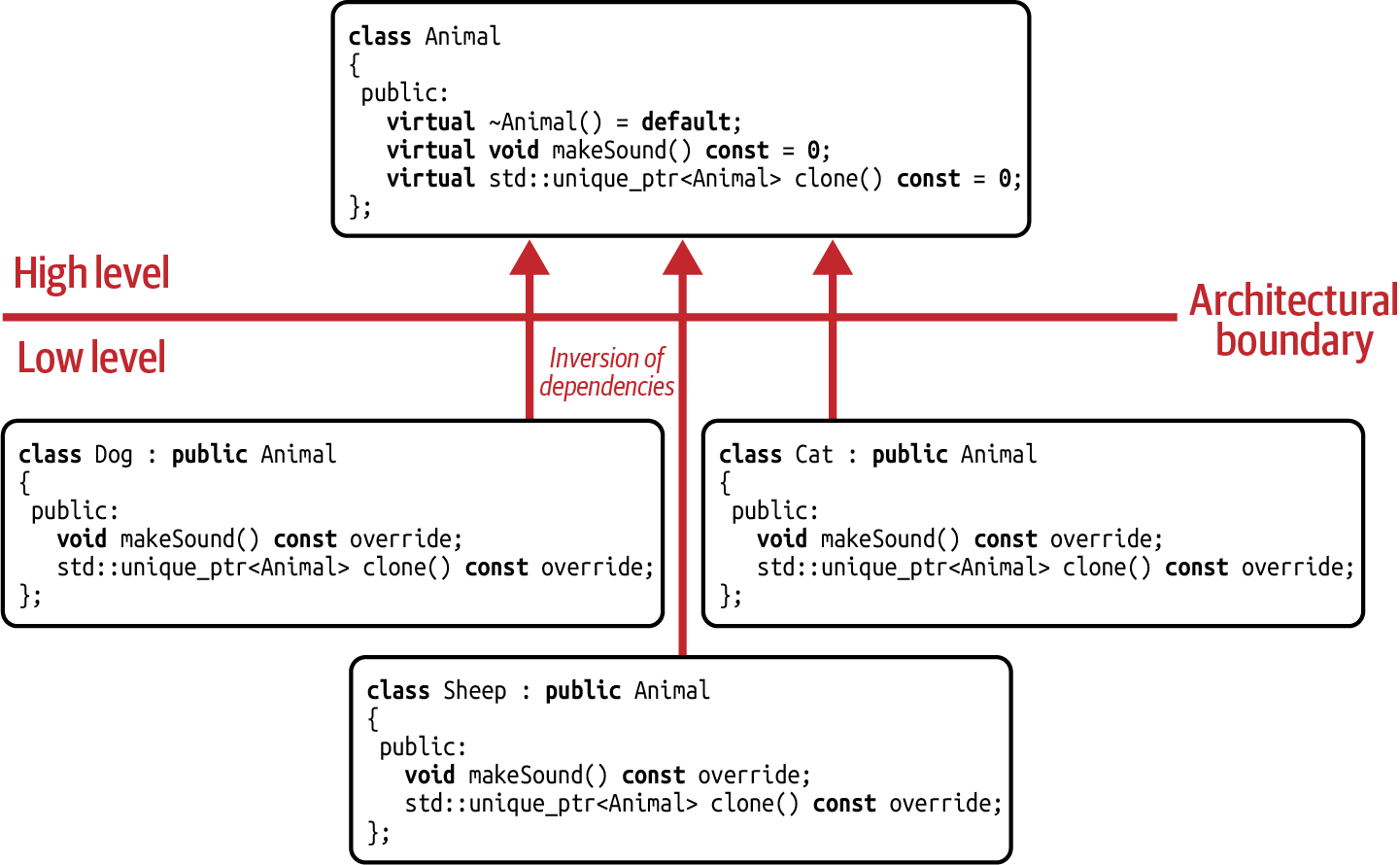
Figure 7-6. Dependency graph for the Prototype design pattern
The clone() function is declared as a pure virtual function, which means that deriving
classes are required to implement it. However, deriving classes cannot simply implement
the function any way they want, but are expected to return an exact copy of themselves
(any other result would violate the LSP; see
“Guideline 6: Adhere to the Expected Behavior of Abstractions”). This copy is
commonly created dynamically by new and returned by a pointer-to-base.
This, of course, results not only in a pointer but also in the need to explicitly
delete the copy again. Since
manual cleanup is considered to be very bad practice in
Modern C++, the pointer is returned as the std::unique_ptr to
Animal.11
The Sheep class is updated accordingly:
//---- <Sheep.h> ----------------#include<Animal.h>classSheep:publicAnimal{public:explicitSheep(std::stringname):name_{std::move(name)}{}voidmakeSound()constoverride;std::unique_ptr<Animal>clone()constoverride;// Prototype design patternprivate:std::stringname_;};//---- <Sheep.cpp> ----------------#include<Sheep.h>#include<iostream>voidSheep::makeSound()const{std::cout<<"baa\n";}std::unique_ptr<Animal>Sheep::clone()const{returnstd::make_unique<Sheep>(*this);// Copy-construct a sheep}
The Sheep class is now required to implement the clone() function and return an
exact copy of the Sheep: Inside its own clone() function, it makes use of the
std::make_unique() function and its own copy constructor, which is always assumed to
do the right thing, even if the Sheep class changes in the future. This approach
helps avoid unnecessary duplication and thus follows the DRY principle (see
“Guideline 2: Design for Change”).
Note that the Sheep class neither deletes nor hides its copy constructor and copy
assignment operator. Hence, if you have a sheep, you can still copy the sheep with the special member functions. That is perfectly OK: the clone() merely adds one
more way to create a copy—a way to perform virtual copying.
With the clone() function in place, we can now create an exact copy of Dolly.
And we can do this so much easier than we could have back in 1996 when they cloned the first Dolly:
#include<Sheep.h>#include<cstdlib>#include<memory>intmain(){std::unique_ptr<Animal>dolly=std::make_unique<Sheep>("Dolly");std::unique_ptr<Animal>dollyClone=dolly->clone();dolly->makeSound();// Triggers the first Dolly's beastly sounddollyClone->makeSound();// The clone sounds just like DollyreturnEXIT_SUCCESS;}
Comparison Between Prototype and std::variant
The Prototype design pattern really is a classic, very OO-centric design pattern, and
since its publication in 1994, it is the go-to solution for providing virtual
copying. Because of this, the function name clone() can almost be considered a keyword
for identifying the Prototype design pattern.
Because of the specific use case, there is no “modern” implementation (except perhaps for
the slight update to use std::unique_ptr instead of a raw pointer). In comparison to
other design patterns, there is also no value semantics solution: as soon as we
have a value, the most natural and intuitive solution would be to build on the two copy
operations (the copy constructor and the copy assignment operator).
“Are you sure that there is no value semantics solution? Consider the following
example using std::variant:”
#include<cstdlib>#include<variant>classDog{};classCat{};classSheep{};intmain(){std::variant<Dog,Cat,Sheep>animal1{/* ... */};autoanimal2=animal1;// Creating a copy of the animalreturnEXIT_SUCCESS;}
“Aren’t we performing an abstract copy operation in this case? And isn’t this copy
operation performed by the copy constructor? So isn’t this an example of
the Prototype design pattern but without the clone() function?” No. Although
it sounds like you have a compelling argument, this is not an example of the
Prototype design pattern. There is a very important difference between our two
examples: in your example, you have a closed set of types (typical of the Visitor
design pattern). The std::variant animal1 contains a dog, a cat, or a sheep,
but nothing else. Therefore, it is possible to perform an explicit copy with the
copy constructor. In my example, I have an open set of types. In other words, I haven’t the slightest clue what kind of animal I have to copy. It could be a dog, a cat,
or a sheep, but it could also be an elephant, a zebra, or a sloth. Anything is possible.
Therefore, I can’t build on the copy constructor but can only copy using a virtual
clone() function.
Analyzing the Shortcomings of the Prototype Design Pattern
Yes, there is no value semantics solution for the Prototype design pattern, but it’s a domestic beast from the realm of reference semantics. Hence, whenever the need arises to apply the Prototype design pattern, we have to live with the few drawbacks that come with it.
Arguably, the first disadvantage is the negative performance impact that comes with the indirection due to pointers. However, since we only require cloning if we have an inheritance hierarchy, it would be unfair to consider this a drawback of Prototype itself. It is rather a consequence of the basic setup of the problem. Since it’s also hard to imagine another implementation without pointers and the associated indirections, it seems to be an intrinsic property of the Prototype design pattern.
The second potential disadvantage is that, very often, the pattern is implemented by dynamic memory. The allocation itself, and also the possible resulting fragmented memory, causes further performance deficiencies. Dynamic memory is not a requirement, however, and you will see in “Guideline 33: Be Aware of the Optimization Potential of Type Erasure” that in certain contexts, you can also build on in-class memory. Still, this optimization applies to only a few special situations, and in most cases, the pattern builds on dynamic memory.
In comparison to the ability to perform an abstract copy operation, the few downsides are
easily acceptable. However, as discussed in “Guideline 22: Prefer Value Semantics over
Reference Semantics”,
our Animal hierarchy would be simpler and more comprehensible if you could replace
it with a value semantics approach and therefore avoid having to apply the reference semantics–based Prototype design pattern. Still, whenever you encounter the need to create an abstract
copy, the Prototype design pattern with a corresponding clone() function is the right choice.
Guideline 31: Use External Polymorphism for Nonintrusive Runtime Polymorphism
In “Guideline 2: Design for Change”, we saw the enormous benefits of the separation of concerns
design principle. In “Guideline 19: Use Strategy to Isolate How Things Are Done”,
we used this power to extract the drawing implementation details from a set of shapes
with the Strategy design pattern. However, although this has significantly reduced
dependencies, and despite the fact that we modernized the solution in
“Guideline 23: Prefer a Value-Based Implementation of Strategy and Command” with the
help of std::function, some disadvantages remained. In particular, the shape classes were
still forced to deal with the draw() operation, although for coupling reasons, it is
undesirable to deal with the implementation details. Additionally, and most importantly,
the Strategy approach proved to be a little impractical for extracting multiple, polymorphic
operations. To further reduce coupling and extract polymorphic operations from
our shapes, we are now continuing this journey and taking the separation of concerns principle
to a completely new, potentially unfamiliar level: we are separating the polymorphic behavior
as a whole. For that purpose, we will apply the External Polymorphism design pattern.
The External Polymorphism Design Pattern Explained
Let’s return to our example of drawing shapes and our latest version of our Circle
class from
“Guideline 23: Prefer a Value-Based Implementation of Strategy and Command”:
//---- <Shape.h> ----------------classShape{public:virtual~Shape()=default;virtualvoiddraw(/*some arguments*/)const=0;};//---- <Circle.h> ----------------#include<Shape.h>#include<memory>#include<functional>#include<utility>classCircle:publicShape{public:usingDrawStrategy=std::function<void(Circleconst&,/*...*/)>;explicitCircle(doubleradius,DrawStrategydrawer):radius_(radius),drawer_(std::move(drawer)){/* Checking that the given radius is valid and that the given 'std::function' instance is not empty */}voiddraw(/*some arguments*/)constoverride{drawer_(*this,/*some arguments*/);}doubleradius()const{returnradius_;}private:doubleradius_;DrawStrategydrawer_;};
With the Strategy design pattern, we have overcome the initial strong coupling to
the implementation details of the draw() member function
(![]() ).
We’ve also found a value semantics solution based on
).
We’ve also found a value semantics solution based on std::function
(![]() ).
However, the
).
However, the draw() member function is still part of the public interface of all classes
deriving from the Shape base class, and all shapes inherit the obligation to implement it
(![]() ).
This is a clear imperfection: arguably, the drawing functionality should be separate,
an isolated aspect of shapes, and shapes in general should be oblivious to the fact
that they can be drawn.12 The fact that we have already extracted the implementation
details considerably strengthens this argument.
).
This is a clear imperfection: arguably, the drawing functionality should be separate,
an isolated aspect of shapes, and shapes in general should be oblivious to the fact
that they can be drawn.12 The fact that we have already extracted the implementation
details considerably strengthens this argument.
“Well, then, let’s just extract the draw() member function, right?” you argue. And you’re right. Unfortunately, this appears to be a hard thing to do at first sight. I hope you
remember “Guideline 15: Design for the Addition of
Types or Operations”, where we came to the conclusion
that you should prefer an object-oriented solution when you primarily want to add types.
From this perspective, it appears as if we are stuck with the virtual draw() function and
the Shape base class, which represents the set of available operations of all shapes, i.e.,
the list of requirements.
There is a solution, though. A pretty astonishing one: we can extract the complete polymorphic behavior with the External Polymorphism design pattern. The pattern was introduced in a paper by Chris Cleeland, Douglas C. Schmidt, and Timothy H. Harrison in 1996.13 Its intent is to enable the polymorphic treatment of nonpolymorphic types (types without a single virtual function).
The External Polymorphism Design Pattern
Intent: “Allow C++ classes unrelated by inheritance and/or having no virtual methods to be treated polymorphically. These unrelated classes can be treated in a common manner by software that uses them.”
Figure 7-7 gives a first impression of how the design pattern
achieves this goal. One of the first striking details is that there is no Shape base
class anymore. In the External Polymorphism design pattern, the different kinds of shapes
(Circle, Square, etc.) are assumed to be plain, nonpolymorphic types. Also, the shapes
are not expected to know anything about drawing. Instead of requiring the shapes to inherit
from a Shape base class, the design pattern introduces a separate inheritance hierarchy
in the form of the ShapeConcept and ShapeModel classes. This external hierarchy
introduces the polymorphic behavior for the shapes by introducing all the operations and
requirements that are expected for shapes.
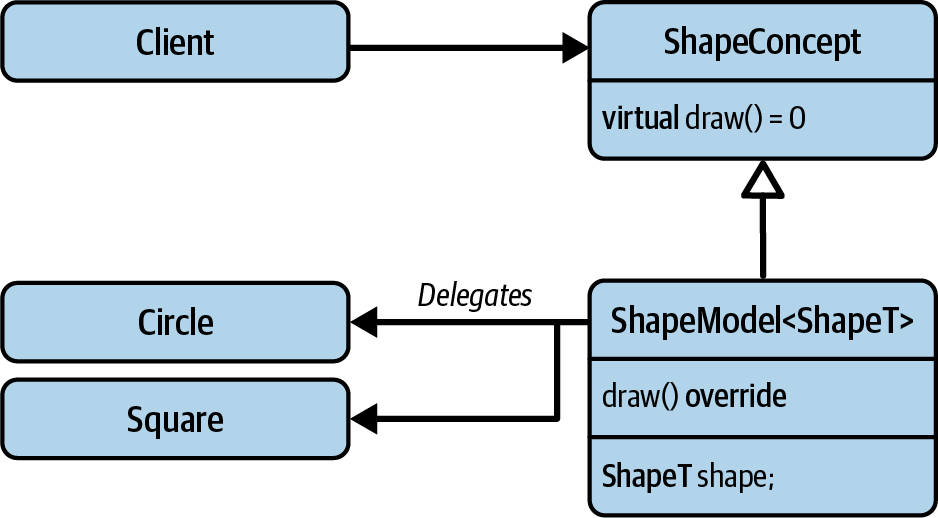
Figure 7-7. The UML representation of the External Polymorphism design pattern
In our simple example, the polymorphic behavior consists of only the draw() function.
However, the set of requirements could, of course, be larger (e.g., rotate(), serialize(), etc.). This set of virtual functions has been moved into the abstract ShapeConcept class, which now takes the place of the previous Shape base class. The major difference is that concrete shapes are not required to know about
ShapeConcept and, in particular, are not expected to inherit
from it. Thus, the shapes are completely decoupled from the set of virtual functions. The
only class inheriting from ShapeConcept is the ShapeModel class template. This class is
instantiated for a specific kind of shape (Circle, Square, etc.) and acts as a wrapper
for it. However,
ShapeModel does not implement the logic of the virtual functions itself
but delegates the request to the desired implementation.
“Wow, that’s amazing! I get the point: this external hierarchy extracts the whole set of
virtual functions and, by that, the entire polymorphic behavior of the shapes.” Yes, exactly.
Again, this is an example of separation of concerns and the SRP. In this case, the complete polymorphic behavior is identified as a
variation point and extracted from the shapes. And again, SRP acts as an enabler for
the OCP: with the ShapeModel class template, you can easily add any new, nonpolymorphic shape type into the ShapeConcept hierarchy.
This works as long as the new type fulfills all of the required operations.
“I’m really impressed. However, I’m not certain what you mean by fulfilling all of the required operations. Could you please elaborate?” Absolutely! I think the benefits will become clear when I show you a concrete code example. So let’s refactor the complete drawing of the shapes example with the External Polymorphism design pattern.
Drawing of Shapes Revisited
Let’s start with the Circle and Square classes:
//---- <Circle.h> ----------------classCircle{public:explicitCircle(doubleradius):radius_(radius){/* Checking that the given radius is valid */}doubleradius()const{returnradius_;}/* Several more getters and circle-specific utility functions */private:doubleradius_;/* Several more data members */};//---- <Square.h> ----------------classSquare{public:explicitSquare(doubleside):side_(side){/* Checking that the given side length is valid */}doubleside()const{returnside_;}/* Several more getters and square-specific utility functions */private:doubleside_;/* Several more data members */};
Both classes have been reduced to basic geometric entities. Both are completely nonpolymorphic, i.e., there is no base class anymore and not a single virtual function. Most importantly, however, the two classes are completely oblivious to any kind of operation, like drawing, rotating, serialization, etc., that could introduce an artificial dependency.
Instead, all of this functionality is introduced in the ShapeConcept base
class and implemented by the ShapeModel class template:14
//---- <Shape.h> ----------------#include<functional>#include<stdexcept>#include<utility>classShapeConcept{public:virtual~ShapeConcept()=default;virtualvoiddraw()const=0;// ... Potentially more polymorphic operations};template<typenameShapeT>classShapeModel:publicShapeConcept{public:usingDrawStrategy=std::function<void(ShapeTconst&)>;explicitShapeModel(ShapeTshape,DrawStrategydrawer):shape_{std::move(shape)},drawer_{std::move(drawer)}{/* Checking that the given 'std::function' is not empty */}voiddraw()constoverride{drawer_(shape_);}// ... Potentially more polymorphic operationsprivate:ShapeTshape_;DrawStrategydrawer_;};
The ShapeConcept class introduces a pure virtual draw() member function
(![]() ).
In our example, this one virtual function represents the entire set of requirements for
shapes. Despite the small size of the set, the
).
In our example, this one virtual function represents the entire set of requirements for
shapes. Despite the small size of the set, the ShapeConcept class represents a classic
abstraction in the sense of the LSP (see
“Guideline 6: Adhere to the Expected Behavior of Abstractions”). This abstraction is implemented
within the ShapeModel class template
(![]() ).
It is noteworthy that instantiations of
).
It is noteworthy that instantiations of
ShapeModel are the only classes to ever inherit
from ShapeConcept; no other class is expected to enter in this relationship. The
ShapeModel class template will be instantiated for every desired type of shape, i.e.,
the ShapeT template parameter is a stand-in for types like Circle, Square, etc.
Note that ShapeModel stores an instance of the corresponding shape
(![]() )
(composition, not inheritance; remember “Guideline 20: Favor Composition over Inheritance”).
It acts as a wrapper that augments the specific shape type with the required
polymorphic behavior (in our case, the
)
(composition, not inheritance; remember “Guideline 20: Favor Composition over Inheritance”).
It acts as a wrapper that augments the specific shape type with the required
polymorphic behavior (in our case, the draw() function).
Since ShapeModel implements the ShapeConcept abstraction, it needs to provide an
implementation for the draw() function. However, it is not the responsibility of the
ShapeModel to implement the draw() details itself. Instead, it should forward a
drawing request to the actual implementation. For that purpose, we can again reach for
the Strategy design pattern and the abstracting power of std::function
(![]() ).
This choice nicely decouples both the implementation details of drawing and all the necessary drawing data (colors, textures, transparency, etc.), which can be
stored inside the callable. Hence,
).
This choice nicely decouples both the implementation details of drawing and all the necessary drawing data (colors, textures, transparency, etc.), which can be
stored inside the callable. Hence, ShapeModel stores an instance of DrawStrategy
(![]() )
and uses that strategy whenever the
)
and uses that strategy whenever the draw() function is triggered
(![]() ).
).
The Strategy design pattern and the std::function are not
your only choices, though. Within the ShapeModel class template, you have complete
flexibility to implement drawing as you see fit. In other words, within the
ShapeModel::draw() function, you define the actual requirements for the specific
shape types. For instance, you could alternatively forward to a member function of
the ShapeT shape (which does not have to be named draw()!), or you could forward
to a free function of the shape.
You just need to make sure that you do not impose artificial requirements on either the
ShapeModel or the ShapeConcept abstraction. Either way, any type used to instantiate
ShapeModel must fulfill these requirements to make the code compile.
Note
From a design perspective, building on a member function would introduce a more restrictive requirement on the given type, and therefore introduce stronger coupling. Building on a free function, however, would enable you to invert dependencies, similar to the use of the Strategy design pattern (see “Guideline 9: Pay Attention to the Ownership of Abstractions”). If you prefer the free function approach, just remember “Guideline 8: Understand the Semantic Requirements of Overload Sets”.
“Isn’t ShapeModel some kind of generalization of the initial Circle and Square
classes? The ones that were also holding the std::function instance?” Yes, this is
an excellent realization. Indeed, you could say that ShapeModel is kind of a templated
version of the initial shape classes. For this reason it helps to reduce the boilerplate
code necessary to introduce the Strategy behavior and improves the implementation with
respect to the DRY principle (see “Guideline 2: Design for Change”). However, you gain a lot more:
for instance, since ShapeModel is already a class template, you can easily switch from
the current runtime Strategy implementation to a compile-time Strategy implementation
(i.e., policy-based design; see
“Guideline 19: Use Strategy to Isolate How Things Are Done”):
template<typenameShapeT,typenameDrawStrategy>classShapeModel:publicShapeConcept{public:explicitShapeModel(ShapeTshape,DrawStrategydrawer):shape_{std::move(shape)},drawer_{std::move(drawer)}{}voiddraw()constoverride{drawer_(shape_);}private:ShapeTshape_;DrawStrategydrawer_;};
Instead of building on std::function, you can pass an additional template parameter
to the ShapeModel class template, which represents the drawing Strategy
(![]() ).
This template parameter could even have a default:
).
This template parameter could even have a default:
structDefaultDrawer{template<typenameT>voidoperator()(Tconst&obj)const{draw(obj);}};template<typenameShapeT,typenameDrawStrategy=DefaultDrawer>classShapeModel:publicShapeConcept{public:explicitShapeModel(ShapeTshape,DrawStrategydrawer=DefaultDrawer{})// ... as before};
In comparison to applying policy-based design to the Circle and Square classes
directly, the compile-time approach in this context holds only benefits and comes with no
disadvantages. First, you gain performance due to fewer runtime indirections (the expected
performance disadvantage of std::function). Second, you do not artificially augment
Circle, Square, and all the other shape classes with a template argument to configure
the drawing behavior. You now only do this for the wrapper, which augments the drawing
behavior, and you do this in exactly one place (which again very nicely adheres to the DRY principle).
Third, you do not force additional code into a header file by turning a regular class
into a class template. Only the slim ShapeModel class, which is already a class template,
needs to reside in a header file. Therefore, you avoid creating additional dependencies.
“Wow, this design pattern is getting better and better. This seriously is a very compelling
combination of inheritance and templates!” Yes, I completely agree. This is
an exemplar
for combining runtime and compile-time polymorphism: the
ShapeConcept base class provides
the abstraction for all possible types, while the deriving ShapeModel class template provides
the code generation for shape-specific code. Most impressively, however, this combination comes
with huge benefits for the reduction of dependencies.
Take a look at
Figure 7-8, which shows the dependency graph for our
implementation of the External Polymorphism design pattern. On the highest level of our
architecture are the ShapeConcept and ShapeModel classes, which together represent
the abstraction of shapes. Circle and Square are possible implementations of this abstraction
but are still completely independent: no inheritance relationship, no composition, nothing. Only
the instantiation of the ShapeModel class template for a specific kind of shape and a specific
DrawStrategy implementation brings all aspects together. However, specifically note that all
of this happens on the lowest level of our architecture: the template code is generated at the
point where all dependencies are known and “injected” into the right level of our
architecture. Thus, we truly have a proper architecture: all dependency connections run toward
the higher levels with an almost automatic adherence to the DIP.
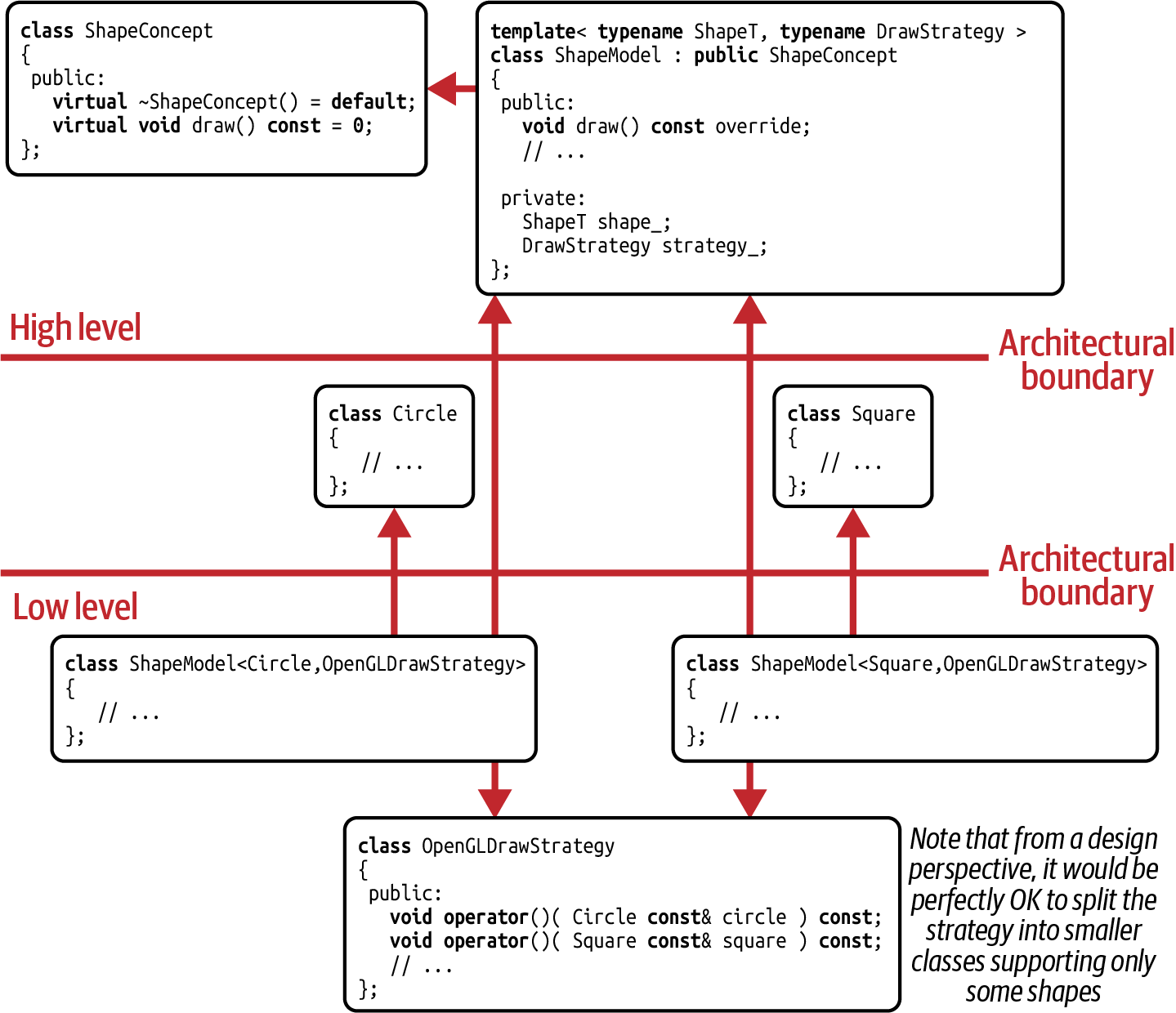
Figure 7-8. Dependency graph for the External Polymorphism design pattern
With this functionality in place, we are now free to implement any desired drawing behavior. For instance, we are free to use OpenGL again:
//---- <OpenGLDrawStrategy.h> ----------------#include<Circle>#include<Square>#include/* OpenGL graphics library headers */classOpenGLDrawStrategy{public:explicitOpenGLDrawStrategy(/* Drawing related arguments */);voidoperator()(Circleconst&circle)const;voidoperator()(Squareconst&square)const;private:/* Drawing related data members, e.g. colors, textures, ... */};
Since OpenGLDrawStrategy does not have to inherit from any base class, you are free to
implement it as you see fit. If you want to, you can combine the implementation
of drawing circles and drawing squares into one class. This does not create any artificial
dependencies, similar to what we experienced in
“Guideline 19: Use Strategy to Isolate How Things Are Done”, where we combined these
functionalities into the base class.
Note
Note that combining drawing circles and squares in one class represents the same thing as inheriting the class from two Strategy base classes. On that level of the architecture, it does not create any artificial dependencies and is merely an implementation detail.
The only convention you need to follow is to provide a function call operator for Circle
(![]() )
and
)
and Square
(![]() ),
as this is the defined calling convention in the
),
as this is the defined calling convention in the
ShapeModel class template.
In the main() function, we put all of the details together:
#include<Circle.h>#include<Square.h>#include<Shape.h>#include<OpenGLDrawStrategy.h>#include<memory>#include<vector>intmain(){usingShapes=std::vector<std::unique_ptr<ShapeConcept>>;usingCircleModel=ShapeModel<Circle,OpenGLDrawStrategy>;usingSquareModel=ShapeModel<Square,OpenGLDrawStrategy>;Shapesshapes{};// Creating some shapes, each one// equipped with an OpenGL drawing strategyshapes.emplace_back(std::make_unique<CircleModel>(Circle{2.3},OpenGLDrawStrategy(/*...red...*/)));shapes.emplace_back(std::make_unique<SquareModel>(Square{1.2},OpenGLDrawStrategy(/*...green...*/)));shapes.emplace_back(std::make_unique<CircleModel>(Circle{4.1},OpenGLDrawStrategy(/*...blue...*/)));// Drawing all shapesfor(autoconst&shape:shapes){shape->draw();}returnEXIT_SUCCESS;}
Again, we first create an empty vector of shapes (this time a vector of std::unique_ptrs
of ShapeConcept)
(![]() )
before we add three shapes. Within the calls to
)
before we add three shapes. Within the calls to std::make_unique(), we instantiate the
ShapeModel class for Circle and Square (called CircleModel
(![]() )
and
)
and SquareModel
(![]() )
to improve readability) and pass the necessary details (the concrete shape and the
corresponding
)
to improve readability) and pass the necessary details (the concrete shape and the
corresponding
OpenGLDrawStrategy). After that, we are able to draw all shapes in the desired way.
Altogether, this approach gives you a lot of awesome advantages:
-
Due to separating concerns and extracting the polymorphic behavior from the shape types, you remove all dependencies on graphics libraries, etc. This creates a very loose coupling and beautifully adheres to the SRP.
-
The shape types become simpler and nonpolymorphic.
-
You’re able to easily add new kinds of shapes. These might even be third-party types, as you are no longer required to intrusively inherit from a
Shapebase class or create an Adapter (see “Guideline 24: Use Adapters to Standardize Interfaces”). Thus, you perfectly adhere to the OCP. -
You significantly reduce the usual inheritance-related boilerplate code and implement it in exactly one place, which very nicely follows the DRY principle.
-
Since the
ShapeConceptandShapeModelclass belong together and together form the abstraction, it’s much easier to adhere to the DIP. -
By reducing the number of indirections by exploiting the available class template, you can improve performance.
There is one more advantage, which I consider to be the most impressive benefit of the
External Polymorphism design pattern: you can, nonintrusively, equip any type with
polymorphic behavior. Really, any type, even something as simple as an int. To demonstrate
this, let’s take a look at the following code snippet, which assumes that ShapeModel
is equipped with a DefaultDrawer, which expects the wrapped type to provide a free
draw() function:
intdraw(inti){// ... drawing an int, for instance by printing it to the command line}intmain(){autoshape=std::make_unique<ShapeModel<int>>(42);shape->draw();// Drawing the integerreturnEXIT_SUCCESS;}
We first provide a free draw() function for an int
(![]() ).
In the
).
In the main() function, we now instantiate a ShapeModel for int
(![]() ).
This line will compile, as the
).
This line will compile, as the int satisfies all the requirements: it provides a free
draw() function. Therefore, in the next line we can “draw” the integer
(![]() ).
).
“Do you really want me to do something like this?” you ask, frowning. No, I do not
want you to do this at home. Please consider this a technical demonstration, not a
recommendation. But nonetheless, this is impressive: we have just nonintrusively equipped an
int with polymorphic behavior. Really impressive indeed!
Comparison Between External Polymorphism and Adapter
“Since you just mentioned the Adapter design pattern, I feel like it’s very similar to the External Polymorphism design pattern. What is the difference between the two?” Excellent point! You address an issue that the original paper by Cleeland, Schmidt, and Harrison also addresses. Yes, these two design patterns are indeed pretty similar, yet there is a very distinctive difference: while the Adapter design pattern is focused on standardizing interfaces and adapts a type or function to an existing interface, the External Polymorphism design pattern creates a new, external hierarchy to abstract from a set of related, nonpolymorphic types. So if you adapt something to an existing interface, you (most probably) apply the Adapter design pattern. If, however, you create a new abstraction for the purpose of treating a set of existing types polymorphically, then you (most likely) apply the External Polymorphism design pattern.
Analyzing the Shortcomings of the External Polymorphism Design Pattern
“I get the feeling that you like the External Polymorphism design pattern a lot, am I right?” you wonder. Oh yes, indeed, I’m amazed by this design pattern. From my point of view, this design pattern is key to loose coupling, and it’s a shame that it is not more widely known. Perhaps this is because many developers have not fully embraced the separation of concerns and tend to put everything into only a few classes. Still, despite my enthusiasm, I do not want to create the impression that everything about External Polymorphism is perfect. No, as stated many times before, every design has its advantages and its disadvantages. The same is true for the External Polymorphism design pattern.
There is only one major disadvantage, though: the External Polymorphism design pattern
does not really fulfill the expectations of a clean and simple solution, and definitely
not the expectations of a value semantics–based solution. It does not help to reduce
pointers, does not reduce the number of manual allocations, does not lower the number
of inheritance hierarchies, and does not help to simplify user code. On the contrary,
since it is necessary to explicitly instantiate the ShapeModel class, user code has
to be rated as slightly more complicated. However, if you consider this a severe
drawback, or if you’re thinking something along the lines of “This should be automated
somehow,” I have very good news for you: in
“Guideline 32: Consider Replacing Inheritance Hierarchies with Type Erasure”, we will take a look
at the modern C++ solution that will elegantly resolve this issue.
Apart from that, I have only two reminders that you should consider as words of caution. The first point to keep in mind is that the application of External Polymorphism does
not save you from thinking about a proper abstraction. The ShapeConcept base class is
just as much subject to the ISP as any other base
class. For instance, we could easily apply External Polymorphism to the Document
example from“Guideline 3: Separate Interfaces to Avoid
Artificial Coupling”:
classDocumentConcept{public:// ...virtual~Document()=default;virtualvoidexportToJSON(/*...*/)const=0;virtualvoidserialize(ByteStream&bs,/*...*/)const=0;// ...};template<typenameDocumentT>classDocumentModel{public:// ...voidexportToJSON(/*...*/)constoverride;voidserialize(ByteStream&bs,/*...*/)constoverride;// ...private:DocumentTdocument_;};
The DocumentConcept class takes the role of the ShapeConcept base class, while the
DocumentModel class template takes the role of the ShapeModel class template. However,
this externalized hierarchy exhibits the same problem as the original hierarchy: for all
code requiring only the exportToJSON() functionality, it introduces the artificial
dependency on ByteStream:
voidexportDocument(DocumentConceptconst&doc){// ...doc.exportToJSON(/* pass necessary arguments */);// ...}
The correct approach would be to separate concerns by segregating the interface into the two orthogonal aspects of JSON export and serialization:
classJSONExportable{public:// ...virtual~JSONExportable()=default;virtualvoidexportToJSON(/*...*/)const=0;// ...};classSerializable{public:// ...virtual~Serializable()=default;virtualvoidserialize(ByteStream&bs,/*...*/)const=0;// ...};template<typenameDocumentT>classDocumentModel:publicJSONExportable,publicSerializable{public:// ...voidexportToJSON(/*...*/)constoverride;voidserialize(ByteStream&bs,/*...*/)constoverride;// ...private:DocumentTdocument_;};
Any function exclusively interested in JSON export can now specifically ask for that functionality:
voidexportDocument(JSONExportableconst&exportable){// ...exportable.exportToJSON(/* pass necessary arguments */);// ...}
Second, be aware that External Polymorphism, just as the Adapter design pattern,
makes it very easy to wrap types that do not fulfill the semantic expectations. Similar
to the duck typing example in
“Guideline 24: Use Adapters to Standardize Interfaces”, where we pretended that a
turkey is a duck, we also pretended that an int is a shape. All we had to do
to fulfill the requirements was provide a free draw() function. Easy. Perhaps too
easy. Therefore, keep in mind that the classes used to instantiate the ShapeModel
class template (e.g., Circle, Square, etc.) have to adhere to the LSP. After all, the
ShapeModel class acts just as a wrapper and passes on the requirements defined by the
ShapeConcept class to the concrete shapes. Thus, the concrete shapes take the
responsibility to properly implement the expected behavior (see
“Guideline 6: Adhere to the Expected Behavior of Abstractions”). Any failure to completely fulfill
the expectations may lead to (potentially subtle) misbehavior. Unfortunately, because these requirements have been externalized, it is a little harder to communicate
the expected behavior.
However, in the int example it was maybe our own fault to be honest. Perhaps the
ShapeConcept base class doesn’t really represent an abstraction of a shape. It is
reasonable to argue that shapes are more than just drawing. Perhaps we should have named
the abstraction Drawable, and the LSP would have been satisfied. Perhaps not. So in the
end, it all comes down to the choice of abstraction. Which brings us back to the title of
Chapter 2: “The Art of Building Abstractions.” No, it isn’t easy, but perhaps these examples demonstrate that it is important. Very important.
It may be the essence of software design.
In summary, although the External Polymorphism design pattern may not satisfy your
expectation in a simple or value-based solution, it must be considered a very important step
toward decoupling software entities. From the perspective of reducing dependencies, this
design pattern appears to be a key ingredient to loose coupling, and is a marvelous example
of the power of separation of concerns. It also gives us one key insight: using this
design pattern, you can nonintrusively equip any type with polymorphic behavior,
e.g., virtual functions, so any type can behave polymorphically, even a simple value type
such as int. This realization opens up a completely new, exciting design space,
which we will continue to explore in the next chapter.
1 ABI stability is an important and often debated topic in the C++ community, in particular just before the release of C++20. If this sounds interesting to you, I recommend the CppCast interviews with Titus Winters and Marshall Clow to get an impression of both sides.
2 Remember that std::unique_ptr cannot be copied. Thus, switching from ElectricEngine to std::unique_ptr<ElectricEngine> renders your class noncopyable. To preserve copy semantics, you have to implement the copy operations manually. When doing this, please keep in mind that the copy operations disable the move operations. In other words, prefer to stick to the Rule of 5.
3 Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software.
4 Usually, the move operations are expected to be noexcept. This is explained by Core Guideline C.66. However, sometimes this might not be possible, for instance, under the assumption that some std::unique_ptr data member is never nullptr.
5 See “Guideline 11: Understand the Purpose of Design Patterns” for my statement about the structural similarity of design patterns.
6 If this dynamic allocation turns out to be a severe impediment or a reason not to use a Bridge, you might look into the Fast-Pimpl idiom, which is based on in-class memory. For that, you might refer to Herb Sutter’s first book: Exceptional C++: 47 Engineering Puzzles, Programming Problems, and Exception-Safety Solutions (Pearson).
7 The difference in size of Person1 is easily explained by the different sizes of std::string implementations for different compilers. Since compiler vendors optimize std::string for different use cases, on Clang 11.1, a single std::string occupies 24 bytes, and on GCC 11.1, it occupies 32 bytes. Therefore, the total size of one instance of Person1 is 152 bytes with Clang 11.1 (six 24-byte std::strings, plus one 4-byte int, plus 4 bytes of padding) or 200 bytes with GCC 11.1 (six 32-byte std::strings, plus one 4-byte int, plus 4 bytes of padding).
8 You may be aware that we are still far away from optimal performance. To move in the direction of optimal performance, we could arrange the data based on how it is used. For this benchmark, this would mean to store all year_of_birth values from all persons in one big static vector of integers. This kind of data arrangement would move us in the direction of data-oriented design. For more information on this paradigm, see for instance Richard Fabian’s book on the subject, Data-Oriented Design: Software Engineering for Limited Resources and Short Schedules.
9 The rules when a compiler will generate these two copy operations are beyond the scope of this book, but here is a short summary: every class has these two operations, meaning they always exist. They have been generated by the compiler, or you have explicitly declared or even defined them (potentially in the private section of the class or via =delete), or they are implicitly deleted. Note that deleting these functions does not mean that they’re gone, but =delete serves as a definition. As these two functions are always part of a class, they will always participate in overload resolution.
10 Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software.
11 Core Guideline R.3 clearly states that a raw pointer (a T*) is nonowning. From this perspective, it would even be incorrect to return a raw pointer-to-base. However, this means that you cannot directly exploit the language feature of covariant return types anymore. If this is desirable or required, a common solution would be to follow the Template Method design pattern and split the clone() function into a private virtual function returning a raw pointer, and a public non-virtual function calling the private function and returning std::unique_ptr.
12 See “Guideline 2: Design for Change” for a similar example with different kinds of documents.
13 Chris Cleeland, Douglas C. Schmidt, and Timothy H. Harrison, “External Polymorphism—An Object Structural Pattern for Transparently Extending C++ Concrete Data Types,” Proceedings of the 3rd Pattern Languages of Programming Conference, Allerton Park, Illinois, September 4–6, 1996.
14 The names Concept and Model are chosen based on the common terminology in the Type Erasure design pattern, where External Polymorphism plays a major role; see Chapter 8.