5
Indexing and searching languages
Introduction
This chapter introduces a range of principles associated with the concept and use of indexing and searching languages. The primary focus of this chapter is on indexing languages that are used to represent subjects. Accordingly the chapter starts by exploring the concept of a subject. Next the types of indexing languages are introduced and, finally, a range of principles that apply to the application and use of indexing languages. At the end of this chapter you will:
recognize the complexities associated with naming subjects and the need to identify relationships between subjects
be familiar with different approaches to indexing and with associated concepts such as specificity and exhausitivity
understand the difference between natural and controlled languages
be aware of the principles of vocabulary control
understand the principles of thesaurus construction
be familiar with the search facilities that are available to support post-coordinate searching.
Approaches to Subject Retrieval
Users often approach information sources not with names in mind, but with a question that requires an answer or a topic for study. Users seek documents or information concerned with a particular subject. This is a common approach to information sources and, in order to provide for it, the document or document representation must include enough data to ensure that items on specific subjects are retrieved.
What is a specific subject? A rabbit is a rabbit; but is it? Europeans will have in mind the European rabbit, Americans the cottontail; they belong to different genera. A rabbit is a concrete entity - that is, we can see it and pick it up (preferably not by its ears) and define it by its physical characteristics (long ears, furry, weighs around a kilogram) and behaviour (hopping movement, digs burrows, breeds freely). Abstract concepts can be more difficult to pin down. Some are fairly straightforward, like Music (encyclopaedia definition: ‘the organized movement of sounds through a continuum of time’); some, like Geography (‘the science that deals with the distribution and arrangement of all the elements of the earth’s surface’) look straightforward until we think of the vast scope of the subject; while Games defies definition - the philosopher Wittgenstein concluded after a long study that the subject could only be defined through its examples. Not only may subjects be in themselves difficult to define, we must remember that they do not exist in isolation in the way that named entities do. If we are looking for information on William Shakespeare, Mount Everest or Microsoft, we can be sure when we have found it that we have come to the right place as these are all ‘classes of one’. Common subjects, on the other hand, form networks of conceptual relationships with other subjects. If we are trying to identify a rabbit, we may not be entirely sure that what we saw was not a hare; the reader in a library looking for the geography books is likely to be directed to at least three widely separated sets of shelves; and library readers everywhere are notorious for asking for the games section when what they are looking for is information on chess. Any system of subject retrieval must then have a mechanism for directing users to other, closely related, subjects.
Why Index?
Now that cheap online storage and retrieval of full text are commonplace, the value of indexing has been questioned. If the individual words in a text are immediately accessible in any combination, why go to the trouble of constructing indexes at all? Why not simply search for combinations of words from the text? The assumption behind this attitude is that a text is ‘about’ what it mentions. Fairthorne put his finger on the weakness of this assumption:
Moby Dick is about a whale, Othello is about a handkerchief, and about other things. The difficulties are to identify which of the things mentioned refer to relevant topics, and how to deal with topics of the document that are not mentioned explicitly… Parts of the document are not always what the entire document is about, nor is a document usually about the sum of the things it mentions.
(Fairthorne, 1969, p. 79)
In other words, this paragraph has just mentioned a whale and a handkerchief, but nobody would suggest that it is about those things. It is the indexer’s job to ensure that a document’s overall topic and, perhaps, its major constituent themes are adequately represented.
What is a Document About?
Information retrieval is in general concerned with what a text is about rather than what it means. What is meaning? One point of view holds that that meaning is inferential: a scientific paper may be about a statistical correlation between tobacco smoking and lung cancer; what it means is that the one may cause the other. Another argument states that indexers should adopt a neutral position and not attempt to impose upon the reader their views on what a document means. There is also the point of view - grounded in literary theory - that meaning is interactive (and to that extent subjective), the result of the interaction between the text and the individual reader. Perhaps the most powerful argument against indexers attempting to represent the meaning of documents is economic: it would simply take too long to do. A trained indexer can grasp what a document is about by scanning it rapidly. To attempt to extract its meaning would involve a far closer study, as well as requiring expert subject knowledge.
Approaches to Indexing
An indexing language can be defined as the terms or codes that might be used as access points in an index. A searching language can be defined as the terms that are used by a searcher when specifying a search requirement If the terms or codes are assigned by an indexer when a database is created, then the indexing language is used in indexing. The same terms or codes may also be used as access points to records during searching. While the indexing language may be distinct from the searching language, clearly, if retrieval is to be successful, the two must be closely related. Indexing languages may be of two different types: controlled-indexing languages or assigned-term systems, and natural-indexing languages or derived-term systems. Each of these is briefly discussed below.
Controlled-indexing languages (assigned-term systems)
With these languages a person controls the terms that are used as index terms. Controlled-indexing languages may be used for names and other labels but much emphasis is placed upon languages with terms that describe subjects. Normally an authority list identifies the terms that may be assigned. Indexing involves a person assigning terms from this list to specific documents on the basis of subjective interpretations of the concepts in the document; in this process the indexer exercises some intellectual discrimination in choosing appropriate terms.
There are two types of subject-based controlled-indexing languages: alphabetical-indexing languages and classification schemes. In alphabetical-indexing languages, such as are recorded in thesauri and subject headings lists, subject terms are the alphabetical names of subjects. Control is exercised over which terms are used, and relationships between terms are indicated, but the terms themselves are ordinary words. In classification schemes each subject is represented by a code or notation. Classification schemes are particularly concerned to place subjects in a framework that crystallizes their relationships one to another. More generally though, classification is implicit in all indexing. A document in which content is wholly or partially specified in the index term RABBITS is thereby classed with other documents to which the same specification has been applied. Controlled-indexing languages take the process of classification one stage further, by displaying semantic links, between rabbits and hares for example. Formal bibliographic classification schemes, such as the DDC and LCC classifications, display these relationships in a systematic manner. They are able, in addition, through their notation to exclude particular connotations of meaning: thus DDC’s 599.322 denotes rabbits as zoological entities, but not as pets (which would be 636.9322).
Thesauri have always been a feature of the document management systems that have been designed to manage larger collections. They are increasingly featuring in OPACs and other information retrieval environments, and their applicability for Internet applications is of interest Thesauri typically show the controlled indexing term, with related, narrower and broader terms, as shown in Figure 5.6. They may be displayed in a window during search strategy formulation, to aid a user in the selection of terms. Often terms can be selected from the thesaurus listing simply by clicking on them. Hypertext links in thesauri listings can be used to move between different occurrences of the same term in the list Another application of thesauri is as a basis for automatic indexing. All terms in the documents that appear in the thesaurus will generate an entry in the inverted index. Related applications of thesauri are in the creation of semantic nets and semantic knowledge bases.
Natural-indexing languages (uncontrolled or derived-term systems)
These languages are not really a distinct or stable language in their own right, but rather are the ‘natural’ or ordinary language of the document being indexed. Strictly, natural language systems are only one type of derived-term system. A derived-term system is one where all descriptors are taken from the document being indexed. Thus, author indexes, title indexes and citation indexes, as well as natural language subject indexes, are derived-term systems. Any terms that appear in the document may be candidates for index terms. Emphasis has traditionally been on the terms in titles and abstracts, but increasingly the full text of the document is used as the basis for indexing. Natural language indexing using the full text of the document may be very detailed, and in some systems some mechanism for deciding which terms are the most important in the indexing of a given document may be appropriate. Such mechanisms are often based upon statistical analysis of the relative frequency of occurrence terms. Natural language indexing can be executed by a human indexer, or automatically by the computer. The computer might index every term in the document, apart from a limited stop-list of very common terms, or may only index those terms that have been listed in a computer-held thesaurus.
Natural language indexing and controlled language indexing are used extensively in many information retrieval applications. Both are used in retrieval on CD-ROM, via the online search services, in document management systems and in online public access catalogues. Controlled-indexing languages are claimed to be more consistent and therefore more efficient and straightforward for the searcher, but research has failed to prove this convincingly. The dilemma facing systems designers is that to offer anything other than natural language indexing in the context of the huge databanks available through the Internet would be prohibitively expensive. On the other hand, controlled language indexing is seen as valuable in a supportive environment for inexperienced users because they do not need to navigate all the variations inherent in natural language. Significant effort is being directed towards the development of system interfaces that manage this variability, either implicitly or explicitly, on behalf of the user. Many databases include terms from controlled indexing languages (often including both alphabetical indexing languages and classification schemes) and also support searching on the text of the record, thus covering all options.
Features of Retrieval Systems
Exhaustivity and Content Specification
It was suggested above that indexes attempt to specify content by means of single words or phrases. Clearly, the whole of the subject content cannot be specified by anything less than the complete text (and may well require more, in the way of footnotes and other glosses, as with the heavily annotated editions of classic writers). Indexing has to try to sum up the salient points, while ignoring the non-essentials. This can be done at a number of levels, which, even though they are presented here as distinct strata, form a continuum. Exhaustivity of indexing is the name given to the depth of indexing which it is the policy of a given indexing system to employ. Exhaustivity is therefore a management decision. The level of exhaustivity at which a system operates can either be built into the system (for example, by restricting the number of fields available for index terms), or it can be controlled operationally, by giving instructions to indexers.

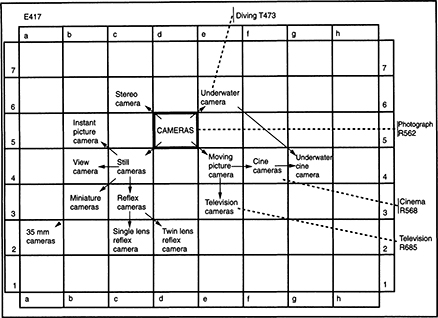
Figure 5.1 Comparing uncontrolled and controlled indexing languages
Summarization refers to the process of conveying the overall subject content of a document in a single word or a short phrase or structured heading: for example, RABbITS, or breeds of RABbITS - breEDS. Indexing at the level of summarization is commonly applied to graphic material - photographs and the like -which convey information perceptually; and also - particularly - to books, which normally have their own detailed indexing systems in the form of back-of-book indexes and contents lists. Library catalogues and published bibliographies are nearly always indexes at the level of summarization. So, too, are some published indexes to periodical literature: for example, British Humanities Index and the range of indexes - Humanities Index, Education Index, etc. - published by the H. W. Wilson Company.
A second level of exhaustivity is found in many databases that are indexes to collections or to periodical literature, and select the most significant subjects in the text - often around six to twelve controlled descriptors. In addition, the words in the title and abstract are available for searching. Contents lists operate at this level.
Even more exhaustive are back-of-book type indexes: indexes to individual documents, which should list every subject discussed in the text (Figure 5.2). The ultimate level of exhaustivity is provided by the text itself. In full-text retrieval systems any word or phrase is potentially available for searching. (Most systems have a stop-list of very common words that have not been indexed and cannot therefore be retrieved.) At this point we have a concordance rather than an index.
Figure 5.3 gives examples of indexing the same journal article at different levels of exhaustivity.
Compare the Abstract, Descriptors, and Identifiers in each. (NB: ERIC and Psyclnfo define ‘Identifiers’ differently.) ERIC’s abstract has 44 words; Psyclnfo’s has 96. For Descriptors and Identifiers the word counts are 20 and 46.
Specificity
Specificity is an aspect of controlled language systems. It refers to the vocabulary of the system, and denotes the extent to which we are able to specify subject content when indexing. Dewey Decimal Classification, for example, specifies rabbits as domestic animals at class 636.9322. This class is, however, unable to specify individual breeds of rabbit: there are no subclasses for k>i>eared or Angora rabbits or any other breed. Neither can this class distinguish between rabbits kept as pets and rabbits grown for meat or for their fur. A specialist manual on keeping pet Angora rabbits has to be classed with all other works on rabbits as domestic animals. This clearly makes searching less precise, as the searcher has to sift through a number of marginally relevant items all classed at the same place. Specificity thus improves the precision of a search: that is, its ability to sift out unwanted material.

Figure 5.2 Levels of exhaustivity within a single work Source: Mulvaney, 1994.

Figure 5.3 Indexing at different levels of exhaustivity
Special systems (i.e. systems confined to one subject area or other field) often use differential levels of specificity. Topics that are central to the subject field are indexed at a higher level of specificity than peripheral subjects. For example, if Domestic Animals is a system’s principal subject field, it would be quite likely to make specific provision for the various breeds of rabbit. If the subject field is something remote, however, there might be no specific provision even for rabbits: we might have to include them under a more general term, like Pets.
Specificity and exhaustivity are related to the extent that in practice greater exhaustivity needs to be matched by greater specificity in the indexing terms. Most book indexes, for example, are both specific and exhaustive. The combination of specificity and exhaustivity is often referred to as depth of indexing.
Complex topics
A final set of definitions concerns the way complex topics are handled. A document may not be simply about rabbits or apples or chess; it may very well deal with some more precise aspect, like breeds of rabbits, or the effect of pre-storage heat treatment on the shelf life of apples. The traditional method of dealing with complex topics has been to encapsulate as much of the topic as possible into a single heading, RABBITS - BREEDS for example, or APPLES - SHELF UFE-£FrecroF-HEATTREATMENT. Indexes of this kind are known as pre-coordinate indexes, because the topics that comprise a heading are strung together or coordinated by the indexer in advance of any searches that may be carried out on any of the topics represented within the heading. These indexes require elaborate rules for the consistent construction of headings, and will be considered in Chapter 6. Because of this lack of flexibility many systems employ a quite different method of handling complex topics. Here the subject of a document is represented by a number of one-concept terms - these are the descriptors in Figure 5.3 - and the searcher is able to combine as many or as few of them as are required, using Boolean logic: for example, CHILD ATTITUDES AND MARTTAL CONFLICT. Systems employing this method of indexing and searching are known as post-coordinate systems. The earliest of these systems were card-based, using specialized stationery and other equipment, but nearly all systems in use today are computerized.
User-friendliness
In 1960 Calvin Mooers expounded his famous law:
An information system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have it.
The corollary of this is that the use of information systems and services will be increased if steps are taken to improve their user-friendliness. Some of the factors influencing user-friendliness are:
Accessibility: the service should be physically accessible to users.
Ease of use: the service should be within the intellectual capabilities of its users. While great strides have been made in improving user interfaces (see Chapter 4), there is always a trade-off between ease of use and system capabilities. The more powerful the functionality of a system, the more complex the instructions and protocols for using it, and its proneness to error on the part of the user.
System error, as opposed to user error. This includes system malfunctions, and output errors caused by inadequacies in the system, as with some automatic indexing and retrieval systems.
Form of output: output may be in the form of actual documents, or document surrogates; if the latter, output may or may not be downloadable. The least convenient output is non-downloadable document surrogates, for example, with manually searched catalogues.
Delay, whether in accessing the service, or in obtaining the search results.
Search Facilities in Post-Coordinate Searching
Search Logic
Search logic is the means of specifying combinations of terms that must be matched for successful retrieval. Boolean search logic is employed in searching most systems. It may be used to link terms from either controlled- or natural-indexing languages, or both. The logic is used to link the terms that describe the concepts present in the statement of the search. As many as 20 to 30 or more search terms may be linked together by search logic in order to frame the search statement. Search logic permits the inclusion in the search statement of all synonyms and related terms, and also specifies acceptable and unacceptable search-term combinations. Search strategies often need to be more complex with natural language terms, in order to accommodate all the potential spelling variations and near-synonyms. In an online search the search statements are evolved one at a time, and feedback is available at each stage. The searcher specifies a search statement and the computer responds with the number of relevant records. With this type of search facility, the search strategy can be refined to yield a satisfactory output.
The Boolean logic operators are AND, OR and NOT.
AND reduces the number of items retrieved:
CHILDREN AND PARENTS retrieves items in which both terms occur.
OR increases the number of items retrieved:
NOT subtracts the second term from the first.
CHILDREN NOT PARENTS retrieves items in which only the first term occurs.
The operators are subject to some variation. A few systems use AND NOT or ANDNOT. Also, operators may often be abbreviated, so that on Dialog * can be used to represent AND and + for OR.
It is common to use more than one operator in a search statement, as in for instance: CHILDREN AND PARENTS AND CONFLICT OR DISCORD. Once more than one operator has been introduced, the priority of execution needs to be considered. In the example above it is necessary to specify whether the search should be conducted as (CHILDREN AND PARENTS AND CONFLICT) OR DISCORD or as CHILDREN AND PARENTS AND (CONFLICT ORDISCORD). This latter is the expected order of execution, and must be specified by the use of parentheses.
The use of parentheses in formulating a search statement is often known as nesting. Each software package (or search service) has its own priority rules (for example, AND may always be processed before OR), and successful searching depends on heeding these rules, and making appropriate use of parentheses. Nesting forces priority, and offers a clear specification from the searcher’s perspective.
Relevance (Confidence) Ranking and Best Match Search Logic
A weakness of Boolean searching is that it returns straight hit or miss responses, and items that partially fulfil the search specifications are excluded. For example, a search on CHILDREN AND PARENTS AND (CONFLICT OR DISCORD) would not return items containing the terms PARENTS AND CONFLICT but not CHILDREN. Many search systems now relevance rank results, listing items matching any of the search terms, with the best matches first. This can be done in a variety of ways, e.g.:
CHILDREN AND PARENTS AND CONFLICT
CHILDREN AND PARENTS AND DISCORD
CHILDREN AND CONFLICT
CHILDREN AND DISCORD
PARENTS AND CONFLICT
PARENTS AND DISCORD
CHILDREN AND PARENTS
CHILDREN
PARENTS
CONFLICT
DISCORD
A variation common in Web search engines is to use implicit OR, then relevance rank the results so that AND combinations are ranked before OR combinations, and adjacency before either. (This is one reason for the huge search sets generated by many simple Web searches.) The user could for example simply enter CHILDREN PARENTS CONFLICT DISCORD.
In most search statements it is possible to designate certain concepts as being more significant than their neighbours. In its role in formulating search profiles, weighted-term logic may be introduced either as a search logic in its own right, or as a means of reducing or ranking (relevancy ranking) the search output from a search whose basic logic is Boolean.
In an application where weighted-term logic is the primary search logic, each search term in a search profile is allocated a weight. These weights can be allocated by the searcher, but more commonly are allocated automatically. Automatic allocation of weights is usually based on the inverse frequency algorithm which weights terms in accordance with the inverse frequency of their occurrence in the database. Thus common words are not seen to be particularly valuable in uniquely identifying documents. A further refinement considers both the frequency and the positioning of the terms - i.e., words in important positions (titles, headers, early in the document) are given a higher ranking than words appearing elsewhere. If the weights are assigned by the searcher, they are associated with a relevance rating on a document which is found containing that term as a search term. Search profiles combine terms and their weights in a simple sum, and items rated as suitable for retrieval must have weights that exceed a specified threshold weight A simple Selective Dissemination of Information (SDD type profile showing the use of weighted-term logic is shown below:
Search description: The use of radioactive isotopes in measuring the productivity of soil.
A simple search profile (which does not explore all possible synonyms) might be:
8 Soil |
4 Plants |
7 Radioisotopes |
3 Food |
7 Isotopes |
2 Environment |
6 Radioactive |
2 Agriculture |
5 Radiation |
1 Productivity |
5 Agricultural chemistry |
1 Water |
A threshold weight appropriate to the specificity of the searcher’s enquiry must be established. For instance, a threshold weight of 12 would retrieve documents with the following combinations of terms assigned, and these documents or records would be regarded as relevant:
Soil and Plants
Soil and Radioisotopes
Soil and Agricultural chemistry
Radioisotopes and Agricultural chemistry
Soil and Food and Agriculture
Documents with the following terms assigned would be rejected on the grounds that their combined weights from each of the terms identified in the records did not exceed the pre-selected threshold:
Productivity and Water
Food and Soil
Radioactive and Agriculture
Alternatively no threshold weight may be used, and then users will simply be presented with records in ranked order, and can make their own choice as to how far down the list they choose to scan.
Weighted-term search logic may also be used to supplement Boolean logic. Here weighted-term logic is a means of limiting or ranking the output from a search that has been conducted with the use of a search profile that was framed in terms of Boolean logic operators. In the search, and prior to display or printing, references or records are ranked according to the weighting that they achieve, and records with sufficiently high rankings will be deemed most relevant, and be selected for display or printing. In this application, relevancy ranking is most often achieved through an analysis of the number of occurrences of search terms or hits in the document.
The inverted indexes that need to be created to support Boolean searching, and relevance ranking, respectively, are different. An inverted index may be stored in the form of a large matrix, with each row corresponding to an individual term, and each column to an individual record. A Boolean search simply requires that each of these cells in the matrix have a value of 1 or 0. A mechanism that uses some type of term-weighting scheme will require the cell of the matrix to have a value n, where n is the result of a more complicated function of a number of variables. These values may be calculated on the basis of term occurrences. Each record may be considered as a vector or sequence of values.
Search Facilities
Standard retrieval facilities are available in most information retrieval applications. These facilities have been developed to cater for a text-based environment, where the user does not know what documents are available and/or does not know the terms by which records can be retrieved. In other database applications, where records can be retrieved through pre-assigned codes, many of the facilities listed below are not necessary. These facilities cater for the uncertainty in document-based systems, such as those of the external online search services, document management systems, CD-ROM applications and online public access catalogues. In command-based systems these faciltities are accessed through the use of an appropriate command; in GUIs the options are likely to be embedded in pull-down menus, or buttons and check boxes on dialog boxes.
Set-up facilities
These facilities set up the environment in which the search will proceed and are therefore environment-dependent. Help and news are common, as well as connection facilities sometimes in the form of logon and logoff facilities. Web-based interfaces often also offer access to information about the search service, its databases and customer service arrangements. The selection of database is usually a further preliminary.
Selecting search terms
Identification of search terms can be assisted by the display of search-term or index listings. The display may show index or search terms and, sometimes, their number of postings.
Entering search terms
Once a search term has been selected it must be entered. This may merely involve clicking on the term in a search-term listing, typing the term in, or using the term as a component in a more complex search statement entering the term itself, or a specific command might need to be issued. The system responds by creating a set of records indexed by that term and display the search term and the number of records in the set.
Combining search terms
Search terms may be combined into search statements with the aid of a search logic as discussed previously in this chapter. Boolean search logic or relevance ranking is common.
Entering phrases
Many search engines and OPACs allow the user to enter a search phrase, such as PURCHASING BOOKS ON THE INTERNET. As discussed above the system will often treat this as an implicit OR search, although some search engines may process phrases as if each of the terms were linked together with AND. Thus the above phrase would be searched as: PURCHASING AND BOOKS AND INTERNET.
Specifying sections of documents or fields in records to be searched
The ability to search for the occurrence of terms in a specific section of a document or in specific fields in a record facilitates more precise searching. For example, through the specification of whether a search might be conducted on a subject field or author field it may be possible to differentiate between documents on an a person (say SHAKESPEARE) as subject and as author. In order to be able to specify appropriate field labels, it is necessary to know the fields in a given database and which fields are indexed for successful field-based searching. Often it may be possible to search on a combination of fields or sections.
Truncation and search-term strings
Truncation supports searching on word stems. By using the truncation character at either end of a word, the system can be instructed to search for a string of characters, regardless of whether that string is a complete word. For example, if the user asks for a search on COUNTR* this would retrieve records including words such as Country, Countries, Countryside and Countrywide. The use of truncation eliminates the need to specify each word variant, and thus simplifies search strategies. This is particularly useful in natural language information retrieval systems where word variations are uncontrolled.
The most basic truncation is right-hand truncation where characters to the right of the character string are ignored. Left-hand truncation can be useful in circumstances where a variety of prefixes might occur. This is particularly useful in searching chemical databases. For example, ‘CHLORIDE might retrieve records of ‘chloride’ with various prefixes. Truncation, or masking as it is called in this context, is sometimes also available in the middle of words. Here truncation can be useful to cater for alternative spellings. So, for example, NA*IONAL will search for records with National and Nacional.
In order to control the array of word variants that might be retrieved as the result of a truncation, in some systems it is possible to specify the number of characters that are to appear after the truncated string. For example, EMPLOY??? might select terms with a maximum of three additional characters.
Proximity, adjacency and context searching
Often a subject is best described by a phrase of two, three or more words. Subjects such as Information Retrieval and Competitive Advantage need two words to describe them. It is useful if a search can be performed for such phrases. One obvious option is to search for the two words ANDed together, for example, INFORMATION AND RETRIEVAL. This should retrieve records containing the phrase but will also retrieve other records where these two words appear, but where they do not appear next to each other. This method, then, only allows crude phrase searching.
Another option is to store such terms as phrases, possibly by inserting hyphens to mark phrases. Then, for example, INFORMATION-RETRIEVAL would be stored as one term in the inverted file. This method is satisfactory but is primarily applicable to controlled indexing; phrases must be marked at input, and searchers must enter the term in exactly the form in which it was originally entered.
A more flexible option is the use of proximity operators. There are various different kinds of proximity operators. These can require that:
two words appear next to each other; for example ‘INFORMATION RETRIEVAL’, INFORMATION ADJ RETRIEVAL, INFORMATION (N) RETRIEVAL, depending on the search system
two words appear within the same field, sentence or paragraph. The first of these is available on most search systems, and is obligatory on some
two words be within a specified distance of one another, with the maximum number of words to come between the two words indicated by the user; e.g. Dialog has INFORMATION (W.3) RETRIEVAL
two words be within a specified distance of one another, with the maximum number of words to come between the two words set by the system. The operator NEAR is found on many Web search engines.
Range searching and limiting
Range searching is particularly useful when selecting records on the basis of numeric or data fields. They might, for instance, be used to select records according to a price field or publication data field. Fairly common range operators are:
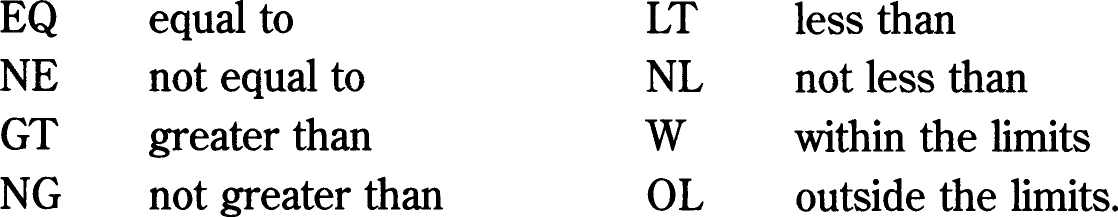
Although range searching is not appropriate in these contexts, examination of the contents of specific field may allow searches to be limited by document type, language or source.
Displaying search or results sets
Shows the user how many documents, search terms and references were found, and thereby indicates whether it might be appropriate to further refine the search.
Displaying records
Once a successful search has been performed, it is necessary to display the records. OPACs first display one-line records and then allow the user to display the full record. Online search services offer a variety of commands for displaying records on the screen, offline printing and downloading. Default formats are the norm, but user-defined formats are becoming more common. These allow users to specify the range of fields to be displayed in the records, and other features of the display. In addition to specifying the record format, users need to be able to specify which records are to be displayed. OPACs tend to let users select records and display them one at a time. CD-ROM and online search services have commands or options that allow the set of records for display to be indicated.
Storing search sets
Many retrieval systems store sets of search specifications by assigning them a running number. The sets can then be reused within the same search session. This permits the user to construct the search in stages, combining search sets by number:
Set 1: CONFLICT
Set 2: DISCORD
Set 3: 1 OR 2
Set 4: CHILDREN
Set 5: PARENTS
Set 6: 4 AND 5
Set 7: 3 AND 6
This may look long-winded, but it reduces typographical errors and gives the searcher the opportunity to reuse any of the terms in different combinations in order to refine the search. A search statement in the form CHILDREN AND PARENTS AND (CONFLICT OR DISCORD) will generate only one search set, and the terms cannot be reused in other combinations.
With systems that do not store search sets, a search has to be entered as a single statement, and once the user moves on to the next search the old search is lost. There may be a facility for refining a search (by performing a search on the set of search results instead of on the whole database), or for storing searches for reuse.
Search management
Search management includes opportunities to review the search strategy that has been adopted and, permanently or temporarily, to save a search profile for subsequent use. Search profiles may be saved temporarily of permanently. Temporary saves are useful for searches where a searcher might wish to reflect on a search, or otherwise come back and complete the search at a later point in time. Permanent saving of the search profile is usually associated with current awareness of selective dissemination of information. The search profile will be run on behalf of the user at regular intervals in order to identify new material, and this will be sent to the user as current awareness notifications. Intelligent agents and other push technologies that refine profiles over a period of time are a recent innovation in this area.
Advanced display options
Records in full-text databases are long, and a full record usually occupies several screens. In such circumstances, special display facilities can support browsing through relevant portions of the text. The ability to stop as soon as the screen is full is useful, as are facilities for moving backwards and forwards through the document. If the text is divided into numbered paragraphs, it is possible to select paragraphs for display. Another approach is to use a KWIC facility, which shows relevant index terms with bits of adjacent text in small windows. Another option that might prove useful is the ability to sort a set of records into order before displaying. Numeric or financial data may be best displayed in reverse or descending order. Some financial databases offer statistical presentation and analysis.
Multi-file searching
Where, as with the online search services, there are a number of databases that might generate relevant records in response to one search, multi-file search facilities are beneficial. The most user-friendly multi-file search option is when other databases can be searched without reformulating the strategy. This requires the system to make the appropriate adjustments in search terms and fields to be searched. The most refined multi-file searching then goes on to produce an integrated set of records drawn from several databases, and with duplicate records eliminated. Many online search services have a database of databases, such as Dialog’s Dialindex (File 411). Available databases are grouped by subject. The searcher specifies a subject group to be searched and enters a search specification. The system returns the number of hits for each database.
Displaying the thesaurus
Where a controlled-indexing language has been used to provide index terms, a thesaurus will often be available in both printed and online formats. This thesaurus displays the controlled vocabulary used and relationships between terms, and is therefore a useful tool in narrowing or broadening searches. It is useful if the thesaurus can be displayed in a window to assist users as they attempt to develop a search strategy. Free-language thesauri that show relationships between terms may be available on some systems, but these take considerable effort to set up. GUIs offer fascinating opportunities for the display of graphical thesauri, showing multiple tree structures and explode options.
Hypermedia
Many systems, including the WWW, offer hypermedia searching. True hypertext searching relies upon an indexer establishing conceptual links between documents. Creators of Web pages often do this when they indicate which terms are to be used as links to other pages. However, in a large database this is very labour-intensive. An alternative is to rely upon the content, including the text and other objects in the record and use the occurrence of objects or terms as the basis for hypermedia links. Thus if the same term or object appears in two records or documents, the user may move from one record to another by, say, clicking on the term or object and without explicitly returning to the index.
Principles of Language Control
At its simplest, a controlled language is a list (known as a thesaurus) of permitted terms and terms which are semantically related. All controlled languages have an alphabetical display sequence. There may also be a systematic (classified) sequence, either as the principal display or as an adjunct to the alphabetical display.
The vocabulary of a controlled language comprises the available terms used for indexing. Such terms describe the content of a document, and so are called descriptors. These may be words, or they may be coded into the notation of a classification schedule, where the notation translates the concepts behind the words. In either case, any relationships between the terms are fixed and permanent.
How does vocabulary control work in practice? Consider the term wagon. The word has a plural, wagons, as well as an alternative spelling, waggon (s), so we must opt for one or other spelling, and have some means of alerting those who use other forms of the word. A wagon is a wheeled vehicle for transporting freight; but it can denote a range of specific vehicles, according to whether the transport is by rail or by road and, if the latter, whether it has an engine or is drawn by a horse or tractor. So for indexing purposes we may well wish to limit our definition to just one of these. If road vehicles, they are often known by their manufacturer’s name and perhaps the name of the model. Finally, there are other words or phrases whose meaning is synonymous or nearly so (cart, truck, lorry), or which belong to the same category but have a wider or narrower meaning (road vehicle, pick-up truck), or which, while not strictly belonging to the same category, are an essential part of the definition of a wagon (freight, goods). With this in mind, let us look at the formal rules of vocabulary control. The basic source is the International and (identical) British Standard Guide to Establishment and Development of Monolingual Thesauri (ISO 2788:1986, BS 5723:1987-ISO, 1986).
Methods of Vocabulary Control
The methods of vocabulary control are:
The form of a term (e.g. its grammatical form and spelling) is controlled.
A choice is made between two or more synonyms or near synonyms to express the same concept.
A decision is made on whether to admit proper names.
A term may be deliberately restricted in meaning to the most effective meaning for the purposes of the thesaurus.
A thesaurus uses a range of symbols to indicate semantic relations. The commonest list is:
SN |
Scope Note |
USE |
Use [another term in preference to this one] |
UF |
Used For |
BT |
Broader Term |
NT |
Narrower Term |
RT |
Related Term |
Construction of Descriptors
Terms used in indexing (descriptors) conform to one of the following types:
Concrete entities:
things and their physical parts: Reptiles, Feet, Microforms, Tropical regions materials: Solvents, Leather, Iron.
Abstract entities:
actions or events: Frost, Walking, Sleep
abstract entities and properties: Hardness, News, Feminism, Poverty
disciplines or sciences: Archaeology, Physics
units of measurement Kilometres.
If a candidate term does not conform to one of these types, it should not be used as it stands. In many cases, a term can be made to conform by being modified in accordance for controlling word forms. These rules are:
Avoid verbs: use Cookery, Opposition not Cook, Oppose
Do not use attributes (adjectives or adverbs) on their own, but only to help define an entity: Yellow fever, Fast food; but not Yellow or Fast on their own. Very occasionally an attribute may be found on its own as a descriptor, if a noun is implied, e.g. Baroque [style].
Avoid adjectives or adverbs of degree, unless they have a technical meaning: Small firms, Very high frequency.
Use nouns and noun phrases, including adjectival and prepositional phrases as appropriate: Women workers, Prisoners of war.
Use the plural number for ‘count’ nouns (how many?): Buildings, Paintings, also for substances or materials treated as a class with more than one member: Plastics, Poisons
Use singular for non-count nouns (how much?): Snow, Painting (notice that it is possible to use both singular and plural if their meanings are distinct), Physics (which is not a plural!); also for parts of the body which occur singly: Mouth, Respiratory system, but Lips, Lungs
Use the most widely accepted spelling: Romania, not Roumania. However, ‘widely accepted’ begs the question: by whom? Some readers will already have noticed the British (rather than American) English spellings of Archaeology and Kilometres above.
Use slang or jargon only if well established and there is no acceptable alternative: Hippies have been with us for long enough to become established (except that they now seem to be transforming themselves into New Age travellers), but the Yuppies of the 1980s fell victim to economic depression. The application of this rule requires a fine judgement. The English language is full of neologisms, which journalists are quick to seize on. Indexers however are a cautious breed, loath to admit a new word that may drop out of fashion after a year or two. Art index did not accept Art nouveau as a heading until the 1950s, and the Library of Congress indexed computers as Electronic calculating machines until 1973. These are extreme cases, but serve to illustrate the fact that controlled vocabularies are poor at keeping up with changes in terminology.
Use abbreviations and acronyms only if they are unambiguous and in common use within the subject field. Words like Radar have ceased to be regarded as acronyms, and it saves space and time to list bodies such as UNICEF as acronyms; but WHO or BP can only lead to ambiguity and misunderstanding. Again, there are grey areas: CD-ROMs? URLs?
Differentiate homographs by a qualifier within parentheses: Cranes (lifting equipment), Cranes (birds). Homographs have the same spelling but different meanings. In a specialist thesaurus only one meaning might apply, and will be clear from the context.
Use a scope note (SN) to exclude possible alternative meanings; or where the meaning is not immediately apparent; or to instruct indexers how a term is to be used. Scope notes in subject headings lists often start with a stock phrase, such as ‘Here are entered…’, as in this example from LCSH:
Conditionality (International relations)
Here are entered works on the requirement that nations meet certain conditions, such as restructuring their economies or respecting human rights, to be eligible to receive foreign aid or loans, or to have normal relations with other nations.
Classification schedules may use SN or some other formula. This example shows some of the kinds of instructional note that may appear after a DDC heading:
Grammar
Descriptive study of morphology and syntax
Including case, categorial, generative, relational grammar
Class here grammatical relations; parts of speech; comprehensive works on phonology and morphology, on phonology and syntax, or on all three Class derivational etymology in 412
Do not invert phrases: Storage batteries not Batteries, storage. (This particular example also carries the risk of ambiguity.)
The inversion rule is quite explicit. Compound terms, that is, multi-word concepts, have for many years been the bugbear of controlled language systems. The problem is whether to invert phrases and, if so, to what extent. In manually searched indexes, inversion brings a useful collocation, as the eye can run down a list from (say) Dogs to Dogs, gun, Dogs, sporting or Dogs, working. The problem is that this construction could be extended to Dogs, hot, which would benefit nobody. Inverted headings are inherently unpredictable, and a distraction to searching. Today’s rules of thesaurus construction presuppose machine-searched indexes, which with keyword access are indifferent to word order and are not intended for sequential searching.
Compound terms then should not be inverted. Other restrictions also apply, notably that they are to be avoided altogether if a noun phrase can be factorized down:
Garage doors |
use instead |
Garages AND Doors |
Coal mining |
use instead |
Coal AND Mining |
Animal behaviour |
use instead |
Animals AND Behaviour |
Factorizing is used when each separate word retains its original meaning. Factorizing should not be used for terms where the original meaning has been lost (Deck chairs), where a different type of entity is denoted (Silk flowers), where one term is used metaphorically (Elbow joints) or where one or both terms are semantically empty on their own (Family problems). Where compound topics like Coal mining are admitted, they are in effect pre-coordinated terms, and are described as having a high pre-coordination level. Normal principles of thesaurus construction require compounds to be reduced to their constituent elements (e.g. Coal mining is retrieved by a Boolean search on COAL AND MINING). Occasionally a single descriptor may pre-coordinate two or more concepts, as with Life satisfaction (a search on LIFE AND SATISFACTION would be likely to generate all manner of false coordinations); or Student evaluation of teacher performance (to make it clear who is evaluating whom). Child behaviour is another instance. It could be factorized into CHILDREN AND BEHAVIOUR without loss of meaning; but the phrase is one that is widely used and understood, so that the convenience and precision of having a ready-made phrase could be considered to outweigh the disadvantage of making the vocabulary larger than is strictly necessary.
Semantic Relationships
Next, semantic relationships must be considered. Semantic relationships between terms are, as their name implies, built into the meanings of the terms. They are permanent, in that they do not change according to whatever document is being indexed or searched. Semantic relationships are stable, i.e., they remain constant within an indexing language and do not change to accommodate the indexing requirements of particular documents. In theory, they ought to be transferable between indexing languages, but in practice other considerations (e.g. disciplinary bias and the degree of specificity required) often militate against this. The rules govern the relationships in meaning between pairs of words (for example Seas/Oceans, Legs/Knees, Food/Diet) - or more precisely how the meaning of the second word relates to the first. There are three basic types of relationship: Equivalence, Hierarchical, and Associative.
Equivalence relationships
Equivalence relationships are relationships where two or more terms are regarded as having the same meaning. One is the preferred term (descriptor); all others are non-preferred terms (non-descriptors). Non-preferred terms are indicated in a thesaurus by the instruction:
Non-preferred term USE Preferred term
Asses USE Donkeys
Under the preferred term is placed the reciprocal of this instruction:
Preferred term
UF Non-preferred term
Donkeys
UF Asses
which serves as a check for both indexers and searchers. Older subject headings lists replace USE and UF with see and x, i.e.:
Asses see Donkeys |
Donkeys x Asses |
The first of these is displayed both in the subject headings list and in indexes based on it. The reciprocal x serves only as an aid to the indexer, and appears in the subject headings list only, and not in the index.
The following subcategories of equivalence relationship have been distinguished:
Variant spellings, word forms, abbreviations, etc. These exemplify the rules for word form control shown above.
Rumania USE Romania
Romania UF Roumania
ROM USE Read Only Memory
Read Only Memory UF ROM
Mouse USE Mice
Mice UF Mouse
Singulars and plurals are distinguished if the plural is irregular and would file a considerable distance away from the singular.
Selling USE Sale
Sale UF Selling
Sea food USE Seafood
Seafood UF Sea food
because of the filing implications. Filing sequences are often Vord by word’ as opposed to letter by letter’
Coal mining USE Coal AND Mining
This is an example of ‘semantic factoring’.
Synonyms. Synonyms are rarely if ever completely interchangeable. In these examples, the co-reference is exact, but they differ in their usage.
Asses USE Donkeys
Donkeys UF Asses
Noble gases USE Inert gases
Inert gases UF Noble gases
Wireless USE Radio
Radio UF Wireles
Elevators USE lifts
Lifts UF Elevators
German measles USE Rubella
Rubella UF German measles
Tax planning USE Tax avoidance
Tax avoidance UF Tax planning
Quasi-synonyms. These are terms whose meanings are different but overlap in ordinary usage, but are treated as synonymous for indexing purposes.
Deceleration USE Acceleration
Acceleration UF Deceleration
Softness USE Hardness
Hardness UF Softness
The above two examples are antonyms: they represent different viewpoints of the same property continuum. The Mowing two examples might or might not be regarded as equivalent, depending on subject field:
Fostering USE Adoption
Adoption UF Fostering
Barley USE Cereals
Cereals UF Barley
These would only be regarded as synonymous if they were on the fringe of the subject field of the thesaurus, where the generic level is set rather higher than for central themes. A thesaurus on social welfare would almost certainly have Fostering RT Adoption (an associative relationship), and one on agriculture would have Barley BT Cereals (a hierarchical relationship). This last is an example of ‘upward posting’: treating a narrower term as if it were equivalent to, rather than a species of, its broader term.
In a classification schedule synonyms are often shown in parentheses, e.g. DDC’s 796.334 Soccer (Association football). Quasi-synonyms may be shown by an inclusion note, e.g. 796.33 Inflated ball driven by foot Example: pushball - where Pushball is not given a specific place in the classification. (Note in passing that in classifications like DDC that are primarily designed for shelf arrangement, headings like ‘Inflated ball driven by foot’ are not intended as a verbal approach: their purpose is to define precisely and unambiguously the scope of a class together with any subclasses it may have.)
Hierarchical relationships
Here both terms are permitted terms (descriptors) and are linked in a broader-to-narrower hierarchy. This use of ‘hierarchy’ and ‘hierarchical’ is precise and technical, and is not to be confused with common, looser usages that denote any kind of descending sequence. Indexers are able to select the most specific term available to index concepts within the document. Searchers can extend a search by transferring from a first access term to a broader (more general) or narrower (more specific) term. Hierarchical relationships are indicated by BT (broader term) and NT (narrower term), e.g.
Sparrows BT Birds |
Birds NT Sparrows |
There are three subcategories of hierarchical relationship:
Generic relationships are easiest to spot: they can be verified by the rule-of thumb: some As are B; all Bs are A
Protest NT Rebellion
Rebellion BT Protest
Reptiles NT Snakes
Snakes BT Reptiles
But not:
Pets NT Budgerigars
Why does this not qualify? Because not all budgerigars are pets. Most hierarchies are unique (a snake is a reptile and not any other kind of living creature), but the next example is a polyhierarchy (as is the Brain example below).
Rocks NT Coal
Coal BT Rocks
Fossil fuels NT Coal
Coal BT Fossil fuels
Partitive, or whole-part relationship. This applies only if the part is unique to the whole:
Science NT Chemistry
Chemistry BT Science
Head NT Brain
Brain BT Head
Central nervous system NT Brain
Brain BT Central nervous system
Canada NT Ontario
Ontario BT Canada
But not:
Buildings NT Doors
A door is a necessary part of any building, but cars, railway carriages etc. also have doors.
Instance (class-of-one). Proper names may be acceptable or not, according to policy. (Sometimes they are regarded as identifiers rather than descriptors, and as such excluded from the thesaurus.)
Mountain regions NT Alps
Alps BT Mountain regions
Hierarchical relations modulate, i.e. they move a step at a time through their hierarchy, e.g.:
Science NT Chemistry
Organic chemistry BT Chemistry
Chemistry NT Organic chemistry
Chemistry BT Science
and not, e.g., Science NT Organic chemistry. If an intermediate step is omitted, there is a very real likelihood that a search will skip over potentially useful material.
Older subject headings lists use see also and its reciprocal xx, e.g.:
Science see also Chemistry
Chemistry xx Science
The first of these would appear both in the subject headings list and in indexes based on them. The reciprocal xx serves only as an aid to the indexer, and appears in the subject headings list only and not in the index. By convention, indexes display see also references only in a downwards (generic-to-specific) direction. Users of these indexes are presumed to be aware that (e.g.) Chemistry is part of Science. See also does not distinguish hierarchical and associative relationships (see below).
In a classification schedule indentation is used to indicate hierarchical relationships, often with different typefaces. There may be a corresponding lengthening of the notation for more specific terms; but many bibliographic classification schemes either do this inconsistently (e.g. DDC) or do not set out to do it at all, as with the LCC and Bliss Bibliographic Classification (BC; 2nd edition, BC2).
Associative relationship
This relationship is not easy to categorize. The International Standard offers two useful clues:
One of the terms should be strongly implied, according to the frames of reference shared by the users of an index, whenever the other is employed as an indexing term… It will frequently be found that one of the terms is a necessary component in any explanation or definition of the other.
(ISO, 1986, p. 17)
As with hierarchical relationships, both terms are descriptors. RT (related term) is the thesaural symbol, and its reciprocal is the same. The following are typical:
Buildings RT Doors |
Doors RT Buildings |
This is the more usual kind of partitive relationship, where the part is not unique to the whole, and is therefore regarded as an associative relationship rather than as hierarchical.

Adjectives are not normally permitted as descriptors. Here, ‘French’ can be used as a noun, to denote the people of France; or as the first word of a phrase, e.g. French music.
Silk flowers RT Flowers |
Flowers RT Silk flowers |
A silk flower is not a flower!
Handicapped children RT Schools for handicapped children
Nested phrases of this kind do not require a reciprocal RT. (Notice in passing that the phrase would now be considered socially unacceptable. A more acceptable phrase today would be: Schools for children with special needs.)
Subject headings lists have in the past used See also and xx. These are the same symbols as are used to denote hierarchical relations, and are used in the same way. It is not uncommon for associative see also references to appear in one direction only.
Classification schedules are by their nature set out hierarchically. There may occasionally be found references to associated topics in other parts of the schedule, e.g. in DDC:
790 |
Recreational & performing arts |
|
Class the sociology of recreation in 306.48 |
There is often a temptation to enter RTs as BT/NT (broader term/narrower term). In some cases it is very difficult to determine whether a relationship should be entered as BT/NT or RT/RT. A rule of thumb is to check whether both terms belong to the same basic type (abstract or concrete entities). If they do not, the relationship cannot be hierarchical, and must be associative (if it is to be admitted at all): e.g., Entomology is a discipline or science (an abstract entity), and cannot therefore belong to the same hierarchy as Insects (which are concrete entities).
Another temptation is to make RTs indiscriminately. The principle of RTs is that there must be an immediate and necessary relationship between the two terms. If the relationship is not direct or not necessary, then the terms either should not be related at all, or at best should be linked indirectly, through a third term. Consider the following:
Authors
RT |
Books |
|
Publications |
|
Textbooks |
Books and Textbooks are hierarchical to Publications. It would be enough therefore to make the one reference
Authors RT Publications
and let users find their own way if they wish to pursue the references through Publications NT Books and Books NT Textbooks. It is also tempting to link topics that are only indirectly connected, e.g., by sharing a common BT. So there is little point in links such as Mice RT Hamsters, simply because they share the common BT Rodents. Subject headings lists have in the past been guilty of some highly tendentious see alsos, such as Journalism see also Libel and slander, with its implication that journalists go around libelling people for a living; or Psychical research see also Personality disorders, suggesting that only those with personality disorders engage in psychical research.