4
Users and interfaces
Introduction
This chapter focuses on users and the user interface with knowledge-based systems. Since systems are designed to facilitate user access to information or knowledge, an important preliminary to systems design and creation is an understanding of the different kinds of users and the way in which users may wish to search or identify information. The chapter also explores some of the approaches to systems design. At the end of this chapter you will:
understand ways of categorizing users
appreciate the value of user models and cognitive modelling
appreciate that indexing and searching processing are complementary
be aware that users have different types of search patterns
be aware of the different types of dialogue styles through which search strategies may be executed.
The earlier chapters in this book have focused on the information or knowledge that is to be organized, identifying some of its inherent structure and exploring the nature and context of the organization of knowledge. The next few chapters explore the range of approaches and devices that have been developed to assist users in exploring knowledge and meeting their requirements for knowledge or information. Understanding the user perspective has been a long-standing principle underlying the design of such systems. It is therefore appropriate that this chapter should consider the different categories of users, some of the purposes for which they might wish to organize knowledge or access information and their search processes. Search processes in electronic information systems are constrained by dialogue styles; accordingly, the chapter concludes with examples of the different dialogue styles in information retrieval systems.
As identified in the Introduction to this book, in systems, such as the Internet, in which the knowledge itself is weakly structured, the searcher encounters a messy information environment, in which it is necessary for them both to identify the range of sources that are appropriate, and to locate individual nuggets of information within those sources. In such a context, the organization of knowledge is increasingly user led. As users collect information, they create a model of the organization of information which it is necessary for them to refine over time, in other words, they learn, and that learning process is an important aspect of their ability to change and survive in an information society. Hence, the importance of the concept of experience in the categorization of users, and the recognition that previous experience influences user success in retrieving information, and in interacting with electronic information through specific dialogue styles.
Users
The objective of any information retrieval system is that is should be used by the group of people for whom it has been designed. The field of human computer interaction has yielded the concept of usability in order to reflect this concern with users: The usability of a product is the degree to which specific users can achieve specific goals within a particular environment, effectively, efficiently and comfortably, and in an acceptable manner’ (Booth, 1989, p. 110).
More specifically, the components of usability which were identified by Bennett (1984) and later operationalized by Shackel (1990) so that they could be tested, can be expressed in terms of:
learnability, or ease of learning - the time and effort required to reach a specified level of use performance
throughput or ease of use - the tasks accomplished by experienced users, the speed of task execution and the errors made
flexibility - the extent to which the system can accommodate changes to the tasks and environments beyond those first specified
attitude - the positive attitude engendered in users by the system.
Designers have also recognized that there are a number of different categories of users. Typical categories are: novice, expert, occasional, frequent, child, older adult, and user with special needs. Many users may fall into more than one of these categories, and none of the categories is mutually exclusive. The categories are used as stereotypes for ranges of experience with public access systems. More specifically:
Novice users are users who have never used a specific system before. They need to learn how to perform information retrieval tasks quickly and easily. Simple and intuitive interfaces are preferable. It is important to remember that whenever a system is changed all users become relative novices, although they may bring a conceptual framework based on their knowledge of other systems to the new system. Similarly, novice users of a particular system, who have used other similar systems will bring an underlying conceptual framework to their learning.
Expert users use the system on a regular basis, and therefore are familiar with most functions and can negotiate any problems that might arise with the system. The expert user can complete the task quickly, but may be frustrated by wizards and menus and other features that slow down interaction with the system.
Many systems have more than one interaction mode to cater for these different categories of users. For example a number of OPACs and CD-ROM systems allow expert users to use short-cut keys rather than menus, and also offer ‘expert user modes’ so that individuals can execute complex search tasks.
Occasional users can often be viewed as near novice users in that, since they use the system infrequently on each occasion that do they use the system, they need to learn how to use the system again. Frequent users, on the other hand, are generally assumed to be expert users, although some frequent users will continue to limit the range of functions that they use, and thus never truly become expert users.
Another important category of user is users with special needs. Such users may be vision or hearing impaired, may have specific physical needs or learning disabilities. The system must be capable of supporting the user’s special need. So, for example, for the user who is hearing impaired the interface must give clear visual cues.
Information managers and intermediaries who search systems on behalf of other users, can generally be expected to be expert users, but they may also require additional functionality so that it is easy to reformat and communicate information to the ultimate end-user.
Cognitive Modelling
For users to make effective use of an information system, they must have a cognitive framework, or mental model upon which to hang their understanding. This mental model is a simplified mental ‘picture’ of what the system does, which assists the user through their interaction with aspects of the system. System designers also need to define these mental models. System design needs to recognize that there may be four models of an information systems:
the user’s mental representation of the system - the mental model
the designer’s conceptual framework for the description of the system - the user model
the image the system presents to its users - the system model
the psychologist’s conceptual model of the user’s mental model - the conceptual model.
The general aim is to produce a coincidence of these four models. Mental models are important in that they are owned by individual users. Every user develops a mental model of the system they use to build surrogates or metaphors that help them to understand complex concepts. Users of electronic information sources may find that their mental model, which has possibly been derived from a print equivalent, may or may not be relevant in the electronic environment. For example, users of library catalogues have found that OPACs differ considerably from the mental models which they may bring for card or microfiche catalogues (Slack, 1991). Problems may arise from the user’s incomplete mental model of the catalogue database and the way in which the OPAC both holds the data and searches for the terms required.
Perceptual models of users describe the way in which users receive, perceive and process information. Users receive information from external sources, interpret the information based on previous experiences, identify a response to the received information and respond according to their decision. This basic ‘human information processing model’ has a number of key features that need to be considered in the design of public access database systems. These include:
perception, which is concerned with the way in which the user interprets images or other stimuli
attention, in which a user filters incoming stimuli to focus on what is perceived to be the most important information.
information processing, or the stages and the task in the use of an information system
memory, including both the short-term memory and long-term memory
learning strategies, which will be employed by the user to enhance their use of the system. These may include learning through doing, active thinking, setting goals and creating plans, analogy, and learning from errors.
In summary, the cognitive frameworks which users bring to interaction with information systems, the use of mental models and the users’ perceptual models are important aspects for the learning and recall of system functions.
The Processes of Searching and Indexing
Both indexing and searching, as performed by people, rather than machines, involve the same three stages:
Familiarization → Analysis → Translation
In systems where computer-based indexing is used, indexing is automatic in accordance with an algorithm, and these three stages are only relevant to the searching process. The user may, however, be called upon to exercise more skill in the design of a search strategy, in order to cater for some of the variability that arises in natural language indexing. We return to this issue in Chapter 5, and elsewhere, when we consider the differences between natural and controlled indexing languages. First we consider the nature of the processes of indexing and searching in a little more detail.
Indexing
Indexing is the process whereby structure can be added to knowledge, in order to support more effective and more efficient retrieval.
The only totally adequate indication of the content of the document is the document in its entirety. Any other indications of document content, such as classification notation or alphabetical subject terms, are partial representations of content; they are surrogates for the document itself.
The objective of the three stages of indexing is to construct a document profile that reflects the document, usually with a focus on the subject of the document. Most documents have many characteristics that might be identified by a searcher as the criterion by which the document would be selected as relevant Any set of search keys for a document can be described as a document profile. Different types of indexes and different user groups may require different sets of search keys (or different document profiles) to be developed in respect of any given document The stages in framing a document profile are:
Step 1: Familiarization This first step involves the indexer in becoming conversant with the subject content of the document to be indexed. Documents are composed of words, and searchers and indexers use words to represent or convey concepts; at this stage, however, it is important for the indexer to attempt to identify the concepts that are represented by the words. In order to achieve good consistent indexing, the indexer must have a thorough appreciation of the structure of the subject and the nature of the contribution that the document is making to the advancement of knowledge. From time to time the indexer may need to consult external reference sources in order to achieve a sufficient understanding of the document for effective indexing. Certainly it will always be necessary to examine the document content, concentrating particularly on the clues offered by the title, the contents page, chapter and section headings and any abstracts, introduction, prefaces or other preliminary matter.
Step 2: Analysis The second step towards constructing an index involves the identification of the concepts within a document which are worthy of indexing. Any one document covers a numbers of different topics. Take, for example, a book entitled Wills and Probate’. This book contains sections on making a will, executors, administration of an estate, pension, tax, house ownership, grants and intestacy, to name but a few. Usually it is possible to identify a central theme in a document and to produce a summary of document content based upon this central theme. Frequently, but not always, this same process will have been attempted by the author when inventing the title, which explains why a title is often useful in indexing. Clearly, indexing must permit access to a document by its central theme, but to what extent should access be provided to secondary or subsidiary topics? This question can usually only be satisfactorily answered with reference to specific user groups and environments.
It is helpful to have such guidelines concerning the types, range and number of concepts to be indexed, but in many circumstances these choices may be at the discretion of the indexer. Many traditional indexing approaches have sought to find a label or indexing term which is co-extensive with the content of the document being indexed; that is, the scope of the indexing term and the document are similar. For example, for the book Wills and Probate’, it would not be sufficient to index this book under the term Wills’ alone, since this heading would not reveal the section of the book on ‘Probate’.
Note: the term ‘analysis’ has been used here in its restrictive meaning. Some authors use ‘analysis’ to apply to all processes associated with the construction of a document profile of any kind. In this definition ‘analysis’ subsumes all of the processes associated with indexing, cataloguing, classification and abstracting.
Step 3: Translation Having identified the central theme of a document, this theme must be described in terms which are present in the controlled indexing language. This will involve describing concepts in terms of the classification scheme, thesauri or list of subject headings. For example, a free interpretation of the subject of a document might be: ‘Social conflict and educational change in England and France between 1789 and 1848’. The concepts represented in this summary might be translated into an alphabetical description of the form: ‘Education - History - England - Social Conflict - France’, or into a classification notation such as, 942.073. To take another example: ‘Radioactivity in the surface and coastal waters of the British Isles’ might be converted to an alphabetical description such as, Water pollutants - Radioactive Materials - Great Britain, or into a classification notation such as, 628.16850941.
This translation involves not only labelling the subject, but possibly also indicating related subjects, as discussed in Chapter 5. The guiding principle in translating concepts into the indexing language of any given system must be that the terms selected and the relationships indicated are consistent with the ‘normal’ user’s perspective on the subject. This coincidence between indexing and user approach is known as user warrant. In other words, the indexing system must be tailored to the needs of users. Given that different users may have different perspectives on the same subject, it is clear that different approaches to indexing and structuring knowledge will be applicable in different environments. To illustrate this point, consider, for example, medicine. The approach suitable in specialized structuring tools for medical research will need to be very specific in order to differentiate between closely related subjects. On the other hand, a collection of general medical books in a public library may deal with the same range of topics as the research databases, but the structuring will probably rely on broader categories, and the terms used for the same ailment may be different. What a doctor might refer to as ‘rubella’, will probably be called ‘German measles’ by the mother of the child with the complaint.
In general, it is important to recognize that there is a great variety of different approaches to indexing, and that this is inevitable, not only for reasons of history and indexer/organizational preference, but also because different situations require different approaches.
Searching
Indexing and searching are complementary. The searcher uses the document profile created by the indexer as a basis for searching, but the searcher does not come to the search process with any knowledge of the specific document profiles of the documents that they might deem useful or relevant. There is great similarity between indexing and searching, and each involves the same three stages:
Step 1: Familiarization A searcher must be adequately familiar with what he or she wishes to retrieve. Although this may seem an obvious statement, there are many instances when the searcher is not fully aware of what can or might be retrieved. Two common circumstances may arise:
The searcher is an information intermediary seeking to identify information or documents on behalf of someone else. Here familiarization can be partially achieved by conducting a reference interview with the end-user. The reference interview should ascertain both a clear subject profile and also other characteristics of the required documents or information, such as any constraints on date, language, source or level. The intermediary also needs to be conversant with the sources to be searched,
The searcher may be the end-user, possibly approaching the search in some ignorance of their real requirements or the literature that might be available to meet those requirements. Some degree of ignorance of this kind is not unusual since the usual objective in consulting an information source is to become better informed. If the search is to be successful, the user will learn about the subject and its literature during the searching process. (Of course, an even more unfortunate situation is where the end-user, poorly informed about the information or documents required, briefs an intermediary, who is then in the position of conducting a search on the basis of incomplete or inaccurate information).
Step 2: Analysis When the objective is clear, the next step is to analyse the concepts present in a search. Sometimes, particularly for a straightforward search in a printed index, it will be sufficient to establish these concepts in the searcher’s mind. On other occasions, where the search must be specified with a number of interacting concepts and other parameters, it will be necessary to write the concepts down. For example, if information is required on ‘primary education’ and this is a search term in a database, then the search profile merely involves the term primary education. If, however, the searcher seeks information on ‘Recovering hydrogen from coal tar in a continuous electrofluid reactor’ and is interested only in reports, books, or periodical articles that provide a review of the subject since 1990, then the search profile will be much more complex. Building a search profile has much in common with building a document profile during indexing. The search profile will comprise a series of search keys representing subjects and other characteristics of the search requirements that together indicate the scope and nature of the search.
Step 3: Translation Translation of the concepts in a search profile will involve reference to a thesaurus, classification scheme (or its index) or list of subject headings that has been used in constructing the index to be searched. Many computer-based systems make this process virtually automatic, and terms can, for instance, be selected from online thesauri. If such tools are not available, consultation of the inverted file that has been constructed for the indexing process may be useful, or reference to other sources of subject terminology, such as thesauri and dictionaries may be of assistance. The quality of translation depends considerably on the support that is available in the system being searched. In a printed index, guidance on indexing practices is useful. In computer-based systems, there will be a range of facilities which support searching on different parts of the record, including, often assigned subject terms, abstracts and the natural language of the text of the document. The development of a search profile is often an evolutionary process, and some approaches to this process are described in the next section.
Finally, it is essential not to forget that successful information retrieval does not only depend upon the effectiveness of indexing and searching in a single source. Most searchers need to use multiple information sources and knowledge structures to locate information and documents. This means that even if individual sources have been carefully indexed, through the use of controlled indexing languages, a user searching several sources, each of which has been indexed using a different controlled language, still has to negotiate a complex maze of different subject terms and subject relationships. Selection of the appropriate sources is key; no amount of searching a source that does not provide access to the information or documents that are being sought will produce a positive outcome!
Search Strategies
Objectives
The set of decisions and actions taken during a search is known as a search strategy. Some searchers are more methodical in the construction of search strategies than others, but every searcher aims to:
retrieve sufficient relevant records
and avoid:
retrieving irrelevant records
retrieving too many records
retrieving too few records.
Directed Searching Versus Browsing
There is a spectrum of searches from the search for a specific document or item of information, (sometimes called known-item searching), through to the almost aimless or general browsing, over the Internet, or in a public library, for ‘something interesting’. Many searches can be placed at some point in the middle of this spectrum; often the user is refining not only the search strategy, but also their information requirements as the search proceeds, so that, a search that may start with browsing may eventually have a very focused intended outcome. Alternatively, the visit to a library or the Internet search that starts with a very targeted objective, may open up other experiences and access to other sources, and suggest other lines of investigation or action that had not occurred to the user at the start of the search. Arguably one of the most important features of the Internet, as opposed to earlier avenues of access to electronic information sources, is the opportunity to browse. Directed searching and browsing can be differentiated thus:
Directed searching is performed by users when they know what they are looking for, and usually possess some characteristic of the information or document (such as its author or a set of subject terms) which they can use as the basis of a specific search.
Browsing is performed when the user has a less precise view of the information or documents that might be available and is not sure whether his or her requirements can be met or how they might be met. Browsing can be general or purposive. Purposive browsing occurs when the user has fairly specific requirements, whereas general browsing may be used as an opportunity to refine the user’s perceptions of their requirements.
Knowledge structuring often needs to be able to cater for both directed searching and browsing.
In summary, it is important to recognize that the user’s experience of the search for information, especially when it embraces a range of different sources, some of which are in print and others in electronic format, is essentially messy. It is likely that useless or irrelevant documents or information will be identified and discarded at various stages in any search experience, and considerations of recall and precision as explored in Chapter 13 are relevant in the individual search experience.
More on Browsing
Browsing is generally preferred to directed searching in situations in which:
the search objective can not be clearly defined, usually because the searcher lacks sufficient information to be able to define it precisely
the cognitive burden, including what the user needs to know about how to search, and how to search a specific system, is less than it might be for directed searching
the system interface encourages browsing through the types of search facilities that it offers.
Browsing involves skimming information and making choices; it is extremely dependent on human perceptual abilities, as applied in the recognition of things of potential interest and the making of choices based upon that recognition. Online search services that used command-based interfaces, and were used primarily by intermediaries, did not support browsing. However, as the range of systems interfaces has grown, many of these interfaces support scanning, and thereby offer the option to browse. Browsing is best performed in environments in which like things have been grouped together. The traditional context for browsing is books arranged on shelves in accordance with a classification scheme, in libraries. Onscreen browsing is facilitated by:
highlighting, so that the user can identify salient words and objects
scrolling, so that the user can scroll through information quickly
menus of commands and lists of titles which summarize information.
Hyperlinks, as discussed further in Chapter 11, underlie the structuring of the Web. Browsing through networks of hyperlinks between documents allows users to navigate through cyberspace, in a non-sequential manner. Search histories can be useful in orientating the user; it is often possible to backtrack through a search to an earlier screen. Nevertheless, browsing can be time-consuming with large data sets, and it is easy for disorientation to result.
More on Directed Searching
A common process is the broadening or narrowing of a search strategy on the basis of the outcome from the first search statement. This can be achieved by using any of the retrieval facilities reviewed below or by introducing different search terms. The effective development of a search strategy requires knowledge of the subject, databases and literature being searched.
Different search strategies might be appropriate for different kinds of searches. Five types of search strategies have been proposed:
Briefsearch - a ‘quick and dirty’ search - is a single search formulation, normally a Boolean combination of terms, to retrieve a few relevant items (see Figure 4.1). It is the fastest, simplest and least expensive approach to searching. Use this strategy:
to retrieve a particular document known to be relevant to the problem
to get a rough idea of what a database contains
to retrieve a few records to examine the index terms which may later be formulated into a search expression for a more detailed search.
Building blocks is the most commonly used approach to online searching (see Figure 4.2). Terms used to represent a facet may be synonyms, near synonyms, narrower terms in a hierarchy or in some way related. These are grouped using OR to create a larger set. The facets representing the main concepts of the search are combined using AND (and on rare occasions OR and NOT). Records should be examined for relevancy and the formulation can be modified in various ways using search heuristics aimed at increasing recall or precision, as necessary.
Successive facets strategy constructs each facet one at a time, successively and as needed (see Figure 4.3). At each step each new facet is intersected with the previous result. Consider using this approach:
if you suspect that ANDing all facets will retrieve few (or no) records due to overspecification
if you suspect that one facet is ambiguous in meaning.
Pairwise facets: the facets are ANDed a pair at a time, rather than all together (see Figure 4.4). Consider this strategy:
if it is thought that all facets are well defined, each with sizeable literature, roughly equivalent in relevancy and specificity of definition of the search problem
if it is considered that the intersection of all the facets at once will result in zero postings.
Citation pearl growing moves from high precision towards increasing the recall of the search (see Figure 4.5). A known highly pertinent document is used to select search terms to be formulated into a search expression. (Briefsearch can often be used to find a small number of relevant documents.) The resulting set can be examined and further search terms added to each facet, a process which can be cycled as many times as necessary. This is a fairly complex process. Consider this approach:
if the terminology of the search problem is not well known
if thesauri and word lists are not available.
Current Awareness and Retrospective Searches
Another important division is between searches for information to update a user’s knowledge on a subject, and searches to find all of the information to date on a subject.

Figure 4.1 Briefsearch

Figure 4.2 Building blocks strategy

Figure 4.3 Successive facets strategy

Figure 4.4 Pairwise facets strategy

Figure 4.5 Citation pearl growing
Current awareness searches are performed when a well-informed user is concerned to locate the latest information on their topic of interest. For example, a doctor may be interested in the results of the latest research on the most effective treatments for cancer. A marketing manager may be interested in the market shares of the various competitor companies in the industry in which they are operating. Some of this information may be formally flagged as new information in newspapers, new issues of journals and newsletters. Current awareness services or alerting services are designed to make it easier for a user to keep abreast of new information in a range of different sources. Many users need to keep abreast of developments in a number of different areas.
Retrospective searches are undertaken when a user wishes to become informed of knowledge on a specific topic. Students may perform such a search when they need to prepare an essay or undertake a literature review for a research project. They may not be interested in locating all the information on a topic, but will be concerned to get a general picture of developments and of the concepts and ideas in the literature in their field of interest. Professionals, such as scientists, might perform a retrospective search when they commence a new project, and want to be sure that their work will not duplicate work that has already been performed elsewhere, and that thereby they will add to knowledge. The output from a retrospective search will include current information, but is likely to extent back over a longer period of time than the output from a current awareness search
Interface Design
Search processes in electronic information systems are constrained by interface design. The search interface is the context in which information searching and seeking is conducted. Interfaces must
be easy and quick to learn
allow users to issue instructions quickly, and respond quickly to that instruction
minimize errors
be easy to remember
make it easy for the user to perform the tasks that they wish to perform.
Interface design has come a long way since the early command-based interfaces. There is an extended range of input devices, including mouse and touch screen, higher resolution monitors, faster processors and more sophisticated software environments. There are a number of different interface styles, but most knowledge-based systems now operate with a graphical user interface (GUI) or Web-based interface. A GUI embraces:
direct manipulation
windows
dialog boxes
form filling
question and answer
menus
buttons and checkboxes
icons
command languages.
We explore these components below, and Figure 4.6 illustrates the development of a search strategy in a GUI.
There are still a few applications that use one or more of these dialogue styles in non-GUIs or Web-based interfaces. In early systems the emphasis was on command-based interfaces and menu-based interfaces. Until a few years ago all information retrieval systems were command based. These systems were regarded as impenetrable for the inexperienced user. The need to learn the command language was aggravated by the fact that nearly every software package used a different command language. Menu-based interfaces were introduced as a means of making systems more accessible to the new and occasional user. They first emerged in CD-ROM, OPAC and some specialist online applications, and later were adopted by online search services as interfaces for their services that are marketed directly to end-users. The first menu-based systems were very simple full-screen menus, but most systems now have full GUI-based interfaces. Menu-based systems often embed the use of commands in a menu-based environment, by offering the searcher a list of commands from which the appropriate commands can be selected. This still requires the searcher to have some appreciation of the effect that the application of a specific command may have, but eliminates the requirement for the searcher to remember the exact form of a command for a given information retrieval system. In information retrieval applications, features of GUI which facilitate the search process include:
the ability to move more easily between applications, so, for example, through the one interface, the user might perform a search on an external databases, download some information, and enter a word-processing package to reformat that data, and then, finally, communicate the reformatted data to a colleague through an e-mail system
the use of windows, so that a user can build a search strategy in one window, while consulting a thesaurus or a help system in another window. Once the search has been completed, the search strategy window can remain on display, while the records are displayed
the use of direct manipulation and the ability to click on hypertext links in a document
much more visually appealing and easy to understand interfaces
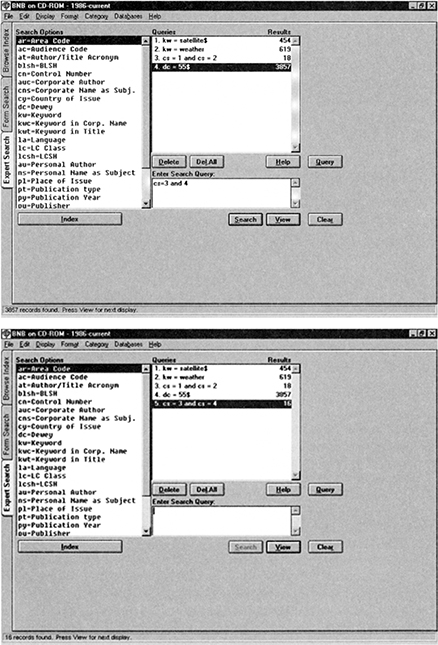
Figure 4.6 Development of a search strategy in a GUI
ease of navigation through different menus and actions available within the system
opportunities for the display of multimedia documents with, for example, an onscreen display of photographs and video.
In general, then, GUIs have made information retrieval systems much more user-friendly, but there are some public access environments, particularly those where a kiosk is used for public access, where the use of the full functionality of a GUI would be seen as confusing by a significant proportion of the users.
Components in GUIs
Direct manipulation
The idea of direct manipulation is that the user’s actions should directly affect what happens on the screen, in the sense that there is a feeling of physically manipulating objects on the screen. Typically, direct manipulation systems have icons representing objects that can be moved around the screen and manipulated by controlling a cursor with a mouse, for example, in moving a file by clicking on an icon representing the file and dragging it to a new location. This makes it easy for novices to learn basic functionality quickly, and experienced users can work extremely rapidly to carry out a wide range of tasks
Windows
A window is a rectangular area on the screen in which an application or document can be viewed. Most windows can be opened, closed, moved and sized. Several windows can be opened simultaneously and most windows can be reduced to an icon, or enlarged to fill the entire desktop. Sometimes windows are displayed within other windows. There are two types of windows: tiled and overlapping. Tiled windows are where the screen is divided up in a regular manner into subscreens with no overlap. Overlapping windows can be nested on top of one another. Windows have a number of uses. Screen areas can be separated for error messages, control menus, working area and help.
Dialog boxes
A dialog box is a special window that appears temporarily to request information. Many dialog boxes contain options that you select to tell the software to execute a command. A dialog box requests information from the user. For example, the user may need to select certain options, type some text or specify settings. Dialog boxes can form the basis of a question and answer or a form-filling dialogue.
The user of a question and answer dialogue is guided through his interaction by questions or prompts on the screen. The user responds to these by entering data through the keyboard. Often questions may require only a simple Yes’ or ‘no’ response, but on other occasions the user may be required to supply some data, such as a code, a password, their name or other textual data. Usually, however, one-word responses are expected. On receiving the user’s response, the computer will evaluate it and act accordingly. This may involve the display of data, additional questions or the execution of a task such as saving a file. The prompt information can easily be tailored to the requirements of the user, and this dialogue style may therefore suit novice and casual users. The main drawback of this dialogue mode is that since an input data item must be validated at each step before continuing with the dialogue, the interaction can be slow. Question and answer dialogue is widely used in a simple form in GUIs where a question might be posed in a dialog box and the user is expected to respond by clicking the Yes or No button.
In a form filling dialogue the user works with a screen-based image of a form. The screen form will have labels, and space into which data are to be entered. It should be possible to move a cursor to any appropriate position on the form for the entering of data. Labels will normally be protected from amendment or overwriting and some users may be able to amend only certain fields, so that others are protected. Form filling is a useful dialogue for inputting records and blocks of data. In searching it is used in Query by Example interfaces. All data input should be validated and errors reported to the user. Form filling, because it may involve large amounts of data entry, can take a lot of user’s time and can be a source of frustration and errors. In form filling dialogues the user has Uttle control over the dialogue, but the approach has the advantage that the user rarely needs to remember commands or their syntax. Form filling can be speeded up by the use of a drop down box from which an option can be selected for entry into the form.
Menus
Menus present a number of alternatives, or a menu on the screen, and ask the user to select one option in order to proceed. The menu options are usually displayed as commands, or as short explanatory pieces of text. Pictures or icons may also be used to represent the menu options. The appropriate option is selected by keying in a code (often a number or letter) for that option, or by pointing to the required option with a mouse or other pointing device. Menus are generally recognized to be a sound approach for the occasional or novice user. Additional help is rarely necessary and little data entry is required of the user. The system designer has restricted the total set of options, and thus the novice user has less potential for mistakes. Menu-based interfaces must be closely denned with the user in mind. This involves careful consideration of menu structure, key presses required and menu bypass techniques. For example, expert users should have the option of accessing a specific screen or making a selection without necessarily passing through all previous menu selections.
Where there are many possible commands and displaying them all might be difficult, menus are sometimes organized hierarchically in tree-like structures. In other words, a menu might not only contain commands, but also routes to other menus. For example a Format command in a word-processing package, when selected from a menu, might display a further menu which listed the options of items for formatting, such as characters or paragraphs.
Today’s interfaces use a number of different types of menus, often in combination. Commonly encountered menu types include:
Single option menus, often used to request a confirmation of a response offered by a user.
Pop-up menus pop up or appear, often in the centre of the screen, and request a response or a selection.
Pull-down menus are often attached to a main menu across the top of the screen. When a user clicks on a menu option on the main menu bar, a further menu appears showing a number of options.
Step-down menus are a series of menus. So, for example, a user may click on an option on the main menu bar at the top of a screen to display a pull-down menu. Options on this menu that will lead to the display of further menus may be indicated, for example, with three dots e.g. Field…. Clicking on these options leads to a further menu. This is known as a step-down menu. These menus can be particularly helpful when there is a series of actions to perform, since they can remind the user of the sequence in which these actions must be completed.
Main menu bars appear at the top or bottom of the screen and remain on the screen while the user performs other functions and displays other menus. They may have pull-down menus attached as indicated above or may simply display some common menu options such as Help, Save, and Exit.
Full screen menus on the Web Some Web search environments use menus that occupy windows that cover much of the screen. Users need to proceed through these menus through a hierarchy, in a similar way to the way in which they might have interacted with full screen menus.
In most of the above uses of menus, the user is free to choose the order in which they issue commands. This requires that the user recognizes the order in which commands need to be executed and appreciates the effect of issuing a command.
Buttons and check boxes
Buttons and check boxes are similar in that you click on them to select an option or to choose a command.
There are two types of buttons, command buttons and option buttons. Command buttons allow you to choose a command, such as Save or Help. Command buttons appear as images of keys. Command buttons displayed with…, such as Set-up, will display a further dialog box when clicked. Option buttons are usually shown as small circles. When clicked and selected the circle is filled with a smaller filled-in circle.
Check boxes are shown as small boxes. When selected the box is filled with an X and clicking on the box turns the option on or off. Often a series of check boxes may be shown in a dialog box to allow the user to set a number of options or settings.
Icons
Icons are graphical representations of various elements in Windows, such as disc drives, applications, embedded and linked objects and documents. An icon can be chosen by double-licking on it. For example, the Main window in Windows shows the main applications that are included in Windows, such as File Manager, Control Panel, Print Manager, Clipboard Viewer, MS-DOS Prompt, Windows Set-up, PIF Editor, and Read Me. Group icons represent other groups of icons. Icons often cover a subset of the commands available through menus, and are a faster route to the issuing of instructions than menus.
Command languages
Command languages are one of the oldest and most widely used dialogue styles. In dialogues based on commands the user enters instructions in the form of commands. The computer recognizes these commands and takes appropriate action. For example, if the user types in PRINT 1-2, the computer responds with a prompt to indicate that the command has been carried out or a message stating why the command cannot be executed.
The command language must include commands for all of the functions that the user might choose to perform and, therefore, since different systems perform different functions, it is inevitable that command languages will differ between systems. Some attempts have been made to adopt standard command languages for systems that perform similar functions, and one result of this is the Common Command Language used by some of the online search services. However, standardization is difficult and an inherent feature of command-based dialogues is the need for users to become familiar with the command language used. An intermediate option that is widely used in GUIs, and is suitable for users with some familiarity with the system, is the use of commands in menus, so that the menus prompt users in their use of commands. This is not, however, effective for new users because they cannot be expected to know what the commands displayed on the menus mean. Commands are useful because they offer direct addressing of objects and functions by name, and the flexibility of system function which a combination of commands can provide. Command languages are preferred by many experienced searchers of online search services. In addition, Web search engines use a range of symbols, for example, to truncate search terms, and to specify adjacency searching (see Figure 11.6).
Voice-Based Dialogues
All of the dialogue styles considered so far are concerned with screen-based communication, with the aid of keyboards, mice, touch screens and similar devices. There are many circumstances in which a voice-based dialogue would be most convenient for the user, and this is another option for knowledge-based systems. Such dialogues would be attractive to the occasional user inputting only Yes’ and ‘no’ and other one-word answers, and also to the user inputting large quantities of textual data. Voice-based dialogues might be voice to voice (i.e. computer and person talk to each other), screen to voice (i.e. person talks, computer shows responses on screen), or voice to keyboard (i.e. computer talks, person operates keyboard).
With voice-to-voice dialogues communication may be remote from a workstation, through a telephone receiver and telecommunications link. All of these modes may have their applications, and the dialogue modes outlined above (e.g. menu, command, form filling) might be employed in a voice-based dialogue. Although there are some applications of such systems, they are limited and further development is to be expected.
Multimedia Interfaces
Multimedia interfaces present interesting challenges to the interface designer with regards to how best to incorporate sound, video, still graphics, text, numbers and animation. Multimedia interfaces can be viewed as having two components:
the navigational interface, which exhibits many of the characteristics of a GUI, such as buttons and windows.
the graphics elements that contribute to the appearance of the application, including backgrounds, textures, colours, the way that the type is displayed on the screen and how the stills, graphics and videos are displayed.
These components need to be integrated so that, for example, the complementary colours of the design may be used to match a still graphic, or the lighting of a sequence of video may be designed to match the look and feel of the rest of the presentation.
There are a number of unanswered questions concerning how people use multimedia interfaces. This may depend on the nature of the application for which the multimedia is being used; application areas embrace entertainment, marketing, information provision and education.
Web Interfaces
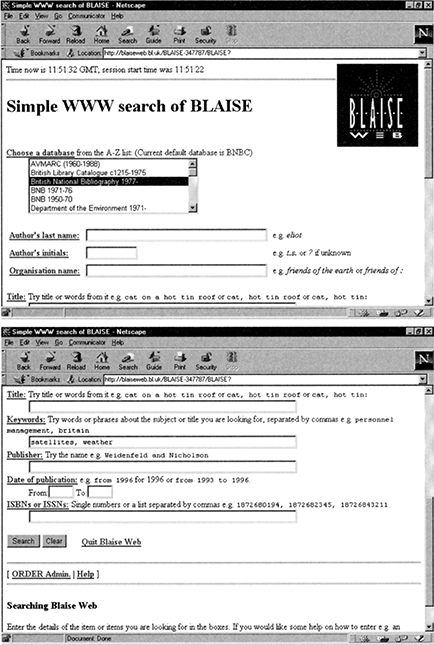
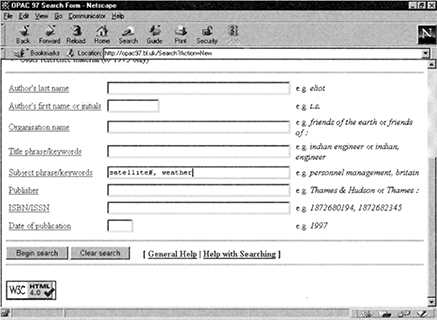
Figure 4.7 compares the Web-based interface and the GUI for access to a specific search service. This illustrates that most of the features that are available in Windows-based GUIs are also available in Web interfaces. Such interfaces, for example, feature form filling, check boxes, menu bars and icons. In addition, they feature hyperlinks, often displayed in a different colour (e.g. red in otherwise black text), which when clicked on allow the user to ‘link’ to other documents. Web screens look a little different from Windows GUI screens, since they are written in HTML. One feature that they do not have is direct manipulation, with associated features such as drag and drop.
Colour in Interface Design
Colour is widely used in today’s systems. Colour can be an effective mechanism for communicating alerts, drawing attention and defining relationships. In a number of database systems, colour is used to draw attention to specific parts of records. In general, colour can be used to:
draw attention to warnings
improve legibility and reduce eyestrain
highlight different parts of the screen display, such as status bars and menus
group elements in menus or status bars together so that, for instance, an instruction is associated with the number of its function key.
Nevertheless, colour must be used with care and with an understanding of how potential users see colour differences and obtain information from colours. Colour used inappropriately can be distracting, confusing or objectionable.
Z39.50 and SR
Z39.50 and SR are standards for information retrieval. Z39.50 is a national US protocol developed by the American National Standards Institute (ANSI), whilst SR or ISO 10162/3 Search and Retrieve is the international standard emanating from the International Standards Organisation. Z39.50 and SR are compatible, but Z39.50 is more frequently used because it has greater functionality.
Z39.50 is an application layer protocol which supports the construction of distributed information retrieval applications (the protocol which relates to data processing). The implementation of the Z39.50 standard allows users of different software products to communicate with each other and to exchange data. Most significantly, the local familiar interface can be made available for searching other remote databases. This means that, for instance, a user can search a remote OPAC mounted under a different library management system, through the interface available in their local library.
Z39.50 functions in a client-server environment. In this context the client is known as the origin and the server as the target. At the client end, a request from the user application is translated into Z39.50 by the origin and sent to the target. At the server end, the target translates the request into a form understandable by the database application, which processes the request, locates the required information and returns it to the target which, in turn, passes it back to the origin. The reciprocal translation process accommodates returning information.
Many, but not all systems suppliers offer Z39.50 clients and/or servers. Z39.50 is used in a number of library management systems, OCLC’s FirstSearch service, for document delivery and interlibrary loan, in the online search services offered by Mead Data Central, and Dialog, and SilverPlatter have embedded it in their Electronic Reference library. Also, while Z39.50 allows the use of a local search interface, this does not mean that all search facilities normally offered by that interface are available. Since the remote database application performs the search, the user is restricted to the facilities of that system. There are also some restrictions imposed by the protocol itself. For example, the protocol does not cover relevance ranking.
Summary
Since systems are designed to facilitate user access to information or knowledge, an important preliminary to systems design and creation is an understanding of the different kinds of users and the way in which users may wish to search or identify information. Users are often categorized on the basis of their level of experience with a given system; more experienced users generally need less support and more powerful applications than novice users. Cognitive models are also important in an appreciation of the way in which users understand and learn to use information systems. Indexing and searching are complementary processes. There are a number of different types of search strategies that may be adopted by different users. Search processes are also constrained by interface design. Most systems have GUIs and/or Web-based interfaces. GUIs use a combination of direct manipulation, windows, dialog boxes, menus, buttons and check boxes, icons, form filling, question and answer and command languages. Voice-based dialogues and multimedia interfeces are also important in some applications. Z39.50 and SR are important standards for information retrieval, which support the construction of distributed applications. Z39-50 allows the use of a local search interface when searching a remote database.
References and Further Reading
Allen, B. (1991) Cognitive research in information science: implications for design. In M. E. Williams (ed.), Annual Review of Information Science and Technology; 26, pp. 3–37. Medford, NJ: Learned Information.
Armstrong, C. J. and Large, J. A. (1999) Manual of Online Search Strategies, 3rd edn. Aldershot: Gower.
Barker, A. L. (1997) DataStar Web: Living up to the hype? An evaluation of the interface and search system. In Online Information 97: Proceedings of the 21st International Online Information Meeting, London, 9–11 December 1997, pp. 213–222. Oxford: Learned Information.
Bastien, J. M. C. and Scapin, D. L. (1995) Evaluating a user interface with ergonomic criteria. International Journal of Human Computer Interaction, 7 (2), 105–121.
Bennett, J. L. (1984) Managing to meet usability requirements. In J. L. Bennett, D. Case, J. Sandelin and M. Smith (eds), Visual Display Terminal: Usability Issues and Health Concerns. Englewood Cliffs, NJ: Prentice Hall.
Beaulieu, M. (1997) Experiments on interfaces to support query expansion. Journal of Documentation, 53 (1), 8–19.
Berkman, R. I. (1994) Find it Online. New York: Wondcrest/McGraw-Hill.
Booth, P. (1989) An introduction to human-computer interaction. Hove: Lawrence Erlbaum.
Borgman, C.L. (1996) Why are online catalogs still hard to use? Journal of the American Society for Information Science, 47 (7), 493–503.
Borgman, C. L., Hirsh, S. G., Walter, V. A. and Gallagher, A. L. (1995) Children’s searching behaviour on browsing and keyword online catalogs: the Science Library catalog projects. Journal of the American Society for Information Science, 46 (9), 663–684.
Bosch, V. M. and Hancock-Beaulieu, M. (1995) CDROM user interface evaluation: the appropriateness of GUFs. Online and CD-ROM review, 19 (5), 255–270.
Butcher, D. R. and Rowley, J. E. (1989) The Searcher/Information Interface Project 2: manual and on-line searching-pilot study. Journal of Information Science, 15, 109–114.
Dempsey, L. (1994) Distributed library and information systems: the significance of Z39,50. Managing Information, 1 (6), 41–42.
Dempsey, L., Russell, R. and Kirriemuir, J. (1996) Towards distributed library systems: Z39.50 in a European context. Program, 30 (1), 1–22.
Galitz, W. O. (1997) Essential Guide to User Interface Design: An Introduction to GUI Design: Principles and Techniques. New York: Wiley.
Head, A. J. (1997) A question of interface design: how do online service GUI’s measure up? Online, 21 (3), 20–29.
Hewitt, S. (1997) The future for mediated online search services in an academic institutions: a case study. Online and CD-ROM Review, 21 (5), 281–284.
Hsieh-Yee, I. (1993) Effects of search experience and subject knowledge on the search tactics of novice and experienced searchers. Journal of the American Society for Information Science, 44 (3), 161–174.
Jasco, P. (1995) WinSPIRS : Windows software for SilverPlatter CD-ROMs. Online, 19 (1), 74–81.
Kearsley, G. and Heller, R. S. (1995) Multimedia in public access settings: evaluation issues. Journal of Educational Multimedia and Hypermedia, 4 (1), 3–24.
Large, A. (1981) The user interface to CD-ROM databases. Journal of Librarianship and Information Science, 23 (4), 203–217.
Mandel, T. (1997) The Elements of User Interface Design. New York: Wiley.
Marchionini, G., Dwiggins, S., Katz, A. and Lin, X. (1993) Information seeking in full text end-user oriented search systems: the roles of domain and search expertise. Library and Information Science Research, 15 (1), 35–69.
McGraw, C. L. (1992) Designing and Evaluating User Interfaces for Knowledge Based Systems. New York and London: Ellis Horwood.
Mohan, L. and Bryne, J. (1995) Designing intuitive icons and toolbars. UNIX Review, 49–54.
Preece, J. (1994) Human-Computer Interaction, Woking.
Puttapithakporn, S. D. (1990) Interface design and user problems and errors: a case study of novice searchers. RQ, 30 (2), 195–204.
Quint, B. (1991) Inside a searcher’s mind: the seven stages of an online search - Part 1 Online, 15 (3), 13–18.
Rowley, J. E. (1995) Human-computer interface and design in Windows based CD-ROMs: an early review. Journal of Library and Information Science, 27 (2), 77–88.
Rowley, J. E. and Butcher, D. R. (1988) The Searcher Information Interface Project - final report. Journal of Information Science, 14, 355–363.
Rowley, J. E. and Slack, F. (1997) The evaluation of interface design on CD-ROMs. Online and CD-ROM Review, 21 (1), 3–14.
Rowley, J. E. and Slack, F. S. (1998) Public Access Interface Design. Aldershot: Gower.
Russell, R. (ed.) (1996) Z39.50 and SR. LITC Report No 7. London: LITC.
Saracevic, T., Kantor, P., Chamis, A. Y. and Trivison, D. (1988) A study of information seeking and retrieving. Journal of the American Society for Information Science, 39 (3) 161–196.
Shackel, B. (1990) Human computer interaction: whence and whither? Journal of the American Society for Information Science, 48 (11), 970–986.
Shaw, D. (1991) The human-computer interface for information retrieval. Annual Review of Information Science and Technology; 26, 155–195.
Shneiderman, B. (1992) Designing the User Interface: Strategies for Effective Human-Computer Interaction, 2nd edn. Reading: Addison-Wesley.
Shuman, B. A. (1993) Cases in Online Search Strategy. Englewood, CO: Libraries Unlimited.
Slack, F. E. (1991) OPACs: Using enhanced transaction logs to achieve more effective online help for subject searching. PhD thesis. Manchester Polytechnic (unpublished).
Stuart, R. (1996) The Design of Virtual Environments. New York: McGraw Hill.
Vaughan, T. (1994) Multi-Media; Making it Work, 2nd edn. Berkeley, CA and London: Osborne McGraw Hill.
Vickery, B. and Vickery, A. (1993) Online search interface design. Journal of Documentation, 49 (2), 103–187.
Wade, A. (1996) Training the end-user. Case study 1: Academic libraries. In R. Biddiscombe (ed.), The End-User Revolution: CD-ROM, Internet and The Changing Role of the Information Professional, pp. 96–109. London: Library Association.
Yee, M. M. (1991) System design and cataloguing meet the user: user interfaces to online public access catalogs. Journal of the American Society for Information Science, 42 (2), 78–98.
Yuan, W. (1997) End-user searching behaviour in information retrieval: a longitudinal study. Journal of the American Society for Information Science, 48 (3), 218–234.