Quick: which of the following would you expect to find in a “filesystem”?
• Processes
• Audio devices
• Kernel data structures and tuning parameters
• Interprocess communication channels
If the system is UNIX or Linux, the answer is “all of the above, and more!” And yes, you might find some files in there, too.1
The basic purpose of a filesystem is to represent and organize the system’s storage resources, but programmers have been eager to avoid reinventing the wheel when it comes to managing other types of objects. It has often proved convenient to map these objects into the filesystem namespace. This unification has some advantages (consistent programming interface, easy access from the shell) and some disadvantages (filesystem implementations akin to Frankenstein’s monster), but like it or not, this is the UNIX (and hence, the Linux) way.
The filesystem can be thought of as comprising four main components:
• A namespace – a way to name things and organize them in a hierarchy
• An API2 – a set of system calls for navigating and manipulating objects
• A security model – a scheme for protecting, hiding, and sharing things
• An implementation – software to tie the logical model to the hardware
Modern kernels define an abstract interface that accommodates many different back-end filesystems. Some portions of the file tree are handled by traditional disk-based implementations. Others are fielded by separate drivers within the kernel. For example, NFS and CIFS filesystems are handled by a driver that forwards the requested operations to a server on another computer.
NFS, the Network File System, is described in Chapter 18.
Unfortunately, the architectural boundaries are not clearly drawn, and quite a few special cases exist. For example, device files furnish a way for programs to communicate with drivers inside the kernel. They are not really data files, but they’re handled through the filesystem and their characteristics are stored on disk.
Another complicating factor is that the kernel supports more than one type of disk-based filesystem. In the modern best-of-breed category are the ext3 and ext4 filesystems that serve as many Linux distributions’ default, along with Sun’s ZFS, Veritas’s VxFS, ReiserFS, JFS from IBM, and the still-in-development Btrfs.
There are also many implementations of foreign filesystems, such as the FAT and NTFS filesystems used by Microsoft Windows and the ISO 9660 filesystem used on older CD-ROMs. (Linux supports more filesystem types than any other variant of UNIX. Its extensive menu of choices gives you lots of flexibility and makes it easy to share files with other systems.)
The filesystem is a rich topic that we approach from several different angles. This chapter tells where to find things on your system and describes the characteristics of files, the meanings of permission bits, and the use of some basic commands that view and set attributes. Chapter 8, Storage, is where you’ll find the more technical filesystem topics such as disk partitioning. Chapter 18, The Network File System, describes the file-sharing systems that are commonly used with Linux. You may also want to refer to Chapter 30, Cooperating with Windows, which discusses software you can use to share filesystems with computers running Windows.
With so many different filesystem implementations available, it may seem strange that this chapter reads as if there were only a single filesystem. We can be vague about the implementations because most modern filesystems either try to provide the traditional filesystem functionality in a faster and more reliable manner or they add extra features as a layer on top of the standard filesystem semantics. Some filesystems do both. For better or worse, too much existing software depends on the model described in this chapter for that model to be discarded.
The filesystem is presented as a single unified hierarchy that starts at the directory / and continues downward through an arbitrary number of subdirectories. / is also called the root directory. This single-hierarchy system differs from the one used by Windows, which retains the concept of partition-specific namespaces.
The list of directories that must be traversed to locate a particular file plus that file’s filename form a pathname. Pathnames can be either absolute (/tmp/foo) or relative (book4/filesystem). Relative pathnames are interpreted starting at the current directory. You might be accustomed to thinking of the current directory as a feature of the shell, but every process has one. (Most processes never change their working directory, so they simply inherit the current directory of the process that started them.)
The terms filename, pathname, and path are more or less interchangeable—or at least, we use them interchangeably in this book. Filename and path can be used for both absolute and relative paths; pathname usually suggests an absolute path.
The filesystem can be arbitrarily deep. However, each component of a pathname (that is, each directory) must have a name no more than 255 characters long. There’s also a limit on the path length you can pass into the kernel as a system call argument (4,095 bytes on Linux, 1,023 bytes on some older systems). To access a file with a pathname longer than this, you must cd to an intermediate directory and use a relative pathname.
The naming of files and directories is essentially unrestricted, except that names are limited in length and must not contain slash characters or nulls. In particular, spaces are permitted. Unfortunately, UNIX has a long tradition of separating command-line arguments at whitespace, so legacy software tends to break when spaces appear within filenames.
Spaces in filenames were once found primarily on filesystems shared with Macs and PCs, but they have now metastasized into UNIX culture and are found in some standard software packages as well. There are no two ways about it: administrative scripts must be prepared to deal with spaces in filenames (not to mention apostrophes, asterisks, and various other menacing punctuation marks).
In the shell and in scripts, spaceful filenames can be quoted to keep their pieces together. For example, the command
$ less "My excellent file.txt"
preserves My excellent file.txt as a single argument to less. You can also escape individual spaces with a backslash. The filename completion feature of the common shells (usually bound to the <Tab> key) does this for you.
When you are writing scripts, a useful weapon to know about is find’s -print0 option. In combination with xargs -0, this option makes the find/xargs combination work correctly regardless of the whitespace contained within filenames. For example, the command
$ find /home -type f -size +1M -print0 | xargs -0 ls -l
prints a long ls listing of every file in /home over one megabyte in size.
 Unfortunately, HP-UX supports find -print0 but not xargs -0, and AIX has neither option. However, you can install the GNU findutils package on either system to obtain current versions of both find and xargs. (Alternatively, you can use the -exec option to find instead of xargs, though it’s fussier and less efficient.)
Unfortunately, HP-UX supports find -print0 but not xargs -0, and AIX has neither option. However, you can install the GNU findutils package on either system to obtain current versions of both find and xargs. (Alternatively, you can use the -exec option to find instead of xargs, though it’s fussier and less efficient.)
The filesystem is composed of smaller chunks—also called filesystems—each of which consists of one directory and its subdirectories and files. It’s normally apparent from context which type of “filesystem” is being discussed, but for clarity in the following discussion, we use the term “file tree” to refer to the overall layout and reserve the word “filesystem” for the chunks attached to the tree.
Most filesystems are disk partitions or disk-based logical volumes, but as we mentioned earlier, they can be anything that obeys the proper API: network file servers, kernel components, memory-based disk emulators, etc. Linux and Solaris even have a nifty “loopback” filesystem that lets you mount individual files as if they were distinct devices. It’s great for developing filesystem images without having to worry about repartitioning your disks.
In most situations, filesystems are attached to the tree with the mount command.3 mount maps a directory within the existing file tree, called the mount point, to the root of the newly attached filesystem. The previous contents of the mount point become inaccessible as long as another filesystem is mounted there. Mount points are usually empty directories, however.
For example,
$ sudo mount /dev/sda4 /users
installs the filesystem stored on the disk partition represented by /dev/sda4 under the path /users. You could then use ls /users to see that filesystem’s contents.
A list of the filesystems that are customarily mounted on a particular system is kept in the /etc/fstab, /etc/vfstab (Solaris), or /etc/filesystems (AIX) file. The
information contained in this file allows filesystems to be checked (with fsck) and mounted (with mount) automatically at boot time. It also serves as documentation for the layout of the filesystems on disk and enables short commands such as mount /usr. See page 260 for a discussion of the fstab file and its brethren.
You detach filesystems with the umount command. umount complains if you try to unmount a filesystem that is in use; the filesystem to be detached must not have open files or processes whose current directories are located there, and if the file-system contains executable programs, they cannot be running.
 Linux has a “lazy” unmount option (umount -l) that removes a filesystem from the naming hierarchy but does not truly unmount it
until all existing file references have been closed. It’s debatable whether this is
a useful option. To begin with, there’s no guarantee that existing references will
ever close on their own. In addition, the “semi-unmounted” state can present inconsistent
filesystem semantics to the programs that are using it; they can read and write through
existing file handles but cannot open new files or perform other filesystem operations.
Linux has a “lazy” unmount option (umount -l) that removes a filesystem from the naming hierarchy but does not truly unmount it
until all existing file references have been closed. It’s debatable whether this is
a useful option. To begin with, there’s no guarantee that existing references will
ever close on their own. In addition, the “semi-unmounted” state can present inconsistent
filesystem semantics to the programs that are using it; they can read and write through
existing file handles but cannot open new files or perform other filesystem operations.
umount -f force-unmounts a busy filesystem and is supported on all our example systems. However, it’s almost always a bad idea to use it on non-NFS mounts, and it may not work on certain types of filesystems (e.g., those that keep journals, such as ext3 or ext4).
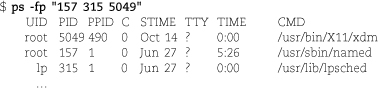
Instead of reaching for umount -f when a filesystem you’re trying to unmount turns out to be busy, run the fuser command to find out which processes hold references to that filesystem. fuser -c mountpoint prints the PID of every process that’s using a file or directory on that filesystem, plus a series of letter codes that show the nature of the activity. For example,

The exact letter codes vary from system to system.Table 6.1 summarizes the meanings of the codes, but the details are usually unimportant; the PIDs are what you want.

Table 6.1 Activity codes shown by fuser -c
To investigate the offending processes, just run ps with the list of PIDs returned by fuser. For example,
Here, the quotation marks force the shell to pass the list of PIDs to ps as a single argument.
On Linux systems, you can avoid the need to launder PIDs through ps by running fuser with the -v flag. This option produces a more readable display that includes the command name.

The letter codes in the ACCESS column are the same ones used in fuser’s nonver-bose output.
A more elaborate alternative to fuser is the lsof utility by Vic Abell. lsof is a more complex and sophisticated program than fuser, and its output is correspondingly verbose. lsof is available from people.freebsd.org/~abe and works on all of our example systems.
Under Linux, scripts in search of specific information about processes’ use of file-systems
can read the files in /proc directly. However, lsof -F, which formats lsof ’s output for easy parsing, is an easier and more portable solution. Use additional
command-line flags to request just the information you need.
Filesystems in the UNIX family have never been very well organized. Various incompatible naming conventions are used simultaneously, and different types of files are scattered randomly around the namespace. In many cases, files are divided by function and not by how likely they are to change, making it difficult to upgrade the operating system. The /etc directory, for example, contains some files that are never customized and some that are entirely local. How do you know which files to preserve during the upgrade? Well, you just have to know…
Despite several incremental improvements over the years (such as the designation of /var as a place to store system-specific data), UNIX and Linux systems are still pretty much a disorganized mess. Nevertheless, there’s a culturally correct place for everything. Most software can be installed with little reconfiguration if your system is set up in a standard way. If you try to improve upon the default structure, you are asking for trouble.
The root filesystem includes the root directory and a minimal set of files and subdirectories. The file that contains the OS kernel usually lives somewhere within the root filesystem, but it has no standard name or location; under Solaris, it is not really even a single file so much as a set of components.
See Chapter 13 for more information about configuring the kernel.
Also part of the root filesystem are /etc for critical system and configuration files, /sbin and /bin for important utilities, and sometimes /tmp for temporary files. /dev is usually a real directory that’s included in the root filesystem, but some or all of it may be overlaid with other filesystems if your system has virtualized its device support. (See page 419 for more information about this topic.)
Some systems keep shared library files and a few other odd things such as the C preprocessor in the /lib directory. Others have moved these items into /usr/lib, sometimes leaving /lib as a symbolic link.
The directories /usr and /var are also of great importance. /usr is where most standard programs are kept, along with various other booty such as on-line manuals and most libraries. It is not strictly necessary that /usr be a separate filesystem, but for convenience in administration it often is. Both /usr and /var must be available to enable the system to come up all the way to multiuser mode.
See page 231 for some reasons why partitioning might be desirable and some rules of thumb to guide it.
/var houses spool directories, log files, accounting information, and various other items that grow or change rapidly and that vary on each host. Since /var contains log files, which are apt to grow in times of trouble, it’s a good idea to put /var on its own filesystem if that is practical.
Home directories of users are often kept on a separate filesystem, usually one that’s mounted in the root directory. Dedicated filesystems can also be used to store bulky items such as source code libraries and databases.
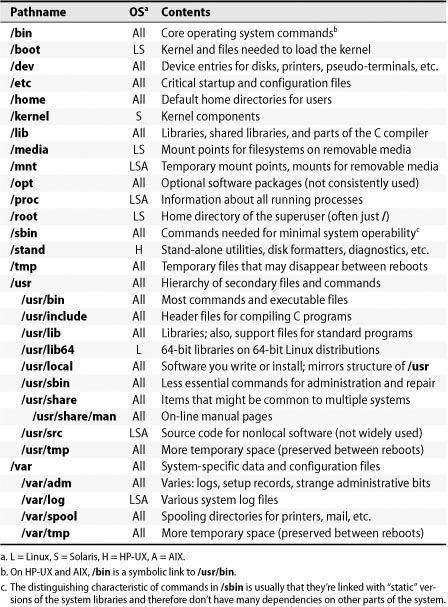
Some of the more important standard directories are listed in Table 6.2. (Alternate rows have been shaded to improve readability.)
On many systems, a hier man page (filesystem man page on Solaris) outlines some general guidelines for the layout of the filesystem. Don’t expect the actual system to conform to the master plan in every respect, however. The Wikipedia page for “UNIX directory structure” is a good general reference as well.
For Linux systems, the Filesystem Hierarchy Standard (pathname.com/fhs) attempts to codify, rationalize, and explain the standard directories. It’s an excellent
resource to consult when you’re trying to figure out where to put something.
We discuss some additional rules and suggestions for the design of local hierarchies on page 407.
Table 6.2 Standard directories and their contents
Most filesystem implementations define seven types of files. Even when developers add something new and wonderful to the file tree (such as the process information under /proc), it must still be made to look like one of these seven types.
• Directories
• Character device files
• Block device files
• Local domain sockets
• Named pipes (FIFOs)
• Symbolic links
You can determine the type of an existing file with ls -ld. The first character of the ls output encodes the type. For example, the following command demonstrates that /usr/include is a directory:

ls uses the codes shown in Table 6.3 to represent the various types of files.
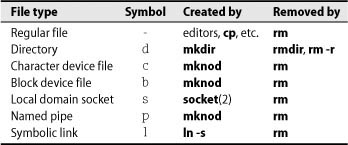
Table 6.3 File-type encoding used by ls
As Table 6.3 shows, rm is the universal tool for deleting files. But how would you delete a file named, say, -f? It’s a legitimate filename under most filesystems, but rm -f doesn’t work because rm interprets the -f as a flag. The answer is either to refer to the file by a longer pathname (such as ./-f) or to use rm’s -- argument to tell it that everything that follows is a filename and not an option (i.e., rm -- -f).
Filenames that contain control characters present a similar problem since reproducing these names from the keyboard can be difficult or impossible. In this situation, you can use shell globbing (pattern matching) to identify the files to delete. When you use pattern matching, it’s a good idea to get in the habit of using the -i option to rm to make rm confirm the deletion of each file. This feature protects you against deleting any “good” files that your pattern inadvertently matches. For example, to delete a file named foo<Control-D>bar, you could use
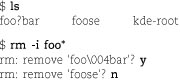
Note that ls shows the control character as a question mark, which can be a bit deceptive.4 If you don’t remember that ? is a shell pattern-matching character and try to rm foo?bar, you might potentially remove more than one file (although not in this example). -i is your friend!
To delete the most horribly named files, you may need to resort to rm -i *.
Another option for removing files with squirrely names is to use an alternative interface to the filesystem such as emacs’s dired mode or a visual tool such as Nautilus.
Regular files consist of a series of bytes; filesystems impose no structure on their contents. Text files, data files, executable programs, and shared libraries are all stored as regular files. Both sequential access and random access are allowed.
A directory contains named references to other files. You can create directories with mkdir and delete them with rmdir if they are empty. You can delete nonempty directories with rm -r.
The special entries “.” and “..” refer to the directory itself and to its parent directory; they may not be removed. Since the root directory has no parent directory, the path “/..” is equivalent to the path “/.” (and both are equivalent to /).
A file’s name is stored within its parent directory, not with the file itself. In fact, more than one directory (or more than one entry in a single directory) can refer to a file at one time, and the references can have different names. Such an arrangement creates the illusion that a file exists in more than one place at the same time.
These additional references (“links,” or “hard links” to distinguish them from symbolic links, discussed below) are synonymous with the original file; as far as the filesystem is concerned, all links to the file are equivalent. The filesystem maintains a count of the number of links that point to each file and does not release the file’s data blocks until its last link has been deleted. Hard links cannot cross filesystem boundaries.
You create hard links with ln and remove them with rm. It’s easy to remember the syntax of ln if you keep in mind that it mirrors the syntax of cp. The command cp oldfile newfile creates a copy of oldfile called newfile, and ln oldfile newfile makes the name newfile an additional reference to oldfile. You can make hard links to directories as well as to flat files, but that’s less commonly done.
You can use ls -l to see how many links to a given file exist. See the ls example output on page 154 for some additional detail.
Hard links are not a distinct type of file. Instead of defining a separate “thing” called a hard link, the filesystem simply allows more than one directory entry to point to the same file. In addition to the file’s contents, the underlying attributes of the file (such as ownerships and permissions) are also shared.
Device files let programs communicate with the system’s hardware and peripherals. The kernel includes (or loads) driver software for each of the system’s devices. This software takes care of the messy details of managing each device so that the kernel proper can remain relatively abstract and hardware independent.
See Chapter 13 for more information about devices and drivers.
Device drivers present a standard communication interface that looks like a regular file. When the filesystem is given a request that refers to a character or block device file, it simply passes the request to the appropriate device driver. It’s important to distinguish device files from device drivers, however. The files are just rendezvous points that communicate with drivers. They are not drivers themselves.
Character device files allow their associated drivers to do their own input and output buffering. Block device files are used by drivers that handle I/O in large chunks and want the kernel to perform buffering for them. In the past, a few types of hardware were represented by both block and character device files, but that configuration is unusual today.
Device files are characterized by two numbers, called the major and minor device numbers. The major device number tells the kernel which driver the file refers to, and the minor device number typically tells the driver which physical unit to address. For example, major device number 4 on a Linux system indicates the serial driver. The first serial port (/dev/tty0) would have major device number 4 and minor device number 0.
Drivers can interpret the minor device numbers that are passed to them in whatever way they please. For example, tape drivers use the minor device number to determine whether the tape should be rewound when the device file is closed.
In the distant past, /dev was a generic directory and the device files within it were created with mknod and removed with rm. A script called MAKEDEV helped standardize the work of creating device files for common pieces of equipment.
Unfortunately, this crude system was ill-equipped to deal with the endless sea of drivers and device types that have appeared over the last few decades. It also facilitated all sorts of potential configuration mismatches: device files that referred to no actual device, devices inaccessible because they had no device files, and so on.
These days, most systems implement some form of automatic device file management that lets the system take a more active role in the configuration of its own device files. In Solaris, for example, the /dev and /devices directories are fully virtualized. On Linux distributions, /dev is a standard directory, but the udevd daemon manages the files within it. (udevd creates and deletes device files in response to hardware changes reported by the kernel.) See Chapter 13, Drivers and the Kernel, for more information about each system’s approach to this task.
Sockets are connections between processes that allow processes to communicate hygienically. UNIX defines several kinds of sockets, most of which involve the use of a network. Local domain sockets are accessible only from the local host and are referred to through a filesystem object rather than a network port. They are sometimes known as “UNIX domain sockets.”
Although socket files are visible to other processes as directory entries, they cannot be read from or written to by processes not involved in the connection. Syslog and the X Window System are examples of standard facilities that use local domain sockets.
See Chapter 11 for more information about syslog.
Local domain sockets are created with the socket system call and removed with the rm command or the unlink system call once they have no more users.
Like local domain sockets, named pipes allow communication between two processes running on the same host. They’re also known as “FIFO files” (FIFO is short for the phrase “first in, first out”). You can create named pipes with mknod and remove them with rm.
As with local domain sockets, real-world instances of named pipes are few and far between. They rarely require administrative intervention.5
Named pipes and local domain sockets serve similar purposes, and the fact that both exist is essentially a historical artifact. Neither of them would exist if UNIX and Linux were designed today; network sockets would stand in for both.
A symbolic or “soft” link points to a file by name. When the kernel comes upon a symbolic link in the course of looking up a pathname, it redirects its attention to the pathname stored as the contents of the link. The difference between hard links and symbolic links is that a hard link is a direct reference, whereas a symbolic link is a reference by name. Symbolic links are distinct from the files they point to.
You create symbolic links with ln -s and remove them with rm. Since symbolic links can contain arbitrary paths, they can refer to files on other filesystems or to nonexistent files. Multiple symbolic links can also form a loop.
A symbolic link can contain either an absolute or a relative path. For example,
$ sudo ln -s archived/secure /var/log/secure
links /var/log/secure to /var/log/archived/secure with a relative path. It creates the symbolic link /var/log/secure with a target of “archived/secure”, as demonstrated by this output from ls:

The entire /var/log directory could then be moved elsewhere without causing the symbolic link to stop working (not that moving this directory is advisable).
It is a common mistake to think that the first argument to ln -s is interpreted relative to your current working directory. However, it is not resolved as a filename by ln; it’s simply a literal string that becomes the target of the symbolic link.
Under the traditional UNIX and Linux filesystem model, every file has a set of nine permission bits that control who can read, write, and execute the contents of the file. Together with three other bits that primarily affect the operation of executable programs, these bits constitute the file’s “mode.”
The twelve mode bits are stored together with four bits of file-type information. The four file-type bits are set when the file is first created and cannot be changed, but the file’s owner and the superuser can modify the twelve mode bits with the chmod (change mode) command. Use ls -l (or ls -ld for a directory) to inspect the values of these bits. An example is given on page 154.
Nine permission bits determine what operations may be performed on a file and by whom. Traditional UNIX does not allow permissions to be set per-user (although all systems now support access control lists of one sort or another; see page 159). Instead, three sets of permissions define access for the owner of the file, the group owners of the file, and everyone else (in that order).7 Each set has three bits: a read bit, a write bit, and an execute bit (also in that order).
It’s convenient to discuss file permissions in terms of octal (base 8) numbers because each digit of an octal number represents three bits and each group of permission bits consists of three bits. The topmost three bits (with octal values of 400, 200, and 100) control access for the owner. The second three (40, 20, and 10) control access for the group. The last three (4, 2, and 1) control access for everyone else (“the world”). In each triplet, the high bit is the read bit, the middle bit is the write bit, and the low bit is the execute bit.
Each user fits into only one of the three permission sets. The permissions used are those that are most specific. For example, the owner of a file always has access determined by the owner permission bits and never the group permission bits. It is possible for the “other” and “group” categories to have more access than the owner, although this configuration would be highly unusual.
On a regular file, the read bit allows the file to be opened and read. The write bit allows the contents of the file to be modified or truncated; however, the ability to delete or rename (or delete and then recreate!) the file is controlled by the permissions on its parent directory because that is where the name-to-dataspace mapping is actually stored.
The execute bit allows the file to be executed. Two types of executable files exist: binaries, which the CPU runs directly, and scripts, which must be interpreted by a shell or some other program. By convention, scripts begin with a line similar to
#!/usr/bin/perl
that specifies an appropriate interpreter. Nonbinary executable files that do not specify an interpreter are assumed to be bash or sh scripts.8
For a directory, the execute bit (often called the “search” or “scan” bit in this context) allows the directory to be entered or passed through while a pathname is evaluated, but not to have its contents listed. The combination of read and execute bits allows the contents of the directory to be listed. The combination of write and execute bits allows files to be created, deleted, and renamed within the directory.
A variety of extensions such as access control lists (see page 159), SELinux (see page 923), and “bonus” permission bits defined by individual filesystems (see page 158) complicate or override the traditional nine-bit permission model. If you’re having trouble explaining the system’s observed behavior, check to see whether one of these factors might be interfering.
The bits with octal values 4000 and 2000 are the setuid and setgid bits. When set on executable files, these bits allow programs to access files and processes that would otherwise be off-limits to the user that runs them. The setuid/setgid mechanism for executables is described on page 105.
When set on a directory, the setgid bit causes newly created files within the directory to take on the group ownership of the directory rather than the default group of the user that created the file. This convention makes it easier to share a directory of files among several users, as long as they belong to a common group. This interpretation of the setgid bit is unrelated to its meaning when set on an executable file, but no ambiguity can exist as to which meaning is appropriate.
On some systems, you can also set the setgid bit on nonexecutable plain files to request special locking behavior when the file is opened. However, we are not aware of any common cases in which this feature is used.
The bit with octal value 1000 is called the sticky bit. It was of historical importance as a modifier for executable files on early UNIX systems. However, that meaning of the sticky bit is now obsolete and modern systems silently ignore it.
If the sticky bit is set on a directory, the filesystem won’t allow you to delete or rename a file unless you are the owner of the directory, the owner of the file, or the superuser. Having write permission on the directory is not enough. This convention helps make directories like /tmp a little more private and secure.
 Solaris and HP-UX are slightly less stringent in their handling of sticky directories:
you can delete a file in a sticky directory if you have write permission on it, even
if you aren’t the owner. This actually makes a lot of sense, though it makes little
practical difference.
Solaris and HP-UX are slightly less stringent in their handling of sticky directories:
you can delete a file in a sticky directory if you have write permission on it, even
if you aren’t the owner. This actually makes a lot of sense, though it makes little
practical difference.
The filesystem maintains about forty separate pieces of information for each file, but most of them are useful only to the filesystem itself. As a system administrator, you will be concerned mostly with the link count, owner, group, mode, size, last access time, last modification time, and type. You can inspect all of these with ls -l (or ls -ld for a directory; without the -d flag, ls lists the directory’s contents).
An attribute change time is also maintained for each file. The conventional name for this time (the “ctime,” short for “change time”) leads some people to believe that it is the file’s creation time. Unfortunately, it is not; it just records the time that the attributes of the file (owner, mode, etc.) were last changed (as opposed to the time at which the file’s contents were modified).
Consider the following example:
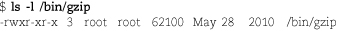
The first field specifies the file’s type and mode. The first character is a dash, so the file is a regular file. (See Table 6.3 on page 148 for other codes.)
The next nine characters in this field are the three sets of permission bits. The
order is owner-group-other, and the order of bits within each set is read-write-execute.
Although these bits have only binary values, ls shows them symbolically with the letters r, w, and x for read, write, and execute. In this case, the owner has all permissions on the
file and everyone else has read and execute permission.
If the setuid bit had been set, the x representing the owner’s execute permission would have been replaced with an s, and if the setgid bit had been set, the x for the group would also have been replaced with an s. The last character of the permissions (execute permission for “other”) is shown
as t if the sticky bit of the file is turned on. If either the setuid/setgid bit or the
sticky bit is set but the corresponding execute bit is not, these bits appear as S or T.
The next field in the listing is the file’s link count. In this case it is 3, indicating that /bin/gzip is just one of three names for this file (the others are /bin/gunzip and /bin/zcat). Each time a hard link is made to a file, the file’s link count is incremented by 1. Symbolic links do not affect the link count.
All directories have at least two hard links: the link from the parent directory and the link from the special file “.” inside the directory itself.
The next two fields in the ls output are the owner and group owner of the file. In this example, the file’s owner is root, and the file also belongs to the group named root. The filesystem actually stores these as the user and group ID numbers rather than as names. If the text versions (names) can’t be determined, ls shows the fields as numbers. This might happen if the user or group that owns the file has been deleted from the /etc/passwd or /etc/group file. It could also indicate a problem with your NIS or LDAP database (if you use one); see Chapter 19.
The next field is the size of the file in bytes. This file is 62,100 bytes long. Next comes the date of last modification: May 28, 2010. The last field in the listing is the name of the file, /bin/gzip.
ls output is slightly different for a device file. For example:
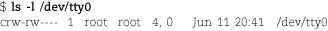
Most fields are the same, but instead of a size in bytes, ls shows the major and minor device numbers. /dev/tty0 is the first virtual console on this (Red Hat) system and is controlled by device driver 4 (the terminal driver).
One ls option that’s useful for scoping out hard links is -i, which makes ls show each file’s “inode number.” Without going into too much detail about filesystem implementations, we’ll just say that the inode number is an index into a table that enumerates all the files in the filesystem. Inodes are the “things” that are pointed to by directory entries; entries that are hard links to the same file have the same inode number. To figure out a complex web of links, you need both ls -li to show link counts and inode numbers and find to search for matches.9
Some other ls options that are important to know are -a to show all entries in a directory (even files whose names start with a dot), -t to sort files by modification time (or -tr to sort in reverse chronological order), -F to show the names of files in a way that distinguishes directories and executable
files, -R to list recursively, and -h to show file sizes in human-readable form (e.g., 8K or 53M).
The chmod command changes the permissions on a file. Only the owner of the file and the superuser can change its permissions. To use the command on early UNIX systems, you had to learn a bit of octal notation, but current versions accept both octal notation and a mnemonic syntax. The octal syntax is generally more convenient for administrators, but it can only be used to specify an absolute value for the permission bits. The mnemonic syntax can modify some bits while leaving others alone.
The first argument to chmod is a specification of the permissions to be assigned, and the second and subsequent arguments are names of files on which permissions should be changed. In the octal case, the first octal digit of the specification is for the owner, the second is for the group, and the third is for everyone else. If you want to turn on the setuid, setgid, or sticky bits, you use four octal digits rather than three, with the three special bits forming the first digit.
Table 6.4 illustrates the eight possible combinations for each set of three bits, where r, w, and x stand for read, write, and execute.
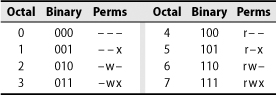
Table 6.4 Permission encoding for chmod
For example, chmod 711 myprog gives all permissions to the owner and execute-only permission to everyone else.10
For the mnemonic syntax, you combine a set of targets (u, g, or o for user, group, other) with an operator (+, -, = to add, remove, or set) and a set of permissions. The chmod man page gives the details, but the syntax is probably best learned by example.Table 6.5 exemplifies some mnemonic operations.
The hard part about using the mnemonic syntax is remembering whether o stands for “owner” or “other”; “other” is correct. Just remember u and g by analogy to UID and GID; only one possibility is left.
 On Linux and OpenSolaris systems, you can also specify the modes to be assigned by
copying them from an existing file. For example, chmod --reference=filea fileb makes fileb’s mode the same as filea’s.
On Linux and OpenSolaris systems, you can also specify the modes to be assigned by
copying them from an existing file. For example, chmod --reference=filea fileb makes fileb’s mode the same as filea’s.
Table 6.5 Examples of chmod’s mnemonic syntax
With the -R option, chmod recursively updates the file permissions within a directory. However, this feat is trickier than it looks because the enclosed files and directories may not share the same attributes; for example, some might be executable files while others are text files. Mnemonic syntax is particularly useful with -R because it preserves bits whose values you don’t set explicitly. For example,
$ chmod -R g+w mydir
adds group write permission to mydir and all its contents without messing up the execute bits of directories and programs.
If you want to adjust execute bits, be wary of chmod -R. It’s blind to the fact that the execute bit has a different interpretation on a directory than it does on a flat file. Therefore, chmod -R a-x probably won’t do what you intend.
The chown command changes a file’s ownership, and the chgrp command changes its group ownership. The syntax of chown and chgrp mirrors that of chmod, except that the first argument is the new owner or group, respectively.
To change a file’s group, you must either be the owner of the file and belong to the group you’re changing to or be the superuser. The rules for changing ownership are more complex and vary among systems. Most systems define some sort of process-specific capability that fine-tunes the behavior of chown.
Like chmod, chown and chgrp offer the recursive -R flag to change the settings of a directory and all the files underneath it. For example, the sequence

could be used to reset the owner and group of files restored from a backup for the user matt. If you’re setting up a user’s home directory, don’t try to chown dot files with a command such as
$ sudo chown -R matt ~matt/.*
since the pattern will matcĥmatt/.. and will therefore end up changing the ownerships of the parent directory and probably the home directories of other users.
chown can change both the owner and group of a file at once with the syntax
chown user:group file …
For example,
$ sudo chown -R matt:staff ~matt/restore
Linux and Solaris take this syntax to its logical end and let you omit either user or group, thus making the chgrp command superfluous. If you include the colon but no group, chown uses the user’s default group.
You can use the built-in shell command umask to influence the default permissions given to the files you create. Every process has its own umask attribute; the shell’s built-in umask command sets the shell’s own umask, which is then inherited by commands that you run.
The umask is specified as a three-digit octal value that represents the permissions to take away. When a file is created, its permissions are set to whatever the creating program requests minus whatever the umask forbids. Thus, the individual digits of the umask allow the permissions shown in Table 6.6.
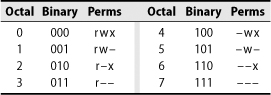
Table 6.6 Permission encoding for umask
For example, umask 027 allows all permissions for the owner but forbids write permission to the group and allows no permissions for anyone else. The default umask value is often 022, which denies write permission to the group and world but allows read permission.
You cannot force users to have a particular umask value because they can always reset it to whatever they want. However, you can put a suitable default in the sample .profile file that you give to new users.
See Chapter 7 for more information about startup files.
Linux’s ext2, ext3, and ext4 filesystems define some supplemental attributes you can turn on to request special semantics—“request” being the operative word, since many of the flags haven’t actually been implemented. For example, one flag makes a file append-only and another makes it immutable and undeletable.
Since these flags don’t apply to filesystems other than the ext* series, Linux uses special commands, lsattr and chattr, to view and change them.Table 6.7 lists the flags that currently work (about 50% of those mentioned in the man page).

Table 6.7 Ext2 and ext3 bonus flags
With the possible exception of the “no backup” flag, it’s not clear that any of these features offer much day-to-day value. The immutable and append-only flags were largely conceived as ways to make the system more resistant to tampering by hackers or hostile code. Unfortunately, they can confuse software and protect only against hackers that don’t know enough to use chattr -ia. Real-world experience has shown that these flags are more often used by hackers than against them.
The S and D options for synchronous writes also merit a special caution. Since they force all filesystem pages associated with a file or directory to be written out immediately on changes, they might seem to offer additional protection against data loss in the event of a crash. However, the order of operations for synchronous updates is unusual and has been known to confuse fsck; recovery of a damaged filesystem might therefore be made more difficult rather than more reliable. File-system journaling, as supported by ext3 and ext4, is usually a better option. The j option can force data journaling for specific files, albeit at some performance cost.
The traditional 9-bit owner/group/other access control system is powerful enough to accommodate most administrative needs. Although the system has clear limitations, it’s very much in keeping with the UNIX traditions (some might say, “former traditions”) of simplicity and predictability.
Virtually all non-UNIX operating systems use a more complicated way of regulating access to files: access control lists, aka ACLs. Each file or directory can have an associated ACL that lists the permission rules to be applied to it. Each of the rules within an ACL is called an access control entry, or ACE.
In general, an access control entry identifies the user or group to which it applies and specifies a set of permissions to be applied to those users. ACLs have no set length and can include permission specifications for multiple users or groups. Most OSes limit the length of an individual ACL, but the limit is high enough (usually at least 32 entries) that it rarely comes into play.
The more sophisticated ACL systems let administrators specify partial sets of permissions or negative permissions; some also have inheritance features that allow access specifications to propagate to newly created filesystem entities.
ACL systems are more powerful than the traditional UNIX model, but they are also an order of magnitude more complex, both for administrators and for software developers. Use them only with a degree of trepidation. Not only are ACLs complicated and tiresome to use, but they can also cause problematic interactions with ACL-unaware backup systems, network file service peers, and even simple programs such as text editors.
ACLs are entropy magnets. Over time, they tend to become increasingly complex and unmaintainable.
The next few sections describe the various ACL systems supported by UNIX and Linux and the multiple sets of commands that manipulate them. Before we dive into those details, however, we should answer the underlying question those details are sure to provoke: “How did this ACL stuff get to be such a train wreck?”
As usual, the culprit is a tortured history of politics, money, and code forks. In this case, a basic understanding of the history helps impose some structure on the current reality.
A POSIX subcommittee first started work on an ACL facility for UNIX in the mid-1990s. To a first approximation, the POSIX ACL model simply extended the traditional UNIX rwx permission system to accommodate permissions for multiple groups and users.
Unfortunately, the POSIX draft never became a formal standard, and the working group was defunded in 1998. Several vendors implemented POSIX ACLs anyway. Other vendors created their own ACL systems. Since there was no clear leader, every implementation looked different.
Meanwhile, it became increasingly common for UNIX and Linux systems to share filesystems with Windows, which has its own ACL conventions. Here the plot thickens, because Windows makes a variety of distinctions that are not found in either the traditional UNIX model or its POSIX ACL equivalent. Windows ACLs are semantically more complex, too; for example, they allow negative permissions (“deny” entries) and have a complicated inheritance scheme.
The architects of version 4 of the NFS protocol—the standard file-sharing protocol used by UNIX—wanted to incorporate ACLs as a first-class entity. Because of the UNIX/Windows split and the inconsistencies among UNIX ACL implementations, it was clear that the systems on the ends of an NFSv4 connection might often be of different types. Each system might understand NFSv4 ACLs, POSIX ACLs, Windows ACLs, or no ACLs at all. The NFSv4 standard would have to be interoperable with these various worlds without causing too many surprises or security problems.
See Chapter 18 for more information about NFS.
Given this constraint, it’s perhaps not surprising that NFSv4 ACLs are essentially a union of all preexisting systems. They are a strict superset of POSIX ACLs, so any POSIX ACL can be represented as an NFSv4 ACL without loss of information. At the same time, NFSv4 ACLs accommodate all the permission bits found on Windows systems, and they have most of Windows’ semantic features as well.
In theory, responsibility for maintaining and enforcing ACLs could be turned over to several different components of the operating system. ACLs could be implemented by the kernel on behalf of all the system’s filesystems, by individual filesystems, or perhaps by higher-level software such as NFS and CIFS servers.
In practice, only filesystems can implement ACLs cleanly, reliably, and with acceptable performance. Hence, ACL support is both OS dependent and filesystem dependent. A filesystem that supports ACLs on one system may not support them on another, or it may feature a somewhat different implementation managed by different commands.
The standard UNIX system calls that manipulate files (open, read, unlink, and so on) make no provision for ACLs. However, they continue to work just fine on systems that have ACLs because the underlying filesystems do their own permission checking. Operations that are not allowed by the relevant ACL simply fail and return a generic “permission denied” error code.
ACL-aware programs use a separate system call or library routine to read or set files’ ACLs. When an operating system first adds support for ACLs, it usually upgrades common utilities such as ls and cp to be at least minimally ACL-aware (for example, by making cp -p preserve ACLs if they are present). In addition, the system must add new commands or command extensions to let users read and set ACLs from the command line. Unfortunately, these commands are not standardized among operating systems, either.
Because ACL implementations are filesystem specific and because systems support multiple filesystem implementations, many systems end up supporting multiple types of ACLs. Even a given filesystem may offer several ACL options, as in IBM’s JFS2. If multiple ACL systems are available, the commands to manipulate them might be the same or different; it depends on the system.
In general, ACL support under UNIX and Linux is currently something of an ad hoc mess. Here are some particulars:
• As of this writing (2010), POSIX-based ACL systems have the lead in implementation and deployment, but NFSv4 ACLs are rapidly gaining ground and will likely become the de facto standard. Currently, only Sun’s ZFS and IBM’s JFS2 have native support for NFS4v4 ACLs.
• Under Linux, POSIX-style ACLs are supported by ReiserFS, XFS, JFS, Btrfs, and the
ext* family of filesystems. They are usually disabled by default; use the -o acl option to mount to turn them on. The getfacl and setfacl commands read and manipulate POSIX ACL entries.
 • Solaris supports POSIX ACLs on the older UFS filesystem and NFSv4 ACLs on ZFS.
The Solaris versions of ls and chmod have been modified to display and edit both types of ACLs.11 Solaris has setfacl and getfacl commands that are vaguely similar to those found on Linux distributions, but they’re
really just there for compatibility and work only for POSIX ACLs.
• Solaris supports POSIX ACLs on the older UFS filesystem and NFSv4 ACLs on ZFS.
The Solaris versions of ls and chmod have been modified to display and edit both types of ACLs.11 Solaris has setfacl and getfacl commands that are vaguely similar to those found on Linux distributions, but they’re
really just there for compatibility and work only for POSIX ACLs.
 • HP-UX designed its own ACL system for its High-performance File System (HFS). When
HP adopted Veritas’s VxFS as its primary filesystem, it also incorporated support
for POSIX-style ACLs.12 Unfortunately, the two ACL systems are controlled by different sets of commands.
HFS is now deprecated, but the HFS ACL commands remain behind for compatibility. We
do not discuss the HFS ACLs in this book.
• HP-UX designed its own ACL system for its High-performance File System (HFS). When
HP adopted Veritas’s VxFS as its primary filesystem, it also incorporated support
for POSIX-style ACLs.12 Unfortunately, the two ACL systems are controlled by different sets of commands.
HFS is now deprecated, but the HFS ACL commands remain behind for compatibility. We
do not discuss the HFS ACLs in this book.
 • AIX’s JFS2 filesystem supports a proprietary ACL system known as AIXC. As of AIX
5.3.0, JFS2 also supports NFSv4-style ACLs. AIX uses the same commands (aclget, aclput, and acledit) to manipulate both types of ACLs, and it provides an aclconvert utility to facilitate migration from one format to another. We do not discuss AIXC
in this book.
• AIX’s JFS2 filesystem supports a proprietary ACL system known as AIXC. As of AIX
5.3.0, JFS2 also supports NFSv4-style ACLs. AIX uses the same commands (aclget, aclput, and acledit) to manipulate both types of ACLs, and it provides an aclconvert utility to facilitate migration from one format to another. We do not discuss AIXC
in this book.
POSIX ACLs are supported on many Linux filesystems and on HP-UX’s VxFS filesystem port (known as JFS). They are also available under Solaris for the deprecated UFS filesystem only.
POSIX ACLs are a mostly straightforward extension of the standard 9-bit UNIX permission model. Read, write, and execute permission are the only capabilities that the ACL system deals with. Embellishments such as the setuid and sticky bits are handled exclusively through the traditional mode bits.
ACLs allow the rwx bits to be set independently for any combination of users and groups.Table 6.8 shows what the individual entries in an ACL can look like.

Table 6.8 Entries that can appear in an access control list
Users and groups can be identified by name or by UID/GID. The exact number of entries that an ACL can contain varies with the filesystem implementation and ranges from a low of 25 with XFS to a virtually unlimited number with ReiserFS and JFS. The ext* filesystems allow 32 entries, which is probably a reasonable limit for manageability in any case.
Files with ACLs retain their original mode bits, but consistency is automatically enforced and the two sets of permissions can never conflict. The following example (which uses the Linux command syntax) demonstrates that the ACL entries update automatically in response to changes made with old-style chmod:

This enforced consistency allows older software with no awareness of ACLs to play reasonably well in the ACL world. However, there’s a twist. Even though the group:: ACL entry in the example above appears to be tracking the middle set of traditional mode bits, that will not always be the case.
To understand why, suppose that a legacy program clears the write bits within all three permission sets of the traditional mode (e.g., chmod ugo-w file). The intention is clearly to make the file unwritable by anyone. But what if the resulting ACL were to look like this?
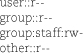
From the perspective of legacy programs, the file appears to be unmodifiable, yet it is actually writable by anyone in group staff. Not good. To reduce the chance of ambiguity and misunderstandings, the following rules are enforced:
• The user:: and other:: ACL entries are by definition identical to the “owner” and “other” permission bits from the traditional mode. Changing the mode changes the corresponding ACL entries, and vice versa.
• In all cases, the effective access permission afforded to the file’s owner and to users not mentioned in another way are those specified in the user:: and other:: ACL entries, respectively.
• If a file has no explicitly defined ACL or has an ACL that consists only of one user::, one group::, and one other:: entry, these ACL entries are identical to the three sets of traditional permission bits. This is the case illustrated in the getfacl example above. (Such an ACL is termed “minimal” and need not actually be implemented as a logically separate ACL.)
• In more complex ACLs, the traditional group permission bits correspond to a special ACL entry called mask rather than the group:: ACL entry. The mask limits the access that the ACL can confer upon all named users, all named groups, and the default group.
In other words, the mask specifies an upper bound on the access that the ACL can assign to individual groups and users. It is conceptually similar to the umask, except that the ACL mask is always in effect and specifies the allowed permissions rather than the permissions to be denied. ACL entries for named users, named groups, and the default group can include permission bits that are not present in the mask, but the kernel simply ignores them.
As a result, the traditional mode bits can never understate the access allowed by the ACL as a whole. Furthermore, clearing a bit from the group portion of the traditional mode clears the corresponding bit in the ACL mask and thereby forbids this permission to everyone but the file’s owner and those who fall in the category of “other.”
When the ACL shown in the previous example is expanded to include entries for a specific user and group, setfacl automatically supplies an appropriate mask:

As seen here, the Linux version of setfacl generates a mask that allows all the permissions granted in the ACL to take effect. If you want to set the mask by hand, include it in the ACL entry list given to setfacl or use the -n option to prevent setfacl from regenerating it. (The Solaris setfacl defaults to not recalculating the mask entry; use the -r flag to regenerate it.)
Note that after the setfacl command, ls -l shows a + sign at the end of the file’s mode to indicate that it now has a real ACL associated with it. The first ls -l shows no + because at that point the ACL is “minimal.” That is, it is entirely described by the 9-bit mode and so does not need to be stored separately.
If you use the traditional chmod command to manipulate the group permissions on an ACL-bearing file, be aware that your changes affect only the mask. To continue the previous example:

The ls output in this case is misleading. Despite the apparently generous group permissions, no one actually has permission to execute the file by reason of group membership. To grant such permission, you must edit the ACL itself.
When a process attempts to access a file, its effective UID is compared to the UID that owns the file. If they are the same, access is determined by the ACL’s user:: permissions. Otherwise, if a matching user-specific ACL entry exists, permissions are determined by that entry in combination with the ACL mask.
If no user-specific entry is available, the filesystem tries to locate a valid group-related entry that provides the requested access; these entries are processed in conjunction with the ACL mask. If no matching entry can be found, the other:: entry prevails.
In addition to the ACL entry types listed in Table 6.8, the ACLs for directories can include default entries that are propagated to the ACLs of newly created files and subdirectories created within them. Subdirectories receive these entries both in the form of active ACL entries and in the form of copies of the default entries. Therefore, the original default entries may eventually propagate down through several layers of the directory hierarchy.
The connection between the parent and child ACLs does not continue once the default entries have been copied. If the parent’s default entries change, the changes are not reflected in the ACLs of existing subdirectories.
In this section, we discuss the characteristics of NFSv4 ACLs and briefly review the Solaris command syntax used to set and inspect them. AIX also supports NFSv4 ACLs, but it uses different commands (aclget, aclput, acledit, et al.) for this purpose. Rather than belaboring the details of any particular command set, we concentrate here on the theory behind the system. Once you understand basic principles, the system-specific commands are easy to pick up.
From a structural perspective, NFSv4 ACLs are similar to Windows ACLs. The main difference between them lies in the specification of the entity to which an access control entry refers.
In both systems, the ACL stores this entity as a string. For Windows ACLs, the string typically contains a Windows security identifier (SID), whereas for NFSv4, the string is typically of the form user:username or group:groupname. It can also be one of the special tokens owner@, group@, or everyone@. In fact, these latter entries are the most common because they correspond to the mode bits found on every file.
Systems such as Samba that share files between UNIX and Windows systems must provide some way of mapping between Windows and NFSv4 principals.
The Windows and NFSv4 permission model is more granular than the traditional UNIX read-write-execute model. The main refinements are as follows:
• NFSv4 distinguishes permission to create files within a directory from permission to create subdirectories.
• NFSv4 has a separate “append” permission bit.
• NFSv4 has separate read and write permissions for data, file attributes, extended attributes, and ACLs.
• NFSv4 controls a user’s ability to change the ownership of a file through the standard ACL system. In traditional UNIX, the ability to change the ownership of files is usually reserved for root.
Table 6.9 shows the various permissions that can be assigned in the NFSv4 system. It also shows the one-letter codes used to represent them and the more verbose names displayed and accepted by Solaris’s ls and chmod commands.
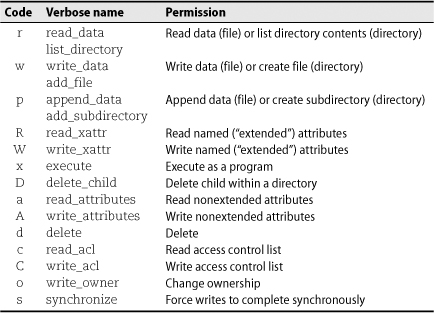
Table 6.9 NFSv4 file permissions
Some permissions have multiple names because they are represented by the same flag value but are interpreted differently for files and directories. This kind of overloading should be familiar from the traditional UNIX permission system. (For example, an x in the traditional system indicates execute permission on a plain file and “traverse” permission on a directory.)
Although the NFSv4 permission model is fairly detailed, the individual permissions should mostly be self-explanatory. The “synchronize” permission allows a client to specify that its modifications to a file should be synchronous—that is, calls to write should not return until the data has actually been saved on disk.
An extended attribute is a named chunk of data that is stored along with a file; most modern filesystems support such attributes, although they are not yet widely used in the real world. At this point, the predominant use of extended attributes is to store ACLs themselves. However, the NFSv4 permission model treats ACLs separately from other extended attributes.
In addition to the garden-variety user:username and group:groupname specifiers, NFSv4 defines several special entities that may be assigned permissions
in an ACL. Most important among these are owner@, group@, and everyone@, which correspond
to the traditional categories in the 9-bit permission model.
The NFSv4 specification (RFC3530) defines a few more special entities such as dialup@ and batch@. From a UNIX perspective, they’re all a bit peculiar. We are not aware of any actual real-world application for these entities; most likely, they exist to facilitate compatibility with Windows.
NFSv4 has several differences from POSIX. For one thing, it has no default entity, used in POSIX to control ACL inheritance. Instead, any individual access control entry (ACE) can be flagged as inheritable (see ACL inheritance, below). NFSv4 also does not use a mask to reconcile the permissions specified in a file’s mode with its ACL. The mode is required to be consistent with the settings specified for owner@, group@, and everyone@, and filesystems that implement NFSv4 ACLs must preserve this consistency when either the mode or the ACL is updated.
In the POSIX ACL system, the filesystem attempts to match the user’s identity to the single most appropriate access control entry. That ACE then provides a complete set of controlling permissions for the file.
The NFSv4 system differs in that an ACE may specify only a partial set of permissions. Each NFSv4 ACE is either an “allow” ACE or a “deny” ACE; it acts more like a mask than an authoritative specification of all possible permissions.13 Multiple ACEs can apply to any given situation.
When deciding whether to allow a particular operation, the filesystem reads the ACL in order, processing ACEs until either all requested permissions have been allowed or some requested permission has been denied. Only ACEs whose entity strings are compatible with the current user’s identity are considered.
It’s possible for the filesystem to reach the end of an NFSv4 ACL without having obtained a definitive answer to a permission query. The NFSv4 standard considers the result to be undefined, but most real-world implementations will choose to deny access, both because this is the convention used by Windows and because it’s the only option that makes sense.
Like POSIX ACLs, NFSv4 ACLs allow newly created objects to inherit access control entries from their enclosing directory. However, the NFSv4 system is a bit more powerful and a lot more confusing. Here are the important points:
• Any ACE can be flagged as inheritable. Inheritance for newly created subdirectories
(dir_inherit or d) and newly created files (file_inherit or f) are flagged separately.
• You can apply different access control entries to new files and new directories by creating separate access control entries on the parent directory and flagging them appropriately. You can also apply a single ACE to all new child entities (of whatever type) by turning on both the d and f flags.
• From the perspective of access determination, access control entries have the same
effect on the parent (source) directory whether or not they are inheritable. If you
want an entry to apply to children but not to the parent directory itself, turn on
the ACE’s inherit_only (i) flag.
• New subdirectories normally inherit two copies of each ACE: one with the inheritance
flags turned off, which applies to the subdirectory itself; and one with the inherit_only flag turned on, which sets up the new subdirectory to propagate its inherited ACEs.
You can suppress the creation of this second ACE by turning on the no_propagate (n) flag on the parent directory’s copy of the ACE. The end result is that the ACE propagates
only to immediate children of the original directory.
• Don’t confuse the propagation of access control entries with true inheritance. Your setting an inheritance-related flag on an ACE simply means that the ACE will be copied to new entities. It does not create any ongoing relationship between the parent and its children. If you later change the ACE entries on the parent directory, the children are not updated.
Table 6.10 summarizes these various inheritance flags.

Table 6.10 NFSv4 ACE inheritance flags
Solaris has integrated its ACL support into ls and chmod, which is a nice approach and a straightforward extension of the commands’ usual
functions. Both POSIX and NFSv4 ACLs are supported in this manner, although here we show only NFSv4
examples. The specific flavor of ACLs that you see or set depends on the underlying
filesystem.
ls -v shows ACL information for filesystem objects. As with -l, you must include the -d option if you want to see the ACL for a directory; otherwise ls -v shows the ACL of every child of the directory. Here’s a simple (!) example:

This newly created directory seems to have a complex ACL, but in fact it’s a fake—
this ACL is just the nine-bit mode shown on the first line of output translated into
ACLese. It is not necessary for the filesystem to store an actual ACL because the
ACL and the mode are equivalent. (Such ACLs are termed “trivial.”) If the directory
had an actual ACL, ls would show the mode bits with a + on the end (i.e., drwxr-xr-x+) to indicate the presence of the ACL.
Each numbered clause represents one access control entry. The format is
index:entity:permissions:inheritance_flags:type
The index numbers are added by ls for clarity and are not part of the actual ACL. They can be used in later chmod commands to identify a specific ACE to be replaced or deleted.
The entity can be the keywords owner@, group@, or everyone@, or a form such as user:username or group:groupname.
The type of an ACE is either allow or deny. Theoretically, alarm and audit are allowed as well, but ZFS doesn’t implement these features.
Both the permissions and the inheritance_flags are slash-separated lists of options. Strangely, ls omits the inheritance_flags field (and one of the colon delimiters) if the flags are all turned off, but it does not do the same with the permissions.
For added confusion, ls displays multiple names for the r (read data/list directory), w (write data/add file), and p (append data/add subdirectory) permission bits, as if they were separate permissions.
In fact, they are file- and directory-specific interpretations of the same bits and
will always be present or absent together.
These quirks, together with the use of a colon as a subdivider within the entity field, make it tricky for scripts to parse ls -v output. If you need to process ACLs programmatically, look first for an existing library (such as the Solaris::ACL Perl module from the Comprehensive Perl Archive Network (CPAN) that facilitates the process. As a last resort, you can use the output of ls -V (described next), since this format is more amenable to parsing.
You can obtain a tabular display of ACL entries with ls -V. In this mode, permissions are represented by their one-letter codes as shown in Table 6.9 on page 167. All possible bits are displayed for each access control entry; those that are turned off are represented by dashes (just as ls displays a file’s traditional mode).

Several aspects of the translation of modes to ACLs merit further discussion. First,
note that the group@ and everyone@ ACEs in the example above differ despite the fact that the corresponding clusters
in the mode are both r-x. That’s not because the translation rules are different for
the group@ and everyone@ categories; rather, it’s because certain permissions can’t really be extrapolated
from the traditional mode.
These “unspecified” permission bits receive default values through additions to the
everyone@ ACEs only. The write_xattr, write_attributes, write_acl, and write_owner permissions are always denied, and the read_xattr, read_attributes, read_acl, and synchronize permissions are always allowed. If you factor out these permissions
from the everyone@ set, you can see that the remaining ACEs for everyone@ are in fact the same as those for group@.
Of course, these “constant” permissions apply only to trivial ACLs. By editing the ACL directly, you can set the bits in any combination.
The mode and the ACL must remain consistent, so whenever you adjust one of these entities,
the other updates automatically to conform to it. ZFS does a good job of determining
the appropriate mode for a given ACL, but its algorithm for generating and updating
ACLs in response to mode changes is rudimentary. The results aren’t functionally incorrect,
but they are often verbose, unreadable, and unmaintainable. In particular, the system
may generate multiple and seemingly inconsistent sets of entries for owner@, group@, and everyone@ that depend on evaluation order for their aggregate effect.
As a general rule, never touch a file or directory’s mode once you’ve applied an ACL. If worse comes to worst, remove the ACL with chmod A- file and start over.
Because ZFS enforces consistency between a file’s mode and its ACL, all files have at least a trivial ACL (virtual or not). Ergo, ACL changes are always updates. You make ACL changes with chmod. The basic syntax is the same as always:
chmod [-R] acl_operation file …
Table 6.11 shows the various types of ACL operations understood by chmod. Unfortunately, there is no ACL analog of chmod’s incremental, symbolic syntax for manipulating traditional modes. You cannot add or remove individual permissions from an ACE; you must replace the entire entry.

Table 6.11 ACL operations understood by Solaris’s chmod
The index numbers referred to in Table 6.11 are those shown by ls -v; they are the ordinals of the access control entries, starting at zero. You can encode the ace fields with either the verbose or one-letter permission names. For example, the command
solaris$ chmod A+user:ben:C:allow /var/tmp/example
gives the user ben permission to edit the ACL on the /var/tmp/example directory. Remember that access determination is an iterative process that works its way down the ACL, so ben retains any rights he had under the previous version of the ACL. The new access control entry goes at the start of the ACL (at index zero), so the command
solaris$ chmod A0- /var/tmp/example
removes the ACE that was just added and reverts the ACL to its original state.
E6.1 What is a umask? Create a umask that would give no permissions to the group or the world.
E6.2 What is the difference between hard links and symbolic (soft) links? When is it appropriate to use one or the other?
 E6.3 What steps would be needed on your system for a Windows NTFS partition to be
automatically mounted from a local hard disk? What’s the most appropriate mount point
for such a partition according to your system’s conventions and the conventions in
use at your site?
E6.3 What steps would be needed on your system for a Windows NTFS partition to be
automatically mounted from a local hard disk? What’s the most appropriate mount point
for such a partition according to your system’s conventions and the conventions in
use at your site?
E6.4 When installing a new system, it’s important to set up the system volumes such
that each filesystem (/var, /usr, etc.) has adequate space for both current and future needs. The Foobar Linux distribution
uses the following defaults:

What are some potential problems with this arrangement on a busy server box?
E6.5 Why is it a good idea to put some partitions (such as /var, /home, and swap) on a separate drive from other data files and programs? What about /tmp? Give specific reasons for each of the filesystems listed.
E6.6 Write a script that finds all the hard links on a filesystem.
E6.7 Give commands to accomplish the following tasks.
a) Set the permissions on the file README to read/write for the owner and read for everyone else.
b) Turn on a file’s setuid bit without changing (or knowing) the current permissions.
c) List the contents of the current directory, sorting by modification time and listing the most recently modified file last.
d) Change the group of a file called shared from “user” to “friends”.
E6.8 By convention, the /tmp directory is available to all users who care to create files there. What prevents
one user from reading or deleting another’s temporary files? What’s to prevent a disgruntled
user from filling up /tmp with junk files? What would be the consequences of such an attack?