UNIX storage is looking more and more like a giant set of Lego blocks that you can put together in an infinite variety of configurations. What will you build? A fighter jet? A dump truck? An advanced technology helicopter with air bags and a night-vision camera?
Traditional hard disks remain the dominant medium for on-line storage, but they’re increasingly being joined by solid state drives (SSDs) for performance-sensitive applications. Running on top of this hardware are a variety of software components that mediate between the raw storage devices and the filesystem hierarchy seen by users. These components include device drivers, partitioning conventions, RAID implementations, logical volume managers, systems for virtualizing disks over a network, and the filesystem implementations themselves.
In this chapter, we discuss the administrative tasks and decisions that occur at each of these layers. We begin with “fast path” instructions for adding a basic disk to each of our example systems. We then review storage-related hardware technologies and look at the general architecture of storage software. We then work our way up the storage stack from low-level formatting up to the filesystem level. Along the way, we cover disk partitioning, RAID systems, logical volume managers, and systems for implementing storage area networks (SANs).
Although vendors all use standardized disk hardware, there’s a lot of variation among systems in the software domain. Accordingly, you’ll see a lot of vendor-specific details in this chapter. We try to cover each system in enough detail that you can at least identify the commands and systems that are used and can locate the necessary documentation.
Before we launch into many pages of storage architecture and theory, let’s first address the most common scenario: you want to install a hard disk and make it accessible through the filesystem. Nothing fancy: no RAID, all the drive’s space in a single logical volume, and the default filesystem type.
Step one is to attach the drive and reboot. Some systems allow hot-addition of disk drives, but we don’t address that case here. Beyond that, the recipes differ slightly among systems.
Regardless of your OS, it’s critically important to identify and format the right disk drive. A newly added drive is not necessarily represented by the highest-numbered device file, and on some systems, the addition of a new drive can change the device names of existing drives. Double-check the identity of the new drive by reviewing its manufacturer, size, and model number before you do anything that’s potentially destructive.
 Run sudo fdisk -l to list the system’s disks and identify the new drive. Then run any convenient partitioning
utility to create a partition table for the drive. For drives 2TB and below, install
a Windows MBR partition table. cfdisk is the easiest utility for this, but you can also use fdisk, sfdisk, parted, or gparted. Larger disks require a GPT partition table, so you must partition with parted or its GNOME GUI, gparted. gparted is a lot easier to use but isn’t usually installed by default.
Run sudo fdisk -l to list the system’s disks and identify the new drive. Then run any convenient partitioning
utility to create a partition table for the drive. For drives 2TB and below, install
a Windows MBR partition table. cfdisk is the easiest utility for this, but you can also use fdisk, sfdisk, parted, or gparted. Larger disks require a GPT partition table, so you must partition with parted or its GNOME GUI, gparted. gparted is a lot easier to use but isn’t usually installed by default.
Put all the drive’s space into one partition of unspecified or “unformatted” type. Do not install a filesystem. Note the device name of the new partition before you leave the partitioning utility; let’s say it’s /dev/sdc1.
Next, run the following command sequence, selecting appropriate names for the volume group (vgname), logical volume (volname), and mount point. (Examples of reasonable choices: homevg, home, and /home.)

In the /etc/fstab file, copy the line for an existing filesystem and adjust it. The device to be mounted is /dev/vgname/volname. If your existing fstab file identifies volumes by UUID, replace the UUID=xxx clause with the device file; UUID identification is not necessary for LVM volumes.
Finally, run sudo mount mountpoint to mount the filesystem.
See page 224 for more details on Linux device files for disks. See page 236 for partitioning information and page 251 for logical volume management. The ext4 filesystem family is discussed starting on page 255.
 Run sudo format and inspect the menu of known disks to identify the name of the new device. Let’s
say it’s c9t0d0. Type <Control-C> to abort.
Run sudo format and inspect the menu of known disks to identify the name of the new device. Let’s
say it’s c9t0d0. Type <Control-C> to abort.
Run zpool create poolname c9t0d0. Choose a simple poolname such as “home” or “extra.” ZFS creates a filesystem and mounts it under / poolname.
See page 225 for more details on disk devices in Solaris. See page 264 for a general overview of ZFS.
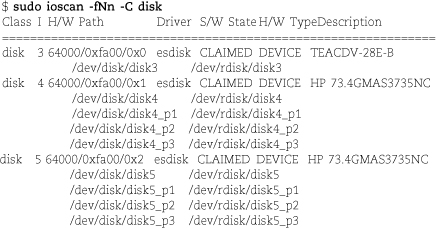
 Run sudo ioscan -fNn -C disk to identify the device files for the new disk; let’s say they are /dev/disk/disk4 and /dev/rdisk/disk4.
Run sudo ioscan -fNn -C disk to identify the device files for the new disk; let’s say they are /dev/disk/disk4 and /dev/rdisk/disk4.
Next, run the following command sequence, selecting appropriate names for the volume group (vgname), logical volume (volname), and mount point. (An example of reasonable choices: homevg, home, and /home.)

In the /etc/fstab file, copy the line for an existing filesystem and adjust it. The device to be mounted is /dev/vgname/volname.
Finally, run sudo mount mountpoint to mount the filesystem.
See page 225 for more details on HP-UX disk device files. See page 251 for logical volume management information. The VxFS filesystem is discussed starting on page 256.
 Run lsdev -C -c disk to see a list of the disks the system is aware of, then run lspv to see which disks are already set up for volume management. The device that appears
in the first list but not the second is your new disk. Let’s say it’s hdisk1.
Run lsdev -C -c disk to see a list of the disks the system is aware of, then run lspv to see which disks are already set up for volume management. The device that appears
in the first list but not the second is your new disk. Let’s say it’s hdisk1.
Next, run the following command sequence, selecting appropriate names for the volume group (vgname), logical volume (volname), and mount point. (Examples of reasonable choices: homevg, home, and /home.)

See page 226 for more details on AIX disk device files, and see page 253 for AIX logical volume management information. The JFS2 filesystem is discussed starting on page 257.
Even in today’s post-Internet world, there are only a few basic ways to store computer data: hard disks, flash memory, magnetic tapes, and optical media. The last two technologies have significant limitations that disqualify them from use as a system’s primary filesystem. However, they’re still commonly used for backups and for “near-line” storage—cases in which instant access and rewritability are not of primary concern.
See page 301 for a summary of current tape technologies.
After 40 years of hard disk technology, system builders are finally getting a practical alternative in the form of solid state disks (SSDs). These flash-memory-based devices offer a different set of tradeoffs from a standard disk, and they’re sure to exert a strong influence over the architectures of databases, filesystems, and operating systems in the years to come.
At the same time, traditional hard disks are continuing their exponential increases in capacity. Twenty years ago, a 60MB hard disk cost $1,000. Today, a garden-variety 1TB drive runs $80 or so. That’s 200,000 times more storage for the money, or double the MB/$ every 1.15 years—nearly twice the rate predicted by Moore’s Law. During that same period, the sequential throughput of mass-market drives has increased from 500 kB/s to 100 MB/s, a comparatively paltry factor of 200. And random-access seek times have hardly budged. The more things change, the more they stay the same.
A third—hybrid—category, hard disks with large flash-memory buffers, was widely touted a few years ago but never actually materialized in the marketplace. It’s not clear to us whether the drives were delayed by technical, manufacturing, or marketing concerns. They may yet appear on the scene, but the implications for system administrators remain unclear.
See page 14 for more information on IEC units (gibibytes, etc.).
Disk sizes are specified in gigabytes that are billions of bytes, as opposed to memory, which is specified in gigabytes (gibibytes, really) of 230 (1,073,741,824) bytes. The difference is about 7%. Be sure to check your units when estimating and comparing capacities.
Hard disks and SSDs are enough alike that they can act as drop-in replacements for each other, at least at the hardware level. They use the same hardware interfaces and interface protocols. And yet they have different strengths, as summarized in Table 8.1. Performance and cost values are as of mid-2010.

Table 8.1 Comparison of hard disk and SSD technology
In the next sections, we take a closer look at each of these technologies.
A typical hard drive contains several rotating platters coated with magnetic film. They are read and written by tiny skating heads that are mounted on a metal arm that swings back and forth to position them. The heads float close to the surface of the platters but do not actually touch.
Reading from a platter is quick; it’s the mechanical maneuvering needed to address a particular sector that drives down random-access throughput. There are two main sources of delay.
First, the head armature must swing into position over the appropriate track. This part is called seek delay. Then, the system must wait for the right sector to pass underneath the head as the platter rotates. That part is rotational latency. Disks can stream data at tens of MB/s if reads are optimally sequenced, but random reads are fortunate to achieve more than a few MB/s.
A set of tracks on different platters that are all the same distance from the spindle is called a cylinder. The cylinder’s data can be read without any additional movement of the arm. Although heads move amazingly fast, they still move much slower than the disks spin around. Therefore, any disk access that does not require the heads to seek to a new position will be faster.
Rotational speeds have increased over time. Currently, 7,200 RPM is the mass-market standard for performance-oriented drives, and 10,000 RPM and 15,000 RPM drives are popular at the high end. Higher rotational speeds decrease latency and increase the bandwidth of data transfers, but the drives tend to run hot.
Hard disks fail frequently. A 2007 Google Labs study of 100,000 drives surprised the tech world with the news that hard disks more than two years old had an average annual failure rate (AFR) of more than 6%, much higher than the failure rates manufacturers predicted based on their extrapolation of short-term testing. The overall pattern was a few months of infant mortality, a two-year honeymoon of annual failure rates of a few percent, and then a jump up to the 6%–8% AFR range. Overall, hard disks in the Google study had less than a 75% chance of surviving a five-year tour of duty.
Interestingly, Google found no correlation between failure rate and two environmental factors that were formerly thought to be important: operating temperature and drive activity. The complete paper can be found at tinyurl.com/fail-pdf.
Disk failures tend to involve either platter surfaces (bad blocks) or the mechanical components. The firmware and hardware interface usually remain operable after a failure, so you can query the disk for details (see page 230).
Drive reliability is often quoted by manufacturers in terms of mean time between failures (MTBF), denominated in hours. A typical value for an enterprise drive is around 1.2 million hours. However, MTBF is a statistical measure and should not be read to imply that an individual drive will run for 140 years before failing.
MTBF is the inverse of AFR in the drive’s steady-state period—that is, after break-in but before wear-out. A manufacturer’s MTBF of 1.2 million hours corresponds to an AFR of 0.7% per year. This value is almost, but not quite, concordant with the AFR range observed by Google (1%–2%) during the first two years of their sample drives’ lives.
Manufacturers’ MTBF values are probably accurate, but they are cherry-picked from the most reliable phase of each drive’s life. MTBF values should therefore be regarded as an upper bound on reliability; they do not predict your actual expected failure rate over the long term. Based on the limited data quoted above, you might consider dividing manufacturers’ MTBFs by a factor of 7.5 or so to arrive at a more realistic estimate of five-year failure rates.
Hard disks are commodity products, and one manufacturer’s model is much like another’s, given similar specifications for spindle speed, hardware interface, and reliability. These days, you need a dedicated qualification laboratory to make fine distinctions among competing drives.
SSDs spread reads and writes across banks of flash memory cells, which are individually rather slow in comparison to modern hard disks. But because of parallelism, the SSD as a whole meets or exceeds the bandwidth of a traditional disk. The great strength of SSDs is that they continue to perform well when data is read or written at random, an access pattern that’s predominant in real-world use.
Storage device manufacturers like to quote sequential transfer rates for their products because the numbers are impressively high. But for traditional hard disks, these sequential numbers have almost no relationship to the throughput observed with random reads and writes. For example, Western Digital’s high-performance Velociraptor drives can achieve nearly 120 MB/s in sequential transfers, but their random read results are more on the order of 2 MB/s. By contrast, Intel’s current-generation SSDs stay above 30 MB/s for all access patterns.
This performance comes at a cost, however. Not only are SSDs more expensive per gigabyte of storage than are hard disks, but they also introduce several new wrinkles and uncertainties into the storage equation.
Each page of flash memory in an SSD (typically 4KiB on current products) can be rewritten only a limited number of times (usually about 100,000, depending on the underlying technology). To limit the wear on any given page, the SSD firmware maintains a mapping table and distributes writes across all the drive’s pages. This remapping is invisible to the operating system, which sees the drive as a linear series of blocks. Think of it as virtual memory for storage.
A further complication is that flash memory pages must be erased before they can be rewritten. Erasing is a separate operation that is slower than writing. It’s also impossible to erase individual pages—clusters of adjacent pages (typically 128 pages or 512KiB) must be erased together. The write performance of an SSD can drop substantially when the pool of pre-erased pages is exhausted and the drive must recover pages on the fly to service ongoing writes.
Rebuilding a buffer of erased pages is harder than it might seem because filesystems typically do not mark or erase data blocks they are no longer using. A storage device doesn’t know that the filesystem now considers a given block to be free; it only knows that long ago someone gave it data to store there. In order for an SSD to maintain its cache of pre-erased pages (and thus, its write performance), the filesystem has to be capable of informing the SSD that certain pages are no longer needed. As of this writing, ext4 and Windows 7’s NTFS are the only common filesystems that offers this feature. But given the enormous interest in SSDs, other filesystems are sure to become more SSD-aware in the near future.
Another touchy subject is alignment. The standard size for a disk block is 512 bytes, but that size is too small for filesystems to deal with efficiently.1 Filesystems manage the disk in terms of clusters of 1KiB to 8KiB in size, and a translation layer maps filesystem clusters into ranges of disk blocks for reads and writes.
On a hard disk, it makes no difference where a cluster begins or ends. But because SSDs can only read or write data in 4KiB pages (despite their emulation of a hard disk’s traditional 512-byte blocks), filesystem cluster boundaries and SSD page boundaries should coincide. You wouldn’t want a 4KiB logical cluster to correspond to half of one 4KiB SSD cluster and half of another—with that layout, the SSD might have to read or write twice as many physical pages as it should to service a given number of logical clusters.
Since filesystems usually count off their clusters starting at the beginning of whatever storage is allocated to them, the alignment issue can be finessed by aligning disk partitions to a power-of-2 boundary that is large in comparison with the likely size of SSD and filesystem pages (e.g., 64KiB). Unfortunately, the Windows MBR partitioning scheme that Linux has inherited does not make such alignment automatic. Check the block ranges that your partitioning tool assigns to make sure they are aligned, keeping in mind that the MBR itself consumes a block. (Windows 7 aligns partitions suitably for SSDs by default.)
The theoretical limits on the rewritability of flash memory are probably less of an issue than they might initially seem. Just as a matter of arithmetic, you would have to stream 100 MB/s of data to a 150GB SSD for more than four continuous years to start running up against the rewrite limit. The more general question of long-term SSD reliability is as yet unanswered, however. SSDs are an immature product category, and early adopters should expect quirks.
The controllers used inside SSDs are rapidly evolving, and there are currently marked differences in performance among manufacturers. The market should eventually converge to a standard architecture for these devices, but that day is still a year or two off. In the short term, careful shopping is essential.
Anand Shimpi’s March 2009 article on SSD technology is a superb introduction to the promise and perils of the SSD. It can be found at tinyurl.com/dexnbt.
These days, only a few interface standards are in common use. If a system supports several different interfaces, use the one that best meets your requirements for speed, redundancy, mobility, and price.
• ATA (Advanced Technology Attachment), known in earlier revisions as IDE, was developed as a simple, low-cost interface for PCs. It was originally called Integrated Drive Electronics because it put the hardware controller in the same box as the disk platters and used a relatively high-level protocol for communication between the computer and the disks. This is now the way that all hard disks work, but at the time it was something of an innovation.
The traditional parallel ATA interface (PATA) connected disks to the motherboard with a 40- or 80-conductor ribbon cable. This style of disk is nearly obsolete, but the installed base is enormous. PATA disks are often labeled as “IDE” to distinguish them from SATA drives (below), but they are true ATA drives. PATA disks are medium to fast in speed, generous in capacity, and unbelievably cheap.
• Serial ATA, SATA, is the successor to PATA. In addition to supporting much higher transfer rates (currently 3 Gb/s, with 6 Gb/s soon to arrive), SATA simplifies connectivity with tidier cabling and a longer maximum cable length. SATA has native support for hot-swapping and (optional) command queueing, two features that finally make ATA a viable alternative to SCSI in server environments.
• Though not as common as it once was, SCSI is one of the most widely supported disk interfaces. It comes in several flavors, all of which support multiple disks on a bus and various speeds and communication styles. SCSI is described in more detail on page 216.
Hard drive manufacturers typically reserve SCSI interfaces for their highest-performing and most rugged drives. You’ll pay more for these drives, but mostly because of the drive features rather than the interface.
• Fibre Channel is a serial interface that is popular in the enterprise environment thanks to its high bandwidth and to the large number of storage devices that can be attached to it at once. Fibre Channel devices connect with a fiber optic or twinaxial copper cable. Speeds range from roughly 1–40 Gb/s depending on the protocol revision.
Common topologies include loops, called Fibre Channel Arbitrated Loops (FC-AL), and fabrics, which are constructed with Fibre Channel switches. Fibre Channel can speak several different protocols, including SCSI and even IP. Devices are identified by a hardwired, 8-byte ID number (a “World Wide Name”) that’s similar to an Ethernet MAC address.
• The Universal Serial Bus (USB) and FireWire (IEEE1394) serial communication systems have become popular for connecting external hard disks. Current speeds are 480 Mb/s for USB and 800 Mb/s for FireWire; both systems are too slow to accommodate a fast disk streaming data at full speed. Upcoming revisions of both standards will offer more competitive speeds (up to 5 Gb/s with USB 3.0).
Hard disks never provide native USB or FireWire interfaces—SATA converters are built into the disk enclosures that feature these ports.
ATA and SCSI are by far the dominant players in the disk drive arena. They are the only interfaces we discuss in detail.
PATA (Parallel Advanced Technology Attachment), also called IDE, was designed to be simple and inexpensive. It is most often found on PCs or low-cost workstations. The original IDE became popular in the late 1980s. A succession of protocol revisions culminating in the current ATA-7 (also known as Ultra ATA/133) added direct memory access (DMA) modes, plug and play features, logical block addressing (LBA), power management, self-monitoring capabilities, and bus speeds up to 133 MB/s. Around the time of ATA-4, the ATA standard also merged with the ATA Packet Interface (ATAPI) protocol, which allows CD-ROM and tape drives to work on an IDE bus.
The PATA connector is a 40-pin header that connects the drive to the interface card with a clumsy ribbon cable. ATA standards beyond Ultra DMA/66 use an 80-conductor cable with more ground pins and therefore less electrical noise. Some nicer cables that are available bundle up the ribbon into a thick cable sleeve, tidying up the chassis and improving air flow. Power cabling for PATA uses a chunky 4-conductor Molex plug.
If a cable or drive is not keyed, be sure that pin 1 on the drive goes to pin 1 on the interface jack. Pin 1 is usually marked with a small “1” on one side of the connector. If it is not marked, a rule of thumb is that pin 1 is usually the one closest to the power connector. Pin 1 on a ribbon cable is usually marked in red. If there is no red stripe on one edge of your cable, just make sure you have the cable oriented so that pin 1 is connected to pin 1 and mark the cable with a red sharpie.
Most PCs have two PATA buses, each of which can host two devices. If you have more than one device on a PATA bus, you must designate one as the master and the other as the slave. A “cable select” jumper setting on modern drives (which is usually the default) lets the devices work out master vs. slave on their own. Occasionally, it does not work correctly and you must explicitly assign the master and slave roles.
No performance advantage accrues from being the master. Some older PATA drives do not like to be slaves, so if you are having trouble getting one configuration to work, try reversing the disks’ roles. If things are still not working out, try making each device the master of its own PATA bus.
Arbitration between master and slave devices on a PATA bus can be relatively slow. If possible, put each PATA drive on its own bus.
As data transfer rates for PATA drives increased, the standard’s disadvantages started to become obvious. Electromagnetic interference and other electrical issues caused reliability concerns at high speeds. Serial ATA, SATA, was invented to address these problems. It is now the predominant hardware interface for storage.
SATA smooths many of PATA’s sharp edges. It improves transfer rates (potentially to 750 MB/s with the upcoming 6 Gb/s SATA) and includes superior error checking. The standard supports hot-swapping, native command queuing, and sundry performance enhancements. SATA eliminates the need for master and slave designations because only a single device can be connected to each channel.
SATA overcomes the 18-inch cable limitation of PATA and introduces new data and power cable standards of 7 and 15 conductors, respectively.2 These cables are infinitely more flexible and easier to work with than their ribbon cable predecessors—no more curving and twisting to fit drives on the same cable. They do seem to be a bit more quality-sensitive than the old PATA ribbon cables, however. We have seen several of the cheap pack-in SATA cables that come with motherboards fail in actual use.3
SATA cables slide easily onto their mating connectors, but they can just as easily slide off. Cables with locking catches are available, but they’re a mixed blessing. On motherboards with six or eight SATA connectors packed together, it can be hard to disengage the locking connectors without a pair of needle-nosed pliers.
SATA also introduces an external cabling standard called eSATA. The cables are electrically identical to standard SATA, but the connectors are slightly different. You can add an eSATA port to a system that has only internal SATA connectors by installing an inexpensive converter bracket.
Be leery of external multidrive enclosures that have only a single eSATA port— some of these are smart (RAID) enclosures that require a proprietary driver. (The drivers rarely support UNIX or Linux.) Others are dumb enclosures that have a SATA port multiplier built in. These are potentially usable on UNIX systems, but since not all SATA host adapters support port expanders, pay close attention to the compatibility information. Enclosures with multiple eSATA ports—one per drive bay—are always safe.
SCSI, the Small Computer System Interface, defines a generic data pipe that can be used by all kinds of peripherals. In the past it was used for disks, tape drives, scanners, and printers, but these days most peripherals have abandoned SCSI in favor of USB.
Many flavors of SCSI interface have been defined since 1986, when SCSI-1 was first adopted as an ANSI standard. Traditional SCSI uses parallel cabling with 8 or 16 conductors.
Unfortunately, there has been no real rhyme or reason to the naming conventions for parallel SCSI. The terms “fast,” “wide,” and “ultra” were introduced at various times to mark significant developments, but as those features became standard, the descriptors vanished from the names. The nimble-sounding Ultra SCSI is in
fact a 20 MB/s standard that no one would dream of using today, so it has had to give way to Ultra2, Ultra3, Ultra-320, and Ultra-640 SCSI. For the curious, the following regular expression matches all the various flavors of parallel SCSI:
(Fast(-Wide)?|Ultra((Wide)?|2 (Wide)?|3|-320|-640)?) SCSI|SCSI-[1-3]
Many different connectors have been used as well. They vary depending on the version of SCSI, the type of connection (internal or external), and the number of data bits sent at once. Exhibit A shows pictures of some common ones. Each connector is shown from the front, as if you were about to plug it into your forehead.
Exhibit A Parallel SCSI connectors (front view, male except where noted)

The only one of these connectors still being manufactured today is the SCA-2, which is an 80-pin connector that includes both power and bus connections.
Each end of a parallel SCSI bus must have a terminating resistor (“terminator”). These resistors absorb signals as they reach the end of the bus and prevent noise from reflecting back onto the bus. Terminators take several forms, from small external plugs that you snap onto a regular port to sets of tiny resistor packs that install onto a device’s circuit boards. Most modern devices are autoterminating.
If you experience seemingly random hardware problems on your SCSI bus, first check that both ends of the bus are properly terminated. Improper termination is one of the most common SCSI configuration mistakes on old SCSI systems, and the errors it produces can be obscure and intermittent.
Parallel SCSI buses use a daisy chain configuration, so most external devices have two SCSI ports.4 The ports are identical and interchangeable—either one can be the input. Internal SCSI devices (including those with SCA-2 connectors) are attached to a ribbon cable, so only one port is needed on the device.
Each device has a SCSI address or “target number” that distinguishes it from the other devices on the bus. Target numbers start at 0 and go up to 7 or 15, depending on whether the bus is narrow or wide. The SCSI controller itself counts as a device and is usually target 7. All other devices must have their target numbers set to unique values. It is a common error to forget that the SCSI controller has a target number and to set a device to the same target number as the controller.
If you’re lucky, a device will have an external thumbwheel with which the target number can be set. Other common ways of setting the target number are DIP switches and jumpers. If it is not obvious how to set the target number on a device, look up the hardware manual on the web.
The SCSI standard supports a form of subaddressing called a “logical unit number.” Each target can have several logical units inside it. A plausible example is a drive array with several disks but only one SCSI controller. If a SCSI device contains only one logical unit, the LUN usually defaults to 0.
The use of logical unit numbers is generally confined to large drive arrays. When you hear “SCSI unit number,” you should assume that it is really a target number that’s being discussed until proven otherwise.
From the perspective of a sysadmin dealing with legacy SCSI hardware, here are the important points to keep in mind:
• Don’t worry about the exact SCSI versions a device claims to support; look at the connectors. If two SCSI devices have the same connectors, they are compatible. That doesn’t necessarily mean that they can achieve the same speeds, however. Communication will occur at the speed of the slower device.
• Even if the connectors are different, the devices can still be made compatible with an adapter if both connectors have the same number of pins.
• Many older workstations have internal SCSI devices such as tape and floppy drives. Check the listing of current devices before you reboot to add a new device.
• After you have added a new SCSI device, check the listing of devices discovered by the kernel when it reboots to make sure that everything you expect is there. Most SCSI drivers do not detect multiple devices that have the same SCSI address (an illegal configuration). SCSI address conflicts lead to strange behavior.
• If you see flaky behavior, check for a target number conflict or a problem with bus termination.
• Remember that your SCSI controller uses one of the SCSI addresses.
As in the PATA world, parallel SCSI is giving way to Serial Attached SCSI (SAS), the SCSI analog of SATA. From the hardware perspective, SAS improves just about every aspect of traditional parallel SCSI.
• Chained buses are passé. Like SATA, SAS is a point-to-point system. SAS allows the use of “expanders” to connect multiple devices to a single host port. They’re analogous to SATA port multipliers, but whereas support for port multipliers is hit or miss, expanders are always supported.
• SAS does not use terminators.
• SCSI target IDs are no longer used. Instead, each SAS device has a Fibre-Channel-style 64-bit World Wide Name (WWN) assigned by the manufacturer. It’s analogous to an Ethernet MAC address.
• The number of devices in a SCSI bus (“SAS domain,” really) is no longer limited to 8 or 16. Up to 16,384 devices can be connected.
SAS currently operates at 3 Gb/s, but speeds are scheduled to increase to 6 Gb/s and then to 12 Gb/s by 2012.
In past editions of this book, SCSI was the obvious interface choice for server applications. It offered the highest available bandwidth, out-of-order command execution (aka tagged command queueing), lower CPU utilization, easier handling of large numbers of storage devices, and access to the market’s most advanced hard drives.
The advent of SATA has removed or minimized most of these advantages, so SCSI simply does not deliver the bang for the buck that it used to. SATA drives compete with (and in some cases, outperform) equivalent SCSI disks in nearly every category. At the same time, both SATA devices and the interfaces and cabling used to connect them are cheaper and far more widely available.
SCSI still holds a few trump cards:
• Manufacturers continue to use the SATA/SCSI divide to stratify the storage market. To help justify premium pricing, the fastest and most reliable drives are still available with only SCSI interfaces.
• SATA is limited to a queue depth of 32 pending operations. SCSI can handle thousands.
• SAS can handle many storage devices (hundreds or thousands) on a single host interface. But keep in mind that all those devices share a single pipe to the host; you are still limited to 3 Gb/s of aggregate bandwidth.
The SAS vs. SATA debate may ultimately be moot because the SAS standard includes support for SATA drives. SAS and SATA connectors are similar enough that a single SAS backplane can accommodate drives of either type. At the logical layer, SATA commands are simply tunneled over the SAS bus.
This convergence is an amazing technical feat, but the economic argument for it is less clear. The expense of a SAS installation is mostly in the host adapter, backplane, and infrastructure; the SAS drives themselves aren’t outrageously priced. Once you’ve invested in a SAS setup, you might as well stick with SAS from end to end. (On the other hand, perhaps the modest price premiums for SAS drives are a result of the fact that SATA drives can easily be substituted for them.)
If you’re used to plugging in a disk and having your Windows system ask if you want to format it, you may be a bit taken aback by the apparent complexity of storage management on UNIX and Linux systems. Why is it all so complicated?
To begin with, much of the complexity is optional. On some systems, you can log in to your system’s desktop, connect that same USB drive, and have much the same experience as on Windows. You’ll get a simple setup for personal data storage. If that’s all you need, you’re good to go.
As usual in this book, we’re primarily interested in enterprise-class storage systems: filesystems that are accessed by many users (both local and remote) and that are reliable, high-performance, easy to back up, and easy to adapt to future needs. These systems require a bit more thought, and UNIX and Linux give you plenty to think about.
Exhibit B shows a typical set of software components that can mediate between a raw storage device and its end users. The specific architecture shown in Exhibit B is for Linux, but our other example systems include similar features, although not necessarily in the same packages.
The arrows in Exhibit B mean “can be built on.” For example, a Linux filesystem can be built on top of a partition, a RAID array, or a logical volume. It’s up to the administrator to construct a stack of modules that connect each storage device to its final application.
Sharp-eyed readers will note that the graph has a cycle, but real-world configurations do not loop. Linux allows RAID and logical volumes to be stacked in either order, but neither component should be used more than once (though it is technically possible to do this).
Here’s what the pieces in Exhibit B represent:
• A storage device is anything that looks like a disk. It can be a hard disk, a flash drive, an SSD, an external RAID array implemented in hardware, or even a network service that provides block-level access to a remote device. The exact hardware doesn’t matter, as long as the device allows random access, handles block I/O, and is represented by a device file.
Exhibit B Storage management layers
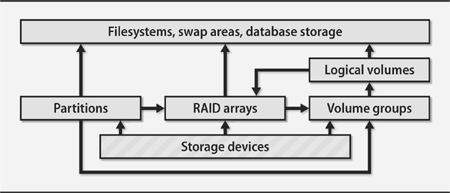
• A partition is a fixed-size subsection of a storage device. Each partition has its own device file and acts much like an independent storage device. For efficiency, the same driver that handles the underlying device usually implements partitioning. Most partitioning schemes consume a few blocks at the start of the device to record the ranges of blocks that make up each partition.
Partitioning is becoming something of a vestigial feature. Linux and Solaris drag it along primarily for compatibility with Windows-partitioned disks. HP-UX and AIX have largely done away with it in favor of logical volume management, though it’s still needed on Itanium-based HP-UX systems.
• A RAID array (a redundant array of inexpensive/independent disks) combines multiple storage devices into one virtualized device. Depending on how you set up the array, this configuration can increase performance (by reading or writing disks in parallel), increase reliability (by duplicating or parity-checking data across multiple disks), or both. RAID can be implemented by the operating system or by various types of hardware.
As the name suggests, RAID is typically conceived of as an aggregation of bare drives, but modern implementations let you use as a component of a RAID array anything that acts like a disk.
• Volume groups and logical volumes are associated with logical volume managers (LVMs). These systems aggregate physical devices to form pools of storage called volume groups. The administrator can then subdivide this pool into logical volumes in much the same way that disks of yore were divided into partitions. For example, a 750GB disk and a 250GB disk could be aggregated into a 1TB volume group and then split into two 500GB logical volumes. At least one volume would include data blocks from both hard disks.
Since the LVM adds a layer of indirection between logical and physical blocks, it can freeze the logical state of a volume simply by making a copy of the mapping table. Therefore, logical volume managers often provide some kind of a “snapshot” feature. Writes to the volume are then directed to new blocks, and the LVM keeps both the old and new mapping tables. Of course, the LVM has to store both the original image and all modified blocks, so it can eventually run out of space if a snapshot is never deleted.
• A filesystem mediates between the raw bag of blocks presented by a partition, RAID array, or logical volume and the standard filesystem interface expected by programs: paths such as /var/spool/mail, UNIX file types, UNIX permissions, etc. The filesystem determines where and how the contents of files are stored, how the filesystem namespace is represented and searched on disk, and how the system is made resistant to (or recoverable from) corruption.
Most storage space ends up as part of a filesystem, but swap space and database storage can potentially be slightly more efficient without “help” from a filesystem. The kernel or database imposes its own structure on the storage, rendering the filesystem unnecessary.
If it seems to you that this system has a few too many little components that simply implement one block storage device in terms of another, you’re in good company. The trend over the last few years has been toward consolidating these components to increase efficiency and remove duplication. Although logical volume managers did not originally function as RAID controllers, most have absorbed some RAID-like features (notably, striping and mirroring). As administrators get comfortable with logical volume management, partitions are disappearing, too.
On the cutting edge today are systems that combine a filesystem, a RAID controller, and an LVM system all in one tightly integrated package. Sun’s ZFS filesystem is the leading example, but the Btrfs filesystem in development for Linux has similar design goals. We have more to say about ZFS on page 264.
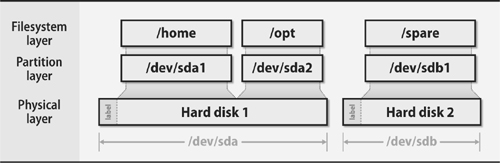
Most setups are relatively simple. Exhibit C illustrates a traditional partitions-andfilesystems schema as it might be found on a couple of data disks on a Linux system. (The boot disk is not shown.) Substitute logical volumes for partitions and the setup is similar on other systems.
In the next sections, we look in more detail at the steps involved in various phases of storage configuration: device wrangling, partitioning, RAID, logical volume management, and the installation of a filesystem. Finally, we double back to cover ZFS and storage area networking.
Exhibit C Traditional data disk partitioning scheme (Linux device names)
The way a disk is attached to the system depends on the interface that is used. The rest is all mounting brackets and cabling. Fortunately, SAS and SATA connections are virtually idiot-proof.
For parallel SCSI, double-check that you have terminated both ends of the SCSI bus, that the cable length is less than the maximum appropriate for the SCSI variant you are using, and that the new SCSI target number does not conflict with the controller or another device on the bus.
Even on hot-pluggable interfaces, it’s conservative to shut the system down before making hardware changes. Some older systems such as AIX default to doing device configuration only at boot time, so the fact that the hardware is hot-pluggable may not translate into immediate visibility at the OS level. In the case of SATA interfaces, hot-pluggability is an implementation option. Some host adapters don’t support it.
After you install a new disk, check to make sure that the system acknowledges its existence at the lowest possible level. On a PC this is easy: the BIOS shows you IDE and SATA disks, and most SCSI cards have their own setup screen that you can invoke before the system boots.
On other types of hardware, you may have to let the system boot and check the diagnostic output from the kernel as it probes for devices. For example, one of our test systems showed the following messages for an older SCSI disk attached to a BusLogic SCSI host adapter.

You may be able to review this information after the system has finished booting by looking in your system log files. See the material starting on page 352 for more information about the handling of boot-time messages from the kernel.
A newly added disk is represented by device files in /dev. See page 150 for general information about device files.
All our example systems create these files for you automatically, but you still need to know where to look for the device files and how to identify the ones that correspond to your new device. Formatting the wrong disk device file is a rapid route to disaster. Table 8.2. summarizes the device naming conventions for disks on our example systems. Instead of showing the abstract pattern according to which devices are named, Table 8.2. simply shows a typical example for the name of the system’s first disk.

Table 8.2. Device naming standard for disks
The block and raw device columns show the path for the disk as a whole, and the partition column shows the path for an example partition.
Linux disk names are assigned in sequence as the kernel enumerates the various interfaces
and devices on the system. Adding a disk can cause existing disks to change their
names. In fact, even rebooting the system can cause name changes.5
Never make changes without verifying the identity of the disk you’re working on, even on a stable system.
Linux provides a couple of ways around the “dancing names” issue. Subdirectories under /dev/disk list disks by various stable characteristics such as their manufacturer ID or connection information. These device names (which are really just links back to /dev/sd*) are stable, but they’re long and awkward.
At the level of filesystems and disk arrays, Linux uses unique ID strings to persistently identify objects. In many cases, the existence of these long IDs is cleverly concealed so that you don’t have to deal with them directly.
Linux doesn’t have raw device files for disks or disk partitions, so just use the block device wherever you might be accustomed to specifying a raw device.
parted -l lists the sizes, partition tables, model numbers, and manufacturers of every disk on the system.
Solaris disk device names are of the form /dev/[r]dsk/cWtXdYsZ, where W is the controller number, X is the SCSI target number, Y is the SCSI logical
unit number (or LUN, almost always 0), and Z is the partition (slice) number. There
are a couple of subtleties: ATA drives show up as cWdYsZ (with no t clause), and disks can have a series of DOS-style partitions, signified by pZ, as well as the Solaris-style slices denoted by sZ.
These device files are actually just symbolic links into the /devices tree, where the real device files live. More generally, Solaris makes an effort to give continuity to device names, even in the face of hardware changes. Once a disk has shown up under a given name, it can generally be found at that name in the future unless you switch controllers or SCSI target IDs.
By convention, slice 2 represents the complete, unpartitioned disk. Unlike Linux, Solaris gives you device files for every possible slice and partition, whether or not those slices and partitions actually exist. Solaris also supports overlapping partitions, but that’s just crazy talk. Oracle may as well ship every Solaris system with a loaded gun.
Hot-plugging should work fine on Solaris. When you add a new disk, devfsadmd should detect it and create the appropriate device files for you. If need be, you can run devfsadm by hand.
HP-UX has traditionally used disk device names patterned after those of Solaris,
which record a lot of hardware-specific information in the device path. As of HP-UX
11i v3, however, those pathnames have been deprecated in favor of “agile addresses”
of the form /dev/disk/disk1. The latter paths are stable and do not change with the details of the system’s hardware
configuration.
Before you boot UNIX, you can obtain a listing of the system’s SCSI devices from the PROM monitor. Unfortunately, the exact way in which this is done varies among machines. After you boot, you can list disks by running ioscan.
The old-style device names are still around in the /dsk and /rdsk directories, and you can continue to use them if you wish—at least for now. Run ioscan -m dsf to see the current mapping between old- and new-style device names.

Note that partitions are now abbreviated p instead of s in the Solaris manner (for “slice”). Unlike Solaris, HP-UX uses names such as disk3 with no partition suffix to represent the entire disk. On Solaris systems, partition 2 represents the whole disk; on HP-UX, it’s just another partition.
The system from which this example comes is Itanium-based and so has disk partitions. Other HP systems use logical volume management instead of partitioning.
AIX’s /dev/hdiskX and /dev/rhdiskX paths are refreshingly simple. Disk names are unfortunately subject to change when
the hardware configuration changes. However, most AIX disks will be under logical
volume management, so the hardware device names are not that important. The logical
volume manager writes a unique ID to each disk as part of the process of inducting
it into a volume group. This labeling allows the system to sort out the disks automatically,
so changes in device names are less troublesome than they might be on other systems.
You can run lsdev -C -c disk to see a list of the disks the system is aware of.
All hard disks come preformatted, and the factory formatting is at least as good as any formatting you can do in the field. It is best to avoid doing a low-level format if it’s not required. Don’t reformat new drives as a matter of course.
If you encounter read or write errors on a disk, first check for cabling, termination, and address problems, all of which can cause symptoms similar to those of a bad block. If after this procedure you are still convinced that the disk has defects, you might be better off replacing it with a new one rather than waiting long hours for a format to complete and hoping the problem doesn’t come back.
The formatting process writes address information and timing marks on the platters to delineate each sector. It also identifies bad blocks, imperfections in the media that result in areas that cannot be reliably read or written. All modern disks have bad block management built in, so neither you nor the driver need to worry about managing defects. The drive firmware substitutes known-good blocks from an area of backup storage on the disk that is reserved for this purpose.
Bad blocks that manifest themselves after a disk has been formatted may or may not be handled automatically. If the drive believes that the affected data can be reliably reconstructed, the newly discovered defect may be mapped out on the fly and the data rewritten to a new location. For more serious or less clearly recoverable errors, the drive aborts the read or write operation and reports the error back to the host operating system.
ATA disks are usually not designed to be formatted outside the factory. However, you may be able to obtain formatting software from the manufacturer, usually for Windows. Make sure the software matches the drive you plan to format and follow the manufacturer’s directions carefully.7
SCSI disks format themselves in response to a standard command that you send from the host computer. The procedure for sending this command varies from system to system. On PCs, you can often send the command from the SCSI controller’s BIOS. To issue the SCSI format command from within the operating system, use the sg_format command on Linux, the format command on Solaris, and the mediainit command on HP-UX.
Various utilities let you verify the integrity of a disk by writing random patterns to it and then reading them back. Thorough tests take a long time (hours) and unfortunately seem to be of little prognostic value. Unless you suspect that a disk is bad and are unable to simply replace it (or you bill by the hour), you should skip these tests. Barring that, let the tests run overnight. Don’t be concerned about “wearing out” a disk with overuse or aggressive testing. Enterprise-class disks are designed for constant activity.
Since 2000, PATA and SATA disks have implemented a “secure erase” command that overwrites the data on the disk by using a method the manufacturer has determined to be secure against recovery efforts. Secure erase is NIST-certified for most needs. Under the U.S. Department of Defense categorization, it’s approved for use at security levels less than “secret.”
Why is this feature even needed? First, filesystems generally do no erasing of their own, so an rm -rf * of a disk’s data leaves everything intact and recoverable with software tools. It’s critically important to remember this fact when disposing of disks, whether their destination is eBay or the trash.
Second, even a manual rewrite of every sector on a disk may leave magnetic traces that are recoverable by a determined attacker with access to a laboratory. Secure erase performs as many overwrites as are needed to eliminate these shadow signals. Magnetic remnants won’t be a serious concern for most sites, but it’s always nice to know that you’re not exporting your organization’s confidential data to the world at large.
Finally, secure erase has the effect of resetting SSDs to their fully erased state. This reset may improve performance in cases in which the ATA TRIM command (the command to erase a block) cannot be issued, either because the filesystem used on the SSD does not know to issue it or because the SSD is connected through a host adapter or RAID interface that does not propagate TRIM.
Unfortunately, UNIX support for sending the secure erase command remains elusive. At this point, your best bet is to reconnect drives to a Windows or Linux system for erasure. DOS software for secure erasing can be found at the Center of Magnetic Recording Research at tinyurl.com/2xoqqw. The MHDD utility also supports secure erase through its fasterase command—see tinyurl.com/2g6r98.
Under Linux, you can use the hdparm command:

There is no analog in the SCSI world to ATA’s secure erase command, but the SCSI “format unit” command described under Formatting and bad block management on page 226 is a reasonable alternative. Another option is to zero-out a drive’s sectors with dd if=/dev/zero of=diskdevice bs=8k.
Many systems have a shred utility that attempts to securely erase the contents of individual files. Unfortunately, it relies on the assumption that a file’s blocks can be overwritten in place. This assumption is invalid in so many circumstances (any filesystem on any SSD, any logical volume that has snapshots, perhaps generally on ZFS) that shred’s general utility is questionable.
For sanitizing an entire PC system at once, another option is Darik’s Boot and Nuke (dban.org). This tool runs from its own boot disk, so it’s not a tool you’ll use every day. It is quite handy for decommissioning old hardware, however.
Linux’s hdparm command can do more than just send secure erase commands. It’s a general way to interact
with the firmware of SATA, IDE, and SAS hard disks. Among other things, hdparm can set drive power options, enable or disable noise reduction options, set the read-only
flag, and print detailed drive information. A few of the options work on SCSI drives,
too (under current Linux kernels).
The syntax is
hdparm [options] device
Scores of options are available, but most are of interest only to driver and kernel developers. Table 8.3. shows a few that are relevant to administrators.

Table 8.3. Useful hdparm options system administrators.
Use hdparm -I to verify that each drive is using the fastest possible DMA transfer mode. hdparm lists all the disk’s supported modes and marks the currently active mode with a star, as shown in the example below.

On any modern system, the optimal DMA mode should be selected by default; if this is not the case, check the BIOS and kernel logs for relevant information to determine why not.
Many drives offer acoustic management, which slows down the motion of the read/write head to attenuate the ticking or pinging sounds it makes. Drives that support acoustic management usually come with the feature turned on, but that’s probably not what you want for production drives that live in a server room. Disable this feature with hdparm -M 254.
Most power consumed by hard disks goes to keep the platters spinning. If you have disks that see only occasional use and you can afford to delay access by 20 seconds or so as the motors are restarted, run hdparm -S to turn on the disks’ internal power management feature. The argument to -S sets the idle time after which the drive enters standby mode and turns off the motor. It’s a one-byte value, so the encoding is somewhat nonlinear. For example, values between 1 and 240 are in multiples of 5 seconds, and values from 241 to 251 are in units of 30 minutes. hdparm shows you its interpretation of the value when you run it; it’s faster to guess, adjust, and repeat than to look up the detailed coding rules.
hdparm includes a simple drive performance test to help evaluate the impact of configuration changes. The -T option reads from the drive’s cache and indicates the speed of data transfer on the bus, independent of throughput from the physical disk media. The -t option reads from the physical platters. As you might expect, physical reads are a lot slower.

100 MB/s or so is about the limit of today’s mass-market 1TB drives, so these results (and the information shown by hdparm -I above) confirm that the drive is correctly configured.
Hard disks are fault-tolerant systems that use error-correction coding and intelligent firmware to hide their imperfections from the host operating system. In some cases, an uncorrectable error that the drive is forced to report to the OS is merely the latest event in a long crescendo of correctable but inauspicious problems. It would be nice to know about those omens before the crisis occurs.
ATA devices, including SATA drives, implement a detailed form of status reporting that is sometimes predictive of drive failures. This standard, called SMART for “self-monitoring, analysis, and reporting technology,” exposes more than 50 operational parameters for investigation by the host computer.
The Google disk drive study mentioned on page 211 has been widely summarized in media reports as concluding that SMART data is not predictive of drive failure. That summary is not accurate. In fact, Google found that four SMART parameters were highly predictive of failure but that failure was not consistently preceded by changes in SMART values. Of failed drives in the study, 56% showed no change in the four most predictive parameters. On the other hand, predicting nearly half of failures sounds pretty good to us!
Those four sensitive SMART parameters are scan error count, reallocation count, off-line reallocation count, and number of sectors “on probation.” Those values should all be zero. A nonzero value in these fields raises the likelihood of failure within 60 days by a factor of 39, 14, 21, or 16, respectively.
To take advantage of SMART data, you need software that queries your drives to obtain it and then judges whether the current readings are sufficiently ominous to warrant administrator notification. Unfortunately, reporting standards vary by drive manufacturer, so decoding isn’t necessarily straightforward. Most SMART monitors collect baseline data and then look for sudden changes in the “bad” direction rather than interpreting absolute values. (According to the Google study, taking account of these “soft” SMART indicators in addition to the Big Four predicts 64% of all failures.)
The standard software for SMART wrangling on UNIX and Linux systems is the smartmontools package from smartmontools.sourceforge.net. It’s installed by default on SUSE and Red Hat systems; on Ubuntu, you’ll have to run apt-get install smartmontools. The package does run on Solaris systems if you build it from the source code.
The smartmontools package consists of a smartd daemon that monitors drives continuously and a smartctl command you can use for interactive queries or for scripting. The daemon has a single configuration file, normally /etc/smartd.conf, which is extensively commented and includes plenty of examples.
SCSI has its own system for out-of-band status reporting, but unfortunately the standard is much less granular in this respect than is SMART. The smartmontools attempt to include SCSI devices in their schema, but the predictive value of the SCSI data is less clear.
Partitioning and logical volume management are both ways of dividing up a disk (or pool of disks, in the case of LVM) into separate chunks of known size. All our example systems support logical volume management, but only Linux, Solaris, and sometimes HP-UX allow traditional partitioning.
You can put individual partitions under the control of a logical volume manager, but you can’t partition a logical volume. Partitioning is the lowest possible level of disk management.
On Solaris, partitioning is required but essentially vestigial; ZFS hides it well
enough that you may not even be aware that it’s occurring. This section contains some
general background information that may be useful to Solaris administrators, but from
a procedural standpoint, the Solaris path diverges rather sharply from that of Linux,
HP-UX, and AIX. Skip ahead to ZFS: all your storage problems solved on page 264 for details. (Or don’t: zpool create newpool newdevice pretty much covers basic configuration.)
Both partitions and logical volumes make backups easier, prevent users from poaching each other’s disk space, and confine potential damage from runaway programs. All systems have a root “partition” that includes / and most of the local host’s configuration data. In theory, everything needed to bring the system up to single-user mode is part of the root partition. Various subdirectories (most commonly /var, /usr, /tmp, /share, and /home) may be broken out into their own partitions or volumes. Most systems also have at least one swap area.
Opinions differ on the best way to divide up disks, as do the defaults used by various systems. Here are some general points to guide you:
• It’s a good idea to have a backup root device that you can boot to if something goes wrong with the normal root partition. Ideally, the backup root lives on a different disk from the normal root so that it can protect against both hardware problems and corruption. However, even a backup root on the same disk has some value.9
• Verify that you can boot from your backup root. The procedure is often nontrivial. You may need special boot-time arguments to the kernel and minor configuration tweaks within the alternate root itself to get everything working smoothly.
• Since the root partition is often duplicated, it should also be small so that having two copies doesn’t consume an unreasonable amount of disk space. This is the major reason that /usr is often a separate volume; it holds the bulk of the system’s libraries and data.
• Putting /tmp on a separate filesystem limits temporary files to a finite size and saves you from having to back them up. Some systems use a memory-based filesystem to hold /tmp for performance reasons. The memory-based filesystems are still backed by swap space, so they work well in a broad range of situations.
• Since log files are kept in /var, it’s a good idea for /var to be a separate disk partition. Leaving /var as part of a small root partition makes it easy to fill the root and bring the machine to a halt.
• It’s useful to put users’ home directories on a separate partition or volume. Even if the root partition is corrupted or destroyed, user data has a good chance of remaining intact. Conversely, the system can continue to operate even after a user’s misguided shell script fills up /home.
• Splitting swap space among several physical disks increases performance. This technique works for filesystems, too; put the busy ones on different disks. See page 1129 for notes on this subject.
• As you add memory to your machine, you should also add swap space. See page 1124 for more information about virtual memory.
• Backups of a partition may be simplified if the entire partition can fit on one piece of media. See page 294.
• Try to cluster quickly-changing information on a few partitions that are backed up frequently.
Systems that allow partitions implement them by writing a “label” at the beginning of the disk to define the range of blocks included in each partition. The exact details vary; the label must often coexist with other startup information (such as a boot block), and it often contains extra information such as a name or unique ID that identifies the disk as a whole. Under Windows, the label is known as the MBR, or master boot record.
The device driver responsible for representing the disk reads the label and uses the partition table to calculate the physical location of each partition. Typically, one or two device files represent each partition (one block device and one character device; Linux has only block devices). Also, a separate set of device files represents the disk as a whole.
Solaris calls partitions “slices,” or more accurately, it calls them slices when
they are implemented with a Solaris-style label and partitions when they are implemented
with a Windows-style MBR. Slice 2 includes the entire expanse of the disk, illustrating
the rather frightening truth that more than one slice can claim a given disk block.
Perhaps the word “slices” was selected because “partition” suggests a simple division,
whereas slices can overlap. The terms are otherwise interchangeable.
Despite the universal availability of logical volume managers, some situations still require or benefit from traditional partitioning.
• On PC hardware, the boot disk must have a partition table. Most systems require MBR partitioning (see Windows-style partitioning, next), but Itanium systems require GPT partitions (page 235). Data disks may remain unpartitioned.
See page 85 for more information about dual booting with Windows.
• Installing a Windows-style MBR makes the disk comprehensible to Windows, even if the contents of the individual partitions are not. If you want to interoperate with Windows (say, by dual booting), you’ll need to install a Windows MBR. But even if you have no particular ambitions along those lines, it may be helpful to consider the ubiquity of Windows and the likelihood that your disk will one day come in contact with it.
Current versions of Windows are well behaved and would never dream of writing randomly to a disk they can’t decipher. However, they will certainly suggest this course of action to any administrator who logs in. The dialog box even sports a helpful “OK, mess up this disk!” button.10 Nothing bad will happen unless someone makes a mistake, but safety is a structural and organizational process.
• Partitions have a defined location on the disk, and they guarantee locality of reference. Logical volumes do not (at least, not by default). In most cases, this fact isn’t terribly important. However, short seeks are faster than long seeks, and the throughput of a disk’s outer cylinders (those containing the lowest-numbered blocks) can exceed the throughput of its inner cylinders by 30% or more.11 For situations in which every ounce of performance counts, you can use partitioning to gain an extra edge. (You can always use logical volume management inside partitions to regain some of the lost flexibility.)
• RAID systems (see page 237) use disks or partitions of matched size. A given RAID implementation may accept entities of different sizes, but it will probably only use the block ranges that all devices have in common. Rather than letting extra space go to waste, you can isolate it in a separate partition. If you do this, however, you should use the spare partition for data that is infrequently accessed; otherwise, use of the partition will degrade the performance of the RAID array.
The Windows MBR occupies a single 512-byte disk block, most of which is consumed by boot code. Only enough space remains to define four partitions. These are termed “primary” partitions because they are defined directly in the MBR.
You can define one of the primary partitions to be an “extended” partition, which means that it contains its own subsidiary partition table. The extended partition is a true partition, and it occupies a defined physical extent on the disk. The subsidiary partition table is stored at the beginning of that partition’s data.
Partitions that you create within the extended partition are called secondary partitions. They are proper subsets of the extended partition.
Keep the following rules of thumb in mind when setting up Windows-partitioned disks. The first is an actual rule. The others exist only because certain BIOSes, boot blocks, or operating systems may require them.
• There can be only one extended partition on a disk.
• The extended partition should be the last of the partitions defined in the MBR; no primary partitions should come after it.
• Some older operating systems don’t like to be installed in secondary partitions. To avoid trouble, stick to primary partitions for OS installations.
The Windows partitioning system lets one partition be marked “active.” Boot loaders look for the active partition and try to load the operating system from it.
Each partition also has a one-byte type attribute that is supposed to indicate the partition’s contents. Generally, the codes represent either filesystem types or operating systems. These codes are not centrally assigned, but over time some common conventions have evolved. They are summarized by Andries E. Brouwer at tinyurl.com/part-types.
The MS-DOS command that partitioned hard disks was called fdisk. Most operating systems that support Windows-style partitions have adopted this name for their own partitioning commands, but there are many variations among fdisks. Windows itself has moved on: the command-line tool in recent versions is called diskpart. Windows also has a partitioning GUI that’s available through the Disk Management plug-in of mmc.
It does not matter whether you partition a disk with Windows or some other operating system. The end result is the same.
Intel’s extensible firmware interface (EFI) project aims to replace the rickety conventions of PC BIOSes with a more modern and functional architecture.12 Al-though systems that use full EFI firmware are still uncommon, EFI’s partitioning scheme has gained widespread support among operating systems. The main reason for this success is that MBR does not support disks larger than 2TB in size. Since 2TB disks are already widely available, this problem has become a matter of some urgency.
The EFI partitioning scheme, known as a “GUID partition table” or GPT, removes the obvious weaknesses of MBR. It defines only one type of partition, and you can create arbitrarily many of them. Each partition has a type specified by a 16-byte ID code (the globally unique ID, or GUID) that requires no central arbitration.
Significantly, GPT retains primitive compatibility with MBR-based systems by dragging along an MBR as the first block of the partition table. This “fakie” MBR makes the disk look like it’s occupied by one large MBR partition (at least, up to the 2TB limit of MBR). It isn’t useful per se, but the hope is that the decoy MBR may at least prevent naïve systems from attempting to reformat the disk.
Versions of Windows from the Vista era forward support GPT disks for data, but only systems with EFI firmware can boot from them. Linux and its GRUB boot loader have fared better: GPT disks are supported by the OS and bootable on any system. Intel-based Mac OS systems use both EFI and GPT partitioning. Solaris understands GPT partitioning, and ZFS uses it by default. However, Solaris boot disks cannot use GPT partitioning.
Although GPT has already been well accepted by operating system kernels, its support among disk management utilities is still spotty. GPT remains a “bleeding edge” format. There is no compelling reason to use it on disks that don’t require it (that is, disks 2TB in size or smaller).
Linux systems give you several options for partitioning. fdisk is a basic command-line partitioning tool. GNU’s parted is a fancier command-line tool that understands several label formats (including
Solaris’s native one) and can move and re-size partitions in addition to simply creating
and deleting them. A GUI version, gparted, runs under GNOME. Another possibility is cfdisk, which is a nice, terminal-based alternative to fdisk.
parted and gparted can theoretically resize several types of filesystems along with the partitions that contain them, but the project home page describes this feature as “buggy and unreliable.” Filesystem-specific utilities are likely to do a better job of adjusting filesystems, but unfortunately, parted does not have a “resize the partition but not the filesystem” command. Go back to fdisk if this is what you need.
In general, we recommend gparted over parted. Both are simple, but gparted lets you specify the size of the partitions you want instead of specifying the starting and ending block ranges. For partitioning the boot disk, most distributions’ graphical installers are the best option since they typically suggest a partitioning plan that works well with that particular distribution’s layout.
ZFS automatically labels disks for you, applying a GPT partition table. However,
you can also partition disks manually with the format command. On x86 systems, an fdisk command is also available. Both interfaces are menu driven and relatively straightforward.
format gives you a nice list of disks to choose from, while fdisk requires you to specify the disk on the command line. Fortunately, format has an fdisk command that runs fdisk as a subprocess, so you can use format as a kind of wrapper to help you pick the right disk.
Solaris understands three partitioning schemes: Windows MBR, GPT, and old-style Solaris partition tables, known as SMI. You must use MBR or SMI for the boot disk, depending on the hardware and whether you are running Solaris or OpenSolaris. For now, it’s probably best to stick to these options for all manually partitioned disks under 2TB.
HP uses disk partitioning only on Itanium (Integrity) boot disks, on which a GPT
partition table and an EFI boot partition are required. The idisk command prints and creates partition tables. Rather than being an interactive partitioning
utility, it reads a partitioning plan from a file or from standard input and uses
that to construct the partition table.
An idisk partitioning specification is mercifully straightforward. The first line contains only a number that specifies the number of partitions to create. Each following line contains a partition type (EFI, HPUX, HPDUMP, or HPSP for swap), a space character, and a size specification such as 128MB or 100%. If a percentage is used, it is interpreted relative to the space remaining on the drive after the preceding partitions have been allocated.
Even with backups, the consequences of a disk failure on a server can be disastrous. RAID, “redundant arrays of inexpensive disks,” is a system that distributes or replicates data across multiple disks.13 RAID not only helps avoid data loss but also minimizes the downtime associated with hardware failures (often to zero) and potentially increases performance.
RAID can be implemented by dedicated hardware that presents a group of hard disks to the operating system as a single composite drive. It can also be implemented simply by the operating system’s reading or writing multiple disks according to the rules of RAID.
Because the disks themselves are always the most significant bottleneck in a RAID implementation, there is no reason to assume that a hardware-based implementation of RAID will necessarily be faster than a software- or OS-based implementation. Hardware RAID has been predominant in the past for two main reasons: lack of software alternatives (no direct OS support for RAID) and hardware’s ability to buffer writes in some form of nonvolatile memory.
The latter feature does improve performance because it makes writes appear to complete instantaneously. It also protects against a potential corruption issue called the “RAID 5 write hole,” which we describe in more detail starting on page 241. But beware: many of the common “RAID cards” sold for PCs have no non-volatile memory at all; they are really just glorified SATA interfaces with some RAID software onboard. RAID implementations on PC motherboards fall into this category as well. You’re really much better off using the RAID features in Linux or OpenSolaris on these systems.
We recently experienced a disk controller failure on an important production server. Although the data was replicated across several physical drives, a faulty hardware RAID controller destroyed the data on all disks. A lengthy and ugly tape restore process ensued, and it was more than two months before the server had completely recovered. The rebuilt server now relies on the kernel’s software to manage its RAID environment, removing the possibility of another RAID controller failure.
RAID can do two basic things. First, it can improve performance by “striping” data across multiple drives, thus allowing several drives to work simultaneously to supply or absorb a single data stream. Second, it can replicate data across multiple drives, decreasing the risk associated with a single failed disk.
Replication assumes two basic forms: mirroring, in which data blocks are reproduced bit-for-bit on several different drives, and parity schemes, in which one or more drives contain an error-correcting checksum of the blocks on the remaining data drives. Mirroring is faster but consumes more disk space. Parity schemes are more disk-space-efficient but have lower performance.
RAID is traditionally described in terms of “levels” that specify the exact details of the parallelism and redundancy implemented by an array. The term is perhaps misleading because “higher” levels are not necessarily “better.” The levels are simply different configurations; use whichever versions suit your needs.
In the following illustrations, numbers identify stripes and the letters a, b, and c identify data blocks within a stripe. Blocks marked p and q are parity blocks.
• “Linear mode,” also known as JBOD (for “just a bunch of disks”) is not even a real RAID level. And yet, every RAID controller seems to implement it. JBOD concatenates the block addresses of multiple drives to create a single, larger virtual drive. It provides no data redundancy or performance benefit. These days, JBOD functionality is best achieved through a logical volume manager rather than a RAID controller.
• RAID level 0 is used strictly to increase performance. It combines two or more drives of equal size, but instead of stacking them end-to-end, it stripes data alternately among the disks in the pool. Sequential reads and writes are therefore spread among several disks, decreasing write and access times.
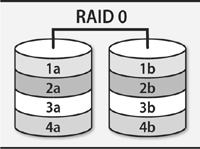
Note that RAID 0 has reliability characteristics that are significantly inferior to separate disks. A two-drive array has roughly double the annual failure rate of a single drive, and so on.
• RAID level 1 is colloquially known as mirroring. Writes are duplicated to two or more drives simultaneously. This arrangement makes writes slightly slower than they would be on a single drive. However, it offers read speeds comparable to RAID 0 because reads can be farmed out among the several duplicate disk drives.
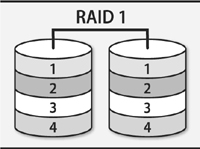
• RAID levels 1+0 and 0+1 are stripes of mirror sets or mirrors of stripe sets. Logically, they are concatenations of RAID 0 and RAID 1, but many controllers and software implementations provide direct support for them. The goal of both modes is to simultaneously obtain the performance of RAID 0 and the redundancy of RAID 1.
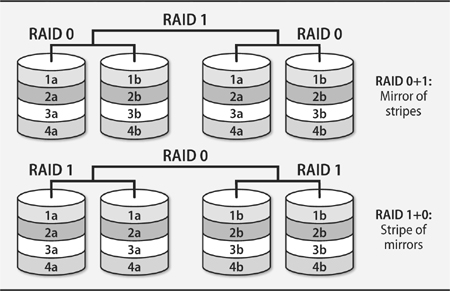
• RAID level 5 stripes both data and parity information, adding redundancy while simultaneously improving read performance. In addition, RAID 5 is more efficient in its use of disk space than is RAID 1. If there are N drives in an array (at least three are required), N–1 of them can store data. The space-efficiency of RAID 5 is therefore at least 67%, whereas that of mirroring cannot be higher than 50%.
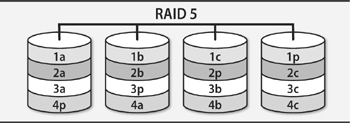
• RAID level 6 is similar to RAID 5 with two parity disks. A RAID 6 array can withstand the complete failure of two drives without losing data.
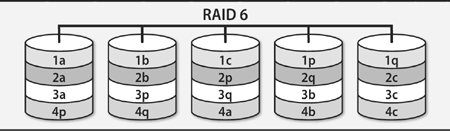
RAID levels 2, 3, and 4 are defined but are rarely deployed. Logical volume managers usually include both striping (RAID 0) and mirroring (RAID 1) features.
For simple striped and mirrored configurations, Linux gives you a choice of using
a dedicated RAID system (md; see page 242) or the logical volume manager. The LVM approach is perhaps more flexible,
while the md approach may be a bit more rigorously predictable. If you opt for md, you can still use LVM to manage the space on the RAID volume. For RAID 5 and RAID
6, you must use md to implement software RAID.
As a RAID system, logical volume manager, and filesystem all rolled into one, Solaris’s
ZFS system supports striping, mirroring, and configurations similar to RAID 5 and
RAID 6. The ZFS architecture puts mirroring and parity arrangements on the lowest
level, whereas striping is done per storage pool (one level up) and is automatic.
This is a nice way to arrange the features because it preserves the clarity of the
RAID configuration. See page 264 for more details on ZFS.
 Logical volume management is the extent of OS-level support for RAID on HPUX and
AIX. (HP even makes you purchase the mirroring feature separately, although it is
bundled in certain enterprise configurations.) If you want a parity-based system,
you’ll need some additional hardware. AIX does come with tools for administering RAID hardware already integrated, however: see Disk Array under
Devices in SMIT.
Logical volume management is the extent of OS-level support for RAID on HPUX and
AIX. (HP even makes you purchase the mirroring feature separately, although it is
bundled in certain enterprise configurations.) If you want a parity-based system,
you’ll need some additional hardware. AIX does come with tools for administering RAID hardware already integrated, however: see Disk Array under
Devices in SMIT.
The Google disk failure study cited on page 211 should be pretty convincing evidence of the need for some form of storage redundancy in most production environments. At an 8% annual failure rate, your organization needs only 150 hard disks in service to expect an average of one failure per month.
JBOD and RAID 0 modes are of no help when hardware problems occur; you must recover your data manually from backups. Other forms of RAID enter a degraded mode in which the offending devices are marked as faulty. The RAID arrays continue to function normally from the perspective of storage clients, although perhaps at reduced performance.
Bad disks must be swapped out for new ones as soon as possible to restore redundancy to the array. A RAID 5 array or two-disk RAID 1 array can only tolerate the failure of a single device. Once that failure has occurred, the array is vulnerable to a second failure.
The specifics of the process are usually pretty simple. You replace the failed disk with another of similar or greater size, then tell the RAID implementation to replace the old disk with the new one. What follows is an extended period during which the parity or mirror information is rewritten to the new, blank disk. Often, this is an overnight operation. The array remains available to clients during this phase, but performance is likely to be very poor.
To limit downtime and the vulnerability of the array to a second failure, most RAID implementations let you designate one or more disks as “hot” spares. When a failure occurs, the faulted disk is automatically swapped for a spare, and the process of resynchronizing the array begins immediately. Where supported, hot spares should be used as a matter of course.
RAID 5 is a popular configuration, but it has some weaknesses, too. The following issues apply to RAID 6 also, but for simplicity we frame the discussion in terms of RAID 5.
See Chapter 10, Backups, for general advice about backing up the system.
First, it’s critically important to note that RAID 5 does not replace regular off-line backups. It protects the system against the failure of one disk—that’s it. It does not protect against the accidental deletion of files. It does not protect against controller failures, fires, hackers, or any number of other hazards.
Second, RAID 5 isn’t known for its great write performance. RAID 5 writes data blocks to N–1 disks and parity blocks to the Nth disk.14 Whenever a random block is written, at least one data block and the parity block for that stripe must be updated. Furthermore, the RAID system doesn’t know what the new parity block should contain until it has read the old parity block and the old data. Each random write therefore expands into four operations: two reads and two writes. (Sequential writes may fare better if the implementation is smart.)
Finally, RAID 5 is vulnerable to corruption in certain circumstances. Its incremental updating of parity data is more efficient than reading the entire stripe and recalculating the stripe’s parity based on the original data. On the other hand, it means that at no point is parity data ever validated or recalculated. If any block in a stripe should fall out of sync with the parity block, that fact will never become evident in normal use; reads of the data blocks will still return the correct data.
Only when a disk fails does the problem become apparent. The parity block will likely have been rewritten many times since the occurrence of the original desynchronization. Therefore, the reconstructed data block on the replacement disk will consist of essentially random data.
This kind of desynchronization between data and parity blocks isn’t all that unlikely, either. Disk drives are not transactional devices. Without an additional layer of safeguards, there is no simple way to guarantee that either two blocks or zero blocks on two different disks will be properly updated. It’s quite possible for a crash, power failure, or communication problem at the wrong moment to create data/parity skew.
This problem is known as the RAID 5 “write hole,” and it has received increasing attention over the last five years or so. One helpful resource is the web site of the Battle Against Any Raid Five,15 baarf.org, which points to a variety of editorials on the subject. You’ll have to decide for yourself whether the problem is significant or overblown. (We lean more toward “significant.”)
The implementors of Solaris’s ZFS filesystem claim that because ZFS uses variable-width stripes, it is immune to the RAID 5 write hole. That’s also why ZFS calls its RAID implementation RAID-Z instead of RAID 5, though in practice the concept is similar.
Another potential solution is “scrubbing,” validating parity blocks one by one while the array is relatively idle. Many RAID implementations include some form of scrubbing function.
The standard software RAID implementation for Linux is called md, the “multiple disks” driver. It’s front-ended by the mdadm command. md supports all the RAID configurations listed above as well as RAID 4. An earlier system known as raidtools is no longer used.
The following example scenario configures a RAID 5 array composed of three identical 500GB hard disks. Although md can use raw disks as components, we prefer to give each disk a partition table for consistency, so we start by running gparted, creating an MBR partition table on each disk (gparted refers to this as the “msdos” style of partition table), and assigning all the disk’s space to a single partition of type “unformatted” (which is unfortunately about as close as you can get to the actual use). It’s not strictly necessary to set the partition type, but it’s a useful reminder to anyone who might inspect the table later. There is also a “raid” flag bit you can set on a partition, although gparted doesn’t make this easy: you must create the partition, execute the pending operations, and then go back to the new partition and edit its flags.
The following command builds a RAID 5 array from our three SCSI partitions:
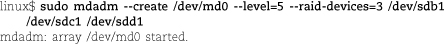
The virtual file /proc/mdstat always contains a summary of md’s status and the status of all the system’s RAID arrays. It is especially useful to keep an eye on the /proc/mdstat file after adding a new disk or replacing a faulty drive. (watch cat /proc/mdstat is a handy idiom.)

The md system does not keep track of which blocks in an array have been used, so it must manually synchronize all the parity blocks with their corresponding data blocks. md calls the operation a “recovery” since it’s essentially the same procedure used when you swap out a bad hard disk. It can take hours on a large array.
Some helpful notifications appear in the /var/log/messages file, too.
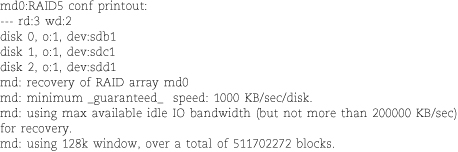
The initial creation command also serves to “activate” the array (make it available for use), but on subsequent reboots it may be necessary to activate the array as a separate step, usually out of a startup script. Red Hat and SUSE include sample startup scripts for RAID, and Ubuntu starts arrays by default.
mdadm does not technically require a configuration file, although it will use a configuration file if one is supplied (typically, /etc/mdadm.conf). We strongly recommend the use of a configuration file. It documents the RAID configuration in a standard way, thus giving administrators an obvious place to look for information when problems occur. The alternative to the use of a configuration file is to specify the configuration on the command line each time the array is activated.
mdadm --detail --scan dumps the current RAID setup into a configuration file. Unfortunately, the configuration it prints is not quite complete. The following commands build a complete configuration file for our example setup:

mdadm can now read this file at startup or shutdown to easily manage the array. To enable the array at startup by using the freshly created /etc/mdadm.conf, we would execute
$ sudo mdadm -As /dev/md0
To stop the array manually, we would use the command
$ sudo mdadm -S /dev/md0
Once you’ve set up the mdadm.conf file, print it out and tape it to the side of the server. It’s not always trivial to reconstruct the components of a RAID setup when something goes wrong.
mdadm has a --monitor mode in which it runs continuously as a daemon process and notifies you by email when problems are detected on a RAID array. Use this feature! To set it up, add a MAILADDR line to your mdadm.conf file to specify the recipient to whom warnings should be sent, and arrange for the monitor daemon to run at boot time. All our example distributions have an init script that does this for you, but the names and procedures for enabling are slightly different.

What happens when a disk actually fails? Let’s find out! mdadm offers a handy option that simulates a failed disk.
Because RAID 5 is a redundant configuration, the array continues to function in degraded mode, so users will not necessarily be aware of the problem.
To remove the drive from the RAID configuration, use mdadm -r:
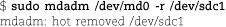
Once the disk has been logically removed, you can shut down the system and replace the drive. Hot-swappable drive hardware lets you make the change without turning off the system or rebooting.
If your RAID components are raw disks, you should replace them with an identical drive only. Partition-based components can be replaced with any partition of similar size, although for bandwidth matching it’s best if the drive hardware is similar. (If your RAID configuration is built on top of partitions, you must run a partitioning utility to define the partitions appropriately before adding the replacement disk to the array.)
In our example, the failure is just simulated, so we can add the drive back to the array without replacing any hardware:

md will immediately start to rebuild the array. As always, you can see its progress in /proc/mdstat. A rebuild may take hours, so consider this fact in your disaster recovery plans.
Imagine a world in which you don’t know exactly how large a partition needs to be. Six months after creating the partition, you discover that it is much too large, but that a neighboring partition doesn’t have enough space… Sound familiar? A logical volume manager lets you reallocate space dynamically from the greedy partition to the needy partition.
Logical volume management is essentially a supercharged and abstracted version of disk partitioning. It groups individual storage devices into “volume groups.” The blocks in a volume group can then be allocated to “logical volumes,” which are represented by block device files and act like disk partitions.
However, logical volumes are more flexible and powerful than disk partitions. Here are some of the magical operations a volume manager lets you carry out:
• Move logical volumes among different physical devices
• Grow and shrink logical volumes on the fly
• Take copy-on-write “snapshots” of logical volumes
• Replace on-line drives without interrupting service
• Incorporate mirroring or striping in your logical volumes
The components of a logical volume can be put together in various ways. Concatenation keeps each device’s physical blocks together and lines the devices up one after another. Striping interleaves the components so that adjacent virtual blocks are actually spread over multiple physical disks. By reducing single-disk bottlenecks, striping can often provide higher bandwidth and lower latency.
All our example systems support logical volume management, and with the exception of Solaris’s ZFS, the systems are all quite similar.
In addition to ZFS, Solaris supports a previous generation of LVM called the Solaris
Volume Manager, formerly Solstice DiskSuite. This volume manager is still supported,
but new deployments should use ZFS.
Linux’s volume manager, called LVM2, is essentially a clone of HP-UX’s volume manager, which is itself based on software by Veritas. The commands for the two systems are essentially identical, but we show examples for both systems because their ancillary commands are somewhat different. AIX’s system has similar abstractions but different command syntax. Table 8.4. illustrates the parallels among these three systems.
In addition to commands that deal with volume groups and logical volumes, Table 8.4. also shows a couple of commands that relate to “physical volumes.” A physical volume is a storage device that has had an LVM label applied; applying such a label is the first step to using the device through the LVM. Linux and HP-UX use pvcreate to apply a label, but AIX’s mkvg does it automatically. In addition to bookkeeping information, the label includes a unique ID to identify the device.
Table 8.4. Comparison of LVM commands
“Physical volume” is a somewhat misleading term because physical volumes need not have a direct correspondence to physical devices. They can be disks, but they can also be disk partitions or RAID arrays. The LVM doesn’t care.
You can control Linux’s LVM implementation (LVM2) with either a large group of simple
commands (the ones illustrated in Table 8.4.) or with the single lvm command and its various subcommands. These options are for all intents and purposes
identical; in fact, the individual commands are really just links to lvm, which looks to see how it’s been called to know how to behave. man lvm is a good introduction to the system and its tools.
A Linux LVM configuration proceeds in a few distinct phases:
• Creating (defining, really) and initializing physical volumes
• Adding the physical volumes to a volume group
• Creating logical volumes on the volume group
LVM commands start with letters that make it clear at which level of abstraction they operate: pv commands manipulate physical volumes, vg commands manipulate volume groups, and lv commands manipulate logical volumes. A few commands with the prefix lvm (e.g., lvmchange) operate on the system as a whole.
In the following example, we set up the /dev/md0 RAID 5 device we created on page 243 for use with LVM and create a logical volume. Since striping and redundancy have already been addressed by the underlying RAID configuration, we won’t make use of the corresponding LVM2 features, although they exist.
Our physical device is now ready to be added to a volume group:
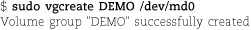
Although we’re using only a single physical device in this example, we could of course add additional devices. In this case, it would be strange to add anything but another RAID 5 array since there is no benefit to partial redundancy. DEMO is an arbitrary name that we’ve selected.
To step back and examine our handiwork, we use the vgdisplay command:

A “PE” is a physical extent, the allocation unit according to which the volume group is subdivided.
The final steps are to create the logical volume within DEMO and then to create a filesystem within that volume. We make the logical volume 100GB in size:
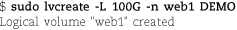
Most of LVM2’s interesting options live at the logical volume level. That’s where striping, mirroring, and contiguous allocation would be requested if we were using those features.
We can now access the volume through the device /dev/DEMO/web1. We discuss filesystems in general starting on page 254, but here is a quick overview of creating a standard filesystem so that we can demonstrate a few additional LVM tricks.
You can create copy-on-write duplicates of any LVM2 logical volume, whether or not it contains a filesystem. This feature is handy for creating a quiescent image of a filesystem to be backed up on tape, but unlike ZFS snapshots, LVM2 snapshots are unfortunately not very useful as a general method of version control.
The problem is that logical volumes are of fixed size. When you create one, storage space is allocated for it up front from the volume group. A copy-on-write duplicate initially consumes no space, but as blocks are modified, the volume manager must find space in which to store both the old and new versions. This space for modified blocks must be set aside when you create the snapshot, and like any LVM volume, the allocated storage is of fixed size.
Note that it does not matter whether you modify the original volume or the snapshot (which by default is writable). Either way, the cost of duplicating the blocks is charged to the snapshot. Snapshots’ allocations can be pared away by activity on the source volume even when the snapshots themselves are idle.
If you do not allocate as much space for a snapshot as is consumed by the volume of which it is an image, you can potentially run out of space in the snapshot. That’s more catastrophic than it sounds because the volume manager then has no way to maintain a coherent image of the snapshot; additional storage space is required just to keep the snapshot the same. The result of running out of space is that LVM stops maintaining the snapshot, and the snapshot becomes irrevocably corrupt.
So, as a matter of practice, LVM snapshots should be either short-lived or as large as their source volumes. So much for “lots of cheap virtual copies.”
To create /dev/DEMO/web1-snap as a snapshot of /dev/DEMO/web1, we would use the following command:
$ sudo lvcreate -L 100G -s -n web1-snap DEMO/web1
Note that the snapshot has its own name and that the source of the snapshot must be specified as volume_group/volume.
In theory, /mnt/web1 should really be unmounted first to ensure the consistency of the filesystem. In practice, ext4 will protect us against filesystem corruption, although we may lose a few of the most recent data block updates. This is a perfectly reasonable compromise for a snapshot used as a backup source.
To check on the status of your snapshots, run lvdisplay. If lvdisplay tells you that a snapshot is “inactive,” that means it has run out of space and should be deleted. There’s very little you can do with a snapshot once it reaches this point.
Filesystem overflows are more common than disk crashes, and one advantage of logical volumes is that they’re much easier to juggle and resize than are hard partitions. We have experienced everything from servers used for personal MP3 storage to a department full of email pack rats.
The logical volume manager doesn’t know anything about the contents of its volumes, so you must do your resizing at both the volume and filesystem levels. The order depends on the specific operation. Reductions must be filesystem-first, and enlargements must be volume-first. Don’t memorize these rules: just think about what’s actually happening and use common sense.
Suppose that in our example, /mnt/web1 has grown more than we predicted and needs another 10GB of space. We first check the volume group to be sure additional space is available.

Plenty of space is available, so we unmount the filesystem and use lvresize to add space to the logical volume.

The lvchange commands are needed to deactivate the volume for resizing and to reactivate it afterwards. This part is only needed because there is an existing snapshot of web1 from our previous example. After the resize operation, the snapshot will “see” the additional 10GB of allocated space, but since the filesystem it contains is only 100GB in size, the snapshot will still be usable.
We can now resize the filesytem with resize2fs. (The 2 comes from the original ext2 filesystem, but the command supports all versions of ext.) Since resize2fs can determine the size of the new filesystem from the volume, we don’t need to specify the new size explicitly. We would have to do so when shrinking the filesystem.

Oops! resize2fs forces you to double-check the consistency of the filesystem before resizing.

That’s it! Examining the output of df again shows the changes:

As of HP-UX 10.20, HP provides a full logical volume manager. It’s a nice addition,
especially when you consider that HP-UX formerly did not even support the notion of
disk partitions. The volume manager is called LVM, just as on Linux, although the
HP-UX version is in fact the original. (Really, it’s Veritas software…)
As a simple example of LVM wrangling, here’s how you would configure a 75GB hard disk for use with the logical volume manager. If you have read through the Linux example above, the following procedure will seem eerily familiar. There are a few minor differences, but the overall process is essentially the same.
The pvcreate command identifies physical volumes.
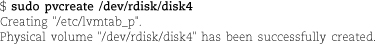
If you will be using the disk as a boot disk, add the -B option to pvcreate to reserve space for a boot block, then run mkboot to install it.
After defining the disk as a physical volume, you add it to a new volume group with the vgcreate command. Two metadata formats exist for volume groups, versions 1.0 and 2.0. You specify which version you want with the -V option when creating a volume group; version 1.0 remains the default. Version 2.0 has higher size limits, but it’s not usable for boot devices or swap volumes. Even version 1.0 metadata has quite generous limits, so it should be fine for most uses. You can see the exact limits with lvmadm. For reference, here are the limits for 1.0:

You can add extra disks to a volume group with vgextend, but this example volume group contains only a single disk.

Once your disks have been added to a convenient volume group, you can split the volume group’s pool of disk space back into logical volumes. The lvcreate command creates a new logical volume. Specify the size of the volume in megabytes with the -L flag or in logical extents (typically 4MiB) with the -l flag. Sizes specified in MiB are rounded up to the nearest multiple of the logical extent size.
To assess the amount of free space remaining in a volume group, run vgdisplay vgname as root. The output includes the extent size and the number of unallocated extents.

The command above creates a 25GB logical volume named web1. Once you’ve created your logical volumes, you can verify them by running vgdisplay -v/dev/vgname to double-check their sizes and make sure they were set up correctly.
In most scenarios, you would then go on to create a filesystem on /dev/vg01/web1 and arrange for it to be mounted at boot time. See page 258 for details.
Another common way to create a logical volume is to use lvcreate to create a zero-length volume and then use lvextend to add storage to it. That way, you can specify exactly which physical volumes in the volume group should compose the logical volume. If you allocate space with lvcreate (as we did above), it simply uses free extents from any available physical volumes in the volume group—good enough for most situations.
As in Linux, striping (which HP-UX’s LVM refers to as “distributed allocation”) and mirroring are features at the logical volume level. You can request them at the time the logical volume is created with lvcreate, or later with lvchange. In contrast to Linux, the logical volume manager does not allow snapshots. However, temporary snapshots are available as a feature of HP’s VxFS filesystem.
If you plan to use a logical volume as a boot or swap device or to store system core dumps, you must specify contiguous allocation and turn off bad block remapping with the -C and -r flags to lvcreate, as shown below.16

You must then run the lvlnboot command to notify the system of the new root and swap volumes. See the man page for lvlnboot for more information about the special procedures for creating boot, swap, and dump volumes.
AIX’s logical volume manager uses a different command set from the volume managers
of Linux and HP-UX, but its underlying architecture and approach are similar. One
potentially confusing point is that AIX calls the objects more commonly known as extents
(that is, the units of space allocation within a volume group) “partitions.” Because
the entities normally referred to as partitions do not exist in AIX, there is no ambiguity within the AIX sphere itself. However, tourists
visiting from other systems may wish to bring along an AIX phrase book.
In other respects—physical volume, volume group, logical volume—AIX terminology is standard. The SMIT interface for logical volume management is pretty complete, but you can also use the commands listed in Table 8.4.
The following four commands create a volume group called webvg, a logical volume called web1 within it, and a JFS2 filesystem inside web1. The filesystem is then mounted in /mnt/web1.

AIX does not require you to label disks to turn them into physical volumes. mkvg and extendvg automatically label disks as part of the induction process. Note that mkvg takes a device name and not the path to a disk device.
You can create the logical volume and the filesystem inside it in separate steps (with mklv and mkfs, respectively), but crfs performs both tasks for you and updates /etc/filesystems as well. The exact name of the logical volume device that holds the filesystem is made up for you in the crfs scenario, but you can determine it by inspecting /etc/filesystems or running mount. (On the other hand, it can be hard to unscramble filesystems in the event of problems if the volumes all have generic names.)
If you run mklv directly, you can specify not only a device name of your choosing but also various options to the volume manager such as striping and mirroring configurations. Snapshots are implemented through the JFS2 filesystem and not through the volume manager.
Even after a hard disk has been conceptually divided into partitions or logical volumes, it is still not ready to hold files. All the abstractions and goodies described in Chapter 6, The Filesystem, must be implemented in terms of raw disk blocks. The filesystem is the code that implements these, and it needs to add a bit of its own overhead and data.
The Berkeley Fast File System implemented by McKusick et al. in the 1980s was an early standard that spread to many UNIX systems. With some small adjustments, it eventually became known as the UNIX File System (UFS) and formed the basis of several other filesystem implementations, including Linux’s ext series, Solaris’s UFS, and IBM’s JFS.
Early systems bundled the filesystem implementation into the kernel, but it soon became apparent that support for multiple filesystem types was an important design goal. UNIX systems developed a well-defined kernel interface that allowed multiple types of filesystems to be active at once. The filesystem interface also abstracted the underlying hardware, so filesystems see approximately the same interface to storage devices as do other UNIX programs that access the disks through device files in /dev.
Support for multiple filesystem types was initially motivated by the need to support NFS and filesystems for removable media. But once the floodgates were opened, the “what if ” era began; many different groups started to work on improved filesystems. Some were system specific, and others (such as ReiserFS) were not tied to any particular OS.
Given that you may have a choice of filesystems, should you investigate the various alternatives and choose the “best” one? Unless you’re setting up a data disk for a very specific application, no. In nearly all situations, it’s better to stick with the system’s defaults. That’s what the system’s documentation and administrative tools probably assume.
Only a few features are truly non-negotiable:
• Good performance
• Tolerance for crashes and power outages without filesystem corruption
• The ability to handle disks and filesystems large enough for your needs
Fortunately, modern systems’ default filesystems already cover these bases. Any improvement you might see from changing filesystems will be marginal and context dependent at best.
The next sections discuss the default filesystems on Linux, HP-UX, and AIX. The ZFS filesystem used by Solaris is administered differently and merits an entire section of its own; that section starts on page 264.
The “second extended filesystem,” ext2, was for a long time the mainstream Linux
standard. It was designed and implemented primarily by Rémy Card, Theodore Ts’o, and
Stephen Tweedie. Although the code for ext2 was written specifically for Linux, it
is functionally similar to the Berkeley Fast File System.
Ext3 adds journaling capability to the existing ext2 code, a conceptually simple modification that increases reliability enormously. Even more interestingly, the ext3 extensions were implemented without changing the fundamental structure of ext2. In fact, you can still mount an ext3 filesystem as an ext2 filesystem—it just won’t have journaling enabled.
Ext3 sets aside an area of the disk for the journal. The journal is allocated as if it were a regular file in the root of the filesystem, so it is not really a distinct structural component.
When a filesystem operation occurs, the required modifications are first written to the journal. When the journal update is complete, a “commit record” is written to mark the end of the entry. Only then is the normal filesystem modified. If a crash occurs during the update, the filesystem uses the journal log to reconstruct a perfectly consistent filesystem.17
Journaling reduces the time needed to perform filesystem consistency checks (see the fsck section on page 259) to approximately one second per filesystem. Barring some type of hardware failure, the state of an ext3 filesystem can almost instantly be assessed and restored.
Ext4 is a comparatively incremental update that raises a few size limits, increases the performance of certain operations, and allows the use of “extents” (disk block ranges) for storage allocation rather than just individual disk blocks. The on-disk format is compatible enough that ext2 and ext3 filesystems can be mounted as ext4 filesystems. Furthermore, ext4 filesystems can be mounted as if they were ext3 filesystems provided that the extent system has not been used.
Use of ext4 over the previous versions is recommended as of Linux kernel 2.6.28.18
It is the default on Ubuntu and SUSE; Red Hat remains on ext3.
It’s easy to add a journal to an existing ext2 filesystem, thereby promoting it to ext3 or ext4 (the distinction is vague because of backward compatibility). Just run tune2fs with the -j option. For example:
# tune2fs -j /dev/hda4
You would then need to modify the corresponding entry in /etc/fstab to read ext4 rather than ext2 (see page 260 for more information on the fstab file).
VxFS is the mainstream HP-UX filesystem. It’s based on a filesystem originally developed
by Veritas Software, now part of Symantec. Since it includes a journal, HP sometimes
refers to it as JFS, the Journaled File System. Don’t confuse this JFS with AIX’s
JFS2, though; they are different filesystems.
VxFS is nearly unique among mainstream filesystems in that it supports clustering; that is, simultaneous modification by multiple, independent computers. This mode of operation involves some performance costs because the filesystem must take extra steps to ensure cache coherency among computers. By default, clustering features are turned off; use the -o cluster option to mount to turn them on.
HFS is HP’s previous mainstream filesystem. It’s based on the UNIX File System and is now deprecated, though still supported.
JFS2 is yet another filesystem that traces its roots back to the Berkeley Fast File
System. The J stands for “journaled,” but JFS2 has some other tricks up its sleeve,
including extents, dynamic allocation of inodes, and the use of a B+ tree structure
to store directory entries.
JFS2 is also interesting in that it’s available under the GNU General Public License. It runs on Linux, too.
Largely because of their common history with UFS, many filesystems share some descriptive terminology. The implementations of the underlying objects have often changed, but the terms are still widely used by administrators as labels for fundamental concepts.
“Inodes” are fixed-length table entries that each hold information about one file. They were originally preallocated at the time a filesystem was created, but some filesystems now create them dynamically as they are needed. Either way, an inode usually has an identifying number that you can see with ls -i.
Inodes are the “things” pointed to by directory entries. When you create a hard link to an existing file, you create a new directory entry, but you do not create a new inode.
On systems that preallocate inodes, you must decide in advance how many to create. It’s impossible to predict exactly how many will someday be needed, so filesystem-building commands use an empirical formula, based on the size of the volume and an average file size, to guesstimate an appropriate number. If you anticipate storing zillions of small files, you may need to increase this number.
A superblock is a record that describes the characteristics of the filesystem. It contains information about the length of a disk block, the size and location of the inode tables, the disk block map and usage information, the size of the block groups, and a few other important parameters of the filesystem. Because damage to the superblock could erase some extremely crucial information, several copies of it are maintained in scattered locations.
Filesystems cache disk blocks to increase efficiency. All types of blocks can be cached, including superblocks, inode blocks, and directory information. Caches are normally not “write-through,” so there may be some delay between the point at which an application thinks it has written a block and the point at which the block is actually saved to disk. Applications can request more predictable behavior for a file, but this option lowers throughput.
The sync system call flushes modified blocks to their permanent homes on disk, possibly making the on-disk filesystem fully consistent for a split second. This periodic save minimizes the amount of data loss that might occur if the machine were to crash with many unsaved blocks. Filesystems can do syncs on their own schedule or leave this up to the OS. Modern filesystems have journaling mechanisms that minimize or eliminate the possibility of structural corruption in the event of a crash, so sync frequency now mostly has to do with how many data blocks might be lost in a crash.
A filesystem’s disk block map is a table of the free blocks it contains. When new files are written, this map is examined to devise an efficient layout scheme. The block usage summary records basic information about the blocks that are already in use. On filesystems that support extents, the information may be significantly more complex than the simple bitmap used by older filesystems.
Filesystems are software packages with multiple components. One part lives in the kernel (or even potentially in user space under Linux; google for FUSE) and implements the nuts and bolts of translating the standard filesystem API into reads and writes of disk blocks. Other parts are user-level commands that initialize new volumes to the standard format, check filesystems for corruption, and perform other format-specific tasks.
Long ago, the standard user-level commands knew about “the filesystem” that the system used, and they simply implemented the appropriate functionality. mkfs created new filesystems, fsck fixed problems, and mount mostly just invoked the appropriate underlying system calls. These days filesystems are more modular, so these commands call filesystem-specific implementations of each utility.
The exact implementation varies. For example, the Linux wrappers look for discrete commands named mkfs.fsname, fsck.fsname, and so on in the normal directories for system commands. (You can run these commands directly, but it’s rarely necessary.) AIX has a central /etc/vfs switch that records metainformation for filesystems (not to be confused with Solaris’s /etc/vfstab, which is equivalent to the fstab or filesystems file on other systems; it’s not needed for ZFS, though).
The general recipe for creating a new filesystem is
mkfs [-T fstype] [-o options] rawdevice
The default fstype may be hard-coded into the wrapper, or it might be specified in /etc/default/fs. The available options are filesystem specific, but it’s rare that you’ll need to use them. Linux uses -t instead of -T, omits the -o designator, and does not have raw disk device files. AIX uses -V instead of -T.
AIX’s crfs can allocate a new logical volume, create a filesystem on it, and update the /etc/filesystems file all in one step.
Two options you may consider tweaking are those that enable snapshots for file-systems that support them (JFS2 and VxFS) and locating the filesystem journal on a separate disk. The latter option can give quite a performance boost in the right circumstances.
Because of block buffering and the fact that disk drives are not really transactional devices, filesystem data structures can potentially become self-inconsistent. If these problems are not corrected quickly, they propagate and snowball.
The original fix for corruption was a command called fsck (“filesystem consistency check,” spelled aloud or pronounced “FS check” or “fisk”) that carefully inspected all data structures and walked the allocation tree for every file. It relied on a set of heuristic rules about what the filesystem state might look like after failures at various points during an update.
The original fsck scheme worked surprisingly well, but because it involved reading all a disk’s data, it could take hours on a large drive. An early optimization was a “filesystem clean” bit that could be set in the superblock when the filesystem was properly unmounted. When the system restarted, it would see the clean bit and know to skip the fsck check.
Now, filesystem journals let fsck pinpoint the activity that was occurring at the time of a failure. fsck can simply rewind the filesystem to the last known consistent state.
Disks are normally fscked automatically at boot time if they are listed in the system’s /etc/fstab, /etc/vfstab, or /etc/filesystems file. The fstab and vfstab files have legacy “fsck sequence” fields that were normally used to order and parallelize filesystem checks. But now that fscks are fast, the only thing that really matters is that the root filesystem be checked first.
You can run fsck by hand to perform an in-depth examination more akin to the original fsck procedure, but be aware of the time required.
Linux ext-family filesystems can be set to force a recheck after they have been remounted
a certain number of times or after a certain period of time, even if all the unmounts
were “clean.” This precaution is good hygiene, and in most cases the default value
(usually around 20 mounts) is acceptable. However, on systems that mount filesystems
frequently, such as desktop workstations, even that frequency of fscks can become tiresome. To increase the interval to 50 mounts, use the tune2fs command:

If a filesystem appears damaged and fsck cannot repair it automatically, do not experiment with it before making an ironclad backup. The best insurance policy is to dd the entire disk to a backup file or backup disk.
Most filesystems create a lost+found directory at the root of each filesystem in which fsck can deposit files whose parent directory cannot be determined. The lost+found directory has some extra space preallocated so that fsck can store orphaned files there without having to allocate additional directory entries on an unstable filesystem. Don’t delete this directory.19
Since the name given to a file is recorded only in the file’s parent directory, names for orphan files are not available and the files placed in lost+found are named with their inode numbers. The inode table does record the UID of the file’s owner, however, so getting a file back to its original owner is relatively easy.
A filesystem must be mounted before it becomes visible to processes. The mount point for a filesystem can be any directory, but the files and subdirectories beneath it are not accessible while a filesystem is mounted there. See Filesystem mounting and unmounting on page 143 for more information.
After installing a new disk, you should mount new filesystems by hand to be sure that everything is working correctly. For example, the command
$ sudo mount /dev/sda1 /mnt/temp
mounts the filesystem in the partition represented by the device file /dev/sd1a (device names will vary among systems) on a subdirectory of /mnt, which is a traditional path used for temporary mounts.
You can verify the size of a filesystem with the df command. The example below uses the Linux -h flag to request “human readable” output. Unfortunately, most systems’ df defaults to an unhelpful unit such as “disk blocks,” but there is usually a flag to make df report something specific such as kibibytes or gibibytes.

You will generally want to configure the system to mount local filesystems at boot time. A configuration file in /etc lists the device names and mount points of all the system’s disks (among other things). On most systems this file is called /etc/fstab (for “filesystem table”), but under both Solaris and AIX it has been restructured and renamed: /etc/vfstab on Solaris and /etc/filesystems on AIX. Here, we use the generic term “filesystem catalog” to refer to all three files.
By default, ZFS filesystems mount themselves automatically and do not require vfstab entries. However, you can change this behavior by setting ZFS filesystem properties.
Swap areas and nonfilesystem mounts should still appear in vfstab.
mount, umount, swapon, and fsck all read the filesystem catalog, so it is helpful if the data presented there is correct and complete. mount and umount use the catalog to figure out what you want done if you specify only a partition name or mount point on the command line. For example, with the Linux fstab configuration shown on page 262, the command
$ sudo mount /media/cdrom0
would have the same effect as typing
$ sudo mount -t udf -o user,noauto,exec,utf8 /dev/scd0 /media/cdrom0
The command mount -a mounts all regular filesystems listed in the filesystem catalog; it is usually executed from the startup scripts at boot time.20 The -t, -F, or -v flag (-t for Linux, -F for Solaris and HP-UX, -v for AIX) with an fstype argument constrains the operation to filesystems of a certain type. For example,
$ sudo mount -at ext4
mounts all local ext4 filesystems. The mount command reads fstab sequentially. Therefore, filesystems that are mounted beneath other filesystems must follow their parent partitions in the fstab file. For example, the line for /var/log must follow the line for /var if /var is a separate filesystem.
The umount command for unmounting filesystems accepts a similar syntax. You cannot unmount a filesystem that a process is using as its current directory or on which files are open. There are commands to identify the processes that are interfering with your umount attempt; see page 144.
The HP-UX fstab file is the most traditional of our example systems. Here are entries for a system
that has only a single volume group:

There are six fields per line, separated by whitespace. Each line describes a single filesystem. The fields are traditionally aligned for readability, but alignment is not required.
The first field gives the device name. The fstab file can include mounts from remote systems, in which case the first field contains an NFS path. The notation server:/export indicates the /export directory on the machine named server.
See Chapter 18 for more information about NFS.
The second field specifies the mount point, and the third field names the type of filesystem. The exact type name used to identify local filesystems varies among machines.
The fourth field specifies mount options to be applied by default. There are many possibilities; see the man page for mount for the ones that are common to all filesystem types. Individual filesystems usually introduce options of their own. All the options shown above are specific to VxFS. For example, the delaylog option sacrifices some reliability for speed. See the mount_vxfs man page for more information about this and other VxFS mount options.
The fifth and sixth fields are vestigial. They are supposedly a “dump frequency” column and a column used to control fsck parallelism. Neither is important on contemporary systems.
Below are some additional examples culled from an Ubuntu system’s fstab. The general format is the same, but Linux systems often include some additional
flourishes.
The first line addresses the /proc filesystem, which is in fact presented by a kernel driver and has no actual backing store. The proc device listed in the first column is just a placeholder.
The second and third lines use partition IDs (UUIDs, which we’ve truncated to make the excerpt more readable) instead of device names to identify volumes. This alternative is useful on Linux systems because the device names of disk partitions are unstable; adding or removing a disk can cause all the other disks to change names (e.g., from /dev/sdb1 to /dev/sdc1). The UUID is linked only to the content of the partition, so it allows the partition to be tracked down wherever it might be hiding. Note that this convention works for the swap partition as well as the root.
The last three lines configure support for CD-ROM and floppy disk devices. The noauto option prevents the system from trying to mount these devices at boot time. (If no media were inserted, the mount attempt would fail and prolong the boot process.) The user option makes all the files on these removable drives appear to be owned by the user who mounts them.
On Solaris systems, the /etc/vfstab file has a slightly reorganized format with the order of some fields being swapped
relative to the Linux and HP-UX scheme. However, the data is still tabular and is
easily readable without much decoding effort. The distinguishing features of the vfstab format are that it has a separate “device to fsck” column and a separate “mount at boot” column.
AIX’s /etc/filesystems file is organized as a series of property lists somewhat reminiscent of YAML or JSON,
although the format is a bit different. Here’s an example configuration for one filesystem:

This format is nice in that it allows arbitrary properties to be associated with each filesystem, so filesystem-type-specific parameters can easily be recorded in the filesystems catalog. AIX automatically maintains this file when you perform disk wrangling operations through SMIT, but it’s fine to edit the file directly, too.
Floppy disks have finally gone the way of the dodo, and good riddance. In their place are friendly, fast, and fun USB drives. These devices come in many flavors: personal “thumb” drives, digital cameras, iPods, and large external disks, to name a few. Most of these are supported by UNIX systems as data storage devices.
In the past, special tricks were necessary to manage USB devices. But now that operating systems have embraced dynamic device management as a fundamental requirement, USB drives are just one more type of device that shows up or disappears without warning.
From the perspective of storage management, the issues are
• Getting the kernel to recognize a device and to assign a device file to it
• Finding out what assignment has been made
The first step usually happens automatically, but systems have commands (such as AIX’s cfgmgr) that you can use to goose the system if need be. Once a device file has been assigned, you can use the normal procedures described in Disk device files on page 224 to find out what it is.
For additional information about dynamic device management, see Chapter 13, Drivers and the Kernel.
Raw partitions or logical volumes, rather than structured filesystems, are normally used for swap space. Instead of using a filesystem to keep track of the swap area’s contents, the kernel maintains its own simplified mapping from memory blocks to swap space blocks.
On some systems, it’s also possible to swap to a file in a filesystem partition. With older kernels this configuration can be slower than using a dedicated partition, but it’s still very handy in a pinch. In any event, logical volume managers eliminate most of the reasons you might want to use a swap file rather than a swap volume.
The more swap space you have, the more virtual memory your processes can allocate. The best virtual memory performance is achieved when the swap area is split among several drives. Of course, the best option of all is to not swap; consider adding RAM if you find yourself needing to optimize swap performance.
See page 1129 for more information about splitting swap areas.
On Linux systems, swap areas must be initialized with mkswap, which takes the device name of the swap volume as an argument.
You can manually enable swapping to a particular device with swapon device on most systems or swap -a device on Solaris. However, you will generally want to have this function performed automatically at boot time. Except on AIX, you can list swap areas in the regular filesystem catalog (fstab or vfstab) by giving them a filesystem type of swap. AIX has a separate file that lists the system’s swap areas, /etc/swapspaces.
To review the system’s current swapping configuration, run swapon -s on Linux systems, swap -s on Solaris and AIX, or swapinfo on HP-UX.
On AIX systems, you can use the mkps command to create a logical volume for swapping, add it to the /etc/swapspaces file, and start using it. This is the command called by the SMIT interface.
ZFS was introduced in 2005 as a component of OpenSolaris, and it quickly made its way to Solaris 10 and to various BSD-based distributions. In 2008, it became usable as a root filesystem, and it has been the front-line filesystem of choice for Solaris ever since.
Although ZFS is usually referred to as a filesystem, it is in fact a comprehensive approach to storage management that includes the functions of a logical volume manager and a RAID controller. It also redefines many common aspects of storage administration to make them simpler, easier, and more consistent. Although the current version of ZFS has a few limitations, most fall into the “not yet implemented” category rather than the “can’t do for architectural reasons” category.
The advantages of ZFS’s integrated approach are clear. If you’re not already familiar with ZFS, we predict that you’ll enjoy working with it. There is little doubt that the system will be widely emulated over the next decade. The open question is how long we’ll have to wait to get ZFS-style features on other systems. Although ZFS is open source software, the terms of its current license unfortunately prevent inclusion in the Linux kernel.
Oracle’s Btrfs filesystem project (“B-tree file system,” officially pronounced “butter FS,” though it’s hard not to think “butter face”) aims to repeat many of ZFS’s advances on the Linux platform. It is already included in current Linux kernels as a technology preview. Ubuntu and SUSE users can experiment with it by installing the btrfs-tools or btrfsprogs packages, respectively. However, Btrfs is not production-ready, and now that Oracle has acquired Sun, the exact futures of both Btrfs and ZFS are uncertain.
Exhibit D shows a schematic of the major objects in the ZFS system and their relationship to each other.
Exhibit D ZFS architecture
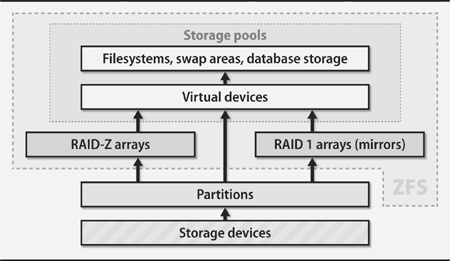
A ZFS “pool” is analogous to a “volume group” in other logical volume management systems. Each pool is composed of “virtual devices,” which can be raw storage devices (disks, partitions, SAN devices, etc.), mirror groups, or RAID arrays. ZFS RAID is similar in spirit to RAID 5 in that it uses one or more parity devices to provide redundancy for the array. However, ZFS calls the scheme RAID-Z and uses variable-sized stripes to eliminate the RAID 5 write hole. All writes to the storage pool are striped across the pool’s virtual devices, so a pool that contains only individual storage devices is effectively an implementation of RAID 0, although the devices in this configuration are not required to be of the same size.
Unfortunately, the current ZFS RAID is a bit brittle in that you cannot add new devices to an array once it has been defined; nor can you permanently remove a device. As in most RAID implementations, devices in a RAID set must be the same size; you can force ZFS to accept mixed sizes, but the size of the smallest volume then dictates the overall size of the array. To use disks of different sizes efficiently in combination with ZFS RAID, you must partition the disks ahead of time and define the leftover regions as separate devices.
Although you can turn over raw, unpartitioned disks to ZFS’s care, ZFS secretly writes a GPT-style partition table onto them and allocates all of each disk’s space to its first partition.
Most configuration and management of ZFS is done through two commands: zpool and zfs. Use zpool to build and manage storage pools. Use zfs to create and manage the entities created from pools, chiefly filesystems and raw volumes used as swap space and database storage.
Before we descend into the details of ZFS, let’s start with a high-level example. Suppose you’ve added a new disk to your Solaris system and the disk has shown up as /dev/dsk/c8d1. (An easy way to determine the correct device is to run sudo format. The format command then shows you a menu of the system’s disks from which you can spot the correct disk before typing <Control-C>.)
The first step is to label the disk and add it to a new storage pool:
solaris$ sudo zpool create demo c8d1
Step two is… well, there is no step two. ZFS labels the disk, creates the pool “demo,” creates a filesystem root inside that pool, and mounts that filesystem as /demo. The filesystem will be remounted automatically when the system boots.
solaris$ ls -a /demo
. ..
It would be even more impressive if we could simply add our new disk to the existing storage pool of the root disk, which is called “rpool” by default. (The command would be sudo zpool add rpool c8d1.) Unfortunately, the root pool can only contain a single virtual device. Other pools can be painlessly extended in this manner, however.
It’s fine for ZFS to automatically create a filesystem on a new storage pool because by default, ZFS filesystems consume no particular amount of space. All filesystems that live in a pool can draw from the pool’s available space.
Unlike traditional filesystems, which are independent of one another, ZFS filesystems are hierarchical and interact with their parent and child filesystems in several ways. You create new filesystems with zfs create.
The -r flag to zfs list makes it recurse through child filesystems. Most other zfs subcommands understand -r, too. Ever helpful, ZFS automounts the new filesystem as soon as we create it.
To simulate traditional filesystems of fixed size, you can adjust the filesystem’s properties to add a “reservation” (an amount of space reserved in the storage pool for the filesystem’s use) and a quota. This adjustment of filesystem properties is one of the keys to ZFS management, and it’s something of a paradigm shift for administrators who are used to other systems. Here, we set both values to 1GB:

The new quota is reflected in the AVAIL column for /demo/new_fs. Similarly, the reservation shows up immediately in the USED column for /demo. That’s because the reservations of /demo’s descendant filesystems are included in its size tally.21
Both property changes are purely bookkeeping entries. The only change to the actual storage pool is the update of a block or two to record the new settings. No process goes out to format the 1GB of space reserved for /demo/new_fs. Most ZFS operations, including the creation of new storage pools and new filesystems, are similarly lightweight.
Using this hierarchical system of space management, you can easily group several filesystems to guarantee that their collective size will not exceed a certain threshold; you do not need to specify limits on individual filesystems.
You must set both the quota and reservation properties to properly emulate a traditional fixed-size filesystem.22 The reservation alone simply ensures that the filesystem will have enough room available to grow at least that large. The quota limits the filesystem’s maximum size without guaranteeing that space will be available for this growth; another object could snatch up all the pool’s free space, leaving no room for /demo/new_fs to expand.
On the other hand, there are few reasons to set up a filesystem this way in real life. We show the use of these properties simply to demonstrate ZFS’s space accounting system and to emphasize that ZFS is compatible with the traditional model, should you wish to enforce it.
Many properties are naturally inherited by child filesystems. For example, if we wanted to mount the root of the demo pool in /opt/demo instead of /demo, we could simply set the root’s mountpoint parameter:

Setting the mountpoint parameter automatically remounts the filesystems, and the mount point change affects child filesystems in a predictable and straightforward way. The usual rules regarding filesystem activity still apply, however; see page 143.
Use zfs get to see the effective value of a particular property; zfs get all dumps them all. The SOURCE column tells you why each property has its particular value: local means that the property was set explicitly, and a dash means that the property is read-only. If the property value is inherited from an ancestor filesystem, SOURCE shows the details of that inheritance as well.

Vigilant readers may notice that the available and referenced properties look suspiciously similar to the AVAIL and REFER columns shown by zfs list. In fact, zfs list is just a different way of displaying filesystem properties. If we had included the full output of our zfs get command above, there would be a used property in there, too. You can specify the properties you want zfs list to show with the -o option.
It wouldn’t make sense to assign values to used and to the other size properties, so these properties are read-only. If the specific rules for calculating used don’t meet your needs, other properties such as usedbychildren and usedbysnapshots may give you better insight into how your disk space is being consumed. See the ZFS admin guide for a complete list.
You can set additional, nonstandard properties on filesystems for your own use and for the use of your local scripts. The process is the same as for standard properties. The names of custom properties must include a colon to distinguish them from standard properties.
Since filesystems consume no space and take no time to create, the optimal number of them is closer to “a lot” than “a few.” If you keep users’ home directories on a ZFS storage pool, it’s recommended that you make each home directory a separate filesystem. There are several reasons for this convention.
• If you need to set disk usage quotas, home directories are a natural granularity at which to do this. You can set quotas on both individual users’ filesystems and on the filesystem that contains all users.
• Snapshots are per filesystem. If each user’s home directory is a separate filesystem, the user can access old snapshots througĥ/.zfs.23 This alone is a huge time saver for administrators because it means that users can service most of their own file restore needs.
• ZFS lets you delegate permission to perform various operations such as taking snapshots and rolling back the filesystem to an earlier state. If you wish, you can give users control over these operations for their own home directories. We do not describe the details of ZFS permission management in this book; see the ZFS Administration Guide.
ZFS is organized around the principle of copy-on-write. Instead of overwriting disk blocks in place, ZFS allocates new blocks and updates pointers. This approach makes ZFS resistant to corruption because operations can never end up half-completed in the event of a power failure or crash. Either the root block is updated or it’s not; the filesystem is consistent either way (though a few recent changes may be “undone”).
Just as in a logical volume manager, ZFS brings copy-on-write to the user level by allowing you to create instantaneous snapshots. However, there’s an important difference: ZFS snapshots are implemented per-filesystem rather than per-volume, so they have arbitrary granularity. Solaris uses this feature to great effect in the Time Slider widget for the GNOME desktop. Much like Mac OS’s Time Machine, the Time Slider is a combination of scheduled tasks that create and manage snapshots at regular intervals and a UI that makes it easy for you to reach older versions of your files.
On the command line, you create snapshots with zfs snapshot. For example, the following command sequence illustrates creation of a snapshot, use of the snapshot through the filesystem’s .zfs/snapshot directory, and reversion of the filesystem to its previous state.

You assign a name to each snapshot at the time it’s created. The complete specifier for a snapshot is usually written in the form filesystem@snapshot.
Use zfs snapshot -r to create snapshots recursively. The effect is the same as executing zfs snapshot on each contained object individually: each subcomponent receives its own snapshot. All the snapshots have the same name, but they’re logically distinct.
ZFS snapshots are read-only, and although they can bear properties, they are not true filesystems. However, you can instantiate a snapshot as a full-fledged, writable filesystem by “cloning” it.

The snapshot that is the basis of the clone remains undisturbed and read-only. However, the new filesystem (demo/subclone in this example) retains a link to both the snapshot and the filesystem on which it’s based, and neither of those entities can be deleted as long as the clone exists.
Cloning isn’t a common operation, but it’s the only way to create a branch in a filesystem’s evolution. The zfs rollback operation demonstrated above can only revert a filesystem to its most recent snapshot, so to use it you must permanently delete (zfs destroy) any snapshots made since the snapshot that is your reversion target. Cloning lets you go back in time without losing access to recent changes.
For example, suppose that you’ve discovered a security breach that occurred some time within the last week. For safety, you want to revert a filesystem to its state of a week ago to be sure it contains no hacker-installed back doors. At the same time, you don’t want to lose recent work or the data for forensic analysis. The solution is to clone the week-ago snapshot to a new filesystem, zfs rename the old filesystem, and then zfs rename the clone in place of the original filesystem.
For good measure, you should also zfs promote the clone; this operation inverts the relationship between the clone and the filesystem of origin. After promotion, the main-line filesystem has access to all the old filesystem’s snapshots, and the old, moved-aside filesystem becomes the “cloned” branch.
You create swap areas and raw storage areas with zfs create, just as you create filesystems. The -V size argument makes zfs treat the new object as a raw volume instead of a filesystem. The size can use any common unit, for example, 128m.
Since the volume does not contain a filesystem, it is not mounted; instead, it shows up in the /dev/zvol/dsk and /dev/zvol/rdsk directories and can be referenced as if it were a hard disk or partition. ZFS mirrors the hierarchical structure of the storage pool in these directories, so sudo zfc create -V 128m demo/swap creates a 128MB swap volume located at /dev/zvol/dsk/demo/swap.
You can create snapshots of raw volumes just as you can with filesystems, but because there’s no filesystem hierarchy in which to put a .zfs/snapshot directory, the snapshots show up in the same directory as their source volumes. Clones work too, just as you’d expect.
By default, raw volumes receive a space reservation equal to their specified size. You’re free to reduce the reservation or do away with it entirely, but note that this can make writes to the volume return an “out of space” error. Clients of raw volumes may not be designed to deal with such an error.
Just as ZFS redefines many aspects of traditional filesystem management, it also changes the way that filesystems are shared over a network. In particular, you can set the sharenfs or sharesmb property of a filesystem to on to make it available through NFS or Solaris’s built-in CIFS server. See Chapter 18, The Network File System, for more information about NFS, and see the section Sharing files with Samba and CIFS on page 1142 for more information about CIFS.
If you leave these properties set to off, that does not mean the filesystems are unsharable; it just means that you must do your own export management with tools such as sharemgr, share, and unshare instead of having ZFS take care of this for you. The sharenfs and sharesmb properties can also take on values other than on and off. If you set a more detailed value, it’s assumed that you want sharing turned on, and the value is passed through zfs share and on to share in the form of command-line arguments.
In a similar vein, shareiscsi=on on a raw volume makes that volume available as an iSCSI target. See page 274 for more information about iSCSI.
By default, all the share* properties are inheritable. If you share /home over NFS, for example, you automatically share the individual home directories beneath it, even if they are defined as separate filesystems. Of course, you can override this behavior by setting an explicit sharenfs=no value on each sub-filesystem.
ZFS uses the NFSv4 standard for access control lists. The nuances of that standard are discussed in more detail in Chapter 6, The Filesystem, starting on page 166. The executive summary is that ZFS provides excellent ACL support for both Windows and NFS clients.
Now that we’ve peeked at some of the features that ZFS offers at the filesystem and block-client level, let’s take a longer swim in ZFS’s storage pools.
Up to this point, we’ve used a pool called “demo” that we created from a single disk back on page 266. Here it is in the output of zpool list:

The pool named rpool contains the bootable root filesystem. Bootable pools are currently restricted in several ways: they can only contain a single virtual device, and that device must be either a mirror array or a single disk drive; it cannot be a RAID array. If it is a disk, it cannot have a GPT partition table.
zpool status adds more detail about the virtual devices that make up a storage pool and reports their current status.
Let’s get rid of this demo pool and set up something a bit more sophisticated. We’ve attached five 500GB SCSI drives to our example system. We first create a pool called “monster” that includes three of those drives in a RAID-Z single-parity configuration.
ZFS also understands raidz2 and raidz3 for double and triple parity configurations. The minimum number of disks is always one more than the number of parity devices. Here, one drive out of three is used for parity, so roughly 1TB is available for use by filesystems.
For illustration, we then add the remaining two drives configured as a mirror.

zpool initially balks at this configuration because the two virtual devices have different redundancy schemes. This particular configuration is OK since both vdevs have some redundancy. In actual use, you should not mix redundant and nonredundant vdevs since there’s no way to predict which blocks might be stored on which devices; partial redundancy is useless.
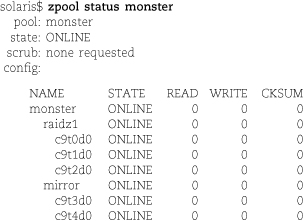
ZFS distributes writes among all a pool’s virtual devices. As demonstrated in this example, it is not necessary for all virtual devices to be the same size.24 However, the components within a redundancy group should be of similar size. If they are not, only the smallest size is used on each component. If you use multiple simple disks together in a storage pool, that is essentially a RAID 0 configuration.
You can add additional vdevs to a pool at any time. However, existing data will not be redistributed to take advantage of parallelism. Unfortunately, you cannot currently add additional devices to an existing RAID array or mirror.
ZFS has an especially nice implementation of read caching that makes good use of SSDs. To set up this configuration, just add the SSDs to the storage pool as vdevs of type cache. The caching system uses an adaptive replacement algorithm developed at IBM that is smarter than a normal LRU (least recently used) cache. It knows about the frequency at which blocks are referenced as well as their recency of use, so reads of large files are not supposed to wipe out the cache.
Hot spares are handled as vdevs of type spare. You can add the same disk to multiple storage pools; whichever pool experiences a disk failure first gets to claim the spare disk.
There are several ways to attach storage resources to a network. Chapter 18, The Network File System, describes NFS, the traditional UNIX protocol used for file sharing. Windows systems use the protocol known variously as CIFS or SMB for similar purposes. The predominant implementation of CIFS for UNIX and Linux is Samba; see Sharing files with Samba and CIFS on page 1142 for more details.
NFS and CIFS are examples of “network-attached storage” (NAS) systems. They are high-level protocols, and their basic operations are along the lines of “open file X and send me the first 4KiB of data” or “adjust the ACL on file Y as described in this request.” These systems are good at arbitrating access to filesystems that many clients want to read or write at once.
A storage area network (SAN) is a lower-level system for abstracting storage, one that makes network storage look like a local hard disk. SAN operations consist primarily of instructions to read or write particular “disk” blocks (though, of course, the block addressing is virtualized by the server in some way). If a client wants to use SAN storage to hold a filesystem, it must provide its own filesystem implementation. On the other hand, SAN volumes can also be used to store swap areas or other data that doesn’t need the structure or overhead of a filesystem.
With the exception of HP’s VxFS, mainstream filesystems are not designed to be updated by multiple clients that are unaware of each other’s existence (at least, not at the level of raw disk blocks).25 Therefore, SAN storage is not typically used as a way of sharing files. Instead, it’s a way to replace local hard disks with centralized storage resources.
Why would you want to do this? Several reasons:
• Every client gets to share the benefits of a sophisticated storage facility that’s optimized for performance, fault tolerance, and disaster recovery.
• Utilization efficiency is increased because every client can have exactly as much storage as it needs. Although space allocations for virtual disks are fixed, they are not limited to the standard sizes of physical hard disks. In addition, virtual disk blocks that the client never writes need never actually be stored on the server.
• At the same time, a SAN makes storage infinitely more flexible and trivial to reconfigure. A “hard disk upgrade” can now be performed in a command or two from an administrator’s terminal window.
• Duplicate block detection techniques can reduce the cost of storing files that are the same on many machines.
• Backup strategy for the enterprise can be unified through the use of shadow copies of block stores on the SAN server. In some cases, every client gets access to advanced snapshot facilities such as those found on logical volume managers, regardless of its operating system or the file-system it’s using.
Performance is always of interest to system administrators, but it’s hard to make general statements about the effect of a SAN on a server’s I/O performance without knowing more about the specific implementation. Networks impose latency costs and bandwidth restrictions that local disks do not. Even with advanced switching hardware, networks are semi-shared resources that can be subject to bandwidth contention among clients. On the positive side, large SAN servers come packed to the gills with memory and SSD caches. They use premium components and spread their physical I/O across many disks. In general, a properly implemented SAN is significantly faster than local storage.
That kind of setup isn’t cheap, however. This is a domain of specialized, enterprise-class hardware, so get that $80 hard disk from Fry’s out of your mind right from the start. Some major players in the SAN space are EMC, NetApp, HP, IBM, and perhaps surprisingly, Dell.
Because network concerns are a major determinant of SAN performance, serious installations have traditionally relied on Fibre Channel networks for their infrastructure. Mainstream Fibre Channel speeds are typically 4 or 8 Gb/s, as opposed to the 1 Gb/s speed of a typical Ethernet.
Ethernet is rapidly gaining ground, however. There are several reasons for this, the two most important being the growing availability of inexpensive 10 Gb/s Ethernets and the increasing prevalence of virtualized servers; virtualization systems generally have better support for Ethernet than for Fibre Channel. Of course, it’s also helpful that Ethernet-based systems don’t require the installation of an expensive secondary physical network infrastructure.
Several communication protocols can implement SAN functionality over Ethernet. The common theme among these protocols is that they each emulate a particular hardware interface that many systems already understand.
The predominant protocol is iSCSI, which presents the virtual storage device to the system as if it lived on a local SCSI bus. Other options are ATA-over-Ethernet (AoE) and Fibre-Channel-over-Ethernet (FCoE). These last options are Ethernet-specific (and therefore limited in their geographical extent), whereas iSCSI runs on top of IP. At present, iSCSI has about 20% of the SAN market, true Fibre Channel has about 60%, and other solutions account for the remaining 20%.
The details of implementing a Fibre Channel deployment are beyond the scope of this book, so here we review only iSCSI in detail. From the host operating system’s perspective, Fibre Channel SAN drives typically look like a pile of SCSI disks, and they can be managed as such.
iSCSI lets you implement a SAN with your existing, cheap network hardware rather than a dedicated Fibre Channel network and expensive Fibre Channel host bus adapters. Your SAN servers will still likely be task-specific systems, but they too can take advantage of commodity hardware.
Borrowing a bit of terminology from traditional SCSI, iSCSI refers to a server that makes virtual disks available over the network as an iSCSI “target.” A client that mounts these disks is called an “initiator,” which makes sense if you keep in mind that the client originates SCSI commands and the server responds to them.
The software components that implement the target and initiator sides of an iSCSI relationship are separate. All modern operating systems include an initiator, although it’s often an optional component. Most systems also have a standard target implementation.
iSCSI is formally specified in RFC3720. Unlike most RFCs, the specification is several hundred pages long, mostly because of the complexity of the underlying SCSI protocol. For the most part, iSCSI administration is simple unless you use the optional Internet Storage Name Service (iSNS) for structured management and discovery of storage resources. iSNS, defined in RFC4171, is an adaptation of Fibre Channel’s management and discovery protocols to IP, so it’s primarily of interest to sites that want to use both Fibre Channel and iSCSI.
Without iSNS, you simply point your initiator at the appropriate server, specify the name of the iSCSI device you want to access, and specify a username and password with which to authenticate. By default, iSCSI authentication uses the Challenge Handshake Authentication Protocol (CHAP) originally defined for the Point-to-Point Protocol (PPP) (see RFC1994), so passwords are not sent in plaintext over the network. Optionally, the initiator can authenticate the target through the use of a second shared secret.
iSCSI can run over IPsec, although that is not required. If you don’t use an IPsec tunnel, data blocks themselves are not encrypted. According to RFC3720, connections that don’t use IPsec must use CHAP secrets at least 12 characters long.
Targets and initiators both have iSCSI names, and several naming schemes are defined. The names in common use are iSCSI Qualified Names (IQNs), which have the following bizarre format:
iqn.yyyy-mm.reversed_DNS_domain:arbitrary_name
In most cases, everything up to the colon is a fixed (i.e., essentially irrelevant) prefix that’s characteristic of your site. You implement your own naming scheme in the arbitrary_name portion of the IQN. The month and year (mm and yyyy) qualify the DNS domain to guard against the possibility of a domain changing hands. Use the original DNS registration date. An actual name looks something like this:
iqn.1995-08.com.example:disk54.db.engr
Despite the specificity of the IQN name format, it is not important that the prefix reflect your actual DNS domain or inception date. Most iSCSI implementations default to using the vendor’s domain as an IQN, and this works fine. It is not even necessary that the IQNs involved in a service relationship have matching prefixes.
If you’re going to put your important data on a SAN, wouldn’t it be nice to eliminate local hard disks entirely? Not only could you eliminate many of the special procedures needed to manage local disks, but you could also allow administrators to “swap” boot drives with a simple reboot, bringing instant upgrades and multiple boot configurations within reach even of Windows systems.
Unfortunately, the use of an iSCSI volume as a boot device is not widely supported. At least, not straightforwardly and not as a mainstream feature. Various Linux projects have made a go of it, but the implementations are necessarily tied to specific hardware and to specific iSCSI initiator software, and no current iSCSI boot project cooperates with the now-predominant initiator software, Open-iSCSI. Similarly, iSCSI boot support for Solaris and OpenSolaris is being worked on, but there’s no production-ready solution yet.
The lone exception among our example systems is AIX, which has a long history of good support for iSCSI. AIX versions 5.3 and later running on POWER hardware have full support for iSCSI booting over IPv4.
There have been at least four different iSCSI initiator implementations for Linux.
Several have died off and others have merged. The sole survivor at this point seems
to be Open-iSCSI, which is the standard initiator packaged with all our example Linux
distributions. To get it up and running, install the open-scsi package on Ubuntu and SUSE and the iscsi-initiator-utils package on Red Hat.
The project’s home page is open-iscsi.org, but don’t go there looking for documentation. None seems to exist other than the man pages for iscsid and iscsiadm, which represent the implementation and the administrative interface for the system, respectively. Unfortunately, the administrative model for Open-iSCSI is best described as “creative.”
In Open-iSCSI’s world, a “node” is an iSCSI target, the thing that’s named with an IQN. Open-iSCSI maintains a database of the nodes it knows about in a hierarchy underneath the directory /etc/iscsi/nodes. Configuration parameters for individual nodes are stored in this tree. Defaults are set in /etc/iscsi/iscsid.conf, but they are sometimes copied to newly defined nodes, so their function is not entirely predictable. The process of setting per-target parameters is painful; iscsiadm tortures you by making you change one parameter at a time and by making you list the IQN and server on each command line.
The saving grace of the system is that iscsid.conf and all the database files are just editable text files. Therefore, the sane approach is to use iscsiadm for the few things it does well and to circumvent it for the others.
To set up the system for simple, static operation with a single username and password for all iSCSI targets, first edit the iscsid.conf file and make sure the following lines are configured as shown:

We show these lines together, but they’ll be separated in the actual file. The file is actually quite nicely commented and contains a variety of commented-out configuration options. Make sure you don’t introduce duplicates.
Next, point iscsiadm at your target server and let it create node entries for each of the targets it discovers by reading that server’s directory. Here, we’ll configure the target called test from the server named iserver.
iscsiadm creates a subdirectory in /etc/iscsi/nodes for each target. If there are targets you don’t want to deal with, it’s fine to just rm -rf their configuration directories. If the server offers many targets and you’d rather just specify the details of the one you want, you can do that, too:

Strangely, these two methods achieve similar results but create different hierarchies under /etc/iscsi/nodes. Whichever version you use, check the text files that are the leaves of the hierarchy to be sure the configuration parameters are set appropriately. If you entered the target manually, you may need to set the property node.startup to automatic by hand.
You can then connect to the remote targets with iscsiadm -m node -l:

You can verify that the system now sees the additional disk by running fdisk -l. (The device files for iSCSI disks are named like those for any other SCSI disk.) If you have set up the configuration files as described above, the connections should be restored automatically at boot time.
For iSCSI target service on Linux systems, the preferred implementation is the iSCSI Enterprise Target package hosted at iscsitarget.sourceforge.net. It’s usually available as a package called iscsitarget.
Solaris includes target and initiator packages; both are optional. All packages related
to iSCSI have “iscsi” in their names. For the initiator side, install the package
SUNWiscsi; you’ll have to reboot afterward.
There is no configuration file; all configuration is performed with the iscsiadm command, which has a rather strange syntax. Four top-level verbs (add, modify, list, and remove) can be applied to a variety of different aspects of the initiator configuration. The following steps perform basic configuration of the initiator as a whole and connect to a target on the server iserver.
At this point you can simply configure the disk normally (for example, by running zpool create iscsi c10t3d0).
The first command sets the initiator’s authentication mode to CHAP and sets the CHAP username to testclient. The -C option sets the password; you cannot combine this option with any others. It’s also possible to set the name and password individually for each target if you prefer.
The modify discovery command enables the use of statically configured targets, and the add command designates the server and IQN of a specific target. All this configuration is persistent across reboots.
To serve iSCSI targets to other systems, you’ll need to install the SUNWiscsitgt package. Administration is structured similarly to the initiator side, but the command is iscsitadm instead of iscsiadm.
To use iSCSI on HP-UX systems, download the iSCSI initiator software from soft-ware.hp.com
and install it with HP-UX’s Software Distributor tool. A kernel rebuild and reboot
are required. Fortunately, the system is well documented in a stand-alone manual,
the HP-UX iSCSI Software Initiator Support Guide, available from docs.hp.com.
Most initiator configuration is performed with the iscsiutil command, installed in /opt/iscsi/bin. Use iscsiutil -l iqn to set the initiator’s IQN, iscsiutil -u -N user to set the global CHAP username (it can also be set per-server or per-target), and iscsiutil -u -W password to set the global CHAP password.
You can then add targets from a particular server with iscsiutil -a -I server. Run ioscan -NH 64000 to activate the server connections and to create virtual disk devices. You can check the status of the system with iscsiutil -p -o.
AIX’s iSCSI initiator comes installed and ready to go. In typical AIX style, most
configuration is done through the system’s ODM database. The iscsi0 device represents
the configuration of the initiator as a whole, and individual target devices can be
defined as ODM entries or in text configuration files in /etc/iscsi. The text configuration files seem to work somewhat more reliably.
AIX does not distinguish between the initiator’s IQN and its CHAP username. The IQN is set on the iscsi0 device; therefore, you should plan on using the same CHAP username on every server. The first step on the fast configuration path is to set that IQN to an appropriate value.
aix$ sudo chdev -l iscsi0 -a initiator_name=’iqn.1994-11.com.admin:client’
We used a different CHAP username for this example than for other systems since “testclient” isn’t technically a valid IQN for the initiator (although in fact it works fine as well).
In the /etc/iscsi/targets file, we add the following entry:
iserver 3260 iqn.1994-11.com.admin:test "chap_password"
The 3260 is the standard server port for iSCSI; we include it here only because the port is required by the file format. To activate the new iSCSI disk, we need only run cfgmgr -l iscsi0. The cfgmgr command prints no confirmation messages, but we can see that the new device has appeared by looking in the /dev directory (on our example system, the new disk is /dev/hdisk2) or by running smitty devices, navigating to the Fixed Disk category, and listing the entries. The latter option is perhaps safer since smitty explicitly shows that hdisk2 is an iSCSI volume.
To disconnect an iSCSI device, you must not only edit the configuration file and reload the configuration with cfgmgr but you must also delete the disk from smitty’s Fixed Disk list.
E8.1 Describe any special considerations that an administrator should take into account when designing a storage architecture for each of the following applications.
a) A server that will host the home directories of about 200 users
b)A swap area for a site’s primary DNS server
c) Storage for the mail queue at a large spam house
d)A large InnoDB (MySQL) database
E8.2 Logical volume managers are powerful but can be confusing if not well understood. Practice adding, removing, and resizing disks in a volume group. Show how you would remove a device from one volume group and add it to another. What would you do if you wanted to move a logical volume from one volume group to another?
 E8.3 Using printed or Internet resources, identify the best-performing SCSI and SATA
drives. Do the benchmarks used to evaluate these drives reflect the way that a busy
server would use its boot disk? What cost premium would you pay for SCSI, and how
much performance improvement (if any) would you get for the money?
E8.3 Using printed or Internet resources, identify the best-performing SCSI and SATA
drives. Do the benchmarks used to evaluate these drives reflect the way that a busy
server would use its boot disk? What cost premium would you pay for SCSI, and how
much performance improvement (if any) would you get for the money?
E8.4 Add a disk to your system and set up a partition or logical volume on the new
disk as a backup root partition. Make sure you can boot from the backup root and that
the system runs normally when so booted. Keep a journal of all the steps required
to complete this task. You may find the script command helpful. (Requires root access.)
E8.5 What is a superblock and what is it used for? Look up the definition of the
ext4 superblock structure in the kernel header files and discuss what each of the
fields in the structure represents.
E8.6 Use mdadm and its -f option to simulate a failed disk in a Linux RAID array. Remove the disk from the
array and add it back. How does /proc/mdstat look at each step?
 E8.7 What fields are stored in an inode on an ext4 filesystem? List the contents
of the inode that represents the /etc/motd file. Where is this file’s filename stored? (Tools such as hexdump and ls -i might help.)
E8.7 What fields are stored in an inode on an ext4 filesystem? List the contents
of the inode that represents the /etc/motd file. Where is this file’s filename stored? (Tools such as hexdump and ls -i might help.)
E8.8 Examine the contents of a directory file with a program such as od or hexdump. Each variable-length record represents a file in that directory. Look up the on-disk
structure of a directory and explain each field, using an example from a real directory
file. Next, look at the lost+found directory on a filesystem that uses them. Why are there so many names there when
the lost+found directory is empty?
 E8.9 Write a program that traverses the filesystem and prints the contents of the
/etc/motd and /etc/magic files. But don’t open the files directly; open the raw device file for the root partition
and use the seek and read system calls to decode the filesystem and find the appropriate data blocks. /etc/motd is usually short and will probably contain only direct blocks. /etc/magic should require you to decode indirect blocks. (If it doesn’t, pick a larger text
file.)
E8.9 Write a program that traverses the filesystem and prints the contents of the
/etc/motd and /etc/magic files. But don’t open the files directly; open the raw device file for the root partition
and use the seek and read system calls to decode the filesystem and find the appropriate data blocks. /etc/motd is usually short and will probably contain only direct blocks. /etc/magic should require you to decode indirect blocks. (If it doesn’t, pick a larger text
file.)
Hint: when reading the system header files, be sure you have found the filesystem’s on-disk inode structure, not the in-core inode structure. (Requires root access.)