LEARNING OBJECTIVES
▪ Define environmental justice and explain how it is spatial
▪ Aspects of the environment often studied using GIS
▪ Common GIS concepts and tools used to study environmental justice
▪ How tools can be combined to answer spatial research questions
The environment can be thought of in terms of the natural world: water, green space and forest, or dumps and hazardous waste sites. It can also be conceptualised in more personal terms; our environment is the day-to-day spatial context of our lived experience. In both senses of the word, geography, and by extension GIS methods, have much to contribute. Both definitions of the ‘environment’ assume spatial variations, patterning and processes to underlie the outcomes we perceive. Environmental justice – as well as environmental law and policy appraisal – are areas of research and social action that aim to measure and demonstrate how one aspect of spatial inequality operates. Typical questions that are addressed in the environmental justice literature have to do with basic fairness: does one group have better access to environmental amenities or goods – parks or open space, for example – than others? Do some groups tend to bear the burden of ‘disamenities’, such as hazardous waste dumps or poor air quality, disproportionately? Often research focuses on differential outcomes by race or ethnicity, but income or even age might also be factors considered. These questions are complex and are conceptualised and analysed in a range of different fashions. In common to virtually all is a dependence on the tools of GIS, both visualisation and methods. We cannot state with confidence that burdens are unequally distributed if we cannot measure what (amenity or disamenity) is close to whom.
Much of the attention in environmental justice and policy evaluation (henceforth referred to simply as environmental justice) is devoted to distributional questions, such as those listed above. The field is larger than the measurement of outcomes, however. What we observe on the ground, fair or unfair, is the result of processes that might privilege one group over another. As Maantay (2007) observes, environmental justice also focuses on unequal protection from environmental ills or ‘disamenities’, as well as unequal representation when policies and laws are being developed. Often, observed outcomes are a combination of unequal representation and unintended consequences. New York City’s recent growth, for example, necessitated conversion of land from industrial to residential purposes. This, inadvertently, led to a concentration of manufacturing activity in the Bronx (a lower income, high minority borough of the city where land was cheaper and residential demand lower), subsequently leading to even poorer air quality and increased adverse health effects for many in the area (Maantay, 2007).
Research and applications in environmental justice range in their use of GIS methods, but virtually all employ at least some. The use of GIS is arguably stronger in those studies that emphasise outcomes. In such cases, GIS is indispensable, as distance, proximity and containment are the fundamental spatial concepts used to judge environmental burden and access. In the case of air quality, especially, GIS is occasionally used to model dispersion of pollutants from a point source and thus estimate burden. Such applications require collaboration between GIS and climate experts. And, of course, GIS lends itself well to visualising the locations of population groups and environmental elements. GIS can also be used to develop solutions to unjust situations. If some groups suffer lack of access to parks, for example, where should new parks be located (Sister et al., 2010)? Or if truck routes through urban neighbourhoods are linked to poor air quality, how might routes be redesigned to minimise impact on neighbourhoods but still meet truck drivers’ requirements (Fisher et al., 2006)? Increasingly, research aims not only to show correlation between population characteristics and locations of environmental hazards and goods but also to show causation. In short, in this field, GIS is used to calculate spatial measures of burden or distribution, but also for visualisation and modelling.
Because a strength of GIS’s contribution to the field of environmental justice lies in burden estimation, and because a range of estimation strategies has been developed, this chapter focuses on how GIS can best be used for outcome studies. The goal of the chapter is to illustrate how conceptualisation of burden can be matched to GIS methods and to provide examples of applications. Along the way, the chapter covers some specific challenges that have been identified with regard to spatial analysis and environmental justice research. It provides examples of common GIS methods introduced in Part I. The chapter also complements material covered in the other chapters in Part II of the book, such as health, crime and emergency planning, and also provides concrete examples of how methods can be combined to address methodological and topical issues related to environmental justice and policy appraisal.
Data and conceptual challenges
The environmental justice and spatial analysis/GIS literature is large. It is common in these published studies, which often highlight a theoretical or conceptual point using a case study, to note challenges associated with measuring environmental injustice (see e.g. Cutter, 1995; Maantay, 2007; Maroko et al., 2009). Some challenges are aspatial. For instance, when measuring burden, how do we identify different groups – by income, by race or by age? Others are clearly spatial and it is these that this section focuses on.
Two main challenges arise where environmental data are concerned. First, data on environmental hazards, such as air or water pollutants, might not be complete or accurate. Knowledge about dangerous substances and their behaviour in nature is also changing. Because the research needs to be done, the analyst likely needs to make assumptions and might need to narrow the scope of the project to match the type of data available. For example, data on measured air quality are spotty in many locations, making it difficult to use actual measures of air pollutants to assess whether, for example, those living close to highways or factories are worse off than those living further away (the first step in studying whether different groups have different levels of exposure being to measure the exposure).
This leads to the second challenge. Our understanding of how people are exposed to substances likely requires assumptions. How far does an individual need to be from an incinerator before its impacts are null? In the air quality example above, what is often done is to use known facts about levels of air pollutants that are dangerous and levels of pollution emitted by various sources to develop estimates of pollution at various distances from the source. This could be done formally, using models of air dispersion. It can also be done using buffers (Chapter 2). Buffers of different radii can be employed to check the sensitivity of results to the size of buffer. Distances might also be used – how far away do different groups live on average from a noxious site? In this case, the challenge is deciding whether straight-line (or Euclidian) or network distance is more appropriate (Maroko et al., 2009). The decision is not a matter of convenience! Ideally, it should be justified by the spatial process at work. Air pollution, for example, does not disperse on a network, so a buffer around a manufacturing plant might be appropriate (it is certainly more straightforward than modelling the actual dispersion in continuous space). Pollutants emitted from trucks, though, are likely emitted along a network, so that it might be best to buffer the route being used. Another example is from the perspective of access to amenities. Being closer to a park is likely better in terms of access, but what is the appropriate distance, whether straight-line or network?
A final challenge is a pan-social science issue – establishing causality. Using GIS, a researcher might establish that one group has more polluting facilities in their neighbourhoods than others or that some groups have more trees or parks, but this does not establish that the location of any of these was because of group characteristics. This leads to explanatory models, using neighbourhoods or similar as units of observation, that attempt to control for other factors that might lead to differential locations. More complicated, though, is the fact that neighbourhoods evolve. Today’s demographic characteristics might not reflect those of the time period when the rubbish dump or incinerator was initially sited. This leads to the difficult but important question whether disamenities are located in poorer/minority neighbourhoods or whether the poor/minorities are constrained to locate in areas containing disamenities (see Cutter (1995) for good background). Neither is good but the appropriate policy response might depend on the answer.
What do we study when we study GIS and environmental justice?
So far this chapter has made ample reference to the idea of environmental ‘amenities’ and ‘disamenities’. An amenity is a good, some aspect of the landscape that is preferred or desired. A disamenity is the opposite: a feature or characteristic in the landscape that is harmful, unpleasant or dangerous. The origins of the environmental justice movement and field of study lie in studying locations of disamenities in relation to population characteristics, but increasingly researchers have expanded their focus to include amenity distribution (there are links here to the geography of happiness and well-being discussed in Chapter 6). In both cases, it is also common to study how some outcome results from the unequal distribution – health and air pollution or health and park access, for example. This section briefly discusses some of the more typical choices for investigation. This is by no means intended to be an exhaustive list, but rather to give a sense of how various elements of the environment are treated.
Air pollution
Poor air quality is an important public health concern that has been associated with a range of illnesses, respiratory and otherwise. Pollutants could be heavy metals, sulfur or nitrogen oxides, or chemical pollutants. They can also be particulate matter, which refers to particles – smoke, debris or chemical compounds – that are very small (10 micrometres or less) and easily inhaled. The United States Environmental Protection Agency distinguishes between ‘criteria pollutants’ and ‘hazardous air pollutants’ or HAPs. The latter, which include benzene and mercury among others, are chemicals known to cause cancer, birth defects or other serious illnesses (United States EPA, 2017). Criteria pollutants are particulate matter, ground-level ozone, nitrogen dioxide, carbon monoxide, sulfur dioxide and lead. Air quality standards in the US are based on measurements of these compounds. Sources of pollution can be point-based and stationary, like factories or incinerators, or mobile as from automobile traffic.
Regardless of pollutant type, air quality stations generally provide insufficient information about air quality across a study area. Instead, many point sources must provide information about pollutants released from the facility and this information can be used in analysis. These data might be more or less complete, requiring interpolation or exclusion of observations. In other cases, information about facilities and mobile sources of air pollution are combined with estimates of pollution that have been calculated elsewhere. These studies tell us, for instance, that highways with a given amount of traffic produce a certain amount of pollution that disperses over some area. This estimate can then be applied to all highways.
Published research on air pollution and environmental justice has investigated neighbourhood characteristics of areas containing both point and mobile pollution sources (e.g. Fisher et al., 2006; Maantay, 2007). Applications focusing on health outcomes might also consider school or park locations, as well as other outdoor spaces where air quality might be important.
Hazardous waste
Land can also be contaminated or polluted. Unlike air, sources of land pollution can be contemporary or historical in nature. Governments track locations of ongoing pollution, such as factories, landfills or toxic waste dumps, but also areas where contamination might have occurred in the past, or was stored in a fashion that the hazard today presents a threat. Research in this area often considers some type of land pollution, such as brownfield or landfill sites and compares these locations to demographic characteristics of the surrounding area. The resulting statistics can then, in turn, be placed aside average characteristics of those areas without the hazardous land use. In areas with a long history of industrial activity, long-term impacts on health (from activities and decisions from decades ago) could be substantial. In the US, for example, underground storage tanks containing hazardous waste might leak over time, such that the burden faces today’s population, rather than that of the past (e.g. Wilson et al., 2012). As in the case of air pollution, measuring the population’s exposure to any type of land contamination often requires extrapolating from other research findings, as the areal extent of pollution is unlikely to have been thoroughly documented for every site.
Green space
Access to parks, forest or other public green space is considered an amenity. Green space allows for recreation and exercise but is also associated with cleaner air and a higher quality of life. Unlike land or air pollution, measuring green space is relatively straightforward. Many urban areas maintain data about parks – their size, as well as availability of recreational facilities. Even in the event of no data, however, satellite imagery can often be used to develop estimates of green space or tree canopy across different areas.
As with ‘disamenity’ studies, the challenge is to estimate exposure (or accessibility) to green space. Some studies approximate access via distance; for instance, if a park is within half a mile, children or adults might be expected to walk to it. Other studies use containment as a metric: which neighbourhoods have parks and how many? At other times, benchmark metrics have been established, against which distribution can be measured. Comber et al. (2008) cite UK guidelines that recommend at least two hectares of green space per 1,000 inhabitants. The guidelines also suggest that each person should have small green space (of at least two hectares/five acres) within 300 metres of home, and larger space (at least 20 hectares/49 acres) within two kilometres. In a similar vein for the US, Sister et al. (2010) cite a guideline of 6–10 acres (2.4–4 hectares) per 1,000 people.
Water
Clean water is an amenity, but also a fundamental requirement to support life. Environmental justice could therefore treat water as a public good that all should have equal access to, for drinking, washing, swimming, fishing or simply enjoying. It could also assess water quality in ways similar to those employed when studying air or land pollution. In the latter case, surface and groundwater are both important and quality will be affected by point source polluters such as factories, power plants or mines, but also by storage sites, which might date from previous eras. In areas of drought and water shortage, access to water itself could become an environmental justice issue.
Common GIS methods employed in environmental justice and policy research
Researchers benefit from a host of GIS and spatial analysis tools that can be used in environmental justice research. This section re-introduces many tools covered in Part I of the book, providing short explanations and examples of research that have employed the method. Remember that methods are often used in conjunction with each other.
Containment or ‘point-in-polygon’
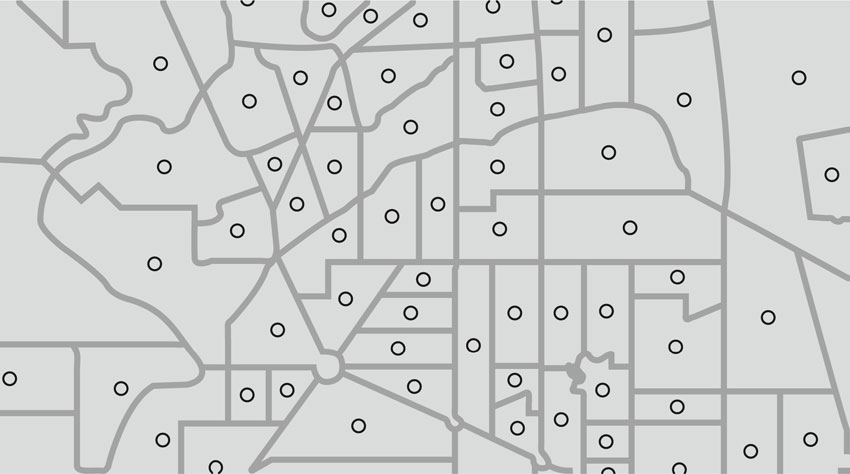
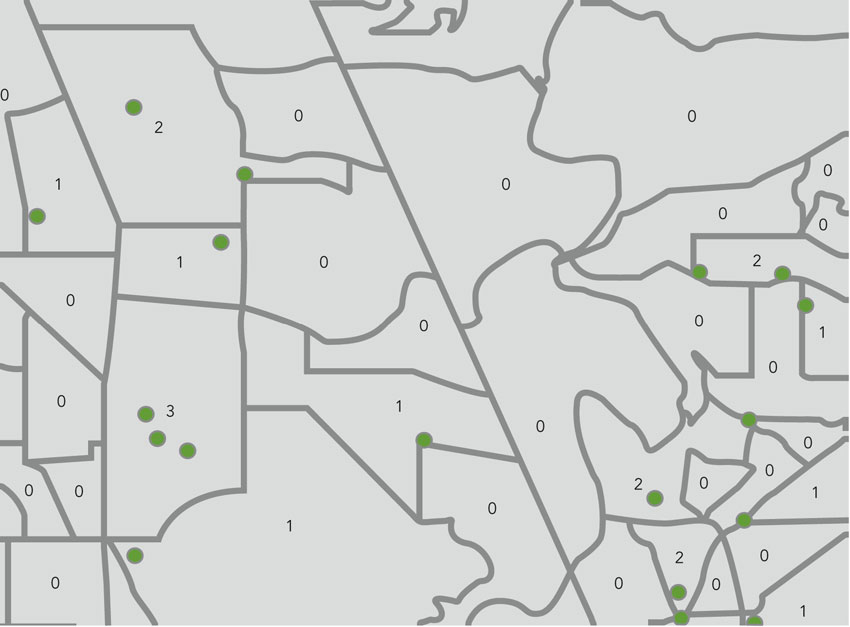
One easy way to estimate community exposure or access is to rule that all areas – often neighbourhoods or their statistical proxies – that possess a feature are exposed to it (or have access). So areas with landfills are exposed, while those without are not. Neighbourhoods with parks have access; those without do not. This is an admittedly simple way of gauging exposure but it is also frequently employed, given its straightforwardness. Figure 13.1 shows areas and parks, with the number of parks counted for each area. The containment method uses a point-in-polygon algorithm (see Chapter 2 for more detail) to count the number of points (parks) in a polygon and generate a variable therefrom. This is what Maroko et al. (2009) refer to as the ‘container method’. In GIS software it is implemented as a spatial join (see Maroko et al., 2009; Davidson and Anderton, 2000). You will have the opportunity to make use of these techniques to explore access to green space in the associated practical. Although quite simple to operationalise, the container method is quite vulnerable to the MAUP, discussed in Chapter 2. In its most basic interpretation, MAUP suggests that results – here, exposure – might be dependent on the size and boundary locations of units. This is almost certainly the case. Moreover, it is quite likely that the units employed, whether census tracts, wards or enumeration districts, bear little resemblance to real neighbourhoods or activity spaces – they are simply administrative or statistical units. Thus the container method, while straightforward and easy to implement, risks generating spurious, useless or uninterpretable results and should be used with caution.
Figure 13.1 Number of points lying within each polygon, which can be used to determine community accessibility to an amenity (or exposure to a hazard)
Buffers
Another way to estimate exposure is to use a buffer, covered in Chapter 2 in more detail, which creates poly-gons of certain radii around points (e.g. stationary sources of pollution or parks) or lines (e.g. highways). Buffers allow for pollutant impact that extends beyond predefined statistical area boundaries. They can also be used to estimate areas affected by different pollution sources, such as highways or incinerators. Maantay (2007) uses buffers of 140 metres from highways and 800 metres from stationary polluters to evaluate whether proximity to these air pollution sources is related to asthma hospitalisations. They can also be used in conjunction with a spatial join to capture how many polluting features lie within a given distance of a neighbourhood. Buffers are an exceedingly versatile and useful tool.
Distance
Another option is to calculate the distance between pollution source and neighbourhood (or park and neighbourhood, etc.). Average distances can then be calculated for each type of neighbourhood to see if differences are detectable. Or, if impact from a pollutant is thought to be limited to some area around it, neighbourhoods can be classified as ‘affected’ or ‘unaffected’ using a distance measure. Distances can be calculated as straight-line or network (see examples in Davidson and Anderton (2000) or Talen and Anselin (1998)).
Cartography
The power of visualising differences in access or exposure should not be underestimated. Maps that show distribution of population by some characteristic (e.g. race/ethnicity or income) and distribution of some environmental amenity or disamenity can help motivate a study or help select locations for more in-depth research (Maroko et al., 2009).
Geometric centroids
Calculating distance or containment with polygons can be tricky, so researchers sometimes collapse polygons down to their geometric centroid, the ‘middle’ of the polygon (Figure 13.2). Point to point distances are then more straightforward to calculate and spatial joins (the ‘point-in-polygon’ measure discussed above) are simpler (Wilson et al., 2012).
Areal interpolation
In order to calculate the number and types of people exposed to some hazard, buffered features are often compared to population in census areas such as tracts or output areas. Because boundaries of these two sets of areas are unlikely to be coincident, it is necessary to estimate the share of population lying only in the portion of the census area exposed to the pollutant. Because we do not generally know how population is distributed within the polygon, we do what is termed an areal interpolation (Flowerdew and Green, 1994; Goodchild and Lam, 1980; also see the discussion in Chapter 8) and assume that the share of area affected is equal to the share of population. So, if 30% of a tract falls within a pollutant buffer, we will assume that 30% of the population does, as well. Figure 13.3 shows, visually, how buffers might only partially cover administrative areas for which we have data. Where buffers cover areas completely, all population numbers and characteristics can be preserved. In those cases where buffers cover only a portion of the area, we can recalculate counts and characteristics using areal interpolation (Maantay, 2007). We provide a practical example of areal interpolation in the practical activities linked to this chapter.
Figure 13.2 Collapsing polygon features (and their attendant attributes) to representative points, or centroids
Figure 13.3 Example of partial coverage of administrative areas by buffers, where areal interpolation can be helpful
Thiessen polygons
If accessibility is the topic of interest, Thiessen polygons offer a different evaluation perspective. Starting from a set of points, the GIS can generate a set of polygons such that borders demarcate areas closest to each point. If we assume that individuals will use the park closest to them, as opposed to employing some threshold distance, we can use Thiessen polygons to determine ‘service areas’ for parks. This is the approach used by Sister et al. (2010) in their analysis of park access in Los Angeles (again see Chapter 9). They then relate numbers of people (and their characteristics) to these service areas to determine where there is more competition for park space.
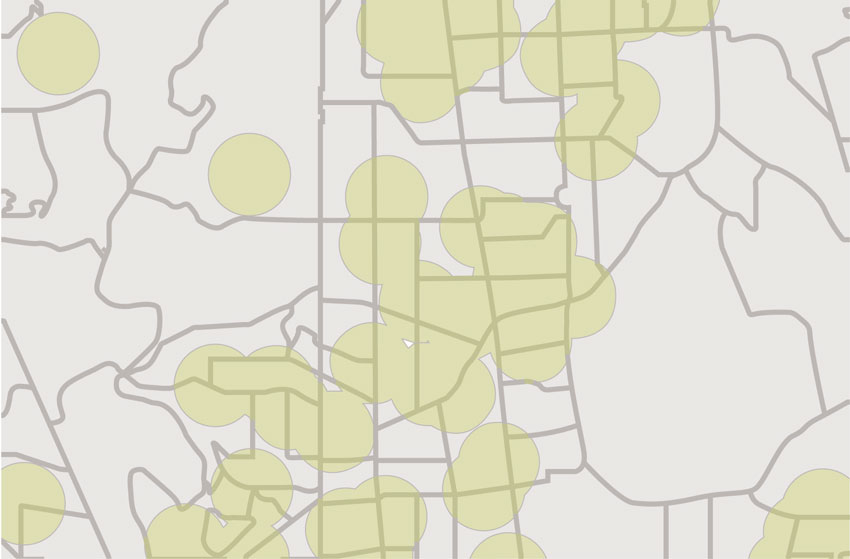
Kernel density
An alternative to distance or containment is to use feature locations to generate a density surface that reflects access or exposure to the feature from every location in the area. This kernel density estimation technique produces a raster that sums point densities for predetermined cell sizes. The density surface can then be summarised to neighbourhood levels, giving a measure of overall exposure/access for each neighbourhood. Although more complicated than other methods discussed here, kernel density avoids having communities assigned one measure of exposure based on containment or distance from a centroid (for more details see Maroko et al., 2009; Moore et al., 2008).
(Geographically Weighted) Regression
To isolate the link between pollutant burden (or access to environmental amenities), researchers might estimate explanatory models that seek to control for other factors that could explain exposure/access. An issue that might arise is spatial non-stationarity in the relationship between the dependent variable and the explanatory variables. For example, in their study of park access in New York City, Maroko et al. (2009) suggest that minority group share might have different predictive power for park size and characteristics, depending on location in the city. They could have used a global regression model but instead use a technique called Geographically Weighted Regression (GWR), which estimates a series of local regression models that allow relationships between the Xs and Ys to vary (Fotheringham et al., 2002). Results can be difficult to interpret and are often best assessed visually on a map. They can help point researchers to unusual locations, however, where predicted relationships are less strong or different.
Applications of GIS in environmental justice
Research that evaluates outcomes – or the differential burden or access of groups to environmental goods and ‘bads’ (and uses these results to make statements about potential environmental injustice) often proceeds in a similar fashion. The distribution of the population is compared to locations of amenities or ‘disamenities’. Where research varies is in terms of the population groups studied, the type of environmental justice issue, and especially how nearness or access is conceptualised and measured. In addition, some studies go beyond exposure or accessibility to compare some health or education outcome to disproportionate exposure to some type of hazard.
Much of the richness in GIS applications comes from the variety of ways in which exposure/accessibility is measured. Once this has been estimated, it can be compared to the spatial distribution of race/ethnic or income groups (or some composite index that captures vulnerability) in an area. Then maps, descriptive statistics or explanatory models can be created that evaluate the hypothesis that some groups are advantaged/disadvantaged over others. Two examples are presented below and each utilises a range of GIS techniques. The case study city is Washington, DC, chosen for a variety of reasons. The capital city of the United States, the District of Columbia is comparable to a city-state or county. It is fairly uniformly urban, with no rural land. It is also known as a racially diverse but very residentially segregated city, which would lead us a priori to expect differential outcomes for a range of variables, including education, access to transportation and employment, and exposure to environmental amenities and disamenities. Last, but most certainly not least, the city government has a strong data provision and transparency policy, such that GIS (and tabular) data for a wide variety of topics are freely available to the public. Table 13.1 provides some basic demographic information for the city as a whole.
Table 13.1 Population characteristics, Washington, DC, 2010
Variable |
Statistics |
Total population |
601,723 |
Total block groups (n) |
450 |
Percentage white, non-Hispanic |
34.8 |
Percentage African-American, non-Hispanic |
50.0 |
Percentage Hispanic |
9.1 |
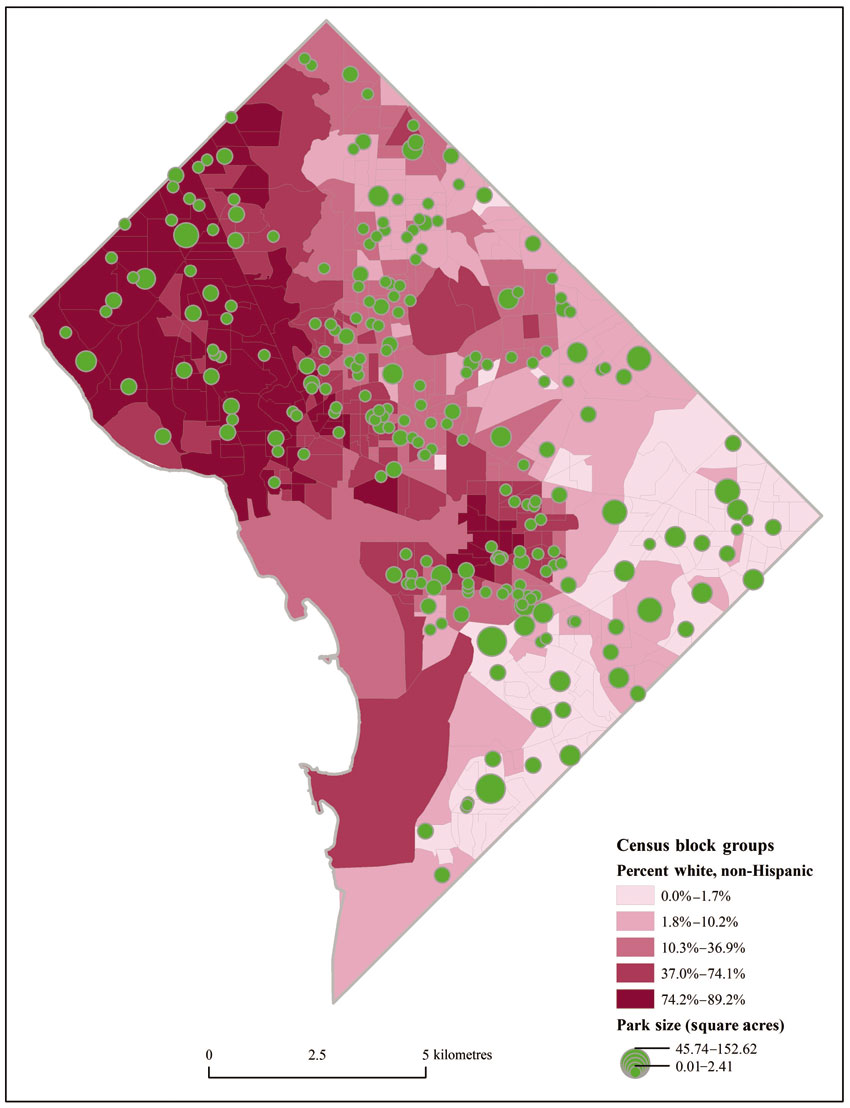
The first example relates to accessibility of parks. As discussed above, access to green space is important for a variety of reasons. Parks, generally the result of public provision of green space and recreational facilities, fulfil not only health and quality of life goals for the population they serve, but their location can also be taken as an indication of the extent of public investment in the communities in which they are located. Decision about park location could also reflect neighbourhood representation at the municipal level. Figure 13.4 shows the distribution of the white, non-Hispanic (WNH) population across census block groups in Washington (a statistical area composed of blocks of groups containing approximately 600–3,000 inhabitants) and the location of parks, classified by size. From the map, it is difficult (if not impossible) to draw conclusions about any relationship between park and population distribution. While perhaps more parks appear in the darker red areas (those that are more occupied by WNH), this could also be a trick of the eye and certainly does not provide any indication of park accessibility for different areas.
Measuring accessibility, however, requires decisions about what constitutes ‘access’. One option is to consider which areas have parks and which do not – the so-called container methods. An alternative is to measure the number of parks within some distance of the neighbourhood. This example uses a one-mile threshold for this distance, using the neighbourhood centroid. Yet another choice, not covered here, would be to use the Washington, DC, road network to see how many parks are within a mile of neighbourhood centroids (using actual streets).
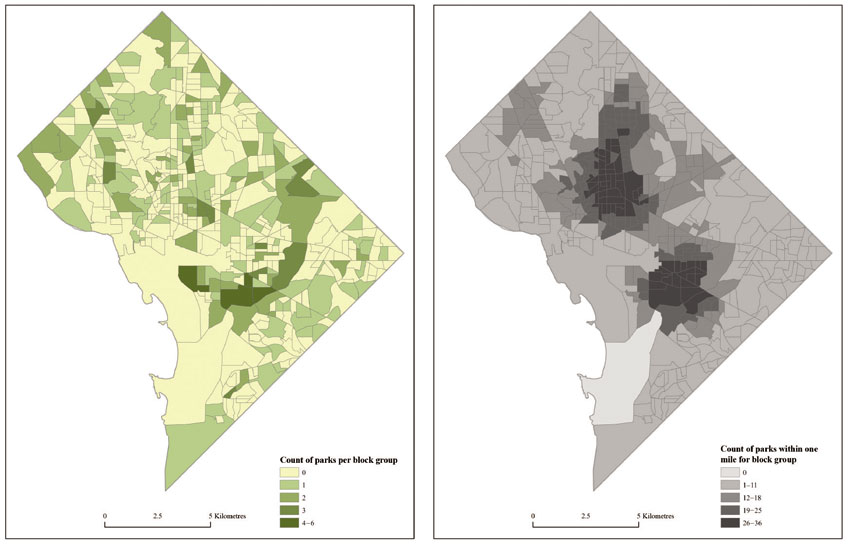
Many block groups in Washington, DC, do not have a park (Figure 13.5, left-hand map). Visual inspection suggests that these areas are located throughout the city and there is no obvious relationship to the distribution of the WNH population. Many of these areas are small, however, and appear to be in proximity to areas containing parks. If we assume that parks within a mile of block group centroids are accessible to those living there, a different picture emerges (Figure 13.5, right-hand map). Now, most block groups have access to at least one park within a mile but two distinct clusters of areas have a very great number of parks to choose from. Checking the correlation between the proportion of the block group population that is WNH and the number of parks within a mile, we find a slight positive correlation (0.19), but Table 13.2 confirms the visual impression that although most inhabitants of the city do not have a park within their block group, almost everyone has at least one park within a mile – and this statistic holds for each demographic group in the table.
Figure 13.4 Park size and distribution of the white, non-Hispanic population in Washington, DC
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
Figure 13.5 Assessing park accessibility via containment (left) and distance (right)
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
Table 13.2 Demographic characteristics of population with access to parks
Total |
Hispanic |
White, NH |
Black, NH |
||
Percentage of population in block groups |
Containing at least one park |
37.3 |
37.3 |
37.2 |
37.5 |
Containing no park |
62.7 |
62.7 |
62.8 |
62.5 |
|
At least one park within a mile |
99.5 |
99.3 |
99.2 |
99.8 |
|
No park within a mile |
0.5 |
0.7 |
0.8 |
0.2 |
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
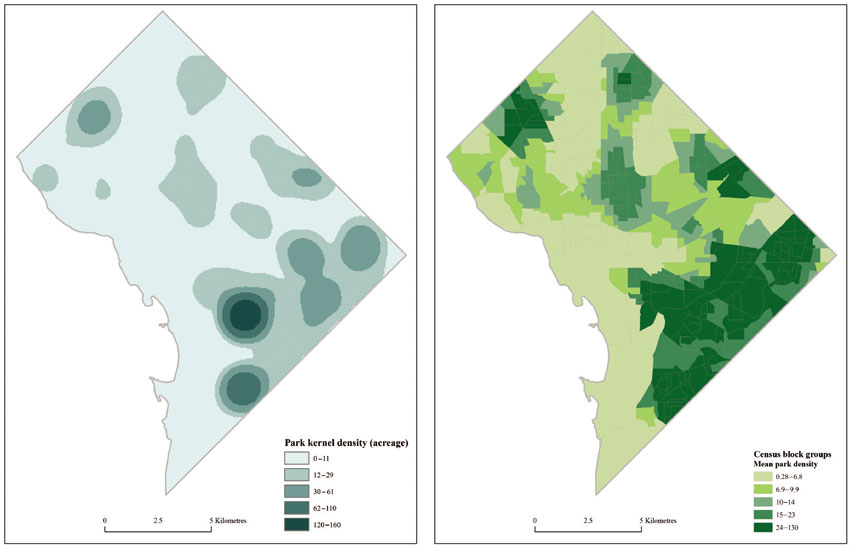
A difficulty with the container and distance methods is that access is treated as binary: one either has parks nearby or not. The kernel density method used in Maroko et al. (2009) gets around this challenge by generating a density surface from the distribution of parks. To understand how this method works, imagine moving point by point across a study area and, at each location, counting how many parks, weighted by size, can be reached within a given distance (in this case, one mile). This number is then summed for each cell of a grid, in this case cell size is 50 metres, and the resulting surface gives an idea of the density, or access, to parks from each cell of the raster. Summing cell values returns the total park acreage in the city; that is, the kernel density method has distributed park access across the city, depending on distance and size of park.
Park density for Washington, DC, is shown in Figure 13.6. The left-hand map shows raster values, density with 50-metre grid cells. The density surface suggests that much of the city has relatively low access to parks, with several clusters of high park density in the south-east and north-west. By using zonal statistics, the average park density can be calculated for each block group. This is shown on the right-hand map of Figure 13.6. Summing or averaging values by statistics area is helpful as it brings all measures back into a common unit of analysis. For example, the correlation between the new mean park density variable and the proportion of the block group population that is WNH is negative (–0.40), suggesting that the more WNH the area, the lower the average access to parks.
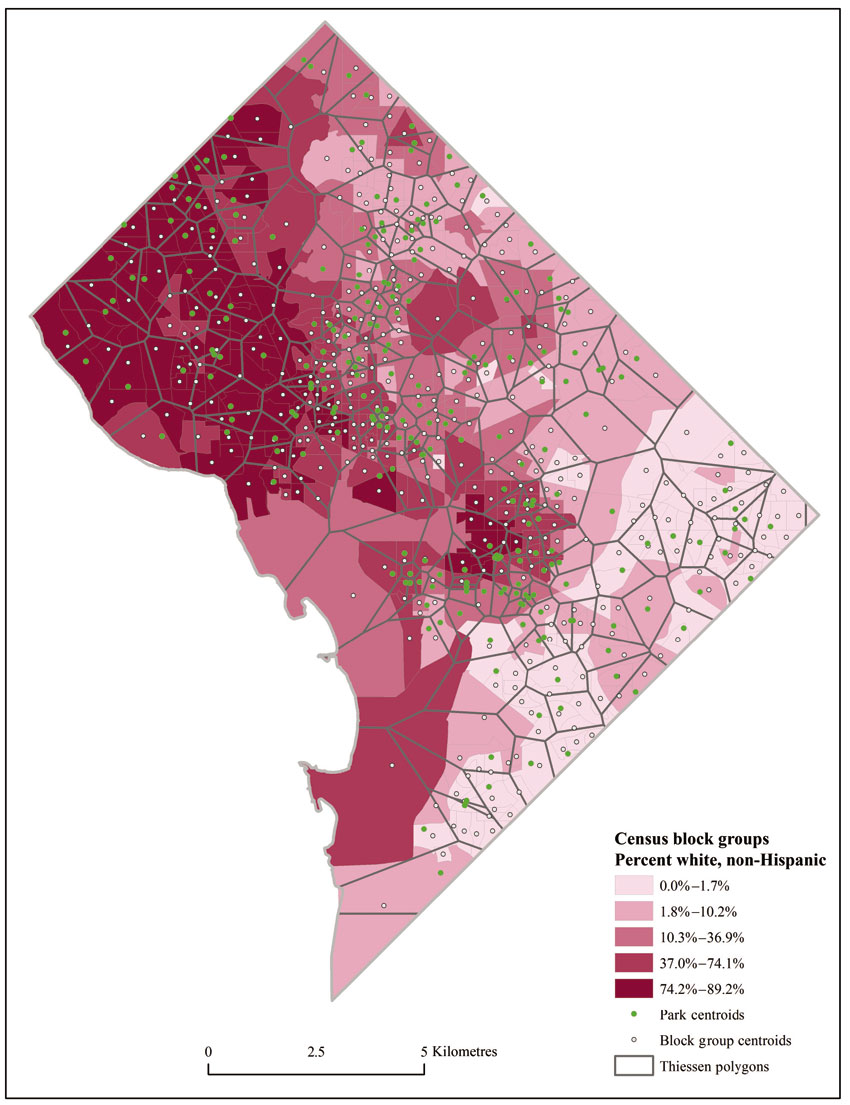
A final method to assess equitable distribution of parks in the city is to look at access in terms of competition for individual parks, as well as park ‘service areas’. The Thiessen polygon technique explained above is applied here. The assumption is that individuals will go to the park closest to them. If this is the case, polygons can be drawn around each park centroid that delineates territory closest to that park. All things being equal, smaller polygons indicate parks that do not have to serve as much territory. Conversely, larger polygons mean more territory served, but also longer distances to reach the park for those on the fringes. Measured this way, park accessibility might be within a mile for some, but further for others.
The visual results indicate a range of size of service area for each park (Figure 13.7). The next questions are: how many people are ‘served’ by each park and what are their characteristics? A preliminary determination of unjust distribution of parks would be indicated by larger areas for minority areas, as well as potential park crowding resulting from parks in minority areas serving larger numbers of people than parks in other locations in the city. To be able to draw these conclusions, the block group population data should be combined (or intersected) with the new Thiessen polygons. As Figure 13.7 shows, intersection of polygons will result in a number of new, smaller polygons for which updated population information will need to be calculated (see areal interpolation, above). Another alternative is to use block group centroids rather than polygons and to allocate population to parks when the centroid falls within the park’s service area.
Figure 13.6 A park density surface (left) using kernel density estimation techniques and average density by block group (right)
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
Figure 13.7 Thiessen polygons for parks, paired with distribution of the white, non-Hispanic population and block group centroids
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
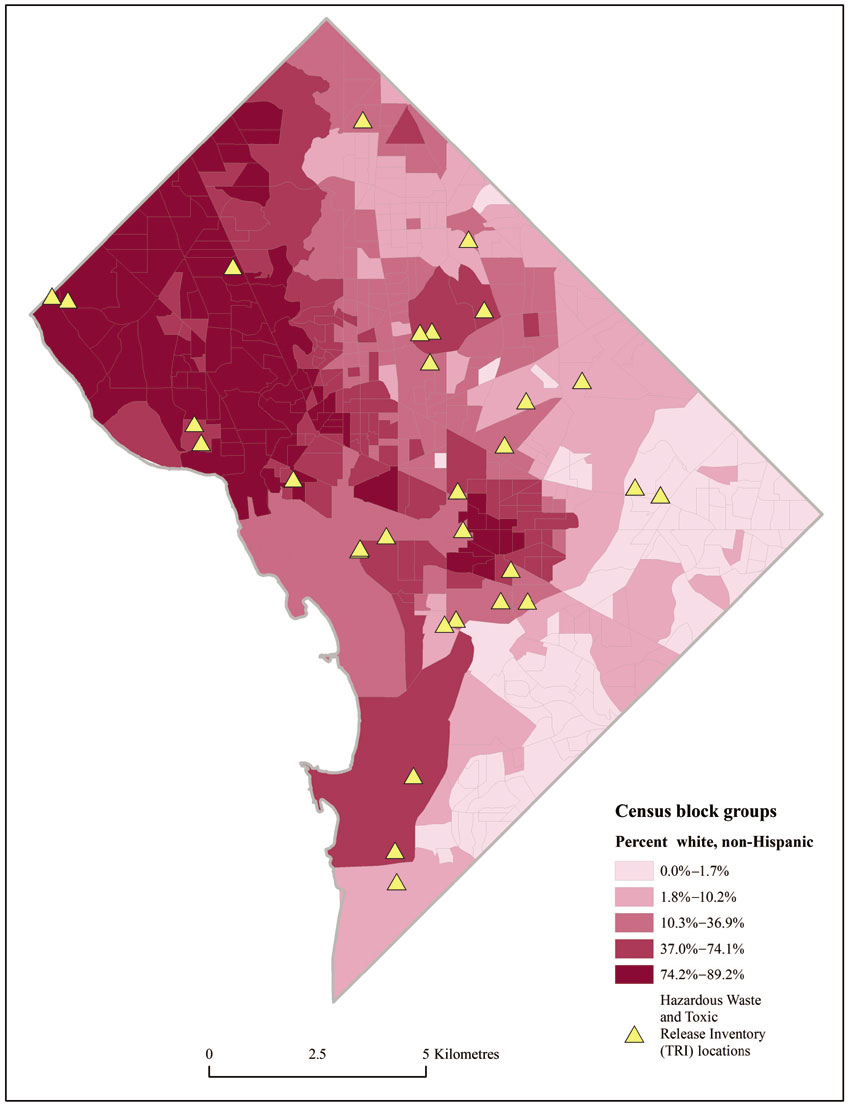
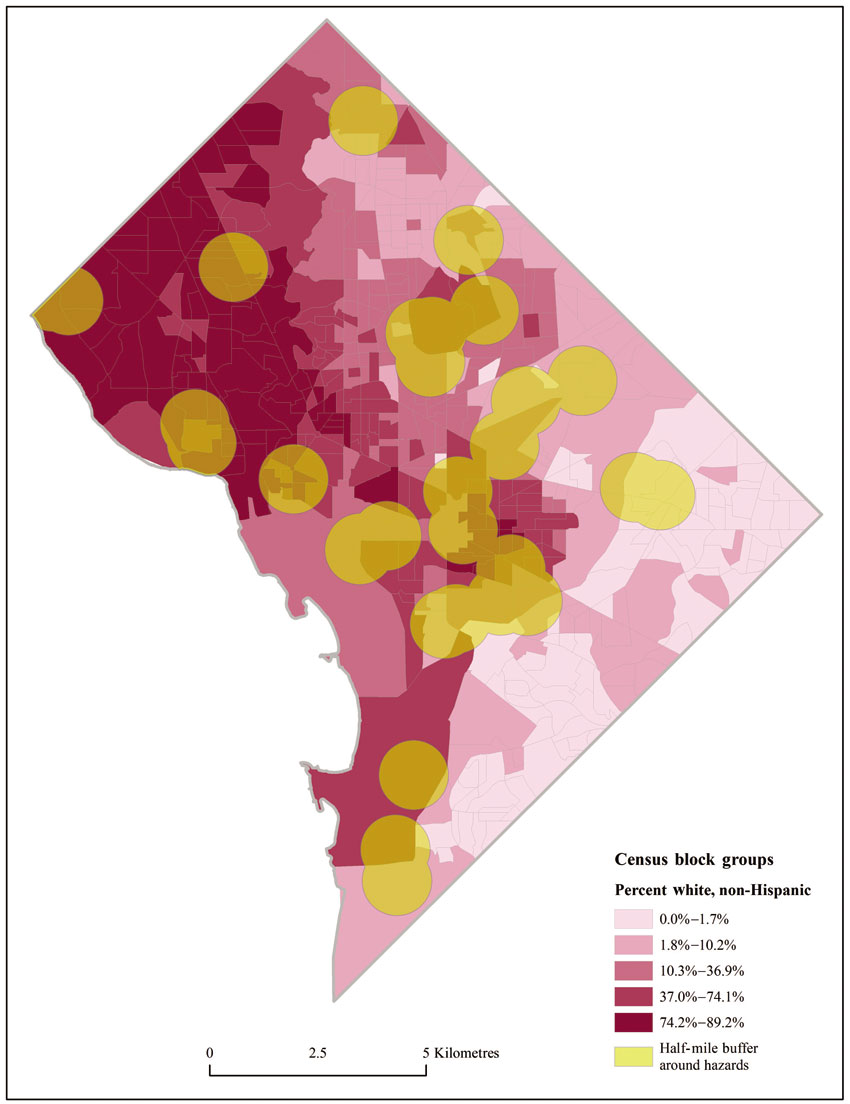
Figure 13.8 Distribution of the white, non-Hispanic population and hazardous waste and TRI locations
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
We now consider a second application of GIS for environmental justice in Washington, DC. This example considers the spatial distribution of hazardous waste and Toxic Release Inventory (TRI) locations. TRI locations are those that must report their release of toxic substances to the federal government. Here, power stations, military bases, and a number of manufacturing plants are included. The question is, who lives near these potential hazards? Are all groups equally likely to live nearby? Visual inspection of the distribution of the WNH population and hazardous waste producers seems to suggest that, if anything, many producers are located in or near predominantly WNH areas (Figure 13.8).
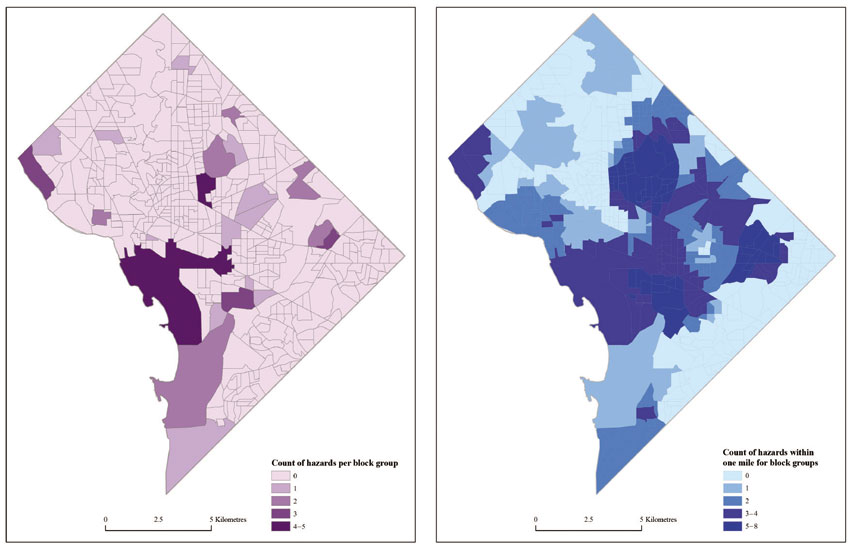
As with the park example above, there are two basic approaches to further spatial analysis. The first calculates the number of facilities located in each block group. The second uses a one-mile buffer around block group centroids to capture the number of facilities within that distance. In the case of block group-level exposure to polluting facilities, it appears that very few areas are directly affected (Figure 13.9, left). Of course, the environmental justice question is whether inhabitants of these areas are different from those elsewhere, poorer or belonging to minority groups. If the definition of exposure is expanded, however, to include all areas within a mile of a polluter, the impact appears much greater. A large portion of the city is exposed to at least five polluters. Conversely, clusters of zero impact (from these facilities using the one-mile buffer) areas are also apparent: one in a predominantly WNH section of the city and one with large shares of minority populations. Table 13.3 presents the information in tabular form. Here, we see that while the bulk of the population lives in a block group containing no polluter, over 60% live within a mile of one. For every racial/ethnic category, the majority of the group lives within a mile of a hazardous waste/TRI source. WNHs are more likely than the overall population to have at least one polluter within a mile of their home. While these results give no preliminary evidence of environmental injustice where these pollution sources are considered, the two block groups with eight pollution sources within a mile are both majority minority (only 13% and 43% WNH). Also, this summary approach does not permit the researcher to assess the impact of any one pollution source individually.
Figure 13.9 Hazard exposure via containment (left) and distance (right)
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
Table 13.3 Demographic characteristics of population exposed to hazards
Total |
Hispanic |
White, NH |
Black, NH |
||
Percentage of population in block groups |
Containing at least one hazard |
6.6 |
4.4 |
7.7 |
6.1 |
Containing no hazard |
93.4 |
95.6 |
92.3 |
93.9 |
|
At least one hazard within a mile |
60.2 |
54.2 |
64.8 |
57.4 |
|
No hazard within a mile |
39.8 |
45.8 |
35.2 |
42.6 |
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
Figure 13.10 A half-mile buffer around hazard locations permits the research to compare characteristics of those living close by and further away
Source: Authors’ calculations from data retrieved from the DC Data Catalog (http://data.dc.gov/)
Another approach, also using buffers, would be to buffer the facilities themselves and then analyse the population characteristics close by and compare them to characteristics of those living further away. This strategy is shown visually in Figure 13.10. By dissolving overlapping buffers, the researcher loses the ability to compare impacts of one facility to another. However, comparing exposed to non-exposed is more straightforward. As with Figure 13.9, buffering facilities seems to indicate impacts in largely WNH areas.
In both examples discussed above – parks and pollution – the emphasis has been on providing visual examples of the techniques introduced earlier in the chapter. While a picture can be worth a thousand words, a strength of the GIS is the generation of numbers. Virtually all of the methods shown above produce data, numbers that can be used to calculate descriptive statistics or estimate models to find the relationship between some aspect of the environment and some set of population characteristics. Articles cited in the chapter are an excellent way to learn more about how GIS output can be used to generate actual findings on environmental justice issues.
This chapter is accompanied by a practical activity (Practical 10: Environmental justice – access to green space in Washington, DC) which makes use of the Washington, DC examples presented throughout this chapter. We give you the opportunity to evaluate access to green spaces (parks), using skills previously introduced, including point-in-polygon and buffer and overlay. You will gain further hands-on experience using areal interpolation, an important tool when working with population counts within artificial spatial units. We also introduce a new technique, Thiessen polygons, in order to delineate park ‘catchment areas’.
All website URLs accessed 30 May 2017.
Comber, A., Brunsdon, C., & Green, E. (2008) Using a GIS-based network analysis to determine urban greenspace accessibility for different ethnic and religious groups. Landscape and Urban Planning, 86(1), 103–113.
Cutter, S. L. (1995) Race, class and environmental justice. Progress in Human Geography, 19(1), 111–122.
Davidson, P., & Anderton, D. L. (2000) Demographics of dumping II: a national environmental equity survey and the distribution of hazardous materials handlers. Demography, 37(4), 461–466.
Fisher, J. B., Kelly, M., & Romm, J. (2006) Scales of environmental justice: combining GIS and spatial analysis for air toxics in West Oakland, California. Health & Place, 12(4), 701–713.
Flowerdew, R., & Green, M. (1994) Areal interpolation and types of data, in A. Fotheringham & P. Rogerson (eds) Spatial Analysis and GIS, Taylor & Francis, Bristol, 121–145.
Fotheringham, A. S., Brunsdon, C., & Charlton, M. (2002) Geographically Weighted Regression: The Analysis of Spatially Varying Relationships, Wiley, London.
Goodchild, M., & Lam, N. (1980) Areal interpolation: a variant of the traditional spatial problem. Geo-Processing, 1, 297–312.
Maantay, J. (2007) Asthma and air pollution in the Bronx: methodological and data considerations in using GIS for environmental justice and health research. Health & Place, 13(1), 32–56.
Maroko, A. R., Maantay, J. A., Sohler, N. L., Grady, K. L., & Arno, P. S. (2009) The complexities of measuring access to parks and physical activity sites in New York City: a quantitative and qualitative approach. International Journal of Health Geographics, 8(34). DOI: https://doi.org/10.1186/1476-072X-8-34.
Moore, L. V., Diez Roux, A. V., Evenson, K. R., McGinn, A. P., & Brines, S. J. (2008) Availability of recreational resources in minority and low socioeconomic status areas. American Journal of Preventive Medicine, 34(1), 16–22.
Sister, C., Wolch, J., & Wilson, J. (2010) Got green? Addressing environmental justice in park provision. GeoJournal, 75(3), 229–248.
Talen, E., & Anselin, L. (1998) Assessing spatial equity: an evaluation of measures of accessibility to public playgrounds. Environment and Planning A, 30(4), 595–613.
United States EPA (2017) Pollutant Types. Available from: www.epa.gov/air-quality-management-process/pollutant-types.
Wilson, S. M., Fraser-Rahim, H., Zhang, H., Williams, E. M., Samantapudi, A. V., Ortiz, K., et al. (2012) The spatial distribution of leaking underground storage tanks in Charleston, South Carolina: an environmental justice analysis. Environmental Justice, 5(4), 198–205.