10
User-Defined Data Types
KNOWLEDGE GOALS
 To know all of the simple data types provided by the C++ language.
To know all of the simple data types provided by the C++ language.
To understand the concept of an enumerated type.
To understand the difference between external and internal representations of character data.
To understand the concept of a record type.
To understand the concept of a pointer variable.
To understand the general concept of a C++ union type.
SKILL GOALS
To be able to:
Use a Typedef statement.
Declare and use an enumeration type.
Use the For and Switch statements with user-defined enumeration types.
Distinguish a named user-defined type from an anonymous user-defined type.
Declare a struct (record) data type, a data structure whose components may be heterogeneous.
Access a member of a struct variable. Define a hierarchical record structure.
Access values stored in a hierarchical record.
Declare variables of pointer types.
Take the addresses of variables and access the variables through pointers.
Write an expression that selects a member of a class, struct, or union that is pointed to by a pointer.
This chapter represents a transition point in your study of computer science and C++ programming. So far, we have emphasized simple variables, control structures, and named processes (functions). After this chapter, the focus shifts to ways to structure (organize) data and to the algorithms necessary to process data in these structured forms. To make this transition, we must examine the concept of data types in greater detail.
Until now, we have worked primarily with the data types int, char, bool, and float. These four data types are adequate for solving a wide variety of problems. Certain programs, however, need other kinds of data. Sometimes the built-in data types cannot adequately represent all the data in a program. C++ has several mechanisms for creating user-defined data types; that is, we can define new data types ourselves. This chapter introduces one of these mechanisms, the enumeration type.
In this chapter, we also expand the definition of a data type to include structured types, which represent collections of components that are referred to by a single name. We begin with a discussion of structured types in general and then examine two structured types provided by the C++ language: struct and union.
10.1 Built-In Simple Types
In Chapter 2, we defined a data type as a specific set of data values (which we call the domain) along with a set of operations on those values. For the int type, the domain is the set of whole numbers from INT_MIN through INT_MAX, and the allowable operations we have seen so far are +, –, *, /, %, ++, - -, and the relational and logical operations. The domain of the float type is the set of all real numbers that a particular computer is capable of representing, and the operations are the same as those for the int type except that modulus (%) is excluded. For the bool type, the domain is the set consisting of the two values true and false, and the allowable operations are the logical (!, &&, ||) and relational operations. The char type, although used primarily to manipulate character data, is classified as an integral type because it uses integers in memory to stand for characters. Later in the chapter we will see how this process works.
The int, char, bool, and float types have a property in common: The domain of each type is made up of indivisible, or atomic, data values. Data types with this property are called simple (or atomic) data types. When we say that a value is atomic, we mean that it is not defined to have component parts that are accessed separately. For example, a single character of type char is atomic, but the string “Good Morning” is not (it is composed of 12 individual characters that we can also access).
Simple (atomic) data type A data type in which each value is atomic (indivisible).
Another way of describing a simple type is to say that only one value can be associated with a variable of that type. In contrast, a structured type is one in which an entire collection of values is associated with a single variable of that type. For example, a string object represents a collection of characters that are given a single name.
FIGURE 10.1 shows the simple types that are built into the C++ language. This figure is a portion of the complete diagram of C++ data types presented in Figure 3.1.
In this figure, one of the types—enum—is not actually a single data type in the sense that int and float are data types. Instead, it is a mechanism with which we can define our own simple data types. We will look at enum later in this chapter.
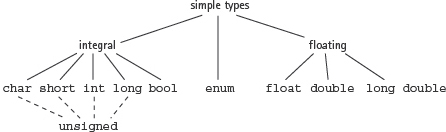
FIGURE 10.1 C++ Simple Types
Numeric Types
The integral types char, short, int, and long represent nothing more than integers of different sizes. Similarly, the floating-point types float, double, and long double simply refer to floating-point numbers of different sizes. What do we mean by sizes?
In C++, sizes are measured in multiples of the size of a char. By definition, the size of a char is 1. On most—but not all—computers, the 1 means one byte. (Recall from Chapter 1 that a byte is a group of eight consecutive bits [1s or 0s].)
Let’s use the notation sizeof (SomeType) to denote the size of a value of type SomeType. Then, by definition, sizeof (char) = 1. Other than char, the sizes of data objects in C++ are machine dependent. On one machine, it might be the case that
sizeof (char) = 1
sizeof (short) = 2
sizeof (int) = 4
sizeof (long) = 8
On another machine, the sizes might be as follows:
sizeof (char) = 1
sizeof (short) = 2
sizeof (int) = 2
sizeof (long) = 4
Despite these variations, the C++ language guarantees that the following statements are true:
 1 = sizeof (char) <= sizeof (short) <= sizeof (int) <= sizeof (long).
1 = sizeof (char) <= sizeof (short) <= sizeof (int) <= sizeof (long).
1 <= sizeof (bool) <= sizeof (long).
sizeof (float) <= sizeof (double) <= sizeof (long double).
A char is at least 8 bits.
A short is at least 16 bits.
A long is at least 32 bits.
For numeric data, the size of a data object determines its range of values. We showed a table of the range of values for numeric data types in Chapter 3 on page 93. Be careful: The actual range of values of a numeric data type is machine dependent. The only constraints on the C++ compiler are the relative sizes of the ranges given earlier. Making an implicit assumption about the actual range in a particular program may cause portability problems when the program is run on another machine.
Range of values The interval within which values of a numeric type must fall, specified in terms of the largest and smallest allowable values.
Recall that the reserved word unsigned may precede the name of certain integral types—unsigned char, unsigned short, unsigned int, unsigned long. Values of these types are nonnegative integers with values from 0 through some machine-dependent maximum value. Although we rarely use unsigned types in this book, we include them in this discussion for thoroughness.
C++ systems provide the header file climits, from which you can determine the maximum and minimum values for your machine. This header file defines the constants CHAR_MAX and CHAR_MIN, SHRT_MAX and SHRT_MIN, INT_MAX and INT_MIN, and LONG_MAX and LONG_MIN. The unsigned types have a minimum value of 0 and maximum values defined by UCHAR_MAX, USHRT_MAX, UINT_MAX, and ULONG_MAX. To find out the values specific to your computer, you could print them out like this:

Code designed for portability should check these adjectives where needed within the program.
Likewise, the standard header file cfloat defines the constants FLT_MAX and FLT_MIN, DBL_MAX and DBL_MIN, and LDBL_MAX and LDBL_MIN. To determine the ranges of values for your machine, you could write a short program that prints out these constants.
We should note that the C++ standard adds header files called limits.h and float.h that also contain these definitions.
Characters
Each computer uses a particular character set, the set of all possible characters with which it is capable of working. ASCII, which consists of 128 different characters, has historically been used by the vast majority of computers. The extended version of the ASCII character set provides 256 characters, which is enough for English but not enough for international use. This limitation gave rise to the Unicode character set, which has a much wider international following.
Unicode allows many more distinct characters than either ASCII or extended ASCII. It was invented primarily to accommodate the larger alphabets and symbols of various international human languages. In C++, the data type wchar_t rather than char is used for Unicode characters. In fact, wchar_t can be used for other, possibly infrequently used, “wide character” sets in addition to Unicode. In this book, we do not examine Unicode or the wchar_t type. Instead, we focus our attention on the char type and the ASCII character set.
Whichever character set is being used, each character has an external representation—the way it looks on an I/O device like a printer—and an internal representation—the way it is stored inside the computer’s memory unit. If you use the char constant 'A' in a C++ program, its external representation is the letter A. That is, if you print it out, you will see an A, as you would expect. Its internal representation, though, is an integer value. The 128 ASCII characters have internal representations 0 through 127. For example, the ASCII table in Appendix E shows that the character 'A' has internal representation 65, and the character 'b' has internal representation 98.
External representation The printable (character) form of a data value.
Internal representation The form in which a data value is stored inside the memory unit.
Let’s look again at the following statement:
someChar = 'A';
Assuming our machine uses the ASCII character set, the compiler translates the constant 'A' into the integer 65. We could also have written the statement as follows:
someChar = 65;
Both statements have exactly the same effect—that of storing 65 into someChar. However, the first is certainly more understandable.
Earlier we mentioned that the computer cannot tell the difference between character and integer data in memory because both are stored internally as integers. However, when we perform I/O operations, the computer does the right thing—it uses the external representation that corresponds to the data type of the expression being printed. Look at this code segment, for example:

When these statements are executed, the output is
97
a
When the << operator outputs someInt, it prints the sequence of characters 9 and 7. To output someChar, it prints the single character a. Even though both variables contain the value 97 internally, the data type of each variable determines how it is printed.
What do you think is output by the following sequence of statements?
char ch = 'D';
ch++;
cout << ch;
If you answered E, you are right. The first statement declares ch and initializes it to the integer value 68 (assuming ASCII). The next statement increments ch to 69, and then its external representation (the letter E) is printed. Extending this idea of incrementing a char variable, we could print the letters A through G as follows:
ch arch;
for (ch = 'A'; ch <= 'G'; ch++)
cout << ch;
This code initializes ch to 'A' (65 in ASCII). Each time through the loop, the external representation of ch is printed. On the final loop iteration, the 'G' is printed and ch is incremented to 'H' (72 in ASCII). The loop test is then false, so the loop terminates.
QUICK CHECK

10.1.1 Is bool considered an integral type or an enum type? (p. 463)
10.1.2 What property do the built-in types int, char, bool, and float have in common? (p. 462)
10.1.3 Other than char, what are the sizes of data objects in C++ dependent on? (p. 463)
10.1.4 What is the name of the character set that provides enough characters for the English language? How many characters can it represent? (p. 464)
10.1.5 What is the name of the character set that can accommodate larger alphabets? (p. 464)
10.1.6 What is the difference between the external and internal representation of a character? (pp. 464–465)
10.2 User-Defined Simple Types
The concept of a data type is fundamental to all of the widely used programming languages. One strength of the C++ language is that it allows programmers to create new data types, tailored to meet the needs of a particular program. Much of the remainder of this book deals with user-defined data types. In this section, we consider how to create our own simple types.
The Typedef Statement
The Typedef statement allows you to introduce a new name for an existing type. Its syntax template is
TypedefStatement
typedef ExistingTypeName NewTypeName;
Before the bool data type was part of the C++ language, many programmers used code like the following to simulate a Boolean type:

In this code, the Typedef statement causes the compiler to substitute the word int for every occurrence of the word Boolean in the rest of the program.
The Typedef statement provides us with a very limited way of defining our own data types. In fact, Typedef does not create a new data type at all: It merely creates an additional name for an existing data type. As far as the compiler is concerned, the domain and operations of the Boolean type in the previous example are identical to the domain and operations of the int type.
Despite the fact that Typedef cannot truly create a new data type, it is a valuable tool for writing self-documenting programs. Before bool was a built-in type, program code that used the identifiers Boolean, TRUE, and FALSE was more descriptive than code that used int, 1, and 0 for Boolean operations.
Names of user-defined types obey the same scope rules that apply to identifiers in general. Most types, like the Boolean example, are defined globally, although it is reasonable to define a new type within a subprogram if that is the only place it is used. The guidelines that determine where a named constant should be defined also apply to data types.
In Chapter 3, we said that the various string operations took as parameters or returned as results unsigned integers, but that we could use int instead. Actually these values should be of type size_type, a type defined in string as
typedef std::size_t size_type;
But what is size_t? It is a type provided in the C std header file that is implementation dependent. This unsigned integer type defines the maximum length of a string in a program compiled by a particular compiler. Given this fact, it is better style to use string::size_type rather than int when working with string operations, because the former type limits precisely the range of values that can be stored in these variables.
string::npos is the largest possible value of type string::size_type, a number like 4294967295 on many machines. This value is suitable for “not a valid position” because the string operations do not let any string become this long.
Enumeration Types
C++ allows the user to define a new simple type by listing (enumerating) the literal values that make up the domain of the type. These literal values must be identifiers, not numbers. The identifiers are separated by commas, and the list is enclosed in braces. Data types defined in this way are called enumeration types. Here’s an example:
Enumeration type A user-defined data type whose domain is an ordered set of literal values expressed as identifiers.
Enumerator One of the values in the domain of an enumeration type.
enum Days {SUN, MON, TUE, WED, THU, FRI, SAT};
This declaration creates a new data type named Days. Whereas Typedef merely creates a synonym for an existing type, an enumeration type like Days is truly a new type and is distinct from any existing type.
The values in the Days type—SUN, MON, TUE, and so forth—are called enumerators. The enumerators are ordered, in the sense that SUN < MON < TUE … < FRI < SAT. Applying relational operators to enumerators is like applying them to characters: The relation that is tested is whether an enumerator “comes before” or “comes after” in the ordering of the data type.
Earlier we saw that the internal representation of a char constant is a nonnegative integer. As we mentioned previously, the 128 ASCII characters are represented in memory as the integers 0 through 127. Values in an enumeration type are also represented internally as integers. By default, the first enumerator has the integer value 0, the second has the value 1, and so forth. Our declaration of the Days enumeration type is similar to the following set of declarations:

If there is some reason that you want different internal representations for the enumerators, you can specify them explicitly like this:
enum Days {SUN = 4, MON = 18, TUE = 9, · · · };
Nevertheless, there is rarely any reason to assign specific values to enumerators. With the Days type, we are interested in the days of the week, not in the way the machine stores this data internally. We do not discuss this feature any further, although you may occasionally see it in C++ programs.
Notice the style we use to capitalize enumerators. Because enumerators are, in essence, named constants, we capitalize the entire identifier. This is purely a style choice. Many C++ programmers use both uppercase and lowercase letters when they invent names for the enumerators.
Here is the syntax template for the declaration of an enumeration type. It is a simplified version; later in the chapter we expand it.
EnumDeclaration
enum Name { Enumerator, Enumerator … };
Each enumerator has the following form:
Enumerator
Identifier = ConstIntExpression
where the optional ConstIntExpression is an integer expression composed only of literal or named constants.
The identifiers used as enumerators must follow the rules for any C++ identifier. For example,
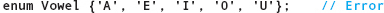
is not legal because the items are not identifiers. The declaration
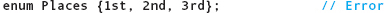
is not legal because identifiers cannot begin with digits. In the declarations

type Starch and type Grain are legal individually, but together they are not. Identifiers in the same scope must be unique, so CORN cannot be defined twice.
Suppose you are writing a program for a veterinary clinic. The program must keep track of many different kinds of animals. The following enumeration type might be used for this purpose:

Here RODENT is a literal, one of the values in the data type Animals. Be sure you understand that RODENT is not a variable name. Instead, RODENT is one of the values that can be stored into the variables inPatient and outPatient.
Next, let’s look at the kinds of operations we might want to perform on variables of enumeration types.
Assignment
The assignment statement
inPatient = DOG;
does not assign the character string "DOG" to inPatient, nor the contents of a variable named DOG. Instead, it assigns the value DOG, which is one of the values in the domain of the data type Animals.
Assignment is a valid operation, as long as the value being stored is of type Animals. Both of the statements
inPatient = DOG;
outPatient = inPatient;
are acceptable. Each expression on the right-hand side is of type Animals—DOG is a literal of type Animals, and inPatient is a variable of type Animals. Although we know that the underlying representation of DOG is the integer 2, the compiler prevents us from making this assignment:

Here is the precise rule:
Implicit type coercion is defined from an enumeration type to an
integral type but not from an integral type to an enumeration type.
Applying this rule to the statements
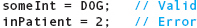
we see that the first statement stores 2 into someInt (because of implicit type coercion), but the second produces a compile-time error. The restriction against storing an integer value into a variable of type Animals is intended to keep you from accidentally storing an out-of-range value:
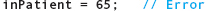
Incrementation
Suppose that you want to “increment” the value in inPatient so that it becomes the next value in the domain:

This statement is illegal for the following reason. The right-hand side is acceptable because implicit type coercion lets you add inPatient to 1; the result is an int value. But the assignment operation is not valid because you can’t store an int value into inPatient. The statement
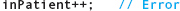
is also invalid because the compiler considers it to have the same semantics as the earlier assignment statement. However, you can escape the type coercion rule by using an explicit type conversion—a type cast—as follows:
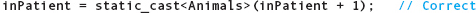
When you use the type cast, the compiler assumes that you know what you are doing and allows it.
The ability to increment a variable of an enumeration type is very useful in loops. Sometimes we need a loop that processes all the values in the domain of the type. We might try the following For loop:

However, as we explained earlier, the compiler will complain about the expression patient++. To increment patient, we must use an assignment expression and a type cast:

The only caution here is that when control exits the loop, the value of patient is 1 greater than the largest value in the domain (SHEEP). If you want to use patient outside the loop, you must reassign it a value that is within the appropriate range for the Animals type.
Comparison
The operation most commonly performed on values of enumeration types is comparison. When you compare two values, their ordering is determined by the order in which you listed the enumerators in the type declaration. For instance, the expression
inPatient <= BIRD
has the value true if inPatient contains the value RODENT, CAT, DOG, or BIRD.
You can also use values of an enumeration type in a Switch statement. Because RODENT, CAT, and so on are literals, they can appear in case labels:

Input and Output
Stream I/O is defined only for the basic built-in types (int, float, and so on), but not for user-defined enumeration types. Values of enumeration types must be input or output indirectly.
To input values, one strategy is to read a string that spells one of the constants in the enumeration type. The idea is to input the string and translate it to one of the literals in the enumeration type by looking at only as many letters as are necessary to determine what the string is.
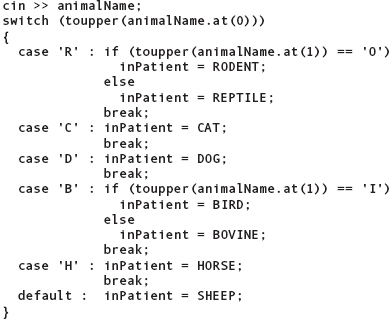
For example, the veterinary clinic program could read the kind of animal as a string, then assign one of the values of type Animals to that patient. Cat, dog, horse, and sheep can be determined by their first letter. Bovine, bird, rodent, and reptile cannot be determined until the second letter is examined. The following program fragment reads in a string representing an animal name and converts it to one of the values in type Animals:
Enumeration type values cannot be printed directly, either. Printing is accomplished by using a Switch statement that prints a character string corresponding to the value.

The following program reads in a value of an enumerated type and prints what it is:
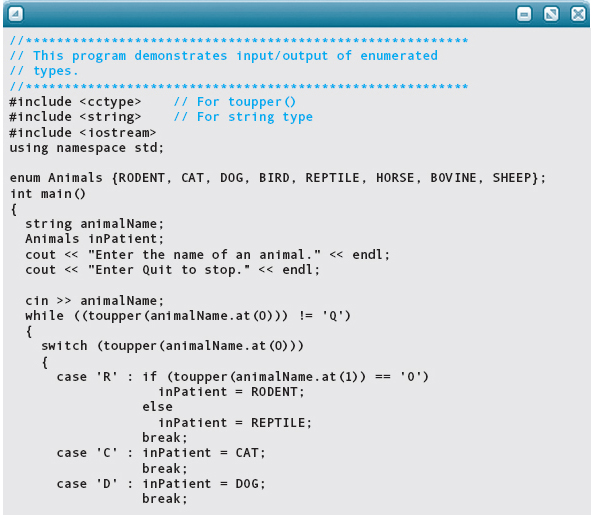
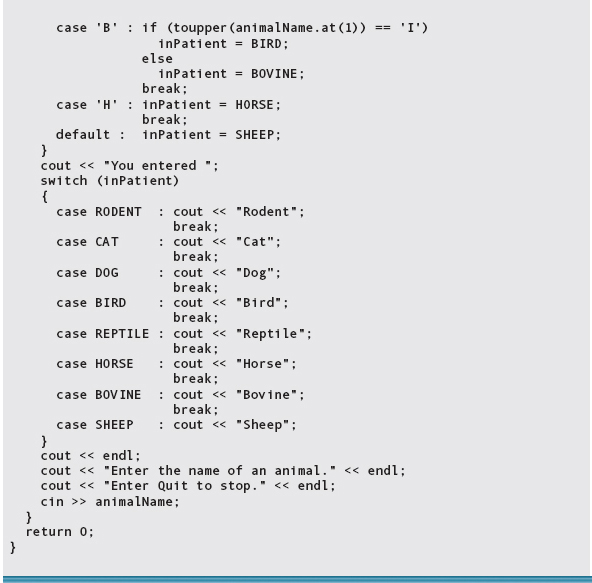
Here is sample output of this program:
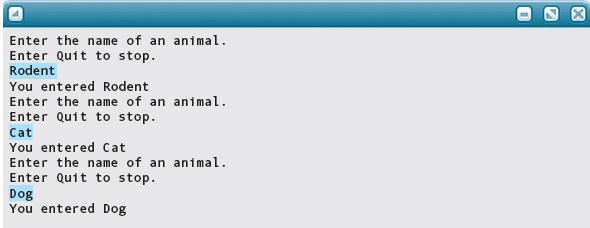
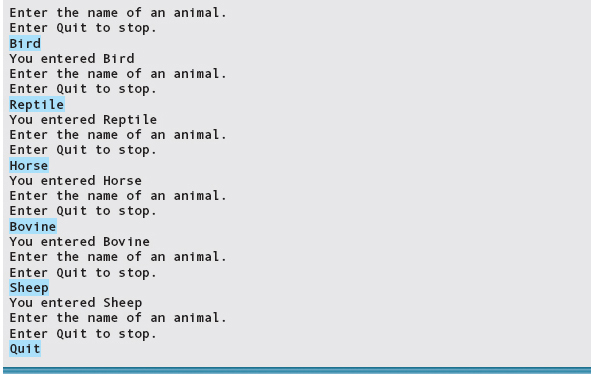
You might ask, Why not use just a pair of letters or an integer number as a code to represent each animal in a program? The answer is that we use enumeration types to make our programs more readable; they are another way to make the code more self-documenting.
Returning a Function Value
So far, we have been using value-returning functions to compute and return values of built-in types such as int, float, and char:
int Factorial( int );
float CargoMoment( int );
C++ allows a function return value to be of any data type—built in or user defined—except an array (a data type we examine in later chapters, and for which there are special rules regarding return from a function).
In the last section, we wrote a Switch statement to convert an input string into a value of type Animals. Now let’s write a value-returning function that performs this task. Notice how the function heading declares the data type of the return value to be Animals:
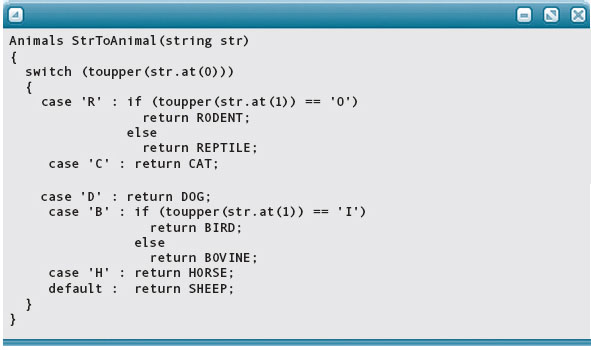
In this function, why didn’t we include a Break statement after each case alternative? Because when one of the alternatives executes a Return statement, control immediately exits the function. It’s not possible for control to “fall through” to the next alternative.
Here is the main function of the previous program, which calls the StrToAnimal function to convert a string into a value of type Animals:
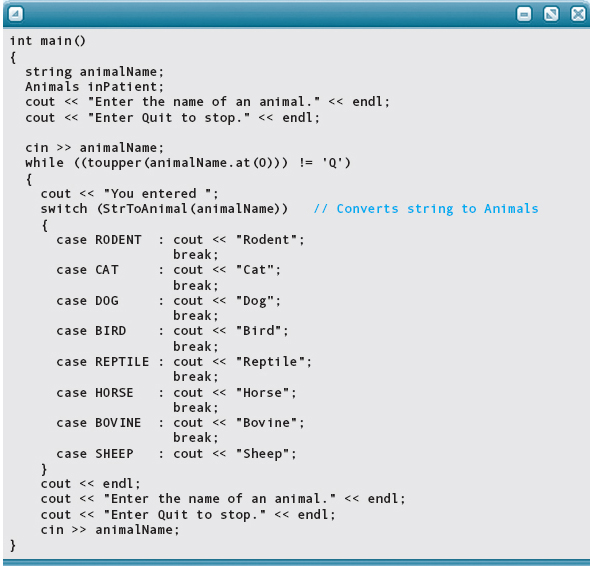
Named and Anonymous Data Types
The enumeration types we have looked at, Animals and Days, are called named types because their declarations included names for the types. Variables of these new data types are declared separately using the type identifiers Animals and Days.
C++ also lets us introduce a new type directly in a variable declaration. Instead of the declarations
enum CoinType {NICKEL, DIME, QUARTER, HALF_DOLLAR};
enum StatusType {OK, OUT_OF_STOCK, BACK_ORDERED};
CoinType change;
StatusType status;
we could write
enum {NICKEL, DIME, QUARTER, HALF_DOLLAR} change;
enum {OK, OUT_OF_STOCK, BACK_ORDERED} status;
A new type declared in a variable declaration is called an anonymous type because it does not have a name—that is, it does not have a type identifier associated with it.
Anonymous type A type that does not have an associated type identifier.
If we can create a data type in a variable declaration, why bother with a separate type declaration that creates a named type? Named types, like named constants, make a program more readable, more understandable, and easier to modify. Also, declaring a type and declaring a variable of that type are two distinct concepts; it is best to keep them separate.
We now give a more complete syntax template for an enumeration type declaration. This template shows that the type name is optional (yielding an anonymous type) and that a list of variables may optionally be included in the declaration.
EnumDeclaration

QUICK CHECK
10.2.1 Write an enumeration type definition for the four seasons. (p. 468)
10.2.2 Write a For loop heading that iterates through the Seasons type defined in Question 10.2.1. (p. 470)
10.2.3 What is the Typedef statement used for? (p. 466)
10.2.4 What is the difference between a Named and Anonymous data type? (p. 476)
10.3 Simple Versus Structured Data Types
A value in a simple type is a single data item; it cannot be broken down into component parts. For example, each int value is a single integer number and cannot be further decomposed. In contrast, a structured data type is a type in which each value is a collection of component items. The entire collection is given a single name, yet each component can still be accessed individually.
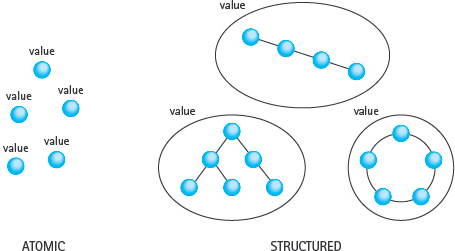
FIGURE 10.2 Atomic (Simple) and Structured Data Types
Structured data type A data type in which each value is a collection of components and whose organization is characterized by the method used to access individual components. The allowable operations on a structured data type include the storage and retrieval of individual components.
An example of a structured data type in C++ is the string class, which is used for creating and manipulating strings. When you declare a variable myString to be of type string, myString does not represent just one atomic data value; rather, it represents an entire collection of characters. Even so, each of the components in the string can be accessed individually by using an expression such as myString.at(3), which accesses the char value at position 3.
Simple data types, both built in and user defined, are the building blocks for structured types. A structured type gathers together a set of component values and usually imposes a specific arrangement on them (see FIGURE 10.2). The method used to access the individual components of a structured type depends on how the components are arranged. As we discuss various ways of structuring data, we will look at the corresponding access mechanisms.
FIGURE 10.3 shows the structured types available in C++. This figure is a portion of the complete diagram presented in Figure 3.1.
The struct and union data types are discussed in this chapter. The array is presented in Chapter 11; the class is the topic of Chapter 12.
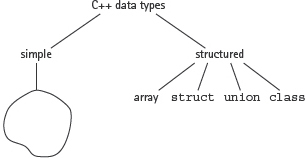
FIGURE 10.3 C++ Structured Types
QUICK CHECK
10.3.1 Simple data types are the building blocks of what? (p. 477)
10.3.2 What are the four structured types in C++? (p. 477)
10.4 Records (Structs)
In computer science, a record is a heterogeneous structured data type. By heterogeneous, we mean that the individual components of a record can be of different data types. Each component of a record is called a field of the record, and each field is given a name called the field name. C++ uses its own terminology with records. A record is a structure called a struct, the fields of a record are called members of the struct, and each member has a member name.1
Record (struct, in C++) A structured data type with a fixed number of components that are accessed by name. The components may be heterogeneous (of different types).
Field (member, in C++) A component of a record.
In C++, record data types are most commonly declared according to the following syntax:
StructDeclaration
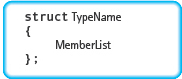
where TypeName is an identifier giving a name to the data type, and MemberList is defined as
MemberList
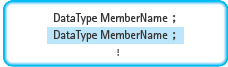
The reserved word struct is an abbreviation for structure. Because the word structure has many other meanings in computer science, we’ll use struct or record to avoid any possible confusion about what we are referring to.
You probably recognize the syntax of a member list as being nearly identical to a series of variable declarations. Be careful: A struct declaration is a type declaration, and we still must declare variables of this type for any memory locations to be associated with the member names. Let’s look at an example that groups together the parts of a mailing address:
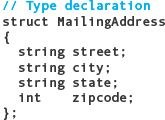

The MailingAddress struct contains four members representing the street address, city name, state, and ZIP code. Note that each member name is given a type. Also, member names must be unique within a struct type, just as variable names must be unique within a block.
The declaration of the MailingAddress data type just specifies the form that variables of this type will have; it doesn’t allocate any space in which to store member values. When we define variables of type MailingAddress, the C++ compiler allocates space within each of the variables that will hold the four members.
Notice, both in this example and in the syntax template, that a struct declaration ends with a semicolon. By now, you have learned not to put a semicolon after the right brace of a compound statement (block). However, the member list in a struct declaration is not considered to be a compound statement; the braces are simply required syntax in the declaration. A struct declaration, like all C++ declaration statements, must end with a semicolon.
Let’s look at another example. We can use a struct to describe a student in a class. We want to store the student’s first and last names, the overall grade-point average prior to this class, the grade on programming assignments, the grade on quizzes, the final exam grade, and the final course grade.
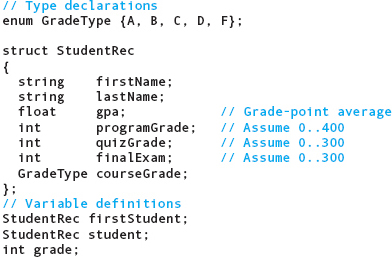
In this example, firstName, lastName, gpa, programGrade, quizGrade, finalExam, and courseGrade are member names within the struct type StudentRec. These member names make up the member list. firstName and lastName are of type string. gpa is a float member. programGrade, quizGrade, and finalExam are int members. courseGrade is of an enumeration data type made up of the grades A through D and F.
Just as we saw with our MailingAddress example, none of the struct members are associated with memory locations until we declare a variable of the StudentRec type. StudentRec is merely a pattern for a struct (see FIGURE 10.4).
The variables firstStudent and student are variables of type StudentRec. Each variable contains space for storing seven member values, according to the pattern specified in the type declaration.
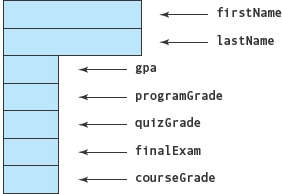
FIGURE 10.4 Pattern for a Struct
Accessing Individual Components
To access an individual member of a struct variable, you give the name of the variable, followed by a dot (period), and then the member name. This expression is called a member selector. The syntax template is
Member selector The expression used to access components of a struct variable. It is formed by using the struct variable name and the member name, separated by a dot (period).
MemberSelector

This syntax for selecting individual components of a struct is often called dot notation. To access the grade-point average of firstStudent, we would write
firstStudent.gpa
To access the final exam score for a student, we would write
student.finalExam
The component of a struct accessed by the member selector is treated just like any other variable of the same type. It may be used in an assignment statement, passed as an argument, and so on. FIGURE 10.5 shows the struct variable student, along with the member selector for each member. In this example, we assume that some processing has already taken place, so values are stored in some of the components.
Let’s demonstrate the use of these member selectors. Using our student variable, the following function takes in a student record as a parameter; adds up the program grade, the quiz grade, and the final exam grade; and returns a letter grade as the result:

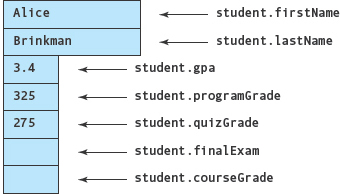
FIGURE 10.5 Struct Variable student with Member Selectors

Aggregate Operations on Structs
In addition to accessing individual components of a struct variable, we can in some cases use aggregate operations. An aggregate operation is one that manipulates the struct as an entire unit.
Aggregate operation An operation on a data structure as a whole, as opposed to an operation on an individual component of the data structure.
The following table summarizes the aggregate operations that C++ supports for struct variables:
Aggregate Operation |
Supported for Structs? |
I/O |
No |
Assignment |
Yes |
Arithmetic |
No |
Comparison |
No |
Argument passage |
Yes, by value or by reference |
Return as a function’s return value |
Yes |
According to the table, one struct variable can be assigned to another. To do so, however, both variables must be declared to be of the same type. For example, given the declarations
StudentRec student;
StudentRec anotherStudent;
the statement
anotherStudent = student;
copies the entire contents of the struct variable student to the variable anotherStudent, member by member.
In contrast, aggregate arithmetic operations and comparisons are not supported (primarily because they wouldn’t make sense):

Furthermore, aggregate I/O is not supported:

We must input or output a struct variable one member at a time:

According to the table, an entire struct can be passed as an argument, as we did in the previous example. The struct variable student was passed as a value parameter because we did not change any field. Had we needed to do so, we would have passed it as a reference parameter. A struct can also be returned as the value of a value-returning function.
Let’s define another function that takes a StudentRec variable as a parameter. The task of this function is to determine if a student’s grade in a course is consistent with his or her overall grade-point average (GPA). We define consistent to mean that the course grade corresponds correctly to the rounded GPA. The GPA is calculated on a four-point scale, where A is 4, B is 3, C is 2, D is 1, and F is 0. If the rounded GPA is 4 and the course grade is A, then the function returns true. If the rounded GPA is 4 and the course grade is not A, then the function returns false. Each of the other grades is tested in the same way.
The Consistent function is coded below. The parameter aStudent, a struct variable of type StudentRec, is passed by value.
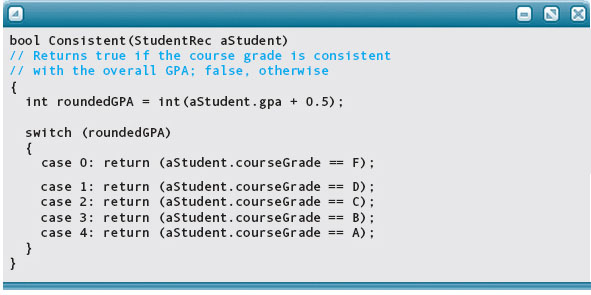
More About Struct Declarations
To complete our initial look at C++ structs, we give a more complete syntax template for a struct type declaration:
StructDeclaration
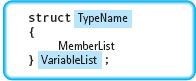
As you can see in the syntax template, two items are optional: TypeName (the name of the struct type being declared) and VariableList (a list of variable names between the right brace and the semicolon). Our examples thus far have declared a type name but have not included a variable list. The variable list allows you not only to declare a struct type, but also to declare variables of that type, all in one statement. For example, you could write the declarations
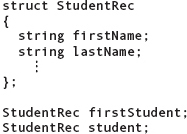
more compactly in the form
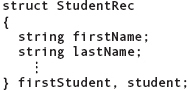
In this book, we avoid combining variable declarations with type declarations, preferring to keep the two notions separate.
If you omit the type name but include the variable list, you create an anonymous type:

Here, someVar is a variable of an anonymous type. No other variables of that type can be declared because the type has no name. Therefore, someVar cannot participate in aggregate operations such as assignment or argument passage. The cautions given previously against anonymous typing of enumeration types apply to struct types as well.
Binding Like Items
When data are obviously related, they should be collected into a record. For example, a name is made up of a first name, a middle name (or initial), and a last name. Rather than keeping these three values as separate variables, they should be bound into a record.
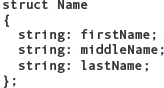
In the billing program for a lawn care service in Chapter 8, input and output files were passed to each module. It would be easier to bind these files into a record and pass them as one variable rather than two.
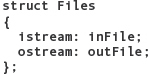
SOFTWARE MAINTENANCE CASE STUDY: Changing a Loop Implementation
MAINTENANCE TASK: Remember the Rich Uncle case study in Chapter 7? This problem counted the number of times certain characters were used in a text file. Now that we know how to implement modules as functions, let’s rewrite the program. Rather than looking at the code, we go back to the top-down design.
Main
Level 0
Open files for processing
IF file not opened okay
Write error message
Return 1
Get a character
DO
Process character
Get a character
WHILE (more data)
Print table
Close files
Let’s incorporate the file processing within a separate module, which takes the name of the file as a parameter.
PrepareFile (In/out: text)
Prompt for file name
Read file name
Open file
IF file not opened okay
Write error message
Return 1
Return
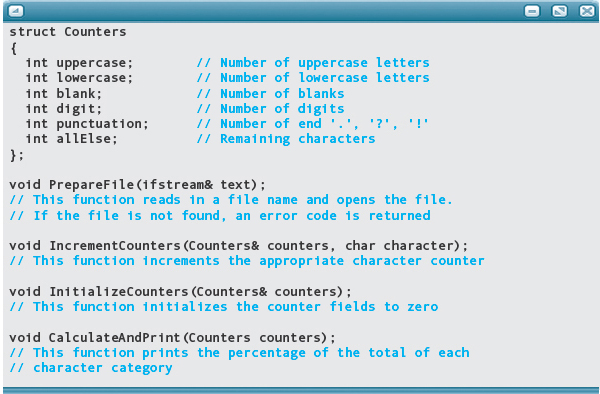
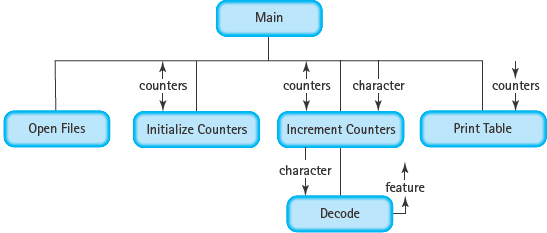
The next module is where the counters get incremented. The counters should be bound together in a record (Counters) and the record should be passed as a parameter to the module, along with the character.
IncrementCounters(In/out: counters, In: character)
Level 1
IF (isupper(character))
Increment uppercaseCounter
ELSE IF (islower(character))
Increment lowercaseCounter
ELSE IF (isdigit(character))
Increment digitCounter
SWITCH (character)
Case ‘ ’: Increment blankCounter
Case ‘.’:
Case ‘!’:
Case ‘?’: Increment punctuationCounter
The last module calculates and prints the percentages. Because the output goes to the standard input device, only the record containing the counters is passed as a parameter.
Calculate and Print Percentages(In: counters)
Set Total to sum of 6 counters
Print ‘Percentage of uppercase letters:’, uppercaseCounter / Total * 100
Print ‘Percentage of lowercase letters:’, lowercaseCounter / Total * 100
Print ‘Percentage of decimal digits:’, digitCounter / Total * 100
Print ‘Percentage of blanks:’, blankCounter / Total * 100
Print ‘Percentage of end-of-sentence punctuation:’, punctuationCounter / Total * 100
Coding these modules is very straightforward. We show the declaration of the record and the function prototypes here and leave the rest of the coding as an exercise. Note that because the counters are encapsulated into a record named Counters, we remove the word “Counter” from the variable names. Also, we need to add one more module: Initialize Counters. This initialization could be done within main, but creating a separate function to handle this task would be better style.
QUICK CHECK
10.4.1 Can an anonymous user-defined type be a parameter in a function? (p. 484)
10.4.2 What is contained between the braces of a struct definition? (p. 478)
10.4.3 Which operator is used as the member selector of a struct? (p. 480)
10.4.4 When is memory allocated to a C++ struct? (p. 478)
10.5 Hierarchical records
We have seen examples in which the components of a record are simple variables and strings. A component of a record can also be another record. Records whose components are themselves records are called hierarchical records.
Hierarchical record A record in which at least one of the components is itself a record.
Let’s look at an example in which a hierarchical structure is appropriate. Suppose a small machine shop keeps information about each of its machines. These data include descriptive information, such as the identification number, a description of the machine, the purchase date, and the cost. They also include statistical information, such as the number of down days, the failure rate, and the date of last service. What is a reasonable way of representing all this information? First, let’s look at a flat (nonhierarchical) record structure that holds this information.

The MachineRec type has 11 members. There is so much detailed information here that it is difficult to quickly get a feeling for what the record represents. Let’s see if we can reorganize it into a hierarchical structure that makes more sense. We can divide the information into two groups: information that changes and information that does not. There are also two dates to be kept: date of purchase and date of last service. These observations suggest use of a record describing a date, a record describing the statistical data, and an overall record containing the other two as components. The following type declarations reflect this structure.
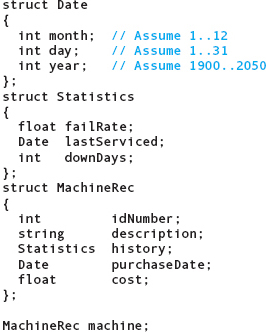
The contents of a machine record are now much more obvious. Two of the components of the struct type MachineRec are themselves structs: purchaseDate is of struct type Date, and history is of struct type Statistics. One of the components of struct type Statistics is, in turn, a struct of type Date.
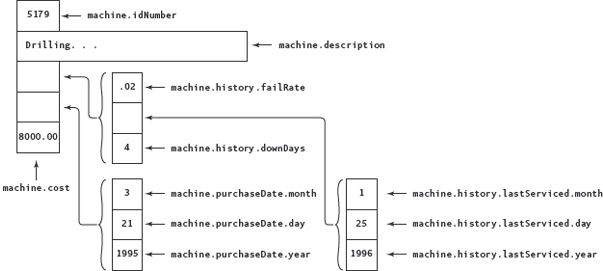
FIGURE 10.6 Hierarchical Records in machine Variable
How do we access the components of a hierarchical structure such as this one? We build the accessing expressions (member selectors) for the members of the embedded structs from left to right, beginning with the struct variable name. Here are some expressions and the components they access:
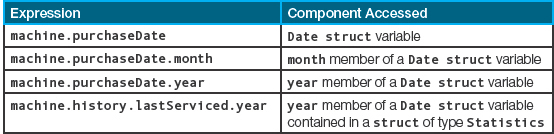
FIGURE 10.6 is a pictorial representation of machine with values. Look carefully at how each component is accessed.
QUICK CHECK
10.5.1 What do we call a data structure that is implemented by a struct that contains other struct types? (p. 486)
10.5.2 How would you write an expression to access the hour member of a struct that is itself a member, called time, of a struct variable called date? (pp. 486–488)
10.5.3 Why are hierarchical records useful? (pp. 486–488)
10.6 Unions
In FIGURE 10.3, we presented a diagram showing the four structured types available in C++. We have discussed struct types and now look briefly at union types.
In C++, a union is defined to be a struct that holds only one of its members at a time during program execution. Here is a declaration of a union type and a union variable:
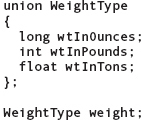
The syntax for declaring a union type is identical to the syntax that we showed earlier for the struct type, except that the word union is substituted for struct.
At run time, the memory space allocated to the variable weight does not include room for three distinct components. Instead, weight can contain only one of the following: either a long value or an int value or a float value. The assumption is that the program will never need a weight in ounces, a weight in pounds, and a weight in tons simultaneously while executing. The purpose of a union is to conserve memory by forcing several values to use the same memory space, one at a time. The following code shows how the weight variable might be used:

After the last assignment statement, the previous float value 4.83 is gone, replaced by the int value 35.
It’s quite reasonable to argue that a union is not a data structure at all. It does not represent a collection of values; it represents only a single value from among several potential values. Nevertheless, unions are grouped together with the structured types because of their similarity to structs.
There is much more to be said about unions, including subtle issues related to their declaration and usage. However, these issues are more appropriate in an advanced study of data structures and systems programming. We have introduced unions here solely so that we could present a complete picture of the structured types provided by C++ and to acquaint you with the general idea in case you encounter unions in other C++ programs.
In the previous sections, we looked at the simple types and structured types available in C++. Now we have only two built-in data types left to cover: pointer types and reference types (see FIGURE 10.7). These types are simple data types, yet in Figure 10.7 we list them separately from the other simple types because their purpose is so special. We refer to pointer types and reference types as address types.
A variable of one of these types does not contain a data value; it contains the memory address of another variable or structure. Address types have two main purposes: They can make a program more efficient—either in terms of speed or in terms of memory usage—and they can be used to build complex data structures. It is this latter use that we emphasize here.
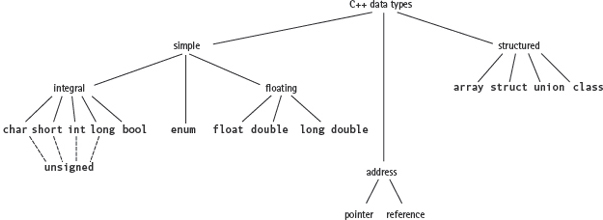
FIGURE 10.7 C++ Data Types
QUICK CHECK
10.6.1 What is a C++ union? (p. 489)
10.6.2 How much space is allocated to a union? (p. 489)
10.6.3 How does a C++ union conserve memory space? (pp. 488–489)
10.7 Pointers
In many ways, we’ve saved the best for last. Pointer types are the most interesting data types of all. Pointers are what their name implies: variables that tell where to find something else. That is, pointers contain the addresses or locations of other variables. Technically, a pointer type is a simple data type that consists of a set of unbounded values, each of which addresses the location of a variable of a given type.
Pointer type A simple data type consisting of an unbounded set of values, each of which addresses or otherwise indicates the location of a variable of a given type. Among the operations defined on pointer variables are assignment and testing for equality.
Let’s begin this discussion by looking at how pointer variables are declared in C++.
Pointer Variables
Surprisingly, the word “pointer” isn’t used in declaring pointer variables; the symbol * (asterisk) is used instead. The declaration
int* intPtr;
states that intPtr is a variable that can point to (that is, contain the address of) an int variable. Here is the syntax template for declaring pointer variables:
PointerVariableDeclaration

This syntax template shows two forms, one for declaring a single variable and the other for declaring several variables. In the first form, the compiler does not care where the asterisk is placed; it can be placed either to the right of the data type or to the left of the variable. Both of the following declarations are equivalent:
int* intPtr;
int *intPtr;
Although C++ programmers use both styles, we prefer the first. Attaching the asterisk to the data type name instead of the variable name readily suggests that intPtr is of type “pointer to int.”
According to the syntax template, if you declare several variables in one statement, you must precede each variable name with an asterisk. Otherwise, only the first variable is taken to be a pointer variable; subsequent variables are not. To avoid unintended errors when declaring pointer variables, it is safest to declare each variable in a separate statement.
Given the declarations
int beta;
int* intPtr;
we can make intPtr point to beta by using the unary & operator, which is called the address-of operator. At run time, the assignment statement
intPtr = β
takes the memory address of beta and stores it into intPtr. Alternatively, we could initialize intPtr in its declaration as follows:
int beta;
int* intPtr = β
Suppose that intPtr and beta happen to be located at memory addresses 5000 and 5008, respectively. Then storing the address of beta into intPtr results in the relationship pictured in FIGURE 10.8.
Because the actual numeric addresses are generally unknown to the C++ programmer, it is more common to display the relationship between a pointer and a pointed-to variable by using rectangles and arrows, as illustrated in FIGURE 10.9.
To access a variable that a pointer points to, we use the unary * operator—the dereference or indirection operator. The expression *intPtr denotes the variable pointed to by intPtr. In our example, intPtr currently points to beta, so the statement
*intPtr = 28;
dereferences intPtr and stores the value 28 into beta. This statement represents indirect addressing of beta: The machine first accesses intPtr, then uses its contents to locate beta. In contrast, the statement
Indirect addressing Accessing a variable in two steps by first using a pointer that gives the location of the variable.
Direct addressing Accessing a variable in one step by using the variable name.
beta = 28;
represents direct addressing of beta. Direct addressing is like opening a post office box (P.O. Box 15, for instance) and finding a package, whereas indirect addressing is like opening P.O. Box 23 and finding a note that says your package is sitting in P.O. Box 15.
Continuing with our example, if we execute the statements then the output is
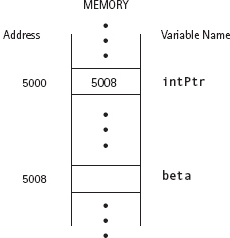
FIGURE 10.8 Machine-Level View of a Pointer Variable

FIGURE 10.9 Graphical Representation of a Pointer
5008
28
The first output statement prints the contents of intPtr (5008); the second prints the contents of the variable pointed to by intPtr (28).
Pointers can point to any type of variable. For example, we can define a pointer to a struct as highlighted here:

The expression *patientPtr denotes a struct variable of type PatientRec. Furthermore, the expressions (*patientPtr).idNum, (*patientPtr).height, and (*patientPtr). weight denote the idNum, height, and weight members of *patientPtr. Notice how the accessing expression is built.
patientPtr |
A pointer variable of type “pointer to PatientRec.” |
*patientPtr |
A struct variable of type PatientRec. |
(*patientPtr).weight |
The weight member of a struct variable of type PatientRec. |
The expression (*patientPtr).weight is a mixture of pointer dereferencing and struct member selection. The parentheses are necessary because the dot operator has higher precedence than the dereference operator (see Appendix B for C++ operator precedence). Without the parentheses, the expression *patientPtr.weight would be interpreted incorrectly as *(patientPtr.weight).
When a pointer points to a struct (or a class or a union) variable, enclosing the pointer dereference within parentheses can become tedious. In addition to the dot operator, C++ provides another member selection operator: ->. This arrow operator consists of two consecutive symbols: a hyphen and a greater-than symbol. By definition,
PointerExpression -> MemberName
is equivalent to
(*PointerExpression).MemberName
As a consequence, we can write
(*patientPtr).weight as patientPtr->weight.
The general guideline for choosing between the two member selection operators (dot and arrow) is the following: Use the dot operator if the first operand denotes a struct, class, or union variable; use the arrow operator if the first operand denotes a pointer to a struct, class, or union variable.
Pointer Expressions
You learned in the early chapters of this book that an arithmetic expression is made up of variables, constants, operator symbols, and parentheses. Similarly, pointer expressions are composed of pointer variables, pointer constants, certain allowable operators, and parentheses. We have already discussed pointer variables—variables that hold addresses of other variables. Let’s look now at pointer constants.
In C++, there is only one literal pointer constant: the value 0. The pointer constant 0, called the NULL pointer, points to absolutely nothing. The statement
intPtr = 0;
stores the NULL pointer into intPtr. This statement does not cause intPtr to point to memory location zero, however; the NULL pointer is guaranteed to be distinct from any actual memory address. Because the NULL pointer does not point to anything, we diagram the NULL pointer as follows, instead of using an arrow to point somewhere:
Instead of using the constant 0, many programmers prefer to use the named constant NULL that is supplied by the standard header file cstddef:2

As with any named constant, the identifier NULL makes a program more self-documenting. Its use also reduces the chance of confusing the NULL pointer with the integer constant 0.
It is an error to dereference the NULL pointer, as it does not point to anything. The NULL pointer is used only as a special value that a program can test for:
if (intPtr == NULL)
DoSomething();
We have now seen three C++ operators that are valid for pointers: =, *, and ->. In addition, the relational operators may be applied to pointers. For example, we can ask if a pointer points to anything with the following test:
if (ptr != NULL)
DoSomething();
It is important to keep in mind that the operations are applied to pointers, not to the pointed-to variables. For example, if intPtr1 and intPtr2 are variables of type int*, the test
if (intPtr1 == intPtr2)
compares the pointers, not the variables to which they point. In other words, we are comparing memory addresses, not int values. To compare the integers that intPtr1 and intPtr2 point to, we would need to write
if (*intPtr1 == *intPtr2)
QUICK CHECK
10.7.1 In declaring a pointer variable called compass that points to an int, there are two ways that you can write the declaration in C++. What are they? (p. 491)
10.8 Reference Types
According to Figure 10.7, there is only one built-in type remaining: the reference type. Like pointer variables, reference variables contain the addresses of other variables. The statement
Reference type A simple data type consisting of an unbounded set of values, each of which is the address of a variable of a given type. The only operation defined on a reference variable is initialization, after which every appearance of the variable is implicitly dereferenced. Unlike a pointer, a reference cannot be set to 0.
int& intRef;
declares that intRef is a variable that can contain the address of an int variable. Here is the syntax template for declaring reference variables:
ReferenceVariableDeclaration

Although both reference variables and pointer variables contain addresses of data objects, there are two fundamental differences between them. First, the dereferencing and address-of operators (* and &) are not used to dereference reference variables. After a reference variable has been declared, the compiler invisibly dereferences every single appearance of that reference variable. If you were to use * or & with a reference variable, it would be applied instead to the object that the variable references.
Using a Reference Variable |
Using a Pointer Variable |
|
|
int gamma = 26; |
int gamma = 26; |
int& intRef = gamma; |
int* intPtr = γ |
// intRef is a reference |
// intPtr is a pointer |
// variable that points |
// variable that points |
// to gamma |
// to gamma |
intRef = 35; |
*intPtr= 35; |
// gamma == 35 |
// gamma == 35 |
intRef = intRef + 3; |
*intPtr= *intPtr+ 3; |
// gamma == 38 |
// gamma == 38 |
Some programmers like to think of a reference variable as an alias for another variable. In the preceding code, we can think of intRef as an alias for gamma. After intRef is initialized in its declaration, everything we do to intRef is actually happening to gamma.
The second difference between reference and pointer variables is that the compiler treats a reference variable as if it were a constant pointer. Thus the value of this variable cannot be reassigned after being initialized. That is, we cannot assign intRef to point to another variable. Any attempt to do so just assigns the new value to the variable to which intRef points. It should also be noted that a reference variable cannot be initialized to 0 or NULL; a reference has to point to something that actually exists. In contrast, a pointer can be set to NULL to indicate that it points to nothing.
By now, you have probably noticed that the ampersand (&) has several meanings in the C++ language. To avoid errors, it is critical to recognize these distinct meanings. The following table summarizes the different uses of the ampersand. Note that a prefix operator precedes its operand(s), an infix operator lies between its operands, and a postfix operator comes after its operand(s).
Position |
Usage |
Meaning |
Prefix |
&Variable |
Address-of operation |
Infix |
Expression & Expression |
Bitwise AND operation (See Appendix B) |
Infix |
Expression && Expression |
Logical AND operation |
Postfix |
DataType& |
Data type (specifically, a reference type) Exception: To declare two variables of a reference type, the & must be attached to each variable name: int & var1, & var2; |
Problem-Solving Case Study
Stylistical Analysis of Text
PROBLEM: Earlier in this chapter, we rewrote the Rich Uncle case study program, implementing the modules as functions. The Case Study Follow-Up Exercises to the original program intrigued you, so you decide to change and enhance the program. Rather than calculating percentages of groups of characters, you will just show counts. You also will determine the average word length and the average sentence length. Because you have just learned about enumerated types, you decide to redo the design using these constructs.
DISCUSSION: The Case Study Follow-Up exercise answers in Chapter 7 suggest that the number of new lines, punctuation marks, and blanks give a good approximation to the number of words. However, if any of these characters appear consecutively, only the first should be counted as an end-of-word symbol. You can use a Boolean variable endOfWord that is set to true when an end-of-word symbol is found. The word counter should be incremented only when endOfWord is false, after which endOfWord is set to true. When an alphanumeric character is read, endOfWord is set to false.
INPUT: Text on the file whose name is read from the keyboard.
OUTPUT: A table giving the file whose name is read from the keyboard, showing the following values:
Total number of alphanumeric characters
Number of uppercase letters
Number of lowercase letters
Number of digits
Number of characters ignored
Number of words
Number of sentences
Average word length
Average sentence length
Problem-Solving Case Study
The main and OpenFiles modules are almost the same as those for the revision in the Software Maintenance Case Study. It is the IncrementCounters module that will change.
INCREMENT COUNTERS: In the Rich Uncle program, you used a combination of If and Switch statements to determine to which category a character belonged. In the revised program, you will use a Switch statement with case labels of an enumerated type. The categories are uppercase, lowercase, digits, end-of-word, end-of-sentence, and ignore.
enum Features {UPPER, LOWER, DIGIT, EOW, EOS, IGNORE};
This module is where the endOfWord switch must be set. It should be set to false when it is declared, set to true when an end-of-word symbol is found, and reset to false when an alphanumeric character is found. For this process to work properly, endOfWord must be marked as a static variable. Recall that a static variable is a local variable that maintains its value from invocation to invocation.
IncrementCounters (In/out: counters, character)
Level 1
Set (static) endOfWord to false
SWITCH (Decode(character))
UPPER: |
Increment counters.uppercase
Set endOfWord to false |
LOWER: |
Increment lowercase
Set endOfWord to false |
DIGIT: |
Increment digit
Set endOfWord to false |
EOW: |
IF NOT endOfWord
Increment word
Set endOfWord to true; |
EOS: |
Increment sentence |
IGNORE: |
Increment ignore |
DECODE: This module takes a character and returns the enumerated type for the category into which it falls. We can use part of the algorithm from the original version, adding the code for the end of a word and the end of a sentence.
Decode(ln: character)
Out: function value—Features
IF isupper(character)
Return UPPER
ELSE IF islower(character)
Return LOWER
ELSE IF isdigit(character)
Return DIGIT
ELSE
SWITCH (character)
‘’.:
‘?’:
‘!’: return EOS
‘ ’:
‘;’:
‘:’:
'\n': return EOW;
Return IGNORE;
Notice that a Switch statement can be used in the last else-clause because characters can be used as case labels. If neither of the first two are matched, control flows into the third case, which has a return beside it that causes execution to jump to the end of the Switch statement. The same is true of the fourth through seventh case labels, which flow through into the last case label, which has a return beside it.
As you look at this algorithm, you realize that the end-of-sentence markers are also end-of-word markers! Yet, you also want to keep the counts separate. You decide to take care of this problem in module CalculateAndPrint by adding the number of sentences to the number of words.
CalculateAndPrint (In/out: table, In: counters)
Level 1
Set totalAlphaNum to counters.uppercase + counters.lowercase + counters.digit
Print on table “Total number of alphanumeric characters:” totalAlphaNum
Print on table “Number of uppercase letters:” counters.uppercase
Print on table “Number of lowercase letters:” counters.lowercase
Print on table “Number of digits:” counters.digit
Print on table “Number of characters ignored:” counters.ignore
Set counters.word to counters.word + counters.sentence
Print on table “Number of words:” counters.word
Print on table “Number of sentences:” counters.sentence
Print on table “Average word length:” float(totalAlphaNum)/counters.word
Print on table “Average sentence length:” float(counters.word)/counters.sentence
“CalculateAndPrint” is a little long. Let’s call the function PrintTable instead.
MODULE STRUCTURE CHART


TESTING: Let’s take a sample of text, calculate the statistics by hand, and compare the results with the output from the program.
Input

Expected Results |
|
Total number of alphanumeric characters: |
527 |
Number of uppercase letters: |
15 |
Number of lowercase letters: |
512 |
Number of digits: |
0 |
Number of characters ignored: |
5 (two pairs of parentheses and a hyphen) |
Number of words: |
96 |
Number of sentences: |
5 |
Average word length: |
5.489 |
Average sentence length: |
19.2 |
Output from the Program
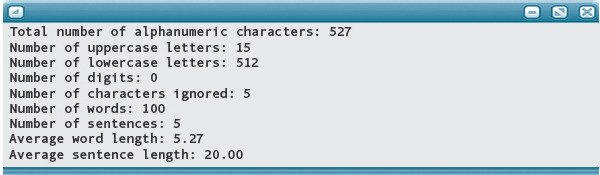
The number of words, average word length, and average sentence length are wrong. You recount the number of words and again come up with 96. You took care of the case where end-of-sentence markers end words by adding the number of sentences to the number of words. But endOfWord wasn’t reset when

When you rerun the program, you get this output:

The number of words is still off by one. Now you see it. You counted “gear-driven” as two words; the program counts it as one. You are asked to examine a solution to this problem in the Case Study Follow-Up Exercises.
Testing and Debugging
Coping with Input Errors
Several times in this book, we’ve had our programs test for invalid data and write error messages if they encountered incorrect input. Writing an error message is certainly necessary, but it is only the first step in handling errors. We must also decide what the program should do next. The problem itself and the severity of the error should determine which action is taken in any error condition. The approach taken also depends on whether the program is being run interactively.
In a program that reads its data only from an input file, there is no interaction with the person who entered the data. The program, therefore, should try to account for the bad data items, if at all possible.
If the invalid data item is not essential, the program can skip it and continue; for example, if a program averaging test grades encounters a negative test score, it could simply skip the negative score. If an educated guess can be made about the probable value of the bad data, it can be set to that value before being processed. In either event, a message should be written stating that an invalid data item was encountered and outlining the steps that were taken. Such messages form an exception report.
If the data item is essential and no guess is possible, processing should be terminated. A message should be written to the user containing as much information as possible about the invalid data item.
In an interactive environment, the program can prompt the user to supply another value. The program should indicate to the user what is wrong with the original data. Another possibility is to write out a list of actions and ask the user to choose among them.
These suggestions on how to handle bad data assume that the program recognizes bad data values. There are two approaches to error detection: passive and active. Passive error detection leaves it to the system to detect errors. This may seem easier, but the programmer relinquishes control of processing when an error occurs. An example of passive error detection is the system’s division-by-zero error.
Active error detection means that the program checks for possible errors and determines an appropriate action if an error occurs. An example of active error detection would be to read a value and use an If statement to see if the value is 0 before dividing it into another number.
Debugging with Pointers
Programs that use pointers are more difficult to write and debug than programs without pointers. Indirect addressing never seems quite as “normal” as direct addressing when you want to get at the contents of a variable.
The errors most commonly associated with the use of pointer variables are as follows:
1. Confusing the pointer variable with the variable it points to.
2. Trying to dereference the NULL pointer or an uninitialized pointer.
Let’s look at each of these potential problems in turn.
If ptr is a pointer variable, care must be taken not to confuse the expressions ptr and *ptr. The expression
ptr
accesses the variable ptr (which contains a memory address). The expression
*ptr
accesses the variable that ptr points to.
ptr1 = ptr2 |
Copies the contents of ptr2 into ptr1. |
*ptr1 = *ptr2 |
Copies the contents of the variable pointed to by ptr2 into the variable pointed to by ptr1. |
*ptr1 = ptr2 |
Illegal—one is a pointer and one is a variable being pointed to. |
ptr1 = *ptr2 |
Illegal—one is a pointer and one is a variable being pointed to. |
The second common error is to dereference the NULL pointer or an uninitialized pointer. On some systems, an attempt to dereference the NULL pointer produces a run-time error message such as NULL POINTER DEREFERENCE, followed immediately by termination of the program. When this event occurs, you have at least some notion of what went wrong with the program. The situation is worse, though, if your program dereferences an uninitialized pointer. In the code fragment
int num;
int* intPtr;
num = *intPtr;
the variable intPtr has not been assigned any value before we dereference it. Initially, it contains some meaningless value such as 315988, but the computer does not know that it is meaningless. The machine simply accesses memory location 315988 and copies whatever it finds there into num. There is no way to test whether a pointer variable contains an undefined value. The only advice we can give for avoiding this problem is to check the code carefully to make sure that every pointer variable is assigned a value before being dereferenced.
Testing and Debugging Hints
1. Avoid using unnecessary side effects in expressions. The test
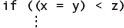
is less clear and more prone to error than the equivalent sequence of statements
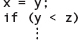
Also, if you accidentally omit the parentheses around the assignment operation, like this:
if (x = y < z)
then, according to C++ operator precedence, x is not assigned the value of y. Instead, it is assigned the value 1 or 0 (the coerced value of the Boolean result of the relational expression y < z).
2. Programs that rely on a particular machine’s character set may not run correctly on another machine. Check which character-handling functions are supplied by the standard library used by the machine on which the program is run. Functions such as tolower, toupper, isalpha, and iscntrl automatically account for the character set being used.
3. If your program increases the value of a positive integer and the result suddenly becomes a negative number, you should suspect integer overflow. On most computers, adding 1 to INT_MAX yields INT_MIN, a negative number.
4. Consider using enumeration types to make your programs more readable, understandable, and modifiable.
5. Avoid anonymous data typing. Give each user-defined type a name.
6. Enumeration type values cannot be input or output directly.
7. The declarations of a struct type must end with semicolons.
8. Be sure to specify the full member selector when referencing a component of a struct variable or class object.
9. To declare two pointer variables in the same statement, you must use
int *p, *q;
You cannot use
int* p, q;
Similarly, you must use
int &m, &n;
to declare two reference variables in the same statement.
10. Do not confuse a pointer with the variable to which it points.
11. Before dereferencing a pointer variable, be sure it has been assigned a meaningful value other than NULL.
12. Pointer variables must be of the same data type to be compared or assigned to one another.
 Summary
Summary
A data type is a set of values (the domain) along with the operations that can be applied to those values. Simple data types are data types whose values are atomic (indivisible).
The integral types in C++ are char, short, int, long, and bool. The most commonly used integral types are int and char. The char type can be used for storing small (usually one-byte) numeric integers or, more often, for storing character data. Character data includes both printable and nonprintable characters.
C++ allows the programmer to define additional data types. The Typedef statement is a simple mechanism for renaming an existing type, although the result is not truly a new data type. In contrast, an enumeration type, which is created by listing the identifiers that make up the domain, is a new data type that is distinct from any existing type. Values of an enumeration type may be assigned, compared in relational expressions, used as case labels in a Switch statement, passed as arguments, and returned as function values. Enumeration types are extremely useful in the writing of clear, self-documenting programs. In succeeding chapters, we look at language features that let us create even more powerful user-defined types.
In addition to being able to create user-defined atomic data types, we can create structured data types. In a structured data type, a name is given to an entire group of components. With many structured types, the group can be accessed as a whole, or each individual component can be accessed separately.
A record is a data structure for grouping together heterogeneous data—that is, data items that are of different types. Individual components of a record are accessed by name. In C++, records are referred to as structures or simply structs. We can use a struct variable to refer to the struct as a whole, or we can use a member selector to access any individual member (component) of the struct. Entire structs of the same type may be assigned directly to each other, passed as arguments, or returned as function return values. Comparison of structs, however, must be done member by member. Reading and writing of structs must also be done member by member.
Pointer types and reference types are simple data types for storing memory addresses. Variables of these types do not contain data; rather, they contain the addresses of other variables or data structures. Pointer variables require explicit dereferencing using the * operator. Reference variables are dereferenced implicitly and are commonly used to pass nonarray arguments by reference.
Quick Check Answers
10.1.1 It is an integral type. 10.1.2 The domain of each type is made up of indivisible, or atomic, data values. 10.1.3 The machine the C++ program is executing on. 10.1.4 ASCII; 256 10.1.5 Unicode 10.1.6 The external representation is what you see when it is printed. The internal representation is the numeric code used by the computer to represent the character. 10.2.1 enum Seasons {SPRING, SUMMER, WINTER, AUTUMN};
10.2.2 for (quarter = SPRING; quarter <= AUTUMN; quarter = static_cast<Seasons>(quarter + 1)) 10.2.3 It is used to introduce a new name for an existing type. 10.2.4 A named data type is associated with a name as part of its declaration and can be used by any number of subsequent declarations. An anonymous data type is used only once and is included directly in a variable declaration. 10.3.1 Structured data types. 10.3.2 array, struct, union, and class 10.4.1 No. 10.4.2 A list of the members of the struct. 10.4.3 The dot (period). 10.4.4 When you declare a variable of the type of the struct. 10.5.1 A hierarchical record. 10.5.2 date.time.hour 10.5.3 They help organize the information they represent making it easier to understand. 10.7.1 int* compass; int *compass; 10.6.1 A C++ union is defined to be a struct that holds only one of its members at a time during program execution. 10.6.2 The maximum of the union’s members. 10.6.3 By allowing a type to have values of different types at different times, avoiding the need to allocate storage for all of the different types at once.
Exam Preparation Exercises
1. All of the integral types in C++ can be signed or unsigned. True or false?
2. The sizeof operator can be used to determine whether a machine’s int type is 32 or 64 bits long. True or false?
3. Floating-point numbers are seldom exactly equal. True or false?
4. The values of enumerator types must be written in uppercase letters. True or false?
5. What are the five integral types in C++?
6. What is wrong with the following pair of enumeration type declarations?
enum Colors {RED, ORANGE, YELLOW, GREEN, BLUE, INDIGO, VIOLET};
enum Flowers{ROSE, DAFFODIL, LILY, VIOLET, COSMOS, ORCHID};
7. Given the declaration of Colors in Exercise 6, what is the value of the expression (YELLOW + 1)?
8. Given the code segment:
enum Flowers{ROSE, DAFFODIL, LILY, VIOLET, COSMOS, ORCHID};
Flowers choice;
choice = LILY;
choice++;
Why does the compiler give an invalid type error message for the last line?
9. Why is it impossible to use an anonymous type with a function parameter?
10. A struct cannot have another struct as a member. True or false?
11. A union is a struct that can hold just one of its members at a time. True or false?
12. Given the following declarations:
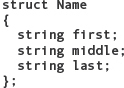
Name yourName;
Name myName;
What are the contents of the two Name variables after each of the following statements, assuming they are executed in the order listed?
a. yourName.first = "George";
b. yourName.last = "Smith";
c. myName = yourName;
d. myName.middle = "Nathaniel";
e. yourName.middle = myName.middle.at(0) + ".";
13. What are the three aggregate operations allowed on structs?
14. How does a union differ from an enumeration type?
15. Given the declaration of the Name type in Exercise 12, and the following declarations:
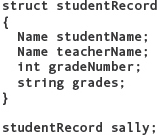
a. How would you assign the name Sally Ellen Strong to the studentName field of variable sally?
b. How would you assign the grade number 7 to that field of sally?
c. How would you assign the fourth letter from the grades field to char variable spring?
16. What happens when a struct is passed as an argument to a value parameter of a function? How does this differ from passing it to a reference parameter?
17. Given the following union declaration:

What does each of the following statements do, assuming they are executed in the order shown?
a. cin >> grade.gradeLetter;
b. if (grade.gradeLetter >= 'A' && grade.gradeLetter <= 'D')
c. grade.gradeNumber = 4 – int(grade.gradeLetter – 'A');
18. Assigning the value NULL to a pointer causes it to point to nothing. True or false?
19. A reference variable can be reassigned a new address value at any time. True or false?
Programming Warm-Up Exercises
1. Declare an enumeration type consisting of the nine planets in their order by distance from the Sun (Mercury first, Pluto last).
2. Write a value-returning function that converts the name of a planet given as a string parameter to a value of the enumeration type declared in Exercise 1. If the string isn’t a proper planet name, return "EARTH".
3. Write a value-returning function that converts a planet of the enumeration type declared in Exercise 1 into the corresponding string. The planet is an input parameter and the string is returned by the function. If the input is not a valid planet, return "Error".
4. Write a For statement that prints out the names of the planets in order, using the enumeration type declared in Exercise 1 and the function declared in Exercise 3.
5. Declare a struct type, Time, that represents an amount of time consisting of minutes and seconds.
6. Write statements that assign the time 6 minutes and 54 seconds to a variable, someTime, of type Time, as declared in Exercise 5.
7. Declare a struct type, Song, that represents a song entry in an MP-3 library. It should have fields for title, album, artist, playing time in minutes and seconds (use the type declared in Exercise 5), and music category. The music category is represented by an enumeration type called Category.
8. Write statements to declare a variable called mySong of type Song, and assign it a set of values. For the playing time, use the variable someTime declared in Exercise 6. Make up values for the other fields. Assume that the enumeration type Category includes any song category that you wish to use.
9. Write a statement to output the playing time from mySong, as declared in Exercise 8, in the format mm:ss.
10. Write a declaration of a union type called Temporal that can hold a time represented as a string, as an integer, or as a value of type Time, as declared in Exercise 5.
11. Write the declaration of a variable called shift of type Temporal, as declared in Exercise 10, and a statement that assigns the value of someTime, as declared in Exercise 6, to shift.
12. Declare a pointer variable intPointer and initialize it to point to an int variable named someInt. Write two assignment statements, the first of which stores the value 451 directly into someInt, and the second of which indirectly stores 451 into the variable pointed to by intPointer.
Programming Problems
1. Programming Problem 4 in Chapter 5 asked you to write a C++ program that asks the user to enter his or her weight and the name of a planet. In Chapter 7, Programming Problem 2 asked you to rewrite the program using a Switch statement. Now, rewrite the program so it uses an enumerated type to represent the planet.
For ease of reference, the information for the original problem is repeated here. The following table gives the factor by which the weight must be multiplied for each planet. The program should output an error message if the user doesn’t input a correct planet name. The prompt and the error message should make it clear to the user how a planet name must be entered. Be sure to use proper formatting and appropriate comments in your code. The output should be labeled clearly and formatted neatly.
Mercury |
0.4155 |
Venus |
0.8975 |
Earth |
1.0 |
Moon |
0.166 |
Mars |
0.3507 |
Jupiter |
2.5374 |
Saturn |
1.0677 |
Uranus |
0.8947 |
Neptune |
1.1794 |
Pluto |
0.0899 |
2. Programming Problem 3 in Chapter 7 asked you to write a program that generates sales-report files for a set of traveling salespeople. In the original problem, we used an integer in the range of 1 through 10 to represent ID numbers for the salespeople. Rewrite the program so that it uses an enumeration type whose values are the names of the salespeople (you can make up the names). The sales file format should replace the salesperson ID number with a string that is the person’s last name, so that a line of the file contains a name, an item number, and a quantity. For convenience, the other information concerning the problem is repeated here.
The company sells eight different products, with IDs numbered 7 through 14 (some older products have been discontinued). The unit prices of the products are given here:
Product Number |
Unit Price |
7 |
345.00 |
8 |
853.00 |
9 |
471.00 |
10 |
933.00 |
11 |
721.00 |
12 |
663.00 |
13 |
507.00 |
14 |
259.00 |
The program reads in the sales file, and generates a separate file for each salesperson containing just his or her sales. Each line from the sales file is copied to the appropriate salesperson’s file, with the salesperson’s name omitted. The file names should be the name of the salesperson with .dat appended (you may have to adjust names that don’t work as file names on your computer, such as hyphenated names or names with apostrophes). The total for the sale (quantity times unit price) is then appended to the record. At the end of processing, the total sales for each salesperson should be output with informative labels to cout. Use functional decomposition to design the program. Make sure that the program handles invalid salesperson’s names. If a salesperson’s name is invalid, write out an error message to cout. If a product number is invalid, write the error message to the salesperson’s file and don’t compute a total for the sale.
3. You are taking a geology class, and the professor wants you to write a program to help students learn the periods of geologic time. The program should let the user enter a range of prehistoric dates (in millions of years), and then output the periods that are included in that range. Each time this output is done, the user is asked if he or she wants to continue. The goal of the exercise is for the student to try to figure out when each period began, so that he or she can make a chart of geologic time.
Within the program, represent the periods with an enumeration type made up of their names. You will probably want to create a function that determines the period corresponding to a date, and another function that returns the string corresponding to each identifier in the enumeration. Then you can use a For loop to output the series of periods in the range. The periods of geologic time are given here:
Period Name |
Starting Date (millions of years) |
Neogene |
23 |
Paleogene |
65 |
Cretaceous |
136 |
Jurassic |
192 |
Triassic |
225 |
Permian |
280 |
Carboniferous |
345 |
Devonian |
395 |
Silurian |
435 |
Ordovician |
500 |
Cambrian |
570 |
Precambrian |
4500 or earlier |
Use functional decomposition to solve this problem. Be sure to use good coding style and documenting comments. The prompts and error messages that are output should be clear and informative.
4. The educational program that you wrote for Problem 3 was a big success. Now the geology professor wants you to write another program to help teach geologic time. In this program, the computer picks a date in geologic time and presents it to the student. The student then guesses which period corresponds to the date. The student is allowed to continue guessing until he or she gets the right answer. Then the program asks the student whether he or she wants to try again, and repeats the process if the answer is “yes.” To solve this problem, you should again use an enumeration type consisting of the names of the periods. In this case, you’ll probably want to make a function that returns the period corresponding to a string containing the name of a period (the program should work with any style of capitalization of the names). You also may want a function that returns the period for a given date.
Use functional design to solve this problem. Be sure to use good coding style and include helpful documenting comments. The prompts and error messages that are output should be clear and informative. You may want to add some interest to the program by keeping track of the number of guesses taken by the user, and offering differing levels of praise and encouragement depending on how well the user is doing.
5. Write a C++ program that determines the largest number for which your computer can represent its factorial exactly using the longdouble type. A factorial is the product of all numbers from 1 to the given number. For example, 10 factorial (written 10!) is
1×2×3×4×5×6×7×8×9×10 = 3,628,800
As you can see, the factorial grows to be a large number very quickly. Your program should keep multiplying the prior factorial by the next integer, then subtract 1 and check whether the difference between the factorial and the factorial minus 1 is less than 1—an error tolerance. When the maximum precision of the type is reached, and least significant digits are truncated to allow the most significant digits of the product to be stored, then subtracting 1 should have no effect on the value. Because floating-point representations may not be exact, however, the expression
abs((number – 1) – number)
may not exactly equal 1. That’s why you need to include a small error tolerance in the comparison.
Use functional decomposition to solve this problem. Code the program using good style and include helpful documenting comments. To keep the user informed of progress, you may wish to output all of the intermediate factorial values. The greatest number and its factorial should be clearly labeled.
Case Study Follow-Up
1. How could you determine whether a hyphen should be counted as an end-of-word symbol or a break in the word due to spacing issues?
2. Implement the change outlined in your answer to Exercise 1.
3. The endOfWord variable is reset to false every time an alphanumeric character is read. Thus it is set to itself over and over again. Can you think of a scheme that would allow you to set it only once?
4. Should error detection be added to program Style? Explain.