MANO
Management, Orchestration, OSS, and Service Assurance
Abstract
In this chapter, we discuss the orchestration of services and introduce elements that are now becoming more common in both current ETSI and open source solution dialogs. We also explore the practicality of moving to NFV en masse across an existing network, which will introduce a number of its own challenges.
Keywords
MANO; OSS; service assurance; network; ETSI
Introduction
While the preceding chapter dealt with the NFV infrastructure (including the VIM), the other new (and big) chunk of logic introduced by NFV centers on Management and Orchestration (MANO).
If we revisit our high-level architecture framework in Fig. 6.1, our focus in this chapter will include a further breakdown of NFV MANO. In particular, we will look at the Virtual Network Function Manager (VNFM) and NFV Orchestrator (NFVO) components as well as some external but related components.
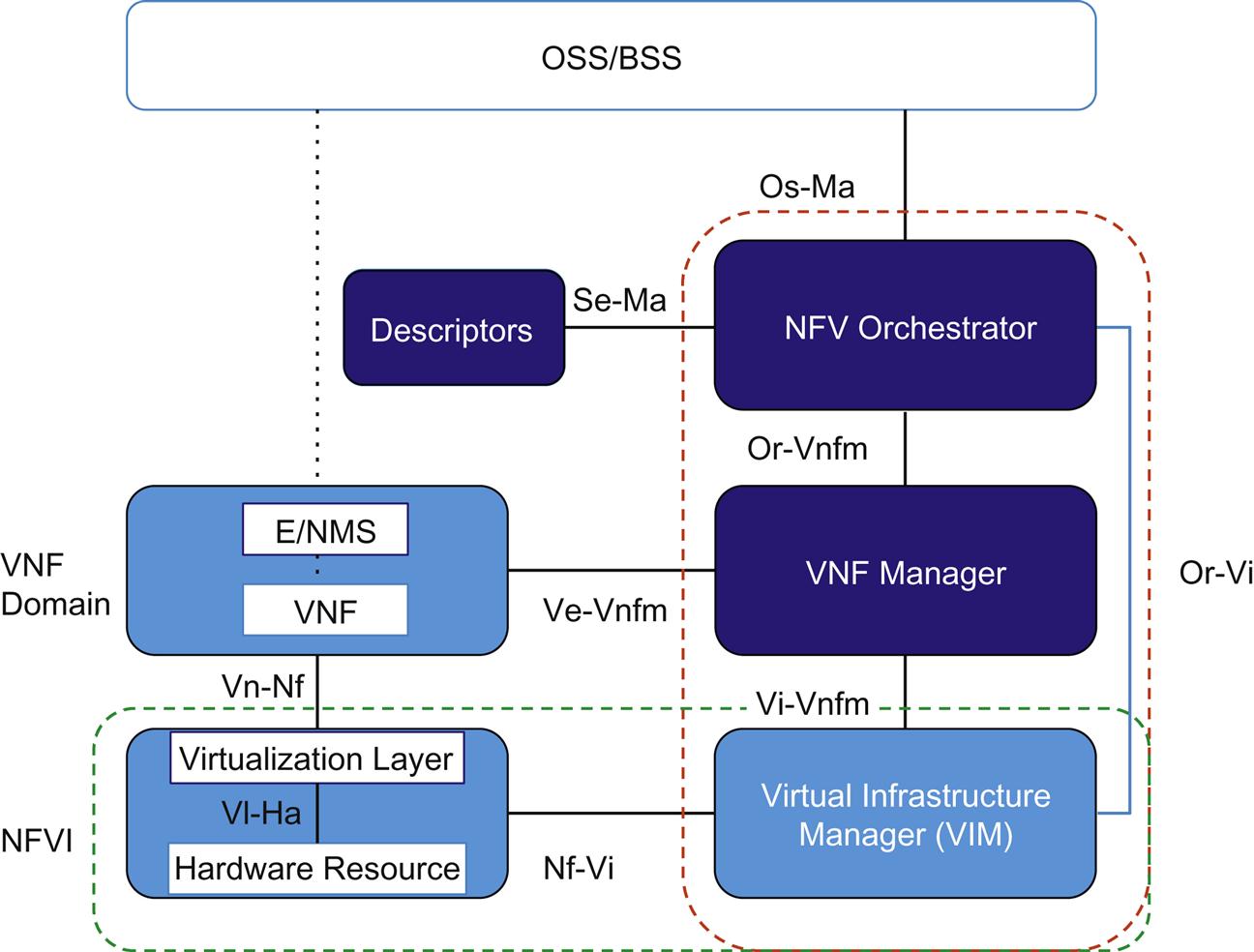
While the original focus of the ETSI architecture was primarily on orchestration and lifecycle management of VNFs, we need to elevate the discussion to the orchestration of services and introduce elements that are now becoming more common in both current ETSI and open source solution dialogs. We also need to explore the practicality of doing this en masse across an existing network, which will introduce a number of its own challenges.
While some concepts rudimentary to the understanding of service chaining and an indicator of the discussion of more complex services in the future (eg, service graphs) were part of the original NFVO vision, familiar elements of service orchestration like the management of a service catalog were not originally emphasized.
The open source orchestration concept of that time was being borrowed from Data Center and was centered on resource orchestration tasks. However, these concepts did (and still do) exist in more integrated vendor-led service orchestration offerings. Logically, the NFVO will become part of existing higher level service orchestrators or will evolve to become a higher level service orchestrator.
Similarly, the scope of the VNFM can be seen as just an element in the larger FCAPS (Fault Management, Configuration Management, Accounting Management, Performance Management, and Security Management) approach to existing service management more common to traditional Operations Support System (OSS) thinking.
Whether by accident or on purpose, one of the outcomes from the NFV MANO perspective is a blurring of the line between service and resource orchestration.
On the other hand, one of the serious oversights of the ETSI architecture lies around its overall impact on OSS. If we ignore the history of OSS in provider service creation, we ignore the potential of NFV and virtualization to become an even worse proposition for network operators. We delve into this in more detail in Chapter 9, An NFV Future.
Our goal in this chapter is to elevate the MANO discussion from resource orchestration and management (VNF centricity) to the service and emphasize one of the “big wins” that will propel NFV—the reimagination of OSS.
Although there is some intersection in the discussion of architectural components covered in our last chapter (eg, VIM), here we will focus more on the darkened blocks in Fig. 6.1.
For completeness, and because it is not considered part of MANO but is relevant to a discussion of OSS/Business Support System (BSS), we will start with a look at the Element Management System (EMS) in the VNF Domain.
The VNF Domain
The VNF Domain, which we will define loosely as the collection of the virtualized network functions and their management interface(s), will not be the focus of any specific chapter in this book. It is not our intention to look at specific-vendor VNFs or services unless they are used in examples.
VNF Domain also has an important functional block often overlooked in discussions around NFV: Element Management.
Element Management and the EMS, has long been a companion to physical network elements, be they servers, switches, routers, or storage arrays. The essence of their functionality is to allow operators to remotely configure, operate, and monitor these pieces of equipment that, in many cases, are located remotely to the network operators.
There are numerous examples of EMS but generally speaking, most equipment vendors offer some sort of EMS along with their products. Some are addons, and some come for free as part of the cost of the product. Most are proprietary and very specific to the product in question, although a few examples over the years of broader EMSs have existed with varying levels of success. In many cases, especially in larger networks, these systems are integrated into a larger OSS/BSS for the purposes of “end to end” monitoring, configuration, and management purposes.
Specifically, this is done to provide a more ubiquitous layer by which a network operator could view the often disparate set of devices both from a single vendor, or especially when multiple appliances were invoked from different vendors.
The OSS interfaces with EMSs primarily using what is referred to as their northbound interfaces. These interfaces are well defined, but not always standards-based. The goal here is to hide these abnormalities from the OSS, which then in turn provides a consistent look, feel, and interfaces to these devices.
Some of the most consistent feedback we have heard from operators planning NFV deployments is that they see the EMS being gradually supplanted by emerging functionality in other aspects of the NFV architecture. We tend to agree and see its inclusion as necessary for a transition period—as older systems and their management mechanisms age out of networks.
The OSS/BSS Block
An OSS/BSS is the traditional frameworks that connect the business to the services created. Example frameworks like those from TM Forum (TMF) were implemented as tightly integrated and closed solutions. Some of the component implementations relied on processes and protocols that did not scale well with an agile, virtualized, and dynamically scaled environment.
Fig. 6.2 shows a simplified OSS/BSS stack for review. There are a number of components in both the BSS and OSS blocks that provide services.
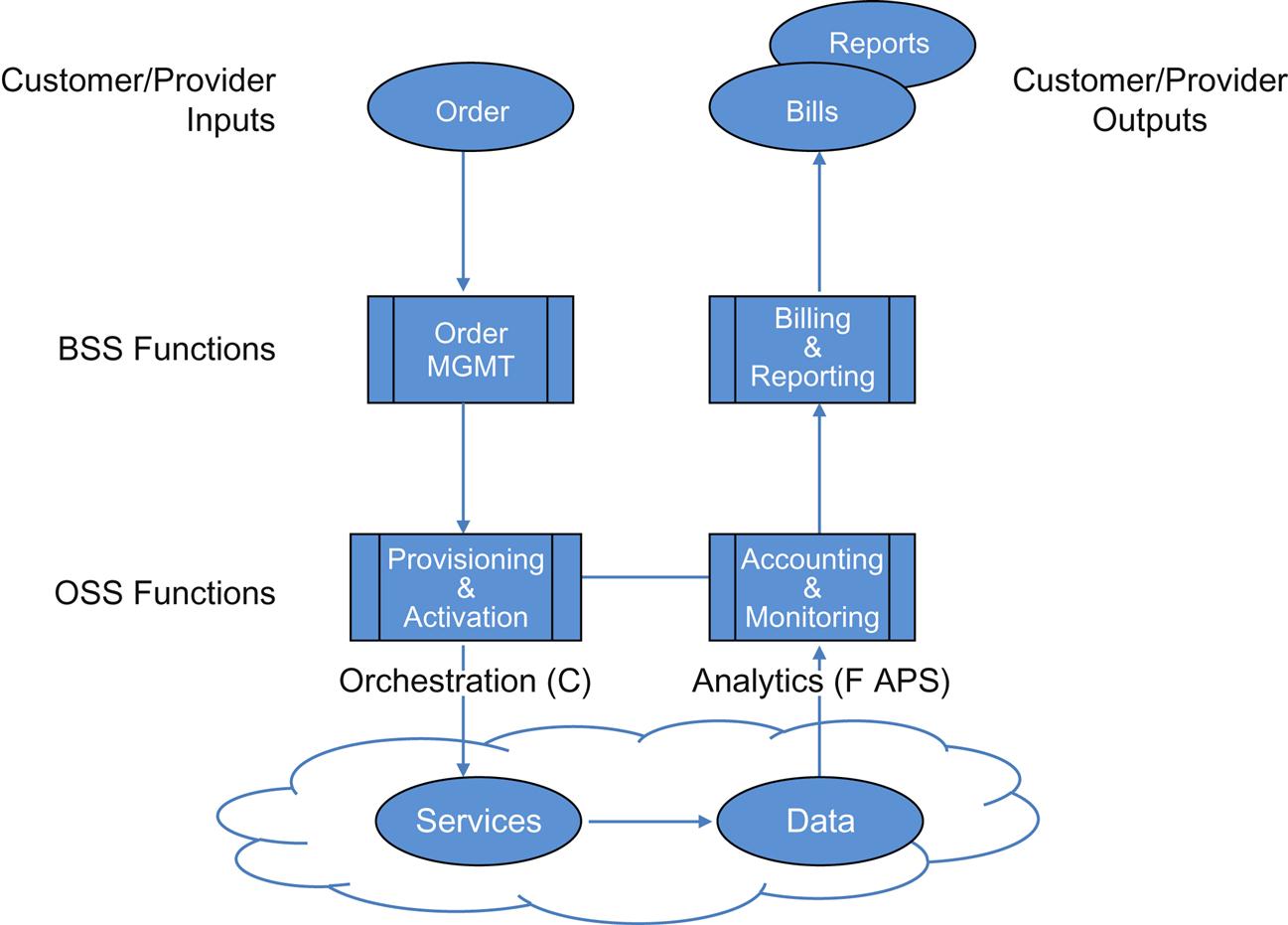
Within the OSS layer, we find the components that we are talking about throughout the chapter. As the picture depicts, the whole discussion of Orchestration overlaps just the “C” portion of FCAPS.
The BSS undertakes customer care and customer experience management. These manifest as order entry and bill delivery in the picture. Hidden inside that high-level description are functions like portal creation/management, billing (and billing mediation), a hefty bit of business analytics, and CRM. That latter function provides the most obvious linkages to OSS.
The OSS high-level accounting and monitoring description hides process engineering for order fulfillment, trouble ticketing, inventory/resource management, and service/resource catalog maintenance. And that’s not an exhaustive list!
Although BSS is less likely to proliferate/duplicate for most of its functions (eg. multiple billing systems), some service offerings in the past came with custom BSS/OSS pairings. The closed nature of the OSS aspects of the solution often led to OSS silo proliferation. Integration into or across existing systems often required expensive customization (further embedding the OSS vendor).
Most service providers have many OSSs—creating a huge cost center.
Many operators point to the costs of integrating new services, particularly new vendors, into their legacy OSS/BSS as a great challenge to service innovation. They also cite the distinct speed or lack thereof, that legacy systems had in regard to deployment, creation, changes to, and destruction of services. The lifecycle management of VNFs alone will create additional stresses on these existing systems. The tooling required to create services through recombinant catalogs of VNFs and edge-specific glue functions, including the associated Service Assurance (SA) definitions and customer and operator portals will probably outstrip their capabilities.
The ETSI GAP analysis did mention the need to integrate NFV with legacy OSS/BSS. This is an unfortunate reality. Telcos rarely, if ever, actually shut down and decommission any existing deployed services or the systems that manage them. While it is possible to evolve to a new “realtime OSS/BSS” that supports the dynamics of NFV and agile concepts such as customer self-service, early deployments are finding that some sort of shim will be needed to the existing OSS/BSS to bridge the gap, at least for the foreseeable future. Market research indicates that early adopters are aware that they are deploying ahead of solution availability in these areas.
Here, the ETSI prescription is notoriously weak, perhaps because this area of service delivery has long remained separate from the network architecture and operations that keeps packets flowing from point A to point B.
This is unfortunate because you cannot talk about service creation unless you can address OSS integration and SA. This is simply because you have to be able to monitor, maintain, and bill for a service.
The ETSI ISG ultimately recognized the importance of changing OSS, suggesting:
“OSS architectures must evolve along the following lines:
• Taking a holistic view of operations rather than the current piece-meal approach.
• Inheriting terms and definitions from standards rather than creating a separate language.
• Flexible architectures rather than static interface definitions.
• Building blocks defined by existing software rather than architecture-specific software.
• Full automation of the capacity management, optimization and reconfiguration cycle should be done by orchestration and cloud management techniques with open and multivendor components rather than vendor-specific management solutions.
• OSS focusing on portfolio management and end-to-end service management.”1
Several individuals can be credited for pushing the thinking forward around this relationship, in spite of the gap.
Reimagining the OSS (and BSS)—Brownfield Partnership
Earlier in the book we pointed at some of the earlier concepts coming out of the Terastream2 project. Before NFV was a “thing” that every operator realized they had to embrace, while the ETSI architecture was nascent, the project architect Peter Lothberg was speaking publicly about the need to integrate the OSS of his project with the existing OSS/BSS as a step in the transition from “legacy OSS/BSS” to what he coined as “real time OSS/BSS.”3 This is represented as a generalization for discussion in Fig. 6.3.
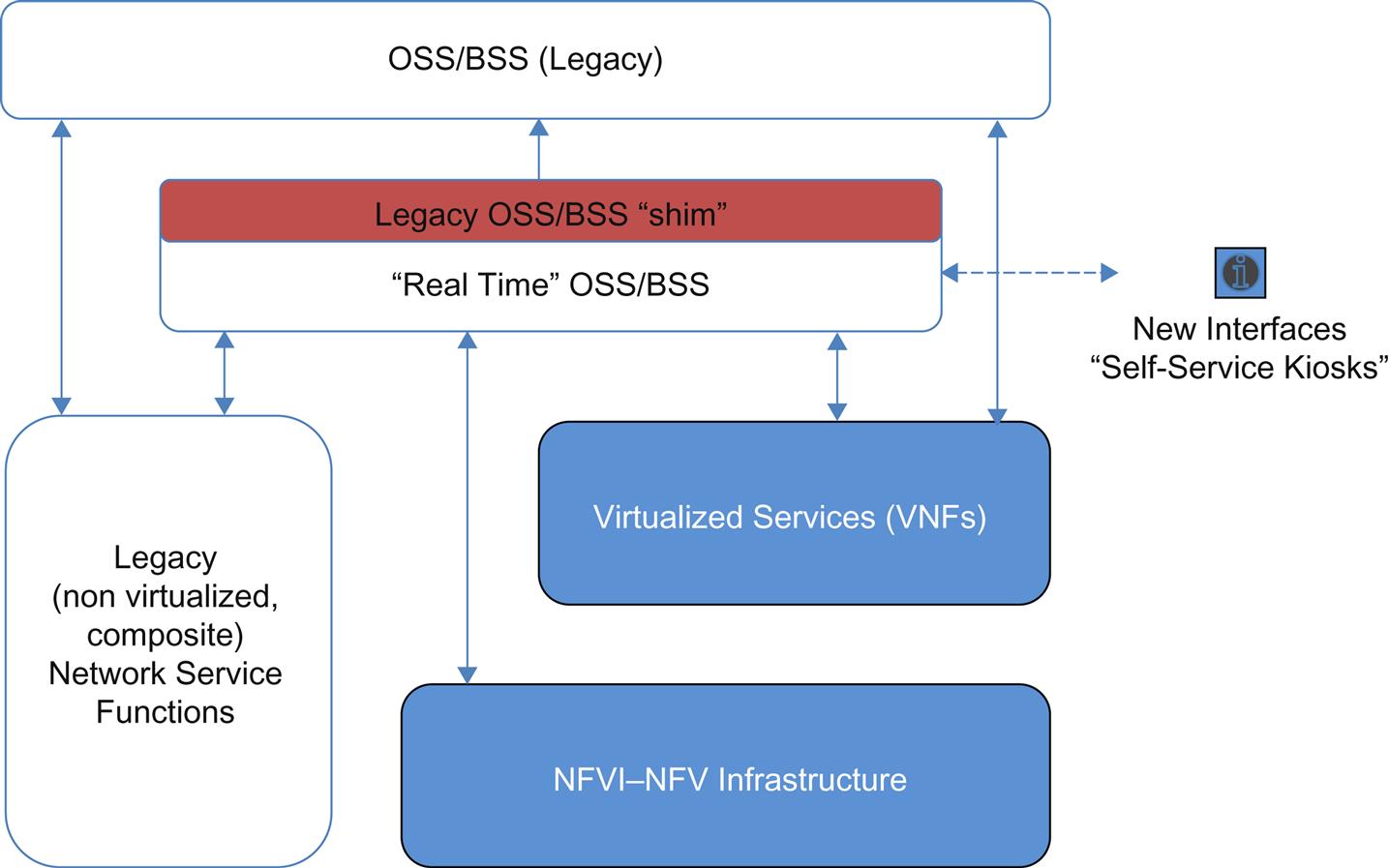
As part of the new architecture, many of the BSS aspects around customer care and experience management (the building of self-service kiosks and monitoring consoles driven through APIs on top of the OSS orchestration and SA pieces) are open, flexible, and modernized.
But the interesting aspect of the transitional OSS/BSS plan is the acknowledgment that the implementation of newer, virtualized services may require some interaction with existing infrastructure—that an operator may not have the luxury of a greenfield there either.
Thus, the first phase architecture has a shim to the existing OSS. This was labeled an “OSS Gateway” and was shown leveraging the billing, CRM, and process engineering of existing systems while also providing a path for resource/inventory reconciliation.
Subsequent phases created a “Fast Track” Order Management system (enabling self-care/customer order kiosks).
The final stage realized a new Real Time BSS (Billing, CRM and Analytics), a Real Time OSS (Process Engine, Service/Resource Catalog and Inventory) bracketed by API-driven Consumer Portal, Partner Portal and Service/Web Developer functionality.
This final stage is also notably prescient in that it shows the ultimate direction a new OSS can lead—to a PaaS environment for service creation.
Reimagining the OSS—Opportunities in SA
Focusing a bit more on the SA aspects of OSS, people like John Evans4 have been tying the idea of the modern “cloud” OSS to the evolution of analytics and the fundamental value of the massive amounts of data generated in modern service provider infrastructure in making informed network-wide service optimizations and comprehensive service impact analysis in response to fault.
John was one of the first architects to articulate that these aspects of OSS were a “big data problem.”
The Next Generation OSS (NGOSS) vision has just a couple of basic principles:
• OSS applications can be viewed as arbitrary functions against an OSS data set.
• The data set is fed by many diverse streams.
• The OSS solution was more a platform for managing and querying that data.
• Current data streams for SA were inflexible, rarely shared, and the resulting analysis functions were relatively ineffective.
Through this lens, looking beyond the closed nature and cost legacy OSSs, the subtlest, but important, problem they create is the impediment to sharing (and thus exploiting) data (Fig. 6.4).
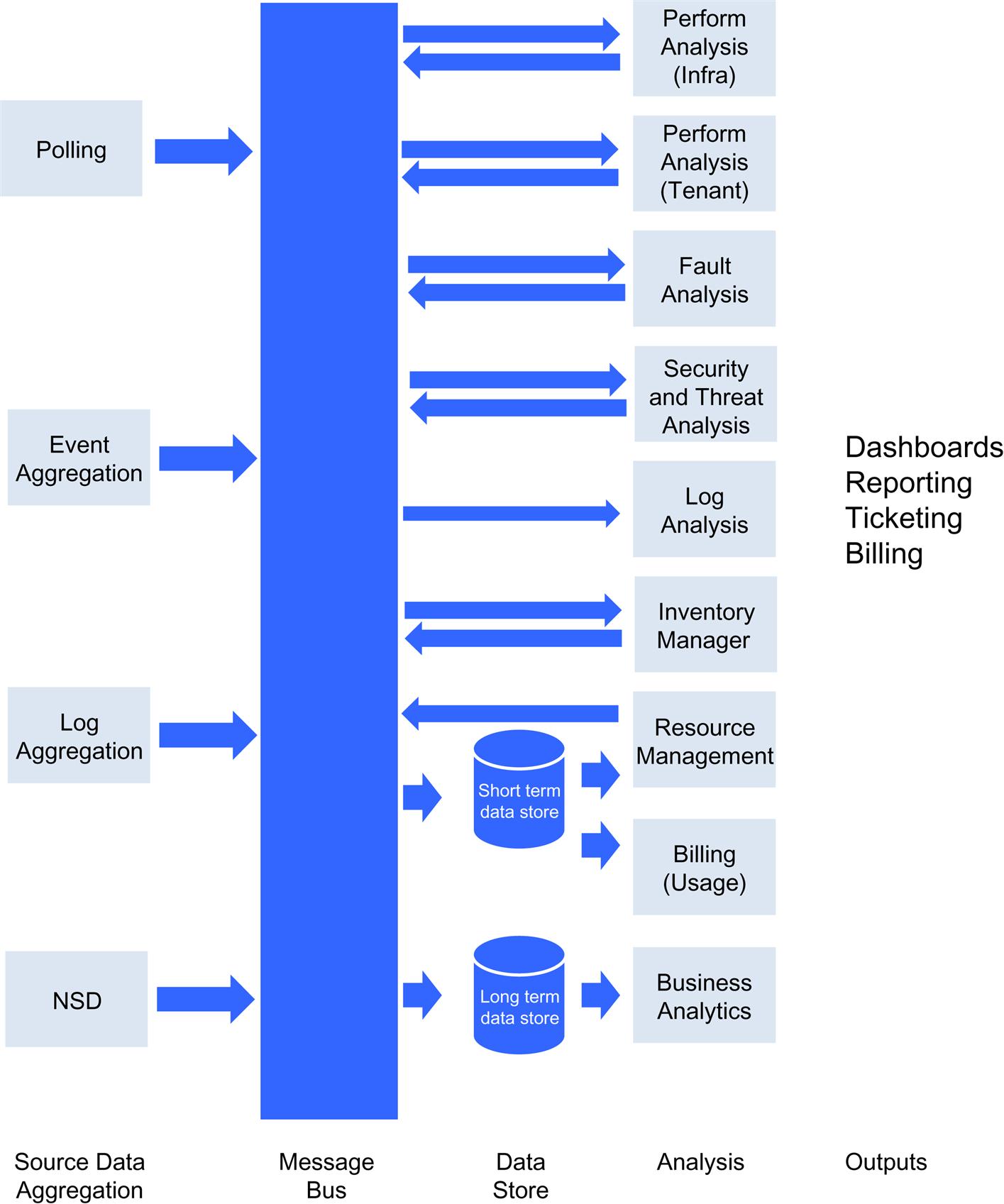
By reworking these aspects of the architecture, you can create a simple, scalable open platform that leverages the innovations in the big data space (high speed message bus technology, open source software for MapReduce, log processing, stream processing,5 etc.).
The principles of the proposed platform enable an analytics-based approach to analysis functions (eg, combinations of streaming apps, real-time queries, and batch processing).
A related concept was proposed as a project for OpenDaylight (by Andrew McLaughlin) that changed traditional less-scalable data collection methodologies associated with traditional SA (eg, SNMP polling and event monitoring) into pub/sub-structures that utilize a similar message design.
All of these ideas push the realization of an NGOSS forward. The most telling and shared characteristics of that OSS vision are that the OSS of the future is a platform not a product (driving back toward the goal of an open framework) and that platform is an architecture that did not exist before.
Interpretations from the Architectural Diagram Reference Points
Backtracking to the brownfield reimagination of OSS, a definition of such an interface/gateway as described in Terastream in some standard form would be very useful here, but it still remains outside of the scope of the ETSI architecture except for the Os-Ma interface. Again, while not formally defined, this conceptually defined interface is critical in the actual operation of an operator’s network many have joined the NFVO to a higher level service orchestrator or existing “legacy” OSS through interfaces of their own volition.
The other reference point (Ve-Vnfm) between EMS and VNF potentially overlaps with the OS-Ma interface with respect to VNF lifecycle management and network service lifecycle management with the only discernable difference being in configuration.6 This overlap is a bit ambiguous in the initial version of the spec, and is something that is being considered in the ETSI phase 2 work.
The Se-Ma reference point is more of an “ingestion” interface used by the MANO system to consume information models related to the Forwarding Graph, services, and NFVI resources. This information can be manifested/understood as service and virtual machine (VM) “catalogs.” This can provide a bridge to a higher level service orchestration function (through a model provider: the model consumer relationship).
Because there is only one new interface here, a common interpretation of the prescribed architecture is that the bulk of the responsibility for service creation seems shifted to NFV Orchestration.
NFV Orchestration (General)
The NFVO provides network-wide service orchestration and management. These services can comprise purely physical elements, purely virtual ones, or a mixture therein.
As we saw in the section on OSS, in the past this functionality was part of OSS and represented by traditional vendors like CA, Amdocs, or Accenture.
With the advent of NFV, there are also new vendor entrants into the evolving OSS space that provide many of these functions (eg, Cienna/Cyan Blue Planet, ALU’s SAM, and Cisco/Tail-f NSO). These products sometimes include their own, proprietary pieces of the architecture, for example their own VNFM software and/or (in some cases) their own virtualization software. Some are evolving from a more modern approach (than their traditional OSS predecessors) to PNF-based service orchestration with the incorporation of virtual element control.
Note that the concept of orchestration does not stop at the infrastructure management we saw in the preceding chapter (compute, disk, and basic network underlay). Recently, the VIM-centric Openstack project started adding projects to try to move forward an open source capability in the area of service orchestration.
There are subtle constructs that expand the resources to create a service lifecycle manager. Before we look at service lifecycle orchestration, we will start by looking at some of these concepts: the service graph, service descriptor, and service catalog.
Service Graphs
As we mentioned earlier, VNFs can be deployed as singletons (ie, an aggregated piece of software that once was running on a physical device), perhaps with explicit external networking connecting the services represented by the VNFs together, or by explicitly chaining them together using mechanisms like the IETF’s Network Service Header (NSH).
The connectivity between VNFs is described in ETSI terminology as a graph between the set of network paths between the VNFs. This is typically a collection of their network interfaces in some sort of forwarding graph. The graph is part of the description for a service. This is demonstrated in Fig. 6.5.
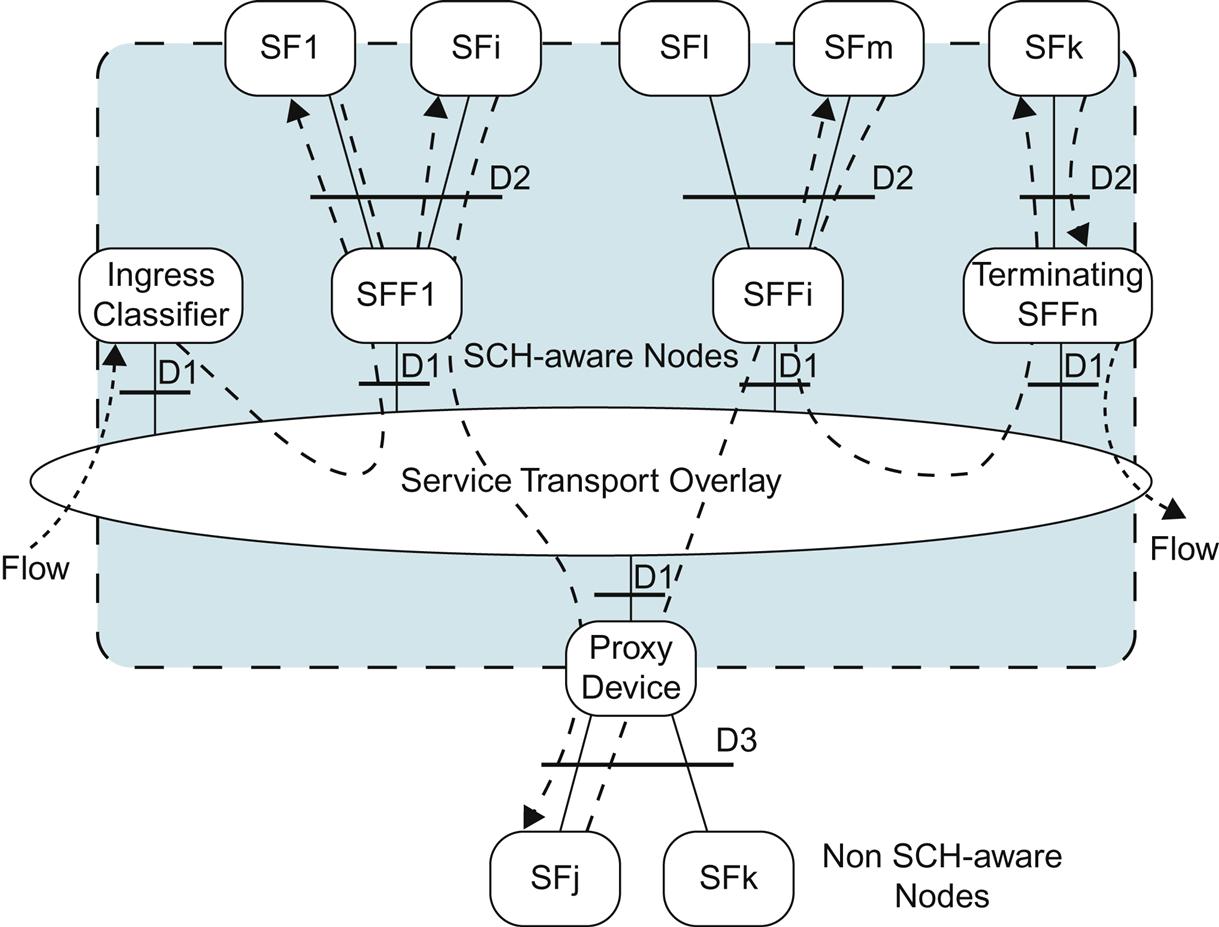
Note that this graph need not be acyclic, as the VNFs themselves maybe responsible for routing traffic. This is also why the concept of nesting forwarding graphs transparently to the end-to-end service is a capability that will be made available. This level of path decomposition is practical in that sub-chains that are copied might make the overall orchestration of service chains easier to define, as well as to deploy in a “cookie cutter” manner. Supporting these path types is important.
Network Service Descriptors and MANO Descriptors
The service graph becomes part of the next element(s) in the architecture (see Fig. 6.1): the service, VNF, and infrastructure descriptions depicted in the figure by the box entitled “Descriptors.” These service components are inputs to the Orchestration system, from which it will create the resulting service.
Information such as forwarding graph nodes, links or other resource constraints, data models or templates such as those depicted in the TOSCA template example below, comprise this input.
Note that this is yet another area in which the use of models like those discussed in Chapter 4, IETF Related Standards: NETMOD, NETCONF, SFC and SPRING, overlap with NFV deployment.
While NETCONF/YANG has emerged as a model for service description for classic Metro Ethernet Forum (MEF) services such as Ethernet Private Line (EPL),7 TOSCA8 has evolved as a preferred model language for virtualized service because of its ability to define application components and their relationships, capabilities, and dependencies.
The current generation of VNFs is becoming more complex (eg, vIMS and vEPC) with additional requirements like associated databases. Most service instances have supporting application dependencies with DHCP, DNS, or other processes and (depending on your philosophy for VNF-M) assurance.
In our examples that follow, we will be talking about Open Source TOSCA orchestration (because that is publicly available for examination). However, NFV provisioning and configuration is only a part of the overall service orchestration picture.
What has evolved outside of the original ETSI specification is a discussion of layered orchestration such as a case where more than one orchestrator may be involved in service realization. For example, in a multidomain configuration where each domain might be managed by different departments, each department could choose a different orchestrator based on its own, localized requirements.
Of course, one set of functionality in one system could be adapted to accommodate another modeling system functionality. Or they can be used in parallel—a best-of-breed orchestrator deployment (both TOSCA for virtual functions and YANG for physical functions). Some of the orchestration vendors in the evolving OSS space have their own viewpoints on the relative benefits of both.9
The Network Service Catalog
The Network Service Catalog is another important element usually found here, although not explicitly called out in the architectural diagram. Its purpose is to manage all of these bits of information including NSD, VNFFG, and VLD, which are related to a network service. It is here that this information is organized into a format in which the network operator can readily consume, deploy, and manage—as well as customize. This information is generally segmented into service profiles and service functions—the combination of which are presented as a service catalog.
A separate repository is used to document the active NFV instances, and associated NFVI resources—the state that results from the interaction between the service orchestration and resource orchestration.
The visualization of the catalog and the service state is normally done through a portal that may be service specific. The Service Repository is the state of the exchanges.
An example is shown in Fig. 6.6. Note there are many variations on this theme, but the concepts are similar across commercial products in this space, as well as the open source efforts.
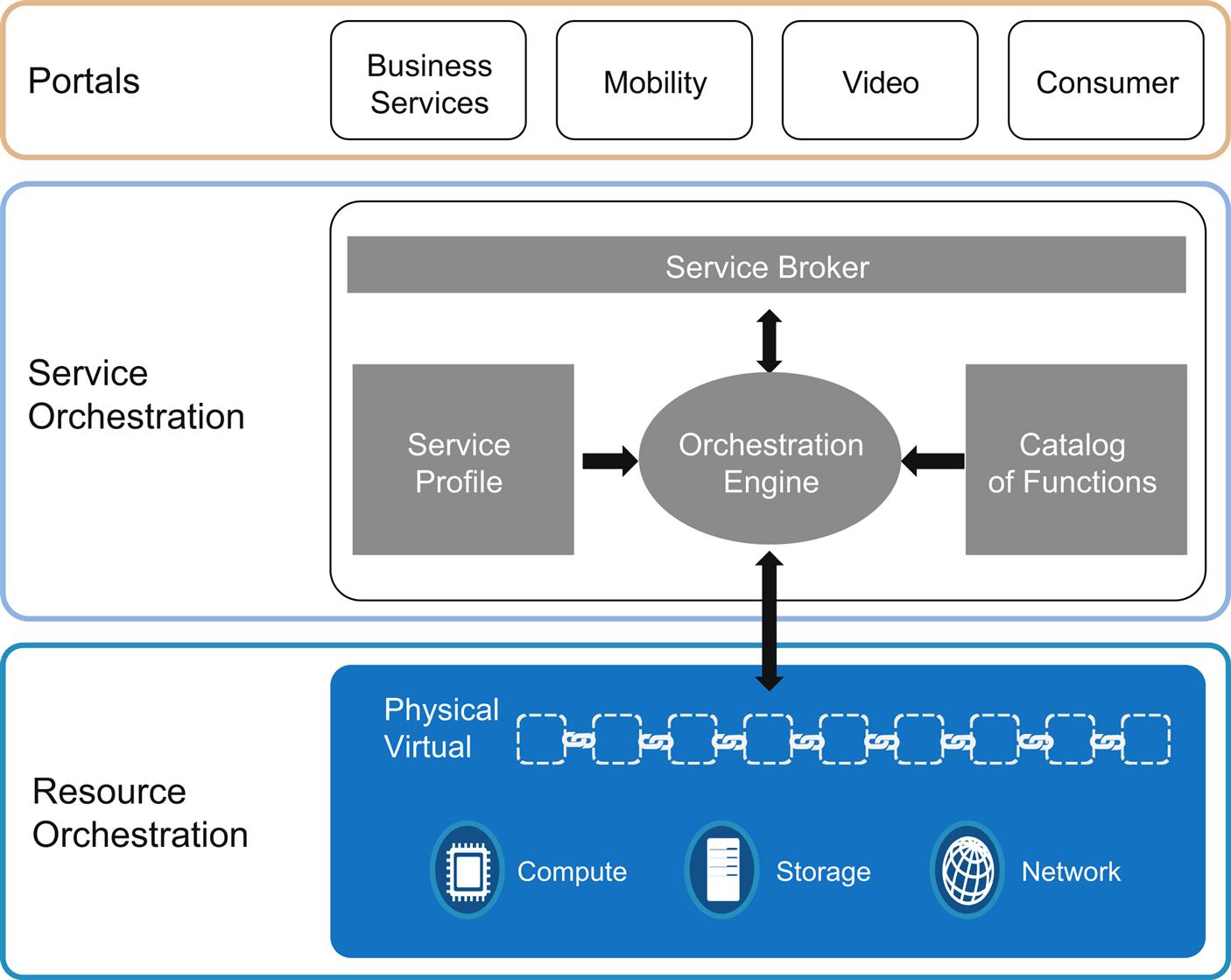
It should be noted that this part of the architecture benefits from standard information/data models such as those being worked by many Standards organizations such as the IETF, MEF or IEEE, as well as those from open source communities such as Open Daylight, Open Config,10 or the Public Yang Repo.11 The reason is because standard templates, or components of those templates can be created once and then shared amongst the various tools available.
Generic Resource and Policy Management for Network Services
The flow of information that is used to implement generic resource management of the underlying resources managed by the Orchestration system includes configuration and state exchange in support of service creation traversing multiple reference points. To achieve this the interface between Orchestration and VNFM, referred to as the Or-Vnfm in Fig. 6.1, constitutes the interface by which one configures the VNF and collects service specific data to pass upstream. The Vi-Vnfm also shown in that figure provides an interface between the VNFM and VNF Domain, which does additional work in virtualized hardware configuration.
The Or-Vi interface between the Orchestration and VIM, provides a virtualized hardware configuration information pathway. Finally, the Nf-Vi interface exists between the NFVI and VIM, and is used to enable physical hardware configuration. This also provides a mapping from the physical hardware to virtual resources thus forming an important part of the platform-independent interface towards the VNF. It is the use of these interfaces as well as the “eye in the sky” management and coordination of the overall network resources, that constitutes the resource management function of the orchestration system.
The VNFM Demarcation Point
As a subset of that view, one might observe that the ETSI architecture suggests that resource management might be divided into two pieces: resource service-specific deployment, allocation and management, and a similar one for VNF-specific tasks.
There are two potential camps emerging around implementation of this aspect of the architecture. As mentioned previously, there is a view that suggests that the NFVO take on total responsibility for simplicity, consistency, and pragmatism, as this is how systems such as Openstack currently function, although recent additions such as Tacker have divided this functionality out into its own identifiable component. Others may see the NFVO dividing up its responsibility with the VNFM where the NFVO is responsible only for service-level resources and the VNFM responsible solely for VNF resources.
How this all plays out is anyone’s guess, but our take is that it is likely to be divided up into two separate sections of functionality. This guess is based on the premise that there is a significant thrust to standardize these functions, as well as the VNFs themselves—or at least the templates used to deploy and manage them within these systems. While several vendor products implement in this fashion, further evidence of this appears to be evolving through a number of open source projects and initiatives such as OPNFV, OPEN-O, or OpenMANO in which the components are being segregated to allow for clean separations and implementations.
There are a number of services that can be bundled under the general umbrella of “VNF lifecycle management”—though not all VNFMs may actually provide these services. These include:
• Manage the “scale up/down” elasticity of the VNF through a rules system or policy.
• Manage startup sequences and the affinities we mentioned previously in the discussion of TOSCA templates.
The VNF monitor in turn can manifest through a range of functions both integrated and external to the function. These tools can often be open source (eg, Ganglia12 or Nagios13), although some custom tools are also found here. The differences in approach between the various implementations of the monitor revolve around whether the monitor requires an imbedded “agent” in the function.
Though the architecture does allow for a relatively static VNFM, it is possible to have multiple VNF-specific VNFMs in a single deployment. The presence of rules, affinities, and policies in a generic VNFM implies some level of flexibility/programmability.
Open Orchestration
The next sections detail and describe a variety of industry efforts underway that attempt to provide open source alternatives to the readily-available proprietary solutions in the Orchestration space with some form of community effort.
These current open source efforts range in approach from the canonical open source efforts in the Linux Foundation, to those that are born of the ETSI organizations, and adopt their mannerisms and governance styles. There is even the “potential” open sourcing of AT&T's ECOMP software (the idea was shopped to the press along with a white paper describing ECOMP and seeking feedback from other operators at ONS 2016), under yet-to-be disclosed licensing and governance. This distinctive “bloom” of efforts makes it particularly difficult for anyone researching the space to determine a specific winner/direction given the multiple efforts have the potential to be counterproductive. We affectionately refer to this situation as “MANO gone wild.”
In fact, at the time of the publication of this book a new organization called no-org.org (http://no-org.org) was created as a reaction to all of the formal organizations forming in this space. Its sole mission is to create an organizational-free space in which individuals can collaborate on open source software for other orchestration projects.
As you might imagine, there are also subsets or components of the wider Orchestration space being worked in some Standards organizations, and those will be called out separately throughout the text.
Where appropriate, we mention proprietary efforts but will not dedicate any indepth sections to those. The reader should keep in mind that these vendor products may address functionality gaps in the open source, and may have different sets of functionality between them. Further, open source may continue to morph—adding projects under different organizations related to NFV MANO.
From here, we will walk through the Openstack Tacker project to illustrate some of the fundamental concepts in the prior section.
Tacker
Tacker is an Openstack project for NFV Orchestration and VNF Management using The ETSI MANO Architecture. In particular, Tacker concerns itself with portions of the NFV Orchestration and VNF management components. The Tacker project kicked off to tackle the NFV Orchestration problem in early 2015. It was later announced at the Openstack Vancouver Summit in May of 2015. The project has met lots of community support and will be added to The Openstack Big Tent soon, meaning it will become a core project that is part of the mainstream distribution.
When looking at Tacker its, key features include:
As we refer back to the reference architecture we discussed above, we will observe that as expected, a subset of the overall functionality is implemented by The Tacker project. This is simply due to the point we made earlier—that the ETSI MANO architecture is a reference point, but is not meant to be taken literally. Through close engagement with the open source community and network operators that wish to use the project in their specific network situations, Tacker has only implemented those components deemed necessary.
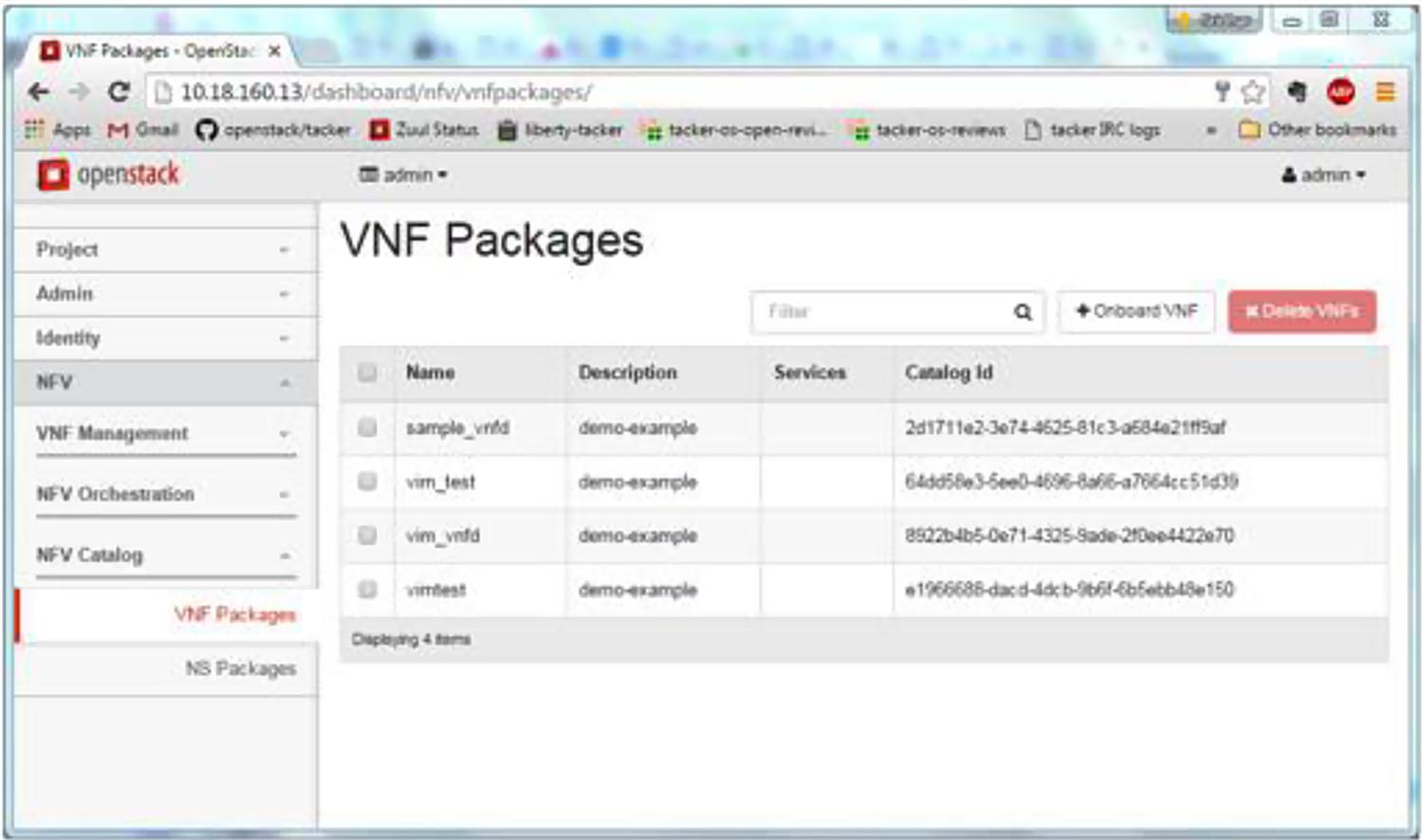
Tacker VNF catalog
This is a repository of VNF Descriptions (VNFDs). It includes VNF definitions using TOSCA14 templates. TOSCA templates are a templating mechanism that in the context of NFV are used to describe the VNF attributes, Openstack Glance image IDs, Performance Monitoring Policy, as well as the Auto-Healing Policy an operator wishes to invoke on the VNF. TOSCA templates also provide Openstack Nova properties and VNF requirements such as those used for the optimal placement of the VNF. As we will discuss in detail in Chapter 8, NFV Infrastructure—Hardware Evolution and Testing, and Chapter 9, An NFV Future, these are quite important and are also rather dependent on the underlying hardware’s support for attributes such as CPU Pinning, NUMA policy, virtualization technology support such as SR-IOV, and so on.
The Tacker VNF catalog function supports multiple VMs per VNF Virtualization Deployment Units (VDUs), as well as the simpler single VNF per-VDU model. The VNF Catalog also includes APIs to onboard and maintain the VNF Catalog. VNFDs are stored in The Tacker Catalog data base.
An example of a Tacker VNF Catalog is shown in Fig. 6.7. Note the catalog shows a variety of choices to choose from when deploying the VNFs that are prepopulated in the catalog. Also note that an import feature for new templates is available, while editing and construction of new ones is simply a function of using a text editor and proper syntactic formatting. Further enhancements to this will allow for more detailed and easier manipulation of the forwarding graph that attaches the constituent components of a VNF (or a service chain).
Tacker VNFM
As we discussed above, one of the critically important functions of the MANO system is the VNFM’s Lifecycle Management function. Tacker API deploys VNFs from its VNF Catalog using a number of functions and approaches. This includes a “pluggable” infrastructure driver framework, which enables the system to scale in terms of vendor support for VNFs and their associated templates used to deploy, configure, and manage their VNFs. This plug-in system might raise questions about the ability of the project to keep up with the creation and maintenance of these templates. There might also be cases where vendors do not wish to put a plug-in driver out into the open community for consumption. In these cases, vendors could distribute the templates along with their proprietary VNFs. The Life Cycle Management feature supports Nova deployment of the VNFs. It also supports the use of HEAT templates (by default) for initial configuration of VNFs. This is achieved using a HEAT driver which uses a TOSCA to HEAT convertor. As one might expect, the TOSCA system does support the instantiation of more than one VM described in a TOSCA template. Finally while TOSCA is capable of describing creation behaviors for VNFs, it also can and does describe termination behaviors as well. If a VNF is defined as using multiple VMs, it will delete all of the VMs associated with the VNF instance.
VNF auto-configuration
In addition to the usual lifecycle management, Tacker is capable of performing bootstrapping and startup configuration of its VNFs or constituent VNFs. To achieve this, the Tacker Extensible Management Driver Framework allows vendors to plug-in their specifics in terms of HEAT or TOSCA templates. It also facilitates VNF configuration based on service selection, which is important from a service catalog perspective in that it allows users the ease and flexibility of choosing from predefined templates or customizing specific ones. Once a VNF has been deployed, its initial configuration can be injected using a variety of approaches. These include pushing initial configuration through an SDN controller such as Open Daylight using NETCONF and YANG models or a “config-drive” which is a preconfigured virtual boot disk from which the VM will boot that contains the initial configuration. Another option is to use a custom mgmt-driver and connect to the VNF using an ssh connection, or use its available REST API in order to apply the initial configuration. These same mechanisms can be used later to update the configuration of the running VNF. The pluggable nature of the framework is operator friendly, extensible, and customizable.
VNF monitoring
The VNF monitor feature of Tacker is used to track specific KPIs of a VNF to determine its health/status. Today, this amounts only to an IP ping message sent to the VNF. A failure to answer after several configurable queries results in Tacker determining that the health threshold for the VNF has been reached, and will then terminate the VNF and restart it if so configured. It should be noted that while this seems like a very simplistic approach, a host of configuration options are being added to allow a network operator to tailor this to their specific needs. Imagine options such as bandwidth usage, memory or CPU consumption, or even failed calls from a virtual call server. In the future, the project will also be adding additional functionality that allows an operator to specify a third action that upon a health threshold trigger causes a VNF “resize” operation rather than a termination and/or restart. This allows Tacker to treat VNFs as an elastic system. Specifically, when a VNF is comprised of a system that scales horizontally, that system can be told to invoke the specific expansion or contraction of itself.
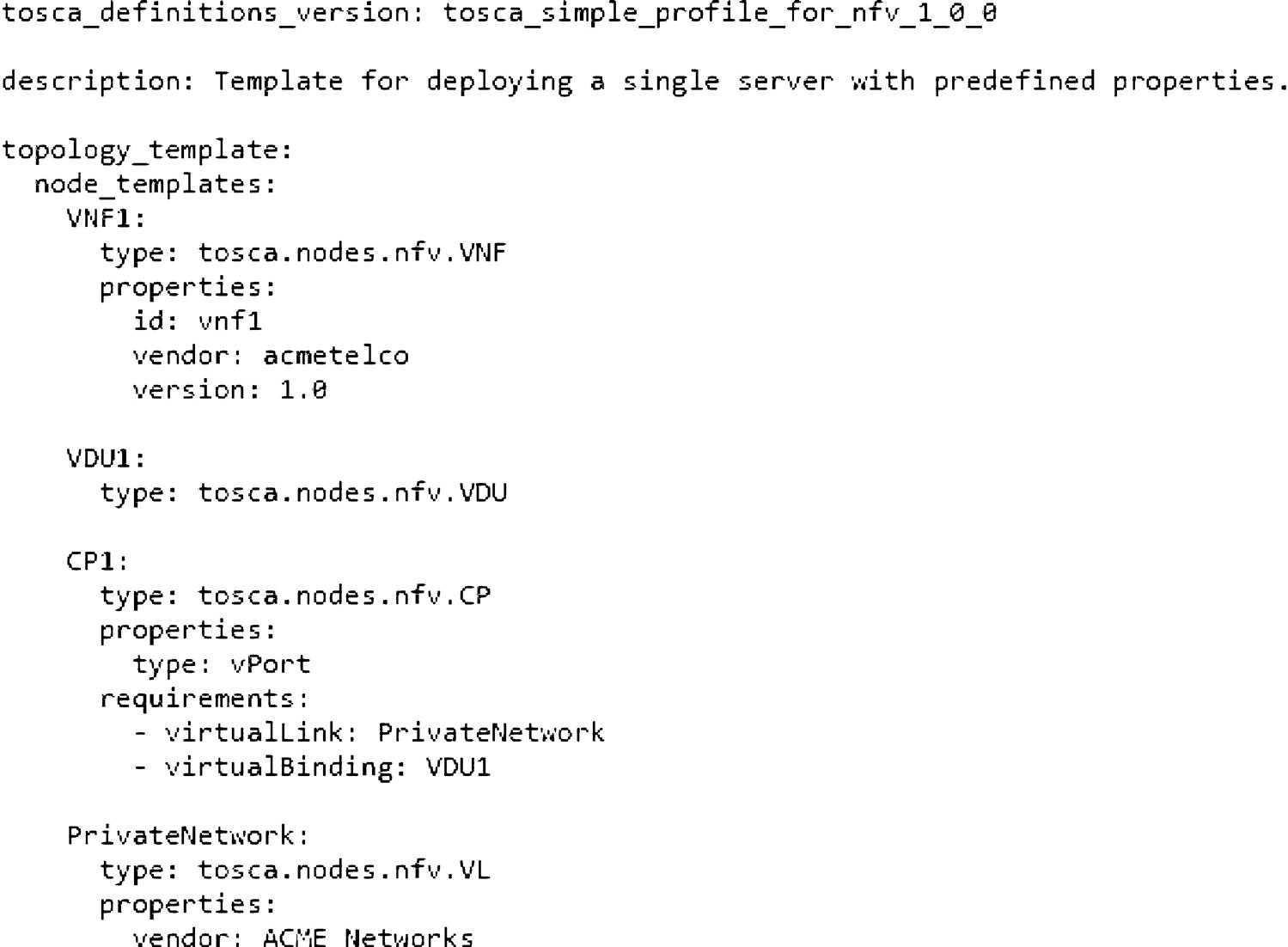
TOSCA templates and parser
Tacker includes support for TOSCA templates via a built-in parser and conversation process to and from HEAT templates. To this end, we wanted to demonstrate a basic TOSCA parser and HEAT translation. First, let us begin by showing a basic TOSCA template. This is shown in Fig. 6.8. Note that we do not want to take too much time here to explain the intricacies of defining TOSCA templates; for that please refer to the footnote reference to OASIS15 for additional information and tutorials.
Now that we have shown a basic template, we will investigate how a basic TOSCA template is consumed by the parser.
To begin, the TOSCA-Parser and Heat-Translator are part of the Openstack Heat orchestration project. The code for these projects is worked on by the upstream open source communities that work there. The latest TOSCA features that have been integrated into the parser include Networking, Block and Object Storage. This should be obvious given its relation to the Openstack project. Other features include:
• The availability to use on command line and user input parameter support.
• Tacker NFV MANO integration using a TOSCA NFV Profile.
• Murano (Application catalog integration) with Openstack client.
• The TOSCA parser is now available as an independent Python library (pypi).
• TOSCA now supports policy schema and group schema constructs.
• Supported Plug-ins: HEAT Orchestration Template (HOT) Generator now supports additional plug-ins to allow translation to other DSLs besides HOT, such as Kubernetes.
With these components and features in mind, let us consider Fig. 6.9. On the left, the parser takes a TOSCA template as input. At this point the TOSCA parser derives TOSCA Types and Nodes, as well as performs validation tests on these elements using syntactic rules. If these are passed, the second phase performs a mapping, validation, generation, and test operation using the TOSCA heat-translator. The output of this phase will be a valid HOT. This can be then deployed—or passed—into a Heat processing engine that uses the template as an instruction set to orchestrate the various Openstack resources such as compute, storage, and networking.
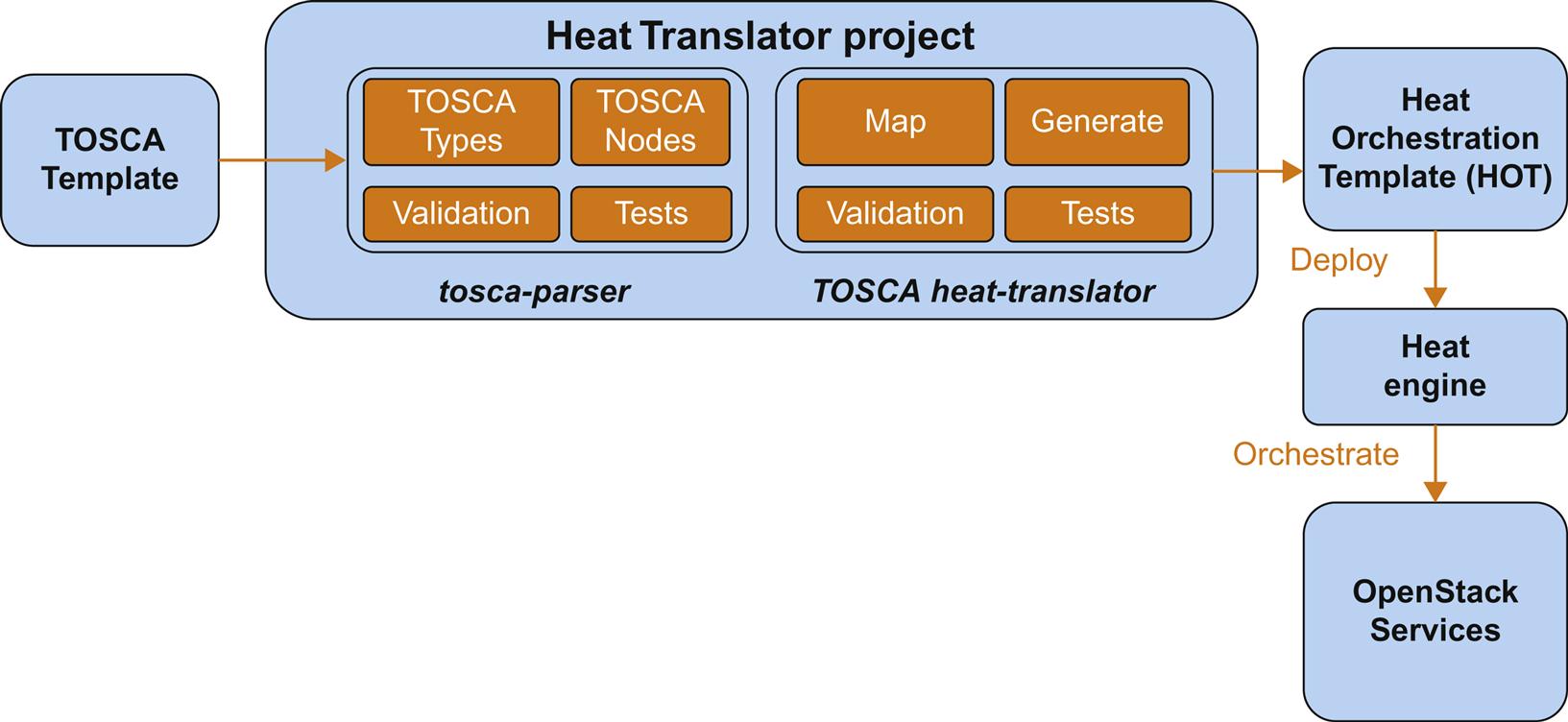
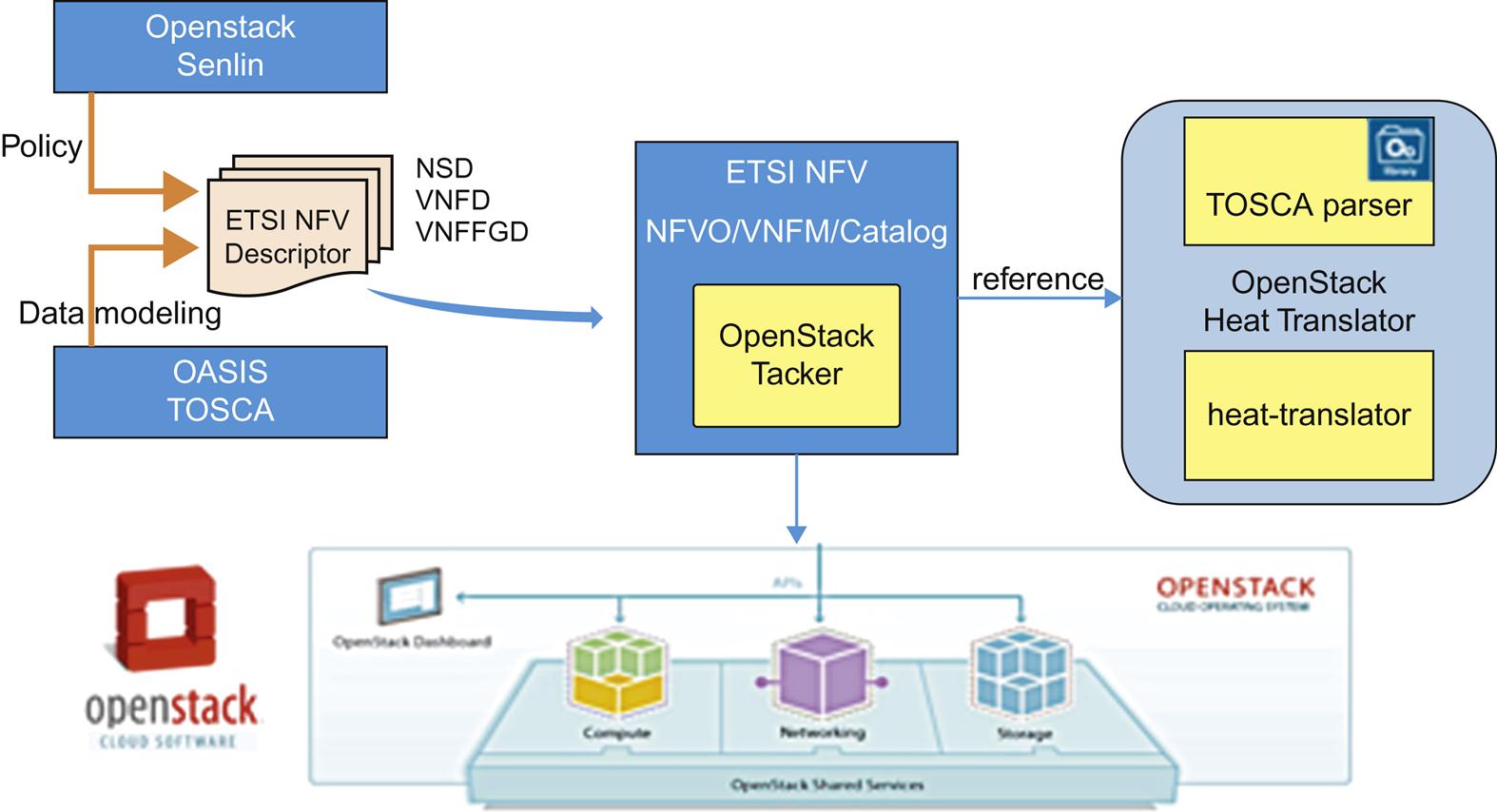
Fig. 6.10 shows the resultant Tacker system with the parser and Openstack components broken out into their constituent pieces. Notice in the figure the workflow from start to finish. On the far left of the process Policy and data modeling are used as inputs to the system as the ETSI NFV Descriptor (as we mentioned earlier in this chapter). Those are consumed by and used as directives by Tacker in order to create, manage, or delete NFV components in the underlying Openstack system components. Those are then referred to specific TOSCA and HEAT reference components. It should be noted that Tacker is working to abstract its interfaces southbound to support other VNFMs including VMware and KVM in the near future, so you could replace either of those with the Openstack components in the figure.
Tacker and service function chaining
Recently Tacker added support for service function chains using what the project refers to as its SFC APIs. In this way, Tacker can now support VNF Forwarding Graph construction using the APIs that project has added to the ODL controller. These APIs allow a user via Tacker to define flow classification rules as well as easily render service chains across instantiated VNFs as part of the normal Tacker workflow. This functionality has added the precursor to the VNF Forwarding Graph Descriptor that we described earlier in the ETSI architecture. It also adds ODL-SFC/netvirtsfc driver support.
The example in Fig. 6.11 shows a service function chain that is comprised of two individual VNFs. These represent two virtual routers on two compute nodes. Tacker would instantiate them as it normally would deploy multiple VMs as part of a VNF, but it could then make the appropriate calls using the SFC API that would then call into the ODL controller to attach network paths between those VMs, thus creating a service graph.
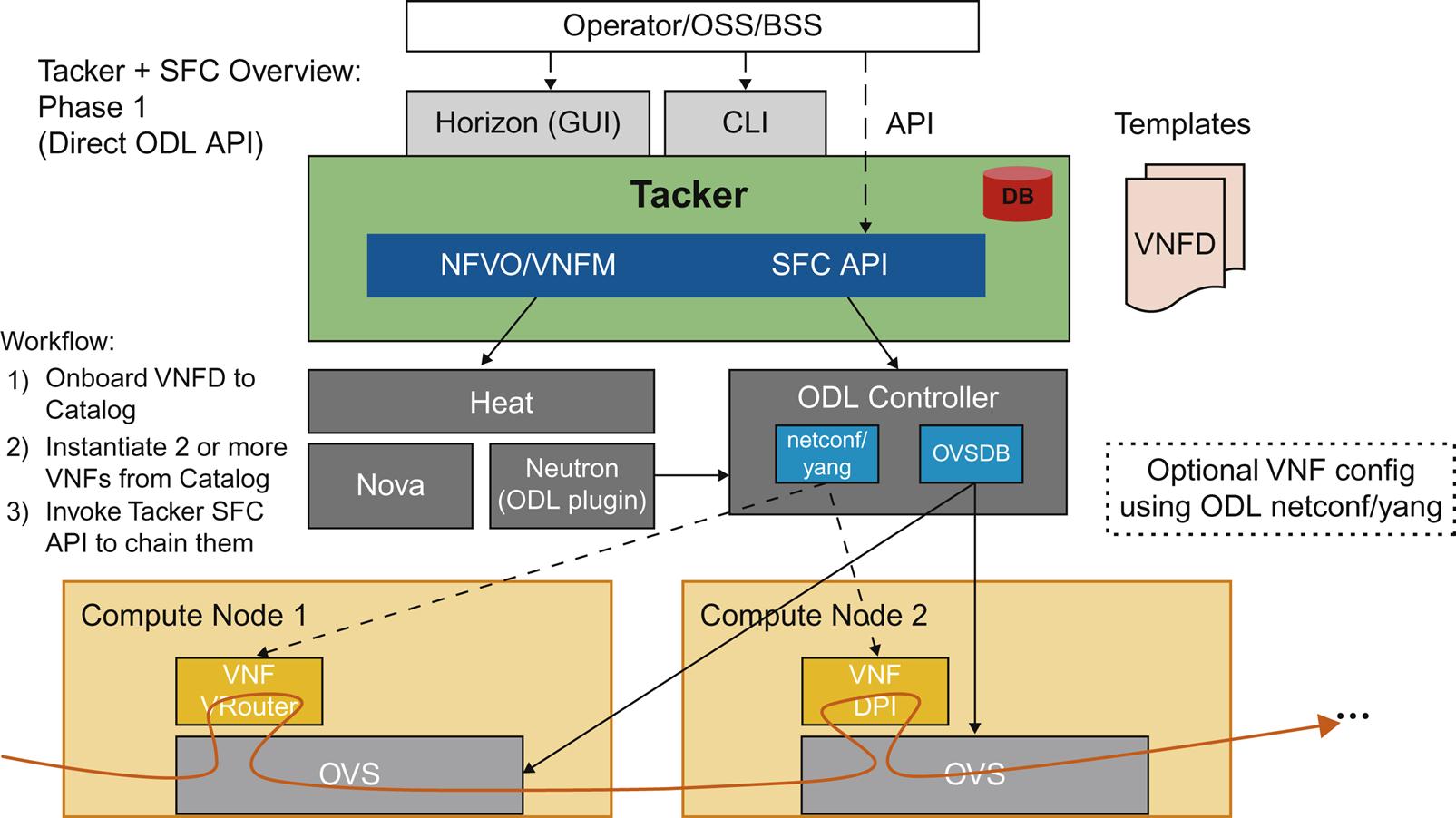
At present, the SFC API supports the use of the controller’s southbound NETCONF and OVS-DB interfaces.
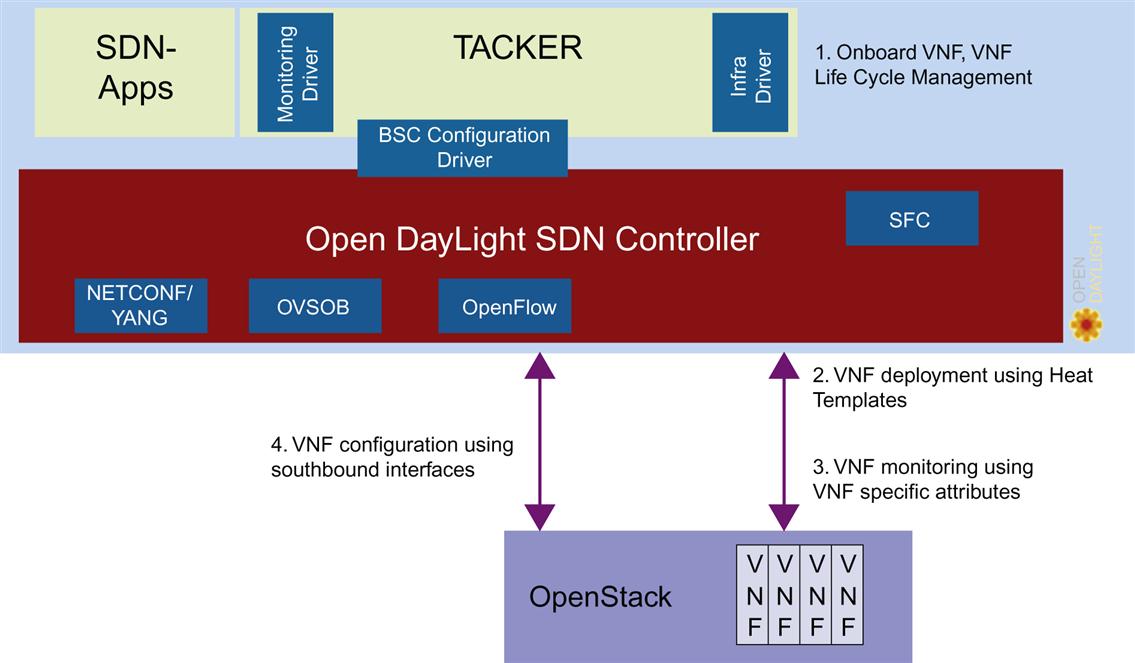
Tacker integration with Open Daylight
As we have already seen, Tacker has been integrated with the Open Daylight controller using its normal northbound RESTCONF APIs. In addition to using the normal interfaces to invoke NETCONF or OVSDB commands southbound towards deployed VNFs, the Tacker project is also considering expanding these interfaces in order to expand connectivity for functions such as health monitoring capabilities for specific health monitoring functions (Fig. 6.12).
Tacker workflow
We will demonstrate all of the just-described features of Tacker by now walking the reader through a workflow. The use case here starts with the user choosing a virtual router from the services catalog and deploying it in a router configuration. Any other compliant VM-based VNF could just as easily be deployed. Once deployed, we will show how the instance’s status is monitored and reported up through the system. We should note that the process can be re-wound to extinguish the instance, or redeploy additional instances as needed by the operator.
In the workflow (Fig. 6.13) we begin at Step 1 in the process. Here the network operator selects a vRouter from the VNFD Catalog. Conceptually, we show the operator selecting this, but in reality all of the communication with the system will be achieved using Tacker’s Rest API.
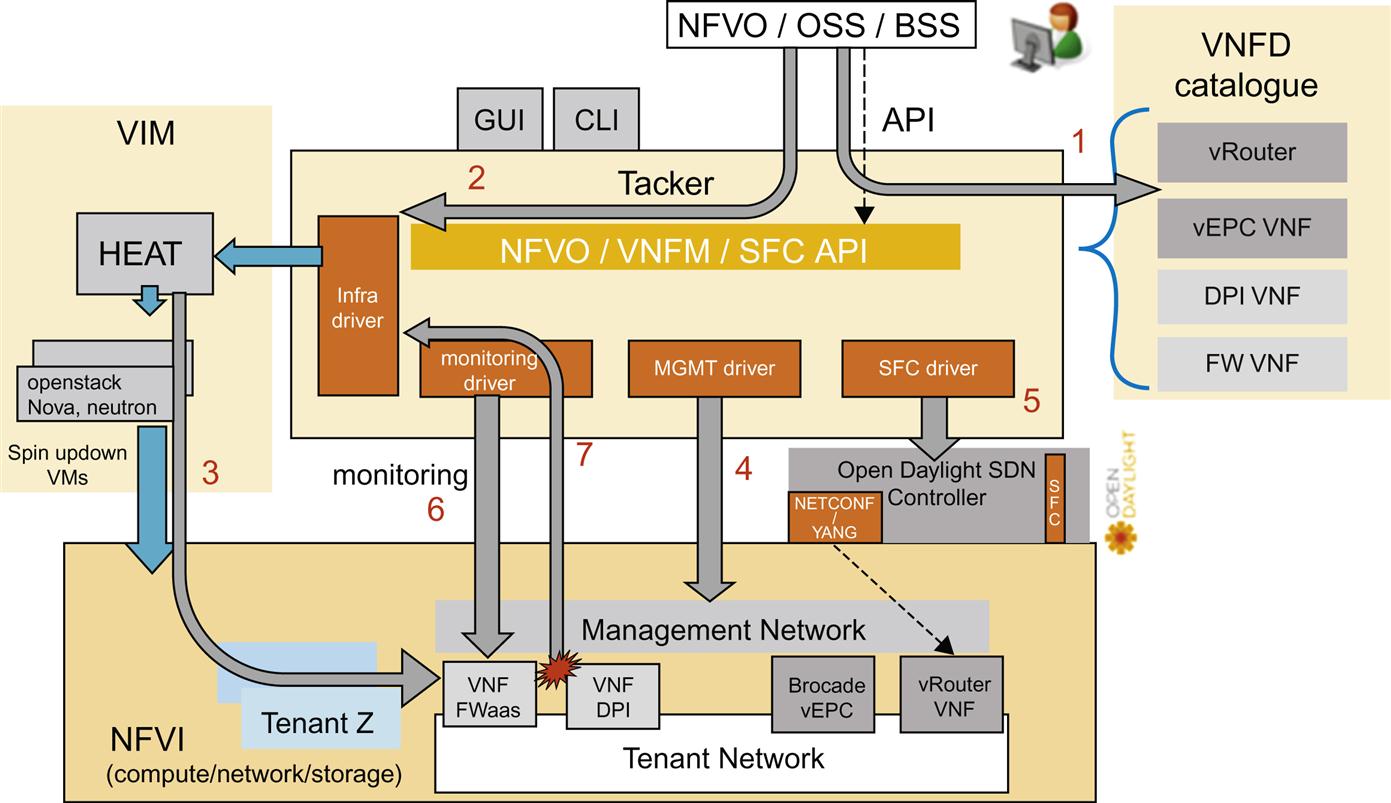
Step 2 has Tacker starting the deployment of the VNF. In this case, it will find its associated HEAT template via its specific infrastructure driver, and use those to push a command to Openstack NOVA to deploy the VNF in Step 3. If any specific constraints about deployment positioning of the VNF are needed, then those are specified at this time.
At this point, the VM representing the vRouter will be launched, and once detected as being booted, the management driver will install its initial configuration. This is a minimal configuration that sets up basic access policies, and the base networking configuration.
In Step 4 we now utilize the management driver connecting Tacker to the Open Daylight controller to push a more comprehensive initial configuration down to the vRouter utilizing its NETCONF interface. If the responses to the configuration are positive, the VM is fully operational.
In Step 5, we optionally invoke the SFC driver in the controller in order to connect this VM to another in order to create a service function chain.
Finally, in Step 6 we establish the health monitoring of the newly-deployed VNF based on the configured policy. In this case, we will simply ping the vRouter and await its replies. If the replies continue at a regular rate, Tacker does nothing except perhaps update internal counters. If the responses to the pings are not received for some preconfigured time, say 30 s, Tacker can be configured to destroy the VNF and optionally kick off a new instance, as well as sending a notification to the operator via its northbound interface to indicate that a fault was detected, and perhaps a corrective action (ie, respawn) was invoked.
Open-O
Formed in early 2016 under the auspices of the Linux Foundation, the primary goal of the Open Orchestration (or Open-O organization) is to develop a comprehensive open source NFVO stack. This software stack is envisioned to also support inter-DC and access or SD-WAN use cases while employing an SDN orchestrator. The project is slated to create a complete open source software solution for NFV/SDN orchestration, multiVIM and multisite use. These components will integrate with existing VIMs and possibly future ones that are not yet defined.
The project also aims at targeting VNF interoperability. While laudable, the practicality of that goal is yet to be determined.
Another important goal is ETSI MANO specification compliance, at least as much as possible within the framework proposed by the organization’s founding members. The organization has support initially from a number of large service providers, and thus has stipulated a desired goal to work on information models as a key component of the project. As we mentioned earlier in the Tacker section and still earlier in the general architecture discussion, templates and their standardization either through traditional standards, or open source methods, is critical to the scale and success of any of these projects. To this end, rapid updates and maintenance of a data model translator are slated as work items.
• Openstack modules and interfaces (select and promote standards)
• SDN services: ODL (Service Chaining)
• Decoupling VIM, VNFM, Orchestrator
• End-to-end SDN services such as Service Chaining, BGP/MPLS VPN, vDCI
Fig. 6.14 demonstrates what the organization began with as a framework or architecture. This looks very similar to what many other approaches are attempting to pull off in this space, so the stack of components and how they are arranged should not come as much of a surprise. At the top level of the architecture, service orchestration is present. This takes a page from the ETSI architecture described earlier and encompasses the same goals. Below this, resource orchestration takes commands from a service orchestrator in order to fulfill the higher level service provisioning requests. In some ways, this is already covered by functionality already present within Openstack for example.

Below this, we find the VFNM, in this case this is defined as the Tacker project we described. Tacker is present in its entirety including the template parsing capabilities.
To the left of the figure are inputs to the system—service descriptors and templates. It is envisioned that these will be leveraged from Tacker as well. In cases where other custom parsing is needed, those functions will be added.
Below the VNFM we have EMS and SDN controller plug-ins (assuming the VIM uses a controller for the networking portion of resource orchestration). The EMS connections will be to proprietary EMSs that are used to manage the specific VNFs deployed by the VNFM.
Finally, underneath this is the NFVI which is comprised of the usual functions that we described earlier in the ETSI architecture.
Open MANO
The Open MANO effort was started by several engineers at Telefonica in 2015 as an attempt to consolidate the MANO open source communities that were (at the time) not well organized or formed. During that period, there was a lull in the ETSI efforts with no real open source alternatives in the industry to vendor provided solutions for orchestration. Also during that period, a number of startups were initiated at this time to solve this problem taking mostly, a proprietary or closed approach using the guidance of the ETSI framework.
The Open MANO approach was largely focused on the performance of virtualized functions that were being used to create services. Efforts here included giving more visibility to the hypervisor and underlying server capabilities such as those we describe later in Chapter 8, NFV Infrastructure—Hardware Evolution and Testing, and Chapter 9, An NFV Future. This was done in an effort to maximize the performance of VNFs. In reality, what was achieved was a minimization of the possibility of suboptimal placement of VMs, but this did not always succeed.
To this end, the effort tried to minimally integrate with open source VNF Management systems such as Openstack, as well as attempt to create their own VNFM (called Open Mano VNFM). There was also an attempt to create an orchestrator called the Open MANO Orchestrator. Fig. 6.15 illustrates the Open MANO approach and architecture.
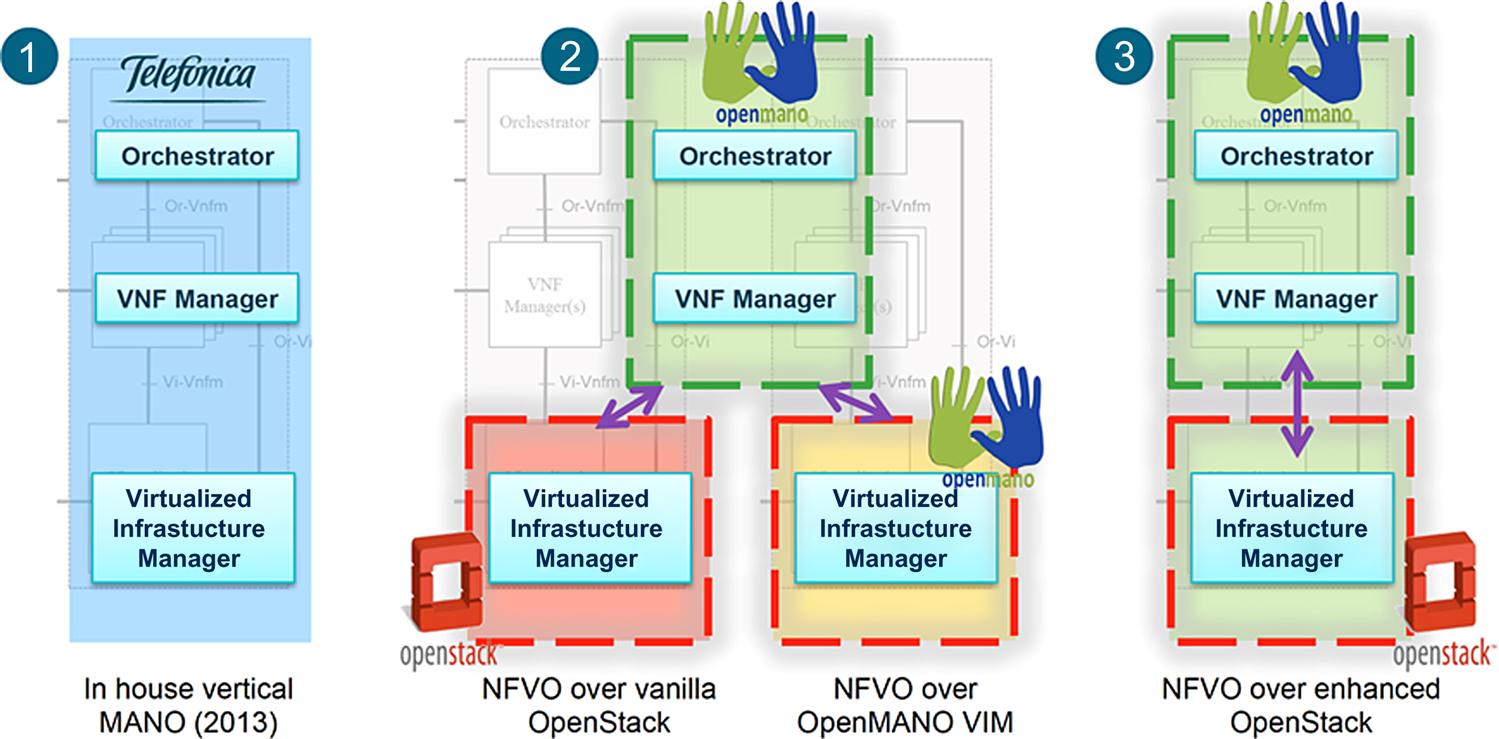
In the end, the organization did not make much progress due to a simple lack of interest by a wider community. The efforts were largely focused on solving Telefonica’s use cases. The effort also faltered in that it did not attract any coders. A lack of coders usually spells certain death for any open source effort, and this happened in this case. The code repository on github is currently slim and only has contributions from a few people.
In February 2016, the Open Source MANO (OSM) project was started under ETSI auspices (https://osm.etsi.org/) with Telefonica as an announced co-founder.
OpenBaton
OpenBaton16 is an open source project providing an implementation of the ETSI MANO specification. It provides a NFVO that closely follows the ETSI MANO specification described earlier in Chapter 3, ETSI NFV ISG, a generic VNFM and a generic EMS function.
The generic VNFM function is able to manage the lifecycle of VNFs based on their descriptors, and also provides a set of libraries which could be used for building your own VNFM. Extension and customization of the VNFM system to manage third party VNFs is done via a set of scripts that need to be built and integrated.
The generic architecture is illustrated in Fig. 6.16.
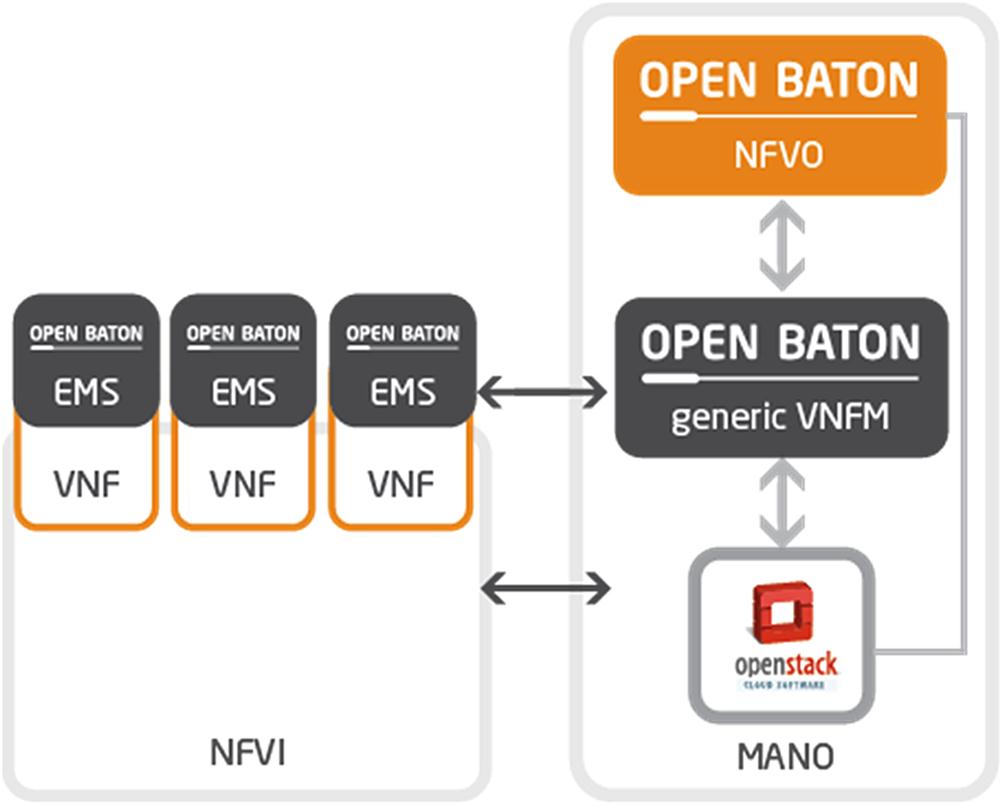
The generic VNFM and EMS can be used that execute generic scripts that are provided, or customized ones that integrate other VNFM solutions. A generic VNFM and EMS can be used to manage such an integration.
Communication between the management system and the VNFMs is accomplished via a message bus with a pub/sub mechanism or by using a RESTFul interface. Interaction with the NFVO subsystem uses either a REST or JMS interface.
The project also supports a developer SDK that can be used to help accelerate the construction of an entirely new VNFM.
OpenBaton is integrated with OpenStack, allowing OpenBaton to reuse and leverage iOpenStack’s many useful functions and features. For example, it uses the OpenStack APIs for requesting virtual compute and networking resources.
The OpenStack API is just one of the VIM interfaces possible. A plug-in mechanism allows potential extension towards the support of multiple cloud systems.
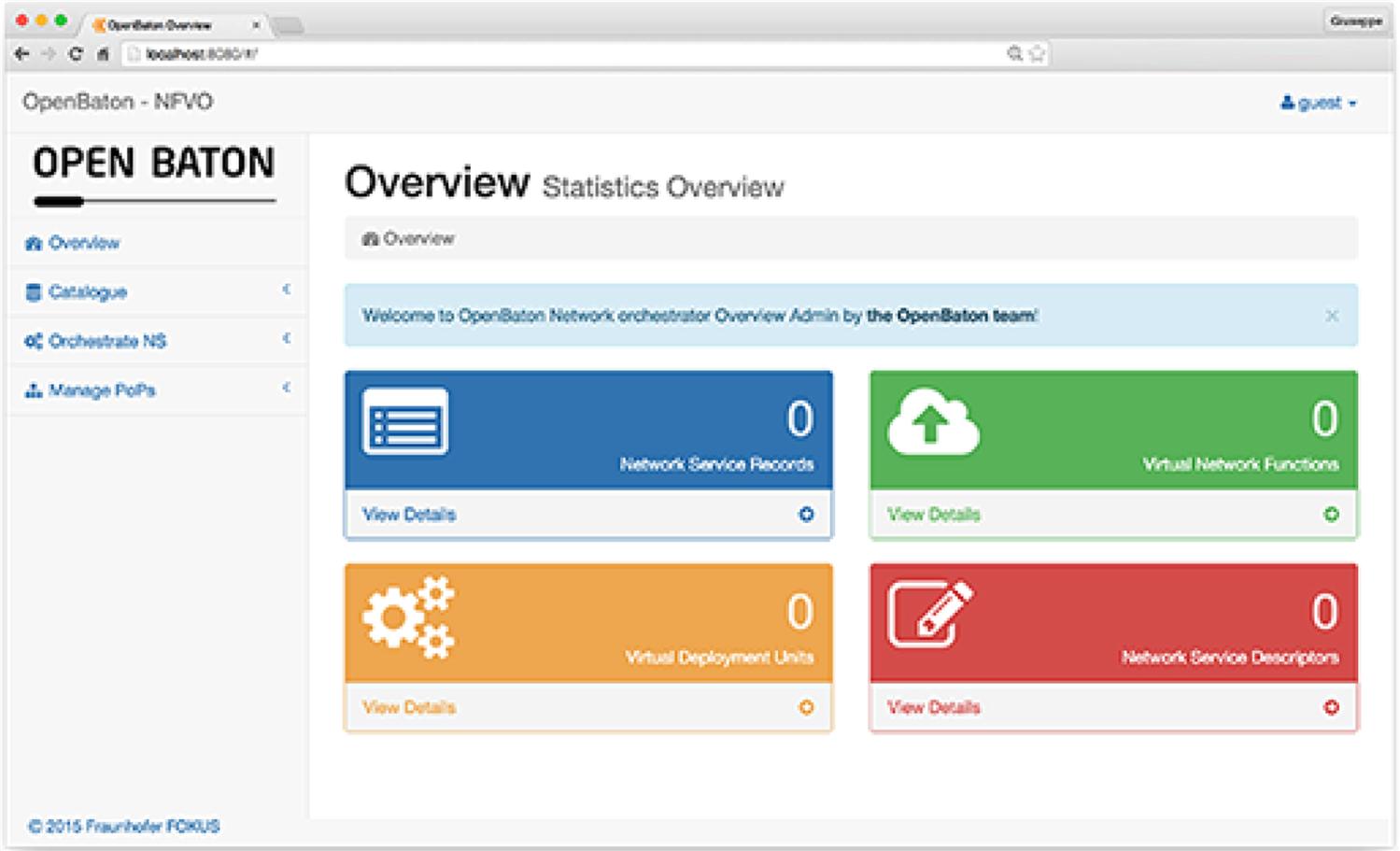
OpenBaton provides the user with a dashboard function (Fig. 6.17). The dashboard is similar to OpenStack’s Horizon interface in that it enables the management of the complete environment. From the dashboard, an operator can control the infrastructure providing “at a glance” and “single pane of glass” views, modify the system’s components and status and perform CRUD operations on existing services.
Architecture on Steroids
As we alluded to in the discussion of Network Service Descriptors, there is a tendency of certain providers to imagine their network resources as multiple independent domains (perpetuating existing organizational subdivision). This returns us to the discussion around a more layered or nested view of service orchestration—which leads to a more complicated picture.
Already some providers are specifying multiple, domain-specific orchestration and control (Fig. 6.18). Neither has been federated in the past.
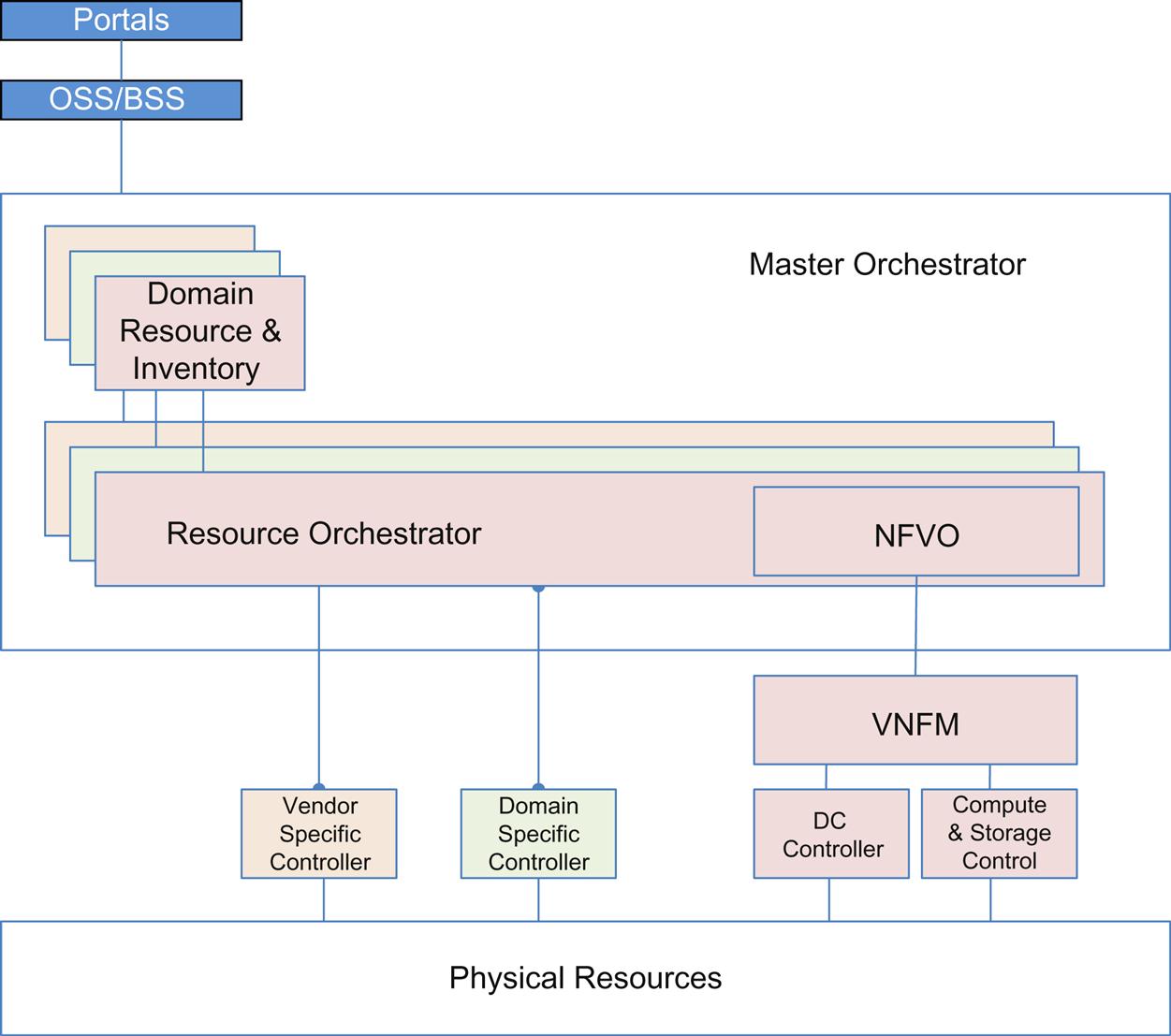
This could be a perceived “best” solution after trying to implement early open source efforts that attempt to implement very complex architectures. Given a lack of appropriate skill sets within the provider, a scarcity of support options from established sources and a lack of immediate full functionality in the solutions, a tendency may arise to invite turnkey silo solutions to get quickly to an implementation that works at scale.
While possible to implement on the orchestration side, a federated orchestration architecture can introduce additional moving parts (eg, an Enterprise Service Bus) to do API brokerage and pacing.
These orchestrators may also need to share NFVO access and attempt to coordinate to avoid multiwriter complications in that resource pool.
Further complications can arise if policy limiting resource access between domains is necessary.
As services span domains, it may be difficult to coordinate feedback from individual lifecycle managers into a master control loop. Because SDN controllers have different internal databases and schema, it can also be difficult to create a consolidated monitoring/SA view unless the controllers can export their state into the big data repositories described earlier in NG-OSS.
Given our earlier focus on the importance of reinventing OSS, providers need to be careful that this sort of architecture does not replicate the existing “multi-OSS” silos that impede them today.
Conclusions
Just like SDN, NFV rarely occurs in a “greenfield” environment.
There is a long tail of existing infrastructure and systems deployments delivering current services to which future solutions need to be grafted. Additionally, there is a cycle of integration and “sun-setting” of closed systems and services ahead, but we predict that, as in the past, it will be much longer than the enthusiasm and optimism around this technology would imply.
Interoperability with legacy systems is paramount to enable a smooth transition to NFV-driven services, full stop.
Admittedly the OSS/BSS can be fairly complex as it is currently implemented, and as such offers some of the most likely resistance to any transition. This is actually logical because this is where the rubber meets the road in terms of these new virtualized systems and services, and the existing physical ones. It is also where much of the human resistance to change exists.
It is for this very reason that users of owners of custom-built OSS/BSS should carefully consider how their existing system is defined, and what its ability is to accommodate any new protocols and interfaces that are being defined for NFV. This includes open source implementations which might not implement standard interfaces, but instead choose to build their own published interfaces.
Ultimately the ability of the combined system to create, deploy and manage services that a network operator sells to its customers will be the measuring stick by which the system lives or dies.
In theory, NFVs should be a logically similar (or the same) extension of existing OSS/BSS implementations, but in practice, observations of existing incarnations of these systems has proven them to not be.17
While the original ETSI work can be interpreted as a mandate for open source solutions, we cannot assume that: (i) that any particular open source organization IS open (check the governance); (ii) that it will provide the only open source solution; (iii) that it won’t expand its mandate and bog down; (iv) that it is going to provide more utility than closed source; and (v) that it will be “free.”
Open source will be an alternative and organizations will have to decide what combination of vendor-provided and open source will make up their architecture.
The ETSI MANO components provide a good example of some of these cautions and trade-offs. There are the multiple MANO projects noted here and maybe more in the future.
As we mentioned earlier in the review of early ETSI work, and in Chapter 5, The NFV Infrastructure Management, there is room for liberal interpretation regarding the construction of the interfaces between and separation of the functional blocks in solutions.
You will notice that, so far, the dominant dialog around MANO does not really include containers or the leap to microservices and a PaaS environment.
Finally, the meta-architecture for MANO is an open question. If operators implement multiple silos or multiple levels of orchestration and control, what manages and binds them? And, how do we avoid repeating the OSS morass of the past?